1. Overview
In this lab, you'll learn how to use Vertex AI - Google Cloud's newly announced managed ML platform - to build end-to-end ML workflows. You'll learn how to go from raw data to deployed model, and will leave this workshop ready to develop and productionize your own ML projects with Vertex AI. In this lab, we're using Cloud Shell to build a custom Docker image to demonstrate custom containers for training with Vertex AI.
While we're using TensorFlow for the model code here, you could easily replace it with another framework.
What you learn
You'll learn how to:
- Build and containerize model training code using Cloud Shell
- Submit a custom model training job to Vertex AI
- Deploy your trained model to an endpoint, and use that endpoint to get predictions
The total cost to run this lab on Google Cloud is about $2.
2. Intro to Vertex AI
This lab uses the newest AI product offering available on Google Cloud. Vertex AI integrates the ML offerings across Google Cloud into a seamless development experience. Previously, models trained with AutoML and custom models were accessible via separate services. The new offering combines both into a single API, along with other new products. You can also migrate existing projects to Vertex AI. If you have any feedback, please see the support page.
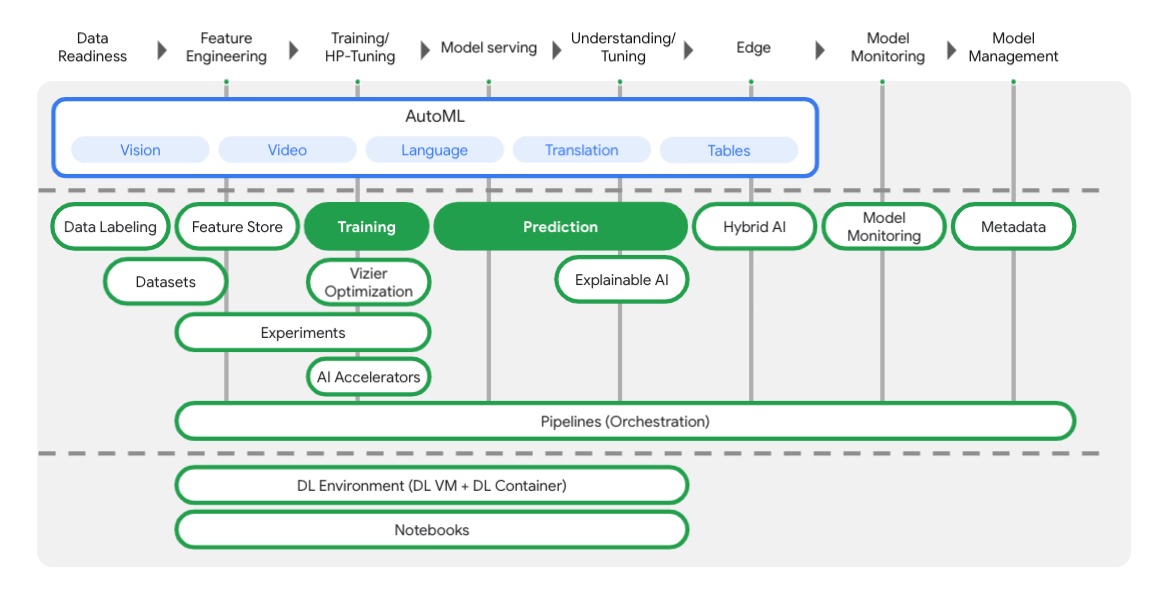
Vertex includes many different tools to help you with each stage of the ML workflow, as you can see from the diagram below. We'll be focused on using Vertex Training and Prediction, highlighted below.
3. Setup your environment
Self-paced environment setup
Sign in to Cloud Console and create a new project or reuse an existing one. (If you don't already have a Gmail or Google Workspace account, you must create one.)

