
1. Einführung und Einrichtung
Webfunktionen
Wir möchten die Funktionslücke zwischen Web und nativen Apps schließen und Entwicklern die Möglichkeit geben, im offenen Web großartige Nutzererlebnisse zu schaffen. Wir sind der festen Überzeugung, dass jeder Entwickler Zugriff auf die Funktionen haben sollte, die er für eine großartige Weboberfläche benötigt. Deshalb setzen wir uns für ein leistungsfähigeres Web ein.
Es gibt jedoch einige Funktionen, z. B. den Dateisystemzugriff und die Erkennung von Inaktivität, die für native Apps, aber nicht im Web verfügbar sind. Aufgrund dieser fehlenden Funktionen können einige Arten von Apps nicht im Web bereitgestellt werden oder sind weniger nützlich.
Wir werden diese neuen Funktionen offen und transparent entwerfen und entwickeln. Dabei werden wir die bestehenden Prozesse für offene Webplattformstandards nutzen und frühzeitig Feedback von Entwicklern und anderen Browseranbietern einholen, um ein interoperables Design zu gewährleisten.
Umfang
In diesem Codelab werden Sie einige Web-APIs ausprobieren, die brandneu sind oder nur hinter einem Flag verfügbar sind. In diesem Codelab geht es also um die APIs selbst und um Anwendungsfälle, die durch diese APIs ermöglicht werden, und nicht um die Entwicklung eines bestimmten Endprodukts.
Lerninhalte
In diesem Codelab lernen Sie die grundlegenden Mechanismen mehrerer innovativer APIs kennen. Diese Mechanismen sind noch nicht in Stein gemeißelt. Wir freuen uns über Ihr Feedback zum Entwicklerablauf.
Voraussetzungen
Da die in diesem Codelab vorgestellten APIs wirklich auf dem neuesten Stand sind, variieren die Anforderungen für jede API. Lesen Sie sich die Kompatibilitätsinformationen am Anfang jedes Abschnitts sorgfältig durch.
Vorgehensweise bei diesem Codelab
Das Codelab muss nicht unbedingt sequenziell durchgearbeitet werden. Jeder Abschnitt steht für eine unabhängige API. Sie können also die für Sie interessantesten Themen auswählen.
2. Badging API
Ziel der Badging API ist es, Nutzer auf Dinge aufmerksam zu machen, die im Hintergrund passieren. Der Einfachheit halber verwenden wir in diesem Codelab die API, um die Aufmerksamkeit der Nutzer auf etwas zu lenken, das im Vordergrund passiert. Anschließend können Sie die Übertragung auf Dinge vornehmen, die im Hintergrund passieren.
Airhorner installieren
Damit diese API funktioniert, benötigen Sie eine PWA, die auf dem Startbildschirm installiert ist. Installieren Sie also zuerst eine PWA, z. B. die berüchtigte, weltberühmte airhorner.com. Klicken Sie rechts oben auf die Schaltfläche Installieren oder verwenden Sie das Dreipunkt-Menü, um die Installation manuell durchzuführen.

Sie werden aufgefordert, den Vorgang zu bestätigen. Klicken Sie auf Installieren.

Sie haben jetzt ein neues Symbol im Dock Ihres Betriebssystems. Klicken Sie darauf, um die PWA zu starten. Sie hat ein eigenes App-Fenster und wird im Standalone-Modus ausgeführt.
|
|
Kennzeichen festlegen
Nachdem Sie eine PWA installiert haben, benötigen Sie numerische Daten (Badges können nur Zahlen enthalten), die auf einem Badge angezeigt werden sollen. Eine einfache Sache, die man in The Air Horner zählen kann, ist seufz die Anzahl der Male, die gehupt wurde. Versuche, mit der installierten Airhorner-App das Horn zu betätigen und das Badge zu prüfen. Bei jedem Hupen wird der Zähler um eins erhöht.

Wie funktioniert das? Im Wesentlichen sieht der Code so aus:
let hornCounter = 0;
const horn = document.querySelector('.horn');
horn.addEventListener('click', () => {
navigator.setExperimentalAppBadge(++hornCounter);
});
Lassen Sie die Schiffshupe ein paar Mal ertönen und sehen Sie sich das Symbol der PWA an: Es wird jedes Mal aktualisiert, wenn die Schiffshupe ertönt. So einfach ist das.

Badge entfernen
Der Zähler geht bis 99 und beginnt dann von vorn. Sie können sie auch manuell zurücksetzen. Öffnen Sie den Tab „Console“ in den Entwicklertools, fügen Sie die folgende Zeile ein und drücken Sie die Eingabetaste.
navigator.setExperimentalAppBadge(0);
Alternativ können Sie das Symbol auch explizit entfernen, wie im folgenden Snippet gezeigt. Das Symbol Ihrer PWA sollte jetzt wieder wie am Anfang aussehen – klar und ohne Badge.
navigator.clearExperimentalAppBadge();

