
1. Visão geral
Neste laboratório, você vai integrar bancos de dados sem servidor(Spanner e Firestore) com aplicativos(Go e Node.js) em execução no Cloud Run. O aplicativo Cymbal Eats inclui vários serviços executados no Cloud Run. Nas etapas a seguir, você vai configurar serviços para usar o banco de dados relacional Cloud Spanner e o Cloud Firestore, um banco de dados de documentos NoSQL. Ao usar produtos sem servidor para a camada de dados e o tempo de execução do aplicativo, você abstrai todo o gerenciamento de infraestrutura e se concentra na criação do aplicativo, em vez de se preocupar com sobrecargas.
2. O que você vai aprender
Neste laboratório, você vai aprender a:
- Integrar o Spanner
- Ativar os serviços gerenciados do Spanner
- Integrar ao código
- Implantar código que se conecta ao Spanner
- Integrar o Firestore
- Ativar os serviços gerenciados do Firestore
- Integrar ao código
- Implantar código que se conecta ao Firestore
3. Configuração e requisitos
Configuração de ambiente personalizada
- Faça login no Console do Google Cloud e crie um novo projeto ou reutilize um existente. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.

- O Nome do projeto é o nome de exibição para os participantes do projeto. É uma string de caracteres não usada pelas APIs do Google e pode ser atualizada quando você quiser.
- O ID do projeto precisa ser exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Cloud gera automaticamente uma string exclusiva. Em geral, não importa o que seja. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, normalmente identificado como
PROJECT_ID. Se você não gostar do ID gerado, crie outro aleatório. Se preferir, teste o seu e confira se ele está disponível. Ele não pode ser mudado após essa etapa e permanece durante o projeto. - Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
- Em seguida, ative o faturamento no console do Cloud para usar os recursos/APIs do Cloud. A execução deste codelab não vai ser muito cara, se tiver algum custo. Para encerrar os recursos e evitar cobranças além deste tutorial, exclua os recursos criados ou exclua o projeto. Novos usuários do Google Cloud estão qualificados para o programa de US$ 300 de avaliação sem custos.
Configurar o ambiente
- Criar uma variável de ID do projeto
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
export SPANNER_INSTANCE=inventory-instance
export SPANNER_DB=inventory-db
export REGION=us-east1
export SPANNER_CONNECTION_STRING=projects/$PROJECT_ID/instances/$SPANNER_INSTANCE/databases/$SPANNER_DB
- Ative as APIs Spanner, Cloud Run, Cloud Build e Artifact Registry.
gcloud services enable \
compute.googleapis.com \
spanner.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
firestore.googleapis.com \
appengine.googleapis.com \
artifactregistry.googleapis.com
- Clonar o repositório
git clone https://github.com/GoogleCloudPlatform/cymbal-eats.git
- Navegue até o diretório
cd cymbal-eats/inventory-service/spanner
4. Criar e configurar uma instância do Spanner
O Spanner é o banco de dados relacional de back-end dos serviços de inventário. Você vai criar uma instância, um banco de dados e um esquema do Spanner nas etapas a seguir.
Criar uma instância
- Crie uma instância do Cloud Spanner
gcloud spanner instances create $SPANNER_INSTANCE --config=regional-${REGION} \
--description="Cymbal Menu Inventory" --nodes=1
Exemplo de resposta
Creating instance...done.
- Verificar se a instância do Spanner está configurada corretamente
gcloud spanner instances list
Exemplo de saída
NAME: inventory-instance DISPLAY_NAME: Cymbal Menu Inventory CONFIG: regional-us-east1 NODE_COUNT: 1 PROCESSING_UNITS: 100 STATE: READY
Criar um banco de dados e um esquema
Crie um banco de dados e use a linguagem de definição de dados (DDL) do SQL padrão do Google para criar o esquema do banco de dados.
- Criar um arquivo DDL
echo "CREATE TABLE InventoryHistory (ItemRowID STRING (36) NOT NULL, ItemID INT64 NOT NULL, InventoryChange INT64, Timestamp TIMESTAMP) PRIMARY KEY(ItemRowID)" >> table.ddl
- Criar o banco de dados do Spanner
gcloud spanner databases create $SPANNER_DB \
--instance=$SPANNER_INSTANCE \
--ddl-file=table.ddl
Exemplo de saída
Creating database...done.
Verificar o estado e o esquema do banco de dados
- Ver o estado do banco de dados
gcloud spanner databases describe $SPANNER_DB \
--instance=$SPANNER_INSTANCE
Exemplo de saída
createTime: '2022-04-22T15:11:33.559300Z' databaseDialect: GOOGLE_STANDARD_SQL earliestVersionTime: '2022-04-22T15:11:33.559300Z' encryptionInfo: - encryptionType: GOOGLE_DEFAULT_ENCRYPTION name: projects/cymbal-eats-7-348013/instances/menu-inventory/databases/menu-inventory state: READY versionRetentionPeriod: 1h
- Conferir o esquema do banco de dados
gcloud spanner databases ddl describe $SPANNER_DB \
--instance=$SPANNER_INSTANCE
Exemplo de saída
CREATE TABLE InventoryHistory ( ItemRowID STRING(36) NOT NULL, ItemID INT64 NOT NULL, InventoryChange INT64, TimeStamp TIMESTAMP, ) PRIMARY KEY(ItemRowID);
5. Integrar o Spanner
Nesta seção, você vai aprender a integrar o Spanner ao seu aplicativo. Além disso, o SQL Spanner oferece bibliotecas de cliente, drivers JDBC, drivers R2DBC, APIs REST e APIs RPC, que permitem integrar o Spanner a qualquer aplicativo.
Na próxima seção, você vai usar a biblioteca de cliente Go para instalar, autenticar e modificar dados no Spanner.
Instalar a biblioteca de cliente
A biblioteca de cliente do Cloud Spanner facilita a integração com o Cloud Spanner usando automaticamente o Application Default Credentials (ADC) para encontrar as credenciais da sua conta de serviço.
Configurar a autenticação
A CLI do Google Cloud e as bibliotecas de cliente do Google Cloud detectam automaticamente quando estão em execução no Google Cloud e usam a conta de serviço de ambiente de execução da revisão atual do Cloud Run. Essa estratégia é chamada de Application Default Credentials e permite a portabilidade de código em vários ambientes.
No entanto, é melhor criar uma identidade dedicada atribuindo a ela uma conta de serviço gerenciada pelo usuário em vez da conta de serviço padrão.
- Conceda o papel de administrador do banco de dados do Spanner à conta de serviço
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/spanner.databaseAdmin"
Exemplo de saída
Updated IAM policy for project [cymbal-eats-6422-3462]. [...]
Como usar bibliotecas de cliente
As bibliotecas de cliente do Spanner abstraem as complexidades da integração com o Spanner e estão disponíveis em muitas linguagens de programação conhecidas.
Criar um cliente do Spanner
O cliente do Spanner é usado para ler e gravar dados em um banco de dados do Cloud Spanner. Um cliente pode ser usado simultaneamente, exceto pelo método Close.
O snippet abaixo cria um cliente do Spanner
main.go
var dataClient *spanner.Client ... dataClient, err = spanner.NewClient(ctx, databaseName)
Pense em um cliente como uma conexão de banco de dados: todas as suas interações com o Cloud Spanner precisam passar por um cliente. Normalmente, você cria um cliente quando o aplicativo é iniciado e depois reutiliza esse cliente para ler, gravar e executar transações. Cada cliente usa recursos no Cloud Spanner.
Modificar dados
Há várias maneiras de inserir, atualizar e excluir dados de um banco de dados do Spanner. Confira abaixo os métodos disponíveis.
Neste laboratório, você vai usar mutações para modificar dados no Spanner.
Mutações no Spanner
Uma Mutation é um contêiner para operações de mutação. Uma mutação representa uma sequência de inserções, atualizações e exclusões que o Cloud Spanner aplica atomicamente a diferentes linhas e tabelas em um banco de dados do Cloud Spanner.
main.go
m := []*spanner.Mutation{}
m = append(m, spanner.Insert(
"inventoryHistory",
inventoryHistoryColumns,
[]interface{}{uuid.New().String(), element.ItemID, element.InventoryChange, time.Now()}))
O snippet de código insere uma nova linha na tabela de histórico de inventário.
Como implantar e testar
Agora que o Spanner está configurado e você revisou os principais elementos de código, implante o aplicativo no Cloud Run.
implantar o aplicativo no Cloud Run.
O Cloud Run pode criar, enviar e implantar seu código automaticamente com um único comando. No comando a seguir, você vai chamar o comando deploy no serviço run, transmitindo variáveis usadas pelo aplicativo em execução, como SPANNER_CONNECTION_STRING, que você criou anteriormente.
- Clique em "Abrir terminal".
- Implantar o serviço de inventário no Cloud Run
gcloud run deploy inventory-service \
--source . \
--region $REGION \
--update-env-vars SPANNER_CONNECTION_STRING=$SPANNER_CONNECTION_STRING \
--allow-unauthenticated \
--project=$PROJECT_ID \
--quiet
Exemplo de saída
Service [inventory-service] revision [inventory-service-00001-sug] has been deployed and is serving 100 percent of traffic. Service URL: https://inventory-service-ilwytgcbca-uk.a.run.app
- Armazenar o URL do serviço
INVENTORY_SERVICE_URL=$(gcloud run services describe inventory-service \
--platform managed \
--region $REGION \
--format=json | jq \
--raw-output ".status.url")
Testar o aplicativo do Cloud Run
Inserir um item
- No Cloud Shell, insira o seguinte comando:
POST_URL=$INVENTORY_SERVICE_URL/updateInventoryItem
curl -i -X POST ${POST_URL} \
--header 'Content-Type: application/json' \
--data-raw '[
{
"itemID": 1,
"inventoryChange": 5
}
]'
Exemplo de saída
HTTP/2 200 access-control-allow-origin: * content-type: application/json x-cloud-trace-context: 10c32f0863d26521497dc26e86419f13;o=1 date: Fri, 22 Apr 2022 21:41:38 GMT server: Google Frontend content-length: 2 OK
Consultar um item
- Consultar o serviço de inventário
GET_URL=$INVENTORY_SERVICE_URL/getAvailableInventory
curl -i ${GET_URL}
Exemplo de resposta
HTTP/2 200
access-control-allow-origin: *
content-type: text/plain; charset=utf-8
x-cloud-trace-context: b94f921e4c2ae90210472c88eb05ace8;o=1
date: Fri, 22 Apr 2022 21:45:50 GMT
server: Google Frontend
content-length: 166
[{"ItemID":1,"Inventory":5}]
6. Conceitos do Spanner
O Cloud Spanner consulta os bancos de dados usando instruções SQL declarativas. As instruções SQL indicam o que o usuário quer sem descrever como os resultados serão obtidos.
- No terminal, insira este comando para consultar a tabela do registro criado anteriormente.
gcloud spanner databases execute-sql $SPANNER_DB \
--instance=$SPANNER_INSTANCE \
--sql='SELECT * FROM InventoryHistory WHERE ItemID=1'
Exemplo de saída
ItemRowID: 1
ItemID: 1
InventoryChange: 3
Timestamp:
Planos de execução de consulta
Um plano de execução de consulta é uma série de etapas que o Spanner usa para obter resultados. Há várias maneiras de adquirir os resultados de uma instrução SQL específica. Os planos de execução de consulta podem ser acessados no console e nas bibliotecas de cliente. Para saber como o Spanner processa consultas SQL:
- No console, abra a página de instâncias do Cloud Spanner.
- Acessar "Instâncias do Cloud Spanner"
- Clique no nome da instância do Cloud Spanner. Na seção de bancos de dados, selecione o que você quer consultar.
- Clique em "Consulta".
- Insira a consulta a seguir no editor de consultas:
SELECT * FROM InventoryHistory WHERE ItemID=1
- Clique em EXECUTAR.
- Clique em "EXPLICAÇÃO"
O Console do Cloud mostra um plano de execução visual para sua consulta.
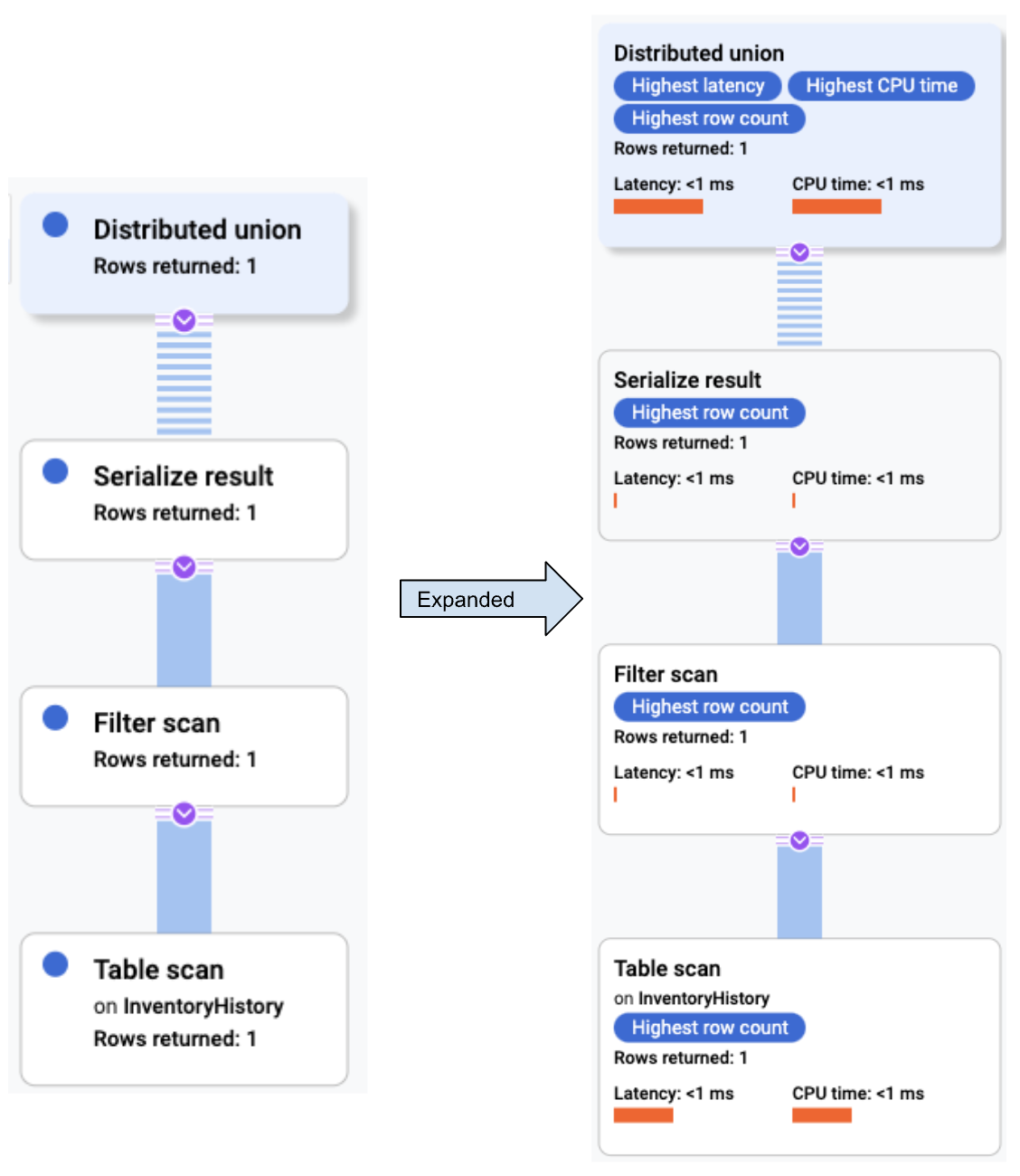
Otimizador de consultas
O otimizador de consultas do Cloud Spanner compara planos de execução alternativos e seleciona o mais eficiente. Com o tempo, o otimizador de consultas vai evoluir, ampliando as opções no plano de execução de consulta e melhorando a precisão das estimativas que informam essas opções, levando a planos de execução de consulta mais eficientes.
O Cloud Spanner implementa as atualizações do otimizador como novas versões do otimizador de consultas. Por padrão, cada banco de dados começa a usar a versão mais recente do otimizador até 30 dias depois do lançamento dessa versão.
Para ver a versão usada ao executar uma consulta no gcloud spanner, defina a flag "–query-mode" como PROFILE.
- Digite o comando a seguir para conferir a versão do otimizador
gcloud spanner databases execute-sql $SPANNER_DB --instance=$SPANNER_INSTANCE \
--query-mode=PROFILE --sql='SELECT * FROM InventoryHistory'
Exemplo de saída
TOTAL_ELAPSED_TIME: 6.18 msecs
CPU_TIME: 5.17 msecs
ROWS_RETURNED: 1
ROWS_SCANNED: 1
OPTIMIZER_VERSION: 3
RELATIONAL Distributed Union
(1 execution, 0.11 msecs total latency)
subquery_cluster_node: 1
|
+- RELATIONAL Distributed Union
| (1 execution, 0.09 msecs total latency)
| call_type: Local, subquery_cluster_node: 2
| |
| \- RELATIONAL Serialize Result
| (1 execution, 0.08 msecs total latency)
| |
| +- RELATIONAL Scan
| | (1 execution, 0.08 msecs total latency)
| | Full scan: true, scan_target: InventoryHistory, scan_type: TableScan
| | |
| | +- SCALAR Reference
| | | ItemRowID
| | |
| | +- SCALAR Reference
| | | ItemID
| | |
| | +- SCALAR Reference
| | | InventoryChange
| | |
| | \- SCALAR Reference
| | Timestamp
| |
| +- SCALAR Reference
| | $ItemRowID
| |
| +- SCALAR Reference
| | $ItemID
| |
| +- SCALAR Reference
| | $InventoryChange
| |
| \- SCALAR Reference
| $Timestamp
|
\- SCALAR Constant
true
ItemRowID: 1
ItemID: 1
InventoryChange: 3
Timestamp:
Atualizar a versão do otimizador
A versão mais recente no momento deste laboratório é a 4. Em seguida, você vai atualizar a tabela do Spanner para usar a versão 4 do otimizador de consultas.
- Atualizar o otimizador
gcloud spanner databases ddl update $SPANNER_DB \
--instance=$SPANNER_INSTANCE \
--ddl='ALTER DATABASE InventoryHistory
SET OPTIONS (optimizer_version = 4)'
Exemplo de saída
Schema updating...done.
- Insira o comando a seguir para conferir a atualização da versão do otimizador:
gcloud spanner databases execute-sql $SPANNER_DB --instance=$SPANNER_INSTANCE \
--query-mode=PROFILE --sql='SELECT * FROM InventoryHistory'
Exemplo de saída
TOTAL_ELAPSED_TIME: 8.57 msecs CPU_TIME: 8.54 msecs ROWS_RETURNED: 1 ROWS_SCANNED: 1 OPTIMIZER_VERSION: 4 [...]
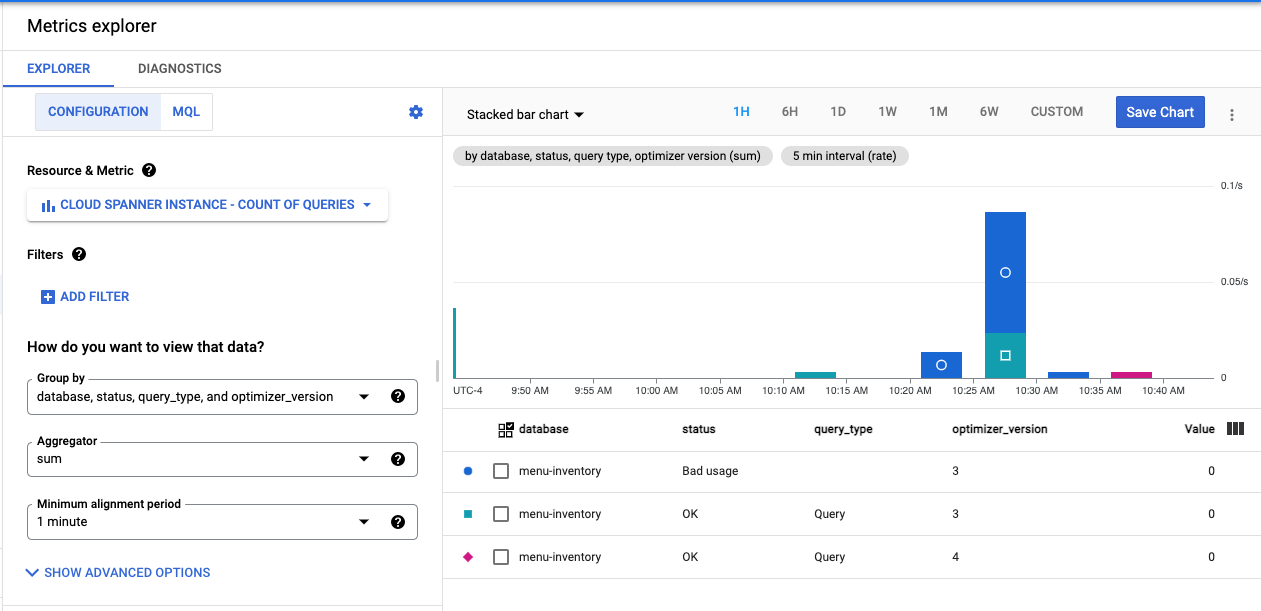
Visualizar a versão do otimizador de consultas no Metrics Explorer
Use o Metrics Explorer no Console do Cloud para visualizar a Contagem de consultas da instância do banco de dados. Você pode ver qual versão do otimizador está sendo usada em cada banco de dados.
- Navegue até o Monitoring no console do Cloud e selecione Metrics Explorer no menu à esquerda.
- No campo Tipo de recurso, selecione "Instância do Cloud Spanner".
- No campo Métrica, selecione "Contagem de consultas" e clique em "Aplicar".
- No campo Agrupar por, selecione "database", "optimizer_version" e "status".
7. Criar e configurar um banco de dados do Firestore
O Firestore é um banco de dados de documentos NoSQL criado para oferecer escalonamento automático, alto desempenho e facilidade no desenvolvimento de aplicativos. Embora a interface do Firestore tenha muitos dos mesmos recursos dos bancos de dados tradicionais, um banco de dados NoSQL é diferente na forma como descreve as relações entre objetos de dados.
A tarefa a seguir vai orientar você na criação de um aplicativo do Cloud Run de serviço de pedidos com suporte do Firestore. O serviço de pedidos vai chamar o serviço de inventário criado na seção anterior para consultar o banco de dados do Spanner antes de iniciar o pedido. Esse serviço garante que haja inventário suficiente e que o pedido possa ser atendido.
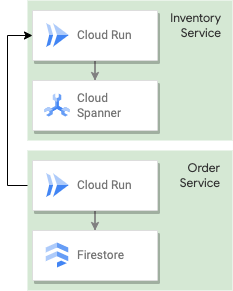
8. Conceitos do Firestore
Modelo de dados
Um banco de dados do Firestore é composto de coleções e documentos.
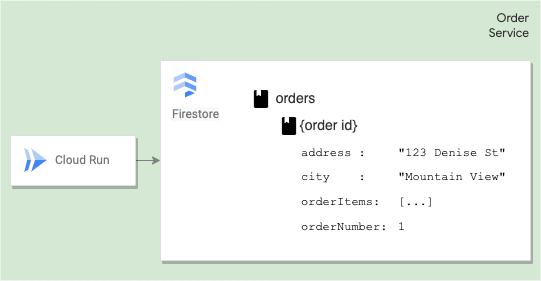
Documentos
Cada documento contém um conjunto de pares de chave-valor. O Firestore é otimizado para armazenar grandes coleções de documentos pequenos.
Coleções
É necessário armazenar todos os documentos em coleções. Os documentos podem conter subcoleções e objetos aninhados, incluindo campos primitivos, como strings, ou objetos complexos, como listas.

Crie um banco de dados Firestore
- Crie o banco de dados do Firestore
gcloud firestore databases create --location=$REGION
Exemplo de saída
Success! Selected Google Cloud Firestore Native database for cymbal-eats-6422-3462
9. Integrar o Firestore ao seu aplicativo
Nesta seção, você vai atualizar a conta de serviço, adicionar contas de serviço de acesso ao Firestore, revisar e implantar as regras de segurança do Firestore e revisar como os dados são modificados no Firestore.
Configurar a autenticação
- Conceder o papel de usuário do Datastore à conta de serviço
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/datastore.user"
Exemplo de saída
Updated IAM policy for project [cymbal-eats-6422-3462].
Regras de Segurança do Firestore
As regras de segurança oferecem controle de acesso e validação de dados em um formato expressivo, mas simples.
- Acesse o diretório order-service/starter-code
cd ~/cymbal-eats/order-service
- Abra o arquivo firestore.rules no editor da nuvem
cat firestore.rules
firestore.rules
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents { ⇐ All database
match /{document=**} { ⇐ All documents
allow read: if true; ⇐ Allow reads
}
match /{document=**} {
allow write: if false; ⇐ Deny writes
}
}
}
Aviso:é uma prática recomendada limitar o acesso ao armazenamento do Firestore. Para este laboratório, todas as leituras são permitidas. Essa não é uma configuração de produção recomendada.
Ativar os serviços gerenciados do Firestore
- Clique em "Abrir terminal".
- Crie o arquivo .firebaserc com o ID do projeto atual. As configurações dos destinos de implantação são armazenadas no arquivo .firebaserc no diretório do projeto.
firebaserc.tmpl
sed "s/PROJECT_ID/$PROJECT_ID/g" firebaserc.tmpl > .firebaserc
- Baixar o binário do Firebase
curl -sL https://firebase.tools | upgrade=true bash
Exemplo de saída
-- Checking for existing firebase-tools on PATH... Your machine already has firebase-tools@10.7.0 installed. Nothing to do. -- All done!
- Implante as regras do Firestore.
firebase deploy
Exemplo de resposta
=== Deploying to 'cymbal-eats-6422-3462'... i deploying firestore i cloud.firestore: checking firestore.rules for compilation errors... ✔ cloud.firestore: rules file firestore.rules compiled successfully i firestore: uploading rules firestore.rules... ✔ firestore: released rules firestore.rules to cloud.firestore ✔ Deploy complete! Project Console: https://console.firebase.google.com/project/cymbal-eats-6422-3462/overview
Modificar dados
Coleções e documentos são criados implicitamente no Firestore. Basta atribuir dados a um documento dentro de uma coleção. Se a coleção ou o documento não existir, o Firestore o criará.
Adicionar dados ao Firestore
Há várias formas de gravar dados no Cloud Firestore:
- Definir os dados de um documento em uma coleção especificando explicitamente um identificador de documento.
- Adicionar um novo documento a uma coleção. Nesse caso, o Cloud Firestore gera automaticamente o identificador do documento.
- Criar um documento vazio com um identificador gerado automaticamente e atribuir dados a ele posteriormente.
A próxima seção vai orientar você na criação de um documento usando o método set.
Definir um documento
Use o método set() para criar um documento. Com o método set(), você precisa especificar um ID para o documento a ser criado.
Confira o snippet de código abaixo.
index.js
const orderDoc = db.doc(`orders/123`);
await orderDoc.set({
orderNumber: 123,
name: Anne,
address: 555 Bright Street,
city: Mountain View,
state: CA,
zip: 94043,
orderItems: [id: 1],
status: 'New'
});
Esse código vai criar um documento especificando um ID de documento gerado pelo usuário 123. Para que o Firestore gere um ID em seu nome, use o método add() ou create().
Atualizar um documento
O método de atualização update() permite atualizar alguns campos de um documento sem substituir o documento inteiro.
No snippet abaixo, o código atualiza o pedido 123
index.js
const orderDoc = db.doc(`orders/123`); await orderDoc.update(name: "Anna");
Excluir um documento
No Firestore, é possível excluir coleções, documentos ou campos específicos de um documento. Para excluir um documento, use o método delete().
O snippet abaixo exclui o pedido 123.
index.js
const orderDoc = db.doc(`orders/123`); await orderDoc.delete();
10. Como implantar e testar
Nesta seção, você vai implantar o aplicativo no Cloud Run e testar os métodos de criação, atualização e exclusão.
implantar o aplicativo no Cloud Run.
- Armazene o URL na variável INVENTORY_SERVICE_URL para integrar ao serviço de inventário.
INVENTORY_SERVICE_URL=$(gcloud run services describe inventory-service \
--region=$REGION \
--format=json | jq \
--raw-output ".status.url")
- Implantar o serviço de pedidos
gcloud run deploy order-service \
--source . \
--platform managed \
--region $REGION \
--allow-unauthenticated \
--project=$PROJECT_ID \
--set-env-vars=INVENTORY_SERVICE_URL=$INVENTORY_SERVICE_URL \
--quiet
Exemplo de saída
[...] Done. Service [order-service] revision [order-service-00001-qot] has been deployed and is serving 100 percent of traffic. Service URL: https://order-service-3jbm3exegq-uk.a.run.app
Testar o aplicativo do Cloud Run
Criar um documento
- Armazenar o URL do aplicativo de serviço de pedidos em uma variável para teste
ORDER_SERVICE_URL=$(gcloud run services describe order-service \
--platform managed \
--region $REGION \
--format=json | jq \
--raw-output ".status.url")
- Criar um pedido e postar um novo pedido no banco de dados do Firestore
curl --request POST $ORDER_SERVICE_URL/order \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "Jane Doe",
"email": "Jane.Doe-cymbaleats@gmail.com",
"address": "123 Maple",
"city": "Buffalo",
"state": "NY",
"zip": "12346",
"orderItems": [
{
"id": 1
}
]
}'
Exemplo de saída
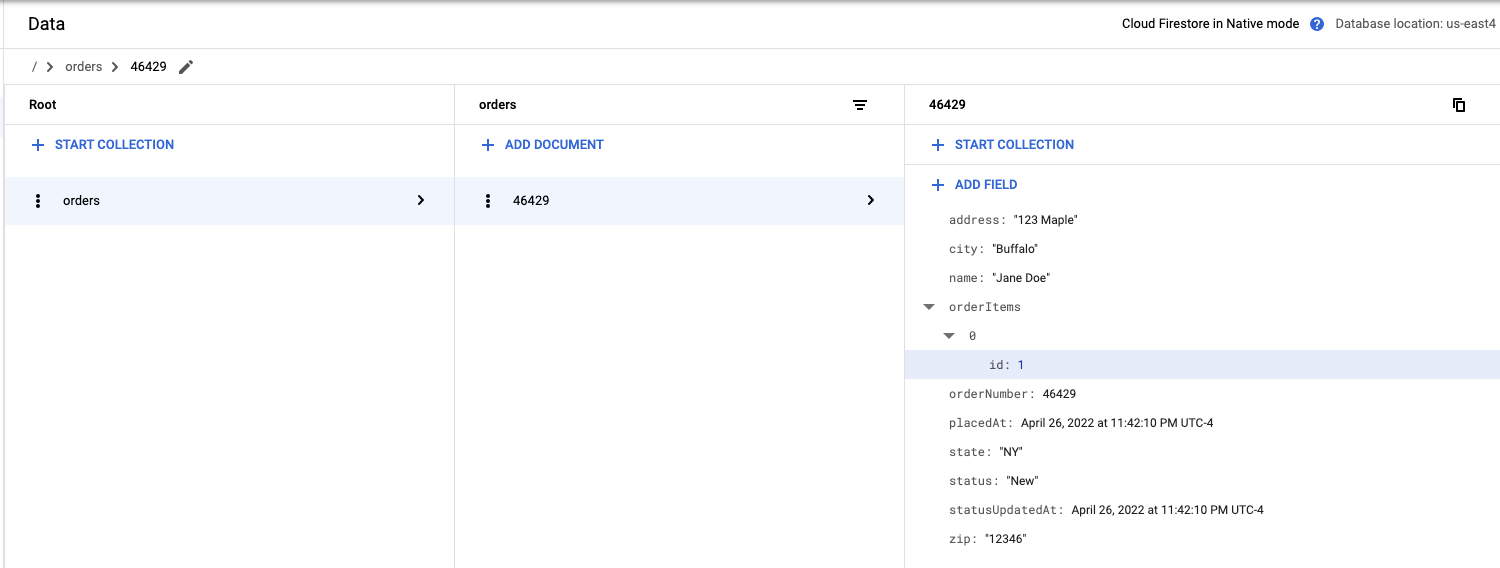
{"orderNumber":46429}
Salve o número do pedido para uso posterior
export ORDER_NUMBER=<value_from_output>
Ver resultados
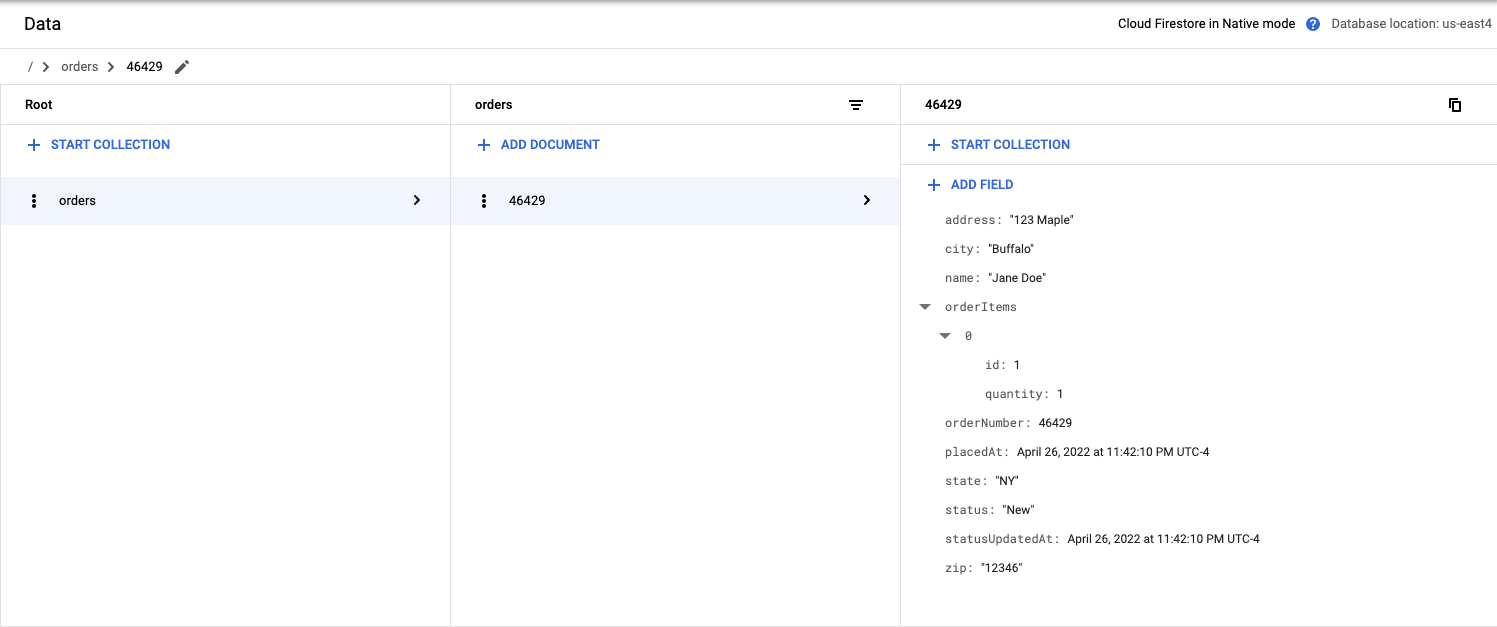
Conferir os resultados no Firestore
- Navegue até o console do Firestore.
- Clique em "Dados".
Atualizar um documento
O pedido enviado não incluiu a quantidade.
- Atualizar o registro e adicionar um par de chave-valor de quantidade
curl --location -g --request PATCH $ORDER_SERVICE_URL/order/${ORDER_NUMBER} \
--header 'Content-Type: application/json' \
--data-raw '{
"orderItems": [
{
"id": 1,
"quantity": 1
}
]
}'
Exemplo de saída
{"status":"success"}
Ver resultados
Conferir os resultados no Firestore
- Navegue até o console do Firestore.
- Clique em "Dados".
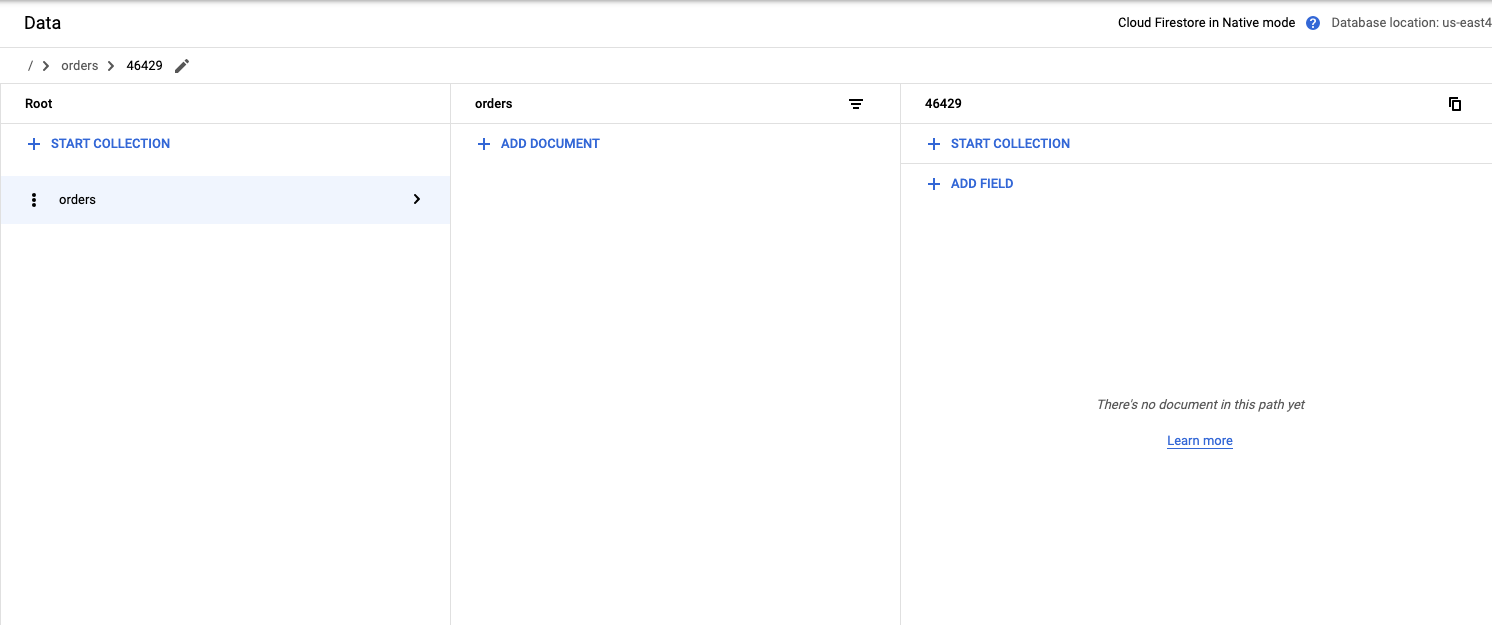
Exclusão de um documento
- Exclua o item 46429 da coleção de pedidos do Firestore.
curl --location -g --request DELETE $ORDER_SERVICE_URL/order/${ORDER_NUMBER}
Ver resultados
- Navegue até o console do Firestore.
- Clique em "Dados".
11. Parabéns!
Parabéns, você concluiu o laboratório!
Qual é a próxima etapa?
Confira outros codelabs do Cymbal Eats:
- Acionar o Cloud Workflows com o Eventarc
- Acionamento do processamento de eventos do Cloud Storage
- Como se conectar a um Cloud SQL particular pelo Cloud Run
- Proteger o aplicativo sem servidor com o Identity-Aware Proxy (IAP)
- Como acionar jobs do Cloud Run com o Cloud Scheduler
- Como fazer implantações com segurança no Cloud Run
- Como proteger o tráfego de entrada do Cloud Run
- Como se conectar ao AlloyDB particular pelo Autopilot do GKE
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto ou mantenha o projeto e exclua cada um dos recursos.
Excluir o projeto
O jeito mais fácil de evitar cobranças é excluindo o projeto que você criou para este tutorial.