
1. Übersicht
In diesem Lab verwenden Sie das What-If-Tool, um ein XGBoost-Modell zu analysieren, das mit Finanzdaten trainiert und auf Cloud AI Platform bereitgestellt wurde.
Lerninhalte
Die folgenden Themen werden behandelt:
- XGBoost-Modell mit einem öffentlichen Hypothekendataset in AI Platform Notebooks trainieren
- XGBoost-Modell in AI Platform bereitstellen
- Modell mit dem What-If-Tool analysieren
Die Gesamtkosten für die Ausführung dieses Labs in Google Cloud betragen etwa 1$.
2. Kurze Einführung in XGBoost
XGBoost ist ein Framework für maschinelles Lernen, das Entscheidungsbäume und Gradient Boosting verwendet, um Vorhersagemodelle zu erstellen. Dabei werden mehrere Entscheidungsbäume auf Grundlage des Scores, der mit verschiedenen Blattknoten in einem Baum verknüpft ist, zusammengefasst.
Das Diagramm unten ist eine Visualisierung eines einfachen Entscheidungsbaummodells, das anhand der Wettervorhersage bewertet, ob ein Sportspiel stattfinden soll:

Warum verwenden wir XGBoost für dieses Modell? Während herkömmliche neuronale Netze bei unstrukturierten Daten wie Bildern und Texten am besten abschneiden, sind Entscheidungsbäume oft sehr gut für strukturierte Daten wie das Hypothekendataset geeignet, das wir in diesem Codelab verwenden.
3. Richten Sie Ihre Umgebung ein.
Für dieses Codelab benötigen Sie ein Google Cloud Platform-Projekt mit aktivierter Abrechnung. Folgen Sie dieser Anleitung, um ein Projekt zu erstellen.
Schritt 1: Cloud AI Platform Models API aktivieren
Rufen Sie in der Cloud Console den Abschnitt „AI Platform-Modelle“ auf und klicken Sie auf „Aktivieren“, falls die API noch nicht aktiviert ist.
Schritt 2: Compute Engine API aktivieren
Rufen Sie Compute Engine auf und wählen Sie Aktivieren aus, falls die API noch nicht aktiviert ist. Sie benötigen diese, um Ihre Notebook-Instanz zu erstellen.
Schritt 3: AI Platform Notebooks-Instanz erstellen
Rufen Sie in der Cloud Console den Abschnitt „AI Platform Notebooks“ auf und klicken Sie auf Neue Instanz. Wählen Sie dann den Instanztyp neueste TF Enterprise 2.x ohne GPUs aus:
Übernehmen Sie die Standardoptionen und klicken Sie auf Erstellen. Nachdem die Instanz erstellt wurde, klicken Sie auf JupyterLab öffnen:

Schritt 4: XGBoost installieren
Nachdem Ihre JupyterLab-Instanz geöffnet wurde, müssen Sie das XGBoost-Paket hinzufügen.
Wählen Sie dazu im Launcher „Terminal“ aus:
Führen Sie dann den folgenden Befehl aus, um die neueste von Cloud AI Platform unterstützte Version von XGBoost zu installieren:
pip3 install xgboost==0.90
Öffnen Sie nach Abschluss des Vorgangs über den Launcher eine Python 3-Notebook-Instanz. Sie können jetzt mit Ihrem Notebook loslegen.
Schritt 5: Python-Pakete importieren
Fügen Sie in der ersten Zelle Ihres Notebooks die folgenden Importe hinzu und führen Sie die Zelle aus. Sie können es ausführen, indem Sie im oberen Menü auf die Rechtspfeiltaste oder auf die Tastenkombination „Befehl + Eingabetaste“ drücken:
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
4. Daten herunterladen und verarbeiten
Wir verwenden ein Hypothekendataset von ffiec.gov, um ein XGBoost-Modell zu trainieren. Wir haben das Original-Dataset vorverarbeitet und eine kleinere Version erstellt, die Sie zum Trainieren des Modells verwenden können. Das Modell sagt voraus, ob ein bestimmter Hypothekenantrag genehmigt wird.
Schritt 1: Vorverarbeiteten Datensatz herunterladen
Wir haben eine Version des Datasets in Google Cloud Storage für Sie bereitgestellt. Sie können es herunterladen, indem Sie den folgenden gsutil-Befehl in Ihrem Jupyter-Notebook ausführen:
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
Schritt 2: Dataset mit Pandas lesen
Bevor wir unseren Pandas DataFrame erstellen, erstellen wir ein Dictionary mit dem Datentyp jeder Spalte, damit Pandas unser Dataset richtig liest:
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
Als Nächstes erstellen wir einen DataFrame und übergeben ihm die oben angegebenen Datentypen. Es ist wichtig, die Daten zu mischen, falls das ursprüngliche Dataset in einer bestimmten Reihenfolge sortiert ist. Dazu verwenden wir das sklearn-Tool shuffle, das wir in der ersten Zelle importiert haben:
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
Mit data.head() können wir uns in Pandas eine Vorschau der ersten fünf Zeilen unseres Datasets ansehen. Nach dem Ausführen der Zelle oben sollte etwa Folgendes angezeigt werden:

Das sind die Funktionen, die wir zum Trainieren unseres Modells verwenden. Wenn Sie ganz nach unten scrollen, sehen Sie die letzte Spalte approved. Das ist das, was wir vorhersagen. Der Wert 1 gibt an, dass eine bestimmte Anwendung genehmigt wurde, und 0, dass sie abgelehnt wurde.
Wenn Sie die Verteilung der genehmigten / abgelehnten Werte im Dataset sehen und ein NumPy-Array der Labels erstellen möchten, führen Sie Folgendes aus:
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
Etwa 66% des Datasets enthalten genehmigte Anträge.
Schritt 3: Dummy-Spalte für kategorische Werte erstellen
Dieser Datensatz enthält eine Mischung aus kategorischen und numerischen Werten. Für XGBoost müssen jedoch alle Features numerisch sein. Anstatt kategoriale Werte mit One-Hot-Codierung darzustellen, verwenden wir für unser XGBoost-Modell die Pandas-Funktion get_dummies.
Mit get_dummies wird eine Spalte mit mehreren möglichen Werten in eine Reihe von Spalten umgewandelt, die jeweils nur 0 und 1 enthalten. Wenn wir beispielsweise eine Spalte „color“ mit den möglichen Werten „blue“ und „red“ haben, würde get_dummies diese in zwei Spalten namens „color_blue“ und „color_red“ mit allen booleschen 0- und 1-Werten umwandeln.
Führen Sie den folgenden Code aus, um Dummy-Spalten für die kategorialen Features zu erstellen:
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
Wenn Sie sich die Daten dieses Mal in der Vorschau ansehen, werden einzelne Features (wie purchaser_type unten) in mehrere Spalten aufgeteilt:

Schritt 4: Daten in Trainings- und Test-Datasets aufteilen
Ein wichtiges Konzept beim maschinellen Lernen ist die Aufteilung in Trainings- und Testsätze. Wir verwenden den Großteil unserer Daten, um unser Modell zu trainieren, und behalten den Rest zurück, um unser Modell mit Daten zu testen, die es noch nie zuvor gesehen hat.
Fügen Sie Ihrem Notebook den folgenden Code hinzu, der die Scikit-Learn-Funktion train_test_split verwendet, um unsere Daten aufzuteilen:
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
Jetzt können Sie Ihr Modell erstellen und trainieren.
5. XGBoost-Modell erstellen, trainieren und bewerten
Schritt 1: XGBoost-Modell definieren und trainieren
Das Erstellen eines Modells in XGBoost ist einfach. Wir verwenden die Klasse XGBClassifier, um das Modell zu erstellen. Dazu müssen wir nur den richtigen objective-Parameter für unsere spezifische Klassifizierungsaufgabe übergeben. In diesem Fall verwenden wir reg:logistic, da es sich um ein binäres Klassifizierungsproblem handelt und das Modell einen einzelnen Wert im Bereich (0,1) ausgeben soll: 0 für „nicht genehmigt“ und 1 für „genehmigt“.
Mit dem folgenden Code wird ein XGBoost-Modell erstellt:
model = xgb.XGBClassifier(
objective='reg:logistic'
)
Sie können das Modell mit einer Zeile Code trainieren, indem Sie die Methode fit() aufrufen und ihr die Trainingsdaten und Labels übergeben.
model.fit(x_train, y_train)
Schritt 2: Genauigkeit des Modells bewerten
Jetzt können wir unser trainiertes Modell verwenden, um mit der Funktion predict() Vorhersagen für unsere Testdaten zu generieren.
Anschließend verwenden wir die accuracy_score-Funktion von Scikit-Learn, um die Genauigkeit unseres Modells basierend auf seiner Leistung bei unseren Testdaten zu berechnen. Wir übergeben die Ground Truth-Werte zusammen mit den vorhergesagten Werten des Modells für jedes Beispiel in unserem Testsatz:
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
Die Genauigkeit sollte bei etwa 87% liegen. Da maschinelles Lernen immer auch ein Zufallselement enthält, kann die Genauigkeit bei Ihnen leicht abweichen.
Schritt 3: Modell speichern
Führen Sie den folgenden Code aus, um das Modell bereitzustellen und in einer lokalen Datei zu speichern:
model.save_model('model.bst')
6. Modell in Cloud AI Platform bereitstellen
Wir haben unser Modell lokal zum Laufen gebracht, aber es wäre schön, wenn wir von überall aus Vorhersagen treffen könnten (nicht nur in diesem Notebook). In diesem Schritt stellen wir sie in der Cloud bereit.
Schritt 1: Cloud Storage-Bucket für das Modell erstellen
Definieren wir zuerst einige Umgebungsvariablen, die wir im restlichen Codelab verwenden werden. Geben Sie unten den Namen Ihres Google Cloud-Projekts, den Namen des Cloud Storage-Buckets, den Sie erstellen möchten (muss global eindeutig sein), und den Versionsnamen für die erste Version Ihres Modells ein:
# Update these to your own GCP project, model, and version names
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
VERSION_NAME = 'v1'
MODEL_NAME = 'xgb_mortgage'
Jetzt können wir einen Storage-Bucket zum Speichern unserer XGBoost-Modelldatei erstellen. Wir verweisen Cloud AI Platform bei der Bereitstellung auf diese Datei.
Führen Sie diesen gsutil-Befehl in Ihrem Notebook aus, um einen Bucket zu erstellen:
!gsutil mb $MODEL_BUCKET
Schritt 2: Modelldatei in Cloud Storage kopieren
Als Nächstes kopieren wir die gespeicherte XGBoost-Modelldatei in Cloud Storage. Führen Sie den folgenden gsutil-Befehl aus:
!gsutil cp ./model.bst $MODEL_BUCKET
Rufen Sie den Storage-Browser in der Cloud Console auf, um zu prüfen, ob die Datei kopiert wurde:

Schritt 3: Modell erstellen und bereitstellen
Das Modell ist fast bereit für die Bereitstellung. Mit dem folgenden ai-platform-Befehl von gcloud wird ein neues Modell in Ihrem Projekt erstellt. Wir nennen sie xgb_mortgage:
!gcloud ai-platform models create $MODEL_NAME --region='global'
Jetzt ist es an der Zeit, das Modell bereitzustellen. Dazu verwenden wir den folgenden gcloud-Befehl:
!gcloud ai-platform versions create $VERSION_NAME \
--model=$MODEL_NAME \
--framework='XGBOOST' \
--runtime-version=2.1 \
--origin=$MODEL_BUCKET \
--python-version=3.7 \
--project=$GCP_PROJECT \
--region='global'
Während die Pipeline ausgeführt wird, können Sie den Abschnitt „Modelle“ in der AI Platform Console aufrufen. Dort sollte die Bereitstellung Ihrer neuen Version angezeigt werden:

Wenn die Bereitstellung erfolgreich abgeschlossen ist, wird anstelle des rotierenden Ladesymbols ein grünes Häkchen angezeigt. Die Bereitstellung sollte 2 bis 3 Minuten dauern.
Schritt 4: Bereitgestelltes Modell testen
Um sicherzugehen, dass Ihr bereitgestelltes Modell funktioniert, testen Sie es mit gcloud, um eine Vorhersage zu treffen. Speichern Sie zuerst eine JSON-Datei mit dem ersten Beispiel aus unserem Testset:
%%writefile predictions.json
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
Testen Sie das Modell, indem Sie diesen Code ausführen:
prediction = !gcloud ai-platform predict --model=xgb_mortgage --region='global' --json-instances=predictions.json --version=$VERSION_NAME --verbosity=none
print(prediction)
In der Ausgabe sollte die Vorhersage Ihres Modells angezeigt werden. Dieses Beispiel wurde genehmigt. Sie sollten also einen Wert sehen, der nahe 1 liegt.
7. What-If-Tool zum Interpretieren des Modells verwenden
Schritt 1: What-If Tool-Visualisierung erstellen
Wenn Sie das What-If Tool mit Ihren AI Platform-Modellen verbinden möchten, müssen Sie ihm eine Teilmenge Ihrer Testbeispiele zusammen mit den Ground Truth-Werten für diese Beispiele übergeben. Erstellen wir ein NumPy-Array mit 500 unserer Testbeispiele und den zugehörigen Ground-Truth-Labels:
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples].values,y_test[:num_wit_examples].reshape(-1,1)))
Das What-If-Tool wird instanziiert, indem einfach ein WitConfigBuilder-Objekt erstellt und das zu analysierende AI Platform-Modell übergeben wird.
Wir verwenden hier den optionalen Parameter adjust_prediction, da das What-If-Tool eine Liste mit Ergebnissen für jede Klasse in unserem Modell (in diesem Fall 2) erwartet. Da unser Modell nur einen einzelnen Wert zwischen 0 und 1 zurückgibt, wandeln wir ihn in dieser Funktion in das richtige Format um:
def adjust_prediction(pred):
return [1 - pred, pred]
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_ai_platform_model(GCP_PROJECT, MODEL_NAME, VERSION_NAME, adjust_prediction=adjust_prediction)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
Das Laden der Visualisierung dauert eine Minute. Wenn die Seite geladen ist, sollten Sie Folgendes sehen:

Auf der y-Achse sehen wir die Vorhersage des Modells. 1 steht für eine approved-Vorhersage mit hoher Konfidenz und 0 für eine denied-Vorhersage mit hoher Konfidenz. Die x-Achse stellt nur die Verteilung aller geladenen Datenpunkte dar.
Schritt 2: Einzelne Datenpunkte ansehen
Die Standardansicht im What-If-Tool ist der Tab Datapoint editor (Editor für Datenpunkte). Hier können Sie auf einen beliebigen einzelnen Datenpunkt klicken, um seine Merkmale zu sehen, Merkmalswerte zu ändern und zu sehen, wie sich diese Änderung auf die Vorhersage des Modells für einen einzelnen Datenpunkt auswirkt.
Im folgenden Beispiel haben wir einen Datenpunkt ausgewählt, der nahe am Grenzwert von 0,5 liegt. Der mit diesem bestimmten Datenpunkt verknüpfte Hypothekenantrag stammt vom CFPB. Wir haben diesen Wert auf 0 geändert und auch den Wert von agency_code_Department of Housing and Urban Development (HUD) auf 1 geändert, um zu sehen, wie sich das auf die Vorhersage des Modells auswirken würde, wenn dieses Darlehen stattdessen von HUD stammen würde:

Wie im unteren linken Bereich des What-If-Tools zu sehen ist, hat sich die approved-Vorhersage des Modells durch die Änderung dieses Features um 32 % verringert. Das könnte darauf hindeuten, dass die Agentur, von der ein Darlehen stammt, einen starken Einfluss auf die Modellausgabe hat. Wir müssen jedoch weitere Analysen durchführen, um sicher zu sein.
Unten links in der Benutzeroberfläche sehen wir auch den Ground Truth-Wert für jeden Datenpunkt und können ihn mit der Vorhersage des Modells vergleichen:

Schritt 3: Kontrafaktische Analyse
Klicken Sie dann auf einen beliebigen Datenpunkt und ziehen Sie den Schieberegler Nächstgelegenen kontrafaktischen Datenpunkt anzeigen nach rechts:
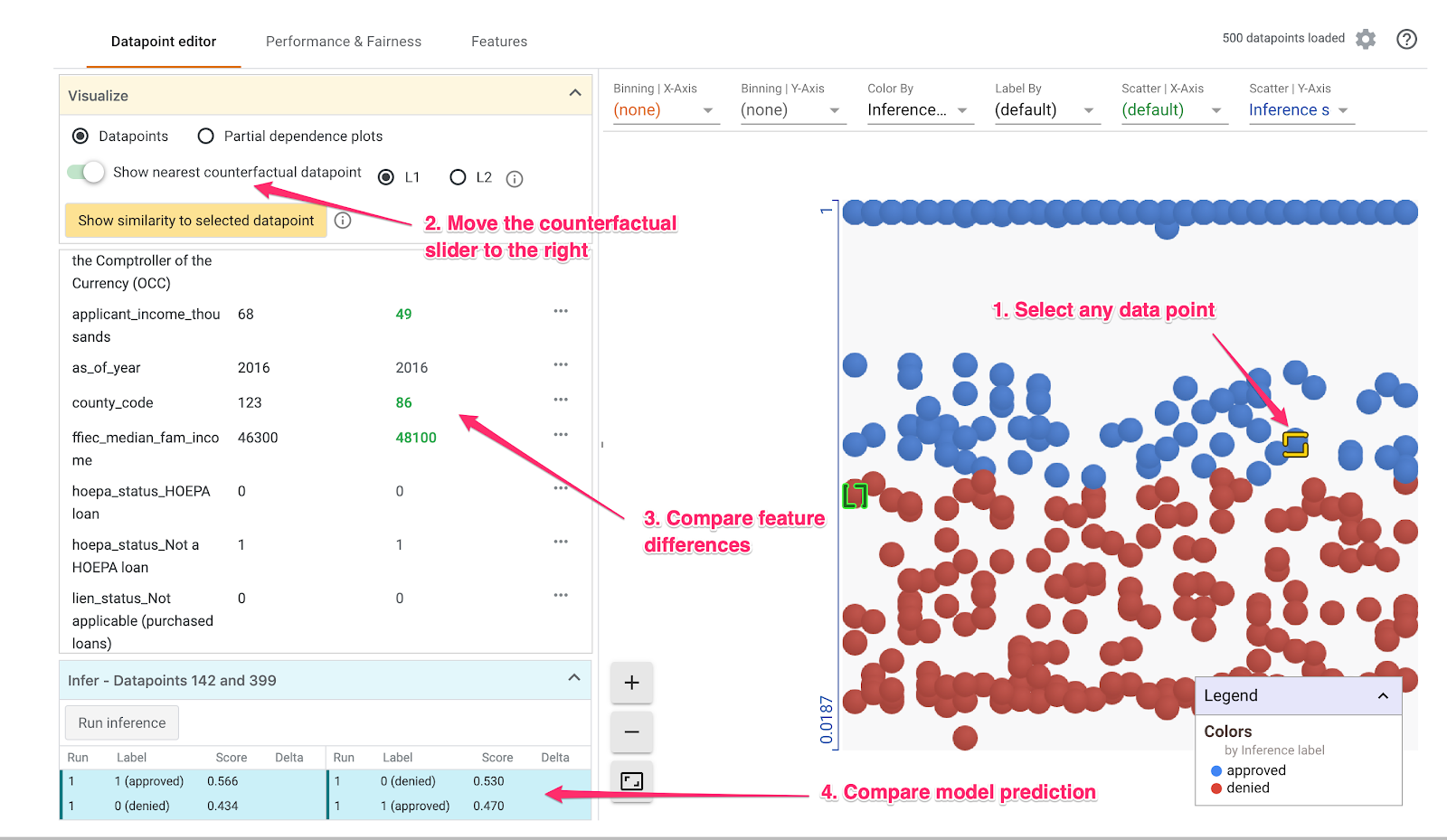
Wenn Sie diese Option auswählen, wird der Datenpunkt mit den ähnlichsten Feature-Werten zum ausgewählten Originaldatenpunkt, aber mit der gegenteiligen Vorhersage angezeigt. Anschließend können Sie durch die Feature-Werte scrollen, um zu sehen, wo sich die beiden Datenpunkte unterschieden haben. Die Unterschiede sind grün und fett hervorgehoben.
Schritt 4: Diagramme zur partiellen Abhängigkeit ansehen
Wenn Sie sehen möchten, wie sich die einzelnen Features insgesamt auf die Vorhersagen des Modells auswirken, setzen Sie ein Häkchen bei Diagramme zur partiellen Abhängigkeit und achten Sie darauf, dass Globale Diagramme zur partiellen Abhängigkeit ausgewählt ist:
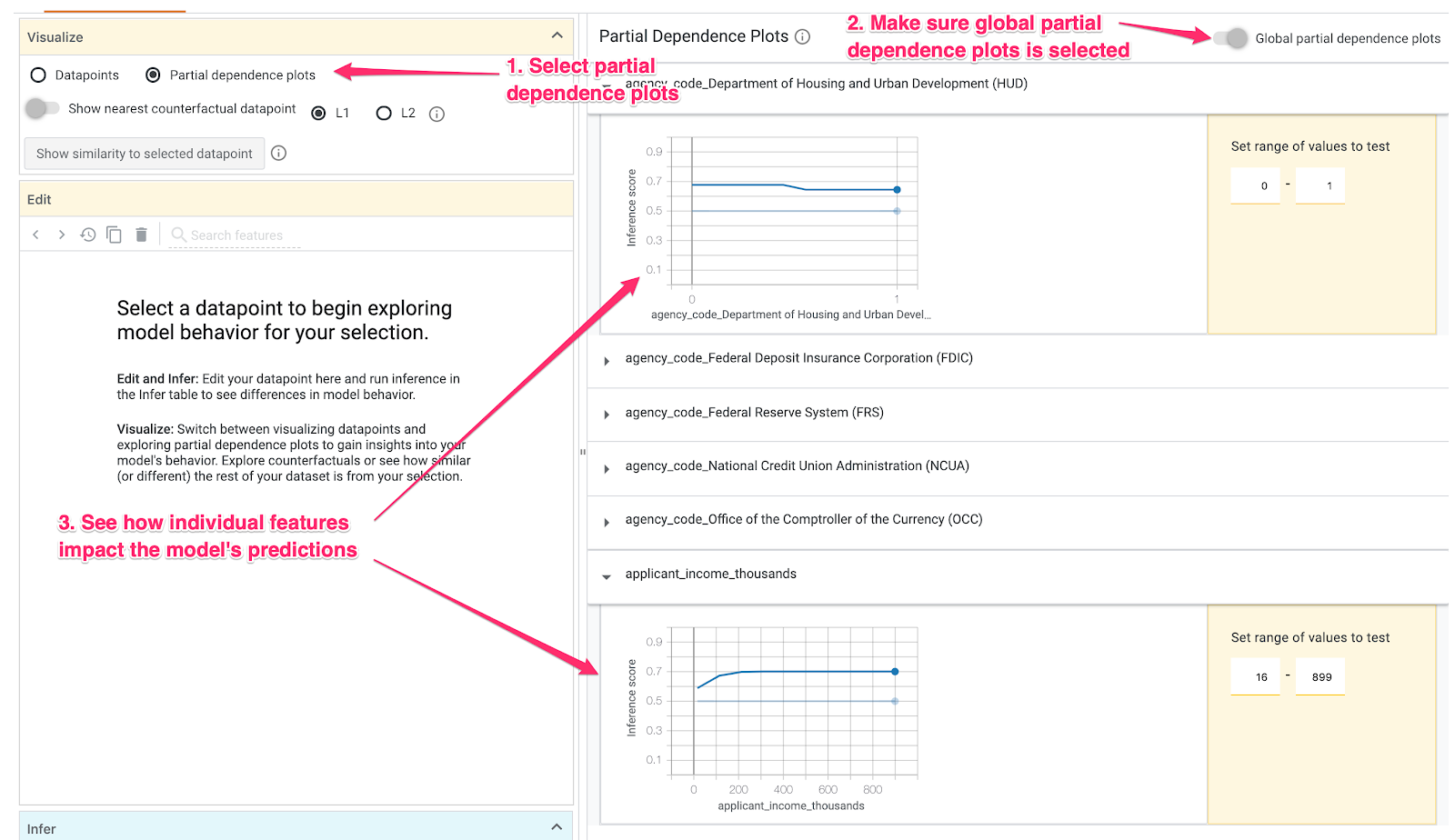
Hier sehen wir, dass Kredite, die von HUD stammen, eine etwas höhere Wahrscheinlichkeit haben, abgelehnt zu werden. Der Graph hat diese Form, weil der Agenturcode ein boolesches Attribut ist. Die Werte können also nur genau 0 oder 1 sein.
applicant_income_thousands ist ein numerisches Merkmal. Im Diagramm zur partiellen Abhängigkeit sehen wir, dass ein höheres Einkommen die Wahrscheinlichkeit einer Genehmigung des Antrags leicht erhöht, aber nur bis zu etwa 200.000 $. Nach 200.000 $hat dieses Feature keine Auswirkungen auf die Vorhersage des Modells.
Schritt 5: Gesamtleistung und Fairness untersuchen
Rufen Sie als Nächstes den Tab Leistung und Fairness auf. Hier sehen Sie die Gesamtleistungsstatistiken zu den Ergebnissen des Modells für das bereitgestellte Dataset, einschließlich Konfusionsmatrizen, PR-Kurven und ROC-Kurven.
Wählen Sie mortgage_status als Ground Truth-Merkmal aus, um eine Wahrheitsmatrix zu sehen:
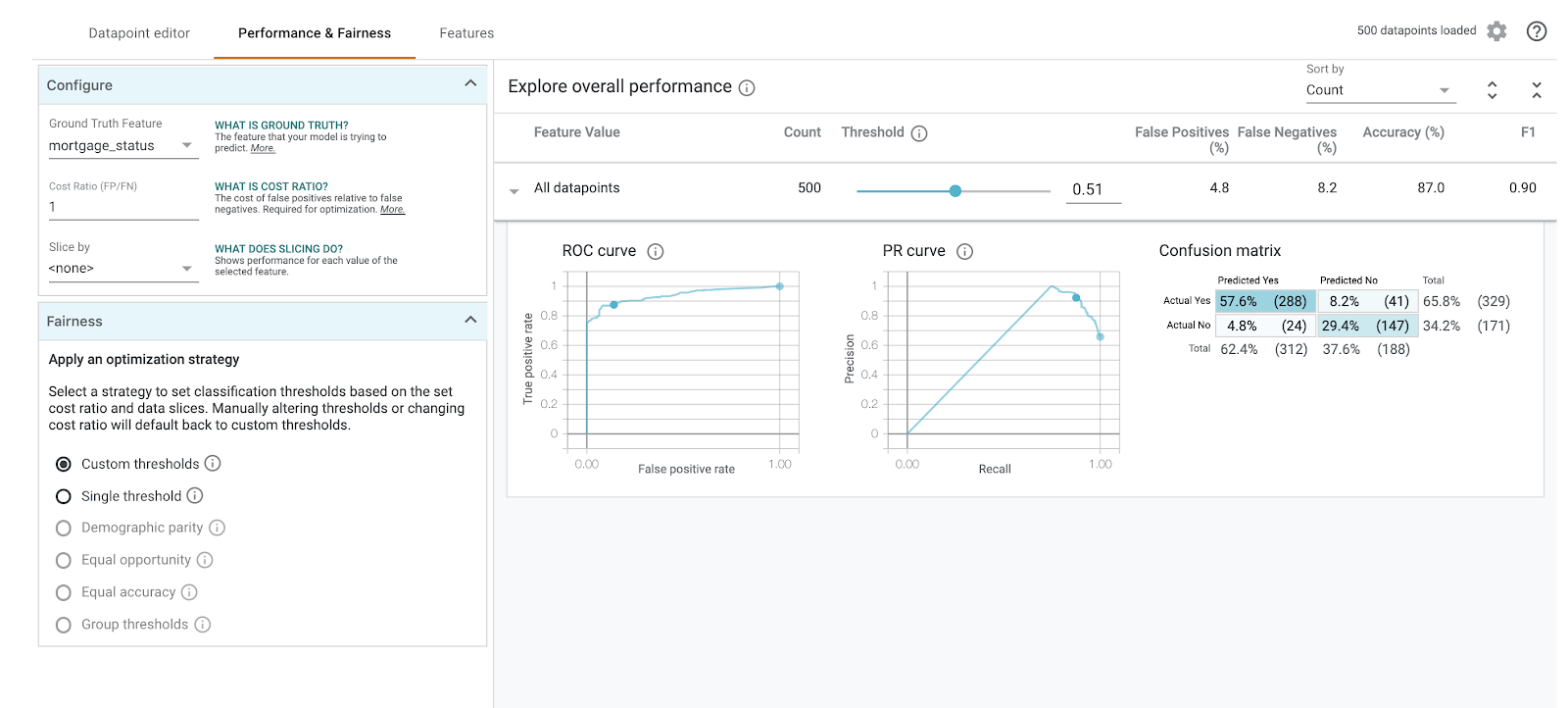
Diese Wahrheitsmatrix zeigt die korrekten und falschen Vorhersagen unseres Modells als Prozentsatz der Gesamtzahl. Wenn Sie die Felder Tatsächlich „Ja“ / Vorhersage „Ja“ und Tatsächlich „Nein“ / Vorhersage „Nein“ addieren, sollte sich dieselbe Genauigkeit wie für Ihr Modell ergeben (ca. 87%).
Sie können auch mit dem Schwellenwert-Schieberegler experimentieren, indem Sie die positive Klassifikationspunktzahl erhöhen und senken, die das Modell zurückgeben muss, bevor es approved für das Darlehen vorhersagt. So können Sie sehen, wie sich das auf die Genauigkeit, falsch positive und falsch negative Ergebnisse auswirkt. In diesem Fall ist die Genauigkeit bei einem Schwellenwert von 0, 55 am höchsten.
Wählen Sie dann links im Drop-down-Menü Aufschlüsseln nach die Option loan_purpose_Home_purchase aus:
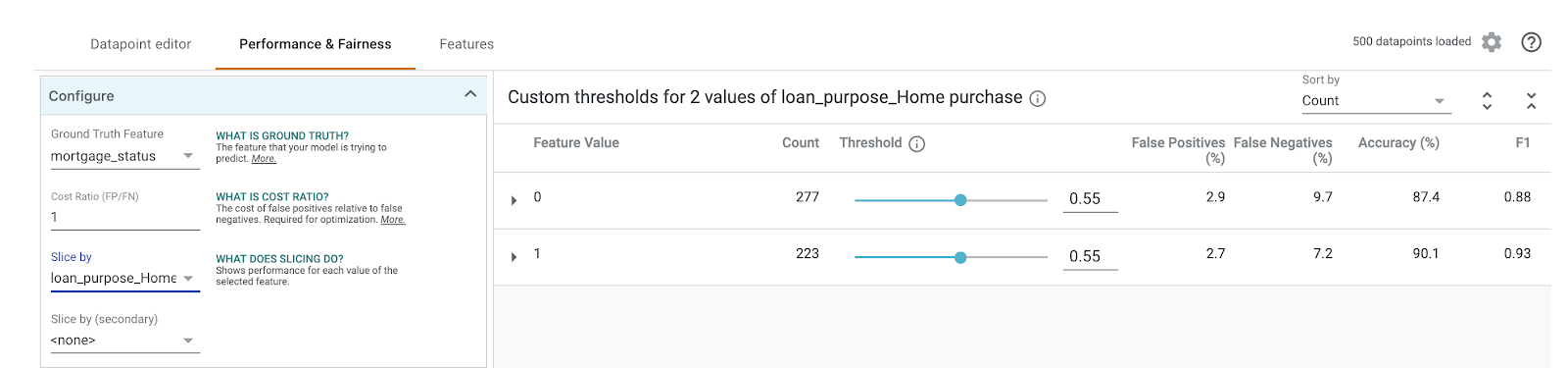
Sie sehen jetzt die Leistung der beiden Teilmengen Ihrer Daten: Der Bereich „0“ wird angezeigt, wenn das Darlehen nicht für den Kauf eines Hauses bestimmt ist, und der Bereich „1“, wenn das Darlehen für den Kauf eines Hauses bestimmt ist. Sehen Sie sich die Genauigkeit, die Rate der fälschlicherweise positiven und die Rate der fälschlicherweise negativen Ergebnisse zwischen den beiden Segmenten an, um Leistungsunterschiede zu erkennen.
Wenn Sie die Zeilen maximieren, um die Konfusionsmatrizen zu sehen, können Sie erkennen, dass das Modell für etwa 70% der Darlehensanträge für den Kauf von Häusern „genehmigt“ vorhersagt und nur für 46% der Darlehen, die nicht für den Kauf von Häusern bestimmt sind (die genauen Prozentsätze variieren je nach Modell):
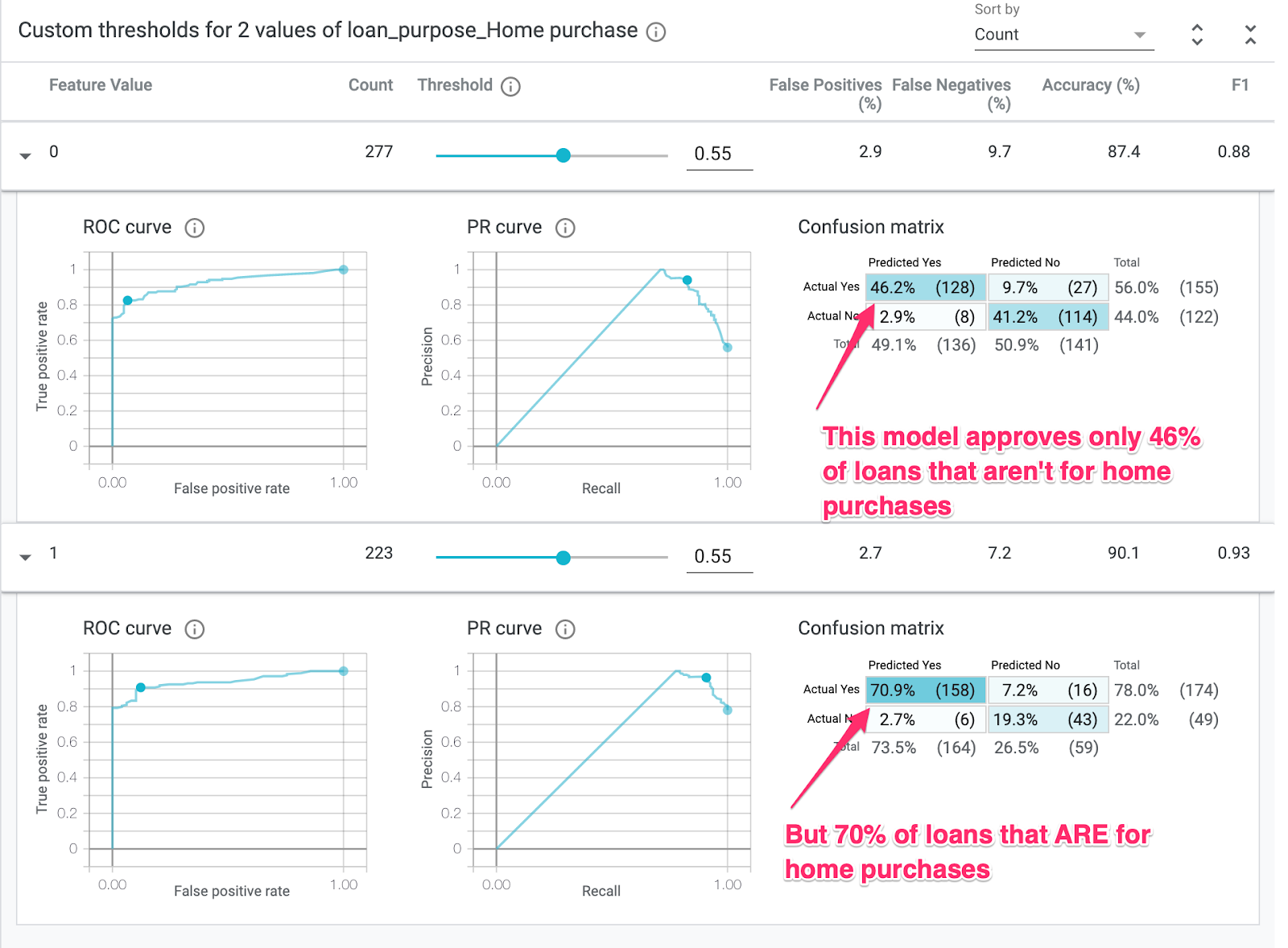
Wenn Sie links in den Optionsfeldern Demografische Parität auswählen, werden die beiden Grenzwerte so angepasst, dass das Modell für einen ähnlichen Prozentsatz von Bewerbern in beiden Segmenten approved vorhersagt. Wie wirkt sich das auf die Genauigkeit, falsch positiven und falsch negativen Ergebnisse für die einzelnen Slices aus?
Schritt 6: Verteilung der Funktionen ansehen
Rufen Sie dann im What-If-Tool den Tab Features auf. Hier sehen Sie die Verteilung der Werte für jedes Feature in Ihrem Dataset:
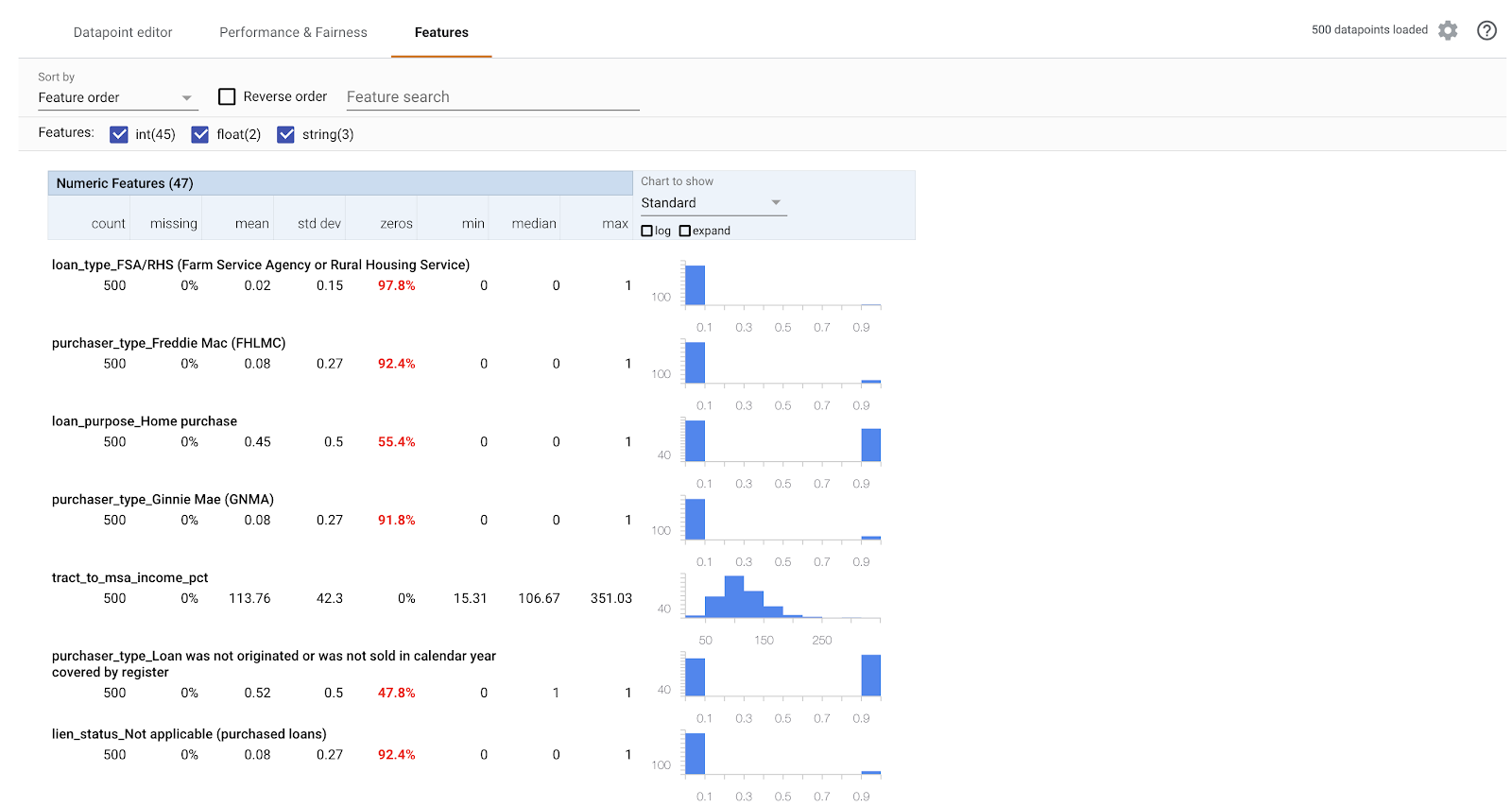
Auf diesem Tab können Sie prüfen, ob Ihr Dataset ausgewogen ist. Beispiel: Nur sehr wenige Darlehen im Dataset stammen von der Farm Service Agency. Um die Genauigkeit des Modells zu verbessern, könnten wir in Betracht ziehen, weitere Darlehen von dieser Agentur hinzuzufügen, sofern die Daten verfügbar sind.
Hier haben wir nur einige Ideen für die explorative Datenanalyse mit dem What-if Tool beschrieben. Sie können das Tool gerne weiter ausprobieren. Es gibt noch viele weitere Bereiche zu entdecken.
8. Bereinigen
Wenn Sie dieses Notebook weiterhin verwenden möchten, empfehlen wir, es auszuschalten, wenn Sie es nicht verwenden. Wählen Sie in der Notebooks-Benutzeroberfläche in der Cloud Console das Notebook und dann Beenden aus:

Wenn Sie alle Ressourcen löschen möchten, die Sie in diesem Lab erstellt haben, löschen Sie einfach die Notebook-Instanz, anstatt sie zu beenden.
Rufen Sie in der Cloud Console über das Navigationsmenü „Storage“ auf und löschen Sie die beiden Buckets, die Sie zum Speichern Ihrer Modell-Assets erstellt haben.