
1. 概要
このラボでは、 What-If ツールを使用して、金融データでトレーニングされ、Cloud AI Platform にデプロイされた XGBoost モデルを分析します。
学習内容
次の方法を学習します。
- AI Platform Notebooks で一般公開されている住宅ローンのデータセットを使用して XGBoost モデルをトレーニングする
- XGBoost モデルを AI Platform にデプロイする
- What-If ツールを使用してモデルを分析する
このラボを Google Cloud で実行するための総費用は約 $1 です。
2. XGBoost の概要
XGBoost は、決定木と勾配ブースティングを使用して予測モデルを構築する機械学習フレームワークです。これは、ツリー内のさまざまなリーフノードに関連付けられたスコアに基づいて、複数の決定木をアンサンブルすることで機能します。
次の図は、天気予報に基づいてスポーツの試合を行うかどうかを評価する単純な決定木モデルの可視化です。
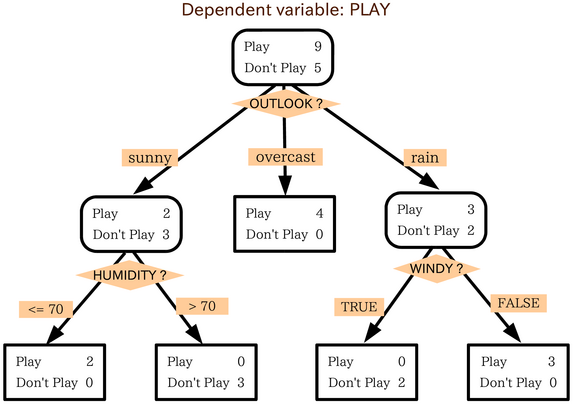
このモデルに XGBoost を使用する理由従来のニューラル ネットワークは、画像やテキストなどの非構造化データで最高のパフォーマンスを発揮することが示されていますが、決定木は、この Codelab で使用する住宅ローンのデータセットなどの構造化データで非常に優れたパフォーマンスを発揮することがよくあります。
3. 環境を設定する
この Codelab を実行するには、課金が有効になっている Google Cloud Platform プロジェクトが必要です。プロジェクトを作成するには、こちらの手順に沿って操作してください。
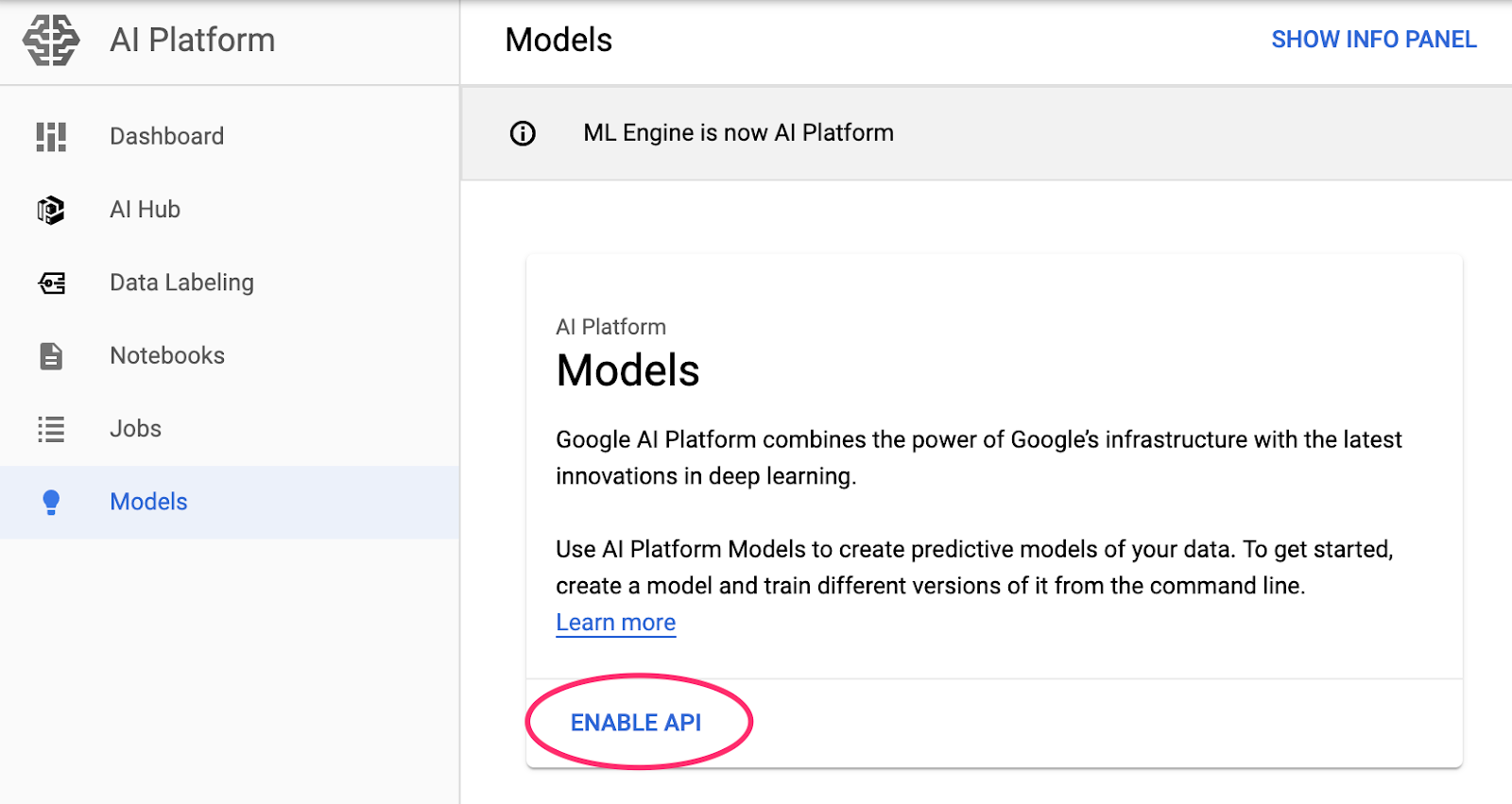
ステップ 1: Cloud AI Platform Models API を有効にする
Cloud コンソールの [AI Platform Models] セクションに移動し、まだ有効になっていない場合は [有効にする] をクリックします。
ステップ 2: Compute Engine API を有効にする
[Compute Engine] に移動し、まだ有効になっていない場合は [有効にする] を選択します。これはノートブック インスタンスを作成するために必要です。
ステップ 3: AI Platform Notebooks インスタンスを作成する
Cloud コンソールの [AI Platform Notebooks] セクションに移動し、[新しいインスタンス] をクリックします。次に、最新の TF Enterprise 2.x インスタンス タイプ(GPU なし )を選択します。

