
1. Présentation
Dans cet atelier, vous allez utiliser l' outil de simulation What-If pour analyser un modèle XGBoost entraîné sur des données financières et déployé sur Cloud AI Platform.
Objectifs de l'atelier
Vous allez apprendre à effectuer les opérations suivantes :
- Entraîner un modèle XGBoost sur un ensemble de données hypothécaires public dans AI Platform Notebooks
- Déployer le modèle XGBoost sur AI Platform
- Analyser le modèle à l'aide de l'outil de simulation What-If
Le coût total d'exécution de cet atelier sur Google Cloud est d'environ 1$.
2. Présentation rapide de XGBoost
XGBoost est un framework de machine learning qui utilise des arbres de décision et le boosting de gradient pour créer des modèles prédictifs. Il fonctionne en combinant plusieurs arbres de décision en fonction du score associé aux différents nœuds feuilles d'un arbre.
Le schéma ci-dessous est une visualisation d'un modèle d'arbre de décision simple qui évalue si un match sportif doit être joué en fonction des prévisions météorologiques :

Pourquoi utilisons-nous XGBoost pour ce modèle ? Alors que les réseaux de neurones traditionnels se sont avérés plus performants sur les données non structurées telles que les images et le texte, les arbres de décision sont souvent extrêmement performants sur les données structurées comme l'ensemble de données hypothécaires que nous utiliserons dans cet atelier de programmation.
3. Configurer votre environnement
Pour suivre cet atelier de programmation, vous aurez besoin d'un projet Google Cloud Platform dans lequel la facturation est activée. Pour créer un projet, suivez les instructions ici.
Étape 1 : Activer l'API Cloud AI Platform Models
Accédez à la section AI Platform Models de la console Cloud, puis cliquez sur "Activer" si elle n'est pas déjà activée.

Étape 2 : Activer l'API Compute Engine
Accédez à Compute Engine et sélectionnez Activer si elle n'est pas déjà activée. Vous en aurez besoin pour créer votre instance de notebook.
Étape 3 : Créer une instance AI Platform Notebooks
Accédez à la section AI Platform Notebooks de la console Cloud, puis cliquez sur Nouvelle instance. Sélectionnez ensuite le dernier type d'instance TF Enterprise 2.x sans GPU :

Utilisez les options par défaut, puis cliquez sur Créer. Une fois l'instance créée, sélectionnez Ouvrir JupyterLab:

Étape 4 : Installer XGBoost
Une fois votre instance JupyterLab ouverte, vous devez ajouter le package XGBoost.
Pour ce faire, sélectionnez "Terminal" dans le lanceur :
Exécutez ensuite la commande suivante pour installer la dernière version de XGBoost compatible avec Cloud AI Platform :
pip3 install xgboost==0.90
Une fois cette opération terminée, ouvrez une instance de notebook Python 3 à partir du lanceur. Vous êtes prêt à commencer à utiliser votre notebook.
Étape 5 : Importer des packages Python
Dans la première cellule de votre notebook, ajoutez les importations suivantes et exécutez la cellule. Pour l'exécuter, appuyez sur le bouton flèche droite dans le menu supérieur ou sur la commande Entrée :
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
4. Télécharger et traiter des données
Nous allons utiliser un ensemble de données hypothécaires provenant de ffiec.gov pour entraîner un modèle XGBoost. Nous avons effectué un prétraitement sur l'ensemble de données d'origine et créé une version plus petite que vous pouvez utiliser pour entraîner le modèle. Le modèle prédira si une demande de prêt hypothécaire spécifique sera approuvée ou non.
Étape 1 : Télécharger l'ensemble de données prétraité
Nous avons mis à votre disposition une version de l'ensemble de données dans Google Cloud Storage. Vous pouvez la télécharger en exécutant la commande gsutil suivante dans votre notebook Jupyter :
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
Étape 2 : Lire l'ensemble de données avec Pandas
Avant de créer notre DataFrame Pandas, nous allons créer un dictionnaire du type de données de chaque colonne afin que Pandas lise correctement notre ensemble de données :
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
Nous allons ensuite créer un DataFrame en lui transmettant les types de données que nous avons spécifiés ci-dessus. Il est important de mélanger nos données au cas où l'ensemble de données d'origine serait ordonné d'une manière spécifique. Pour ce faire, nous utilisons un utilitaire sklearn appelé shuffle, que nous avons importé dans la première cellule :
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
data.head() nous permet de prévisualiser les cinq premières lignes de notre ensemble de données dans Pandas. Vous devriez voir quelque chose comme ceci après avoir exécuté la cellule ci-dessus :

Ce sont les caractéristiques que nous allons utiliser pour entraîner notre modèle. Si vous faites défiler la page jusqu'à la fin, vous verrez la dernière colonne approved, qui est ce que nous prédisons. La valeur 1 indique qu'une demande spécifique a été approuvée, et 0 qu'elle a été refusée.
Pour afficher la distribution des valeurs approuvées / refusées dans l'ensemble de données et créer un tableau NumPy des libellés, exécutez la commande suivante :
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
Environ 66 % de l'ensemble de données contient des demandes approuvées.
Étape 3 : Créer une colonne factice pour les valeurs catégorielles
Cet ensemble de données contient un mélange de valeurs catégorielles et numériques, mais XGBoost exige que toutes les caractéristiques soient numériques. Au lieu de représenter les valeurs catégorielles à l'aide de l'encodage one-hot, nous allons tirer parti de la fonction Pandas get_dummies pour notre modèle XGBoost.
get_dummies prend une colonne avec plusieurs valeurs possibles et la convertit en une série de colonnes contenant chacune uniquement des 0 et des 1. Par exemple, si nous avions une colonne "color" avec les valeurs possibles "blue" et "red", get_dummies la transformerait en deux colonnes appelées "color_blue" et "color_red" avec toutes les valeurs booléennes 0 et 1.
Pour créer des colonnes factices pour nos caractéristiques catégorielles, exécutez le code suivant :
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
Lorsque vous prévisualisez les données cette fois-ci, vous voyez des caractéristiques uniques (comme purchaser_type illustré ci-dessous) divisées en plusieurs colonnes :

