
1. מבוא
ב-codelab הזה תלמדו איך להשתמש בשילוב של Cloud SQL ל-PostgreSQL עם AI על ידי שילוב של חיפוש וקטורי עם הטמעות של Vertex AI.

דרישות מוקדמות
- הבנה בסיסית של Google Cloud ושל המסוף
- מיומנויות בסיסיות בממשק שורת הפקודה וב-Cloud Shell
מה תלמדו
- איך פורסים מופע של Cloud SQL ל-PostgreSQL
- איך יוצרים מסד נתונים ומפעילים את השילוב של Cloud SQL עם AI
- איך טוענים נתונים למסד הנתונים
- איך משתמשים ב-Cloud SQL Studio
- איך משתמשים במודל הטמעה של Vertex AI ב-Cloud SQL
- איך משתמשים ב-Vertex AI Studio
- איך משפרים את התוצאה באמצעות מודל גנרטיבי של Vertex AI
- איך לשפר את הביצועים באמצעות אינדקס וקטורי
מה תצטרכו
- חשבון Google Cloud ופרויקט Google Cloud
- דפדפן אינטרנט כמו Chrome שתומך במסוף Google Cloud וב-Cloud Shell
2. הגדרה ודרישות
הגדרת פרויקט
- נכנסים למסוף Google Cloud. אם עדיין אין לכם חשבון Gmail או חשבון Google Workspace, אתם צריכים ליצור חשבון.
משתמשים בחשבון לשימוש אישי ולא בחשבון לצורכי עבודה או בחשבון בית ספרי.
- יוצרים פרויקט חדש או משתמשים בפרויקט קיים. כדי ליצור פרויקט חדש במסוף Google Cloud, לוחצים על הלחצן 'בחירת פרויקט' בכותרת, וייפתח חלון קופץ.

בחלון Select a project (בחירת פרויקט), לוחצים על הלחצן New Project (פרויקט חדש) כדי לפתוח תיבת דו-שיח לפרויקט החדש.
בתיבת הדו-שיח, מזינים את שם הפרויקט המועדף ובוחרים את המיקום.
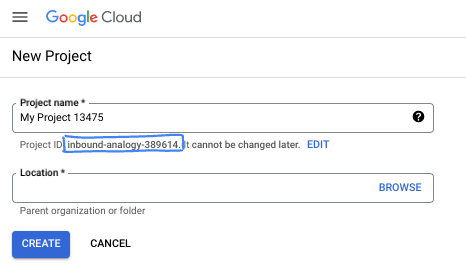
- שם הפרויקט הוא השם המוצג של המשתתפים בפרויקט הזה. שם הפרויקט לא משמש את ממשקי Google API, ואפשר לשנות אותו בכל שלב.
- מזהה הפרויקט הוא ייחודי לכל הפרויקטים ב-Google Cloud ואי אפשר לשנות אותו אחרי שהוא מוגדר. מסוף Google Cloud יוצר באופן אוטומטי מזהה ייחודי, אבל אפשר להתאים אותו אישית. אם לא אהבתם את המזהה שנוצר, אתם יכולים ליצור מזהה אקראי אחר או לספק מזהה משלכם כדי לבדוק אם הוא זמין. ברוב ה-codelabs, תצטרכו להפנות למזהה הפרויקט שלכם, שבדרך כלל מזוהה באמצעות placeholder בשם PROJECT_ID.
- לידיעתכם, יש ערך שלישי, מספר פרויקט, שחלק מממשקי ה-API משתמשים בו. מידע נוסף על שלושת הערכים האלה מופיע במאמרי העזרה.
הפעלת החיוב
יש שתי דרכים להפעיל את החיוב. אתם יכולים להשתמש בחשבון החיוב האישי שלכם או לממש את הקרדיטים באמצעות השלבים הבאים.
מימוש קרדיטים בשווי 5 $ל-Google Cloud (אופציונלי)
כדי להשתתף בסדנה הזו, צריך חשבון לחיוב עם יתרה מסוימת. אם אתם מתכננים להשתמש בחיוב משלכם, אתם יכולים לדלג על השלב הזה.
- לוחצים על הקישור הזה ונכנסים לחשבון Google אישי.
- יוצג לכם משהו כזה:

- לוחצים על הלחצן כאן אפשר לגשת לזיכויים. תועברו לדף להגדרת פרופיל החיוב. אם מוצג לכם מסך הרשמה לתקופת ניסיון בחינם, לחצו על 'ביטול' והמשיכו לקשר את החיוב.
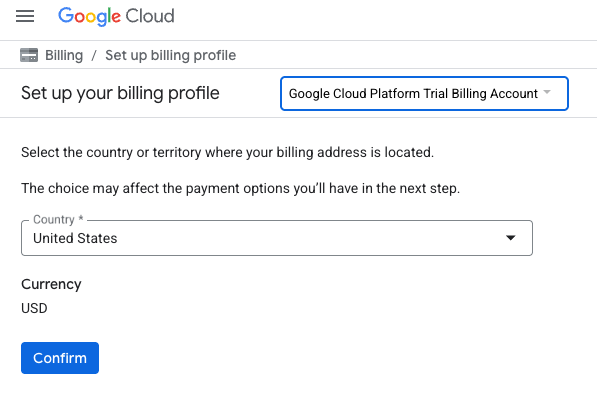
- לוחצים על 'אישור'. עכשיו אתם מחוברים לחשבון לחיוב ב-Google Cloud Platform לניסיון.
הגדרה של חשבון לחיוב לשימוש אישי
אם הגדרתם חיוב באמצעות קרדיטים ל-Google Cloud, אתם יכולים לדלג על השלב הזה.
כדי להגדיר חשבון לחיוב לשימוש אישי, עוברים לכאן כדי להפעיל את החיוב ב-Cloud Console.
טיפים ממשתמשים:
- העלות של השלמת ה-Lab הזה במשאבי Cloud צריכה להיות פחות מ-3 דולר ארה"ב.
- כדי למחוק משאבים ולמנוע חיובים נוספים, אפשר לבצע את השלבים בסוף ה-Lab הזה.
- משתמשים חדשים זכאים לתקופת ניסיון בחינם בשווי 300$.
הפעלת Cloud Shell
אפשר להפעיל את Google Cloud מרחוק מהמחשב הנייד, אבל ב-codelab הזה תשתמשו ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
ב-מסוף Google Cloud, לוחצים על סמל Cloud Shell בסרגל הכלים שבפינה הימנית העליונה:
אפשר גם ללחוץ על G ואז על S. אם אתם נמצאים במסוף Google Cloud, או אם אתם משתמשים בקישור הזה, רצף הפעולות הזה יפעיל את Cloud Shell.
יחלפו כמה רגעים עד שההקצאה והחיבור לסביבת העבודה יושלמו. בסיום התהליך, אמור להופיע משהו כזה:

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את כל העבודה ב-codelab הזה בדפדפן. לא צריך להתקין שום דבר.
3. לפני שמתחילים
הפעלת ה-API
פלט:
כדי להשתמש ב-Cloud SQL, ב-Compute Engine, ב-Networking services וב-Vertex AI, צריך להפעיל את ממשקי ה-API שלהם בפרויקט בענן שלכם ב-Google Cloud.
במסוף Cloud Shell, מוודאים שמזהה הפרויקט מוגדר:
gcloud config set project [YOUR-PROJECT-ID]
מגדירים את משתנה הסביבה PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
מפעילים את כל השירותים הנדרשים:
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
הפלט הצפוי
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
מבוא לממשקי ה-API
- Cloud SQL Admin API (
sqladmin.googleapis.com) מאפשר לכם ליצור, להגדיר ולנהל מכונות Cloud SQL באופן פרוגרמטי. הוא מספק את רמת הבקרה לשירות מסד הנתונים הרלציוני המנוהל של Google (תומך ב-MySQL, PostgreSQL ושרת SQL), ומטפל במשימות כמו הקצאת משאבים, גיבויים, זמינות גבוהה ושינוי גודל. - Compute Engine API (
compute.googleapis.com) מאפשר לכם ליצור ולנהל מכונות וירטואליות (VM), דיסקים לאחסון מתמיד והגדרות רשת. היא מספקת את הבסיס של תשתית כשירות (IaaS) שנדרש להפעלת עומסי העבודה ולאירוח התשתית הבסיסית של שירותים מנוהלים רבים. - Cloud Resource Manager API (
cloudresourcemanager.googleapis.com) מאפשר לכם לנהל באופן פרוגרמטי את המטא-נתונים וההגדרות של הפרויקט בענן שלכם ב-Google Cloud. היא מאפשרת לכם לארגן משאבים, לטפל במדיניות של ניהול זהויות והרשאות גישה (IAM) ולאמת הרשאות בהיררכיית הפרויקט. - Service Networking API (
servicenetworking.googleapis.com) מאפשר לכם להגדיר באופן אוטומטי קישוריות פרטית בין רשת Virtual Private Cloud (VPC) שלכם לבין שירותים מנוהלים של Google. היא נדרשת במיוחד כדי ליצור גישה פרטית לכתובות IP בשירותים כמו AlloyDB, כדי שהם יוכלו לתקשר בצורה מאובטחת עם המשאבים האחרים שלכם. - Vertex AI API (
aiplatform.googleapis.com) מאפשר לאפליקציות שלכם ליצור מודלים של למידת מכונה, לפרוס אותם ולבצע להם התאמה לעומס (scaling). הוא מספק ממשק מאוחד לכל שירותי ה-AI של Google Cloud, כולל גישה למודלים של AI גנרטיבי (כמו Gemini) ואימון מודלים בהתאמה אישית.
4. יצירת מכונה של Cloud SQL
יצירת מכונה של Cloud SQL עם שילוב של מסד נתונים עם Vertex AI.
יצירת סיסמה למסד נתונים
הגדרת סיסמה למשתמש ברירת המחדל במסד הנתונים. אתם יכולים להגדיר סיסמה משלכם או להשתמש בפונקציה אקראית כדי ליצור סיסמה:
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
שימו לב לערך שנוצר עבור הסיסמה:
echo $CLOUDSQL_PASSWORD
יצירת מכונת Cloud SQL ל-PostgreSQL
אפשר ליצור מופעי Cloud SQL בדרכים שונות, כמו מסוף Google Cloud, כלי אוטומציה כמו Terraform או Google Cloud SDK. בשיעור ה-Lab הזה נשתמש בעיקר בכלי gcloud של Google Cloud SDK. במאמרי העזרה מוסבר איך ליצור מופע באמצעות כלים אחרים.
