
1. Introduzione
In questo codelab imparerai a utilizzare l'integrazione dell'AI di Cloud SQL per PostgreSQL combinando la ricerca vettoriale con gli embedding di Vertex AI.

Prerequisiti
- Una conoscenza di base di Google Cloud e della console
- Competenze di base nell'interfaccia a riga di comando e in Cloud Shell
Cosa imparerai a fare
- Come eseguire il deployment di un'istanza Cloud SQL per PostgreSQL
- Come creare un database e abilitare l'integrazione di Cloud SQL AI
- Come caricare i dati nel database
- Come utilizzare Cloud SQL Studio
- Come utilizzare il modello di embedding Vertex AI in Cloud SQL
- Come utilizzare Vertex AI Studio
- Come arricchire il risultato utilizzando il modello generativo Vertex AI
- Come migliorare il rendimento utilizzando l'indice vettoriale
Che cosa ti serve
- Un account Google Cloud e un progetto Google Cloud
- Un browser web come Chrome che supporta la console Google Cloud e Cloud Shell
2. Configurazione e requisiti
Configurazione del progetto
- Accedi alla console Google Cloud. Se non hai ancora un account Gmail o Google Workspace, devi crearne uno.
Utilizza un account personale anziché un account di lavoro o della scuola.
- Crea un nuovo progetto o riutilizzane uno esistente. Per creare un nuovo progetto nella console Google Cloud, fai clic sul pulsante Seleziona un progetto nell'intestazione per aprire una finestra popup.

Nella finestra Seleziona un progetto, premi il pulsante Nuovo progetto per aprire una finestra di dialogo per il nuovo progetto.
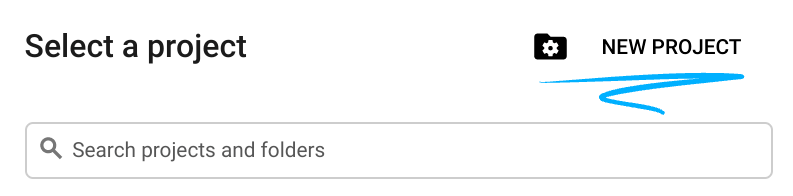
Nella finestra di dialogo, inserisci il nome del progetto che preferisci e scegli la posizione.
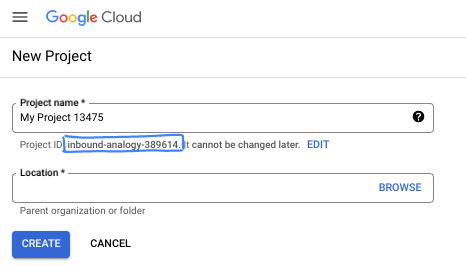
- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. Il nome del progetto non viene utilizzato dalle API di Google e può essere modificato in qualsiasi momento.
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Google Cloud genera automaticamente un ID univoco, ma puoi personalizzarlo. Se l'ID generato non ti piace, puoi generarne un altro casuale o fornirne uno tuo per verificarne la disponibilità. Nella maggior parte dei codelab, devi fare riferimento all'ID progetto, in genere identificato con il segnaposto PROJECT_ID.
- Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
Abilita fatturazione
Per attivare la fatturazione, hai due opzioni. Puoi utilizzare il tuo account di fatturazione personale o riscattare i crediti seguendo questi passaggi.
Riscatta i crediti Google Cloud (facoltativo)
Per partecipare a questo workshop, devi disporre di un account di fatturazione con del credito. Per iniziare, utilizza i crediti del banner nella parte superiore di questo codelab. Se hai già collegato un account di fatturazione, puoi saltare questo passaggio.
Configurare un account di fatturazione personale
Se hai configurato la fatturazione utilizzando i crediti Google Cloud, puoi saltare questo passaggio.
Per configurare un account di fatturazione personale, vai qui per abilitare la fatturazione nella console Cloud.
Alcune note:
- Il completamento di questo lab dovrebbe costare meno di 3 $in risorse cloud.
- Per evitare ulteriori addebiti, puoi seguire i passaggi alla fine di questo lab per eliminare le risorse.
- I nuovi utenti hanno diritto alla prova senza costi di 300$.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:
In alternativa, puoi premere G e poi S. Questa sequenza attiverà Cloud Shell se ti trovi nella console Google Cloud o utilizza questo link.
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
3. Prima di iniziare
Abilita l'API
Output:
Per utilizzare Cloud SQL, Compute Engine, Servizi di rete e Vertex AI, devi abilitare le rispettive API nel tuo progetto Google Cloud.
All'interno del terminale Cloud Shell, assicurati che l'ID progetto sia configurato:
gcloud config set project [YOUR-PROJECT-ID]
Imposta la variabile di ambiente PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Attiva tutti i servizi necessari:
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Output previsto:
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Presentazione delle API
- L'API Cloud SQL Admin (
sqladmin.googleapis.com) consente di creare, configurare e gestire le istanze Cloud SQL in modo programmatico. Fornisce il control plane per il servizio di database relazionale completamente gestito di Google (che supporta MySQL, PostgreSQL e SQL Server), gestendo attività come il provisioning, i backup, l'alta affidabilità e lo scaling. - L'API Compute Engine (
compute.googleapis.com) consente di creare e gestire macchine virtuali (VM), dischi permanenti e impostazioni di rete. Fornisce le basi di Infrastructure as a Service (IaaS) necessarie per eseguire i carichi di lavoro e ospitare l'infrastruttura sottostante per molti servizi gestiti. - L'API Cloud Resource Manager (
cloudresourcemanager.googleapis.com) ti consente di gestire in modo programmatico i metadati e la configurazione del tuo progetto Google Cloud. Consente di organizzare le risorse, gestire i criteri IAM (Identity and Access Management) e convalidare le autorizzazioni nella gerarchia dei progetti. - L'API Service Networking (
servicenetworking.googleapis.com) ti consente di automatizzare la configurazione della connettività privata tra la tua rete Virtual Private Cloud (VPC) e i servizi gestiti di Google. È necessario in particolare per stabilire l'accesso IP privato per servizi come AlloyDB, in modo che possano comunicare in modo sicuro con le altre risorse. - L'API Vertex AI (
aiplatform.googleapis.com) consente alle tue applicazioni di creare, eseguire il deployment e scalare modelli di machine learning. Fornisce l'interfaccia unificata per tutti i servizi di AI di Google Cloud, incluso l'accesso ai modelli di AI generativa (come Gemini) e l'addestramento di modelli personalizzati.
4. Crea un'istanza Cloud SQL
Crea l'istanza Cloud SQL con l'integrazione del database con Vertex AI.
Crea password database
Definisci la password per l'utente del database predefinito. Puoi definire la tua password o utilizzare una funzione casuale per generarla:
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
Prendi nota del valore generato per la password:
echo $CLOUDSQL_PASSWORD
Crea un'istanza Cloud SQL per PostgreSQL
Le istanze Cloud SQL possono essere create in diversi modi, ad esempio tramite la console Google Cloud, strumenti di automazione come Terraform o Google Cloud SDK. Nel lab utilizzeremo principalmente lo strumento gcloud di Google Cloud SDK. Puoi leggere la documentazione per scoprire come creare un'istanza utilizzando altri strumenti.
Nella sessione di Cloud Shell esegui:
gcloud sql instances create my-cloudsql-instance \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--region=us-central1 \
--edition=ENTERPRISE \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on
Dopo aver creato l'istanza, dobbiamo impostare una password per l'utente predefinito nell'istanza e verificare se possiamo connetterci con la password.
gcloud sql users set-password postgres \
--instance=my-cloudsql-instance \
--password=$CLOUDSQL_PASSWORD
Esegui il comando "gcloud sql connect" come mostrato nella casella e inserisci la password nel prompt quando è pronto per la connessione.
gcloud sql connect my-cloudsql-instance --user=postgres
Esci dalla sessione psql per ora utilizzando la scorciatoia da tastiera Ctrl + D o eseguendo il comando exit
exit
Abilita l'integrazione di Vertex AI
Concedi i privilegi necessari al service account Cloud SQL interno per poter utilizzare l'integrazione di Vertex AI.
Trova l'email dell'account di servizio interno di Cloud SQL ed esportala come variabile.
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
Concedi l'accesso a Vertex AI al service account Cloud SQL:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Scopri di più sulla creazione e sulla configurazione delle istanze nella documentazione di Cloud SQL qui.
5. Prepara il database
Ora dobbiamo creare un database e attivare il supporto dei vettori.
Crea database
Crea un database con il nome quickstart_db .Per farlo, abbiamo diverse opzioni, come i client di database da riga di comando come psql per PostgreSQL, SDK o Cloud SQL Studio. Utilizzeremo l'SDK (gcloud) per creare database e connetterci all'istanza.
In Cloud Shell, esegui il comando per creare il database
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
Attivare le estensioni
Per poter lavorare con Vertex AI e i vettori, dobbiamo attivare due estensioni nel database creato.
In Cloud Shell, esegui il comando per connetterti al database creato (dovrai fornire la password).
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
Poi, dopo aver stabilito la connessione, nella sessione SQL devi eseguire due comandi:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector CASCADE;
Esci dalla sessione SQL:
exit;
6. Carica dati
Ora dobbiamo creare oggetti nel database e caricare i dati. Utilizzeremo i dati fittizi di Cymbal Store. I dati sono disponibili nel bucket Google Storage pubblico in formato CSV.
Innanzitutto, dobbiamo creare tutti gli oggetti richiesti nel nostro database. Per farlo, utilizzeremo i comandi gcloud sql connect e gcloud storage già noti per scaricare e importare gli oggetti dello schema nel nostro database.
In Cloud Shell, esegui e fornisci la password annotata durante la creazione dell'istanza:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
Che cosa abbiamo fatto esattamente nel comando precedente? Ci siamo connessi al nostro database ed abbiamo eseguito il codice SQL scaricato, che ha creato tabelle, indici e sequenze.
Il passaggio successivo consiste nel caricare i dati e, per farlo, dobbiamo scaricare i file CSV da Google Cloud Storage.
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv .
Poi dobbiamo connetterci al database.
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
e importa i dati dai nostri file CSV.
\copy cymbal_products from 'cymbal_products.csv' csv header
\copy cymbal_inventory from 'cymbal_inventory.csv' csv header
\copy cymbal_stores from 'cymbal_stores.csv' csv header
Se disponi di dati tuoi e i tuoi file CSV sono compatibili con lo strumento di importazione Cloud SQL disponibile da console Cloud, puoi utilizzarlo al posto dell'approccio da riga di comando.
7. Crea incorporamenti
Il passaggio successivo consiste nel creare embedding per le descrizioni dei nostri prodotti utilizzando il modello textembedding-004 di Google Vertex AI e archiviarli come dati vettoriali.
Connettiti al database (se hai chiuso la sessione o la precedente è stata disconnessa):
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
e crea una colonna virtuale embedding nella tabella cymbal_products utilizzando la funzione di incorporamento. Il comando crea una colonna virtuale "embedding" che memorizzerà i nostri vettori con gli embedding generati in base alla colonna "product_description". Inoltre, crea incorporamenti per tutte le righe esistenti nella tabella. Il modello è definito come il primo parametro della funzione di incorporamento e i dati di origine come il secondo parametro.
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005',product_description)) STORED;
Potrebbe volerci un po' di tempo, ma per 900-1000 righe non dovrebbe richiedere più di 5 minuti e di solito è molto più veloce.
Quando inseriamo una nuova riga nella tabella o aggiorniamo product_description per qualsiasi riga esistente, i dati della colonna virtuale per la colonna "incorporamento" vengono rigenerati in base a "product_description".
8. Esegui ricerca di somiglianze
Ora possiamo eseguire la ricerca utilizzando la ricerca di similarità in base ai valori vettoriali calcolati per le descrizioni e al valore vettoriale ottenuto per la nostra richiesta.
La query SQL può essere eseguita dalla stessa interfaccia a riga di comando utilizzando gcloud sql connect o, in alternativa, da Cloud SQL Studio. È preferibile gestire query complesse e multiriga in Cloud SQL Studio.
Avvia Cloud SQL Studio
Nella console, fai clic sull'istanza Cloud SQL che abbiamo creato in precedenza.
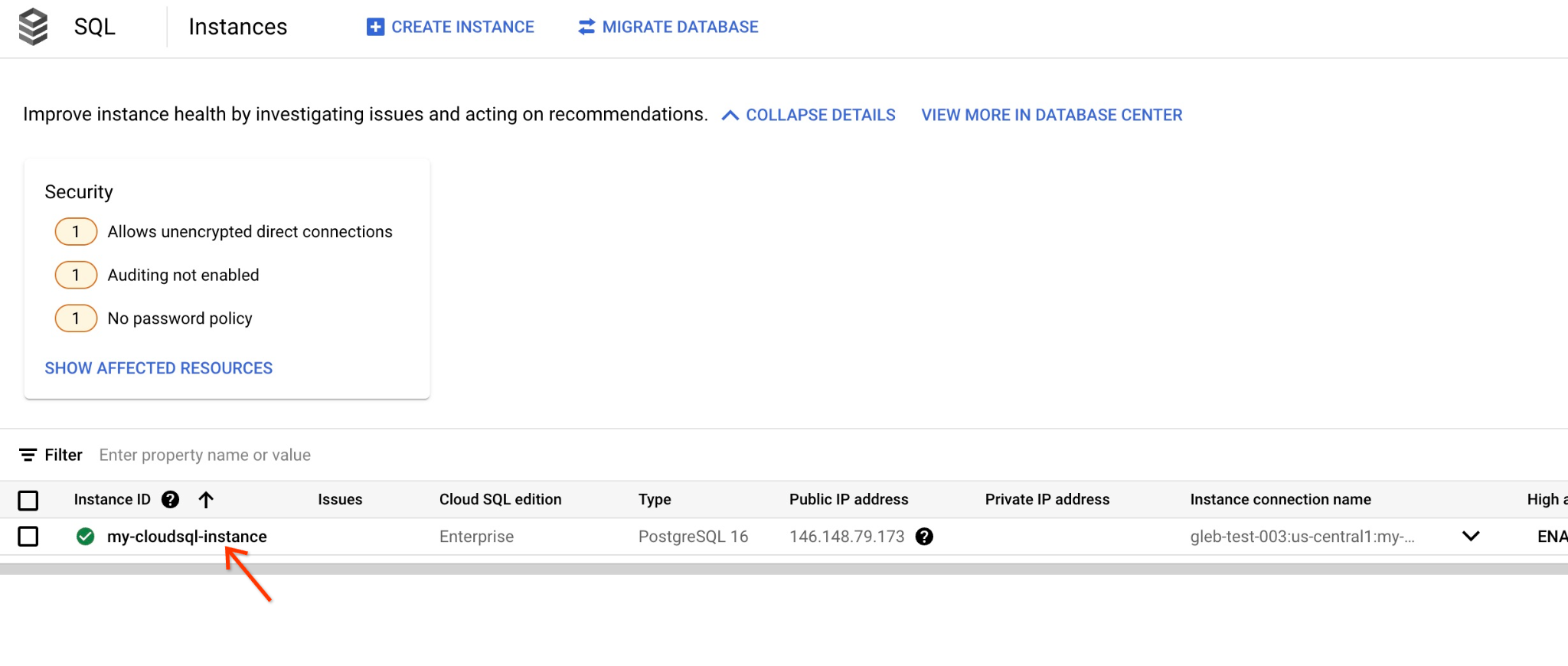
Quando è aperto nel riquadro a destra, possiamo vedere Cloud SQL Studio. Cliccaci sopra.
Si aprirà una finestra di dialogo in cui fornire il nome del database e le credenziali:
- Database: quickstart_db
- Utente: postgres
- Password: la password annotata per l'utente del database principale
e fai clic sul pulsante "AUTENTICA".
Si aprirà la finestra successiva, in cui devi fare clic sulla scheda "Editor" sul lato destro per aprire l'editor SQL.
Ora siamo pronti per eseguire le query.
Esegui query
Esegui una query per ottenere un elenco dei prodotti disponibili più strettamente correlati alla richiesta di un cliente. La richiesta che passeremo a Vertex AI per ottenere il valore del vettore è: "Quali tipi di alberi da frutto crescono bene qui?"
Ecco la query che puoi eseguire per scegliere i primi 10 elementi più adatti alla nostra richiesta:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
Copia e incolla la query nell'editor di Cloud SQL Studio e premi il pulsante "RUN" (ESECUZIONE) oppure incollala nella sessione della riga di comando che si connette al database quickstart_db.
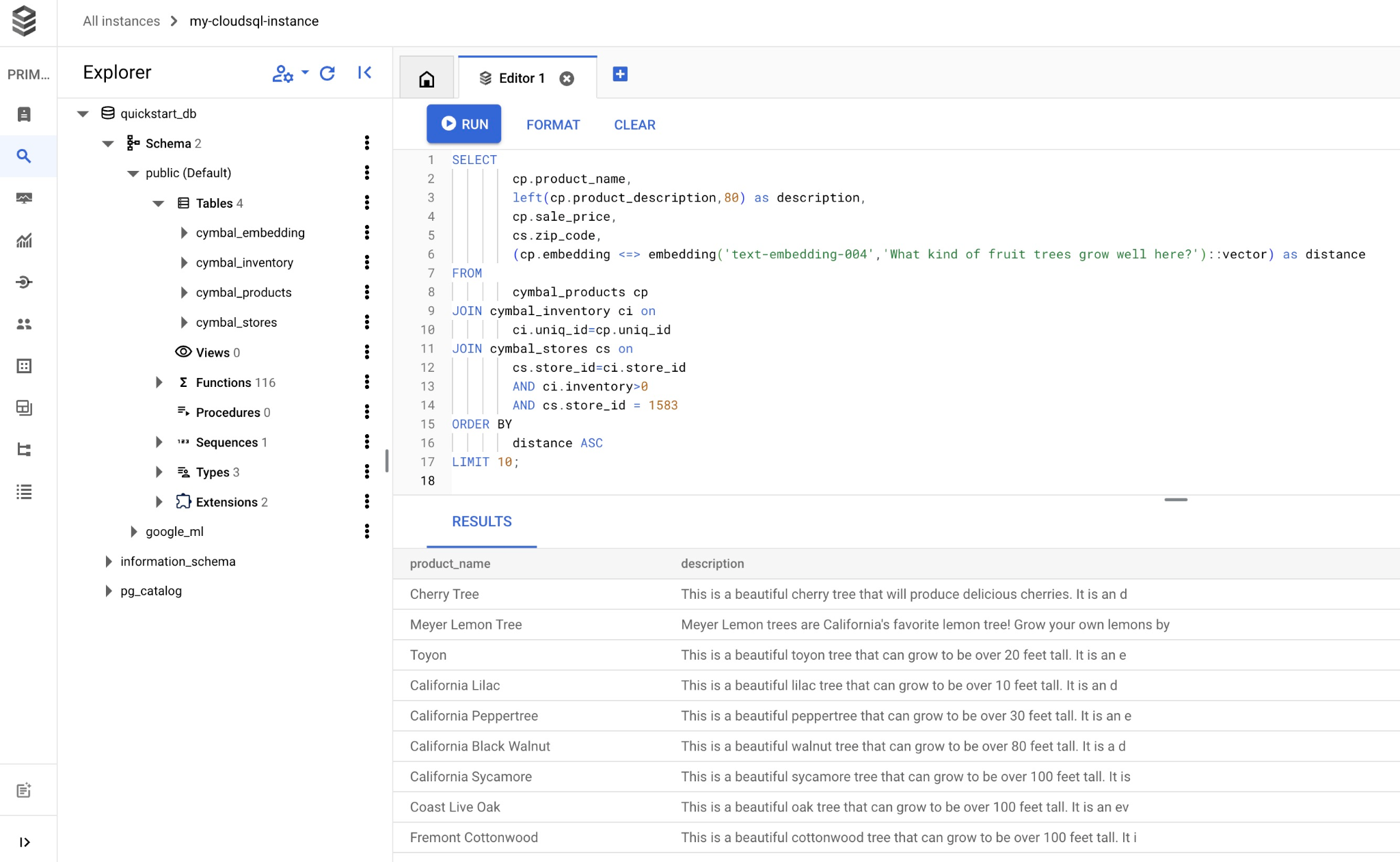
Ecco un elenco di prodotti scelti che corrispondono alla query.
product_name | description | sale_price | zip_code | distance -------------------------+----------------------------------------------------------------------------------+------------+----------+--------------------- Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397 Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228 Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668 California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498 California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247 California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597 California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755 Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371 Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058 Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093 (10 rows)
9. Migliorare la risposta dell'LLM utilizzando i dati recuperati
Possiamo migliorare la risposta del LLM di AI generativa a un'applicazione client utilizzando il risultato della query eseguita e preparare un output significativo utilizzando i risultati della query forniti come parte del prompt di un modello linguistico di base di AI generativa di Vertex AI.
Per farlo, dobbiamo generare un file JSON con i risultati della ricerca vettoriale, quindi utilizzare questo file JSON generato come aggiunta a un prompt per un modello LLM in Vertex AI per creare un output significativo. Nel primo passaggio generiamo il JSON, poi lo testiamo in Vertex AI Studio e nell'ultimo passaggio lo incorporiamo in un'istruzione SQL che può essere utilizzata in un'applicazione.
Generare l'output in formato JSON
Modifica la query per generare l'output in formato JSON e restituire una sola riga da passare a Vertex AI
Cloud SQL per PostgreSQL
Ecco un esempio di query:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Ecco il JSON previsto nell'output:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Esegui il prompt in Vertex AI Studio
Possiamo utilizzare il JSON generato per fornirlo come parte del prompt al modello di testo di AI generativa in Vertex AI Studio
Apri Vertex AI Studio nella console cloud.
Potrebbe chiederti di attivare API aggiuntive, ma puoi ignorare la richiesta. Non abbiamo bisogno di altre API per completare il lab.
Inserisci un prompt in Studio.

Ecco il prompt che utilizzeremo:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
Ecco come appare quando sostituiamo il segnaposto JSON con la risposta della query:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
Ecco il risultato quando eseguiamo il prompt con i nostri valori JSON:
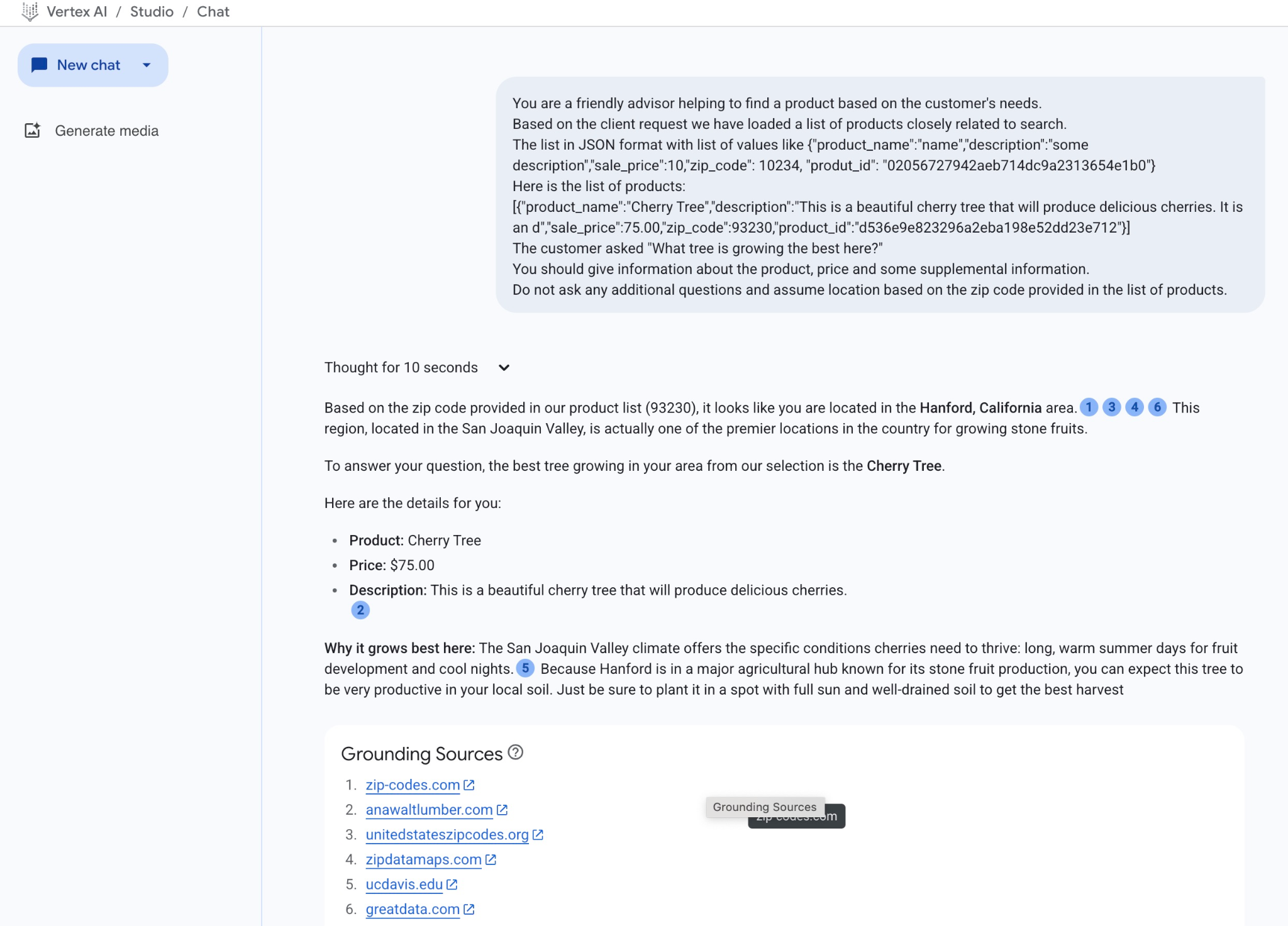
Di seguito è riportata la risposta ottenuta dal modello in questo esempio. Tieni presente che la tua risposta potrebbe essere diversa a causa delle modifiche al modello e ai parametri nel tempo:
"In base al codice postale fornito nel nostro elenco di prodotti (93230), sembra che tu ti trovi nella zona di Hanford, in California.1346 Questa regione, situata nella San Joaquin Valley, è in realtà una delle località più importanti del paese per la coltivazione di drupacee.
Per rispondere alla tua domanda, l'albero migliore che cresce nella tua zona tra quelli della nostra selezione è il ciliegio.
Ecco i dettagli:
Prodotto: Ciliegio
Prezzo: 75,00 $
Descrizione: questo è un bellissimo ciliegio che produrrà deliziose ciliegie.2
Perché cresce meglio qui: il clima della San Joaquin Valley offre le condizioni specifiche di cui le ciliegie hanno bisogno per prosperare: lunghe e calde giornate estive per lo sviluppo dei frutti e notti fresche.5 Poiché Hanford si trova in un importante centro agricolo noto per la produzione di drupacee, puoi aspettarti che questo albero sia molto produttivo nel tuo terreno locale. Assicurati di piantarla in un punto soleggiato e con un terreno ben drenato per ottenere il miglior raccolto"
Esegui il prompt in PSQL
Possiamo anche utilizzare l'integrazione di Cloud SQL AI con Vertex AI per ottenere la risposta simile da un modello generativo utilizzando SQL direttamente nel database. Tuttavia, per utilizzare il modello gemini-2.0-flash-exp dobbiamo prima registrarlo.
Esegui in Cloud SQL per PostgreSQL
Esegui l'upgrade dell'estensione alla versione 1.4.2 o successive (se la versione attuale è precedente). Connettiti al database quickstart_db da gcloud sql connect come mostrato in precedenza (o utilizza Cloud SQL Studio) ed esegui:
SELECT extversion from pg_extension where extname='google_ml_integration';
Se il valore restituito è inferiore a 1.4.3, esegui:
ALTER EXTENSION google_ml_integration UPDATE TO '1.4.3';
Poi dobbiamo impostare il flag di database google_ml_integration.enable_model_support su "on". Per verificare le impostazioni attuali, esegui.
show google_ml_integration.enable_model_support;
L'output previsto dalla sessione psql è "on":
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Se viene visualizzato "off", dobbiamo aggiornare il flag del database. Per farlo, puoi utilizzare l'interfaccia della console web o eseguire il seguente comando gcloud.
gcloud sql instances patch my-cloudsql-instance \
--database-flags google_ml_integration.enable_model_support=on,cloudsql.enable_google_ml_integration=on
L'esecuzione del comando in background richiede circa 1-3 minuti. Dopodiché, puoi verificare il nuovo flag nella sessione psql o utilizzando Cloud SQL Studio connettendoti al database quickstart_db.
show google_ml_integration.enable_model_support;
L'output previsto dalla sessione psql è "on":
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Poi dobbiamo registrare due modelli. Il primo è il modello text-embedding-005 già utilizzato. Deve essere registrato perché abbiamo attivato le funzionalità di registrazione dei modelli.
Per registrare l'esecuzione del modello in psql o Cloud SQL Studio, esegui il seguente codice:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'cloudsql_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
Il modello successivo da registrare è gemini-2.0-flash-001, che verrà utilizzato per generare l'output di facile utilizzo.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'https://us-central1-aiplatform.googleapis.com/v1/projects/$PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'cloudsql_service_agent_iam');
Puoi sempre verificare l'elenco dei modelli registrati selezionando le informazioni da google_ml.model_info_view.
select model_id,model_type from google_ml.model_info_view;
Ecco un output di esempio
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
--------------------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
gemini-1.5-pro:streamGenerateContent | generic
gemini-1.5-pro:generateContent | generic
gemini-1.0-pro:generateContent | generic
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
Ora possiamo utilizzare il JSON generato in una sottoquery per fornirlo come parte del prompt al modello di testo di AI generativa utilizzando SQL.
Nella sessione psql o Cloud SQL Studio al database, esegui la query
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> google_ml.embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
Ecco l'output previsto. L'output potrebbe variare a seconda della versione del modello e dei parametri:
"That's a great question! It sounds like you're looking to add some delicious fruit to your garden.\n\nBased on the products we have that are closely related to your search, I can tell you about a fantastic option:\n\n**Cherry Tree**" "\n* **Description:** This beautiful deciduous tree will produce delicious cherries. It grows to be about 15 feet tall, with dark green leaves in summer that turn a beautiful red in the fall. Cherry trees are known for their beauty, shade, and privacy. They prefer a cool, moist climate and sandy soil." "\n* **Price:** $75.00\n* **Grows well in:** USDA Zones 4-9.\n\nTo confirm if this Cherry Tree will thrive in your specific location, you might want to check which USDA Hardiness Zone your area falls into. If you're in zones 4-9, this" " could be a wonderful addition to your yard!"
10. Crea un indice dei vicini più prossimi
Il nostro set di dati è piuttosto piccolo e il tempo di risposta dipende principalmente dalle interazioni con i modelli di AI. Tuttavia, quando hai milioni di vettori, la ricerca vettoriale può richiedere una parte significativa del nostro tempo di risposta e sovraccaricare il sistema. Per migliorare, possiamo creare un indice in base ai nostri vettori.
Crea indice HNSW
Per il nostro test, proveremo il tipo di indice HNSW. HNSW sta per Hierarchical Navigable Small World e rappresenta un indice del grafico multilivello.
Per creare l'indice per la colonna di incorporamento, dobbiamo definire la colonna di incorporamento, la funzione di distanza e, facoltativamente, parametri come m o ef_constructions. Puoi leggere informazioni dettagliate sui parametri nella documentazione.
CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
Output previsto:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64); CREATE INDEX quickstart_db=>
Confronta risposta
Ora possiamo eseguire la query di ricerca vettoriale in modalità EXPLAIN e verificare se l'indice è stato utilizzato.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Output previsto:
Aggregate (cost=779.12..779.13 rows=1 width=32) (actual time=1.066..1.069 rows=1 loops=1)
-> Subquery Scan on trees (cost=769.05..779.12 rows=1 width=142) (actual time=1.038..1.041 rows=1 loops=1)
-> Limit (cost=769.05..779.11 rows=1 width=158) (actual time=1.022..1.024 rows=1 loops=1)
-> Nested Loop (cost=769.05..9339.69 rows=852 width=158) (actual time=1.020..1.021 rows=1 loops=1)
-> Nested Loop (cost=768.77..9316.48 rows=852 width=945) (actual time=0.858..0.859 rows=1 loops=1)
-> Index Scan using cymbal_products_embeddings_hnsw on cymbal_products cp (cost=768.34..2572.47 rows=941 width=941) (actual time=0.532..0.539 rows=3 loops=1)
Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,...
<redacted>
...,0.017593635,-0.040275685,-0.03914233,-0.018452475,0.00826032,-0.07372604
]'::vector)
-> Index Scan using product_inventory_pkey on cymbal_inventory ci (cost=0.42..7.17 rows=1 width=37) (actual time=0.104..0.104 rows=0 loops=3)
Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text))
Filter: (inventory > 0)
Rows Removed by Filter: 1
-> Materialize (cost=0.28..8.31 rows=1 width=8) (actual time=0.133..0.134 rows=1 loops=1)
-> Index Scan using product_stores_pkey on cymbal_stores cs (cost=0.28..8.30 rows=1 width=8) (actual time=0.129..0.129 rows=1 loops=1)
Index Cond: (store_id = 1583)
Planning Time: 112.398 ms
Execution Time: 1.221 ms
Dall'output possiamo vedere chiaramente che la query utilizzava "Index Scan using cymbal_products_embeddings_hnsw".
Se eseguiamo la query senza explain:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Output previsto (l'output può variare in base al modello e all'indice):
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Possiamo vedere che il risultato è lo stesso e restituire lo stesso ciliegio che era in cima alla nostra ricerca senza indice. A seconda dei parametri e del tipo di indice, è possibile che il risultato sia leggermente diverso e restituisca un record principale diverso per l'albero. Durante i miei test, la query indicizzata ha restituito risultati in 131,301 ms rispetto a 167,631 ms senza alcun indice, ma avevamo a che fare con un set di dati molto piccolo e la differenza sarebbe più sostanziale su dati più grandi.
Puoi provare diversi indici disponibili per i vettori e altri lab ed esempi con l'integrazione di Langchain disponibili nella documentazione.
11. Liberare spazio
Elimina l'istanza Cloud SQL
Elimina l'istanza Cloud SQL al termine del lab
In Cloud Shell definisci le variabili di progetto e di ambiente se la connessione è stata interrotta e tutte le impostazioni precedenti sono andate perse:
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
Elimina l'istanza:
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
Output console previsto:
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
12. Complimenti
Congratulazioni per aver completato il codelab.
Questo lab fa parte del percorso di apprendimento AI pronta per la produzione con Google Cloud.
- Esplora il curriculum completo per colmare il divario tra prototipo e produzione.
- Condividi i tuoi progressi con l'hashtag
#ProductionReadyAI.
Argomenti trattati
- Come eseguire il deployment di un'istanza Cloud SQL per PostgreSQL
- Come creare un database e abilitare l'integrazione di Cloud SQL AI
- Come caricare i dati nel database
- Come utilizzare Cloud SQL Studio
- Come utilizzare il modello di embedding Vertex AI in Cloud SQL
- Come utilizzare Vertex AI Studio
- Come arricchire il risultato utilizzando il modello generativo Vertex AI
- Come migliorare il rendimento utilizzando l'indice vettoriale
Prova un codelab simile per AlloyDB con l'indice ScaNN anziché HNSW
13. Sondaggio
Output: