
1. مقدمة
في هذا الدرس التطبيقي حول الترميز، ستتعرّف على كيفية استخدام ميزة دمج الذكاء الاصطناعي في Cloud SQL for PostgreSQL من خلال الجمع بين البحث المتّجه وتضمينات Vertex AI.

المتطلبات الأساسية
- فهم أساسي لـ Google Cloud وGoogle Cloud Console
- مهارات أساسية في واجهة سطر الأوامر وCloud Shell
ما ستتعلمه
- كيفية نشر نسخة افتراضية من Cloud SQL لـ PostgreSQL
- كيفية إنشاء قاعدة بيانات وتفعيل عمليات الدمج مع الذكاء الاصطناعي في Cloud SQL
- كيفية تحميل البيانات إلى قاعدة البيانات
- كيفية استخدام Cloud SQL Studio
- كيفية استخدام نموذج التضمين في Vertex AI في Cloud SQL
- كيفية استخدام Vertex AI Studio
- كيفية تحسين النتيجة باستخدام نموذج الذكاء الاصطناعي التوليدي من Vertex AI
- كيفية تحسين الأداء باستخدام فهرس المتجهات
المتطلبات
- حساب على Google Cloud ومشروع على Google Cloud
- متصفّح ويب، مثل Chrome، متوافق مع "وحدة تحكّم Google Cloud" وCloud Shell
2. الإعداد والمتطلبات
إعداد المشروع
- سجِّل الدخول إلى Google Cloud Console. إذا لم يكن لديك حساب على Gmail أو Google Workspace، عليك إنشاء حساب.
استخدام حساب شخصي بدلاً من حساب تديره المؤسسة التعليمية أو حساب تابع للعمل.
- أنشئ مشروعًا جديدًا أو أعِد استخدام مشروع حالي. لإنشاء مشروع جديد في Google Cloud Console، انقر على الزر "اختيار مشروع" في العنوان، ما سيؤدي إلى فتح نافذة منبثقة.

في نافذة "اختيار مشروع"، انقر على الزر "مشروع جديد" الذي سيفتح مربع حوار للمشروع الجديد.
في مربّع الحوار، أدخِل اسم المشروع المفضّل لديك واختَر الموقع الجغرافي.
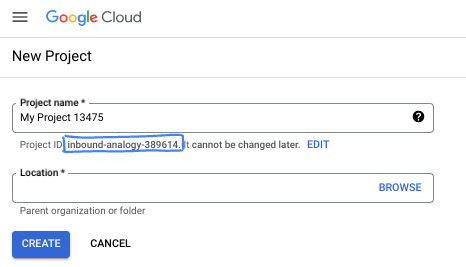
- اسم المشروع هو الاسم المعروض للمشاركين في هذا المشروع. لا تستخدم Google APIs اسم المشروع، ويمكن تغييره في أي وقت.
- رقم تعريف المشروع فريد في جميع مشاريع Google Cloud ولا يمكن تغييره (لا يمكن تغييره بعد ضبطه). تنشئ وحدة تحكّم Google Cloud تلقائيًا معرّفًا فريدًا، ولكن يمكنك تخصيصه. إذا لم يعجبك المعرّف الذي تم إنشاؤه، يمكنك إنشاء معرّف عشوائي آخر أو تقديم معرّفك الخاص للتحقّق من توفّره. في معظم دروس البرمجة، عليك الرجوع إلى رقم تعريف مشروعك، والذي يتم تحديده عادةً باستخدام العنصر النائب PROJECT_ID.
- للعلم، هناك قيمة ثالثة، وهي رقم المشروع، تستخدمها بعض واجهات برمجة التطبيقات. يمكنك الاطّلاع على مزيد من المعلومات عن كل هذه القيم الثلاث في المستندات.
تفعيل الفوترة
لتفعيل الفوترة، لديك خياران. يمكنك استخدام حساب الفوترة الشخصي أو تحصيل قيمة الرصيد باتّباع الخطوات التالية.
تحصيل قيمة أرصدة Google Cloud (اختياري)
لإجراء ورشة العمل هذه، يجب أن يكون لديك حساب فوترة يتضمّن بعض الرصيد. استخدِم الرصيد من البانر في أعلى هذا الدرس التطبيقي للبدء. إذا كنت مرتبطًا بحساب فوترة، يمكنك تخطّي هذه الخطوة.
إعداد حساب فوترة شخصي
إذا أعددت الفوترة باستخدام أرصدة Google Cloud، يمكنك تخطّي هذه الخطوة.
لإعداد حساب فوترة شخصي، انتقِل إلى هنا لتفعيل الفوترة في Cloud Console.
ملاحظات:
- يجب أن تبلغ تكلفة إكمال هذا المختبر أقل من 3 دولارات أمريكية من موارد السحابة الإلكترونية.
- يمكنك اتّباع الخطوات في نهاية هذا المختبر لحذف الموارد وتجنُّب المزيد من الرسوم.
- يمكن للمستخدمين الجدد الاستفادة من فترة تجريبية مجانية بقيمة 300 دولار أمريكي.
بدء Cloud Shell
على الرغم من إمكانية تشغيل Google Cloud عن بُعد من الكمبيوتر المحمول، ستستخدم في هذا الدرس التطبيقي حول الترميز Google Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
من Google Cloud Console، انقر على رمز Cloud Shell في شريط الأدوات أعلى يسار الصفحة:
يمكنك بدلاً من ذلك الضغط على G ثم S. سيؤدي هذا التسلسل إلى تفعيل Cloud Shell إذا كنت تستخدم Google Cloud Console أو هذا الرابط.
لن يستغرق توفير البيئة والاتصال بها سوى بضع لحظات. عند الانتهاء، من المفترض أن يظهر لك ما يلي:

يتم تحميل هذه الآلة الافتراضية مزوّدة بكل أدوات التطوير التي ستحتاج إليها. توفّر هذه الخدمة دليلًا منزليًا ثابتًا بسعة 5 غيغابايت، وتعمل على Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. يمكن إكمال جميع المهام في هذا الدرس العملي ضمن المتصفّح. لست بحاجة إلى تثبيت أي تطبيق.
3- قبل البدء
تفعيل واجهة برمجة التطبيقات
إخراج:
لاستخدام Cloud SQL و Compute Engine و خدمات الشبكات و Vertex AI، عليك تفعيل واجهات برمجة التطبيقات الخاصة بها في مشروعك على Google Cloud.
داخل نافذة Cloud Shell، تأكَّد من إعداد رقم تعريف مشروعك:
gcloud config set project [YOUR-PROJECT-ID]
اضبط متغيّر البيئة PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
فعِّل جميع الخدمات اللازمة:
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
الناتج المتوقّع
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
لمحة عن واجهات برمجة التطبيقات
- تتيح لك Cloud SQL Admin API (
sqladmin.googleapis.com) إنشاء مثيلات Cloud SQL وتكوينها وإدارتها آليًا. توفر هذه الخدمة لوحة التحكّم لخدمة قواعد البيانات الارتباطية المُدارة بالكامل من Google (التي تتوافق مع MySQL وPostgreSQL وSQL Server)، وتتعامل مع مهام مثل توفير الموارد وعمليات النسخ الاحتياطي والتوفّر العالي وتغيير الحجم. - تتيح لك Compute Engine API (
compute.googleapis.com) إنشاء الأجهزة الافتراضية والأقراص الثابتة وإعدادات الشبكة وإدارتها. توفّر هذه المنطقة الأساس المطلوب لتشغيل أحجام العمل واستضافة البنية التحتية الأساسية للعديد من الخدمات المُدارة. - تتيح لك Cloud Resource Manager API (
cloudresourcemanager.googleapis.com) إدارة البيانات الوصفية وإعدادات مشروعك على السحابة الإلكترونية من Google آليًا. تتيح لك هذه الخدمة تنظيم الموارد والتعامل مع سياسات "إدارة الهوية والوصول" (IAM) والتحقّق من صحة الأذونات في جميع مستويات بنية المشروع. - تتيح لك Service Networking API (
servicenetworking.googleapis.com) إمكانية إعداد الاتصال الخاص بين شبكة السحابة الافتراضية الخاصة (VPC) وخدمات Google المُدارة بشكل آلي. وهي مطلوبة تحديدًا لإتاحة الوصول إلى عناوين IP الخاصة للخدمات، مثل AlloyDB، حتى تتمكّن من التواصل بشكل آمن مع مواردك الأخرى. - تتيح Vertex AI API (
aiplatform.googleapis.com) لتطبيقاتك إنشاء نماذج تعلُّم الآلة ونشرها وتوسيع نطاقها. توفّر هذه المنصة واجهة موحّدة لجميع خدمات الذكاء الاصطناعي من Google Cloud، بما في ذلك إمكانية الوصول إلى نماذج الذكاء الاصطناعي التوليدي (مثل Gemini) وتدريب النماذج المخصّصة.
4. إنشاء مثيل Cloud SQL
أنشئ مثيل Cloud SQL مع دمج قاعدة البيانات مع Vertex AI.
إنشاء كلمة مرور لقاعدة البيانات
حدِّد كلمة مرور لمستخدم قاعدة البيانات التلقائي. يمكنك تحديد كلمة المرور الخاصة بك أو استخدام دالة عشوائية لإنشاء كلمة مرور:
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
دوِّن القيمة التي تم إنشاؤها لكلمة المرور:
echo $CLOUDSQL_PASSWORD
إنشاء مثيل Cloud SQL for PostgreSQL
يمكن إنشاء مثيلات Cloud SQL بطرق مختلفة، مثل Google Cloud Console أو أدوات التشغيل الآلي مثل Terraform أو Google Cloud SDK. في المختبر، سنستخدم بشكل أساسي أداة gcloud في Google Cloud SDK. يمكنك الاطّلاع في المستندات على كيفية إنشاء آلة افتراضية باستخدام أدوات أخرى.
في جلسة Cloud Shell، نفِّذ ما يلي:
gcloud sql instances create my-cloudsql-instance \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--region=us-central1 \
--edition=ENTERPRISE \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on
بعد إنشاء الجهاز الافتراضي، علينا ضبط كلمة مرور للمستخدم التلقائي في الجهاز الافتراضي والتحقّق من إمكانية الاتصال باستخدام كلمة المرور.
gcloud sql users set-password postgres \
--instance=my-cloudsql-instance \
--password=$CLOUDSQL_PASSWORD
نفِّذ الأمر gcloud sql connect كما هو موضّح في المربّع، وأدخِل كلمة المرور في الطلب عندما يكون جاهزًا للاتصال.
gcloud sql connect my-cloudsql-instance --user=postgres
اخرج من جلسة psql الآن باستخدام اختصار لوحة المفاتيح ctrl+d أو تنفيذ أمر الخروج
exit
تفعيل عملية الدمج مع Vertex AI
امنح الأذونات اللازمة لحساب خدمة Cloud SQL الداخلي لتتمكّن من استخدام ميزة التكامل مع Vertex AI.
ابحث عن عنوان البريد الإلكتروني لحساب الخدمة الداخلي في Cloud SQL وصدِّره كمتغيّر.
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
امنح حساب خدمة Cloud SQL إذن الوصول إلى Vertex AI:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
يمكنك الاطّلاع على مزيد من المعلومات حول إنشاء المثيل وإعداده في مستندات Cloud SQL هنا.
5- إعداد قاعدة البيانات
الآن، علينا إنشاء قاعدة بيانات وتفعيل ميزة "المتّجهات".
إنشاء قاعدة بيانات
أنشئ قاعدة بيانات بالاسم quickstart_db .ولإجراء ذلك، تتوفّر لدينا خيارات مختلفة، مثل برامج قواعد البيانات المستندة إلى سطر الأوامر، مثل psql لـ PostgreSQL أو حزمة تطوير البرامج (SDK) أو Cloud SQL Studio. سنستخدم حزمة تطوير البرامج (gcloud) لإنشاء قواعد البيانات والاتصال بالمثيل.
في Cloud Shell، نفِّذ الأمر لإنشاء قاعدة البيانات
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
تفعيل الإضافات
لكي نتمكّن من استخدام Vertex AI والمتّجهات، علينا تفعيل إضافتَين في قاعدة البيانات التي أنشأناها.
في Cloud Shell، نفِّذ الأمر للاتصال بقاعدة البيانات التي تم إنشاؤها (عليك تقديم كلمة المرور).
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
بعد إتمام عملية الربط بنجاح، عليك تنفيذ أمرين في جلسة SQL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector CASCADE;
الخروج من جلسة SQL:
exit;
6. تحميل البيانات
الآن، علينا إنشاء عناصر في قاعدة البيانات وتحميل البيانات. سنستخدم بيانات وهمية من Cymbal Store. تتوفّر البيانات في حزمة Google Storage العامة بتنسيق CSV.
أولاً، علينا إنشاء جميع العناصر المطلوبة في قاعدة البيانات. لإجراء ذلك، سنستخدم الأمرين gcloud sql connect وgcloud storage المألوفين لتنزيل عناصر المخطط واستيرادها إلى قاعدة البيانات.
في Cloud Shell، نفِّذ كلمة المرور التي تم تدوينها عند إنشاء الجهاز الظاهري:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
ما الذي فعلناه بالضبط في الأمر السابق؟ لقد ربطنا قاعدة البيانات الخاصة بنا ونفّذنا رمز SQL الذي تم تنزيله والذي أنشأ الجداول والفهارس والتسلسلات.
الخطوة التالية هي تحميل البيانات، ولإجراء ذلك، علينا تنزيل ملفات CSV من Google Cloud Storage.
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv .
بعد ذلك، علينا الاتصال بقاعدة البيانات.
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
واستيراد البيانات من ملفات CSV.
\copy cymbal_products from 'cymbal_products.csv' csv header
\copy cymbal_inventory from 'cymbal_inventory.csv' csv header
\copy cymbal_stores from 'cymbal_stores.csv' csv header
إذا كانت لديك بياناتك الخاصة وكانت ملفات CSV متوافقة مع أداة الاستيراد في Cloud SQL المتاحة من Cloud Console، يمكنك استخدامها بدلاً من طريقة سطر الأوامر.
7. إنشاء تضمينات
الخطوة التالية هي إنشاء تضمينات لأوصاف منتجاتنا باستخدام نموذج textembedding-004 من Google Vertex AI وتخزينها كبيانات متجهة.
الربط بقاعدة البيانات (في حال الخروج أو إلغاء ربط الجلسة السابقة):
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
وأنشئ عمودًا افتراضيًا embedding في جدول cymbal_products باستخدام دالة embedding. ينشئ الأمر عمودًا افتراضيًا باسم "embedding" سيخزّن المتّجهات مع عمليات التضمين التي تم إنشاؤها استنادًا إلى العمود "product_description". ينشئ أيضًا تضمينات لجميع الصفوف الحالية في الجدول. يتم تحديد النموذج كالمَعلمة الأولى لدالة التضمين، ويتم تحديد بيانات المصدر كالمَعلمة الثانية.
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005',product_description)) STORED;
قد يستغرق ذلك بعض الوقت، ولكن بالنسبة إلى 900 إلى 1,000 صف، يجب ألا يستغرق أكثر من 5 دقائق، وعادةً ما يكون أسرع من ذلك بكثير.
عندما نُدرج صفًا جديدًا في الجدول أو نعدّل product_description لأي صف حالي، ستتم إعادة إنشاء بيانات العمود الافتراضي لعمود "التضمين" مرة أخرى استنادًا إلى "product_description".
8. تشغيل ميزة "البحث عن صور مشابهة"
يمكننا الآن إجراء البحث باستخدام البحث عن التشابه استنادًا إلى قيم المتجهات المحسوبة للأوصاف وقيمة المتجه التي نحصل عليها لطلبنا.
يمكن تنفيذ طلب بحث SQL من واجهة سطر الأوامر نفسها باستخدام gcloud sql connect أو من Cloud SQL Studio كبديل. من الأفضل إدارة أي استعلام معقّد ومتعدد الصفوف في Cloud SQL Studio.
بدء Cloud SQL Studio
في وحدة التحكّم، انقر على مثيل Cloud SQL الذي أنشأناه سابقًا.
عندما تكون مفتوحة في اللوحة اليسرى، يمكننا رؤية Cloud SQL Studio. انقروا عليها.
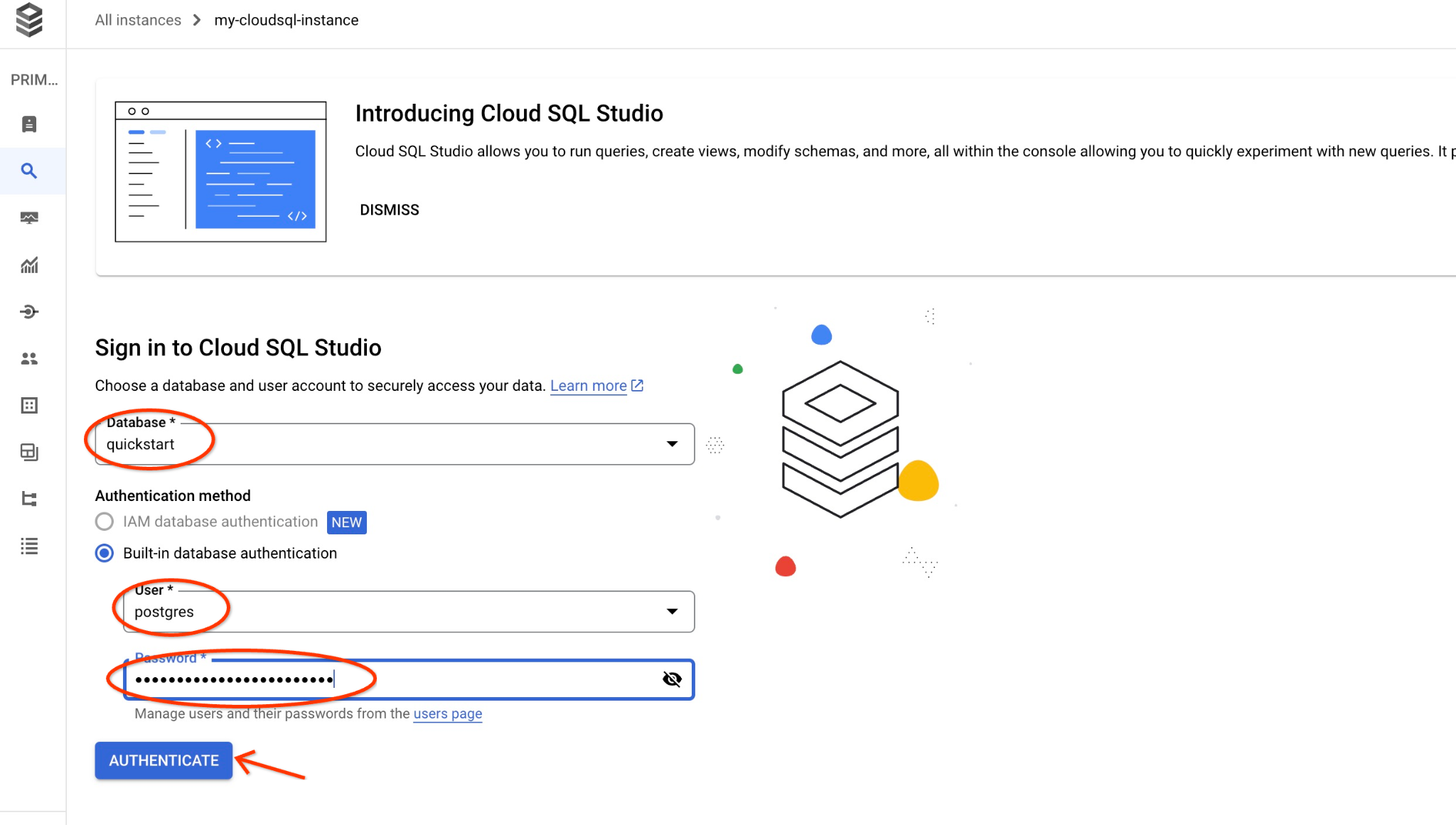
سيتم فتح مربّع حوار حيث يمكنك تقديم اسم قاعدة البيانات وبيانات الاعتماد:
- قاعدة البيانات: quickstart_db
- المستخدم: postgres
- كلمة المرور: كلمة المرور التي دوّنتها لمستخدم قاعدة البيانات الرئيسية
وانقر على الزر "المصادقة".
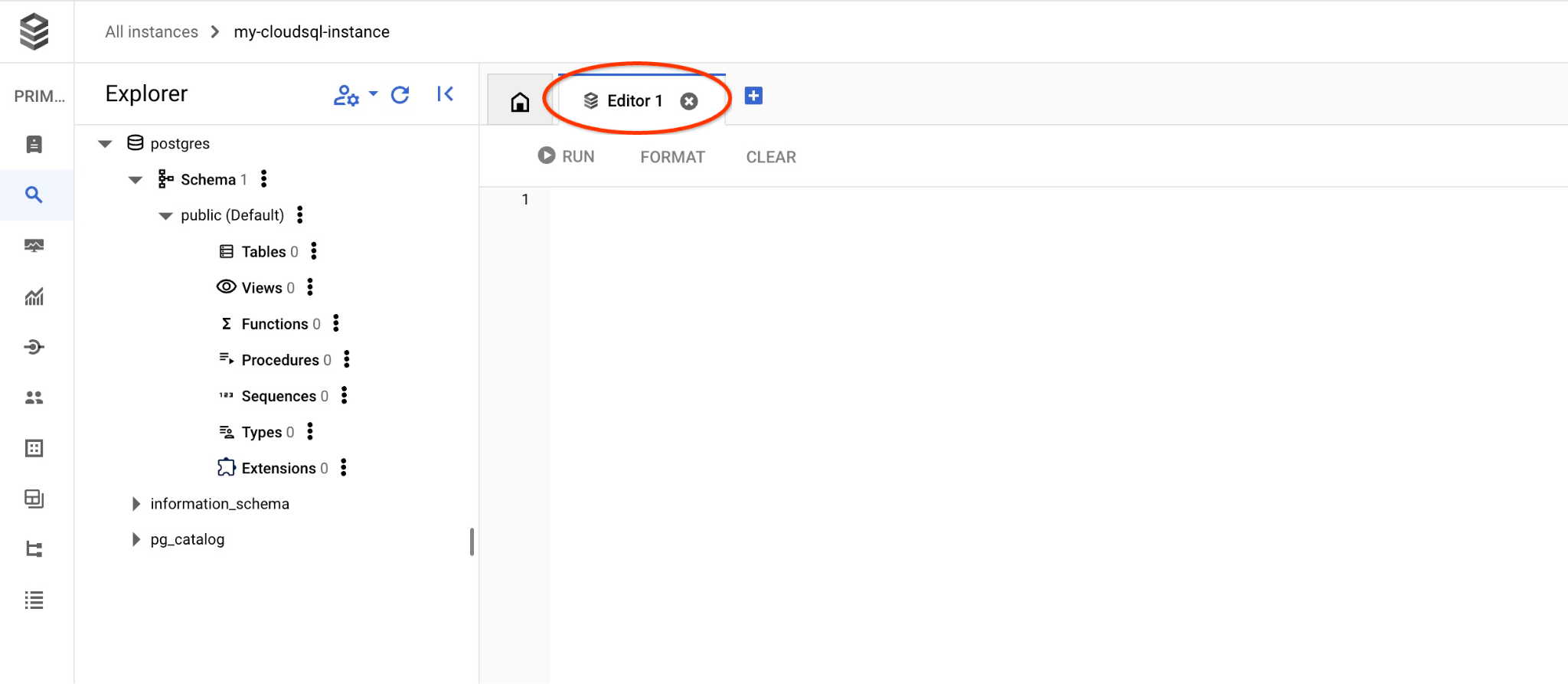
سيتم فتح النافذة التالية حيث تنقر على علامة التبويب "المحرّر" (Editor) على الجانب الأيسر لفتح "محرّر SQL" (SQL Editor).
نحن الآن جاهزون لتشغيل طلبات البحث.
تنفيذ طلب البحث
تنفيذ طلب بحث للحصول على قائمة بالمنتجات المتاحة الأكثر صلة بطلب العميل سيكون الطلب الذي سنمرّره إلى Vertex AI للحصول على قيمة المتّجه على النحو التالي: "ما هي أنواع أشجار الفاكهة التي تنمو جيدًا هنا؟"
في ما يلي طلب البحث الذي يمكنك تنفيذه لاختيار أول 10 عناصر الأكثر ملاءمةً لطلبنا:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
انسخ طلب البحث والصقه في محرّر Cloud SQL Studio، ثم انقر على الزر "تنفيذ" (RUN) أو الصقه في جلسة سطر الأوامر التي تتصل بقاعدة بيانات quickstart_db.
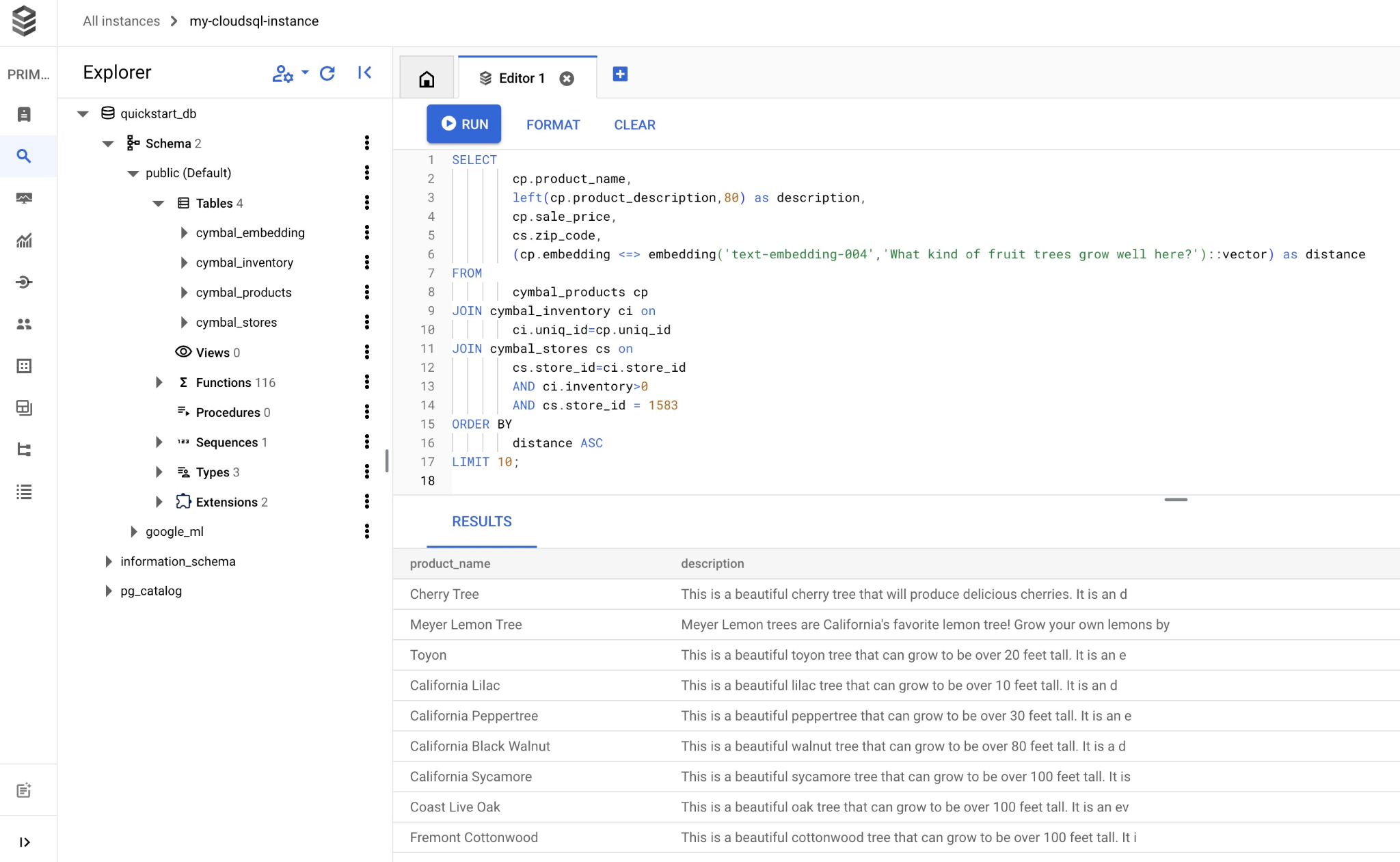
في ما يلي قائمة بالمنتجات التي تم اختيارها لتتطابق مع طلب البحث.
product_name | description | sale_price | zip_code | distance -------------------------+----------------------------------------------------------------------------------+------------+----------+--------------------- Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397 Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228 Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668 California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498 California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247 California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597 California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755 Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371 Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058 Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093 (10 rows)
9- تحسين ردود النماذج اللغوية الكبيرة باستخدام البيانات المسترجَعة
يمكننا تحسين ردّ النموذج اللغوي الكبير للذكاء الاصطناعي التوليدي على تطبيق العميل باستخدام نتيجة طلب البحث الذي تم تنفيذه وإعداد ناتج مفيد باستخدام نتائج طلب البحث المقدَّمة كجزء من الطلب إلى نموذج لغوي أساسي توليدي في Vertex AI.
لتحقيق ذلك، علينا إنشاء ملف JSON يتضمّن نتائج البحث المستند إلى المتّجهات، ثم استخدام ملف JSON الذي تم إنشاؤه كإضافة إلى طلب موجّه إلى نموذج لغوي كبير في Vertex AI لإنشاء إخراج ذي معنى. في الخطوة الأولى، ننشئ ملف JSON، ثم نختبره في Vertex AI Studio، وفي الخطوة الأخيرة، ندمجه في عبارة SQL يمكن استخدامها في أحد التطبيقات.
إنشاء ناتج بتنسيق JSON
عدِّل طلب البحث لإنشاء الإخراج بتنسيق JSON وعرض صف واحد فقط ليتم تمريره إلى Vertex AI
Cloud SQL for PostgreSQL
في ما يلي مثال على طلب البحث:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
في ما يلي تنسيق JSON المتوقّع في الناتج:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
تشغيل الطلب في Vertex AI Studio
يمكننا استخدام ملف JSON الذي تم إنشاؤه لتضمينه كجزء من الطلب المقدَّم إلى نموذج الذكاء الاصطناعي التوليدي المستند إلى نص في Vertex AI Studio.
افتح Vertex AI Studio في Cloud Console.
قد يُطلب منك تفعيل واجهات برمجة تطبيقات إضافية، ولكن يمكنك تجاهل الطلب. لا نحتاج إلى أي واجهات برمجة تطبيقات إضافية لإكمال الدرس التطبيقي.
إدخال طلب في "استوديو YouTube"
إليك الطلب الذي سنستخدمه:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
في ما يلي طريقة ظهورها عند استبدال العنصر النائب JSON بالاستجابة من طلب البحث:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
في ما يلي النتيجة عند تشغيل الطلب باستخدام قيم JSON:
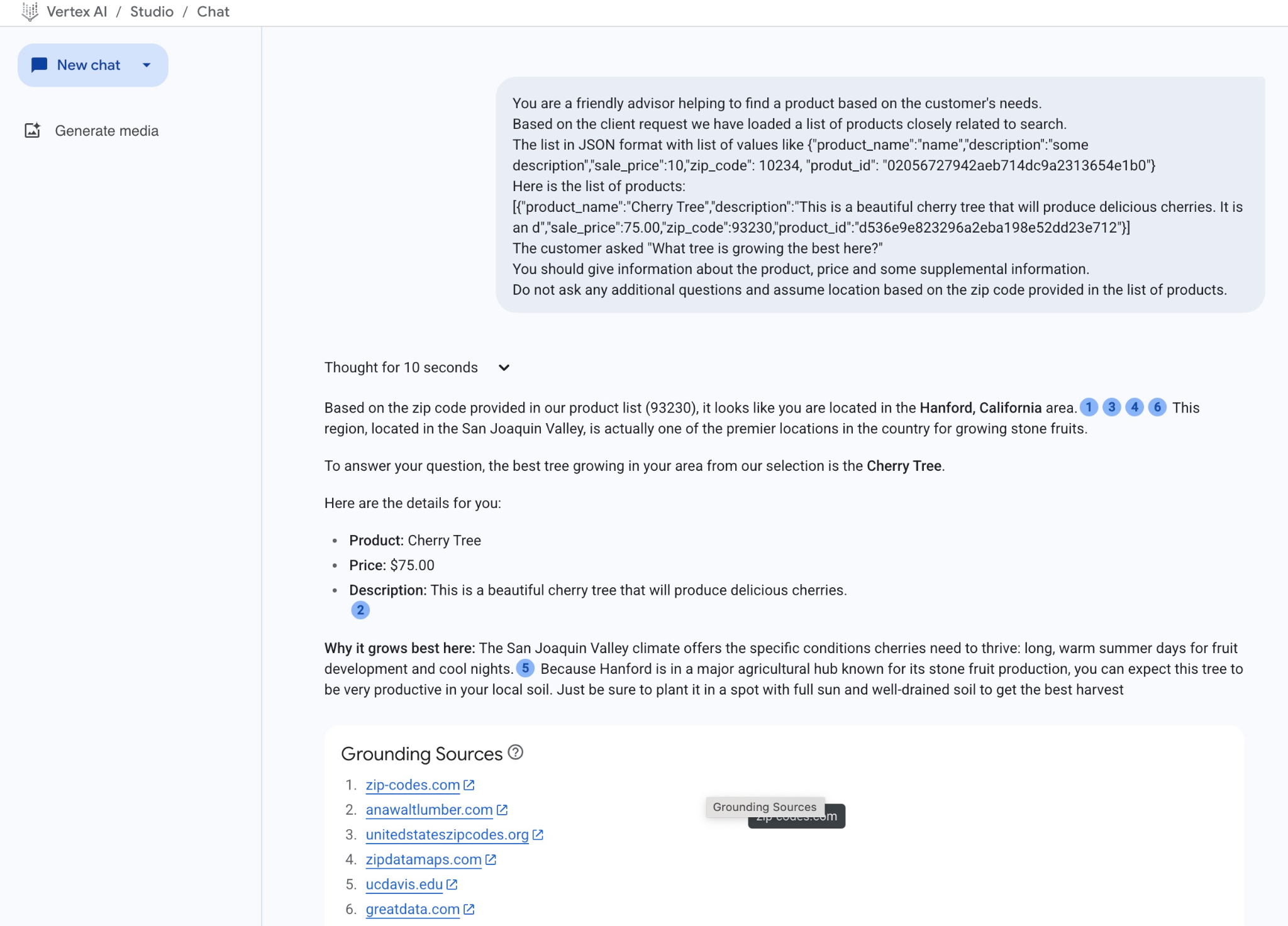
في ما يلي الإجابة التي حصلنا عليها من النموذج في هذا المثال. يُرجى العِلم أنّ إجابتك قد تختلف بسبب التغييرات التي تطرأ على النموذج والمَعلمات بمرور الوقت:
"استنادًا إلى الرمز البريدي المقدَّم في قائمة منتجاتنا (93230)، يبدو أنّك مقيم في منطقة هانفورد بولاية كاليفورنيا.1346 هذه المنطقة الواقعة في وادي سان جواكين هي في الواقع إحدى أفضل المناطق في البلد لزراعة الفاكهة ذات النواة الصلبة.
للإجابة عن سؤالك، أفضل شجرة تنمو في منطقتك من مجموعتنا هي شجرة الكرز.
إليك التفاصيل:
المنتج: شجرة الكرز
السعر: 75.00 دولار أمريكي
الوصف: هذه شجرة كرز جميلة ستنتج كرزًا لذيذًا.2
سبب نموها بشكل أفضل هنا: يوفّر مناخ وادي سان جواكين الظروف المحددة التي تحتاجها أشجار الكرز لتنمو بشكل جيد، وهي أيام صيفية طويلة ودافئة لنمو الثمار وليالٍ باردة.5 وبما أنّ مدينة هانفورد تقع في مركز زراعي رئيسي معروف بإنتاج الفاكهة ذات النواة الصلبة، يمكنك توقّع أن تكون هذه الشجرة مثمرة جدًا في تربتك المحلية. ما عليك سوى زراعتها في مكان مشمس تمامًا وتربة جيدة التصريف للحصول على أفضل محصول".
تنفيذ الطلب في PSQL
يمكننا أيضًا استخدام عملية دمج Cloud SQL AI مع Vertex AI للحصول على الردّ المشابه من نموذج توليدي باستخدام SQL مباشرةً في قاعدة البيانات. ولكن لاستخدام نموذج gemini-2.0-flash-exp، علينا تسجيله أولاً.
التشغيل في Cloud SQL for PostgreSQL
رقِّي الإضافة إلى الإصدار 1.4.2 أو إصدار أحدث (إذا كان الإصدار الحالي أقدم). اتّصِل بقاعدة بيانات quickstart_db من gcloud sql connect كما هو موضّح سابقًا (أو استخدِم Cloud SQL Studio) ونفِّذ ما يلي:
SELECT extversion from pg_extension where extname='google_ml_integration';
إذا كانت القيمة المعروضة أقل من 1.4.3، نفِّذ ما يلي:
ALTER EXTENSION google_ml_integration UPDATE TO '1.4.3';
بعد ذلك، علينا ضبط علامة قاعدة البيانات google_ml_integration.enable_model_support على "on". للتحقّق من الإعدادات الحالية، نفِّذ ما يلي:
show google_ml_integration.enable_model_support;
الناتج المتوقّع من جلسة psql هو "on":
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
إذا ظهرت القيمة "إيقاف"، علينا تعديل علامة قاعدة البيانات. لإجراء ذلك، يمكنك استخدام واجهة وحدة تحكّم الويب أو تنفيذ أمر gcloud التالي.
gcloud sql instances patch my-cloudsql-instance \
--database-flags google_ml_integration.enable_model_support=on,cloudsql.enable_google_ml_integration=on
يستغرق تنفيذ الأمر في الخلفية من دقيقة واحدة إلى 3 دقائق تقريبًا. بعد ذلك، يمكنك التحقّق من العلامة الجديدة في جلسة psql أو باستخدام Cloud SQL Studio من خلال الاتصال بقاعدة بيانات quickstart_db.
show google_ml_integration.enable_model_support;
الناتج المتوقّع من جلسة psql هو "on":
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
بعد ذلك، علينا تسجيل نموذجين. أولها هو نموذج text-embedding-005 المستخدَم حاليًا. يجب تسجيله لأنّنا فعّلنا إمكانات تسجيل النماذج.
لتسجيل عملية تنفيذ النموذج في psql أو Cloud SQL Studio، استخدِم الرمز التالي:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'cloudsql_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
والنموذج التالي الذي يجب تسجيله هو gemini-2.0-flash-001 الذي سيتم استخدامه لإنشاء النتائج سهلة الاستخدام.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'https://us-central1-aiplatform.googleapis.com/v1/projects/$PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'cloudsql_service_agent_iam');
يمكنك دائمًا التحقّق من قائمة النماذج المسجّلة من خلال اختيار معلومات من google_ml.model_info_view.
select model_id,model_type from google_ml.model_info_view;
في ما يلي مثال على الناتج
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
--------------------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
gemini-1.5-pro:streamGenerateContent | generic
gemini-1.5-pro:generateContent | generic
gemini-1.0-pro:generateContent | generic
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
يمكننا الآن استخدام JSON الذي تم إنشاؤه في طلب فرعي لتوفيره كجزء من الطلب إلى نموذج نصي للذكاء الاصطناعي التوليدي باستخدام لغة الاستعلامات البنيوية (SQL).
في جلسة psql أو Cloud SQL Studio لقاعدة البيانات، شغِّل الاستعلام
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> google_ml.embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
وفي ما يلي الناتج المتوقّع. قد يختلف الناتج حسب إصدار النموذج والمعلمات.:
"That's a great question! It sounds like you're looking to add some delicious fruit to your garden.\n\nBased on the products we have that are closely related to your search, I can tell you about a fantastic option:\n\n**Cherry Tree**" "\n* **Description:** This beautiful deciduous tree will produce delicious cherries. It grows to be about 15 feet tall, with dark green leaves in summer that turn a beautiful red in the fall. Cherry trees are known for their beauty, shade, and privacy. They prefer a cool, moist climate and sandy soil." "\n* **Price:** $75.00\n* **Grows well in:** USDA Zones 4-9.\n\nTo confirm if this Cherry Tree will thrive in your specific location, you might want to check which USDA Hardiness Zone your area falls into. If you're in zones 4-9, this" " could be a wonderful addition to your yard!"
10. إنشاء فهرس أقرب جار
مجموعة البيانات لدينا صغيرة جدًا، ويعتمد وقت الاستجابة بشكل أساسي على التفاعلات مع نماذج الذكاء الاصطناعي. ولكن عندما يكون لديك ملايين المتجهات، يمكن أن يستغرق البحث المتجه جزءًا كبيرًا من وقت الاستجابة ويفرض حملاً كبيرًا على النظام. لتحسين ذلك، يمكننا إنشاء فهرس فوق المتجهات.
إنشاء فهرس HNSW
سنستخدم نوع الفهرس HNSW في اختبارنا. يشير HNSW إلى Hierarchical Navigable Small World ويمثّل فهرسًا للرسوم البيانية المتعددة الطبقات.
لإنشاء الفهرس لعمود التضمين، علينا تحديد عمود التضمين ودالة المسافة، ويمكننا اختياريًا تحديد مَعلمات مثل m أو ef_constructions. يمكنك الاطّلاع على تفاصيل حول المَعلمات في المستندات.
CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
الناتج المتوقّع:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64); CREATE INDEX quickstart_db=>
مقارنة الردود
يمكننا الآن تشغيل طلب البحث عن تطابق المتجهات في وضع EXPLAIN والتحقّق من استخدام الفهرس.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
الناتج المتوقّع:
Aggregate (cost=779.12..779.13 rows=1 width=32) (actual time=1.066..1.069 rows=1 loops=1)
-> Subquery Scan on trees (cost=769.05..779.12 rows=1 width=142) (actual time=1.038..1.041 rows=1 loops=1)
-> Limit (cost=769.05..779.11 rows=1 width=158) (actual time=1.022..1.024 rows=1 loops=1)
-> Nested Loop (cost=769.05..9339.69 rows=852 width=158) (actual time=1.020..1.021 rows=1 loops=1)
-> Nested Loop (cost=768.77..9316.48 rows=852 width=945) (actual time=0.858..0.859 rows=1 loops=1)
-> Index Scan using cymbal_products_embeddings_hnsw on cymbal_products cp (cost=768.34..2572.47 rows=941 width=941) (actual time=0.532..0.539 rows=3 loops=1)
Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,...
<redacted>
...,0.017593635,-0.040275685,-0.03914233,-0.018452475,0.00826032,-0.07372604
]'::vector)
-> Index Scan using product_inventory_pkey on cymbal_inventory ci (cost=0.42..7.17 rows=1 width=37) (actual time=0.104..0.104 rows=0 loops=3)
Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text))
Filter: (inventory > 0)
Rows Removed by Filter: 1
-> Materialize (cost=0.28..8.31 rows=1 width=8) (actual time=0.133..0.134 rows=1 loops=1)
-> Index Scan using product_stores_pkey on cymbal_stores cs (cost=0.28..8.30 rows=1 width=8) (actual time=0.129..0.129 rows=1 loops=1)
Index Cond: (store_id = 1583)
Planning Time: 112.398 ms
Execution Time: 1.221 ms
من الناتج، يمكننا أن نرى بوضوح أنّ طلب البحث كان يستخدم "فحص الفهرس باستخدام cymbal_products_embeddings_hnsw".
وإذا نفّذنا الاستعلام بدون explain:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
الناتج المتوقّع (يمكن أن يختلف الناتج استنادًا إلى النموذج والفهرس):
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
يمكننا أن نرى أنّ النتيجة هي نفسها، ونعرض شجرة الكرز نفسها التي كانت في أعلى نتائج البحث بدون فهرس. استنادًا إلى المَعلمات ونوع الفهرس، من المحتمل أن تكون النتيجة مختلفة قليلاً وأن تعرض سجلًّا مختلفًا في أعلى الشجرة. أثناء اختباراتي، عرض الاستعلام المفهرس النتائج في 131.301 ملي ثانية مقابل 167.631 ملي ثانية بدون أي فهرس، ولكن كنا نتعامل مع مجموعة بيانات صغيرة جدًا وسيكون الفرق أكبر بكثير في البيانات الأكبر.
يمكنك تجربة فهارس مختلفة متاحة للمتجهات والمزيد من المعامل والأمثلة مع دمج Langchain المتوفّر في المستندات.
11. تنظيف البيئة
حذف مثيل Cloud SQL
محو مثيل Cloud SQL عند الانتهاء من المختبر
في Cloud Shell، حدِّد متغيرات المشروع والبيئة إذا تم قطع الاتصال وفقدت جميع الإعدادات السابقة:
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
احذف موضع التكرار باتّباع الخطوات التالية:
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
12. تهانينا
تهانينا على إكمال هذا الدرس العملي.
هذا المختبر هو جزء من مسار "الذكاء الاصطناعي الجاهز للإنتاج" التعليمي على Google Cloud.
- استكشاف المنهج الدراسي الكامل لسدّ الفجوة بين النموذج الأوّلي والإنتاج
- شارِك مستوى تقدّمك باستخدام الهاشتاغ
#ProductionReadyAI.
المواضيع التي تناولناها
- كيفية نشر نسخة افتراضية من Cloud SQL لـ PostgreSQL
- كيفية إنشاء قاعدة بيانات وتفعيل عمليات الدمج مع الذكاء الاصطناعي في Cloud SQL
- كيفية تحميل البيانات إلى قاعدة البيانات
- كيفية استخدام Cloud SQL Studio
- كيفية استخدام نموذج التضمين في Vertex AI في Cloud SQL
- كيفية استخدام Vertex AI Studio
- كيفية تحسين النتيجة باستخدام نموذج الذكاء الاصطناعي التوليدي من Vertex AI
- كيفية تحسين الأداء باستخدام فهرس المتجهات
جرِّب برنامج codelab مشابهًا لـ AlloyDB باستخدام فهرس ScaNN بدلاً من HNSW.
13. الاستطلاع
إخراج: