1. 總覽
在本實驗室中,您將瞭解如何使用 Vertex AI (Google Cloud 新推出的受管理機器學習平台),建構端對端機器學習工作流程。您將瞭解如何從原始資料到部署模型,並在研討會結束後,準備好使用 Vertex AI 開發及將自己的機器學習專案推送至實際工作環境。在本實驗室中,我們將使用 Cloud Shell 建構自訂 Docker 映像檔,示範如何使用 Vertex AI 訓練自訂容器。
雖然我們在此使用 TensorFlow 做為模型程式碼,但您可以輕鬆換成其他架構。
課程內容
內容如下:
- 使用 Cloud Shell 建構模型訓練程式碼並容器化
- 將自訂模型訓練工作提交至 Vertex AI
- 將訓練完的模型部署至端點,並使用該端點取得預測結果
在 Google Cloud 上執行這個實驗室的總費用約為 $2 美元。
2. Vertex AI 簡介
本實驗室使用 Google Cloud 最新推出的 AI 產品服務。Vertex AI 整合了 Google Cloud 機器學習服務,提供流暢的開發體驗。以 AutoML 訓練的模型和自訂模型,先前需透過不同的服務存取。這項新服務將兩者併至單一 API,並加入其他新產品。您也可以將現有專案遷移至 Vertex AI。如有任何意見,請參閱支援頁面。
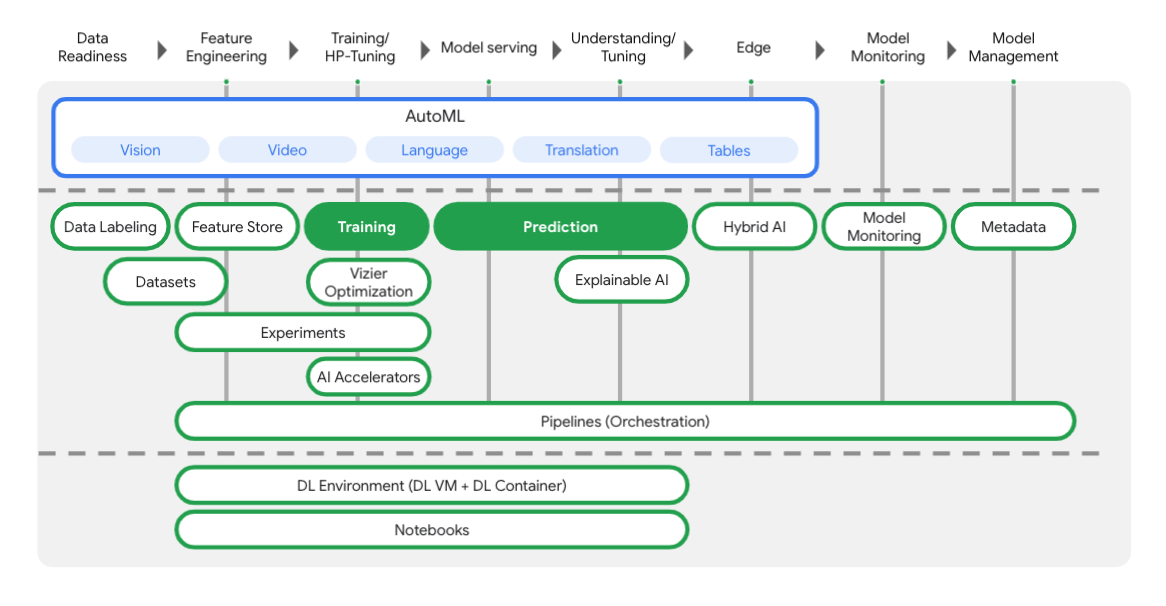
如以下圖表所示,Vertex 包含許多不同的工具,可協助您完成機器學習工作流程的每個階段。我們將著重於使用 Vertex Training 和 Prediction,如下所示。
3. 設定環境
自修實驗室環境設定
登入 Cloud 控制台,建立新專案或重複使用現有專案。(如果沒有 Gmail 或 Google Workspace 帳戶,請先建立帳戶)。

請記住專案 ID,這是所有 Google Cloud 專案中不重複的名稱 (很抱歉,上述名稱已遭占用,無法使用!)。
接著,您必須在 Cloud 控制台中啟用帳單,才能使用 Google Cloud 資源。
完成本程式碼研究室的費用應該不高,甚至完全免費。請務必按照「清除」部分的指示操作,瞭解如何停用資源,避免在本教學課程結束後繼續產生帳單費用。Google Cloud 新使用者可參加價值$300 美元的免費試用計畫。
步驟 1:啟動 Cloud Shell
在本實驗室中,您將在 Cloud Shell 工作階段中操作,這是由 Google Cloud 中執行的虛擬機器代管的指令解譯器。您也可以在本機電腦上輕鬆執行本節內容,但使用 Cloud Shell 可讓所有人在一致的環境中,獲得可重現的體驗。完成實驗室後,歡迎在自己的電腦上重試這個部分。
啟用 Cloud Shell
在 Cloud 控制台的右上角,按一下下方的按鈕來啟用 Cloud Shell:

如果您是首次啟動 Cloud Shell,系統會顯示中繼畫面 (位於需捲動位置),說明這個指令列環境。點選「繼續」後,這則訊息日後就不會再出現。以下是這個初次畫面的樣子:
佈建並連至 Cloud Shell 預計只需要幾分鐘。

這部虛擬機器搭載您需要的所有開發工具,並提供永久的 5GB 主目錄,而且可在 Google Cloud 運作,大幅提升網路效能並強化驗證功能。本程式碼研究室幾乎所有工作都可在瀏覽器或 Chromebook 上完成。
連線至 Cloud Shell 後,您應會發現自己通過驗證,且專案已設為您的專案 ID。
在 Cloud Shell 中執行下列指令,確認您已通過驗證:
gcloud auth list
指令輸出
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
在 Cloud Shell 中執行下列指令,確認 gcloud 指令知道您的專案:
gcloud config list project
指令輸出
[core] project = <PROJECT_ID>
如未設定,請輸入下列指令手動設定專案:
gcloud config set project <PROJECT_ID>
指令輸出
Updated property [core/project].
Cloud Shell 有幾個環境變數,包括 GOOGLE_CLOUD_PROJECT,其中包含目前雲端專案的名稱。我們會在整個實驗室的各個地方使用這個檔案。您可以執行下列指令來查看:
echo $GOOGLE_CLOUD_PROJECT
步驟 2:啟用 API
在後續步驟中,您會瞭解需要這些服務的原因和位置,但現在請執行下列指令,授予專案 Compute Engine、Container Registry 和 Vertex AI 服務的存取權:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
這時應該會顯示類似以下的成功訊息:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
步驟 3:建立 Cloud Storage 值區
如要在 Vertex AI 上執行訓練工作,我們需要儲存空間值區來儲存已儲存的模型資產。在 Cloud Shell 終端機中執行下列指令,建立 bucket:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
步驟 4:別名 Python 3
本實驗室的程式碼使用 Python 3。為確保您在本實驗室中建立的指令碼執行時使用 Python 3,請在 Cloud Shell 中執行下列指令,建立別名:
alias python=python3
我們將在本實驗室中訓練及提供服務的模型,是以 TensorFlow 文件中的這項教學課程為基礎。本教學課程使用 Kaggle 的 Auto MPG 資料集,預測車輛的燃油效率。
4. 將訓練程式碼容器化
我們會將訓練程式碼放入 Docker 容器,並將這個容器推送至 Google Container Registry,藉此將訓練工作提交至 Vertex。使用這種方法,我們可以訓練以任何架構建構的模型。
步驟 1:設定檔案
首先,在 Cloud Shell 的終端機中執行下列指令,建立 Docker 容器所需的檔案:
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
現在,您應該會有類似下方的 mpg/ 目錄:
+ Dockerfile
+ trainer/
+ train.py
如要查看及編輯這些檔案,請使用 Cloud Shell 的內建程式碼編輯器。點選 Cloud Shell 右上選單列中的按鈕,即可在編輯器和終端機之間切換:

步驟 2:建立 Dockerfile
如要將程式碼容器化,請先建立 Dockerfile。在 Dockerfile 中,我們會納入執行映像檔所需的所有指令。這會安裝我們使用的所有程式庫,並設定訓練程式碼的進入點。
在 Cloud Shell 檔案編輯器中開啟 mpg/ 目錄,然後按兩下開啟 Dockerfile:
然後將下列內容複製到這個檔案中:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
這個 Dockerfile 使用 深度學習容器 TensorFlow 企業版 2.3 Docker 映像檔。Google Cloud 上的深度學習容器預先安裝了許多常見的機器學習和資料科學框架。我們使用的版本包含 TF Enterprise 2.3、Pandas、Scikit-learn 等。下載該映像檔後,這個 Dockerfile 會設定訓練程式碼的進入點,我們會在下一個步驟中新增程式碼。
步驟 3:新增模型訓練程式碼
在 Cloud Shell 編輯器中開啟 train.py 檔案,然後複製下列程式碼 (改編自 TensorFlow 文件中的教學課程)。
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
將上述程式碼複製到 mpg/trainer/train.py 檔案後,請返回 Cloud Shell 中的終端機,然後執行下列指令,將您自己的 bucket 名稱新增至檔案:
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
步驟 4:在本機建構及測試容器
在終端機中執行下列指令,定義變數並指定 Google Container Registry 中容器映像檔的 URI:
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
接著,從 mpg 目錄的根層級執行下列指令,建構容器:
docker build ./ -t $IMAGE_URI
建構容器後,請將容器推送至 Google Container Registry:
docker push $IMAGE_URI
如要確認映像檔已推送至 Container Registry,請前往主控台的「Container Registry」部分,畫面應如下所示:
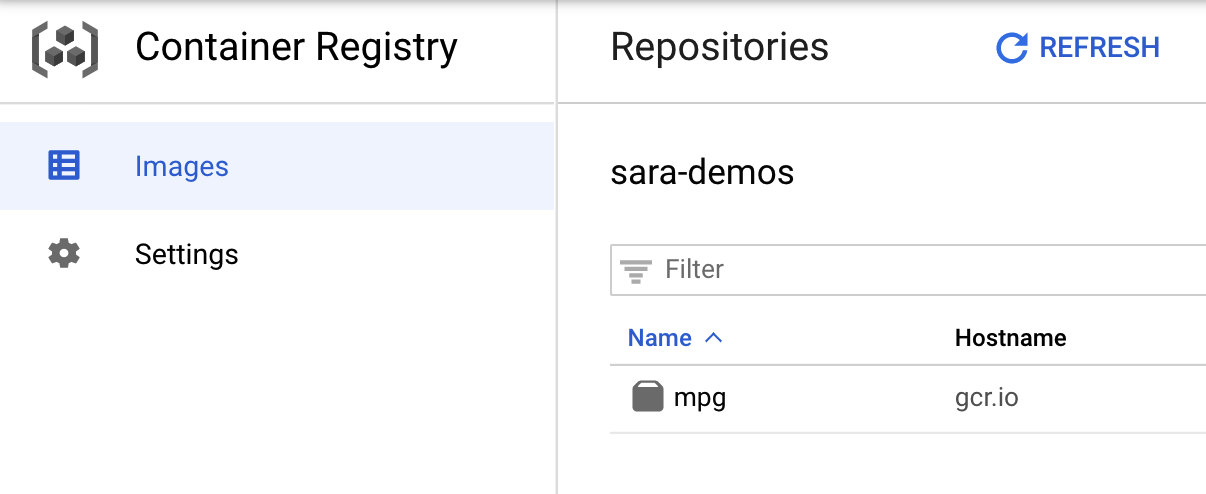
容器已推送至 Container Registry,現在可以開始執行自訂模型訓練工作。
5. 在 Vertex AI 中執行訓練工作
Vertex 提供兩種模型訓練選項:
- AutoML:輕鬆訓練高品質模型,僅需最基本的機器學習專業知識。
- 自訂訓練:使用 Google Cloud 其中一個預先建構的容器,或使用自己的容器,在雲端執行自訂訓練應用程式。
在本實驗室中,我們將透過 Google Container Registry 上的自訂容器,使用自訂訓練。首先,請前往 Cloud 控制台的 Vertex 專區,然後點選「訓練」部分:
步驟 1:啟動訓練工作
按一下「建立」,輸入訓練工作和已部署模型的參數:
- 在「Dataset」(資料集) 下方,選取「No managed dataset」(沒有代管資料集)
- 然後選取「Custom training (advanced)」(自訂訓練 (進階)) 做為訓練方法,並點按「Continue」(繼續)。
- 在「Model name」(模型名稱) 中輸入
mpg(或您想為模型命名的任何名稱) - 按一下 [Continue] (繼續)。
在「容器設定」步驟中,選取「自訂容器」:

在第一個方塊 (容器映像檔) 中,按一下「瀏覽」,然後找出您剛推送至 Container Registry 的容器。如下所示:
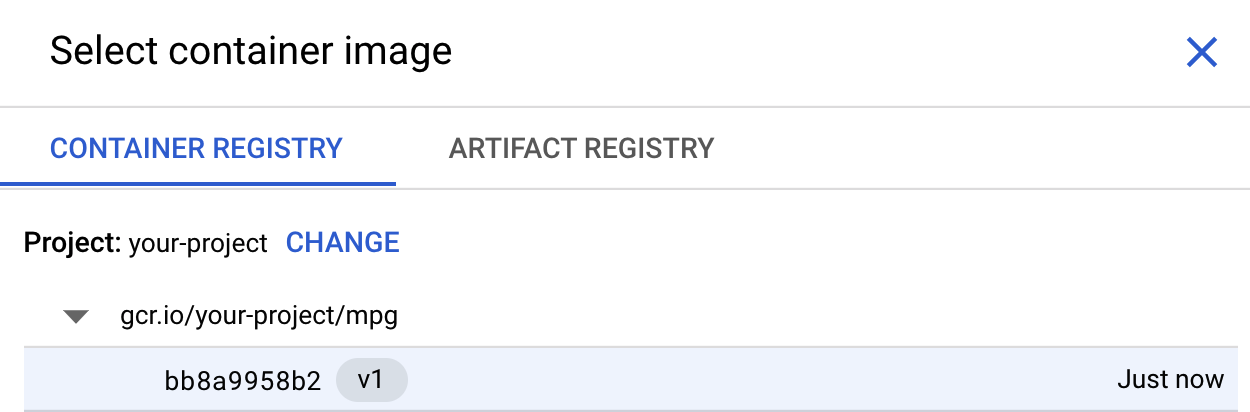
其餘欄位保留空白,然後點選「繼續」。
本教學課程不會使用超參數調整功能,因此請取消勾選「啟用超參數調整」方塊,然後按一下「繼續」。
在「Compute and pricing」(運算和價格) 中,保留選取的區域,然後選取「n1-standard-4」做為機型:
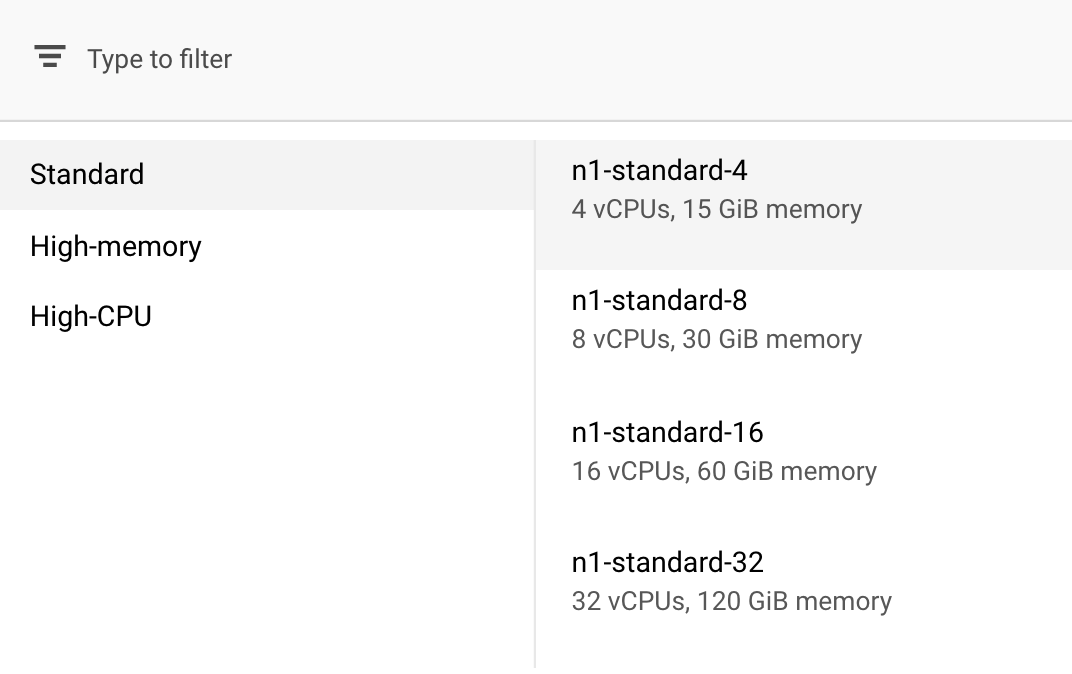
由於這個示範中的模型訓練速度很快,因此我們使用較小的機型。
在「預測容器」步驟下方,選取「無預測容器」:
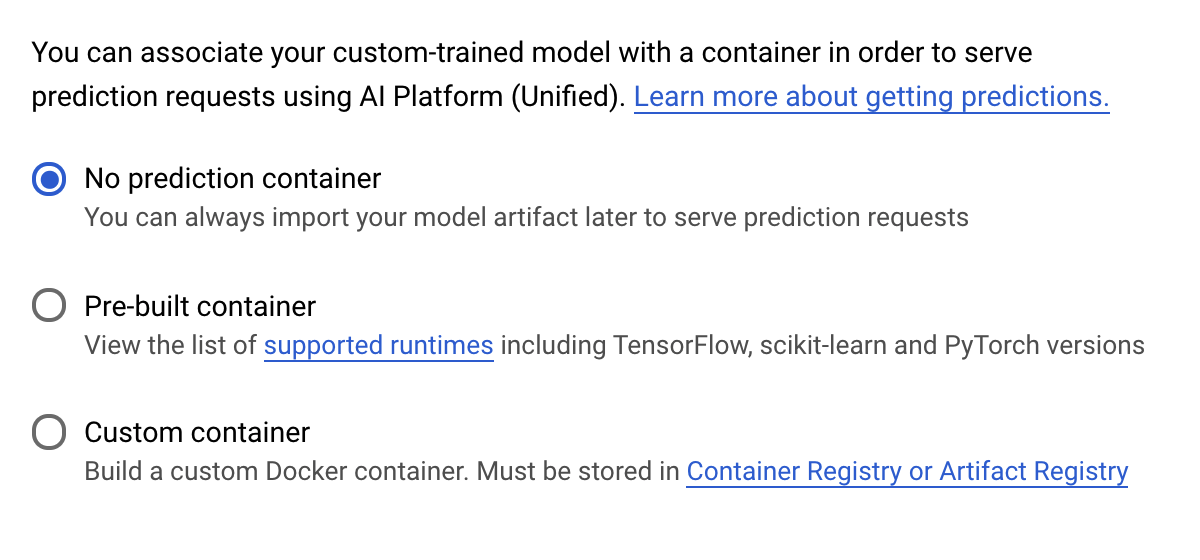
6. 部署模型端點
在這個步驟中,我們會為訓練好的模型建立端點。我們可以透過 Vertex AI API,使用這個端點取得模型的預測結果。為此,我們在公開 GCS 值區中提供匯出的訓練模型資產版本。
在機構中,通常會由一個團隊或個人負責建構模型,另一個團隊則負責部署模型。我們將逐步說明如何運用已訓練的模型,並部署模型以進行預測。
我們將使用 Vertex AI SDK 建立模型、將模型部署至端點,並取得預測結果。
步驟 1:安裝 Vertex SDK
在 Cloud Shell 終端機中執行下列指令,安裝 Vertex AI SDK:
pip3 install google-cloud-aiplatform --upgrade --user
我們可以透過這個 SDK 與 Vertex 的許多不同部分互動。
步驟 2:建立模型並部署端點
接著,我們會建立 Python 檔案,並使用 SDK 建立模型資源,然後部署至端點。在 Cloud Shell 的檔案編輯器中,依序選取「File」和「New File」:
將檔案命名為 deploy.py。在編輯器中開啟這個檔案,然後複製下列程式碼:
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
接著,返回 Cloud Shell 中的終端機,cd返回根目錄,然後執行您剛建立的 Python 指令碼:
cd ..
python3 deploy.py | tee deploy-output.txt
建立資源時,終端機中會記錄更新內容。這項作業會在 10 到 15 分鐘內完成。如要確保運作正常,請前往 Vertex AI 控制台的「Models」部分:
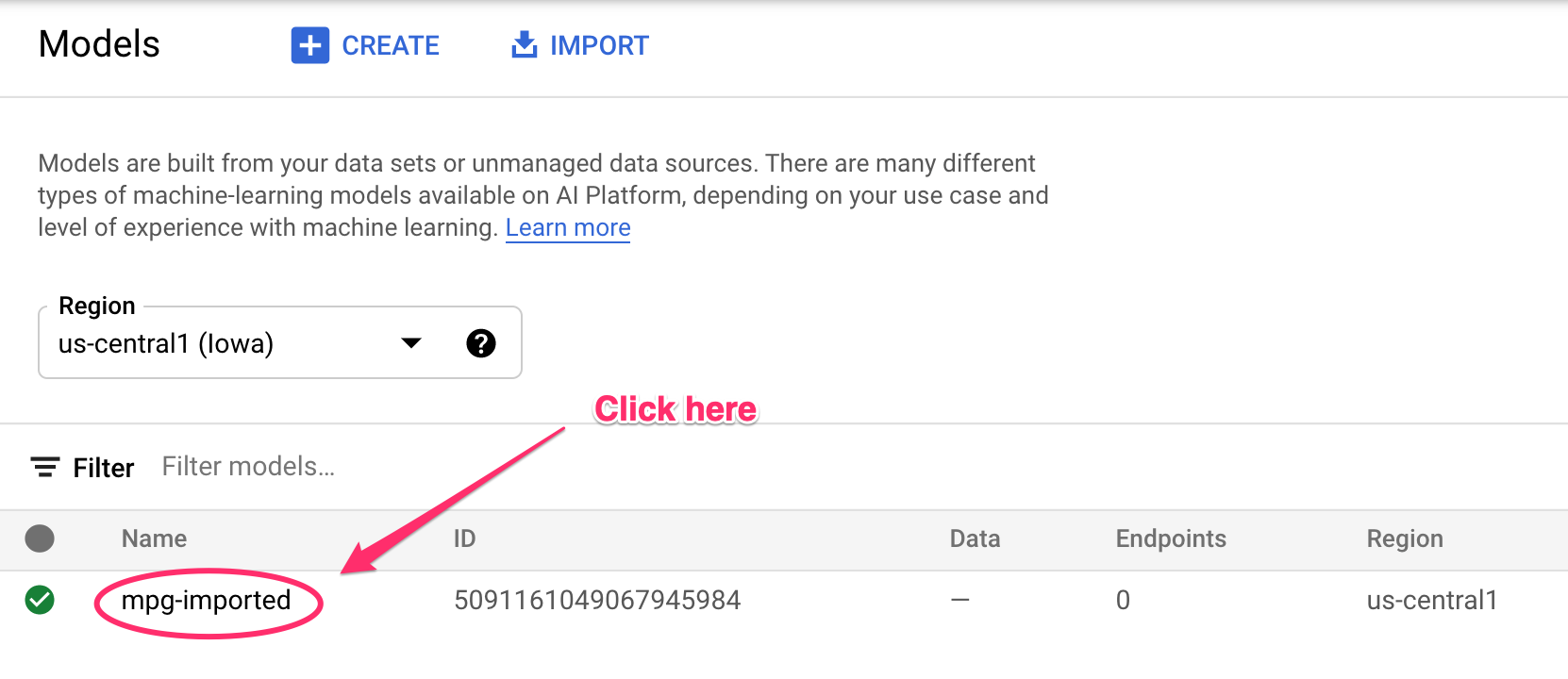
按一下「mgp-imported」,您應該會看到該模型正在建立端點:
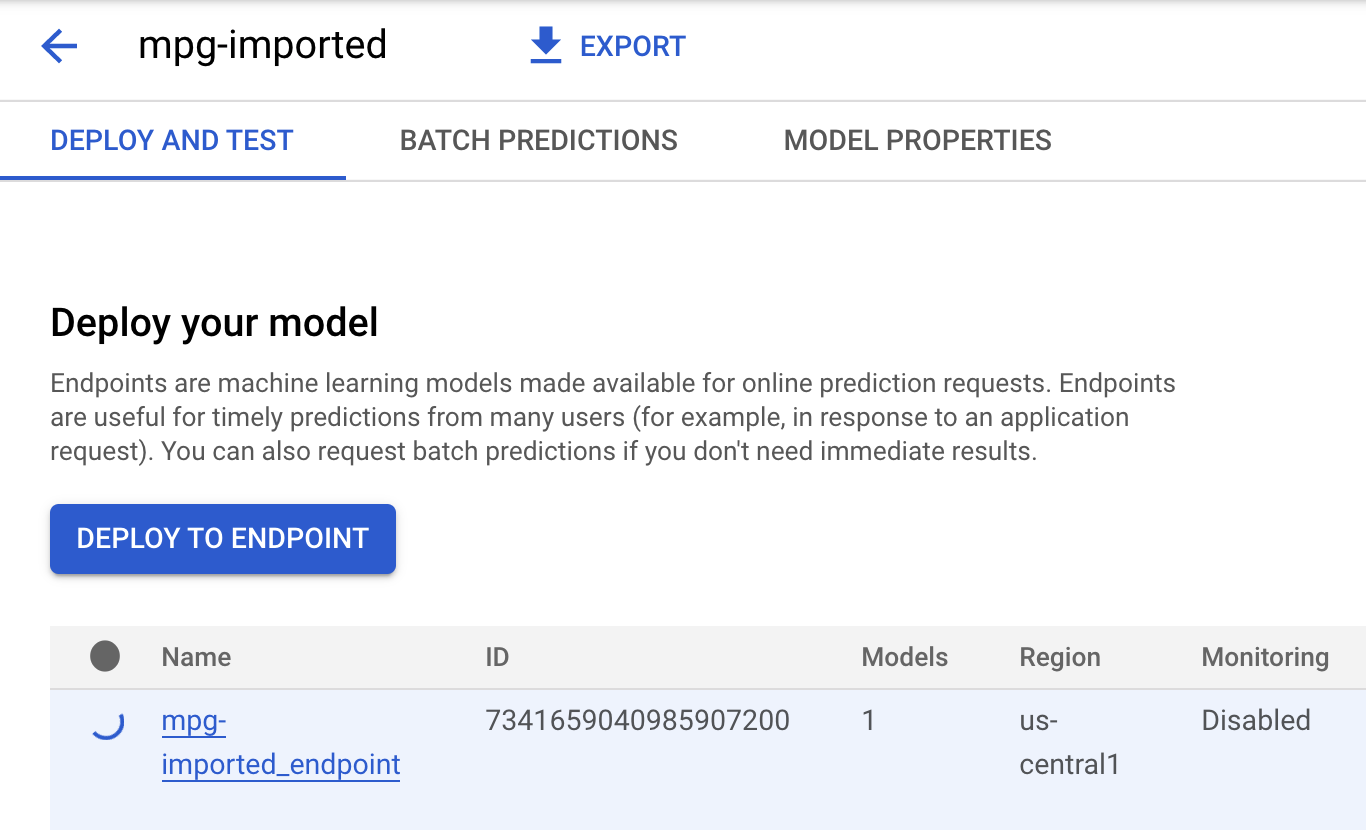
端點部署完成後,您會在 Cloud Shell 終端機中看到類似下列記錄的內容:
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
您將在下一個步驟中使用此項目,取得已部署端點的預測結果。
步驟 3:在部署的端點上取得預測結果
在 Cloud Shell 編輯器中,建立名為 predict.py 的新檔案:
開啟 predict.py,然後將下列程式碼貼入其中:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
接著返回終端機,輸入下列指令,將預測檔案中的 ENDPOINT_STRING 替換為您自己的端點:
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
現在可以執行 predict.py 檔案,從部署的模型端點取得預測結果:
python3 predict.py
您應該會看到 API 的回應記錄,以及測試預測的預估燃油效率。
🎉 恭喜!🎉
您已瞭解如何使用 Vertex AI 執行下列作業:
- 在自訂容器中提供訓練程式碼,即可訓練模型。本範例使用 TensorFlow 模型,但您可以使用自訂容器,訓練以任何架構建構的模型。
- 使用預先建構的容器部署 TensorFlow 模型,與訓練時使用的工作流程相同。
- 建立模型端點並產生預測結果。
如要進一步瞭解 Vertex AI 的其他部分,請參閱說明文件。如要查看步驟 5 中啟動的訓練工作結果,請前往 Vertex 控制台的訓練專區。
7. 清除
如要刪除已部署的端點,請前往 Vertex 控制台的「端點」部分,然後按一下刪除圖示:

如要刪除 Storage Bucket,請使用 Cloud 控制台中的導覽選單瀏覽至 Storage,選取 bucket,然後按一下「Delete」: