
1. Übersicht
Moderne Reisende erwarten Konversationen in natürlicher Sprache. Anstatt sich durch komplexe UI-Filter zu klicken, möchten sie einfach fragen: „Kann ich meinen Hund mit in den Bus um 9 Uhr nach Boston nehmen?“ Dazu ist ein Agent erforderlich, der sowohl unstrukturierte Daten (PDF-Richtlinien) als auch strukturierte Daten (SQL-Zeitpläne) verarbeiten kann.
In diesem Lab erstellen wir den Cymbal Transit Agent mit folgenden Tools:
- LangChain4j:Das führende Java-Framework für die KI-Orchestrierung.
- AlloyDB:Eine leistungsstarke, PostgreSQL-kompatible Datenbank.
- MCP Toolbox Java SDK:Eine standardisierte Möglichkeit, Java-basierte Agenten mit externen Tools und Datenquellen zu verbinden.
Aufgaben
Cymbal Bus Agent, eine Java Spring Boot-Anwendung, die Folgendes umfasst:
- AlloyDB-Datenbank und MCP Toolbox Java SDK für die Tool-Orchestrierung mit den Agenten.
- Cloud Run für die Toolbox-Bereitstellung und -Anwendung (Agent-Bereitstellung).
- LangChain4J-Bibliothek für das Agenten- und LLM-Framework in einer Spring Boot-Anwendung mit Java 17.
Lerninhalte
- LangChain4J zum Erstellen von spezialisierten Agenten und untergeordneten Agenten verwenden, die mit dem MCP Toolbox for Databases Java SDK orchestriert werden
- Hier erfahren Sie, wie Sie AlloyDB für Daten und KI einrichten und verwenden.
- So verwenden Sie die MCP Toolbox, um Agenten mit AlloyDB-Datentools zu verbinden.
- So stellen Sie die Lösung mit Cloud Run bereit oder führen sie lokal aus.
Die Architektur
- AlloyDB for PostgreSQL:Dient als leistungsstarke operative Datenbank für unsere Routen-, Richtlinien- und Buchungsdatensätze. Sie ist die Grundlage für die Vektorsuche und das Abrufen von Informationen.
- MCP Toolbox for Databases Java SDK:Fungiert als „Orchestration Maestro“ und stellt AlloyDB-Daten als ausführbare Tools bereit, die von den Agenten aufgerufen werden können.
Mit dem MCP Toolbox Java SDK können Sie Agenten für Unternehmensanwendungen ganz einfach mit Ihren Datenbanktools orchestrieren.
- LangChain4J:Eine Open-Source-Java-Bibliothek, die die Integration von Large Language Models (LLMs) in Java-Anwendungen vereinfacht. Es bietet Tools und Abstraktionen zum Erstellen von KI-basierten Anwendungen, einschließlich Chatbots, Agents und Retrieval-Augmented Generation (RAG)-Systemen.
- Cloud Run:Eine vollständig verwaltete SERVERLOSE Plattform, mit der Sie mühelos Apps oder Websites schnell in jeder Sprache, jeder Bibliothek und jedem Binärprogramm erstellen und bereitstellen können. Sie können Code in Ihrer bevorzugten Sprache, Ihrem bevorzugten Framework und Ihren bevorzugten Bibliotheken schreiben, als Container verpacken und „gcloud run deploy“ ausführen. So wird Ihre Anwendung veröffentlicht und erhält alles, was für die Ausführung in der Produktion erforderlich ist. Das Erstellen eines Containers ist völlig optional. Wenn Sie Go, Node.js, Python, Java, .NET Core oder Ruby verwenden, können Sie die Option für das quellbasierte Deployment verwenden, die den Container für Sie erstellt. Beachten Sie dabei die Best Practices für die von Ihnen verwendete Sprache.
Voraussetzungen
2. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.

- Sobald die Verbindung mit der Cloud Shell hergestellt ist, prüfen Sie mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
- Aktivieren Sie die erforderlichen APIs: Folgen Sie dem Link und aktivieren Sie die APIs.
Alternativ können Sie dazu den gcloud-Befehl verwenden. Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
Wichtige Hinweise und Fehlerbehebung
Das „Geisterprojekt“-Syndrom | Sie haben |
Die Abrechnungsbarrikade | Sie haben das Projekt aktiviert, aber das Rechnungskonto vergessen. AlloyDB ist eine leistungsstarke Engine, die nicht startet, wenn der „Benzintank“ (Abrechnung) leer ist. |
Verzögerung bei der API-Weitergabe | Sie haben auf „APIs aktivieren“ geklickt, aber in der Befehlszeile wird weiterhin |
Kontingent – Häufig gestellte Fragen | Wenn Sie ein brandneues Testkonto verwenden, erreichen Sie möglicherweise ein regionales Kontingent für AlloyDB-Instanzen. Wenn |
Verborgener Kundenservicemitarbeiter | Manchmal wird dem AlloyDB-Dienst-Agenten die Rolle |
3. Datenbank einrichten
Das Herzstück unserer Anwendung ist AlloyDB for PostgreSQL. Wir haben die leistungsstarken Vektorfähigkeiten und die integrierte spaltenbasierte Engine genutzt,um Einbettungen für über 50.000 SCM-Datensätze zu generieren. Dies ermöglicht eine Vektoranalyse in nahezu Echtzeit, sodass unsere Agenten Inventaranomalien oder Logistikrisiken in riesigen Datasets in Millisekunden erkennen können.
In diesem Lab verwenden wir AlloyDB als Datenbank für die Testdaten. Darin werden Cluster verwendet, um alle Ressourcen wie Datenbanken und Logs zu speichern. Jeder Cluster hat eine primäre Instanz, die einen Zugriffspunkt auf die Daten bietet. Tabellen enthalten die tatsächlichen Daten.
Erstellen wir einen AlloyDB-Cluster, eine AlloyDB-Instanz und eine AlloyDB-Tabelle, in die das Test-Dataset geladen wird.
- Klicken Sie auf den Button oder kopieren Sie den Link unten in den Browser, in dem der Google Cloud Console-Nutzer angemeldet ist.
Alternativ können Sie in Ihrem Projekt, in dem Sie das Abrechnungskonto eingelöst haben, zum Cloud Shell-Terminal wechseln, das GitHub-Repository klonen und mit den folgenden Befehlen zum Projekt navigieren:
git clone https://github.com/AbiramiSukumaran/easy-alloydb-setup
cd easy-alloydb-setup
- Sobald dieser Schritt abgeschlossen ist, wird das Repository in Ihren lokalen Cloud Shell-Editor geklont und Sie können den folgenden Befehl über den Projektordner ausführen. Achten Sie darauf, dass Sie sich im Projektverzeichnis befinden:
sh run.sh
- Verwenden Sie jetzt die Benutzeroberfläche (klicken Sie auf den Link im Terminal oder auf den Link „Vorschau im Web“ im Terminal).
- Geben Sie die Details für Projekt-ID, Cluster- und Instanznamen ein, um zu beginnen.
- Holen Sie sich einen Kaffee, während die Logs durchlaufen. Hier können Sie nachlesen, wie das im Hintergrund funktioniert.
Wichtige Hinweise und Fehlerbehebung
Das Problem mit der Geduld | Datenbankcluster sind eine schwere Infrastruktur. Wenn Sie die Seite aktualisieren oder die Cloud Shell-Sitzung beenden, weil sie „hängt“, kann es passieren, dass eine „Geisterinstanz“ entsteht, die teilweise bereitgestellt wurde und ohne manuellen Eingriff nicht gelöscht werden kann. |
Region stimmt nicht überein | Wenn Sie Ihre APIs in |
Zombie-Cluster | Wenn Sie zuvor denselben Namen für einen Cluster verwendet und ihn nicht gelöscht haben, wird im Skript möglicherweise angezeigt, dass der Clustername bereits vorhanden ist. Cluster-Namen müssen innerhalb eines Projekts eindeutig sein. |
Cloud Shell-Zeitüberschreitung | Wenn Ihre Kaffeepause 30 Minuten dauert, wird Cloud Shell möglicherweise inaktiv und die Verbindung zum |
4. Schemabereitstellung
Sobald Ihr AlloyDB-Cluster und Ihre Instanz ausgeführt werden, können Sie im SQL-Editor von AlloyDB Studio die KI-Erweiterungen aktivieren und das Schema bereitstellen.
Möglicherweise müssen Sie warten, bis die Instanz erstellt wurde. Melden Sie sich dann mit den Anmeldedaten in AlloyDB an, die Sie beim Erstellen des Clusters erstellt haben. Verwenden Sie die folgenden Daten für die Authentifizierung bei PostgreSQL:
- Nutzername: „
postgres“ - Datenbank: „
postgres“ - Passwort: „
alloydb“ (oder das Passwort, das Sie bei der Erstellung festgelegt haben)
Nachdem Sie sich erfolgreich in AlloyDB Studio authentifiziert haben, werden SQL-Befehle im Editor eingegeben. Sie können mehrere Editorfenster hinzufügen, indem Sie auf das Pluszeichen rechts neben dem letzten Fenster klicken.
Sie geben Befehle für AlloyDB in Editorfenstern ein und verwenden bei Bedarf die Optionen „Ausführen“, „Formatieren“ und „Löschen“.
Erweiterungen aktivieren
Für die Entwicklung dieser App verwenden wir die Erweiterungen pgvector und google_ml_integration. Mit der pgvector-Erweiterung können Sie Vektoreinbettungen speichern und durchsuchen. Die Erweiterung google_ml_integration bietet Funktionen, mit denen Sie auf Vertex AI-Vorhersageendpunkte zugreifen können, um Vorhersagen in SQL zu erhalten. Aktivieren Sie diese Erweiterungen, indem Sie die folgenden DDLs ausführen:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Berechtigung gewähren
Führen Sie die folgende Anweisung aus, um die Ausführung der Funktion „embedding“ zu gewähren:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB-Dienstkonto die Rolle „Vertex AI User“ gewähren
Gewähren Sie in der Google Cloud IAM-Konsole dem AlloyDB-Dienstkonto (das so aussieht: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) Zugriff auf die Rolle „Vertex AI-Nutzer“. PROJECT_NUMBER enthält Ihre Projektnummer.
Alternativ können Sie den folgenden Befehl im Cloud Shell-Terminal ausführen:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Tabelle erstellen
Sie können eine Tabelle mit der folgenden DDL-Anweisung in AlloyDB Studio erstellen:
DROP TABLE IF EXISTS transit_policies;
DROP TABLE IF EXISTS bus_schedules;
DROP TABLE IF EXISTS bookings;
-- Table 1: Transit Policies (Unstructured Data for RAG)
CREATE TABLE transit_policies (
policy_id SERIAL PRIMARY KEY,
category VARCHAR(50),
policy_text TEXT,
policy_embedding vector(768)
);
-- Table 2: Intercity Bus Schedules (Structured Data)
CREATE TABLE bus_schedules (
trip_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
origin_city VARCHAR(100),
destination_city VARCHAR(100),
departure_time TIMESTAMP,
arrival_time TIMESTAMP,
available_seats INT DEFAULT 50,
ticket_price DECIMAL(6,2)
);
-- Table 3: Booking Ledger (Transactional Action Data)
CREATE TABLE bookings (
booking_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
trip_id UUID REFERENCES bus_schedules(trip_id),
passenger_id VARCHAR(100),
status VARCHAR(20) DEFAULT 'CONFIRMED',
booking_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
In der Spalte policy_embedding können die Vektorwerte einiger Textfelder gespeichert werden.
Datenaufnahme
Führen Sie die folgenden SQL-Anweisungen aus, um Datensätze in die entsprechenden Tabellen einzufügen:
- Unstrukturierte Richtlinien einfügen und REAL EMBEDDINGS nativ in AlloyDB generieren
-- 1. Insert Unstructured Policies and GENERATE REAL EMBEDDINGS natively in AlloyDB
INSERT INTO transit_policies (category, policy_text, policy_embedding)
VALUES
('Pets', 'Service animals are always welcome. Small pets (under 25 lbs) are allowed in secure carriers for a $25 fee. Large dogs are not permitted on standard coaches.', embedding('text-embedding-005', 'Service animals are always welcome. Small pets (under 25 lbs) are allowed in secure carriers for a $25 fee. Large dogs are not permitted on standard coaches.')),
('Luggage', 'Each passenger is allowed one carry-on (up to 15 lbs) and two stowed bags (up to 50 lbs each) free of charge. Additional bags cost $15 each.', embedding('text-embedding-005', 'Each passenger is allowed one carry-on (up to 15 lbs) and two stowed bags (up to 50 lbs each) free of charge. Additional bags cost $15 each.')),
('Refunds', 'Tickets are fully refundable up to 24 hours before departure. Within 24 hours, tickets can be exchanged for travel credit only.', embedding('text-embedding-005', 'Tickets are fully refundable up to 24 hours before departure. Within 24 hours, tickets can be exchanged for travel credit only.'));
- Mit generate_series mehr als 200 realistische Zeitpläne für 7 Tage generieren
-- 2. Generate 200+ Realistic Schedules for the Next 7 Days using generate_series
INSERT INTO bus_schedules (origin_city, destination_city, departure_time, arrival_time, ticket_price, available_seats)
SELECT
origin,
destination,
-- Generate departures every 4 hours starting from tomorrow
(CURRENT_DATE + 1) + (interval '4 hours' * seq) AS dep_time,
(CURRENT_DATE + 1) + (interval '4 hours' * seq) + interval '4.5 hours' AS arr_time,
ROUND((RANDOM() * 30 + 25)::numeric, 2) AS price, -- Random price between $25 and $55
FLOOR(RANDOM() * 50 + 1) AS seats -- Random seats between 1 and 50
FROM
(VALUES
('New York', 'Boston'), ('Boston', 'New York'),
('Philadelphia', 'Washington DC'), ('Washington DC', 'Philadelphia'),
('Seattle', 'Portland'), ('Portland', 'Seattle')
) AS routes(origin, destination)
CROSS JOIN generate_series(1, 40) AS seq; -- 6 routes * 40 time slots = 240 distinct trips ingested!
Einbettungen generieren
Einbettungen werden automatisch in die INSERT-Anweisung in die Tabelle „transit_policies“ mit der Funktion „embedding('text-embedding-005', '<<policytext>>')“ aufgenommen.
Wichtige Hinweise und Fehlerbehebung
Die „Passwort vergessen“-Schleife | Wenn Sie die Einrichtung mit nur einem Klick verwendet haben und sich nicht mehr an Ihr Passwort erinnern, rufen Sie in der Konsole die Seite „Instance basic information“ (Allgemeine Informationen zur Instanz) auf und klicken Sie auf „Edit“ (Bearbeiten), um das |
Fehler „Erweiterung nicht gefunden“ | Wenn |
IAM-Weiterleitungsprobleme | Sie haben den IAM-Befehl
|
Falsche Vektordimension | Die Spalte |
Tippfehler bei der Projekt-ID | Wenn Sie im |
5. Tools und Toolbox einrichten
Die MCP Toolbox for Databases ist ein Open-Source-MCP-Server für Datenbanken. Damit können Sie Tools einfacher, schneller und sicherer entwickeln, da Komplexitäten wie Connection Pooling, Authentifizierung und mehr abgedeckt werden. Mit der Toolbox können Sie GenAI-Tools erstellen, mit denen Ihre Agenten auf Daten in Ihrer Datenbank zugreifen können.
Wir verwenden die MCP-Toolbox (Model Context Protocol) für Datenbanken als „Dirigent“. Sie fungiert als standardisierte Middleware zwischen unseren Agents und AlloyDB. Durch die Definition einer tools.yaml-Konfiguration werden komplexe Datenbankvorgänge automatisch als übersichtliche, ausführbare Tools wie find-bus-schedules and routes oder query-schedules for specific routes verfügbar gemacht und autonome Aktionen wie book-ticket ausgeführt. Dadurch ist kein manuelles Connection Pooling oder Boilerplate-SQL in der Agentenlogik mehr erforderlich.
Toolbox-Server installieren
Erstellen Sie im Cloud Shell-Terminal einen Ordner zum Speichern der neuen YAML-Datei für die Tools und der Toolbox-Binärdatei:
mkdir cymbal-bus-toolbox
cd cymbal-bus-toolbox
Führen Sie in diesem neuen Ordner die folgenden Befehle aus:
# see releases page for other versions
export VERSION=0.27.0
curl -L -o toolbox https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Erstellen Sie als Nächstes die Datei tools.yaml in diesem neuen Ordner. Rufen Sie dazu den Cloud Shell-Editor auf und kopieren Sie den Inhalt dieser Repository-Datei in die Datei „tools.yaml“.
... (Refer to entire file in the repo)
tools:
find-bus-schedules:
kind: postgres-sql
source: alloydb
description: Find all available bus schedules.
statement: |
SELECT CAST(trip_id AS TEXT) trip_id, departure_time, arrival_time, ticket_price, available_seats , origin_city, destination_city
FROM bus_schedules;
query-schedules:
kind: postgres-sql
source: alloydb
description: Find available bus schedules between an origin and destination city.
parameters:
- name: origin
type: string
description: The departure city name.
- name: destination
type: string
description: The arrival city name.
statement: |
SELECT CAST(trip_id AS TEXT) trip_id, departure_time, arrival_time, ticket_price, available_seats
FROM bus_schedules
WHERE lower(origin_city) = lower($1)
AND lower(destination_city) = lower($2)
AND available_seats > 0
ORDER BY departure_time ASC
LIMIT 5;
book-ticket:
kind: postgres-sql
source: alloydb
description: Books a ticket for a specific trip, decrementing available seats and generating a confirmed booking record.
parameters:
- name: trip_id
type: string
description: The UUID of the trip schedule to book.
- name: passenger_name
type: string
description: Name or ID of the passenger (Bound securely via backend or AuthToken).
authServices:
- name: google_auth
field: sub
statement: |
WITH updated_schedule AS (
UPDATE bus_schedules
SET available_seats = available_seats - 1
WHERE trip_id = CAST($1 AS UUID) AND available_seats > 0
RETURNING trip_id
)
INSERT INTO bookings (trip_id, passenger_id)
SELECT trip_id, $2
FROM updated_schedule
RETURNING CAST(booking_id as TEXT) as booking_id, trip_id, passenger_id, status, booking_time;
search-policies:
kind: postgres-sql
source: alloydb
description: Semantic search for transit policies regarding luggage, pets, refunds, and general rules.
parameters:
- name: search_query
type: string
description: The user's question about transit policies to be embedded and searched.
statement: |
SELECT category, policy_text
FROM transit_policies
ORDER BY policy_embedding <=> CAST(embedding('text-embedding-005', $1) AS vector(768))
LIMIT 2;
Hinweis:
- Vergessen Sie nicht, in der Einrichtung von „tools.yaml“ ipType: "private" in die AlloyDB-Quellkonfiguration aufzunehmen.
- Denken Sie auch daran, die MCP Toolbox-Dienst-URL in den clientId-Parameter für die authServices-Konfiguration aufzunehmen. Möglicherweise erhalten Sie den Link erst nach der ersten Bereitstellung. Sie müssen die Bereitstellungsschritte also zweimal ausführen, damit der Anwendungsfall für authentifizierte Tools funktioniert.
- Die folgenden Optionen zum lokalen Testen der Toolbox funktionieren nicht, wenn Ihre AlloyDB-Verbindung auf „privat“ gesetzt ist. Sie müssen sie auf „öffentlich“ setzen, um sie lokal zu testen, oder einen Proxy für die Verbindung verwenden. Aber keine Sorge. In unserem Fall stellen wir sie direkt in Cloud Run bereit und testen sie dann.
So testen Sie die Datei „tools.yaml“ auf dem lokalen Server:
./toolbox --tools-file "tools.yaml"
Alternativ können Sie es in der Benutzeroberfläche testen:
./toolbox --ui
Stellen wir sie in Cloud Run bereit.
Cloud Run-Bereitstellung
- Legen Sie die Umgebungsvariable PROJECT_ID fest:
export PROJECT_ID="my-project-id"
- Initialisieren Sie die gcloud CLI:
gcloud init
gcloud config set project $PROJECT_ID
- Die folgenden APIs müssen aktiviert sein:
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Erstellen Sie ein Backend-Dienstkonto, falls Sie noch keines haben:
gcloud iam service-accounts create toolbox-identity
- Berechtigungen zur Verwendung von Secret Manager erteilen:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
- Gewähren Sie dem Dienstkonto zusätzliche Berechtigungen, die für unsere AlloyDB-Quelle spezifisch sind (roles/alloydb.client und roles/serviceusage.serviceUsageConsumer).
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- Laden Sie „tools.yaml“ als Secret hoch:
gcloud secrets create tools-cymbal-transit --data-file=tools.yaml
- Wenn Sie bereits ein Secret haben und die Secret-Version aktualisieren möchten, führen Sie Folgendes aus:
gcloud secrets versions add tools-cymbal-transit --data-file=tools.yaml
- Legen Sie eine Umgebungsvariable für das Container-Image fest, das Sie für Cloud Run verwenden möchten:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Stellen Sie die Toolbox mit dem folgenden Befehl in Cloud Run bereit:
Wenn Sie öffentlichen Zugriff in Ihrer AlloyDB-Instanz aktiviert haben, folgen Sie dem Befehl unten für die Bereitstellung in Cloud Run:
gcloud run deploy toolbox-cymbal-transit \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-cymbal-transit:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
Wenn Sie ein VPC-Netzwerk verwenden, verwenden Sie den folgenden Befehl:
gcloud run deploy toolbox-cymbal-transit \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-cymbal-transit:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network <<YOUR_NETWORK_NAME>> \
--subnet <<YOUR_SUBNET_NAME>> \
--allow-unauthenticated
Hinweis: Rufen Sie nach der Bereitstellung die Liste der Cloud Run-Dienste auf und prüfen Sie, ob auf dem Tab „Sicherheit“ dieses Dienstes die Option „Öffentlichen Zugriff zulassen“ ausgewählt ist.
6. Einrichtung der Agentenanwendung
Klonen Sie dieses Repository in Ihr Projekt und sehen wir uns die einzelnen Schritte an.
Führen Sie zum Klonen des Repositorys im Cloud Shell-Terminal (im Stammverzeichnis oder an einem beliebigen Ort, an dem Sie das Projekt erstellen möchten) den folgenden Befehl aus:
git clone https://github.com/googleapis/mcp-toolbox-sdk-java
Mit dem oben stehenden Befehl wird das gesamte mcp-toolbox-sdk-java geklont. Wir benötigen nur das Beispielprojekt. Wechseln Sie also in das Stammverzeichnis des Projekts im Repository:
cd mcp-toolbox-sdk-java/demo-applications/cymbal-transit
- Dadurch sollte das Projekt erstellt werden. Sie können dies im Cloud Shell Editor überprüfen.
- Öffnen Sie „CymbalTransitController.java“ und legen Sie Umgebungsvariablen fest:
- GCP_PROJECT_ID
- GCP_REGION
- GEMINI_MODEL_NAME
- MCP_TOOLBOX_URL
Alternativ (nur für Entwicklungszwecke) können Sie auch die entsprechenden Platzhalter für Fallback-Werte ersetzen.
7. Schritt-für-Schritt-Anleitung zum Code
CymbalTransitController fungiert als Einstiegspunkt für unseren Cloud Run-Dienst. Sie verwaltet den Unterhaltungsfluss und sorgt dafür, dass der Agent Zugriff auf die aktuelle Anfrage des Nutzers hat.
Die Implementierung folgt einer mehrschichtigen Architektur, die KI-Orchestrierung, Tool-Bridging und Low-Level-MCP-Kommunikation trennt.
1. KI-Agent-Konfiguration (AgentConfiguration)
In dieser Klasse wird @Configuration von Spring verwendet, um die KI-Komponenten zu starten. Es initialisiert das VertexAiGeminiChatModel und bindet es an unsere Agent-Schnittstelle.
@Bean
ChatLanguageModel geminiChatModel() {
return VertexAiGeminiChatModel.builder()
.project(projectId)
.location(region)
.modelName(modelName)
.build();
}
@Bean
TransitAgent transitAgent(ChatLanguageModel chatLanguageModel, TransitAgentTools tools) {
return AiServices.builder(TransitAgent.class)
.chatLanguageModel(chatLanguageModel)
.chatMemoryProvider(memoryId -> MessageWindowChatMemory.withMaxMessages(20))
.tools(tools)
.build();
}
Bedeutung : AiServices bindet die Schnittstelle an das LLM. Durch MessageWindowChatMemory merkt sich der Agent Nutzereinstellungen (z. B. eine zuvor erwähnte Transportbox für Haustiere) für bis zu 20 Nachrichten innerhalb einer einzelnen Sitzung.
2. Die KI-Agent-Schnittstelle (TransitAgent)
Mit der Annotation @SystemMessage werden die „Persona“ und die betrieblichen Einschränkungen definiert, insbesondere eine Routing-Strategie.
@SystemMessage({
"You are the Cymbal Transit Concierge.",
"CRITICAL INSTRUCTION: On your very first interaction, you MUST use the 'findAllSchedules' tool to fetch and memorize the broad bus routes.",
"ONLY if the user asks a specifically narrowed-down question... should you route to the specific tools like 'querySchedules', 'bookTicket', 'searchPolicies'.",
"Don't show any asterisks while listing results. Keep it formatted and numbered or bulleted."
})
String chat(@MemoryId String sessionId, @UserMessage String userMessage);
Bedeutung:Mit dieser Strategie wird die Latenz minimiert. Indem der KI-Agent zuerst allgemeine Daten abruft, kann er allgemeine Routing-Fragen anhand seines internen Kontexts beantworten, ohne redundante Backend-Aufrufe auszuführen.
3. Toolbox Bridge (TransitAgentTools)
Dieser Dienst fungiert als „Hände“ des Agents und übersetzt LangChain4j-Tool-Aufrufe in Ausführungslogik.
@Tool("Fetches the initial, broad dataset of all available bus schedules and routes.")
public String findAllSchedules() {
return mcpService.findAllSchedules().join();
}
@Tool("Book a ticket for a passenger using a specific trip ID.")
public String bookTicket(String tripId, String passengerName) {
return mcpService.bookTicket(tripId, passengerName).join();
}
Synchrone Ausführung:MCP-Aufrufe sind zwar asynchron (es wird CompletableFuture zurückgegeben), das LLM benötigt jedoch ein Ergebnis, bevor es mit dem „Denkprozess“ fortfahren kann. Wir verwenden .join(), um dem KI-Agenten synchrone Ergebnisse zurückzugeben.
4. Der MCP Toolbox-Dienst (McpToolboxService)
Dies ist die Kommunikationsschicht, die das MCP Toolbox Java SDK verwendet, um mit dem AlloyDB-Backend zu interagieren.
// Identity Management: Fetching OIDC ID Token for Auth
GoogleCredentials credentials = GoogleCredentials.getApplicationDefault();
this.idToken = ((IdTokenProvider) credentials)
.idTokenWithAudience(targetUrl, Collections.emptyList())
.getTokenValue();
// Dynamic Invocation: Executing a tool by name
public CompletableFuture<String> findAllSchedules() {
return mcpClient.invokeTool("find-bus-schedules", Collections.emptyMap()).thenApply(result -> {
return result.content().stream()
.map(content -> content.text())
.collect(Collectors.joining(", ", "[", "]"));
});
}
Bedeutung : McpToolboxClient übernimmt die anspruchsvolle JSON-RPC-Kommunikation. Die Methode bookTicket demonstriert insbesondere die Fähigkeit des SDKs, komplexe Parameter dynamisch zu binden.
5. Der REST-Controller (TransitAgentController)
Der endgültige Endpunkt ist viel einfacher, da LangChain4j den Status und die Logik verwaltet.
@PostMapping("/chat")
public ResponseEntity<String> handleUserChat(@RequestBody String userMessage, HttpSession session) {
String sessionId = session.getId();
String agentResponse = transitAgent.chat(sessionId, userMessage);
return ResponseEntity.ok(agentResponse);
}
Bedeutung:Durch die Zuordnung der HttpSession-ID zu @MemoryId wird sichergestellt, dass die Reisepläne verschiedener Nutzer nicht vermischt werden. Gleichzeitig bleibt der Controller-Code übersichtlich und lesbar.
8. MCP Toolbox: Signifikanz und Java SDK
Was ist das MCP?
Das Model Context Protocol (MCP) ist wie ein universeller Übersetzer für KI. MCP wurde entwickelt, um die Verbindung von KI-Modellen mit externen Tools und Datasets zu standardisieren. Es ersetzt benutzerdefinierte, fragmentierte Integrationsskripts durch ein sicheres, universelles Protokoll. Ganz gleich, ob Ihr Agent eine transaktionale SQL-Abfrage ausführen, Tausende von Richtliniendokumenten durchsuchen oder eine REST API auslösen muss – MCP bietet eine einzige, einheitliche Schnittstelle.
MCP Toolbox for Databases
Entwicklungsteams gehen über einfache Chatbots hinaus und entwickeln agentische Systeme, die direkt mit unternehmenskritischen Datenbanken interagieren. Die Entwicklung dieser Enterprise-Agents führt jedoch oft zu Integrationsproblemen, die durch benutzerdefinierten Glue-Code, instabile APIs und komplexe Datenbanklogik verursacht werden.
Um diese hartcodierten Engpässe durch eine sichere, einheitliche Steuerungsebene zu ersetzen, freuen wir uns, das Java SDK für die MCP Toolbox for Databases (Model Context Protocol) anzukündigen. Mit dieser Version wird die erstklassige, typsichere Agent-Orchestrierung in das weltweit am weitesten verbreitete Unternehmensökosystem eingeführt. Die ausgereifte Architektur von Java ist speziell für diese strengen Anforderungen konzipiert und bietet die hohe Nebenläufigkeit, strenge Transaktionsintegrität und robuste Statusverwaltung, die erforderlich sind, um geschäftskritische KI-Agenten in der Produktion sicher zu skalieren.
Warum das Java SDK?
Mit dem MCP Toolbox Java SDK können Java-Entwickler:
- Tools verwenden:Stellen Sie eine Verbindung zu einem MCP-Server (z. B. der MCP Toolbox für AlloyDB) her und wandeln Sie die Funktionen automatisch in Java-Methoden um, die LangChain4j versteht.
- Typsicherheit:Nutzen Sie die starke Typisierung von Java für Tool-Parameter, um Laufzeitfehler bei Tool-Aufrufen zu reduzieren.
- Enterprise-Bereitschaft:Einfache Integration in Spring Boot, Quarkus, Micronaut usw.
- Einfache Verbindung:Sie müssen keinen Boilerplate-JSON-RPC-Code schreiben.
- Authentifizierung standardisieren:Die native Unterstützung für Google Cloud-OIDC-Tokens sorgt für eine sichere Ausführung von Tools.
und vieles mehr.
Abhängigkeiten: pom.xml-Konfiguration
Fügen Sie Ihrem Maven-Projekt die folgende Abhängigkeit hinzu, um das aktuelle MCP Toolbox Java SDK einzubinden:
<dependency>
<groupId>com.google.cloud.mcp</groupId>
<artifactId>mcp-toolbox-sdk-java</artifactId>
<version>0.2.0</version>
</dependency>
Fügen Sie Ihrem Maven-Projekt die folgende Abhängigkeit hinzu, um das LangChain4j-Artefakt einzubinden:
<!-- LangChain4j Core & Gemini -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.35.0</version>
</dependency>
Das war es!!! Wir haben das Projekt erfolgreich geklont und die Details des KI-Agents, des MCP Toolbox Java SDK und des Kontexts durchgegangen.
9. Lokal ausführen
Wenn Sie den KI-Agenten auf Ihrem Computer testen möchten, müssen Sie ihn auf Ihren bereitgestellten MCP Toolbox-Server verweisen.
- Legen Sie Umgebungsvariablen fest:
export GCP_PROJECT_ID="<<YOUR_PROJECT_ID>>"
export GCP_REGION="us-central1"
export GEMINI_MODEL_NAME="gemini-2.5-flash"
export MCP_TOOLBOX_URL="<<YOUR_TOOLBOX_ENDPOINT_URL>>/mcp"
- Mit Maven ausführen:
mvn compile
mvn spring-boot:run
Dadurch sollte Ihr Agent lokal gestartet werden und Sie sollten ihn testen können.
10. In Cloud Run bereitstellen
Stellen Sie die App in Cloud Run bereit, indem Sie den folgenden Befehl im Cloud Shell-Terminal ausführen, in dem das Projekt geklont wurde. Achten Sie darauf, dass Sie sich im Stammordner des Projekts befinden.
WENN SIE SICH NICHT IM STAMMVERZEICHNIS DES AKTUELLEN PROJEKTS BEFINDEN, führen Sie diesen Befehl im Cloud Shell-Terminal aus:
cd cymbal-transit
Wenn Sie sich bereits im Stammverzeichnis von cymbal-transit befinden, führen Sie den folgenden Befehl aus, um die App direkt in Cloud Run bereitzustellen:
gcloud run deploy cymbal-transit --source . --set-env-vars GCP_PROJECT_ID=<<YOUR_PROJECT_ID>>,GCP_REGION=us-central1,GEMINI_MODEL_NAME=gemini-2.5-flash,MCP_TOOLBOX_URL=<<YOUR_MCP_TOOLBOX_URL>> --allow-unauthenticated
Ersetzen Sie die Werte für die Platzhalter <<YOUR_PROJECT>> and <<YOUR_MCP_TOOLBOX_URL>>.
Nach Abschluss des Befehls wird eine Dienst-URL ausgegeben. Kopieren.
Weisen Sie dem Cloud Run-Dienstkonto die Rolle AlloyDB-Client zu.So kann Ihre serverlose Anwendung einen sicheren Tunnel zur Datenbank herstellen.
Führen Sie diesen Befehl in Ihrem Cloud Shell-Terminal aus:
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
Hinweis: Rufen Sie nach der Bereitstellung die Liste der Cloud Run-Dienste auf und prüfen Sie, ob auf dem Tab „Sicherheit“ dieses Dienstes die Option „Öffentlichen Zugriff zulassen“ ausgewählt ist.
Verwenden Sie nun die Dienst-URL (den zuvor kopierten Cloud Run-Endpunkt), um die App zu testen.
Hinweis:Wenn ein Dienstproblem auftritt und als Grund der Arbeitsspeicher angegeben wird, versuchen Sie, das zugewiesene Arbeitsspeicherlimit auf 1 GiB zu erhöhen, um das Problem zu testen.
11. Demo
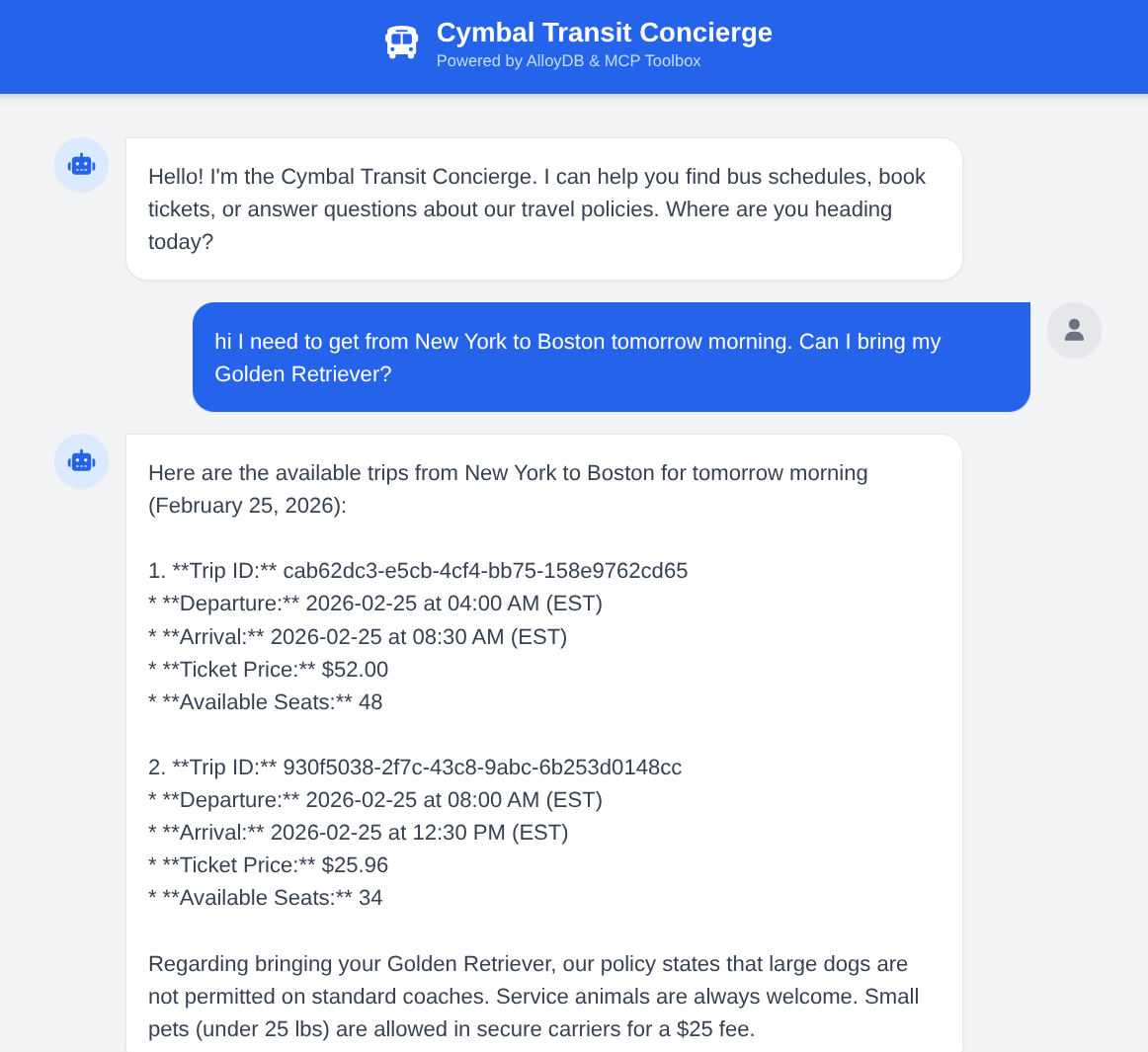
Agent fragen: „Ich muss morgen früh von New York nach Boston. Kann ich meinen Golden Retriever mitbringen?“ Beobachten Sie, wie der Agent:
- Sucht nach Richtlinien für große Hunde.
- Findet bestimmte Zeitpläne.
- Fasst die schnellste Fahrt mit einer Fahrt-ID zusammen.
- Außerdem wird ein Ticket gebucht, wenn Sie auf diese Aktionsanfrage reagieren.
12. Bereinigen
Vergessen Sie nicht, den AlloyDB-Cluster und die AlloyDB-Instanz zu löschen, wenn Sie dieses Lab abgeschlossen haben.
Dadurch sollte der Cluster zusammen mit seinen Instanzen bereinigt werden.
13. Glückwunsch
Sie haben erfolgreich einen komplexen Java-basierten Transit-Agenten erstellt. Durch die Verwendung von LangChain4j für die Orchestrierung und des MCP Toolbox Java SDK für die Datenverbindung haben Sie ein System geschaffen, das Agenten, Tools und Datenquellen übergreifend arbeiten kann. Wenn Sie mit der Orchestrierung Ihrer agentenbasierten Anwendungen mit MCP Toolbox for Databases über mehrere Datenbanken hinweg, auch plattformübergreifend, beginnen möchten, können Sie noch heute das Java SDK verwenden. Hier finden Sie den Blogbeitrag zur Einführung mit detaillierteren Informationen zur Bibliothek. Wenn Sie weitere solche Anwendungen selbstständig, kostenlos, in Ihrem eigenen Tempo und unter Anleitung eines Kursleiters entwickeln möchten, registrieren Sie sich für Code Vipassana unter https://codevipassana.dev.