
۱. مقدمه
در این آزمایشگاه کد، نحوه استفاده از Cloud SQL برای ادغام MySQL Vertex AI را با ترکیب جستجوی برداری با تعبیههای Vertex AI خواهید آموخت.

پیشنیازها
- درک اولیه از گوگل کلود، کنسول
- مهارتهای پایه در رابط خط فرمان و Cloud Shell
آنچه یاد خواهید گرفت
- نحوه استقرار Cloud SQL برای نمونه PostgreSQL
- نحوه ایجاد پایگاه داده و فعال کردن ادغام Cloud SQL AI
- نحوه بارگذاری دادهها در پایگاه داده
- نحوه استفاده از کلود اس کیو ال استودیو
- نحوه استفاده از مدل تعبیه هوش مصنوعی Vertex در Cloud SQL
- نحوه استفاده از استودیوی هوش مصنوعی ورتکس
- چگونه با استفاده از مدل مولد هوش مصنوعی Vertex، نتیجه را غنی کنیم؟
- چگونه با استفاده از شاخص برداری، عملکرد را بهبود بخشیم؟
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود
- یک مرورگر وب مانند کروم که از کنسول گوگل کلود و کلود شل پشتیبانی میکند
۲. تنظیمات و الزامات
راهاندازی پروژه
- وارد کنسول ابری گوگل شوید. اگر از قبل حساب جیمیل یا گوگل ورکاسپیس ندارید، باید یکی ایجاد کنید .
به جای حساب کاری یا تحصیلی از حساب شخصی استفاده کنید.
- یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. برای ایجاد یک پروژه جدید در کنسول Google Cloud، در سربرگ، روی دکمه «انتخاب پروژه» کلیک کنید که یک پنجره بازشو باز میشود.

در پنجره انتخاب پروژه، دکمه «پروژه جدید» را فشار دهید که یک کادر محاورهای برای پروژه جدید باز میکند.
در کادر محاورهای، نام پروژه مورد نظر خود را وارد کرده و مکان را انتخاب کنید.
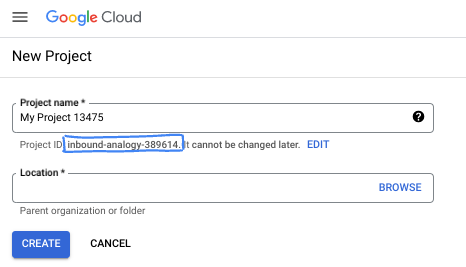
- نام پروژه ، نام نمایشی برای شرکتکنندگان این پروژه است. نام پروژه توسط APIهای گوگل استفاده نمیشود و میتوان آن را در هر زمانی تغییر داد.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد و غیرقابل تغییر است (پس از تنظیم، دیگر قابل تغییر نیست). کنسول گوگل کلود به طور خودکار یک شناسه منحصر به فرد تولید میکند، اما میتوانید آن را سفارشی کنید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید یا شناسه خودتان را برای بررسی در دسترس بودن آن ارائه دهید. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را که معمولاً با عبارت PROJECT_ID مشخص میشود، ارجاع دهید.
- برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
فعال کردن صورتحساب
برای فعال کردن پرداخت، دو گزینه دارید. میتوانید از حساب پرداخت شخصی خود استفاده کنید یا میتوانید با مراحل زیر اعتبار خود را بازخرید کنید.
استفاده از اعتبار گوگل کلود (اختیاری)
برای اجرای این کارگاه، به یک حساب صورتحساب با مقداری اعتبار نیاز دارید. برای شروع از اعتبارهای موجود در بنر بالای این codelab استفاده کنید. اگر از قبل به یک حساب صورتحساب متصل هستید، میتوانید از این مرحله صرف نظر کنید.
یک حساب پرداخت شخصی تنظیم کنید
اگر صورتحساب را با استفاده از اعتبارهای Google Cloud تنظیم کردهاید، میتوانید از این مرحله صرف نظر کنید.
برای تنظیم یک حساب پرداخت شخصی، به اینجا بروید تا پرداخت را در کنسول ابری فعال کنید .
برخی نکات:
- تکمیل این آزمایشگاه باید کمتر از ۳ دلار آمریکا از طریق منابع ابری هزینه داشته باشد.
- شما میتوانید مراحل انتهای این آزمایش را برای حذف منابع دنبال کنید تا از هزینههای بیشتر جلوگیری شود.
- کاربران جدید واجد شرایط استفاده از دوره آزمایشی رایگان ۳۰۰ دلاری هستند.
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
همچنین میتوانید دکمههای G و سپس S را فشار دهید. اگر در کنسول ابری گوگل باشید یا از این لینک استفاده کنید، این توالی، Cloud Shell را فعال میکند.
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
۳. قبل از شروع
فعال کردن API
برای استفاده از Cloud SQL ، Compute Engine ، Networking services و Vertex AI ، باید API های مربوط به آنها را در پروژه Google Cloud خود فعال کنید.
در داخل ترمینال Cloud Shell، مطمئن شوید که شناسه پروژه شما تنظیم شده است:
gcloud config set project [YOUR-PROJECT-ID]
متغیر محیطی PROJECT_ID را تنظیم کنید:
PROJECT_ID=$(gcloud config get-value project)
فعال کردن تمام سرویسهای لازم:
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
خروجی مورد انتظار
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
معرفی API ها
- رابط برنامهنویسی کاربردی مدیریت SQL ابری (
sqladmin.googleapis.com) به شما امکان میدهد نمونههای SQL ابری را به صورت برنامهنویسیشده ایجاد، پیکربندی و مدیریت کنید. این رابط، صفحه کنترلی را برای سرویس پایگاه داده رابطهای کاملاً مدیریتشده گوگل (با پشتیبانی از MySQL، PostgreSQL و SQL Server) فراهم میکند و وظایفی مانند تأمین، پشتیبانگیری، دسترسیپذیری بالا و مقیاسپذیری را مدیریت میکند. - رابط برنامهنویسی کاربردی موتور محاسبات (compute Engine API ) (
compute.googleapis.com) به شما امکان میدهد ماشینهای مجازی (VM)، دیسکهای پایدار و تنظیمات شبکه را ایجاد و مدیریت کنید. این رابط، پایه و اساس زیرساخت به عنوان سرویس (IaaS) مورد نیاز برای اجرای بارهای کاری شما و میزبانی زیرساختهای اساسی برای بسیاری از سرویسهای مدیریتشده را فراهم میکند. - رابط برنامهنویسی کاربردی مدیریت منابع ابری (
cloudresourcemanager.googleapis.com) به شما امکان میدهد تا به صورت برنامهنویسی، فرادادهها و پیکربندی پروژه گوگل کلود خود را مدیریت کنید. این رابط به شما امکان میدهد منابع را سازماندهی کنید، سیاستهای مدیریت هویت و دسترسی (IAM) را مدیریت کنید و مجوزها را در سلسله مراتب پروژه اعتبارسنجی کنید. - API شبکهسازی سرویس (
servicenetworking.googleapis.com) به شما امکان میدهد تا راهاندازی اتصال خصوصی بین شبکه ابر خصوصی مجازی (VPC) و سرویسهای مدیریتشده گوگل را خودکار کنید. این API بهطور خاص برای ایجاد دسترسی IP خصوصی برای سرویسهایی مانند AlloyDB لازم است تا بتوانند بهطور ایمن با سایر منابع شما ارتباط برقرار کنند. - رابط برنامهنویسی کاربردی هوش مصنوعی ورتکس (
aiplatform.googleapis.com) به برنامههای شما امکان ساخت، استقرار و مقیاسبندی مدلهای یادگیری ماشین را میدهد. این رابط، رابط یکپارچهای را برای همه سرویسهای هوش مصنوعی گوگل کلود، از جمله دسترسی به مدلهای هوش مصنوعی مولد (مانند Gemini) و آموزش مدلهای سفارشی، فراهم میکند.
۴. یک نمونه SQL ابری ایجاد کنید
ایجاد نمونه Cloud SQL با ادغام پایگاه داده با Vertex AI.
ایجاد رمز عبور پایگاه داده
برای کاربر پیشفرض پایگاه داده، رمز عبور تعریف کنید. میتوانید رمز عبور خودتان را تعریف کنید یا از یک تابع تصادفی برای تولید آن استفاده کنید:
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
به مقدار تولید شده برای رمز عبور توجه کنید:
echo $CLOUDSQL_PASSWORD
ایجاد Cloud SQL برای نمونه MySQL
پرچم cloudsql_vector را میتوان هنگام ایجاد یک نمونه فعال کرد. پشتیبانی از بردار در حال حاضر برای MySQL 8.0 R20241208.01_00 یا جدیدتر در دسترس است.
در جلسه Cloud Shell دستور زیر را اجرا کنید:
gcloud sql instances create my-cloudsql-instance \
--database-version=MYSQL_8_4 \
--tier=db-custom-2-8192 \
--region=us-central1 \
--enable-google-ml-integration \
--edition=ENTERPRISE \
--root-password=$CLOUDSQL_PASSWORD
ما میتوانیم اجرای اتصال خود را از طریق Cloud Shell تأیید کنیم.
gcloud sql connect my-cloudsql-instance --user=root
دستور را اجرا کنید و وقتی آماده اتصال شد، رمز عبور خود را در اعلان وارد کنید.
خروجی مورد انتظار:
$gcloud sql connect my-cloudsql-instance --user=root Allowlisting your IP for incoming connection for 5 minutes...done. Connecting to database with SQL user [root].Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 71 Server version: 8.4.4-google (Google) Copyright (c) 2000, 2025, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
فعلاً با استفاده از میانبر صفحهکلید ctrl+d یا اجرای دستور exit از جلسه mysql خارج شوید.
exit
ادغام هوش مصنوعی Vertex را فعال کنید
امتیازات لازم را به حساب سرویس ابری داخلی SQL اعطا کنید تا بتواند از ادغام Vertex AI استفاده کند.
ایمیل حساب کاربری سرویس داخلی Cloud SQL را پیدا کنید و آن را به عنوان یک متغیر خروجی بگیرید.
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
دسترسی به Vertex AI را به حساب سرویس Cloud SQL اعطا کنید:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
اطلاعات بیشتر در مورد ایجاد و پیکربندی نمونه را در مستندات Cloud SQL اینجا بخوانید.
۵. آمادهسازی پایگاه داده
حالا باید یک پایگاه داده ایجاد کنیم و پشتیبانی از بردار را فعال کنیم.
ایجاد پایگاه داده
یک پایگاه داده با نام quickstart_db ایجاد کنید. برای انجام این کار، گزینههای مختلفی مانند کلاینتهای پایگاه داده خط فرمان مانند mysql برای mySQL، SDK یا Cloud SQL Studio داریم. ما از SDK (gcloud) برای ایجاد پایگاه داده استفاده خواهیم کرد.
در Cloud Shell دستور ایجاد پایگاه داده را اجرا کنید
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
۶. بارگذاری دادهها
حالا باید اشیاء را در پایگاه داده ایجاد کنیم و دادهها را بارگذاری کنیم. ما قصد داریم از دادههای فروشگاه فرضی Cymbal استفاده کنیم. دادهها در قالب SQL (برای طرحواره) و CSV (برای دادهها) در دسترس هستند.
Cloud Shell محیط اصلی ما برای اتصال به پایگاه داده، ایجاد تمام اشیاء و بارگذاری دادهها خواهد بود.
ابتدا باید IP عمومی Cloud Shell خود را به لیست شبکههای مجاز برای نمونه Cloud SQL خود اضافه کنیم. در cloud shell دستور زیر را اجرا کنید:
gcloud sql instances patch my-cloudsql-instance --authorized-networks=$(curl ifconfig.me)
اگر جلسه شما از بین رفت، آن را مجدداً تنظیم کردید یا از ابزار دیگری استفاده میکنید، متغیر CLOUDSQL_PASSWORD خود را دوباره صادر کنید:
export CLOUDSQL_PASSWORD=...your password defined for the instance...
حالا میتوانیم تمام اشیاء مورد نیاز را در پایگاه داده خود ایجاد کنیم. برای این کار، از ابزار MySQL mysql به همراه ابزار curl که دادهها را از منبع عمومی دریافت میکند، استفاده خواهیم کرد.
در پوسته ابری دستور زیر را اجرا کنید:
export INSTANCE_IP=$(gcloud sql instances describe my-cloudsql-instance --format="value(ipAddresses.ipAddress)")
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_mysql_schema.sql | mysql --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db
دقیقاً در دستور قبلی چه کاری انجام دادیم؟ به پایگاه داده خود متصل شدیم و کد SQL دانلود شده را اجرا کردیم که جداول، ایندکسها و توالیها را ایجاد میکرد.
مرحله بعدی بارگذاری دادههای cymbal_products است. ما از همان ابزارهای curl و mysql استفاده میکنیم.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_products.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_products FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
سپس با cymbal_stores ادامه میدهیم.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_stores.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_stores FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
و با cymbal_inventory که تعداد هر محصول در هر فروشگاه را دارد، تکمیل میشود.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_inventory.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_inventory FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
اگر دادههای نمونه خودتان و فایلهای CSV سازگار با ابزار وارد کردن SQL ابری موجود در کنسول ابری را دارید، میتوانید به جای رویکرد ارائه شده از آن استفاده کنید.
۷. ایجاد جاسازیها
مرحله بعدی ساخت جاسازیها برای توضیحات محصولاتمان با استفاده از مدل textembedding-005 از Google Vertex AI و ذخیره آنها در ستون جدید در جدول cymbal_products است.
برای ذخیره دادههای برداری، باید قابلیت برداری را در نمونه Cloud SQL خود فعال کنیم. در Cloud Shell اجرا کنید:
gcloud sql instances patch my-cloudsql-instance \
--database-flags=cloudsql_vector=on
اتصال به پایگاه داده:
mysql --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db
و با استفاده از تابع embedding ، یک ستون جدید در جدول cymbal_products ایجاد کنید. آن ستون جدید، بردارهای embedding را بر اساس متن موجود در ستون product_description نگه میدارد.
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) using varbinary;
UPDATE cymbal_products SET embedding = mysql.ml_embedding('text-embedding-005', product_description);
تولید جاسازیهای برداری برای ۲۰۰۰ ردیف معمولاً کمتر از ۵ دقیقه طول میکشد، اما گاهی اوقات میتواند کمی بیشتر طول بکشد و اغلب خیلی سریعتر تمام میشود.
۸. جستجوی شباهت را اجرا کنید
اکنون میتوانیم جستجوی خود را با استفاده از جستجوی شباهت بر اساس مقادیر برداری محاسبهشده برای توصیفها و مقدار برداری که برای درخواست خود با استفاده از همان مدل جاسازی تولید میکنیم، اجرا کنیم.
پرسوجوی SQL را میتوان از همان رابط خط فرمان یا به عنوان جایگزین، از Cloud SQL Studio اجرا کرد. مدیریت هر پرسوجوی چندردیفی و پیچیده در Cloud SQL Studio بهتر است.
ایجاد یک کاربر
ما به یک کاربر جدید نیاز داریم که بتواند از Cloud SQL Studio استفاده کند. ما قصد داریم یک کاربر از نوع داخلی student با همان رمز عبوری که برای کاربر root استفاده کردهایم، ایجاد کنیم.
در Cloud Shell دستور زیر را اجرا کنید:
gcloud sql users create student --instance=my-cloudsql-instance --password=$CLOUDSQL_PASSWORD --host=%
شروع به کار با Cloud SQL Studio
در کنسول، روی نمونهی Cloud SQL که قبلاً ایجاد کردهایم کلیک کنید.
وقتی در پنل سمت راست باز شد، میتوانیم Cloud SQL Studio را ببینیم. روی آن کلیک کنید.
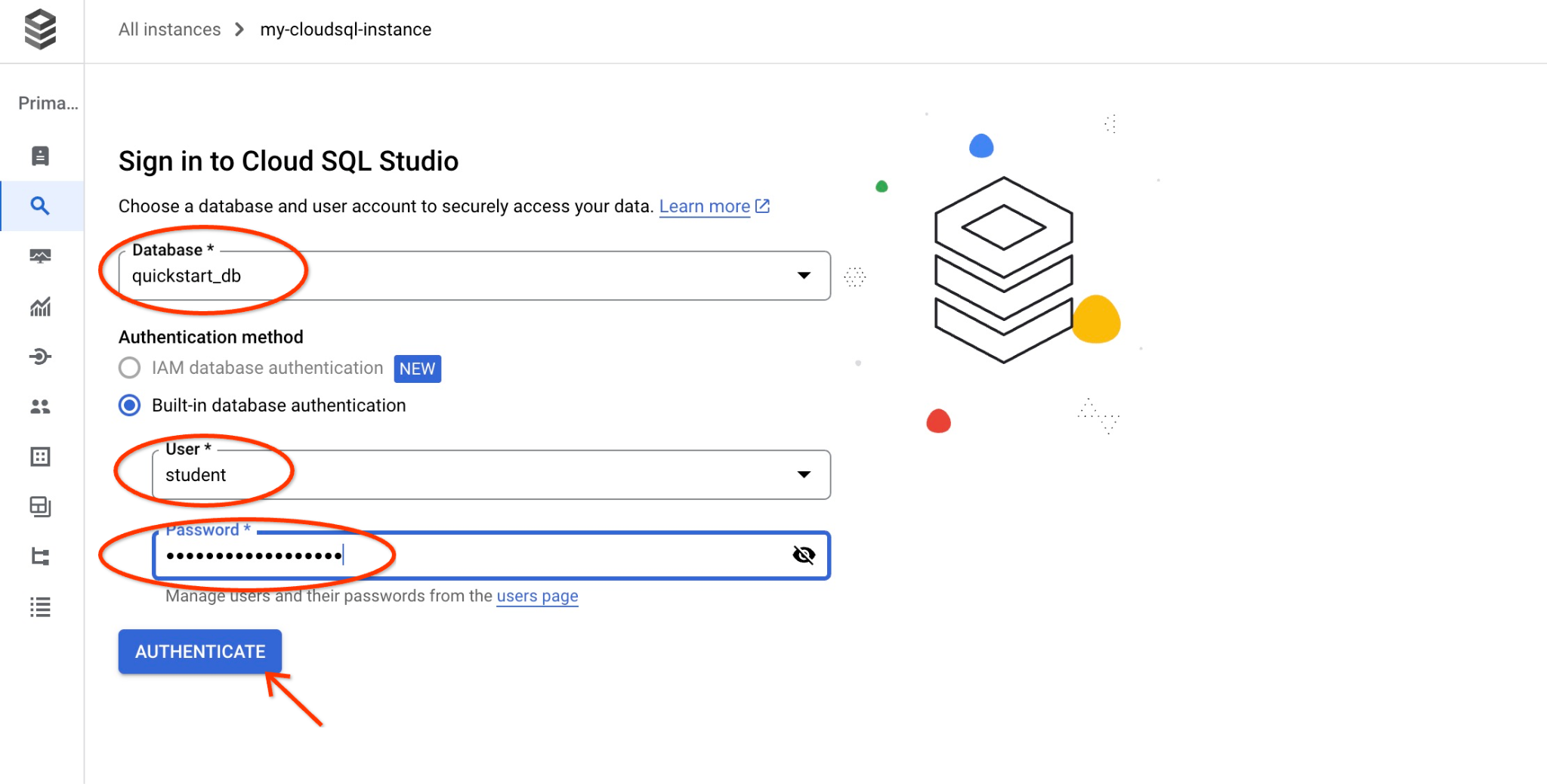
یک کادر محاورهای باز میشود که در آن نام پایگاه داده و اطلاعات کاربری خود را وارد میکنید:
- پایگاه داده: quickstart_db
- کاربر: دانشجو
- رمز عبور: رمز عبور یادداشت شده شما برای کاربر
و روی دکمه "تایید هویت" کلیک کنید.
پنجره بعدی باز میشود که در آن روی تب "Editor" در سمت راست کلیک کنید تا ویرایشگر SQL باز شود.
حالا ما آمادهایم تا کوئریهایمان را اجرا کنیم.
اجرای کوئری
یک کوئری اجرا کنید تا لیستی از محصولات موجود که بیشترین ارتباط را با درخواست مشتری دارند، دریافت کنید. درخواستی که قرار است برای دریافت مقدار بردار به Vertex AI ارسال کنیم، چیزی شبیه به این است: «چه نوع درختان میوهای اینجا خوب رشد میکنند؟»
اجرای کوئری با cosine_distance برای جستجوی برداری KNN (دقیق)
این کوئری است که میتوانید با استفاده از تابع cosine_distance برای انتخاب ۵ مورد اول که برای درخواست ما مناسبتر هستند، اجرا کنید:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cosine_distance(cp.embedding ,@query_vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
کوئری را کپی کرده و در ویرایشگر Cloud SQL Studio پیست کنید و دکمه "RUN" را فشار دهید یا آن را در جلسه خط فرمان خود که به پایگاه داده quickstart_db متصل میشود، پیست کنید.
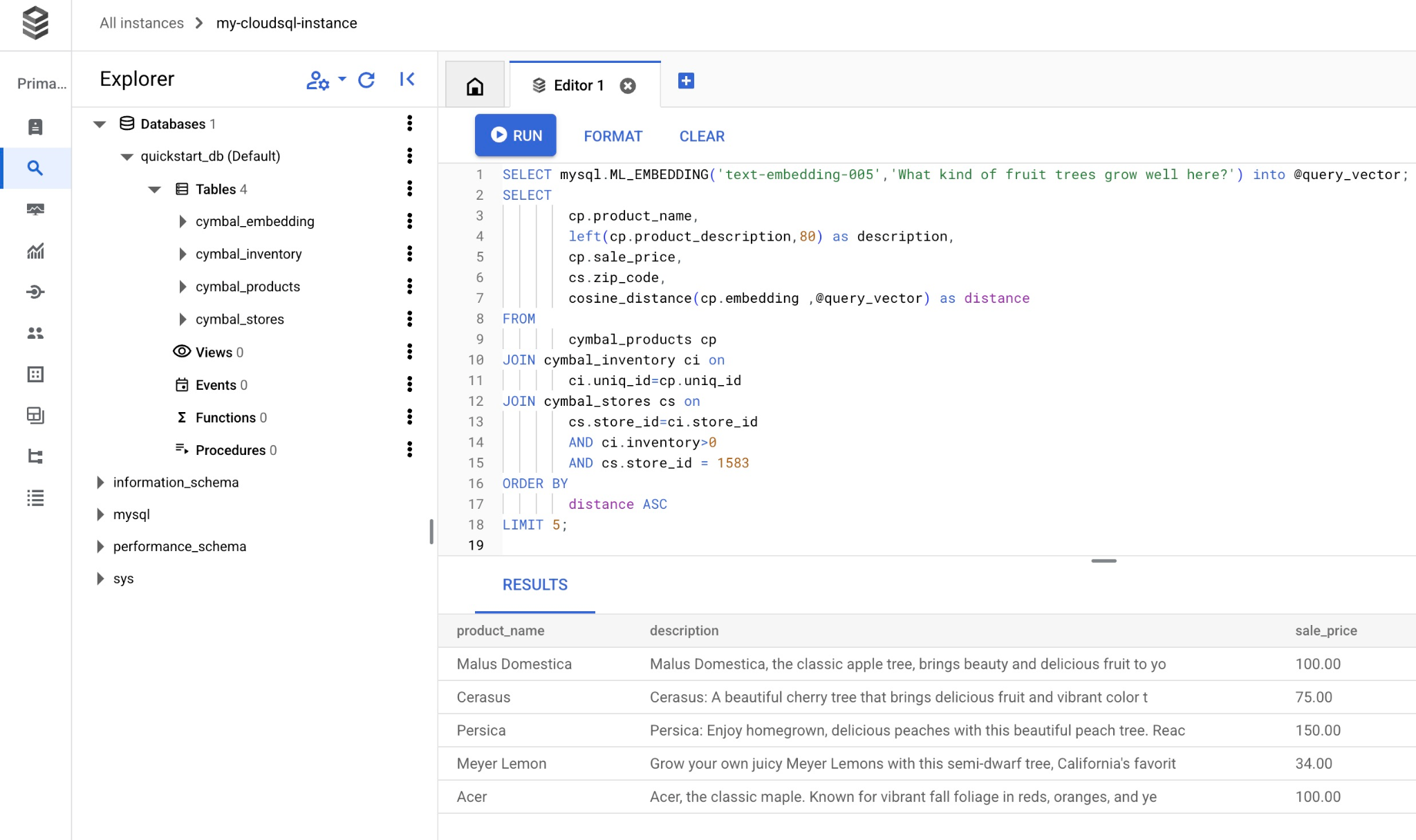
و در اینجا لیستی از محصولات انتخاب شده مطابق با عبارت جستجو شده آمده است.
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| product_name | description | sale_price | zip_code | distance |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 |
| Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 |
| Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 |
| Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 |
| Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
5 rows in set (0.13 sec)
اجرای کوئری با تابع cosine_distance، 0.13 ثانیه طول کشید.
اجرای کوئری با approx_distance برای جستجوی برداری KNN (دقیق)
حالا همان کوئری را اجرا میکنیم اما با استفاده از جستجوی KNN و با استفاده از تابع approx_distance. اگر برای جاسازیهایمان اندیس ANN نداشته باشیم، به طور خودکار به جستجوی دقیق در پشت صحنه برمیگردد:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
و در اینجا لیستی از محصولاتی که توسط پرس و جو برگردانده شده است، آمده است.
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| product_name | description | sale_price | zip_code | distance |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 |
| Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 |
| Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 |
| Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 |
| Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
5 rows in set, 1 warning (0.12 sec)
اجرای کوئری فقط ۰.۱۲ ثانیه طول کشید. ما همان نتایج تابع cosine_distance را دریافت کردیم.
۹. بهبود پاسخ LLM با استفاده از دادههای بازیابی شده
ما میتوانیم پاسخ Gen AI LLM به یک برنامه کلاینت را با استفاده از نتیجه پرسوجوی اجرا شده بهبود بخشیم و با استفاده از نتایج پرسوجوی ارائه شده به عنوان بخشی از اعلان به یک مدل زبان پایه مولد Vertex AI، یک خروجی معنادار تهیه کنیم.
برای دستیابی به این هدف، باید با نتایج جستجوی برداری خود یک JSON تولید کنیم، سپس از آن JSON تولید شده به عنوان یک اعلان برای یک مدل LLM در Vertex AI استفاده کنیم تا یک خروجی معنادار ایجاد کنیم. در مرحله اول، JSON را تولید میکنیم، سپس آن را در Vertex AI Studio آزمایش میکنیم و در مرحله آخر، آن را در یک عبارت SQL که میتواند در یک برنامه استفاده شود، قرار میدهیم.
تولید خروجی با فرمت JSON
پرسوجو را طوری تغییر دهید که خروجی را با فرمت JSON تولید کند و فقط یک ردیف برای ارسال به Vertex AI برگرداند.
در اینجا مثالی از پرس و جو با استفاده از جستجوی ANN آورده شده است:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine')) ASC
LIMIT 1)
SELECT json_arrayagg(json_object('product_name',product_name,'description',description,'sale_price',sale_price,'zip_code',zip_code,'product_id',product_id)) FROM trees;
و این هم JSON مورد انتظار در خروجی:
[{"zip_code": 93230, "product_id": "23e41a71d63d8bbc9bdfa1d118cfddc5", "sale_price": 100.00, "description": "Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo", "product_name": "Malus Domestica"}]
اجرای اعلان در Vertex AI Studio
ما میتوانیم از JSON تولید شده برای ارائه آن به عنوان بخشی از prompt به مدل متنی هوش مصنوعی مولد در Vertex AI Studio استفاده کنیم.
Vertex AI Studio Prompt را در کنسول ابری باز کنید.
ممکن است از شما بخواهد APIهای اضافی را فعال کنید، اما میتوانید این درخواست را نادیده بگیرید. ما برای تکمیل آزمایش خود به هیچ API اضافی نیاز نداریم.
یک دستور در استودیو قرار دهید.
این دستوری است که قرار است از آن استفاده کنیم:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
و در اینجا نحوه نمایش آن را مشاهده میکنید وقتی که جاینگهدار JSON را با پاسخ حاصل از پرسوجو جایگزین میکنیم:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
{"zip_code": 93230, "product_id": "23e41a71d63d8bbc9bdfa1d118cfddc5", "sale_price": 100.00, "description": "Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo", "product_name": "Malus Domestica"}
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
و این نتیجهای است که وقتی اعلان را با مقادیر JSON خود و با استفاده از مدل gemini-2.5-flash اجرا میکنیم، حاصل میشود:
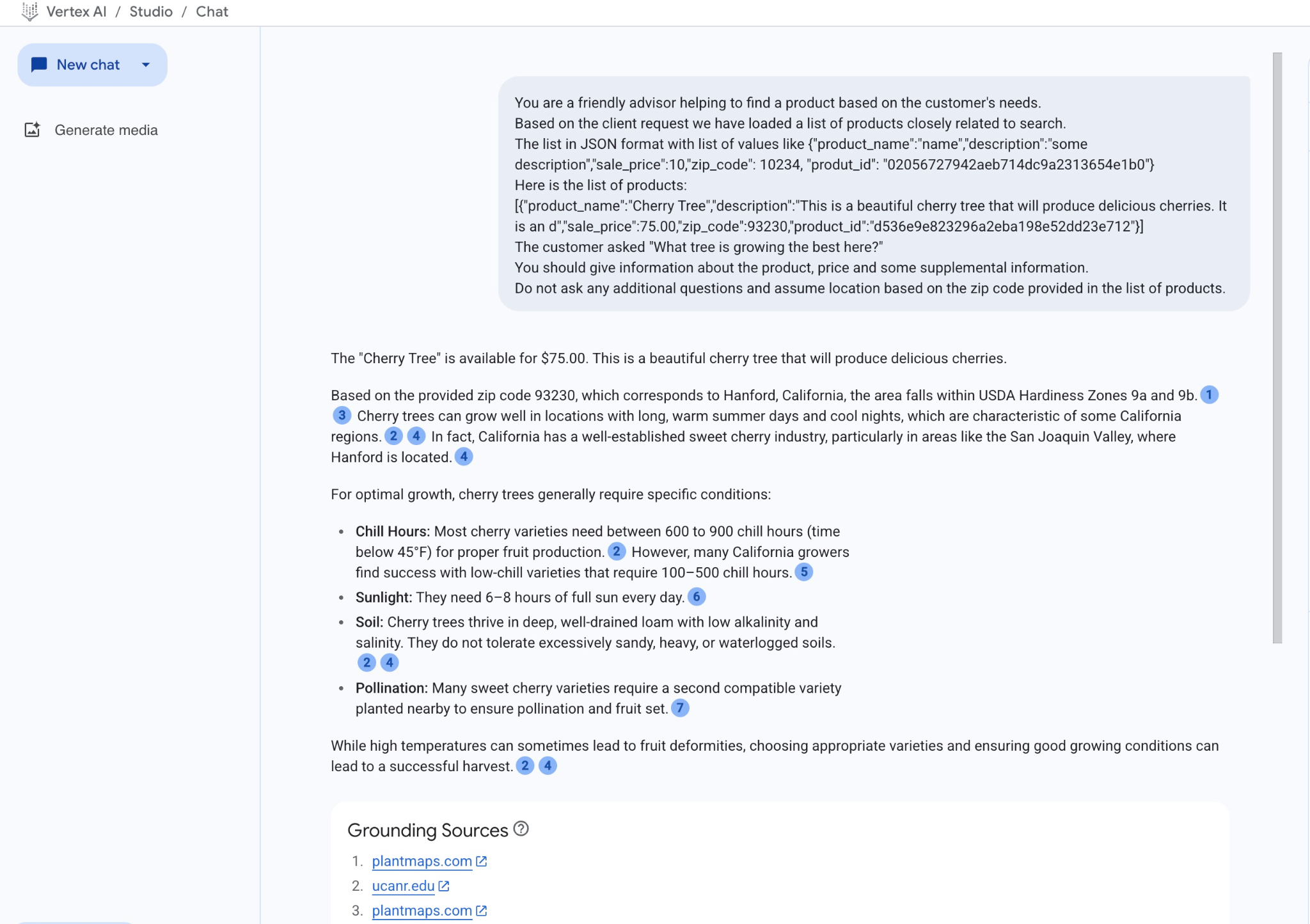
پاسخی که از مدل در این مثال دریافت کردیم، با استفاده از نتایج جستجوی معنایی و بهترین محصول منطبق موجود در کد پستی ذکر شده، ارائه میشود.
اجرای اعلان در SQL
ما همچنین میتوانیم از ادغام هوش مصنوعی Cloud SQL با Vertex AI استفاده کنیم تا پاسخ مشابهی را از یک مدل مولد با استفاده از SQL مستقیماً در پایگاه داده دریافت کنیم.
اکنون میتوانیم از نتایج تولید شده در یک subquery با JSON برای ارائه آن به عنوان بخشی از prompt به مدل متنی هوش مصنوعی مولد با استفاده از SQL استفاده کنیم.
در جلسه mysql یا Cloud SQL Studio به پایگاه داده، کوئری را اجرا کنید.
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine')) ASC
LIMIT 1),
prompt AS (
SELECT
CONCAT( 'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:', json_arrayagg(json_object('product_name',trees.product_name,'description',trees.description,'sale_price',trees.sale_price,'zip_code',trees.zip_code,'product_id',trees.product_id)) , 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information') AS prompt_text
FROM
trees),
response AS (
SELECT
mysql.ML_PREDICT_ROW('publishers/google/models/gemini-2.0-flash-001:generateContent',
json_object('contents',
json_object('role',
'user',
'parts',
json_array(
json_object('text',
prompt_text))))) AS resp
FROM
prompt)
SELECT
JSON_EXTRACT(resp, '$.candidates[0].content.parts[0].text')
FROM
response;
و این نمونه خروجی است. خروجی شما ممکن است بسته به نسخه مدل و پارامترها متفاوت باشد:
"Okay, I see you're looking for fruit trees that grow well in your area. Based on the available product, the **Malus Domestica** (Apple Tree) is a great option to consider!\n\n* **Product:** Malus Domestica (Apple Tree)\n* **Description:** This classic apple tree grows to about 30 feet tall and provides beautiful seasonal color with green leaves in summer and fiery colors in the fall. It's known for its strength and provides good shade. Most importantly, it produces delicious apples!\n* **Price:** \\$100.00\n* **Growing Zones:** This particular apple tree is well-suited for USDA zones 4-8. Since your zip code is 93230, you are likely in USDA zone 9a or 9b. While this specific tree is rated for zones 4-8, with proper care and variety selection, apple trees can still thrive in slightly warmer climates. You may need to provide extra care during heat waves.\n\n**Recommendation:** I would recommend investigating varieties of Malus Domestica suited to slightly warmer climates or contacting a local nursery/arborist to verify if it is a good fit for your local climate conditions.\n"
خروجی در قالب markdown ارائه میشود.
۱۰. ایجاد یک شاخص نزدیکترین همسایه
مجموعه دادههای ما نسبتاً کوچک است و زمان پاسخ در درجه اول به تعامل با مدلهای هوش مصنوعی بستگی دارد. اما وقتی میلیونها بردار دارید، جستجوی برداری میتواند بخش قابل توجهی از زمان پاسخ ما را بگیرد و بار زیادی را بر سیستم وارد کند. برای بهبود آن میتوانیم یک شاخص بر روی بردارهای خود بسازیم.
ایجاد شاخص ScanANN
ما قصد داریم نوع شاخص ScanANN را برای آزمایش خود امتحان کنیم.
برای ساخت اندیس برای ستون جاسازی، باید معیار فاصله خود را برای ستون جاسازی تعریف کنیم. میتوانید جزئیات پارامترها را در مستندات مطالعه کنید.
CREATE VECTOR INDEX cymbal_products_embedding_idx ON cymbal_products(embedding) USING SCANN DISTANCE_MEASURE=COSINE;
مقایسه پاسخ
اکنون میتوانیم دوباره جستجوی برداری را اجرا کنیم و نتایج را ببینیم
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
خروجی مورد انتظار:
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ | product_name | description | sale_price | zip_code | distance | +-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ | Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 | | Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 | | Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 | | Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 | | Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 | +-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ 5 rows in set (0.08 sec)
میتوانیم ببینیم که زمان اجرا فقط کمی متفاوت بوده است، اما برای چنین مجموعه داده کوچکی انتظار میرود. این تفاوت باید برای مجموعه دادههای بزرگ با میلیونها بردار بسیار قابل توجهتر باشد.
و میتوانیم با استفاده از دستور EXPLAIN نگاهی به طرح اجرایی بیندازیم:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
EXPLAIN ANALYZE SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
طرح اجرایی (خلاصه):
...
-> Nested loop inner join (cost=443 rows=5) (actual time=1.14..1.18 rows=5 loops=1)
-> Vector index scan on cp (cost=441 rows=5) (actual time=1.1..1.1 rows=5 loops=1)
-> Single-row index lookup on cp using PRIMARY (uniq_id=cp.uniq_id) (cost=0.25 rows=1) (actual time=0.0152..0.0152 rows=1 loops=5)
...
میتوانیم ببینیم که از اسکن شاخص برداری در cp (نام مستعار جدول cymbal_products) استفاده میکرده است.
شما میتوانید با دادههای خودتان آزمایش کنید یا کوئریهای جستجوی مختلف را امتحان کنید تا ببینید جستجوی معنایی در MySQL چگونه کار میکند.
۱۱. محیط را تمیز کنید
نمونه Cloud SQL را حذف کنید
وقتی کارتان با آزمایشگاه تمام شد، نمونه Cloud SQL را از بین ببرید.
در پوسته ابری، اگر اتصال شما قطع شده و تمام تنظیمات قبلی از بین رفته است، متغیرهای پروژه و محیط را تعریف کنید:
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
حذف نمونه:
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
خروجی مورد انتظار کنسول:
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
۱۲. تبریک
تبریک میگویم که آزمایشگاه کد را تمام کردی.
مسیر یادگیری فضای ابری گوگل
این آزمایشگاه بخشی از پروژه «هوش مصنوعی آماده تولید با مسیر یادگیری ابری گوگل» است.
- برای پر کردن شکاف بین نمونه اولیه و تولید، برنامه درسی کامل را بررسی کنید .
- پیشرفت خود را با هشتگ
#ProductionReadyAIبه اشتراک بگذارید.
آنچه ما پوشش دادهایم
- نحوه استقرار Cloud SQL برای نمونه PostgreSQL
- نحوه ایجاد پایگاه داده و فعال کردن ادغام Cloud SQL AI
- نحوه بارگذاری دادهها در پایگاه داده
- نحوه استفاده از کلود اس کیو ال استودیو
- نحوه استفاده از مدل تعبیه هوش مصنوعی Vertex در Cloud SQL
- نحوه استفاده از استودیوی هوش مصنوعی ورتکس
- چگونه با استفاده از مدل مولد هوش مصنوعی Vertex، نتیجه را غنی کنیم؟
- چگونه با استفاده از شاخص برداری، عملکرد را بهبود بخشیم؟
برای AlloyDB از codelab مشابه یا برای Cloud SQL از codelab برای Postgres استفاده کنید.
۱۳. نظرسنجی
خروجی: