
1. 概览
在本实验中,您将使用 What-If 工具分析在金融数据上训练并部署在 Cloud AI Platform 上的 XGBoost 模型。
学习内容
您将了解如何:
- 在 AI Platform Notebooks 中基于公开的抵押贷款数据集训练 XGBoost 模型
- 将 XGBoost 模型部署到 AI Platform
- 使用 What-If 工具分析模型
在 Google Cloud 上运行此实验的总费用约为 1 美元。
2. XGBoost 快速入门
XGBoost 是一种机器学习框架,它使用决策树和梯度提升来构建预测模型。它的工作原理是,根据树中不同叶节点的相关得分,将多个决策树集成在一起。
下图是一个简单的决策树模型的可视化图表,该模型可根据天气预报评估是否应进行体育赛事:

为什么我们在此模型中使用 XGBoost?虽然传统神经网络在图像和文本等非结构化数据方面表现出色,但决策树在结构化数据(例如我们将在本 Codelab 中使用的抵押贷款数据集)方面通常表现得非常好。
3. 设置环境
您需要一个启用了结算功能的 Google Cloud Platform 项目才能运行此 Codelab。如需创建项目,请按照此处的说明操作。
第 1 步:启用 Cloud AI Platform Models API
前往 Cloud 控制台的 AI Platform 模型部分,然后点击“启用”(如果尚未启用)。

第 2 步:启用 Compute Engine API
前往 Compute Engine,然后选择启用(如果尚未启用)。您需要此权限才能创建笔记本实例。
第 3 步:创建 AI Platform Notebooks 实例
前往 Cloud 控制台的 AI Platform Notebooks 部分,然后点击新建实例。然后选择不带 GPU 的最新 TF 企业版 2.x 实例类型:

使用默认选项,然后点击创建。创建实例后,选择打开 JupyterLab:

第 4 步:安装 XGBoost
打开 JupyterLab 实例后,您需要添加 XGBoost 软件包。
为此,请从启动器中选择“终端”:
然后,运行以下命令以安装 Cloud AI Platform 支持的最新版 XGBoost:
pip3 install xgboost==0.90
完成后,从启动器中打开 Python 3 笔记本实例。您可以在笔记本中开始操作了!
第 5 步:导入 Python 软件包
在笔记本的第一个单元中,添加以下导入并运行该单元。您可以通过按顶部菜单中的向右箭头按钮或按 Command-Enter 来运行它:
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
4. 下载和处理数据
我们将使用 ffiec.gov 中的抵押贷款数据集来训练 XGBoost 模型。我们对原始数据集进行了一些预处理,并创建了一个较小的版本供您用于训练模型。该模型将预测特定抵押贷款申请是否会获得批准。
第 1 步:下载预处理的数据集
我们已在 Google Cloud Storage 中为您提供该数据集的一个版本。您可以在 Jupyter 笔记本中运行以下 gsutil 命令来下载该文件:
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
第 2 步:使用 Pandas 读取数据集
在创建 Pandas DataFrame 之前,我们将创建一个包含每个列的数据类型的字典,以便 Pandas 正确读取我们的数据集:
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
接下来,我们将创建一个 DataFrame,并向其传递上面指定的数据类型。如果原始数据集以特定方式排序,那么对数据进行随机化处理非常重要。我们使用名为 shuffle 的 sklearn 实用程序来执行此操作,该实用程序已在第一个单元格中导入:
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
data.head() 可让我们在 Pandas 中预览数据集的前五行。运行上述单元格后,您应该会看到类似以下内容:

这些是我们将用于训练模型的特征。如果您一直滚动到末尾,会看到最后一列 approved,这是我们要预测的内容。值 1 表示特定申请已获批准,值 0 表示特定申请已被拒绝。
如需查看数据集中已批准 / 已拒绝值的分布情况并创建标签的 NumPy 数组,请运行以下代码:
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
大约 66% 的数据集包含已获批的应用。
第 3 步:为类别值创建虚拟列
此数据集包含分类值和数值,但 XGBoost 要求所有特征都为数值。对于 XGBoost 模型,我们将利用 Pandas get_dummies 函数,而不是使用独热编码来表示分类值。
get_dummies 接受具有多个可能值的列,并将其转换为一系列仅包含 0 和 1 的列。例如,如果我们有一个“颜色”列,其可能的值为“蓝色”和“红色”,则 get_dummies 会将其转换为两个列,分别名为“color_blue”和“color_red”,其中包含所有布尔值 0 和 1。
如需为分类特征创建虚拟列,请运行以下代码:
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
这次预览数据时,您会看到单个功能(如下面的 purchaser_type 所示)拆分成了多列:

第 4 步:将数据拆分为训练集和测试集
机器学习中的一个重要概念是训练 / 测试拆分。我们将使用大部分数据来训练模型,并将剩余数据留作测试之用,以测试模型在从未见过的数据上的表现。
将以下代码添加到笔记本中,该代码使用 Scikit Learn 函数 train_test_split 拆分数据:
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
现在,您可以构建和训练模型了!
5. 构建、训练和评估 XGBoost 模型
第 1 步:定义和训练 XGBoost 模型
在 XGBoost 中创建模型非常简单。我们将使用 XGBClassifier 类别创建模型,只需为我们的特定分类任务传递正确的 objective 参数即可。在本例中,我们使用 reg:logistic,因为我们有一个二元分类问题,并且希望模型输出一个介于 (0,1) 范围内的单个值:0 表示未获批,1 表示已获批。
以下代码将创建一个 XGBoost 模型:
model = xgb.XGBClassifier(
objective='reg:logistic'
)
您只需一行代码即可训练模型,即调用 fit() 方法并向其传递训练数据和标签。
model.fit(x_train, y_train)
第 2 步:评估模型的准确率
现在,我们可以使用训练好的模型通过 predict() 函数对测试数据进行预测。
然后,我们将使用 Scikit Learn 的 accuracy_score 函数,根据模型在测试数据上的表现来计算模型的准确率。我们将向其传递标准答案值以及模型针对测试集中每个示例的预测值:
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
您应该会看到准确率约为 87%,但由于机器学习中始终存在随机性因素,因此您的准确率会略有不同。
第 3 步:保存模型
为了部署模型,请运行以下代码将其保存到本地文件:
model.save_model('model.bst')
6. 将模型部署到 Cloud AI Platform
我们已让模型在本地运行,但如果能从任何位置(而不仅仅是此笔记本!)对模型进行预测,那就更好了。在此步骤中,我们将它部署到云端。
第 1 步:为模型创建 Cloud Storage 存储分区
我们先定义一些环境变量,以便在整个 Codelab 的其余部分中使用。请在下方填写您的 Google Cloud 项目名称、您要创建的 Cloud Storage 存储分区的名称(必须是全局唯一的)以及模型的第一个版本的版本名称:
# Update these to your own GCP project, model, and version names
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
VERSION_NAME = 'v1'
MODEL_NAME = 'xgb_mortgage'
现在,我们已准备好创建一个存储分区来存储 XGBoost 模型文件。部署时,我们将让 Cloud AI Platform 指向此文件。
在笔记本中运行以下 gsutil 命令以创建存储分区:
!gsutil mb $MODEL_BUCKET
第 2 步:将模型文件复制到 Cloud Storage
接下来,我们将 XGBoost 保存的模型文件复制到 Cloud Storage。运行以下 gsutil 命令:
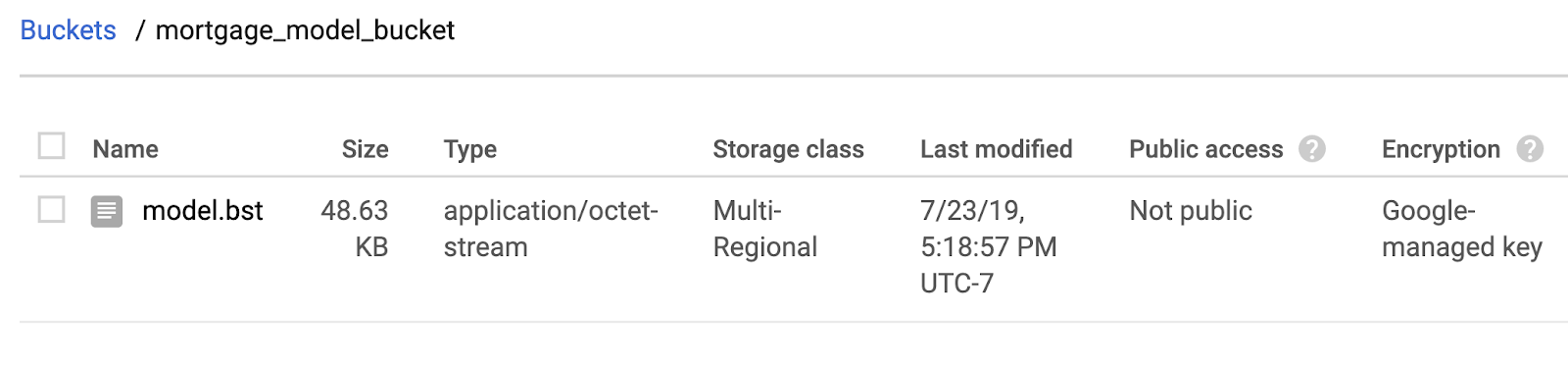
!gsutil cp ./model.bst $MODEL_BUCKET
前往 Cloud 控制台中的存储浏览器,确认文件已复制:
第 3 步:创建和部署模型
我们很快就可以部署模型了!以下 ai-platform gcloud 命令将在您的项目中创建一个新模型。我们将此变量命名为 xgb_mortgage:
!gcloud ai-platform models create $MODEL_NAME --region='global'
现在可以部署模型了。我们可以使用以下 gcloud 命令来完成此操作:
!gcloud ai-platform versions create $VERSION_NAME \
--model=$MODEL_NAME \
--framework='XGBOOST' \
--runtime-version=2.1 \
--origin=$MODEL_BUCKET \
--python-version=3.7 \
--project=$GCP_PROJECT \
--region='global'
在运行此命令期间,请检查 AI Platform 控制台的模型部分。您应该会看到新版本正在部署:

部署成功完成后,加载旋转图标会变为绿色对勾标记。部署应需要 2-3 分钟。
第 4 步:测试已部署的模型
为确保已部署的模型正常运行,请使用 gcloud 进行预测来测试该模型。首先,保存一个 JSON 文件,其中包含测试集中的第一个示例:
%%writefile predictions.json
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
运行以下代码来测试模型:
prediction = !gcloud ai-platform predict --model=xgb_mortgage --region='global' --json-instances=predictions.json --version=$VERSION_NAME --verbosity=none
print(prediction)
您应该会在输出中看到模型的预测结果。此特定示例已获批,因此您应该会看到接近 1 的值。
7. 使用 What-if 工具解读模型
第 1 步:创建假设分析工具可视化图表
如需将 What-If 工具连接到 AI Platform 模型,您需要向该工具传递一部分测试示例以及这些示例的标准答案值。我们来创建一个包含 500 个测试示例及其评估依据标签的 NumPy 数组:
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples].values,y_test[:num_wit_examples].reshape(-1,1)))
实例化 What-If 工具非常简单,只需创建一个 WitConfigBuilder 对象,然后将要分析的 AI Platform 模型传递给该对象即可。
我们在此处使用了可选的 adjust_prediction 参数,因为 What-if 工具预期模型中的每个类别(在本例中为 2 个)都有一个分数列表。由于我们的模型仅返回一个介于 0 到 1 之间的值,因此我们在此函数中将其转换为正确的格式:
def adjust_prediction(pred):
return [1 - pred, pred]
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_ai_platform_model(GCP_PROJECT, MODEL_NAME, VERSION_NAME, adjust_prediction=adjust_prediction)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
请注意,加载可视化图表需要一分钟时间。加载后,您应该会看到以下内容:

y 轴显示了模型的预测,其中 1 表示高置信度的 approved 预测,0 表示高置信度的 denied 预测。X 轴只是所有已加载数据点的分布。
第 2 步:探索各个数据点
What-If 工具的默认视图是数据点编辑器标签页。您可以在此处点击任意单个数据点,查看其特征、更改特征值,并了解相应更改对模型针对单个数据点的预测结果有何影响。
在下面的示例中,我们选择了一个接近 0.5 阈值的数据点。与此特定数据点关联的房贷申请源自 CFPB。我们将该特征更改为 0,并将 agency_code_Department of Housing and Urban Development (HUD) 的值更改为 1,以查看如果这笔贷款改为由 HUD 提供,模型的预测结果会发生什么变化:

从假设分析工具的左下角部分可以看出,更改此特征后,模型的 approved 预测值显著下降了 32%。这可能表明贷款的原始机构对模型的输出有很大影响,但我们需要进行更多分析才能确定。
在界面左下角,我们还可以看到每个数据点的标准答案值,并将其与模型的预测进行比较:

第 3 步:反事实分析
接下来,点击任意数据点,然后将显示最近的反事实数据点滑块向右移动:
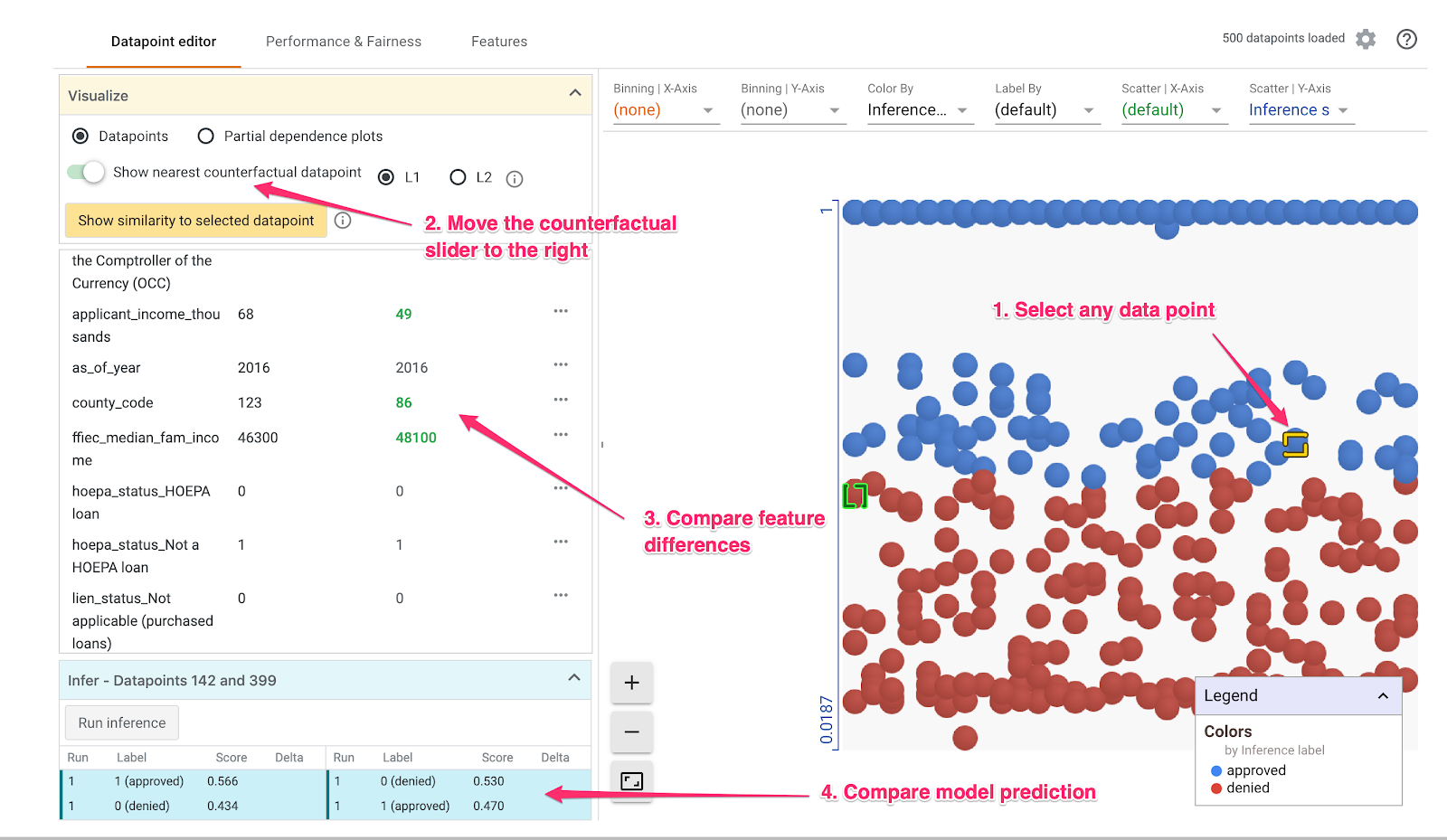
选择此选项后,系统会显示与您选择的原始数据点具有最相似的特征值但预测结果相反的数据点。然后,您可以滚动浏览特征值,查看两个数据点之间的差异(差异以绿色粗体突出显示)。
第 4 步:查看部分依赖关系图
如需查看每个特征对模型总体预测的影响,请勾选边际效应图框,并确保已选择全局边际效应图:

在此我们可以看到,源自 HUD 的贷款被拒的可能性略高。之所以出现这种形状的图表,是因为代理机构代码是一个布尔值特征,因此值只能是 0 或 1。
applicant_income_thousands 是一个数值特征,在边际相关性图中,我们可以看到,收入越高,申请获得批准的可能性就越大,但只有在收入达到 20 万美元左右时才会出现这种情况。超过 20 万美元后,此特征不会影响模型的预测。
第 5 步:探索总体性能和公平性
接下来,前往效果和公平性标签页。此图表显示了模型在所提供数据集上的结果的总体性能统计信息,包括混淆矩阵、PR 曲线和 ROC 曲线。
选择 mortgage_status 作为标准答案特征,以查看混淆矩阵:

此混淆矩阵显示了模型正确和错误的预测结果,以占总数的百分比表示。如果您将实际为“是”/预测为“是”和实际为“否”/预测为“否”这两个正方形中的数字相加,得到的总和应与模型的准确率(大约 87%)相同。
您还可以尝试使用阈值滑块,提高和降低模型在决定预测贷款结果为 approved 之前需要返回的正分类分数,并查看这会如何改变准确率、假正例和假负例。在这种情况下,当阈值约为 0.55 时,准确率最高。
接下来,在左侧的细分依据下拉菜单中,选择 loan_purpose_Home_purchase:

现在,您将看到两个数据子集的性能:“0”切片表示贷款不是用于购房,“1”切片表示贷款用于购房。查看这两个切片之间的准确率、假正例率和假负例率,以寻找效果差异。
如果您展开行以查看混淆矩阵,则会发现,对于购房贷款申请,模型预测为“已批准”的比例约为 70%,而对于非购房贷款,模型预测为“已批准”的比例仅为 46%(确切百分比因模型而异):

如果您从左侧的单选按钮中选择人口统计均等,系统会调整这两个阈值,使模型在两个切片中预测为 approved 的申请人比例相似。这会对每个切片的准确率、假正例和假负例产生什么影响?
第 6 步:探索功能分布
最后,前往 What-If 工具中的特征标签页。此图表显示了数据集中每个特征的值分布:

您可以使用此标签页确保数据集是平衡的。例如,数据集中的贷款似乎很少来自农业服务局。为了提高模型准确性,如果数据可用,我们可能会考虑添加来自该机构的更多贷款。
我们在此仅介绍了几种假设分析工具探索思路。欢迎继续探索此工具,还有很多其他方面值得探索!
8. 清理
如果您想继续使用此笔记本电脑,建议您在不使用时将其关闭。在 Cloud 控制台的笔记本界面中,选择笔记本,然后选择停止:

如果您想删除在本实验中创建的所有资源,只需删除笔记本实例,而不是停止它。
使用 Cloud 控制台中的导航菜单,浏览到“存储空间”,然后删除您创建的用于存储模型资产的两个存储分区。