
1. Présentation
Les voyageurs modernes s'attendent à des expériences conversationnelles. Au lieu de parcourir des filtres d'interface utilisateur complexes, ils veulent poser la question suivante : "Puis-je emmener mon chien dans le bus de 9h pour Boston ?" Cela nécessite un agent capable de raisonner sur des données non structurées (règles au format PDF) et des données structurées (plannings SQL).
Dans cet atelier, nous allons créer l'agent Cymbal Transit à l'aide des éléments suivants :
- LangChain4j : framework Java de référence pour l'orchestration de l'IA.
- AlloyDB : base de données hautes performances compatible avec PostgreSQL.
- SDK Java MCP Toolbox : une méthode standardisée pour connecter des agents Java à des outils et des sources de données externes.
Ce que vous allez faire
Cymbal Bus Agent, une application Java Spring Boot composée des éléments suivants :
- Base de données AlloyDB et SDK Java MCP Toolbox pour l'orchestration des outils avec les agents.
- Cloud Run pour le déploiement de la boîte à outils et de l'application (déploiement de l'agent).
- Bibliothèque LangChain4J pour le framework d'agent et de LLM dans une application Spring Boot avec Java 17.
Points abordés
- Utiliser LangChain4J pour créer des agents et sous-agents spécialisés orchestrés à l'aide du SDK Java de MCP Toolbox for Databases
- Configurer et utiliser AlloyDB pour les données et l'IA
- Découvrez comment utiliser MCP Toolbox pour connecter des agents aux outils de données AlloyDB.
- Découvrez comment déployer la solution à l'aide de Cloud Run ou l'exécuter en local.
Architecture
- AlloyDB pour PostgreSQL : sert de base de données opérationnelle à hautes performances contenant nos itinéraires, nos règles et nos enregistrements de réservations. Il alimente la recherche et la récupération vectorielles.
- SDK Java MCP Toolbox for Databases : agit comme le "maître de l'orchestration" en exposant les données AlloyDB sous forme d'outils exécutables que les agents peuvent appeler.
Le SDK Java MCP Toolbox permet d'orchestrer des agents avec vos outils de base de données sans effort pour les applications de niveau entreprise.
- LangChain4j : bibliothèque Java Open Source qui simplifie l'intégration de grands modèles de langage (LLM) dans les applications Java. Il fournit des outils et des abstractions pour créer des applications optimisées par l'IA, y compris des chatbots, des agents et des systèmes de génération augmentée par récupération (RAG).
- Cloud Run : plate-forme SANS SERVEUR entièrement gérée qui vous permet de créer et de déployer facilement des applications ou des sites Web rapidement dans n'importe quel langage, bibliothèque ou binaire. Vous pouvez écrire du code en utilisant le langage, le framework et les bibliothèques de votre choix, l'empaqueter en tant que conteneur, puis exécuter "gcloud run deploy". Votre application sera alors disponible, et fournie avec tout ce dont elle a besoin pour s'exécuter en production. La création d'un conteneur est totalement facultative. Si vous utilisez Go, Node.js, Python, Java, .NET Core ou Ruby, vous pouvez choisir l'option de déploiement basé sur la source qui crée le conteneur en suivant les bonnes pratiques du langage que vous utilisez.
Conditions requises
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API requises : suivez ce lien et activez les API.
Vous pouvez également utiliser la commande gcloud. Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
Problèmes et dépannage
Syndrome du projet fantôme | Vous avez exécuté |
Barricade de facturation | Vous avez activé le projet, mais oublié le compte de facturation. AlloyDB est un moteur hautes performances. Il ne démarrera pas si le "réservoir" (la facturation) est vide. |
Décalage de la propagation de l'API | Vous avez cliqué sur "Activer les API", mais la ligne de commande indique toujours |
Quags de quota | Si vous utilisez un tout nouveau compte d'essai, vous pouvez atteindre un quota régional pour les instances AlloyDB. Si |
Agent du service"Masqué" | Il arrive que le compte de service AlloyDB ne reçoive pas automatiquement le rôle |
3. Configuration de la base de données
AlloyDB pour PostgreSQL est au cœur de notre application. Nous avons tiré parti de ses puissantes fonctionnalités vectorielles et de son moteur de données en colonnes intégré pour générer des embeddings pour plus de 50 000 enregistrements SCM. Cela permet une analyse vectorielle en temps quasi réel, ce qui permet à nos agents d'identifier les anomalies d'inventaire ou les risques logistiques dans de grands ensembles de données en quelques millisecondes.
Dans cet atelier, nous allons utiliser AlloyDB comme base de données pour les données de test. Il utilise des clusters pour stocker toutes les ressources, telles que les bases de données et les journaux. Chaque cluster possède une instance principale qui fournit un point d'accès aux données. Les tables contiennent les données réelles.
Commençons par créer un cluster, une instance et une table AlloyDB dans lesquels l'ensemble de données de test sera chargé.
- Cliquez sur le bouton ou copiez le lien ci-dessous dans le navigateur dans lequel l'utilisateur de la console Google Cloud est connecté.
Vous pouvez également accéder au terminal Cloud Shell depuis le projet dans lequel vous avez utilisé le compte de facturation, cloner le dépôt GitHub et accéder au projet à l'aide des commandes ci-dessous :
git clone https://github.com/AbiramiSukumaran/easy-alloydb-setup
cd easy-alloydb-setup
- Une fois cette étape terminée, le dépôt sera cloné dans votre éditeur Cloud Shell local. Vous pourrez ensuite exécuter la commande ci-dessous à partir du dossier du projet (assurez-vous d'être dans le répertoire du projet) :
sh run.sh
- Utilisez maintenant l'interface utilisateur (en cliquant sur le lien dans le terminal ou sur le lien "Aperçu sur le Web" dans le terminal).
- Saisissez les détails de l'ID de projet, du nom du cluster et du nom de l'instance pour commencer.
- Allez prendre un café pendant que les journaux défilent. Pour en savoir plus sur le fonctionnement en coulisses, cliquez ici.
Problèmes et dépannage
Le problème de la patience | Les clusters de bases de données sont une infrastructure lourde. Si vous actualisez la page ou mettez fin à la session Cloud Shell parce qu'elle semble bloquée, vous risquez de vous retrouver avec une instance "fantôme" partiellement provisionnée et impossible à supprimer sans intervention manuelle. |
Région non concordante | Si vous avez activé vos API dans |
Clusters de zombies | Si vous avez déjà utilisé le même nom pour un cluster et que vous ne l'avez pas supprimé, le script peut indiquer que le nom du cluster existe déjà. Les noms de clusters doivent être uniques dans un projet. |
Délai d'inactivité de Cloud Shell | Si votre pause-café dure 30 minutes, Cloud Shell peut se mettre en veille et déconnecter le processus |
4. Provisionnement de schémas
Une fois votre cluster et votre instance AlloyDB en cours d'exécution, accédez à l'éditeur SQL AlloyDB Studio pour activer les extensions d'IA et provisionner le schéma.
Vous devrez peut-être attendre que votre instance soit créée. Une fois le cluster créé, connectez-vous à AlloyDB à l'aide des identifiants que vous avez créés. Utilisez les données suivantes pour vous authentifier auprès de PostgreSQL :
- Nom d'utilisateur : "
postgres" - Base de données : "
postgres" - Mot de passe : "
alloydb" (ou celui que vous avez défini lors de la création)
Une fois l'authentification réussie dans AlloyDB Studio, les commandes SQL sont saisies dans l'éditeur. Vous pouvez ajouter plusieurs fenêtres de l'éditeur en cliquant sur le signe plus à droite de la dernière fenêtre.
Vous saisirez les commandes pour AlloyDB dans les fenêtres de l'éditeur, en utilisant les options "Exécuter", "Mettre en forme" et "Effacer" selon les besoins.
Activer les extensions
Pour créer cette application, nous allons utiliser les extensions pgvector et google_ml_integration. L'extension pgvector vous permet de stocker et de rechercher des embeddings vectoriels. L'extension google_ml_integration fournit les fonctions que vous utilisez pour accéder aux points de terminaison de prédiction Vertex AI afin d'obtenir des prédictions en SQL. Activez ces extensions en exécutant les LDD suivants :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Accorder l'autorisation
Exécutez l'instruction ci-dessous pour accorder l'exécution de la fonction "embedding" :
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Attribuer le RÔLE Utilisateur Vertex AI au compte de service AlloyDB
Dans la console Google Cloud IAM, accordez au compte de service AlloyDB (qui ressemble à ceci : service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) l'accès au rôle "Utilisateur Vertex AI". PROJECT_NUMBER correspondra au numéro de votre projet.
Vous pouvez également exécuter la commande ci-dessous à partir du terminal Cloud Shell :
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Créer une table
Vous pouvez créer une table à l'aide de l'instruction LDD ci-dessous dans AlloyDB Studio :
DROP TABLE IF EXISTS transit_policies;
DROP TABLE IF EXISTS bus_schedules;
DROP TABLE IF EXISTS bookings;
-- Table 1: Transit Policies (Unstructured Data for RAG)
CREATE TABLE transit_policies (
policy_id SERIAL PRIMARY KEY,
category VARCHAR(50),
policy_text TEXT,
policy_embedding vector(768)
);
-- Table 2: Intercity Bus Schedules (Structured Data)
CREATE TABLE bus_schedules (
trip_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
origin_city VARCHAR(100),
destination_city VARCHAR(100),
departure_time TIMESTAMP,
arrival_time TIMESTAMP,
available_seats INT DEFAULT 50,
ticket_price DECIMAL(6,2)
);
-- Table 3: Booking Ledger (Transactional Action Data)
CREATE TABLE bookings (
booking_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
trip_id UUID REFERENCES bus_schedules(trip_id),
passenger_id VARCHAR(100),
status VARCHAR(20) DEFAULT 'CONFIRMED',
booking_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
La colonne policy_embedding permettra de stocker les valeurs vectorielles de certains champs de texte.
Ingestion de données
Exécutez l'ensemble d'instructions SQL ci-dessous pour insérer des enregistrements en masse dans les tables respectives :
- Insérer des règles non structurées et GÉNÉRER DES EMBEDDINGS RÉELS en mode natif dans AlloyDB
-- 1. Insert Unstructured Policies and GENERATE REAL EMBEDDINGS natively in AlloyDB
INSERT INTO transit_policies (category, policy_text, policy_embedding)
VALUES
('Pets', 'Service animals are always welcome. Small pets (under 25 lbs) are allowed in secure carriers for a $25 fee. Large dogs are not permitted on standard coaches.', embedding('text-embedding-005', 'Service animals are always welcome. Small pets (under 25 lbs) are allowed in secure carriers for a $25 fee. Large dogs are not permitted on standard coaches.')),
('Luggage', 'Each passenger is allowed one carry-on (up to 15 lbs) and two stowed bags (up to 50 lbs each) free of charge. Additional bags cost $15 each.', embedding('text-embedding-005', 'Each passenger is allowed one carry-on (up to 15 lbs) and two stowed bags (up to 50 lbs each) free of charge. Additional bags cost $15 each.')),
('Refunds', 'Tickets are fully refundable up to 24 hours before departure. Within 24 hours, tickets can be exchanged for travel credit only.', embedding('text-embedding-005', 'Tickets are fully refundable up to 24 hours before departure. Within 24 hours, tickets can be exchanged for travel credit only.'));
- Générer plus de 200 plannings réalistes pour sept jours à l'aide de generate_series
-- 2. Generate 200+ Realistic Schedules for the Next 7 Days using generate_series
INSERT INTO bus_schedules (origin_city, destination_city, departure_time, arrival_time, ticket_price, available_seats)
SELECT
origin,
destination,
-- Generate departures every 4 hours starting from tomorrow
(CURRENT_DATE + 1) + (interval '4 hours' * seq) AS dep_time,
(CURRENT_DATE + 1) + (interval '4 hours' * seq) + interval '4.5 hours' AS arr_time,
ROUND((RANDOM() * 30 + 25)::numeric, 2) AS price, -- Random price between $25 and $55
FLOOR(RANDOM() * 50 + 1) AS seats -- Random seats between 1 and 50
FROM
(VALUES
('New York', 'Boston'), ('Boston', 'New York'),
('Philadelphia', 'Washington DC'), ('Washington DC', 'Philadelphia'),
('Seattle', 'Portland'), ('Portland', 'Seattle')
) AS routes(origin, destination)
CROSS JOIN generate_series(1, 40) AS seq; -- 6 routes * 40 time slots = 240 distinct trips ingested!
Générer des embeddings
Les embeddings sont automatiquement couverts dans l'instruction d'insertion dans la table transit_policies à l'aide de la fonction "embedding('text-embedding-005', '<<policytext>>')".
Problèmes et dépannage
La boucle "Mot de passe oublié" | Si vous avez utilisé la configuration "En un clic" et que vous ne vous souvenez plus de votre mot de passe, accédez à la page "Informations de base sur l'instance" dans la console, puis cliquez sur "Modifier" pour réinitialiser le mot de passe |
Erreur "Extension introuvable" | Si |
Problèmes de propagation IAM | Vous avez exécuté la commande IAM
|
Incompatibilité de la dimension du vecteur | La colonne |
Faute de frappe dans l'ID du projet | Dans l'appel |
5. Configuration des outils et de la boîte à outils
MCP Toolbox for Databases est un serveur MCP Open Source pour les bases de données. Il vous permet de développer des outils plus facilement, plus rapidement et de manière plus sécurisée en gérant les complexités telles que le regroupement de connexions, l'authentification et plus encore. La boîte à outils vous aide à créer des outils d'IA générative qui permettent à vos agents d'accéder aux données de votre base de données.
Nous utilisons MCP (Model Context Protocol) Toolbox for Databases comme "chef d'orchestre". Il sert de middleware standardisé entre nos agents et AlloyDB. En définissant une configuration tools.yaml, la boîte à outils expose automatiquement des opérations de base de données complexes sous forme d'outils propres et exécutables tels que find-bus-schedules and routes ou query-schedules for specific routes, et exécute des actions autonomes telles que book-ticket. Cela élimine le besoin de regroupement de connexions manuel ou de code SQL récurrent dans la logique de l'agent.
Installer le serveur Toolbox
Dans le terminal Cloud Shell, créez un dossier pour enregistrer votre nouveau fichier YAML d'outils et le fichier binaire de la boîte à outils :
mkdir cymbal-bus-toolbox
cd cymbal-bus-toolbox
Dans ce nouveau dossier, exécutez l'ensemble de commandes suivant :
# see releases page for other versions
export VERSION=0.27.0
curl -L -o toolbox https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Ensuite, créez le fichier tools.yaml dans ce nouveau dossier en accédant à l'éditeur Cloud Shell, puis copiez le contenu de ce fichier repo dans le fichier tools.yaml.
... (Refer to entire file in the repo)
tools:
find-bus-schedules:
kind: postgres-sql
source: alloydb
description: Find all available bus schedules.
statement: |
SELECT CAST(trip_id AS TEXT) trip_id, departure_time, arrival_time, ticket_price, available_seats , origin_city, destination_city
FROM bus_schedules;
query-schedules:
kind: postgres-sql
source: alloydb
description: Find available bus schedules between an origin and destination city.
parameters:
- name: origin
type: string
description: The departure city name.
- name: destination
type: string
description: The arrival city name.
statement: |
SELECT CAST(trip_id AS TEXT) trip_id, departure_time, arrival_time, ticket_price, available_seats
FROM bus_schedules
WHERE lower(origin_city) = lower($1)
AND lower(destination_city) = lower($2)
AND available_seats > 0
ORDER BY departure_time ASC
LIMIT 5;
book-ticket:
kind: postgres-sql
source: alloydb
description: Books a ticket for a specific trip, decrementing available seats and generating a confirmed booking record.
parameters:
- name: trip_id
type: string
description: The UUID of the trip schedule to book.
- name: passenger_name
type: string
description: Name or ID of the passenger (Bound securely via backend or AuthToken).
authServices:
- name: google_auth
field: sub
statement: |
WITH updated_schedule AS (
UPDATE bus_schedules
SET available_seats = available_seats - 1
WHERE trip_id = CAST($1 AS UUID) AND available_seats > 0
RETURNING trip_id
)
INSERT INTO bookings (trip_id, passenger_id)
SELECT trip_id, $2
FROM updated_schedule
RETURNING CAST(booking_id as TEXT) as booking_id, trip_id, passenger_id, status, booking_time;
search-policies:
kind: postgres-sql
source: alloydb
description: Semantic search for transit policies regarding luggage, pets, refunds, and general rules.
parameters:
- name: search_query
type: string
description: The user's question about transit policies to be embedded and searched.
statement: |
SELECT category, policy_text
FROM transit_policies
ORDER BY policy_embedding <=> CAST(embedding('text-embedding-005', $1) AS vector(768))
LIMIT 2;
Remarque :
- Dans la configuration tools.yaml, n'oubliez pas d'inclure ipType: "private" dans la configuration de la source AlloyDB.
- N'oubliez pas non plus d'inclure l'URL du service MCP Toolbox dans le paramètre clientId pour la configuration authServices. Il est possible que vous ne receviez le lien qu'après le déploiement initial. Vous devrez donc exécuter les étapes de déploiement deux fois pour vous assurer que le cas d'utilisation des outils authentifiés fonctionne.
- Les options ci-dessous permettant de tester la boîte à outils en local ne fonctionneront pas si votre connexion AlloyDB est définie comme privée. Vous devez la définir comme publique pour la tester en local ou utiliser un proxy pour la connexion. Mais ne vous inquiétez pas. Dans notre cas, nous allons la déployer directement sur Cloud Run, puis la tester.
Pour tester le fichier tools.yaml sur le serveur local :
./toolbox --tools-file "tools.yaml"
Vous pouvez également le tester dans l'UI :
./toolbox --ui
Déployons-le dans Cloud Run comme suit.
Déploiement Cloud Run
- Définissez la variable d'environnement PROJECT_ID :
export PROJECT_ID="my-project-id"
- Initialisez la gcloud CLI :
gcloud init
gcloud config set project $PROJECT_ID
- Vous devez activer les API suivantes :
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Créez un compte de service backend si vous n'en avez pas déjà un :
gcloud iam service-accounts create toolbox-identity
- Accordez des autorisations pour utiliser Secret Manager :
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
- Accorder des autorisations supplémentaires au compte de service, spécifiques à notre source AlloyDB (roles/alloydb.client et roles/serviceusage.serviceUsageConsumer)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- Importez tools.yaml en tant que secret :
gcloud secrets create tools-cymbal-transit --data-file=tools.yaml
- Si vous avez déjà un secret et que vous souhaitez mettre à jour sa version, exécutez la commande suivante :
gcloud secrets versions add tools-cymbal-transit --data-file=tools.yaml
- Définissez une variable d'environnement sur l'image de conteneur que vous souhaitez utiliser pour Cloud Run :
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Déployez la boîte à outils sur Cloud Run à l'aide de la commande suivante :
Si vous avez activé l'accès public dans votre instance AlloyDB, suivez la commande ci-dessous pour le déploiement sur Cloud Run :
gcloud run deploy toolbox-cymbal-transit \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-cymbal-transit:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
Si vous utilisez un réseau VPC, exécutez la commande ci-dessous :
gcloud run deploy toolbox-cymbal-transit \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-cymbal-transit:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network <<YOUR_NETWORK_NAME>> \
--subnet <<YOUR_SUBNET_NAME>> \
--allow-unauthenticated
Remarque : Une fois le service déployé, accédez à la liste des services Cloud Run et assurez-vous que l'option "Autoriser l'accès public" est sélectionnée dans l'onglet "Sécurité" de ce service.
6. Configurer l'application d'agent
Clonez ce dépôt dans votre projet et examinons-le.
Pour cloner ce dépôt, exécutez la commande suivante depuis le terminal Cloud Shell (dans le répertoire racine ou à l'emplacement où vous souhaitez créer ce projet) :
git clone https://github.com/googleapis/mcp-toolbox-sdk-java
La commande ci-dessus clone en fait l'intégralité de mcp-toolbox-sdk-java. Nous n'avons besoin que de l'exemple de projet. Accédez au répertoire racine du projet dans le dépôt :
cd mcp-toolbox-sdk-java/demo-applications/cymbal-transit
- Le projet devrait être créé. Vous pouvez le vérifier dans l'éditeur Cloud Shell.
- Ouvrez CymbalTransitController.java et définissez les variables d'environnement :
- GCP_PROJECT_ID
- GCP_REGION
- GEMINI_MODEL_NAME
- MCP_TOOLBOX_URL
Vous pouvez également (uniquement à des fins de développement) remplacer les espaces réservés pour les valeurs de remplacement respectives.
7. Tutoriel du code
CymbalTransitController sert de point d'entrée pour notre service Cloud Run. Il gère le flux de conversation et s'assure que l'agent a accès à la requête actuelle de l'utilisateur.
L'implémentation suit une architecture en couches qui sépare l'orchestration de l'IA, le pontage des outils et la communication MCP de bas niveau.
1. Configuration de l'agent d'IA (AgentConfiguration)
Cette classe utilise @Configuration de Spring pour amorcer les composants d'IA. Il initialise VertexAiGeminiChatModel et le lie à notre interface Agent.
@Bean
ChatLanguageModel geminiChatModel() {
return VertexAiGeminiChatModel.builder()
.project(projectId)
.location(region)
.modelName(modelName)
.build();
}
@Bean
TransitAgent transitAgent(ChatLanguageModel chatLanguageModel, TransitAgentTools tools) {
return AiServices.builder(TransitAgent.class)
.chatLanguageModel(chatLanguageModel)
.chatMemoryProvider(memoryId -> MessageWindowChatMemory.withMaxMessages(20))
.tools(tools)
.build();
}
Importance : AiServices lie l'interface au LLM. MessageWindowChatMemory permet à l'agent de mémoriser les préférences de l'utilisateur (comme une cage de transport pour animaux de compagnie mentionnée précédemment) pour un maximum de 20 messages au cours d'une même session.
2. Interface de l'agent IA (TransitAgent)
L'annotation @SystemMessage définit le "Persona" et les contraintes opérationnelles, en particulier une stratégie de routage.
@SystemMessage({
"You are the Cymbal Transit Concierge.",
"CRITICAL INSTRUCTION: On your very first interaction, you MUST use the 'findAllSchedules' tool to fetch and memorize the broad bus routes.",
"ONLY if the user asks a specifically narrowed-down question... should you route to the specific tools like 'querySchedules', 'bookTicket', 'searchPolicies'.",
"Don't show any asterisks while listing results. Keep it formatted and numbered or bulleted."
})
String chat(@MemoryId String sessionId, @UserMessage String userMessage);
Importance : cette stratégie minimise la latence. En récupérant d'abord des données générales, l'agent peut répondre aux questions générales sur le routage à l'aide de son contexte interne sans effectuer d'appels de backend redondants.
3. Toolbox Bridge (TransitAgentTools)
Ce service sert de "mains" à l'agent, en traduisant les appels d'outils LangChain4j en logique d'exécution.
@Tool("Fetches the initial, broad dataset of all available bus schedules and routes.")
public String findAllSchedules() {
return mcpService.findAllSchedules().join();
}
@Tool("Book a ticket for a passenger using a specific trip ID.")
public String bookTicket(String tripId, String passengerName) {
return mcpService.bookTicket(tripId, passengerName).join();
}
Exécution synchrone : bien que les appels MCP soient asynchrones (renvoyant CompletableFuture), le LLM a besoin d'un résultat avant de pouvoir poursuivre son processus de "réflexion". Nous utilisons .join() pour renvoyer des résultats synchrones à l'agent.
4. Service MCP Toolbox (McpToolboxService)
Il s'agit de la couche de communication qui utilise le SDK Java de MCP Toolbox pour interagir avec le backend AlloyDB.
// Identity Management: Fetching OIDC ID Token for Auth
GoogleCredentials credentials = GoogleCredentials.getApplicationDefault();
this.idToken = ((IdTokenProvider) credentials)
.idTokenWithAudience(targetUrl, Collections.emptyList())
.getTokenValue();
// Dynamic Invocation: Executing a tool by name
public CompletableFuture<String> findAllSchedules() {
return mcpClient.invokeTool("find-bus-schedules", Collections.emptyMap()).thenApply(result -> {
return result.content().stream()
.map(content -> content.text())
.collect(Collectors.joining(", ", "[", "]"));
});
}
Importance : McpToolboxClient gère la majeure partie de la communication JSON-RPC. La méthode bookTicket illustre spécifiquement la capacité du SDK à lier des paramètres complexes de manière dynamique.
5. Contrôleur REST (TransitAgentController)
Le point de terminaison final est radicalement simplifié, car LangChain4j gère l'état et la logique.
@PostMapping("/chat")
public ResponseEntity<String> handleUserChat(@RequestBody String userMessage, HttpSession session) {
String sessionId = session.getId();
String agentResponse = transitAgent.chat(sessionId, userMessage);
return ResponseEntity.ok(agentResponse);
}
Importance : En associant l'ID HttpSession à @MemoryId, nous nous assurons que les plans de voyage de différents utilisateurs ne sont pas mélangés, tout en conservant un code de contrôleur propre et lisible.
8. MCP Toolbox : importance et SDK Java
Qu'est-ce que MCP ?
Considérez le protocole MCP (Model Context Protocol) comme un traducteur universel pour l'IA. Créé pour standardiser la façon dont les modèles d'IA se connectent aux outils et ensembles de données externes, le protocole MCP remplace les scripts d'intégration personnalisés et fragmentés par un protocole universel et sécurisé. Que votre agent doive exécuter une requête SQL transactionnelle, effectuer une recherche dans des milliers de documents de règles ou déclencher une API REST, MCP fournit une interface unique et unifiée.
MCP Toolbox for Databases
Les équipes d'ingénierie ne se contentent plus de simples chatbots et créent des systèmes agentiques qui interagissent directement avec les bases de données critiques. Toutefois, la création de ces agents d'entreprise se heurte souvent à un mur d'intégration de code de colle personnalisé, d'API fragiles et de logique de base de données complexe.
Pour remplacer ces goulots d'étranglement codés en dur par un plan de contrôle sécurisé et unifié, nous sommes ravis d'annoncer le SDK Java pour la boîte à outils MCP (Model Context Protocol) pour les bases de données. Cette version apporte une orchestration d'agents de premier ordre et de type sécurisé à l'écosystème d'entreprise le plus largement adopté au monde. L'architecture mature de Java est spécialement conçue pour répondre à ces exigences rigoureuses. Elle offre la haute simultanéité, l'intégrité transactionnelle stricte et la gestion d'état robuste nécessaires pour mettre à l'échelle en toute sécurité les agents d'IA critiques en production.
Pourquoi le SDK Java ?
Le SDK Java MCP Toolbox permet aux développeurs Java d'effectuer les opérations suivantes :
- Utiliser des outils : se connecter à un serveur MCP (comme MCP Toolbox pour AlloyDB) et transformer automatiquement ses fonctionnalités en méthodes Java que LangChain4j comprend.
- Sécurité des types : profitez du typage fort de Java pour les paramètres d'outils, ce qui réduit les erreurs d'"hallucination" d'exécution dans les appels d'outils.
- Prêt pour l'entreprise : intégrez-le facilement à Spring Boot, Quarkus, Micronaut, etc.
- Connectez-vous sans effort : évitez d'écrire du code JSON-RPC récurrent.
- Authentification standardisée : la compatibilité native avec les jetons Google Cloud OIDC garantit l'exécution sécurisée des outils.
Dépendances : configuration pom.xml
Ajoutez la dépendance suivante à votre projet Maven pour inclure le dernier SDK Java MCP Toolbox :
<dependency>
<groupId>com.google.cloud.mcp</groupId>
<artifactId>mcp-toolbox-sdk-java</artifactId>
<version>0.2.0</version>
</dependency>
Ajoutez la dépendance suivante à votre projet Maven pour inclure l'artefact LangChain4j :
<!-- LangChain4j Core & Gemini -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.35.0</version>
</dependency>
Et voilà ! Nous avons cloné le projet et examiné en détail l'agent, le SDK Java MCP Toolbox et le contexte.
9. Exécuter localement
Pour tester l'agent sur votre machine, vous devez le rediriger vers votre serveur MCP Toolbox déployé.
- Définissez les variables d'environnement :
export GCP_PROJECT_ID="<<YOUR_PROJECT_ID>>"
export GCP_REGION="us-central1"
export GEMINI_MODEL_NAME="gemini-2.5-flash"
export MCP_TOOLBOX_URL="<<YOUR_TOOLBOX_ENDPOINT_URL>>/mcp"
- Exécutez avec Maven :
mvn compile
mvn spring-boot:run
Votre agent devrait démarrer en local et vous devriez pouvoir le tester.
10. Déployons-la sur Cloud Run.
Déployez-le sur Cloud Run en exécutant la commande suivante depuis le terminal Cloud Shell où le projet est cloné. Assurez-vous d'être dans le dossier racine du projet.
SI VOUS N'ÊTES PAS DANS LE DOSSIER RACINE DE NOTRE PROJET ACTUEL, exécutez cette commande dans votre terminal Cloud Shell :
cd cymbal-transit
Si vous êtes déjà dans la racine cymbal-transit, exécutez la commande ci-dessous pour déployer directement l'application sur Cloud Run :
gcloud run deploy cymbal-transit --source . --set-env-vars GCP_PROJECT_ID=<<YOUR_PROJECT_ID>>,GCP_REGION=us-central1,GEMINI_MODEL_NAME=gemini-2.5-flash,MCP_TOOLBOX_URL=<<YOUR_MCP_TOOLBOX_URL>> --allow-unauthenticated
Remplacez les valeurs des espaces réservés <<YOUR_PROJECT>> and <<YOUR_MCP_TOOLBOX_URL>>.
Une fois la commande terminée, une URL de service s'affiche. Copiez-le.
Attribuez le rôle Client AlloyDB au compte de service Cloud Run.Cela permet à votre application sans serveur de se connecter de manière sécurisée à la base de données.
Exécutez la commande suivante dans votre terminal Cloud Shell :
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
Remarque : Une fois le service déployé, accédez à la liste des services Cloud Run et assurez-vous que l'option "Autoriser l'accès public" est sélectionnée dans l'onglet "Sécurité" de ce service.
Utilisez maintenant l'URL du service (point de terminaison Cloud Run que vous avez copié précédemment) et testez l'application.
Remarque : Si vous rencontrez un problème de service et que la mémoire est indiquée comme cause, essayez d'augmenter la limite de mémoire allouée à 1 Gio pour le tester.
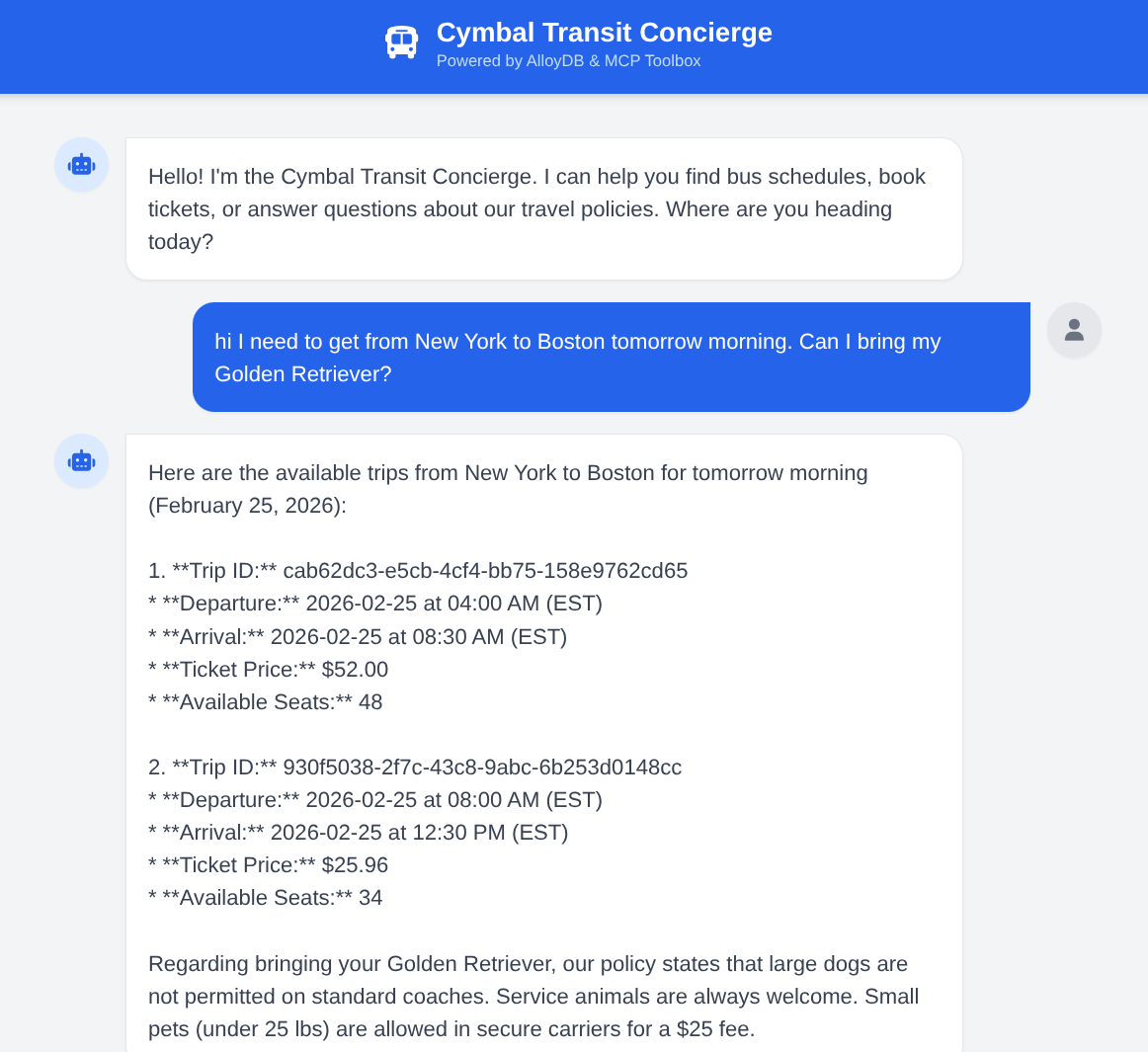
11. Démo
Demandez à l'agent : "Je dois aller de New York à Boston demain matin. Puis-je venir avec mon golden retriever ?" Observez comment l'agent :
- Recherches de règles pour les grands chiens.
- Trouve des programmations spécifiques.
- Résume le trajet le plus rapide avec un ID de trajet.
- Réserve également un billet si vous donnez suite à cette demande d'action.
12. Effectuer un nettoyage
Une fois cet atelier terminé, n'oubliez pas de supprimer le cluster et l'instance AlloyDB.
Il devrait nettoyer le cluster ainsi que ses instances.
13. Félicitations
Vous avez réussi à créer un agent de transit sophistiqué basé sur Java. En utilisant LangChain4j pour l'orchestration et le SDK Java de MCP Toolbox pour la connectivité des données, vous avez créé un système capable de raisonner sur les agents, les outils et les sources de données. Si vous souhaitez commencer à orchestrer vos applications agentiques avec MCP Toolbox for Databases sur plusieurs bases de données, même sur différentes plates-formes, commencez dès aujourd'hui avec le SDK Java. Consultez l'annonce de lancement sur le blog pour en savoir plus sur la bibliothèque. Si vous souhaitez créer d'autres applications de ce type de manière pratique, sans frais, à votre rythme et avec un instructeur, inscrivez-vous à Code Vipassana sur https://codevipassana.dev.