
1. Introducción
En este lab, aprenderás a usar rutinas de predicción personalizadas en Vertex AI para escribir lógica personalizada de procesamiento previo y posterior. Si bien en este ejemplo se usa Scikit-learn, las rutinas de predicción personalizadas pueden funcionar con otros frameworks de AA de Python, como XGBoost, PyTorch y TensorFlow.
Qué aprenderás
- Escribe lógica de predicción personalizada con rutinas de predicción personalizadas
- Prueba el contenedor y el modelo de entrega personalizados de forma local
- Prueba el contenedor de servicio personalizado en Vertex AI Predictions
2. Introducción a Vertex AI
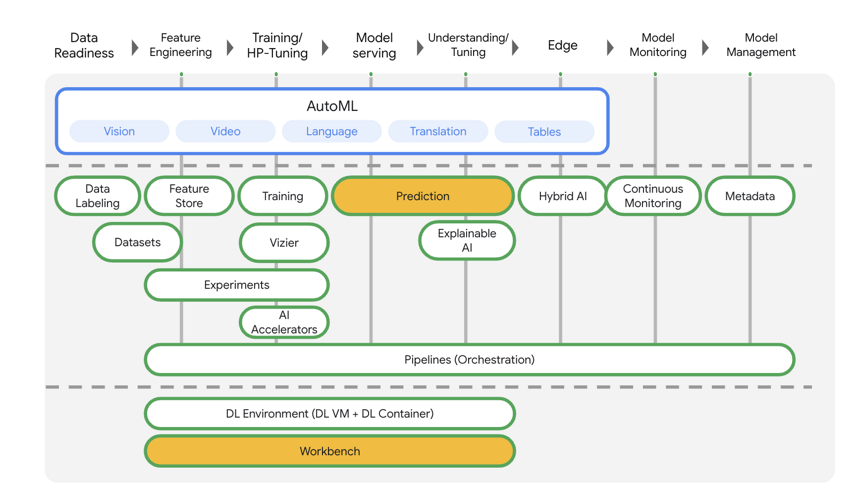
En este lab, se utiliza la oferta de productos de IA más reciente de Google Cloud. Vertex AI integra las ofertas de AA de Google Cloud en una experiencia de desarrollo fluida. Anteriormente, se podía acceder a los modelos personalizados y a los entrenados con AutoML mediante servicios independientes. La nueva oferta combina ambos en una sola API, junto con otros productos nuevos. También puedes migrar proyectos existentes a Vertex AI.
Vertex AI incluye muchos productos distintos para respaldar flujos de trabajo de AA de extremo a extremo. Este lab se enfocará en Predictions y Workbench.
3. Descripción general del caso de uso
En este lab, compilarás un modelo de regresión de bosque aleatorio para predecir el precio de un diamante en función de atributos como el corte, la claridad y el tamaño.
Escribirás una lógica de procesamiento previo personalizada para verificar que los datos en el momento de la entrega estén en el formato que espera el modelo. También escribirás una lógica de procesamiento posterior personalizada para redondear las predicciones y convertirlas en cadenas. Para escribir esta lógica, usarás rutinas de predicción personalizadas.
Introducción a las rutinas de predicción personalizadas
Los contenedores precompilados de Vertex AI controlan las solicitudes de predicción realizando la operación de predicción del framework de aprendizaje automático. Antes de las rutinas de predicción personalizadas, si querías procesar previamente la entrada antes de que se realizara la predicción o procesar posteriormente la predicción del modelo antes de devolver el resultado, debías compilar un contenedor personalizado.
Para compilar un contenedor de servicio personalizado, se requiere escribir un servidor HTTP que encapsule el modelo entrenado, traduzca las solicitudes HTTP en entradas del modelo y traduzca las salidas del modelo en respuestas.
Con las rutinas de predicción personalizadas, Vertex AI te proporciona los componentes relacionados con la entrega, de modo que puedas concentrarte en tu modelo y las transformaciones de datos.
Qué compilarás
Configurarás una red de VPC llamada aiml-vpc que consta de una subred de la estación de trabajo que se usa para implementar un notebook administrado por el usuario y acceder al extremo de predicción en línea y al modelo implementado en us-central1, como se ilustra en la figura 1 a continuación.
Figure1

4. Habilita las APIs del instructivo
Paso 1: Habilita la API de Compute Engine
Ve a Compute Engine y selecciona Habilitar si aún no está habilitada. La necesitarás para crear la instancia de notebook.
Paso 2: Habilita la API de Artifact Registry
Navega a Artifact Registry y selecciona Habilitar si aún no lo has hecho. La usarás para crear un contenedor de servicio personalizado.
Paso 3: Habilita la API de Vertex AI
Navega a la sección Vertex AI de la consola de Cloud y haz clic en Habilitar la API de Vertex AI.
Paso 4: Crea una instancia de Vertex AI Workbench
Habilita la API de Notebooks si aún no está habilitada.
5. Crea aiml-vpc
En este instructivo, se usan variables para facilitar la implementación de la configuración de gcloud en Cloud Shell.
Dentro de Cloud Shell, haz lo siguiente:
gcloud config list project
gcloud config set project [YOUR-PROJECT-NAME]
projectid=YOUR-PROJECT-NAME
echo $projectid
Crea la VPC de aiml
Dentro de Cloud Shell, haz lo siguiente:
gcloud compute networks create aiml-vpc --project=$projectid --subnet-mode=custom
Crea la subred del notebook administrado por el usuario
Dentro de Cloud Shell, crea la subred workbench-subnet.
gcloud compute networks subnets create workbench-subnet --project=$projectid --range=172.16.10.0/28 --network=aiml-vpc --region=us-central1 --enable-private-ip-google-access
Configuración de Cloud Router y NAT
Cloud NAT se usa en el instructivo para descargar paquetes de software, ya que el notebook administrado por el usuario no tiene una dirección IP externa. Cloud NAT proporciona capacidades de NAT de salida, lo que significa que los hosts de Internet no pueden iniciar la comunicación con un notebook administrado por el usuario, lo que lo hace más seguro.
Dentro de Cloud Shell, crea el Cloud Router regional, us-central1.
gcloud compute routers create cloud-router-us-central1-aiml-nat --network aiml-vpc --region us-central1
Dentro de Cloud Shell, crea la puerta de enlace de Cloud NAT regional, us-central1.
gcloud compute routers nats create cloud-nat-us-central1 --router=cloud-router-us-central1-aiml-nat --auto-allocate-nat-external-ips --nat-all-subnet-ip-ranges --region us-central1
6. Crea el notebook administrado por el usuario
Crea una cuenta de servicio administrada por el usuario (notebook)
En la siguiente sección, crearás una cuenta de servicio administrada por el usuario que se asociará con Vertex Workbench (notebook) que se usa en el instructivo.
En el instructivo, se aplicarán las siguientes reglas a la cuenta de servicio:
Dentro de Cloud Shell, crea la cuenta de servicio.
gcloud iam service-accounts create user-managed-notebook-sa \
--display-name="user-managed-notebook-sa"
En Cloud Shell, actualiza la cuenta de servicio con el rol de administrador de Storage.
gcloud projects add-iam-policy-binding $projectid --member="serviceAccount:user-managed-notebook-sa@$projectid.iam.gserviceaccount.com" --role="roles/storage.admin"
Dentro de Cloud Shell, actualiza la cuenta de servicio con el rol de usuario de Vertex AI.
gcloud projects add-iam-policy-binding $projectid --member="serviceAccount:user-managed-notebook-sa@$projectid.iam.gserviceaccount.com" --role="roles/aiplatform.user"
Dentro de Cloud Shell, actualiza la cuenta de servicio con el rol de administrador de Artifact Registry.
gcloud projects add-iam-policy-binding $projectid --member="serviceAccount:user-managed-notebook-sa@$projectid.iam.gserviceaccount.com" --role="roles/artifactregistry.admin"
Dentro de Cloud Shell, enumera la cuenta de servicio y anota la dirección de correo electrónico que se usará cuando crees el notebook administrado por el usuario.
gcloud iam service-accounts list
Crea el notebook administrado por el usuario
En la siguiente sección, crea un notebook administrado por el usuario que incorpore la cuenta de servicio creada anteriormente, user-managed-notebook-sa.
Dentro de Cloud Shell, crea la instancia de private-client.
gcloud notebooks instances create workbench-tutorial \
--vm-image-project=deeplearning-platform-release \
--vm-image-family=common-cpu-notebooks \
--machine-type=n1-standard-4 \
--location=us-central1-a \
--shielded-secure-boot \
--subnet-region=us-central1 \
--subnet=workbench-subnet \
--no-public-ip --service-account=user-managed-notebook-sa@$projectid.iam.gserviceaccount.com
7. Escribe el código de entrenamiento
Paso 1: Crea un bucket de Cloud Storage
Almacenarás el modelo y los artefactos de preprocesamiento en un bucket de Cloud Storage. Si ya tienes un bucket en tu proyecto que deseas usar, puedes omitir este paso.
Desde el selector, abre una nueva sesión de terminal.

En la terminal, ejecuta el siguiente comando para definir una variable de entorno en tu proyecto. Asegúrate de reemplazar your-cloud-project por el ID del proyecto:
PROJECT_ID='your-cloud-project'
Luego, ejecuta el siguiente comando en tu terminal para crear un bucket nuevo en el proyecto.
BUCKET="gs://${PROJECT_ID}-cpr-bucket"
gsutil mb -l us-central1 $BUCKET
Paso 2: Entrena el modelo
Desde la terminal, crea un directorio nuevo llamado cpr-codelab y cambia a él con el comando cd.
mkdir cpr-codelab
cd cpr-codelab
En el navegador de archivos, navega al nuevo directorio cpr-codelab y, luego, usa el selector para crear un nuevo notebook de Python 3 llamado task.ipynb.

Tu directorio cpr-codelab ahora debería verse de la siguiente manera:
+ cpr-codelab/
+ task.ipynb
En el notebook, pega el siguiente código.
Primero, escribe un archivo requirements.txt.
%%writefile requirements.txt
fastapi
uvicorn==0.17.6
joblib~=1.1.1
numpy>=1.17.3, <1.24.0
scikit-learn~=1.0.0
pandas
google-cloud-storage>=2.2.1,<3.0.0dev
google-cloud-aiplatform[prediction]>=1.18.2
El modelo que implementes tendrá un conjunto diferente de dependencias preinstaladas que el entorno de tu notebook. Por este motivo, te recomendamos que incluyas todas las dependencias del modelo en requirements.txt y, luego, uses pip para instalar las mismas dependencias en el notebook. Más adelante, probarás el modelo de forma local antes de implementarlo en Vertex AI para verificar que los entornos coincidan.
Pip instala las dependencias en el notebook.
!pip install -U --user -r requirements.txt
Ten en cuenta que deberás reiniciar el kernel después de que se complete la instalación de pip.
A continuación, crea los directorios en los que almacenarás el modelo y los artefactos de procesamiento previo.
USER_SRC_DIR = "src_dir"
!mkdir $USER_SRC_DIR
!mkdir model_artifacts
# copy the requirements to the source dir
!cp requirements.txt $USER_SRC_DIR/requirements.txt
Tu directorio cpr-codelab ahora debería verse de la siguiente manera:
+ cpr-codelab/
+ model_artifacts/
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
Ahora que la estructura de directorios está configurada, es hora de entrenar un modelo.
Primero, importa las bibliotecas.
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
import joblib
import logging
# set logging to see the docker container logs
logging.basicConfig(level=logging.INFO)
Luego, define las siguientes variables. Asegúrate de reemplazar PROJECT_ID por el ID de tu proyecto y BUCKET_NAME por el bucket que creaste en el paso anterior.
REGION = "us-central1"
MODEL_ARTIFACT_DIR = "sklearn-model-artifacts"
REPOSITORY = "diamonds"
IMAGE = "sklearn-image"
MODEL_DISPLAY_NAME = "diamonds-cpr"
# Replace with your project
PROJECT_ID = "{PROJECT_ID}"
# Replace with your bucket
BUCKET_NAME = "gs://{BUCKET_NAME}"
Carga los datos desde la biblioteca de Seaborn y, luego, crea dos marcos de datos, uno con las funciones y el otro con la etiqueta.
data = sns.load_dataset('diamonds', cache=True, data_home=None)
label = 'price'
y_train = data['price']
x_train = data.drop(columns=['price'])
Veamos los datos de entrenamiento. Puedes ver que cada fila representa un diamante.
x_train.head()
Y las etiquetas, que son los precios correspondientes.
y_train.head()
Ahora, define una transformación de columna de sklearn para codificar con one-hot los atributos categóricos y escalar los atributos numéricos.
column_transform = make_column_transformer(
(preprocessing.OneHotEncoder(sparse=False), [1,2,3]),
(preprocessing.StandardScaler(), [0,4,5,6,7,8]))
Define el modelo de bosque aleatorio
regr = RandomForestRegressor(max_depth=10, random_state=0)
A continuación, crea una canalización de sklearn. Esto significa que los datos que se ingresen en esta canalización primero se codificarán o se ajustarán y, luego, se pasarán al modelo.
my_pipeline = make_pipeline(column_transform, regr)
Ajusta la canalización a los datos de entrenamiento
my_pipeline.fit(x_train, y_train)
Probemos el modelo para asegurarnos de que funcione según lo esperado. Llama al método de predicción en el modelo y pasa una muestra de prueba.
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])
Ahora podemos guardar la canalización en el directorio model_artifacts y copiarla en el bucket de Cloud Storage.
joblib.dump(my_pipeline, 'model_artifacts/model.joblib')
!gsutil cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
Paso 3: Guarda un artefacto de procesamiento previo
A continuación, crearás un artefacto de procesamiento previo. Este artefacto se cargará en el contenedor personalizado cuando se inicie el servidor del modelo. Tu artefacto de procesamiento previo puede tener casi cualquier forma (como un archivo pickle), pero en este caso, escribirás un diccionario en un archivo JSON.
clarity_dict={"Flawless": "FL",
"Internally Flawless": "IF",
"Very Very Slightly Included": "VVS1",
"Very Slightly Included": "VS2",
"Slightly Included": "S12",
"Included": "I3"}
El atributo de claridad en nuestros datos de entrenamiento siempre estuvo en el formato abreviado (es decir, "FL" en lugar de "Flawless"). En el momento de la entrega, verifica que los datos de este atributo también se abrevian. Esto se debe a que nuestro modelo sabe cómo hacer codificación one-hot "FL" pero no "impecable". Escribirás esta lógica personalizada de procesamiento previo más adelante. Por ahora, solo guarda esta tabla de consulta en un archivo JSON y, luego, escríbela en el bucket de Cloud Storage.
import json
with open("model_artifacts/preprocessor.json", "w") as f:
json.dump(clarity_dict, f)
!gsutil cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
Tu directorio local cpr-codelab ahora debería verse de la siguiente manera:
+ cpr-codelab/
+ model_artifacts/
+ model.joblib
+ preprocessor.json
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
8. Crea un contenedor de entrega personalizado con el servidor de modelo de CPR
Ahora que se entrenó el modelo y se guardó el artefacto de preprocesamiento, es hora de compilar el contenedor de entrega personalizado. Por lo general, la compilación de un contenedor de entrega requiere escribir código del servidor de modelos. Sin embargo, con las rutinas de predicción personalizadas, Vertex AI Predictions genera un servidor de modelos y compila una imagen de contenedor personalizada para ti.
Un contenedor de procesamiento personalizado contiene los siguientes 3 fragmentos de código:
- Servidor del modelo (el SDK lo generará automáticamente y se almacenará en scr_dir/)
- Servidor HTTP que aloja el modelo
- Es responsable de configurar rutas, puertos, etcétera.
- Es responsable de los aspectos del servidor web relacionados con el control de una solicitud, como la deserialización del cuerpo de la solicitud y la serialización de la respuesta, la configuración de los encabezados de respuesta, etcétera.
- En este ejemplo, usarás el controlador predeterminado, google.cloud.aiplatform.prediction.handler.PredictionHandler, que se proporciona en el SDK.
- Es responsable de la lógica de AA para procesar una solicitud de predicción.
Cada uno de estos componentes se puede personalizar según los requisitos de tu caso de uso. En este ejemplo, solo implementarás el predictor.
El predictor es responsable de la lógica de AA para procesar una solicitud de predicción, como el preprocesamiento y el posprocesamiento personalizados. Para escribir una lógica de predicción personalizada, crearás una subclase de la interfaz de Predictor de Vertex AI.
Esta versión de las rutinas de predicción personalizadas incluye predictores XGBoost y Sklearn reutilizables, pero, si necesitas usar un framework diferente, puedes crear el tuyo propio creando una subclase del predictor base.
A continuación, puedes ver un ejemplo del predictor de Sklearn. Este es todo el código que necesitarías escribir para compilar este servidor de modelos personalizado.

En tu notebook, pega el siguiente código para crear una subclase de SklearnPredictor y escribirla en un archivo de Python en src_dir/. Ten en cuenta que, en este ejemplo, solo personalizamos la carga, el procesamiento previo y el procesamiento posterior, y no el método de predicción.
%%writefile $USER_SRC_DIR/predictor.py
import joblib
import numpy as np
import json
from google.cloud import storage
from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor
class CprPredictor(SklearnPredictor):
def __init__(self):
return
def load(self, artifacts_uri: str) -> None:
"""Loads the sklearn pipeline and preprocessing artifact."""
super().load(artifacts_uri)
# open preprocessing artifact
with open("preprocessor.json", "rb") as f:
self._preprocessor = json.load(f)
def preprocess(self, prediction_input: np.ndarray) -> np.ndarray:
"""Performs preprocessing by checking if clarity feature is in abbreviated form."""
inputs = super().preprocess(prediction_input)
for sample in inputs:
if sample[3] not in self._preprocessor.values():
sample[3] = self._preprocessor[sample[3]]
return inputs
def postprocess(self, prediction_results: np.ndarray) -> dict:
"""Performs postprocessing by rounding predictions and converting to str."""
return {"predictions": [f"${value}" for value in np.round(prediction_results)]}
Analicemos cada uno de estos métodos con mayor detalle.
- El método load carga el artefacto de preprocesamiento, que, en este caso, es un diccionario que asigna los valores de claridad del diamante a sus abreviaturas.
- El método de preprocesamiento usa ese artefacto para garantizar que, en el momento de la entrega, la función de claridad esté en su formato abreviado. De lo contrario, convierte la cadena completa en su abreviatura.
- El método de posprocesamiento devuelve el valor predicho como una cadena con un signo de dólar y redondea el valor.
A continuación, usa el SDK de Vertex AI para Python para compilar la imagen. Con las rutinas de predicción personalizadas, se generará el Dockerfile y se compilará una imagen para ti.
from google.cloud import aiplatform
aiplatform.init(project=PROJECT_ID, location=REGION)
import os
from google.cloud.aiplatform.prediction import LocalModel
from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR
local_model = LocalModel.build_cpr_model(
USER_SRC_DIR,
f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}",
predictor=CprPredictor,
requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"),
)
Escribe un archivo de prueba con dos muestras para la predicción. Una de las instancias tiene el nombre abreviado de claridad, pero la otra necesita convertirse primero.
import json
sample = {"instances": [
[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43],
[0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}
with open('instances.json', 'w') as fp:
json.dump(sample, fp)
Implementa un modelo local para probar el contenedor de manera local.
with local_model.deploy_to_local_endpoint(
artifact_uri = 'model_artifacts/', # local path to artifacts
) as local_endpoint:
predict_response = local_endpoint.predict(
request_file='instances.json',
headers={"Content-Type": "application/json"},
)
health_check_response = local_endpoint.run_health_check()
Puedes ver los resultados de la predicción con lo siguiente:
predict_response.content
9. Implementar el modelo en Vertex AI
Ahora que probaste el contenedor de manera local, debes enviar la imagen a Artifact Registry y subir el modelo a Vertex AI Model Registry.
Primero, configura Docker para acceder a Artifact Registry.
!gcloud artifacts repositories create {REPOSITORY} --repository-format=docker \
--location=us-central1 --description="Docker repository"
!gcloud auth configure-docker {REGION}-docker.pkg.dev --quiet
Luego, envía la imagen.
local_model.push_image()
Y sube el modelo.
model = aiplatform.Model.upload(local_model = local_model,
display_name=MODEL_DISPLAY_NAME,
artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)
Cuando se suba el modelo, deberías verlo en la consola:
A continuación, implementa el modelo para que puedas usarlo para las predicciones en línea. Las rutinas de predicción personalizadas también funcionan con la predicción por lotes, por lo que, si tu caso de uso no requiere predicciones en línea, no es necesario que implementes el modelo.
Luego, envía la imagen.
endpoint = model.deploy(machine_type="n1-standard-2")
Por último, prueba el modelo implementado obteniendo una predicción.
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])
🎉 ¡Felicitaciones! 🎉
Aprendiste a usar Vertex AI para hacer lo siguiente:
- Escribe lógica personalizada de procesamiento previo y posterior con rutinas de predicción personalizadas
Cosmopup cree que los codelabs son increíbles.

¿Qué sigue?
Lecturas y videos adicionales
- ¿Qué es Vertex AI?
- Comienza a usar Vertex AI
- ¿Qué solución de IA/AA en Vertex AI es adecuada para mí?
- Crea un sistema de respuesta de preguntas con Vertex AI