
1. Genel Bakış
Bu laboratuvarda, finansal veriler üzerinde eğitilmiş ve Cloud AI Platform'da dağıtılmış bir XGBoost modelini analiz etmek için What-If Aracı'nı kullanacaksınız.
Öğrenecekleriniz
Öğrenecekleriniz:
- AI Platform Notebooks'ta herkese açık bir ipotek veri kümesi üzerinde XGBoost modeli eğitme
- XGBoost modelini AI Platform'a dağıtma
- What-If Aracı'nı kullanarak modeli analiz etme
Bu laboratuvarı Google Cloud'da çalıştırmanın toplam maliyeti yaklaşık 1 ABD dolarıdır.
2. XGBoost hakkında kısa bilgiler
XGBoost, tahmin modelleri oluşturmak için karar ağaçları ve gradyan artırma kullanan bir makine öğrenimi çerçevesidir. Bir ağaçtaki farklı yaprak düğümleriyle ilişkili puana göre birden fazla karar ağacını bir araya getirerek çalışır.
Aşağıdaki diyagram, hava durumuna göre bir spor müsabakasının oynanıp oynanmaması gerektiğini değerlendiren basit bir karar ağacı modelinin görselleştirilmiş halidir:

Bu modelde neden XGBoost kullanıyoruz? Geleneksel sinir ağlarının, resim ve metin gibi yapılandırılmamış verilerde en iyi performansı gösterdiği kanıtlanmış olsa da karar ağaçları, bu codelab'de kullanacağımız ipotek veri kümesi gibi yapılandırılmış verilerde genellikle son derece iyi performans gösterir.
3. Ortamınızı ayarlama
Bu codelab'i çalıştırmak için faturalandırmanın etkin olduğu bir Google Cloud Platform projesine ihtiyacınız vardır. Proje oluşturmak için buradaki talimatları uygulayın.
1. adım: Cloud AI Platform Models API'yi etkinleştirin
Cloud Console'unuzun AI Platform Modelleri bölümüne gidin ve henüz etkinleştirilmemişse Etkinleştir'i tıklayın.

2. adım: Compute Engine API'yi etkinleştirin
Compute Engine'e gidin ve henüz etkinleştirilmemişse Etkinleştir'i seçin. Not defteri örneğinizi oluşturmak için bu bilgiye ihtiyacınız vardır.
3. adım: AI Platform Notebooks örneği oluşturun
Cloud Console'unuzun AI Platform Notebooks bölümüne gidin ve New Instance'ı (Yeni Örnek) tıklayın. Ardından, GPU'suz en yeni TF Enterprise 2.x örnek türünü seçin:

Varsayılan seçenekleri kullanıp Oluştur'u tıklayın. Örnek oluşturulduktan sonra Open JupyterLab'i (JupyterLab'i aç) seçin:

4. adım: XGBoost'u yükleyin
JupyterLab örneğiniz açıldıktan sonra XGBoost paketini eklemeniz gerekir.
Bunu yapmak için başlatıcıdan Terminal'i seçin:

Ardından, Cloud AI Platform tarafından desteklenen XGBoost'un en son sürümünü yüklemek için aşağıdaki komutu çalıştırın:
pip3 install xgboost==0.90
Bu işlem tamamlandıktan sonra başlatıcıdan bir Python 3 not defteri örneği açın. Not defterinizi kullanmaya başlayabilirsiniz.
5. adım: Python paketlerini içe aktarın
Not defterinizin ilk hücresine aşağıdaki içe aktarma işlemlerini ekleyin ve hücreyi çalıştırın. Bu işlemi, üst menüdeki sağ ok düğmesine veya command-enter tuşlarına basarak uygulayabilirsiniz:
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
4. Verileri indirme ve işleme
XGBoost modelini eğitmek için ffiec.gov adresindeki bir ipotek veri kümesini kullanacağız. Orijinal veri kümesinde bazı ön işlemler yaptık ve modeli eğitmek için kullanabileceğiniz daha küçük bir sürüm oluşturduk. Model, belirli bir ipotek başvurusunun onaylanıp onaylanmayacağını tahmin eder.
1. adım: Önceden işlenmiş veri kümesini indirin
Veri kümesinin bir sürümünü Google Cloud Storage'da sizin için kullanıma sunduk. Aşağıdaki gsutil komutu Jupyter not defterinizde çalıştırarak indirebilirsiniz:
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
2. adım: Veri kümesini Pandas ile okuyun
Pandas DataFrame'imizi oluşturmadan önce, Pandas'ın veri kümemizi doğru şekilde okuması için her sütunun veri türünün bir sözlüğünü oluşturacağız:
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
Ardından, yukarıda belirttiğimiz veri türlerini ileterek bir DataFrame oluşturacağız. Orijinal veri kümesi belirli bir şekilde sıralanmışsa verilerimizi karıştırmamız önemlidir. Bunu yapmak için ilk hücreye aktardığımız shuffle adlı bir sklearn yardımcı programını kullanırız:
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
data.head(), Pandas'taki veri kümemizin ilk beş satırını önizlememize olanak tanır. Yukarıdaki hücreyi çalıştırdıktan sonra şuna benzer bir sonuç görürsünüz:
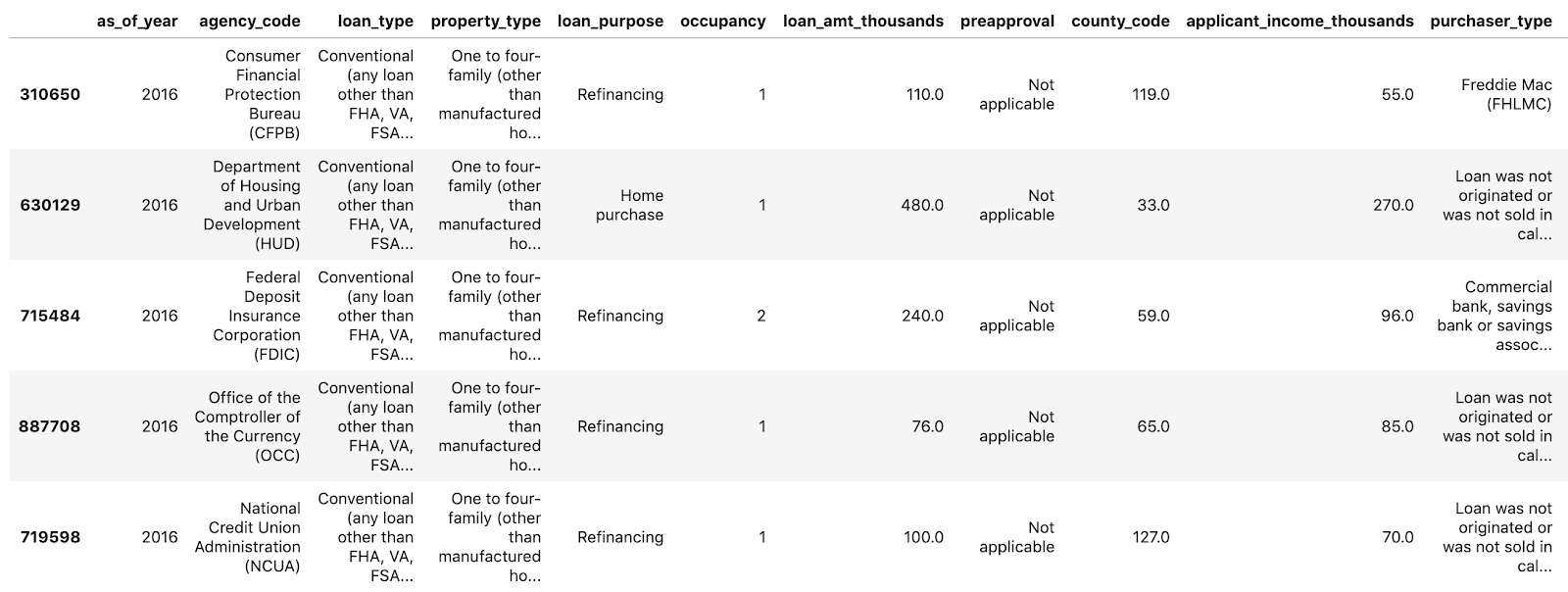
Modelimizi eğitmek için kullanacağımız özellikler şunlardır: En sona kaydırdığınızda, tahmin ettiğimiz şey olan son sütunu approved görürsünüz. 1 değeri, belirli bir uygulamanın onaylandığını, 0 değeri ise reddedildiğini gösterir.
Veri kümesindeki onaylanan / reddedilen değerlerin dağılımını görmek ve etiketlerin bir numpy dizisini oluşturmak için aşağıdakileri çalıştırın:
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
Veri kümesinin yaklaşık% 66'sı onaylanmış uygulamaları içerir.
3. adım: Kategorik değerler için sahte sütun oluşturma
Bu veri kümesi, kategorik ve sayısal değerlerin bir karışımını içerir ancak XGBoost, tüm özelliklerin sayısal olmasını gerektirir. Kategorik değerleri one-hot kodlama kullanarak temsil etmek yerine, XGBoost modelimizde Pandas get_dummies işlevinden yararlanacağız.
get_dummies, birden çok olası değer içeren bir sütunu alır ve her biri yalnızca 0 ve 1 içeren bir sütun serisine dönüştürür. Örneğin, olası değerleri "mavi" ve "kırmızı" olan bir "renk" sütunumuz varsa get_dummies, bunu "color_blue" ve "color_red" adlı 2 sütuna dönüştürür ve tüm Boole değerleri 0 ve 1 olur.
Kategorik özelliklerimiz için sahte sütunlar oluşturmak üzere aşağıdaki kodu çalıştırın:
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
Bu kez verileri önizlediğinizde, tek özelliklerin (ör. aşağıda gösterilen purchaser_type) birden fazla sütuna bölündüğünü görürsünüz:

4. adım: Verileri eğitim ve test kümelerine bölme
Makine öğrenimindeki önemli kavramlardan biri eğitim / test ayrımıdır. Verilerimizin çoğunu alıp modelimizi eğitmek için kullanacağız. Geri kalanını ise modelimizi daha önce hiç görmediği verilerle test etmek için ayıracağız.
Verilerimizi bölmek için Scikit Learn işlevi train_test_split'yı kullanan not defterinize aşağıdaki kodu ekleyin:
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
Artık modelinizi oluşturup eğitmeye hazırsınız.
5. XGBoost modeli oluşturma, eğitme ve değerlendirme
1. adım: XGBoost modelini tanımlayın ve eğitin
XGBoost'ta model oluşturmak kolaydır. Modeli oluşturmak için XGBClassifier sınıfını kullanacağız ve belirli sınıflandırma görevimiz için doğru objective parametresini iletmemiz yeterli olacak. Bu durumda, ikili sınıflandırma problemimiz olduğu ve modelin (0,1) aralığında tek bir değer (onaylanmadı için reg:logistic, onaylandı için 1) vermesini istediğimiz için reg:logistic kullanıyoruz.0
Aşağıdaki kod, bir XGBoost modeli oluşturur:
model = xgb.XGBClassifier(
objective='reg:logistic'
)
fit() yöntemini çağırıp eğitim verilerini ve etiketlerini ileterek modeli tek bir kod satırıyla eğitebilirsiniz.
model.fit(x_train, y_train)
2. adım: Modelinizin doğruluğunu değerlendirin
Artık eğitilmiş modelimizi kullanarak predict() işleviyle test verilerimiz üzerinde tahminler oluşturabiliriz.
Ardından, modelimizin test verilerimizdeki performansına göre doğruluğunu hesaplamak için Scikit Learn'ün accuracy_score işlevini kullanacağız. Bu işleme, test setimizdeki her örnek için kesin referans değerleri ve modelin tahmin edilen değerleri iletilir:
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
Doğruluk oranı yaklaşık %87 olmalıdır ancak makine öğreniminde her zaman rastgelelik unsuru olduğundan bu oran sizde biraz farklılık gösterebilir.
3. adım: Modelinizi kaydedin
Modeli dağıtmak için aşağıdaki kodu çalıştırarak modeli yerel bir dosyaya kaydedin:
model.save_model('model.bst')
6. Modeli Cloud AI Platform'a dağıtma
Modelimiz yerel olarak çalışıyor ancak her yerden (yalnızca bu not defterinden değil) tahminlerde bulunabilmek güzel olurdu. Bu adımda, modeli buluta dağıtacağız.
1. adım: Modelimiz için Cloud Storage paketi oluşturun
Öncelikle, codelab'in geri kalanında kullanacağımız bazı ortam değişkenlerini tanımlayalım. Aşağıdaki değerleri Google Cloud projenizin adı, oluşturmak istediğiniz Cloud Storage paketinin adı (global olarak benzersiz olmalıdır) ve modelinizin ilk sürümünün sürüm adıyla doldurun:
# Update these to your own GCP project, model, and version names
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
VERSION_NAME = 'v1'
MODEL_NAME = 'xgb_mortgage'
Artık XGBoost model dosyamızı depolamak için bir depolama paketi oluşturmaya hazırız. Dağıtım sırasında Cloud AI Platform'u bu dosyaya yönlendireceğiz.
Paket oluşturmak için not defterinizden şu gsutil komutunu çalıştırın:
!gsutil mb $MODEL_BUCKET
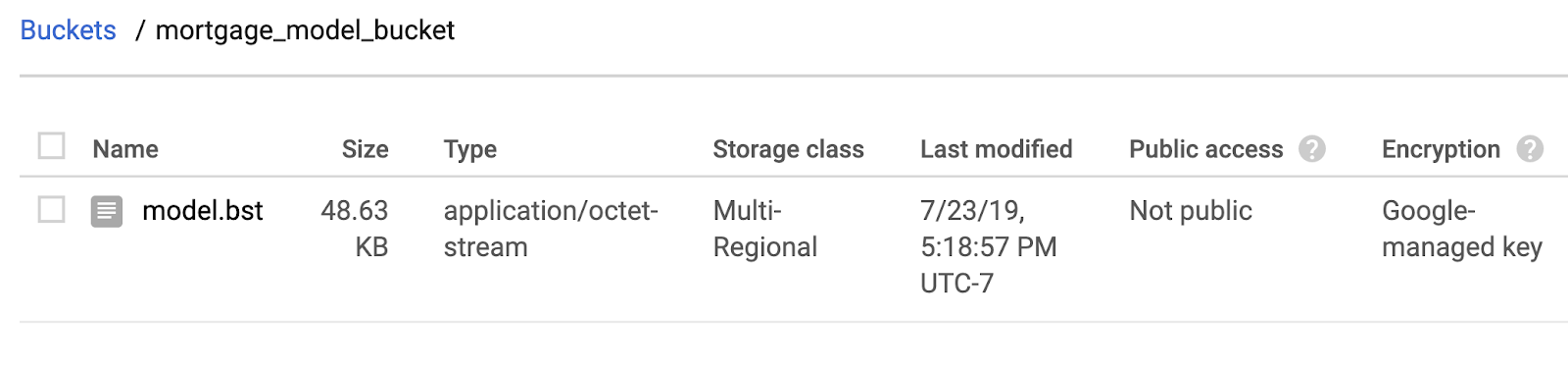
2. adım: Model dosyasını Cloud Storage'a kopyalayın
Ardından, XGBoost kaydedilmiş model dosyamızı Cloud Storage'a kopyalayacağız. Aşağıdaki gsutil komutunu çalıştırın:
!gsutil cp ./model.bst $MODEL_BUCKET
Dosyanın kopyalandığını doğrulamak için Cloud Console'unuzdaki depolama tarayıcısına gidin:
3. adım: Modeli oluşturun ve dağıtın
Modeli dağıtmaya neredeyse hazırız. Aşağıdaki ai-platform gcloud komutu, projenizde yeni bir model oluşturur. Buna xgb_mortgage adını verelim:
!gcloud ai-platform models create $MODEL_NAME --region='global'
Şimdi modeli dağıtma zamanı. Bu işlemi aşağıdaki gcloud komutuyla yapabiliriz:
!gcloud ai-platform versions create $VERSION_NAME \
--model=$MODEL_NAME \
--framework='XGBOOST' \
--runtime-version=2.1 \
--origin=$MODEL_BUCKET \
--python-version=3.7 \
--project=$GCP_PROJECT \
--region='global'
Bu işlem çalışırken AI Platform Console'un modeller bölümünü kontrol edin. Yeni sürümünüzün dağıtıldığını görürsünüz:

Dağıtım başarıyla tamamlandığında yükleme döner simgesinin yerinde yeşil bir onay işareti görürsünüz. Dağıtım işlemi 2-3 dakika sürer.
4. adım: Dağıtılan modeli test edin
Dağıtılan modelinizin çalıştığından emin olmak için gcloud'u kullanarak tahmin oluşturarak modeli test edin. Öncelikle, test setimizdeki ilk örneği içeren bir JSON dosyası kaydedin:
%%writefile predictions.json
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
Bu kodu çalıştırarak modelinizi test edin:
prediction = !gcloud ai-platform predict --model=xgb_mortgage --region='global' --json-instances=predictions.json --version=$VERSION_NAME --verbosity=none
print(prediction)
Çıkışta modelinizin tahminini görmeniz gerekir. Bu örnek onaylandığı için 1'e yakın bir değer görmeniz gerekir.
7. Modelinizi yorumlamak için What-If Aracı'nı kullanma
1. adım: Senaryo Analizi Aracı görselleştirmesini oluşturun
What-If Aracı'nı AI Platform modellerinize bağlamak için bu araca test örneklerinizin bir alt kümesini ve bu örneklerin kesin referans değerlerini iletmeniz gerekir. Şimdi, gerçek referans değer etiketleriyle birlikte 500 test örneğimizden oluşan bir NumPy dizisi oluşturalım:
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples].values,y_test[:num_wit_examples].reshape(-1,1)))
What-If Aracı'nı başlatmak, WitConfigBuilder nesnesi oluşturup analiz etmek istediğimiz AI Platform modelini bu nesneye iletmek kadar basittir.
Burada isteğe bağlı adjust_prediction parametresini kullanıyoruz. Çünkü "Ne Olursa?" aracı, modelimizdeki her sınıf için bir puan listesi (bu örnekte 2) bekliyor. Modelimiz yalnızca 0 ile 1 arasında tek bir değer döndürdüğünden bu işlevde doğru biçime dönüştürürüz:
def adjust_prediction(pred):
return [1 - pred, pred]
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_ai_platform_model(GCP_PROJECT, MODEL_NAME, VERSION_NAME, adjust_prediction=adjust_prediction)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
Görselleştirmenin yüklenmesinin bir dakika süreceğini unutmayın. Yüklendiğinde aşağıdakileri görmeniz gerekir:
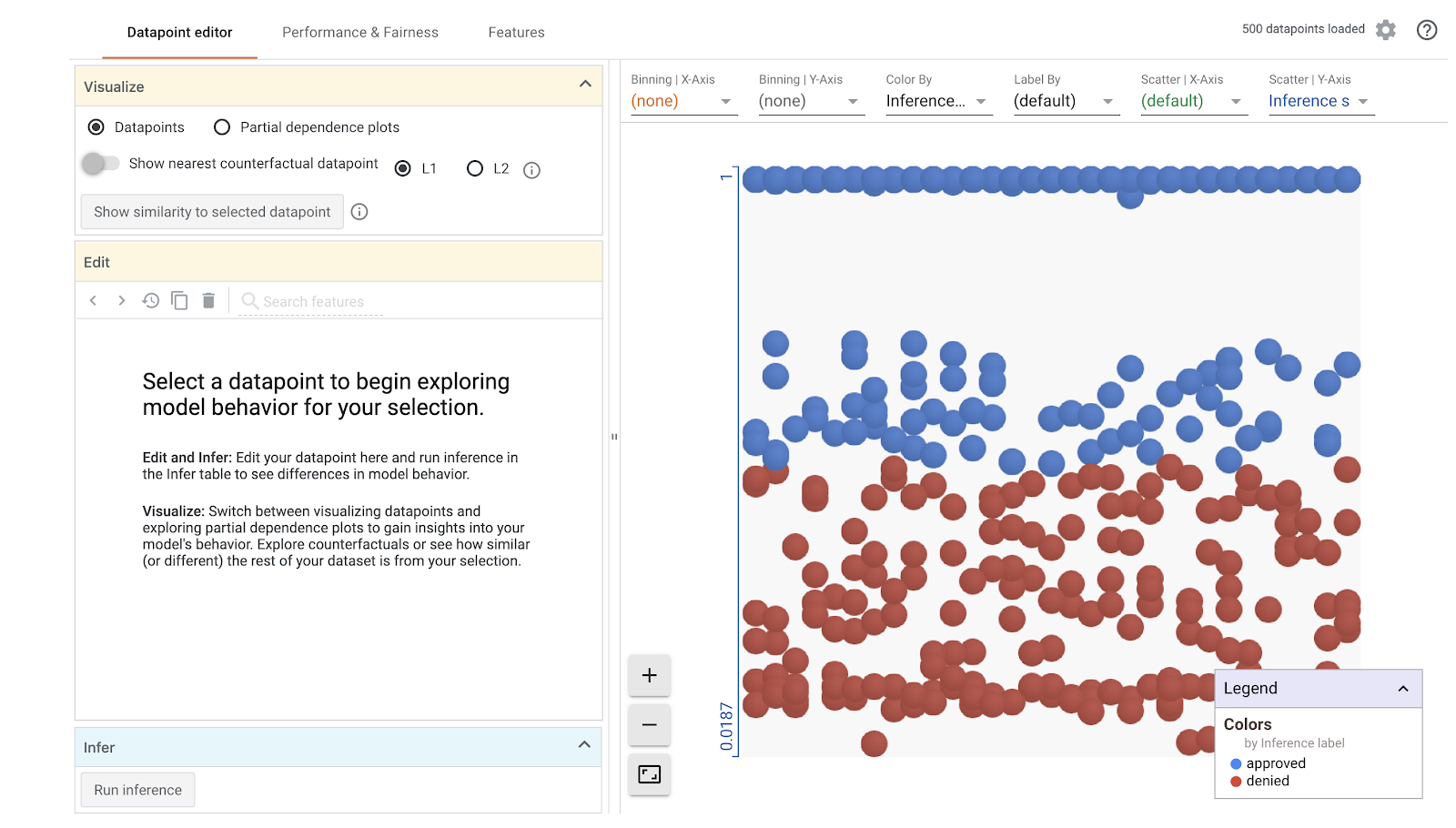
Y ekseni, modelin tahminini gösterir. 1, yüksek güvene sahip bir approved tahmini, 0 ise yüksek güvene sahip bir denied tahminidir. X ekseni, yalnızca yüklenen tüm veri noktalarının dağılımıdır.
2. adım: Tek tek veri noktalarını inceleyin
Ne Olursa Olsun Aracı'ndaki varsayılan görünüm Veri noktası düzenleyici sekmesidir. Burada, özelliklerini görmek, özellik değerlerini değiştirmek ve bu değişikliğin modelin tek bir veri noktasıyla ilgili tahminini nasıl etkilediğini görmek için herhangi bir veri noktasını tıklayabilirsiniz.
Aşağıdaki örnekte, 0,5 eşiğine yakın bir veri noktası seçtik. Bu belirli veri noktasıyla ilişkili ipotek başvurusu CFPB'den gelmiştir. Bu özelliği 0 olarak değiştirdik ve bu kredinin HUD'dan alınması durumunda modelin tahmininde ne gibi değişiklikler olacağını görmek için agency_code_Department of Housing and Urban Development (HUD) değerini 1 olarak değiştirdik:
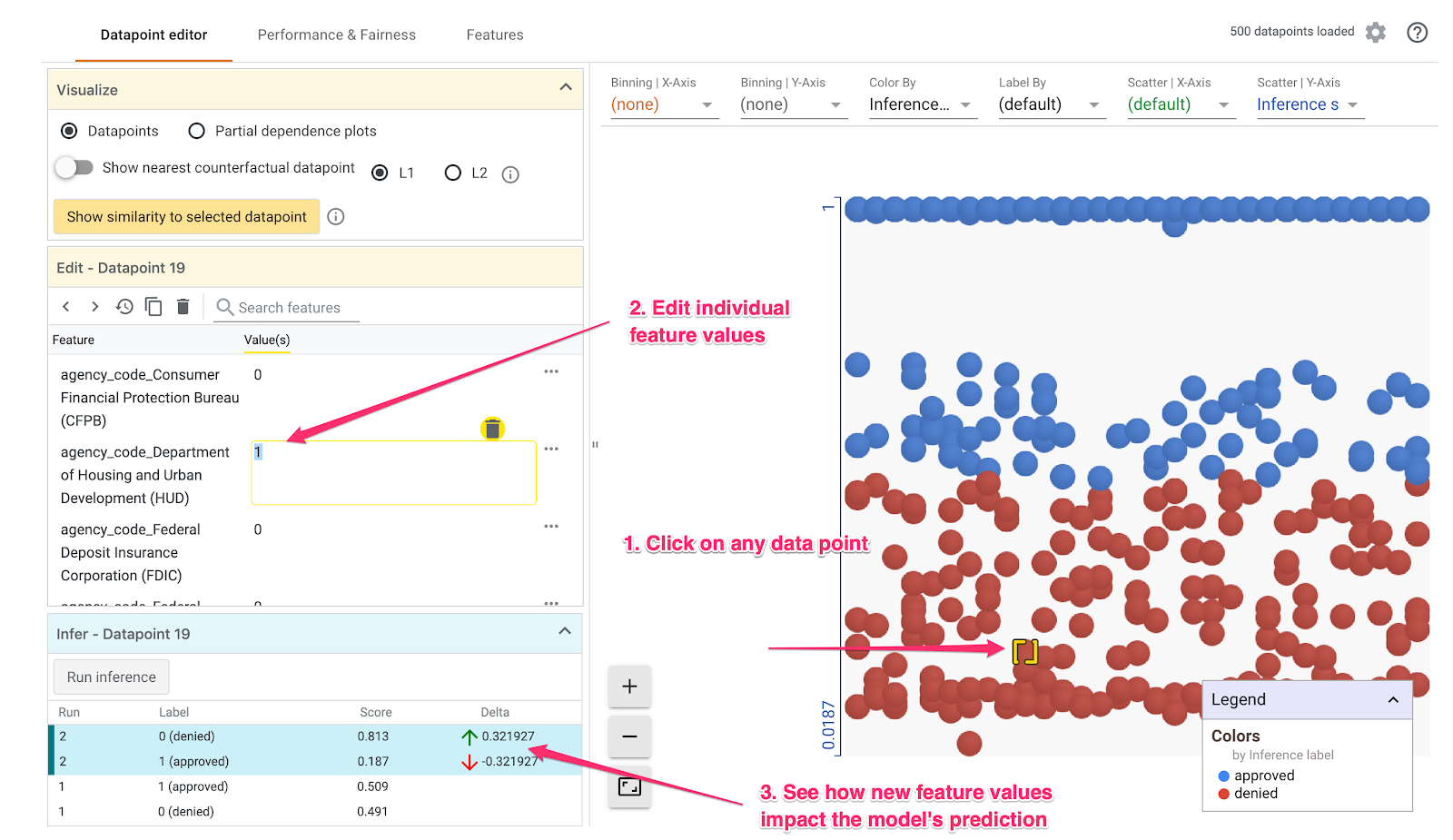
Ne Olursa Olsun Aracı'nın sol alt bölümünde görebileceğimiz gibi, bu özelliği değiştirmek modelin approved tahminini %32 oranında düşürdü. Bu durum, kredinin alındığı kurumun modelin çıktısı üzerinde büyük bir etkisi olduğunu gösterebilir ancak emin olmak için daha fazla analiz yapmamız gerekir.
Kullanıcı arayüzünün sol alt kısmında, her veri noktasının kesin referans değerini de görebilir ve modelin tahminiyle karşılaştırabiliriz:
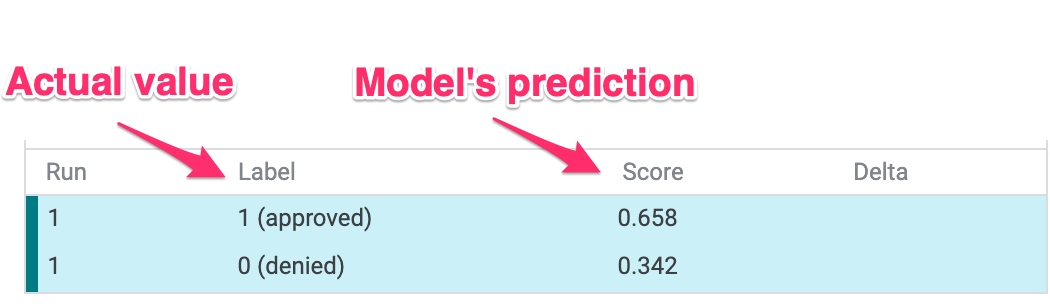
3. adım: Karşı olgusal analiz
Ardından, herhangi bir veri noktasını tıklayın ve En yakın karşı olgusal veri noktasını göster kaydırma çubuğunu sağa hareket ettirin:

Bu seçeneği belirlediğinizde, seçtiğiniz orijinal veri noktasına en benzer özellik değerlerine sahip olan ancak tahmini ters yönde olan veri noktası gösterilir. Ardından, iki veri noktasının nerede farklılaştığını görmek için özellik değerleri arasında kaydırabilirsiniz (farklılıklar yeşil renkte ve kalın olarak vurgulanır).
4. adım: Kısmi bağımlılık grafiklerine bakın
Her özelliğin modelin genel tahminlerini nasıl etkilediğini görmek için Kısmi bağımlılık grafikleri kutusunu işaretleyin ve Genel kısmi bağımlılık grafikleri'nin seçili olduğundan emin olun:
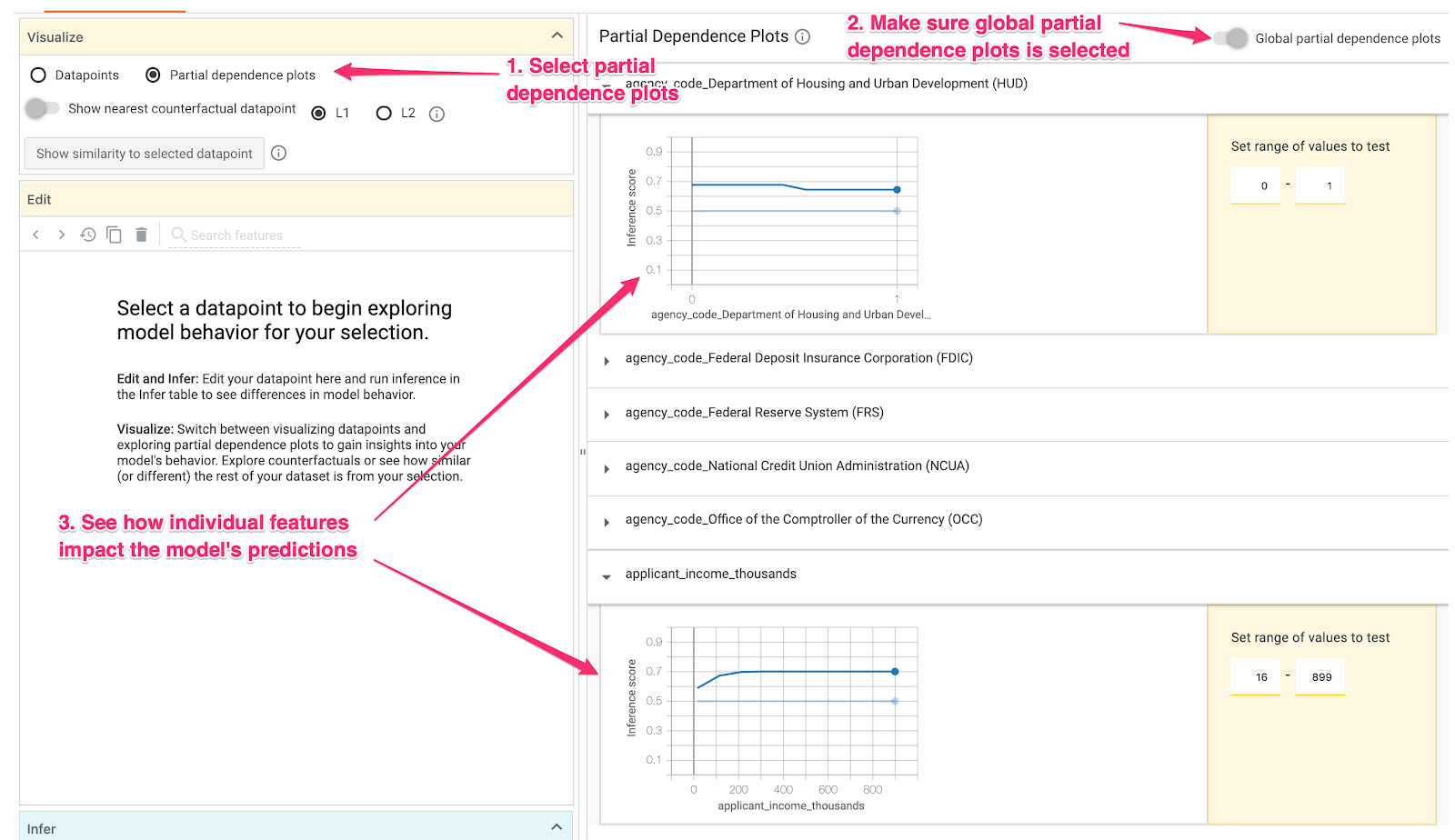
Burada, HUD'dan alınan kredilerin reddedilme olasılığının biraz daha yüksek olduğunu görüyoruz. Grafiğin bu şekilde olmasının nedeni, ajans kodunun bir boole özelliği olmasıdır. Bu nedenle değerler yalnızca tam olarak 0 veya 1 olabilir.
applicant_income_thousands sayısal bir özelliktir ve kısmi bağımlılık grafiğinde daha yüksek gelirin, başvurunun onaylanma olasılığını biraz artırdığını ancak yalnızca yaklaşık 200.000 ABD dolarına kadar artırdığını görebiliriz. 200.000 ABD dolarından sonra bu özellik, modelin tahminini etkilemez.
5. adım: Genel performansı ve tarafsızlığı inceleyin
Ardından Performans ve Algoritmik Adalet sekmesine gidin. Bu bölümde, sağlanan veri kümesindeki modelin sonuçlarıyla ilgili genel performans istatistikleri (karmaşıklık matrisleri, PR eğrileri ve ROC eğrileri dahil) gösterilir.
Karışıklık matrisini görmek için Gerçek Doğru Özelliği olarak mortgage_status simgesini seçin:
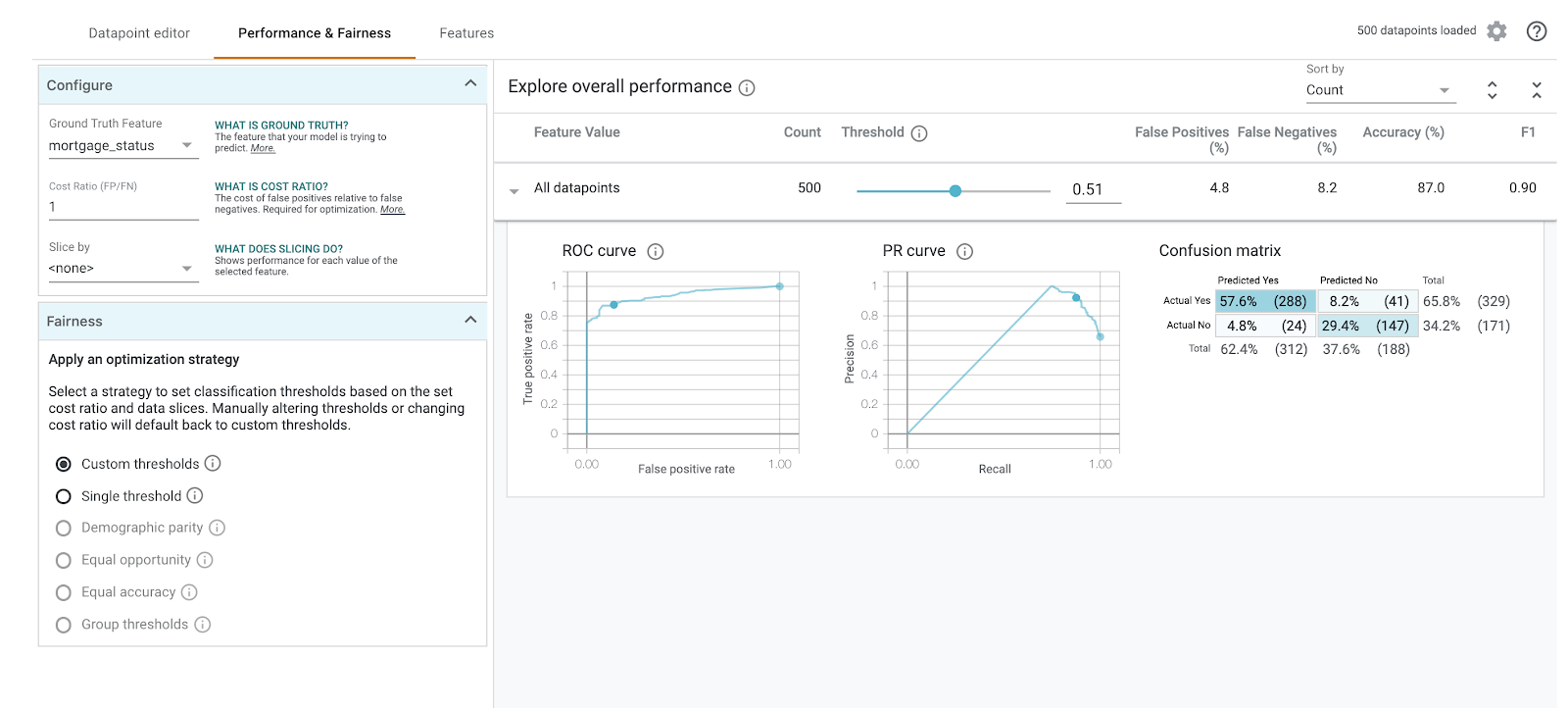
Bu karışıklık matrisi, modelimizin doğru ve yanlış tahminlerini toplamın yüzdesi olarak gösterir. Gerçek Evet / Tahmin Edilen Evet ve Gerçek Hayır / Tahmin Edilen Hayır karelerini topladığınızda modelinizle aynı doğruluk oranını (yaklaşık %87) elde etmeniz gerekir.
Ayrıca, modelin kredi için approved tahminine karar vermeden önce döndürmesi gereken pozitif sınıflandırma puanını yükseltip alçaltarak eşik kaydırıcısıyla denemeler yapabilir ve bunun doğruluğu, yanlış pozitifleri ve yanlış negatifleri nasıl değiştirdiğini görebilirsiniz. Bu durumda doğruluk, 0,55 eşiğinde en yüksektir.
Ardından, soldaki Dilimle açılır listesinde loan_purpose_Home_purchase simgesini seçin:

Artık verilerinizin iki alt kümesindeki performansı göreceksiniz: "0" dilimi, kredinin ev satın alma için olmadığı zamanı, "1" dilimi ise kredinin ev satın alma için olduğu zamanı gösterir. Performanstaki farklılıkları görmek için iki dilim arasındaki doğruluk, yanlış pozitif ve yanlış negatif oranını inceleyin.
Satırları genişleterek karmaşıklık matrislerine baktığınızda modelin, ev satın alma amaçlı kredi başvurularının yaklaşık% 70'i ve ev satın alma amaçlı olmayan kredilerin yalnızca% 46'sı için "onaylandı" tahmininde bulunduğunu görebilirsiniz (Kesin yüzdeler modelinize göre değişir):
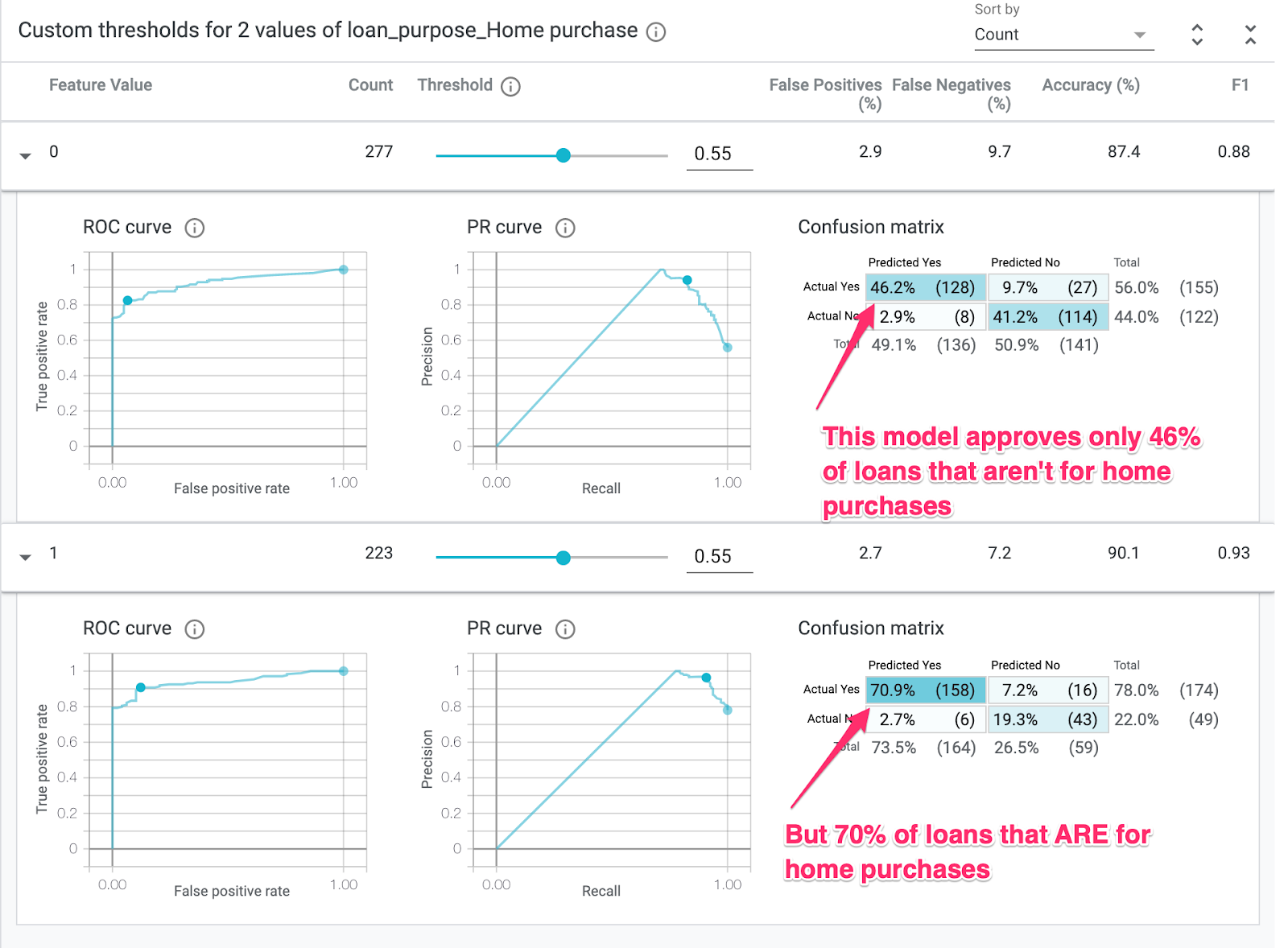
Soldaki radyo düğmelerinden Demografik eşitlik'i seçerseniz modelin her iki dilimde de benzer bir başvuru yüzdesi için approved tahmin etmesi amacıyla iki eşik ayarlanır. Bu durum, her dilimin doğruluğunu, yanlış pozitiflerini ve yanlış negatiflerini nasıl etkiler?
6. adım: Özellik dağıtımını keşfedin
Son olarak, What-If Aracı'nda Özellikler sekmesine gidin. Bu, veri kümenizdeki her özelliğin değer dağılımını gösterir:
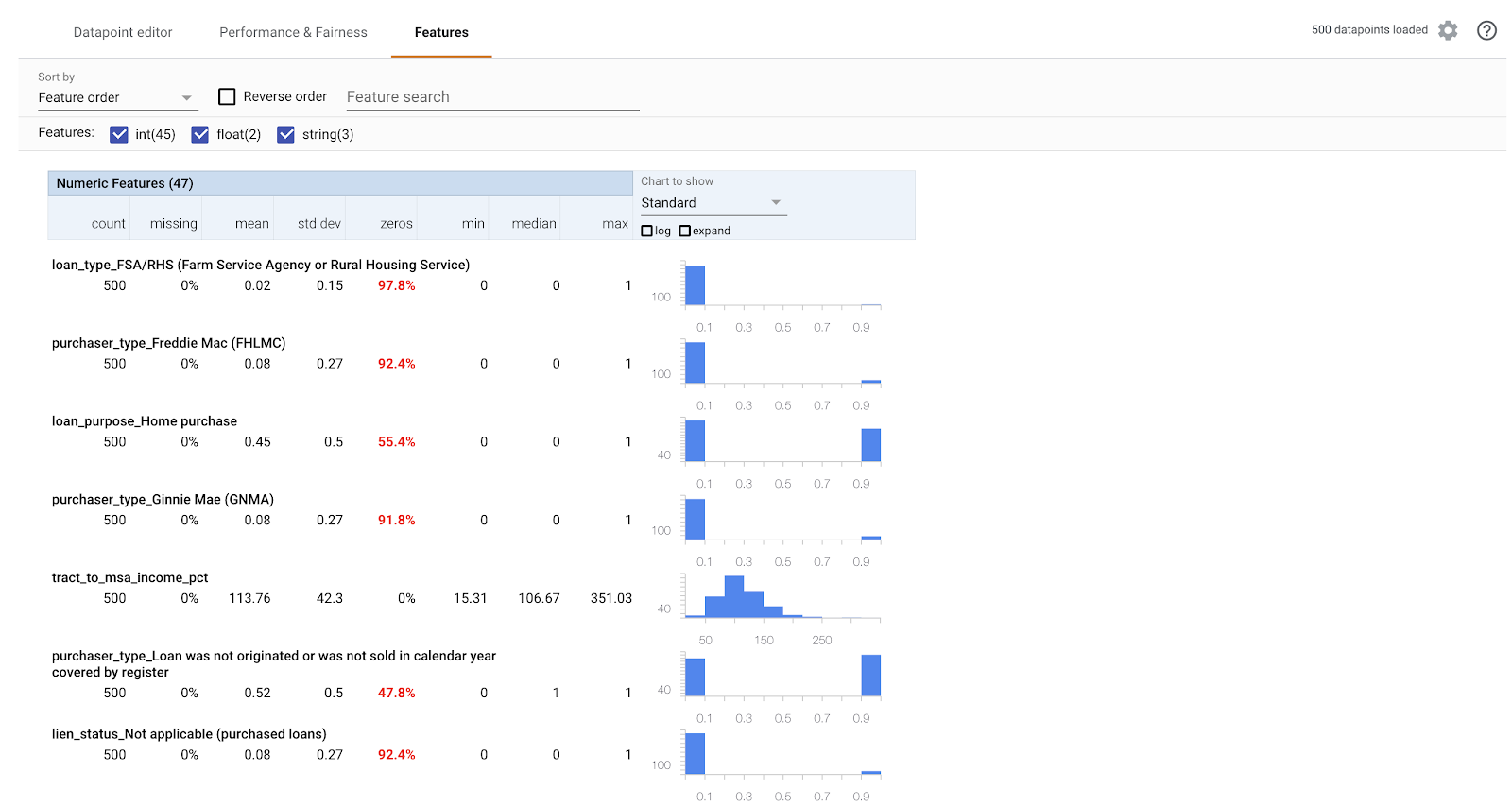
Veri kümenizin dengeli olduğundan emin olmak için bu sekmeyi kullanabilirsiniz. Örneğin, veri kümesindeki çok az sayıda kredinin Farm Service Agency'den alındığı görülüyor. Modelin doğruluğunu artırmak için veriler mevcutsa bu kuruluştan daha fazla kredi ekleyebiliriz.
Burada What-If Aracı ile ilgili keşif fikirlerinden yalnızca birkaçı açıklanmıştır. Aracı kullanmaya devam edebilirsiniz. Keşfedebileceğiniz daha birçok alan var.
8. Temizleme
Bu not defterini kullanmaya devam etmek istiyorsanız kullanmadığınız zamanlarda kapatmanız önerilir. Cloud Console'unuzdaki Notebooks kullanıcı arayüzünde not defterini ve ardından Durdur'u seçin:

Bu laboratuvarda oluşturduğunuz tüm kaynakları silmek istiyorsanız not defteri örneğini durdurmak yerine silmeniz yeterlidir.
Cloud Console'daki gezinme menüsünü kullanarak Storage'a gidin ve model varlıklarınızı depolamak için oluşturduğunuz her iki paketi de silin.