
1. 简介
在本实验中,您将学习如何在 Vertex AI 上使用自定义预测例程编写自定义预处理和后处理逻辑。虽然此示例使用的是 Scikit-learn,但自定义预测例程也可以与其他 Python 机器学习框架(如 XGBoost、PyTorch 和 TensorFlow)搭配使用。
学习内容
- 使用自定义预测例程编写自定义预测逻辑
- 在本地测试自定义服务容器和模型
- 在 Vertex AI Predictions 上测试自定义服务容器
2. Vertex AI 简介
本实验使用的是 Google Cloud 上提供的最新 AI 产品。Vertex AI 将整个 Google Cloud 的机器学习产品集成到无缝的开发体验中。以前,使用 AutoML 训练的模型和自定义模型是通过不同的服务访问的。现在,该新产品与其他新产品一起将这两种模型合并到一个 API 中。您还可以将现有项目迁移到 Vertex AI。
Vertex AI 包含许多不同的产品,可支持端到端机器学习工作流。本实验将重点介绍 Predictions 和 Workbench。
3. 用例概览
在本实验中,您将构建一个随机森林回归模型,以根据切割、清晰度和尺寸等属性预测钻石的价格。
您将编写自定义预处理逻辑,以检查供应时的数据是否采用模型所需的格式。您还将编写自定义后处理逻辑,以对预测进行四舍五入并将其转换为字符串。如需编写此逻辑,您需要使用自定义预测例程。
自定义预测例程简介
Vertex AI 预构建容器通过执行机器学习框架的预测操作来处理预测请求。在自定义预测例程之前,如果您想在执行预测之前对输入进行预处理,或者在返回结果之前对模型的预测结果进行后处理,则需要构建自定义容器。
构建自定义服务容器需要编写 HTTP 服务器,用于封装经过训练的模型、将 HTTP 请求转换为模型输入,并将模型输出转换为响应。
借助自定义预测例程,Vertex AI 可为您提供与服务相关的组件,以便您专注于模型和数据转换。
构建内容
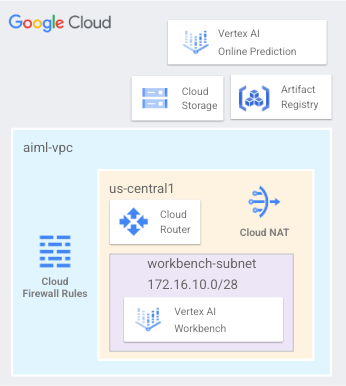
您将设置一个名为 aaml-vpc 的 VPC 网络,其中包含一个工作台子网,该子网用于部署用户管理的笔记本,以及访问部署在 us-central1 中的在线预测和模型端点(如图 1 所示)。
Figure1
4. 启用教程 API
第 1 步:启用 Compute Engine API
前往 Compute Engine,然后选择“启用”(如果尚未启用)。您需要用它来创建笔记本实例。
第 2 步:启用 Artifact Registry API
前往 Artifact Registry,然后选择“启用”(如果尚未启用)。您将使用此文件创建自定义服务容器。
第 3 步:启用 Vertex AI API
前往 Cloud 控制台的 Vertex AI 部分,然后点击“启用 Vertex AI API”。
第 4 步:创建 Vertex AI Workbench 实例
启用笔记本 API(如果尚未启用)。
5. 创建 aml-vpc
本教程利用 $variables 辅助在 Cloud Shell 中实现 gcloud 配置。
在 Cloud Shell 中,执行以下操作:
gcloud config list project
gcloud config set project [YOUR-PROJECT-NAME]
projectid=YOUR-PROJECT-NAME
echo $projectid
创建 aml-vpc
在 Cloud Shell 中,执行以下操作:
gcloud compute networks create aiml-vpc --project=$projectid --subnet-mode=custom
创建用户管理的笔记本子网
在 Cloud Shell 中,创建工作台子网。
gcloud compute networks subnets create workbench-subnet --project=$projectid --range=172.16.10.0/28 --network=aiml-vpc --region=us-central1 --enable-private-ip-google-access
Cloud Router 和 NAT 配置
本教程使用 Cloud NAT 下载软件包,因为用户管理的笔记本没有外部 IP 地址。Cloud NAT 提供出站流量 NAT 功能,这意味着不允许互联网主机与用户管理的笔记本进行通信,从而提高了安全性。
在 Cloud Shell 中,创建区域级 Cloud Router 路由器 us-central1。
gcloud compute routers create cloud-router-us-central1-aiml-nat --network aiml-vpc --region us-central1
在 Cloud Shell 中,创建区域级 Cloud NAT 网关 us-central1。
gcloud compute routers nats create cloud-nat-us-central1 --router=cloud-router-us-central1-aiml-nat --auto-allocate-nat-external-ips --nat-all-subnet-ip-ranges --region us-central1
6. 创建用户管理的笔记本
创建用户管理的服务账号 (Notebook)
在下一部分中,您将创建一个用户管理的服务账号,该账号将与本教程中使用的 Vertex Workbench (Notebook) 相关联。
在本教程中,服务账号将应用以下规则:
在 Cloud Shell 中,创建服务账号。
gcloud iam service-accounts create user-managed-notebook-sa \
--display-name="user-managed-notebook-sa"
