
১. ভূমিকা
এই কোডল্যাবে আপনি শিখবেন কীভাবে ভেক্টর সার্চের সাথে ভার্টেক্স এআই এমবেডিংস-এর সমন্বয় ঘটিয়ে পোস্টগ্রেসকিউএল এআই ইন্টিগ্রেশনের জন্য ক্লাউড এসকিউএল ব্যবহার করতে হয়।

পূর্বশর্ত
- গুগল ক্লাউড, কনসোল সম্পর্কে প্রাথমিক ধারণা
- কমান্ড লাইন ইন্টারফেস এবং ক্লাউড শেলে প্রাথমিক দক্ষতা
আপনি যা শিখবেন
- কীভাবে একটি Cloud SQL for PostgreSQL ইনস্ট্যান্স স্থাপন করবেন
- কীভাবে ডাটাবেস তৈরি করবেন এবং ক্লাউড এসকিউএল এআই ইন্টিগ্রেশন সক্রিয় করবেন
- ডাটাবেসে ডেটা লোড করার পদ্ধতি
- ক্লাউড এসকিউএল স্টুডিও কীভাবে ব্যবহার করবেন
- ক্লাউড SQL-এ ভার্টেক্স এআই এমবেডিং মডেল কীভাবে ব্যবহার করবেন
- ভার্টেক্স এআই স্টুডিও কীভাবে ব্যবহার করবেন
- ভার্টেক্স এআই জেনারেটিভ মডেল ব্যবহার করে ফলাফলকে কীভাবে আরও সমৃদ্ধ করা যায়
- ভেক্টর ইনডেক্স ব্যবহার করে কীভাবে পারফরম্যান্স উন্নত করা যায়
আপনার যা যা লাগবে
- একটি গুগল ক্লাউড অ্যাকাউন্ট এবং গুগল ক্লাউড প্রজেক্ট
- ক্রোমের মতো একটি ওয়েব ব্রাউজার যা গুগল ক্লাউড কনসোল এবং ক্লাউড শেল সমর্থন করে।
২. সেটআপ এবং প্রয়োজনীয়তা
প্রজেক্ট সেটআপ
- Google Cloud Console- এ সাইন-ইন করুন। যদি আপনার আগে থেকে Gmail বা Google Workspace অ্যাকাউন্ট না থাকে, তবে আপনাকে একটি তৈরি করতে হবে।
কর্মক্ষেত্র বা শিক্ষা প্রতিষ্ঠানের অ্যাকাউন্টের পরিবর্তে ব্যক্তিগত অ্যাকাউন্ট ব্যবহার করুন।
- একটি নতুন প্রজেক্ট তৈরি করুন অথবা বিদ্যমান কোনো প্রজেক্ট পুনরায় ব্যবহার করুন। গুগল ক্লাউড কনসোলে একটি নতুন প্রজেক্ট তৈরি করতে, হেডারে থাকা 'Select a project' বোতামটিতে ক্লিক করুন, যা একটি পপ-আপ উইন্ডো খুলবে।

'Select a project' উইন্ডোতে 'New Project' বোতামটি চাপুন, যা নতুন প্রজেক্টের জন্য একটি ডায়ালগ বক্স খুলবে।
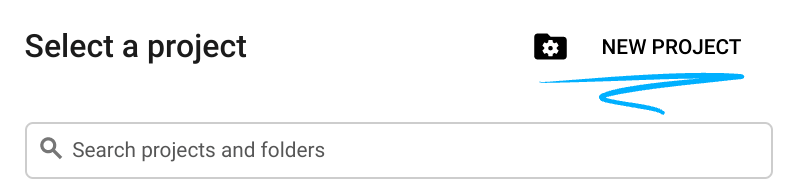
ডায়ালগ বক্সে আপনার পছন্দের প্রজেক্টের নাম দিন এবং অবস্থান নির্বাচন করুন।
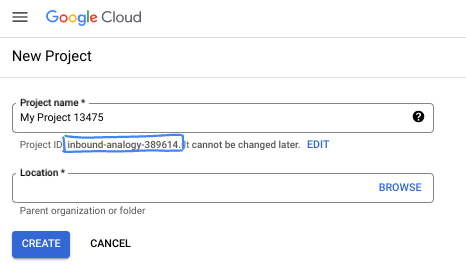
- প্রজেক্টের নামটি এই প্রকল্পের অংশগ্রহণকারীদের জন্য প্রদর্শিত নাম। প্রজেক্টের নামটি গুগল এপিআই দ্বারা ব্যবহৃত হয় না এবং এটি যেকোনো সময় পরিবর্তন করা যেতে পারে।
- প্রজেক্ট আইডি সমস্ত গুগল ক্লাউড প্রজেক্ট জুড়ে অনন্য এবং অপরিবর্তনীয় (একবার সেট করার পর এটি পরিবর্তন করা যায় না)। গুগল ক্লাউড কনসোল স্বয়ংক্রিয়ভাবে একটি অনন্য আইডি তৈরি করে, কিন্তু আপনি এটি কাস্টমাইজ করতে পারেন। তৈরি করা আইডিটি আপনার পছন্দ না হলে, আপনি এলোমেলোভাবে আরেকটি তৈরি করতে পারেন অথবা সেটির প্রাপ্যতা যাচাই করার জন্য আপনার নিজের আইডি দিতে পারেন। বেশিরভাগ কোডল্যাবে, আপনাকে আপনার প্রজেক্ট আইডি উল্লেখ করতে হবে, যা সাধারণত PROJECT_ID নামক প্লেসহোল্ডার দ্বারা চিহ্নিত করা হয়।
- আপনার অবগতির জন্য জানাচ্ছি যে, তৃতীয় একটি ভ্যালু রয়েছে, যা হলো প্রজেক্ট নম্বর , এবং কিছু এপিআই এটি ব্যবহার করে থাকে। ডকুমেন্টেশনে এই তিনটি ভ্যালু সম্পর্কে আরও বিস্তারিত জানুন।
বিলিং সক্ষম করুন
বিলিং চালু করার জন্য আপনার কাছে দুটি বিকল্প আছে। আপনি হয় আপনার ব্যক্তিগত বিলিং অ্যাকাউন্ট ব্যবহার করতে পারেন অথবা নিম্নলিখিত ধাপগুলো অনুসরণ করে ক্রেডিট রিডিম করতে পারেন।
গুগল ক্লাউড ক্রেডিট রিডিম করুন (ঐচ্ছিক)
এই ওয়ার্কশপটি চালানোর জন্য আপনার কিছু ক্রেডিট সহ একটি বিলিং অ্যাকাউন্ট প্রয়োজন। শুরু করার জন্য এই কোডল্যাবের উপরের ব্যানার থেকে ক্রেডিট ব্যবহার করুন। আপনি যদি ইতিমধ্যেই একটি বিলিং অ্যাকাউন্টের সাথে সংযুক্ত থাকেন, তাহলে আপনি এই ধাপটি এড়িয়ে যেতে পারেন।
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট তৈরি করুন
আপনি যদি গুগল ক্লাউড ক্রেডিট ব্যবহার করে বিলিং সেট আপ করেন, তাহলে এই ধাপটি এড়িয়ে যেতে পারেন।
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট তৈরি করতে, ক্লাউড কনসোলে বিলিং চালু করার জন্য এখানে যান ।
কিছু নোট:
- এই ল্যাবটি সম্পন্ন করতে ক্লাউড রিসোর্সে ৩ মার্কিন ডলারের কম খরচ হওয়া উচিত।
- পরবর্তী চার্জ এড়াতে, এই ল্যাবের শেষে দেওয়া ধাপগুলো অনুসরণ করে আপনি রিসোর্সগুলো মুছে ফেলতে পারেন।
- নতুন ব্যবহারকারীরা ৩০০ মার্কিন ডলারের ফ্রি ট্রায়ালের জন্য যোগ্য।
ক্লাউড শেল শুরু করুন
যদিও গুগল ক্লাউড আপনার ল্যাপটপ থেকে দূরবর্তীভাবে পরিচালনা করা যায়, এই কোডল্যাবে আপনি গুগল ক্লাউড শেল ব্যবহার করবেন, যা ক্লাউডে চালিত একটি কমান্ড লাইন পরিবেশ।
গুগল ক্লাউড কনসোল থেকে, উপরের ডানদিকের টুলবারে থাকা ক্লাউড শেল আইকনটিতে ক্লিক করুন:
বিকল্পভাবে আপনি প্রথমে G এবং তারপর S চাপতে পারেন। আপনি যদি গুগল ক্লাউড কনসোলের মধ্যে থাকেন, তাহলে এই ক্রমটি ক্লাউড শেল সক্রিয় করবে অথবা এই লিঙ্কটি ব্যবহার করুন।
পরিবেশটি প্রস্তুত করতে এবং এর সাথে সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগবে। এটি শেষ হলে, আপনি এইরকম কিছু দেখতে পাবেন:

এই ভার্চুয়াল মেশিনটিতে আপনার প্রয়োজনীয় সমস্ত ডেভেলপমেন্ট টুলস লোড করা আছে। এটি একটি স্থায়ী ৫ জিবি হোম ডিরেক্টরি প্রদান করে এবং গুগল ক্লাউডে চলে, যা নেটওয়ার্ক পারফরম্যান্স ও অথেনটিকেশনকে ব্যাপকভাবে উন্নত করে। এই কোডল্যাবে আপনার সমস্ত কাজ একটি ব্রাউজারের মধ্যেই করা যাবে। আপনাকে কিছুই ইনস্টল করতে হবে না।
৩. শুরু করার আগে
এপিআই সক্ষম করুন
আউটপুট:
Cloud SQL , Compute Engine , Networking services , এবং Vertex AI ব্যবহার করার জন্য, আপনাকে আপনার Google Cloud প্রজেক্টে এগুলোর নিজ নিজ API সক্রিয় করতে হবে।
ক্লাউড শেল টার্মিনালের ভিতরে, নিশ্চিত করুন যে আপনার প্রজেক্ট আইডি সেটআপ করা আছে:
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID এনভায়রনমেন্ট ভেরিয়েবল সেট করুন:
PROJECT_ID=$(gcloud config get-value project)
সকল প্রয়োজনীয় পরিষেবা সক্রিয় করুন:
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
প্রত্যাশিত আউটপুট
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
এপিআইগুলো চালু করা হচ্ছে
- ক্লাউড এসকিউএল অ্যাডমিন এপিআই (
sqladmin.googleapis.com) আপনাকে প্রোগ্রাম্যাটিকভাবে ক্লাউড এসকিউএল ইনস্ট্যান্স তৈরি, কনফিগার এবং পরিচালনা করার সুযোগ দেয়। এটি গুগলের সম্পূর্ণভাবে পরিচালিত রিলেশনাল ডেটাবেস পরিষেবার (যা MySQL, PostgreSQL, এবং SQL Server সমর্থন করে) জন্য কন্ট্রোল প্লেন প্রদান করে এবং প্রভিশনিং, ব্যাকআপ, হাই অ্যাভেইলেবিলিটি ও স্কেলিং-এর মতো কাজগুলো পরিচালনা করে। - কম্পিউট ইঞ্জিন এপিআই (
compute.googleapis.com) আপনাকে ভার্চুয়াল মেশিন (VM), পারসিস্টেন্ট ডিস্ক এবং নেটওয়ার্ক সেটিংস তৈরি ও পরিচালনা করার সুযোগ দেয়। এটি আপনার ওয়ার্কলোড চালানোর জন্য এবং অনেক পরিচালিত পরিষেবার অন্তর্নিহিত পরিকাঠামো হোস্ট করার জন্য প্রয়োজনীয় মূল ইনফ্রাস্ট্রাকচার-অ্যাজ-এ-সার্ভিস (IaaS) ভিত্তি প্রদান করে। - ক্লাউড রিসোর্স ম্যানেজার এপিআই (
cloudresourcemanager.googleapis.com) আপনাকে প্রোগ্রাম্যাটিকভাবে আপনার গুগল ক্লাউড প্রজেক্টের মেটাডেটা এবং কনফিগারেশন পরিচালনা করার সুযোগ দেয়। এটি আপনাকে রিসোর্স সংগঠিত করতে, আইডেন্টিটি অ্যান্ড অ্যাক্সেস ম্যানেজমেন্ট (IAM) পলিসি পরিচালনা করতে এবং প্রজেক্টের স্তরবিন্যাস জুড়ে অনুমতি যাচাই করতে সক্ষম করে। - সার্ভিস নেটওয়ার্কিং এপিআই (
servicenetworking.googleapis.com) আপনাকে আপনার ভার্চুয়াল প্রাইভেট ক্লাউড (VPC) নেটওয়ার্ক এবং গুগলের পরিচালিত পরিষেবাগুলির মধ্যে ব্যক্তিগত সংযোগ স্থাপন স্বয়ংক্রিয় করতে সাহায্য করে। AlloyDB-এর মতো পরিষেবাগুলির জন্য ব্যক্তিগত আইপি অ্যাক্সেস স্থাপন করতে এটি বিশেষভাবে প্রয়োজন, যাতে তারা আপনার অন্যান্য রিসোর্সগুলির সাথে নিরাপদে যোগাযোগ করতে পারে। - ভার্টেক্স এআই এপিআই (
aiplatform.googleapis.com) আপনার অ্যাপ্লিকেশনগুলোকে মেশিন লার্নিং মডেল তৈরি, স্থাপন এবং স্কেল করতে সক্ষম করে। এটি গুগল ক্লাউডের সমস্ত এআই পরিষেবার জন্য একটি সমন্বিত ইন্টারফেস প্রদান করে, যার মধ্যে জেনারেটিভ এআই মডেল (যেমন জেমিনি) এবং কাস্টম মডেল প্রশিক্ষণের সুবিধাও রয়েছে।
৪. একটি ক্লাউড এসকিউএল ইনস্ট্যান্স তৈরি করুন
Vertex AI-এর সাথে ডাটাবেস ইন্টিগ্রেশন সহ ক্লাউড SQL ইনস্ট্যান্স তৈরি করুন।
ডাটাবেস পাসওয়ার্ড তৈরি করুন
ডিফল্ট ডাটাবেস ব্যবহারকারীর জন্য পাসওয়ার্ড নির্ধারণ করুন। আপনি নিজের পাসওয়ার্ড নির্ধারণ করতে পারেন অথবা একটি র্যান্ডম ফাংশন ব্যবহার করে তা তৈরি করতে পারেন:
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
পাসওয়ার্ডের জন্য তৈরি হওয়া মানটি লক্ষ্য করুন:
echo $CLOUDSQL_PASSWORD
পোস্টগ্রেসকিউএল ইনস্ট্যান্সের জন্য ক্লাউড এসকিউএল তৈরি করুন
ক্লাউড এসকিউএল ইনস্ট্যান্স বিভিন্ন উপায়ে তৈরি করা যায়, যেমন গুগল ক্লাউড কনসোল, টেরাফর্মের মতো অটোমেশন টুল অথবা গুগল ক্লাউড এসডিকে। এই ল্যাবে আমরা প্রধানত গুগল ক্লাউড এসডিকে-র gcloud টুলটি ব্যবহার করব। অন্যান্য টুল ব্যবহার করে কীভাবে ইনস্ট্যান্স তৈরি করতে হয়, তা আপনি ডকুমেন্টেশনে পড়ে নিতে পারেন।
ক্লাউড শেল সেশনে নিম্নলিখিতটি সম্পাদন করুন:
gcloud sql instances create my-cloudsql-instance \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--region=us-central1 \
--edition=ENTERPRISE \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on
ইনস্ট্যান্সটি তৈরি করার পর, আমাদের ইনস্ট্যান্সের ডিফল্ট ব্যবহারকারীর জন্য একটি পাসওয়ার্ড সেট করতে হবে এবং সেই পাসওয়ার্ড দিয়ে সংযোগ করা যাচ্ছে কিনা তা যাচাই করতে হবে।
gcloud sql users set-password postgres \
--instance=my-cloudsql-instance \
--password=$CLOUDSQL_PASSWORD
বক্সে দেখানো নির্দেশ অনুযায়ী " gcloud sql connect" কমান্ডটি চালান এবং সংযোগ করার জন্য প্রস্তুত হলে প্রম্পটে আপনার পাসওয়ার্ড দিন।
gcloud sql connect my-cloudsql-instance --user=postgres
আপাতত psql সেশন থেকে বের হওয়ার জন্য ctrl+d কিবোর্ড শর্টকাট ব্যবহার করুন অথবা exit কমান্ডটি চালান।
exit
ভার্টেক্স এআই ইন্টিগ্রেশন সক্ষম করুন
Vertex AI ইন্টিগ্রেশন ব্যবহার করার জন্য অভ্যন্তরীণ ক্লাউড SQL পরিষেবা অ্যাকাউন্টকে প্রয়োজনীয় বিশেষাধিকার প্রদান করুন।
ক্লাউড এসকিউএল অভ্যন্তরীণ পরিষেবা অ্যাকাউন্টের ইমেলটি খুঁজে বের করুন এবং এটিকে একটি ভেরিয়েবল হিসেবে এক্সপোর্ট করুন।
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
ক্লাউড SQL পরিষেবা অ্যাকাউন্টে Vertex AI-কে অ্যাক্সেস দিন:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
ইনস্ট্যান্স তৈরি এবং কনফিগারেশন সম্পর্কে আরও জানতে এখানে ক্লাউড এসকিউএল ডকুমেন্টেশন পড়ুন।
৫. ডাটাবেস প্রস্তুত করুন
এখন আমাদের একটি ডাটাবেস তৈরি করতে হবে এবং ভেক্টর সাপোর্ট সক্রিয় করতে হবে।
ডাটাবেস তৈরি করুন
`quickstart_db` নামে একটি ডাটাবেস তৈরি করুন। এটি করার জন্য আমাদের কাছে বিভিন্ন বিকল্প রয়েছে, যেমন কমান্ড লাইন ডাটাবেস ক্লায়েন্ট (PostgreSQL-এর জন্য psql-এর মতো), SDK বা ক্লাউড SQL স্টুডিও। আমরা ডাটাবেস তৈরি করতে এবং ইনস্ট্যান্সে সংযোগ করার জন্য SDK (gcloud) ব্যবহার করব।
ক্লাউড শেলে ডাটাবেস তৈরি করার জন্য কমান্ডটি চালান।
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
এক্সটেনশনগুলি সক্ষম করুন
ভার্টেক্স এআই এবং ভেক্টর নিয়ে কাজ করতে হলে আমাদের তৈরি করা ডেটাবেসে দুটি এক্সটেনশন সক্রিয় করতে হবে।
ক্লাউড শেলে তৈরি করা ডেটাবেসে সংযোগ করার জন্য কমান্ডটি চালান (আপনাকে আপনার পাসওয়ার্ড দিতে হবে)।
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
তারপর, সফলভাবে সংযোগ স্থাপন হলে, এসকিউএল সেশনে আপনাকে দুটি কমান্ড চালাতে হবে:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector CASCADE;
SQL সেশন থেকে প্রস্থান:
exit;
৬. ডেটা লোড করুন
এখন আমাদের ডাটাবেসে অবজেক্ট তৈরি করতে হবে এবং ডেটা লোড করতে হবে। আমরা কাল্পনিক সিম্বল স্টোরের ডেটা ব্যবহার করতে যাচ্ছি। ডেটাগুলো পাবলিক গুগল স্টোরেজ বাকেটে CSV ফরম্যাটে উপলব্ধ আছে।
প্রথমে আমাদের ডাটাবেসে সমস্ত প্রয়োজনীয় অবজেক্ট তৈরি করতে হবে। এর জন্য আমরা আমাদের ডাটাবেসে স্কিমা অবজেক্টগুলো ডাউনলোড ও ইম্পোর্ট করতে আগে থেকেই পরিচিত gcloud sql connect এবং gcloud storage কমান্ডগুলো ব্যবহার করব।
ক্লাউড শেলে, ইনস্ট্যান্সটি তৈরি করার সময় লিখে রাখা পাসওয়ার্ডটি চালান এবং প্রদান করুন:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
আগের কমান্ডে আমরা ঠিক কী করেছিলাম? আমরা আমাদের ডাটাবেসের সাথে সংযোগ স্থাপন করে ডাউনলোড করা SQL কোডটি এক্সিকিউট করেছিলাম, যা টেবিল, ইনডেক্স এবং সিকোয়েন্স তৈরি করেছিল।
পরবর্তী ধাপ হলো ডেটা লোড করা এবং তা করার জন্য আমাদের গুগল ক্লাউড স্টোরেজ থেকে CSV ফাইলগুলো ডাউনলোড করতে হবে।
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv .
এরপর আমাদের ডাটাবেসের সাথে সংযোগ করতে হবে।
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
এবং আমাদের CSV ফাইলগুলো থেকে ডেটা ইম্পোর্ট করুন।
\copy cymbal_products from 'cymbal_products.csv' csv header
\copy cymbal_inventory from 'cymbal_inventory.csv' csv header
\copy cymbal_stores from 'cymbal_stores.csv' csv header
আপনার নিজের ডেটা থাকলে এবং আপনার CSV ফাইলগুলো ক্লাউড কনসোলে উপলব্ধ ক্লাউড SQL ইম্পোর্ট টুলের সাথে সামঞ্জস্যপূর্ণ হলে, আপনি কমান্ড লাইন পদ্ধতির পরিবর্তে সেটি ব্যবহার করতে পারেন।
৭. এমবেডিং তৈরি করুন
পরবর্তী পদক্ষেপ হলো গুগল ভার্টেক্স এআই-এর টেক্সটএম্বেডিং-০০৪ মডেল ব্যবহার করে আমাদের পণ্যের বিবরণের জন্য এম্বেডিং তৈরি করা এবং সেগুলোকে ভেক্টর ডেটা হিসেবে সংরক্ষণ করা।
ডাটাবেসে সংযোগ করুন (যদি আপনি বেরিয়ে গিয়ে থাকেন বা আপনার পূর্ববর্তী সেশনটি সংযোগ বিচ্ছিন্ন হয়ে গিয়ে থাকে):
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
এবং এমবেডিং ফাংশন ব্যবহার করে আমাদের cymbal_products টেবিলে একটি ভার্চুয়াল কলাম এমবেডিং তৈরি করুন। এই কমান্ডটি " embedding " নামে একটি ভার্চুয়াল কলাম তৈরি করে, যেখানে " product_description " কলামের উপর ভিত্তি করে তৈরি এমবেডিং সহ আমাদের ভেক্টরগুলো সংরক্ষণ করা হবে। এছাড়াও এটি টেবিলের সমস্ত বিদ্যমান সারির জন্য এমবেডিং তৈরি করে। এমবেডিং ফাংশনের প্রথম প্যারামিটার হিসেবে মডেলটি এবং দ্বিতীয় প্যারামিটার হিসেবে সোর্স ডেটা সংজ্ঞায়িত করা হয়।
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005',product_description)) STORED;
এতে কিছুটা সময় লাগতে পারে, কিন্তু ৯০০-১০০০ সারির জন্য ৫ মিনিটের বেশি লাগার কথা নয় এবং সাধারণত এটি আরও দ্রুত হয়।
যখন আমরা টেবিলে একটি নতুন সারি যোগ করি বা কোনো বিদ্যমান সারির 'product_description' আপডেট করি, তখন ' product_description'- এর উপর ভিত্তি করে ' embedding ' কলামের ভার্চুয়াল কলাম ডেটা পুনরায় তৈরি হবে।
৮. সাদৃশ্য অনুসন্ধান চালান
এখন আমরা বিবরণগুলোর জন্য গণনা করা ভেক্টর মান এবং আমাদের অনুরোধের জন্য প্রাপ্ত ভেক্টর মানের উপর ভিত্তি করে সাদৃশ্য অনুসন্ধান ব্যবহার করে আমাদের অনুসন্ধানটি চালাতে পারি।
SQL কোয়েরিটি একই কমান্ড লাইন ইন্টারফেস থেকে gcloud sql connect ব্যবহার করে অথবা বিকল্প হিসেবে Cloud SQL Studio থেকে চালানো যেতে পারে। যেকোনো একাধিক সারি এবং জটিল কোয়েরি Cloud SQL Studio-তে পরিচালনা করা শ্রেয়।
ক্লাউড এসকিউএল স্টুডিও শুরু করুন
কনসোলে আমরা আগে তৈরি করা ক্লাউড এসকিউএল ইনস্ট্যান্সটিতে ক্লিক করুন।
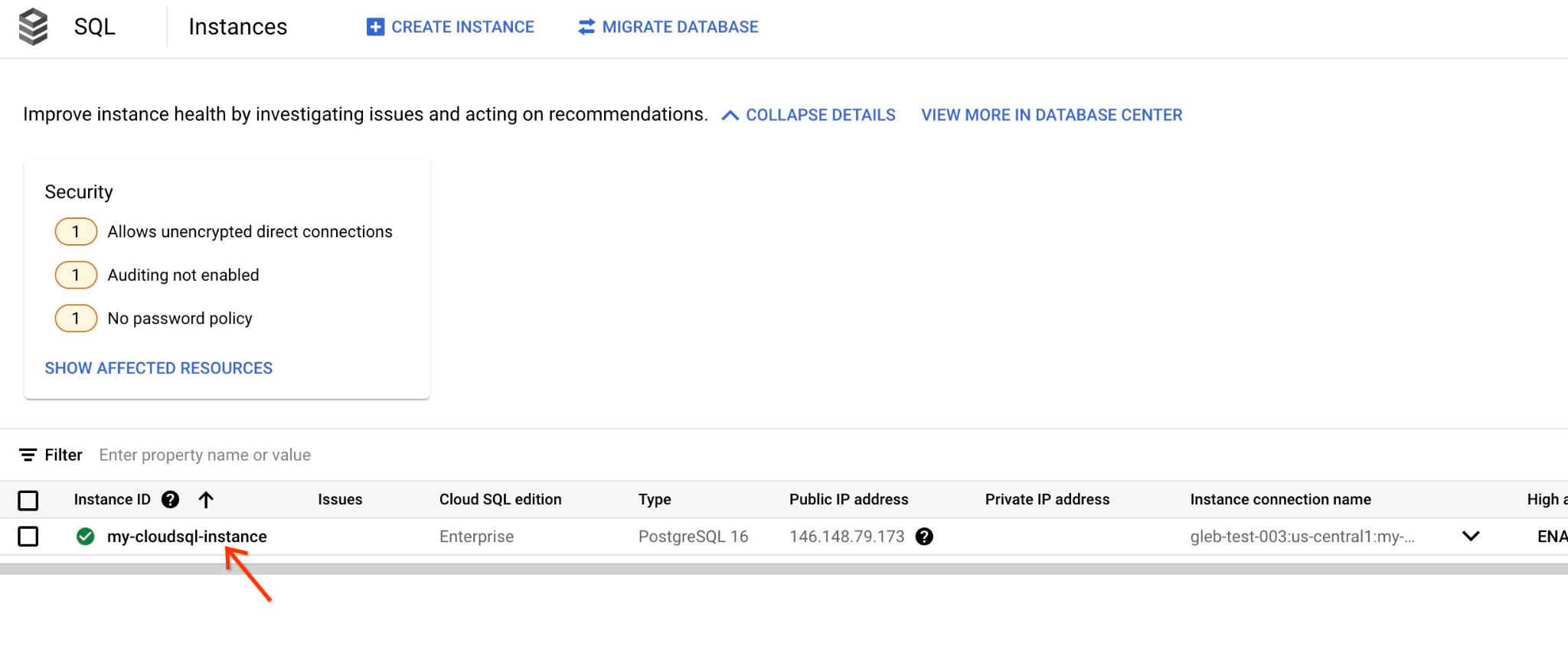
যখন এটি খুলবে, ডান প্যানেলে আমরা ক্লাউড এসকিউএল স্টুডিও দেখতে পাব। সেটিতে ক্লিক করুন।
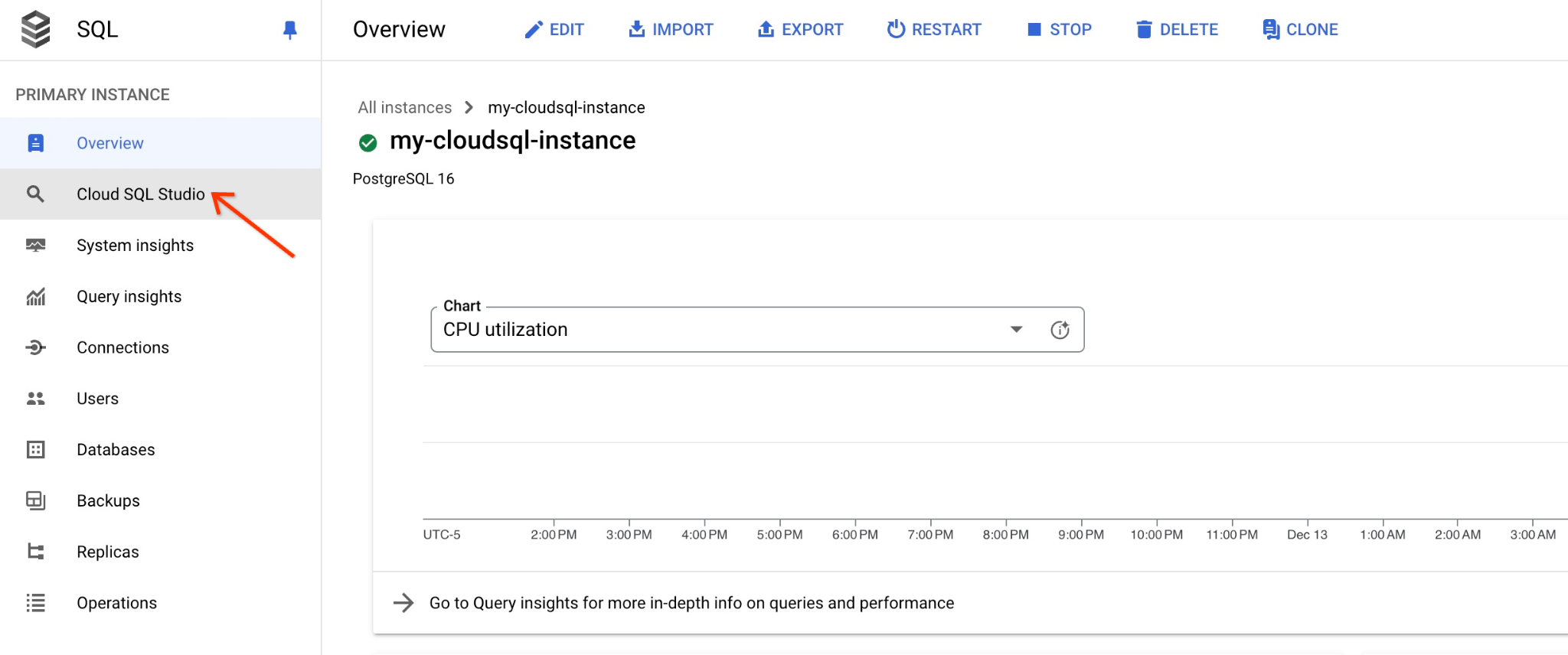
এটি একটি ডায়ালগ বক্স খুলবে যেখানে আপনাকে ডেটাবেসের নাম এবং আপনার পরিচয়পত্র প্রদান করতে হবে:
- ডাটাবেস: quickstart_db
- ব্যবহারকারী: পোস্টগ্রেস
- পাসওয়ার্ড: প্রধান ডাটাবেস ব্যবহারকারীর জন্য আপনার লিখে রাখা পাসওয়ার্ড।
এবং "AUTHENTICATE" বোতামটিতে ক্লিক করুন।
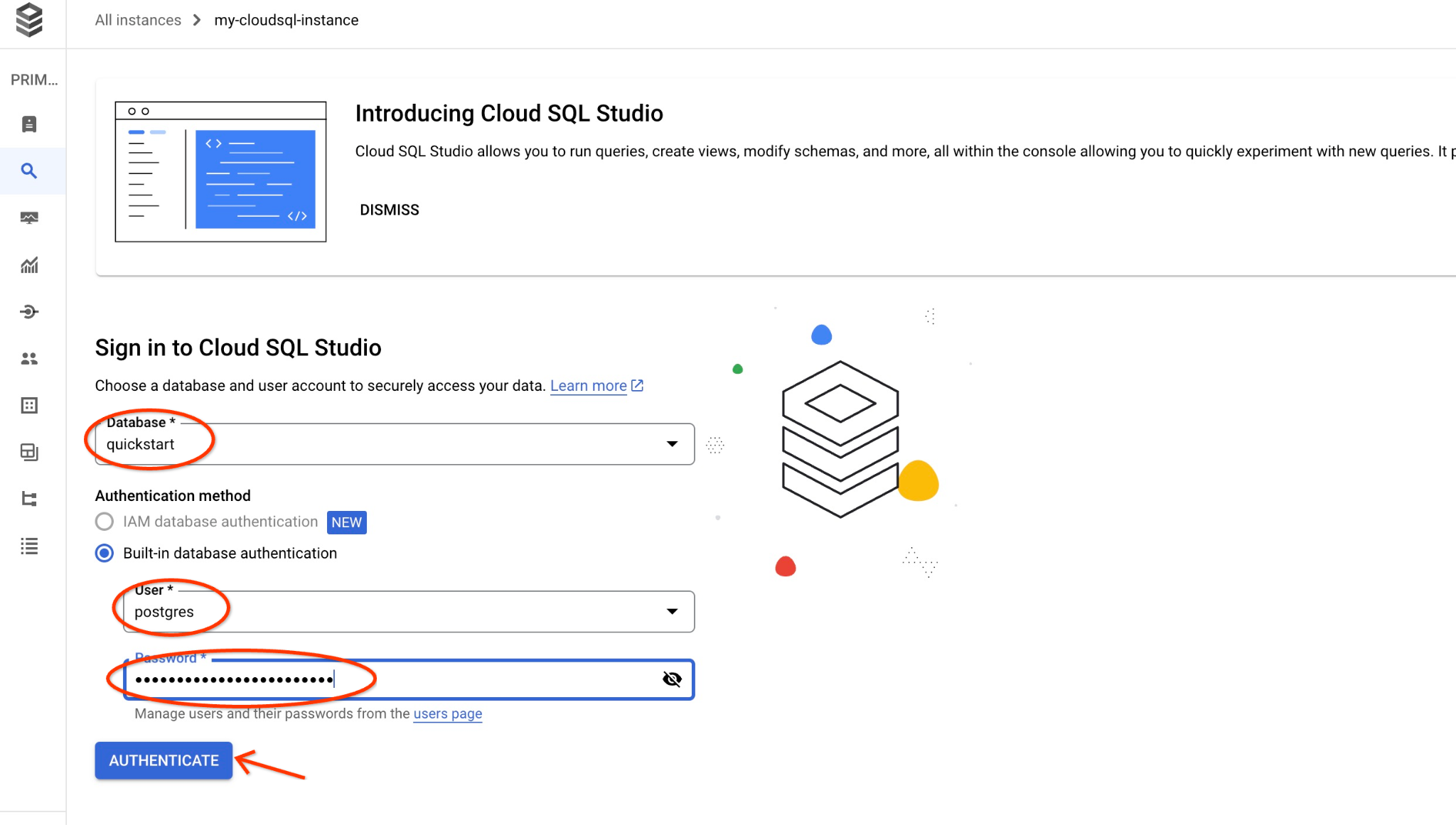
এটি পরবর্তী উইন্ডোটি খুলবে, যেখানে আপনি SQL এডিটর খোলার জন্য ডানদিকের "এডিটর" ট্যাবে ক্লিক করবেন।
এখন আমরা আমাদের কোয়েরিগুলো চালানোর জন্য প্রস্তুত।
কোয়েরি চালান
ক্লায়েন্টের অনুরোধের সাথে সবচেয়ে ঘনিষ্ঠভাবে সম্পর্কিত উপলব্ধ পণ্যগুলির একটি তালিকা পেতে একটি কোয়েরি চালান। ভেক্টর মানটি পাওয়ার জন্য আমরা ভার্টেক্স এআই-কে যে অনুরোধটি পাঠাবো তা শুনতে এইরকম: "এখানে কোন ধরণের ফলের গাছ ভালো জন্মায়?"
আমাদের অনুরোধের জন্য সবচেয়ে উপযুক্ত প্রথম ১০টি আইটেম বেছে নিতে আপনি এই কোয়েরিটি চালাতে পারেন:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
কোয়েরিটি কপি করে ক্লাউড এসকিউএল স্টুডিও এডিটরে পেস্ট করুন এবং "RUN" বোতামটি চাপুন, অথবা quickstart_db ডেটাবেসে সংযোগকারী আপনার কমান্ড লাইন সেশনে এটি পেস্ট করুন।
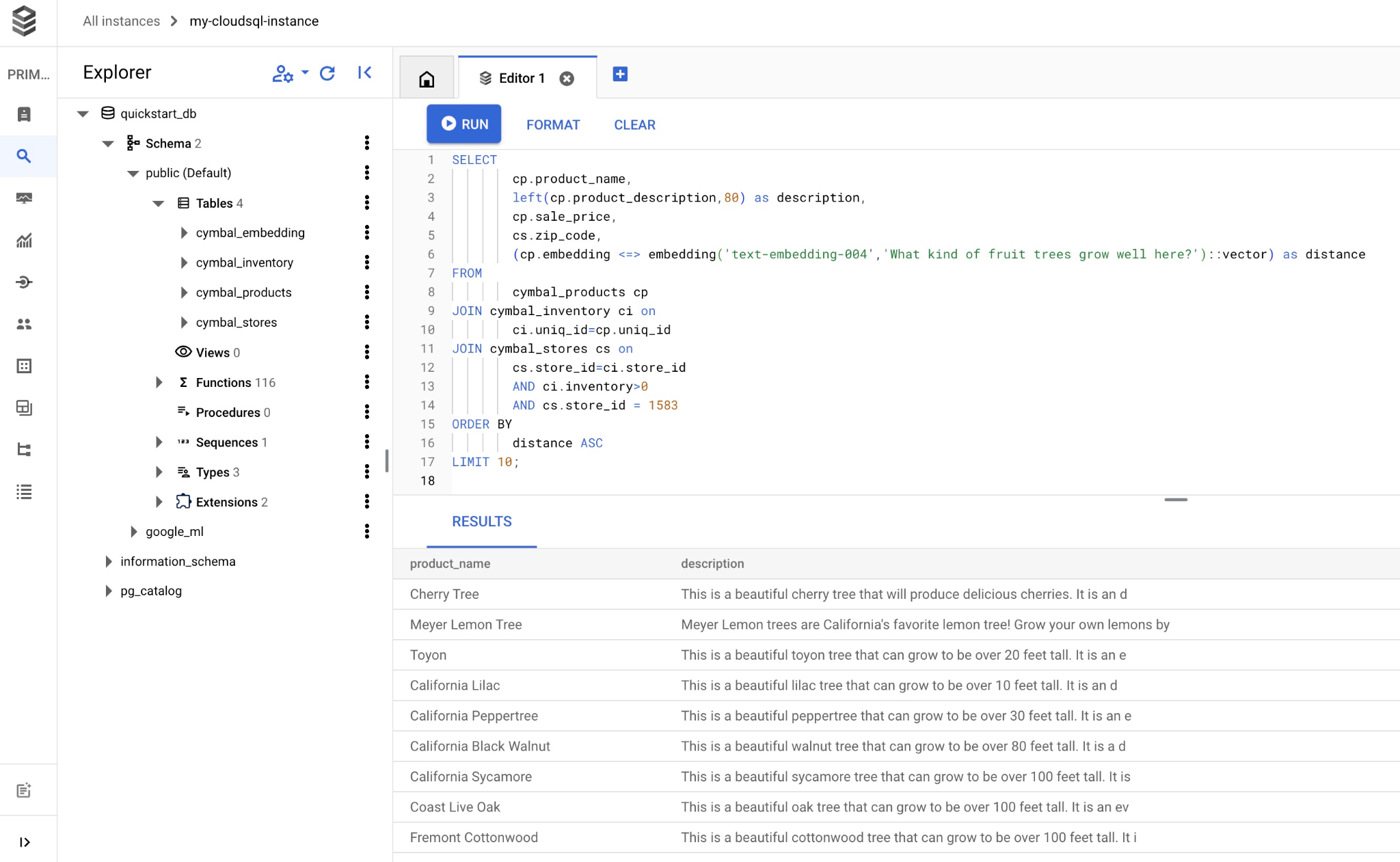
এবং এখানে অনুসন্ধানের সাথে মিলে যাওয়া নির্বাচিত পণ্যগুলির একটি তালিকা রয়েছে।
product_name | description | sale_price | zip_code | distance -------------------------+----------------------------------------------------------------------------------+------------+----------+--------------------- Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397 Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228 Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668 California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498 California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247 California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597 California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755 Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371 Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058 Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093 (10 rows)
৯. সংগৃহীত ডেটা ব্যবহার করে এলএলএম প্রতিক্রিয়া উন্নত করুন
আমরা সম্পাদিত কোয়েরির ফলাফল ব্যবহার করে একটি ক্লায়েন্ট অ্যাপ্লিকেশনের জন্য Gen AI LLM-এর প্রতিক্রিয়া উন্নত করতে পারি এবং Vertex AI জেনারেটিভ ফাউন্ডেশন ল্যাঙ্গুয়েজ মডেলের প্রম্পটের অংশ হিসেবে সরবরাহকৃত কোয়েরির ফলাফল ব্যবহার করে একটি অর্থপূর্ণ আউটপুট প্রস্তুত করতে পারি।
এটি অর্জন করতে, আমাদের ভেক্টর সার্চের ফলাফল দিয়ে একটি JSON তৈরি করতে হবে এবং তারপর একটি অর্থপূর্ণ আউটপুট তৈরির জন্য Vertex AI-তে একটি LLM মডেলের প্রম্পটের সাথে সেই তৈরি করা JSON-টি ব্যবহার করতে হবে। প্রথম ধাপে আমরা JSON তৈরি করি, তারপর Vertex AI Studio-তে এটি পরীক্ষা করি এবং শেষ ধাপে এটিকে একটি SQL স্টেটমেন্টে অন্তর্ভুক্ত করি যা কোনো অ্যাপ্লিকেশনে ব্যবহার করা যেতে পারে।
আউটপুট JSON ফরম্যাটে তৈরি করুন
আউটপুট JSON ফরম্যাটে তৈরি করতে এবং Vertex AI-তে পাঠানোর জন্য শুধুমাত্র একটি সারি ফেরত দিতে কোয়েরিটি পরিবর্তন করুন।
পোস্টগ্রেসকিউএল-এর জন্য ক্লাউড এসকিউএল
কোয়েরিটির উদাহরণ নিচে দেওয়া হলো:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
এবং আউটপুটে প্রত্যাশিত JSON নিচে দেওয়া হলো:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Vertex AI Studio-তে প্রম্পটটি চালান।
আমরা তৈরি করা JSON-টি Vertex AI Studio-তে থাকা জেনারেটিভ AI টেক্সট মডেলের প্রম্পটের অংশ হিসেবে সরবরাহ করতে পারি।
ক্লাউড কনসোলে Vertex AI Studio খুলুন।
এটি আপনাকে অতিরিক্ত এপিআই (API) সক্রিয় করতে বলতে পারে, কিন্তু আপনি অনুরোধটি উপেক্ষা করতে পারেন। আমাদের ল্যাবটি শেষ করার জন্য কোনো অতিরিক্ত এপিআই-এর প্রয়োজন নেই।
স্টুডিওতে একটি প্রম্পট দিন।
আমরা এই নির্দেশিকাটি ব্যবহার করতে যাচ্ছি:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
এবং কোয়েরি থেকে প্রাপ্ত প্রতিক্রিয়া দ্বারা JSON প্লেসহোল্ডারটি প্রতিস্থাপন করলে এটি দেখতে এইরকম হয়:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
এবং আমাদের JSON মানগুলো দিয়ে প্রম্পটটি চালালে এই ফলাফলটি পাওয়া যায়:
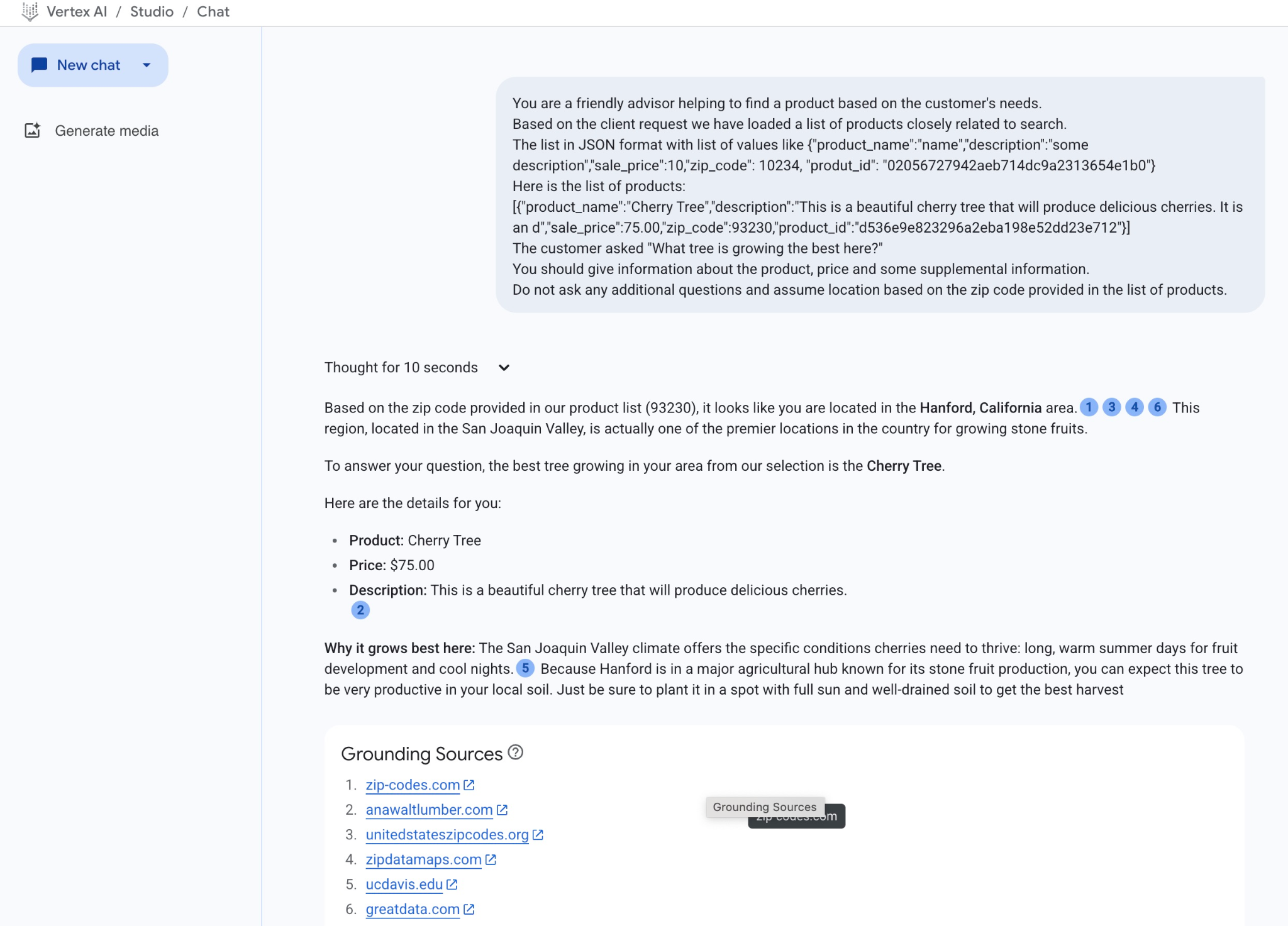
এই উদাহরণে মডেল থেকে আমরা যে উত্তরটি পেয়েছি তা নিচে দেওয়া হলো। উল্লেখ্য যে, সময়ের সাথে সাথে মডেল এবং প্যারামিটারের পরিবর্তনের কারণে আপনার উত্তর ভিন্ন হতে পারে:
আমাদের পণ্যের তালিকায় প্রদত্ত জিপ কোড (93230) অনুসারে, মনে হচ্ছে আপনি ক্যালিফোর্নিয়ার হ্যানফোর্ড এলাকায় আছেন।1346 স্যান হোয়াকিন উপত্যকায় অবস্থিত এই অঞ্চলটি প্রকৃতপক্ষে পাথুরে ফল চাষের জন্য দেশের অন্যতম সেরা স্থান।
আপনার প্রশ্নের উত্তরে বলতে হয়, আমাদের তালিকা থেকে আপনার এলাকায় জন্মানো সেরা গাছটি হলো চেরি গাছ।
আপনার জন্য বিস্তারিত বিবরণ নিচে দেওয়া হলো:
পণ্য: চেরি গাছ
মূল্য: $৭৫.০০
বিবরণ: এটি একটি সুন্দর চেরি গাছ যা সুস্বাদু চেরি ফল দেবে।২
কেন এটি এখানে সবচেয়ে ভালো জন্মায়: সান জোয়াকিন ভ্যালির জলবায়ু চেরির ভালোভাবে বেড়ে ওঠার জন্য প্রয়োজনীয় নির্দিষ্ট পরিবেশ প্রদান করে: ফল বিকাশের জন্য দীর্ঘ, উষ্ণ গ্রীষ্মের দিন এবং শীতল রাত।৫ যেহেতু হ্যানফোর্ড স্টোন ফ্রুট উৎপাদনের জন্য পরিচিত একটি প্রধান কৃষি কেন্দ্রে অবস্থিত, তাই আপনি আশা করতে পারেন যে এই গাছটি আপনার স্থানীয় মাটিতে খুব ফলনশীল হবে। সেরা ফলন পেতে, এটিকে অবশ্যই পর্যাপ্ত সূর্যালোক এবং সুনিষ্কাশিত মাটিতে রোপণ করবেন।
PSQL-এ প্রম্পটটি চালান
আমরা ভার্টেক্স এআই (Vertex AI)-এর সাথে ক্লাউড এসকিউএল এআই (Cloud SQL AI) ইন্টিগ্রেশন ব্যবহার করে সরাসরি ডেটাবেসে এসকিউএল (SQL) ব্যবহার করে একটি জেনারেটিভ মডেল থেকে অনুরূপ প্রতিক্রিয়া পেতে পারি। কিন্তু gemini-2.0-flash-exp মডেলটি ব্যবহার করার জন্য আমাদের প্রথমে এটি রেজিস্টার করতে হবে।
PostgreSQL-এর জন্য ক্লাউড SQL-এ চালান
এক্সটেনশনটি সংস্করণ ১.৪.২ বা উচ্চতর সংস্করণে আপগ্রেড করুন (যদি বর্তমান সংস্করণটি এর চেয়ে নিম্নতর হয়)। পূর্বে দেখানো পদ্ধতি অনুযায়ী gcloud sql connect ব্যবহার করে quickstart_db ডাটাবেসে সংযোগ করুন (অথবা Cloud SQL Studio ব্যবহার করুন) এবং নিম্নলিখিত কমান্ডটি চালান:
SELECT extversion from pg_extension where extname='google_ml_integration';
যদি প্রত্যাবর্তিত মান 1.4.3-এর চেয়ে কম হয়, তাহলে কার্যকর করুন:
ALTER EXTENSION google_ml_integration UPDATE TO '1.4.3';
এরপর আমাদের google_ml_integration.enable_model_support ডাটাবেস ফ্ল্যাগটি 'on'-এ সেট করতে হবে। বর্তমান সেটিংস যাচাই করতে এটি চালান।
show google_ml_integration.enable_model_support;
psql সেশন থেকে প্রত্যাশিত আউটপুট হল "on":
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
যদি এটি 'off' দেখায়, তাহলে আমাদের ডাটাবেস ফ্ল্যাগ আপডেট করতে হবে। এটি করার জন্য আপনি ওয়েব কনসোল ইন্টারফেস ব্যবহার করতে পারেন অথবা নিম্নলিখিত gcloud কমান্ডটি চালাতে পারেন।
gcloud sql instances patch my-cloudsql-instance \
--database-flags google_ml_integration.enable_model_support=on,cloudsql.enable_google_ml_integration=on
কমান্ডটি ব্যাকগ্রাউন্ডে কার্যকর হতে প্রায় ১-৩ মিনিট সময় নেয়। এরপর আপনি psql সেশনে অথবা Cloud SQL Studio ব্যবহার করে quickstart_db ডেটাবেসে সংযোগ করে নতুন ফ্ল্যাগটি যাচাই করতে পারবেন।
show google_ml_integration.enable_model_support;
psql সেশন থেকে প্রত্যাশিত আউটপুট হল "on":
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
এরপর আমাদের দুটি মডেল রেজিস্টার করতে হবে। প্রথমটি হলো আগে থেকে ব্যবহৃত text-embedding-005 মডেলটি। যেহেতু আমরা মডেল রেজিস্ট্রেশনের সুবিধা চালু করেছি, তাই এটি রেজিস্টার করা প্রয়োজন।
মডেলটি রেজিস্টার করতে psql অথবা Cloud SQL Studio-তে নিম্নলিখিত কোডটি চালান:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'cloudsql_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
এবং এর পরের যে মডেলটি আমাদের নিবন্ধন করতে হবে তা হলো gemini-2.0-flash-001 , যা ব্যবহারকারী-বান্ধব আউটপুট তৈরি করতে ব্যবহৃত হবে।
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'https://us-central1-aiplatform.googleapis.com/v1/projects/$PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'cloudsql_service_agent_iam');
আপনি google_ml.model_info_view থেকে তথ্য নির্বাচন করে নিবন্ধিত মডেলগুলির তালিকা সর্বদা যাচাই করতে পারেন।
select model_id,model_type from google_ml.model_info_view;
এখানে নমুনা আউটপুট দেওয়া হল
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
--------------------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
gemini-1.5-pro:streamGenerateContent | generic
gemini-1.5-pro:generateContent | generic
gemini-1.0-pro:generateContent | generic
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
এখন আমরা SQL ব্যবহার করে জেনারেটেড JSON-কে একটি সাবকোয়েরিতে রেখে জেনারেটিভ এআই টেক্সট মডেলের প্রম্পটের অংশ হিসেবে সরবরাহ করতে পারি।
psql বা Cloud SQL Studio সেশনে ডাটাবেসে কোয়েরিটি চালান।
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> google_ml.embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
এবং এই হলো প্রত্যাশিত আউটপুট। মডেল সংস্করণ এবং প্যারামিটারের উপর নির্ভর করে আপনার আউটপুট ভিন্ন হতে পারে।
"That's a great question! It sounds like you're looking to add some delicious fruit to your garden.\n\nBased on the products we have that are closely related to your search, I can tell you about a fantastic option:\n\n**Cherry Tree**" "\n* **Description:** This beautiful deciduous tree will produce delicious cherries. It grows to be about 15 feet tall, with dark green leaves in summer that turn a beautiful red in the fall. Cherry trees are known for their beauty, shade, and privacy. They prefer a cool, moist climate and sandy soil." "\n* **Price:** $75.00\n* **Grows well in:** USDA Zones 4-9.\n\nTo confirm if this Cherry Tree will thrive in your specific location, you might want to check which USDA Hardiness Zone your area falls into. If you're in zones 4-9, this" " could be a wonderful addition to your yard!"
১০. একটি নিকটতম-প্রতিবেশী সূচক তৈরি করুন।
আমাদের ডেটাসেট বেশ ছোট এবং রেসপন্স টাইম মূলত এআই মডেলের সাথে ইন্টারঅ্যাকশনের উপর নির্ভর করে। কিন্তু যখন লক্ষ লক্ষ ভেক্টর থাকে, তখন ভেক্টর সার্চ আমাদের রেসপন্স টাইমের একটি উল্লেখযোগ্য অংশ নিয়ে নিতে পারে এবং সিস্টেমের উপর প্রচণ্ড চাপ সৃষ্টি করতে পারে। এর উন্নতি করতে আমরা আমাদের ভেক্টরগুলোর উপর একটি ইনডেক্স তৈরি করতে পারি।
HNSW সূচক তৈরি করুন
আমরা আমাদের পরীক্ষার জন্য HNSW ইনডেক্স টাইপটি ব্যবহার করে দেখব। HNSW-এর পূর্ণরূপ হলো Hierarchical Navigable Small World এবং এটি একটি মাল্টিলেয়ার গ্রাফ ইনডেক্সকে বোঝায়।
আমাদের এমবেডিং কলামের জন্য ইনডেক্স তৈরি করতে, আমাদের এমবেডিং কলাম, ডিসট্যান্স ফাংশন এবং ঐচ্ছিকভাবে m বা ef_constructions-এর মতো প্যারামিটার নির্ধারণ করতে হবে। আপনি ডকুমেন্টেশনে প্যারামিটারগুলো সম্পর্কে বিস্তারিতভাবে পড়তে পারেন।
CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
প্রত্যাশিত আউটপুট:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64); CREATE INDEX quickstart_db=>
প্রতিক্রিয়ার তুলনা করুন
এখন আমরা EXPLAIN মোডে ভেক্টর সার্চ কোয়েরিটি চালিয়ে ইনডেক্সটি ব্যবহৃত হয়েছে কিনা তা যাচাই করতে পারি।
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
প্রত্যাশিত আউটপুট:
Aggregate (cost=779.12..779.13 rows=1 width=32) (actual time=1.066..1.069 rows=1 loops=1)
-> Subquery Scan on trees (cost=769.05..779.12 rows=1 width=142) (actual time=1.038..1.041 rows=1 loops=1)
-> Limit (cost=769.05..779.11 rows=1 width=158) (actual time=1.022..1.024 rows=1 loops=1)
-> Nested Loop (cost=769.05..9339.69 rows=852 width=158) (actual time=1.020..1.021 rows=1 loops=1)
-> Nested Loop (cost=768.77..9316.48 rows=852 width=945) (actual time=0.858..0.859 rows=1 loops=1)
-> Index Scan using cymbal_products_embeddings_hnsw on cymbal_products cp (cost=768.34..2572.47 rows=941 width=941) (actual time=0.532..0.539 rows=3 loops=1)
Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,...
<redacted>
...,0.017593635,-0.040275685,-0.03914233,-0.018452475,0.00826032,-0.07372604
]'::vector)
-> Index Scan using product_inventory_pkey on cymbal_inventory ci (cost=0.42..7.17 rows=1 width=37) (actual time=0.104..0.104 rows=0 loops=3)
Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text))
Filter: (inventory > 0)
Rows Removed by Filter: 1
-> Materialize (cost=0.28..8.31 rows=1 width=8) (actual time=0.133..0.134 rows=1 loops=1)
-> Index Scan using product_stores_pkey on cymbal_stores cs (cost=0.28..8.30 rows=1 width=8) (actual time=0.129..0.129 rows=1 loops=1)
Index Cond: (store_id = 1583)
Planning Time: 112.398 ms
Execution Time: 1.221 ms
আউটপুট থেকে আমরা পরিষ্কারভাবে দেখতে পাচ্ছি যে কোয়েরিটি "Index Scan using cymbal_products_embeddings_hnsw" ব্যবহার করছিল।
এবং যদি আমরা এক্সপ্লেইন ছাড়া কোয়েরিটি চালাই:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
প্রত্যাশিত আউটপুট (মডেল এবং সূচকের উপর ভিত্তি করে আউটপুট ভিন্ন হতে পারে):
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
আমরা দেখতে পাচ্ছি যে ফলাফল একই এবং এটি সেই একই চেরি ট্রি ফেরত দিচ্ছে যা আমাদের ইনডেক্স ছাড়া অনুসন্ধানে শীর্ষে ছিল। প্যারামিটার এবং ইনডেক্সের ধরনের উপর নির্ভর করে, ফলাফল সামান্য ভিন্ন হতে পারে এবং ট্রি-এর জন্য একটি ভিন্ন শীর্ষ রেকর্ড ফেরত দিতে পারে। আমার পরীক্ষার সময়, ইনডেক্সযুক্ত কোয়েরিটি ১৩১.৩০১ মিলিসেকেন্ডে ফলাফল ফেরত দিয়েছে, যেখানে কোনো ইনডেক্স ছাড়া সময় লেগেছে ১৬৭.৬৩১ মিলিসেকেন্ড। তবে আমরা একটি খুব ছোট ডেটাসেট নিয়ে কাজ করছিলাম এবং আরও বড় ডেটাসেটের ক্ষেত্রে এই পার্থক্য আরও বেশি হবে।
আপনি ভেক্টরগুলোর জন্য উপলব্ধ বিভিন্ন ইনডেক্স এবং ডকুমেন্টেশনে ল্যাংচেইন ইন্টিগ্রেশন সহ আরও ল্যাব ও উদাহরণ চেষ্টা করে দেখতে পারেন।
১১. পরিবেশ পরিষ্কার করা
ক্লাউড SQL ইনস্ট্যান্সটি মুছে ফেলুন
ল্যাবের কাজ শেষ হলে ক্লাউড SQL ইনস্ট্যান্সটি ধ্বংস করে দিন।
যদি আপনার সংযোগ বিচ্ছিন্ন হয়ে যায় এবং পূর্বের সমস্ত সেটিংস হারিয়ে যায়, তাহলে ক্লাউড শেলে প্রজেক্ট এবং এনভায়রনমেন্ট ভেরিয়েবলগুলো নির্ধারণ করুন:
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
ইনস্ট্যান্সটি মুছে ফেলুন:
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
১২. অভিনন্দন
কোডল্যাবটি সম্পন্ন করার জন্য অভিনন্দন।
এই ল্যাবটি ‘প্রোডাকশন-রেডি এআই উইথ গুগল ক্লাউড’ লার্নিং পাথের একটি অংশ।
- প্রোটোটাইপ থেকে উৎপাদনে উত্তরণের ব্যবধান পূরণ করতে সম্পূর্ণ পাঠ্যক্রমটি অন্বেষণ করুন ।
-
#ProductionReadyAIহ্যাশট্যাগটি ব্যবহার করে আপনার অগ্রগতি শেয়ার করুন।
আমরা যা আলোচনা করেছি
- কীভাবে একটি Cloud SQL for PostgreSQL ইনস্ট্যান্স স্থাপন করবেন
- কীভাবে ডাটাবেস তৈরি করবেন এবং ক্লাউড এসকিউএল এআই ইন্টিগ্রেশন সক্রিয় করবেন
- ডাটাবেসে ডেটা লোড করার পদ্ধতি
- ক্লাউড এসকিউএল স্টুডিও কীভাবে ব্যবহার করবেন
- ক্লাউড SQL-এ ভার্টেক্স এআই এমবেডিং মডেল কীভাবে ব্যবহার করবেন
- ভার্টেক্স এআই স্টুডিও কীভাবে ব্যবহার করবেন
- ভার্টেক্স এআই জেনারেটিভ মডেল ব্যবহার করে ফলাফলকে কীভাবে আরও সমৃদ্ধ করা যায়
- ভেক্টর ইনডেক্স ব্যবহার করে কীভাবে পারফরম্যান্স উন্নত করা যায়
HNSW-এর পরিবর্তে ScaNN ইনডেক্স ব্যবহার করে AlloyDB-এর জন্য অনুরূপ কোডল্যাবটি চেষ্টা করুন।
১৩. জরিপ
আউটপুট: