
1. Introduzione
In questo lab imparerai a utilizzare le routine di previsione personalizzate su Vertex AI per scrivere una logica di pre-elaborazione e post-elaborazione personalizzata. Sebbene questo esempio utilizzi Scikit-learn, le routine di previsione personalizzate possono funzionare con altri framework ML di Python come XGBoost, PyTorch e TensorFlow.
Cosa imparerai a fare
- Scrivi una logica di previsione personalizzata con routine di previsione personalizzate
- Testa a livello locale il modello e il container di pubblicazione personalizzato
- Testa il container di pubblicazione personalizzato su Vertex AI Predictions
2. Introduzione a Vertex AI
Questo lab utilizza la più recente offerta di prodotti AI disponibile su Google Cloud. Vertex AI integra le offerte ML di Google Cloud in un'esperienza di sviluppo fluida. In precedenza, i modelli addestrati con AutoML e i modelli personalizzati erano accessibili tramite servizi separati. La nuova offerta combina entrambi in un'unica API, insieme ad altri nuovi prodotti. Puoi anche migrare progetti esistenti su Vertex AI.
Vertex AI include molti prodotti diversi per supportare i flussi di lavoro ML end-to-end. Questo lab è incentrato su Predictions e Workbench.
3. Panoramica del caso d'uso
In questo lab creerai un modello di regressione della foresta casuale per prevedere il prezzo di un diamante in base ad attributi come taglio, chiarezza e dimensione.
Scriverai una logica di pre-elaborazione personalizzata per verificare che i dati al momento della pubblicazione siano nel formato previsto dal modello. Inoltre, scriverai una logica di post-elaborazione personalizzata per arrotondare le previsioni e convertirle in stringhe. Per scrivere questa logica, utilizzerai routine di previsione personalizzate.
Introduzione alle routine di previsione personalizzate
I container predefiniti Vertex AI gestiscono le richieste di previsione eseguendo l'operazione di previsione del framework di machine learning. Prima delle routine di previsione personalizzate, se volessi pre-elaborare l'input prima dell'esecuzione della previsione o post-elaborare la previsione del modello prima di restituire il risultato, devi creare un container personalizzato.
La creazione di un container di pubblicazione personalizzato richiede la scrittura di un server HTTP che esegue il wrapping del modello addestrato, traduce le richieste HTTP in input del modello e converte gli output del modello in risposte.
Con le routine di previsione personalizzate, Vertex AI fornisce per te i componenti correlati alla pubblicazione, in modo che tu possa concentrarti sul modello e sulle trasformazioni dei dati.
Cosa creerai
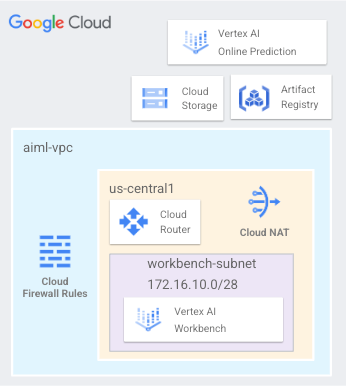
Configurerai una rete VPC denominata aiml-vpc composta da una subnet workbench utilizzata per eseguire il deployment di un blocco note gestito dall'utente e accedere alla previsione online e all'endpoint del modello di cui è stato eseguito il deployment in us-central1 illustrato nella figura 1 di seguito.
Figure1
4. Abilita le API per i tutorial
Passaggio 1: abilita l'API Compute Engine
Vai a Compute Engine e seleziona Abilita se non è già abilitato. Ne avrai bisogno per creare la tua istanza di blocco note.
Passaggio 2: abilita l'API Artifact Registry
Passa ad Artifact Registry e seleziona Abilita se non lo è già. Lo utilizzerai per creare un container di pubblicazione personalizzato.
Passaggio 3: abilita l'API Vertex AI
Vai alla sezione Vertex AI della tua console Cloud e fai clic su Abilita API Vertex AI.
Passaggio 4: crea un'istanza di Vertex AI Workbench
Attiva l'API Notebooks, se non è già attivo.
5. Crea il file aiml-vpc
Questo tutorial utilizza $variables per facilitare l'implementazione della configurazione di gcloud in Cloud Shell.
All'interno di Cloud Shell, esegui queste operazioni:
gcloud config list project
gcloud config set project [YOUR-PROJECT-NAME]
projectid=YOUR-PROJECT-NAME
echo $projectid
Crea aiml-vpc
All'interno di Cloud Shell, esegui queste operazioni:
gcloud compute networks create aiml-vpc --project=$projectid --subnet-mode=custom
Crea la subnet del blocco note gestito dall'utente
All'interno di Cloud Shell, crea la subnet workbench-subnet.
gcloud compute networks subnets create workbench-subnet --project=$projectid --range=172.16.10.0/28 --network=aiml-vpc --region=us-central1 --enable-private-ip-google-access
Router Cloud e configurazione NAT
Nel tutorial viene utilizzato Cloud NAT per scaricare pacchetti software, poiché il blocco note gestito dall'utente non ha un indirizzo IP esterno. Cloud NAT fornisce funzionalità NAT in uscita, pertanto agli host internet non è consentito avviare comunicazioni con un blocco note gestito dall'utente, rendendolo più sicuro.
All'interno di Cloud Shell, crea il router Cloud a livello di regione, us-central1.
gcloud compute routers create cloud-router-us-central1-aiml-nat --network aiml-vpc --region us-central1
All'interno di Cloud Shell, crea il gateway cloud nat regionale, us-central1.
gcloud compute routers nats create cloud-nat-us-central1 --router=cloud-router-us-central1-aiml-nat --auto-allocate-nat-external-ips --nat-all-subnet-ip-ranges --region us-central1
6. Crea il blocco note gestito dall'utente
Creare un account di servizio gestito dall'utente (blocco note)
Nella sezione seguente creerai un account di servizio gestito dall'utente che verrà associato a Vertex Workbench (Notebook) utilizzato nel tutorial.
Nel tutorial, all'account di servizio verranno applicate le seguenti regole:
In Cloud Shell, crea l'account di servizio.
gcloud iam service-accounts create user-managed-notebook-sa \
--display-name="user-managed-notebook-sa"
All'interno di Cloud Shell, aggiorna l'account di servizio con il ruolo Storage Admin.
gcloud projects add-iam-policy-binding $projectid --member="serviceAccount:user-managed-notebook-sa@$projectid.iam.gserviceaccount.com" --role="roles/storage.admin"
All'interno di Cloud Shell, aggiorna l'account di servizio con il ruolo Vertex AI User.
gcloud projects add-iam-policy-binding $projectid --member="serviceAccount:user-managed-notebook-sa@$projectid.iam.gserviceaccount.com" --role="roles/aiplatform.user"
All'interno di Cloud Shell, aggiorna l'account di servizio con il ruolo Artifact Registry Admin.
gcloud projects add-iam-policy-binding $projectid --member="serviceAccount:user-managed-notebook-sa@$projectid.iam.gserviceaccount.com" --role="roles/artifactregistry.admin"
All'interno di Cloud Shell, elenca l'account di servizio e prendi nota dell'indirizzo email che verrà utilizzato durante la creazione del blocco note gestito dall'utente.
gcloud iam service-accounts list
Crea il blocco note gestito dall'utente
Nella sezione seguente, crea un blocco note gestito dall'utente che incorpora l'account di servizio creato in precedenza, user-managed-notebook-sa.
All'interno di Cloud Shell, crea l'istanza client privato.
gcloud notebooks instances create workbench-tutorial \
--vm-image-project=deeplearning-platform-release \
--vm-image-family=common-cpu-notebooks \
--machine-type=n1-standard-4 \
--location=us-central1-a \
--shielded-secure-boot \
--subnet-region=us-central1 \
--subnet=workbench-subnet \
--no-public-ip --service-account=user-managed-notebook-sa@$projectid.iam.gserviceaccount.com
7. Scrivi il codice di addestramento
Passaggio 1: crea un bucket Cloud Storage
Archivierai il modello e gli artefatti di pre-elaborazione in un bucket Cloud Storage. Se nel progetto hai già un bucket che vuoi utilizzare, puoi saltare questo passaggio.
Da Avvio app apri una nuova sessione del terminale.

Dal terminale, esegui quanto segue per definire una variabile env per il tuo progetto, assicurandoti di sostituire your-cloud-project con l'ID del tuo progetto:
PROJECT_ID='your-cloud-project'
Quindi, esegui questo comando nel terminale per creare un nuovo bucket nel tuo progetto.
BUCKET="gs://${PROJECT_ID}-cpr-bucket"
gsutil mb -l us-central1 $BUCKET
Passaggio 2: addestra il modello
Dal terminale, crea una nuova directory denominata cpr-codelab e accedi con cd.
mkdir cpr-codelab
cd cpr-codelab
Nel browser di file, passa alla nuova directory cpr-codelab, quindi utilizza Avvio app per creare un nuovo blocco note Python 3 chiamato task.ipynb.
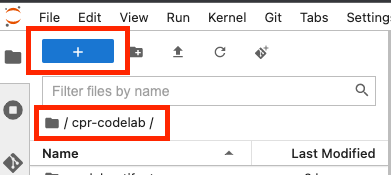
La directory cpr-codelab dovrebbe avere il seguente aspetto:
+ cpr-codelab/
+ task.ipynb
Incolla il codice seguente nel blocco note.
Innanzitutto, scrivi un file requirements.txt.
%%writefile requirements.txt
fastapi
uvicorn==0.17.6
joblib~=1.1.1
numpy>=1.17.3, <1.24.0
scikit-learn~=1.0.0
pandas
google-cloud-storage>=2.2.1,<3.0.0dev
google-cloud-aiplatform[prediction]>=1.18.2
Il modello di cui esegui il deployment avrà un set di dipendenze diverso preinstallato rispetto all'ambiente del tuo blocco note. Per questo motivo, è consigliabile elencare tutte le dipendenze del modello nel file requirements.txt, quindi utilizzare pip per installare le stesse dipendenze nel blocco note. Successivamente, testerai il modello localmente prima di eseguirne il deployment in Vertex AI per verificare la corrispondenza degli ambienti.
Pip installa le dipendenze nel blocco note.
!pip install -U --user -r requirements.txt
Tieni presente che dovrai riavviare il kernel al termine dell'installazione di pip.
Quindi, crea le directory in cui archivierai il modello e gli artefatti di pre-elaborazione.
USER_SRC_DIR = "src_dir"
!mkdir $USER_SRC_DIR
!mkdir model_artifacts
# copy the requirements to the source dir
!cp requirements.txt $USER_SRC_DIR/requirements.txt
La directory cpr-codelab dovrebbe avere il seguente aspetto:
+ cpr-codelab/
+ model_artifacts/
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
Ora che la struttura di directory è impostata, è il momento di addestrare un modello.
Innanzitutto, importa le librerie.
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
import joblib
import logging
# set logging to see the docker container logs
logging.basicConfig(level=logging.INFO)
Poi definisci le seguenti variabili. Assicurati di sostituire PROJECT_ID con l'ID progetto e BUCKET_NAME con il bucket che hai creato nel passaggio precedente.
REGION = "us-central1"
MODEL_ARTIFACT_DIR = "sklearn-model-artifacts"
REPOSITORY = "diamonds"
IMAGE = "sklearn-image"
MODEL_DISPLAY_NAME = "diamonds-cpr"
# Replace with your project
PROJECT_ID = "{PROJECT_ID}"
# Replace with your bucket
BUCKET_NAME = "gs://{BUCKET_NAME}"
Carica i dati dalla libreria Seaborn e crea due frame di dati, uno con le caratteristiche e l'altro con l'etichetta.
data = sns.load_dataset('diamonds', cache=True, data_home=None)
label = 'price'
y_train = data['price']
x_train = data.drop(columns=['price'])
Diamo un'occhiata ai dati di addestramento. Puoi vedere che ogni riga rappresenta un rombo.
x_train.head()
E le etichette, che sono i prezzi corrispondenti.
y_train.head()
Ora, definisci una trasformazione di colonna sklearn in una codifica a caldo delle caratteristiche categoriche e scala le caratteristiche numeriche
column_transform = make_column_transformer(
(preprocessing.OneHotEncoder(sparse=False), [1,2,3]),
(preprocessing.StandardScaler(), [0,4,5,6,7,8]))
Definisci il modello di foresta casuale
regr = RandomForestRegressor(max_depth=10, random_state=0)
Poi, crea una pipeline sklearn. Ciò significa che i dati inviati a questa pipeline verranno prima codificati/scalati e poi passati al modello.
my_pipeline = make_pipeline(column_transform, regr)
Adatta la pipeline ai dati di addestramento
my_pipeline.fit(x_train, y_train)
Proviamo il modello per assicurarci che funzioni come previsto. Chiama il metodo di previsione sul modello, passando un campione di test.
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])
Ora possiamo salvare la pipeline nella directory model_artifacts e copiarla nel bucket Cloud Storage
joblib.dump(my_pipeline, 'model_artifacts/model.joblib')
!gsutil cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
Passaggio 3: salva un artefatto di pre-elaborazione
A questo punto creerai un artefatto di pre-elaborazione. Questo artefatto verrà caricato nel container personalizzato all'avvio del server del modello. L'artefatto di pre-elaborazione può essere di quasi qualsiasi forma (ad esempio un file di pickle), ma in questo caso scriverai un dizionario in un file JSON.
clarity_dict={"Flawless": "FL",
"Internally Flawless": "IF",
"Very Very Slightly Included": "VVS1",
"Very Slightly Included": "VS2",
"Slightly Included": "S12",
"Included": "I3"}
La funzionalità di chiarezza nei dati di addestramento era sempre in forma abbreviata (ovvero "FL" invece di "Flawless"). Al momento della pubblicazione, vogliamo verificare che i dati per questa funzionalità siano anche abbreviati. Questo perché il nostro modello sa come codificare a caldo "FL" ma non "impeccabile". Scriverai questa logica di pre-elaborazione personalizzata in un secondo momento. Per il momento, però, salva questa tabella di ricerca in un file json e poi scrivilo nel bucket Cloud Storage.
import json
with open("model_artifacts/preprocessor.json", "w") as f:
json.dump(clarity_dict, f)
!gsutil cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
La directory cpr-codelab locale dovrebbe avere il seguente aspetto:
+ cpr-codelab/
+ model_artifacts/
+ model.joblib
+ preprocessor.json
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
8. Crea un container di pubblicazione personalizzato utilizzando il server del modello CPR
Ora che il modello è stato addestrato e che l'artefatto di pre-elaborazione è stato salvato, è il momento di creare il container di pubblicazione personalizzato. In genere, la creazione di un container di pubblicazione richiede la scrittura del codice del server del modello. Tuttavia, con le routine di previsione personalizzate, Vertex AI Predictions genera un server modello e crea un'immagine container personalizzata per te.
Un container di pubblicazione personalizzato contiene le tre parti di codice seguenti:
- Server del modello (verrà generato automaticamente dall'SDK e archiviato in scr_dir/)
- Server HTTP che ospita il modello
- Responsabile della configurazione di route/porte ecc.
- Responsabile degli aspetti relativi ai server web della gestione di una richiesta, come la deserializzazione del corpo della richiesta, la serializzazione della risposta, l'impostazione delle intestazioni della risposta e così via.
- In questo esempio utilizzerai il gestore predefinito google.cloud.aiplatform.prediction.handler.PredictionGestori fornito nell'SDK.
- Responsabile della logica ML per l'elaborazione di una richiesta di previsione.
Ognuno di questi componenti può essere personalizzato in base ai requisiti del caso d'uso. In questo esempio, implementerai solo il predittore.
Il predittore è responsabile della logica ML per l'elaborazione di una richiesta di previsione, come la pre-elaborazione e la post-elaborazione personalizzate. Per scrivere una logica di previsione personalizzata, dovrai creare una sottoclasse dell'interfaccia di Vertex AI Predictor.
Questa versione di routine di previsione personalizzate include predittori XGBoost e Sklearn riutilizzabili, ma se devi utilizzare un framework diverso puoi crearne uno personalizzato creando sottoclassi del predittore di base.
Di seguito è riportato un esempio del predittore Sklearn. Questo è tutto il codice da scrivere per creare il server del modello personalizzato.

Nel blocco note, incolla il codice seguente per la sottoclasse SklearnPredictor e scrivilo in un file Python nella sezione src_dir/. Tieni presente che in questo esempio personalizziamo solo i metodi di caricamento, pre-elaborazione e post-elaborazione, e non il metodo di previsione.
%%writefile $USER_SRC_DIR/predictor.py
import joblib
import numpy as np
import json
from google.cloud import storage
from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor
class CprPredictor(SklearnPredictor):
def __init__(self):
return
def load(self, artifacts_uri: str) -> None:
"""Loads the sklearn pipeline and preprocessing artifact."""
super().load(artifacts_uri)
# open preprocessing artifact
with open("preprocessor.json", "rb") as f:
self._preprocessor = json.load(f)
def preprocess(self, prediction_input: np.ndarray) -> np.ndarray:
"""Performs preprocessing by checking if clarity feature is in abbreviated form."""
inputs = super().preprocess(prediction_input)
for sample in inputs:
if sample[3] not in self._preprocessor.values():
sample[3] = self._preprocessor[sample[3]]
return inputs
def postprocess(self, prediction_results: np.ndarray) -> dict:
"""Performs postprocessing by rounding predictions and converting to str."""
return {"predictions": [f"${value}" for value in np.round(prediction_results)]}
Esaminiamo più in dettaglio ognuno di questi metodi.
- Il metodo di caricamento viene caricato nell'artefatto di pre-elaborazione, che in questo caso è un dizionario che mappa i valori della chiarezza dei diamanti alle relative abbreviazioni.
- Il metodo di pre-elaborazione utilizza questo artefatto per garantire che al momento della pubblicazione la funzionalità di chiarezza sia nel suo formato abbreviato. In caso contrario, converte l'intera stringa nella sua abbreviazione.
- Il metodo postprocess restituisce il valore previsto come stringa con il simbolo $ e lo arrotonda.
Quindi, utilizza l'SDK Python di Vertex AI per creare l'immagine. Utilizzando routine di previsione personalizzate, verrà generato il Dockerfile e verrà creata un'immagine per te.
from google.cloud import aiplatform
aiplatform.init(project=PROJECT_ID, location=REGION)
import os
from google.cloud.aiplatform.prediction import LocalModel
from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR
local_model = LocalModel.build_cpr_model(
USER_SRC_DIR,
f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}",
predictor=CprPredictor,
requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"),
)
Scrivi un file di test con due esempi per la previsione. Una delle istanze ha il nome chiaro abbreviato, ma l'altra deve essere prima convertita.
import json
sample = {"instances": [
[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43],
[0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}
with open('instances.json', 'w') as fp:
json.dump(sample, fp)
Testa il container in locale eseguendo il deployment di un modello locale.
with local_model.deploy_to_local_endpoint(
artifact_uri = 'model_artifacts/', # local path to artifacts
) as local_endpoint:
predict_response = local_endpoint.predict(
request_file='instances.json',
headers={"Content-Type": "application/json"},
)
health_check_response = local_endpoint.run_health_check()
Puoi vedere i risultati della previsione con:
predict_response.content
9. Esegui il deployment del modello su Vertex AI
Ora che hai testato il container in locale, è il momento di eseguire il push dell'immagine ad Artifact Registry e di caricare il modello in Vertex AI Model Registry.
Innanzitutto, configura Docker per accedere ad Artifact Registry.
!gcloud artifacts repositories create {REPOSITORY} --repository-format=docker \
--location=us-central1 --description="Docker repository"
!gcloud auth configure-docker {REGION}-docker.pkg.dev --quiet
Quindi, esegui il push dell'immagine.
local_model.push_image()
Quindi, carica il modello.
model = aiplatform.Model.upload(local_model = local_model,
display_name=MODEL_DISPLAY_NAME,
artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)
Una volta caricato il modello, dovresti vederlo nella console:
Quindi, esegui il deployment del modello in modo da poterlo utilizzare per le previsioni online. Le routine di previsione personalizzate funzionano anche con la previsione batch, quindi se il tuo caso d'uso non richiede previsioni online, non è necessario eseguire il deployment del modello.
Quindi, esegui il push dell'immagine.
endpoint = model.deploy(machine_type="n1-standard-2")
Infine, testa il modello di cui hai eseguito il deployment ricevendo una previsione.
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])
🎉 Complimenti! 🎉
Hai imparato come utilizzare Vertex AI per:
- Scrivi una logica di pre-elaborazione e post-elaborazione personalizzata con routine di previsione personalizzate
Cosmopup pensa che i codelab siano straordinari.

Passaggi successivi
Per approfondire Video
- Che cos'è Vertex AI?
- Inizia a utilizzare Vertex AI
- Quale soluzione di IA/ML su Vertex AI fa al caso mio?
- Creazione di un sistema di question answering con Vertex AI