1. खास जानकारी
इस लैब में, आपको एंड-टू-एंड एमएल वर्कफ़्लो बनाने के लिए, Vertex AI का इस्तेमाल करने का तरीका बताया जाएगा. Vertex AI, Google Cloud का नया मैनेज किया गया एमएल प्लैटफ़ॉर्म है. आपको रॉ डेटा से लेकर डिप्लॉय किए गए मॉडल तक पहुंचने का तरीका बताया जाएगा. साथ ही, इस वर्कशॉप के बाद, Vertex AI की मदद से अपने एमएल प्रोजेक्ट डेवलप करने और उन्हें प्रोडक्शन के लिए तैयार करने का तरीका पता चल जाएगा. इस लैब में, हम Cloud Shell का इस्तेमाल करके, पसंद के मुताबिक बनाई गई Docker इमेज तैयार कर रहे हैं. इससे, Vertex AI की मदद से ट्रेनिंग के लिए, पसंद के मुताबिक कंटेनर दिखाए जा सकते हैं.
यहां मॉडल कोड के लिए TensorFlow का इस्तेमाल किया जा रहा है. हालांकि, इसे किसी दूसरे फ़्रेमवर्क से आसानी से बदला जा सकता है.
आपको ये सब सीखने को मिलेगा
आपको, इनके बारे में जानकारी मिलेगी:
- Cloud Shell का इस्तेमाल करके, मॉडल ट्रेनिंग कोड बनाएं और उसे कंटेनर में बदलें
- Vertex AI पर कस्टम मॉडल ट्रेनिंग का काम सबमिट करना
- ट्रेन किए गए मॉडल को किसी एंडपॉइंट पर डिप्लॉय करें और उस एंडपॉइंट का इस्तेमाल करके अनुमान पाएं
Google Cloud पर इस लैब को चलाने की कुल लागत करीब 2 डॉलर है.
2. Vertex AI के बारे में जानकारी
इस लैब में, Google Cloud पर उपलब्ध एआई प्रॉडक्ट की नई सुविधा का इस्तेमाल किया जाता है. Vertex AI, Google Cloud के सभी एमएल प्रॉडक्ट को एक साथ इंटिग्रेट करता है, ताकि डेवलपर को बेहतर अनुभव मिल सके. पहले, AutoML और कस्टम मॉडल से ट्रेन किए गए मॉडल को अलग-अलग सेवाओं के ज़रिए ऐक्सेस किया जा सकता था. नए ऑफ़र में, इन दोनों को एक ही एपीआई में शामिल किया गया है. साथ ही, इसमें अन्य नए प्रॉडक्ट भी शामिल हैं. मौजूदा प्रोजेक्ट को भी Vertex AI पर माइग्रेट किया जा सकता है. अगर आपको कोई सुझाव देना है या शिकायत करनी है, तो कृपया सहायता पेज पर जाएं.
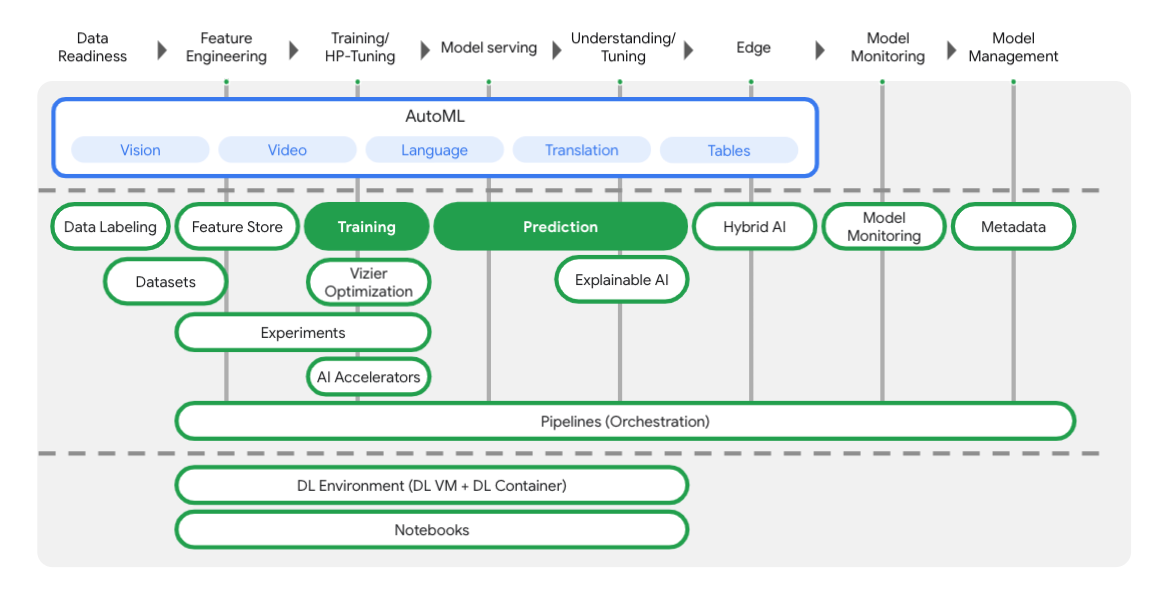
Vertex में, एमएल वर्कफ़्लो के हर चरण में आपकी मदद करने के लिए कई अलग-अलग टूल शामिल हैं. इन्हें नीचे दिए गए डायग्राम में देखा जा सकता है. हमारा फ़ोकस, नीचे हाइलाइट किए गए Vertex Training और Prediction का इस्तेमाल करने पर होगा.
3. अपना एनवायरमेंट सेट अप करना
अपनी स्पीड से एनवायरमेंट सेट अप करना
Cloud Console में साइन इन करें. इसके बाद, नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. (अगर आपके पास पहले से Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.)

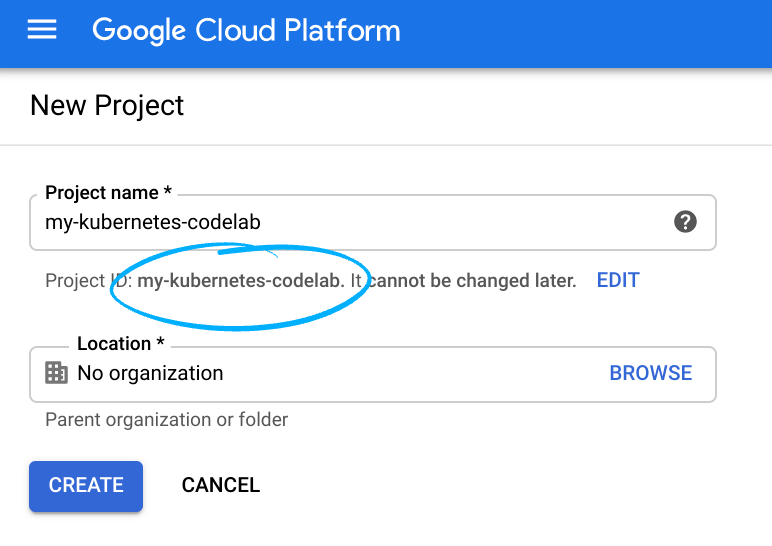
प्रोजेक्ट आईडी याद रखें. यह सभी Google Cloud प्रोजेक्ट के लिए एक यूनीक नाम होता है. ऊपर दिया गया नाम पहले ही इस्तेमाल किया जा चुका है. इसलिए, यह आपके लिए काम नहीं करेगा. माफ़ करें!
इसके बाद, Google Cloud संसाधनों का इस्तेमाल करने के लिए, आपको Cloud Console में बिलिंग चालू करनी होगी.
इस कोडलैब को पूरा करने में ज़्यादा खर्च नहीं आएगा. "सफ़ाई करना" सेक्शन में दिए गए निर्देशों का पालन करना न भूलें. इसमें बताया गया है कि संसाधनों को कैसे बंद किया जाए, ताकि इस ट्यूटोरियल के बाद आपको बिलिंग न करनी पड़े. Google Cloud के नए उपयोगकर्ताओं को, मुफ़्त में आज़माने के लिए 300 डॉलर का क्रेडिट मिलता है.
पहला चरण: Cloud Shell शुरू करना
इस लैब में, आपको Cloud Shell सेशन में काम करना होगा. यह एक कमांड इंटरप्रेटर है, जिसे Google के क्लाउड में चल रही वर्चुअल मशीन होस्ट करती है. इस सेक्शन को अपने कंप्यूटर पर भी आसानी से चलाया जा सकता है. हालांकि, Cloud Shell का इस्तेमाल करने से, सभी लोगों को एक जैसे एनवायरमेंट में एक जैसा अनुभव मिलता है. लैब के बाद, अपने कंप्यूटर पर इस सेक्शन को फिर से आज़माया जा सकता है.
Cloud Shell चालू करें
Cloud Console में सबसे ऊपर दाईं ओर, Cloud Shell चालू करें के लिए, नीचे दिए गए बटन पर क्लिक करें:

अगर आपने पहले कभी Cloud Shell का इस्तेमाल नहीं किया है, तो आपको एक इंटरमीडिएट स्क्रीन (नीचे फ़ोल्ड की गई) दिखेगी. इसमें Cloud Shell के बारे में जानकारी दी गई होगी. अगर ऐसा है, तो जारी रखें पर क्लिक करें. इसके बाद, आपको यह स्क्रीन कभी नहीं दिखेगी. एक बार दिखने वाली स्क्रीन ऐसी दिखती है:
Cloud Shell से कनेक्ट होने में कुछ ही सेकंड लगेंगे.

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद होते हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है और Google Cloud में चलता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में ज़्यादातर काम, सिर्फ़ ब्राउज़र या Chromebook की मदद से किया जा सकता है.
Cloud Shell से कनेक्ट होने के बाद, आपको दिखेगा कि आपकी पुष्टि पहले ही हो चुकी है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर पहले ही सेट कर दिया गया है.
पुष्टि करें कि आपने Cloud Shell में पुष्टि कर ली है. इसके लिए, यह कमांड चलाएं:
gcloud auth list
कमांड आउटपुट
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं:
gcloud config list project
कमांड आउटपुट
[core] project = <PROJECT_ID>
अगर ऐसा नहीं है, तो इस कमांड का इस्तेमाल करके इसे सेट किया जा सकता है:
gcloud config set project <PROJECT_ID>
कमांड आउटपुट
Updated property [core/project].
Cloud Shell में कुछ एनवायरमेंट वैरिएबल होते हैं. इनमें GOOGLE_CLOUD_PROJECT भी शामिल है. इसमें हमारे मौजूदा Cloud प्रोजेक्ट का नाम होता है. हम इसका इस्तेमाल इस लैब में कई जगहों पर करेंगे. इसे चलाने पर आपको यह दिखेगा:
echo $GOOGLE_CLOUD_PROJECT
दूसरा चरण: एपीआई चालू करना
बाद के चरणों में, आपको पता चलेगा कि इन सेवाओं की ज़रूरत कहां है और क्यों. हालांकि, फ़िलहाल इस कमांड को चलाकर, अपने प्रोजेक्ट को Compute Engine, Container Registry, और Vertex AI सेवाओं का ऐक्सेस दें:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
इससे, इस तरह का मैसेज दिखेगा:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
तीसरा चरण: Cloud Storage बकेट बनाना
Vertex AI पर ट्रेनिंग का काम करने के लिए, हमें एक स्टोरेज बकेट की ज़रूरत होगी. इसमें हम सेव की गई मॉडल ऐसेट को सेव करेंगे. बकेट बनाने के लिए, Cloud Shell टर्मिनल में ये कमांड चलाएं:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
चौथा चरण: Python 3 को उपनाम देना
इस लैब में Python 3 का इस्तेमाल किया गया है. इस लैब में बनाई जाने वाली स्क्रिप्ट को चलाने के लिए, Python 3 का इस्तेमाल किया जाना चाहिए. इसके लिए, Cloud Shell में यह कमांड चलाकर एक एलियास बनाएं:
alias python=python3
इस लैब में जिस मॉडल को ट्रेन किया जाएगा और इस्तेमाल किया जाएगा वह TensorFlow के दस्तावेज़ों में दिए गए इस ट्यूटोरियल पर आधारित है. इस ट्यूटोरियल में, किसी वाहन की ईंधन दक्षता का अनुमान लगाने के लिए, Kaggle के Auto MPG डेटासेट का इस्तेमाल किया गया है.
4. ट्रेनिंग कोड को कंटेनर में रखना
हम इस ट्रेनिंग जॉब को Vertex पर सबमिट करेंगे. इसके लिए, हम अपने ट्रेनिंग कोड को Docker कंटेनर में डालेंगे और इस कंटेनर को Google Container Registry पर पुश करेंगे. इस तरीके का इस्तेमाल करके, हम किसी भी फ़्रेमवर्क से बनाए गए मॉडल को ट्रेन कर सकते हैं.
पहला चरण: फ़ाइलें सेट अप करना
शुरू करने के लिए, Cloud Shell में मौजूद टर्मिनल से ये निर्देश चलाएं. इससे वे फ़ाइलें बन जाएंगी जिनकी हमें Docker कंटेनर के लिए ज़रूरत होगी:
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
अब आपके पास mpg/ डायरेक्ट्री होनी चाहिए, जो इस तरह दिखती है:
+ Dockerfile
+ trainer/
+ train.py
इन फ़ाइलों को देखने और उनमें बदलाव करने के लिए, हम Cloud Shell के पहले से मौजूद कोड एडिटर का इस्तेमाल करेंगे. Cloud Shell में सबसे ऊपर दाईं ओर मौजूद मेन्यू बार में मौजूद इस बटन पर क्लिक करके, एडिटर और टर्मिनल के बीच स्विच किया जा सकता है:

दूसरा चरण: Dockerfile बनाना
अपने कोड को कंटेनर में रखने के लिए, हम सबसे पहले एक Dockerfile बनाएंगे. हम अपने Dockerfile में, इमेज को चलाने के लिए ज़रूरी सभी कमांड शामिल करेंगे. इससे, इस्तेमाल की जा रही सभी लाइब्रेरी इंस्टॉल हो जाएंगी. साथ ही, ट्रेनिंग कोड के लिए एंट्री पॉइंट सेट अप हो जाएगा.
Cloud Shell फ़ाइल एडिटर में, अपनी mpg/ डायरेक्ट्री खोलें. इसके बाद, Dockerfile खोलने के लिए उस पर दो बार क्लिक करें:
इसके बाद, इस फ़ाइल में यह कोड कॉपी करके चिपकाएं:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
इस Dockerfile में, Deep Learning Container TensorFlow Enterprise 2.3 Docker इमेज का इस्तेमाल किया गया है. Google Cloud पर मौजूद डीप लर्निंग कंटेनर में, एमएल और डेटा साइंस के कई सामान्य फ़्रेमवर्क पहले से इंस्टॉल होते हैं. हम जिस लाइब्रेरी का इस्तेमाल कर रहे हैं उसमें TF Enterprise 2.3, Pandas, Scikit-learn वगैरह शामिल हैं. उस इमेज को डाउनलोड करने के बाद, यह Dockerfile हमारे ट्रेनिंग कोड के लिए एंट्रीपॉइंट सेट अप करता है. इसे हम अगले चरण में जोड़ेंगे.
तीसरा चरण: मॉडल ट्रेनिंग कोड जोड़ना
Cloud Shell एडिटर में जाकर, train.py फ़ाइल खोलें. इसके बाद, यहां दिया गया कोड कॉपी करें. यह कोड, TensorFlow के दस्तावेज़ में दिए गए ट्यूटोरियल से लिया गया है.
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
ऊपर दिए गए कोड को mpg/trainer/train.py फ़ाइल में कॉपी करने के बाद, Cloud Shell में मौजूद टर्मिनल पर वापस जाएं. इसके बाद, फ़ाइल में अपने बकेट का नाम जोड़ने के लिए, यह कमांड चलाएं:
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
चौथा चरण: कंटेनर को स्थानीय तौर पर बनाना और उसकी जांच करना
Google Container Registry में मौजूद कंटेनर इमेज के यूआरआई के साथ वैरिएबल को तय करने के लिए, अपने टर्मिनल से यह कमांड चलाएं:
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
इसके बाद, mpg डायरेक्ट्री के रूट से यह कमांड चलाकर कंटेनर बनाएं:
docker build ./ -t $IMAGE_URI
कंटेनर बनाने के बाद, उसे Google Container Registry पर पुश करें:
docker push $IMAGE_URI
यह पुष्टि करने के लिए कि आपकी इमेज को Container Registry में पुश कर दिया गया है, आपको अपनी कंसोल के Container Registry सेक्शन पर जाकर कुछ ऐसा दिखेगा:
कंटेनर को Container Registry में पुश करने के बाद, अब हम कस्टम मॉडल ट्रेनिंग जॉब शुरू करने के लिए तैयार हैं.
5. Vertex AI पर ट्रेनिंग जॉब चलाना
Vertex, मॉडल को ट्रेन करने के लिए दो विकल्प देता है:
- AutoML: कम मेहनत और एमएल की विशेषज्ञता के साथ अच्छी क्वालिटी के मॉडल को ट्रेन करें.
- कस्टम ट्रेनिंग: Google Cloud के पहले से बने कंटेनर में से किसी एक का इस्तेमाल करके, क्लाउड में अपने कस्टम ट्रेनिंग ऐप्लिकेशन चलाएं. इसके अलावा, अपने कंटेनर का भी इस्तेमाल किया जा सकता है.
इस लैब में, हम Google Container Registry पर मौजूद अपने कस्टम कंटेनर के ज़रिए कस्टम ट्रेनिंग का इस्तेमाल कर रहे हैं. शुरू करने के लिए, Cloud Console के Vertex सेक्शन में मौजूद ट्रेनिंग सेक्शन पर जाएं:
पहला चरण: ट्रेनिंग जॉब शुरू करना
ट्रेनिंग जॉब और डिप्लॉय किए गए मॉडल के पैरामीटर डालने के लिए, बनाएं पर क्लिक करें:
- डेटासेट में जाकर, कोई मैनेज किया गया डेटासेट नहीं चुनें
- इसके बाद, ट्रेनिंग के तरीके के तौर पर कस्टम ट्रेनिंग (ऐडवांस) चुनें और जारी रखें पर क्लिक करें.
- मॉडल का नाम के लिए,
mpgडालें. इसके अलावा, अपने मॉडल के लिए कोई भी नाम डाला जा सकता है - जारी रखें पर क्लिक करें
कंटेनर की सेटिंग वाले चरण में, कस्टम कंटेनर चुनें:

पहले बॉक्स (कंटेनर इमेज) में, ब्राउज़ करें पर क्लिक करें. इसके बाद, उस कंटेनर को ढूंढें जिसे आपने अभी-अभी Container Registry में पुश किया है. यह कुछ ऐसी नज़र आनी चाहिए:
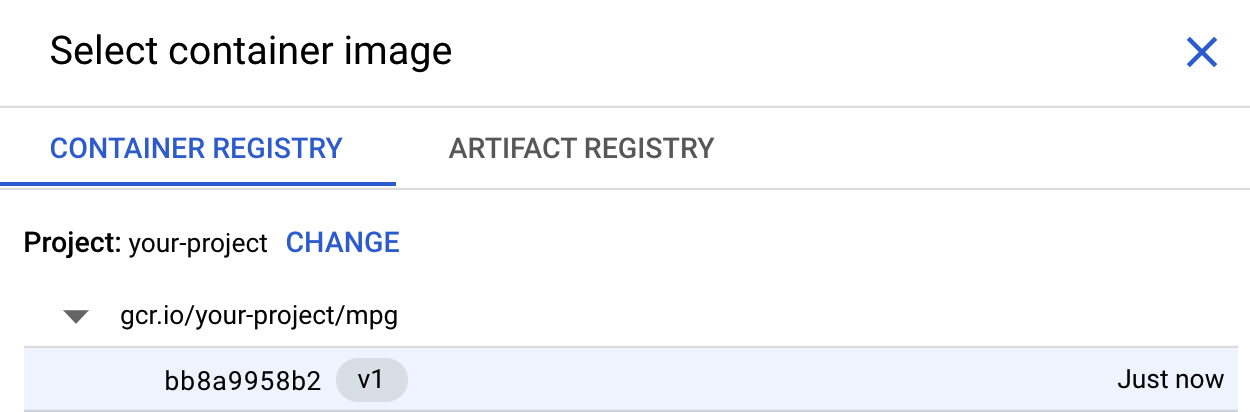
बाकी फ़ील्ड को खाली छोड़ दें और जारी रखें पर क्लिक करें.
हम इस ट्यूटोरियल में हाइपरपैरामीटर ट्यूनिंग का इस्तेमाल नहीं करेंगे. इसलिए, 'हाइपरपैरामीटर ट्यूनिंग चालू करें' बॉक्स से सही का निशान हटाएं और जारी रखें पर क्लिक करें.
कंप्यूट और कीमत में, चुने गए क्षेत्र को वैसे ही रहने दें और मशीन टाइप के तौर पर n1-standard-4 चुनें:
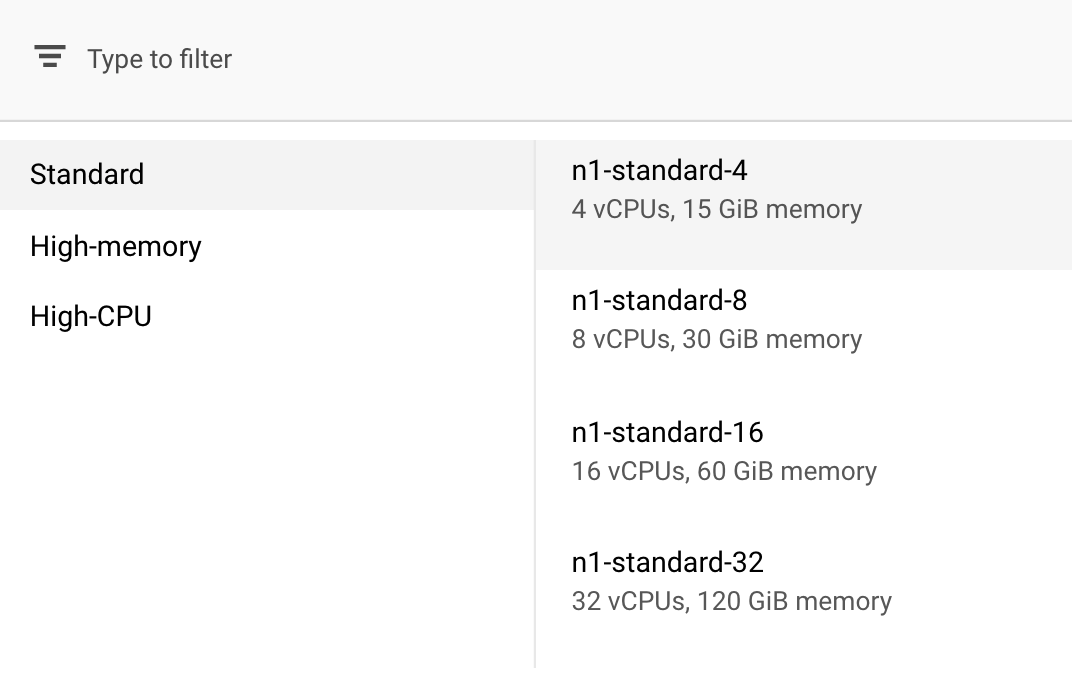
इस डेमो में मौजूद मॉडल को कम समय में ट्रेन किया जा सकता है. इसलिए, हम छोटे मशीन टाइप का इस्तेमाल कर रहे हैं.
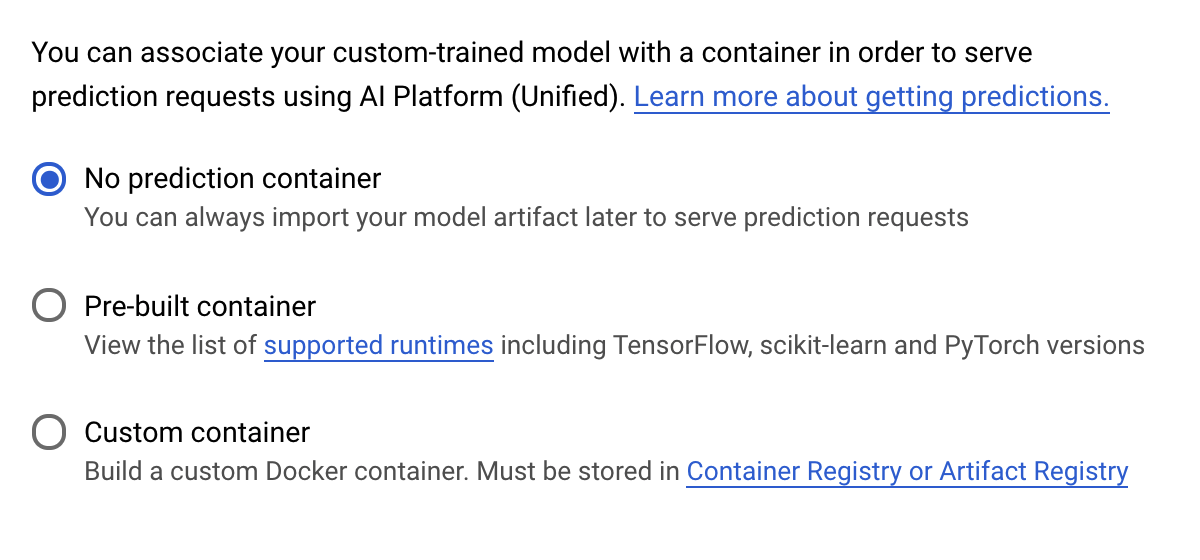
अनुमान लगाने वाले कंटेनर चरण में जाकर, अनुमान लगाने वाला कोई कंटेनर नहीं चुनें:
6. मॉडल एंडपॉइंट डिप्लॉय करना
इस चरण में, हम अपने ट्रेन किए गए मॉडल के लिए एक एंडपॉइंट बनाएंगे. हम इसका इस्तेमाल, Vertex AI API के ज़रिए अपने मॉडल पर अनुमान पाने के लिए कर सकते हैं. इसके लिए, हमने एक्सपोर्ट की गई ट्रेन किए गए मॉडल की ऐसेट का एक वर्शन, सार्वजनिक GCS बकेट में उपलब्ध कराया है.
किसी संगठन में, मॉडल बनाने की ज़िम्मेदारी किसी एक टीम या व्यक्ति के पास होती है. वहीं, मॉडल को डिप्लॉय करने की ज़िम्मेदारी किसी दूसरी टीम के पास होती है. यहां हम आपको ऐसे मॉडल को इस्तेमाल करने का तरीका बताएंगे जिसे पहले ही ट्रेन किया जा चुका है. साथ ही, हम आपको यह भी बताएंगे कि उसे अनुमान लगाने के लिए कैसे डिप्लॉय किया जाता है.
यहां हम मॉडल बनाने, उसे किसी एंडपॉइंट पर डिप्लॉय करने, और अनुमान पाने के लिए Vertex AI SDK का इस्तेमाल करेंगे.
पहला चरण: Vertex SDK इंस्टॉल करना
Vertex AI SDK टूल इंस्टॉल करने के लिए, Cloud Shell टर्मिनल में यह कमांड चलाएं:
pip3 install google-cloud-aiplatform --upgrade --user
हम इस SDK का इस्तेमाल, Vertex के कई अलग-अलग हिस्सों के साथ इंटरैक्ट करने के लिए कर सकते हैं.
दूसरा चरण: मॉडल बनाना और एंडपॉइंट डिप्लॉय करना
इसके बाद, हम एक Python फ़ाइल बनाएंगे. साथ ही, एसडीके का इस्तेमाल करके एक मॉडल संसाधन बनाएंगे और उसे किसी एंडपॉइंट पर डिप्लॉय करेंगे. Cloud Shell में मौजूद फ़ाइल एडिटर में जाकर, फ़ाइल और फिर नई फ़ाइल चुनें:
फ़ाइल को deploy.py नाम दें. इस फ़ाइल को अपने एडिटर में खोलें और यह कोड कॉपी करें:
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
इसके बाद, Cloud Shell में वापस टर्मिनल पर जाएं, cd वापस अपनी रूट डायरेक्ट्री में जाएं, और अभी बनाई गई इस Python स्क्रिप्ट को चलाएं:
cd ..
python3 deploy.py | tee deploy-output.txt
जब संसाधन बनाए जा रहे होंगे, तब आपको अपने टर्मिनल पर लॉग किए गए अपडेट दिखेंगे. इसे पूरा होने में 10 से 15 मिनट लगेंगे. यह पक्का करने के लिए कि यह सुविधा सही तरीके से काम कर रही है, Vertex AI में अपनी कंसोल के मॉडल सेक्शन पर जाएं:
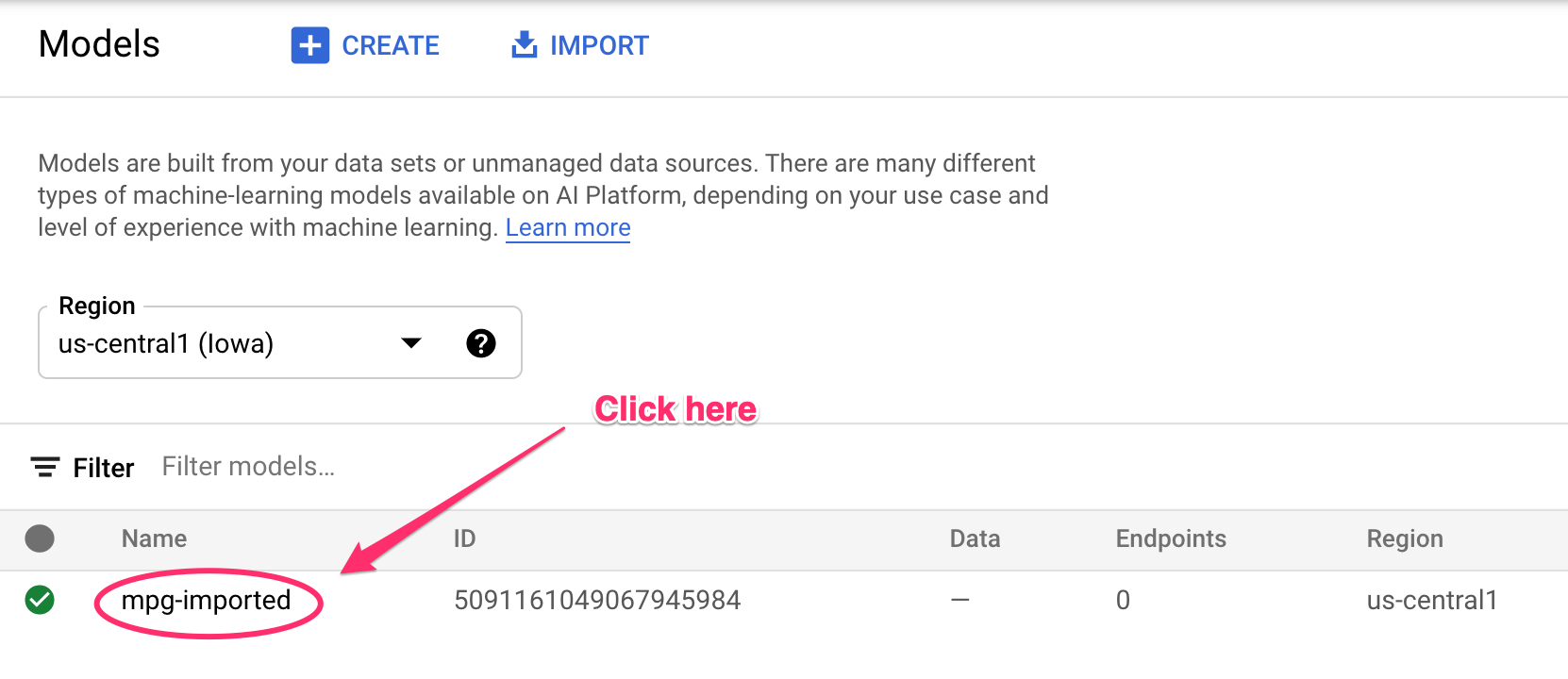
mgp-imported पर क्लिक करें. इसके बाद, आपको उस मॉडल के लिए अपना एंडपॉइंट बनता हुआ दिखेगा:
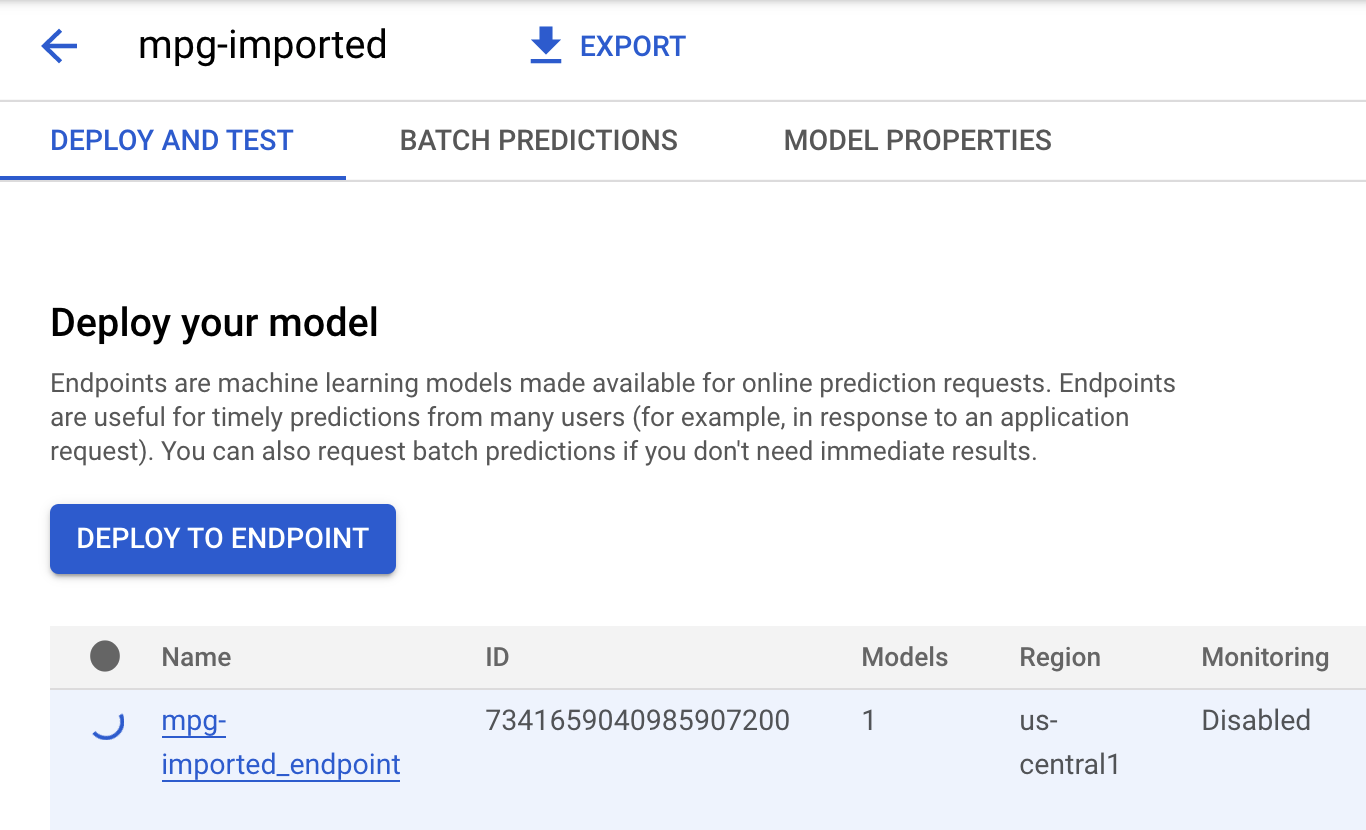
एंडपॉइंट डिप्लॉय होने के बाद, आपको Cloud Shell टर्मिनल में कुछ ऐसा लॉग दिखेगा:
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
इसका इस्तेमाल अगले चरण में किया जाएगा, ताकि डिप्लॉय किए गए एंडपॉइंट के बारे में अनुमान लगाया जा सके.
तीसरा चरण: डिप्लॉय किए गए एंडपॉइंट पर अनुमान पाना
Cloud Shell एडिटर में, predict.py नाम की एक नई फ़ाइल बनाएं:
predict.py खोलें और इसमें यह कोड चिपकाएं:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
इसके बाद, अपने टर्मिनल पर वापस जाएं और ENDPOINT_STRING को अपनी predict फ़ाइल में अपने एंडपॉइंट से बदलने के लिए, यह डालें:
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
अब, डिप्लॉय किए गए मॉडल एंडपॉइंट से अनुमान पाने के लिए, predict.py फ़ाइल को चलाने का समय आ गया है:
python3 predict.py
आपको एपीआई का जवाब लॉग किया हुआ दिखेगा. साथ ही, टेस्ट के लिए अनुमानित ईंधन दक्षता भी दिखेगी.
🎉 बधाई हो! 🎉
आपने Vertex AI का इस्तेमाल करके ये काम करने का तरीका सीखा है:
- कस्टम कंटेनर में ट्रेनिंग कोड डालकर, मॉडल को ट्रेन करें. इस उदाहरण में, TensorFlow मॉडल का इस्तेमाल किया गया है. हालांकि, कस्टम कंटेनर का इस्तेमाल करके, किसी भी फ़्रेमवर्क से बनाए गए मॉडल को ट्रेन किया जा सकता है.
- ट्रेनिंग के लिए इस्तेमाल किए गए वर्कफ़्लो के तहत, पहले से बने कंटेनर का इस्तेमाल करके TensorFlow मॉडल डिप्लॉय करें.
- मॉडल एंडपॉइंट बनाएं और अनुमान जनरेट करें.
Vertex AI के अलग-अलग हिस्सों के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें. अगर आपको चरण 5 में शुरू किए गए ट्रेनिंग जॉब के नतीजे देखने हैं, तो अपनी Vertex Console के ट्रेनिंग सेक्शन पर जाएं.
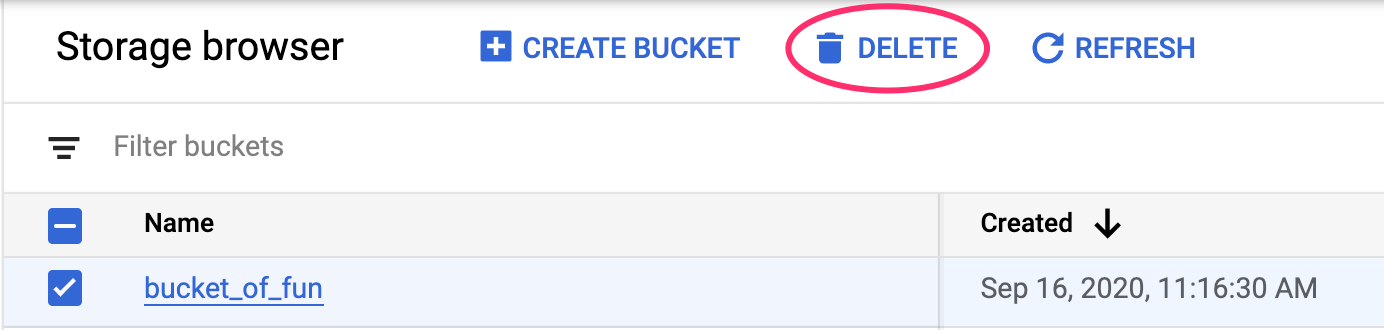
7. साफ़-सफ़ाई सेवा
तैनात किए गए एंडपॉइंट को मिटाने के लिए, Vertex Console के एंडपॉइंट सेक्शन पर जाएं और मिटाएं आइकॉन पर क्लिक करें:

स्टोरेज बकेट को मिटाने के लिए, Cloud Console में नेविगेशन मेन्यू का इस्तेमाल करके, स्टोरेज पर जाएं. इसके बाद, अपनी बकेट चुनें और मिटाएं पर क्लिक करें: