1. ภาพรวม
ในแล็บนี้ คุณจะได้เรียนรู้วิธีใช้ Vertex AI ซึ่งเป็นแพลตฟอร์ม ML ที่มีการจัดการซึ่ง Google Cloud เพิ่งประกาศเปิดตัว เพื่อสร้างเวิร์กโฟลว์ ML แบบครบวงจร คุณจะได้เรียนรู้วิธีเปลี่ยนจากข้อมูลดิบเป็นโมเดลที่ติดตั้งใช้งานแล้ว และจะออกจากเวิร์กช็อปนี้พร้อมที่จะพัฒนาและนำโปรเจ็กต์ ML ของคุณเองไปใช้งานจริงด้วย Vertex AI ใน Lab นี้ เราจะใช้ Cloud Shell เพื่อสร้างอิมเมจ Docker ที่กำหนดเองเพื่อสาธิตคอนเทนเนอร์ที่กำหนดเองสำหรับการฝึกด้วย Vertex AI
แม้ว่าเราจะใช้ TensorFlow สำหรับโค้ดโมเดลที่นี่ แต่คุณก็สามารถแทนที่ด้วยเฟรมเวิร์กอื่นได้อย่างง่ายดาย
สิ่งที่คุณจะได้เรียนรู้
โดยคุณจะได้เรียนรู้วิธีต่อไปนี้
- สร้างและทำโค้ดการฝึกโมเดลให้เป็นคอนเทนเนอร์โดยใช้ Cloud Shell
- ส่งงานการฝึกโมเดลที่กำหนดเองไปยัง Vertex AI
- ทำให้โมเดลที่ฝึกแล้วใช้งานได้ในปลายทาง และใช้ปลายทางนั้นเพื่อรับการคาดการณ์
ค่าใช้จ่ายทั้งหมดในการเรียกใช้ Lab นี้ใน Google Cloud อยู่ที่ประมาณ $2
2. ข้อมูลเบื้องต้นเกี่ยวกับ Vertex AI
แล็บนี้ใช้ผลิตภัณฑ์ AI ใหม่ล่าสุดที่พร้อมให้บริการใน Google Cloud Vertex AI ผสานรวมข้อเสนอ ML ใน Google Cloud เข้ากับประสบการณ์การพัฒนาที่ราบรื่น ก่อนหน้านี้ โมเดลที่ฝึกด้วย AutoML และโมเดลที่กำหนดเองจะเข้าถึงได้ผ่านบริการแยกต่างหาก ข้อเสนอใหม่นี้จะรวมทั้ง 2 อย่างไว้ใน API เดียว พร้อมกับผลิตภัณฑ์ใหม่อื่นๆ นอกจากนี้ คุณยังย้ายข้อมูลโปรเจ็กต์ที่มีอยู่ไปยัง Vertex AI ได้ด้วย หากมีข้อเสนอแนะ โปรดดูหน้าการสนับสนุน
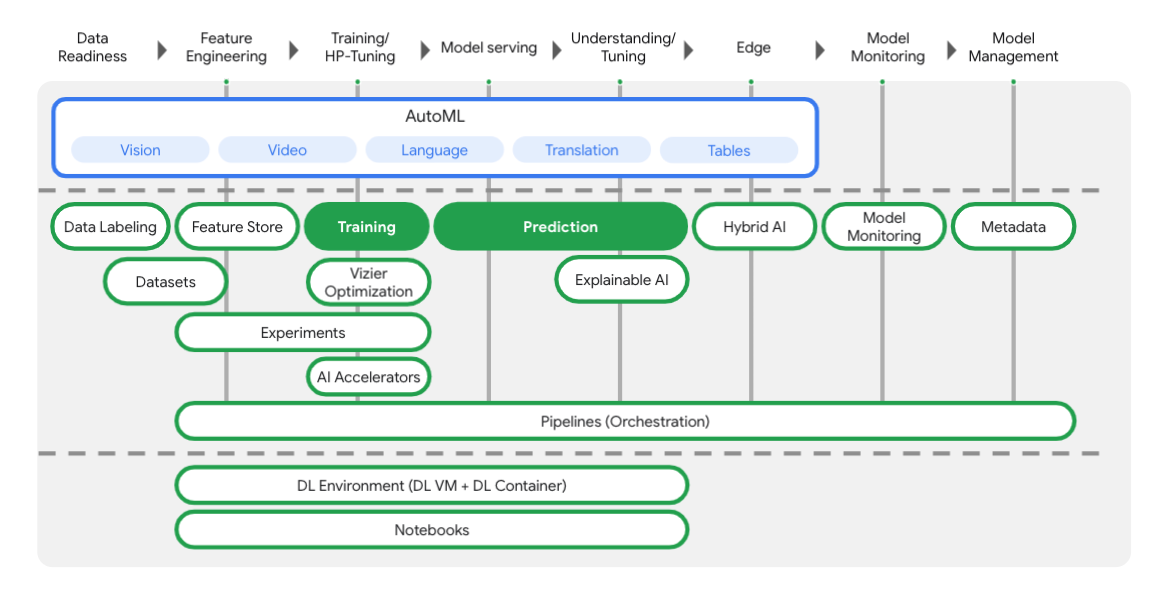
Vertex มีเครื่องมือมากมายที่จะช่วยคุณในแต่ละขั้นตอนของเวิร์กโฟลว์ ML ดังที่เห็นจากแผนภาพด้านล่าง เราจะมุ่งเน้นที่การใช้ Vertex Training และ Prediction ซึ่งไฮไลต์ไว้ด้านล่าง
3. ตั้งค่าสภาพแวดล้อม
การตั้งค่าสภาพแวดล้อมแบบเรียนรู้ด้วยตนเอง
ลงชื่อเข้าใช้ Cloud Console แล้วสร้างโปรเจ็กต์ใหม่หรือใช้โปรเจ็กต์ที่มีอยู่ซ้ำ (หากยังไม่มีบัญชี Gmail หรือ Google Workspace คุณต้องสร้างบัญชี)

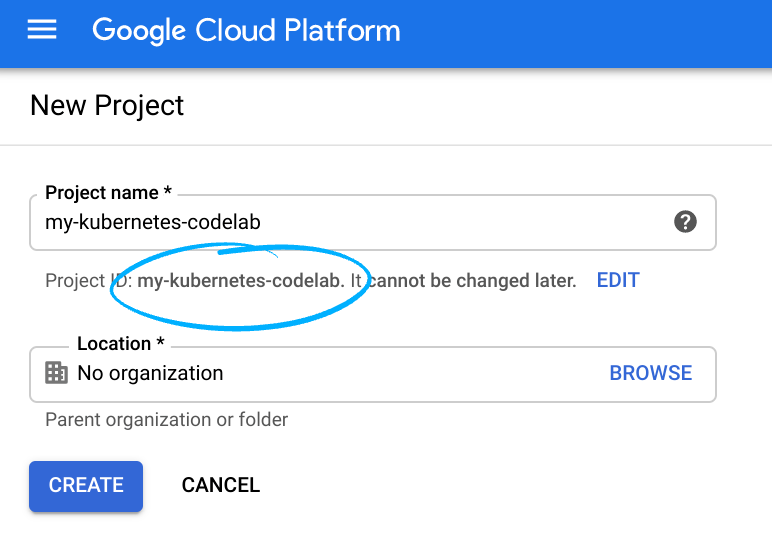
โปรดจดจำรหัสโปรเจ็กต์ ซึ่งเป็นชื่อที่ไม่ซ้ำกันในโปรเจ็กต์ Google Cloud ทั้งหมด (ชื่อด้านบนถูกใช้ไปแล้วและจะใช้ไม่ได้ ขออภัย)
จากนั้นคุณจะต้องเปิดใช้การเรียกเก็บเงินใน Cloud Console เพื่อใช้ทรัพยากร Google Cloud
การทำตาม Codelab นี้ไม่ควรมีค่าใช้จ่ายมากนัก หรืออาจไม่มีเลย โปรดทำตามวิธีการในส่วน "การล้างข้อมูล" ซึ่งจะแนะนำวิธีปิดทรัพยากรเพื่อไม่ให้มีการเรียกเก็บเงินนอกเหนือจากบทแนะนำนี้ ผู้ใช้ Google Cloud รายใหม่มีสิทธิ์เข้าร่วมโปรแกรมช่วงทดลองใช้ฟรีมูลค่า$300 USD
ขั้นตอนที่ 1: เริ่ม Cloud Shell
ในแล็บนี้ คุณจะได้ทำงานในเซสชัน Cloud Shell ซึ่งเป็นตัวแปลคำสั่งที่โฮสต์โดยเครื่องเสมือนที่ทำงานในระบบคลาวด์ของ Google คุณสามารถเรียกใช้ส่วนนี้ในเครื่องคอมพิวเตอร์ของคุณเองได้อย่างง่ายดาย แต่การใช้ Cloud Shell จะช่วยให้ทุกคนเข้าถึงประสบการณ์ที่ทำซ้ำได้ในสภาพแวดล้อมที่สอดคล้องกัน หลังจากแล็บแล้ว คุณสามารถลองทำส่วนนี้อีกครั้งในคอมพิวเตอร์ของคุณเองได้
เปิดใช้งาน Cloud Shell
จากด้านขวาบนของ Cloud Console ให้คลิกปุ่มด้านล่างเพื่อเปิดใช้งาน Cloud Shell

หากไม่เคยเริ่มใช้ Cloud Shell มาก่อน คุณจะเห็นหน้าจอระดับกลาง (ครึ่งหน้าล่าง) ที่อธิบายว่า Cloud Shell คืออะไร ในกรณีนี้ ให้คลิกต่อไป (และคุณจะไม่เห็นหน้าจอนี้อีก) หน้าจอแบบครั้งเดียวจะมีลักษณะดังนี้
การจัดสรรและเชื่อมต่อกับ Cloud Shell จะใช้เวลาไม่นาน

เครื่องเสมือนนี้มีเครื่องมือพัฒนาซอฟต์แวร์ทั้งหมดที่คุณต้องการ โดยมีไดเรกทอรีหลักแบบถาวรขนาด 5 GB และทำงานใน Google Cloud ซึ่งช่วยเพิ่มประสิทธิภาพเครือข่ายและการตรวจสอบสิทธิ์ได้อย่างมาก คุณสามารถทำงานในโค้ดแล็บนี้ได้โดยใช้เพียงเบราว์เซอร์หรือ Chromebook
เมื่อเชื่อมต่อกับ Cloud Shell แล้ว คุณควรเห็นว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและโปรเจ็กต์ได้รับการตั้งค่าเป็นรหัสโปรเจ็กต์ของคุณแล้ว
เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคุณได้รับการตรวจสอบสิทธิ์แล้ว
gcloud auth list
เอาต์พุตจากคำสั่ง
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
เอาต์พุตจากคำสั่ง
[core] project = <PROJECT_ID>
หากไม่ได้ตั้งค่าไว้ คุณสามารถตั้งค่าได้ด้วยคำสั่งนี้
gcloud config set project <PROJECT_ID>
เอาต์พุตจากคำสั่ง
Updated property [core/project].
Cloud Shell มีตัวแปรสภาพแวดล้อม 2-3 ตัว รวมถึง GOOGLE_CLOUD_PROJECT ซึ่งมีชื่อโปรเจ็กต์ที่อยู่ในระบบคลาวด์ปัจจุบันของเรา เราจะใช้ข้อมูลนี้ในที่ต่างๆ ตลอดทั้งแล็บนี้ คุณดูได้โดยเรียกใช้คำสั่งต่อไปนี้
echo $GOOGLE_CLOUD_PROJECT
ขั้นตอนที่ 2: เปิดใช้ API
ในขั้นตอนต่อๆ ไป คุณจะเห็นว่าบริการเหล่านี้จำเป็นต้องใช้ที่ใด (และเพราะเหตุใด) แต่ตอนนี้ ให้เรียกใช้คำสั่งนี้เพื่อให้โปรเจ็กต์เข้าถึงบริการ Compute Engine, Container Registry และ Vertex AI
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
ซึ่งควรจะแสดงข้อความว่าดำเนินการสำเร็จคล้ายกับข้อความนี้
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
ขั้นตอนที่ 3: สร้าง Bucket ของ Cloud Storage
หากต้องการเรียกใช้งานการฝึกใน Vertex AI เราจะต้องมีที่เก็บข้อมูลเพื่อจัดเก็บชิ้นงานของโมเดลที่บันทึกไว้ เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล Cloud Shell เพื่อสร้าง Bucket
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
ขั้นตอนที่ 4: ตั้งชื่อแทน Python 3
โค้ดในแล็บนี้ใช้ Python 3 หากต้องการให้แน่ใจว่าคุณใช้ Python 3 เมื่อเรียกใช้สคริปต์ที่คุณจะสร้างใน Lab นี้ ให้สร้างนามแฝงโดยเรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell
alias python=python3
โมเดลที่เราจะฝึกและให้บริการในแล็บนี้สร้างขึ้นจากบทแนะนำนี้จากเอกสารประกอบของ TensorFlow บทแนะนำนี้ใช้ชุดข้อมูล MPG อัตโนมัติจาก Kaggle เพื่อคาดการณ์การประหยัดพลังงานของยานพาหนะ
4. สร้างคอนเทนเนอร์โค้ดการฝึก
เราจะส่งงานการฝึกนี้ไปยัง Vertex โดยใส่โค้ดการฝึกในคอนเทนเนอร์ Docker และพุชคอนเทนเนอร์นี้ไปยัง Google Container Registry การใช้แนวทางนี้ช่วยให้เราฝึกโมเดลที่สร้างด้วยเฟรมเวิร์กใดก็ได้
ขั้นตอนที่ 1: ตั้งค่าไฟล์
หากต้องการเริ่มต้น ให้เรียกใช้คำสั่งต่อไปนี้จากเทอร์มินัลใน Cloud Shell เพื่อสร้างไฟล์ที่เราจะใช้สำหรับคอนเทนเนอร์ Docker
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
ตอนนี้คุณควรมีไดเรกทอรี mpg/ ที่มีลักษณะดังนี้
+ Dockerfile
+ trainer/
+ train.py
เราจะใช้ตัวแก้ไขโค้ดแบบในตัวของ Cloud Shell เพื่อดูและแก้ไขไฟล์เหล่านี้ คุณสามารถสลับไปมาระหว่างเอดิเตอร์กับเทอร์มินัลได้โดยคลิกปุ่มในแถบเมนูด้านขวาบนใน Cloud Shell ดังนี้

ขั้นตอนที่ 2: สร้าง Dockerfile
หากต้องการสร้างคอนเทนเนอร์โค้ด เราจะสร้าง Dockerfile ก่อน ใน Dockerfile เราจะใส่คำสั่งทั้งหมดที่จำเป็นในการเรียกใช้อิมเมจ ซึ่งจะติดตั้งไลบรารีทั้งหมดที่เราใช้และตั้งค่าจุดแรกเข้าสำหรับโค้ดการฝึก
จากโปรแกรมแก้ไขไฟล์ของ Cloud Shell ให้เปิดไดเรกทอรี mpg/ แล้วดับเบิลคลิกเพื่อเปิด Dockerfile
จากนั้นคัดลอกข้อมูลต่อไปนี้ลงในไฟล์นี้
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
Dockerfile นี้ใช้อิมเมจ Docker ของ Deep Learning Container TensorFlow Enterprise 2.3 คอนเทนเนอร์การเรียนรู้เชิงลึกใน Google Cloud มาพร้อมกับเฟรมเวิร์ก ML และวิทยาศาสตร์ข้อมูลทั่วไปหลายรายการที่ติดตั้งไว้ล่วงหน้า เวอร์ชันที่เราใช้มี TF Enterprise 2.3, Pandas, Scikit-learn และอื่นๆ หลังจากดาวน์โหลดอิมเมจดังกล่าวแล้ว Dockerfile นี้จะตั้งค่าจุดแรกเข้าสำหรับโค้ดการฝึกของเรา ซึ่งเราจะเพิ่มในขั้นตอนถัดไป
ขั้นตอนที่ 3: เพิ่มโค้ดการฝึกโมเดล
จากโปรแกรมแก้ไข Cloud Shell ให้เปิดไฟล์ train.py แล้วคัดลอกโค้ดด้านล่าง (โค้ดนี้ดัดแปลงมาจากบทแนะนำในเอกสาร TensorFlow)
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
เมื่อคัดลอกโค้ดด้านบนลงในไฟล์ mpg/trainer/train.py แล้ว ให้กลับไปที่เทอร์มินัลใน Cloud Shell แล้วเรียกใช้คำสั่งต่อไปนี้เพื่อเพิ่มชื่อ Bucket ของคุณเองลงในไฟล์
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
ขั้นตอนที่ 4: สร้างและทดสอบคอนเทนเนอร์ในเครื่อง
จากเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อกำหนดตัวแปรที่มี URI ของอิมเมจคอนเทนเนอร์ใน Google Container Registry
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
จากนั้นสร้างคอนเทนเนอร์โดยเรียกใช้คำสั่งต่อไปนี้จากรูทของไดเรกทอรี mpg
docker build ./ -t $IMAGE_URI
เมื่อสร้างคอนเทนเนอร์แล้ว ให้พุชไปยัง Google Container Registry โดยทำดังนี้
docker push $IMAGE_URI
หากต้องการยืนยันว่าระบบได้พุชอิมเมจไปยัง Container Registry แล้ว คุณควรเห็นข้อความต่อไปนี้เมื่อไปที่ส่วน Container Registry ของคอนโซล
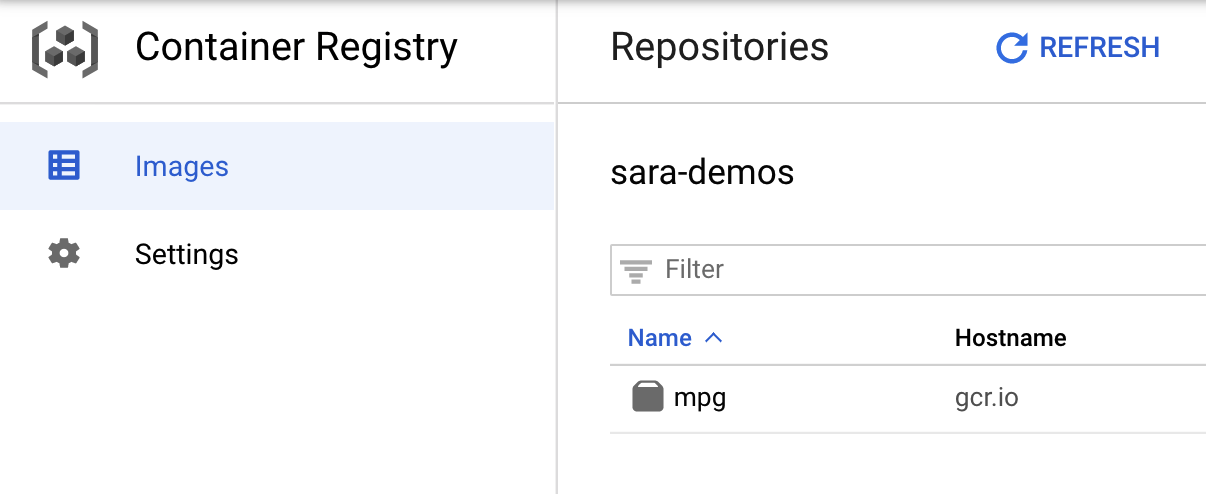
เมื่อส่งคอนเทนเนอร์ไปยัง Container Registry แล้ว ตอนนี้เราก็พร้อมที่จะเริ่มงานฝึกโมเดลที่กำหนดเองแล้ว
5. เรียกใช้งานการฝึกใน Vertex AI
Vertex มีตัวเลือกในการฝึกโมเดล 2 แบบ ได้แก่
- AutoML: ฝึกโมเดลที่มีคุณภาพสูงอย่างง่ายดายโดยไม่ต้องมีความเชี่ยวชาญขั้นสูงด้าน ML
- การฝึกที่กำหนดเอง: เรียกใช้แอปพลิเคชันการฝึกที่กำหนดเองในระบบคลาวด์โดยใช้หนึ่งในคอนเทนเนอร์ที่สร้างไว้ล่วงหน้าของ Google Cloud หรือใช้คอนเทนเนอร์ของคุณเอง
ในแล็บนี้ เราจะใช้การฝึกที่กำหนดเองผ่านคอนเทนเนอร์ที่กำหนดเองของเราเองใน Google Container Registry หากต้องการเริ่มต้นใช้งาน ให้ไปที่ส่วนการฝึกในส่วน Vertex ของคอนโซล Cloud
ขั้นตอนที่ 1: เริ่มงานการฝึก
คลิกสร้างเพื่อป้อนพารามิเตอร์สำหรับงานการฝึกและโมเดลที่ใช้งานจริง
- ในส่วนชุดข้อมูล ให้เลือกไม่มีชุดข้อมูลที่มีการจัดการ
- จากนั้นเลือกการฝึกแบบกำหนดเอง (ขั้นสูง) เป็นวิธีการฝึก แล้วคลิกต่อไป
- ป้อน
mpg(หรือชื่อโมเดลที่คุณต้องการ) สำหรับชื่อโมเดล - คลิกต่อไป
ในขั้นตอนการตั้งค่าคอนเทนเนอร์ ให้เลือกคอนเทนเนอร์ที่กำหนดเอง

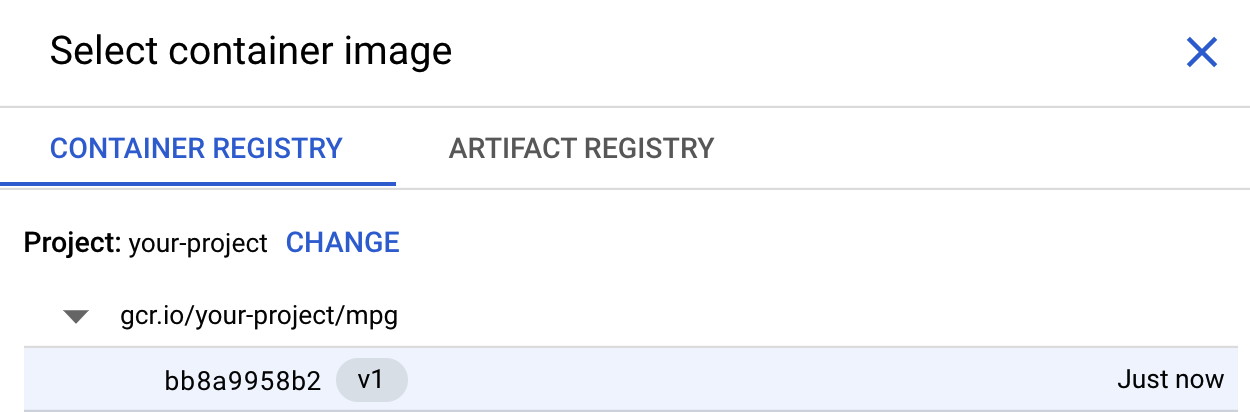
ในช่องแรก (อิมเมจคอนเทนเนอร์) ให้คลิกเรียกดู แล้วค้นหาคอนเทนเนอร์ที่คุณเพิ่งพุชไปยัง Container Registry ซึ่งควรมีหน้าตาเช่นนี้
เว้นช่องที่เหลือว่างไว้ แล้วคลิกดำเนินการต่อ
เราจะไม่ใช้การปรับแต่งไฮเปอร์พารามิเตอร์ในบทแนะนำนี้ ดังนั้นให้ยกเลิกการเลือกช่อง "เปิดใช้การปรับแต่งไฮเปอร์พารามิเตอร์" แล้วคลิกต่อไป
ในการคำนวณและราคา ให้ปล่อยภูมิภาคที่เลือกไว้ตามเดิม แล้วเลือก n1-standard-4 เป็นประเภทเครื่อง
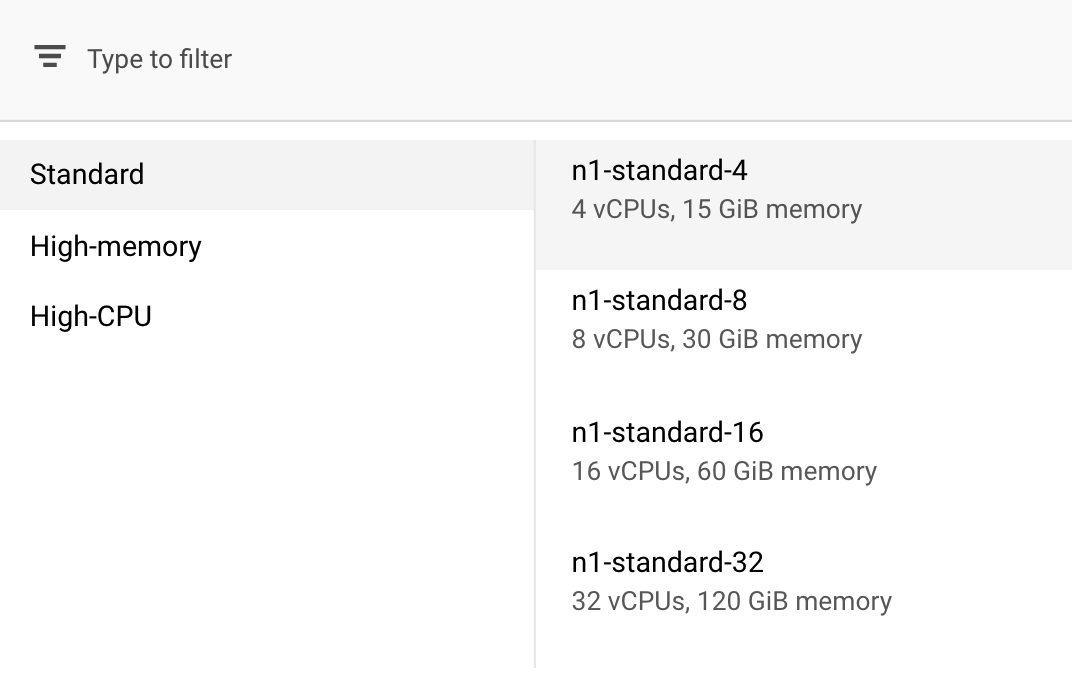
เนื่องจากโมเดลในการสาธิตนี้ฝึกได้อย่างรวดเร็ว เราจึงใช้ประเภทเครื่องที่เล็กลง
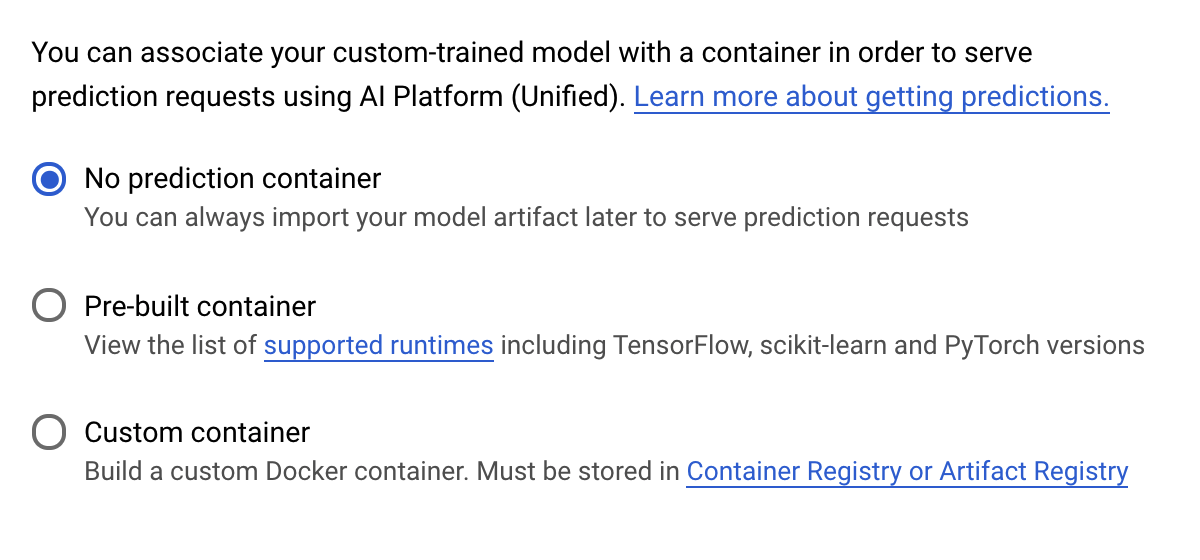
ในขั้นตอนคอนเทนเนอร์การคาดการณ์ ให้เลือกไม่มีคอนเทนเนอร์การคาดการณ์
6. ทำให้ใช้งานได้ปลายทางโมเดล
ในขั้นตอนนี้ เราจะสร้างปลายทางสำหรับโมเดลที่ฝึกแล้ว เราสามารถใช้ข้อมูลนี้เพื่อรับการคาดการณ์ในโมเดลผ่าน Vertex AI API โดยเราได้สร้างเวอร์ชันของชิ้นงานโมเดลที่ฝึกแล้วซึ่งส่งออกไว้ใน Bucket ของ GCS ที่เป็นแบบสาธารณะ
ในองค์กร มักจะมีทีมหรือบุคคลหนึ่งที่รับผิดชอบในการสร้างโมเดล และอีกทีมหนึ่งที่รับผิดชอบในการติดตั้งใช้งาน ขั้นตอนที่เราจะทำในที่นี้จะแสดงวิธีนำโมเดลที่ฝึกแล้วไปทำให้ใช้งานได้เพื่อการคาดการณ์
ในที่นี้ เราจะใช้ Vertex AI SDK เพื่อสร้างโมเดล ทำให้ใช้งานได้กับปลายทาง และรับการคาดการณ์
ขั้นตอนที่ 1: ติดตั้ง Vertex SDK
จากเทอร์มินัล Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้เพื่อติดตั้ง Vertex AI SDK
pip3 install google-cloud-aiplatform --upgrade --user
เราสามารถใช้ SDK นี้เพื่อโต้ตอบกับส่วนต่างๆ ของ Vertex ได้
ขั้นตอนที่ 2: สร้างโมเดลและติดตั้งใช้งานปลายทาง
จากนั้นเราจะสร้างไฟล์ Python และใช้ SDK เพื่อสร้างทรัพยากรโมเดลและทำให้ใช้งานได้ที่ปลายทาง จากเครื่องมือแก้ไขไฟล์ใน Cloud Shell ให้เลือกไฟล์ แล้วเลือกไฟล์ใหม่
ตั้งชื่อไฟล์ deploy.py เปิดไฟล์นี้ในโปรแกรมแก้ไขและคัดลอกโค้ดต่อไปนี้
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
จากนั้นกลับไปที่เทอร์มินัลใน Cloud Shell cd กลับไปที่ไดเรกทอรีรูท แล้วเรียกใช้สคริปต์ Python ที่คุณเพิ่งสร้างขึ้น
cd ..
python3 deploy.py | tee deploy-output.txt
คุณจะเห็นการอัปเดตที่บันทึกไว้ในเทอร์มินัลขณะที่ระบบสร้างทรัพยากร ซึ่งจะใช้เวลา 10-15 นาที หากต้องการตรวจสอบว่าทำงานอย่างถูกต้อง ให้ไปที่ส่วนโมเดลของคอนโซลใน Vertex AI แล้วทำดังนี้
คลิก mgp-imported แล้วคุณจะเห็นว่าระบบกำลังสร้างปลายทางสำหรับโมเดลนั้น
ในเทอร์มินัล Cloud Shell คุณจะเห็นบันทึกคล้ายกับบันทึกต่อไปนี้เมื่อการติดตั้งใช้งานอุปกรณ์ปลายทางเสร็จสมบูรณ์
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
คุณจะต้องใช้ข้อมูลนี้ในขั้นตอนถัดไปเพื่อรับการคาดการณ์ในเอนโดพอยต์ที่ใช้งาน
ขั้นตอนที่ 3: รับการคาดการณ์ในปลายทางที่ทำให้ใช้งานได้
สร้างไฟล์ใหม่ชื่อ predict.py ในโปรแกรมแก้ไข Cloud Shell
เปิด predict.py แล้ววางโค้ดต่อไปนี้ลงไป
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
จากนั้นกลับไปที่เทอร์มินัลแล้วป้อนคำสั่งต่อไปนี้เพื่อแทนที่ ENDPOINT_STRING ในไฟล์ predict ด้วยปลายทางของคุณเอง
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
ตอนนี้ได้เวลาเรียกใช้ไฟล์ predict.py เพื่อรับการคาดการณ์จากปลายทางโมเดลที่ทำให้ใช้งานได้แล้ว
python3 predict.py
คุณควรเห็นการตอบกลับของ API ที่บันทึกไว้ พร้อมกับประสิทธิภาพการใช้เชื้อเพลิงที่คาดการณ์ไว้สำหรับการคาดการณ์การทดสอบของเรา
🎉 ยินดีด้วย 🎉
คุณได้เรียนรู้วิธีใช้ Vertex AI เพื่อทำสิ่งต่อไปนี้
- ฝึกโมเดลโดยระบุโค้ดการฝึกในคอนเทนเนอร์ที่กำหนดเอง คุณใช้โมเดล TensorFlow ในตัวอย่างนี้ แต่สามารถฝึกโมเดลที่สร้างด้วยเฟรมเวิร์กใดก็ได้โดยใช้คอนเทนเนอร์ที่กำหนดเอง
- ทำให้โมเดล TensorFlow ใช้งานได้โดยใช้คอนเทนเนอร์ที่สร้างไว้ล่วงหน้าเป็นส่วนหนึ่งของเวิร์กโฟลว์เดียวกันกับที่ใช้สำหรับการฝึก
- สร้างปลายทางโมเดลและสร้างการคาดการณ์
ดูข้อมูลเพิ่มเติมเกี่ยวกับส่วนต่างๆ ของ Vertex AI ได้ที่เอกสารประกอบ หากต้องการดูผลลัพธ์ของงานการฝึกที่เริ่มในขั้นตอนที่ 5 ให้ไปที่ส่วนการฝึกของคอนโซล Vertex
7. ล้างข้อมูล
หากต้องการลบปลายทางที่ทำให้ใช้งานได้ ให้ไปที่ส่วนปลายทางของคอนโซล Vertex แล้วคลิกไอคอนลบ

หากต้องการลบ Storage Bucket ให้ใช้เมนูการนำทางใน Cloud Console ไปที่ Storage เลือก Bucket แล้วคลิกลบ