Feedback
Was halten Sie von dieser API? Bitte helfen Sie uns, indem Sie kurz auf diese Umfrage antworten:
War diese API intuitiv zu verwenden?
Konnten Sie das Beispiel ausführen?
Haben Sie noch etwas zu sagen? Haben Funktionen gefehlt? Bitte geben Sie uns in dieser Umfrage kurz Feedback. Vielen Dank!
3. Native File System API
Mit der Native File System API können Entwickler leistungsstarke Web-Apps erstellen, die mit Dateien auf dem lokalen Gerät des Nutzers interagieren. Nachdem ein Nutzer einer Web-App Zugriff gewährt hat, kann diese API Änderungen direkt in Dateien und Ordnern auf dem Gerät des Nutzers lesen oder speichern.
Datei lesen
Das „Hello, world“-Beispiel der Native File System API besteht darin, eine lokale Datei zu lesen und den Dateiinhalt abzurufen. Erstellen Sie eine einfache .txt-Datei und geben Sie Text ein. Rufen Sie als Nächstes eine sichere Website auf, die über HTTPS bereitgestellt wird, z. B. example.com, und öffnen Sie die DevTools-Konsole. Fügen Sie das folgende Code-Snippet in die Konsole ein. Da für die Native File System API eine Nutzeraktion erforderlich ist, hängen wir einen Doppelklick-Handler an das Dokument an. Wir benötigen das Dateihandle später, daher machen wir es einfach zu einer globalen Variablen.
document.ondblclick = async () => {
window.handle = await window.chooseFileSystemEntries();
const file = await handle.getFile();
document.body.textContent = await file.text();
};
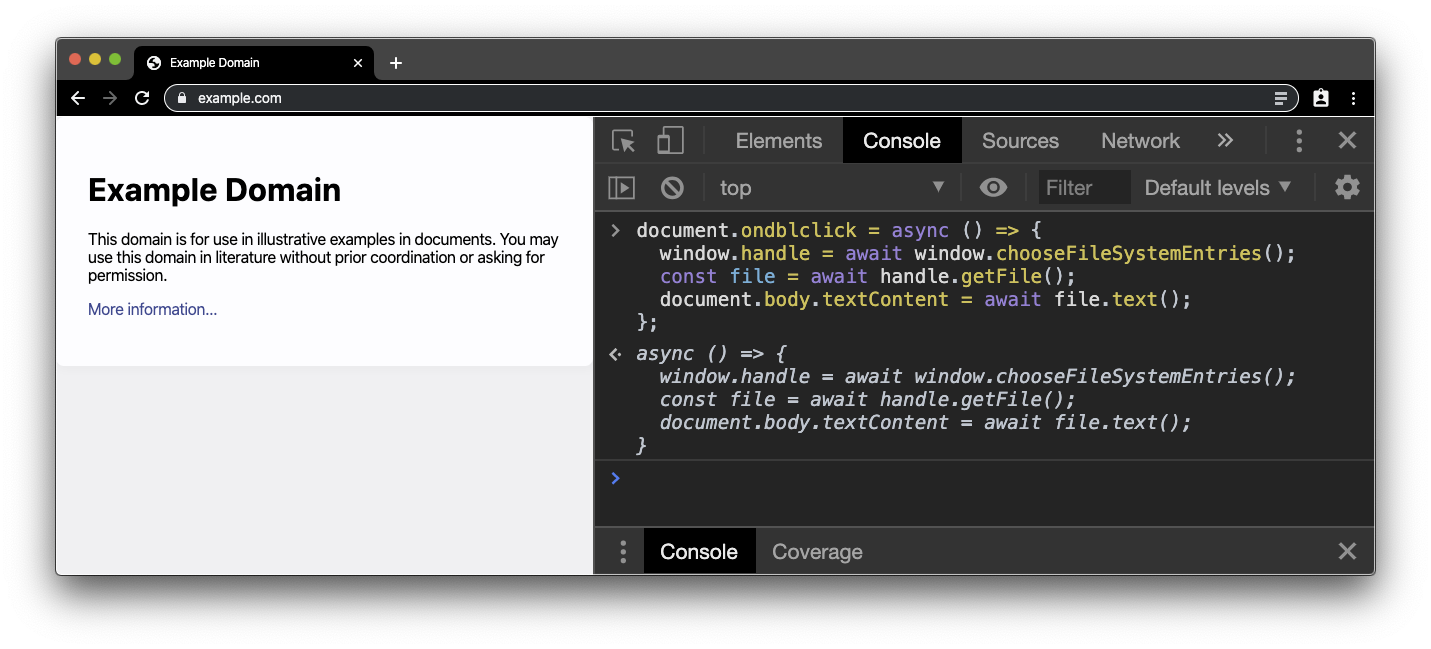
Wenn Sie dann auf der Seite example.com doppelklicken, wird eine Dateiauswahl angezeigt.
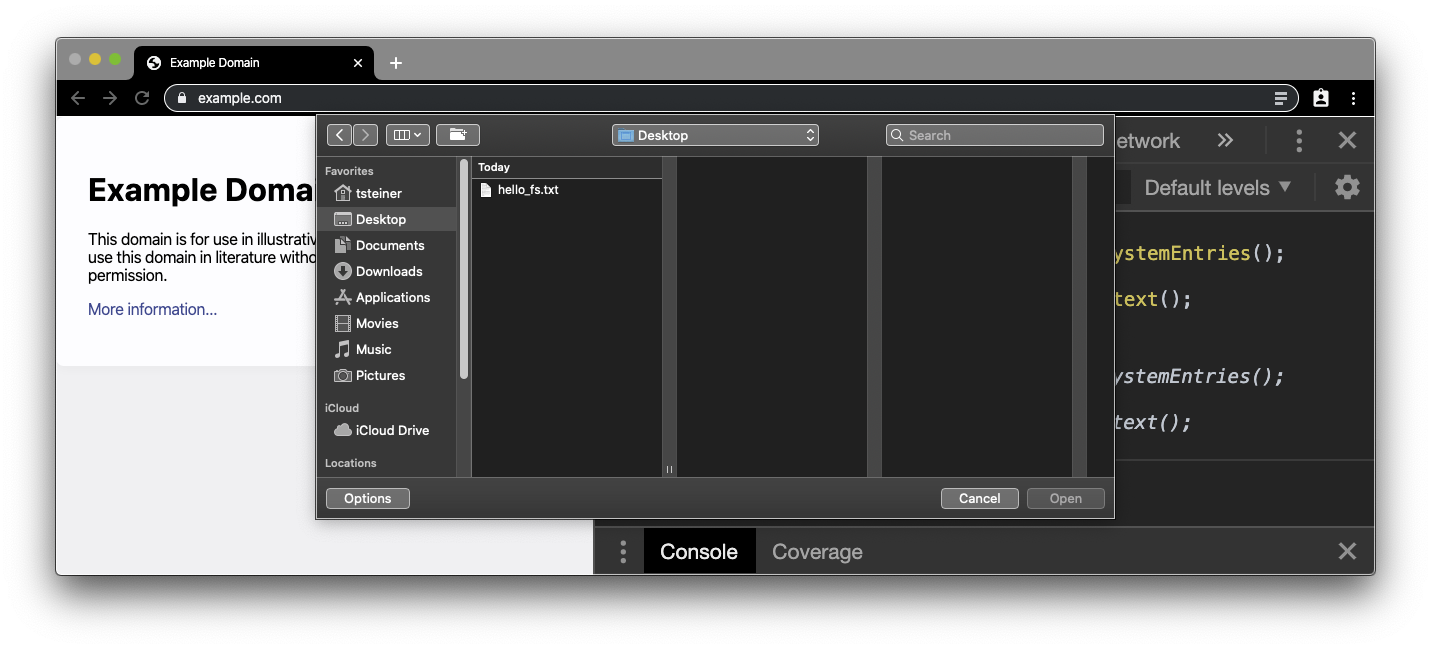
Wählen Sie die .txt-Datei aus, die Sie zuvor erstellt haben. Der Dateiinhalt ersetzt dann den tatsächlichen body-Inhalt von example.com.
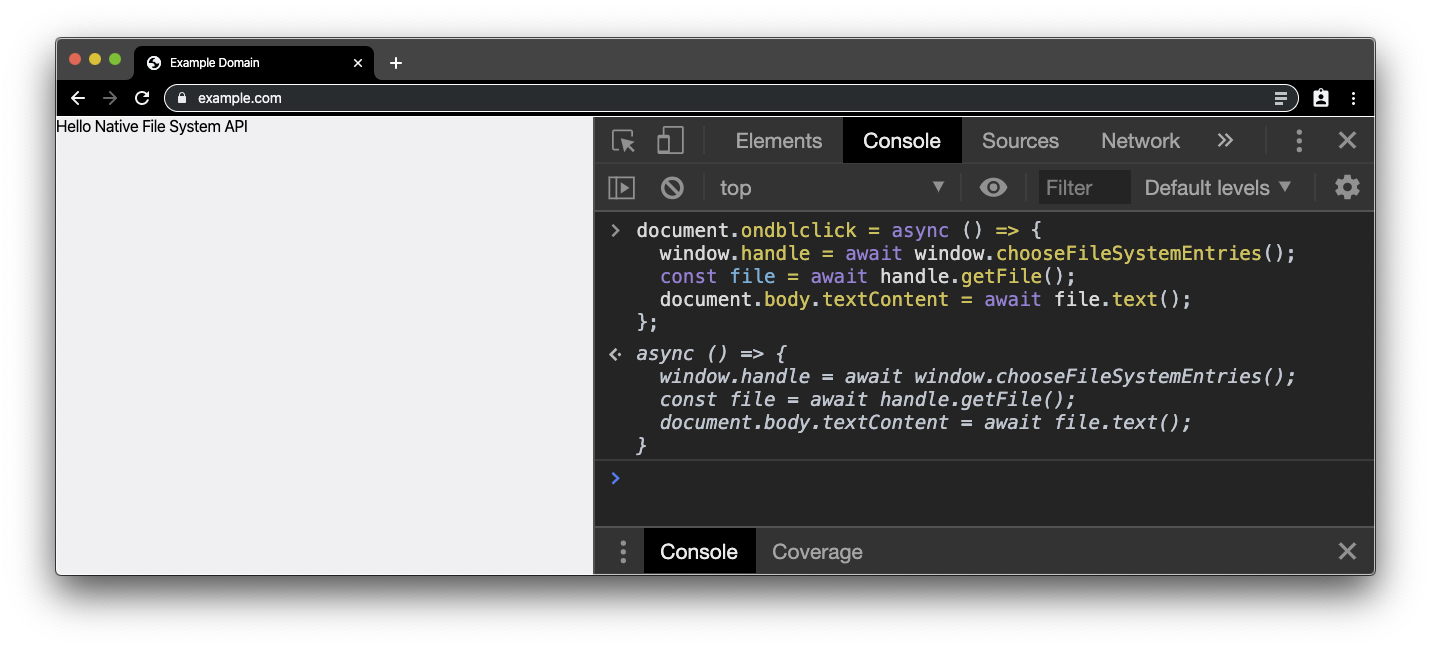
Dateien speichern
Als Nächstes möchten wir einige Änderungen vornehmen. Machen wir body also bearbeitbar, indem wir das folgende Code-Snippet einfügen. Sie können den Text jetzt so bearbeiten, als wäre der Browser ein Texteditor.
document.body.contentEditable = true;
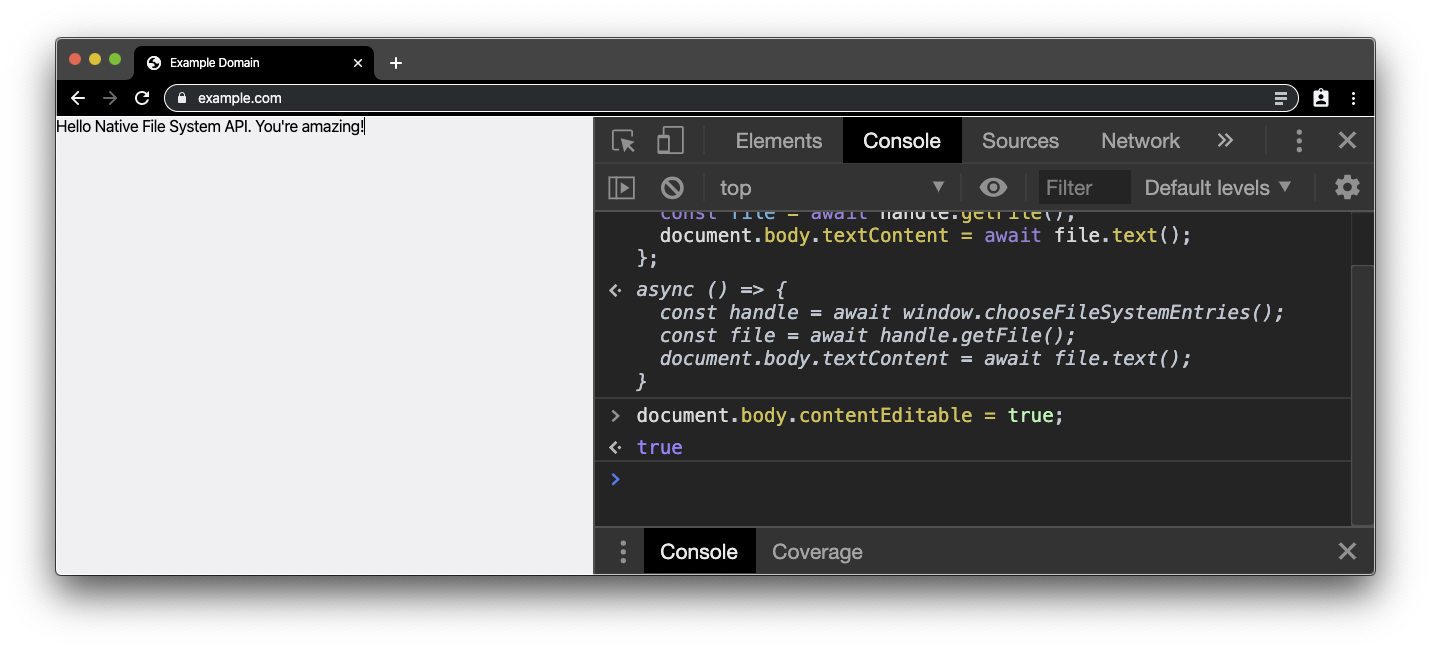
Nun möchten wir diese Änderungen in die Originaldatei zurückschreiben. Daher benötigen wir einen Writer für das Dateihandle, den wir erhalten, indem wir den folgenden Snippet in die Konsole einfügen. Auch hier benötigen wir eine Nutzeraktion. Dieses Mal warten wir auf einen Klick im Hauptdokument.
document.onclick = async () => {
const writer = await handle.createWriter();
await writer.truncate(0);
await writer.write(0, document.body.textContent);
await writer.close();
};

Wenn Sie jetzt auf das Dokument klicken (nicht doppelklicken), wird eine Berechtigungsaufforderung angezeigt. Wenn Sie die Berechtigung erteilen, enthält die Datei die Inhalte, die Sie zuvor in body bearbeitet haben. Prüfen Sie die Änderungen, indem Sie die Datei in einem anderen Editor öffnen. Alternativ können Sie den Vorgang auch noch einmal starten, indem Sie noch einmal auf das Dokument doppelklicken und die Datei neu öffnen.
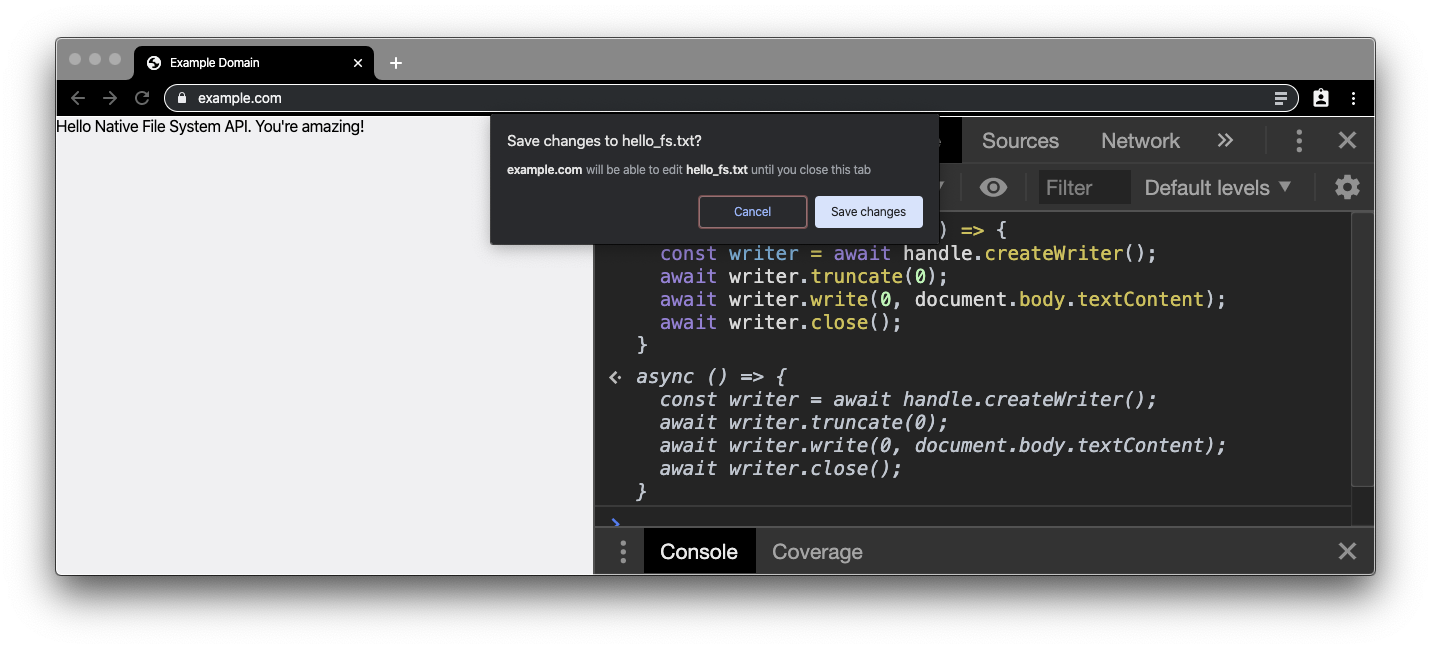

Glückwunsch! Sie haben gerade den kleinsten Texteditor der Welt [citation needed] erstellt.
Feedback
Was halten Sie von dieser API? Bitte helfen Sie uns, indem Sie kurz auf diese Umfrage antworten:
War diese API intuitiv zu verwenden?
Konnten Sie das Beispiel ausführen?
Haben Sie noch etwas zu sagen? Haben Funktionen gefehlt? Bitte geben Sie uns in dieser Umfrage kurz Feedback. Vielen Dank!
4. Shape Detection API
Die Shape Detection API bietet Zugriff auf beschleunigte Formerkennungen (z.B. für menschliche Gesichter) und funktioniert mit Standbildern und/oder Live-Bildfeeds. Betriebssysteme haben leistungsstarke und hochoptimierte Funktionserkennungen wie den Android-FaceDetector. Die Shape Detection API macht diese nativen Implementierungen verfügbar und stellt sie über eine Reihe von JavaScript-Schnittstellen bereit.
Derzeit werden die Gesichtserkennung über die FaceDetector-Schnittstelle, die Barcodeerkennung über die BarcodeDetector-Schnittstelle und die Texterkennung (optische Zeichenerkennung) über die TextDetector-Schnittstelle unterstützt.
Gesichtserkennung
Ein faszinierendes Feature der Shape Detection API ist die Gesichtserkennung. Dazu benötigen wir eine Seite mit Gesichtern. Diese Seite mit dem Gesicht des Autors ist ein guter Anfang. Das sieht in etwa so aus wie im Screenshot unten. In einem unterstützten Browser werden das umgebende Rechteck des Gesichts und die markanten Stellen im Gesicht erkannt.
Sie können sehen, wie wenig Code dafür erforderlich war, indem Sie das Glitch-Projekt remixen oder bearbeiten, insbesondere die Datei „script.js“.

Wenn Sie nicht nur das Gesicht des Autors, sondern das gesamte Bild dynamisch gestalten möchten, rufen Sie diese Google-Suchergebnisseite mit Gesichtern in einem privaten Tab oder im Gastmodus auf. Öffnen Sie nun auf dieser Seite die Chrome-Entwicklertools, indem Sie mit der rechten Maustaste auf eine beliebige Stelle klicken und dann Untersuchen auswählen. Fügen Sie als Nächstes auf dem Tab „Konsole“ den folgenden Snippet ein. Im Code werden erkannte Gesichter mit einem halbdurchsichtigen roten Rechteck hervorgehoben.
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const faces = await new FaceDetector().detect(img);
faces.forEach(face => {
const div = document.createElement('div');
const box = face.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 0, 0, 0.5)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left + left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
img.before(div);
});
} catch(e) {
console.error(e);
}
});
Sie werden feststellen, dass einige DOMException-Meldungen angezeigt werden und nicht alle Bilder verarbeitet werden. Das liegt daran, dass die Above-the-fold-Bilder als Daten-URIs inline eingefügt werden und daher darauf zugegriffen werden kann. Die Below-the-fold-Bilder stammen hingegen von einer anderen Domain, die nicht für die Unterstützung von CORS konfiguriert ist. Für die Demo müssen wir uns darum nicht kümmern.
Erkennung von Gesichtsmerkmalen
macOS unterstützt nicht nur die Erkennung von Gesichtern an sich, sondern auch die Erkennung von markanten Stellen im Gesicht. Wenn Sie die Erkennung von Gesichtsmerkmalen testen möchten, fügen Sie den folgenden Snippet in die Konsole ein. Hinweis: Die Anordnung der Sehenswürdigkeiten ist aufgrund von crbug.com/914348 nicht perfekt. Sie können aber sehen, wohin die Reise geht und wie leistungsstark diese Funktion sein kann.
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const faces = await new FaceDetector().detect(img);
faces.forEach(face => {
const div = document.createElement('div');
const box = face.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 0, 0, 0.5)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left + left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
img.before(div);
const landmarkSVG = document.createElementNS('http://www.w3.org/2000/svg', 'svg');
landmarkSVG.style.position = 'absolute';
landmarkSVG.classList.add('landmarks');
landmarkSVG.setAttribute('viewBox', `0 0 ${img.width} ${img.height}`);
landmarkSVG.style.width = `${img.width}px`;
landmarkSVG.style.height = `${img.height}px`;
face.landmarks.map((landmark) => {
landmarkSVG.innerHTML += `<polygon class="landmark-${landmark.type}" points="${
landmark.locations.map((point) => {
return `${scaleX * point.x},${scaleY * point.y} `;
}).join(' ')
}" /></svg>`;
});
div.before(landmarkSVG);
});
} catch(e) {
console.error(e);
}
});
Barcodeerkennung
Die zweite Funktion der Shape Detection API ist die Barcode-Erkennung. Wie zuvor benötigen wir eine Seite mit Barcodes, z. B. diese. Wenn Sie die Datei in einem Browser öffnen, werden die verschiedenen QR‑Codes entschlüsselt. Sehen Sie sich das Glitch-Projekt an, insbesondere die Datei „script.js“, um zu sehen, wie es gemacht wird. Sie können das Projekt auch remixen oder bearbeiten.

Wenn Sie etwas Dynamischeres möchten, können Sie wieder die Google Bildersuche verwenden. Rufen Sie dieses Mal in Ihrem Browser auf einem privaten Tab oder im Gastmodus diese Google-Suchergebnisseite auf. Fügen Sie den Snippet jetzt auf dem Tab „Console“ der Chrome-Entwicklertools ein. Nach kurzer Zeit werden die erkannten Barcodes mit dem Rohwert und dem Barcodetyp versehen.
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const barcodes = await new BarcodeDetector().detect(img);
barcodes.forEach(barcode => {
const div = document.createElement('div');
const box = barcode.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 255, 255, 0.75)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left - left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
div.style.color = 'black';
div.style.fontSize = '14px';
div.textContent = `${barcode.rawValue}`;
img.before(div);
});
} catch(e) {
console.error(e);
}
});
Texterkennung
Die letzte Funktion der Shape Detection API ist die Texterkennung. Sie wissen ja, wie es geht: Wir brauchen eine Seite mit Bildern, die Text enthalten, wie diese mit Scanergebnissen von Google Books. In unterstützten Browsern wird der erkannte Text angezeigt und ein Begrenzungsrahmen um Textpassagen gezeichnet. Sehen Sie sich das Glitch-Projekt an, insbesondere die Datei „script.js“, um zu sehen, wie es gemacht wird. Sie können das Projekt auch remixen oder bearbeiten.

Wenn Sie das dynamisch testen möchten, rufen Sie diese Suchergebnisseite in einem privaten Tab oder im Gastmodus auf. Fügen Sie den Snippet jetzt auf dem Tab „Console“ der Chrome-Entwicklertools ein. Nach einer Weile wird ein Teil des Textes erkannt.
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const texts = await new TextDetector().detect(img);
texts.forEach(text => {
const div = document.createElement('div');
const box = text.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 255, 255, 0.75)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left - left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
div.style.color = 'black';
div.style.fontSize = '14px';
div.innerHTML = text.rawValue;
img.before(div);
});
} catch(e) {
console.error(e);
}
});
Feedback
Was halten Sie von dieser API? Bitte helfen Sie uns, indem Sie kurz auf diese Umfrage antworten:
War diese API intuitiv zu verwenden?
Konnten Sie das Beispiel ausführen?
Haben Sie noch etwas zu sagen? Haben Funktionen gefehlt? Bitte geben Sie uns in dieser Umfrage kurz Feedback. Vielen Dank!
5. Web Share Target API
Mit der Web Share Target API können installierte Web-Apps sich beim zugrunde liegenden Betriebssystem als Freigabe-Ziel registrieren, um freigegebene Inhalte entweder über die Web Share API oder über Systemereignisse wie die Freigabeschaltfläche auf Betriebssystemebene zu empfangen.
PWA installieren, um Inhalte zu teilen
Als Erstes benötigen Sie eine PWA, die Sie freigeben können. Dieses Mal ist Airhorner (zum Glück) nicht geeignet, aber die Web Share Target-Demo-App kann helfen. Installieren Sie die App auf dem Startbildschirm Ihres Geräts.

Inhalte in der PWA teilen
Als Nächstes benötigen Sie etwas, das Sie teilen können, z. B. ein Foto aus Google Fotos. Verwenden Sie die Schaltfläche „Teilen“ und wählen Sie die Scrapbook-PWA als Ziel für das Teilen aus.

Wenn Sie auf das App-Symbol tippen, gelangen Sie direkt zur Scrapbook-PWA und das Foto ist sofort zu sehen.

Wie funktioniert das? Weitere Informationen finden Sie im Web-App-Manifest der Scrapbook-PWA. Die Konfiguration für die Web Share Target API befindet sich im Attribut "share_target" des Manifests, das im Feld "action" auf eine URL verweist, die mit Parametern wie in "params" beschrieben versehen wird.
Die freigebende Seite füllt diese URL-Vorlage dann entsprechend aus (entweder über eine Freigabeaktion oder programmatisch vom Entwickler über die Web Share API), sodass die empfangende Seite die Parameter extrahieren und damit etwas tun kann, z. B. sie anzeigen.
{
"action": "/_share-target",
"enctype": "multipart/form-data",
"method": "POST",
"params": {
"files": [{
"name": "media",
"accept": ["audio/*", "image/*", "video/*"]
}]
}
}
Feedback
Was halten Sie von dieser API? Bitte helfen Sie uns, indem Sie kurz auf diese Umfrage antworten:
War diese API intuitiv zu verwenden?
Konnten Sie das Beispiel ausführen?
Haben Sie noch etwas zu sagen? Haben Funktionen gefehlt? Bitte geben Sie uns in dieser Umfrage kurz Feedback. Vielen Dank!
6. Wake Lock API
Um den Akku zu schonen, wechseln die meisten Geräte schnell in den Ruhemodus, wenn sie nicht verwendet werden. Das ist in den meisten Fällen in Ordnung, aber einige Anwendungen müssen den Bildschirm oder das Gerät aktiv halten, um ihre Arbeit zu erledigen. Die Wake Lock API bietet eine Möglichkeit, zu verhindern, dass das Gerät den Bildschirm dimmt oder sperrt oder in den Ruhemodus wechselt. Diese Funktion ermöglicht neue Erlebnisse, für die bisher eine native App erforderlich war.
Bildschirmschoner einrichten
Wenn Sie die Wake Lock API testen möchten, müssen Sie zuerst dafür sorgen, dass Ihr Gerät in den Ruhemodus wechselt. Aktivieren Sie daher in den Einstellungen Ihres Betriebssystems einen Bildschirmschoner Ihrer Wahl und legen Sie fest, dass er nach einer Minute startet. Lass dein Gerät für genau diese Zeit in Ruhe, um zu prüfen, ob es funktioniert. Die Screenshots unten zeigen macOS, aber Sie können diese Schritte natürlich auch auf Ihrem Android-Mobilgerät oder einer beliebigen unterstützten Desktop-Plattform ausführen.
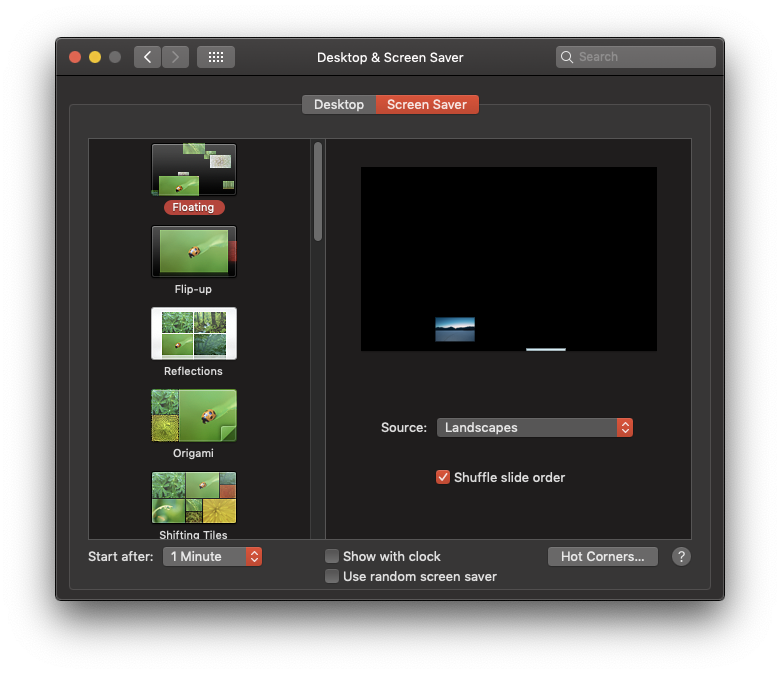
Wake Lock für das Display festlegen
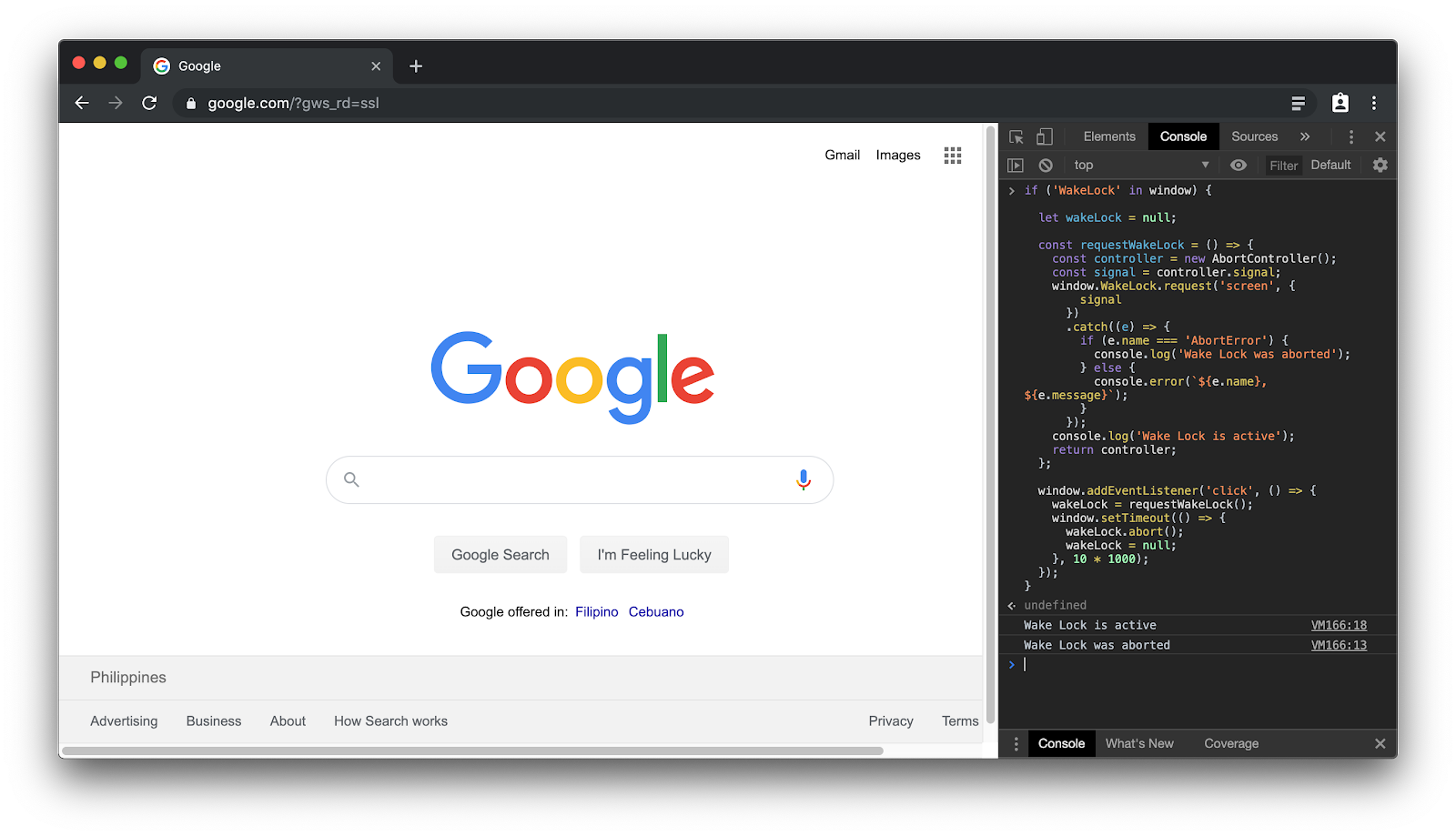
Nachdem Sie nun wissen, dass Ihr Bildschirmschoner funktioniert, verwenden Sie einen Wake Lock vom Typ "screen", um zu verhindern, dass der Bildschirmschoner seine Aufgabe erfüllt. Rufen Sie die Wake Lock-Demo-App auf und klicken Sie auf Aktivieren .
screen Kästchen Wake Lock (Wakelock).

Ab diesem Zeitpunkt ist ein Wake Lock aktiv. Wenn Sie Ihr Gerät eine Minute lang nicht berühren, sehen Sie, dass der Bildschirmschoner nicht gestartet wurde.
Wie funktioniert das? Um das herauszufinden, rufen Sie das Glitch-Projekt für die Wake Lock-Demo-App auf und sehen Sie sich script.js an. Das Wesentliche des Codes ist im folgenden Snippet zu sehen. Öffnen Sie einen neuen Tab (oder verwenden Sie einen beliebigen Tab, der gerade geöffnet ist) und fügen Sie den Code unten in die Chrome-Entwicklertools-Konsole ein. Wenn Sie auf das Fenster klicken, sollte ein Wake Lock angezeigt werden, das genau 10 Sekunden lang aktiv ist (siehe Konsolenprotokolle). Der Bildschirmschoner sollte nicht gestartet werden.
if ('wakeLock' in navigator && 'request' in navigator.wakeLock) {
let wakeLock = null;
const requestWakeLock = async () => {
try {
wakeLock = await navigator.wakeLock.request('screen');
wakeLock.addEventListener('release', () => {
console.log('Wake Lock was released');
});
console.log('Wake Lock is active');
} catch (e) {
console.error(`${e.name}, ${e.message}`);
}
};
requestWakeLock();
window.setTimeout(() => {
wakeLock.release();
}, 10 * 1000);
}
Feedback
Was halten Sie von dieser API? Bitte helfen Sie uns, indem Sie kurz auf diese Umfrage antworten:
War diese API intuitiv zu verwenden?
Konnten Sie das Beispiel ausführen?
Haben Sie noch etwas zu sagen? Haben Funktionen gefehlt? Bitte geben Sie uns in dieser Umfrage kurz Feedback. Vielen Dank!
7. Contact Picker API
Eine API, die uns besonders begeistert, ist die Contact Picker API. So kann eine Web-App auf Kontakte aus dem nativen Kontaktmanager des Geräts zugreifen. Ihre Web-App hat dann Zugriff auf die Namen, E‑Mail-Adressen und Telefonnummern Ihrer Kontakte. Sie können angeben, ob Sie nur einen oder mehrere Kontakte und ob Sie alle Felder oder nur eine Teilmenge von Namen, E‑Mail-Adressen und Telefonnummern wünschen.
Datenschutzaspekte
Wenn die Auswahl geöffnet wird, können Sie die Kontakte auswählen, die Sie teilen möchten. Es gibt keine Option zum Auswählen aller Elemente. Das ist so gewollt, da wir möchten, dass das Teilen eine bewusste Entscheidung ist. Der Zugriff ist auch nicht fortlaufend, sondern eine einmalige Entscheidung.
Auf Kontakte zugreifen
Der Zugriff auf Kontakte ist ganz einfach. Bevor die Auswahl geöffnet wird, können Sie angeben, welche Felder Sie benötigen (die Optionen sind name, email und telephone) und ob Sie auf mehrere oder nur einen Kontakt zugreifen möchten. Sie können diese API auf einem Android-Gerät testen, indem Sie die Demoanwendung öffnen. Der relevante Abschnitt des Quellcodes ist im Grunde das folgende Snippet:
getContactsButton.addEventListener('click', async () => {
const contacts = await navigator.contacts.select(
['name', 'email'],
{multiple: true});
if (!contacts.length) {
// No contacts were selected, or picker couldn't be opened.
return;
}
console.log(contacts);
});

8. Async Clipboard API
Text kopieren und einfügen
Bisher gab es keine Möglichkeit, Bilder programmatisch in die Zwischenablage des Systems zu kopieren und einzufügen. Vor Kurzem haben wir die Unterstützung von Bildern in der Async Clipboard API hinzugefügt.
Jetzt können Sie Bilder kopieren und einfügen. Neu ist, dass Sie auch Bilder in die Zwischenablage schreiben können. Die asynchrone Zwischenablage-API unterstützt das Kopieren und Einfügen von Text schon seit einiger Zeit. Sie können Text in die Zwischenablage kopieren, indem Sie navigator.clipboard.writeText() aufrufen, und ihn später einfügen, indem Sie navigator.clipboard.readText() aufrufen.
Bilder kopieren und einfügen
Jetzt können Sie auch Bilder in die Zwischenablage schreiben. Dazu benötigen Sie die Bilddaten als Blob, das Sie dann an den Konstruktor des Zwischenablageelements übergeben. Schließlich können Sie dieses Zwischenablageelement mit navigator.clipboard.write() kopieren.
// Copy: Writing image to the clipboard
try {
const imgURL = 'https://developers.google.com/web/updates/images/generic/file.png';
const data = await fetch(imgURL);
const blob = await data.blob();
await navigator.clipboard.write([
new ClipboardItem(Object.defineProperty({}, blob.type, {
value: blob,
enumerable: true
}))
]);
console.log('Image copied.');
} catch(e) {
console.error(e, e.message);
}
Das Einfügen des Bilds aus der Zwischenablage sieht ziemlich kompliziert aus, besteht aber eigentlich nur darin, den Blob aus dem Zwischenablageelement abzurufen. Da es mehrere geben kann, müssen Sie sie durchlaufen, bis Sie die gewünschte gefunden haben. Aus Sicherheitsgründen ist diese Funktion derzeit auf PNG-Bilder beschränkt. In Zukunft werden möglicherweise weitere Bildformate unterstützt.
async function getClipboardContents() {
try {
const clipboardItems = await navigator.clipboard.read();
for (const clipboardItem of clipboardItems) {
try {
for (const type of clipboardItem.types) {
const blob = await clipboardItem.getType(type);
console.log(URL.createObjectURL(blob));
}
} catch (e) {
console.error(e, e.message);
}
}
} catch (e) {
console.error(e, e.message);
}
}
Sie können diese API in einer Demo-App in Aktion sehen. Die relevanten Ausschnitte aus dem Quellcode sind oben eingebettet. Das Kopieren von Bildern in die Zwischenablage ist ohne Berechtigung möglich. Sie müssen jedoch den Zugriff zum Einfügen aus der Zwischenablage gewähren.
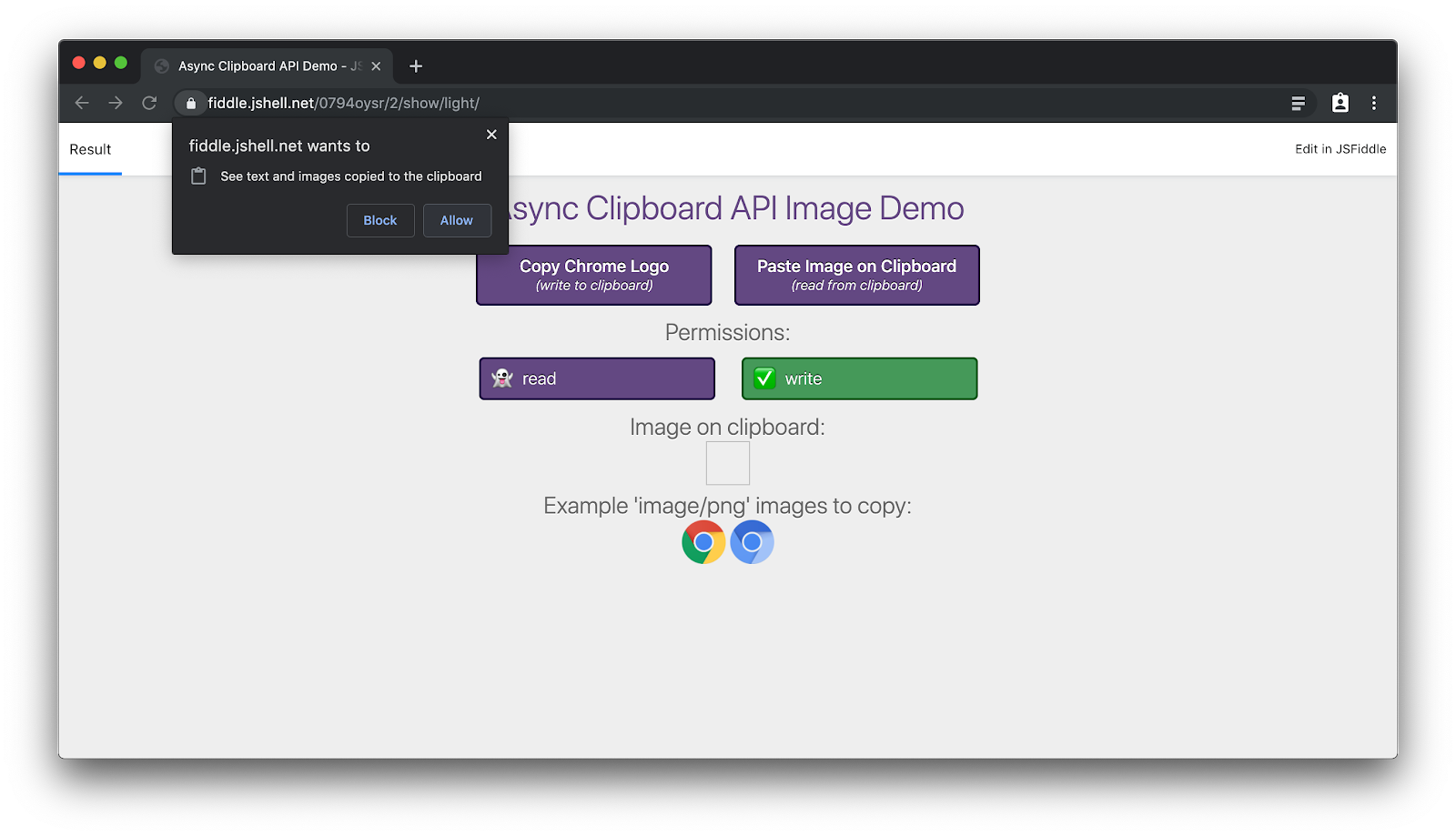
Nachdem Sie den Zugriff gewährt haben, können Sie das Bild aus der Zwischenablage lesen und in die Anwendung einfügen:

9. Geschafft!
Herzlichen Glückwunsch, Sie haben das Codelab abgeschlossen. Die meisten APIs sind noch in der Entwicklung und werden aktiv bearbeitet. Daher ist das Team auf Ihr Feedback angewiesen. Nur durch die Interaktion mit Personen wie Ihnen können wir diese APIs richtig entwickeln.
Wir empfehlen Ihnen außerdem, sich regelmäßig unsere Landingpage zu Funktionen anzusehen. Wir halten sie auf dem neuesten Stand und sie enthält Links zu allen ausführlichen Artikeln zu den APIs, mit denen wir arbeiten. Mach weiter so!
Tom und das gesamte Capabilities-Team 🐡