デフォルトのオプションを使用して、[作成] をクリックします。インスタンスが作成されたら、[JUPYTERLAB を開く] を選択します。

ステップ 4: XGBoost をインストールする
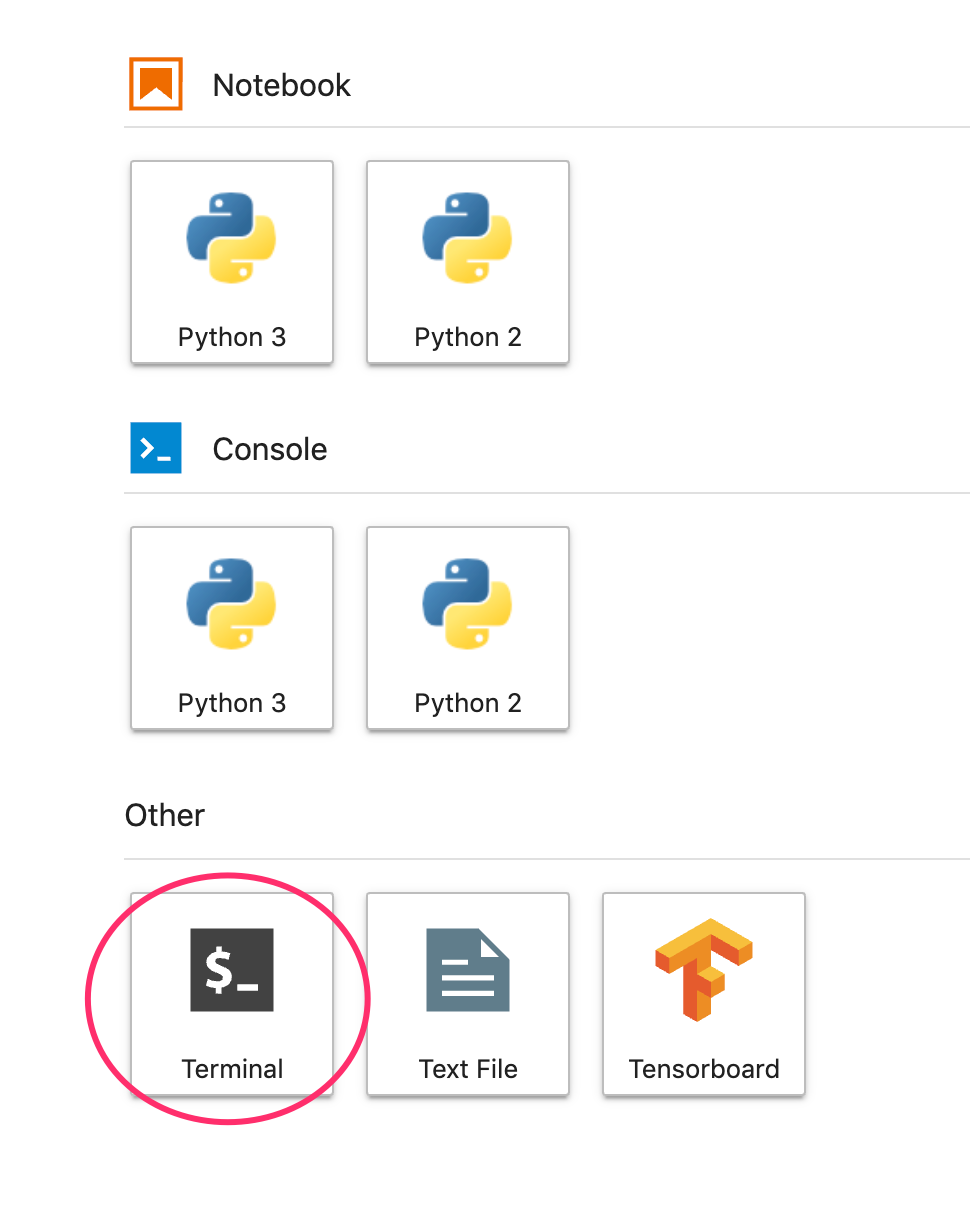
JupyterLab インスタンスが開いたら、XGBoost パッケージを追加する必要があります。
これを行うには、ランチャーから [ターミナル] を選択します。
次に、次のコマンドを実行して、Cloud AI Platform でサポートされている最新バージョンの XGBoost をインストールします。
pip3 install xgboost==0.90
完了したら、ランチャーから Python 3 ノートブック インスタンスを開きます。これで、ノートブックで作業を開始する準備ができました。
ステップ 5: Python パッケージをインポートする
ノートブックの最初のセルに次のインポートを追加して、セルを実行します。実行するには、上部のメニューの右矢印ボタンを押すか、command-enter を押します。
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
4. データをダウンロードして処理する
ffiec.gov の 住宅ローンのデータセットを使用して、XGBoost モデルをトレーニングします。元のデータセットに前処理を行い、モデルのトレーニングに使用できる小さなバージョンを作成しました。モデルは、特定の住宅ローンの申請が承認されるかどうかを予測します。
ステップ 1: 前処理済みのデータセットをダウンロードする
Google Cloud Storage でデータセットのバージョンを利用できるようにしました。ダウンロードするには、Jupyter ノートブックで次の gsutil コマンドを実行します。
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
ステップ 2: Pandas でデータセットを読み取る
Pandas DataFrame を作成する前に、各列のデータ型の dict を作成して、Pandas がデータセットを正しく読み取れるようにします。
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
次に、上記のデータ型を渡して DataFrame を作成します。元のデータセットが特定の順序で並んでいる場合は、データをシャッフルすることが重要です。これを行うには、最初のセルでインポートした shuffle という sklearn ユーティリティを使用します。
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
data.head() を使用すると、Pandas でデータセットの最初の 5 行をプレビューできます。上記のセルを実行すると、次のような出力が表示されます。

これらは、モデルのトレーニングに使用する特徴です。最後までスクロールすると、予測対象の最後の列 approved が表示されます。値 1 は特定の申請が承認されたことを示し、0 は拒否されたことを示します。
データセット内の承認済み / 拒否済みの値の分布を確認し、ラベルの numpy 配列を作成するには、次のコマンドを実行します。
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
データセットの約 66% に承認済みの申請が含まれています。
ステップ 3: カテゴリ値のダミー列を作成する
このデータセットにはカテゴリ値と数値が混在していますが、XGBoost ではすべての特徴が数値である必要があります。XGBoost モデルでは、ワンホット エンコードを使用してカテゴリ値を表すのではなく、Pandas の get_dummies 関数を利用します。
get_dummies は、複数の値を持つ列を受け取り、0 と 1 のみを含む一連の列に変換します。たとえば、「青」と「赤」の値を持つ「色」という列がある場合、get_dummies はこれを「color_blue」と「color_red」という 2 つの列に変換し、すべてのブール値は 0 と 1 になります。
カテゴリ特徴のダミー列を作成するには、次のコードを実行します。
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
今回データをプレビューすると、単一の特徴(下の purchaser_type など)が複数の列に分割されます。

ステップ 4: データをトレーニング セットとテストセットに分割する
機械学習の重要なコンセプトは、トレーニング データとテストデータの分割です。データの大部分を使用してモデルをトレーニングし、残りのデータはモデルをテストするために使用します。
次のコードをノートブックに追加します。このコードでは、Scikit Learn 関数 train_test_split を使用してデータを分割します。
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
これで、モデルを構築してトレーニングする準備ができました。
5. XGBoost モデルを構築、トレーニング、評価する
ステップ 1: XGBoost モデルを定義してトレーニングする
XGBoost でモデルを作成するのは簡単です。XGBClassifier クラスを使用してモデルを作成し、特定の分類タスクに適した objective パラメータを渡すだけです。この例では、二項分類の問題があり、モデルが (0,1) の範囲の単一の値を出力するようにするため、reg:logistic を使用します。0 は承認されず、1 は承認されます。
次のコードは、XGBoost モデルを作成します。
model = xgb.XGBClassifier(
objective='reg:logistic'
)
1 行のコードでモデルをトレーニングできます。fit() メソッドを呼び出し、トレーニング データとラベルを渡します。
model.fit(x_train, y_train)
ステップ 2: モデルの精度を評価する
トレーニング済みのモデルを使用して、predict() 関数を使用してテストデータに対する予測を生成できます。
次に、Scikit Learn の accuracy_score 関数を使用して、テストデータでのパフォーマンスに基づいてモデルの精度を計算します。テストセットの各例について、実際の値とモデルの予測値を渡します。
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
精度は 87% 程度になりますが、機械学習には常にランダム性があるため、多少異なります。
ステップ 3: モデルを保存する
モデルをデプロイするには、次のコードを実行してローカル ファイルに保存します。
model.save_model('model.bst')
6. モデルを Cloud AI Platform にデプロイする
モデルはローカルで動作しますが、どこからでも(このノートブックだけでなく)予測を行うことができると便利です。このステップでは、クラウドにデプロイします。
ステップ 1: モデルの Cloud Storage バケットを作成する
まず、この Codelab の残りの部分で使用する環境変数を定義しましょう。下の値に、Google Cloud プロジェクトの名前、作成する Cloud Storage バケットの名前(グローバルに一意である必要があります)、モデルの最初のバージョンのバージョン名を入力します。
# Update these to your own GCP project, model, and version names
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
VERSION_NAME = 'v1'
MODEL_NAME = 'xgb_mortgage'
これで、XGBoost モデルファイルを保存するストレージ バケットを作成する準備ができました。デプロイ時に、Cloud AI Platform がこのファイルを指すようにします。
ノートブック内からこの gsutil コマンドを実行してバケットを作成します。
!gsutil mb $MODEL_BUCKET
ステップ 2: モデルファイルを Cloud Storage にコピーする
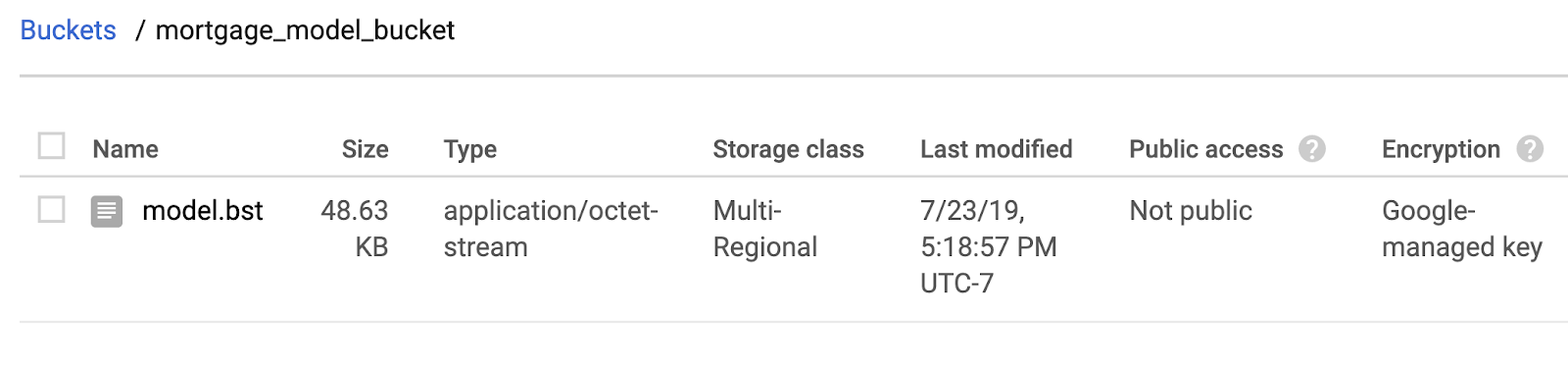
次に、保存した XGBoost モデルファイルを Cloud Storage にコピーします。次の gsutil コマンドを実行します。
!gsutil cp ./model.bst $MODEL_BUCKET
Cloud コンソールのストレージ ブラウザに移動して、ファイルがコピーされていることを確認します。
ステップ 3: モデルを作成してデプロイする
モデルをデプロイする準備がほぼ整いました。次の ai-platform gcloud コマンドは、プロジェクトに新しいモデルを作成します。ここでは xgb_mortgage とします。
!gcloud ai-platform models create $MODEL_NAME --region='global'
モデルをデプロイします。次の gcloud コマンドで実行できます。
!gcloud ai-platform versions create $VERSION_NAME \
--model=$MODEL_NAME \
--framework='XGBOOST' \
--runtime-version=2.1 \
--origin=$MODEL_BUCKET \
--python-version=3.7 \
--project=$GCP_PROJECT \
--region='global'
実行中に、AI Platform コンソールの [モデル] セクション を確認します。新しいバージョンがデプロイされていることがわかります。

デプロイが正常に完了すると、読み込みスピナーの場所に緑色のチェックマークが表示されます。デプロイには 2 ~ 3 分 かかります。
ステップ 4: デプロイされたモデルをテストする
デプロイされたモデルが動作していることを確認するには、gcloud を使用して予測を行います。まず、テストセットの最初の例を含む JSON ファイルを保存します。
%%writefile predictions.json
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
次のコードを実行してモデルをテストします。
prediction = !gcloud ai-platform predict --model=xgb_mortgage --region='global' --json-instances=predictions.json --version=$VERSION_NAME --verbosity=none
print(prediction)
出力にモデルの予測が表示されます。この例では承認されているため、1 に近い値が表示されます。
7. What-If ツールを使用してモデルを解釈する
ステップ 1: What-If ツールの可視化を作成する
What-If ツールを AI Platform モデルに接続するには、テスト例のサブセットと、それらの例の実際の値を渡す必要があります。テスト例の 500 個の Numpy 配列と、その実際のラベルを作成しましょう。
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples].values,y_test[:num_wit_examples].reshape(-1,1)))
What-If ツールをインスタンス化するには、WitConfigBuilder オブジェクトを作成し、分析する AI Platform モデルを渡します。
ここでは、What-If ツールがモデル内の各クラス(この場合は 2 つ)のスコアのリストを必要とするため、オプションの adjust_prediction パラメータを使用します。モデルは 0 ~ 1 の単一の値のみを返すため、この関数で正しい形式に変換します。
def adjust_prediction(pred):
return [1 - pred, pred]
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_ai_platform_model(GCP_PROJECT, MODEL_NAME, VERSION_NAME, adjust_prediction=adjust_prediction)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
可視化の読み込みには 1 分ほどかかります。読み込まれると、次のようになります。

y 軸はモデルの予測を示します。1 は信頼度の高い approved 予測、0 は信頼度の高い denied 予測です。x 軸は、読み込まれたすべてのデータポイントの広がりです。
ステップ 2: 個々のデータポイントを調べる
What-If ツールのデフォルト ビューは [データポイント エディタ] タブです。ここで、個々のデータポイントをクリックして特徴を確認し、特徴値を変更して、その変更が個々のデータポイントに対するモデルの予測にどのように影響するかを確認できます。
次の例では、0.5 のしきい値に近いデータポイントを選択しました。この特定のデータポイントに関連付けられた住宅ローンの申請は、CFPB からのものでした。その特徴を 0 に変更し、agency_code_Department of Housing and Urban Development (HUD) の値を 1 に変更して、このローンが HUD から発生した場合にモデルの予測がどうなるかを確認しました。

What-If ツールの左下のセクションでわかるように、この特徴を変更すると、モデルの approved 予測が 32% 大幅に減少しました。これは、ローンの発生元機関がモデルの出力に大きな影響を与えている可能性があることを示していますが、確認するにはさらに分析を行う必要があります。
UI の左下には、各データポイントの実際の値も表示され、モデルの予測と比較できます。

ステップ 3: 反事実分析
次に、任意のデータポイントをクリックし、[最も近い反事実データポイントを表示] スライダーを右に移動します。
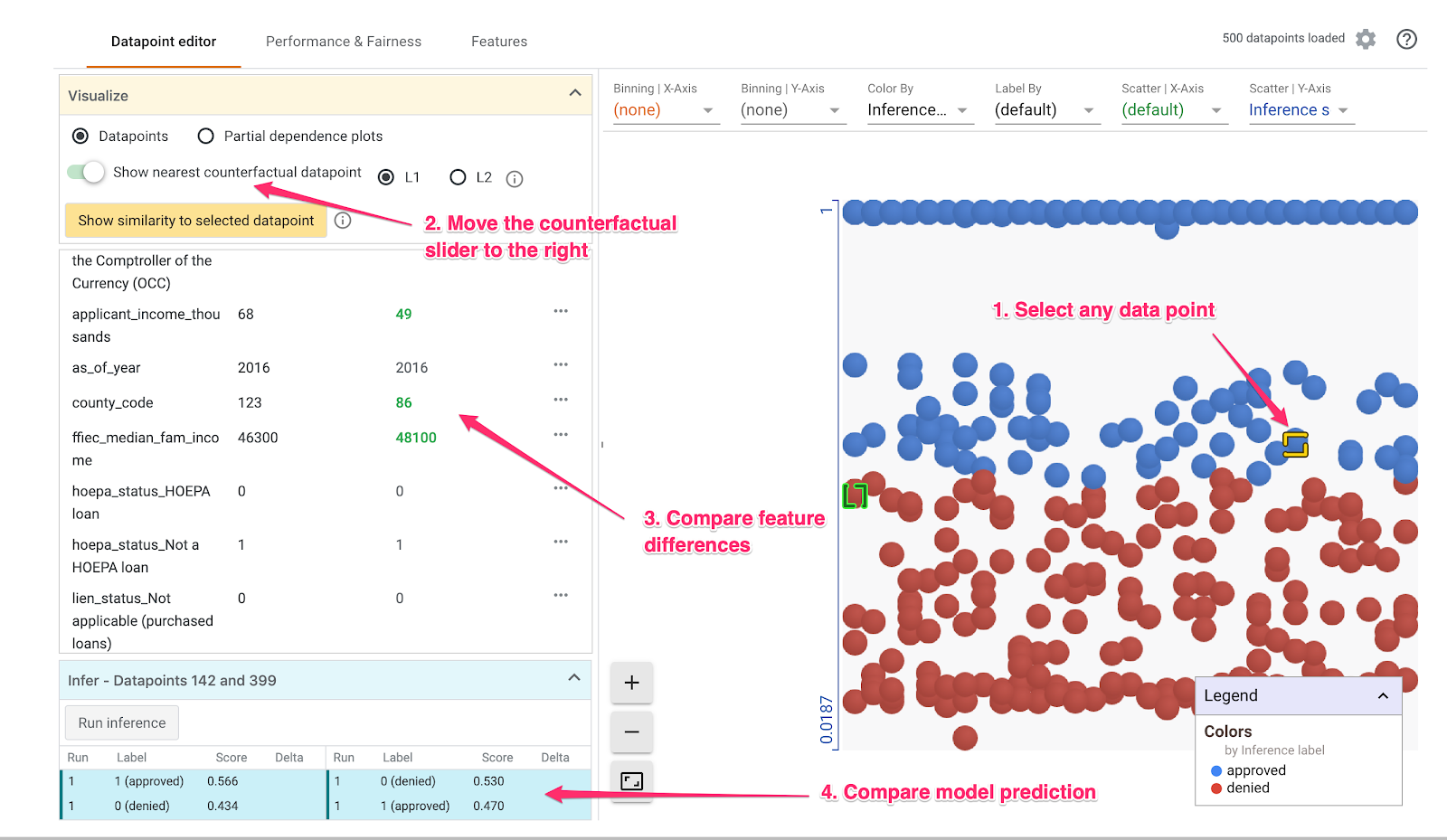
これを選択すると、選択した元のデータポイントに最も類似した特徴値を持つデータポイントが表示されますが、予測は逆になります。 特徴値をスクロールして、2 つのデータポイントの違いを確認できます(違いは緑色で太字でハイライト表示されます)。
ステップ 4: 部分依存プロットを確認する
各特徴がモデルの予測に全体的にどのように影響するかを確認するには、[部分依存プロット] チェックボックスをオンにして、[グローバル部分依存プロット] が選択されていることを確認します。

ここでは、HUD からのローンは拒否される可能性がわずかに高いことがわかります。グラフがこの形状になっているのは、機関コードがブール値の特徴であるため、値は 0 または 1 になります。
applicant_income_thousands は数値の特徴です。部分依存プロットでは、収入が多いほど申請が承認される可能性がわずかに高くなりますが、20 万ドル程度までです。20 万ドルを超えると、この特徴はモデルの予測に影響しません。
ステップ 5: 全体的なパフォーマンスと公平性を調べる
次に、[パフォーマンスと公平性] タブに移動します。ここでは、混同行列、PR 曲線、ROC 曲線など、提供されたデータセットに対するモデルの結果に関する全体的なパフォーマンス統計が表示されます。
混同行列を表示するには、グラウンド トゥルースの特徴として mortgage_status を選択します。
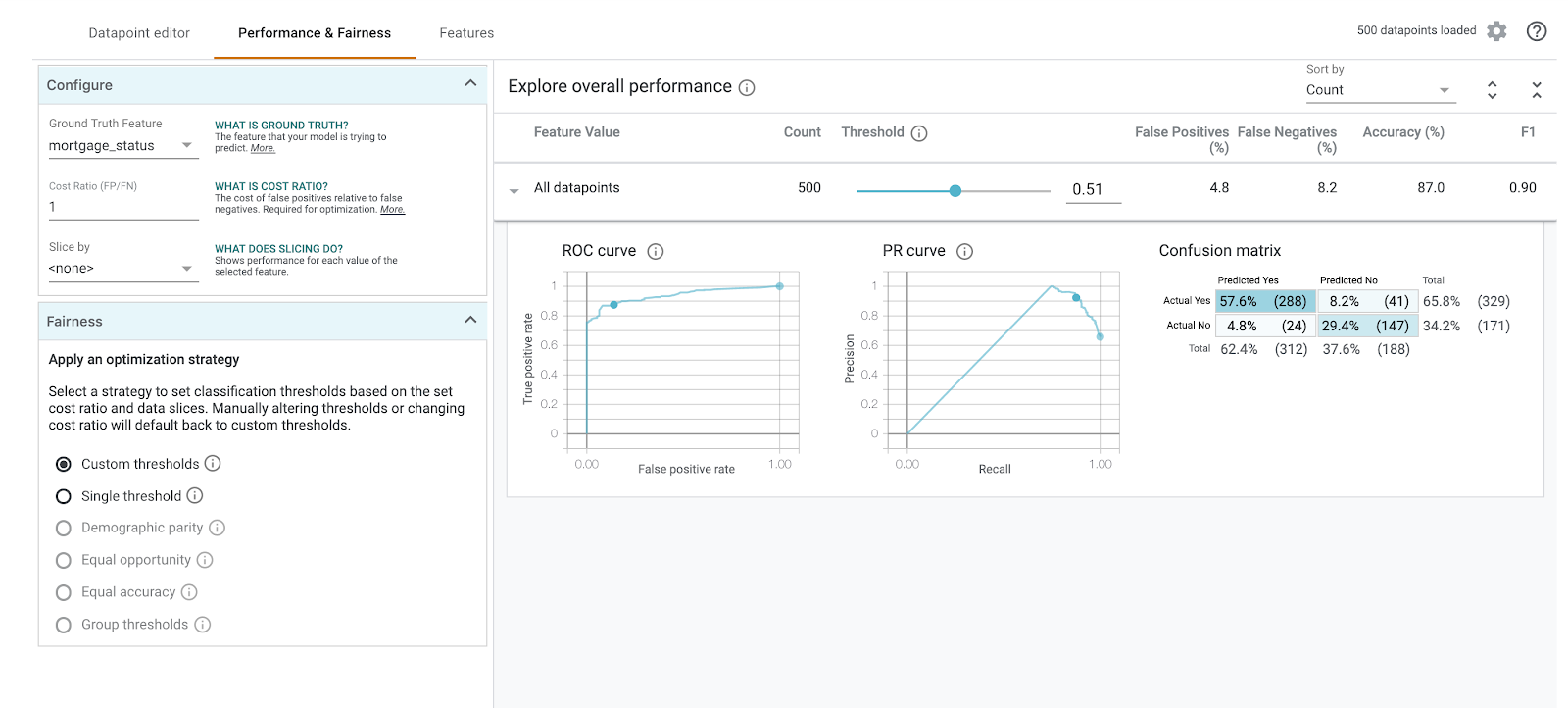
この混同行列は、モデルの正解と不正解の予測を合計の割合として示しています。 [Actual Yes / Predicted Yes] と [Actual No / Predicted No] の正方形を足すと、モデルと同じ精度(約 87%)になります。
しきい値スライダーを操作して、モデルがローンの approved を予測する前に返す必要がある正の分類スコアを上げ下げし、精度、偽陽性、偽陰性がどのように変化するかを確認することもできます。この場合、精度は 0.55 のしきい値で最も高くなります。
次に、左側の [Slice by] プルダウンで loan_purpose_Home_purchase を選択します。
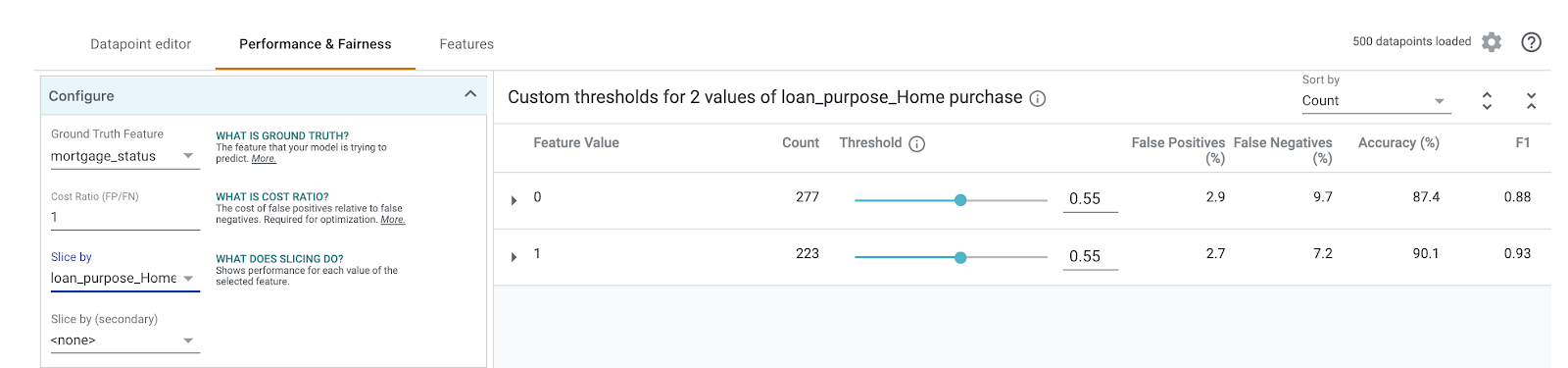
データの 2 つのサブセットのパフォーマンスが表示されます。「0」スライスはローンが住宅購入用でない場合を示し、「1」スライスはローンが住宅購入用の場合を示します。2 つのスライス間の精度、偽陽性率、偽陰性率を確認して、パフォーマンスの違いを確認します。
行を展開して混同行列を確認すると、モデルは住宅購入のローン申請の約 70% で「承認」を予測し、住宅購入以外のローンの 46% でのみ「承認」を予測しています(正確な割合はモデルによって異なります)。
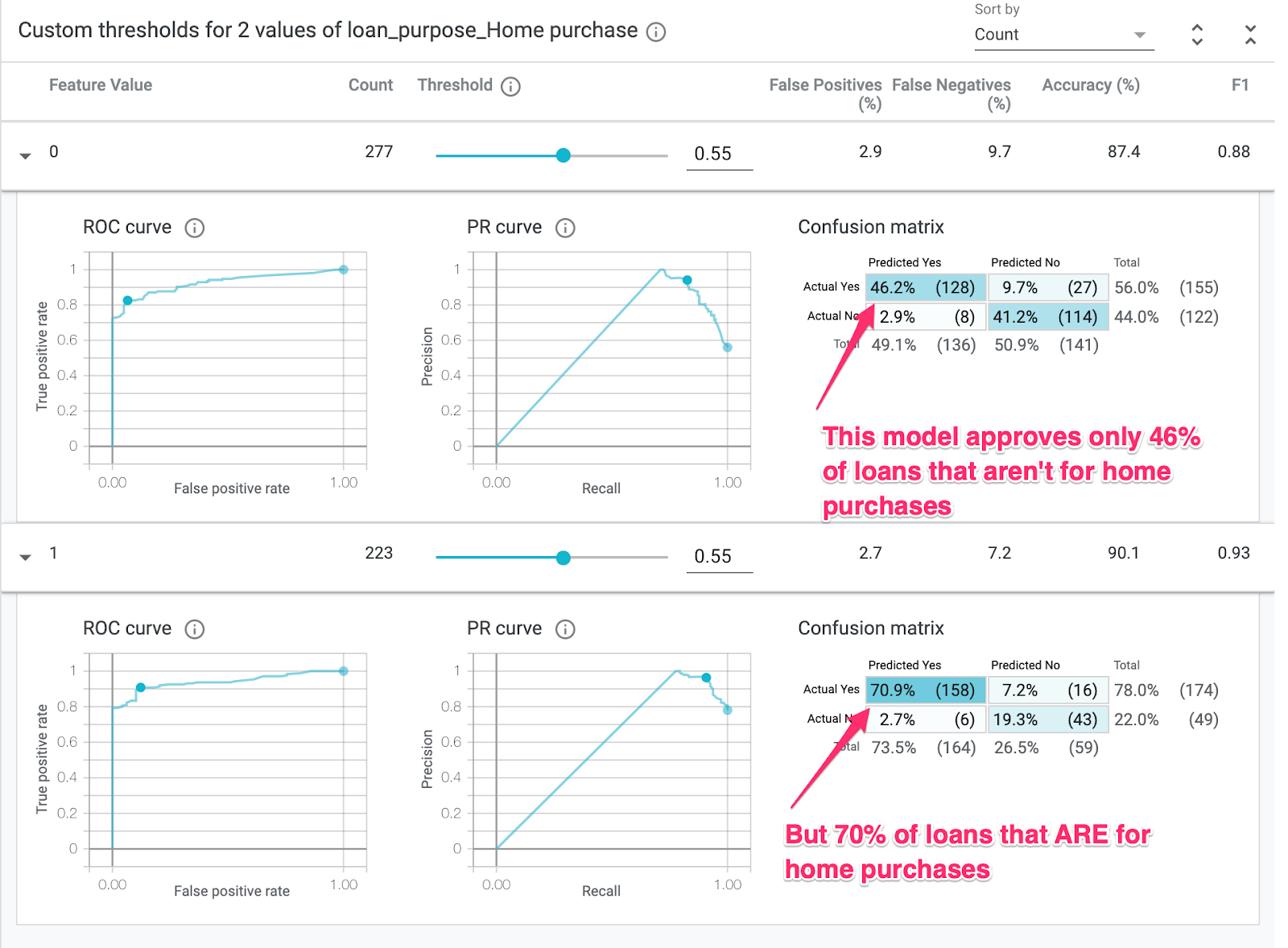
左側のラジオボタンから [Demographic parity] を選択すると、2 つのしきい値が調整され、両方のスライスで同様の割合の申請者に対してモデルが approved を予測します。これにより、各スライスの精度、偽陽性、偽陰性はどのように変化しますか?
ステップ 6: 特徴の分布を調べる
最後に、What-If ツールの [Features] タブに移動します。データセット内の各特徴の値の分布が表示されます。

このタブを使用して、データセットのバランスが取れていることを確認できます。たとえば、データセット内のローンは、農務省の機関から発生したものが非常に少ないようです。モデルの精度を高めるために、データが利用可能な場合は、その機関からのローンを追加することを検討してください。
ここでは、What-If ツールのデータ探索のアイデアをいくつか説明しました。このツールを自由に試してみてください。他にも探索できる領域がたくさんあります。
8. クリーンアップ
このノートブックを引き続き使用する場合は、未使用時にオフにすることをおすすめします。Cloud コンソールの Notebooks UI で、ノートブックを選択して [停止] をクリックします。

このラボで作成したリソースをすべて削除する場合は、ノートブック インスタンスを停止するのではなく削除します。
Cloud コンソールのナビゲーション メニューで [ストレージ] に移動し、モデルアセットを保存するために作成した両方のバケットを削除します。