
1. परिचय
इस कोडलैब में, आपको Cloud SQL for PostgreSQL के साथ एआई इंटिग्रेशन का इस्तेमाल करने का तरीका बताया जाएगा. इसके लिए, वेक्टर सर्च को Vertex AI एम्बेडिंग के साथ जोड़ा जाता है.

ज़रूरी शर्तें
- Google Cloud और Console की बुनियादी जानकारी
- कमांड लाइन इंटरफ़ेस और Cloud Shell में बुनियादी कौशल
आपको क्या सीखने को मिलेगा
- PostgreSQL के लिए Cloud SQL इंस्टेंस को डिप्लॉय करने का तरीका
- डेटाबेस बनाने और Cloud SQL AI इंटिग्रेशन को चालू करने का तरीका
- डेटाबेस में डेटा लोड करने का तरीका
- Cloud SQL Studio का इस्तेमाल कैसे करें
- Cloud SQL में Vertex AI एम्बेडिंग मॉडल का इस्तेमाल कैसे करें
- Vertex AI Studio का इस्तेमाल कैसे करें
- Vertex AI के जनरेटिव मॉडल का इस्तेमाल करके, नतीजे को बेहतर बनाने का तरीका
- वेक्टर इंडेक्स का इस्तेमाल करके परफ़ॉर्मेंस को बेहतर बनाने का तरीका
आपको इन चीज़ों की ज़रूरत होगी
- Google Cloud खाता और Google Cloud प्रोजेक्ट
- Google Cloud Console और Cloud Shell के साथ काम करने वाला वेब ब्राउज़र, जैसे कि Chrome
2. सेटअप और ज़रूरी शर्तें
प्रोजेक्ट सेटअप करना
- Google Cloud Console में साइन इन करें. अगर आपके पास पहले से कोई Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.
ऑफ़िस या स्कूल वाले खाते के बजाय, निजी खाते का इस्तेमाल करें.
- कोई नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. Google Cloud Console में नया प्रोजेक्ट बनाने के लिए, हेडर में मौजूद 'कोई प्रोजेक्ट चुनें' बटन पर क्लिक करें. इससे एक पॉप-अप विंडो खुलेगी.

'कोई प्रोजेक्ट चुनें' विंडो में, 'नया प्रोजेक्ट' बटन दबाएं. इससे नए प्रोजेक्ट के लिए एक डायलॉग बॉक्स खुलेगा.
डायलॉग बॉक्स में, प्रोजेक्ट का पसंदीदा नाम डालें और जगह चुनें.
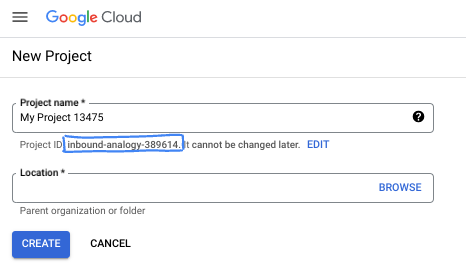
- प्रोजेक्ट का नाम, इस प्रोजेक्ट में हिस्सा लेने वाले लोगों के लिए डिसप्ले नेम होता है. प्रोजेक्ट के नाम का इस्तेमाल Google API नहीं करते हैं. इसे कभी भी बदला जा सकता है.
- प्रोजेक्ट आईडी, सभी Google Cloud प्रोजेक्ट के लिए यूनीक होता है. साथ ही, इसे बदला नहीं जा सकता. Google Cloud Console, यूनीक आईडी अपने-आप जनरेट करता है. हालांकि, इसे अपनी पसंद के मुताबिक बनाया जा सकता है. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा आईडी जनरेट करें. इसके अलावा, अपने हिसाब से कोई आईडी डालें और देखें कि वह उपलब्ध है या नहीं. ज़्यादातर कोडलैब में, आपको अपने प्रोजेक्ट आईडी का रेफ़रंस देना होगा. इसे आम तौर पर, PROJECT_ID प्लेसहोल्डर से पहचाना जाता है.
- आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जिसे प्रोजेक्ट नंबर कहते हैं. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
बिलिंग चालू करना
बिलिंग चालू करने के लिए, आपके पास दो विकल्प हैं. आपके पास निजी बिलिंग खाते का इस्तेमाल करने का विकल्प होता है. इसके अलावा, यहां दिए गए तरीके से क्रेडिट रिडीम किए जा सकते हैं.
Google Cloud क्रेडिट रिडीम करना (ज़रूरी नहीं है)
इस वर्कशॉप को चलाने के लिए, आपके पास कुछ क्रेडिट वाला बिलिंग खाता होना चाहिए. शुरू करने के लिए, इस कोडलैब के सबसे ऊपर मौजूद बैनर में दिए गए क्रेडिट का इस्तेमाल करें. अगर आपका खाता पहले से ही किसी बिलिंग खाते से कनेक्ट है, तो इस चरण को छोड़ा जा सकता है.
निजी बिलिंग खाता सेट अप करना
अगर आपने Google Cloud क्रेडिट का इस्तेमाल करके बिलिंग सेट अप की है, तो इस चरण को छोड़ा जा सकता है.
निजी बिलिंग खाता सेट अप करने के लिए, Cloud Console में बिलिंग चालू करने के लिए यहां जाएं.
ध्यान दें:
- इस लैब को पूरा करने में, क्लाउड संसाधनों पर 3 डॉलर से कम खर्च आना चाहिए.
- ज़्यादा शुल्क से बचने के लिए, इस लैब के आखिर में दिए गए निर्देशों का पालन करके संसाधनों को मिटाया जा सकता है.
- नए उपयोगकर्ता, 300 डॉलर के मुफ़्त क्रेडिट का इस्तेमाल कर सकते हैं.
Cloud Shell शुरू करें
Google Cloud को अपने लैपटॉप से रिमोटली ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद टूलबार पर, Cloud Shell आइकॉन पर क्लिक करें:
इसके अलावा, G और फिर S दबाकर भी यह सुविधा ऐक्सेस की जा सकती है. इस क्रम से, Cloud Shell चालू हो जाएगा. इसके लिए, आपको Google Cloud Console में होना चाहिए या इस लिंक का इस्तेमाल करना होगा.
इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे. यह प्रोसेस पूरी होने के बाद, आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद होते हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में मौजूद सभी टास्क, ब्राउज़र में किए जा सकते हैं. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
3. शुरू करने से पहले
एपीआई चालू करना
आउटपुट:
Cloud SQL, Compute Engine, नेटवर्किंग सेवाएं, और Vertex AI का इस्तेमाल करने के लिए, आपको अपने Google Cloud प्रोजेक्ट में इनसे जुड़े एपीआई चालू करने होंगे.
Cloud Shell टर्मिनल में, पक्का करें कि आपका प्रोजेक्ट आईडी सेट अप हो:
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID एनवायरमेंट वैरिएबल सेट करें:
PROJECT_ID=$(gcloud config get-value project)
सभी ज़रूरी सेवाएं चालू करें:
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
अनुमानित आउटपुट
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
एपीआई के बारे में जानकारी
- Cloud SQL Admin API (
sqladmin.googleapis.com) की मदद से, Cloud SQL इंस्टेंस को प्रोग्राम के हिसाब से बनाया, कॉन्फ़िगर किया, और मैनेज किया जा सकता है. यह Google की पूरी तरह से मैनेज की गई रिलेशनल डेटाबेस सेवा के लिए कंट्रोल प्लेन उपलब्ध कराता है. यह MySQL, PostgreSQL, और SQL Server को सपोर्ट करता है. यह सेवा, प्रोविज़निंग, बैकअप, हाई अवेलेबिलिटी, और स्केलिंग जैसे टास्क को मैनेज करती है. - Compute Engine API (
compute.googleapis.com) की मदद से, वर्चुअल मशीनें (वीएम), परसिस्टेंट डिस्क, और नेटवर्क सेटिंग बनाई और मैनेज की जा सकती हैं. यह मुख्य Infrastructure-as-a-Service (IaaS) फ़ाउंडेशन उपलब्ध कराता है. इसकी मदद से, अपने वर्कलोड चलाए जा सकते हैं. साथ ही, मैनेज की जाने वाली कई सेवाओं के लिए बुनियादी इंफ़्रास्ट्रक्चर को होस्ट किया जा सकता है. - Cloud Resource Manager API (
cloudresourcemanager.googleapis.com) की मदद से, Google Cloud प्रोजेक्ट के मेटाडेटा और कॉन्फ़िगरेशन को प्रोग्राम के हिसाब से मैनेज किया जा सकता है. इससे आपको संसाधनों को व्यवस्थित करने, पहचान और ऐक्सेस मैनेजमेंट (IAM) नीतियों को मैनेज करने, और प्रोजेक्ट के क्रम में अनुमतियों की पुष्टि करने में मदद मिलती है. - Service Networking API (
servicenetworking.googleapis.com) की मदद से, अपने वर्चुअल प्राइवेट क्लाउड (वीपीसी) नेटवर्क और Google की मैनेज की गई सेवाओं के बीच निजी कनेक्टिविटी को अपने-आप सेट अप किया जा सकता है. AlloyDB जैसी सेवाओं के लिए, प्राइवेट आईपी ऐक्सेस सेट अप करना ज़रूरी है. इससे वे आपके अन्य संसाधनों के साथ सुरक्षित तरीके से कम्यूनिकेट कर पाती हैं. - Vertex AI API (
aiplatform.googleapis.com) की मदद से, आपके ऐप्लिकेशन मशीन लर्निंग मॉडल बना सकते हैं, उन्हें डिप्लॉय कर सकते हैं, और बड़े पैमाने पर उपलब्ध करा सकते हैं. यह Google Cloud की सभी एआई सेवाओं के लिए, एक जैसा इंटरफ़ेस उपलब्ध कराता है. इसमें जनरेटिव एआई मॉडल (जैसे, Gemini) का ऐक्सेस और कस्टम मॉडल ट्रेनिंग शामिल है.
4. Cloud SQL इंस्टेंस बनाना
Vertex AI के साथ डेटाबेस इंटिग्रेशन वाला Cloud SQL इंस्टेंस बनाएं.
डेटाबेस का पासवर्ड बनाना
डिफ़ॉल्ट डेटाबेस उपयोगकर्ता के लिए पासवर्ड तय करें. आपके पास अपना पासवर्ड तय करने या पासवर्ड जनरेट करने के लिए, रैंडम फ़ंक्शन का इस्तेमाल करने का विकल्प होता है:
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
पासवर्ड के लिए जनरेट की गई वैल्यू नोट करें:
echo $CLOUDSQL_PASSWORD
PostgreSQL के लिए Cloud SQL इंस्टेंस बनाना
Cloud SQL इंस्टेंस को अलग-अलग तरीकों से बनाया जा सकता है. जैसे, Google Cloud Console, Terraform जैसे ऑटोमेशन टूल या Google Cloud SDK. इस लैब में, हम मुख्य रूप से Google Cloud SDK gcloud टूल का इस्तेमाल करेंगे. अन्य टूल का इस्तेमाल करके इंस्टेंस बनाने का तरीका जानने के लिए, दस्तावेज़ पढ़ें.
Cloud Shell सेशन में यह कमांड चलाएं:
gcloud sql instances create my-cloudsql-instance \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--region=us-central1 \
--edition=ENTERPRISE \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on
इंस्टेंस बनाने के बाद, हमें इंस्टेंस में डिफ़ॉल्ट उपयोगकर्ता के लिए पासवर्ड सेट करना होगा. साथ ही, यह पुष्टि करनी होगी कि हम पासवर्ड से कनेक्ट कर सकते हैं या नहीं.
gcloud sql users set-password postgres \
--instance=my-cloudsql-instance \
--password=$CLOUDSQL_PASSWORD
बॉक्स में दिखाई गई "gcloud sql connect" कमांड चलाएं. इसके बाद, कनेक्ट करने के लिए तैयार होने पर, प्रॉम्प्ट में अपना पासवर्ड डालें.
gcloud sql connect my-cloudsql-instance --user=postgres
ctrl+d कीबोर्ड शॉर्टकट का इस्तेमाल करके या exit कमांड को लागू करके, फ़िलहाल psql सेशन से बाहर निकलें
exit
Vertex AI इंटिग्रेशन की सुविधा चालू करना
Vertex AI इंटिग्रेशन का इस्तेमाल करने के लिए, इंटरनल Cloud SQL सेवा खाते को ज़रूरी अनुमतियां दें.
Cloud SQL के इंटरनल सेवा खाते का ईमेल पता ढूंढता है और उसे वैरिएबल के तौर पर एक्सपोर्ट करता है.
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
Cloud SQL सेवा खाते को Vertex AI का ऐक्सेस दें:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Cloud SQL के दस्तावेज़ में इंस्टेंस बनाने और कॉन्फ़िगर करने के बारे में ज़्यादा जानने के लिए, यहां जाएं.
5. डेटाबेस तैयार करना
अब हमें एक डेटाबेस बनाना होगा और वेक्टर के लिए सहायता चालू करनी होगी.
डेटाबेस बनाना
quickstart_db नाम का डेटाबेस बनाएं. इसके लिए, हमारे पास अलग-अलग विकल्प हैं. जैसे, कमांड लाइन डेटाबेस क्लाइंट, जैसे कि PostgreSQL के लिए psql, SDK या Cloud SQL Studio. हम डेटाबेस बनाने और इंस्टेंस से कनेक्ट करने के लिए, SDK टूल (gcloud) का इस्तेमाल करेंगे.
डेटाबेस बनाने के लिए, Cloud Shell में यह कमांड चलाएं
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
एक्सटेंशन चालू करना
Vertex AI और वेक्टर के साथ काम करने के लिए, हमें बनाए गए डेटाबेस में दो एक्सटेंशन चालू करने होंगे.
बनाए गए डेटाबेस से कनेक्ट करने के लिए, Cloud Shell में कमांड चलाएं. इसके लिए, आपको अपना पासवर्ड डालना होगा
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
इसके बाद, कनेक्शन बन जाने पर, आपको SQL सेशन में दो निर्देश चलाने होंगे:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector CASCADE;
एसक्यूएल सेशन से बाहर निकलने के लिए:
exit;
6. डेटा लोड करें
अब हमें डेटाबेस में ऑब्जेक्ट बनाने और डेटा लोड करने की ज़रूरत है. हम काल्पनिक Cymbal Store के डेटा का इस्तेमाल करेंगे. यह डेटा, CSV फ़ॉर्मैट में सार्वजनिक Google Storage बकेट पर उपलब्ध है.
सबसे पहले, हमें अपने डेटाबेस में सभी ज़रूरी ऑब्जेक्ट बनाने होंगे. इसके लिए, हम पहले से इस्तेमाल की जा रही gcloud sql connect और gcloud storage कमांड का इस्तेमाल करेंगे. इससे, स्कीमा ऑब्जेक्ट को अपने डेटाबेस में डाउनलोड और इंपोर्ट किया जा सकेगा.
क्लाउड शेल में, इंस्टेंस बनाते समय नोट किया गया पासवर्ड डालें और उसे लागू करें:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
हमने पिछले निर्देश में क्या किया था? हमने अपने डेटाबेस से कनेक्ट किया और डाउनलोड किए गए SQL कोड को लागू किया. इससे टेबल, इंडेक्स, और सीक्वेंस बनाए गए.
अगला चरण, डेटा लोड करना है. इसके लिए, हमें Google Cloud Storage से CSV फ़ाइलें डाउनलोड करनी होंगी.
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv .
इसके बाद, हमें डेटाबेस से कनेक्ट करना होगा.
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
साथ ही, हमारी CSV फ़ाइलों से डेटा इंपोर्ट करें.
\copy cymbal_products from 'cymbal_products.csv' csv header
\copy cymbal_inventory from 'cymbal_inventory.csv' csv header
\copy cymbal_stores from 'cymbal_stores.csv' csv header
अगर आपके पास अपना डेटा है और आपकी CSV फ़ाइलें, Cloud कंसोल में उपलब्ध Cloud SQL इंपोर्ट टूल के साथ काम करती हैं, तो कमांड-लाइन के बजाय इसका इस्तेमाल किया जा सकता है.
7. Create Embeddings
अगला चरण, Google Vertex AI के textembedding-004 मॉडल का इस्तेमाल करके, अपने प्रॉडक्ट के ब्यौरे के लिए एम्बेडिंग बनाना है. इसके बाद, उन्हें वेक्टर डेटा के तौर पर सेव करना है.
डेटाबेस से कनेक्ट करें. ऐसा तब करें, जब आपने कनेक्शन बंद कर दिया हो या आपका पिछला सेशन डिसकनेक्ट हो गया हो:
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
साथ ही, एम्बेडिंग फ़ंक्शन का इस्तेमाल करके, cymbal_products टेबल में एम्बेडिंग नाम का वर्चुअल कॉलम बनाएं. इस कमांड से, "embedding" नाम का एक वर्चुअल कॉलम बनता है. इसमें, "product_description" कॉलम के आधार पर जनरेट किए गए एम्बेडिंग के साथ हमारे वेक्टर सेव किए जाएंगे. साथ ही, यह टेबल की सभी मौजूदा लाइनों के लिए एम्बेडिंग बनाता है. मॉडल को एम्बेडिंग फ़ंक्शन के पहले पैरामीटर के तौर पर और सोर्स डेटा को दूसरे पैरामीटर के तौर पर तय किया जाता है.
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005',product_description)) STORED;
इसमें कुछ समय लग सकता है. हालांकि, 900 से 1,000 लाइनों के लिए, इसमें पांच मिनट से ज़्यादा नहीं लगने चाहिए. आम तौर पर, यह प्रोसेस इससे काफ़ी कम समय में पूरी हो जाती है.
जब हम टेबल में कोई नई लाइन जोड़ते हैं या किसी मौजूदा लाइन के लिए product_description अपडेट करते हैं, तो "embedding" कॉलम के लिए वर्चुअल कॉलम का डेटा, "product_description" के आधार पर फिर से जनरेट होगा.
8. मिलते-जुलते प्रॉडक्ट खोजने की सुविधा का इस्तेमाल करना
अब हम समानता के आधार पर खोज करने की सुविधा का इस्तेमाल करके खोज कर सकते हैं. इसके लिए, ब्यौरों के लिए कैलकुलेट की गई वेक्टर वैल्यू और हमारे अनुरोध के लिए मिली वेक्टर वैल्यू का इस्तेमाल किया जाता है.
SQL क्वेरी को उसी कमांड-लाइन इंटरफ़ेस से gcloud sql connect का इस्तेमाल करके या Cloud SQL Studio से चलाया जा सकता है. एक से ज़्यादा लाइनों वाली और मुश्किल क्वेरी को Cloud SQL Studio में मैनेज करना बेहतर होता है.
Cloud SQL Studio शुरू करना
कंसोल में, उस Cloud SQL इंस्टेंस पर क्लिक करें जिसे हमने पहले बनाया था.
जब यह दाईं ओर के पैनल में खुला होता है, तब हमें Cloud SQL Studio दिखता है. इस पर क्लिक करें.
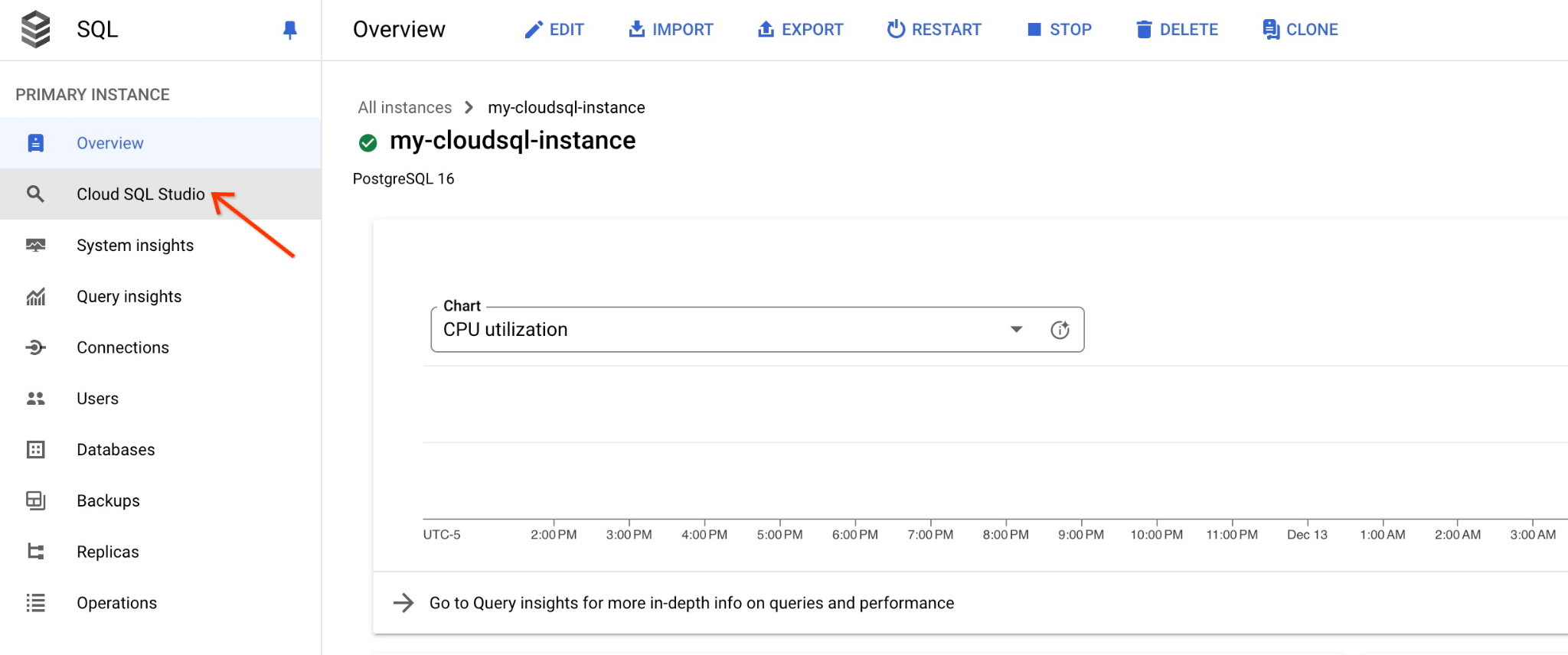
इससे एक डायलॉग बॉक्स खुलेगा. इसमें आपको डेटाबेस का नाम और अपने क्रेडेंशियल देने होंगे:
- डेटाबेस: quickstart_db
- उपयोगकर्ता: postgres
- पासवर्ड: मुख्य डेटाबेस उपयोगकर्ता के लिए नोट किया गया पासवर्ड
इसके बाद, "पुष्टि करें" बटन पर क्लिक करें.
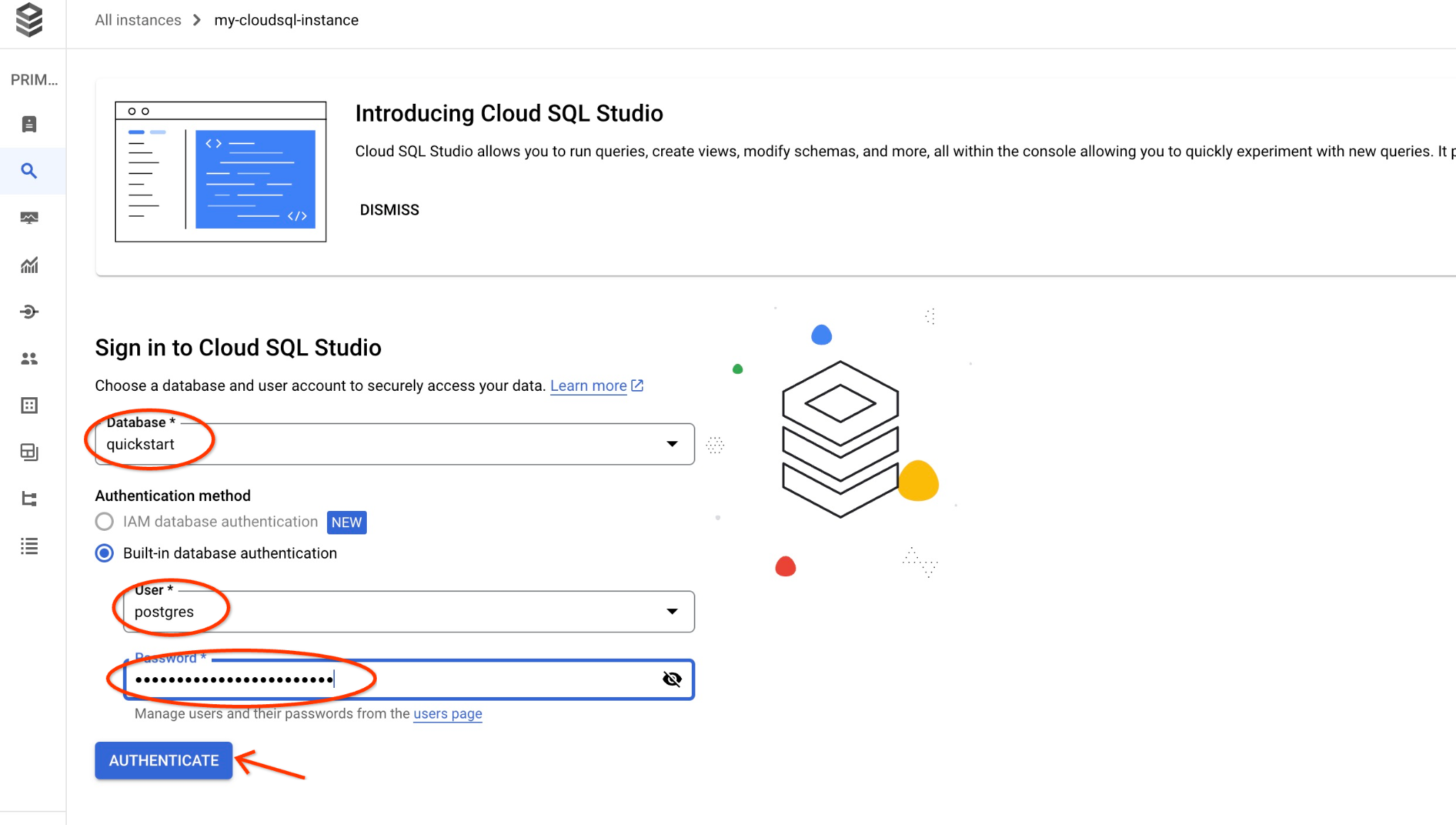
इससे अगली विंडो खुलेगी. इसमें SQL एडिटर खोलने के लिए, दाईं ओर मौजूद "एडिटर" टैब पर क्लिक करें.
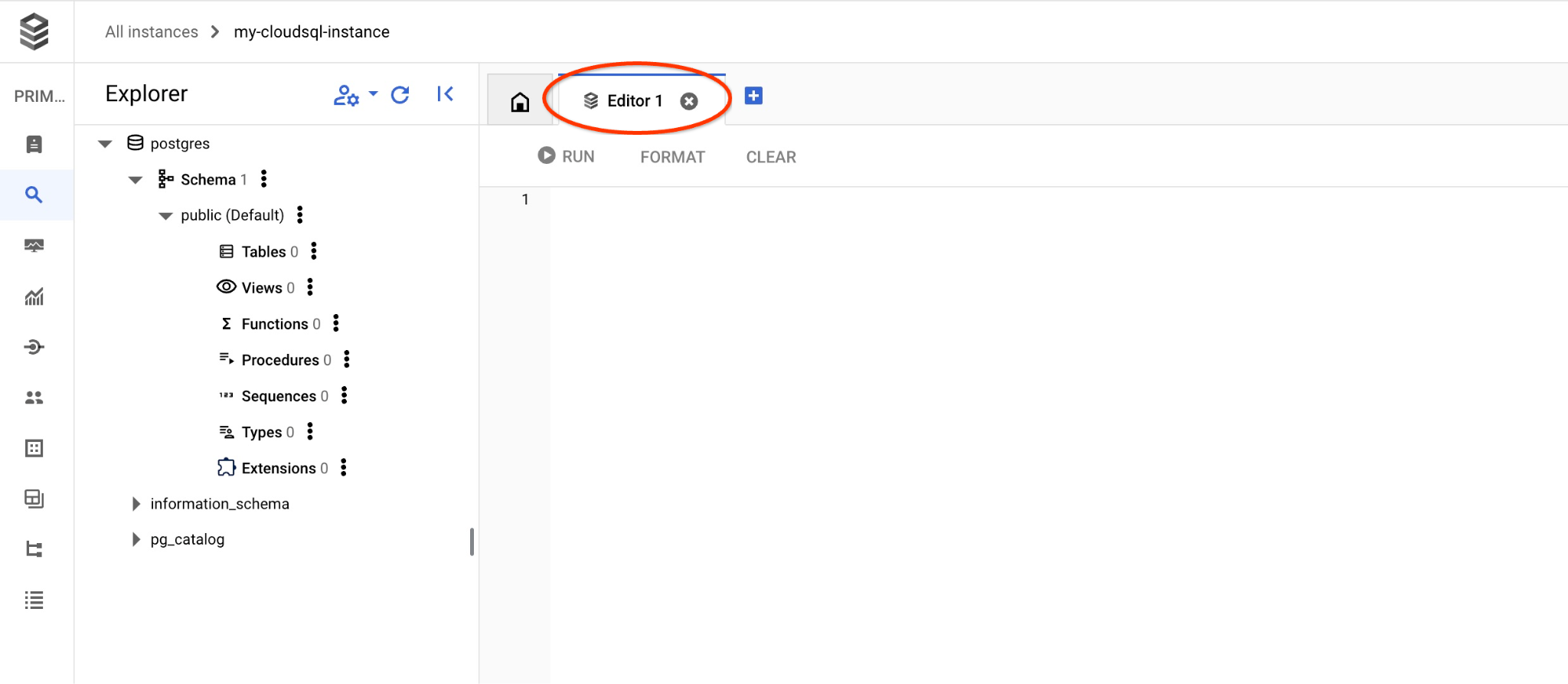
अब हम अपनी क्वेरी चलाने के लिए तैयार हैं.
क्वेरी चलाएं
क्लाइंट के अनुरोध से मिलते-जुलते उपलब्ध प्रॉडक्ट की सूची पाने के लिए, क्वेरी चलाएं. वेक्टर वैल्यू पाने के लिए, हम Vertex AI को यह अनुरोध भेजेंगे: "यहां किस तरह के फलों के पेड़ अच्छी तरह से उगते हैं?"
यहां दी गई क्वेरी को चलाकर, हमारे अनुरोध के हिसाब से सबसे सही 10 आइटम चुने जा सकते हैं:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
क्वेरी को Cloud SQL Studio एडिटर में कॉपी करके चिपकाएं. इसके बाद, "चलाएं" बटन दबाएं. इसके अलावा, इसे quickstart_db डेटाबेस से कनेक्ट करने वाले कमांड-लाइन सेशन में भी चिपकाया जा सकता है.
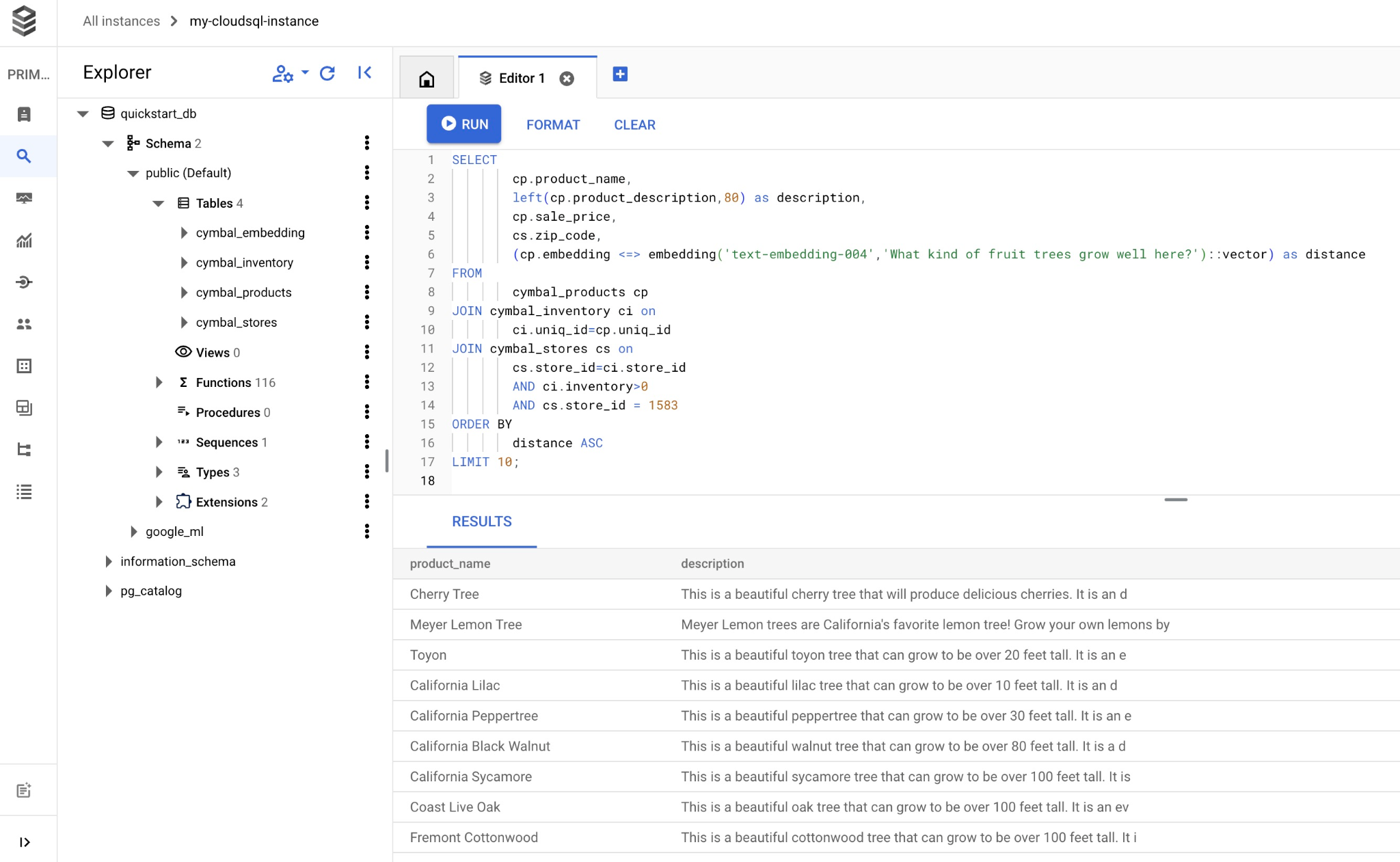
यहां क्वेरी से मेल खाने वाले चुने गए प्रॉडक्ट की सूची दी गई है.
product_name | description | sale_price | zip_code | distance -------------------------+----------------------------------------------------------------------------------+------------+----------+--------------------- Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397 Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228 Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668 California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498 California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247 California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597 California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755 Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371 Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058 Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093 (10 rows)
9. एलएलएम के जवाब को बेहतर बनाने के लिए, खोजे गए डेटा का इस्तेमाल करना
हम क्वेरी के नतीजे का इस्तेमाल करके, क्लाइंट ऐप्लिकेशन के लिए Gen AI LLM के जवाब को बेहतर बना सकते हैं. साथ ही, क्वेरी के नतीजों को प्रॉम्प्ट के तौर पर इस्तेमाल करके, Vertex AI के जनरेटिव फ़ाउंडेशन लैंग्वेज मॉडल के लिए काम का आउटपुट तैयार कर सकते हैं.
इसके लिए, हमें वेक्टर सर्च से मिले नतीजों का इस्तेमाल करके एक JSON जनरेट करना होगा. इसके बाद, उस JSON को Vertex AI में मौजूद एलएलएम मॉडल के प्रॉम्प्ट में जोड़ना होगा, ताकि काम का आउटपुट तैयार किया जा सके. पहले चरण में, हम JSON जनरेट करते हैं. इसके बाद, हम इसे Vertex AI Studio में टेस्ट करते हैं. आखिरी चरण में, हम इसे SQL स्टेटमेंट में शामिल करते हैं, जिसका इस्तेमाल किसी ऐप्लिकेशन में किया जा सकता है.
JSON फ़ॉर्मैट में आउटपुट जनरेट करना
क्वेरी में बदलाव करके, JSON फ़ॉर्मैट में आउटपुट जनरेट करें. साथ ही, Vertex AI को सिर्फ़ एक लाइन का डेटा भेजें
PostgreSQL के लिए Cloud SQL
क्वेरी का उदाहरण यहां दिया गया है:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
यहां आउटपुट में अनुमानित JSON दिया गया है:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Vertex AI Studio में प्रॉम्प्ट चलाएं
हम जनरेट किए गए JSON का इस्तेमाल, Vertex AI Studio में जनरेटिव एआई टेक्स्ट मॉडल को प्रॉम्प्ट के तौर पर देने के लिए कर सकते हैं
Cloud Console में Vertex AI Studio खोलें.
यह आपसे अतिरिक्त एपीआई चालू करने के लिए कह सकता है. हालांकि, इस अनुरोध को अनदेखा किया जा सकता है. हमें लैब को पूरा करने के लिए, किसी अन्य एपीआई की ज़रूरत नहीं है.
Studio में कोई प्रॉम्प्ट डालें.
हम इस प्रॉम्प्ट का इस्तेमाल करने वाले हैं:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
यहां बताया गया है कि क्वेरी के रिस्पॉन्स से JSON प्लेसहोल्डर को बदलने पर, यह कैसा दिखता है:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
यहां JSON वैल्यू के साथ प्रॉम्प्ट चलाने पर मिला नतीजा दिया गया है:
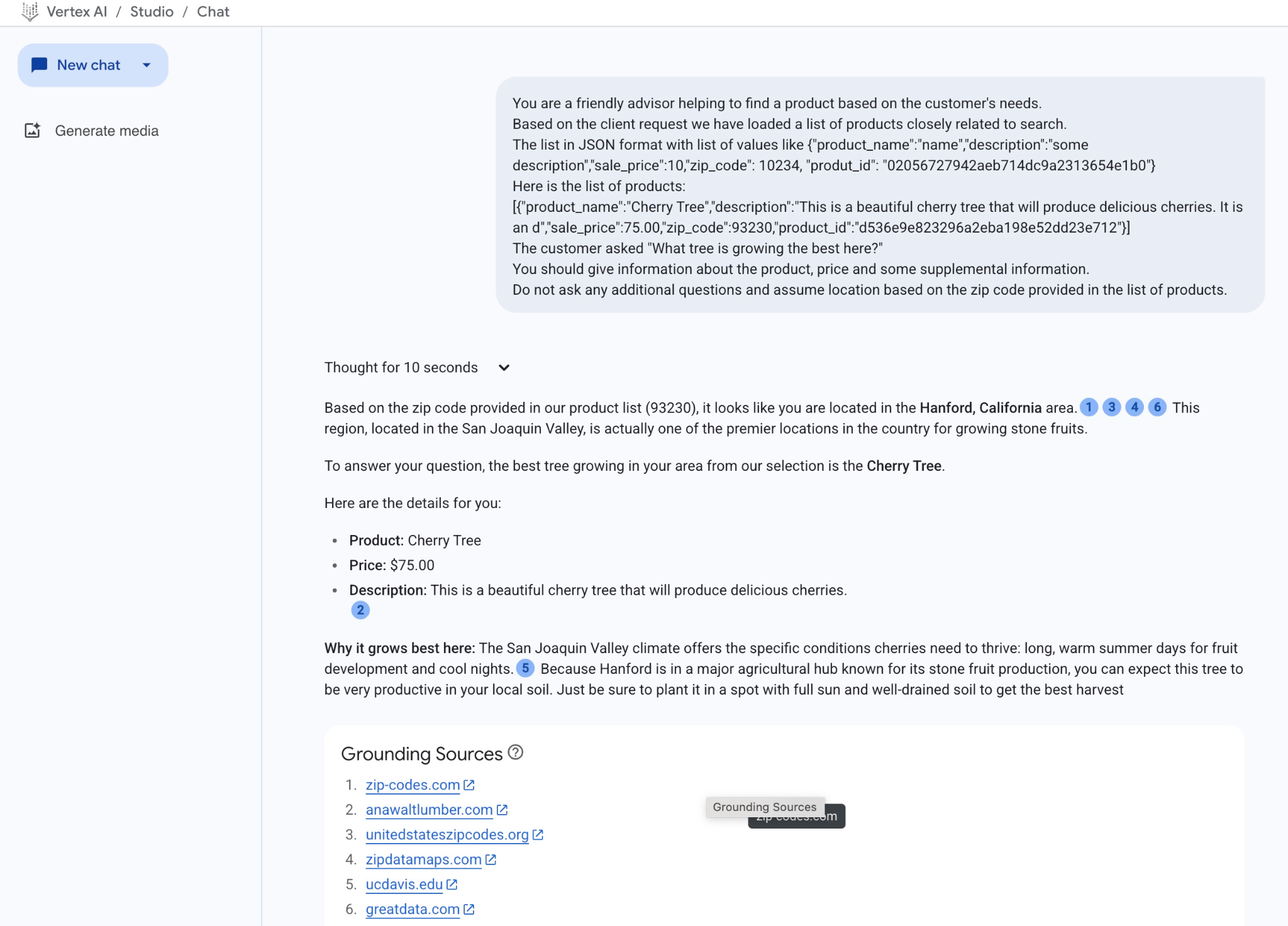
इस उदाहरण में, मॉडल से मिला जवाब यहां दिया गया है. ध्यान दें कि समय के साथ मॉडल और पैरामीटर में बदलाव होने की वजह से, आपके जवाब में अंतर हो सकता है:
"OBased on the zip code provided in our product list (93230), it looks like you are located in the Hanford, California area.1346 This region, located in the San Joaquin Valley, is actually one of the premier locations in the country for growing stone fruits.
आपके सवाल का जवाब देने के लिए, हमारे चुने गए विकल्पों में से आपके इलाके में सबसे अच्छा उगने वाला पेड़ चेरी का पेड़ है.
आपके लिए यहां जानकारी दी गई है:
प्रॉडक्ट: चेरी का पेड़
कीमत: 7,500 रुपये
ब्यौरा: यह एक सुंदर चेरी का पेड़ है, जिस पर स्वादिष्ट चेरी लगेंगी.2
यहां यह पौधा सबसे अच्छी तरह से क्यों बढ़ता है: सैन जोकिन वैली का मौसम, चेरी के पौधे के लिए सबसे अच्छा होता है. यहां गर्मियों के दिन लंबे और गर्म होते हैं, जिससे फल अच्छी तरह से विकसित हो पाते हैं. साथ ही, रातें ठंडी होती हैं.5 हैंफ़र्ड, कृषि के लिए एक प्रमुख केंद्र है. यह स्टोन फ़्रूट (गुठली वाले फल) के उत्पादन के लिए जाना जाता है. इसलिए, आपको अपने इलाके की मिट्टी में इस पेड़ से अच्छी पैदावार मिल सकती है. बस यह पक्का करें कि इसे ऐसी जगह पर लगाया गया हो जहां सूरज की पूरी रोशनी मिलती हो और मिट्टी अच्छी तरह से सूखी हो, ताकि आपको अच्छी फ़सल मिल सके"
PSQL में प्रॉम्प्ट चलाना
हम Cloud SQL के साथ Vertex AI के एआई इंटिग्रेशन का इस्तेमाल करके, डेटाबेस में सीधे तौर पर एसक्यूएल का इस्तेमाल करके, जनरेटिव मॉडल से मिलता-जुलता जवाब पा सकते हैं. हालांकि, gemini-2.0-flash-exp मॉडल का इस्तेमाल करने के लिए, हमें इसे पहले रजिस्टर करना होगा.
PostgreSQL के लिए Cloud SQL में चलाना
अगर एक्सटेंशन का मौजूदा वर्शन इससे पहले का है, तो इसे 1.4.2 या इसके बाद के वर्शन पर अपग्रेड करें. gcloud sql connect से quickstart_db डेटाबेस से कनेक्ट करें. इसे पहले दिखाया जा चुका है. इसके अलावा, Cloud SQL Studio का इस्तेमाल करें और यह कमांड चलाएं:
SELECT extversion from pg_extension where extname='google_ml_integration';
अगर दिखाई गई वैल्यू 1.4.3 से कम है, तो यह कमांड चलाएं:
ALTER EXTENSION google_ml_integration UPDATE TO '1.4.3';
इसके बाद, हमें google_ml_integration.enable_model_support डेटाबेस फ़्लैग को "चालू है" पर सेट करना होगा. मौजूदा सेटिंग लागू करने के लिए, इस कमांड का इस्तेमाल करें.
show google_ml_integration.enable_model_support;
psql सेशन से मिलने वाला अनुमानित आउटपुट "on" है:
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
अगर यह "बंद है" के तौर पर दिखता है, तो हमें डेटाबेस फ़्लैग को अपडेट करना होगा. इसके लिए, वेब कंसोल इंटरफ़ेस का इस्तेमाल किया जा सकता है या नीचे दिए गए gcloud कमांड को चलाया जा सकता है.
gcloud sql instances patch my-cloudsql-instance \
--database-flags google_ml_integration.enable_model_support=on,cloudsql.enable_google_ml_integration=on
इस कमांड को बैकग्राउंड में पूरा होने में करीब एक से तीन मिनट लगते हैं. इसके बाद, psql सेशन में या quickstart_db डेटाबेस से कनेक्ट करके Cloud SQL Studio का इस्तेमाल करके, नए फ़्लैग की पुष्टि की जा सकती है.
show google_ml_integration.enable_model_support;
psql सेशन से मिलने वाला अनुमानित आउटपुट "on" है:
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
इसके बाद, हमें दो मॉडल रजिस्टर करने होंगे. पहला मॉडल, text-embedding-005 है, जिसका इस्तेमाल पहले ही किया जा चुका है. इसे रजिस्टर करना ज़रूरी है, क्योंकि हमने मॉडल रजिस्ट्रेशन की सुविधाएं चालू की हैं.
psql या Cloud SQL Studio में मॉडल रन को रजिस्टर करने के लिए, यह कोड डालें:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'cloudsql_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
हमें जिस अगले मॉडल को रजिस्टर करना है वह gemini-2.0-flash-001 है. इसका इस्तेमाल, लोगों के लिए आसानी से समझ में आने वाला आउटपुट जनरेट करने के लिए किया जाएगा.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'https://us-central1-aiplatform.googleapis.com/v1/projects/$PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'cloudsql_service_agent_iam');
google_ml.model_info_view से जानकारी चुनकर, रजिस्टर किए गए मॉडल की सूची की पुष्टि कभी भी की जा सकती है.
select model_id,model_type from google_ml.model_info_view;
यहां आउटपुट का सैंपल दिया गया है
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
--------------------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
gemini-1.5-pro:streamGenerateContent | generic
gemini-1.5-pro:generateContent | generic
gemini-1.0-pro:generateContent | generic
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
अब हम सबक्वेरी में जनरेट किए गए JSON का इस्तेमाल कर सकते हैं. इसके बाद, SQL का इस्तेमाल करके, इसे जनरेटिव एआई टेक्स्ट मॉडल को प्रॉम्प्ट के तौर पर दिया जा सकता है.
डेटाबेस के psql या Cloud SQL Studio सेशन में क्वेरी चलाएं
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> google_ml.embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
यहां अनुमानित आउटपुट दिया गया है. मॉडल के वर्शन और पैरामीटर के आधार पर, आपका आउटपुट अलग-अलग हो सकता है.:
"That's a great question! It sounds like you're looking to add some delicious fruit to your garden.\n\nBased on the products we have that are closely related to your search, I can tell you about a fantastic option:\n\n**Cherry Tree**" "\n* **Description:** This beautiful deciduous tree will produce delicious cherries. It grows to be about 15 feet tall, with dark green leaves in summer that turn a beautiful red in the fall. Cherry trees are known for their beauty, shade, and privacy. They prefer a cool, moist climate and sandy soil." "\n* **Price:** $75.00\n* **Grows well in:** USDA Zones 4-9.\n\nTo confirm if this Cherry Tree will thrive in your specific location, you might want to check which USDA Hardiness Zone your area falls into. If you're in zones 4-9, this" " could be a wonderful addition to your yard!"
10. सबसे नज़दीकी पड़ोसी इंडेक्स बनाना
हमारा डेटासेट काफ़ी छोटा है. जवाब देने में लगने वाला समय, मुख्य रूप से एआई मॉडल के साथ इंटरैक्शन पर निर्भर करता है. हालांकि, लाखों वेक्टर होने पर, वेक्टर सर्च में जवाब देने में लगने वाले समय का एक बड़ा हिस्सा लग सकता है. साथ ही, इससे सिस्टम पर ज़्यादा लोड पड़ सकता है. इससे हम अपने वेक्टर के ऊपर एक इंडेक्स बना सकते हैं.
एचएनएसडब्ल्यू इंडेक्स बनाना
हम अपने टेस्ट के लिए, HNSW इंडेक्स टाइप का इस्तेमाल करेंगे. एचएनएसडब्ल्यू का मतलब हायरार्किकल नेविगेबल स्मॉल वर्ल्ड है. यह एक मल्टीलेयर ग्राफ़ इंडेक्स होता है.
एम्बेडिंग कॉलम के लिए इंडेक्स बनाने के लिए, हमें एम्बेडिंग कॉलम और दूरी के फ़ंक्शन को तय करना होगा. साथ ही, m या ef_constructions जैसे पैरामीटर तय करने होंगे. दस्तावेज़ में जाकर, पैरामीटर के बारे में ज़्यादा जानकारी पाएं.
CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
अनुमानित आउटपुट:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64); CREATE INDEX quickstart_db=>
जवाब की तुलना करें
अब हम EXPLAIN मोड में वेक्टर सर्च क्वेरी चला सकते हैं और पुष्टि कर सकते हैं कि इंडेक्स का इस्तेमाल किया गया है या नहीं.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
अनुमानित आउटपुट:
Aggregate (cost=779.12..779.13 rows=1 width=32) (actual time=1.066..1.069 rows=1 loops=1)
-> Subquery Scan on trees (cost=769.05..779.12 rows=1 width=142) (actual time=1.038..1.041 rows=1 loops=1)
-> Limit (cost=769.05..779.11 rows=1 width=158) (actual time=1.022..1.024 rows=1 loops=1)
-> Nested Loop (cost=769.05..9339.69 rows=852 width=158) (actual time=1.020..1.021 rows=1 loops=1)
-> Nested Loop (cost=768.77..9316.48 rows=852 width=945) (actual time=0.858..0.859 rows=1 loops=1)
-> Index Scan using cymbal_products_embeddings_hnsw on cymbal_products cp (cost=768.34..2572.47 rows=941 width=941) (actual time=0.532..0.539 rows=3 loops=1)
Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,...
<redacted>
...,0.017593635,-0.040275685,-0.03914233,-0.018452475,0.00826032,-0.07372604
]'::vector)
-> Index Scan using product_inventory_pkey on cymbal_inventory ci (cost=0.42..7.17 rows=1 width=37) (actual time=0.104..0.104 rows=0 loops=3)
Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text))
Filter: (inventory > 0)
Rows Removed by Filter: 1
-> Materialize (cost=0.28..8.31 rows=1 width=8) (actual time=0.133..0.134 rows=1 loops=1)
-> Index Scan using product_stores_pkey on cymbal_stores cs (cost=0.28..8.30 rows=1 width=8) (actual time=0.129..0.129 rows=1 loops=1)
Index Cond: (store_id = 1583)
Planning Time: 112.398 ms
Execution Time: 1.221 ms
आउटपुट से हमें साफ़ तौर पर पता चलता है कि क्वेरी में "cymbal_products_embeddings_hnsw का इस्तेमाल करके इंडेक्स स्कैन किया गया".
अगर हम explain के बिना क्वेरी चलाते हैं, तो हमें यह जवाब मिलता है:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
अनुमानित आउटपुट (मॉडल और इंडेक्स के आधार पर आउटपुट अलग-अलग हो सकता है):
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
हम देख सकते हैं कि नतीजा एक जैसा है. साथ ही, हम उसी चेरी के पेड़ की इमेज को खोज के नतीजों में सबसे ऊपर दिखा सकते हैं जिसे हमने इंडेक्स नहीं किया था. पैरामीटर और इंडेक्स के टाइप के आधार पर, यह हो सकता है कि नतीजा थोड़ा अलग हो और ट्री के लिए अलग टॉप रिकॉर्ड दिखे. मेरे टेस्ट के दौरान, इंडेक्स की गई क्वेरी ने 131.301 मि॰से॰ में नतीजे दिखाए. वहीं, बिना इंडेक्स वाली क्वेरी ने 167.631 मि॰से॰ में नतीजे दिखाए. हालांकि, हम बहुत छोटे डेटासेट का इस्तेमाल कर रहे थे. बड़े डेटासेट पर यह अंतर ज़्यादा होगा.
वेक्टर के लिए उपलब्ध अलग-अलग इंडेक्स और LangChain इंटिग्रेशन के साथ उपलब्ध ज़्यादा लैब और उदाहरणों को आज़माया जा सकता है. ये सभी दस्तावेज़ में उपलब्ध हैं.
11. पर्यावरण को साफ़-सुथरा रखना
Cloud SQL इंस्टेंस मिटाना
लैब का काम पूरा होने के बाद, Cloud SQL इंस्टेंस को मिटाएं
अगर आपका कनेक्शन बंद हो गया है और पिछली सभी सेटिंग मिट गई हैं, तो क्लाउड शेल में प्रोजेक्ट और एनवायरमेंट वैरिएबल तय करें:
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
इंस्टेंस मिटाएं:
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
12. बधाई हो
कोडलैब पूरा करने के लिए बधाई.
यह लैब, 'Google Cloud के साथ प्रोडक्शन-रेडी एआई' लर्निंग पाथ का हिस्सा है.
- प्रोटोटाइप से प्रोडक्शन तक के अंतर को कम करने के लिए, पूरा पाठ्यक्रम देखें.
- अपनी प्रोग्रेस को
#ProductionReadyAIहैशटैग के साथ शेयर करें.
हमने क्या-क्या बताया
- PostgreSQL के लिए Cloud SQL इंस्टेंस को डिप्लॉय करने का तरीका
- डेटाबेस बनाने और Cloud SQL AI इंटिग्रेशन को चालू करने का तरीका
- डेटाबेस में डेटा लोड करने का तरीका
- Cloud SQL Studio का इस्तेमाल कैसे करें
- Cloud SQL में Vertex AI एम्बेडिंग मॉडल का इस्तेमाल कैसे करें
- Vertex AI Studio का इस्तेमाल कैसे करें
- Vertex AI जनरेटिव मॉडल का इस्तेमाल करके, नतीजे को बेहतर बनाने का तरीका
- वेक्टर इंडेक्स का इस्तेमाल करके परफ़ॉर्मेंस को बेहतर बनाने का तरीका
HNSW के बजाय ScaNN इंडेक्स का इस्तेमाल करके, AlloyDB के लिए इसी तरह का कोडलैब आज़माएं
13. सर्वे
आउटपुट: