
1. Introducción
En este codelab, aprenderás a usar la integración de IA de Cloud SQL para PostgreSQL combinando la búsqueda de vectores con los embeddings de Vertex AI.

Requisitos previos
- Conocimientos básicos sobre Google Cloud y la consola
- Habilidades básicas de la interfaz de línea de comandos y de Cloud Shell
Qué aprenderás
- Cómo implementar una instancia de Cloud SQL para PostgreSQL
- Cómo crear una base de datos y habilitar la integración de IA de Cloud SQL
- Cómo cargar datos en la base de datos
- Cómo usar Cloud SQL Studio
- Cómo usar el modelo de incorporación de Vertex AI en Cloud SQL
- Cómo usar Vertex AI Studio
- Cómo enriquecer el resultado con el modelo generativo de Vertex AI
- Cómo mejorar el rendimiento con el índice de vectores
Requisitos
- Una cuenta de Google Cloud y un proyecto de Google Cloud
- Un navegador web, como Chrome, que admita la consola de Google Cloud y Cloud Shell
2. Configuración y requisitos
Configuración del proyecto
- Accede a la consola de Google Cloud. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.
Usa una cuenta personal en lugar de una cuenta de trabajo o institución educativa.
- Crea un proyecto nuevo o reutiliza uno existente. Para crear un proyecto nuevo en la consola de Google Cloud, haz clic en el botón Seleccionar un proyecto en el encabezado, lo que abrirá una ventana emergente.

En la ventana Selecciona un proyecto, presiona el botón Proyecto nuevo, que abrirá un cuadro de diálogo para el proyecto nuevo.
En el cuadro de diálogo, ingresa el nombre del proyecto que prefieras y elige la ubicación.
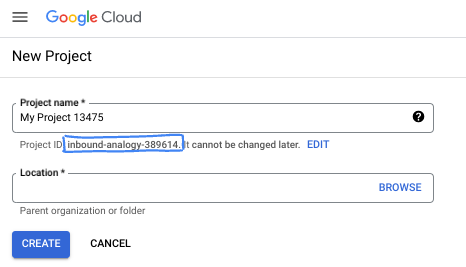
- El Nombre del proyecto es el nombre visible de los participantes de este proyecto. El nombre del proyecto no se usa en las APIs de Google y se puede cambiar en cualquier momento.
- El ID del proyecto es único en todos los proyectos de Google Cloud y es inmutable (no se puede cambiar después de configurarlo). La consola de Google Cloud genera automáticamente un ID único, pero puedes personalizarlo. Si no te gusta el ID generado, puedes generar otro aleatorio o proporcionar el tuyo para verificar su disponibilidad. En la mayoría de los codelabs, deberás hacer referencia al ID de tu proyecto, que suele identificarse con el marcador de posición PROJECT_ID.
- Recuerda que hay un tercer valor, un número de proyecto, que usan algunas APIs. Obtén más información sobre estos tres valores en la documentación.
Habilitar facturación
Para habilitar la facturación, tienes dos opciones. Puedes usar tu cuenta de facturación personal o canjear créditos siguiendo los pasos que se indican a continuación.
Canjea USD 5 en créditos de Google Cloud (opcional)
Para realizar este taller, necesitas una cuenta de facturación con algo de crédito. Si planeas usar tu propia facturación, puedes omitir este paso.
- Haz clic en este vínculo y accede con una Cuenta de Google personal.
- Verá un resultado similar al que se detalla a continuación:

- Haz clic en el botón HAZ CLIC AQUÍ PARA ACCEDER A TU CRÉDITO. Esto te dirigirá a una página para configurar tu perfil de facturación. Si aparece una pantalla de registro de prueba gratuita, haz clic en Cancelar y continúa con la vinculación de la facturación.
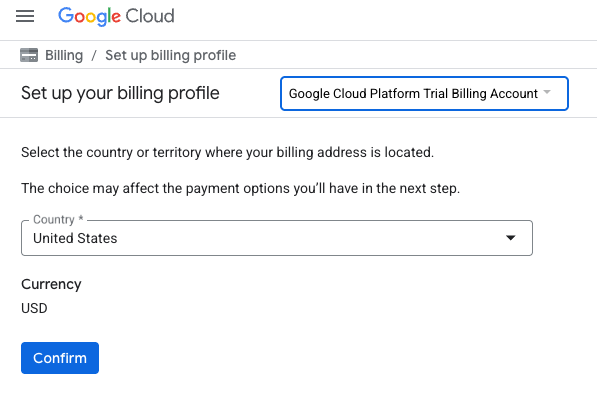
- Haz clic en Confirmar. Ahora estás conectado a una cuenta de facturación de prueba de Google Cloud Platform.
Configura una cuenta de facturación personal
Si configuraste la facturación con créditos de Google Cloud, puedes omitir este paso.
Para configurar una cuenta de facturación personal, ve aquí para habilitar la facturación en Cloud Console.
Notas:
- Completar este lab debería costar menos de USD 3 en recursos de Cloud.
- Puedes seguir los pasos al final de este lab para borrar recursos y evitar cargos adicionales.
- Los usuarios nuevos son aptos para obtener la prueba gratuita de USD 300.
Inicia Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En Google Cloud Console, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:
También puedes presionar G y, luego, S. Esta secuencia activará Cloud Shell si estás en la consola de Google Cloud o usas este vínculo.
El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
3. Antes de comenzar
Habilita la API
Resultado:
Para usar Cloud SQL, Compute Engine, servicios de redes y Vertex AI, debes habilitar sus respectivas APIs en tu proyecto de Google Cloud.
En la terminal de Cloud Shell, asegúrate de que tu ID del proyecto esté configurado:
gcloud config set project [YOUR-PROJECT-ID]
Configura la variable de entorno PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Habilita todos los servicios necesarios con el siguiente comando:
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Resultado esperado
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Presentamos las APIs
- La API de Cloud SQL Admin (
sqladmin.googleapis.com) te permite crear, configurar y administrar instancias de Cloud SQL de forma programática. Proporciona el plano de control para el servicio de base de datos relacional completamente administrado de Google (compatible con MySQL, PostgreSQL y SQL Server), y controla tareas como el aprovisionamiento, las copias de seguridad, la alta disponibilidad y el ajuste de escala. - La API de Compute Engine (
compute.googleapis.com) te permite crear y administrar máquinas virtuales (VM), discos persistentes y parámetros de configuración de red. Proporciona la base de infraestructura como servicio (IaaS) principal necesaria para ejecutar tus cargas de trabajo y alojar la infraestructura subyacente de muchos servicios administrados. - La API de Cloud Resource Manager (
cloudresourcemanager.googleapis.com) te permite administrar de forma programática los metadatos y la configuración de tu proyecto de Google Cloud. Te permite organizar recursos, controlar políticas de Identity and Access Management (IAM) y validar permisos en toda la jerarquía del proyecto. - La API de Service Networking (
servicenetworking.googleapis.com) te permite automatizar la configuración de la conectividad privada entre tu red de nube privada virtual (VPC) y los servicios administrados de Google. Se requiere específicamente para establecer el acceso a la IP privada para servicios como AlloyDB, de modo que puedan comunicarse de forma segura con tus otros recursos. - La API de Vertex AI (
aiplatform.googleapis.com) permite que tus aplicaciones compilen, implementen y escalen modelos de aprendizaje automático. Proporciona la interfaz unificada para todos los servicios de IA de Google Cloud, incluido el acceso a modelos de IA generativa (como Gemini) y el entrenamiento de modelos personalizados.
4. Cree una instancia de Cloud SQL
Crea una instancia de Cloud SQL con integración de bases de datos en Vertex AI.
Crea una contraseña para la base de datos
Define la contraseña para el usuario de la base de datos predeterminado. Puedes definir tu propia contraseña o usar una función aleatoria para generar una:
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
Observa el valor generado para la contraseña:
echo $CLOUDSQL_PASSWORD
Crea una instancia de Cloud SQL para PostgreSQL
Las instancias de Cloud SQL se pueden crear de diferentes maneras, como la consola de Google Cloud, herramientas de automatización como Terraform o el SDK de Google Cloud. En el lab, usaremos principalmente la herramienta gcloud del SDK de Google Cloud. En la documentación, puedes leer cómo crear una instancia con otras herramientas.
En la sesión de Cloud Shell, ejecuta el siguiente comando:
gcloud sql instances create my-cloudsql-instance \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--region=us-central1 \
--edition=ENTERPRISE \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on
Después de crear la instancia, debemos establecer una contraseña para el usuario predeterminado en la instancia y verificar si podemos conectarnos con la contraseña.
gcloud sql users set-password postgres \
--instance=my-cloudsql-instance \
--password=$CLOUDSQL_PASSWORD
Ejecuta el comando "gcloud sql connect" tal como se muestra en el cuadro y, luego, ingresa tu contraseña en el mensaje cuando esté listo para conectarse.
gcloud sql connect my-cloudsql-instance --user=postgres
Sal de la sesión de psql por ahora con la combinación de teclas Ctrl + D o ejecutando el comando exit.
exit
Habilitar la integración en Vertex AI
Otorga los privilegios necesarios a la cuenta de servicio interna de Cloud SQL para poder usar la integración de Vertex AI.
Busca el correo electrónico de la cuenta de servicio interna de Cloud SQL y expórtalo como una variable.
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
Otorga acceso a Vertex AI a la cuenta de servicio de Cloud SQL:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Obtén más información sobre la creación y configuración de instancias en la documentación de Cloud SQL aquí.
5. Prepara la base de datos
Ahora debemos crear una base de datos y habilitar la compatibilidad con vectores.
Crear base de datos
Crea una base de datos con el nombre quickstart_db .Para ello, tenemos diferentes opciones, como clientes de bases de datos de línea de comandos, como psql para PostgreSQL, el SDK o Cloud SQL Studio. Usaremos el SDK (gcloud) para crear bases de datos y conectarnos a la instancia.
En Cloud Shell, ejecuta el comando para crear la base de datos.
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
Habilitar extensiones
Para poder trabajar con Vertex AI y vectores, debemos habilitar dos extensiones en la base de datos que creamos.
En Cloud Shell, ejecuta el comando para conectarte a la base de datos creada (deberás proporcionar tu contraseña).
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
Luego, después de conectarte correctamente, en la sesión de SQL, debes ejecutar dos comandos:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector CASCADE;
Sal de la sesión de SQL:
exit;
6. Cargar datos
Ahora debemos crear objetos en la base de datos y cargar datos. Usaremos datos ficticios de Cymbal Store. Los datos están disponibles en el bucket público de Google Storage en formato CSV.
Primero, debemos crear todos los objetos necesarios en nuestra base de datos. Para ello, usaremos los comandos gcloud sql connect y gcloud storage que ya conocemos para descargar e importar los objetos de esquema a nuestra base de datos.
En Cloud Shell, ejecuta el siguiente comando y proporciona la contraseña que anotaste cuando creamos la instancia:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
¿Qué hicimos exactamente en el comando anterior? Nos conectamos a nuestra base de datos y ejecutamos el código SQL descargado, que creó tablas, índices y secuencias.
El siguiente paso es cargar los datos, y, para ello, debemos descargar los archivos CSV de Google Cloud Storage.
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv .
Luego, debemos conectarnos a la base de datos.
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
Importar datos de nuestros archivos CSV
\copy cymbal_products from 'cymbal_products.csv' csv header
\copy cymbal_inventory from 'cymbal_inventory.csv' csv header
\copy cymbal_stores from 'cymbal_stores.csv' csv header
Si tienes tus propios datos y tus archivos CSV son compatibles con la herramienta de importación de Cloud SQL disponible en Cloud Console, puedes usarla en lugar del enfoque de línea de comandos.
7. Crea embeddings
El siguiente paso es crear embeddings para las descripciones de nuestros productos con el modelo textembedding-004 de Google Vertex AI y almacenarlos como datos vectoriales.
Conéctate a la base de datos (si saliste o se desconectó tu sesión anterior):
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
Luego, crea una columna virtual embedding en nuestra tabla cymbal_products con la función de embedding. El comando crea una columna virtual "embedding" que almacenará nuestros vectores con embeddings generados en función de la columna "product_description". También crea embeddings para todas las filas existentes en la tabla. El modelo se define como el primer parámetro de la función de incorporación y los datos de origen como el segundo parámetro.
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005',product_description)) STORED;
Puede tardar un poco, pero para entre 900 y 1,000 filas, no debería demorar más de 5 minutos y, por lo general, es mucho más rápido.
Cuando insertamos una fila nueva en la tabla o actualizamos product_description para cualquier fila existente, los datos de la columna virtual para la columna "embedding" se volverán a generar en función de "product_description".
8. Ejecuta la búsqueda de similitud
Ahora podemos ejecutar nuestra búsqueda con la búsqueda de similitud basada en los valores de vectores calculados para las descripciones y el valor de vector que obtenemos para nuestra solicitud.
La consulta SQL se puede ejecutar desde la misma interfaz de línea de comandos con gcloud sql connect o, como alternativa, desde Cloud SQL Studio. Es mejor administrar cualquier consulta compleja y de varias filas en Cloud SQL Studio.
Inicia Cloud SQL Studio
En la consola, haz clic en la instancia de Cloud SQL que creamos antes.
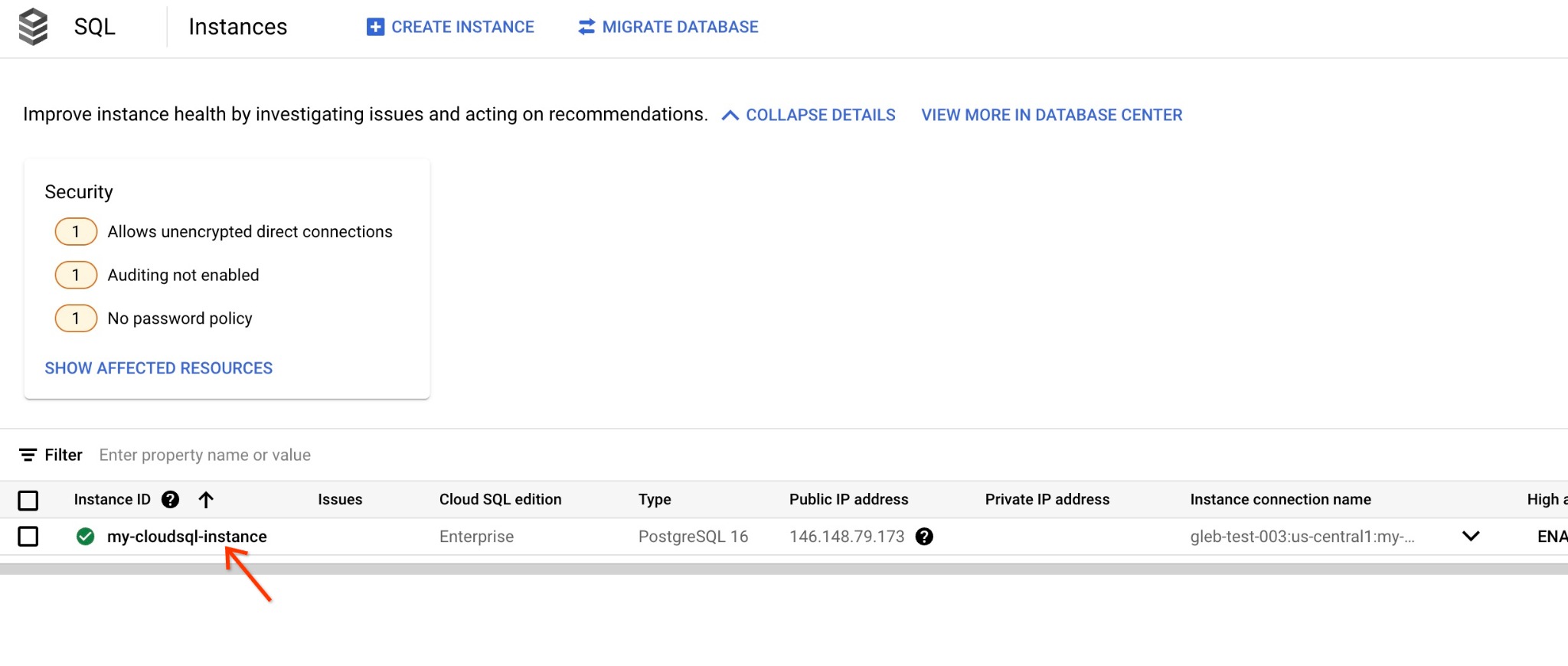
Cuando se abre en el panel derecho, podemos ver Cloud SQL Studio. Haz clic en ella.
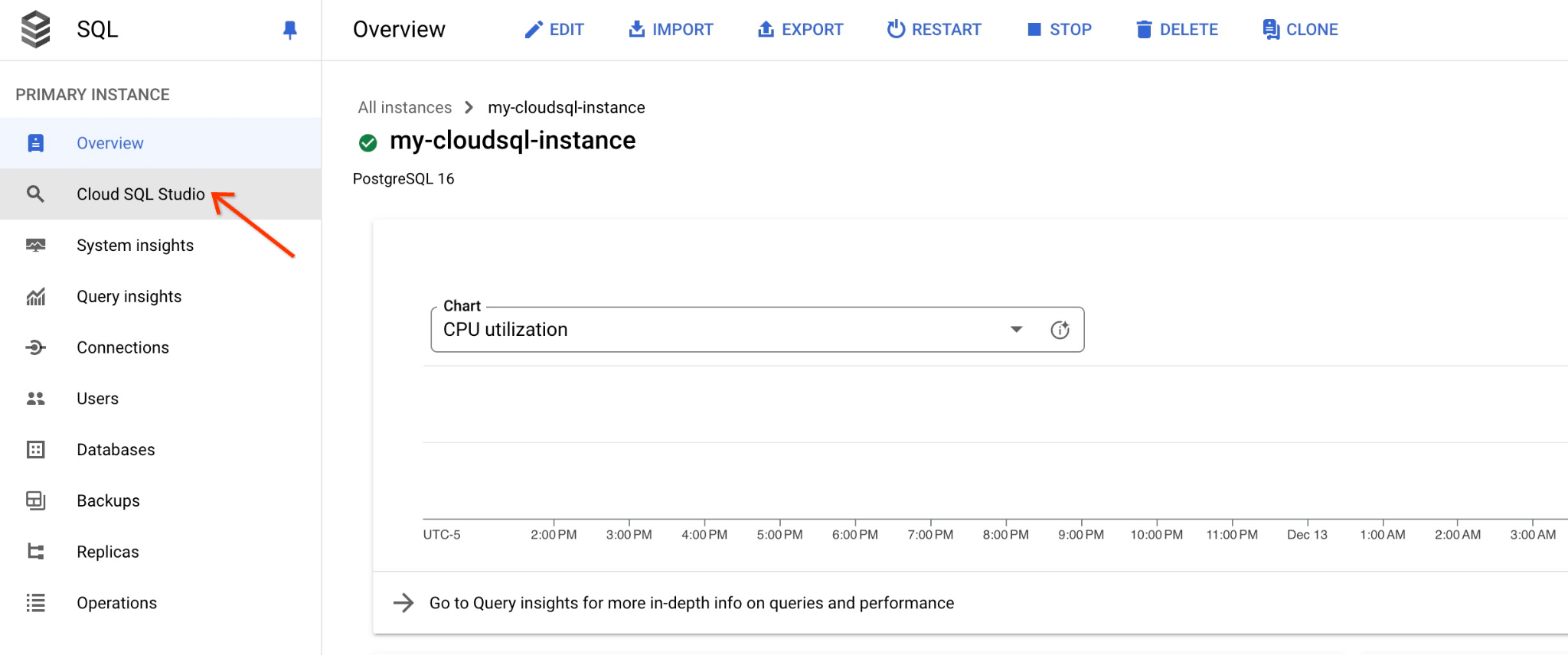
Se abrirá un diálogo en el que deberás proporcionar el nombre de la base de datos y tus credenciales:
- Base de datos: quickstart_db
- Usuario: postgres
- Contraseña: La contraseña que anotaste para el usuario principal de la base de datos
Luego, haz clic en el botón “AUTHENTICATE”.
Se abrirá la siguiente ventana, en la que debes hacer clic en la pestaña "Editor" del lado derecho para abrir el editor de SQL.
Ahora, ya podemos ejecutar nuestras consultas.
Ejecutar consulta
Ejecuta una búsqueda para obtener una lista de los productos disponibles que se relacionan más estrechamente con la solicitud de un cliente. La solicitud que le pasaremos a Vertex AI para obtener el valor del vector será algo así como "¿Qué tipo de árboles frutales crecen bien aquí?".
Esta es la consulta que puedes ejecutar para elegir los primeros 10 elementos más adecuados para nuestra solicitud:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
Copia y pega la consulta en el editor de Cloud SQL Studio y presiona el botón "EJECUTAR" o pégala en tu sesión de línea de comandos que se conecta a la base de datos quickstart_db.
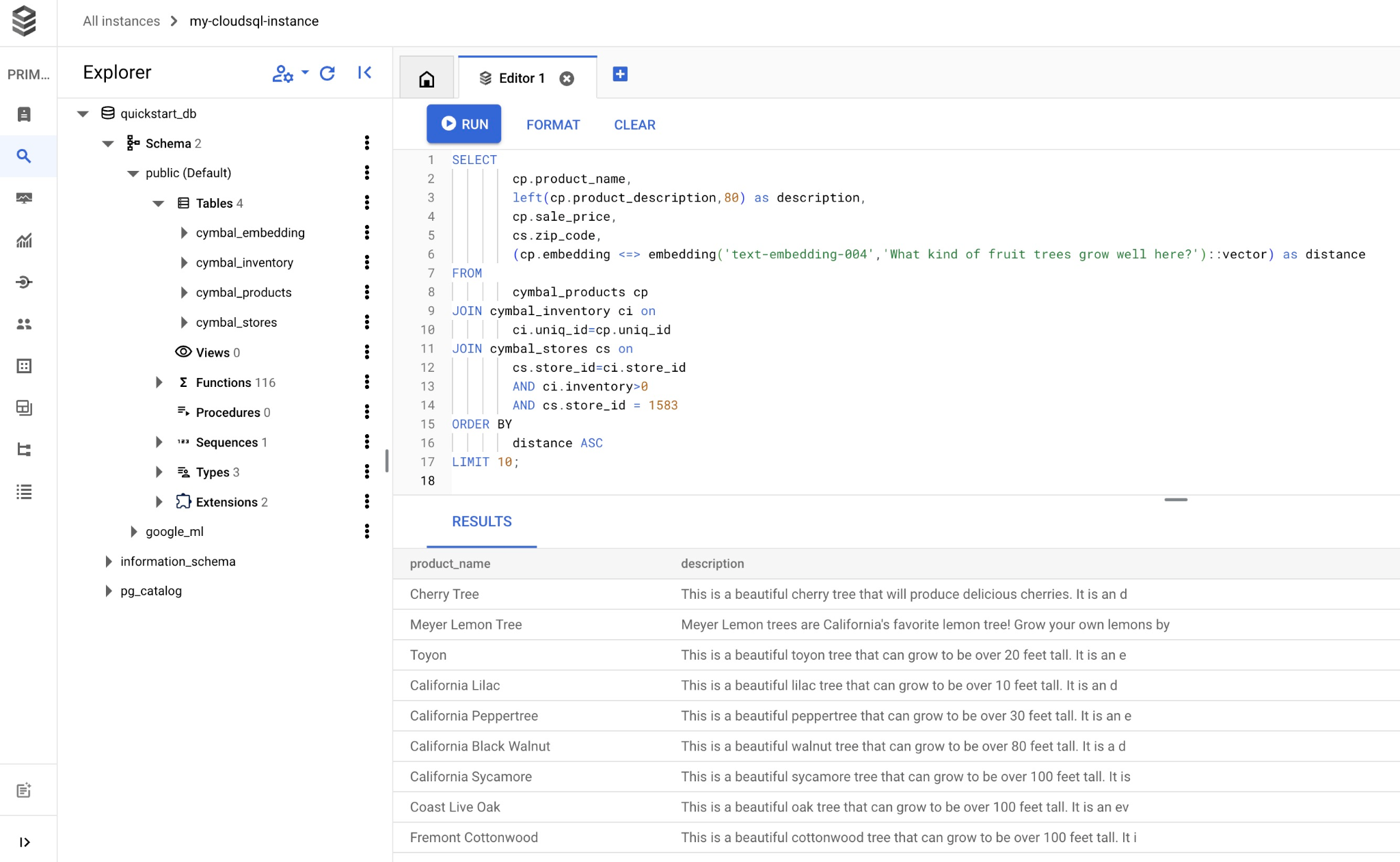
Aquí se muestra una lista de los productos elegidos que coinciden con la búsqueda.
product_name | description | sale_price | zip_code | distance -------------------------+----------------------------------------------------------------------------------+------------+----------+--------------------- Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397 Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228 Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668 California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498 California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247 California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597 California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755 Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371 Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058 Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093 (10 rows)
9. Mejora la respuesta del LLM con los datos recuperados
Podemos mejorar la respuesta del LLM de IA generativa a una aplicación cliente usando el resultado de la búsqueda ejecutada y preparar un resultado significativo usando los resultados de la búsqueda proporcionados como parte de la instrucción a un modelo de lenguaje fundamental generativo de Vertex AI.
Para lograrlo, debemos generar un archivo JSON con los resultados de la búsqueda vectorial y, luego, usar ese archivo JSON generado como complemento de una instrucción para un modelo de LLM en Vertex AI y crear un resultado significativo. En el primer paso, generamos el JSON, luego lo probamos en Vertex AI Studio y, en el último paso, lo incorporamos a una instrucción SQL que se puede usar en una aplicación.
Genera resultados en formato JSON
Modifica la consulta para generar el resultado en formato JSON y devolver solo una fila para pasar a Vertex AI.
Cloud SQL para PostgreSQL
A continuación, se muestra un ejemplo de la consulta:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Y aquí está el JSON esperado en el resultado:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Ejecuta la instrucción en Vertex AI Studio
Podemos usar el JSON generado para proporcionarlo como parte de la instrucción al modelo de texto de IA generativa en Vertex AI Studio.
Abre Vertex AI Studio en la consola de Cloud.
Es posible que te solicite que habilites APIs adicionales, pero puedes ignorar la solicitud. No necesitamos ninguna API adicional para terminar el lab.
Coloca una instrucción en Studio.
Esta es la instrucción que usaremos:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
Y así se ve cuando reemplazamos el marcador de posición JSON por la respuesta de la búsqueda:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
Y aquí está el resultado cuando ejecutamos la instrucción con nuestros valores JSON:
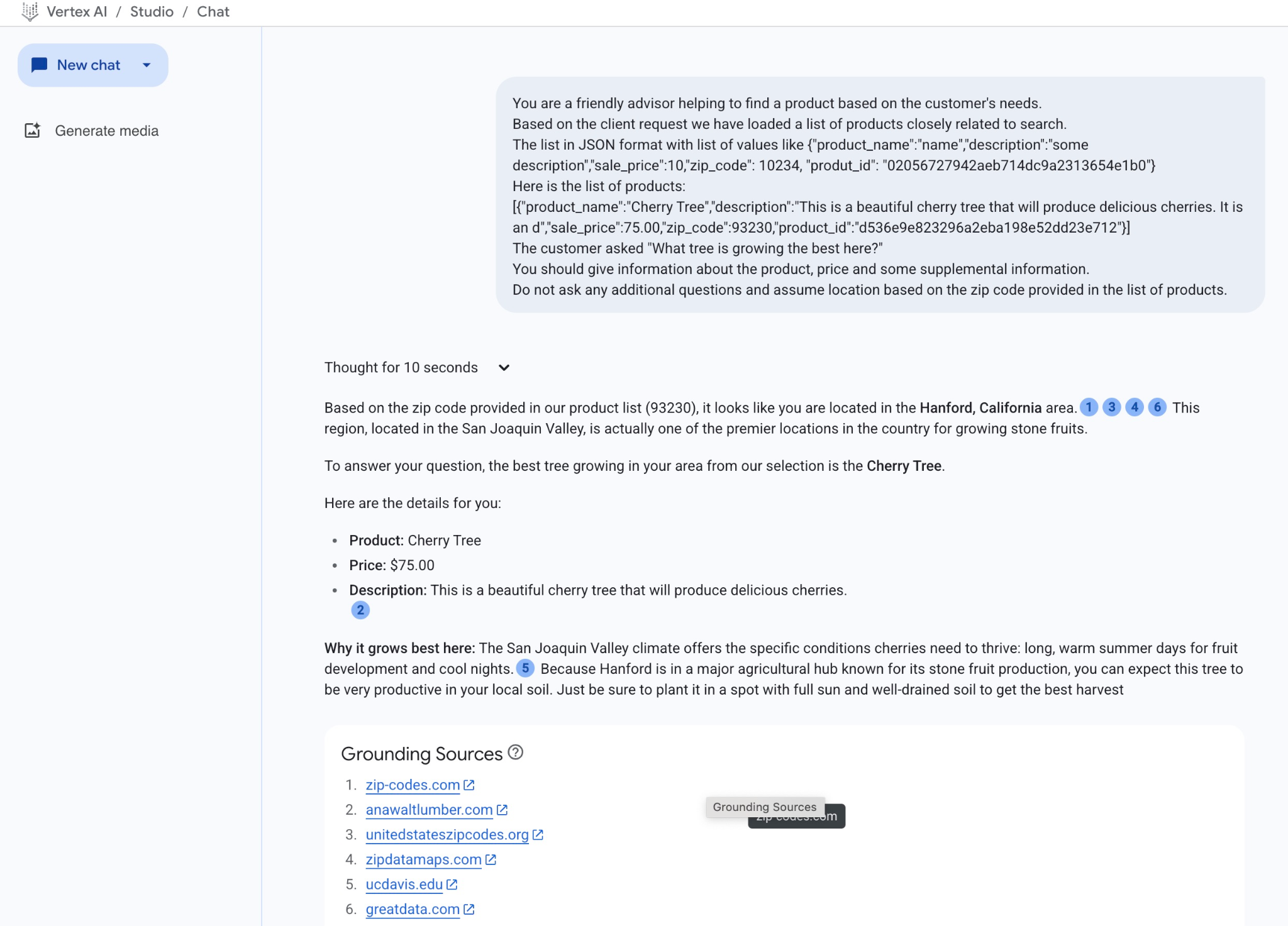
A continuación, se muestra la respuesta que obtuvimos del modelo en este ejemplo. Ten en cuenta que tu respuesta puede ser diferente debido a los cambios en el modelo y los parámetros a lo largo del tiempo:
"Según el código postal que proporcionaste en nuestra lista de productos (93230), parece que te encuentras en el área de Hanford, California.1346 Esta región, ubicada en el valle de San Joaquín, es en realidad uno de los principales lugares del país para cultivar frutas de hueso.
Para responder tu pregunta, el mejor árbol que crece en tu área de nuestra selección es el cerezo.
Aquí tienes los detalles:
Producto: Cerezo
Precio: USD 75.00
Descripción: Este es un hermoso cerezo que producirá cerezas deliciosas.2
Por qué crece mejor aquí: El clima del valle de San Joaquín ofrece las condiciones específicas que necesitan las cerezas para prosperar: días largos y cálidos de verano para el desarrollo de la fruta y noches frescas.5 Debido a que Hanford se encuentra en un importante centro agrícola conocido por su producción de frutas de hueso, puedes esperar que este árbol sea muy productivo en tu suelo local. Solo asegúrate de plantarla en un lugar con pleno sol y suelo bien drenado para obtener la mejor cosecha"
Ejecuta la instrucción en PSQL
También podemos usar la integración de IA de Cloud SQL con Vertex AI para obtener una respuesta similar de un modelo generativo usando SQL directamente en la base de datos. Sin embargo, para usar el modelo gemini-2.0-flash-exp, primero debemos registrarlo.
Ejecutar en Cloud SQL para PostgreSQL
Actualiza la extensión a la versión 1.4.2 o posterior (si la versión actual es anterior). Conéctate a la base de datos quickstart_db desde gcloud sql connect como se mostró antes (o usa Cloud SQL Studio) y ejecuta lo siguiente:
SELECT extversion from pg_extension where extname='google_ml_integration';
Si el valor que se muestra es inferior a 1.4.3, ejecuta lo siguiente:
ALTER EXTENSION google_ml_integration UPDATE TO '1.4.3';
Luego, debemos establecer la marca de base de datos google_ml_integration.enable_model_support en "on". Para verificar la configuración actual, ejecuta el siguiente comando.
show google_ml_integration.enable_model_support;
El resultado esperado de la sesión de psql es "on":
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Si se muestra "desactivado", debemos actualizar la marca de la base de datos. Para ello, puedes usar la interfaz de la consola web o ejecutar el siguiente comando de gcloud.
gcloud sql instances patch my-cloudsql-instance \
--database-flags google_ml_integration.enable_model_support=on,cloudsql.enable_google_ml_integration=on
El comando tarda entre 1 y 3 minutos en ejecutarse en segundo plano. Luego, puedes verificar la nueva marca en la sesión de psql o con Cloud SQL Studio conectándote a la base de datos quickstart_db.
show google_ml_integration.enable_model_support;
El resultado esperado de la sesión de psql es "on":
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Luego, debemos registrar dos modelos. El primero es el modelo text-embedding-005 que ya se usó. Debe registrarse, ya que habilitamos las capacidades de registro del modelo.
Para registrar la ejecución del modelo en psql o Cloud SQL Studio, usa el siguiente código:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'cloudsql_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
El siguiente modelo que debemos registrar es gemini-2.0-flash-001, que se usará para generar el resultado fácil de usar.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'https://us-central1-aiplatform.googleapis.com/v1/projects/$PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'cloudsql_service_agent_iam');
Siempre puedes verificar la lista de modelos registrados seleccionando información de google_ml.model_info_view.
select model_id,model_type from google_ml.model_info_view;
Este es un ejemplo de resultado:
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
--------------------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
gemini-1.5-pro:streamGenerateContent | generic
gemini-1.5-pro:generateContent | generic
gemini-1.0-pro:generateContent | generic
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
Ahora podemos usar el JSON generado en una subconsulta para proporcionarlo como parte de la instrucción al modelo de texto de IA generativa con SQL.
En la sesión de psql o Cloud SQL Studio de la base de datos, ejecuta la consulta.
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> google_ml.embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
Y este es el resultado esperado. Tu resultado puede variar según la versión y los parámetros del modelo:
"That's a great question! It sounds like you're looking to add some delicious fruit to your garden.\n\nBased on the products we have that are closely related to your search, I can tell you about a fantastic option:\n\n**Cherry Tree**" "\n* **Description:** This beautiful deciduous tree will produce delicious cherries. It grows to be about 15 feet tall, with dark green leaves in summer that turn a beautiful red in the fall. Cherry trees are known for their beauty, shade, and privacy. They prefer a cool, moist climate and sandy soil." "\n* **Price:** $75.00\n* **Grows well in:** USDA Zones 4-9.\n\nTo confirm if this Cherry Tree will thrive in your specific location, you might want to check which USDA Hardiness Zone your area falls into. If you're in zones 4-9, this" " could be a wonderful addition to your yard!"
10. Crea un índice de vecinos más cercanos
Nuestro conjunto de datos es bastante pequeño, y el tiempo de respuesta depende principalmente de las interacciones con los modelos de IA. Sin embargo, cuando tienes millones de vectores, la búsqueda de vectores puede ocupar una parte importante de nuestro tiempo de respuesta y generar una carga alta en el sistema. Para mejorar eso, podemos crear un índice sobre nuestros vectores.
Crea un índice de HNSW
Probaremos el tipo de índice HNSW para nuestra prueba. HNSW significa Hierarchical Navigable Small World y representa un índice de gráfico multicapa.
Para compilar el índice de nuestra columna de incorporación, debemos definir nuestra columna de incorporación, la función de distancia y, de manera opcional, parámetros como m o ef_constructions. Puedes leer sobre los parámetros en detalle en la documentación.
CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
Resultado esperado:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64); CREATE INDEX quickstart_db=>
Compare Response
Ahora podemos ejecutar la consulta de búsqueda vectorial en el modo EXPLAIN y verificar si se usó el índice.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Resultado esperado:
Aggregate (cost=779.12..779.13 rows=1 width=32) (actual time=1.066..1.069 rows=1 loops=1)
-> Subquery Scan on trees (cost=769.05..779.12 rows=1 width=142) (actual time=1.038..1.041 rows=1 loops=1)
-> Limit (cost=769.05..779.11 rows=1 width=158) (actual time=1.022..1.024 rows=1 loops=1)
-> Nested Loop (cost=769.05..9339.69 rows=852 width=158) (actual time=1.020..1.021 rows=1 loops=1)
-> Nested Loop (cost=768.77..9316.48 rows=852 width=945) (actual time=0.858..0.859 rows=1 loops=1)
-> Index Scan using cymbal_products_embeddings_hnsw on cymbal_products cp (cost=768.34..2572.47 rows=941 width=941) (actual time=0.532..0.539 rows=3 loops=1)
Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,...
<redacted>
...,0.017593635,-0.040275685,-0.03914233,-0.018452475,0.00826032,-0.07372604
]'::vector)
-> Index Scan using product_inventory_pkey on cymbal_inventory ci (cost=0.42..7.17 rows=1 width=37) (actual time=0.104..0.104 rows=0 loops=3)
Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text))
Filter: (inventory > 0)
Rows Removed by Filter: 1
-> Materialize (cost=0.28..8.31 rows=1 width=8) (actual time=0.133..0.134 rows=1 loops=1)
-> Index Scan using product_stores_pkey on cymbal_stores cs (cost=0.28..8.30 rows=1 width=8) (actual time=0.129..0.129 rows=1 loops=1)
Index Cond: (store_id = 1583)
Planning Time: 112.398 ms
Execution Time: 1.221 ms
En el resultado, podemos ver claramente que la consulta usó "Index Scan using cymbal_products_embeddings_hnsw".
Y si ejecutamos la consulta sin explicarla:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Resultado esperado (el resultado puede variar según el modelo y el índice):
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Podemos ver que el resultado es el mismo y devolver el mismo árbol de cerezo que estaba en la parte superior de nuestra búsqueda sin índice. Según los parámetros y el tipo de índice, es posible que el resultado sea ligeramente diferente y muestre un registro superior diferente para el árbol. Durante mis pruebas, la consulta indexada devolvió resultados en 131.301 ms en comparación con los 167.631 ms sin ningún índice, pero estábamos trabajando con un conjunto de datos muy pequeño, y la diferencia sería más sustancial en un conjunto de datos más grande.
Puedes probar diferentes índices disponibles para los vectores y más labs y ejemplos con la integración de LangChain disponibles en la documentación.
11. Limpia el entorno
Borra la instancia de Cloud SQL.
Cuando termines el lab, destruye la instancia de Cloud SQL
En Cloud Shell, define el proyecto y las variables de entorno si te desconectaste y se perdieron todos los parámetros de configuración anteriores:
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
Borra la instancia:
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
Resultado esperado en la consola:
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
12. Felicitaciones
Felicitaciones por completar el codelab.
Este lab forma parte de la ruta de aprendizaje de IA lista para producción con Google Cloud.
- Explora el plan de estudios completo para cerrar la brecha entre el prototipo y la producción.
- Comparte tu progreso con el hashtag
#ProductionReadyAI.
Temas abordados
- Cómo implementar una instancia de Cloud SQL para PostgreSQL
- Cómo crear una base de datos y habilitar la integración de IA de Cloud SQL
- Cómo cargar datos en la base de datos
- Cómo usar Cloud SQL Studio
- Cómo usar el modelo de incorporación de Vertex AI en Cloud SQL
- Cómo usar Vertex AI Studio
- Cómo enriquecer el resultado con el modelo generativo de Vertex AI
- Cómo mejorar el rendimiento con el índice de vectores
Prueba un codelab similar para AlloyDB con el índice ScaNN en lugar de HNSW
13. Encuesta
Resultado: