
1. Введение
В этом практическом занятии вы узнаете, как использовать Cloud SQL для интеграции ИИ с PostgreSQL, комбинируя векторный поиск с векторными представлениями ИИ Vertex.

Предварительные требования
- Базовое понимание Google Cloud и консоли.
- Базовые навыки работы с командной строкой и Cloud Shell.
Что вы узнаете
- Как развернуть экземпляр Cloud SQL для PostgreSQL
- Как создать базу данных и включить интеграцию Cloud SQL с искусственным интеллектом
- Как загрузить данные в базу данных
- Как использовать Cloud SQL Studio
- Как использовать модель встраивания Vertex AI в Cloud SQL
- Как использовать Vertex AI Studio
- Как улучшить результаты, используя генеративную модель Vertex AI
- Как повысить производительность с помощью векторного индекса
Что вам понадобится
- Аккаунт Google Cloud и проект Google Cloud
- Веб-браузер, такой как Chrome , поддерживающий консоль Google Cloud и Cloud Shell.
2. Настройка и требования
Настройка проекта
- Войдите в консоль Google Cloud . Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .
Используйте личный аккаунт вместо рабочего или учебного.
- Создайте новый проект или используйте существующий. Чтобы создать новый проект в консоли Google Cloud, в заголовке нажмите кнопку «Выбрать проект», после чего откроется всплывающее окно.

В окне «Выберите проект» нажмите кнопку «Новый проект», после чего откроется диалоговое окно для создания нового проекта.
В диалоговом окне введите желаемое название проекта и выберите местоположение.
- Название проекта — это отображаемое имя участников данного проекта. Название проекта не используется API Google и может быть изменено в любое время.
- Идентификатор проекта (Project ID) уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Google Cloud автоматически генерирует уникальный идентификатор, но вы можете настроить его. Если вам не нравится сгенерированный идентификатор, вы можете сгенерировать другой случайный или указать свой собственный, чтобы проверить его доступность. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта, который обычно обозначается заполнителем PROJECT_ID.
- К вашему сведению, существует третье значение — номер проекта , которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
Включить выставление счетов
Для включения оплаты у вас есть два варианта. Вы можете использовать свой личный платежный аккаунт или обменять средства, выполнив следующие шаги.
Использовать кредиты Google Cloud (необязательно)
Для проведения этого мастер-класса вам потребуется платежный аккаунт с достаточным балансом. Используйте средства, указанные на баннере вверху этого руководства, чтобы начать. Если у вас уже есть платежный аккаунт, вы можете пропустить этот шаг.
Создайте личный платежный аккаунт.
Если вы настроили оплату с использованием кредитов Google Cloud, этот шаг можно пропустить.
Чтобы настроить личный платежный аккаунт, перейдите сюда, чтобы включить оплату в облачной консоли.
Несколько замечаний:
- Выполнение этой лабораторной работы должно обойтись менее чем в 3 доллара США в виде облачных ресурсов.
- В конце этой лабораторной работы вы можете выполнить действия по удалению ресурсов, чтобы избежать дальнейших списаний средств.
- Новые пользователи могут воспользоваться бесплатной пробной версией стоимостью 300 долларов США .
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:
В качестве альтернативы вы можете нажать G, а затем S. Эта последовательность активирует Cloud Shell, если вы находитесь в консоли Google Cloud, или воспользуйтесь этой ссылкой .
Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть что-то подобное:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
3. Прежде чем начать
Включить API
Выход:
Для использования Cloud SQL , Compute Engine , сетевых сервисов и Vertex AI необходимо включить соответствующие API в вашем проекте Google Cloud.
В терминале Cloud Shell убедитесь, что идентификатор вашего проекта указан правильно:
gcloud config set project [YOUR-PROJECT-ID]
Установите переменную среды PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Включите все необходимые службы:
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Ожидаемый результат
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Представляем API.
- API администратора Cloud SQL (
sqladmin.googleapis.com) позволяет программно создавать, настраивать и управлять экземплярами Cloud SQL. Он предоставляет панель управления для полностью управляемой реляционной базы данных Google (поддерживающей MySQL, PostgreSQL и SQL Server), обрабатывая такие задачи, как выделение ресурсов, резервное копирование, обеспечение высокой доступности и масштабирование. - API Compute Engine (
compute.googleapis.com) позволяет создавать и управлять виртуальными машинами (ВМ), постоянными дисками и сетевыми настройками. Он предоставляет базовую инфраструктуру как услугу (IaaS), необходимую для запуска ваших рабочих нагрузок и размещения базовой инфраструктуры для множества управляемых сервисов. - API Cloud Resource Manager (
cloudresourcemanager.googleapis.com) позволяет программно управлять метаданными и конфигурацией вашего проекта Google Cloud. Он позволяет организовывать ресурсы, управлять политиками управления идентификацией и доступом (IAM) и проверять разрешения в иерархии проекта. - API для настройки сетевого взаимодействия сервисов (
servicenetworking.googleapis.com) позволяет автоматизировать настройку частного подключения между вашей виртуальной частной сетью (VPC) и управляемыми сервисами Google. Он необходим для установления частного IP-доступа для таких сервисов, как AlloyDB, чтобы они могли безопасно взаимодействовать с другими вашими ресурсами. - API Vertex AI (
aiplatform.googleapis.com) позволяет вашим приложениям создавать, развертывать и масштабировать модели машинного обучения. Он предоставляет единый интерфейс для всех сервисов искусственного интеллекта Google Cloud, включая доступ к моделям генеративного ИИ (например, Gemini) и обучению пользовательских моделей.
4. Создайте экземпляр Cloud SQL.
Создайте экземпляр Cloud SQL с интеграцией базы данных с Vertex AI.
Создать пароль для базы данных
Задайте пароль для пользователя базы данных по умолчанию. Вы можете задать собственный пароль или использовать функцию генерации случайного пароля:
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
Обратите внимание на сгенерированное значение пароля:
echo $CLOUDSQL_PASSWORD
Создание экземпляра Cloud SQL для PostgreSQL
Экземпляры Cloud SQL можно создавать различными способами, например, через консоль Google Cloud, инструменты автоматизации, такие как Terraform, или Google Cloud SDK. В лабораторной работе мы будем использовать в основном инструмент gcloud из Google Cloud SDK. Инструкции по созданию экземпляра с помощью других инструментов можно найти в документации .
В сессии Cloud Shell выполните следующую команду:
gcloud sql instances create my-cloudsql-instance \
--database-version=POSTGRES_17 \
--tier=db-custom-1-3840 \
--region=us-central1 \
--edition=ENTERPRISE \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on
После создания экземпляра необходимо установить пароль для пользователя по умолчанию в этом экземпляре и проверить, можем ли мы подключиться с этим паролем.
gcloud sql users set-password postgres \
--instance=my-cloudsql-instance \
--password=$CLOUDSQL_PASSWORD
Выполните команду " gcloud sql connect", как показано в окне, и введите свой пароль в командной строке, когда система будет готова к подключению.
gcloud sql connect my-cloudsql-instance --user=postgres
Временно выйдите из сессии psql, используя сочетание клавиш Ctrl+D или команду exit.
exit
Включите интеграцию Vertex AI
Предоставьте необходимые права доступа внутренней учетной записи облачной службы SQL, чтобы иметь возможность использовать интеграцию с Vertex AI.
Найдите адрес электронной почты внутренней службы Cloud SQL и экспортируйте его в качестве переменной.
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
Предоставьте учетной записи службы Cloud SQL доступ к Vertex AI:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Подробнее о создании и настройке экземпляров можно прочитать в документации Cloud SQL здесь .
5. Подготовка базы данных
Теперь нам нужно создать базу данных и включить поддержку векторов.
Создать базу данных
Создайте базу данных с именем quickstart_db . Для этого у нас есть различные варианты, такие как клиенты баз данных командной строки, например psql для PostgreSQL, SDK или Cloud SQL Studio. Мы будем использовать SDK (gcloud) для создания баз данных и подключения к экземпляру.
В оболочке Cloud Shell выполните команду для создания базы данных.
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
Включить расширения
Для работы с Vertex AI и векторами нам необходимо включить два расширения в созданной нами базе данных.
В Cloud Shell выполните команду для подключения к созданной базе данных (вам потребуется ввести свой пароль).
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
После успешного подключения в SQL-сессии необходимо выполнить две команды:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector CASCADE;
Выход из SQL-сессии:
exit;
6. Загрузка данных
Теперь нам нужно создать объекты в базе данных и загрузить данные. Мы будем использовать вымышленные данные Cymbal Store. Данные доступны в общедоступном хранилище Google Storage в формате CSV.
Сначала нам нужно создать все необходимые объекты в нашей базе данных. Для этого мы воспользуемся уже знакомыми командами gcloud sql connect и gcloud storage, чтобы загрузить и импортировать объекты схемы в нашу базу данных.
В облачной оболочке выполните команду и введите пароль, указанный при создании экземпляра:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
Что именно мы сделали в предыдущей команде? Мы подключились к нашей базе данных и выполнили загруженный SQL-код, который создал таблицы, индексы и последовательности.
Следующий шаг — загрузка данных, для чего нам нужно скачать CSV-файлы из облачного хранилища Google.
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv .
gcloud storage cp gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv .
Затем нам нужно подключиться к базе данных.
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
И импортировать данные из наших CSV-файлов.
\copy cymbal_products from 'cymbal_products.csv' csv header
\copy cymbal_inventory from 'cymbal_inventory.csv' csv header
\copy cymbal_stores from 'cymbal_stores.csv' csv header
Если у вас есть собственные данные, и ваши CSV-файлы совместимы с инструментом импорта Cloud SQL, доступным в консоли Cloud, вы можете использовать его вместо подхода с использованием командной строки.
7. Создайте векторные представления.
Следующий шаг — создание векторных представлений для описаний наших продуктов с использованием модели textembedding-004 от Google Vertex AI и сохранение их в виде векторных данных.
Подключитесь к базе данных (если вы вышли из системы или ваша предыдущая сессия прервалась):
gcloud sql connect my-cloudsql-instance --database quickstart_db --user=postgres
И создадим виртуальный столбец embedding в нашей таблице cymbal_products, используя функцию embedding. Команда создаст виртуальный столбец " embedding ", который будет хранить наши векторы с эмбеддингами, сгенерированными на основе столбца " product_description ". Также она создаст эмбеддинги для всех существующих строк в таблице. Модель определяется как первый параметр для функции embedding, а исходные данные — как второй параметр.
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005',product_description)) STORED;
Это может занять некоторое время, но для 900-1000 строк это не должно занять более 5 минут, а обычно происходит гораздо быстрее.
При добавлении новой строки в таблицу или обновлении параметра product_description для любой существующей строки данные виртуального столбца " embedding " будут сгенерированы заново на основе значения " product_description ".
8. Выполните поиск сходства.
Теперь мы можем выполнить поиск, используя поиск по сходству на основе векторных значений, рассчитанных для описаний, и векторного значения, полученного для нашего запроса.
SQL-запрос можно выполнить из того же интерфейса командной строки, используя gcloud sql connect , или, в качестве альтернативы, из Cloud SQL Studio. Любые многострочные и сложные запросы лучше обрабатывать в Cloud SQL Studio.
Запустите Cloud SQL Studio
В консоли щелкните по созданному ранее экземпляру Cloud SQL.
Когда программа откроется, на правой панели вы увидите Cloud SQL Studio. Щёлкните по ней.
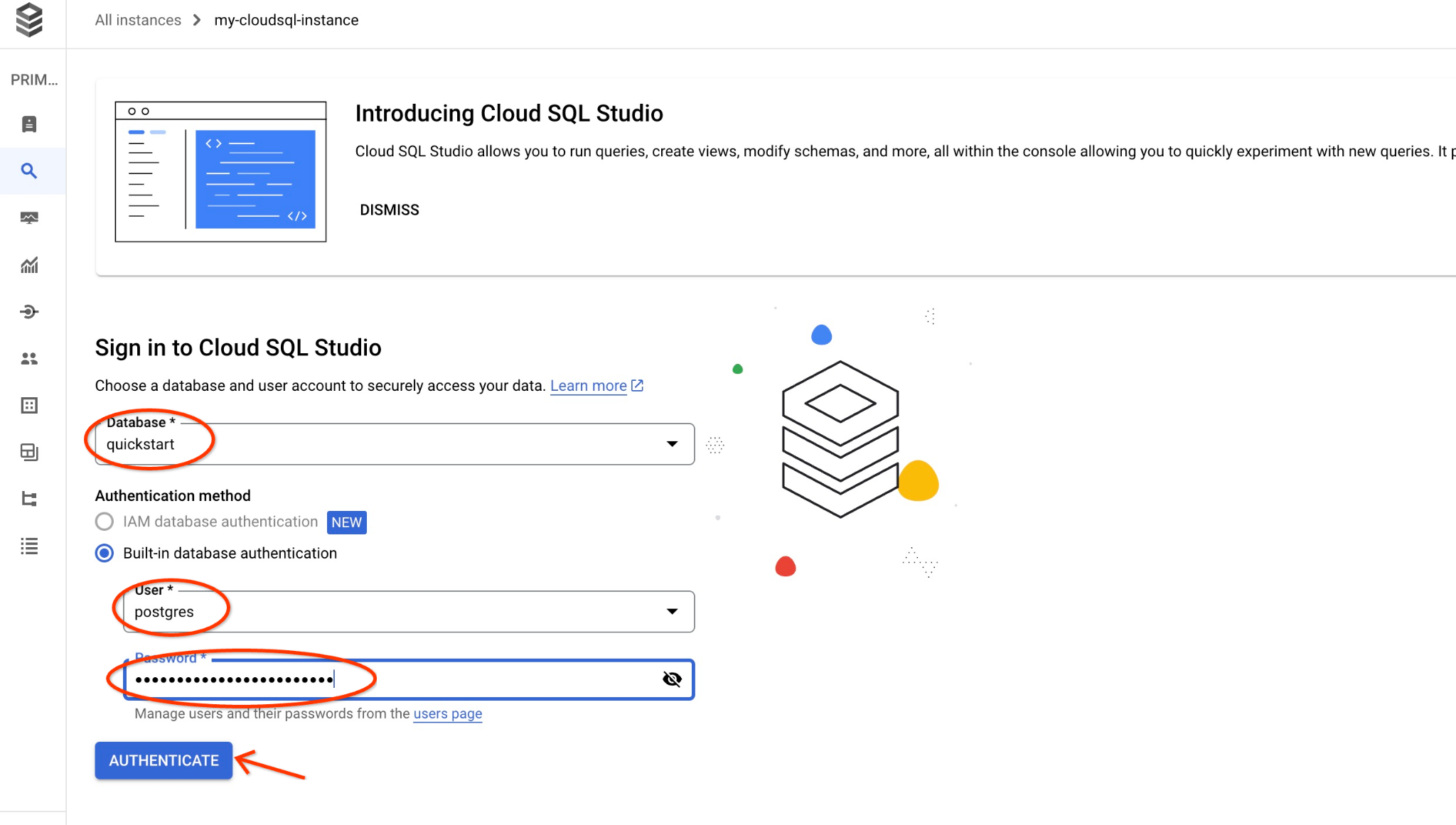
Откроется диалоговое окно, в котором вы укажете имя базы данных и свои учетные данные:
- База данных: quickstart_db
- Пользователь: postgres
- Пароль: ваш записанный пароль для основного пользователя базы данных.
И нажмите кнопку «Аутентифицировать».
Откроется следующее окно, где вам нужно будет щелкнуть вкладку «Редактор» справа, чтобы открыть редактор SQL-запросов.
Теперь мы готовы запустить наши запросы.
Выполнить запрос
Выполните запрос, чтобы получить список доступных товаров, наиболее точно соответствующих запросу клиента. Запрос, который мы собираемся передать в Vertex AI для получения векторного значения, звучит примерно так: «Какие фруктовые деревья хорошо растут здесь?»
Вот запрос, который вы можете выполнить, чтобы выбрать первые 10 элементов, наиболее подходящих для нашего запроса:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
Скопируйте и вставьте запрос в редактор Cloud SQL Studio и нажмите кнопку «Выполнить» или вставьте его в командную строку, подключившись к базе данных quickstart_db.
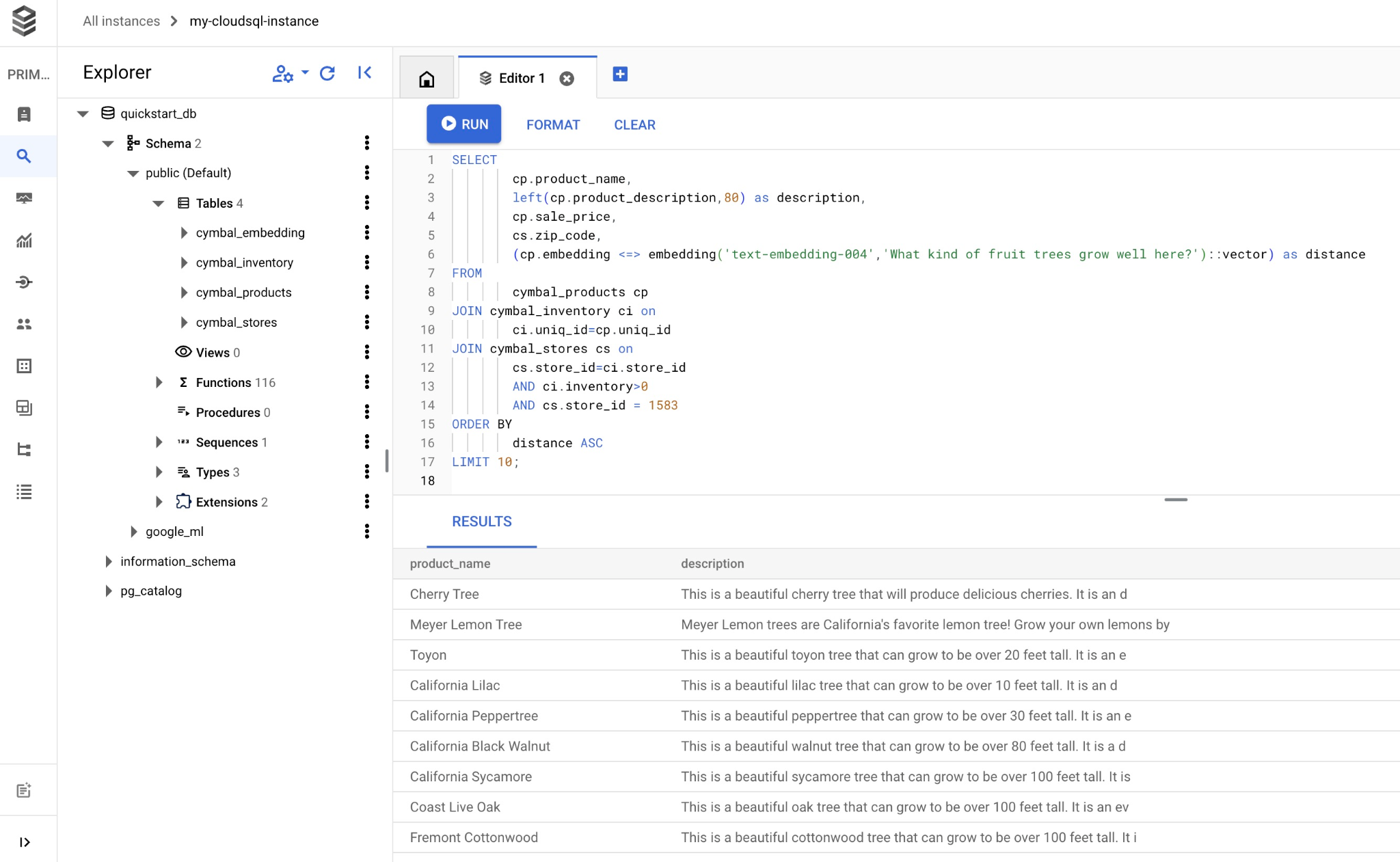
А вот список товаров, выбранных в соответствии с запросом.
product_name | description | sale_price | zip_code | distance -------------------------+----------------------------------------------------------------------------------+------------+----------+--------------------- Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397 Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228 Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668 California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498 California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247 California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597 California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755 Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371 Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058 Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093 (10 rows)
9. Улучшение ответа LLM с использованием полученных данных.
Мы можем улучшить ответ Gen AI LLM клиентскому приложению, используя результат выполненного запроса, и подготовить осмысленный вывод, используя предоставленные результаты запроса в качестве части подсказки для генеративной базовой языковой модели Vertex AI.
Для этого нам необходимо сгенерировать JSON с результатами векторного поиска, а затем использовать этот сгенерированный JSON в качестве дополнения к запросу для модели LLM в Vertex AI, чтобы создать осмысленный результат. На первом этапе мы генерируем JSON, затем тестируем его в Vertex AI Studio, а на последнем этапе включаем его в SQL-запрос, который можно использовать в приложении.
Сгенерировать выходные данные в формате JSON.
Измените запрос так, чтобы он генерировал выходные данные в формате JSON и возвращал только одну строку для передачи в Vertex AI.
Cloud SQL для PostgreSQL
Вот пример запроса:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
А вот ожидаемый JSON-код в выходных данных:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Запустите командную строку в Vertex AI Studio.
Мы можем использовать сгенерированный JSON для предоставления его в качестве части текстовой модели подсказки для генеративного ИИ в Vertex AI Studio.
Откройте Vertex AI Studio Studio в облачной консоли.
Возможно, система запросит включение дополнительных API, но вы можете проигнорировать этот запрос. Нам не нужны дополнительные API для завершения лабораторной работы.
Разместите подсказку в Студии.
Вот подсказка, которую мы будем использовать:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
А вот как это выглядит, когда мы заменяем JSON-заполнитель ответом на запрос:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
А вот результат, полученный при запуске запроса с использованием наших JSON-значений:
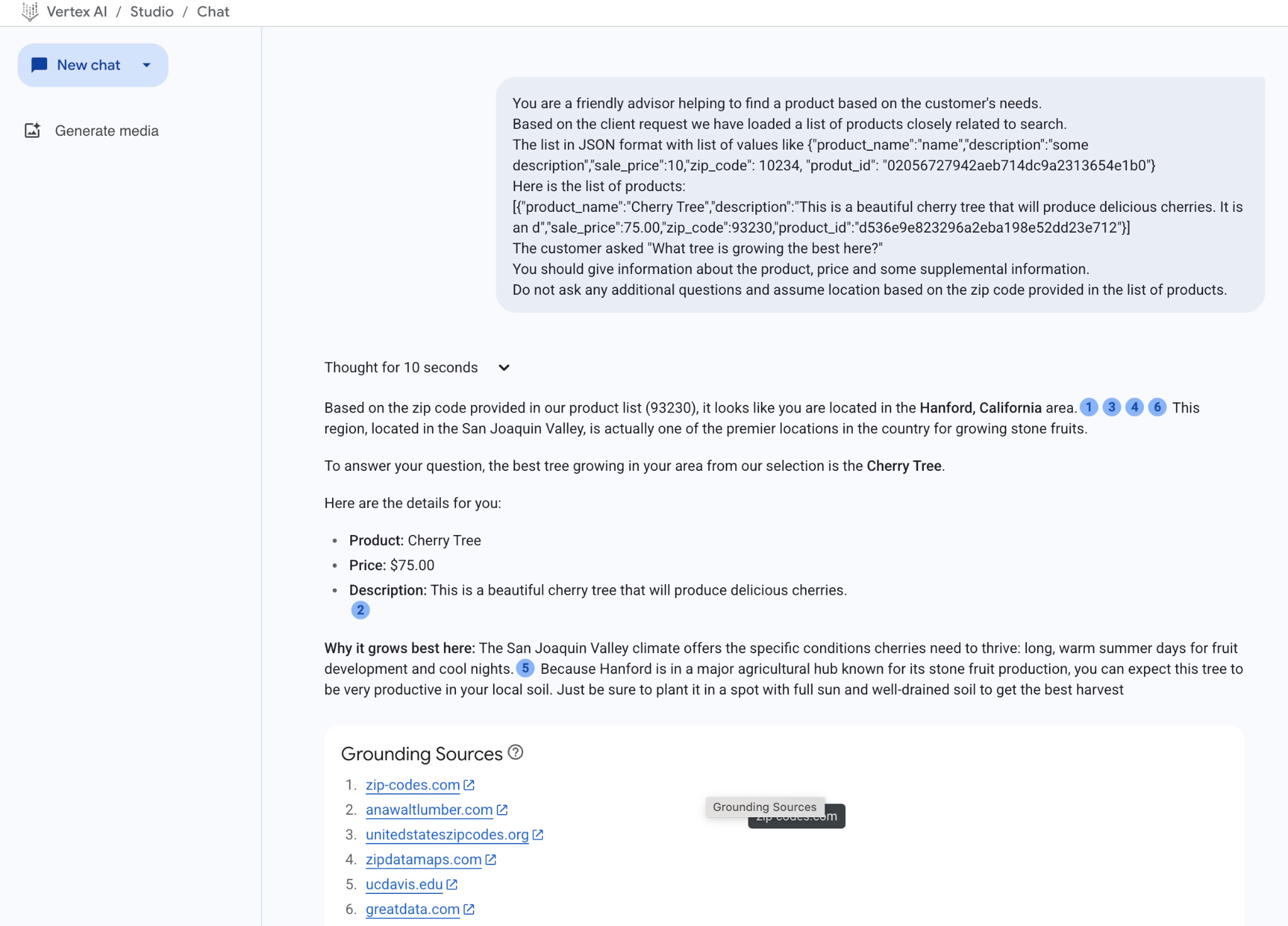
Ниже приведён ответ, полученный нами из модели в этом примере. Обратите внимание, что ваш ответ может отличаться из-за изменений модели и параметров с течением времени:
«Судя по почтовому индексу, указанному в нашем списке товаров (93230), вы находитесь в районе Хэнфорда, штат Калифорния. Этот регион, расположенный в долине Сан-Хоакин, является одним из лучших мест в стране для выращивания косточковых фруктов.»
Отвечая на ваш вопрос, скажу, что из нашего ассортимента лучшее дерево, произрастающее в вашем регионе, — это вишня.
Вот подробности:
Продукт: Вишневое дерево
Цена: 75,00 долларов США
Описание: Это прекрасное вишневое дерево, которое будет давать вкусные ягоды.
Почему оно лучше всего растет здесь: Климат долины Сан-Хоакин предлагает специфические условия, необходимые черешне для процветания: длинные, теплые летние дни для развития плодов и прохладные ночи.<sup>5</sup> Поскольку Хэнфорд находится в крупном сельскохозяйственном центре, известном своим производством косточковых фруктов, вы можете ожидать, что это дерево будет очень продуктивным на вашей местной почве. Просто убедитесь, что вы посадили его на солнечном месте с хорошо дренированной почвой, чтобы получить наилучший урожай.
Запустите командную строку в PSQL.
Мы также можем использовать интеграцию Cloud SQL AI с Vertex AI, чтобы получить аналогичный ответ от генеративной модели, используя SQL непосредственно в базе данных. Но для использования модели gemini-2.0-flash-exp нам необходимо сначала ее зарегистрировать.
Запуск в Cloud SQL для PostgreSQL
Обновите расширение до версии 1.4.2 или выше (если текущая версия ниже). Подключитесь к базе данных quickstart_db через gcloud sql connect, как было показано ранее (или используйте Cloud SQL Studio), и выполните:
SELECT extversion from pg_extension where extname='google_ml_integration';
Если возвращаемое значение меньше 1.4.3, выполните следующее:
ALTER EXTENSION google_ml_integration UPDATE TO '1.4.3';
Затем необходимо установить флаг базы данных google_ml_integration.enable_model_support в значение "on". Для проверки текущих настроек выполните следующую команду.
show google_ml_integration.enable_model_support;
Ожидаемый результат работы сессии psql: "on":
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Если отображается "off", то необходимо обновить флаг базы данных. Для этого можно использовать веб-консоль или выполнить следующую команду gcloud.
gcloud sql instances patch my-cloudsql-instance \
--database-flags google_ml_integration.enable_model_support=on,cloudsql.enable_google_ml_integration=on
Выполнение команды в фоновом режиме занимает от 1 до 3 минут. Затем вы можете проверить новый флаг в сессии psql или с помощью Cloud SQL Studio, подключившись к базе данных quickstart_db.
show google_ml_integration.enable_model_support;
Ожидаемый результат работы сессии psql: "on":
quickstart_db => show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Затем нам нужно зарегистрировать две модели. Первая — это уже используемая модель text-embedding-005 . Ее необходимо зарегистрировать, поскольку мы включили возможность регистрации моделей.
Для регистрации модели выполните следующий код в psql или Cloud SQL Studio:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'cloudsql_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
Следующая модель, которую нам нужно зарегистрировать, — gemini-2.0-flash-001 , которая будет использоваться для генерации удобного для пользователя вывода.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'https://us-central1-aiplatform.googleapis.com/v1/projects/$PROJECT_ID/locations/us-central1/publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'cloudsql_service_agent_iam');
Вы всегда можете проверить список зарегистрированных моделей, выбрав информацию в представлении google_ml.model_info_view.
select model_id,model_type from google_ml.model_info_view;
Вот пример выходных данных.
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
--------------------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
gemini-1.5-pro:streamGenerateContent | generic
gemini-1.5-pro:generateContent | generic
gemini-1.0-pro:generateContent | generic
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
Теперь мы можем использовать сгенерированный JSON-код в подзапросе, чтобы передать его в качестве части запроса для модели генерации текста с помощью SQL.
В сессии psql или Cloud SQL Studio выполните запрос к базе данных.
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> google_ml.embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
Вот ожидаемый результат. Ваш результат может отличаться в зависимости от версии модели и параметров.
"That's a great question! It sounds like you're looking to add some delicious fruit to your garden.\n\nBased on the products we have that are closely related to your search, I can tell you about a fantastic option:\n\n**Cherry Tree**" "\n* **Description:** This beautiful deciduous tree will produce delicious cherries. It grows to be about 15 feet tall, with dark green leaves in summer that turn a beautiful red in the fall. Cherry trees are known for their beauty, shade, and privacy. They prefer a cool, moist climate and sandy soil." "\n* **Price:** $75.00\n* **Grows well in:** USDA Zones 4-9.\n\nTo confirm if this Cherry Tree will thrive in your specific location, you might want to check which USDA Hardiness Zone your area falls into. If you're in zones 4-9, this" " could be a wonderful addition to your yard!"
10. Создайте индекс ближайшего соседа.
Наш набор данных довольно мал, и время отклика в основном зависит от взаимодействия с моделями ИИ. Но когда у вас миллионы векторов, векторный поиск может занимать значительную часть времени отклика и создавать высокую нагрузку на систему. Чтобы улучшить ситуацию, мы можем построить индекс на основе наших векторов.
Создать индекс HNSW
Для нашего теста мы попробуем использовать индекс типа HNSW. HNSW расшифровывается как Hierarchical Navigable Small World (иерархический навигационный малый мир) и представляет собой многослойный графовый индекс.
Для построения индекса для нашего столбца встраивания нам необходимо определить сам столбец встраивания, функцию расстояния и, при необходимости, параметры, такие как m или ef_constructions. Подробную информацию о параметрах можно найти в документации .
CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
Ожидаемый результат:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_hnsw ON cymbal_products USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64); CREATE INDEX quickstart_db=>
Сравните ответ
Теперь мы можем выполнить запрос векторного поиска в режиме EXPLAIN и проверить, был ли использован индекс.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Ожидаемый результат:
Aggregate (cost=779.12..779.13 rows=1 width=32) (actual time=1.066..1.069 rows=1 loops=1)
-> Subquery Scan on trees (cost=769.05..779.12 rows=1 width=142) (actual time=1.038..1.041 rows=1 loops=1)
-> Limit (cost=769.05..779.11 rows=1 width=158) (actual time=1.022..1.024 rows=1 loops=1)
-> Nested Loop (cost=769.05..9339.69 rows=852 width=158) (actual time=1.020..1.021 rows=1 loops=1)
-> Nested Loop (cost=768.77..9316.48 rows=852 width=945) (actual time=0.858..0.859 rows=1 loops=1)
-> Index Scan using cymbal_products_embeddings_hnsw on cymbal_products cp (cost=768.34..2572.47 rows=941 width=941) (actual time=0.532..0.539 rows=3 loops=1)
Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,...
<redacted>
...,0.017593635,-0.040275685,-0.03914233,-0.018452475,0.00826032,-0.07372604
]'::vector)
-> Index Scan using product_inventory_pkey on cymbal_inventory ci (cost=0.42..7.17 rows=1 width=37) (actual time=0.104..0.104 rows=0 loops=3)
Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text))
Filter: (inventory > 0)
Rows Removed by Filter: 1
-> Materialize (cost=0.28..8.31 rows=1 width=8) (actual time=0.133..0.134 rows=1 loops=1)
-> Index Scan using product_stores_pkey on cymbal_stores cs (cost=0.28..8.30 rows=1 width=8) (actual time=0.129..0.129 rows=1 loops=1)
Index Cond: (store_id = 1583)
Planning Time: 112.398 ms
Execution Time: 1.221 ms
Из выходных данных ясно видно, что запрос использовал "Index Scan using cymbal_products_embeddings_hnsw".
А если мы выполним запрос без оператора explain:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Ожидаемый результат (результат может отличаться в зависимости от модели и индекса):
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Мы видим, что результат тот же, и возвращается то же самое вишневое дерево, которое было на вершине нашего поиска без индекса. В зависимости от параметров и типа индекса результат может немного отличаться и возвращать другую верхнюю запись для дерева. В ходе моих тестов индексированный запрос вернул результаты за 131,301 мс против 167,631 мс без индекса, но мы работали с очень небольшим набором данных, и разница была бы более существенной на большем объеме данных.
Вы можете попробовать различные индексы, доступные для векторов, а также ознакомиться с дополнительными лабораторными работами и примерами интеграции с Langchain в документации .
11. Очистка окружающей среды
Удалите экземпляр Cloud SQL.
После завершения лабораторной работы удалите экземпляр Cloud SQL.
В облачной оболочке укажите переменные проекта и среды на случай, если соединение было разорвано и все предыдущие настройки были потеряны:
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
Удалите экземпляр:
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
Ожидаемый вывод в консоль:
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
12. Поздравляем!
Поздравляем с завершением практического занятия!
Данная лабораторная работа является частью учебного курса "Готовый к внедрению ИИ в производство с использованием Google Cloud".
- Изучите полный учебный план , чтобы преодолеть разрыв между прототипом и серийным производством.
- Делитесь своими успехами, используя хэштег
#ProductionReadyAI.
Что мы рассмотрели
- Как развернуть экземпляр Cloud SQL для PostgreSQL
- Как создать базу данных и включить интеграцию Cloud SQL с искусственным интеллектом
- Как загрузить данные в базу данных
- Как использовать Cloud SQL Studio
- Как использовать модель встраивания Vertex AI в Cloud SQL
- Как использовать Vertex AI Studio
- Как улучшить результаты, используя генеративную модель Vertex AI
- Как повысить производительность с помощью векторного индекса
Попробуйте аналогичный практический пример для AlloyDB с индексом ScaNN вместо HNSW.
13. Опрос
Выход: