
1. Introduction et configuration
Fonctionnalités Web
Nous souhaitons combler le fossé de fonctionnalités entre le Web et les applications natives, et permettre aux développeurs de créer facilement des expériences de qualité sur le Web ouvert. Nous sommes convaincus que chaque développeur devrait avoir accès aux fonctionnalités dont il a besoin pour créer une expérience Web de qualité. Nous nous engageons à rendre le Web plus performant.
Toutefois, certaines fonctionnalités, comme l'accès au système de fichiers et la détection de l'inactivité, sont disponibles en mode natif, mais pas sur le Web. Ces fonctionnalités manquantes signifient que certains types d'applications ne peuvent pas être diffusés sur le Web ou sont moins utiles.
Nous concevrons et développerons ces nouvelles fonctionnalités de manière ouverte et transparente, en utilisant les processus de normes de plate-forme Web ouverte existants, tout en recueillant les premiers commentaires des développeurs et d'autres fournisseurs de navigateurs au fur et à mesure de l'itération sur la conception, afin de garantir une conception interopérable.
Objectifs de l'atelier
Dans cet atelier de programmation, vous allez découvrir plusieurs API Web qui sont nouvelles ou disponibles uniquement derrière un indicateur. Cet atelier de programmation se concentre donc sur les API elles-mêmes et sur les cas d'utilisation qu'elles permettent, plutôt que sur la création d'un produit final spécifique.
Points abordés
Cet atelier de programmation vous apprendra les mécanismes de base de plusieurs API de pointe. Notez que ces mécanismes ne sont pas encore définitifs. Vos commentaires sur le flux de développement sont donc très importants pour nous.
Prérequis
Les exigences varient pour chaque API, car celles présentées dans cet atelier de programmation sont vraiment à la pointe de la technologie. Veuillez lire attentivement les informations sur la compatibilité au début de chaque section.
Comment aborder l'atelier de programmation
Il n'est pas nécessaire de suivre l'atelier de programmation dans l'ordre. Chaque section représente une API indépendante. N'hésitez pas à choisir ce qui vous intéresse le plus.
2. API Badging
L'objectif de l'API Badging est d'attirer l'attention des utilisateurs sur les événements qui se produisent en arrière-plan. Pour simplifier la démonstration dans cet atelier de programmation, utilisons l'API pour attirer l'attention des utilisateurs sur ce qui se passe au premier plan. Vous pouvez ensuite transposer mentalement ce concept à ce qui se passe en arrière-plan.
Installer Airhorner
Pour que cette API fonctionne, vous avez besoin d'une PWA installée sur l'écran d'accueil. La première étape consiste donc à installer une PWA, comme la célèbre airhorner.com. Appuyez sur le bouton Installer en haut à droite ou utilisez le menu à trois points pour l'installer manuellement.

Un message de confirmation s'affiche. Cliquez sur Installer.

Une nouvelle icône s'affiche désormais dans le dock de votre système d'exploitation. Cliquez dessus pour lancer la PWA. Elle aura sa propre fenêtre d'application et s'exécutera en mode autonome.
|
|

Définir un badge
Maintenant que vous avez installé une PWA, vous avez besoin de données numériques (les badges ne peuvent contenir que des chiffres) à afficher sur un badge. Dans The Air Horner, il est facile de compter, soupir, le nombre de fois où le klaxon a retenti. En fait, avec l'application Airhorner installée, essayez de faire retentir la corne et vérifiez le badge. Il augmente d'une unité chaque fois que vous klaxonnez.
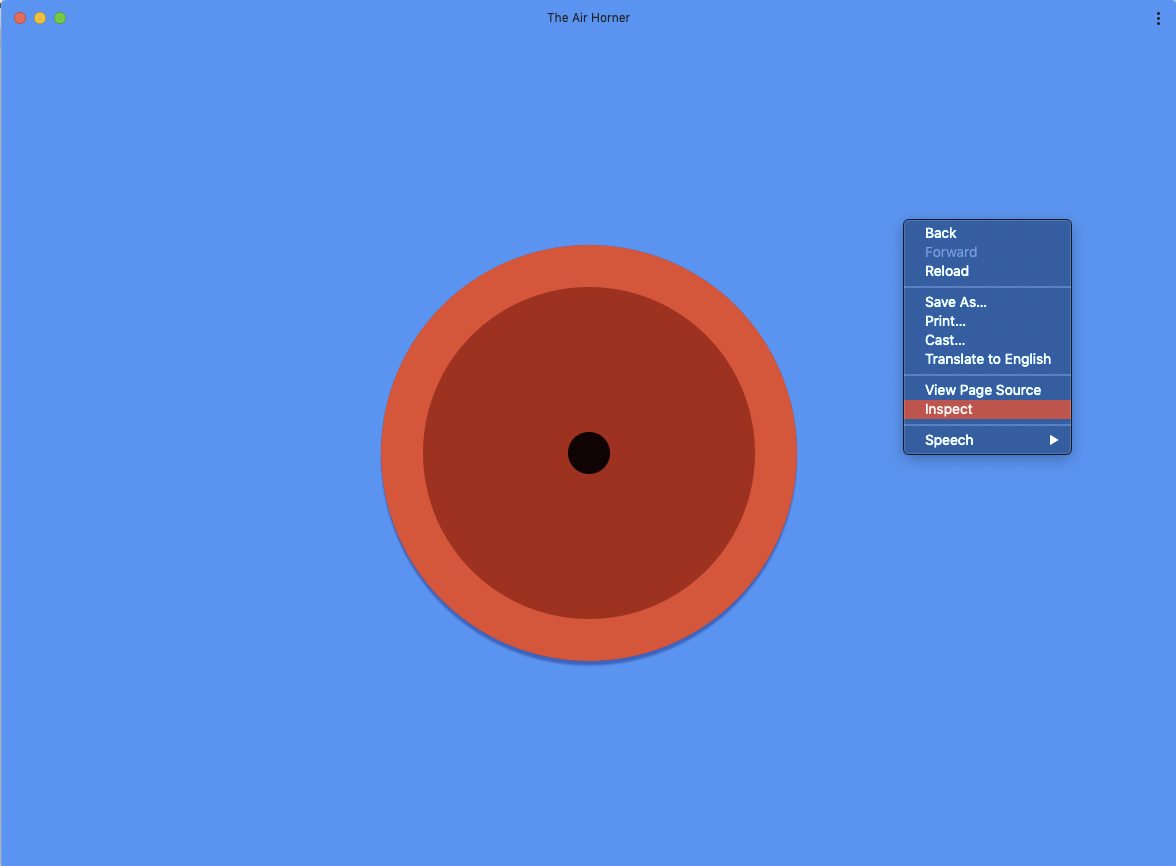
Comment ça marche ? En substance, le code est le suivant :
let hornCounter = 0;
const horn = document.querySelector('.horn');
horn.addEventListener('click', () => {
navigator.setExperimentalAppBadge(++hornCounter);
});
Faites retentir la corne de brume plusieurs fois et vérifiez l'icône de la PWA : elle se met à jour à chaque fois que la corne de brume retentit. C'est aussi simple que ça.

Effacer un badge
Le compteur va jusqu'à 99, puis redémarre. Vous pouvez également le réinitialiser manuellement. Ouvrez l'onglet "Console" des outils de développement, collez la ligne ci-dessous, puis appuyez sur Entrée.
navigator.setExperimentalAppBadge(0);
Vous pouvez également supprimer le badge en l'effaçant explicitement, comme indiqué dans l'extrait suivant. L'icône de votre PWA devrait maintenant être à nouveau claire et sans badge, comme au début.
navigator.clearExperimentalAppBadge();

Commentaires
Qu'avez-vous pensé de cette API ? Aidez-nous en répondant brièvement à cette enquête :
Cette API était-elle intuitive à utiliser ?
Avez-vous réussi à exécuter l'exemple ?
Avez-vous d'autres commentaires ? Manquait-il des fonctionnalités ? Veuillez répondre à cette courte enquête pour nous faire part de vos commentaires. Merci !
3. API Native File System
L'API Native File System permet aux développeurs de créer des applications Web puissantes qui interagissent avec les fichiers sur l'appareil local de l'utilisateur. Une fois qu'un utilisateur a accordé l'accès à une application Web, cette API permet aux applications Web de lire ou d'enregistrer les modifications directement dans les fichiers et dossiers de l'appareil de l'utilisateur.
Lire un fichier
Le "Hello, world" de l'API Native File System consiste à lire un fichier local et à obtenir son contenu. Créez un fichier .txt brut et saisissez du texte. Ensuite, accédez à n'importe quel site sécurisé (c'est-à-dire un site diffusé via HTTPS), comme example.com, et ouvrez la console des outils pour les développeurs. Collez l'extrait de code ci-dessous dans la console. Étant donné que l'API Native File System nécessite un geste de l'utilisateur, nous attachons un gestionnaire de double-clic au document. Nous aurons besoin du handle de fichier plus tard. Nous allons donc en faire une variable globale.
document.ondblclick = async () => {
window.handle = await window.chooseFileSystemEntries();
const file = await handle.getFile();
document.body.textContent = await file.text();
};
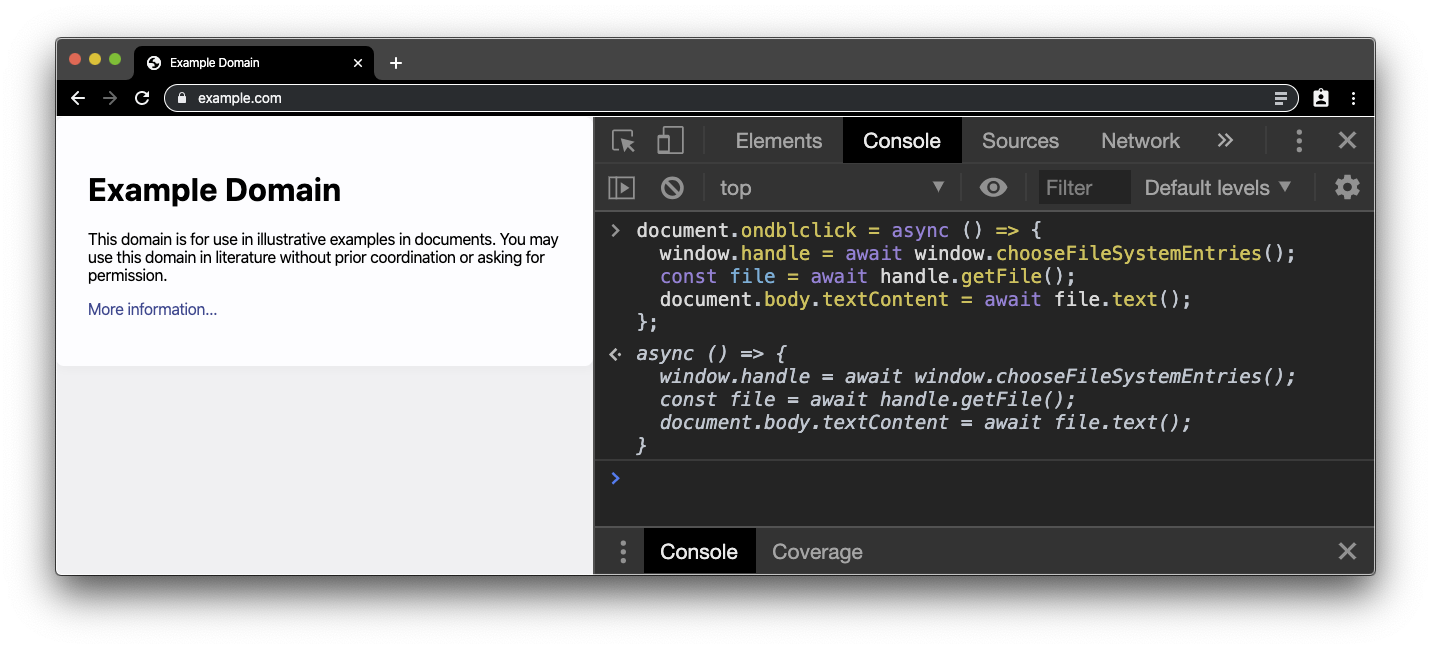
Lorsque vous double-cliquez n'importe où sur la page example.com, un sélecteur de fichiers s'affiche.

Sélectionnez le fichier .txt que vous avez créé précédemment. Le contenu du fichier remplacera ensuite le contenu body réel de example.com.

Enregistrer un fichier
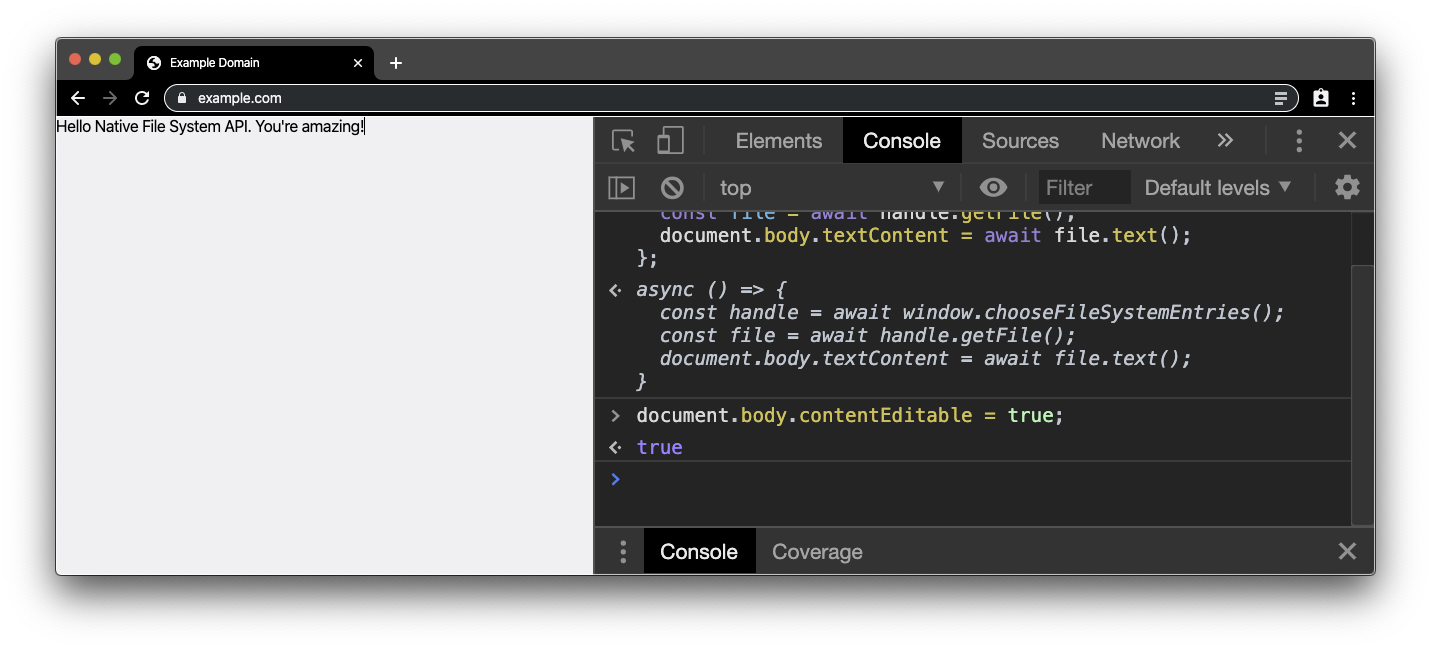
Ensuite, nous allons apporter quelques modifications. Nous allons donc rendre body modifiable en y collant l'extrait de code ci-dessous. Vous pouvez maintenant modifier le texte comme si le navigateur était un éditeur de texte.
document.body.contentEditable = true;
Nous allons maintenant réécrire ces modifications dans le fichier d'origine. Nous avons donc besoin d'un writer sur le handle de fichier, que nous pouvons obtenir en collant l'extrait ci-dessous dans la console. Là encore, nous avons besoin d'un geste de l'utilisateur. Cette fois, nous attendons un clic sur le document principal.
document.onclick = async () => {
const writer = await handle.createWriter();
await writer.truncate(0);
await writer.write(0, document.body.textContent);
await writer.close();
};
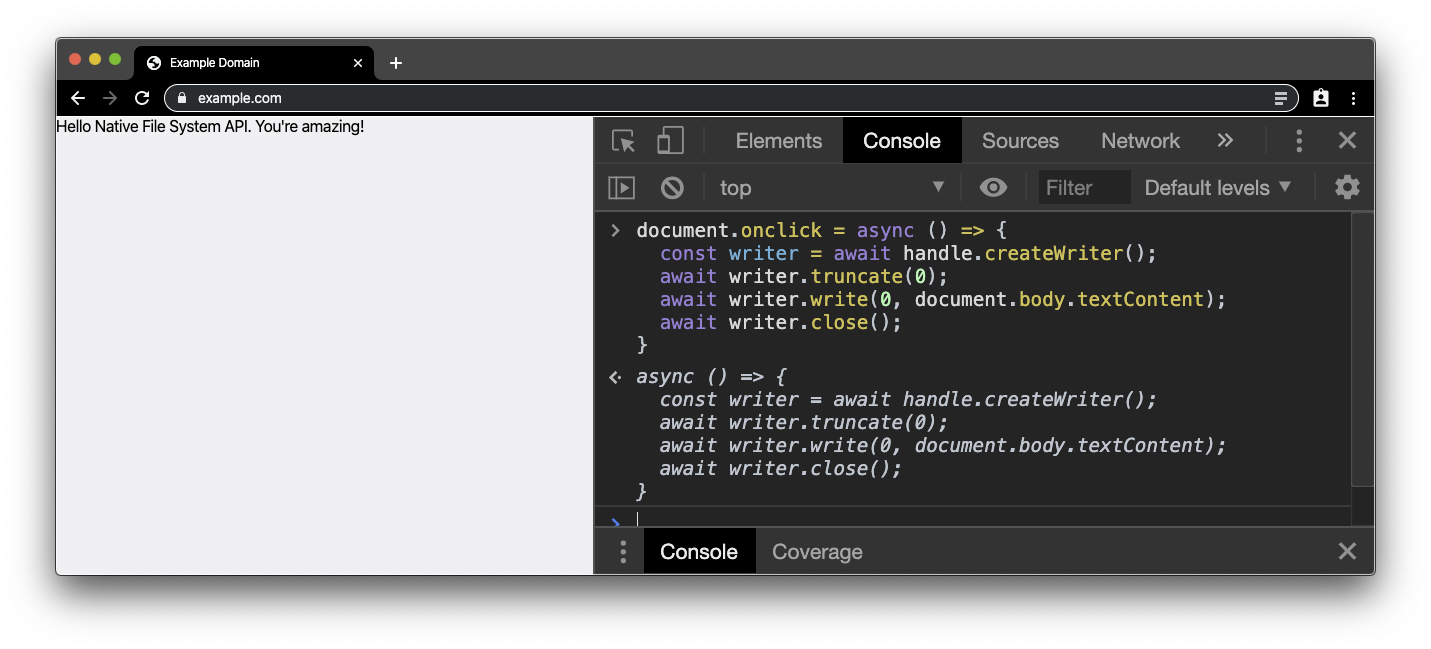
Lorsque vous cliquez (et non double-cliquez) sur le document, une invite d'autorisation s'affiche. Lorsque vous accordez l'autorisation, le contenu du fichier correspond à ce que vous avez modifié dans body auparavant. Vérifiez les modifications en ouvrant le fichier dans un autre éditeur (ou recommencez le processus en double-cliquant à nouveau sur le document et en rouvrant votre fichier).


Félicitations ! Vous venez de créer le plus petit éditeur de texte au monde [citation needed].
Commentaires
Qu'avez-vous pensé de cette API ? Aidez-nous en répondant brièvement à cette enquête :
Cette API était-elle intuitive à utiliser ?
Avez-vous réussi à exécuter l'exemple ?
Avez-vous d'autres commentaires ? Manquait-il des fonctionnalités ? Veuillez répondre à cette courte enquête pour nous faire part de vos commentaires. Merci !
4. API Shape Detection
L'API Shape Detection permet d'accéder à des détecteurs de formes accélérés (par exemple, pour les visages humains) et fonctionne sur des images fixes et/ou des flux d'images en direct. Les systèmes d'exploitation disposent de détecteurs de fonctionnalités performants et hautement optimisés, tels que FaceDetector sur Android. L'API Shape Detection ouvre ces implémentations natives et les expose via un ensemble d'interfaces JavaScript.
Actuellement, les fonctionnalités compatibles sont la détection de visages via l'interface FaceDetector, la détection de codes-barres via l'interface BarcodeDetector et la détection de texte (reconnaissance optique des caractères) via l'interface TextDetector.
Détection de visages
La détection des visages est une fonctionnalité fascinante de l'API Shape Detection. Pour le tester, nous avons besoin d'une page avec des visages. Cette page avec le visage de l'auteur est un bon point de départ. Le résultat devrait ressembler à la capture d'écran ci-dessous. Dans un navigateur compatible, le cadre de sélection du visage et les points de repère du visage seront reconnus.
Pour voir la quantité de code nécessaire, remaniez ou modifiez le projet Glitch, en particulier le fichier script.js.

Si vous souhaitez créer une vidéo entièrement dynamique et ne pas vous contenter de travailler avec le visage de l'auteur, accédez à cette page de résultats de recherche Google pleine de visages dans un onglet privé ou en mode Invité. Sur cette page, ouvrez les outils pour les développeurs Chrome en effectuant un clic droit n'importe où, puis en cliquant sur Inspecter. Ensuite, dans l'onglet "Console", collez l'extrait de code ci-dessous. Le code met en évidence les visages détectés à l'aide d'un cadre rouge semi-transparent.
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const faces = await new FaceDetector().detect(img);
faces.forEach(face => {
const div = document.createElement('div');
const box = face.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 0, 0, 0.5)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left + left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
img.before(div);
});
} catch(e) {
console.error(e);
}
});
Vous remarquerez qu'il y a des messages DOMException et que toutes les images ne sont pas traitées. En effet, les images above-the-fold sont intégrées en tant qu'URI de données et sont donc accessibles, tandis que les images below-the-fold proviennent d'un autre domaine qui n'est pas configuré pour prendre en charge CORS. Pour la démonstration, nous n'avons pas à nous en soucier.
Détection de points de repère sur le visage
En plus des visages en tant que tels, macOS permet également de détecter les points de repère du visage. Pour tester la détection des points de repère du visage, collez l'extrait de code suivant dans la console. Rappel : la liste des points de repère n'est pas parfaite en raison de crbug.com/914348, mais vous pouvez voir où cela mène et à quel point cette fonctionnalité peut être puissante.
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const faces = await new FaceDetector().detect(img);
faces.forEach(face => {
const div = document.createElement('div');
const box = face.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 0, 0, 0.5)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left + left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
img.before(div);
const landmarkSVG = document.createElementNS('http://www.w3.org/2000/svg', 'svg');
landmarkSVG.style.position = 'absolute';
landmarkSVG.classList.add('landmarks');
landmarkSVG.setAttribute('viewBox', `0 0 ${img.width} ${img.height}`);
landmarkSVG.style.width = `${img.width}px`;
landmarkSVG.style.height = `${img.height}px`;
face.landmarks.map((landmark) => {
landmarkSVG.innerHTML += `<polygon class="landmark-${landmark.type}" points="${
landmark.locations.map((point) => {
return `${scaleX * point.x},${scaleY * point.y} `;
}).join(' ')
}" /></svg>`;
});
div.before(landmarkSVG);
});
} catch(e) {
console.error(e);
}
});
Détection de codes-barres
La deuxième fonctionnalité de l'API Shape Detection est la détection de codes-barres. Comme précédemment, nous avons besoin d'une page contenant des codes-barres, comme celle-ci. Lorsque vous l'ouvrez dans un navigateur, les différents codes QR décryptés s'affichent. Remixez ou modifiez le projet Glitch, en particulier le fichier script.js, pour voir comment procéder.

Si vous souhaitez quelque chose de plus dynamique, vous pouvez à nouveau utiliser la recherche d'images Google. Cette fois, dans votre navigateur, accédez à cette page de résultats de recherche Google dans un onglet privé ou en mode Invité. Collez ensuite l'extrait ci-dessous dans l'onglet "Console" des outils pour les développeurs Chrome. Après un court instant, les codes-barres reconnus seront annotés avec la valeur brute et le type de code-barres.
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const barcodes = await new BarcodeDetector().detect(img);
barcodes.forEach(barcode => {
const div = document.createElement('div');
const box = barcode.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 255, 255, 0.75)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left - left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
div.style.color = 'black';
div.style.fontSize = '14px';
div.textContent = `${barcode.rawValue}`;
img.before(div);
});
} catch(e) {
console.error(e);
}
});
Détection de texte
La dernière fonctionnalité de l'API Shape Detection est la détection de texte. Vous connaissez maintenant la marche à suivre : nous avons besoin d'une page contenant des images avec du texte, comme celle-ci avec les résultats de l'analyse Google Livres. Dans les navigateurs compatibles, le texte reconnu s'affiche et un cadre de délimitation est dessiné autour des passages de texte. Remixez ou modifiez le projet Glitch, en particulier le fichier script.js, pour voir comment procéder.

Pour tester cela de manière dynamique, accédez à cette page de résultats de recherche dans un onglet privé ou en mode Invité. Collez ensuite l'extrait ci-dessous dans l'onglet "Console" des outils pour les développeurs Chrome. En attendant un peu, une partie du texte sera reconnue.
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const texts = await new TextDetector().detect(img);
texts.forEach(text => {
const div = document.createElement('div');
const box = text.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 255, 255, 0.75)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left - left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
div.style.color = 'black';
div.style.fontSize = '14px';
div.innerHTML = text.rawValue;
img.before(div);
});
} catch(e) {
console.error(e);
}
});
Commentaires
Qu'avez-vous pensé de cette API ? Aidez-nous en répondant brièvement à cette enquête :
Cette API était-elle intuitive à utiliser ?
Avez-vous réussi à exécuter l'exemple ?
Avez-vous d'autres commentaires ? Manquait-il des fonctionnalités ? Veuillez répondre à cette courte enquête pour nous faire part de vos commentaires. Merci !
5. API Web Share Target
L'API Web Share Target permet aux applications Web installées de s'enregistrer auprès du système d'exploitation sous-jacent en tant que cible de partage pour recevoir du contenu partagé à partir de l'API Web Share ou d'événements système, comme le bouton de partage au niveau du système d'exploitation.
Installer une PWA pour partager vers
Pour commencer, vous avez besoin d'une PWA que vous pouvez partager. Cette fois, Airhorner (heureusement) ne fera pas l'affaire, mais l'application de démonstration Web Share Target est là pour vous aider. Installez l'application sur l'écran d'accueil de votre appareil.

Partager du contenu avec la PWA
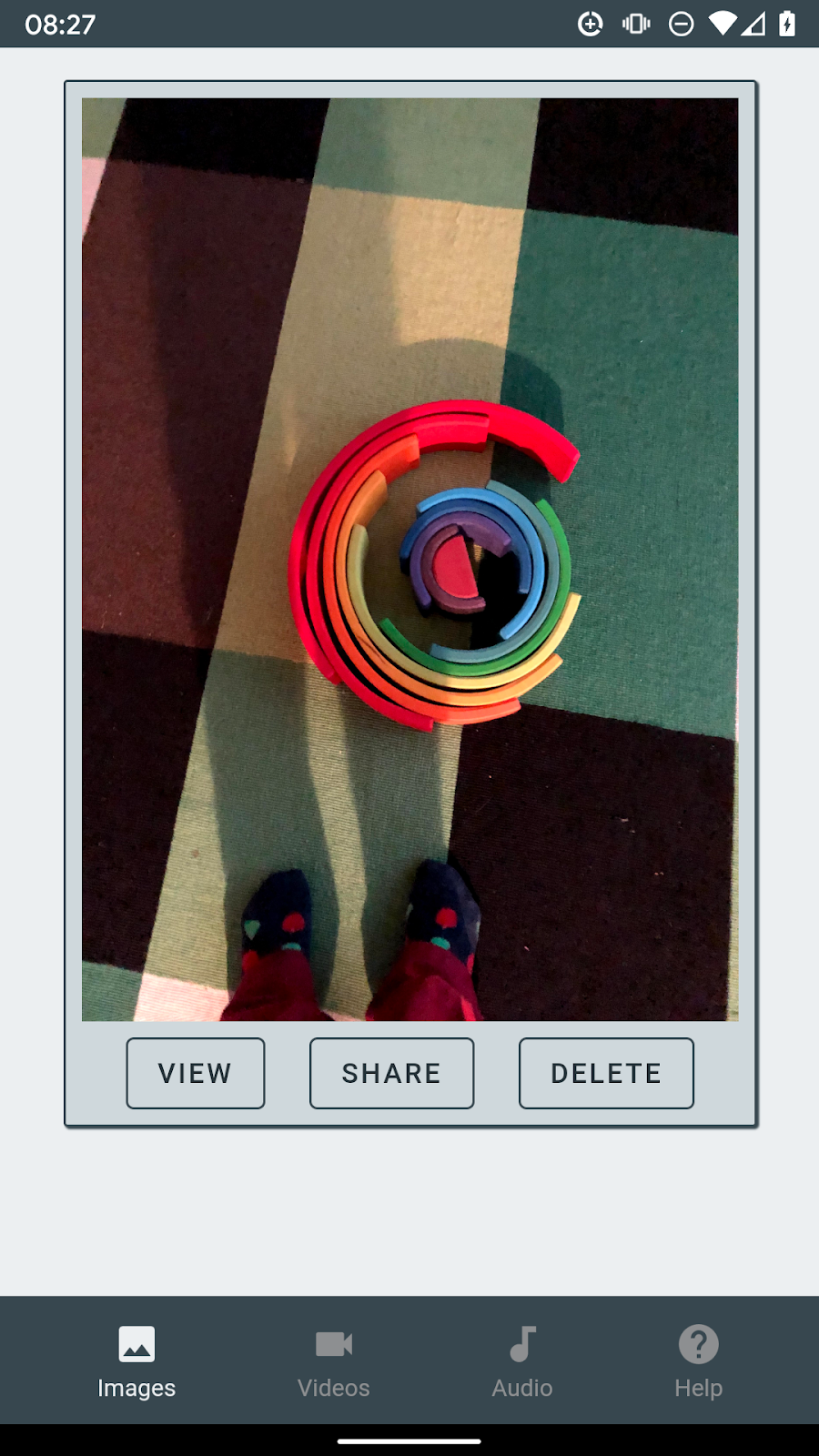
Ensuite, vous avez besoin d'un élément à partager, comme une photo de Google Photos. Utilisez le bouton de partage et sélectionnez la PWA Scrapbook comme cible de partage.
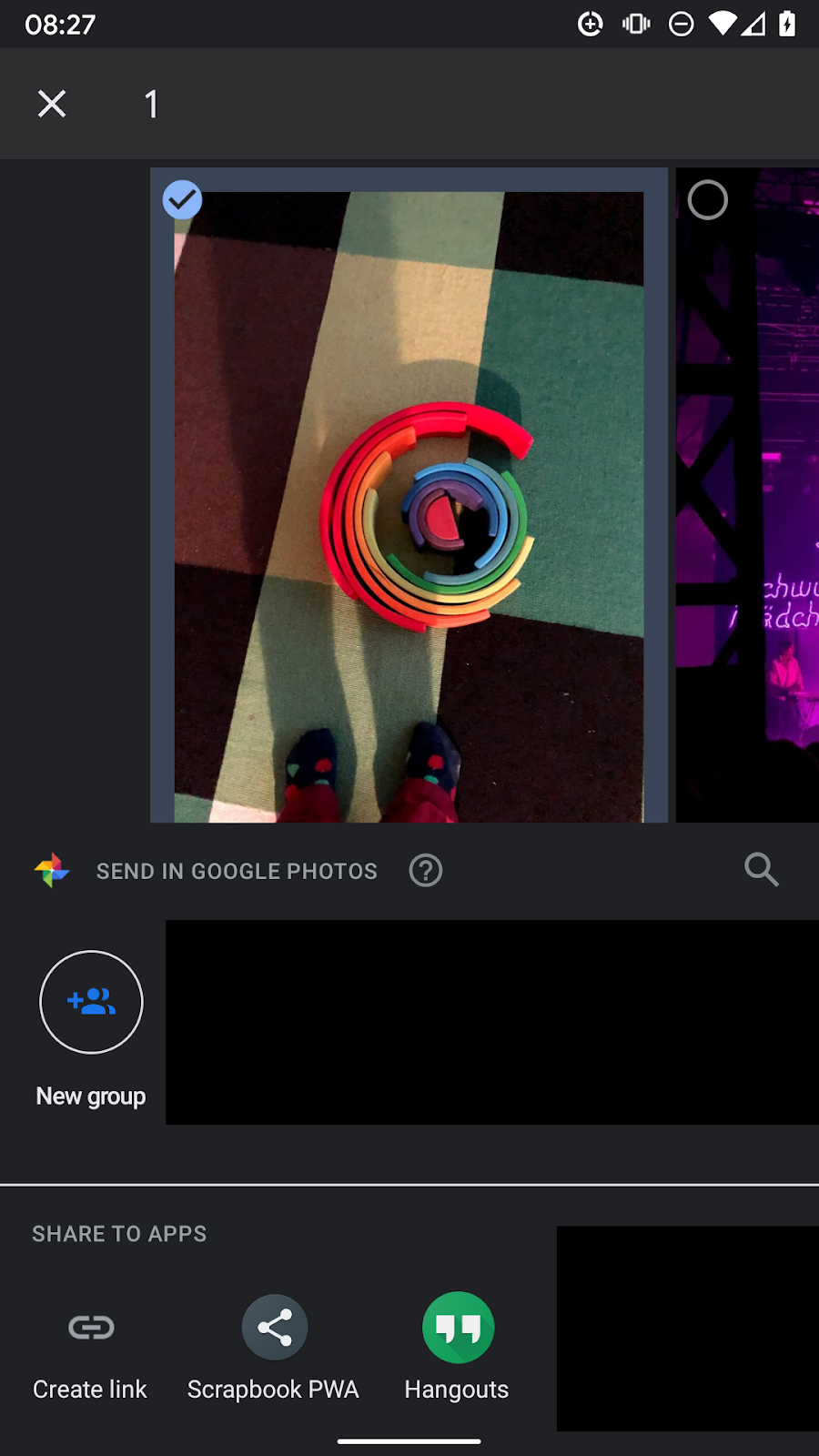
Lorsque vous appuyez sur l'icône de l'application, vous êtes directement redirigé vers la PWA Scrapbook, et la photo s'y trouve.
Comment ça marche ? Pour le savoir, explorez le fichier manifeste d'application Web de la PWA Scrapbook. La configuration permettant à l'API Web Share Target de fonctionner se trouve dans la propriété "share_target" du fichier manifeste, qui, dans son champ "action", pointe vers une URL décorée avec les paramètres listés dans "params".
Le côté partage remplit ensuite ce modèle d'URL en conséquence (soit par le biais d'une action de partage, soit de manière programmatique par le développeur à l'aide de l'API Web Share), afin que le côté réception puisse ensuite extraire les paramètres et les utiliser, par exemple pour les afficher.
{
"action": "/_share-target",
"enctype": "multipart/form-data",
"method": "POST",
"params": {
"files": [{
"name": "media",
"accept": ["audio/*", "image/*", "video/*"]
}]
}
}
Commentaires
Qu'avez-vous pensé de cette API ? Aidez-nous en répondant brièvement à cette enquête :
Cette API était-elle intuitive à utiliser ?
Avez-vous réussi à exécuter l'exemple ?
Avez-vous d'autres commentaires ? Manquait-il des fonctionnalités ? Veuillez répondre à cette courte enquête pour nous faire part de vos commentaires. Merci !
6. API Wake Lock
Pour éviter de décharger la batterie, la plupart des appareils se mettent rapidement en veille lorsqu'ils sont inactifs. Si cela ne pose généralement pas de problème, certaines applications ont besoin de maintenir l'écran ou l'appareil allumés pour effectuer leur tâche. L'API Wake Lock permet d'empêcher l'écran de l'appareil de s'assombrir et de se verrouiller, ou d'empêcher l'appareil de passer en mode veille. Cette fonctionnalité permet de créer de nouvelles expériences qui, jusqu'à présent, nécessitaient une application native.
Configurer un économiseur d'écran
Pour tester l'API Wake Lock, vous devez d'abord vous assurer que votre appareil se mettrait en veille. Par conséquent, dans le volet des préférences de votre système d'exploitation, activez l'économiseur d'écran de votre choix et assurez-vous qu'il se lance au bout d'une minute. Assurez-vous que cela fonctionne en laissant votre appareil tranquille pendant exactement cette durée (oui, je sais, c'est douloureux). Les captures d'écran ci-dessous montrent macOS, mais vous pouvez bien sûr essayer cette fonctionnalité sur votre appareil Android mobile ou sur n'importe quelle plate-forme de bureau compatible.

Définir un wakelock d'écran
Maintenant que vous savez que votre économiseur d'écran fonctionne, vous allez utiliser un wakelock de type "screen" pour l'empêcher de faire son travail. Accédez à l'application de démonstration Wake Lock, puis cliquez sur Activate (Activer).
Cochez la case screen Wakelock.

À partir de ce moment, un wakelock est actif. Si vous êtes assez patient pour laisser votre appareil sans le toucher pendant une minute, vous verrez que l'économiseur d'écran ne s'est pas déclenché.
Voyons le fonctionnement. Pour le savoir, accédez au projet Glitch de l'application de démonstration Wake Lock et consultez script.js. L'essentiel du code se trouve dans l'extrait ci-dessous. Ouvrez un nouvel onglet (ou utilisez un onglet déjà ouvert) et collez le code ci-dessous dans la console des outils pour les développeurs Chrome. Lorsque vous cliquez sur la fenêtre, vous devriez voir un wakelock actif pendant exactement 10 secondes (voir les journaux de la console). Votre économiseur d'écran ne devrait pas démarrer.
if ('wakeLock' in navigator && 'request' in navigator.wakeLock) {
let wakeLock = null;
const requestWakeLock = async () => {
try {
wakeLock = await navigator.wakeLock.request('screen');
wakeLock.addEventListener('release', () => {
console.log('Wake Lock was released');
});
console.log('Wake Lock is active');
} catch (e) {
console.error(`${e.name}, ${e.message}`);
}
};
requestWakeLock();
window.setTimeout(() => {
wakeLock.release();
}, 10 * 1000);
}

Commentaires
Qu'avez-vous pensé de cette API ? Aidez-nous en répondant brièvement à cette enquête :
Cette API était-elle intuitive à utiliser ?
Avez-vous réussi à exécuter l'exemple ?
Avez-vous d'autres commentaires ? Manquait-il des fonctionnalités ? Veuillez répondre à cette courte enquête pour nous faire part de vos commentaires. Merci !
7. API Contact Picker
L'API Sélecteur de contacts est une API qui nous enthousiasme particulièrement. Elle permet à une application Web d'accéder aux contacts depuis le gestionnaire de contacts natif de l'appareil. Votre application Web a ainsi accès aux noms, adresses e-mail et numéros de téléphone de vos contacts. Vous pouvez spécifier si vous souhaitez un ou plusieurs contacts, et si vous voulez tous les champs ou seulement un sous-ensemble de noms, d'adresses e-mail et de numéros de téléphone.
Considérations relatives à la confidentialité
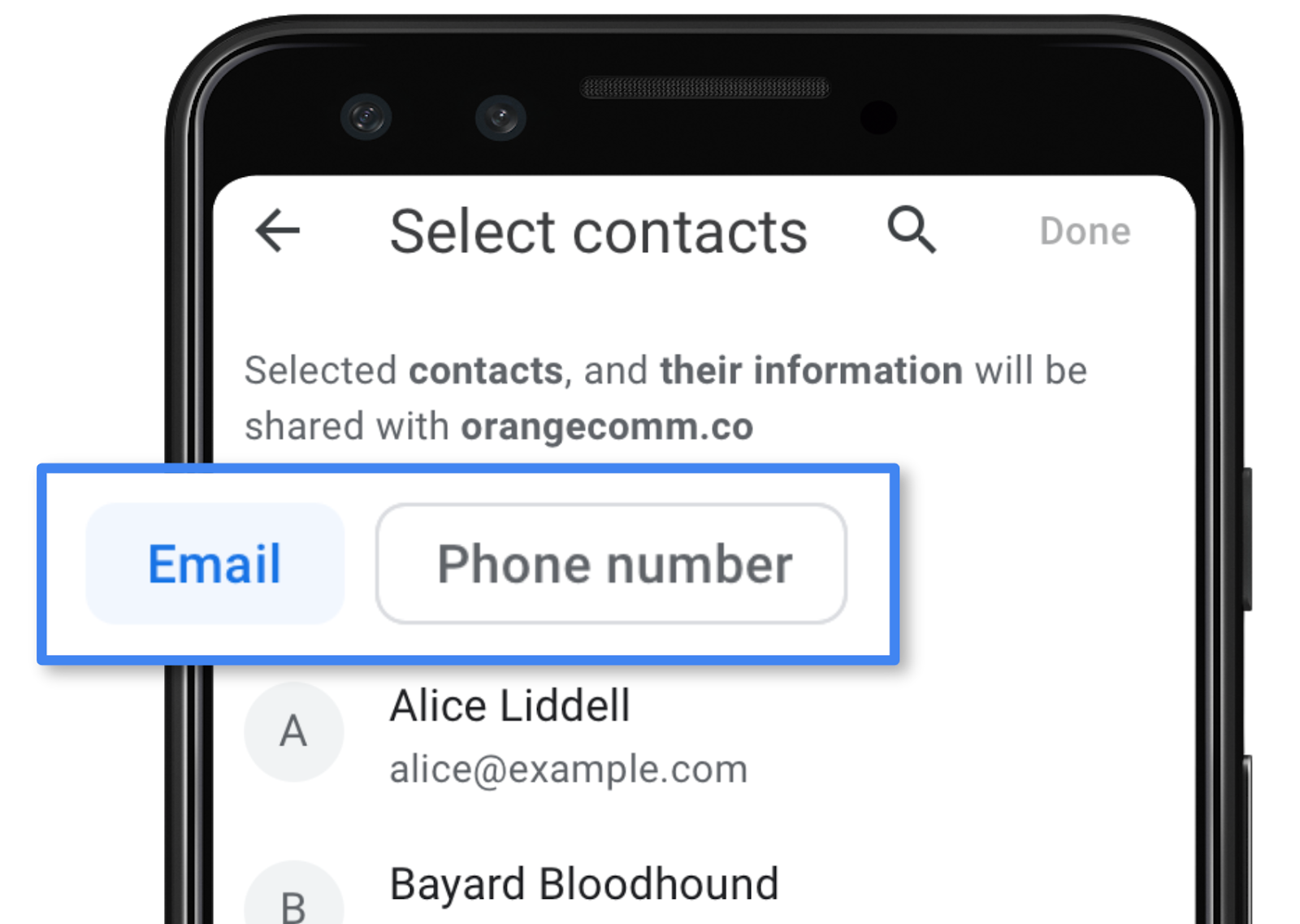
Une fois le sélecteur ouvert, vous pouvez sélectionner les contacts avec lesquels vous souhaitez partager des informations. Vous remarquerez qu'il n'y a pas d'option "Tout sélectionner". C'est intentionnel : nous voulons que le partage soit une décision consciente. De même, l'accès n'est pas continu, mais plutôt une décision ponctuelle.
Accéder aux contacts
Accéder aux contacts est une tâche simple. Avant l'ouverture du sélecteur, vous pouvez spécifier les champs souhaités (les options étant name, email et telephone), et si vous souhaitez accéder à plusieurs contacts ou à un seul. Vous pouvez tester cette API sur un appareil Android en ouvrant l'application de démonstration. La section concernée du code source est essentiellement l'extrait ci-dessous :
getContactsButton.addEventListener('click', async () => {
const contacts = await navigator.contacts.select(
['name', 'email'],
{multiple: true});
if (!contacts.length) {
// No contacts were selected, or picker couldn't be opened.
return;
}
console.log(contacts);
});
8. API Async Clipboard
Copier et coller du texte
Jusqu'à présent, il n'était pas possible de copier et coller des images dans le presse-papiers du système de manière programmatique. Récemment, nous avons ajouté la prise en charge des images à l'API Async Clipboard.
Vous pouvez désormais copier et coller des images. La nouveauté, c'est que vous pouvez également écrire des images dans le presse-papiers. L'API Clipboard asynchrone permet de copier et coller du texte depuis un certain temps. Vous pouvez copier du texte dans le presse-papiers en appelant navigator.clipboard.writeText(), puis le coller ultérieurement en appelant navigator.clipboard.readText().
Copier et coller des images
Vous pouvez désormais écrire des images dans le presse-papiers. Pour que cela fonctionne, vous avez besoin des données d'image sous forme de blob, que vous transmettez ensuite au constructeur d'élément de presse-papiers. Enfin, vous pouvez copier cet élément du presse-papiers en appelant navigator.clipboard.write().
// Copy: Writing image to the clipboard
try {
const imgURL = 'https://developers.google.com/web/updates/images/generic/file.png';
const data = await fetch(imgURL);
const blob = await data.blob();
await navigator.clipboard.write([
new ClipboardItem(Object.defineProperty({}, blob.type, {
value: blob,
enumerable: true
}))
]);
console.log('Image copied.');
} catch(e) {
console.error(e, e.message);
}
Le collage de l'image depuis le presse-papiers semble assez complexe, mais il consiste en fait à récupérer le blob à partir de l'élément du presse-papiers. Comme il peut y en avoir plusieurs, vous devez les parcourir en boucle jusqu'à trouver celui qui vous intéresse. Pour des raisons de sécurité, cette fonctionnalité est actuellement limitée aux images PNG, mais d'autres formats d'image pourront être pris en charge à l'avenir.
async function getClipboardContents() {
try {
const clipboardItems = await navigator.clipboard.read();
for (const clipboardItem of clipboardItems) {
try {
for (const type of clipboardItem.types) {
const blob = await clipboardItem.getType(type);
console.log(URL.createObjectURL(blob));
}
} catch (e) {
console.error(e, e.message);
}
}
} catch (e) {
console.error(e, e.message);
}
}
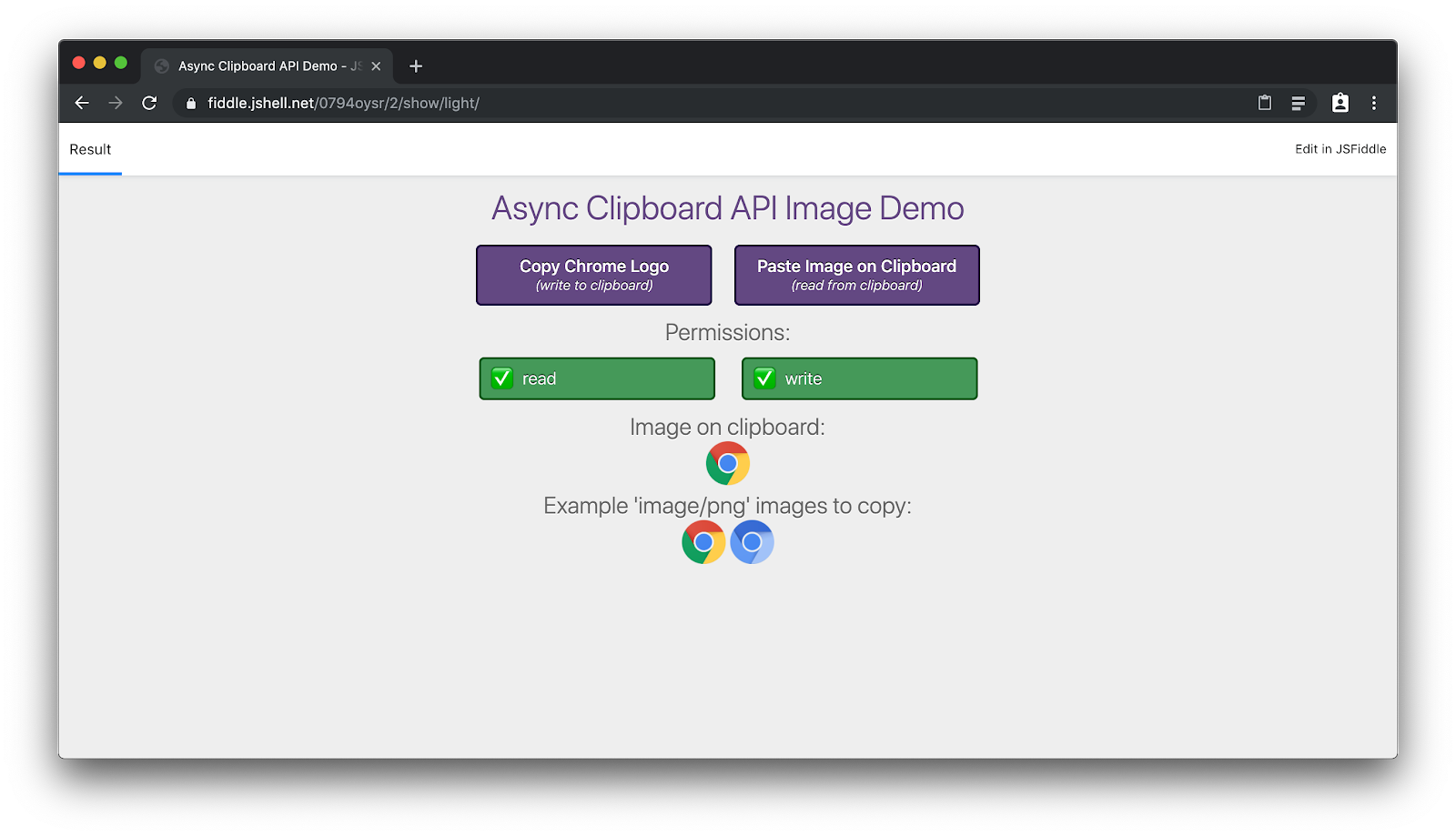
Vous pouvez voir cette API en action dans une application de démonstration. Les extraits de code source correspondants sont intégrés ci-dessus. Vous pouvez copier des images dans le presse-papiers sans autorisation, mais vous devez accorder l'accès pour coller depuis le presse-papiers.

Une fois l'accès accordé, vous pouvez lire l'image à partir du presse-papiers et la coller dans l'application :
9. Félicitations,
Félicitations, vous avez terminé cet atelier de programmation. Pour rappel, la plupart des API sont encore en cours de développement et de modification. L'équipe apprécie donc beaucoup vos commentaires, car seule l'interaction avec des personnes comme vous nous aidera à mettre au point ces API.
Nous vous encourageons également à consulter régulièrement la page de destination des fonctionnalités. Nous le tiendrons à jour. Il contient des pointeurs vers tous les articles détaillés concernant les API sur lesquelles nous travaillons. Continuez comme ça !
Tom et toute l'équipe Fonctionnalités 🐡