
1. Visão geral
Neste laboratório, você vai usar a Ferramenta What-If para analisar um modelo XGBoost treinado em dados financeiros e implantado na IA do Google Cloud.
Conteúdo do laboratório
Você vai aprender a:
- Treinar um modelo XGBoost em um conjunto de dados públicos de hipoteca no AI Platform Notebooks
- Implantar o modelo XGBoost na AI Platform
- Analisar o modelo usando a Ferramenta What-If
O custo total da execução deste laboratório no Google Cloud é de aproximadamente US$1.
2. Noções básicas sobre o XGBoost
XGBoost é um framework de machine learning que usa árvores de decisão e boost de gradiente para criar modelos preditivos. Ele funciona reunindo várias árvores de decisão com base na pontuação associada a diferentes nós folha em uma árvore.
O diagrama abaixo é uma visualização de um modelo de árvore de decisão simples que avalia se um jogo esportivo deve ser disputado com base na previsão do tempo:

Por que estamos usando o XGBoost para esse modelo? Embora as redes neurais tradicionais tenham mostrado o melhor desempenho em dados não estruturados, como imagens e texto, as árvores de decisão geralmente têm um desempenho muito bom em dados estruturados, como o conjunto de dados de hipoteca que usaremos neste codelab.
3. Configurar o ambiente
Para executar este codelab, você vai precisar de um projeto do Google Cloud Platform com o faturamento ativado. Para criar um projeto, siga as instruções aqui.
Etapa 1: ativar a API Models da IA do Google Cloud
Navegue até a seção AI Platform Models do console do Cloud e clique em "Ativar" se ela ainda não estiver ativada.
Etapa 2: ativar a API Compute Engine
Acesse Compute Engine e selecione Ativar caso essa opção ainda não esteja ativada. Você vai precisar disso para criar sua instância de notebook.
Etapa 3: criar uma instância do AI Platform Notebooks
Navegue até a seção "AI Platform Notebooks" do console do Cloud e clique em **Nova instância**. Em seguida, selecione o tipo de instância TF Enterprise 2.x mais recente sem GPUs:
Use as opções padrão e clique em Criar. Quando a instância tiver sido criada, selecione Abrir o JupyterLab:

Etapa 4: instalar o XGBoost
Depois que a instância do JupyterLab for aberta, você precisará adicionar o pacote XGBoost.
Para fazer isso, selecione "Terminal" no menu inicial:

Em seguida, execute o comando a seguir para instalar a versão mais recente do XGBoost com suporte da IA do Google Cloud:
pip3 install xgboost==0.90
Depois que isso for concluído, abra uma instância do notebook Python 3 no menu inicial. Agora você pode começar a trabalhar no notebook.
Etapa 5: importar pacotes Python
Na primeira célula do notebook, adicione as importações a seguir e execute a célula. Você pode executar isso pressionando o botão de seta para a direita no menu superior ou pressionando "comando-enter":
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
4. Fazer o download e processar dados
Vamos usar um conjunto de dados de hipoteca de ffiec.gov para treinar um modelo XGBoost. Fizemos algum pré-processamento no conjunto de dados original e criamos uma versão menor para você usar no treinamento do modelo. O modelo vai prever se um pedido de hipoteca específico será aprovado ou não.
Etapa 1: fazer o download do conjunto de dados pré-processado
Disponibilizamos uma versão do conjunto de dados no Google Cloud Storage. Para fazer o download, execute o comando gsutil a seguir no notebook do Jupyter:
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
Etapa 2: ler o conjunto de dados com o Pandas
Antes de criar o DataFrame do Pandas, vamos criar um dicionário do tipo de dados de cada coluna para que o Pandas leia nosso conjunto de dados corretamente:
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
Em seguida, vamos criar um DataFrame, transmitindo os tipos de dados especificados acima. É importante embaralhar os dados caso o conjunto de dados original seja ordenado de uma maneira específica. Usamos um utilitário sklearn chamado shuffle para fazer isso, que importamos na primeira célula:
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
data.head() permite visualizar as cinco primeiras linhas do conjunto de dados no Pandas. Depois de executar a célula acima, você verá algo como isto:

Esses são os recursos que usaremos para treinar nosso modelo. Se você rolar até o final, verá a última coluna approved, que é o que estamos prevendo. Um valor de 1 indica que um aplicativo específico foi aprovado e 0 indica que ele foi negado.
Para conferir a distribuição de valores aprovados / negados no conjunto de dados e criar uma matriz numpy dos rótulos, execute o seguinte comando:
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
Cerca de 66% do conjunto de dados contém aplicativos aprovados.
Etapa 3: criar uma coluna fictícia para valores categóricos
Esse conjunto de dados contém uma combinação de valores categóricos e numéricos, mas o XGBoost exige que todos os recursos sejam numéricos. Em vez de representar valores categóricos usando a codificação one-hot, para nosso modelo XGBoost, vamos aproveitar a função get_dummies do Pandas.
get_dummies usa uma coluna com vários valores possíveis e a converte em uma série de colunas, cada uma com apenas 0s e 1s. Por exemplo, se tivéssemos uma coluna "cor" com valores possíveis de "azul" e "vermelho", get_dummies transformaria isso em duas colunas chamadas "color_blue" e "color_red" com todos os valores booleanos 0 e 1.
Para criar colunas fictícias para nossos recursos categóricos, execute o código a seguir:
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
Quando você visualizar os dados desta vez, verá recursos únicos (como purchaser_type mostrado abaixo) divididos em várias colunas:

Etapa 4: dividir dados em conjuntos de treinamento e teste
Um conceito importante no machine learning é a divisão de treinamento / teste. Vamos usar a maioria dos nossos dados para treinar o modelo e reservar o restante para testar o modelo em dados que ele nunca viu antes.
Adicione o código a seguir ao notebook, que usa a função train_test_split do Scikit Learn para dividir nossos dados:
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
Agora você está pronto para criar e treinar seu modelo.
5. Criar, treinar e avaliar um modelo XGBoost
Etapa 1: definir e treinar o modelo XGBoost
Criar um modelo no XGBoost é simples. Vamos usar a classe XGBClassifier para criar o modelo e só precisamos transmitir o parâmetro objective correto para nossa tarefa de classificação específica. Nesse caso, usamos reg:logistic, já que temos um problema de classificação binária e queremos que o modelo gere um único valor no intervalo de (0,1): 0 para não aprovado e 1 para aprovado.
O código a seguir cria um modelo XGBoost:
model = xgb.XGBClassifier(
objective='reg:logistic'
)
É possível treinar o modelo com uma linha de código, chamando o método fit() e transmitindo os dados e rótulos de treinamento.
model.fit(x_train, y_train)
Etapa 2: avaliar a acurácia do modelo
Agora podemos usar nosso modelo treinado para gerar previsões sobre nossos dados de teste com a função predict().
Em seguida, vamos usar a função accuracy_score do Scikit Learn para calcular a precisão do modelo com base no desempenho dele nos dados de teste. Vamos transmitir os valores de informações empíricas junto com os valores previstos do modelo para cada exemplo no conjunto de testes:
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
Você verá uma acurácia de cerca de 87%, mas a sua vai variar um pouco, já que sempre há um elemento de aleatoriedade no aprendizado de máquina.
Etapa 3: salvar o modelo
Para implantar o modelo, execute o código a seguir para salvá-lo em um arquivo local:
model.save_model('model.bst')
6. Implantar o modelo na AI Platform da IA do Google Cloud
Nosso modelo está funcionando localmente, mas seria bom se pudéssemos fazer previsões nele de qualquer lugar (não apenas neste notebook). Nesta etapa, vamos implantá-lo na nuvem.
Etapa 1: criar um bucket do Cloud Storage para nosso modelo
Primeiro, vamos definir algumas variáveis de ambiente que usaremos no restante do codelab. Preencha os valores abaixo com o nome do projeto na nuvem do Google, o nome do bucket do Cloud Storage que você quer criar (precisa ser globalmente exclusivo) e o nome da versão para a primeira versão do modelo:
# Update these to your own GCP project, model, and version names
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
VERSION_NAME = 'v1'
MODEL_NAME = 'xgb_mortgage'
Agora estamos prontos para criar um bucket de armazenamento para armazenar o arquivo modelo XGBoost. Vamos apontar a AI Platform do Cloud para esse arquivo quando implantarmos.
Execute este comando gsutil no notebook para criar um bucket:
!gsutil mb $MODEL_BUCKET
Etapa 2: copiar o arquivo modelo para o Cloud Storage
Em seguida, vamos copiar o arquivo do modelo salvo do XGBoost para o Cloud Storage. Execute o comando gsutil a seguir:
!gsutil cp ./model.bst $MODEL_BUCKET
Acesse o navegador de armazenamento no console do Cloud para confirmar se o arquivo foi copiado:

Etapa 3: criar e implantar o modelo
Quase tudo pronto para implantar o modelo. O comando ai-platform gcloud a seguir cria um novo modelo no seu projeto. Vamos chamar esse modelo de xgb_mortgage:
!gcloud ai-platform models create $MODEL_NAME --region='global'
Agora é hora de implantar o modelo. Podemos fazer isso com este comando gcloud:
!gcloud ai-platform versions create $VERSION_NAME \
--model=$MODEL_NAME \
--framework='XGBOOST' \
--runtime-version=2.1 \
--origin=$MODEL_BUCKET \
--python-version=3.7 \
--project=$GCP_PROJECT \
--region='global'
Enquanto isso estiver em execução, confira a seção de modelos do console da AI Platform. Você verá a nova versão sendo implantada:

Quando a implantação for concluída, você verá uma marca de seleção verde onde o indicador de carregamento está. A implantação leva 2 a 3 minutos.
Etapa 4: testar o modelo implantado
Para garantir que o modelo implantado esteja funcionando, teste-o usando o gcloud para fazer uma previsão. Primeiro, salve um arquivo JSON com o primeiro exemplo do nosso conjunto de testes:
%%writefile predictions.json
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
Teste o modelo executando este código:
prediction = !gcloud ai-platform predict --model=xgb_mortgage --region='global' --json-instances=predictions.json --version=$VERSION_NAME --verbosity=none
print(prediction)
Você verá a previsão do modelo na saída. Esse exemplo específico foi aprovado, então você verá um valor próximo a 1.
7. Usar a Ferramenta What-If para interpretar o modelo
Etapa 1: criar a visualização da Ferramenta What-If
Para conectar a Ferramenta What-If aos modelos da AI Platform, é necessário transmitir um subconjunto dos exemplos de teste junto com os valores de informações empíricas desses exemplos. Vamos criar uma matriz Numpy de 500 exemplos de teste junto com os rótulos de informações empíricas:
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples].values,y_test[:num_wit_examples].reshape(-1,1)))
Instanciar a Ferramenta What-If é tão simples quanto criar um objeto WitConfigBuilder e transmitir o modelo da AI Platform que queremos analisar.
Usamos o parâmetro adjust_prediction opcional aqui porque a Ferramenta What-If espera uma lista de pontuações para cada classe no modelo (neste caso, 2). Como nosso modelo retorna apenas um único valor de 0 a 1, o transformamos para o formato correto nesta função:
def adjust_prediction(pred):
return [1 - pred, pred]
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_ai_platform_model(GCP_PROJECT, MODEL_NAME, VERSION_NAME, adjust_prediction=adjust_prediction)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
O carregamento da visualização leva um minuto. Quando ele for carregado, você verá o seguinte:
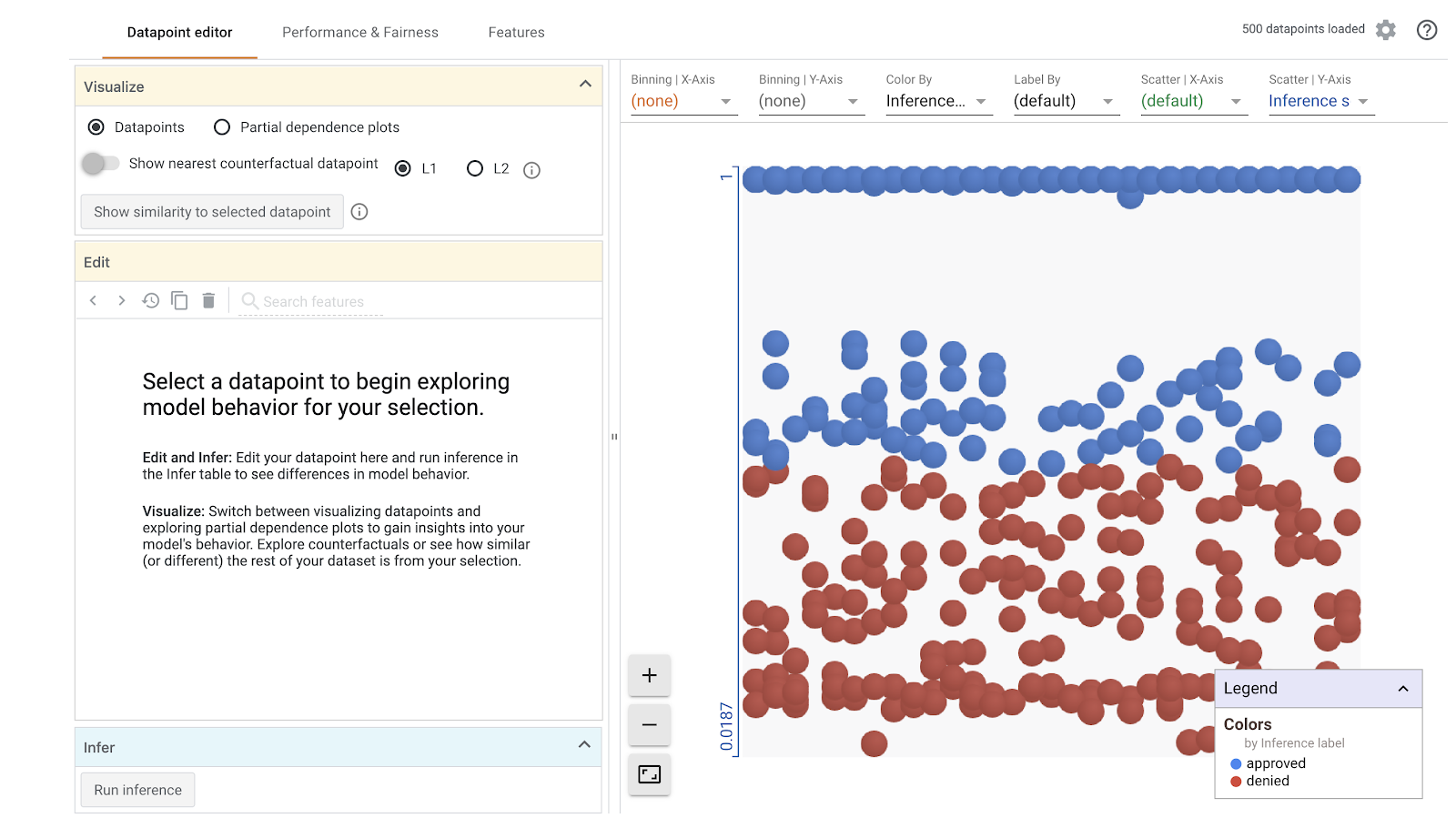
O eixo y mostra a previsão do modelo, com 1 sendo uma previsão approved de alta confiança e 0 sendo uma previsão denied de alta confiança. O eixo x é apenas a distribuição de todos os pontos de dados carregados.
Etapa 2: analisar pontos de dados individuais
A visualização padrão na Ferramenta What-If é a guia Editor de pontos de dados. Nela, é possível clicar em qualquer ponto de dados individual para conferir os recursos, mudar os valores dos recursos e conferir como essa mudança afeta a previsão do modelo em um ponto de dados individual.
No exemplo abaixo, escolhemos um ponto de dados próximo ao limite de 0,5. O pedido de hipoteca associado a esse ponto de dados específico foi originado do CFPB. Mudamos esse recurso para 0 e também mudamos o valor de agency_code_Department of Housing and Urban Development (HUD) para 1 para conferir o que aconteceria com a previsão do modelo se esse empréstimo fosse originado do HUD:

Como podemos ver na seção inferior esquerda da Ferramenta What-If, a mudança desse recurso diminuiu significativamente a previsão approved do modelo em 32%. Isso pode indicar que a agência de origem de um empréstimo tem um impacto significativo na saída do modelo, mas precisamos fazer mais análises para ter certeza.
Na parte inferior esquerda da interface, também podemos conferir o valor de informações empíricas de cada ponto de dados e compará-lo com a previsão do modelo:

Etapa 3: análise contrafactual
Em seguida, clique em qualquer ponto de dados e mova o controle deslizante Mostrar o ponto de dados contrafactual mais próximo para a direita:
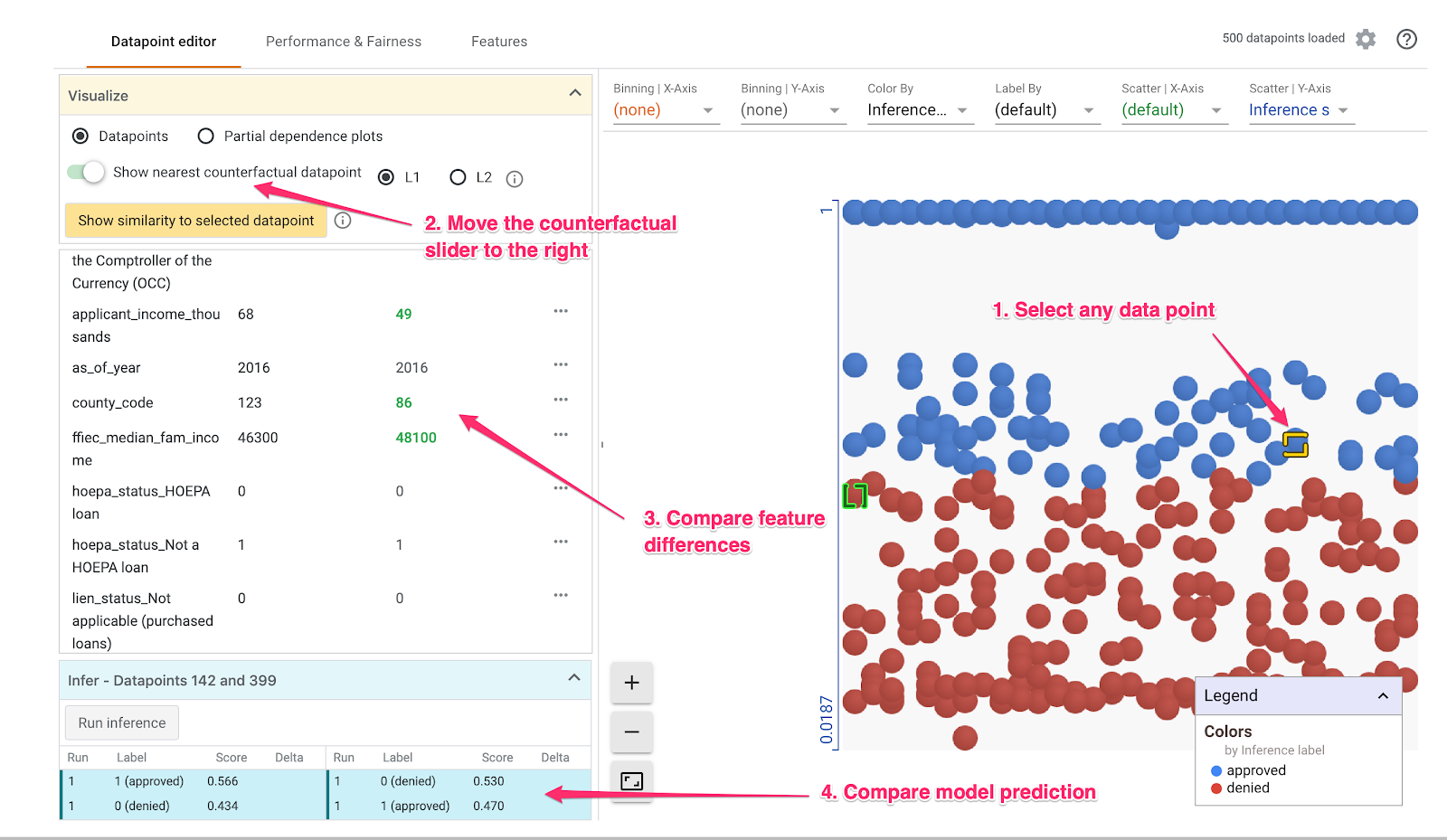
Ao selecionar essa opção, você verá o ponto de dados que tem os valores de recursos mais semelhantes ao original selecionado, mas a previsão oposta. Em seguida, role os valores dos recursos para conferir onde os dois pontos de dados diferiram (as diferenças são destacadas em verde e negrito).
Etapa 4: analisar gráficos de dependência parcial
Para conferir como cada recurso afeta as previsões do modelo em geral, marque a caixa Gráficos de dependência parcial e verifique se a opção Gráficos de dependência parcial global está selecionada:

Aqui, podemos ver que os empréstimos originados do HUD têm uma probabilidade ligeiramente maior de serem negados. O gráfico tem esse formato porque o código da agência é um recurso booleano, então os valores só podem ser exatamente 0 ou 1.
applicant_income_thousands é um recurso numérico e, no gráfico de dependência parcial, podemos ver que uma renda maior aumenta ligeiramente a probabilidade de um aplicativo ser aprovado, mas apenas até cerca de US $200 mil. Depois de US $200 mil, esse recurso não afeta a previsão do modelo.
Etapa 5: analisar a performance e a imparcialidade gerais
Em seguida, acesse a guia Performance e imparcialidade. Ela mostra estatísticas gerais de performance sobre os resultados do modelo no conjunto de dados fornecido, incluindo matrizes de confusão, curvas PR e curvas ROC.
Selecione mortgage_status como o recurso de informações empíricas para conferir uma matriz de confusão:
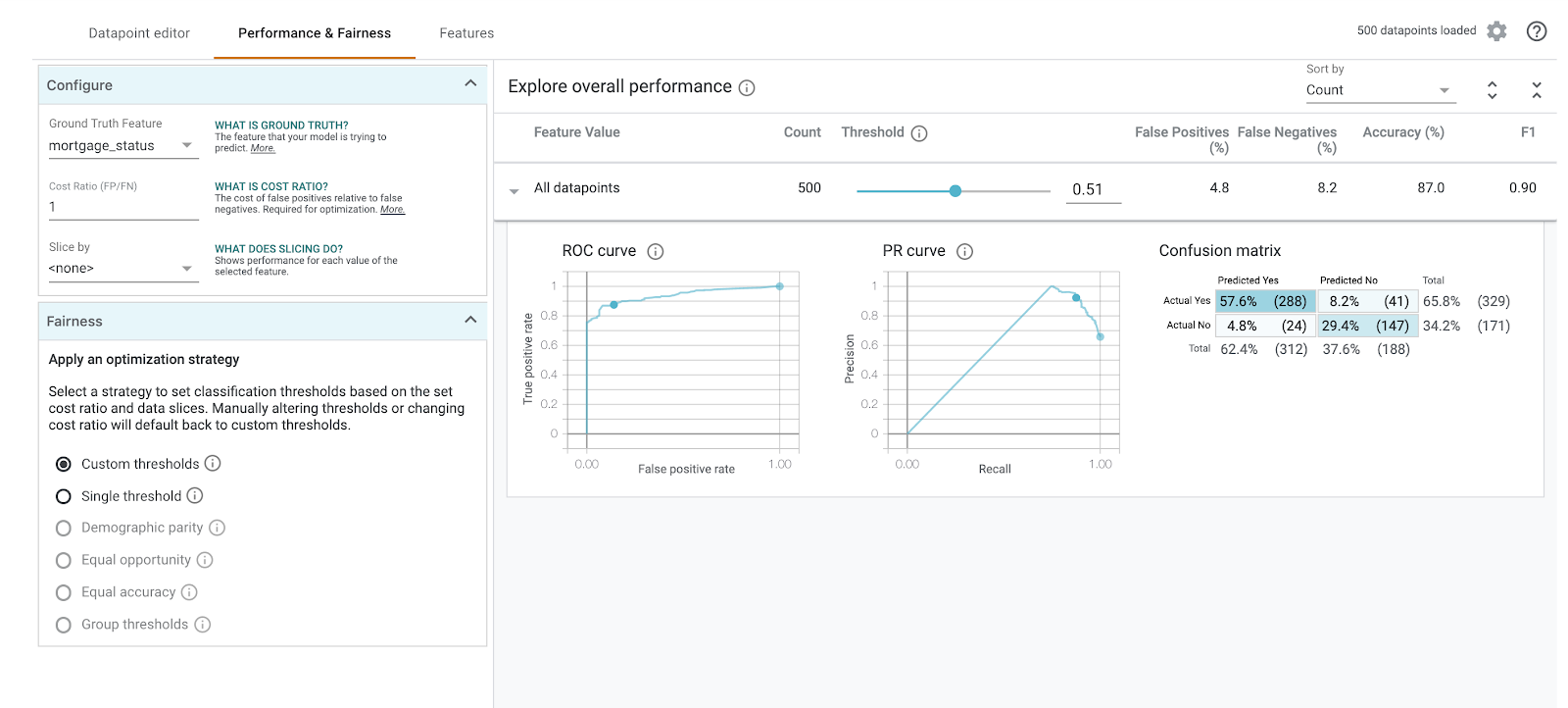
Essa matriz de confusão mostra as previsões corretas e incorretas do modelo como uma porcentagem do total. Se você somar os quadrados Sim real / Sim previsto e Não real / Não previsto, eles vão adicionar a mesma acurácia do modelo (cerca de 87%).
Você também pode testar o controle deslizante de limite, aumentando e diminuindo a pontuação de classificação positiva que o modelo precisa retornar antes de decidir prever approved para o empréstimo, e conferir como isso muda a acurácia, os falsos positivos e os falsos negativos. Nesse caso, a precisão é maior em torno de um limite de 0,55.
Em seguida, no menu suspenso Fatiar por à esquerda, selecione loan_purpose_Home_purchase:

Agora você verá a performance nos dois subconjuntos de dados: a fatia "0" mostra quando o empréstimo não é para uma compra de casa, e a fatia "1" é para quando o empréstimo é para uma compra de casa. Confira a acurácia, a taxa de falsos positivos e a taxa de falsos negativos entre as duas frações para procurar diferenças no desempenho.
Se você expandir as linhas para conferir as matrizes de confusão, poderá ver que o modelo prevê "aprovado" para cerca de 70% dos pedidos de empréstimo para compras de casas e apenas 46% dos empréstimos que não são para compras de casas (as porcentagens exatas vão variar no seu modelo):

Se você selecionar Paridade demográfica nos botões de opção à esquerda, os dois limites serão ajustados para que o modelo preveja approved para uma porcentagem semelhante de candidatos em ambas as fatias. O que isso faz com a precisão, os falsos positivos e os falsos negativos de cada fatia?
Etapa 6: analisar a distribuição de recursos
Por fim, navegue até a guia Recursos na Ferramenta What-If. Ela mostra a distribuição de valores para cada recurso no conjunto de dados:

Use essa guia para garantir que o conjunto de dados esteja equilibrado. Por exemplo, parece que muito poucos empréstimos no conjunto de dados foram originados da Farm Service Agency. Para melhorar a acurácia do modelo, podemos adicionar mais empréstimos dessa agência se os dados estiverem disponíveis.
Descrevemos apenas algumas ideias de análise da Ferramenta What-If aqui. Sinta-se à vontade para continuar usando a ferramenta. Há muitas outras áreas para explorar.
8. Revisão dos dados
Se você quiser continuar usando esse notebook, recomendamos que o desative quando não estiver em uso. Na interface de Notebooks no console do Cloud, selecione o notebook e clique em Parar:

Se você quiser excluir todos os recursos criados neste laboratório, basta excluir a instância do notebook em vez de interrompê-la.
Usando o menu de navegação no console do Cloud, acesse o Storage e exclua os dois buckets criados para armazenar os recursos do modelo.