Étape 4 : Diviser les données en ensembles d'entraînement et de test
Un concept important dans le machine learning est la division entraînement / test. Nous allons prendre la majorité de nos données et les utiliser pour entraîner notre modèle, et nous allons mettre de côté le reste pour tester notre modèle sur des données qu'il n'a jamais vues auparavant.
Ajoutez le code suivant à votre notebook, qui utilise la fonction Scikit Learn train_test_split pour diviser nos données :
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
Vous êtes maintenant prêt à créer et à entraîner votre modèle.
5. Créer, entraîner et évaluer un modèle XGBoost
Étape 1 : Définir et entraîner le modèle XGBoost
Créer un modèle dans XGBoost est simple. Nous allons utiliser la classe XGBClassifier pour créer le modèle, et nous n'avons qu'à transmettre le bon paramètre objective pour notre tâche de classification spécifique. Dans ce cas, nous utilisons reg:logistic, car nous avons un problème de classification binaire et nous voulons que le modèle génère une seule valeur comprise entre 0 et 1 : 0 pour "non approuvé" et 1 pour "approuvé".
Le code suivant crée un modèle XGBoost :
model = xgb.XGBClassifier(
objective='reg:logistic'
)
Vous pouvez entraîner le modèle avec une seule ligne de code, en appelant la méthode fit() et en lui transmettant les données et les libellés d'entraînement.
model.fit(x_train, y_train)
Étape 2 : Évaluer la précision de votre modèle
Nous pouvons maintenant utiliser notre modèle entraîné pour générer des prédictions sur nos données de test avec la fonction predict().
Nous allons ensuite utiliser la fonction accuracy_score de Scikit Learn pour calculer la précision de notre modèle en fonction de ses performances sur nos données de test. Nous allons lui transmettre les valeurs de vérité terrain ainsi que les valeurs prédites du modèle pour chaque exemple de notre ensemble de test :
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
Vous devriez obtenir une précision d'environ 87 %, mais la vôtre variera légèrement, car il existe toujours un élément d'aléatoire dans le machine learning.
Étape 3 : Enregistrer votre modèle
Pour déployer le modèle, exécutez le code suivant pour l'enregistrer dans un fichier local :
model.save_model('model.bst')
6. Déployer le modèle sur Cloud AI Platform
Notre modèle fonctionne en local, mais il serait intéressant de pouvoir effectuer des prédictions à partir de n'importe où (et pas seulement de ce notebook). Dans cette étape, nous allons le déployer dans le cloud.
Étape 1 : Créer un bucket Cloud Storage pour notre modèle
Commençons par définir des variables d'environnement que nous utiliserons tout au long de cet atelier de programmation. Renseignez les valeurs ci-dessous avec le nom de votre projet Google Cloud, le nom du bucket Cloud Storage que vous souhaitez créer (qui doit être globalement unique) et le nom de la première version de votre modèle :
# Update these to your own GCP project, model, and version names
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
VERSION_NAME = 'v1'
MODEL_NAME = 'xgb_mortgage'
Nous allons maintenant créer un bucket de stockage pour stocker notre fichier de modèle XGBoost. Nous allons pointer Cloud AI Platform vers ce fichier lors du déploiement.
Exécutez cette commande gsutil depuis votre notebook pour créer un bucket :
!gsutil mb $MODEL_BUCKET
Étape 2 : Copier le fichier de modèle dans Cloud Storage
Nous allons ensuite copier notre fichier de modèle XGBoost enregistré dans Cloud Storage. Exécutez la commande gsutil suivante :
!gsutil cp ./model.bst $MODEL_BUCKET
Accédez au navigateur de stockage dans la console Cloud pour vérifier que le fichier a été copié :

Étape 3 : Créer et déployer le modèle
Nous sommes presque prêts à déployer le modèle. La commande gcloud ai-platform suivante crée un modèle dans votre projet. Nous allons l'appeler xgb_mortgage :
!gcloud ai-platform models create $MODEL_NAME --region='global'
Il est maintenant temps de déployer le modèle. Nous pouvons le faire avec cette commande gcloud :
!gcloud ai-platform versions create $VERSION_NAME \
--model=$MODEL_NAME \
--framework='XGBOOST' \
--runtime-version=2.1 \
--origin=$MODEL_BUCKET \
--python-version=3.7 \
--project=$GCP_PROJECT \
--region='global'
Pendant son exécution, consultez la section Modèles de votre console AI Platform. Vous devriez voir votre nouvelle version en cours de déploiement :

Une fois le déploiement terminé, une coche verte s'affiche à l'emplacement de l'icône de chargement. Le déploiement devrait prendre 2 à 3 minutes.
Étape 4 : Tester le modèle déployé
Pour vous assurer que votre modèle déployé fonctionne, testez-le à l'aide de gcloud pour effectuer une prédiction. Commencez par enregistrer un fichier JSON avec le premier exemple de notre ensemble de test :
%%writefile predictions.json
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
Testez votre modèle en exécutant ce code :
prediction = !gcloud ai-platform predict --model=xgb_mortgage --region='global' --json-instances=predictions.json --version=$VERSION_NAME --verbosity=none
print(prediction)
Vous devriez voir la prédiction de votre modèle dans la sortie. Cet exemple particulier a été approuvé. Vous devriez donc voir une valeur proche de 1.
7. Utiliser l'outil de simulation What-If pour interpréter votre modèle
Étape 1 : Créer la visualisation de l'outil de simulation What-If
Pour connecter l'outil de simulation What-If à vos modèles AI Platform, vous devez lui transmettre un sous-ensemble de vos exemples de test ainsi que les valeurs de vérité terrain pour ces exemples. Créons un tableau NumPy de 500 de nos exemples de test ainsi que leurs libellés de vérité terrain :
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples].values,y_test[:num_wit_examples].reshape(-1,1)))
L'instanciation de l'outil de simulation What-If est aussi simple que la création d'un objet WitConfigBuilder et la transmission du modèle AI Platform que nous souhaitons analyser.
Nous utilisons ici le paramètre facultatif adjust_prediction, car l'outil de simulation What-If attend une liste de scores pour chaque classe de notre modèle (dans ce cas, 2). Comme notre modèle ne renvoie qu'une seule valeur comprise entre 0 et 1, nous la transformons au format correct dans cette fonction :
def adjust_prediction(pred):
return [1 - pred, pred]
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_ai_platform_model(GCP_PROJECT, MODEL_NAME, VERSION_NAME, adjust_prediction=adjust_prediction)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
Notez que le chargement de la visualisation prendra une minute. Une fois le chargement terminé, vous devriez voir ce qui suit :
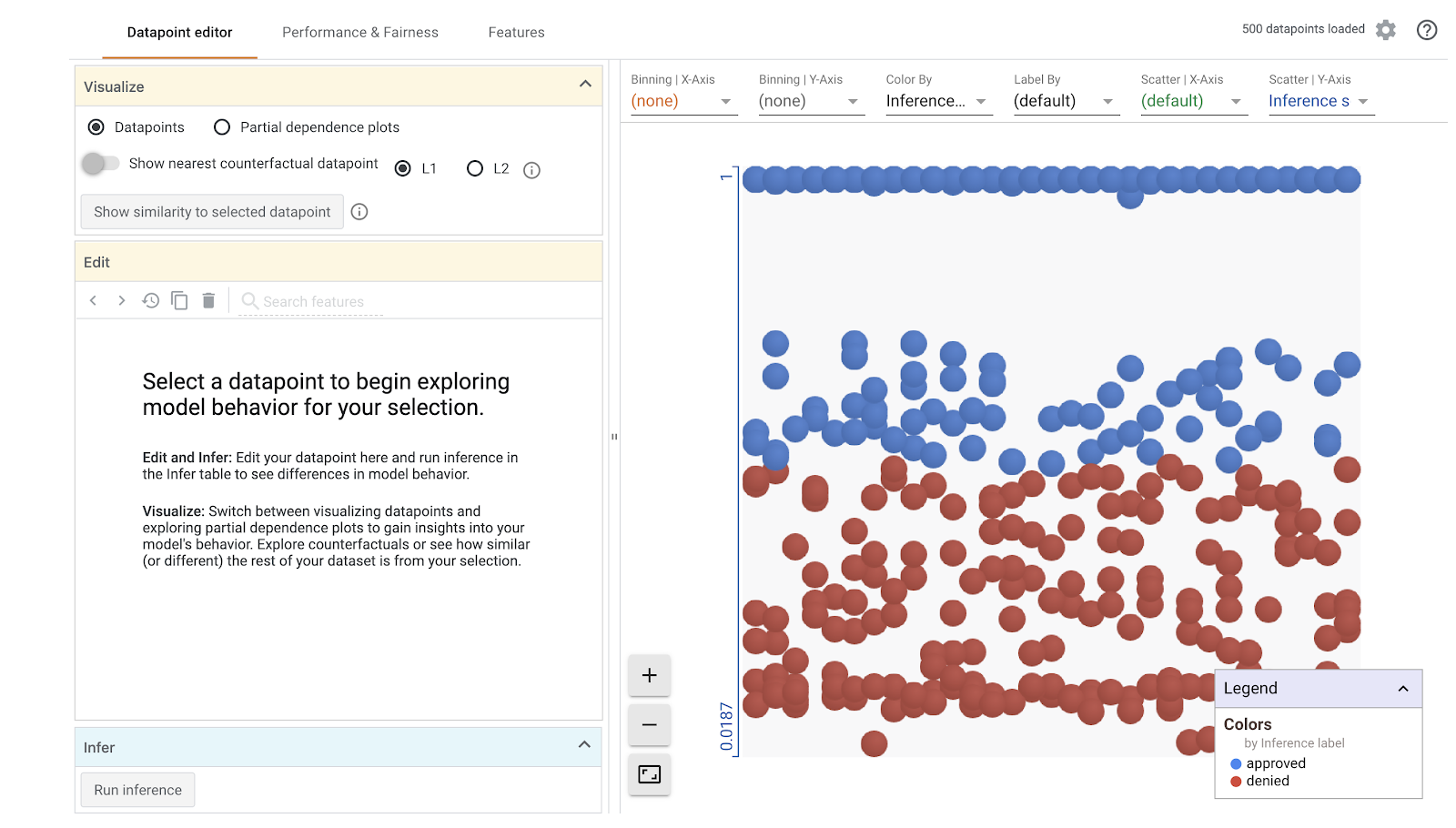
L'axe des y indique la prédiction du modèle, 1 étant une prédiction approved très fiable et 0 une prédiction denied très fiable. L'axe des x correspond simplement à la répartition de tous les points de données chargés.
Étape 2 : Explorer des points de données individuels
La vue par défaut de l'outil de simulation What-If est l'onglet Éditeur de points de données. Vous pouvez cliquer sur n'importe quel point de données individuel pour afficher ses caractéristiques, modifier les valeurs des caractéristiques et voir comment cette modification a un impact sur la prédiction du modèle sur un point de données individuel.
Dans l'exemple ci-dessous, nous avons choisi un point de données proche du seuil de 0,5. La demande de prêt hypothécaire associée à ce point de données particulier provient du CFPB. Nous avons modifié cette caractéristique en 0 et également la valeur de agency_code_Department of Housing and Urban Development (HUD) en 1 pour voir ce qui se passerait pour la prédiction du modèle si ce prêt provenait plutôt du HUD :

Comme nous pouvons le voir dans la section en bas à gauche de l'outil de simulation What-If, la modification de cette caractéristique a considérablement réduit la prédiction approved du modèle de 32 %. Cela peut indiquer que l'agence d'origine d'un prêt a un impact important sur la sortie du modèle, mais nous devrons effectuer une analyse plus approfondie pour en être sûrs.
Dans la partie inférieure gauche de l'interface utilisateur, nous pouvons également voir la valeur de vérité terrain pour chaque point de données et la comparer à la prédiction du modèle :

Étape 3 : Analyse contrefactuelle
Cliquez ensuite sur n'importe quel point de données et déplacez le curseur Afficher le point de données contrefactuel le plus proche vers la droite :

Cette sélection affiche le point de données dont les valeurs de caractéristiques sont les plus similaires à celles de l'original que vous avez sélectionné, mais avec la prédiction opposée. Vous pouvez ensuite parcourir les valeurs des caractéristiques pour voir où les deux points de données diffèrent (les différences sont mises en surbrillance en vert et en gras).
Étape 4 : Examiner les graphiques de dépendance partielle
Pour voir comment chaque caractéristique affecte les prédictions du modèle dans leur ensemble, cochez la case Graphiques de dépendance partielle et assurez-vous que l'option Graphiques de dépendance partielle globaux est sélectionnée :
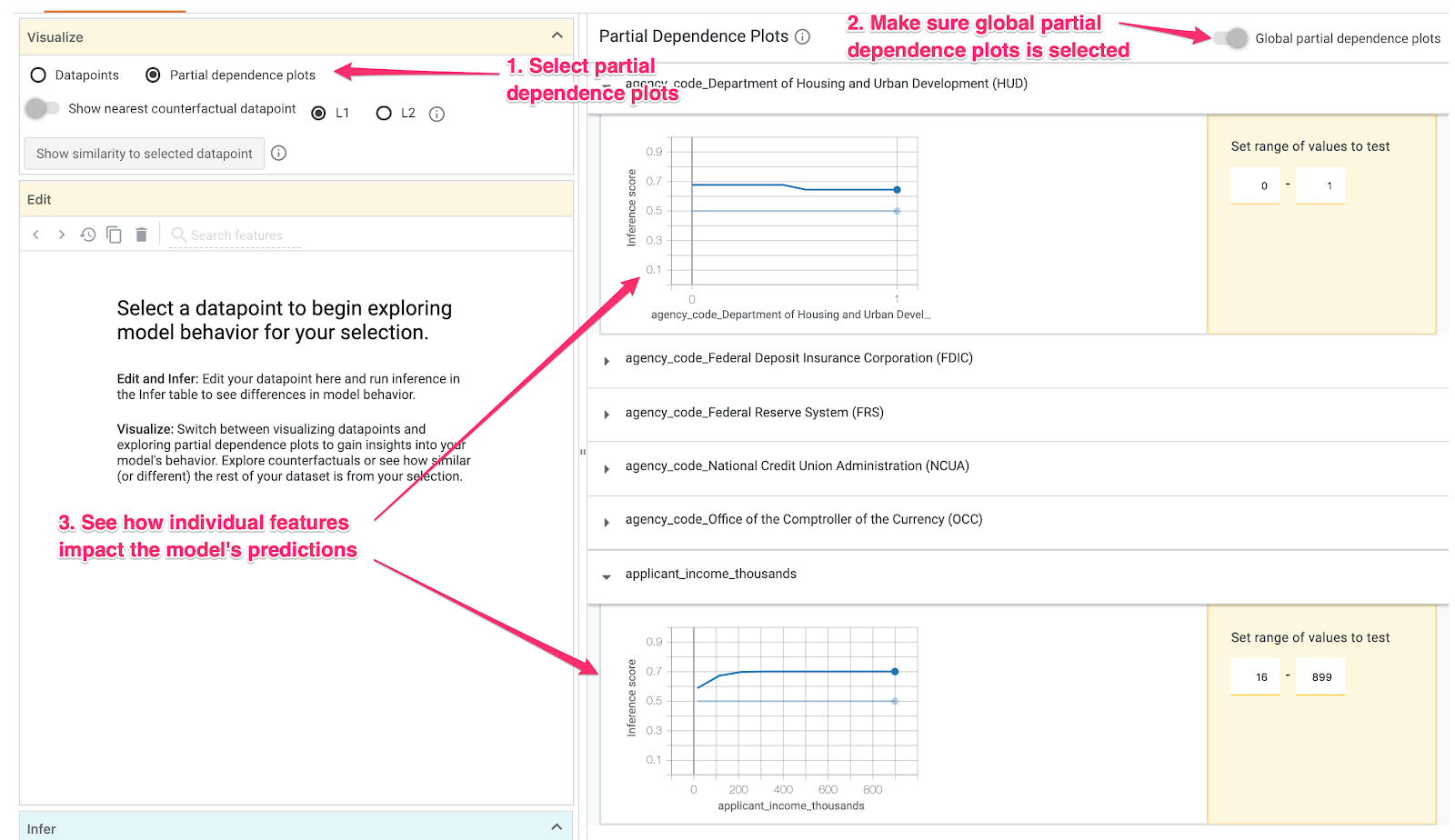
Nous pouvons voir ici que les prêts provenant du HUD ont une probabilité légèrement plus élevée d'être refusés. Le graphique a cette forme, car le code d'agence est une caractéristique booléenne. Les valeurs ne peuvent donc être que 0 ou 1.
applicant_income_thousands est une caractéristique numérique. Dans le graphique de dépendance partielle, nous pouvons voir qu'un revenu plus élevé augmente légèrement la probabilité d'approbation d'une demande, mais seulement jusqu'à environ 200 000 $. Au-delà de 200 000 $, cette caractéristique n'a pas d'impact sur la prédiction du modèle.
Étape 5 : Explorer les performances globales et l'équité
Accédez ensuite à l'onglet Performances et équité. Il affiche les statistiques de performances globales sur les résultats du modèle sur l'ensemble de données fourni, y compris les matrices de confusion, les courbes PR et les courbes ROC.
Sélectionnez mortgage_status comme caractéristique de vérité terrain pour afficher une matrice de confusion :

Cette matrice de confusion montre les prédictions correctes et incorrectes de notre modèle en tant que pourcentage du total. Si vous additionnez les cases Oui réel / Oui prédit et Non réel / Non prédit, vous devriez obtenir la même précision que votre modèle (environ 87 %).
Vous pouvez également tester le curseur de seuil, en augmentant et en diminuant le score de classification positive que le modèle doit renvoyer avant de décider de prédire approved pour le prêt, et voir comment cela modifie la précision, les faux positifs et les faux négatifs. Dans ce cas, la précision est la plus élevée autour d'un seuil de 0,55.
Ensuite, dans le menu déroulant Découper par à gauche, sélectionnez loan_purpose_Home_purchase :

Vous verrez maintenant les performances sur les deux sous-ensembles de vos données : la tranche "0" indique quand le prêt n'est pas destiné à l'achat d'une maison, et la tranche "1" indique quand le prêt est destiné à l'achat d'une maison. Vérifiez la précision, le taux de faux positifs et le taux de faux négatifs entre les deux tranches pour rechercher les différences de performances.
Si vous développez les lignes pour examiner les matrices de confusion, vous pouvez voir que le modèle prédit "approuvé" pour environ 70 % des demandes de prêt pour l'achat d'une maison et seulement 46 % des prêts qui ne sont pas destinés à l'achat d'une maison (les pourcentages exacts varient selon votre modèle) :

Si vous sélectionnez Parité démographique dans les boutons radio à gauche, les deux seuils seront ajustés de sorte que le modèle prédise approved pour un pourcentage similaire de candidats dans les deux tranches. Quel est l'impact sur la précision, les faux positifs et les faux négatifs pour chaque tranche ?
Étape 6 : Explorer la distribution des caractéristiques
Enfin, accédez à l'onglet Caractéristiques de l'outil de simulation What-If. Il affiche la distribution des valeurs pour chaque caractéristique de votre ensemble de données :

Vous pouvez utiliser cet onglet pour vous assurer que votre ensemble de données est équilibré. Par exemple, il semble que très peu de prêts de l'ensemble de données proviennent de la Farm Service Agency. Pour améliorer la précision du modèle, nous pourrions envisager d'ajouter davantage de prêts de cette agence si les données sont disponibles.
Nous avons décrit ici quelques idées d'exploration de l'outil de simulation What-If. N'hésitez pas à continuer à utiliser l'outil. Il existe de nombreuses autres zones à explorer.
8. Nettoyage
Si vous souhaitez continuer à utiliser ce notebook, nous vous recommandons de le désactiver lorsque vous ne l'utilisez pas. À partir de l'interface utilisateur de Notebooks dans la console Cloud, sélectionnez le notebook, puis cliquez sur Arrêter :

Si vous souhaitez supprimer toutes les ressources que vous avez créées dans cet atelier, supprimez simplement l'instance de notebook au lieu de l'arrêter.
Dans le menu de navigation de la console Cloud, accédez à "Stockage" et supprimez les deux buckets que vous avez créés pour stocker les éléments de votre modèle.