
1. บทนำ
ในโค้ดแล็บนี้ คุณจะได้เรียนรู้วิธีใช้การผสานรวม AI ของ Cloud SQL สำหรับ PostgreSQL โดยการรวมการค้นหาแบบเวกเตอร์เข้ากับการฝัง Vertex AI

ข้อกำหนดเบื้องต้น
- ความเข้าใจพื้นฐานเกี่ยวกับ Google Cloud และคอนโซล
- ทักษะพื้นฐานในอินเทอร์เฟซบรรทัดคำสั่งและ Cloud Shell
สิ่งที่คุณจะได้เรียนรู้
- วิธีติดตั้งใช้งานอินสแตนซ์ Cloud SQL สำหรับ PostgreSQL
- วิธีสร้างฐานข้อมูลและเปิดใช้การผสานรวม AI ของ Cloud SQL
- วิธีโหลดข้อมูลลงในฐานข้อมูล
- วิธีใช้ Cloud SQL Studio
- วิธีใช้โมเดลการฝัง Vertex AI ใน Cloud SQL
- วิธีใช้ Vertex AI Studio
- วิธีเพิ่มคุณค่าให้กับผลลัพธ์โดยใช้โมเดล Generative AI ของ Vertex AI
- วิธีปรับปรุงประสิทธิภาพโดยใช้ดัชนีเวกเตอร์
สิ่งที่คุณต้องมี
- บัญชี Google Cloud และโปรเจ็กต์ Google Cloud
- เว็บเบราว์เซอร์ เช่น Chrome ที่รองรับ Google Cloud Console และ Cloud Shell
2. การตั้งค่าและข้อกำหนด
การตั้งค่าโปรเจ็กต์
- ลงชื่อเข้าใช้ Google Cloud Console หากยังไม่มีบัญชี Gmail หรือ Google Workspace คุณต้องสร้างบัญชี
ใช้บัญชีส่วนตัวแทนบัญชีงานหรือบัญชีโรงเรียน
- สร้างโปรเจ็กต์ใหม่หรือนำโปรเจ็กต์ที่มีอยู่มาใช้ซ้ำ หากต้องการสร้างโปรเจ็กต์ใหม่ใน Google Cloud Console ให้คลิกปุ่มเลือกโปรเจ็กต์ในส่วนหัว ซึ่งจะเปิดหน้าต่างป๊อปอัป

ในหน้าต่างเลือกโปรเจ็กต์ ให้กดปุ่มโปรเจ็กต์ใหม่ ซึ่งจะเปิดกล่องโต้ตอบสำหรับโปรเจ็กต์ใหม่
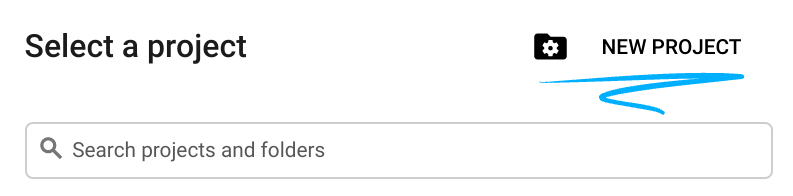
ในกล่องโต้ตอบ ให้ป้อนชื่อโปรเจ็กต์ที่ต้องการและเลือกตำแหน่ง
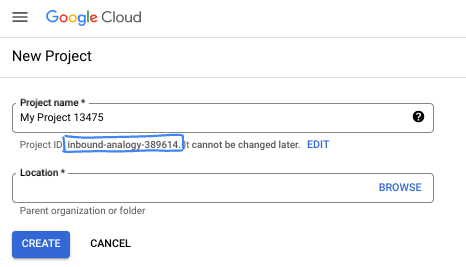
- ชื่อโปรเจ็กต์คือชื่อที่แสดงสำหรับผู้เข้าร่วมโปรเจ็กต์นี้ Google API จะไม่ใช้ชื่อโปรเจ็กต์ และคุณสามารถเปลี่ยนชื่อได้ทุกเมื่อ
- รหัสโปรเจ็กต์จะไม่ซ้ำกันในโปรเจ็กต์ Google Cloud ทั้งหมดและเปลี่ยนแปลงไม่ได้ (เปลี่ยนไม่ได้หลังจากตั้งค่าแล้ว) คอนโซล Google Cloud จะสร้างรหัสที่ไม่ซ้ำกันโดยอัตโนมัติ แต่คุณสามารถปรับแต่งได้ หากไม่ชอบรหัสที่สร้างขึ้น คุณสามารถสร้างรหัสแบบสุ่มอีกรหัสหนึ่งหรือระบุรหัสของคุณเองเพื่อตรวจสอบความพร้อมใช้งานได้ ใน Codelab ส่วนใหญ่ คุณจะต้องอ้างอิงรหัสโปรเจ็กต์ ซึ่งโดยปกติจะระบุด้วยตัวยึดตำแหน่ง PROJECT_ID
- โปรดทราบว่ายังมีค่าที่ 3 ซึ่งคือหมายเลขโปรเจ็กต์ที่ API บางตัวใช้ ดูข้อมูลเพิ่มเติมเกี่ยวกับค่าทั้ง 3 นี้ได้ในเอกสารประกอบ
เปิดใช้การเรียกเก็บเงิน
คุณมี 2 ตัวเลือกในการเปิดใช้การเรียกเก็บเงิน คุณจะใช้บัญชีสำหรับการเรียกเก็บเงินส่วนตัวหรือแลกรับเครดิตได้โดยทำตามขั้นตอนต่อไปนี้
แลกรับเครดิต Google Cloud มูลค่า $5 (ไม่บังคับ)
หากต้องการจัดเวิร์กช็อปนี้ คุณต้องมีบัญชีสำหรับการเรียกเก็บเงินที่มีเครดิตอยู่บ้าง หากวางแผนที่จะใช้การเรียกเก็บเงินของคุณเอง ให้ข้ามขั้นตอนนี้
- คลิกลิงก์นี้แล้วลงชื่อเข้าใช้ด้วยบัญชี Google ส่วนบุคคล
- คุณจะเห็นข้อความคล้ายกับข้อความต่อไปนี้

- คลิกปุ่มคลิกที่นี่เพื่อเข้าถึงเครดิต ซึ่งจะนำคุณไปยังหน้าเพื่อตั้งค่าโปรไฟล์การเรียกเก็บเงิน หากเห็นหน้าจอลงชื่อสมัครใช้ช่วงทดลองใช้ฟรี ให้คลิกยกเลิกและดำเนินการลิงก์การเรียกเก็บเงินต่อ
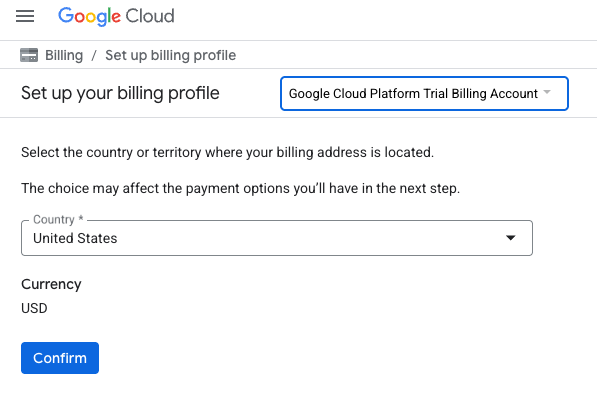
- คลิก "ยืนยัน" ตอนนี้คุณเชื่อมต่อกับบัญชีสำหรับการเรียกเก็บเงินของ Google Cloud Platform เวอร์ชันทดลองใช้งานแล้ว
ตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว
หากตั้งค่าการเรียกเก็บเงินโดยใช้เครดิต Google Cloud คุณจะข้ามขั้นตอนนี้ได้
หากต้องการตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว ให้ไปที่นี่เพื่อเปิดใช้การเรียกเก็บเงินใน Cloud Console
ข้อควรทราบ
- การทำแล็บนี้ควรมีค่าใช้จ่ายน้อยกว่า $3 USD ในทรัพยากรระบบคลาวด์
- คุณสามารถทำตามขั้นตอนที่ส่วนท้ายของแล็บนี้เพื่อลบทรัพยากรเพื่อหลีกเลี่ยงการเรียกเก็บเงินเพิ่มเติม
- ผู้ใช้ใหม่มีสิทธิ์ใช้ช่วงทดลองใช้ฟรีมูลค่า$300 USD
เริ่มต้น Cloud Shell
แม้ว่าคุณจะใช้งาน Google Cloud จากระยะไกลจากแล็ปท็อปได้ แต่ใน Codelab นี้คุณจะใช้ Google Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานในระบบคลาวด์
จาก Google Cloud Console ให้คลิกไอคอน Cloud Shell ในแถบเครื่องมือด้านขวาบน
หรือจะกด G แล้วตามด้วย S ก็ได้ ลำดับนี้จะเปิดใช้งาน Cloud Shell หากคุณอยู่ใน Google Cloud Console หรือใช้ลิงก์นี้
การจัดสรรและเชื่อมต่อกับสภาพแวดล้อมจะใช้เวลาเพียงไม่กี่นาที เมื่อเสร็จแล้ว คุณควรเห็นข้อความคล้ายกับตัวอย่างต่อไปนี้

เครื่องเสมือนนี้มาพร้อมเครื่องมือพัฒนาซอฟต์แวร์ทั้งหมดที่คุณต้องการ โดยมีไดเรกทอรีหลักแบบถาวรขนาด 5 GB และทำงานบน Google Cloud ซึ่งช่วยเพิ่มประสิทธิภาพเครือข่ายและการตรวจสอบสิทธิ์ได้อย่างมาก คุณสามารถทำงานทั้งหมดใน Codelab นี้ได้ภายในเบราว์เซอร์ คุณไม่จำเป็นต้องติดตั้งอะไร
3. ก่อนเริ่มต้น
เปิดใช้ API
เอาต์พุต:
หากต้องการใช้ Cloud SQL, Compute Engine, บริการเครือข่าย และ Vertex AI คุณต้องเปิดใช้ API ที่เกี่ยวข้องในโปรเจ็กต์ Google Cloud
ตรวจสอบว่าได้ตั้งค่ารหัสโปรเจ็กต์ในเทอร์มินัล Cloud Shell แล้วโดยทำดังนี้
gcloud config set project [YOUR-PROJECT-ID]
ตั้งค่าตัวแปรสภาพแวดล้อม PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
เปิดใช้บริการที่จำเป็นทั้งหมด
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
ผลลัพธ์ที่คาดหวัง
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
ขอแนะนำ API
- Cloud SQL Admin API (
sqladmin.googleapis.com) ช่วยให้คุณสร้าง กำหนดค่า และจัดการอินสแตนซ์ Cloud SQL ได้แบบเป็นโปรแกรม โดยจะมอบ Control Plane สำหรับบริการฐานข้อมูลเชิงสัมพันธ์ที่มีการจัดการครบวงจรของ Google (รองรับ MySQL, PostgreSQL และ SQL Server) ซึ่งจะจัดการงานต่างๆ เช่น การจัดสรร การสำรองข้อมูล ความพร้อมใช้งานสูง และการปรับขนาด - Compute Engine API (
compute.googleapis.com) ช่วยให้คุณสร้างและจัดการเครื่องเสมือน (VM), Persistent Disk และการตั้งค่าเครือข่ายได้ โดยมีพื้นฐานด้าน Infrastructure-as-a-Service (IaaS) หลักที่จำเป็นต่อการเรียกใช้เวิร์กโหลดและโฮสต์โครงสร้างพื้นฐานที่อยู่เบื้องหลังสำหรับบริการที่มีการจัดการจำนวนมาก - Cloud Resource Manager API (
cloudresourcemanager.googleapis.com) ช่วยให้คุณจัดการข้อมูลเมตาและการกำหนดค่าของโปรเจ็กต์ Google Cloud แบบเป็นโปรแกรมได้ ซึ่งช่วยให้คุณจัดระเบียบทรัพยากร จัดการนโยบาย Identity and Access Management (IAM) และตรวจสอบสิทธิ์ในลำดับชั้นของโปรเจ็กต์ได้ - Service Networking API (
servicenetworking.googleapis.com) ช่วยให้คุณตั้งค่าการเชื่อมต่อส่วนตัวระหว่างเครือข่าย Virtual Private Cloud (VPC) กับบริการที่มีการจัดการของ Google โดยอัตโนมัติได้ โดยเฉพาะอย่างยิ่งจำเป็นต้องสร้างการเข้าถึง IP ส่วนตัวสำหรับบริการต่างๆ เช่น AlloyDB เพื่อให้สื่อสารกับทรัพยากรอื่นๆ ได้อย่างปลอดภัย - Vertex AI API (
aiplatform.googleapis.com) ช่วยให้แอปพลิเคชันของคุณสร้าง ปรับใช้ และปรับขนาดโมเดลแมชชีนเลิร์นนิงได้ โดยมีอินเทอร์เฟซแบบรวมสำหรับบริการ AI ทั้งหมดของ Google Cloud รวมถึงการเข้าถึงโมเดล Generative AI (เช่น Gemini) และการฝึกโมเดลที่กำหนดเอง
4. สร้างอินสแตนซ์ Cloud SQL
สร้างอินสแตนซ์ Cloud SQL ที่ผสานรวมฐานข้อมูลกับ Vertex AI
สร้างรหัสผ่านฐานข้อมูล
กำหนดรหัสผ่านสำหรับผู้ใช้ฐานข้อมูลเริ่มต้น คุณกำหนดรหัสผ่านเองหรือใช้ฟังก์ชันแบบสุ่มเพื่อสร้างรหัสผ่านก็ได้ โดยทำดังนี้
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
จดค่าที่สร้างขึ้นสำหรับรหัสผ่าน
echo $CLOUDSQL_PASSWORD
สร้างอินสแตนซ์ Cloud SQL สำหรับ PostgreSQL
คุณสร้างอินสแตนซ์ Cloud SQL ได้หลายวิธี เช่น คอนโซล Google Cloud, เครื่องมืออัตโนมัติอย่าง Terraform หรือ Google Cloud SDK ในแล็บนี้ เราจะใช้เครื่องมือ gcloud ของ Google Cloud SDK เป็นหลัก คุณอ่านวิธีสร้างอินสแตนซ์โดยใช้เครื่องมืออื่นๆ ได้ในเอกสารประกอบ
ในเซสชัน Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้
gcloud sql instances create my-cloudsql-instance \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--region=us-central1 \
--edition=ENTERPRISE \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on
หลังจากสร้างอินสแตนซ์แล้ว เราต้องตั้งรหัสผ่านสำหรับผู้ใช้เริ่มต้นในอินสแตนซ์และยืนยันว่าเราเชื่อมต่อด้วยรหัสผ่านได้หรือไม่
gcloud sql users set-password postgres \
--instance=my-cloudsql-instance \
--password=$CLOUDSQL_PASSWORD
เรียกใช้คำสั่ง "gcloud sql connect" ตามที่แสดงในช่องและป้อนรหัสผ่านในข้อความแจ้งเมื่อพร้อมเชื่อมต่อ
gcloud sql connect my-cloudsql-instance --user=postgres
ออกจากเซสชัน psql ก่อนโดยใช้แป้นพิมพ์ลัด Ctrl+D หรือเรียกใช้คำสั่ง exit
exit
เปิดใช้การผสานรวม Vertex AI
มอบสิทธิ์ที่จำเป็นให้กับบัญชีบริการ Cloud SQL ภายในเพื่อให้ใช้การผสานรวม Vertex AI ได้
ค้นหาอีเมลบัญชีบริการภายในของ Cloud SQL แล้วส่งออกเป็นตัวแปร
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
ให้สิทธิ์เข้าถึง Vertex AI แก่บัญชีบริการ Cloud SQL โดยทำดังนี้
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
อ่านเพิ่มเติมเกี่ยวกับการสร้างและการกำหนดค่าอินสแตนซ์ได้ในเอกสารประกอบ Cloud SQL ที่นี่
5. เตรียมฐานข้อมูล
ตอนนี้เราต้องสร้างฐานข้อมูลและเปิดใช้การรองรับเวกเตอร์
สร้างฐานข้อมูล
สร้างฐานข้อมูลชื่อ quickstart_db โดยเรามีตัวเลือกต่างๆ เช่น ไคลเอ็นต์ฐานข้อมูลบรรทัดคำสั่ง เช่น psql สำหรับ PostgreSQL, SDK หรือ Cloud SQL Studio เราจะใช้ SDK (gcloud) ในการสร้างฐานข้อมูลและเชื่อมต่อกับอินสแตนซ์
ใน Cloud Shell ให้เรียกใช้คำสั่งเพื่อสร้างฐานข้อมูล
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
เปิดใช้ส่วนขยาย
หากต้องการทำงานกับ Vertex AI และเวกเตอร์ เราต้องเปิดใช้ 2 ส่วนขยายในฐานข้อมูลที่สร้างขึ้น
ใน Cloud Shell ให้เรียกใช้คำสั่งเพื่อเชื่อมต่อกับฐานข้อมูลที่สร้างขึ้น (คุณจะต้องระบุรหัสผ่าน)
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
จากนั้นหลังจากเชื่อมต่อสำเร็จแล้ว คุณต้องเรียกใช้ 2 คำสั่งในเซสชัน SQL ดังนี้
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector CASCADE;
ออกจากเซสชัน SQL
exit;
6. โหลดข้อมูล
ตอนนี้เราต้องสร้างออบเจ็กต์ในฐานข้อมูลและโหลดข้อมูล เราจะใช้ข้อมูลร้าน Cymbal Store ที่สมมติขึ้น ข้อมูลนี้พร้อมใช้งานในที่เก็บข้อมูล Google สาธารณะในรูปแบบ CSV
ก่อนอื่นเราต้องสร้างออบเจ็กต์ที่จำเป็นทั้งหมดในฐานข้อมูล โดยเราจะใช้คำสั่ง gcloud sql connect และคำสั่ง gcloud storage ที่คุ้นเคยอยู่แล้วเพื่อดาวน์โหลดและนำเข้าออบเจ็กต์สคีมาไปยังฐานข้อมูล
ใน Cloud Shell ให้เรียกใช้และระบุรหัสผ่านที่จดไว้เมื่อเราสร้างอินสแตนซ์
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
เราทำอะไรในคำสั่งก่อนหน้านี้ เราเชื่อมต่อกับฐานข้อมูลและเรียกใช้โค้ด SQL ที่ดาวน์โหลดมา ซึ่งจะสร้างตาราง ดัชนี และลำดับ
ขั้นตอนถัดไปคือการโหลดข้อมูล ซึ่งเราต้องดาวน์โหลดไฟล์ CSV จาก Google Cloud Storage
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv .
จากนั้นเราต้องเชื่อมต่อกับฐานข้อมูล
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
และนำเข้าข้อมูลจากไฟล์ CSV
\copy cymbal_products from 'cymbal_products.csv' csv header
\copy cymbal_inventory from 'cymbal_inventory.csv' csv header
\copy cymbal_stores from 'cymbal_stores.csv' csv header
หากคุณมีข้อมูลของตัวเองและไฟล์ CSV เข้ากันได้กับเครื่องมือนำเข้า Cloud SQL ที่มีอยู่ใน Cloud Console คุณสามารถใช้เครื่องมือดังกล่าวแทนวิธีการบรรทัดคำสั่งได้
7. สร้างการฝัง
ขั้นตอนถัดไปคือการสร้างการฝังสำหรับคำอธิบายผลิตภัณฑ์โดยใช้โมเดล textembedding-004 จาก Google Vertex AI และจัดเก็บเป็นข้อมูลเวกเตอร์
เชื่อมต่อกับฐานข้อมูล (หากคุณออกหรือเซสชันก่อนหน้าถูกยกเลิกการเชื่อมต่อ)
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
และสร้างคอลัมน์เสมือน Embedding ในตาราง cymbal_products โดยใช้ฟังก์ชัน Embedding คำสั่งนี้จะสร้างคอลัมน์เสมือน "embedding" ซึ่งจะจัดเก็บเวกเตอร์ของเราพร้อมการฝังที่สร้างขึ้นตามคอลัมน์ "product_description" นอกจากนี้ยังสร้างการฝังสำหรับแถวทั้งหมดที่มีอยู่ในตารางด้วย โดยกำหนดโมเดลเป็นพารามิเตอร์แรกสำหรับฟังก์ชันการฝัง และกำหนดข้อมูลต้นทางเป็นพารามิเตอร์ที่สอง
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005',product_description)) STORED;
ซึ่งอาจใช้เวลาสักพัก แต่สำหรับแถว 900-1000 แถว ไม่ควรใช้เวลาเกิน 5 นาที และโดยปกติจะเร็วกว่านั้นมาก
เมื่อเราแทรกแถวใหม่ลงในตารางหรืออัปเดต product_description สำหรับแถวที่มีอยู่ ข้อมูลคอลัมน์เสมือนสำหรับคอลัมน์ "embedding" จะได้รับการสร้างใหม่ตาม "product_description"
8. เรียกใช้การค้นหาความคล้ายคลึง
ตอนนี้เราสามารถเรียกใช้การค้นหาโดยใช้การค้นหาความคล้ายกันตามค่าเวกเตอร์ที่คำนวณสำหรับคำอธิบายและค่าเวกเตอร์ที่เราได้รับสำหรับคำขอ
คุณเรียกใช้คำค้นหา SQL ได้จากอินเทอร์เฟซบรรทัดคำสั่งเดียวกันโดยใช้ gcloud sql connect หรือจาก Cloud SQL Studio การค้นหาแบบหลายแถวและการค้นหาที่ซับซ้อนควรจัดการใน Cloud SQL Studio
เริ่ม Cloud SQL Studio
ในคอนโซล ให้คลิกอินสแตนซ์ Cloud SQL ที่เราสร้างไว้ก่อนหน้านี้
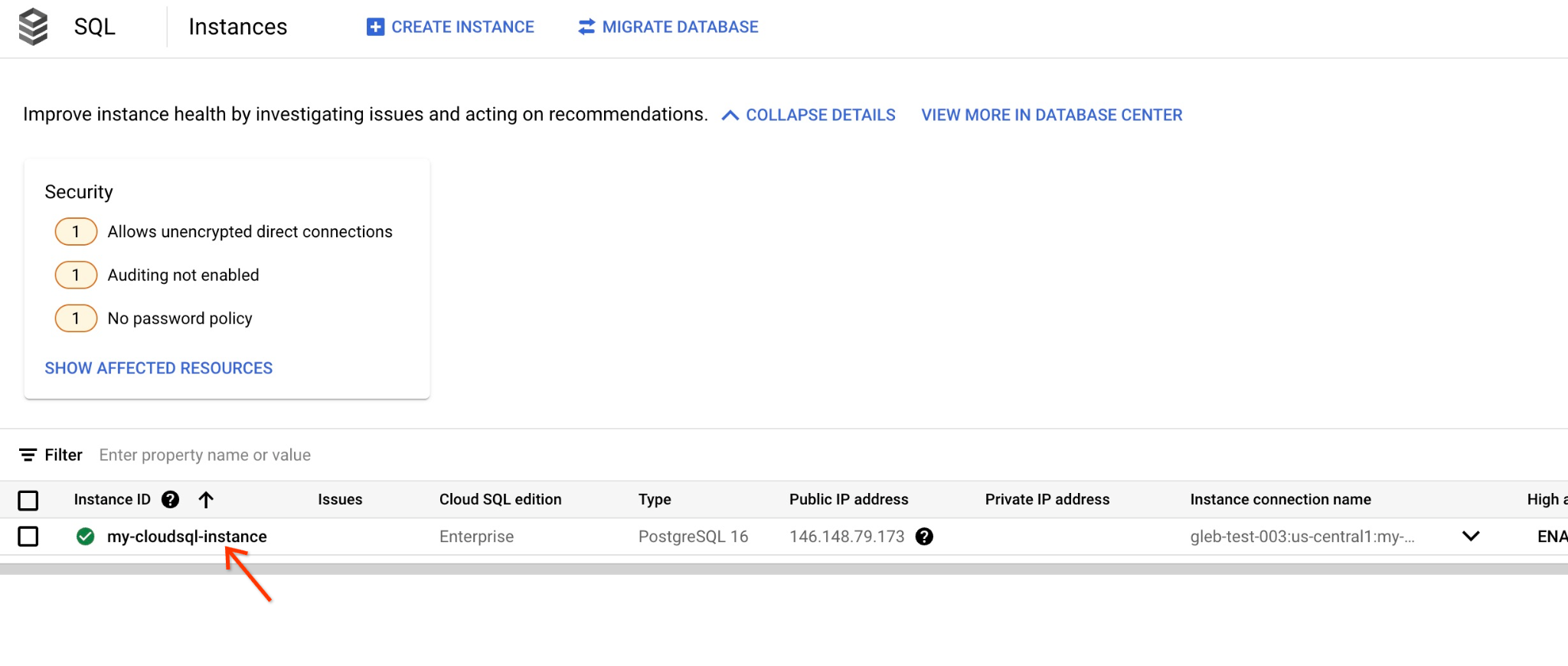
เมื่อเปิดในแผงด้านขวา เราจะเห็น Cloud SQL Studio ให้คลิกไอคอนนั้น
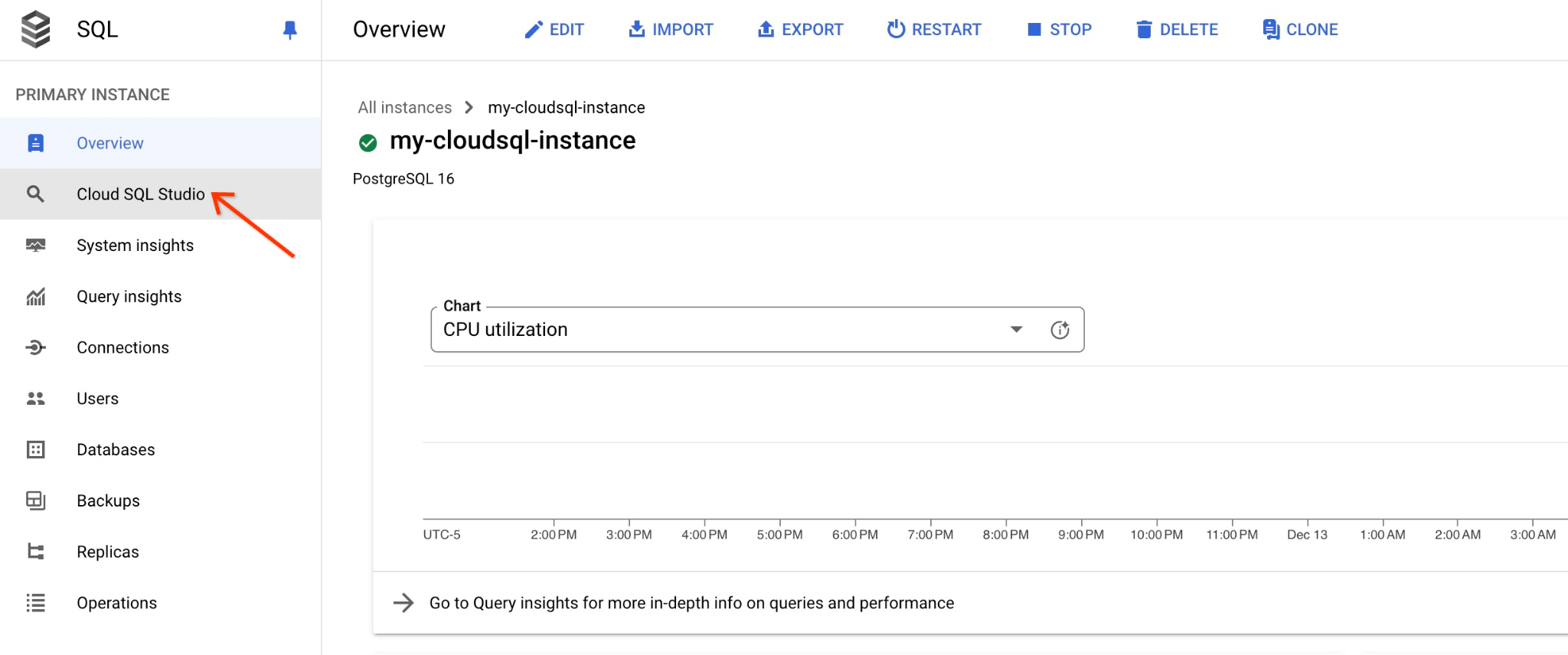
ซึ่งจะเป็นการเปิดกล่องโต้ตอบที่คุณระบุชื่อฐานข้อมูลและข้อมูลเข้าสู่ระบบ
- ฐานข้อมูล: quickstart_db
- ผู้ใช้: postgres
- รหัสผ่าน: รหัสผ่านที่คุณจดไว้สำหรับผู้ใช้ฐานข้อมูลหลัก
แล้วคลิกปุ่ม "ยืนยันตัวตน"
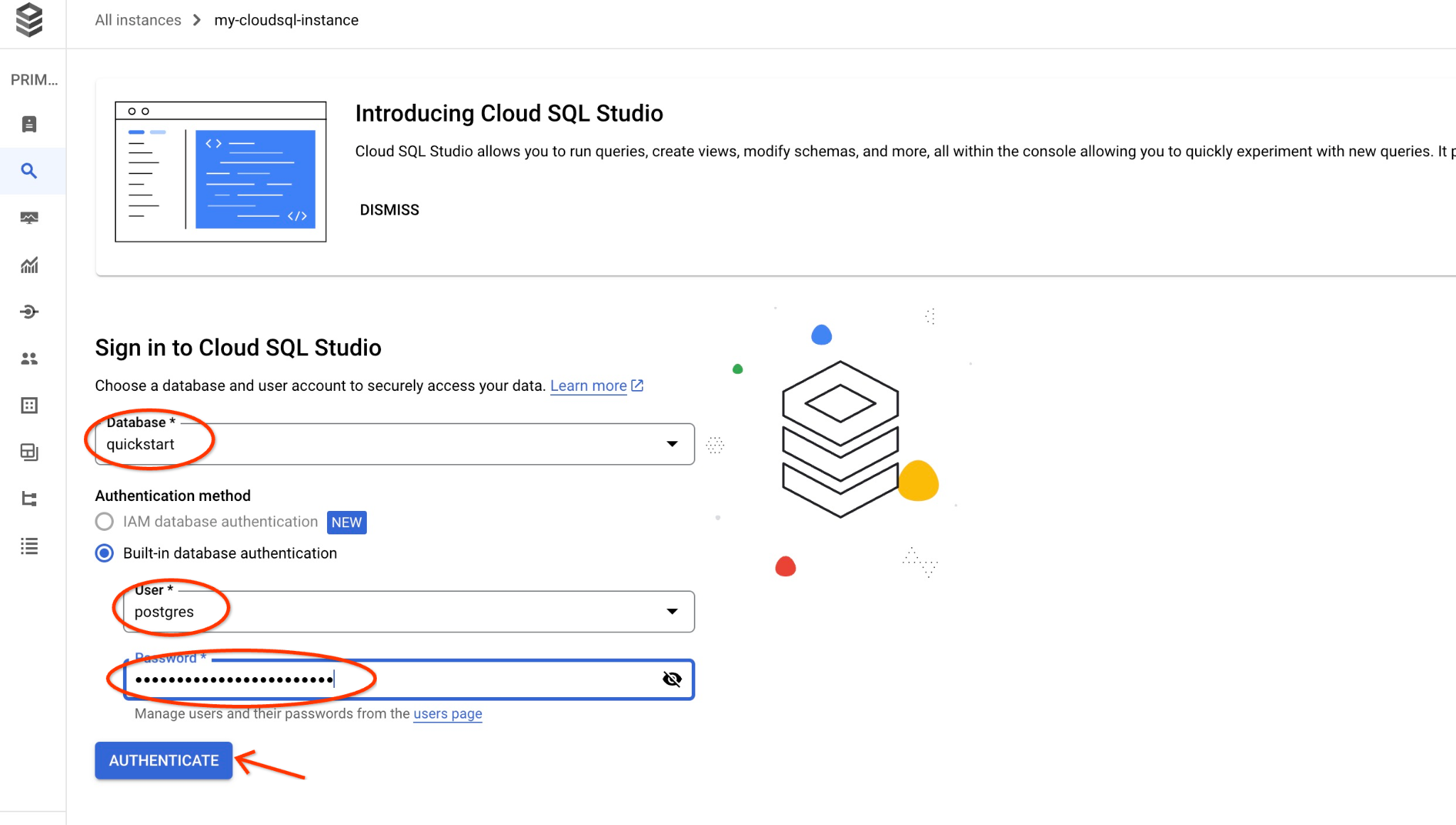
หน้าต่างถัดไปจะเปิดขึ้น ให้คลิกแท็บ "เอดิเตอร์" ทางด้านขวาเพื่อเปิด SQL Editor
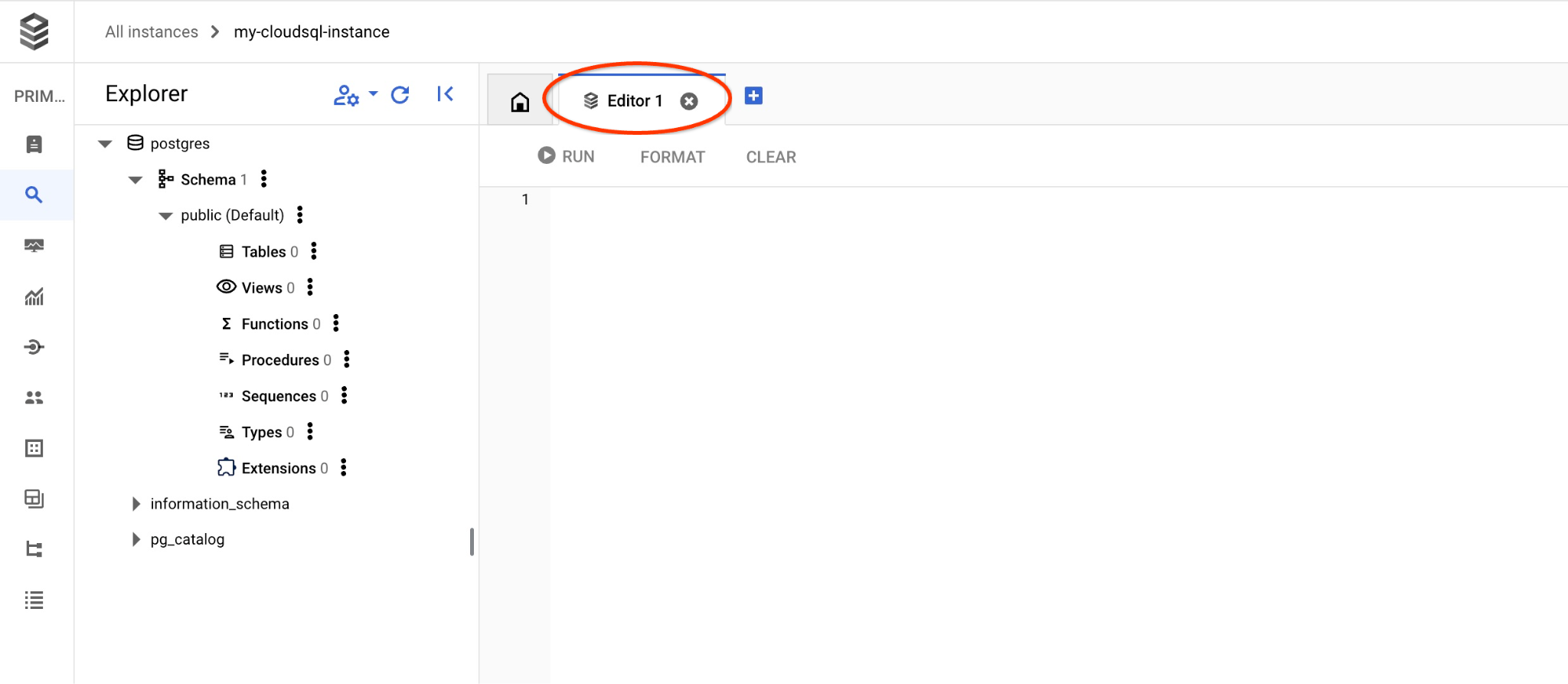
ตอนนี้เราพร้อมที่จะเรียกใช้การค้นหาแล้ว
ดำเนินการค้นหา
เรียกใช้การค้นหาเพื่อดูรายการผลิตภัณฑ์ที่มีอยู่ซึ่งเกี่ยวข้องกับคำขอของลูกค้ามากที่สุด คำขอที่เราจะส่งไปยัง Vertex AI เพื่อรับค่าเวกเตอร์มีลักษณะดังนี้ "ที่นี่ปลูกต้นไม้ผลชนิดใดได้ดี"
นี่คือการค้นหาที่คุณเรียกใช้เพื่อเลือก 10 รายการแรกที่เหมาะกับคำขอของเรามากที่สุด
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
คัดลอกและวางการค้นหาลงในโปรแกรมแก้ไข Cloud SQL Studio แล้วกดปุ่ม "RUN" หรือวางในเซสชันบรรทัดคำสั่งที่เชื่อมต่อกับฐานข้อมูล quickstart_db
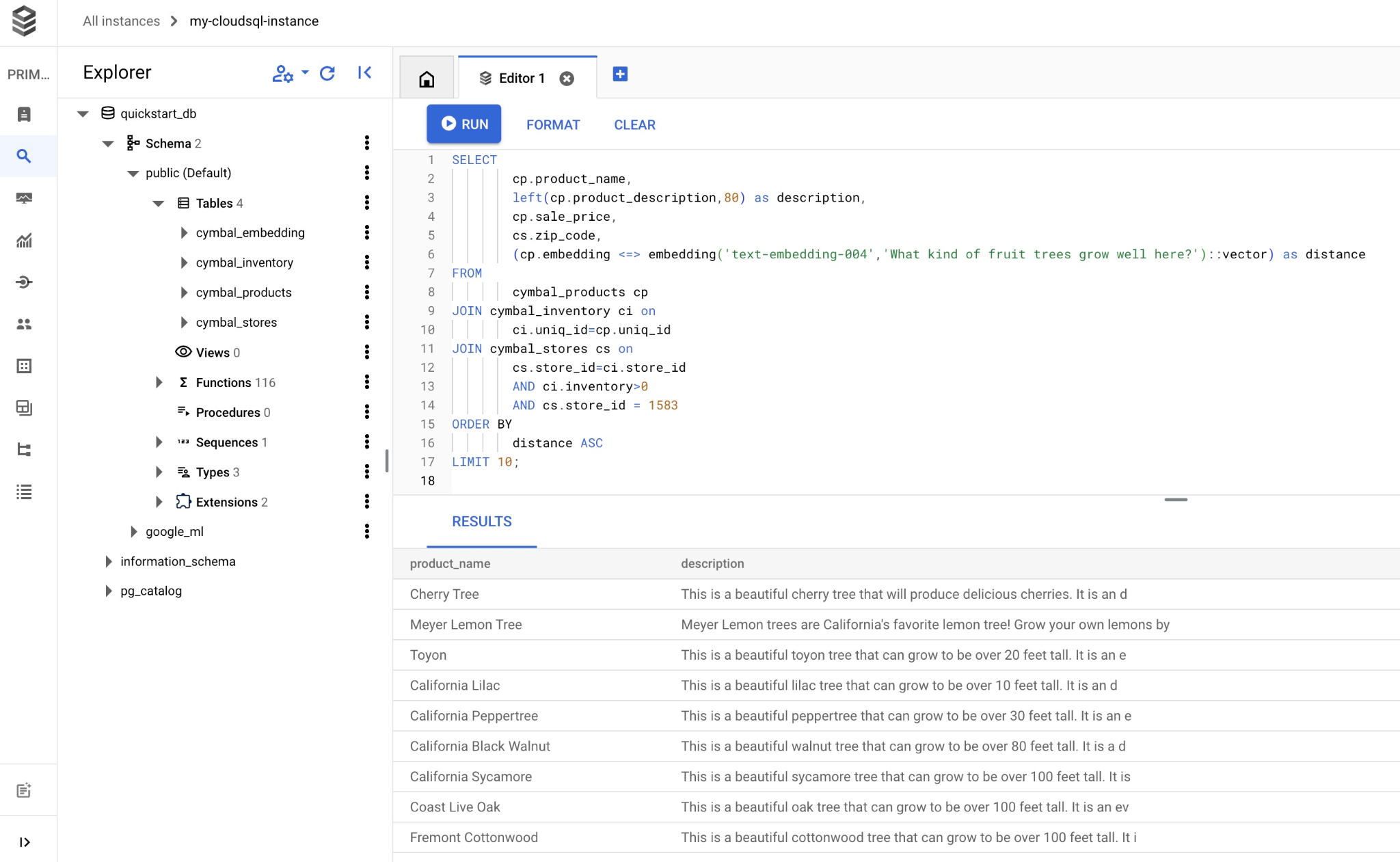
และนี่คือรายการผลิตภัณฑ์ที่เลือกซึ่งตรงกับคำค้นหา
product_name | description | sale_price | zip_code | distance -------------------------+----------------------------------------------------------------------------------+------------+----------+--------------------- Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397 Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228 Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668 California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498 California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247 California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597 California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755 Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371 Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058 Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093 (10 rows)
9. ปรับปรุงคำตอบของ LLM โดยใช้ข้อมูลที่ดึงมา
เราสามารถปรับปรุงคำตอบของ LLM ของ Gen AI ให้กับแอปพลิเคชันไคลเอ็นต์ได้โดยใช้ผลลัพธ์ของคำค้นหาที่ดำเนินการแล้ว และเตรียมเอาต์พุตที่มีความหมายโดยใช้ผลลัพธ์ของคำค้นหาที่ระบุเป็นส่วนหนึ่งของพรอมต์ไปยังโมเดลภาษาพื้นฐานแบบ Generative ของ Vertex AI
ในการดำเนินการดังกล่าว เราต้องสร้าง JSON ที่มีผลลัพธ์จากการค้นหาเวกเตอร์ จากนั้นใช้ JSON ที่สร้างขึ้นเป็นส่วนเพิ่มเติมของพรอมต์สำหรับโมเดล LLM ใน Vertex AI เพื่อสร้างเอาต์พุตที่มีความหมาย ในขั้นตอนแรก เราจะสร้าง JSON จากนั้นทดสอบใน Vertex AI Studio และในขั้นตอนสุดท้าย เราจะรวมไว้ในคำสั่ง SQL ซึ่งสามารถใช้ในแอปพลิเคชันได้
สร้างเอาต์พุตในรูปแบบ JSON
แก้ไขคําค้นหาเพื่อสร้างเอาต์พุตในรูปแบบ JSON และแสดงผลเพียงแถวเดียวเพื่อส่งไปยัง Vertex AI
Cloud SQL สำหรับ PostgreSQL
ตัวอย่างคำค้นหา
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
และนี่คือ JSON ที่คาดไว้ในเอาต์พุต
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
เรียกใช้พรอมต์ใน Vertex AI Studio
เราสามารถใช้ JSON ที่สร้างขึ้นเพื่อจัดหาเป็นส่วนหนึ่งของพรอมต์ไปยังโมเดลข้อความ Generative AI ใน Vertex AI Studio
เปิด Vertex AI Studio ใน Cloud Console
โดยอาจขอให้คุณเปิดใช้ API เพิ่มเติม แต่คุณสามารถเพิกเฉยต่อคำขอนี้ได้ เราไม่จำเป็นต้องใช้ API เพิ่มเติมเพื่อทำแล็บให้เสร็จ
ใส่พรอมต์ใน Studio
พรอมต์ที่เราจะใช้มีดังนี้
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
และนี่คือลักษณะที่ปรากฏเมื่อเราแทนที่ตัวยึดตำแหน่ง JSON ด้วยการตอบกลับจากการค้นหา
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
และนี่คือผลลัพธ์เมื่อเราเรียกใช้พรอมต์ด้วยค่า JSON

คำตอบที่เราได้รับจากโมเดลในตัวอย่างนี้มีดังนี้ โปรดทราบว่าคำตอบของคุณอาจแตกต่างกันเนื่องจากการเปลี่ยนแปลงโมเดลและพารามิเตอร์เมื่อเวลาผ่านไป
"จากรหัสไปรษณีย์ที่ระบุไว้ในรายการผลิตภัณฑ์ของเรา (93230) ดูเหมือนว่าคุณจะอยู่ในย่านแฮนฟอร์ด แคลิฟอร์เนีย1346 ภูมิภาคนี้ตั้งอยู่ในหุบเขาซานโจควิน ซึ่งเป็นหนึ่งในสถานที่ชั้นนำของประเทศสำหรับการปลูกผลไม้ที่มีเมล็ดแข็ง
หากต้องการตอบคำถามของคุณ ต้นไม้ที่เหมาะกับการปลูกในพื้นที่ของคุณมากที่สุดจากตัวเลือกของเราคือต้นเชอร์รี
รายละเอียดสำหรับคุณมีดังนี้
ผลิตภัณฑ์: Cherry Tree
ราคา: $75.00
คำอธิบาย: นี่คือต้นเชอร์รีที่สวยงามซึ่งจะให้ผลเชอร์รีแสนอร่อย2
เหตุผลที่ต้นเชอร์รีเติบโตได้ดีที่สุดที่นี่: สภาพอากาศในหุบเขา San Joaquin มีสภาพที่เฉพาะเจาะจงซึ่งต้นเชอร์รีต้องการในการเจริญเติบโต นั่นคือ วันที่อบอุ่นยาวนานในฤดูร้อนสำหรับการพัฒนาผล และคืนที่เย็นสบาย5 เนื่องจาก Hanford อยู่ในศูนย์กลางการเกษตรที่สำคัญซึ่งขึ้นชื่อเรื่องการผลิตผลไม้ที่มีเมล็ดแข็ง คุณจึงคาดหวังได้ว่าต้นไม้ชนิดนี้จะให้ผลผลิตจำนวนมากในดินในพื้นที่ของคุณ เพียงแค่ปลูกในที่ที่มีแดดจัดและดินระบายน้ำได้ดี คุณก็จะเก็บเกี่ยวผลผลิตได้ดีที่สุด"
เรียกใช้พรอมต์ใน PSQL
นอกจากนี้ เรายังใช้การผสานรวม AI ของ Cloud SQL กับ Vertex AI เพื่อรับคำตอบที่คล้ายกันจากโมเดล Generative AI โดยใช้ SQL ในฐานข้อมูลได้โดยตรง แต่หากต้องการใช้โมเดล gemini-2.0-flash-exp เราต้องลงทะเบียนโมเดลก่อน
เรียกใช้ใน Cloud SQL สำหรับ PostgreSQL
อัปเกรดส่วนขยายเป็นเวอร์ชัน 1.4.2 ขึ้นไป (หากเวอร์ชันปัจจุบันต่ำกว่า) เชื่อมต่อกับฐานข้อมูล quickstart_db จาก gcloud sql connect ตามที่แสดงก่อนหน้านี้ (หรือใช้ Cloud SQL Studio) แล้วเรียกใช้คำสั่งต่อไปนี้
SELECT extversion from pg_extension where extname='google_ml_integration';
หากค่าที่แสดงน้อยกว่า 1.4.3 ให้ดำเนินการดังนี้
ALTER EXTENSION google_ml_integration UPDATE TO '1.4.3';
จากนั้นเราต้องตั้งค่าสถานะฐานข้อมูล google_ml_integration.enable_model_support เป็น "เปิด" หากต้องการยืนยันการตั้งค่าปัจจุบัน ให้ดำเนินการ
show google_ml_integration.enable_model_support;
เอาต์พุตที่คาดไว้จากเซสชัน psql คือ "on"
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
หากแสดงเป็น "ปิด" แสดงว่าเราต้องอัปเดตแฟล็กฐานข้อมูล หากต้องการดำเนินการดังกล่าว คุณสามารถใช้อินเทอร์เฟซคอนโซลเว็บหรือเรียกใช้คำสั่ง gcloud ต่อไปนี้
gcloud sql instances patch my-cloudsql-instance \
--database-flags google_ml_integration.enable_model_support=on,cloudsql.enable_google_ml_integration=on
คำสั่งนี้จะใช้เวลาประมาณ 1-3 นาทีในการดำเนินการในเบื้องหลัง จากนั้นคุณจะยืนยันแฟล็กใหม่ในเซสชัน psql หรือใช้ Cloud SQL Studio ที่เชื่อมต่อกับฐานข้อมูล quickstart_db ได้
show google_ml_integration.enable_model_support;
เอาต์พุตที่คาดไว้จากเซสชัน psql คือ "on"
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
จากนั้นเราต้องลงทะเบียนโมเดล 2 รายการ โมเดลแรกคือโมเดล text-embedding-005 ที่ใช้ไปแล้ว คุณต้องลงทะเบียนเนื่องจากเราเปิดใช้ความสามารถในการลงทะเบียนโมเดล
หากต้องการลงทะเบียนการเรียกใช้โมเดลใน psql หรือ Cloud SQL Studio ให้เรียกใช้โค้ดต่อไปนี้
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'cloudsql_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
และโมเดลถัดไปที่เราต้องลงทะเบียนคือ gemini-2.0-flash-001 ซึ่งจะใช้เพื่อสร้างเอาต์พุตที่ใช้งานง่าย
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'https://us-central1-aiplatform.googleapis.com/v1/projects/$PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'cloudsql_service_agent_iam');
คุณตรวจสอบรายการโมเดลที่ลงทะเบียนได้ทุกเมื่อโดยเลือกข้อมูลจาก google_ml.model_info_view
select model_id,model_type from google_ml.model_info_view;
เอาต์พุตตัวอย่างมีดังนี้
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
--------------------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
gemini-1.5-pro:streamGenerateContent | generic
gemini-1.5-pro:generateContent | generic
gemini-1.0-pro:generateContent | generic
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
ตอนนี้เราสามารถใช้ JSON ที่สร้างขึ้นในคำสั่งย่อยเพื่อจัดหาเป็นส่วนหนึ่งของพรอมต์ไปยังโมเดลข้อความ Generative AI โดยใช้ SQL
ในเซสชัน psql หรือ Cloud SQL Studio ที่จะเรียกใช้การค้นหาฐานข้อมูล ให้เรียกใช้การค้นหา
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> google_ml.embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
และนี่คือเอาต์พุตที่คาดไว้ เอาต์พุตของคุณอาจแตกต่างกันไปตามเวอร์ชันโมเดลและพารามิเตอร์
"That's a great question! It sounds like you're looking to add some delicious fruit to your garden.\n\nBased on the products we have that are closely related to your search, I can tell you about a fantastic option:\n\n**Cherry Tree**" "\n* **Description:** This beautiful deciduous tree will produce delicious cherries. It grows to be about 15 feet tall, with dark green leaves in summer that turn a beautiful red in the fall. Cherry trees are known for their beauty, shade, and privacy. They prefer a cool, moist climate and sandy soil." "\n* **Price:** $75.00\n* **Grows well in:** USDA Zones 4-9.\n\nTo confirm if this Cherry Tree will thrive in your specific location, you might want to check which USDA Hardiness Zone your area falls into. If you're in zones 4-9, this" " could be a wonderful addition to your yard!"
10. สร้างดัชนีเพื่อนบ้านที่ใกล้ที่สุด
ชุดข้อมูลของเรามีขนาดเล็กมาก และเวลาในการตอบกลับจะขึ้นอยู่กับการโต้ตอบกับโมเดล AI เป็นหลัก แต่เมื่อมีเวกเตอร์หลายล้านรายการ การค้นหาเวกเตอร์อาจใช้เวลาในการตอบกลับของเราเป็นส่วนสำคัญและทำให้ระบบมีภาระงานสูง เพื่อปรับปรุงให้ดียิ่งขึ้น เราจึงสร้างดัชนีบนเวกเตอร์
สร้างดัชนี HNSW
เราจะลองใช้ดัชนีประเภท HNSW สำหรับการทดสอบ HNSW ย่อมาจาก Hierarchical Navigable Small World และแสดงถึงดัชนีกราฟหลายเลเยอร์
หากต้องการสร้างดัชนีสำหรับคอลัมน์การฝัง เราต้องกำหนดคอลัมน์การฝัง ฟังก์ชันระยะทาง และพารามิเตอร์ที่ไม่บังคับ เช่น m หรือ ef_constructions คุณสามารถอ่านรายละเอียดเกี่ยวกับพารามิเตอร์ได้ในเอกสารประกอบ
CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
ผลลัพธ์ที่คาดไว้
quickstart_db=> CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64); CREATE INDEX quickstart_db=>
เปรียบเทียบคำตอบ
ตอนนี้เราสามารถเรียกใช้การค้นหาเวกเตอร์ในโหมด EXPLAIN และตรวจสอบว่ามีการใช้ดัชนีหรือไม่
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
ผลลัพธ์ที่คาดไว้
Aggregate (cost=779.12..779.13 rows=1 width=32) (actual time=1.066..1.069 rows=1 loops=1)
-> Subquery Scan on trees (cost=769.05..779.12 rows=1 width=142) (actual time=1.038..1.041 rows=1 loops=1)
-> Limit (cost=769.05..779.11 rows=1 width=158) (actual time=1.022..1.024 rows=1 loops=1)
-> Nested Loop (cost=769.05..9339.69 rows=852 width=158) (actual time=1.020..1.021 rows=1 loops=1)
-> Nested Loop (cost=768.77..9316.48 rows=852 width=945) (actual time=0.858..0.859 rows=1 loops=1)
-> Index Scan using cymbal_products_embeddings_hnsw on cymbal_products cp (cost=768.34..2572.47 rows=941 width=941) (actual time=0.532..0.539 rows=3 loops=1)
Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,...
<redacted>
...,0.017593635,-0.040275685,-0.03914233,-0.018452475,0.00826032,-0.07372604
]'::vector)
-> Index Scan using product_inventory_pkey on cymbal_inventory ci (cost=0.42..7.17 rows=1 width=37) (actual time=0.104..0.104 rows=0 loops=3)
Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text))
Filter: (inventory > 0)
Rows Removed by Filter: 1
-> Materialize (cost=0.28..8.31 rows=1 width=8) (actual time=0.133..0.134 rows=1 loops=1)
-> Index Scan using product_stores_pkey on cymbal_stores cs (cost=0.28..8.30 rows=1 width=8) (actual time=0.129..0.129 rows=1 loops=1)
Index Cond: (store_id = 1583)
Planning Time: 112.398 ms
Execution Time: 1.221 ms
จากเอาต์พุต เราจะเห็นได้อย่างชัดเจนว่าคําค้นหาใช้ "Index Scan using cymbal_products_embeddings_hnsw"
และหากเราเรียกใช้การค้นหาโดยไม่มีคำอธิบาย
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
ผลลัพธ์ที่คาดไว้ (ผลลัพธ์อาจแตกต่างกันไปตามโมเดลและดัชนี)
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
เราเห็นว่าผลลัพธ์เหมือนกันและแสดงต้นเชอร์รีต้นเดียวกันซึ่งอยู่ด้านบนในการค้นหาของเราโดยไม่มีดัชนี ผลลัพธ์อาจแตกต่างกันเล็กน้อยและแสดงระเบียนสูงสุดที่แตกต่างกันสำหรับทรี ขึ้นอยู่กับพารามิเตอร์และประเภทดัชนี ในการทดสอบของฉัน คำค้นหาที่จัดทำดัชนีแสดงผลลัพธ์ใน 131.301 มิลลิวินาที เทียบกับ 167.631 มิลลิวินาทีที่ไม่มีดัชนี แต่เรากำลังจัดการกับชุดข้อมูลขนาดเล็กมาก และความแตกต่างจะมีความสำคัญมากขึ้นในข้อมูลขนาดใหญ่
คุณลองใช้ดัชนีต่างๆ ที่พร้อมใช้งานสำหรับเวกเตอร์ รวมถึงห้องทดลองและตัวอย่างเพิ่มเติมที่มีการผสานรวม Langchain ได้ในเอกสารประกอบ
11. ล้างข้อมูลในสภาพแวดล้อม
ลบอินสแตนซ์ Cloud SQL
ทำลายอินสแตนซ์ Cloud SQL เมื่อคุณทำแล็บเสร็จแล้ว
ใน Cloud Shell ให้กำหนดตัวแปรโปรเจ็กต์และตัวแปรสภาพแวดล้อมหากคุณถูกตัดการเชื่อมต่อและสูญเสียการตั้งค่าก่อนหน้านี้ทั้งหมด
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
ลบอินสแตนซ์
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
เอาต์พุตของคอนโซลที่คาดไว้
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
12. ขอแสดงความยินดี
ขอแสดงความยินดีที่ทำ Codelab เสร็จสมบูรณ์
แล็บนี้เป็นส่วนหนึ่งของเส้นทางการเรียนรู้ AI ที่พร้อมใช้งานจริงด้วย Google Cloud
- ดูหลักสูตรทั้งหมดเพื่อเชื่อมช่องว่างจากต้นแบบไปสู่การผลิต
- แชร์ความคืบหน้าของคุณด้วยแฮชแท็ก
#ProductionReadyAI
สิ่งที่เราได้พูดถึง
- วิธีติดตั้งใช้งานอินสแตนซ์ Cloud SQL สำหรับ PostgreSQL
- วิธีสร้างฐานข้อมูลและเปิดใช้การผสานรวม AI ของ Cloud SQL
- วิธีโหลดข้อมูลลงในฐานข้อมูล
- วิธีใช้ Cloud SQL Studio
- วิธีใช้โมเดลการฝัง Vertex AI ใน Cloud SQL
- วิธีใช้ Vertex AI Studio
- วิธีเพิ่มคุณค่าให้กับผลลัพธ์โดยใช้โมเดล Generative AI ของ Vertex AI
- วิธีปรับปรุงประสิทธิภาพโดยใช้ดัชนีเวกเตอร์
ลองใช้ codelab ที่คล้ายกันสำหรับ AlloyDB ที่มีดัชนี ScaNN แทน HNSW
13. แบบสำรวจ
เอาต์พุต: