
1. Descripción general
En este lab, usarás la Herramienta What-If para analizar un modelo de XGBoost entrenado con datos financieros y que se implementó en AI Platform de Cloud.
Qué aprenderá
Aprenderás a hacer lo siguiente:
- Entrenar un modelo de XGBoost con un conjunto de datos públicos sobre hipotecas en AI Platform Notebooks
- Implementar el modelo de XGBoost en AI Platform
- Analizar el modelo con la Herramienta What-If
El costo total de la ejecución de este lab en Google Cloud es de aproximadamente $1.
2. Una breve introducción a XGBoost
XGBoost es un framework de aprendizaje automático que usa árboles de decisión y boosting de gradiente para compilar modelos predictivos. Funciona mediante el ensamble de varios árboles de decisión en función de la puntuación asociada con diferentes nodos hoja en un árbol.
El siguiente diagrama es una visualización de un modelo simple de árbol de decisión que evalúa si se debe jugar un partido deportivo en función del pronóstico del tiempo:

¿Por qué usamos XGBoost para este modelo? Si bien se demostró que las redes neuronales tradicionales funcionan mejor con datos no estructurados, como imágenes y texto, los árboles de decisión suelen funcionar extremadamente bien con datos estructurados, como el conjunto de datos de hipotecas que usaremos en este codelab.
3. Cómo configurar tu entorno
Para ejecutar este codelab, necesitarás un proyecto de Google Cloud Platform que tenga habilitada la facturación. Para crear un proyecto, sigue las instrucciones que se indican aquí.
Paso 1: Habilita la API de AI Platform Models
Navega a la sección AI Platform Models de la consola de Cloud y haz clic en Habilitar si aún no está habilitada.

Paso 2: Habilita la API de Compute Engine
Navega a Compute Engine y selecciona Habilitar si aún no está habilitada. La necesitarás para crear la instancia de notebook.
Paso 3: Crea una instancia de AI Platform Notebooks
Navega a la sección AI Platform Notebooks de la consola de Cloud y haz clic en Instancia nueva. Luego, selecciona el tipo de instancia TF Enterprise 2.x más reciente sin GPUs:

Usa las opciones predeterminadas y, luego, haz clic en Crear. Una vez que se crea la instancia, selecciona Abrir JupyterLab:

Paso 4: Instala XGBoost
Una vez que se abra la instancia de JupyterLab, deberás agregar el paquete XGBoost.
Para ello, selecciona Terminal en el selector:

Luego, ejecuta lo siguiente para instalar la versión más reciente de XGBoost compatible con AI Platform de Cloud:
pip3 install xgboost==0.90
Una vez que se complete, abre una instancia de notebook de Python 3 desde el selector. Ya puedes comenzar a usar tu notebook.
Paso 5: Importa paquetes de Python
En la primera celda de tu notebook, agrega las siguientes importaciones y ejecuta la celda. Para ejecutarla, presiona el botón de flecha derecha en el menú superior o presiona Comando + Intro:
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
4. Descarga y procesa datos
Usaremos un conjunto de datos de hipotecas de ffiec.gov para entrenar un modelo de XGBoost. Realizamos un procesamiento previo en el conjunto de datos original y creamos una versión más pequeña para que la uses para entrenar el modelo. El modelo predecirá si se aprobará o no una solicitud de hipoteca en particular.
Paso 1: Descarga el conjunto de datos procesado previamente
Tenemos una versión del conjunto de datos disponible para ti en Google Cloud Storage. Para descargarla, ejecuta el siguiente comando gsutil en tu notebook de Jupyter:
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
Paso 2: Lee el conjunto de datos con Pandas
Antes de crear nuestro DataFrame de Pandas, crearemos un diccionario del tipo de datos de cada columna para que Pandas lea nuestro conjunto de datos correctamente:
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
A continuación, crearemos un DataFrame y le pasaremos los tipos de datos que especificamos anteriormente. Es importante reorganizar nuestros datos en caso de que el conjunto de datos original esté ordenado de una manera específica. Usamos una utilidad sklearn llamada shuffle para hacer esto, que importamos en la primera celda:
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
data.head() nos permite obtener una vista previa de las primeras cinco filas de nuestro conjunto de datos en Pandas. Deberías ver algo como esto después de ejecutar la celda anterior:

Estos son los atributos que usaremos para entrenar nuestro modelo. Si te desplazas hasta el final, verás la última columna approved, que es lo que predecimos. Un valor de 1 indica que se aprobó una solicitud en particular, y 0 indica que se rechazó.
Para ver la distribución de los valores aprobados o rechazados en el conjunto de datos y crear un array de NumPy de las etiquetas, ejecuta lo siguiente:
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
Alrededor del 66% del conjunto de datos contiene solicitudes aprobadas.
Paso 3: Crea una columna ficticia para valores categóricos
Este conjunto de datos contiene una combinación de valores categóricos y numéricos, pero XGBoost requiere que todos los atributos sean numéricos. En lugar de representar valores categóricos con codificación one-hot, para nuestro modelo de XGBoost, aprovecharemos la función get_dummies de Pandas.
get_dummies toma una columna con varios valores posibles y la convierte en una serie de columnas, cada una con solo 0 y 1. Por ejemplo, si tuviéramos una columna "color" con valores posibles de "azul" y "rojo", get_dummies la transformaría en 2 columnas llamadas "color_blue" y "color_red" con todos los valores booleanos 0 y 1.
Para crear columnas ficticias para nuestros atributos categóricos, ejecuta el siguiente código:
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
Cuando obtengas una vista previa de los datos esta vez, verás atributos únicos (como purchaser_type que se muestra a continuación) divididos en varias columnas:

Paso 4: Divide los datos en conjuntos de entrenamiento y de prueba
Un concepto importante en el aprendizaje automático es la división de entrenamiento y prueba. Tomaremos la mayoría de nuestros datos y los usaremos para entrenar nuestro modelo, y reservaremos el resto para probar nuestro modelo con datos que nunca antes haya visto.
Agrega el siguiente código a tu notebook, que usa la función train_test_split de Scikit Learn para dividir nuestros datos:
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
Ahora ya puedes compilar y entrenar tu modelo.
5. Compila, entrena y evalúa un modelo de XGBoost
Paso 1: Define y entrena el modelo de XGBoost
Crear un modelo en XGBoost es simple. Usaremos la clase XGBClassifier para crear el modelo y solo necesitamos pasar el parámetro objective correcto para nuestra tarea de clasificación específica. En este caso, usamos reg:logistic, ya que tenemos un problema de clasificación binaria y queremos que el modelo genere un solo valor en el rango de (0,1): 0 para no aprobado y 1 para aprobado.
El siguiente código creará un modelo de XGBoost:
model = xgb.XGBClassifier(
objective='reg:logistic'
)
Puedes entrenar el modelo con una línea de código, llamar al método fit() y pasarle los datos y las etiquetas de entrenamiento.
model.fit(x_train, y_train)
Paso 2: Evalúa la exactitud de tu modelo
Ahora podemos usar nuestro modelo entrenado para generar predicciones sobre nuestros datos de prueba con la función predict().
Luego, usaremos la función accuracy_score de Scikit Learn para calcular la exactitud de nuestro modelo en función de su rendimiento en nuestros datos de prueba. Le pasaremos los valores de verdad fundamental junto con los valores predichos del modelo para cada ejemplo en nuestro conjunto de pruebas:
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
Deberías ver una exactitud de alrededor del 87%, pero la tuya variará ligeramente, ya que siempre hay un elemento de aleatoriedad en el aprendizaje automático.
Paso 3: Guarda tu modelo
Para implementar el modelo, ejecuta el siguiente código para guardarlo en un archivo local:
model.save_model('model.bst')
6. Implementa el modelo en AI Platform de Cloud
Tenemos nuestro modelo funcionando de forma local, pero sería bueno si pudiéramos hacer predicciones en él desde cualquier lugar (no solo en este notebook). En este paso, lo implementaremos en la nube.
Paso 1: Crea un bucket de Cloud Storage para nuestro modelo
Primero, definamos algunas variables de entorno que usaremos durante el resto del codelab. Completa los valores que se indican a continuación con el nombre de tu proyecto de Google Cloud, el nombre del bucket de Cloud Storage que deseas crear (debe ser único a nivel global) y el nombre de la versión de la primera versión de tu modelo:
# Update these to your own GCP project, model, and version names
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
VERSION_NAME = 'v1'
MODEL_NAME = 'xgb_mortgage'
Ahora ya podemos crear un bucket de almacenamiento para almacenar nuestro archivo del modelo de XGBoost. Cuando implementemos, dirigiremos AI Platform de Cloud a este archivo.
Ejecuta este comando gsutil desde tu notebook para crear un bucket:
!gsutil mb $MODEL_BUCKET
Paso 2: Copia el archivo del modelo en Cloud Storage
A continuación, copiaremos nuestro archivo del modelo guardado de XGBoost en Cloud Storage. Ejecuta el siguiente comando gsutil:
!gsutil cp ./model.bst $MODEL_BUCKET
Dirígete al navegador de almacenamiento en la consola de Cloud para confirmar que se copió el archivo:

Paso 3: Crea e implementa el modelo
Ya casi estamos listos para implementar el modelo. El siguiente comando ai-platform de gcloud creará un modelo nuevo en tu proyecto. Lo llamaremos xgb_mortgage:
!gcloud ai-platform models create $MODEL_NAME --region='global'
Ahora es el momento de implementar el modelo. Podemos hacerlo con este comando de gcloud:
!gcloud ai-platform versions create $VERSION_NAME \
--model=$MODEL_NAME \
--framework='XGBOOST' \
--runtime-version=2.1 \
--origin=$MODEL_BUCKET \
--python-version=3.7 \
--project=$GCP_PROJECT \
--region='global'
Mientras se ejecuta, consulta la sección de modelos de tu consola de AI Platform. Deberías ver que se implementa tu versión nueva allí:

Cuando la implementación se complete correctamente, verás una marca de verificación verde donde está el ícono giratorio de carga. La implementación debería tardar entre 2 y 3 minutos.
Paso 4: Prueba el modelo implementado
Para asegurarte de que tu modelo implementado funcione, pruébalo con gcloud para hacer una predicción. Primero, guarda un archivo JSON con el primer ejemplo de nuestro conjunto de pruebas:
%%writefile predictions.json
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
Para probar tu modelo, ejecuta este código:
prediction = !gcloud ai-platform predict --model=xgb_mortgage --region='global' --json-instances=predictions.json --version=$VERSION_NAME --verbosity=none
print(prediction)
Deberías ver la predicción de tu modelo en el resultado. Este ejemplo en particular se aprobó, por lo que deberías ver un valor cercano a 1.
7. Usa la Herramienta What-If para interpretar tu modelo
Paso 1: Crea la visualización de la Herramienta What-If
Para conectar la Herramienta What-If a tus modelos de AI Platform, debes pasarle un subconjunto de tus ejemplos de prueba junto con los valores de verdad fundamental para esos ejemplos. Creemos un array de NumPy de 500 de nuestros ejemplos de prueba junto con sus etiquetas de verdad fundamental:
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples].values,y_test[:num_wit_examples].reshape(-1,1)))
Crear una instancia de la Herramienta What-If es tan simple como crear un objeto WitConfigBuilder y pasarle el modelo de AI Platform que nos gustaría analizar.
Usamos el parámetro opcional adjust_prediction aquí porque la Herramienta What-If espera una lista de puntuaciones para cada clase en nuestro modelo (en este caso, 2). Dado que nuestro modelo solo muestra un valor único de 0 a 1, lo transformamos al formato correcto en esta función:
def adjust_prediction(pred):
return [1 - pred, pred]
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_ai_platform_model(GCP_PROJECT, MODEL_NAME, VERSION_NAME, adjust_prediction=adjust_prediction)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
Ten en cuenta que tardará un minuto en cargar la visualización. Cuando se cargue, deberías ver lo siguiente:

El eje y nos muestra la predicción del modelo, con 1 como una predicción approved de alta confianza y 0 como una predicción denied de alta confianza. El eje x es solo la dispersión de todos los datos cargados.
Paso 2: Explora los datos individuales
La vista predeterminada en la Herramienta What-If es la pestaña Editor de datos. Aquí puedes hacer clic en cualquier dato individual para ver sus atributos, cambiar los valores de los atributos y ver cómo ese cambio afecta la predicción del modelo en un dato individual.
En el siguiente ejemplo, elegimos un dato cercano al umbral de 0 .5. La solicitud de hipoteca asociada con este dato en particular se originó en la CFPB. Cambiamos ese atributo a 0 y también cambiamos el valor de agency_code_Department of Housing and Urban Development (HUD) a 1 para ver qué sucedería con la predicción del modelo si este préstamo se originara en el HUD:
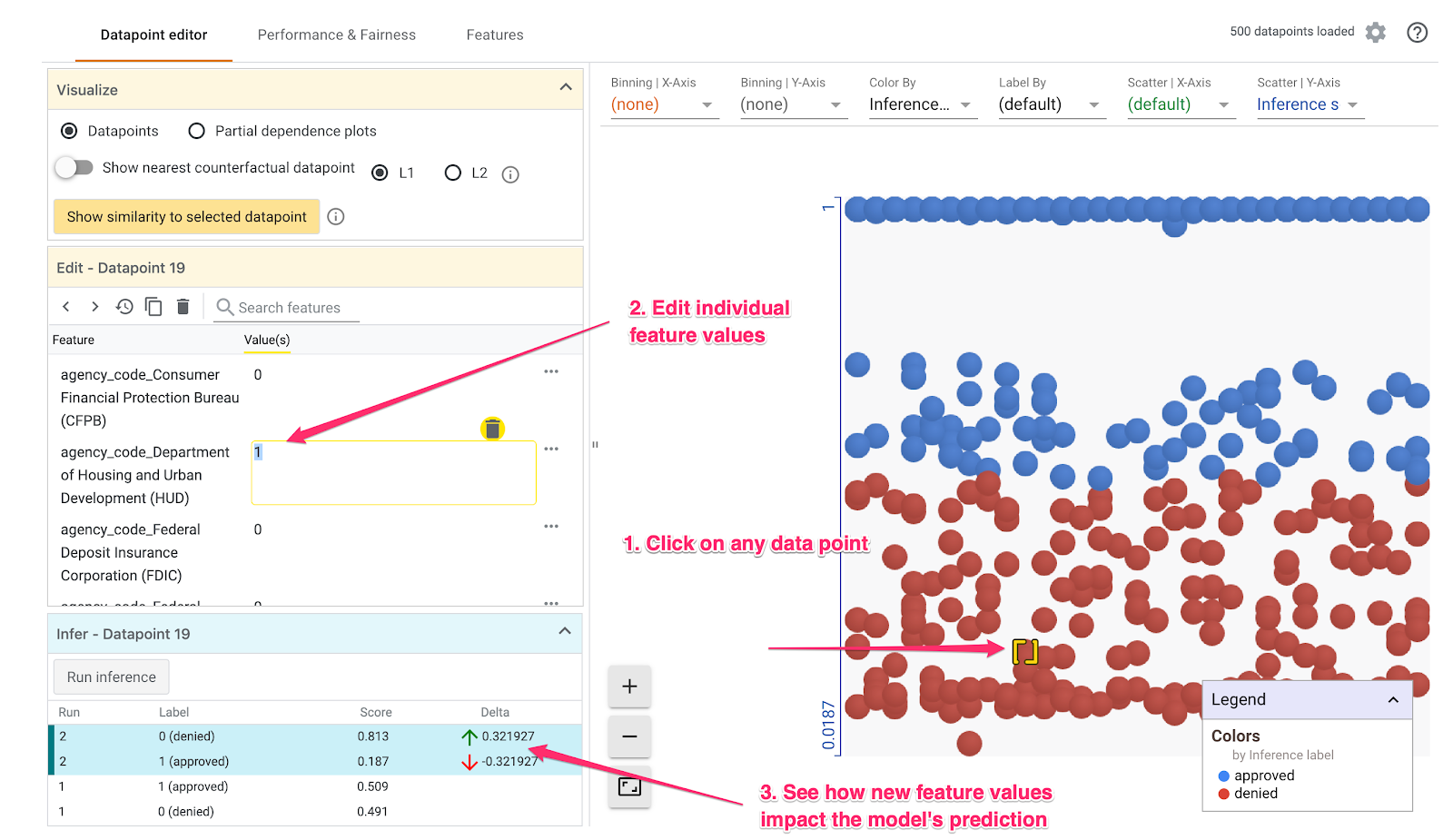
Como podemos ver en la sección inferior izquierda de la Herramienta What-If, cambiar este atributo disminuyó significativamente la predicción approved del modelo en un 32%. Esto podría indicar que la agencia de la que se originó un préstamo tiene un gran impacto en el resultado del modelo, pero deberemos realizar más análisis para asegurarnos.
En la parte inferior izquierda de la IU, también podemos ver el valor de verdad fundamental para cada dato y compararlo con la predicción del modelo:

Paso 3: Análisis contrafactual
A continuación, haz clic en cualquier dato y mueve el control deslizante Mostrar el dato contrafactual más cercano hacia la derecha:
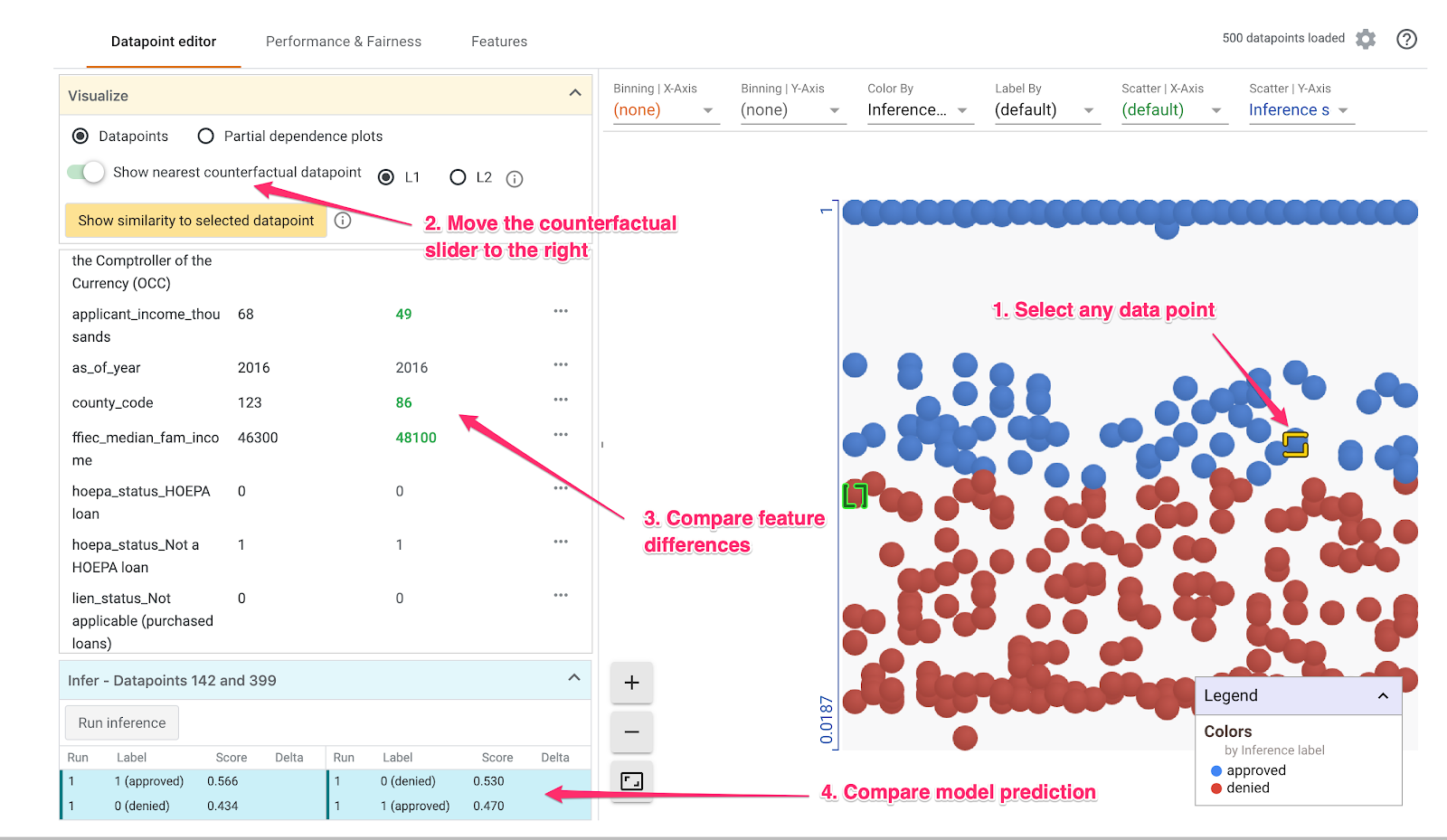
Si seleccionas esta opción, se mostrará el dato que tiene los valores de atributos más similares al original que seleccionaste, pero la predicción opuesta. Luego, puedes desplazarte por los valores de los atributos para ver dónde difieren los dos datos (las diferencias se resaltan en verde y en negrita).
Paso 4: Observa los gráficos de dependencia parcial
Para ver cómo afecta cada atributo a las predicciones del modelo en general, marca la casilla Gráficos de dependencia parcial y asegúrate de que esté seleccionado Gráficos de dependencia parcial globales:

Aquí podemos ver que los préstamos que se originan en el HUD tienen una probabilidad ligeramente mayor de ser rechazados. El gráfico tiene esta forma porque el código de agencia es un atributo booleano, por lo que los valores solo pueden ser exactamente 0 o 1.
applicant_income_thousands es un atributo numérico y, en el gráfico de dependencia parcial, podemos ver que un ingreso más alto aumenta ligeramente la probabilidad de que se apruebe una solicitud, pero solo hasta alrededor de USD 200,000. Después de USD 200,000, este atributo no afecta la predicción del modelo.
Paso 5: Explora el rendimiento general y la equidad
A continuación, ve a la pestaña Rendimiento y equidad. En esta pestaña, se muestran estadísticas de rendimiento generales sobre los resultados del modelo en el conjunto de datos proporcionado, incluidas las matrices de confusión, las curvas PR y las curvas ROC.
Selecciona mortgage_status como el atributo de verdad fundamental para ver una matriz de confusión:

Esta matriz de confusión muestra las predicciones correctas e incorrectas de nuestro modelo como un porcentaje del total. Si sumas los cuadrados Sí real / Sí predicho y No real / No predicho, deberías obtener la misma exactitud que tu modelo (alrededor del 87%).
También puedes experimentar con el control deslizante de umbral, aumentar y disminuir la puntuación de clasificación positiva que el modelo necesita mostrar antes de decidir predecir approved para el préstamo, y ver cómo cambia la exactitud, los falsos positivos y los falsos negativos. En este caso, la exactitud es más alta alrededor de un umbral de 0.55.
A continuación, en el menú desplegable Segmentar por de la izquierda, selecciona loan_purpose_Home_purchase:
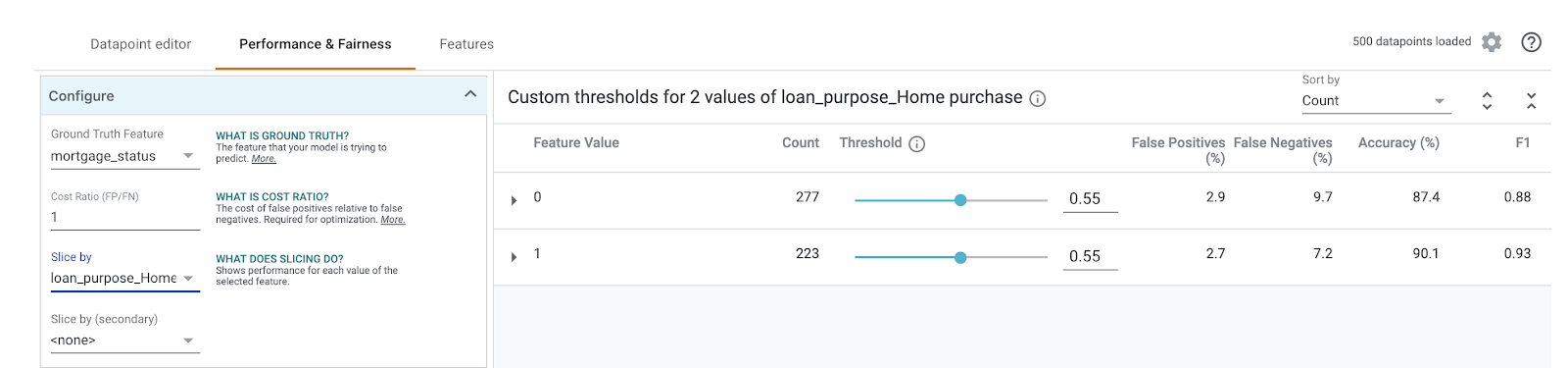
Ahora verás el rendimiento en los dos subconjuntos de tus datos: el segmento "0" muestra cuándo el préstamo no es para la compra de una casa, y el segmento "1" es para cuando el préstamo es para la compra de una casa. Consulta la exactitud, la tasa de falsos positivos y la tasa de falsos negativos entre los dos segmentos para buscar diferencias en el rendimiento.
Si expandes las filas para observar las matrices de confusión, puedes ver que el modelo predice "aprobado" para aproximadamente el 70% de las solicitudes de préstamo para la compra de viviendas y solo el 46% de los préstamos que no son para la compra de viviendas (los porcentajes exactos variarán en tu modelo):
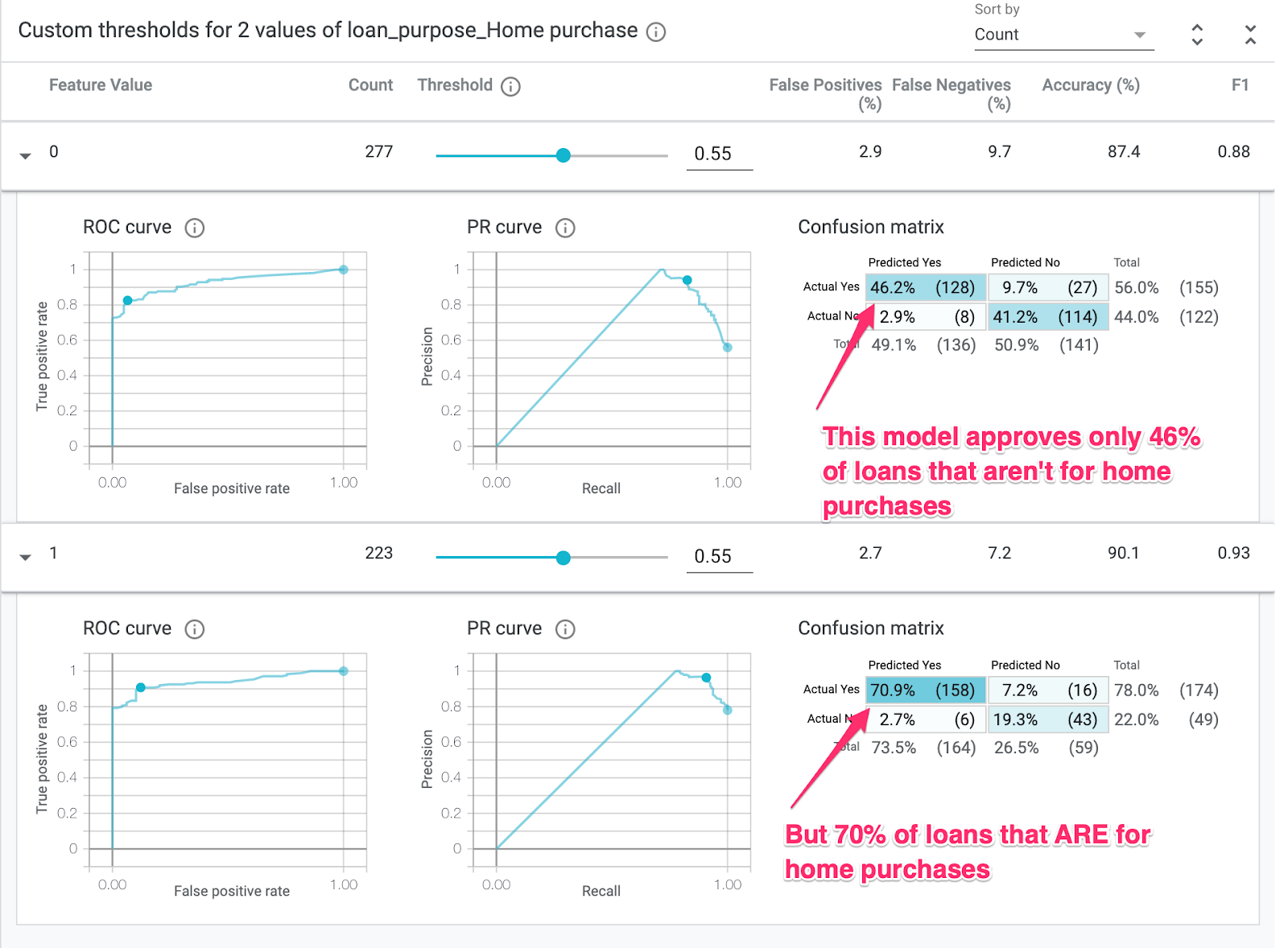
Si seleccionas Paridad demográfica en los botones de selección de la izquierda, los dos umbrales se ajustarán de modo que el modelo prediga approved para un porcentaje similar de solicitantes en ambos segmentos. ¿Qué sucede con la exactitud, los falsos positivos y los falsos negativos para cada segmento?
Paso 6: Explora la distribución de atributos
Por último, navega a la pestaña Atributos en la Herramienta What-If. En esta pestaña, se muestra la distribución de valores para cada atributo en tu conjunto de datos:

Puedes usar esta pestaña para asegurarte de que tu conjunto de datos esté equilibrado. Por ejemplo, parece que muy pocos préstamos en el conjunto de datos se originaron en la Farm Service Agency. Para mejorar la exactitud del modelo, podríamos considerar agregar más préstamos de esa agencia si los datos están disponibles.
Aquí describimos solo algunas ideas de exploración de la Herramienta What-If. No dudes en seguir jugando con la herramienta, ya que hay muchas más áreas para explorar.
8. Limpieza
Si deseas seguir usando este notebook, te recomendamos que lo desactives cuando no lo uses. En la IU de Notebooks de la consola de Cloud, selecciona el notebook y, luego, haz clic en Detener:

Si deseas borrar todos los recursos que creaste en este lab, simplemente borra la instancia de notebook en lugar de detenerla.
En el menú de navegación de la consola de Cloud, navega a Almacenamiento y borra los dos buckets que creaste para almacenar los recursos del modelo.