在 Cloud Shell 中,使用 Storage Admin 角色更新服务账号。
gcloud projects add-iam-policy-binding $projectid --member="serviceAccount:user-managed-notebook-sa@$projectid.iam.gserviceaccount.com" --role="roles/storage.admin"
在 Cloud Shell 中,使用 Vertex AI User 角色更新服务账号。
gcloud projects add-iam-policy-binding $projectid --member="serviceAccount:user-managed-notebook-sa@$projectid.iam.gserviceaccount.com" --role="roles/aiplatform.user"
在 Cloud Shell 中,使用 Artifact Registry Admin 角色更新服务账号。
gcloud projects add-iam-policy-binding $projectid --member="serviceAccount:user-managed-notebook-sa@$projectid.iam.gserviceaccount.com" --role="roles/artifactregistry.admin"
在 Cloud Shell 中,列出服务账号并记下在创建用户管理的笔记本时要使用的电子邮件地址。
gcloud iam service-accounts list
创建用户管理的笔记本
在下一部分中,创建一个用户管理的笔记本,其中包含之前创建的服务账号 user-managed-notebook-sa。
在 Cloud Shell 中,创建 private-client 实例。
gcloud notebooks instances create workbench-tutorial \
--vm-image-project=deeplearning-platform-release \
--vm-image-family=common-cpu-notebooks \
--machine-type=n1-standard-4 \
--location=us-central1-a \
--shielded-secure-boot \
--subnet-region=us-central1 \
--subnet=workbench-subnet \
--no-public-ip --service-account=user-managed-notebook-sa@$projectid.iam.gserviceaccount.com
7. 编写训练代码
第 1 步:创建 Cloud Storage 存储分区
您将模型和预处理工件存储到 Cloud Storage 存储分区中。如果项目中已有要使用的存储分区,则可以跳过此步骤。
在启动器中打开一个新的终端会话。

从终端运行以下命令,为您的项目定义环境变量,确保将 your-cloud-project 替换为您的项目 ID:
PROJECT_ID='your-cloud-project'
接下来,在终端中运行以下命令,以便在项目中创建一个新的存储桶。
BUCKET="gs://${PROJECT_ID}-cpr-bucket"
gsutil mb -l us-central1 $BUCKET
第 2 步:训练模型
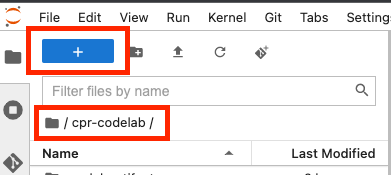
在终端中,新建一个名为 cpr-codelab 的目录,然后通过 cd 命令进入该目录。
mkdir cpr-codelab
cd cpr-codelab
在文件浏览器中,导航到新的 cpr-codelab 目录,然后使用启动器新建一个名为 task.ipynb 的 Python 3 笔记本。
您的 cpr-codelab 目录现在应如下所示:
+ cpr-codelab/
+ task.ipynb
在笔记本中,粘贴以下代码。
首先,编写 requirements.txt 文件。
%%writefile requirements.txt
fastapi
uvicorn==0.17.6
joblib~=1.1.1
numpy>=1.17.3, <1.24.0
scikit-learn~=1.0.0
pandas
google-cloud-storage>=2.2.1,<3.0.0dev
google-cloud-aiplatform[prediction]>=1.18.2
您部署的模型将预安装一组与笔记本环境不同的依赖项。因此,您需要在 requirements.txt 中列出模型的所有依赖项,然后使用 pip 在笔记本中安装完全相同的依赖项。稍后,您将在本地测试模型,然后再将其部署到 Vertex AI,以仔细检查环境是否匹配。
Pip 会在笔记本中安装依赖项。
!pip install -U --user -r requirements.txt
请注意,在 pip 安装完成后,你需要重启内核。
接下来,创建用于存储模型和预处理工件的目录。
USER_SRC_DIR = "src_dir"
!mkdir $USER_SRC_DIR
!mkdir model_artifacts
# copy the requirements to the source dir
!cp requirements.txt $USER_SRC_DIR/requirements.txt
您的 cpr-codelab 目录现在应如下所示:
+ cpr-codelab/
+ model_artifacts/
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
现在目录结构已设置完毕,可以开始训练模型了!
首先,导入库。
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
import joblib
import logging
# set logging to see the docker container logs
logging.basicConfig(level=logging.INFO)
然后定义以下变量。请务必将 PROJECT_ID 替换为您的项目 ID,将 BUCKET_NAME 替换为您在上一步中创建的存储分区。
REGION = "us-central1"
MODEL_ARTIFACT_DIR = "sklearn-model-artifacts"
REPOSITORY = "diamonds"
IMAGE = "sklearn-image"
MODEL_DISPLAY_NAME = "diamonds-cpr"
# Replace with your project
PROJECT_ID = "{PROJECT_ID}"
# Replace with your bucket
BUCKET_NAME = "gs://{BUCKET_NAME}"
从 Seaborn 库加载数据,然后创建两个数据帧,一个有特征,另一个有标签。
data = sns.load_dataset('diamonds', cache=True, data_home=None)
label = 'price'
y_train = data['price']
x_train = data.drop(columns=['price'])
我们来看看训练数据。您可以看到每一行代表一个菱形。
x_train.head()
标签,也就是相应的价格。
y_train.head()
现在,定义一个 sklearn 列转换,以便对分类特征进行热编码并缩放数值特征
column_transform = make_column_transformer(
(preprocessing.OneHotEncoder(sparse=False), [1,2,3]),
(preprocessing.StandardScaler(), [0,4,5,6,7,8]))
定义随机森林模型
regr = RandomForestRegressor(max_depth=10, random_state=0)
接下来,创建 sklearn 流水线。这意味着,馈送到此流水线的数据会先进行编码/缩放,然后再传递给模型。
my_pipeline = make_pipeline(column_transform, regr)
根据训练数据拟合流水线
my_pipeline.fit(x_train, y_train)
我们来尝试一下该模型,以确保它按预期工作。对该模型调用预测方法,并传入测试样本。
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])
现在我们可以将流水线保存到 model_artifacts 目录,并将其复制到 Cloud Storage 存储分区
joblib.dump(my_pipeline, 'model_artifacts/model.joblib')
!gsutil cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
第 3 步:保存预处理工件
接下来,您将创建一个预处理工件。当模型服务器启动时,此工件将加载到自定义容器中。您的预处理工件几乎可以是任何形式(例如 Pickle 文件),但在这种情况下,您将写出一个字典到 JSON 文件。
clarity_dict={"Flawless": "FL",
"Internally Flawless": "IF",
"Very Very Slightly Included": "VVS1",
"Very Slightly Included": "VS2",
"Slightly Included": "S12",
"Included": "I3"}
训练数据中的清晰度特征始终采用缩写形式(即“FL”而非“Flawless”)。投放时,我们需要检查此地图项的数据是否也采用缩写。这是因为我们的模型知道如何对“FL”进行热编码,而不是“Flawless”。稍后您将编写此自定义预处理逻辑。但现在,只需将此查询表保存为 JSON 文件,然后将其写入 Cloud Storage 存储分区。
import json
with open("model_artifacts/preprocessor.json", "w") as f:
json.dump(clarity_dict, f)
!gsutil cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
您的本地 cpr-codelab 目录现在应如下所示:
+ cpr-codelab/
+ model_artifacts/
+ model.joblib
+ preprocessor.json
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
8. 使用 CPR 模型服务器构建自定义服务容器
现在模型已经过训练并保存了预处理工件,接下来可以构建自定义服务容器了。通常,构建服务容器需要编写模型服务器代码。但是,借助自定义预测例程,Vertex AI Predictions 会生成模型服务器并为您构建自定义容器映像。
自定义服务容器包含以下 3 段代码:
- 模型服务器(将由 SDK 自动生成并存储在 scr_dir/ 中)
- 托管模型的 HTTP 服务器
- 负责设置路由/端口等。
- 负责处理请求的网络服务器方面,例如对请求正文进行反序列化、序列化响应、设置响应标头等。
- 在此示例中,您将使用 SDK 中提供的默认处理程序 google.cloud.aiplatform.predict.handler.PredictionHandler。
- 负责处理预测请求的机器学习逻辑。
其中每个组件都可以根据用例的要求进行自定义。在此示例中,您只需实现预测器即可。
预测器负责处理预测请求的机器学习逻辑,例如自定义预处理和后处理。如需编写自定义预测逻辑,您需要创建 Vertex AI Predictor 接口的子类。
此版本的自定义预测例程附带可重复使用的 XGBoost 和 Sklearn 预测器,但如果您需要使用其他框架,可以通过对基本预测器进行子类化来创建自己的框架。
您可以查看下面的 Sklearn 预测器示例。这些就是构建这个自定义模型服务器需要编写的全部代码。

在笔记本中,粘贴以下代码,将 SklearnPredictor 子类化,并将其写入 src_dir/ 中的 Python 文件。请注意,在此示例中,我们仅自定义加载、预处理和后处理方法,而不是预测方法。
%%writefile $USER_SRC_DIR/predictor.py
import joblib
import numpy as np
import json
from google.cloud import storage
from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor
class CprPredictor(SklearnPredictor):
def __init__(self):
return
def load(self, artifacts_uri: str) -> None:
"""Loads the sklearn pipeline and preprocessing artifact."""
super().load(artifacts_uri)
# open preprocessing artifact
with open("preprocessor.json", "rb") as f:
self._preprocessor = json.load(f)
def preprocess(self, prediction_input: np.ndarray) -> np.ndarray:
"""Performs preprocessing by checking if clarity feature is in abbreviated form."""
inputs = super().preprocess(prediction_input)
for sample in inputs:
if sample[3] not in self._preprocessor.values():
sample[3] = self._preprocessor[sample[3]]
return inputs
def postprocess(self, prediction_results: np.ndarray) -> dict:
"""Performs postprocessing by rounding predictions and converting to str."""
return {"predictions": [f"${value}" for value in np.round(prediction_results)]}
我们来深入了解一下每种方法。
- 加载方法会加载预处理工件,在本例中,该工件是将菱形清晰度值映射到其缩写的字典。
- 预处理方法使用该工件来确保提供时清晰度特征采用的是缩写格式。否则,它会将整个字符串转换为其缩写。
- 后处理方法将预测值作为带有 $ 符号的字符串返回,并对值进行四舍五入。
接下来,使用 Vertex AI Python SDK 构建映像。使用自定义预测例程,系统将生成 Dockerfile 并为您构建映像。
from google.cloud import aiplatform
aiplatform.init(project=PROJECT_ID, location=REGION)
import os
from google.cloud.aiplatform.prediction import LocalModel
from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR
local_model = LocalModel.build_cpr_model(
USER_SRC_DIR,
f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}",
predictor=CprPredictor,
requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"),
)
编写包含两个预测样本的测试文件。其中一个实例具有明确名称缩写,但另一个实例需要先进行转换。
import json
sample = {"instances": [
[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43],
[0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}
with open('instances.json', 'w') as fp:
json.dump(sample, fp)
通过部署本地模型在本地测试容器。
with local_model.deploy_to_local_endpoint(
artifact_uri = 'model_artifacts/', # local path to artifacts
) as local_endpoint:
predict_response = local_endpoint.predict(
request_file='instances.json',
headers={"Content-Type": "application/json"},
)
health_check_response = local_endpoint.run_health_check()
您可以通过以下方式查看预测结果:
predict_response.content
9. 将模型部署到 Vertex AI
现在,您已经在本地测试了容器,是时候将映像推送到 Artifact Registry 并将模型上传到 Vertex AI Model Registry 了。
首先,配置 Docker 以访问 Artifact Registry。
!gcloud artifacts repositories create {REPOSITORY} --repository-format=docker \
--location=us-central1 --description="Docker repository"
!gcloud auth configure-docker {REGION}-docker.pkg.dev --quiet
然后推送映像。
local_model.push_image()
然后上传模型。
model = aiplatform.Model.upload(local_model = local_model,
display_name=MODEL_DISPLAY_NAME,
artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)
上传模型后,您应该会在控制台中看到它:
接下来,部署模型以便将其用于在线预测。自定义预测例程也适用于批量预测,因此如果您的用例不需要在线预测,则无需部署模型。
然后推送映像。
endpoint = model.deploy(machine_type="n1-standard-2")
最后,通过获取预测结果来测试已部署的模型。
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])
🎉 恭喜!🎉
您学习了如何使用 Vertex AI 执行以下操作:
- 使用自定义预测例程编写自定义预处理和后处理逻辑
Cosmopup 认为 Codelab 很棒!!