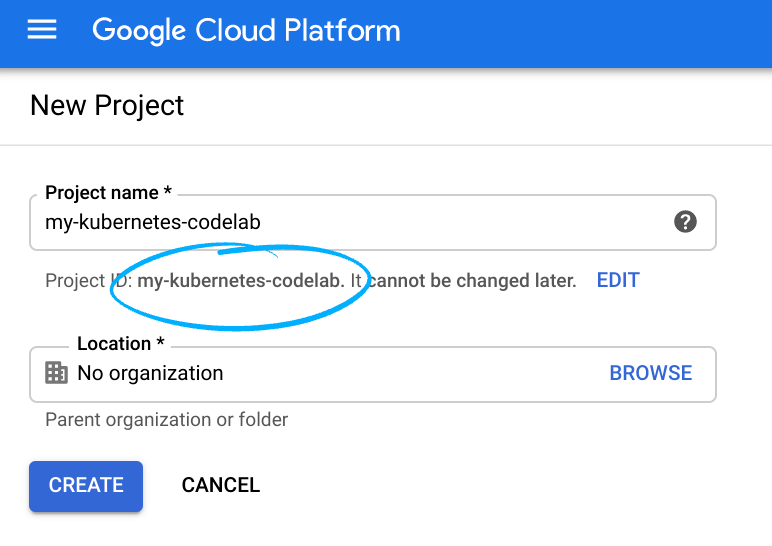
Remember the project ID, a unique name across all Google Cloud projects (the name above has already been taken and will not work for you, sorry!).
Next, you'll need to enable billing in Cloud Console in order to use Google Cloud resources.
Running through this codelab shouldn't cost much, if anything at all. Be sure to to follow any instructions in the "Cleaning up" section which advises you how to shut down resources so you don't incur billing beyond this tutorial. New users of Google Cloud are eligible for the $300 USD Free Trial program.
Step 1: Start Cloud Shell
In this lab you're going to work in a Cloud Shell session, which is a command interpreter hosted by a virtual machine running in Google's cloud. You could just as easily run this section locally on your own computer, but using Cloud Shell gives everyone access to a reproducible experience in a consistent environment. After the lab, you're welcome to retry this section on your own computer.
Activate Cloud Shell
From the top right of the Cloud Console, click the button below to Activate Cloud Shell:

If you've never started Cloud Shell before, you're presented with an intermediate screen (below the fold) describing what it is. If that's the case, click Continue (and you won't ever see it again). Here's what that one-time screen looks like:
It should only take a few moments to provision and connect to Cloud Shell.

This virtual machine is loaded with all the development tools you need. It offers a persistent 5GB home directory and runs in Google Cloud, greatly enhancing network performance and authentication. Much, if not all, of your work in this codelab can be done with simply a browser or your Chromebook.
Once connected to Cloud Shell, you should see that you are already authenticated and that the project is already set to your project ID.
Run the following command in Cloud Shell to confirm that you are authenticated:
gcloud auth list
Command output
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Run the following command in Cloud Shell to confirm that the gcloud command knows about your project:
gcloud config list project
Command output
[core] project = <PROJECT_ID>
If it is not, you can set it with this command:
gcloud config set project <PROJECT_ID>
Command output
Updated property [core/project].
Cloud Shell has a few environment variables, including GOOGLE_CLOUD_PROJECT which contains the name of our current Cloud project. We'll use this in various places throughout this lab. You can see it by running:
echo $GOOGLE_CLOUD_PROJECT
Step 2: Enable APIs
In later steps, you'll see where these services are needed (and why), but for now, run this command to give your project access to the Compute Engine, Container Registry, and Vertex AI services:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
This should produce a successful message similar to this one:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Step 3: Create a Cloud Storage Bucket
To run a training job on Vertex AI, we'll need a storage bucket to store our saved model assets. Run the following commands in your Cloud Shell terminal to create a bucket:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
Step 4: Alias Python 3
The code in this lab uses Python 3. To ensure you use Python 3 when you run the scripts you'll create in this lab, create an alias by running the following in Cloud Shell:
alias python=python3
The model we'll be training and serving in this lab is built upon this tutorial from the TensorFlow docs. The tutorial uses the Auto MPG dataset from Kaggle to predict the fuel efficiency of a vehicle.
4. Containerize training code
We'll submit this training job to Vertex by putting our training code in a Docker container and pushing this container to Google Container Registry. Using this approach, we can train a model built with any framework.
Step 1: Set up files
To start, from the terminal in Cloud Shell, run the following commands to create the files we'll need for our Docker Container:
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
You should now have an mpg/ directory that looks like the following:
+ Dockerfile
+ trainer/
+ train.py
To view and edit these files, we'll use Cloud Shell's built-in code editor. You can switch back and forth between the editor and the terminal by clicking on the button on the top right menu bar in Cloud Shell:

Step 2: Create a Dockerfile
To containerize our code we'll first create a Dockerfile. In our Dockerfile we'll include all the commands needed to run our image. It'll install all the libraries we're using and set up the entry point for our training code.
From the Cloud Shell file editor, open your mpg/ directory and then double-click to open the Dockerfile:
Then copy the following into this file:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
This Dockerfile uses the Deep Learning Container TensorFlow Enterprise 2.3 Docker image. The Deep Learning Containers on Google Cloud come with many common ML and data science frameworks pre-installed. The one we're using includes TF Enterprise 2.3, Pandas, Scikit-learn, and others. After downloading that image, this Dockerfile sets up the entrypoint for our training code, which we'll add in the next step.
Step 3: Add model training code
From the Cloud Shell editor, next open the train.py file and copy the code below (this is adapted from the tutorial in the TensorFlow docs).
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
Once you've copied the code above into the mpg/trainer/train.py file, return to the Terminal in your Cloud Shell and run the following command to add your own bucket name to the file:
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
Step 4: Build and test the container locally
From your Terminal, run the following to define a variable with the URI of your container image in Google Container Registry:
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
Then, build the container by running the following from the root of your mpg directory:
docker build ./ -t $IMAGE_URI
Once you've built the container, push it to Google Container Registry:
docker push $IMAGE_URI
To verify your image was pushed to Container Registry, you should see something like this when you navigate to the Container Registry section of your console:
With our container pushed to Container Registry, we're now ready to kick off a custom model training job.
5. Run a training job on Vertex AI
Vertex gives you two options for training models:
- AutoML: Train high-quality models with minimal effort and ML expertise.
- Custom training: Run your custom training applications in the cloud using one of Google Cloud's pre-built containers or use your own.
In this lab, we're using custom training via our own custom container on Google Container Registry. To start, navigate to the Training section in the Vertex section of your Cloud console:
Step 1: Kick off the training job
Click Create to enter the parameters for your training job and deployed model:
- Under Dataset, select No managed dataset
- Then select Custom training (advanced) as your training method and click Continue.
- Enter
mpg(or whatever you'd like to call your model) for Model name - Click Continue
In the Container settings step, select Custom container:

In the first box (Container image), click Browse and find the container you just pushed to Container Registry. It should look something like this:
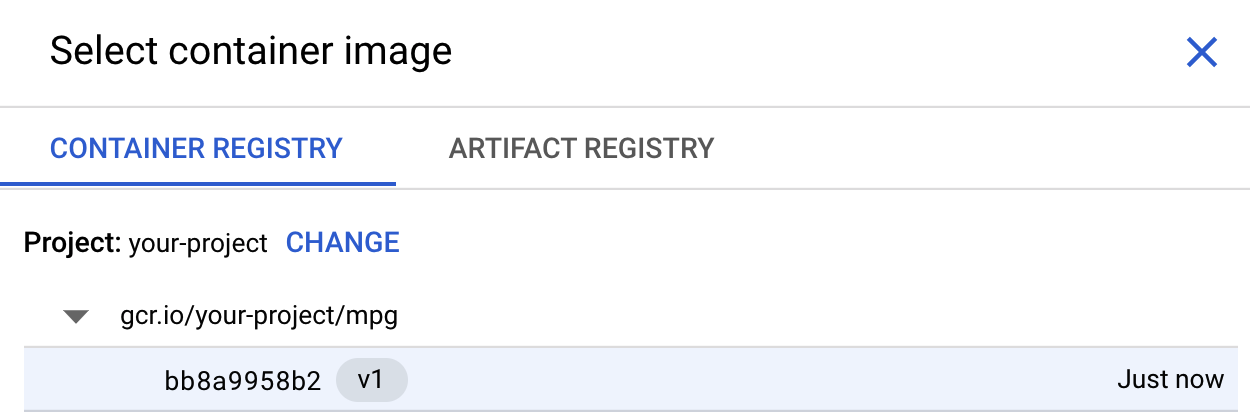
Leave the rest of the fields blank and click Continue.