בסשן Cloud Shell, מריצים את הפקודה:
gcloud sql instances create my-cloudsql-instance \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--region=us-central1 \
--edition=ENTERPRISE \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on
אחרי שיוצרים את המופע, צריך להגדיר סיסמה למשתמש שמוגדר כברירת מחדל במופע ולאמת שאפשר להתחבר באמצעות הסיסמה.
gcloud sql users set-password postgres \
--instance=my-cloudsql-instance \
--password=$CLOUDSQL_PASSWORD
מריצים את הפקודה gcloud sql connect כמו שהיא מוצגת בתיבה, ומזינים את הסיסמה בהנחיה כשהיא מוכנה להתחבר.
gcloud sql connect my-cloudsql-instance --user=postgres
יוצאים מהסשן של psql באמצעות מקשי הקיצור Ctrl+d או באמצעות הפעלת הפקודה exit.
exit
הפעלת השילוב עם Vertex AI
נותנים את ההרשאות הנדרשות לחשבון השירות הפנימי של Cloud SQL כדי שיהיה אפשר להשתמש בשילוב עם Vertex AI.
מאתרים את כתובת האימייל של חשבון השירות הפנימי של Cloud SQL ומייצאים אותה כמשתנה.
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
מעניקים לחשבון השירות של Cloud SQL גישה ל-Vertex AI:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
מידע נוסף על יצירה והגדרה של מכונות זמין במאמרי העזרה של Cloud SQL כאן.
5. הכנת מסד הנתונים
עכשיו צריך ליצור מסד נתונים ולהפעיל תמיכה בווקטורים.
יצירת מסד נתונים
יוצרים מסד נתונים בשם quickstart_db .כדי לעשות זאת, יש לנו אפשרויות שונות, כמו לקוחות מסד נתונים של שורת פקודה, למשל psql ל-PostgreSQL, SDK או Cloud SQL Studio. נשתמש ב-SDK (gcloud) כדי ליצור מסדי נתונים ולהתחבר למופע.
מריצים את הפקודה ב-Cloud Shell כדי ליצור את מסד הנתונים.
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
הפעלת תוספים
כדי לעבוד עם Vertex AI ועם וקטורים, צריך להפעיל שתי תוספים במסד הנתונים שיצרנו.
ב-Cloud Shell, מריצים את הפקודה כדי להתחבר למסד הנתונים שנוצר (צריך להזין את הסיסמה)
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
אחרי שהחיבור יצליח, צריך להריץ שתי פקודות בסשן ה-SQL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector CASCADE;
יציאה מהסשן של SQL:
exit;
6. טען נתונים
עכשיו צריך ליצור אובייקטים במסד הנתונים ולטעון נתונים. נשתמש בנתונים פיקטיביים של חנות מצלתיים. הנתונים זמינים בקטגוריית Google Storage ציבורית בפורמט CSV.
קודם צריך ליצור את כל האובייקטים הנדרשים במסד הנתונים. לשם כך נשתמש בפקודות המוכרות gcloud sql connect ו-gcloud storage כדי להוריד ולייבא את אובייקטי הסכימה למסד הנתונים שלנו.
ב-Cloud Shell, מריצים את הפקודה ומזינים את הסיסמה שרשמתם כשיצרתם את המכונה:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
מה בדיוק עשינו בפקודה הקודמת? התחברנו למסד הנתונים והפעלנו את קוד ה-SQL שהורד, שיצר טבלאות, אינדקסים ורצפים.
השלב הבא הוא לטעון את הנתונים, ולשם כך צריך להוריד את קובצי ה-CSV מ-Google Cloud Storage.
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv .
אחר כך צריך להתחבר למסד הנתונים.
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
לייבא נתונים מקובצי ה-CSV שלנו.
\copy cymbal_products from 'cymbal_products.csv' csv header
\copy cymbal_inventory from 'cymbal_inventory.csv' csv header
\copy cymbal_stores from 'cymbal_stores.csv' csv header
אם יש לכם נתונים משלכם וקובצי ה-CSV שלכם תואמים לכלי הייבוא של Cloud SQL שזמין במסוף Cloud, אתם יכולים להשתמש בו במקום בגישה של שורת הפקודה.
7. יצירת הטמעות
השלב הבא הוא ליצור הטבעות לתיאורי המוצרים באמצעות המודל textembedding-004 מ-Google Vertex AI ולאחסן אותן כנתוני וקטור.
התחברות למסד הנתונים (אם יצאתם או שהסשן הקודם שלכם נותק):
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
אפשר גם ליצור עמודה וירטואלית embedding בטבלה cymbal_products באמצעות פונקציית ה-embedding. הפקודה יוצרת עמודה וירטואלית בשם embedding, שבה יישמרו הווקטורים עם ההטמעות שנוצרו על סמך העמודה product_description. בנוסף, הוא יוצר הטמעות לכל השורות הקיימות בטבלה. המודל מוגדר כפרמטר הראשון של פונקציית ההטמעה, ונתוני המקור מוגדרים כפרמטר השני.
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005',product_description)) STORED;
התהליך עשוי להימשך זמן מה, אבל אם יש 900-1000 שורות הוא לא אמור להימשך יותר מ-5 דקות, ובדרך כלל הוא מסתיים הרבה יותר מהר.
כשמוסיפים שורה חדשה לטבלה או מעדכנים את הערך של product_description בשורה קיימת, הנתונים בעמודה הווירטואלית embedding נוצרים מחדש על סמך הערך של product_description.
8. הרצת חיפוש דמיון
עכשיו אפשר להריץ את החיפוש באמצעות חיפוש דמיון שמבוסס על ערכים וקטוריים שחושבו עבור התיאורים, ועל הערך הווקטורי שמתקבל עבור הבקשה.
אפשר להריץ את שאילתת ה-SQL מאותו ממשק שורת פקודה באמצעות gcloud sql connect או לחלופין מ-Cloud SQL Studio. מומלץ לנהל שאילתות מורכבות עם כמה שורות ב-Cloud SQL Studio.
הפעלת Cloud SQL Studio
במסוף, לוחצים על מכונת Cloud SQL שיצרנו קודם.
כשהוא פתוח בחלונית הימנית, אפשר לראות את Cloud SQL Studio. לוחצים עליו.
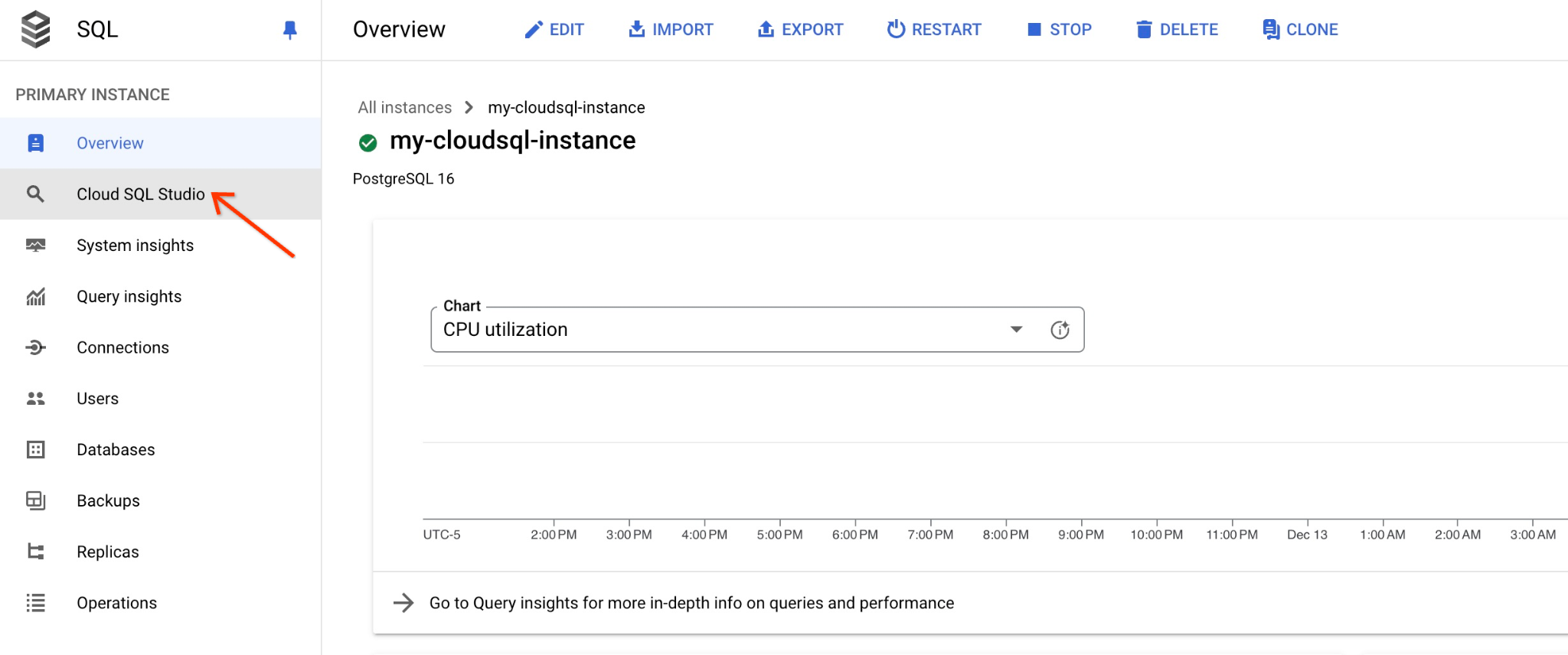
תיפתח תיבת דו-שיח שבה תצטרכו לציין את שם מסד הנתונים ואת פרטי הכניסה שלכם:
- מסד נתונים: quickstart_db
- משתמש: postgres
- סיסמה: הסיסמה שרשמתם למשתמש הראשי במסד הנתונים
ולוחצים על הלחצן 'אימות'.
ייפתח החלון הבא, שבו לוחצים על הכרטיסייה 'עורך' בצד שמאל כדי לפתוח את עורך ה-SQL.
עכשיו אפשר להריץ את השאילתות.
הרצת השאילתה
מריצים שאילתה כדי לקבל רשימה של מוצרים זמינים שקשורים באופן הכי הדוק לבקשה של לקוח. הבקשה שאנחנו מעבירים ל-Vertex AI כדי לקבל את ערך הווקטור היא: "What kind of fruit trees grow well here?" (אילו עצי פרי גדלים כאן היטב?).
זו השאילתה שאפשר להריץ כדי לבחור את 10 הפריטים הראשונים שהכי מתאימים לבקשה שלנו:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
מעתיקים ומדביקים את השאילתה בכלי לעריכת שאילתות ב-Cloud SQL Studio ולוחצים על הלחצן RUN (הפעלה), או מדביקים אותה בסשן של שורת הפקודה שמתחבר למסד הנתונים quickstart_db.
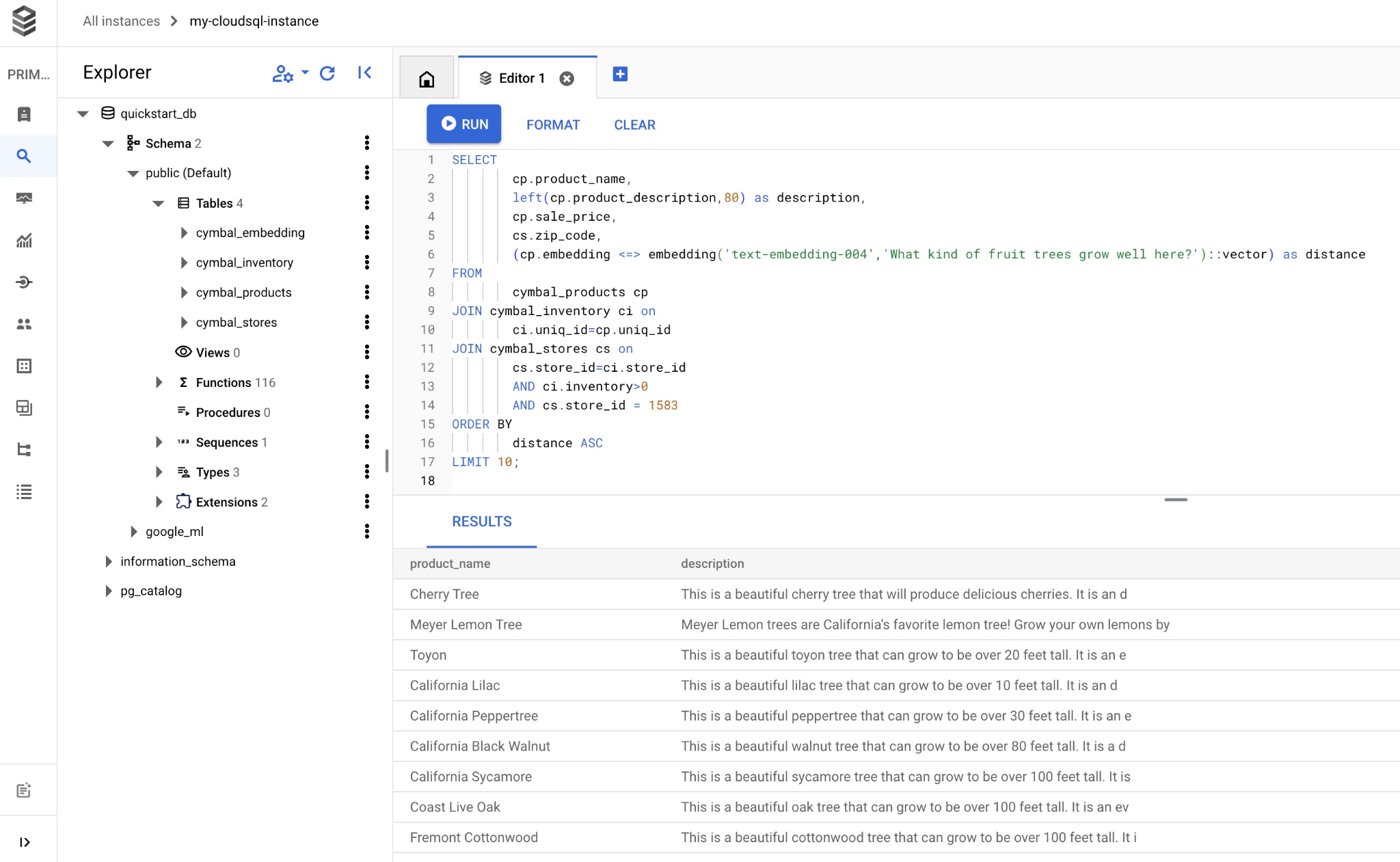
וכאן מוצגת רשימה של מוצרים שתואמים לשאילתה.
product_name | description | sale_price | zip_code | distance -------------------------+----------------------------------------------------------------------------------+------------+----------+--------------------- Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397 Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228 Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668 California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498 California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247 California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597 California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755 Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371 Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058 Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093 (10 rows)
9. שיפור התשובה של LLM באמצעות נתונים שאוחזרו
אנחנו יכולים לשפר את התשובה של מודל שפה גדול (LLM) של AI גנרטיבי לאפליקציית לקוח באמצעות התוצאה של השאילתה שהופעלה, ולהכין פלט משמעותי באמצעות תוצאות השאילתה שסופקו כחלק מההנחיה למודל שפה בסיסי גנרטיבי של Vertex AI.
כדי לעשות את זה, צריך ליצור קובץ JSON עם התוצאות של החיפוש הווקטורי, ואז להשתמש בקובץ ה-JSON שנוצר כתוספת להנחיה למודל LLM ב-Vertex AI כדי ליצור פלט משמעותי. בשלב הראשון אנחנו יוצרים את ה-JSON, אחר כך בודקים אותו ב-Vertex AI Studio ובשלב האחרון משלבים אותו בהצהרת SQL שאפשר להשתמש בה באפליקציה.
יצירת פלט בפורמט JSON
משנים את השאילתה כדי ליצור את הפלט בפורמט JSON ולהחזיר רק שורה אחת להעברה אל Vertex AI
Cloud SQL ל-PostgreSQL
דוגמה לשאילתה:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
וכאן מופיע קובץ ה-JSON הצפוי בפלט:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
הרצת ההנחיה ב-Vertex AI Studio
אפשר להשתמש ב-JSON שנוצר כדי לספק אותו כחלק מההנחיה למודל טקסט של AI גנרטיבי ב-Vertex AI Studio
פותחים את Vertex AI Studio במסוף Cloud.
יכול להיות שתתבקשו להפעיל ממשקי API נוספים, אבל אפשר להתעלם מהבקשה. אנחנו לא צריכים עוד ממשקי API כדי לסיים את ה-Lab.
מזינים הנחיה ב-Studio.
זו ההנחיה שבה נשתמש:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
וכך נראית התגובה לשאילתה אחרי שמחליפים את הפלייסהולדר של ה-JSON:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
וזה מה שקורה כשמריצים את ההנחיה עם ערכי ה-JSON:
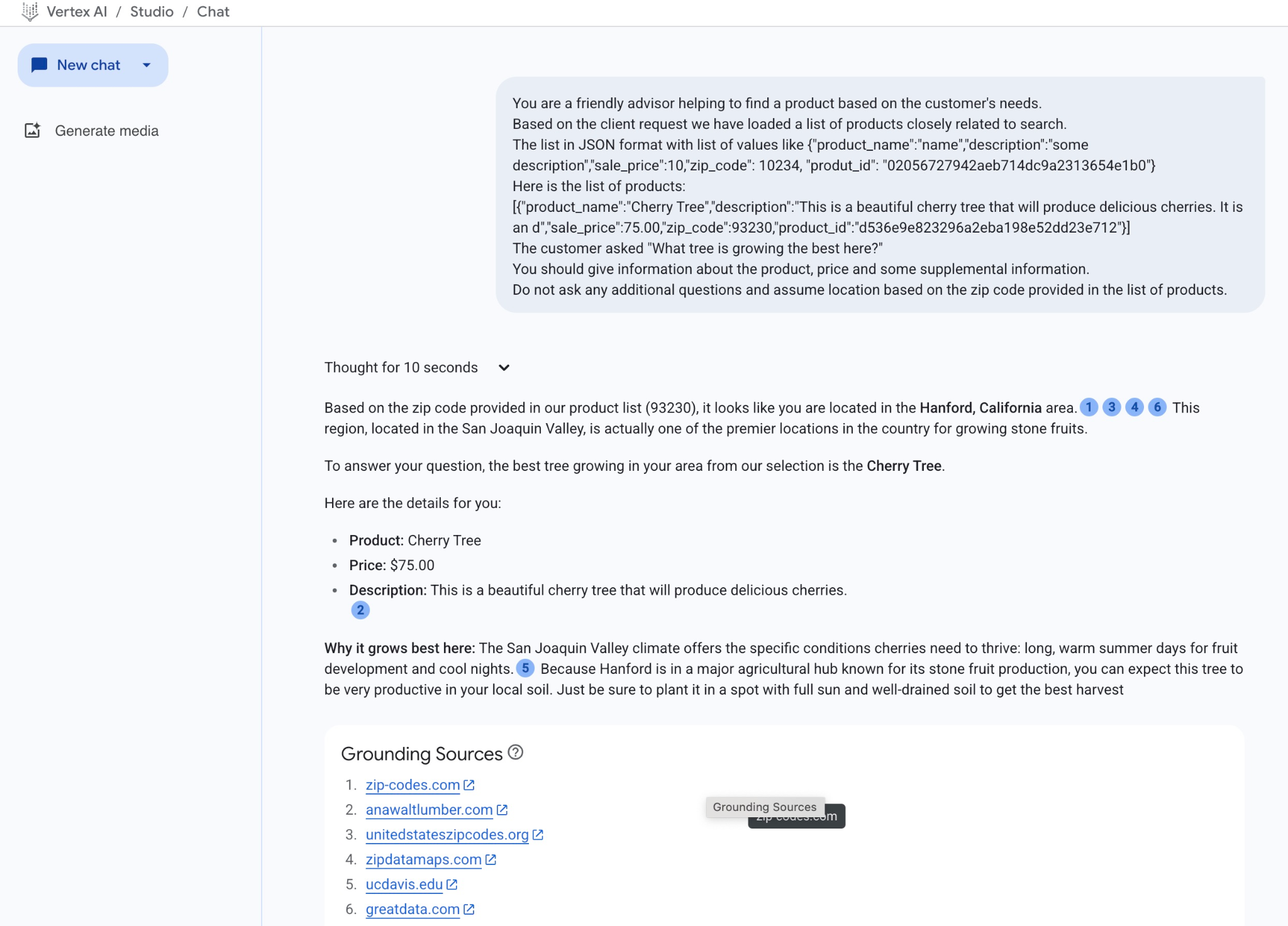
התשובה שקיבלנו מהמודל בדוגמה הזו מופיעה בהמשך. שימו לב שהתשובה שלכם עשויה להיות שונה בגלל שינויים במודל ובפרמטרים לאורך זמן:
"על סמך המיקוד שצוין ברשימת המוצרים שלנו (93230), נראה שאתה נמצא באזור של האנפורד, קליפורניה.1346 האזור הזה, שנמצא בעמק סן חואקין, הוא למעשה אחד המקומות המובילים במדינה לגידול פירות גרעיניים.
כדי לענות על השאלה שלך, העץ הכי טוב שגדל באזור שלך מתוך המבחר שלנו הוא עץ הדובדבן.
הנה הפרטים:
המוצר: עץ דובדבן
המחיר: 75.00$
תיאור: זהו עץ דובדבן יפהפה שיניב דובדבנים טעימים.2
למה הוא גדל הכי טוב כאן: האקלים בעמק סן חואקין מספק את התנאים הספציפיים שדרושים לדובדבנים כדי לשגשג: ימי קיץ ארוכים וחמים להתפתחות הפרי ולילות קרירים.5 מכיוון שהנפורד נמצאת במרכז חקלאי גדול שמוכר בייצור פירות גרעיניים, אפשר לצפות שהעץ הזה יהיה מאוד פורה באדמה המקומית. רק חשוב לשתול אותו במקום עם שמש מלאה וקרקע מנוקזת היטב כדי לקבל את היבול הטוב ביותר"
הרצת ההנחיה ב-PSQL
אפשר גם להשתמש בשילוב של Cloud SQL AI עם Vertex AI כדי לקבל תשובה דומה ממודל גנרטיבי באמצעות SQL ישירות במסד הנתונים. אבל כדי להשתמש במודל gemini-2.0-flash-exp, צריך לרשום אותו קודם.
הרצה ב-Cloud SQL ל-PostgreSQL
משדרגים את התוסף לגרסה 1.4.2 ומעלה (אם הגרסה הנוכחית נמוכה יותר). מתחברים למסד הנתונים quickstart_db באמצעות gcloud sql connect כמו שמוצג למעלה (או באמצעות Cloud SQL Studio) ומריצים את הפקודה:
SELECT extversion from pg_extension where extname='google_ml_integration';
אם הערך שמוחזר קטן מ-1.4.3, מריצים את הפקודה:
ALTER EXTENSION google_ml_integration UPDATE TO '1.4.3';
לאחר מכן צריך להגדיר את דגל מסד הנתונים google_ml_integration.enable_model_support לערך 'on'. כדי לבדוק את ההגדרות הנוכחיות, מריצים את הפקודה.
show google_ml_integration.enable_model_support;
הפלט הצפוי מהסשן של psql הוא 'on':
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
אם מופיעה האפשרות 'מושבת', צריך לעדכן את הדגל של מסד הנתונים. כדי לעשות זאת, אפשר להשתמש בממשק של מסוף האינטרנט או להריץ את פקודת gcloud הבאה.
gcloud sql instances patch my-cloudsql-instance \
--database-flags google_ml_integration.enable_model_support=on,cloudsql.enable_google_ml_integration=on
הפעלת הפקודה ברקע נמשכת כדקה עד 3 דקות. אחרי כן תוכלו לאמת את הדגל החדש בסשן psql או באמצעות Cloud SQL Studio, על ידי התחברות למסד הנתונים quickstart_db.
show google_ml_integration.enable_model_support;
הפלט הצפוי מהסשן של psql הוא 'on':
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
אחר כך צריך לרשום שני מודלים. הראשון הוא המודל text-embedding-005 שכבר נמצא בשימוש. צריך לרשום אותו כי הפעלנו את היכולות של רישום המודל.
כדי לרשום את הרצת המודל ב-psql או ב-Cloud SQL Studio, מריצים את הקוד הבא:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'cloudsql_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
המודל הבא שצריך לרשום הוא gemini-2.0-flash-001, שישמש ליצירת הפלט הידידותי למשתמש.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'https://us-central1-aiplatform.googleapis.com/v1/projects/$PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'cloudsql_service_agent_iam');
תמיד אפשר לבדוק את רשימת המודלים הרשומים על ידי בחירת מידע מהתצוגה google_ml.model_info_view.
select model_id,model_type from google_ml.model_info_view;
פלט לדוגמה
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
--------------------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
gemini-1.5-pro:streamGenerateContent | generic
gemini-1.5-pro:generateContent | generic
gemini-1.0-pro:generateContent | generic
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
עכשיו אפשר להשתמש ב-JSON שנוצר בשאילתת משנה כדי לספק אותו כחלק מההנחיה למודל טקסט של AI גנרטיבי באמצעות SQL.
בסשן של psql או Cloud SQL Studio במסד הנתונים, מריצים את השאילתה
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> google_ml.embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
וכאן מופיע הפלט הצפוי. הפלט שיתקבל עשוי להיות שונה בהתאם לגרסת המודל ולפרמטרים שלו:
"That's a great question! It sounds like you're looking to add some delicious fruit to your garden.\n\nBased on the products we have that are closely related to your search, I can tell you about a fantastic option:\n\n**Cherry Tree**" "\n* **Description:** This beautiful deciduous tree will produce delicious cherries. It grows to be about 15 feet tall, with dark green leaves in summer that turn a beautiful red in the fall. Cherry trees are known for their beauty, shade, and privacy. They prefer a cool, moist climate and sandy soil." "\n* **Price:** $75.00\n* **Grows well in:** USDA Zones 4-9.\n\nTo confirm if this Cherry Tree will thrive in your specific location, you might want to check which USDA Hardiness Zone your area falls into. If you're in zones 4-9, this" " could be a wonderful addition to your yard!"
10. יצירת אינדקס של השכן הקרוב ביותר
מערך הנתונים שלנו קטן יחסית, וזמן התגובה תלוי בעיקר באינטראקציות עם מודלים של AI. אבל כשמדובר במיליוני וקטורים, חיפוש הווקטורים יכול לתפוס חלק משמעותי מזמן התגובה שלנו ולהעמיס על המערכת. כדי לשפר את היכולת שלנו ליצור אינדקס על בסיס הווקטורים.
יצירת אינדקס HNSW
אנחנו ננסה את סוג האינדקס HNSW לבדיקה שלנו. HNSW מייצג Hierarchical Navigable Small World (עולם קטן היררכי שניתן לניווט) והוא אינדקס גרפים רב-שכבתי.
כדי ליצור את האינדקס של עמודת ההטמעה, צריך להגדיר את עמודת ההטמעה, את פונקציית המרחק ואת הפרמטרים האופציונליים כמו m או ef_constructions. אפשר לקרוא על הפרמטרים בפירוט במאמרי העזרה.
CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
הפלט אמור להיראות כך:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64); CREATE INDEX quickstart_db=>
השוואת תשובות
עכשיו אפשר להריץ את שאילתת החיפוש הווקטורי במצב EXPLAIN כדי לוודא שהאינדקס נמצא בשימוש.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
הפלט אמור להיראות כך:
Aggregate (cost=779.12..779.13 rows=1 width=32) (actual time=1.066..1.069 rows=1 loops=1)
-> Subquery Scan on trees (cost=769.05..779.12 rows=1 width=142) (actual time=1.038..1.041 rows=1 loops=1)
-> Limit (cost=769.05..779.11 rows=1 width=158) (actual time=1.022..1.024 rows=1 loops=1)
-> Nested Loop (cost=769.05..9339.69 rows=852 width=158) (actual time=1.020..1.021 rows=1 loops=1)
-> Nested Loop (cost=768.77..9316.48 rows=852 width=945) (actual time=0.858..0.859 rows=1 loops=1)
-> Index Scan using cymbal_products_embeddings_hnsw on cymbal_products cp (cost=768.34..2572.47 rows=941 width=941) (actual time=0.532..0.539 rows=3 loops=1)
Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,...
<redacted>
...,0.017593635,-0.040275685,-0.03914233,-0.018452475,0.00826032,-0.07372604
]'::vector)
-> Index Scan using product_inventory_pkey on cymbal_inventory ci (cost=0.42..7.17 rows=1 width=37) (actual time=0.104..0.104 rows=0 loops=3)
Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text))
Filter: (inventory > 0)
Rows Removed by Filter: 1
-> Materialize (cost=0.28..8.31 rows=1 width=8) (actual time=0.133..0.134 rows=1 loops=1)
-> Index Scan using product_stores_pkey on cymbal_stores cs (cost=0.28..8.30 rows=1 width=8) (actual time=0.129..0.129 rows=1 loops=1)
Index Cond: (store_id = 1583)
Planning Time: 112.398 ms
Execution Time: 1.221 ms
מהפלט אפשר לראות בבירור שהשאילתה השתמשה ב-"Index Scan using cymbal_products_embeddings_hnsw".
ואם מריצים את השאילתה בלי explain:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
הפלט הצפוי (הפלט יכול להיות שונה בהתאם למודל ולאינדקס):
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
אנחנו יכולים לראות שהתוצאה זהה, ולהחזיר את אותו עץ דובדבן שהיה בראש תוצאות החיפוש שלנו בלי אינדקס. בהתאם לפרמטרים ולסוג האינדקס, יכול להיות שהתוצאה תהיה שונה מעט ותחזיר רשומה עליונה שונה עבור העץ. במהלך הבדיקות שלי, השאילתה עם האינדקס החזירה תוצאות תוך 131.301 אלפיות השנייה לעומת 167.631 אלפיות השנייה ללא אינדקס. עם זאת, עבדנו עם מערך נתונים קטן מאוד, וההבדל יהיה משמעותי יותר בנתונים גדולים יותר.
אפשר לנסות אינדקסים שונים שזמינים לווקטורים, וגם עוד שיעורי Lab ודוגמאות עם שילוב של langchain שזמינים במאמרי עזרה.
11. ניקוי הסביבה
מחיקת המופע ב-Cloud SQL
כיבוי סופי של מופע Cloud SQL בסיום שיעור ה-Lab
אם התנתקתם וכל ההגדרות הקודמות אבדו, מגדירים את משתני הפרויקט והסביבה ב-Cloud Shell:
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
מוחקים את המכונה:
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
הפלט הצפוי במסוף:
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
12. מזל טוב
כל הכבוד, סיימתם את ה-Codelab.
שיעור ה-Lab הזה הוא חלק מתוכנית הלימודים בנושא AI מוכן לייצור באמצעות Google Cloud.
- כאן אפשר לעיין בתוכנית הלימודים המלאה כדי לגשר על הפער בין אב טיפוס לבין ייצור.
- שתפו את ההתקדמות שלכם באמצעות ההאשטאג
#ProductionReadyAI.
מה כיסינו
- איך פורסים מופע של Cloud SQL ל-PostgreSQL
- איך יוצרים מסד נתונים ומפעילים את השילוב של Cloud SQL עם AI
- איך טוענים נתונים למסד הנתונים
- איך משתמשים ב-Cloud SQL Studio
- איך משתמשים במודל הטמעה של Vertex AI ב-Cloud SQL
- איך משתמשים ב-Vertex AI Studio
- איך משפרים את התוצאה באמצעות מודל גנרטיבי של Vertex AI
- איך לשפר את הביצועים באמצעות אינדקס וקטורי
אפשר לנסות Codelab דומה ל-AlloyDB עם אינדקס ScaNN במקום HNSW
13. סקר
פלט: