
1. סקירה כללית
בשיעור ה-Lab הזה תלמדו איך להשתמש ב-Vertex AI – פלטפורמת ה-ML המנוהלת החדשה של Google Cloud – כדי ליצור תהליכי עבודה של ML מקצה לקצה. תלמדו איך להפוך נתונים גולמיים למודל פרוס, ותצאו מהסדנה הזו מוכנים לפתח ולהפעיל פרויקטים משלכם של למידת מכונה באמצעות Vertex AI. במעבדה הזו נשתמש ב-Cloud Shell כדי ליצור אימג' מותאם אישית של Docker, כדי להדגים קונטיינרים בהתאמה אישית לאימון באמצעות Vertex AI.
אמנם אנחנו משתמשים ב-TensorFlow לקוד המודל כאן, אבל אפשר להחליף אותו בקלות ב-framework אחר.
מה לומדים
במאמר הזה נסביר איך:
- יצירה של קוד לאימון מודלים והעברה שלו לקונטיינר באמצעות Cloud Shell
- שליחת משימת אימון של מודל בהתאמה אישית אל Vertex AI
- פריסת המודל שאומן לנקודת קצה, ושימוש בנקודת הקצה הזו כדי לקבל חיזויים
העלות הכוללת של הרצת ה-Lab הזה ב-Google Cloud היא בערך 2$.
2. מבוא ל-Vertex AI
בשיעור ה-Lab הזה נעשה שימוש במוצר ה-AI החדש ביותר שזמין ב-Google Cloud. Vertex AI משלב את מוצרי ה-ML ב-Google Cloud לחוויית פיתוח חלקה. בעבר, היה אפשר לגשת למודלים שאומנו באמצעות AutoML ולמודלים בהתאמה אישית דרך שירותים נפרדים. המוצר החדש משלב את שניהם ב-API אחד, יחד עם מוצרים חדשים אחרים. אפשר גם להעביר פרויקטים קיימים אל Vertex AI. אם יש לך משוב, אפשר לעיין בדף התמיכה.
Vertex כולל כלים רבים ושונים שיעזרו לכם בכל שלב בתהליך העבודה של למידת מכונה, כפי שניתן לראות בתרשים שלמטה. נתמקד בשימוש ב-Training וב-Prediction של Vertex, שמודגשים בהמשך.

3. הגדרת הסביבה
הגדרת סביבה בקצב עצמי
נכנסים אל Cloud Console ויוצרים פרויקט חדש או משתמשים בפרויקט קיים. (אם עדיין אין לכם חשבון Gmail או Google Workspace, אתם צריכים ליצור חשבון).

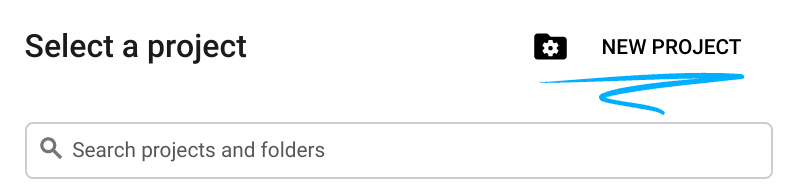
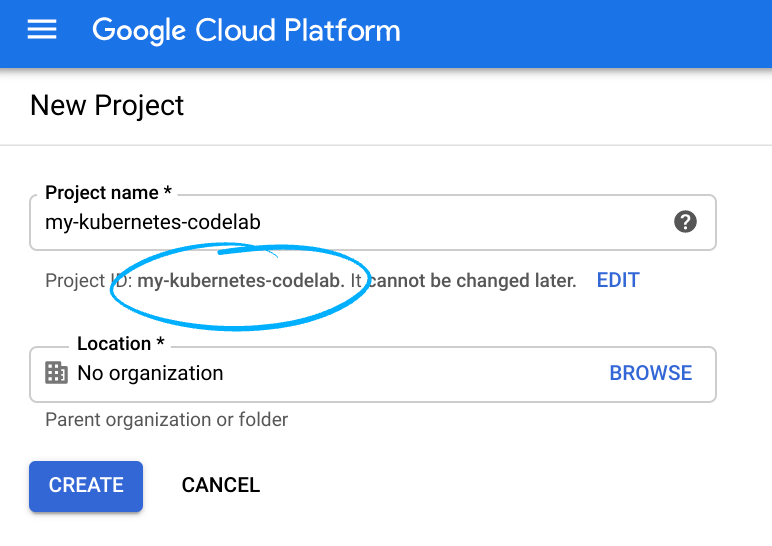
חשוב לזכור את מזהה הפרויקט, שהוא שם ייחודי בכל הפרויקטים ב-Google Cloud (השם שלמעלה כבר תפוס ולא יתאים לכם, מצטערים!).
לאחר מכן, תצטרכו להפעיל את החיוב ב-Cloud Console כדי להשתמש במשאבים של Google Cloud.
העלות של התרגול הזה לא אמורה להיות גבוהה, ואולי אפילו לא תצטרכו לשלם בכלל. חשוב לפעול לפי ההוראות שבקטע 'ניקוי' כדי להשבית את המשאבים, וכך לא תחויבו על שימוש מעבר למה שמוסבר במדריך הזה. משתמשים חדשים ב-Google Cloud זכאים לתוכנית תקופת ניסיון בחינם בשווי 300$.
שלב 1: הפעלת Cloud Shell
בשיעור ה-Lab הזה תעבדו בסשן של Cloud Shell, שהוא מתורגמן פקודות שמתארח במכונה וירטואלית שפועלת בענן של Google. אפשר להריץ את הקטע הזה בקלות במחשב שלכם, אבל השימוש ב-Cloud Shell מאפשר לכולם גישה לחוויה שניתנת לשחזור בסביבה עקבית. אחרי הסדנה, אתם מוזמנים לנסות שוב את החלק הזה במחשב שלכם.

הפעלת Cloud Shell
בפינה הימנית העליונה של Cloud Console, לוחצים על הלחצן Activate Cloud Shell (הפעלת Cloud Shell):

אם זו הפעם הראשונה שאתם מפעילים את Cloud Shell, יוצג לכם מסך ביניים (בחלק הנגלל) עם תיאור של הכלי. במקרה כזה, לוחצים על המשך (והמסך הזה לא יוצג לכם יותר). כך נראה המסך החד-פעמי:
הקצאת המשאבים והחיבור ל-Cloud Shell נמשכים רק כמה רגעים.

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות של הרשת. אפשר לבצע את רוב העבודה ב-codelab הזה, אם לא את כולה, באמצעות דפדפן או Chromebook.
אחרי שמתחברים ל-Cloud Shell, אמור להופיע אימות שכבר בוצע ושהפרויקט כבר הוגדר לפי מזהה הפרויקט.
מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שעברתם אימות:
gcloud auth list
פלט הפקודה
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט:
gcloud config list project
פלט הפקודה
[core] project = <PROJECT_ID>
אם הוא לא מוגדר, אפשר להגדיר אותו באמצעות הפקודה הבאה:
gcloud config set project <PROJECT_ID>
פלט הפקודה
Updated property [core/project].
ל-Cloud Shell יש כמה משתני סביבה, כולל GOOGLE_CLOUD_PROJECT שמכיל את השם של פרויקט בענן הנוכחי. נשתמש בזה במקומות שונים במהלך שיעור ה-Lab הזה. אפשר לראות אותו על ידי הפעלת הפקודה:
echo $GOOGLE_CLOUD_PROJECT
שלב 2: הפעלת ממשקי API
בשלבים הבאים נסביר איפה צריך את השירותים האלה (ולמה), אבל בינתיים, מריצים את הפקודה הזו כדי להעניק לפרויקט גישה לשירותים Compute Engine, Container Registry ו-Vertex AI:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
אמורה להופיע הודעה על הצלחה, כמו זו:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
שלב 3: יצירת קטגוריה של Cloud Storage
כדי להריץ משימת אימון ב-Vertex AI, נצטרך קטגוריית אחסון לאחסון נכסי המודל השמורים. כדי ליצור קטגוריה, מריצים את הפקודות הבאות במסוף Cloud Shell:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
שלב 4: יצירת כינוי ל-Python 3
הקוד במעבדה הזו משתמש ב-Python 3. כדי לוודא שמשתמשים ב-Python 3 כשמריצים את הסקריפטים שתיצרו בשיעור ה-Lab הזה, יוצרים כינוי על ידי הרצת הפקודה הבאה ב-Cloud Shell:
alias python=python3
המודל שנאמן ונשתמש בו בשיעור ה-Lab הזה מבוסס על המדריך הזה ממסמכי TensorFlow. במדריך הזה נעשה שימוש במערך הנתונים Auto MPG מ-Kaggle כדי לחזות את יעילות צריכת הדלק של כלי רכב.
4. יצירת קונטיינר לקוד האימון
נשלח את משימת האימון הזו ל-Vertex על ידי הכנסת קוד האימון שלנו לקונטיינר Docker והעברת הקונטיינר הזה אל Google Container Registry. באמצעות הגישה הזו, אנחנו יכולים לאמן מודל שנבנה עם כל מסגרת.
שלב 1: הגדרת קבצים
כדי להתחיל, מריצים את הפקודות הבאות בטרמינל ב-Cloud Shell כדי ליצור את הקבצים שנצטרך בשביל קובץ ה-Docker Container:
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
עכשיו אמורה להיות לכם ספרייה בשם mpg/ שנראית כך:
+ Dockerfile
+ trainer/
+ train.py
כדי להציג ולערוך את הקבצים האלה, נשתמש בעורך הקוד המובנה של Cloud Shell. אפשר לעבור בין העורך לבין הטרמינל בלחיצה על הכפתור בסרגל התפריטים השמאלי העליון ב-Cloud Shell:

שלב 2: יצירת Dockerfile
כדי להוסיף את הקוד שלנו לקונטיינר, קודם ניצור קובץ Dockerfile. בקובץ Dockerfile נכלול את כל הפקודות שנדרשות להרצת התמונה. הסקריפט יתקין את כל הספריות שבהן אנחנו משתמשים ויגדיר את נקודת הכניסה לקוד ההדרכה.
בעורך הקבצים של Cloud Shell, פותחים את הספרייה mpg/ ולוחצים לחיצה כפולה כדי לפתוח את Dockerfile:

מעתיקים את הקוד הבא לקובץ:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
קובץ ה-Dockerfile הזה משתמש בקובץ האימג' של Docker TensorFlow Enterprise 2.3 של Deep Learning Container. הקונטיינרים של Deep Learning ב-Google Cloud מגיעים עם הרבה frameworks נפוצים של ML ומדעי נתונים שהותקנו מראש. הסביבה שבה אנחנו משתמשים כוללת את TF Enterprise 2.3, Pandas, Scikit-learn ועוד. אחרי שמורידים את התמונה הזו, קובץ ה-Dockerfile הזה מגדיר את נקודת הכניסה לקוד האימון שלנו, שנוסיף בשלב הבא.
שלב 3: הוספת קוד לאימון המודל
ב-Cloud Shell Editor, פותחים את הקובץ train.py ומעתיקים את הקוד שבהמשך (הקוד הזה מבוסס על המדריך במסמכי TensorFlow).
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
אחרי שמעתיקים את הקוד שלמעלה לקובץ mpg/trainer/train.py, חוזרים למסוף ב-Cloud Shell ומריצים את הפקודה הבאה כדי להוסיף את שם הקטגוריה שלכם לקובץ:
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
שלב 4: פיתוח ובדיקה של הקונטיינר באופן מקומי
במסוף, מריצים את הפקודה הבאה כדי להגדיר משתנה עם ה-URI של קובץ אימג' של קונטיינר ב-Google Container Registry:
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
לאחר מכן, בונים את הקונטיינר על ידי הרצת הפקודה הבאה מתיקיית השורש של mpg:
docker build ./ -t $IMAGE_URI
אחרי שיוצרים את הקונטיינר, מעבירים אותו אל Google Container Registry:
docker push $IMAGE_URI
כדי לוודא שהתמונה נדחפה ל-Container Registry, כשעוברים אל הקטע Container Registry במסוף אמור להופיע משהו כזה:

אחרי שדחפנו את מאגר התגים ל-Container Registry, אפשר להתחיל להריץ משימת אימון של מודל בהתאמה אישית.
5. הרצת משימת אימון ב-Vertex AI
ב-Vertex יש שתי אפשרויות לאימון מודלים:
- AutoML: אימון מודלים באיכות גבוהה עם מאמץ מינימלי ומומחיות ב-ML.
- אימון מותאם אישית: הפעלת אפליקציות אימון מותאמות אישית בענן באמצעות אחד מהקונטיינרים המובנים מראש של Google Cloud, או שימוש בקונטיינר משלכם.
במעבדה הזו אנחנו משתמשים באימון מותאם אישית באמצעות קונטיינר מותאם אישית משלנו ב-Google Container Registry. כדי להתחיל, עוברים לקטע Training בקטע Vertex במסוף Cloud:
שלב 1: הפעלת משימת האימון
לוחצים על יצירה כדי להזין את הפרמטרים של משימת האימון והמודל שנפרס:
- בקטע מערך נתונים, בוחרים באפשרות אין מערך נתונים מנוהל.
- לאחר מכן בוחרים באפשרות Custom training (advanced) (אימון בהתאמה אישית (מתקדם)) בתור שיטת האימון ולוחצים על Continue (המשך).
- מזינים
mpg(או כל שם אחר שרוצים לתת למודל) בשדה שם המודל. - לוחצים על המשך.
בשלב Container settings (הגדרות מאגר התגים), בוחרים באפשרות Custom container (מאגר תגים בהתאמה אישית):

בתיבה הראשונה (קובץ אימג' של קונטיינר), לוחצים על Browse ומחפשים את הקונטיינר שהעברתם בדחיפה ל-Container Registry. הוא אמור להיראות כך:
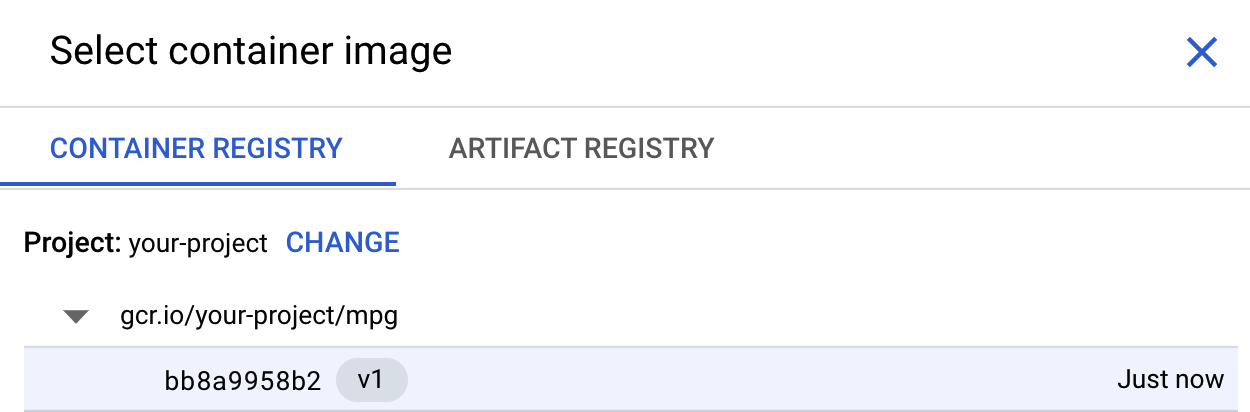
משאירים את שאר השדות ריקים ולוחצים על המשך.
במדריך הזה לא נשתמש בכוונון היפרפרמטרים, לכן משאירים את התיבה 'הפעלת כוונון היפרפרמטרים' לא מסומנת ולוחצים על המשך.
בקטע Compute and pricing, משאירים את האזור שנבחר כמו שהוא ובוחרים באפשרות n1-standard-4 בשדה סוג מכונה:
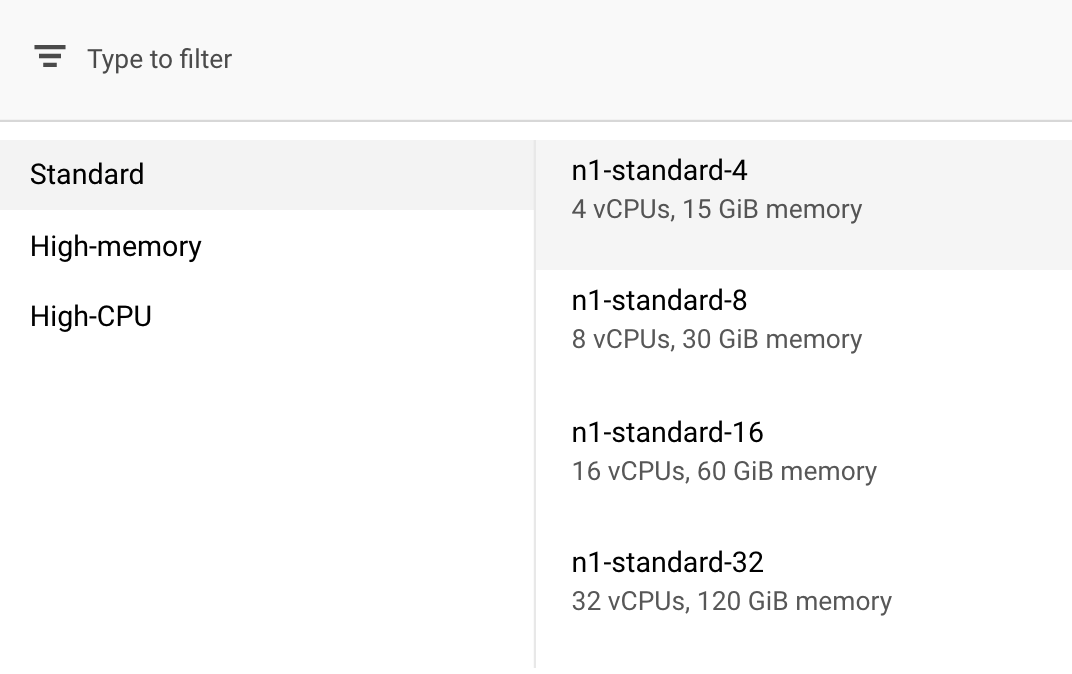
בגלל שהמודל בהדגמה הזו מתאמן במהירות, אנחנו משתמשים בסוג מכונה קטן יותר.
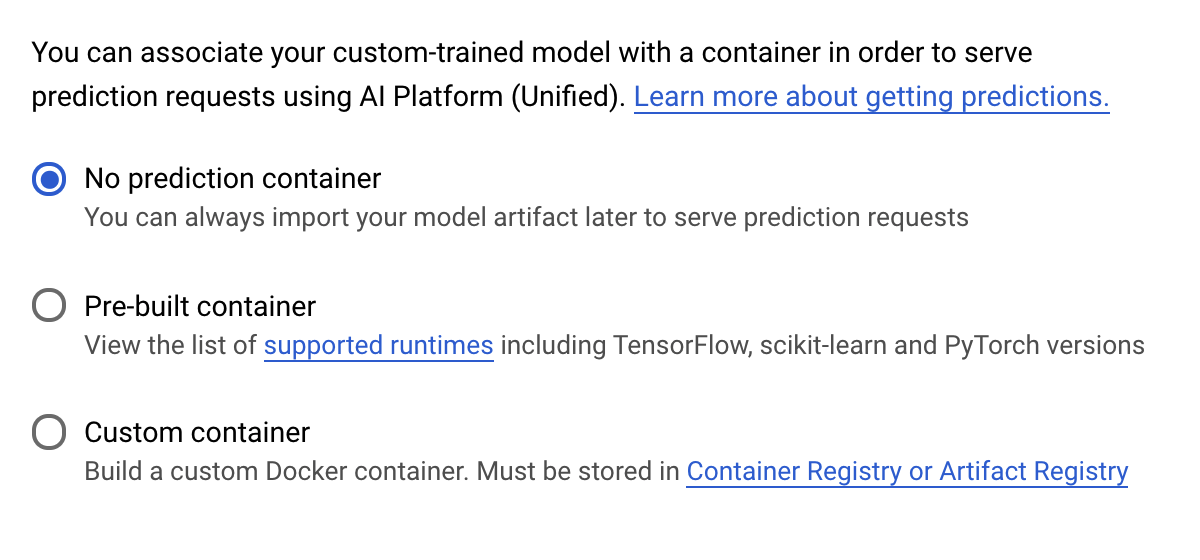
בשלב Prediction container (מאגר תגים לחיזוי), בוחרים באפשרות No prediction container (ללא מאגר תגים לחיזוי):
6. פריסת נקודת קצה של מודל
בשלב הזה ניצור נקודת קצה (endpoint) למודל שאומן. אנחנו יכולים להשתמש בזה כדי לקבל חיזויים לגבי המודל שלנו באמצעות Vertex AI API. לשם כך, העמדנו לרשותכם גרסה של נכסי המודל המאומן שיוצאו בקטגוריה ציבורית של GCS.
בארגון, בדרך כלל צוות אחד או אדם אחד אחראים לבניית המודל, וצוות אחר אחראי לפריסה שלו. במאמר הזה נסביר איך לקחת מודל שכבר אומן ולפרוס אותו לחיזוי.
בשלב הזה נשתמש ב-Vertex AI SDK כדי ליצור מודל, לפרוס אותו לנקודת קצה ולקבל חיזוי.
שלב 1: התקנה של Vertex SDK
בטרמינל של Cloud Shell, מריצים את הפקודה הבאה כדי להתקין את Vertex AI SDK:
pip3 install google-cloud-aiplatform --upgrade --user
אנחנו יכולים להשתמש ב-SDK הזה כדי ליצור אינטראקציה עם חלקים שונים ב-Vertex.
שלב 2: יצירת מודל ופריסת נקודת קצה
בשלב הבא ניצור קובץ Python ונשתמש ב-SDK כדי ליצור משאב של מודל ולפרוס אותו לנקודת קצה. בכלי לעריכת קבצים ב-Cloud Shell, לוחצים על קובץ ואז על קובץ חדש:
נותנים לקובץ את השם deploy.py. פותחים את הקובץ בעורך ומעתיקים את הקוד הבא:
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
אחר כך חוזרים לטרמינל ב-Cloud Shell, cd חוזרים לספריית הבסיס ומריצים את סקריפט Python שיצרתם:
cd ..
python3 deploy.py | tee deploy-output.txt
תראו עדכונים שמתועדים במסוף בזמן יצירת המשאבים. התהליך יימשך 10-15 דקות. כדי לוודא שהיא פועלת כמו שצריך, עוברים אל הקטע Models במסוף ב-Vertex AI:
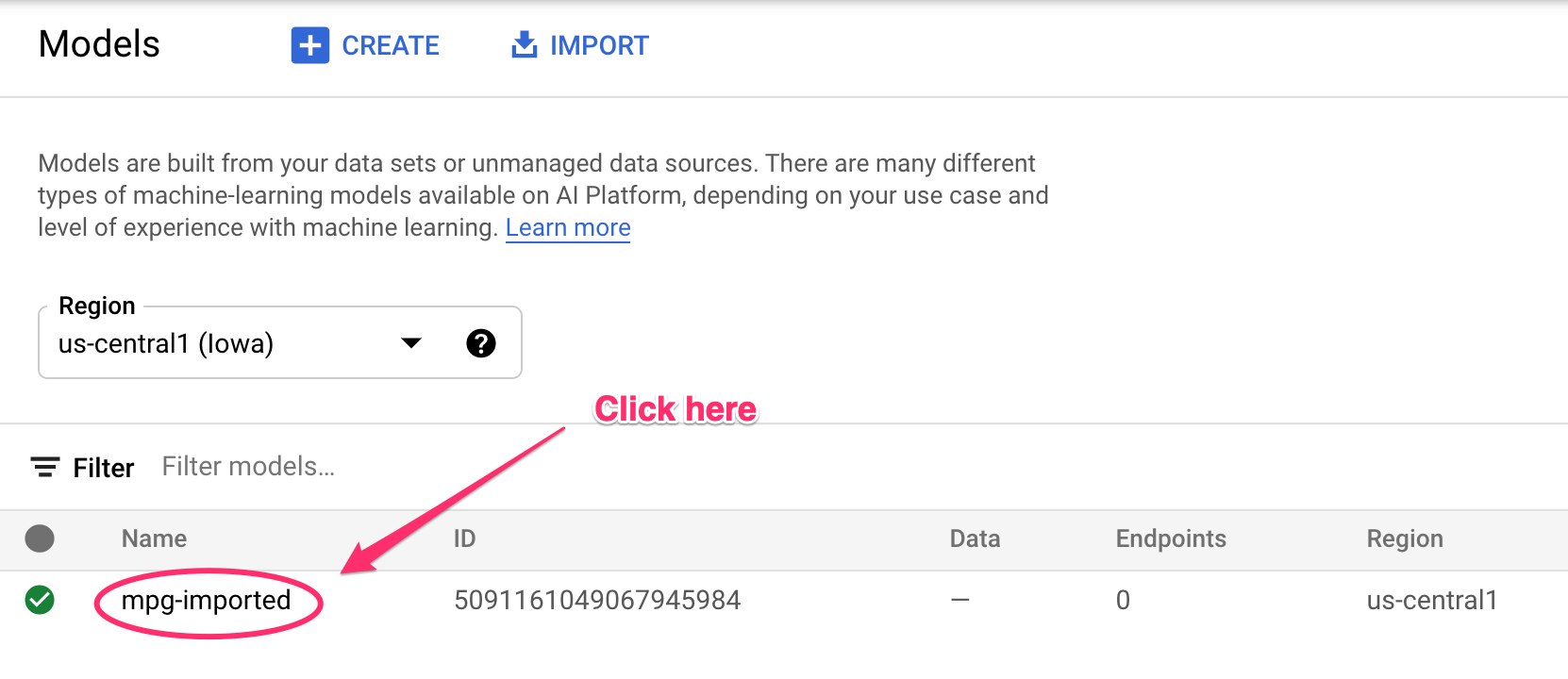
לוחצים על mgp-imported ונקודת הקצה של המודל אמורה להיווצר:
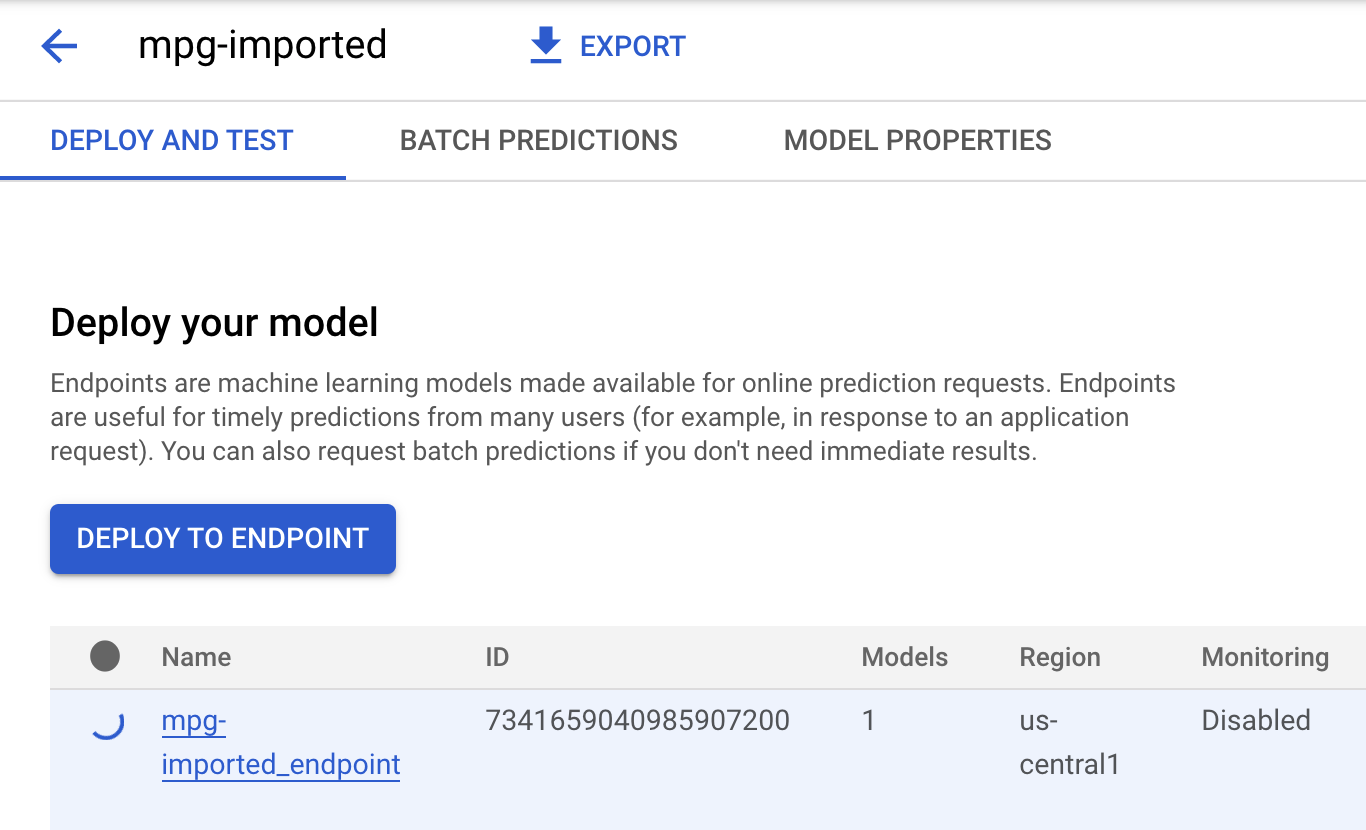
בטרמינל של Cloud Shell, אחרי שהפריסה של נקודת הקצה תסתיים, יופיע יומן שדומה לזה:
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
תשתמשו בזה בשלב הבא כדי לקבל תחזית לגבי נקודת הקצה שפרסתם.
שלב 3: קבלת חיזויים בנקודת הקצה שנפרסה
ב-Cloud Shell Editor, יוצרים קובץ חדש בשם predict.py:
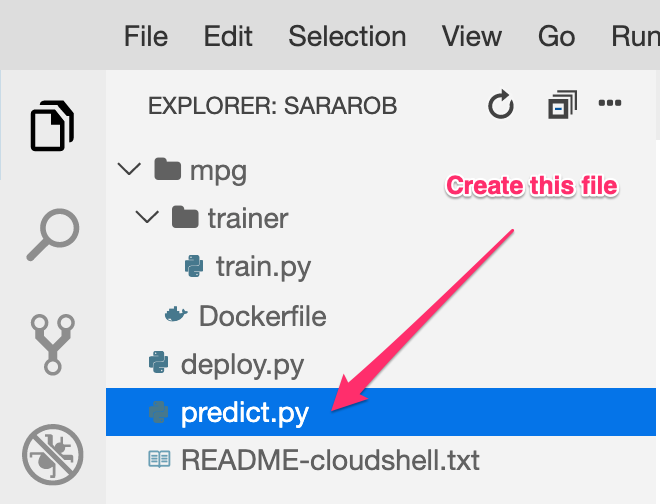
פותחים את predict.py ומדביקים בו את הקוד הבא:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
אחר כך חוזרים לטרמינל ומזינים את הפקודה הבאה כדי להחליף את ENDPOINT_STRING בקובץ predict בנקודת הקצה שלכם:
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
עכשיו הגיע הזמן להריץ את הקובץ predict.py כדי לקבל תחזית מנקודת הקצה של המודל שפרסנו:
python3 predict.py
התשובה של ה-API אמורה להופיע ביומן, יחד עם נתון החיזוי של צריכת הדלק שחושב בבדיקה.
🎉 איזה כיף! 🎉
למדתם איך להשתמש ב-Vertex AI כדי:
- לאמן מודל על ידי ציון קוד האימון בקונטיינר בהתאמה אישית. בדוגמה הזו השתמשנו במודל TensorFlow, אבל אפשר לאמן מודל שנבנה עם כל מסגרת באמצעות קונטיינרים בהתאמה אישית.
- פריסת מודל TensorFlow באמצעות קונטיינר מוכן מראש כחלק מאותו תהליך עבודה שבו השתמשתם לאימון.
- יוצרים נקודת קצה של מודל ומפיקים חיזוי.
מידע נוסף על חלקים שונים ב-Vertex AI זמין בתיעוד. כדי לראות את התוצאות של משימת האימון שהתחלתם בשלב 5, עוברים אל הקטע training במסוף Vertex.
7. הסרת המשאבים
כדי למחוק את נקודת הקצה שפרסתם, עוברים אל הקטע Endpoints במסוף Vertex ולוחצים על סמל המחיקה:

כדי למחוק את קטגוריית האחסון, בתפריט הניווט ב-Cloud Console, עוברים אל Storage, בוחרים את הקטגוריה ולוחצים על Delete:
