
1. Tổng quan
Trong phòng thí nghiệm này, bạn sẽ sử dụng Công cụ What-if để phân tích một mô hình XGBoost được huấn luyện trên dữ liệu tài chính và triển khai trên Nền tảng Trí tuệ nhân tạo của Cloud.
Kiến thức bạn sẽ học được
Bạn sẽ tìm hiểu cách:
- Huấn luyện một mô hình XGBoost trên một tập dữ liệu thế chấp công khai trong Nền tảng Trí tuệ nhân tạo Notebooks
- Triển khai mô hình XGBoost lên Nền tảng Trí tuệ nhân tạo
- Phân tích mô hình bằng Công cụ What-if
Tổng chi phí để chạy phòng thí nghiệm này trên Google Cloud là khoảng 1 USD.
2. Giới thiệu nhanh về XGBoost
XGBoost là một khung học máy sử dụng cây quyết định và tăng cường độ dốc để xây dựng các mô hình dự đoán. Khung này hoạt động bằng cách kết hợp nhiều cây quyết định dựa trên điểm số liên kết với các nút lá khác nhau trong một cây.
Sơ đồ bên dưới là hình ảnh trực quan của một mô hình cây quyết định đơn giản, đánh giá xem có nên chơi một trận đấu thể thao dựa trên dự báo thời tiết hay không:
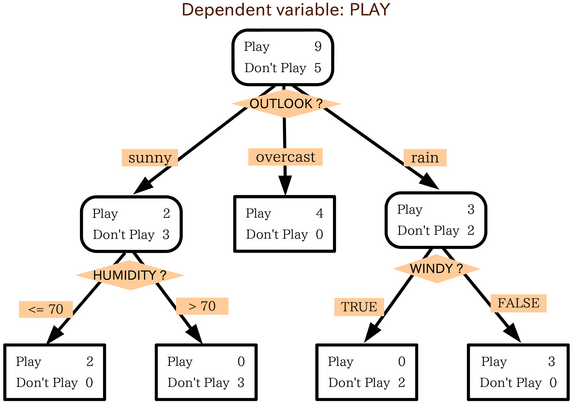
Tại sao chúng ta sử dụng XGBoost cho mô hình này? Mặc dù các mạng nơ-ron truyền thống đã được chứng minh là hoạt động tốt nhất trên dữ liệu phi cấu trúc như hình ảnh và văn bản, nhưng cây quyết định thường hoạt động cực kỳ tốt trên dữ liệu có cấu trúc như tập dữ liệu thế chấp mà chúng ta sẽ sử dụng trong lớp học lập trình này.
3. Thiết lập môi trường
Bạn cần có một dự án trên Google Cloud Platform có bật tính năng thanh toán để chạy lớp học lập trình này. Để tạo một dự án, hãy làm theo hướng dẫn tại đây.
Bước 1: Bật API Mô hình Nền tảng Trí tuệ nhân tạo trên Cloud
Chuyển đến phần Mô hình Nền tảng Trí tuệ nhân tạo của Cloud Console rồi nhấp vào Bật nếu bạn chưa bật.

Bước 2: Bật API Compute Engine
Chuyển đến Compute Engine rồi chọn Bật nếu bạn chưa bật. Bạn sẽ cần API này để tạo phiên bản sổ tay.
Bước 3: Tạo một thực thể AI Platform Notebooks
Chuyển đến phần Nền tảng Trí tuệ nhân tạo Notebooks của bảng điều khiển Cloud rồi nhấp vào Phiên bản mới. Sau đó, hãy chọn loại phiên bản TF Enterprise 2.x mới nhất không có GPU:
Sử dụng các tuỳ chọn mặc định rồi nhấp vào Tạo. Sau khi tạo phiên bản, hãy chọn Mở JupyterLab:

Bước 4: Cài đặt XGBoost
Sau khi mở phiên bản JupyterLab, bạn cần thêm gói XGBoost.
Để thực hiện việc này, hãy chọn Terminal (Thiết bị đầu cuối) trong trình chạy:

Sau đó, hãy chạy lệnh sau để cài đặt phiên bản XGBoost mới nhất được Nền tảng Trí tuệ nhân tạo của Cloud hỗ trợ:
pip3 install xgboost==0.90
Sau khi hoàn tất, hãy mở một phiên bản sổ tay Python 3 từ trình chạy. Bạn đã sẵn sàng bắt đầu trong sổ tay!
Bước 5: Nhập các gói Python
Trong ô đầu tiên của sổ tay, hãy thêm các lệnh nhập sau đây rồi chạy ô. Bạn có thể kích hoạt bằng cách nhấn vào nút mũi tên phải trong trình đơn trên cùng hoặc nhấn command-enter:
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
4. Tải và xử lý dữ liệu
Chúng ta sẽ sử dụng một tập dữ liệu thế chấp từ ffiec.gov để huấn luyện một mô hình XGBoost. Chúng tôi đã thực hiện một số bước tiền xử lý trên tập dữ liệu gốc và tạo một phiên bản nhỏ hơn để bạn sử dụng huấn luyện mô hình. Mô hình này sẽ dự đoán liệu một đơn xin thế chấp cụ thể có được phê duyệt hay không.
Bước 1: Tải tập dữ liệu đã xử lý trước xuống
Chúng tôi đã cung cấp một phiên bản của tập dữ liệu cho bạn trong Google Cloud Storage. Bạn có thể tải tập dữ liệu này xuống bằng cách chạy lệnh gsutil sau đây trong sổ tay Jupyter:
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
Bước 2: Đọc tập dữ liệu bằng Pandas
Trước khi tạo Pandas DataFrame, chúng ta sẽ tạo một từ điển về kiểu dữ liệu của từng cột để Pandas đọc tập dữ liệu của chúng ta một cách chính xác:
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
Tiếp theo, chúng ta sẽ tạo một DataFrame, truyền cho DataFrame các kiểu dữ liệu mà chúng ta đã chỉ định ở trên. Điều quan trọng là phải xáo trộn dữ liệu trong trường hợp tập dữ liệu gốc được sắp xếp theo một cách cụ thể. Chúng ta sử dụng một tiện ích sklearn có tên là shuffle để thực hiện việc này. Chúng ta đã nhập tiện ích này trong ô đầu tiên:
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
data.head() cho phép chúng ta xem trước 5 hàng đầu tiên của tập dữ liệu trong Pandas. Bạn sẽ thấy một nội dung như sau sau khi chạy ô ở trên:

Đây là các tính năng mà chúng ta sẽ sử dụng để huấn luyện mô hình. Nếu bạn cuộn xuống cuối cùng, bạn sẽ thấy cột cuối cùng approved, đây là nội dung mà chúng ta đang dự đoán. Giá trị 1 cho biết một đơn xin cụ thể đã được phê duyệt và 0 cho biết đơn xin đó đã bị từ chối.
Để xem phân phối các giá trị được phê duyệt / bị từ chối trong tập dữ liệu và tạo một mảng numpy gồm các nhãn, hãy chạy lệnh sau:
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
Khoảng 66% tập dữ liệu chứa các đơn xin được phê duyệt.
Bước 3: Tạo cột giả cho các giá trị phân loại
Tập dữ liệu này chứa hỗn hợp các giá trị phân loại và giá trị số, nhưng XGBoost yêu cầu tất cả các tính năng phải là giá trị số. Thay vì biểu diễn các giá trị phân loại bằng phương thức mã one-hot , đối với mô hình XGBoost, chúng ta sẽ tận dụng hàm get_dummies của Pandas.
get_dummies lấy một cột có nhiều giá trị có thể và chuyển đổi cột đó thành một chuỗi cột, mỗi cột chỉ có giá trị 0 và 1. Ví dụ: nếu chúng ta có một cột "màu" với các giá trị có thể là "xanh dương" và "đỏ", thì get_dummies sẽ chuyển đổi cột này thành 2 cột có tên là "color_blue" và "color_red" với tất cả các giá trị boolean 0 và 1.
Để tạo các cột giả cho các tính năng phân loại, hãy chạy mã sau:
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
Khi xem trước dữ liệu lần này, bạn sẽ thấy các tính năng đơn lẻ (như purchaser_type được minh hoạ bên dưới) được chia thành nhiều cột:

Bước 4: Chia dữ liệu thành tập huấn luyện và tập kiểm thử
Một khái niệm quan trọng trong học máy là chia tập huấn luyện / tập kiểm thử. Chúng ta sẽ lấy phần lớn dữ liệu và sử dụng dữ liệu đó để huấn luyện mô hình, đồng thời dành phần còn lại để kiểm thử mô hình trên dữ liệu mà mô hình chưa từng thấy trước đây.
Thêm mã sau đây vào sổ tay. Mã này sử dụng hàm Scikit Learn train_test_split để chia dữ liệu:
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
Bây giờ, bạn đã sẵn sàng xây dựng và huấn luyện mô hình!
5. Xây dựng, huấn luyện và đánh giá một mô hình XGBoost
Bước 1: Xác định và huấn luyện mô hình XGBoost
Việc tạo một mô hình trong XGBoost rất đơn giản. Chúng ta sẽ sử dụng lớp XGBClassifier để tạo mô hình và chỉ cần truyền tham số objective phù hợp cho tác vụ phân loại cụ thể. Trong trường hợp này, chúng ta sử dụng reg:logistic vì chúng ta có một vấn đề phân loại nhị phân và chúng ta muốn mô hình xuất ra một giá trị duy nhất trong phạm vi (0,1): 0 cho trường hợp không được phê duyệt và 1 cho trường hợp được phê duyệt.
Mã sau đây sẽ tạo một mô hình XGBoost:
model = xgb.XGBClassifier(
objective='reg:logistic'
)
Bạn có thể huấn luyện mô hình bằng một dòng mã, gọi phương thức fit() và truyền cho phương thức này dữ liệu huấn luyện và nhãn.
model.fit(x_train, y_train)
Bước 2: Đánh giá độ chính xác của mô hình
Giờ đây, chúng ta có thể sử dụng mô hình đã huấn luyện để tạo dự đoán trên dữ liệu kiểm thử bằng hàm predict().
Sau đó, chúng ta sẽ sử dụng hàm accuracy_score của Scikit Learn để tính toán độ chính xác của mô hình dựa trên hiệu suất của mô hình trên dữ liệu kiểm thử. Chúng ta sẽ truyền cho hàm này các giá trị thông tin thực tế cùng với các giá trị dự đoán của mô hình cho từng ví dụ trong tập kiểm định:
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
Bạn sẽ thấy độ chính xác khoảng 87%, nhưng độ chính xác của bạn sẽ thay đổi một chút vì luôn có yếu tố ngẫu nhiên trong học máy.
Bước 3: Lưu mô hình
Để triển khai mô hình, hãy chạy mã sau đây để lưu mô hình vào một tệp cục bộ:
model.save_model('model.bst')
6. Triển khai mô hình lên Nền tảng Trí tuệ nhân tạo của Cloud
Chúng ta đã có mô hình hoạt động cục bộ, nhưng sẽ rất tốt nếu chúng ta có thể đưa ra dự đoán trên mô hình đó từ mọi nơi (không chỉ sổ tay này!). Trong bước này, chúng ta sẽ triển khai mô hình lên đám mây.
Bước 1: Tạo một bộ chứa Cloud Storage cho mô hình
Trước tiên, hãy xác định một số biến môi trường mà chúng ta sẽ sử dụng trong phần còn lại của lớp học lập trình. Điền các giá trị bên dưới bằng tên dự án trên đám mây của Google Cloud, tên của bộ chứa Cloud Storage mà bạn muốn tạo (phải là duy nhất trên toàn cầu) và tên phiên bản cho phiên bản đầu tiên của mô hình:
# Update these to your own GCP project, model, and version names
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
VERSION_NAME = 'v1'
MODEL_NAME = 'xgb_mortgage'
Bây giờ, chúng ta đã sẵn sàng tạo một bộ chứa lưu trữ để lưu trữ tệp mô hình XGBoost. Chúng ta sẽ trỏ Nền tảng Trí tuệ nhân tạo của Cloud vào tệp này khi triển khai.
Chạy lệnh gsutil này từ trong sổ tay để tạo một bộ chứa:
!gsutil mb $MODEL_BUCKET
Bước 2: Sao chép tệp mô hình vào Cloud Storage
Tiếp theo, chúng ta sẽ sao chép tệp mô hình đã lưu XGBoost vào Cloud Storage. Chạy lệnh gsutil sau:
!gsutil cp ./model.bst $MODEL_BUCKET
Chuyển đến trình duyệt bộ nhớ trong Cloud Console để xác nhận rằng tệp đã được sao chép:

Bước 3: Tạo và triển khai mô hình
Chúng ta gần như đã sẵn sàng triển khai mô hình! Lệnh ai-platform gcloud sau đây sẽ tạo một mô hình mới trong dự án của bạn. Chúng ta sẽ gọi mô hình này là xgb_mortgage:
!gcloud ai-platform models create $MODEL_NAME --region='global'
Bây giờ là lúc triển khai mô hình. Chúng ta có thể thực hiện việc đó bằng lệnh gcloud này:
!gcloud ai-platform versions create $VERSION_NAME \
--model=$MODEL_NAME \
--framework='XGBOOST' \
--runtime-version=2.1 \
--origin=$MODEL_BUCKET \
--python-version=3.7 \
--project=$GCP_PROJECT \
--region='global'
Trong khi lệnh này đang chạy, hãy kiểm tra phần mô hình của bảng điều khiển Nền tảng Trí tuệ nhân tạo. Bạn sẽ thấy phiên bản mới của mình đang triển khai tại đó:

Khi quá trình triển khai hoàn tất thành công, bạn sẽ thấy dấu kiểm màu xanh lục ở vị trí vòng quay tải. Quá trình triển khai sẽ mất 2 – 3 phút.
Bước 4: Kiểm thử mô hình đã triển khai
Để đảm bảo mô hình đã triển khai đang hoạt động, hãy kiểm thử mô hình bằng gcloud để đưa ra dự đoán. Trước tiên, hãy lưu một tệp JSON có ví dụ đầu tiên từ tập kiểm định:
%%writefile predictions.json
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
Kiểm thử mô hình bằng cách chạy mã này:
prediction = !gcloud ai-platform predict --model=xgb_mortgage --region='global' --json-instances=predictions.json --version=$VERSION_NAME --verbosity=none
print(prediction)
Bạn sẽ thấy dự đoán của mô hình trong đầu ra. Ví dụ cụ thể này đã được phê duyệt, vì vậy, bạn sẽ thấy một giá trị gần bằng 1.
7. Sử dụng Công cụ What-if để diễn giải mô hình
Bước 1: Tạo hình ảnh trực quan của Công cụ What-if
Để kết nối Công cụ What-if với các mô hình Nền tảng Trí tuệ nhân tạo, bạn cần truyền cho công cụ này một tập hợp con gồm các ví dụ kiểm thử cùng với các giá trị thực tế cho những ví dụ đó. Hãy tạo một mảng Numpy gồm 500 ví dụ kiểm thử cùng với nhãn thực tế của chúng:
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples].values,y_test[:num_wit_examples].reshape(-1,1)))
Việc tạo thực thể Công cụ What-if cũng đơn giản như tạo một đối tượng WitConfigBuilder và truyền cho đối tượng đó mô hình Nền tảng Trí tuệ nhân tạo mà chúng ta muốn phân tích.
Chúng ta sử dụng tham số adjust_prediction không bắt buộc ở đây vì Công cụ What-if mong đợi một danh sách điểm số cho mỗi loại trong mô hình của chúng ta (trong trường hợp này là 2). Vì mô hình của chúng ta chỉ trả về một giá trị duy nhất từ 0 đến 1, nên chúng ta sẽ chuyển đổi giá trị đó thành định dạng chính xác trong hàm này:
def adjust_prediction(pred):
return [1 - pred, pred]
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_ai_platform_model(GCP_PROJECT, MODEL_NAME, VERSION_NAME, adjust_prediction=adjust_prediction)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
Xin lưu ý rằng quá trình tải hình ảnh trực quan sẽ mất một phút. Khi tải, bạn sẽ thấy như sau:
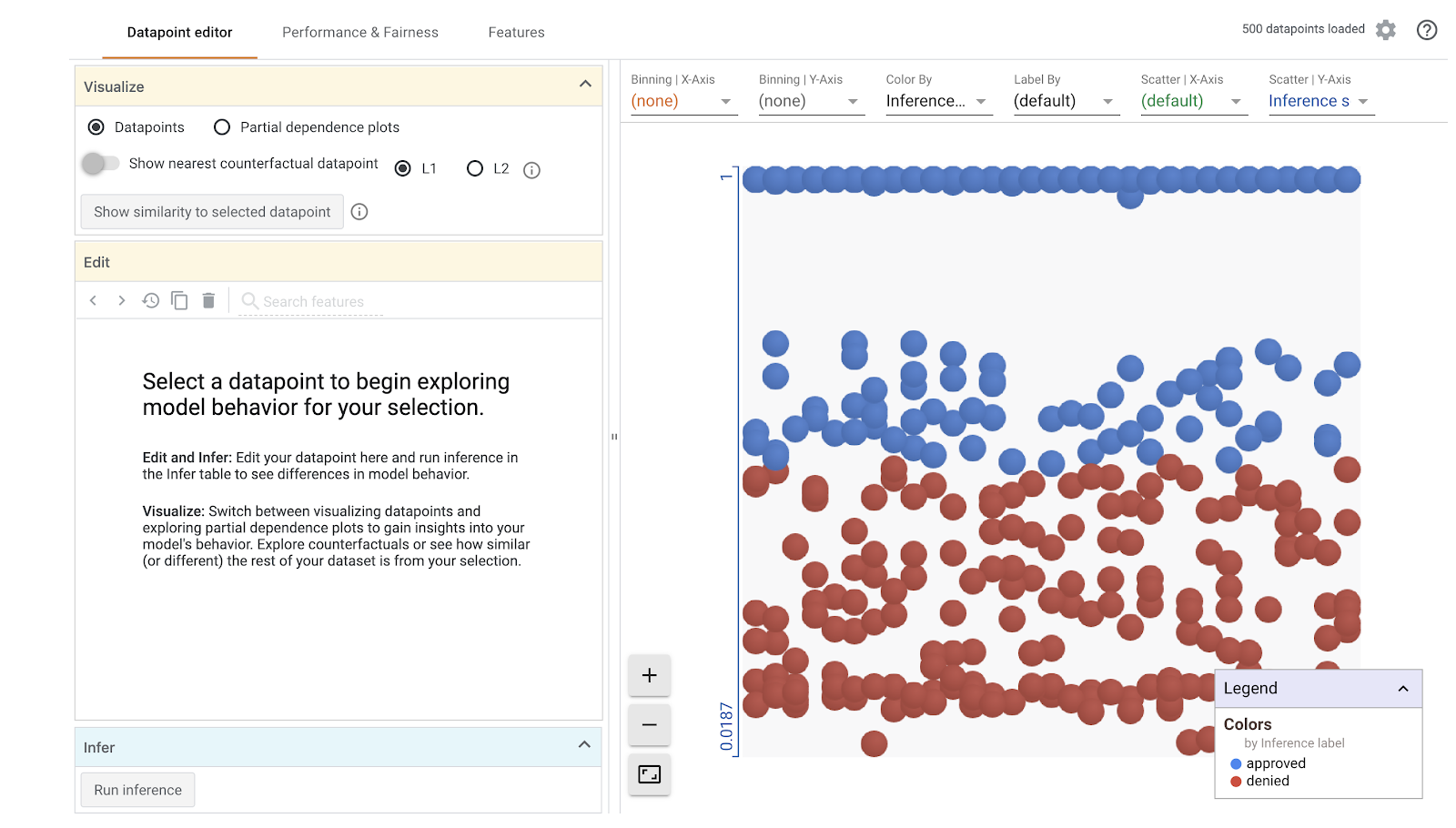
Trục y cho chúng ta thấy dự đoán của mô hình, trong đó 1 là dự đoán approved có độ tin cậy cao và 0 là dự đoán denied có độ tin cậy cao. Trục x chỉ là sự phân tán của tất cả các điểm dữ liệu đã tải.
Bước 2: Khám phá các điểm dữ liệu riêng lẻ
Chế độ xem mặc định trên Công cụ What-if là thẻ Trình chỉnh sửa điểm dữ liệu. Tại đây, bạn có thể nhấp vào bất kỳ điểm dữ liệu riêng lẻ nào để xem các tính năng của điểm dữ liệu đó, thay đổi giá trị tính năng và xem thay đổi đó tác động đến dự đoán của mô hình trên một điểm dữ liệu riêng lẻ như thế nào.
Trong ví dụ bên dưới, chúng ta đã chọn một điểm dữ liệu gần với ngưỡng 0,5. Đơn xin thế chấp liên kết với điểm dữ liệu cụ thể này bắt nguồn từ CFPB. Chúng ta đã thay đổi tính năng đó thành 0 và cũng thay đổi giá trị của agency_code_Department of Housing and Urban Development (HUD) thành 1 để xem điều gì sẽ xảy ra với dự đoán của mô hình nếu khoản vay này bắt nguồn từ HUD:
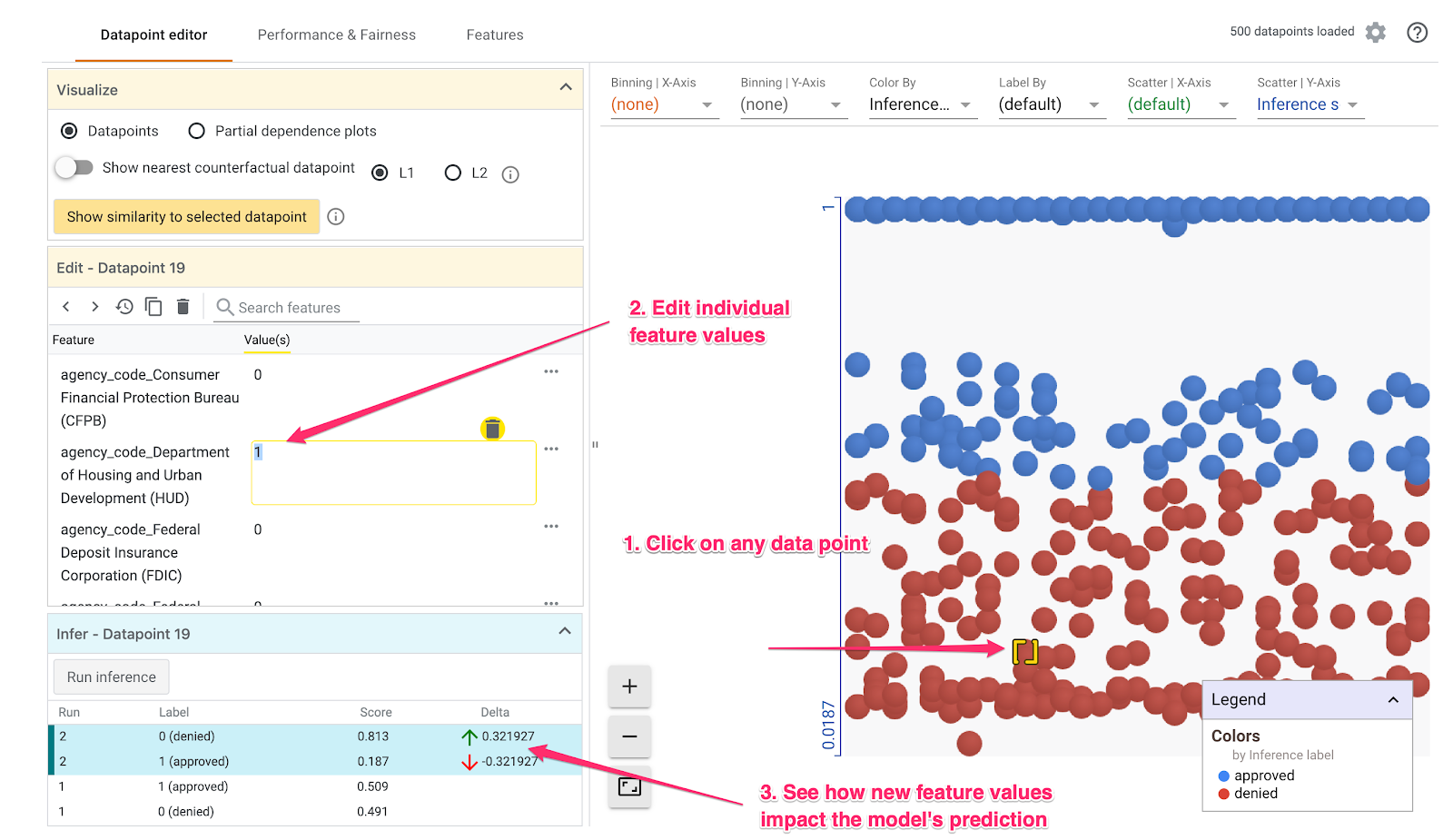
Như chúng ta có thể thấy trong phần dưới cùng bên trái của Công cụ What-if, việc thay đổi tính năng này đã làm giảm đáng kể dự đoán approved của mô hình xuống 32%. Điều này có thể cho thấy rằng cơ quan mà khoản vay bắt nguồn có tác động mạnh mẽ đến đầu ra của mô hình, nhưng chúng ta cần phân tích thêm để chắc chắn.
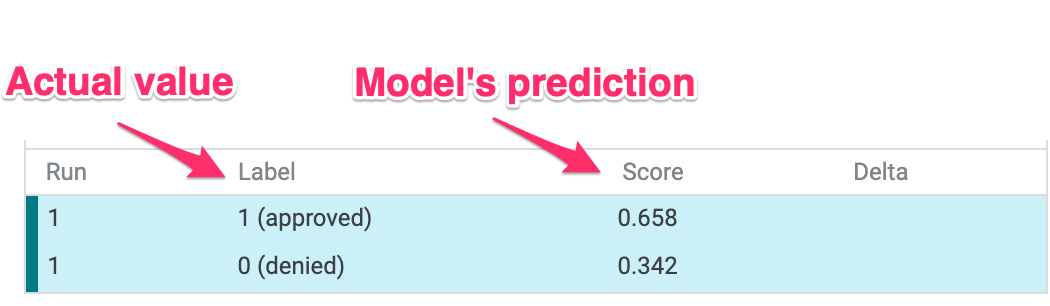
Ở phần dưới cùng bên trái của giao diện người dùng, chúng ta cũng có thể thấy giá trị thực tế cho từng điểm dữ liệu và so sánh giá trị đó với dự đoán của mô hình:
Bước 3: Phân tích phản thực tế
Tiếp theo, hãy nhấp vào bất kỳ điểm dữ liệu nào rồi di chuyển thanh trượt Show nearest counterfactual datapoint (Hiển thị điểm dữ liệu phản thực tế gần nhất) sang bên phải:

Khi chọn mục này, bạn sẽ thấy điểm dữ liệu có các giá trị tính năng tương tự nhất với điểm dữ liệu gốc mà bạn đã chọn, nhưng dự đoán ngược lại. Sau đó, bạn có thể cuộn qua các giá trị tính năng để xem điểm dữ liệu nào khác nhau (sự khác biệt được đánh dấu bằng màu xanh lục và in đậm).
Bước 4: Xem biểu đồ phụ thuộc một phần
Để xem từng tính năng ảnh hưởng đến dự đoán của mô hình như thế nào, hãy đánh dấu vào hộp Partial dependence plots (Biểu đồ phụ thuộc một phần) và đảm bảo bạn đã chọn Global partial dependence plots (Biểu đồ phụ thuộc một phần trên toàn cầu):

Tại đây, chúng ta có thể thấy rằng các khoản vay bắt nguồn từ HUD có khả năng bị từ chối cao hơn một chút. Biểu đồ có hình dạng này vì mã cơ quan là một tính năng boolean, vì vậy, các giá trị chỉ có thể là chính xác 0 hoặc 1.
applicant_income_thousands là một tính năng số và trong biểu đồ phụ thuộc một phần, chúng ta có thể thấy rằng thu nhập cao hơn sẽ làm tăng nhẹ khả năng đơn xin được phê duyệt, nhưng chỉ lên đến khoảng 200 nghìn USD. Sau 200 nghìn USD, tính năng này không ảnh hưởng đến dự đoán của mô hình.
Bước 5: Khám phá hiệu suất và tính công bằng tổng thể
Tiếp theo, hãy chuyển đến thẻ Performance &Fairness (Hiệu suất và tính công bằng). Thẻ này cho thấy số liệu thống kê hiệu suất tổng thể về kết quả của mô hình trên tập dữ liệu được cung cấp, bao gồm ma trận nhầm lẫn, đường cong PR và đường cong ROC.
Chọn mortgage_status làm Tính năng thực tế để xem ma trận nhầm lẫn:
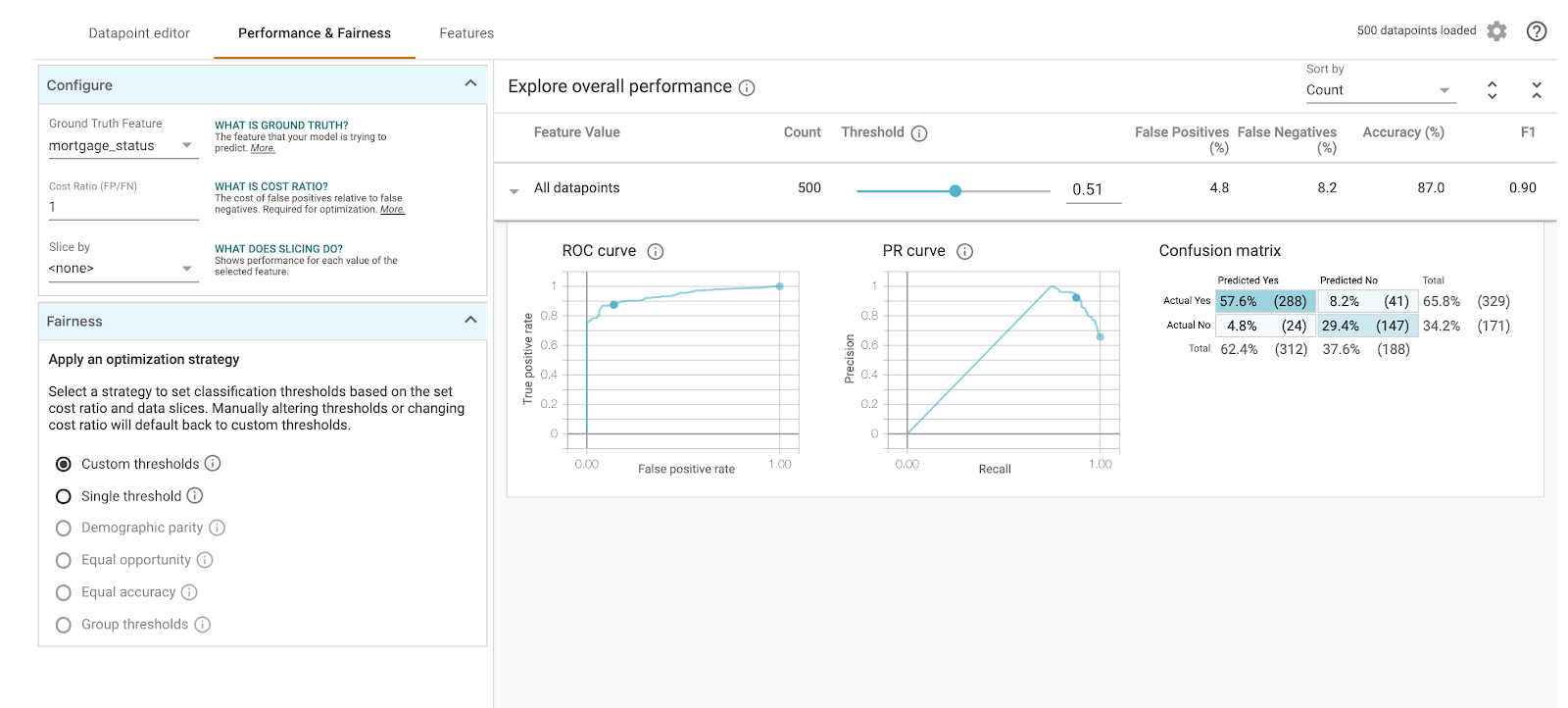
Ma trận nhầm lẫn này cho thấy các dự đoán đúng và không chính xác của mô hình dưới dạng tỷ lệ phần trăm của tổng số. Nếu bạn cộng các ô Actual Yes/Predicted Yes (Thực tế có/Dự đoán có) và Actual No/Predicted No (Thực tế không/Dự đoán không), thì tổng sẽ bằng độ chính xác của mô hình (khoảng 87%).
Bạn cũng có thể thử nghiệm với thanh trượt ngưỡng, tăng và giảm điểm phân loại dương mà mô hình cần trả về trước khi quyết định dự đoán approved cho khoản vay, đồng thời xem điều đó thay đổi độ chính xác, dương tính giả và âm tính giả như thế nào. Trong trường hợp này, độ chính xác cao nhất là khoảng ngưỡng 0,55.
Tiếp theo, trên trình đơn thả xuống Slice by (Phân đoạn theo) ở bên trái, hãy chọn loan_purpose_Home_purchase:
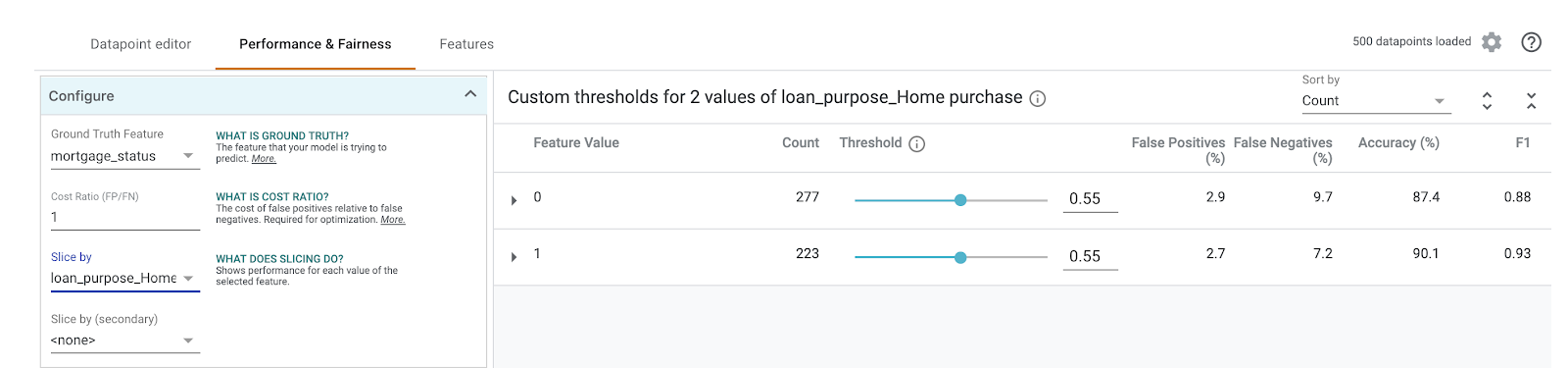
Bây giờ, bạn sẽ thấy hiệu suất trên 2 tập hợp con của dữ liệu: phân đoạn "0" cho biết khi khoản vay không phải là để mua nhà và phân đoạn "1" là khi khoản vay là để mua nhà. Kiểm tra độ chính xác, tỷ lệ dương tính giả và tỷ lệ âm tính giả giữa 2 phân đoạn để tìm sự khác biệt về hiệu suất.
Nếu bạn mở rộng các hàng để xem ma trận nhầm lẫn, bạn có thể thấy rằng mô hình dự đoán "được phê duyệt" cho khoảng 70% đơn xin vay mua nhà và chỉ 46% khoản vay không phải để mua nhà (tỷ lệ phần trăm chính xác sẽ khác nhau trên mô hình của bạn):

Nếu bạn chọn Demographic parity (Tính ngang bằng về nhân khẩu học) từ các nút chọn ở bên trái, thì 2 ngưỡng sẽ được điều chỉnh để mô hình dự đoán approved cho tỷ lệ phần trăm tương tự của người nộp đơn trong cả 2 phân đoạn. Điều này ảnh hưởng như thế nào đến độ chính xác, dương tính giả và âm tính giả cho từng phân đoạn?
Bước 6: Khám phá phân phối tính năng
Cuối cùng, hãy chuyển đến thẻ Features (Tính năng) trong Công cụ What-if. Thẻ này cho bạn thấy phân phối các giá trị cho từng tính năng trong tập dữ liệu:

Bạn có thể sử dụng thẻ này để đảm bảo tập dữ liệu của mình được cân bằng. Ví dụ: có vẻ như rất ít khoản vay trong tập dữ liệu bắt nguồn từ Cơ quan Dịch vụ Nông trại. Để cải thiện độ chính xác của mô hình, chúng ta có thể cân nhắc thêm nhiều khoản vay từ cơ quan đó nếu có dữ liệu.
Chúng tôi chỉ mô tả một vài ý tưởng khám phá Công cụ What-if tại đây. Bạn có thể tiếp tục khám phá công cụ này, còn rất nhiều khu vực khác để khám phá!
8. Dọn dẹp
Nếu bạn muốn tiếp tục sử dụng sổ tay này, bạn nên tắt sổ tay khi không sử dụng. Trong giao diện người dùng Notebooks của Cloud Console, hãy chọn sổ tay rồi chọn Stop (Dừng):

Nếu bạn muốn xoá tất cả các tài nguyên đã tạo trong phòng thí nghiệm này, chỉ cần xoá phiên bản sổ tay thay vì dừng phiên bản đó.
Sử dụng trình đơn Điều hướng trong Cloud Console, duyệt đến Storage (Bộ nhớ) rồi xoá cả 2 bộ chứa mà bạn đã tạo để lưu trữ tài sản mô hình.