We won't use hyperparameter tuning in this tutorial, so leave the Enable hyperparameter tuning box unchecked and click Continue.
In Compute and pricing, leave the selected region as-is and select n1-standard-4 as your machine type:
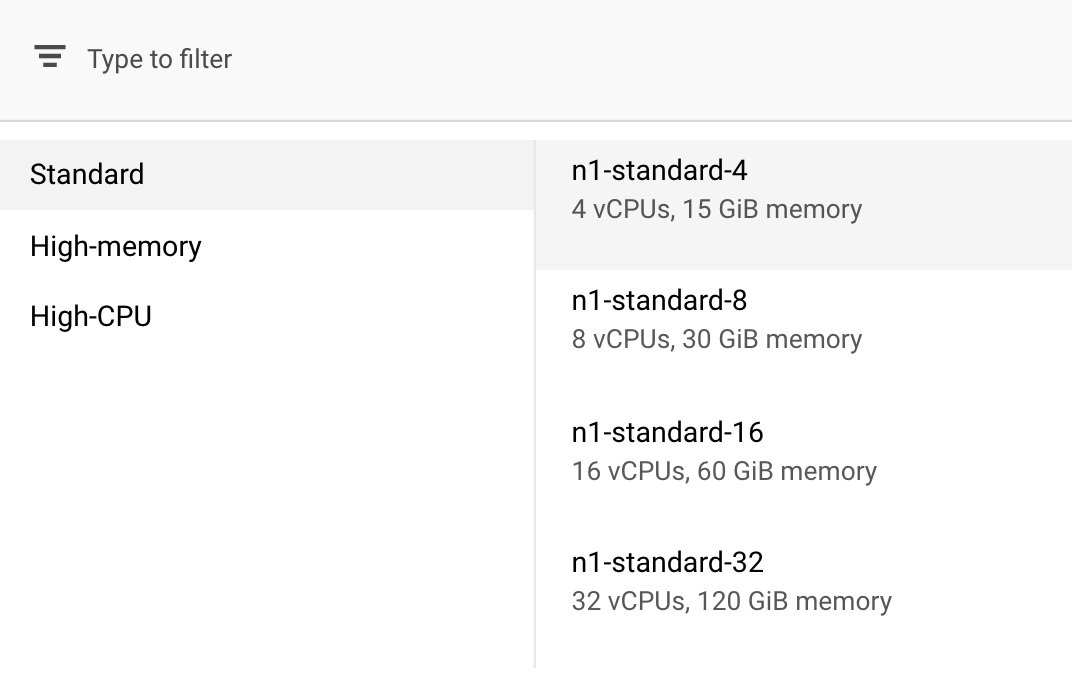
Because the model in this demo trains quickly, we're using a smaller machine type.
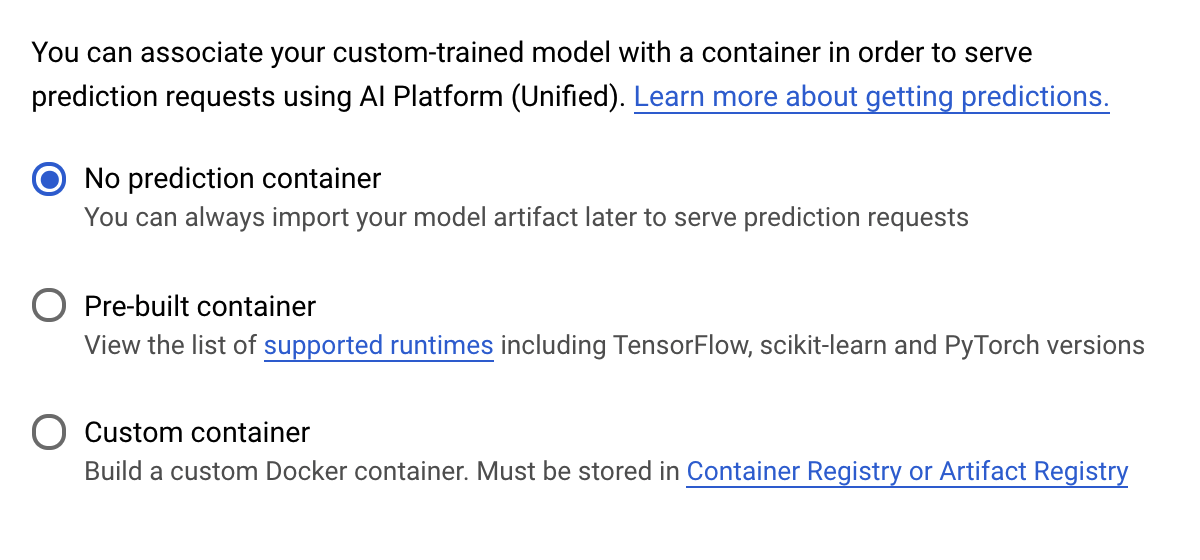
Under the Prediction container step, select No prediction container:
6. Deploy a model endpoint
In this step we'll create an endpoint for our trained model. We can use this to get predictions on our model via the Vertex AI API. To do this, we've made a version of the exported trained model assets available in a public GCS bucket.
In an organization, it's common to have one team or individual in charge of building the model, and a different team in charge of deploying it. The steps we'll go through here will show you how to take a model that's already been trained and deploy it for prediction.
Here we'll be using the Vertex AI SDK to create a model, deploy it to an endpoint, and get a prediction.
Step 1: Install Vertex SDK
From your Cloud Shell terminal, run the following to install the Vertex AI SDK:
pip3 install google-cloud-aiplatform --upgrade --user
We can use this SDK to interact with many different parts of Vertex.
Step 2: Create model and deploy endpoint
Next we'll create a Python file and use the SDK to create a model resource and deploy it to an endpoint. From the File editor in Cloud Shell, select File and then New File:
Name the file deploy.py. Open this file in your editor and copy the following code:
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
Next, navigate back to the Terminal in Cloud Shell, cd back into your root dir, and run this Python script you've just created:
cd ..
python3 deploy.py | tee deploy-output.txt
You'll see updates logged to your terminal as resources are being created. This will take 10-15 minutes to run. To ensure it's working correctly, navigate to the Models section of your console in Vertex AI:
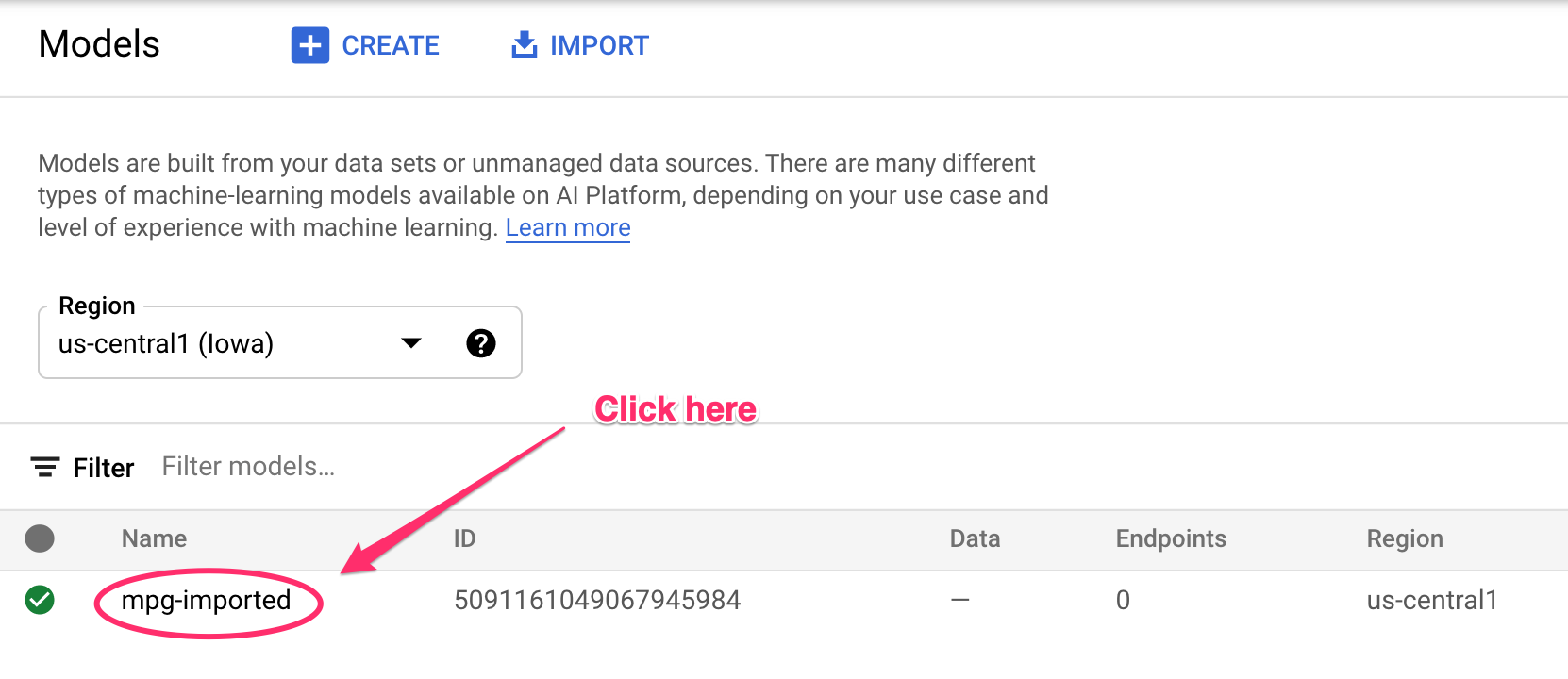
Click on mgp-imported and you should see your endpoint for that model being created:
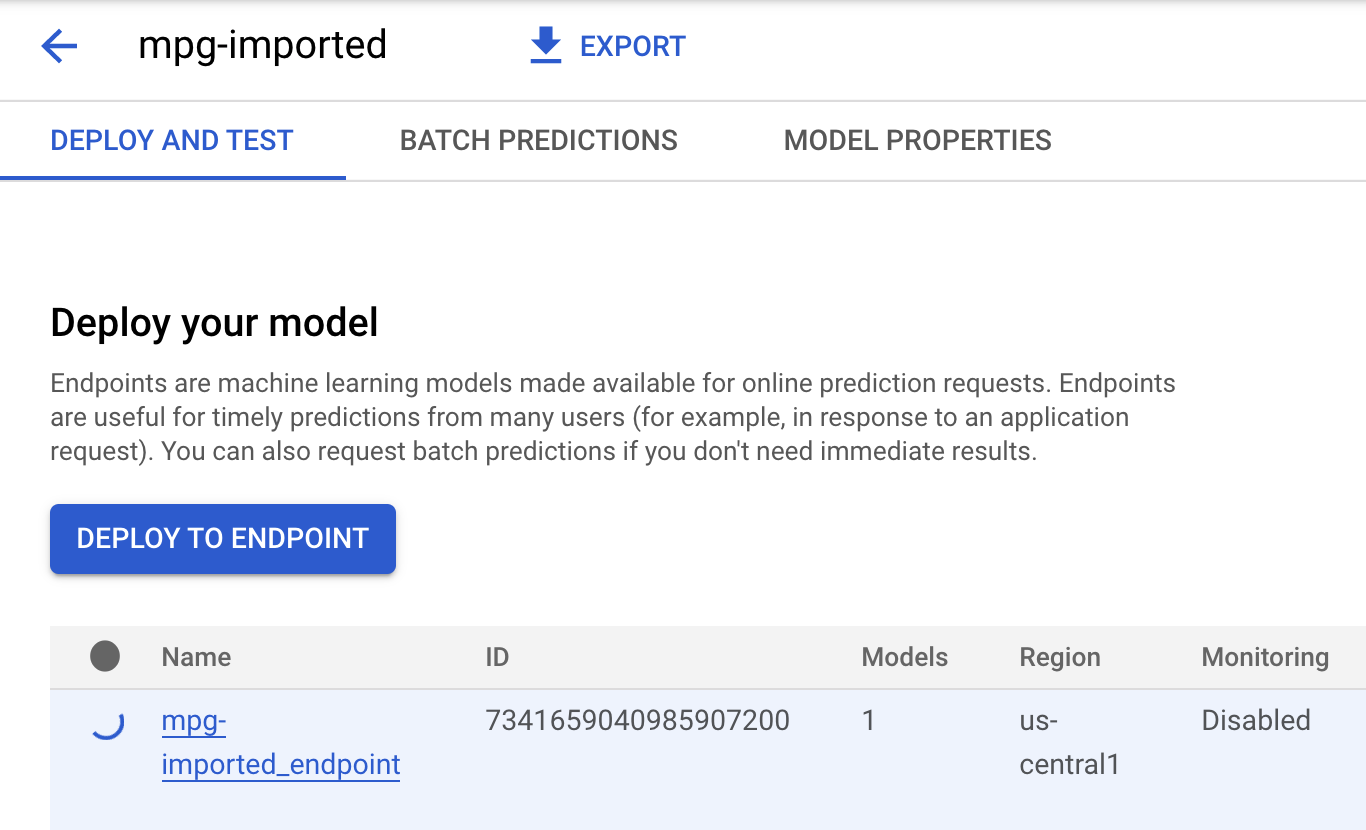
In your Cloud Shell Terminal, you'll see something like the following log when your endpoint deploy has completed:
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
You'll use this in the next step to get a prediction on your deployed endopint.
Step 3: Get predictions on the deployed endpoint
In your Cloud Shell editor, create a new file called predict.py:
Open predict.py and paste the following code into it:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
Next, go back to your Terminal and enter the following to replace ENDPOINT_STRING in the predict file with your own endpoint:
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
Now it's time to run the predict.py file to get a prediction from our deployed model endpoint:
python3 predict.py
You should see the API's response logged, along with the predicted fuel efficiency for our test prediction.
🎉 Congratulations! 🎉
You've learned how to use Vertex AI to:
- Train a model by providing the training code in a custom container. You used a TensorFlow model in this example, but you can train a model built with any framework using custom containers.
- Deploy a TensorFlow model using a pre-built container as part of the same workflow you used for training.
- Create a model endpoint and generate a prediction.
To learn more about different parts of Vertex AI, check out the documentation. If you'd like to see the results of the training job you started in Step 5, navigate to the training section of your Vertex console.
7. Cleanup
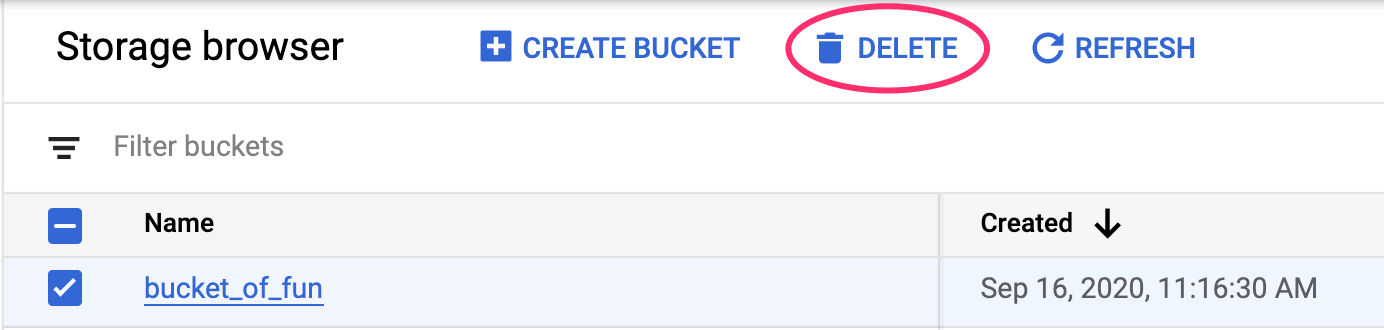
To delete the endpoint you deployed, navigate to the Endpoints section of your Vertex console and click the delete icon:

To delete the Storage Bucket, using the Navigation menu in your Cloud Console, browse to Storage, select your bucket, and click Delete: