
1. Giới thiệu
Trong lớp học lập trình này, bạn sẽ tìm hiểu cách sử dụng tính năng tích hợp AI của Cloud SQL cho PostgreSQL bằng cách kết hợp tính năng tìm kiếm vectơ với các vectơ nhúng của Vertex AI.

Điều kiện tiên quyết
- Có kiến thức cơ bản về Google Cloud Console
- Kỹ năng cơ bản về giao diện dòng lệnh và Cloud Shell
Kiến thức bạn sẽ học được
- Cách triển khai một phiên bản Cloud SQL cho PostgreSQL
- Cách tạo cơ sở dữ liệu và bật tính năng tích hợp AI của Cloud SQL
- Cách tải dữ liệu vào cơ sở dữ liệu
- Cách sử dụng Cloud SQL Studio
- Cách sử dụng mô hình nhúng Vertex AI trong Cloud SQL
- Cách sử dụng Vertex AI Studio
- Cách làm phong phú kết quả bằng mô hình tạo sinh Vertex AI
- Cách cải thiện hiệu suất bằng chỉ mục vectơ
Bạn cần có
- Tài khoản Google Cloud và dự án trên Google Cloud
- Một trình duyệt web như Chrome hỗ trợ Google Cloud Console và Cloud Shell
2. Thiết lập và yêu cầu
Thiết lập dự án
- Đăng nhập vào Google Cloud Console. Nếu chưa có tài khoản Gmail hoặc Google Workspace, bạn phải tạo một tài khoản.
Sử dụng tài khoản cá nhân thay vì tài khoản do nơi làm việc hoặc trường học cấp.
- Tạo một dự án mới hoặc sử dụng lại một dự án hiện có. Để tạo một dự án mới trong Google Cloud Console, trong tiêu đề, hãy nhấp vào nút Chọn dự án. Thao tác này sẽ mở một cửa sổ bật lên.

Trong cửa sổ Chọn một dự án, hãy nhấn vào nút Dự án mới. Thao tác này sẽ mở một hộp thoại cho dự án mới.
Trong hộp thoại, hãy nhập tên Dự án mà bạn muốn và chọn vị trí.
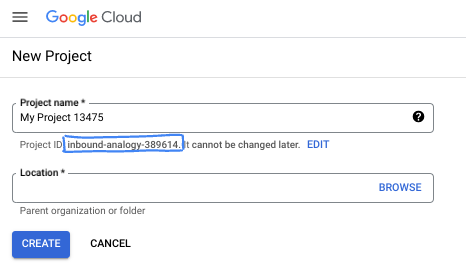
- Tên dự án là tên hiển thị của những người tham gia dự án này. Tên dự án không được các API của Google sử dụng và bạn có thể thay đổi tên này bất cứ lúc nào.
- Mã dự án là mã duy nhất trên tất cả các dự án trên Google Cloud và không thể thay đổi (bạn không thể thay đổi mã này sau khi đã đặt). Bảng điều khiển Google Cloud tự động tạo một mã nhận dạng duy nhất, nhưng bạn có thể tuỳ chỉnh mã này. Nếu không thích mã nhận dạng được tạo, bạn có thể tạo một mã nhận dạng ngẫu nhiên khác hoặc cung cấp mã nhận dạng của riêng bạn để kiểm tra xem mã đó có còn trống hay không. Trong hầu hết các lớp học lập trình, bạn sẽ cần tham chiếu đến mã dự án của mình. Mã này thường được xác định bằng phần giữ chỗ PROJECT_ID.
- Để bạn nắm được thông tin, có một giá trị thứ ba là Số dự án mà một số API sử dụng. Tìm hiểu thêm về cả 3 giá trị này trong tài liệu.
Bật tính năng thanh toán
Để bật tính năng thanh toán, bạn có 2 lựa chọn. Bạn có thể sử dụng tài khoản thanh toán cá nhân hoặc đổi tín dụng theo các bước sau.
Đổi 5 USD tín dụng Google Cloud (không bắt buộc)
Để tham gia hội thảo này, bạn cần có một Tài khoản thanh toán có sẵn một số tín dụng. Nếu dự định sử dụng hệ thống thanh toán của riêng mình, bạn có thể bỏ qua bước này.
- Nhấp vào đường liên kết này rồi đăng nhập bằng Tài khoản Google cá nhân.
- Bạn sẽ thấy nội dung như sau:

- Nhấp vào nút NHẤP VÀO ĐÂY ĐỂ XEM CÁC KHOẢN TÍN DỤNG. Thao tác này sẽ đưa bạn đến một trang để thiết lập hồ sơ thanh toán. Nếu bạn thấy màn hình đăng ký dùng thử miễn phí, hãy nhấp vào huỷ và tiếp tục liên kết thông tin thanh toán.
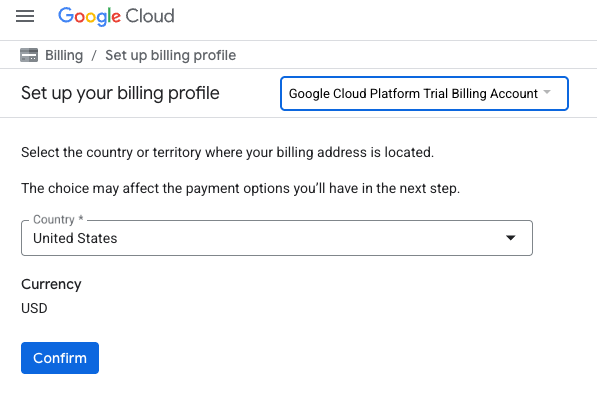
- Nhấp vào Xác nhận. Giờ đây, bạn đã kết nối với một Tài khoản thanh toán dùng thử của Google Cloud Platform.
Thiết lập tài khoản thanh toán cá nhân
Nếu thiết lập thông tin thanh toán bằng tín dụng Google Cloud, bạn có thể bỏ qua bước này.
Để thiết lập tài khoản thanh toán cá nhân, hãy truy cập vào đây để bật tính năng thanh toán trong Cloud Console.
Một số lưu ý:
- Việc hoàn thành bài thực hành này sẽ tốn ít hơn 3 USD cho các tài nguyên trên đám mây.
- Bạn có thể làm theo các bước ở cuối bài thực hành này để xoá tài nguyên nhằm tránh bị tính thêm phí.
- Người dùng mới sẽ đủ điều kiện dùng thử miễn phí 300 USD.
Khởi động Cloud Shell
Mặc dù có thể vận hành Google Cloud từ xa trên máy tính xách tay, nhưng trong lớp học lập trình này, bạn sẽ sử dụng Google Cloud Shell, một môi trường dòng lệnh chạy trên Cloud.
Trên Bảng điều khiển Google Cloud, hãy nhấp vào biểu tượng Cloud Shell trên thanh công cụ ở trên cùng bên phải:
Hoặc bạn có thể nhấn phím G rồi nhấn phím S. Trình tự này sẽ kích hoạt Cloud Shell nếu bạn đang ở trong Google Cloud Console hoặc sử dụng đường liên kết này.
Quá trình này chỉ mất vài phút để cung cấp và kết nối với môi trường. Khi quá trình này kết thúc, bạn sẽ thấy như sau:

Máy ảo này được trang bị tất cả các công cụ phát triển mà bạn cần. Nó cung cấp một thư mục chính có dung lượng 5 GB và chạy trên Google Cloud, giúp tăng cường đáng kể hiệu suất mạng và hoạt động xác thực. Bạn có thể thực hiện mọi thao tác trong lớp học lập trình này trong trình duyệt. Bạn không cần cài đặt bất cứ thứ gì.
3. Trước khi bắt đầu
Bật API
Kết quả:
Để sử dụng Cloud SQL, Compute Engine, Dịch vụ mạng và Vertex AI, bạn cần bật các API tương ứng trong dự án của mình trên Google Cloud.
Trong thiết bị đầu cuối Cloud Shell, hãy đảm bảo rằng bạn đã thiết lập mã dự án:
gcloud config set project [YOUR-PROJECT-ID]
Đặt biến môi trường PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Bật tất cả các dịch vụ cần thiết:
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Kết quả đầu ra dự kiến
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Giới thiệu về các API
- Cloud SQL Admin API (
sqladmin.googleapis.com) cho phép bạn tạo, định cấu hình và quản lý các phiên bản Cloud SQL theo phương thức lập trình. Dịch vụ này cung cấp lớp kiểm soát cho dịch vụ cơ sở dữ liệu quan hệ được quản lý hoàn toàn của Google (hỗ trợ MySQL, PostgreSQL và SQL Server), xử lý các tác vụ như cung cấp, sao lưu, khả năng đáp ứng cao và mở rộng quy mô. - Compute Engine API (
compute.googleapis.com) cho phép bạn tạo và quản lý máy ảo (VM), đĩa liên tục và chế độ cài đặt mạng. Nền tảng này cung cấp nền tảng Cơ sở hạ tầng dưới dạng dịch vụ (IaaS) cốt lõi cần thiết để chạy các khối lượng công việc và lưu trữ cơ sở hạ tầng cơ bản cho nhiều dịch vụ được quản lý. - Cloud Resource Manager API (
cloudresourcemanager.googleapis.com) cho phép bạn quản lý siêu dữ liệu và cấu hình của dự án trên Google Cloud theo phương thức lập trình. Việc này giúp bạn sắp xếp tài nguyên, xử lý các chính sách Quản lý danh tính và quyền truy cập (IAM) cũng như xác thực các quyền trong hệ thống phân cấp dự án. - Service Networking API (
servicenetworking.googleapis.com) cho phép bạn tự động hoá việc thiết lập kết nối riêng tư giữa mạng Virtual Private Cloud (VPC) và các dịch vụ được quản lý của Google. Bạn cần thiết lập quyền truy cập vào IP riêng cho các dịch vụ như AlloyDB để các dịch vụ này có thể giao tiếp an toàn với các tài nguyên khác của bạn. - Vertex AI API (
aiplatform.googleapis.com) cho phép các ứng dụng của bạn xây dựng, triển khai và mở rộng quy mô các mô hình học máy. Vertex AI cung cấp giao diện hợp nhất cho tất cả các dịch vụ AI của Google Cloud, bao gồm cả quyền truy cập vào các mô hình AI tạo sinh (như Gemini) và hoạt động huấn luyện mô hình tuỳ chỉnh.
4. Tạo một phiên bản Cloud SQL
Tạo phiên bản Cloud SQL có tích hợp cơ sở dữ liệu với Vertex AI.
Tạo mật khẩu cơ sở dữ liệu
Xác định mật khẩu cho người dùng cơ sở dữ liệu mặc định. Bạn có thể tự xác định mật khẩu hoặc sử dụng một hàm ngẫu nhiên để tạo mật khẩu:
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
Ghi lại giá trị được tạo cho mật khẩu:
echo $CLOUDSQL_PASSWORD
Tạo phiên bản Cloud SQL cho PostgreSQL
Bạn có thể tạo các phiên bản Cloud SQL bằng nhiều cách, chẳng hạn như Google Cloud Console, các công cụ tự động hoá như terraform hoặc Google Cloud SDK. Trong phòng thí nghiệm, chúng ta sẽ chủ yếu sử dụng công cụ gcloud của Google Cloud SDK. Bạn có thể đọc trong tài liệu để biết cách tạo một thực thể bằng các công cụ khác.
Trong phiên Cloud Shell, hãy thực thi:
gcloud sql instances create my-cloudsql-instance \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--region=us-central1 \
--edition=ENTERPRISE \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on
Sau khi tạo phiên bản, chúng ta cần đặt mật khẩu cho người dùng mặc định trong phiên bản và xác minh xem chúng ta có thể kết nối bằng mật khẩu đó hay không.
gcloud sql users set-password postgres \
--instance=my-cloudsql-instance \
--password=$CLOUDSQL_PASSWORD
Chạy lệnh "gcloud sql connect" như trong hộp và nhập mật khẩu vào lời nhắc khi bạn đã sẵn sàng kết nối.
gcloud sql connect my-cloudsql-instance --user=postgres
Thoát khỏi phiên psql bằng phím tắt ctrl+d hoặc thực thi lệnh exit
exit
Bật tính năng tích hợp Vertex AI
Cấp các đặc quyền cần thiết cho tài khoản dịch vụ Cloud SQL nội bộ để có thể sử dụng tính năng tích hợp Vertex AI.
Tìm địa chỉ email của tài khoản dịch vụ nội bộ Cloud SQL và xuất địa chỉ đó dưới dạng một biến.
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
Cấp quyền truy cập cho Vertex AI vào tài khoản dịch vụ Cloud SQL:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Đọc thêm về cách tạo và định cấu hình phiên bản trong tài liệu Cloud SQL tại đây.
5. Chuẩn bị cơ sở dữ liệu
Bây giờ, chúng ta cần tạo một cơ sở dữ liệu và bật tính năng hỗ trợ vectơ.
Tạo cơ sở dữ liệu
Tạo một cơ sở dữ liệu có tên là quickstart_db .Để làm như vậy, chúng ta có nhiều lựa chọn như các ứng dụng cơ sở dữ liệu dòng lệnh (chẳng hạn như psql cho PostgreSQL), SDK hoặc Cloud SQL Studio. Chúng ta sẽ dùng SDK (gcloud) để tạo cơ sở dữ liệu và kết nối với phiên bản.
Trong Cloud Shell, hãy thực thi lệnh để tạo cơ sở dữ liệu
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
Bật tiện ích
Để có thể làm việc với Vertex AI và các vectơ, chúng ta cần bật 2 tiện ích trong cơ sở dữ liệu đã tạo.
Trong Cloud Shell, hãy thực thi lệnh để kết nối với cơ sở dữ liệu đã tạo (bạn sẽ cần cung cấp mật khẩu)
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
Sau đó, sau khi kết nối thành công, trong phiên sql, bạn cần chạy 2 lệnh:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector CASCADE;
Thoát khỏi phiên SQL:
exit;
6. Tải dữ liệu
Bây giờ, chúng ta cần tạo các đối tượng trong cơ sở dữ liệu và tải dữ liệu. Chúng ta sẽ sử dụng dữ liệu giả định của Cửa hàng Cymbal. Dữ liệu có trong vùng lưu trữ công khai của Google ở định dạng CSV.
Trước tiên, chúng ta cần tạo tất cả các đối tượng bắt buộc trong cơ sở dữ liệu. Để làm như vậy, chúng ta sẽ sử dụng các lệnh gcloud sql connect và gcloud storage quen thuộc để tải xuống và nhập các đối tượng lược đồ vào cơ sở dữ liệu của mình.
Trong cloud shell, hãy thực thi và cung cấp mật khẩu đã ghi lại khi chúng ta tạo phiên bản:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
Chúng ta đã làm gì trong lệnh trước đó? Chúng tôi đã kết nối với cơ sở dữ liệu và thực thi mã SQL đã tải xuống để tạo các bảng, chỉ mục và chuỗi.
Bước tiếp theo là tải dữ liệu và để làm như vậy, chúng ta cần tải các tệp CSV xuống từ Google Cloud Storage.
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv .
Sau đó, chúng ta cần kết nối với cơ sở dữ liệu.
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
Và nhập dữ liệu từ các tệp CSV của chúng tôi.
\copy cymbal_products from 'cymbal_products.csv' csv header
\copy cymbal_inventory from 'cymbal_inventory.csv' csv header
\copy cymbal_stores from 'cymbal_stores.csv' csv header
Nếu có dữ liệu riêng và tệp CSV của bạn tương thích với công cụ nhập Cloud SQL có trong Cloud Console, thì bạn có thể sử dụng công cụ này thay vì phương pháp dòng lệnh.
7. Tạo mục nhúng
Bước tiếp theo là tạo các mục nhúng cho nội dung mô tả sản phẩm bằng cách sử dụng mô hình textembedding-004 của Google Vertex AI và lưu trữ các mục đó dưới dạng dữ liệu vectơ.
Kết nối với cơ sở dữ liệu (nếu bạn thoát hoặc phiên trước của bạn bị ngắt kết nối):
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
Tạo một cột ảo embedding trong bảng cymbal_products bằng hàm embedding. Lệnh này sẽ tạo một cột ảo "embedding" (nhúng) để lưu trữ các vectơ có giá trị nhúng được tạo dựa trên cột "product_description" (mô tả sản phẩm). Ngoài ra, thao tác này sẽ tạo các mục nhúng cho tất cả các hàng hiện có trong bảng. Mô hình được xác định là tham số đầu tiên cho hàm nhúng và dữ liệu nguồn là tham số thứ hai.
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005',product_description)) STORED;
Quá trình này có thể mất một khoảng thời gian, nhưng đối với 900 đến 1.000 hàng, quá trình này sẽ không mất quá 5 phút và thường nhanh hơn nhiều.
Khi chúng tôi chèn một hàng mới vào bảng hoặc cập nhật product_description cho bất kỳ hàng hiện có nào, dữ liệu cột ảo cho cột "embedding" sẽ được tạo lại dựa trên "product_description".
8. Chạy tính năng Tìm kiếm tương tự
Giờ đây, chúng ta có thể chạy tìm kiếm bằng cách sử dụng tính năng tìm kiếm tương tự dựa trên các giá trị vectơ được tính cho nội dung mô tả và giá trị vectơ mà chúng ta nhận được cho yêu cầu của mình.
Bạn có thể thực thi truy vấn SQL từ cùng một giao diện dòng lệnh bằng cách sử dụng gcloud sql connect hoặc từ Cloud SQL Studio. Bạn nên quản lý mọi truy vấn phức tạp và có nhiều hàng trong Cloud SQL Studio.
Khởi động Cloud SQL Studio
Trong bảng điều khiển, hãy nhấp vào phiên bản Cloud SQL mà chúng ta đã tạo trước đó.
Khi mở trên bảng điều khiển bên phải, chúng ta có thể thấy Cloud SQL Studio. Hãy nhấp vào thẻ đó.
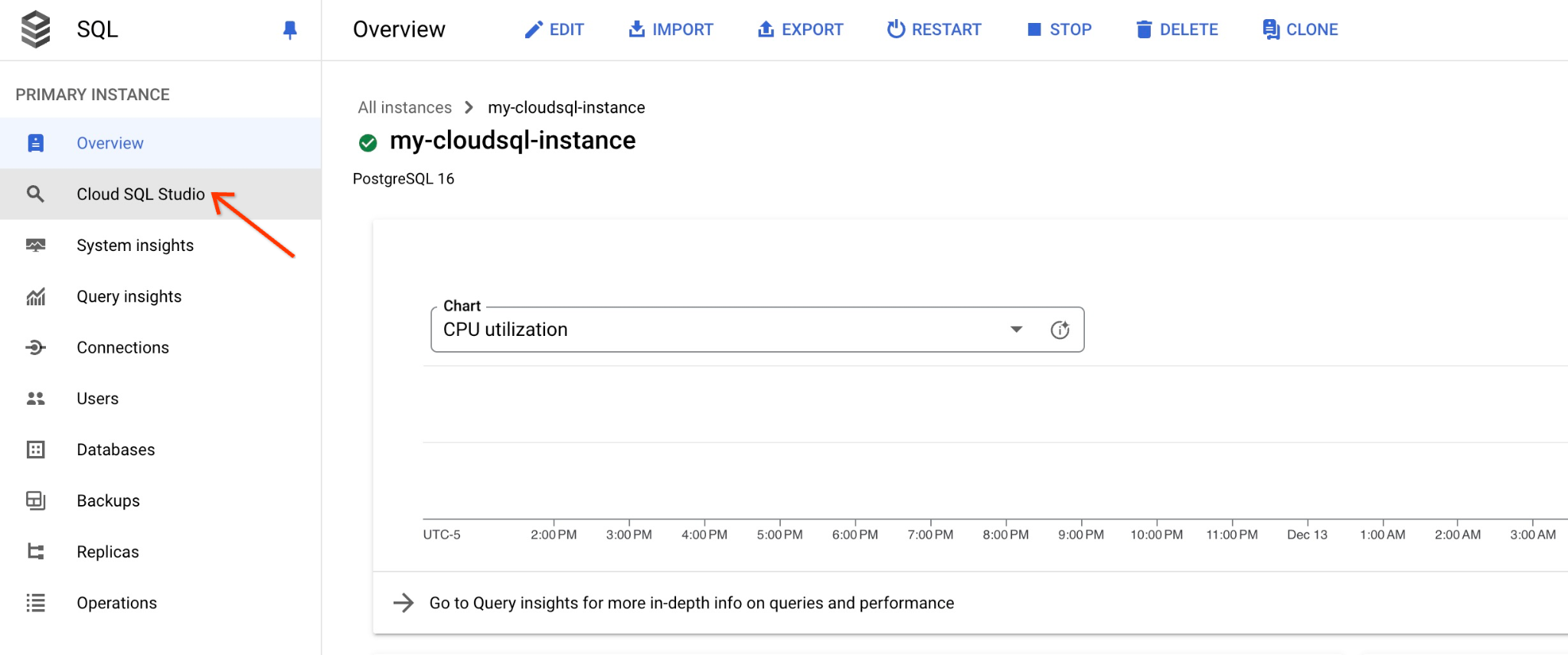
Thao tác này sẽ mở một hộp thoại để bạn cung cấp tên cơ sở dữ liệu và thông tin đăng nhập:
- Cơ sở dữ liệu: quickstart_db
- Người dùng: postgres
- Mật khẩu: mật khẩu bạn đã ghi lại cho người dùng cơ sở dữ liệu chính
Sau đó, nhấp vào nút "XÁC THỰC".
Thao tác này sẽ mở cửa sổ tiếp theo, nơi bạn nhấp vào thẻ "Trình chỉnh sửa" ở bên phải để mở Trình chỉnh sửa SQL.
Giờ đây, chúng ta đã sẵn sàng chạy các truy vấn.
Chạy truy vấn
Chạy một truy vấn để nhận danh sách các sản phẩm hiện có liên quan chặt chẽ nhất đến yêu cầu của khách hàng. Yêu cầu mà chúng ta sẽ truyền đến Vertex AI để nhận giá trị vectơ có dạng "What kind of fruit trees grow well here?" (Loại cây ăn quả nào phát triển tốt ở đây?)
Sau đây là truy vấn mà bạn có thể chạy để chọn 10 mục đầu tiên phù hợp nhất với yêu cầu của chúng tôi:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
Sao chép và dán truy vấn vào trình chỉnh sửa Cloud SQL Studio rồi nhấn nút "RUN" (CHẠY) hoặc dán truy vấn đó vào phiên dòng lệnh kết nối với cơ sở dữ liệu quickstart_db.
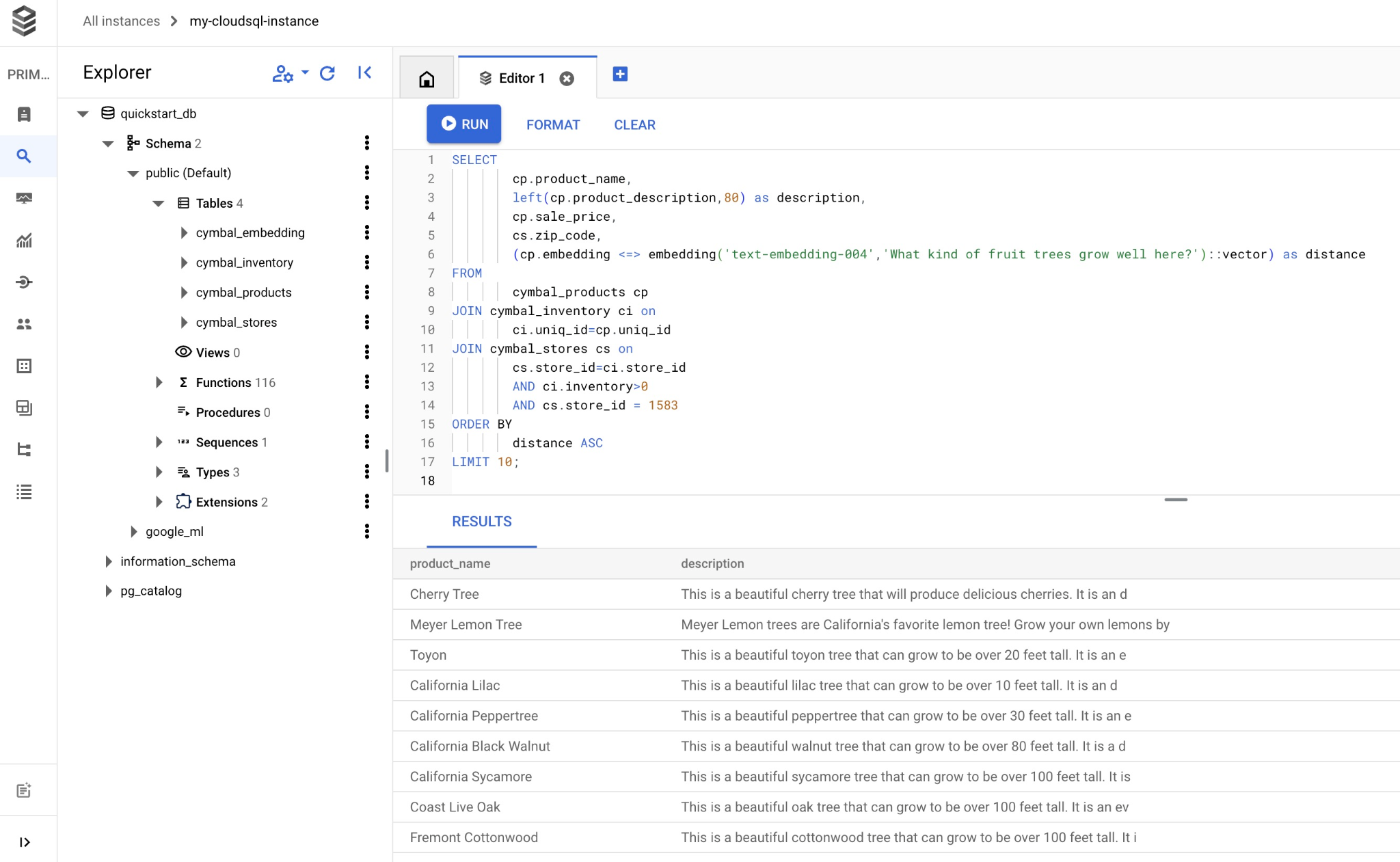
Sau đây là danh sách các sản phẩm được chọn trùng khớp với cụm từ tìm kiếm.
product_name | description | sale_price | zip_code | distance -------------------------+----------------------------------------------------------------------------------+------------+----------+--------------------- Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397 Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228 Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668 California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498 California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247 California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597 California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755 Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371 Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058 Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093 (10 rows)
9. Cải thiện câu trả lời của LLM bằng dữ liệu đã truy xuất
Chúng tôi có thể cải thiện câu trả lời của LLM AI tạo sinh cho một ứng dụng khách bằng cách sử dụng kết quả của truy vấn đã thực thi và chuẩn bị một đầu ra có ý nghĩa bằng cách sử dụng kết quả truy vấn được cung cấp làm một phần của câu lệnh cho mô hình ngôn ngữ cơ sở tạo sinh của Vertex AI.
Để đạt được điều đó, chúng ta cần tạo một JSON có kết quả từ tìm kiếm vectơ, sau đó sử dụng JSON đã tạo đó làm thông tin bổ sung cho một câu lệnh đối với mô hình LLM trong Vertex AI để tạo ra một đầu ra có ý nghĩa. Ở bước đầu tiên, chúng ta sẽ tạo JSON, sau đó kiểm thử JSON đó trong Vertex AI Studio và ở bước cuối cùng, chúng ta sẽ kết hợp JSON đó vào một câu lệnh SQL có thể dùng trong một ứng dụng.
Tạo đầu ra ở định dạng JSON
Sửa đổi truy vấn để tạo đầu ra ở định dạng JSON và chỉ trả về một hàng để chuyển đến Vertex AI
Cloud SQL cho PostgreSQL
Sau đây là ví dụ về truy vấn:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Và đây là JSON dự kiến trong đầu ra:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Chạy câu lệnh trong Vertex AI Studio
Chúng ta có thể sử dụng JSON đã tạo để cung cấp JSON này như một phần của câu lệnh cho mô hình văn bản AI tạo sinh trong Vertex AI Studio
Mở Vertex AI Studio trong Cloud Console.
Có thể bạn sẽ được yêu cầu bật các API bổ sung nhưng bạn có thể bỏ qua yêu cầu này. Chúng ta không cần thêm API nào để hoàn thành bài thực hành này.
Đưa ra một câu lệnh trong Studio.
Sau đây là câu lệnh mà chúng ta sẽ sử dụng:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
Sau đây là cách hiển thị khi chúng ta thay thế phần giữ chỗ JSON bằng phản hồi từ truy vấn:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
Và đây là kết quả khi chúng ta chạy câu lệnh với các giá trị JSON:
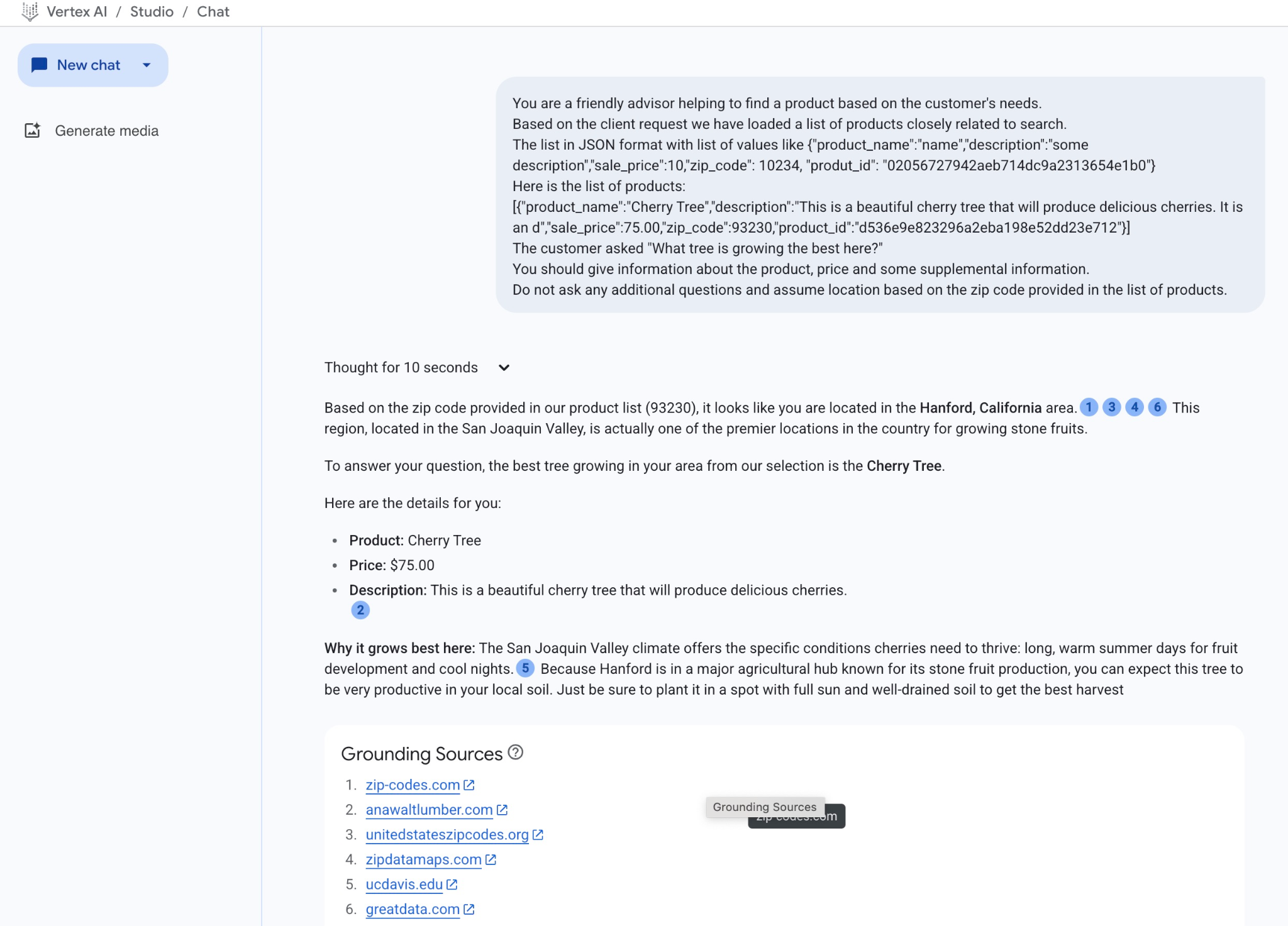
Sau đây là câu trả lời mà chúng tôi nhận được từ mô hình trong ví dụ này. Xin lưu ý rằng câu trả lời của bạn có thể khác do mô hình và các tham số thay đổi theo thời gian:
"Dựa trên mã bưu chính mà bạn cung cấp trong danh sách sản phẩm của chúng tôi (93230), có vẻ như bạn đang ở khu vực Hanford, California.1346 Khu vực này nằm ở Thung lũng San Joaquin và thực sự là một trong những địa điểm hàng đầu của quốc gia để trồng các loại quả hạch.
Để trả lời câu hỏi của bạn, cây phù hợp nhất để trồng ở khu vực của bạn trong số các lựa chọn của chúng tôi là Cây anh đào.
Sau đây là thông tin chi tiết dành cho bạn:
Sản phẩm: Cây anh đào
Giá: 750.000 VND
Mô tả: Đây là một cây anh đào đẹp sẽ cho ra những quả anh đào thơm ngon.2
Lý do cây phát triển tốt nhất ở đây: Khí hậu Thung lũng San Joaquin mang đến những điều kiện cụ thể mà cây anh đào cần để phát triển: ngày hè dài và ấm áp để quả phát triển, cùng với đêm mát mẻ.5 Vì Hanford nằm trong một trung tâm nông nghiệp lớn nổi tiếng về sản xuất quả hạch, nên bạn có thể kỳ vọng cây này sẽ rất năng suất trong đất địa phương. Hãy nhớ trồng cây ở nơi có nhiều ánh nắng và đất thoát nước tốt để có vụ thu hoạch tốt nhất"
Chạy lời nhắc trong PSQL
Chúng ta cũng có thể sử dụng tính năng tích hợp AI của Cloud SQL với Vertex AI để nhận được phản hồi tương tự từ một mô hình tạo sinh bằng cách sử dụng SQL ngay trong cơ sở dữ liệu. Nhưng để sử dụng mô hình gemini-2.0-flash-exp, trước tiên chúng ta cần đăng ký mô hình này.
Chạy trong Cloud SQL cho PostgreSQL
Nâng cấp tiện ích lên phiên bản 1.4.2 trở lên (nếu phiên bản hiện tại thấp hơn). Kết nối với cơ sở dữ liệu quickstart_db từ gcloud sql connect như đã trình bày trước đó (hoặc sử dụng Cloud SQL Studio) và thực thi:
SELECT extversion from pg_extension where extname='google_ml_integration';
Nếu giá trị trả về nhỏ hơn 1.4.3, hãy thực thi:
ALTER EXTENSION google_ml_integration UPDATE TO '1.4.3';
Sau đó, chúng ta cần đặt cờ cơ sở dữ liệu google_ml_integration.enable_model_support thành "on". Để xác minh các chế độ cài đặt hiện tại, hãy thực thi.
show google_ml_integration.enable_model_support;
Kết quả đầu ra dự kiến từ phiên psql là "on":
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Nếu trạng thái là "tắt" thì chúng ta cần cập nhật cờ cơ sở dữ liệu. Để thực hiện việc đó, bạn có thể sử dụng giao diện bảng điều khiển trên web hoặc chạy lệnh gcloud sau.
gcloud sql instances patch my-cloudsql-instance \
--database-flags google_ml_integration.enable_model_support=on,cloudsql.enable_google_ml_integration=on
Lệnh này mất khoảng 1 đến 3 phút để thực thi trong nền. Sau đó, bạn có thể xác minh cờ mới trong phiên psql hoặc bằng cách sử dụng Cloud SQL Studio kết nối với cơ sở dữ liệu quickstart_db.
show google_ml_integration.enable_model_support;
Kết quả đầu ra dự kiến từ phiên psql là "on":
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Sau đó, chúng ta cần đăng ký 2 mô hình. Mô hình đầu tiên là mô hình text-embedding-005 đã được sử dụng. Bạn cần đăng ký vì chúng tôi đã bật các chức năng đăng ký mô hình.
Để đăng ký lượt chạy mô hình trong psql hoặc Cloud SQL Studio, hãy dùng mã sau:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'cloudsql_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
Và mô hình tiếp theo mà chúng ta cần đăng ký là gemini-2.0-flash-001. Mô hình này sẽ được dùng để tạo đầu ra thân thiện với người dùng.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'https://us-central1-aiplatform.googleapis.com/v1/projects/$PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'cloudsql_service_agent_iam');
Bạn luôn có thể xác minh danh sách các mô hình đã đăng ký bằng cách chọn thông tin từ google_ml.model_info_view.
select model_id,model_type from google_ml.model_info_view;
Sau đây là kết quả mẫu
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
--------------------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
gemini-1.5-pro:streamGenerateContent | generic
gemini-1.5-pro:generateContent | generic
gemini-1.0-pro:generateContent | generic
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
Giờ đây, chúng ta có thể sử dụng JSON được tạo trong một truy vấn phụ để cung cấp JSON đó dưới dạng một phần của câu lệnh cho mô hình văn bản AI tạo sinh bằng SQL.
Trong phiên psql hoặc Cloud SQL Studio đối với cơ sở dữ liệu, hãy chạy truy vấn
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> google_ml.embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
Và đây là kết quả dự kiến. Kết quả đầu ra của bạn có thể khác tuỳ thuộc vào phiên bản mô hình và các tham số:
"That's a great question! It sounds like you're looking to add some delicious fruit to your garden.\n\nBased on the products we have that are closely related to your search, I can tell you about a fantastic option:\n\n**Cherry Tree**" "\n* **Description:** This beautiful deciduous tree will produce delicious cherries. It grows to be about 15 feet tall, with dark green leaves in summer that turn a beautiful red in the fall. Cherry trees are known for their beauty, shade, and privacy. They prefer a cool, moist climate and sandy soil." "\n* **Price:** $75.00\n* **Grows well in:** USDA Zones 4-9.\n\nTo confirm if this Cherry Tree will thrive in your specific location, you might want to check which USDA Hardiness Zone your area falls into. If you're in zones 4-9, this" " could be a wonderful addition to your yard!"
10. Tạo chỉ mục lân cận gần nhất
Tập dữ liệu của chúng tôi khá nhỏ và thời gian phản hồi chủ yếu phụ thuộc vào các lượt tương tác với mô hình AI. Nhưng khi bạn có hàng triệu vectơ, tính năng tìm kiếm vectơ có thể chiếm một phần đáng kể trong thời gian phản hồi và gây tải lớn cho hệ thống. Để cải thiện, chúng ta có thể tạo một chỉ mục trên các vectơ.
Tạo chỉ mục HNSW
Chúng ta sẽ thử loại chỉ mục HNSW cho kiểm thử. HNSW là viết tắt của Hierarchical Navigable Small World (Thế giới nhỏ có thể điều hướng theo hệ thống phân cấp) và biểu thị một chỉ mục biểu đồ nhiều lớp.
Để tạo chỉ mục cho cột nhúng, chúng ta cần xác định cột nhúng, hàm khoảng cách và các tham số (không bắt buộc) như m hoặc ef_constructions. Bạn có thể đọc thông tin chi tiết về các tham số trong tài liệu.
CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
Kết quả đầu ra dự kiến:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64); CREATE INDEX quickstart_db=>
So sánh câu trả lời
Giờ đây, chúng ta có thể chạy truy vấn tìm kiếm vectơ ở chế độ EXPLAIN và xác minh xem chỉ mục đã được sử dụng hay chưa.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Kết quả đầu ra dự kiến:
Aggregate (cost=779.12..779.13 rows=1 width=32) (actual time=1.066..1.069 rows=1 loops=1)
-> Subquery Scan on trees (cost=769.05..779.12 rows=1 width=142) (actual time=1.038..1.041 rows=1 loops=1)
-> Limit (cost=769.05..779.11 rows=1 width=158) (actual time=1.022..1.024 rows=1 loops=1)
-> Nested Loop (cost=769.05..9339.69 rows=852 width=158) (actual time=1.020..1.021 rows=1 loops=1)
-> Nested Loop (cost=768.77..9316.48 rows=852 width=945) (actual time=0.858..0.859 rows=1 loops=1)
-> Index Scan using cymbal_products_embeddings_hnsw on cymbal_products cp (cost=768.34..2572.47 rows=941 width=941) (actual time=0.532..0.539 rows=3 loops=1)
Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,...
<redacted>
...,0.017593635,-0.040275685,-0.03914233,-0.018452475,0.00826032,-0.07372604
]'::vector)
-> Index Scan using product_inventory_pkey on cymbal_inventory ci (cost=0.42..7.17 rows=1 width=37) (actual time=0.104..0.104 rows=0 loops=3)
Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text))
Filter: (inventory > 0)
Rows Removed by Filter: 1
-> Materialize (cost=0.28..8.31 rows=1 width=8) (actual time=0.133..0.134 rows=1 loops=1)
-> Index Scan using product_stores_pkey on cymbal_stores cs (cost=0.28..8.30 rows=1 width=8) (actual time=0.129..0.129 rows=1 loops=1)
Index Cond: (store_id = 1583)
Planning Time: 112.398 ms
Execution Time: 1.221 ms
Từ đầu ra, chúng ta có thể thấy rõ rằng truy vấn đang sử dụng "Index Scan using cymbal_products_embeddings_hnsw".
Và nếu chúng ta chạy truy vấn mà không có explain:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Kết quả đầu ra dự kiến (kết quả đầu ra có thể khác nhau tuỳ thuộc vào mô hình và chỉ mục):
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Chúng ta có thể thấy kết quả vẫn như cũ và trả về cùng một cây Anh đào ở vị trí đầu tiên trong kết quả tìm kiếm không có chỉ mục. Tuỳ thuộc vào các tham số và loại chỉ mục, có thể kết quả sẽ hơi khác và trả về một bản ghi hàng đầu khác cho cây. Trong các thử nghiệm của tôi, truy vấn được lập chỉ mục trả về kết quả trong 131,301 mili giây so với 167,631 mili giây mà không có chỉ mục nào, nhưng chúng tôi đang xử lý một tập dữ liệu rất nhỏ và sự khác biệt sẽ đáng kể hơn trên một dữ liệu lớn hơn.
Bạn có thể thử các chỉ mục khác nhau có sẵn cho các vectơ và nhiều phòng thí nghiệm cũng như ví dụ khác có tích hợp langchain trong tài liệu.
11. Dọn dẹp môi trường
Xoá phiên bản Cloud SQL
Huỷ phiên bản Cloud SQL khi bạn hoàn tất lớp học lập trình
Trong cloud shell, hãy xác định dự án và các biến môi trường nếu bạn bị ngắt kết nối và mất tất cả các chế độ cài đặt trước đó:
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
Xoá phiên bản:
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
Kết quả đầu ra dự kiến trên bảng điều khiển:
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
12. Xin chúc mừng
Chúc mừng bạn đã hoàn thành lớp học lập trình này.
Phòng thí nghiệm này thuộc Lộ trình học tập về AI sẵn sàng cho sản xuất trên Google Cloud.
- Khám phá toàn bộ chương trình giảng dạy để thu hẹp khoảng cách từ nguyên mẫu đến sản xuất.
- Chia sẻ tiến trình của bạn bằng thẻ bắt đầu bằng #
#ProductionReadyAI.
Nội dung đã đề cập
- Cách triển khai một phiên bản Cloud SQL cho PostgreSQL
- Cách tạo cơ sở dữ liệu và bật tính năng tích hợp AI của Cloud SQL
- Cách tải dữ liệu vào cơ sở dữ liệu
- Cách sử dụng Cloud SQL Studio
- Cách sử dụng mô hình nhúng Vertex AI trong Cloud SQL
- Cách sử dụng Vertex AI Studio
- Cách làm phong phú kết quả bằng mô hình tạo sinh Vertex AI
- Cách cải thiện hiệu suất bằng chỉ mục vectơ
Hãy thử lớp học lập trình tương tự cho AlloyDB bằng chỉ mục ScaNN thay vì HNSW
13. Khảo sát
Kết quả: