
1. Einführung
Es ist Montagmorgen und der CFO hat Sie gerade kontaktiert. Der durchschnittliche Bestellwert ist diesen Monat um 7% gesunken, der Gesamtumsatz ist jedoch gleich geblieben. Irgendetwas stimmt nicht und der Vorstand möchte bis Freitag Antworten.
Ihr Unternehmen, Cymbal Pets, ist einer der größten Onlinehändler für Tierbedarf in den USA. Die benötigten Daten sind auf drei Google Cloud-Dienste verteilt: Transaktionsdaten in BigQuery, Kunden- und Produktdatensätze in Cloud SQL und Marketingdateien in Cloud Storage. Normalerweise müssen Sie für eine dienstübergreifende Untersuchung wie diese zwischen Konsolen wechseln, Boilerplate-Code für die Verbindung schreiben und Ergebnisse manuell zusammenfügen.
In diesem Codelab verwenden Sie das Google Cloud Data Agent Kit (DAK) in der Antigravity IDE, um die Anomalie mithilfe natürlicher Sprache zu untersuchen. Sie beschreiben, wonach Sie suchen, und der KI-Agent kümmert sich um die Verbindungen, SQL und dienstübergreifenden Joins in BigQuery, Cloud SQL und Cloud Storage. Sobald Sie den Fall gelöst haben, bitten Sie den Agent, eine dbt-Pipeline zu erstellen, mit der Sie Ihre Ergebnisse operationalisieren, einen Fehler bei der Datenmodellierung zu beheben und dem CFO eine auf Prognosen basierende Empfehlung zu geben.
Aufgaben
- Daten-Assets in BigQuery, Cloud SQL und Cloud Storage mit dem Knowledge Catalog ermitteln
- Anomalien untersuchen, indem Sie mehrere Dienste in einer einzigen Unterhaltung mit MCP-Tools abfragen
- dbt-Pipeline erstellen, um dienstübergreifende Daten mit Staging-Modellen und automatisierten Tests zu stagen und zu verknüpfen
- Fehlerbehebung bei einem Problem mit der Datenmodellierung, während der Agent eine Fan-out-Fehler selbst diagnostiziert und refaktoriert
- Zukünftige Trends vorhersagen und eine datengestützte Empfehlung mit der
AI.FORECASTvon BigQuery abgeben
Voraussetzungen
- Ein Webbrowser wie Chrome
- Ein Google Cloud-Projekt mit aktivierter Abrechnung
- Grundkenntnisse in SQL und der Google Cloud Console
Dieses Codelab richtet sich an fortgeschrittene Datenexperten (Analytics Engineers, Datenanalysten, Data Scientists).
Die in diesem Codelab erstellten Ressourcen sollten weniger als 5 $ kosten.
2. Vorbereitung
In diesem Abschnitt führen Sie ein Setupscript aus, mit dem Ihre gesamte Lab-Umgebung bereitgestellt wird: ein BigQuery-Dataset mit Bestelldaten, eine Cloud SQL Postgres-Instanz mit Kunden- und Produktdaten und ein Cloud Storage-Bucket mit Aufzeichnungen von Werbekampagnen. Die Ausführung des Skripts dauert etwa 8 bis 10 Minuten. Die Bereitstellung von Cloud SQL ist der Engpass.
Cloud Shell starten
Sie verwenden Google Cloud Shell, um das Setupscript auszuführen.
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.

- Legen Sie nach der Verbindung Ihre Projekt-ID fest und bestätigen Sie Ihre Umgebung:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
Es sollte eine Meldung wie die folgende angezeigt werden:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Repository klonen
Klonen Sie das Codelab-Repository in Ihre Cloud Shell-Umgebung:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/agentic-data-labs
git checkout main
cd codelabs/agentic-data-labs/
Setup-Skript ausführen
Das Setupskript bereitet Ihre gesamte Lab-Umgebung in wenigen Minuten vor. Dabei werden APIs aktiviert, BigQuery-Daten geladen und erweitert, Werbe-Assets in GCS hochgeladen und dann automatisch ein Hintergrund-Worker gestartet, um Cloud SQL Postgres im Hintergrund bereitzustellen und zu konfigurieren, während Sie das Codelab starten.
Das Skript generiert automatisch ein sicheres Cloud SQL-Passwort und speichert es automatisch in der Datei .env.
cd ~/devrel-demos/codelabs/agentic-data-labs/scripts
chmod +x setup.sh setup_sql.sh
./setup.sh
Wenn der Vorgang abgeschlossen ist, wird eine Zusammenfassung der Vordergrundumgebung angezeigt:
╔══════════════════════════════════════════════════════╗
║ Base Setup complete! ║
╚══════════════════════════════════════════════════════╝
Your core BigQuery and GCS assets are ready.
Cloud SQL is currently provisioning in the background and will be fully ready by Step 4.
BigQuery: YOUR_PROJECT_ID.cymbal_pets
├── orders
└── order_items
GCS: gs://YOUR_PROJECT_ID-cymbal-pets-raw
└── promo_events.json
Während Sie mit den nächsten Schritten des Labs fortfahren, wird die Datenbank im Hintergrund bereitgestellt und mit Daten gefüllt. Sie können den Fortschritt jederzeit in einem separaten Terminalfenster mit dem folgenden Befehl überwachen:
tail -f /tmp/cloudsql_setup.log
Beachten Sie die Datenarchitektur: Transaktionsdaten (Bestellungen und Bestellpositionen) befinden sich in BigQuery, während operative Daten (Kunden, Haustierprofile und Produkte) in Cloud SQL gespeichert werden. Diese Aufteilung spiegelt wider, wie Daten in realen Organisationen oft auf verschiedene Dienste verteilt sind. Das macht eine dienstübergreifende Untersuchung interessant.
Zusammenfassung des Abschnitts:Sie haben das Setupscript ausgeführt, um Ihre Lab-Umgebung zu starten, und die Bereitstellung der Hintergrunddatenbank wurde gestartet.
3. IDE und Data Agent Kit einrichten
Antigravity IDE öffnen
Sie müssen nicht warten, bis Cloud SQL fertig ist. Öffnen Sie die Antigravity IDE und stellen Sie eine Verbindung zu Ihrem Google Cloud-Projekt her.
- Falls noch nicht geschehen, laden Sie die Antigravity IDE von der Google Antigravity-Downloadseite herunter und installieren Sie sie.
- Starten Sie die Desktopanwendung Antigravity IDE.
- Erstellen Sie einen neuen, leeren Ordner auf Ihrem lokalen Computer (z. B. mit dem Namen
agentic-data-labs) und öffnen Sie ihn in der IDE, indem Sie Ordner öffnen auswählen. Dieser Ordner dient als Ihr lokaler Arbeitsbereich für das Codelab.
Data Agent Kit-Erweiterung installieren
Die Erweiterung „Google Cloud Data Agent Kit“ bietet eine enge Integration mit Google Cloud-Datendiensten direkt in Ihrem Editor. So können Sie mit BigQuery, Cloud SQL, Cloud Storage und anderen Diensten interagieren, ohne den Kontext wechseln zu müssen.
- Klicken Sie in der Antigravity IDE in der Aktivitätsleiste ganz links auf dem Bildschirm auf das Symbol Erweiterungen (es sieht aus wie vier Quadrate).
- Geben Sie oben im Bereich „Erweiterungen“ in der Suchleiste
Google Cloud Data Agent Kitein. - Suchen Sie nach der Erweiterung Google Cloud Data Agent Kit, die von
googlecloudtoolsveröffentlicht wurde. - Klicken Sie auf die Schaltfläche Installieren.
- Möglicherweise werden Sie gefragt, ob Sie dem Herausgeber „googlecloudtools“ und seinen Erweiterungen vertrauen. Klicken Sie auf Verlagen und Webpublishern vertrauen und installieren, um fortzufahren.
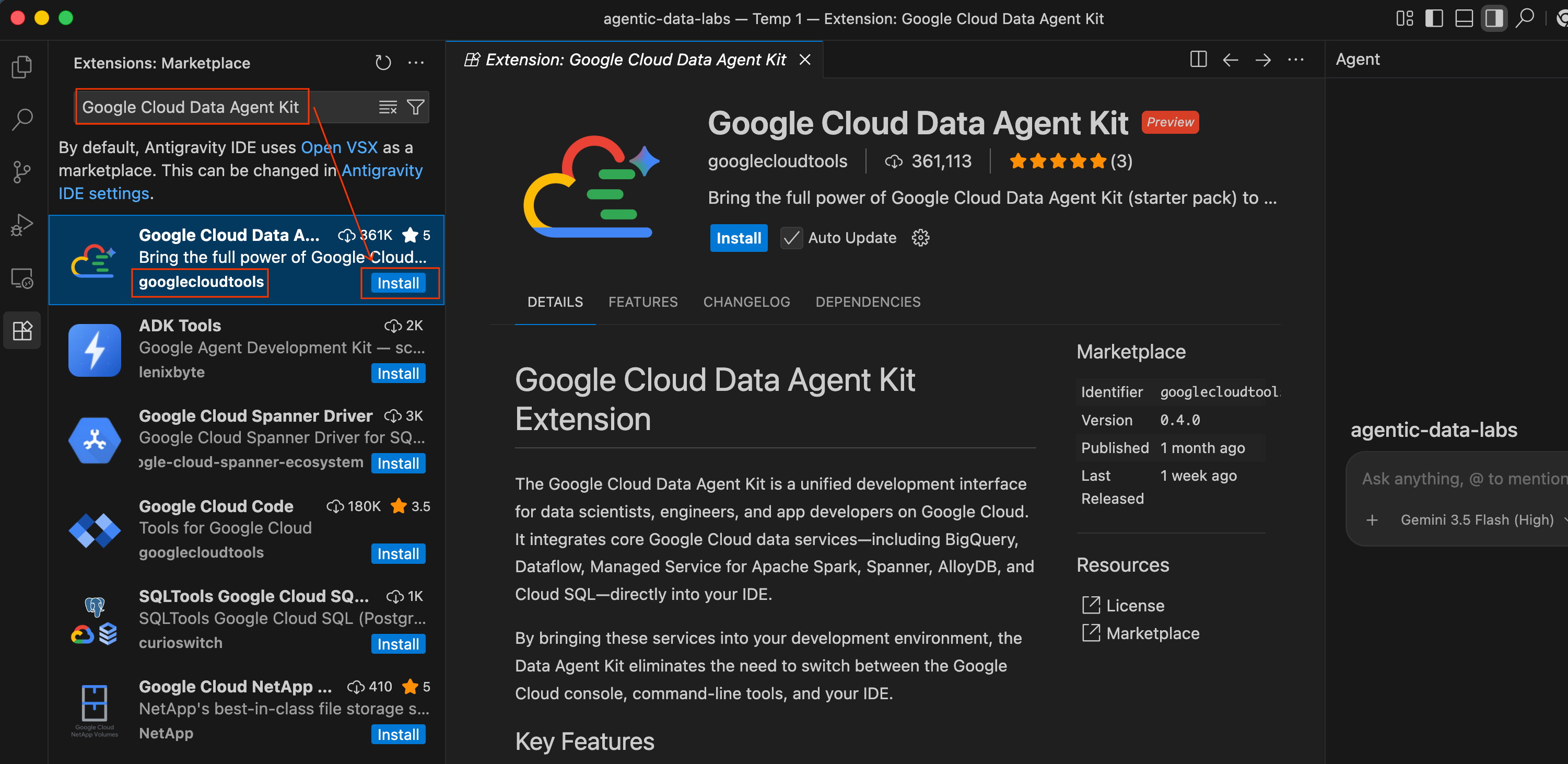
Nach der Installation wird in der Aktivitätsleiste ganz links in der Antigravity IDE ein neues Symbol für das Google Cloud Data Agent Kit angezeigt.
Erweiterung authentifizieren und konfigurieren
Verknüpfen Sie die Erweiterung nach der Installation mit Ihrem Google Cloud-Projekt.
- Eine Onboarding-Seite mit dem Titel „Willkommen im Google Cloud Data Agent Kit“ sollte automatisch geöffnet werden. Wenn Sie nicht in Ihrem Cloud-Konto angemeldet sind, folgen Sie der Anleitung, um den Zugriff zu gewähren.
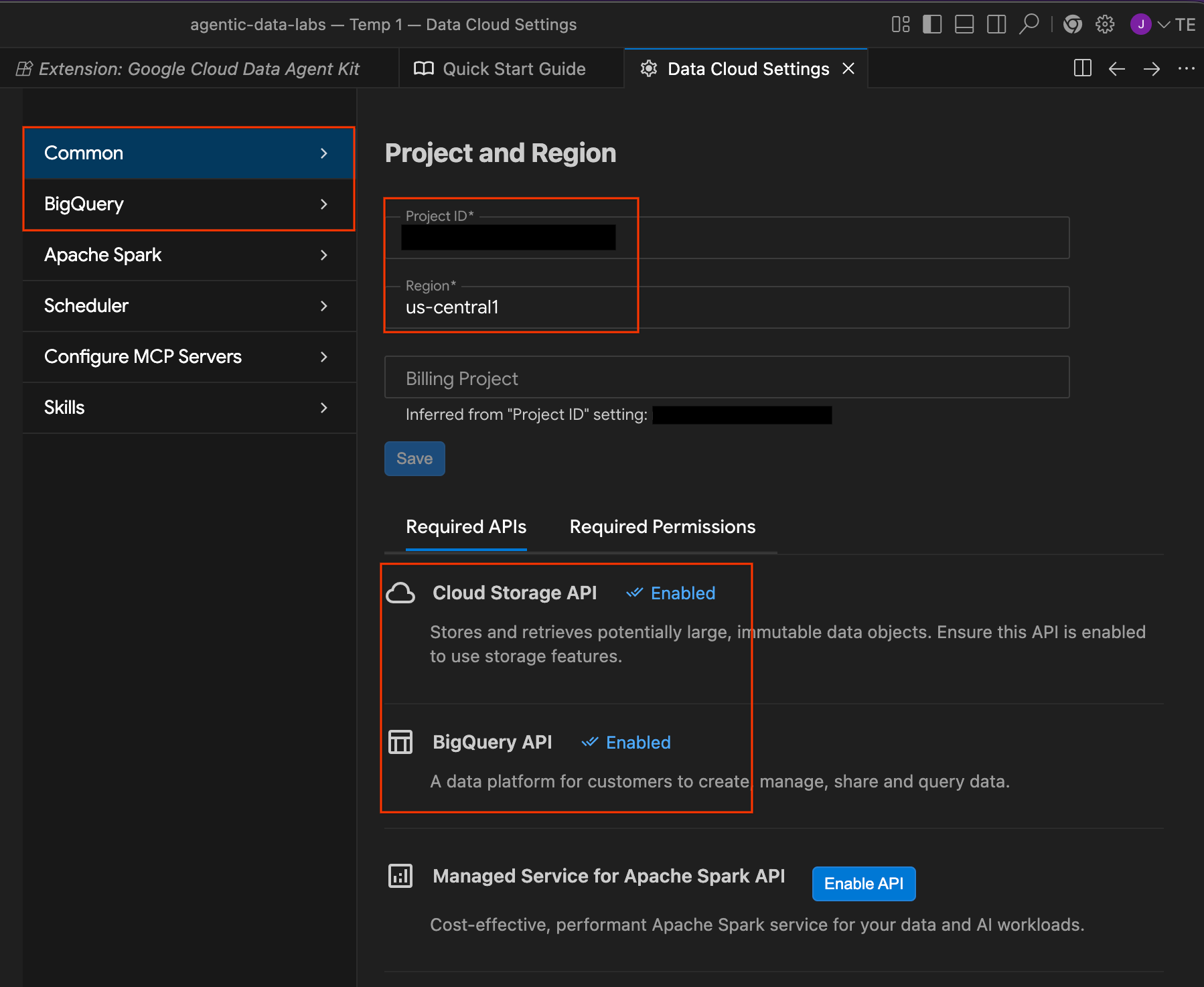
- Suchen Sie im Abschnitt Konfigurationszusammenfassung nach dem Projektfeld. Klicken Sie auf das Drop-down-Menü und wählen Sie Ihr Google Cloud-Projekt aus. Legen Sie als Region
us-central1fest. Wählen Sie dann MCP-Server konfigurieren aus.

- Klicken Sie im Bereich MCP Configuration (MCP-Konfiguration), um BigQuery und Cloud SQL zu aktivieren. Klicken Sie dann auf Jetzt starten.
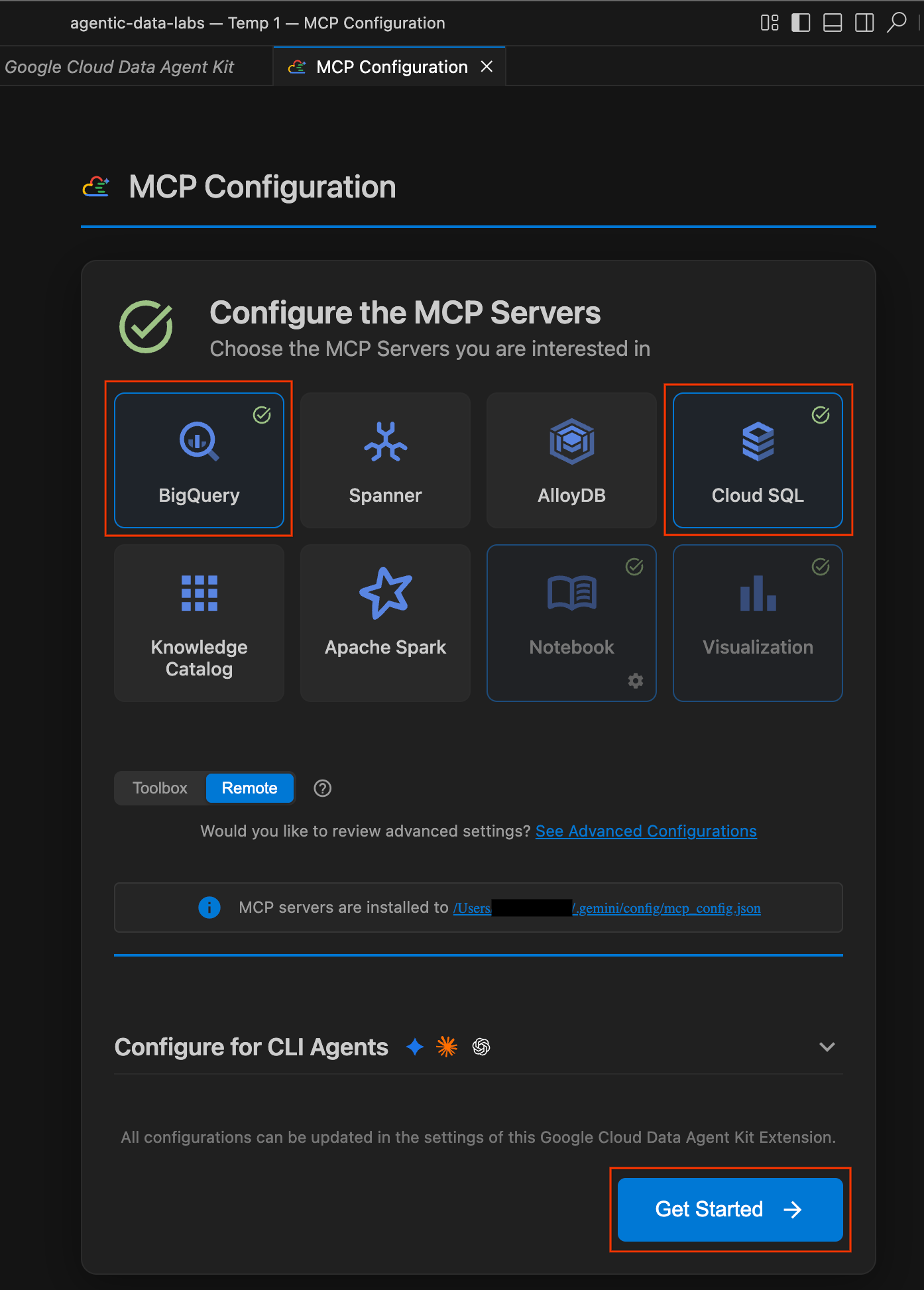
Konfigurationsoptionen ansehen
Nach Abschluss der Einrichtung werden Sie zur Seite „Erste Schritte mit dem Google Cloud Data Agent Kit“ weitergeleitet.
- Klicken Sie unter „Einrichtung und Konfiguration“ auf Jetzt starten.
- Der Bereich Data Agent-Konfiguration wird geöffnet. Tabs ansehen:
- Projekt und Region:Prüfen Sie die ausgewählte Projekt-ID und ob die erforderlichen APIs (Cloud Storage API, BigQuery API, Catalog API und Cloud SQL Admin API) aktiviert sind.
- BigQuery:Konfigurieren Sie den standardmäßigen Standort für Ihre BigQuery-Abfragen. Verwenden Sie die Region
us-central1. - MCP-Server konfigurieren:Hier können Sie die aktivierten MCP-Server (BigQuery, Notebooks, Cloud SQL usw.) ansehen, die es KI-Agenten ermöglichen, sicher mit Ihren Daten zu interagieren.
- Skills:Nutzen Sie vordefinierte Skills, die Agents spezielle Funktionen für komplexe Datenaufgaben bieten.
Zusammenfassung des Abschnitts:Sie haben die Antigravity IDE geöffnet, eine Verbindung zu Ihrem Google Cloud-Projekt hergestellt, die Remote-MCP-Server des Data Agent Kit konfiguriert und die Verbindung durch Ausführen einer Abfrage für BigQuery überprüft.
4. Daten entdecken
Es ist an der Zeit, den Rahmen abzustecken. Der CFO sagt, dass der durchschnittliche Bestellwert im letzten Monat um 7% gesunken ist, der Gesamtumsatz aber gleich geblieben ist. Bevor Sie den Kundenservicemitarbeiter bitten, Nachforschungen anzustellen, sollten Sie sich erst einmal mit den Daten vertraut machen, mit denen Sie arbeiten.
In diesem Abschnitt sehen Sie sich das Data Agent Kit-Panel manuell an, um sich einen Überblick zu verschaffen. Bevor Sie mit dem Abfragen Ihrer Daten beginnen, ist es wichtig, dass Sie sie verstehen.
BigQuery-Tabellen ansehen
- Erweitern Sie im Bereich „Data Agent Kit“ unter KATALOG Ihr Projekt → BigQuery →
cymbal_pets. - Klicken Sie auf die Tabelle
orders. Ein neuer Tab mit den Details der Tabelle wird geöffnet. - Sehen Sie sich die Tabs auf der linken Seite der Tabellenansicht an:
- Daten: Hier können Sie sich die tatsächlichen Zeilen ansehen. Scrollen Sie durch das Dataset und sehen Sie sich die Spalten an.
- Schema: Überprüfen Sie die Spaltennamen und -typen. Beachten Sie Felder wie
order_typeundpromo_code, die später wichtig werden. - Andere Tabs (Details, Statistiken, Datenprofil usw.): Sie können auf Metadaten, Datenherkunft und Qualitätsdetails zugreifen, die Sie normalerweise in der Google Cloud Console finden – und das alles, ohne den Editor zu verlassen.
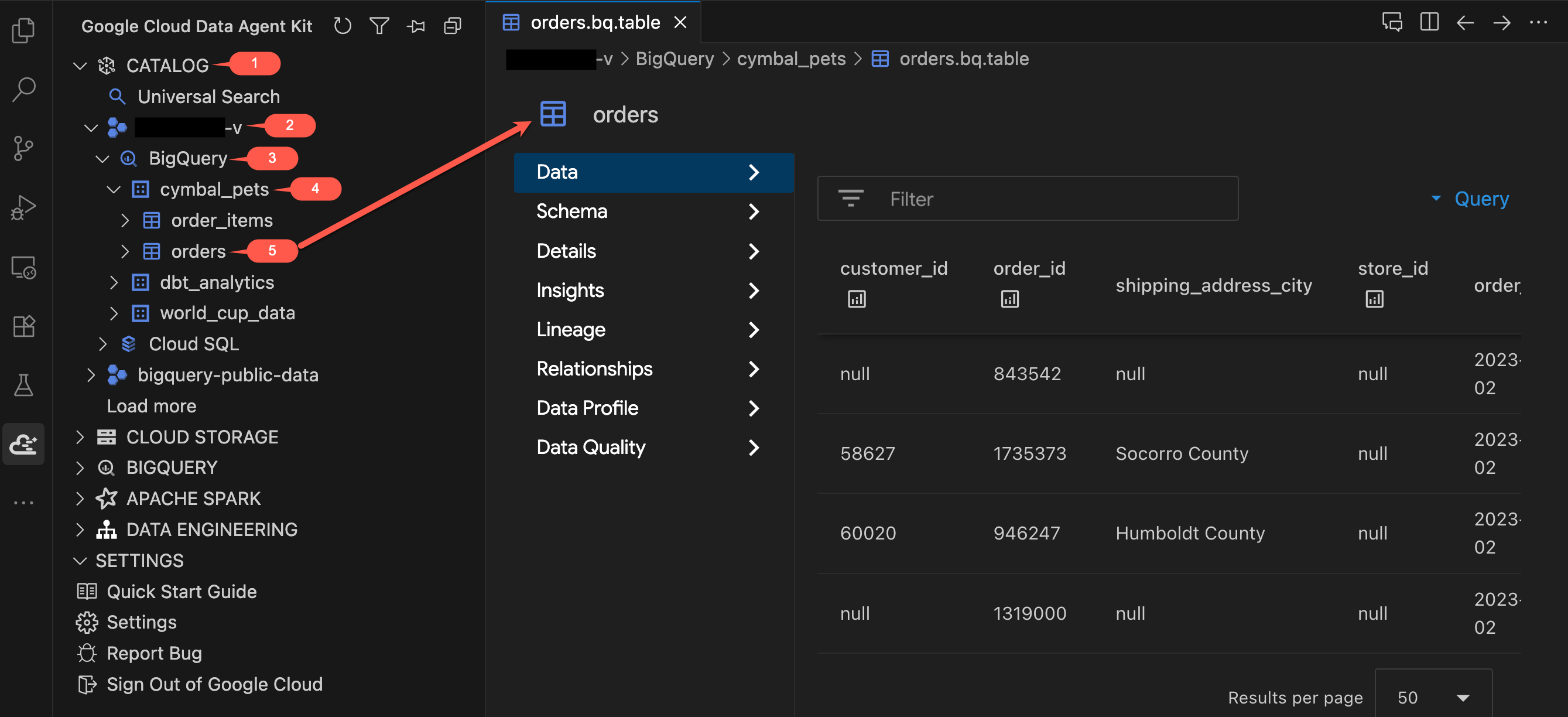
- Klicken Sie nun auf die Tabelle
order_itemsund sehen Sie sich ihr Schema an. Beachten Sie die Felderquantityundprice.
Cloud SQL-Tabellen untersuchen
Das Setupscript hat auch Kunden-, Haustier- und Produktdaten in einer PostgreSQL-Datenbank in Cloud SQL platziert.
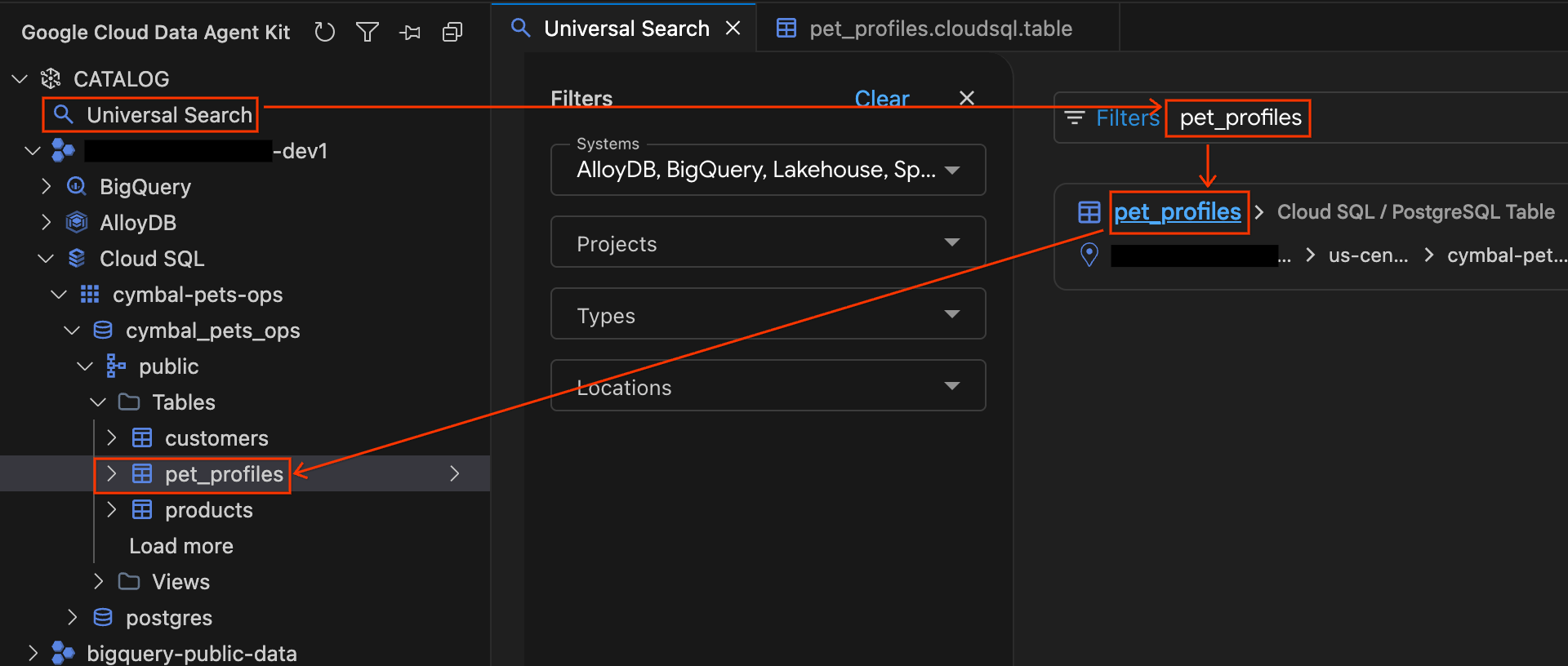
- Klicken Sie im Bereich „Data Agent Kit“ unter dem Abschnitt KATALOG auf Universelle Suche.
- Geben Sie
pet_profilesin das Suchfeld ein und drücken Sie die Eingabetaste. - Klicken Sie in den Suchergebnissen auf das PostgreSQL-Tabellenergebnis für
pet_profiles(unter der Cloud SQL-Instanz Ihres Projekts). Das Akkordeon in der Seitenleiste wird automatisch maximiert und zeigt Ihnen genau, wo sich die Tabelle im Datenbankbaum befindet. Klicken Sie nun in der Baumstruktur direkt darüber auf die Tabellecustomers, um ihre Details zu öffnen, und sehen Sie sich die Tabs Schema und Details an.
Cloud Storage-Dateien ansehen
Schließlich werden Datensätze zu Marketing- und Werbekampagnen als rohe JSON-Dateien in Cloud Storage gespeichert.
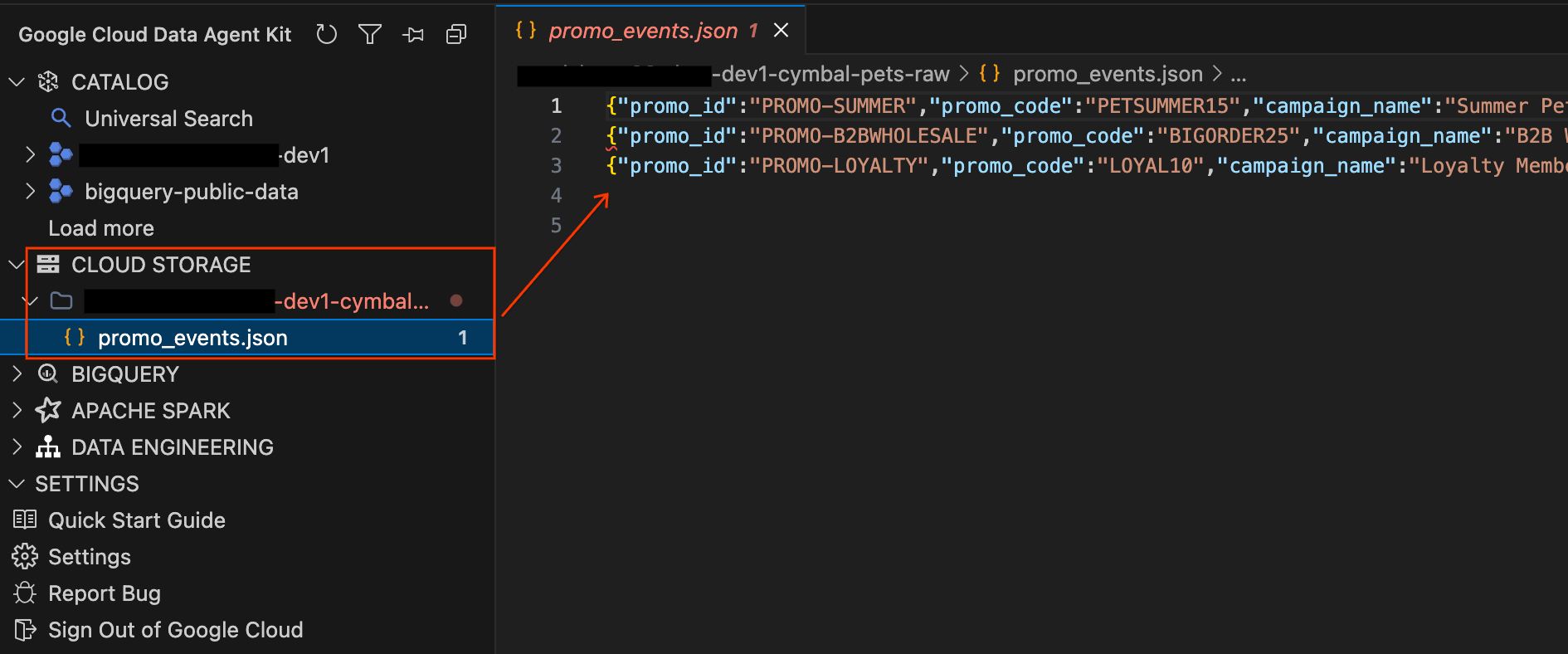
- Erweitern Sie im linken Bereich „Data Agent Kit“ den Abschnitt CLOUD STORAGE. Suchen Sie den Raw-Bucket Ihres Projekts (
YOUR_PROJECT_ID-cymbal-pets-raw). - Klicken Sie im Bucket auf die Datei
promo_events.json. Ein neuer Editor-Tab wird geöffnet, auf dem Sie die JSON Lines-Rohinhalte der Marketingkampagnen direkt in der IDE ansehen können.
Inventur
Das wissen Sie jetzt über die Datenlandschaft:
Dienst | Tabellen | Was ist da? |
BigQuery |
| ~1,9 Mio.Aufträge, ~4,3 Mio.Werbebuchungen, Zeitraum 2023–2025 |
Cloud SQL |
| ~92.000 Kunden, ~7.600 Haustierprofile, 206 Produkte |
Cloud Storage |
| Datensätze für Werbekampagnen |
Die Daten sind auf drei Dienste verteilt. Bei einem herkömmlichen Workflow müssten Sie Verbindungen einrichten, Integrationscode schreiben und Ergebnisse manuell zusammenführen. Im nächsten Schritt lassen Sie den KI-Agenten all das in einer einzigen Unterhaltung erledigen.
Zusammenfassung des Abschnitts:Sie haben das Data Agent Kit-Panel verwendet, um die Datenarchitektur in BigQuery, Cloud SQL und Cloud Storage manuell zu untersuchen. Sie wissen jetzt, wo sich die Daten befinden und welche Felder verfügbar sind. Sie können also mit der Untersuchung beginnen.
5. Zahlen folgen
Jetzt beginnt die Untersuchung. Sie verwenden den Chatbereich, um den KI-Agenten zu bitten, Daten zum durchschnittlichen Bestellwert aus BigQuery abzurufen. Der durchschnittliche Bestellwert ist ein Unternehmensmesswert, der den durchschnittlichen Betrag in US-Dollar angibt, der pro Bestellung ausgegeben wird. Der Agent führt in Ihrem Namen Abfragen mit MCP-Tools aus. Sie können jede SQL-Abfrage sehen, die er ausführt.
Trend des durchschnittlichen Bestellwerts abrufen
- Geben Sie im Chatbereich auf der rechten Seite der IDE den folgenden Prompt ein und drücken Sie die Eingabetaste:
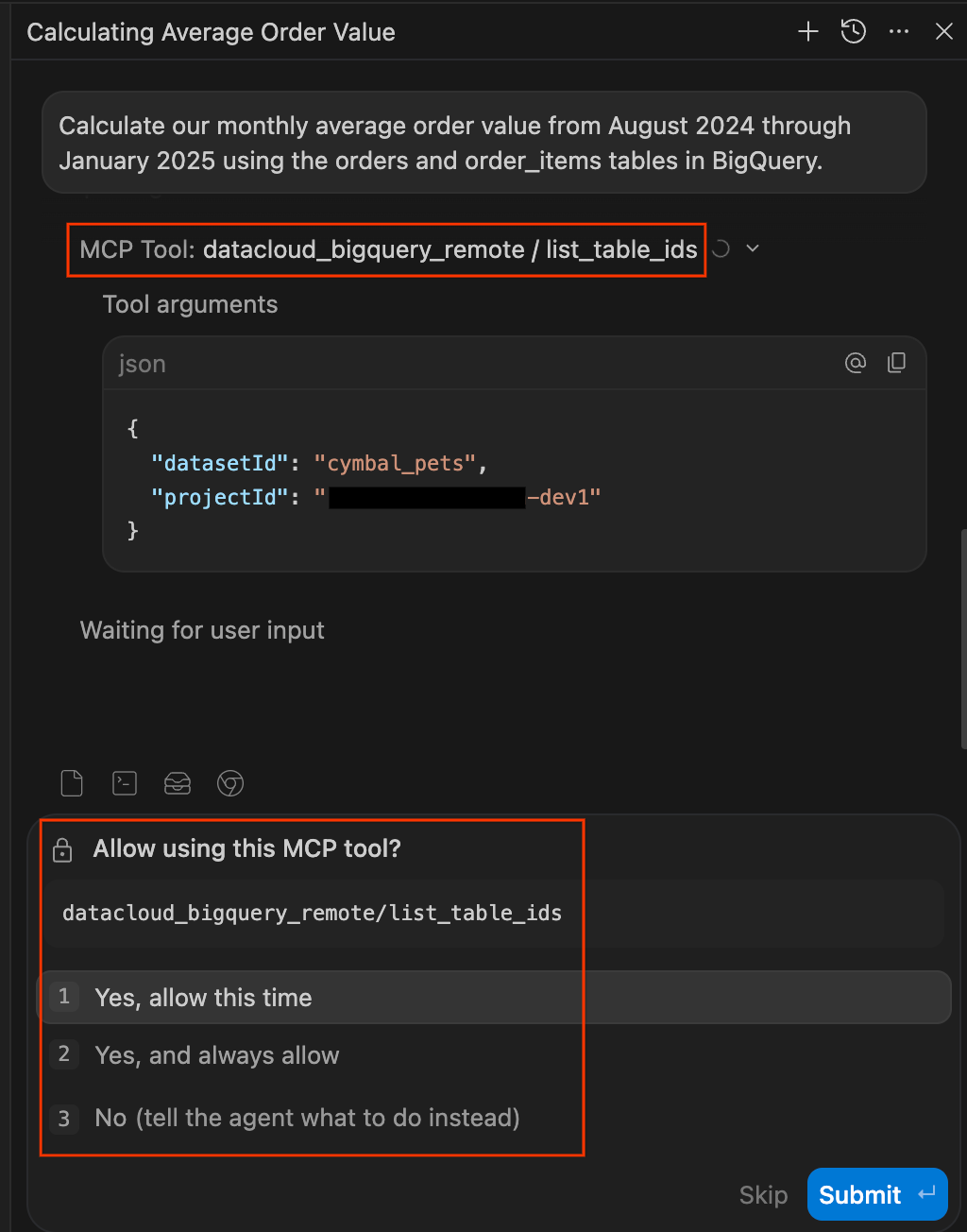
Calculate our monthly average order value from August 2024 through January 2025 using the orders and order_items tables in BigQuery. - Zugriffsberechtigungen für Daten genehmigen: Es ist gut, vorsichtig zu sein, wenn KI-Agents Abfragen für Ihre Datenbanken ausführen. Mit dem Data Agent Kit behalten Sie die Kontrolle, da Sie vor dem Zugriff auf Daten um eine ausdrückliche Genehmigung gebeten werden. Wenn Sie dazu aufgefordert werden, können Sie Folgendes auswählen:
- Dieses Mal erlauben:Genehmigt die einmalige Verwendung (ideal für die Überprüfung von Anfragen mit hohem Risiko).
- Immer zulassen:Genehmigt die fortlaufende Verwendung dieses bestimmten Tools für die Sitzung.
- Nein:Die Aktion wird vollständig blockiert.
list_table_idsoderexecute_sql_readonlyverwendet. Sie können diese auch „immer zulassen“.
- Sehen Sie sich an, wie der Agent funktioniert. Der Chatbereich dient auch als Transparenzprotokoll für alle Aktionen des Agenten. Statt einer Blackbox zeigt der KI-Agent Ihnen seine Überlegungen und Aktionen in Echtzeit.
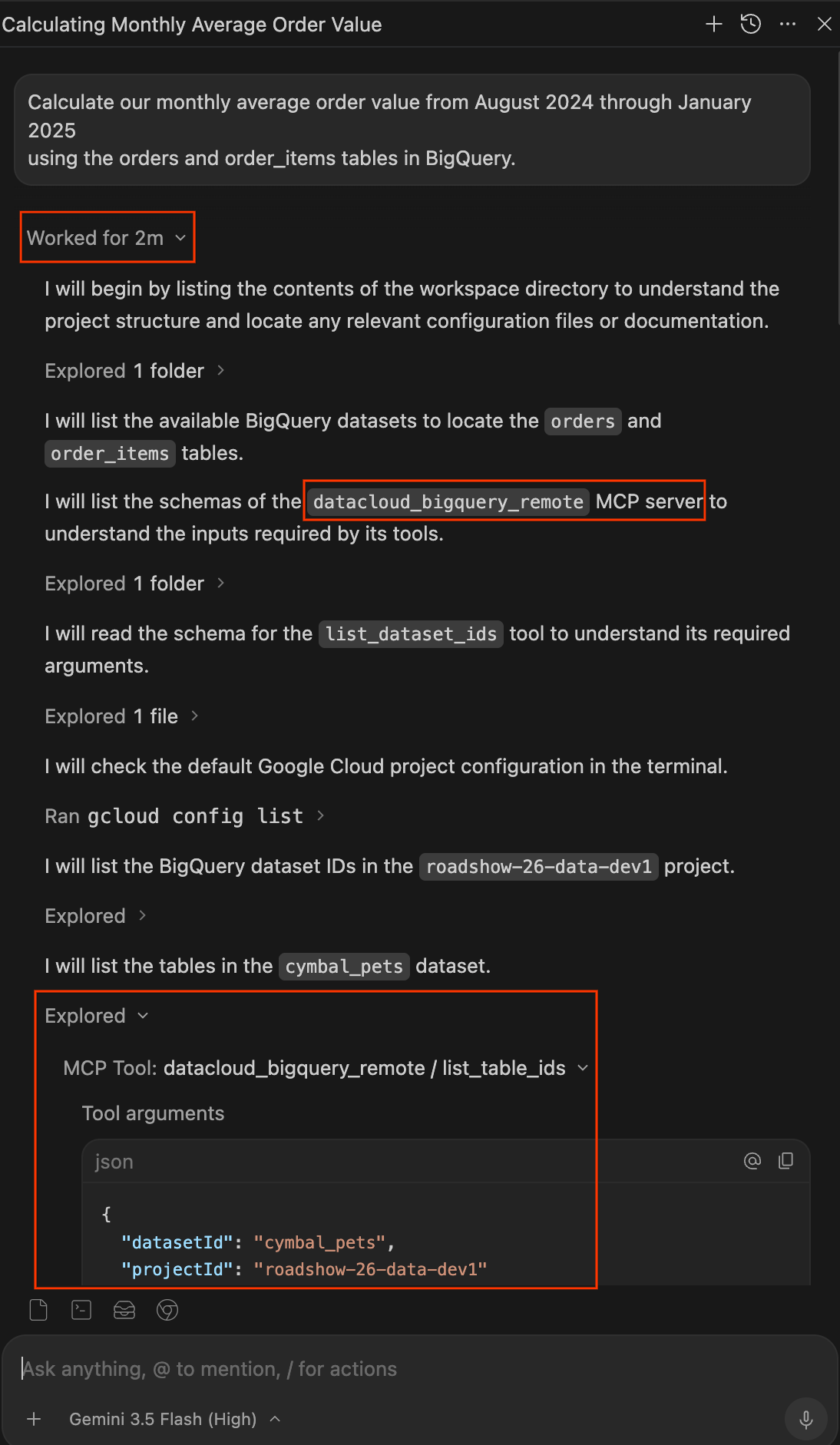
- Wenn der Agent fertig ist, klicken Sie unter Ihrem Prompt auf das Drop-down-Menü Worked for Xm (Xm-Arbeitszeit), um das vollständige Arbeitslog zu maximieren. Hier können Sie genau nachvollziehen, wie die Antwort zustande gekommen ist:
- Untersucht:Wenn Sie diese Elemente maximieren, sehen Sie, wie der Agent Dateien liest, Ordner durchsucht oder MCP-Tools wie
datacloud_bigquery_remote / list_table_idsundexecute_sql_readonlyaufruft. Sie können die genauen JSON-Argumente sehen, die an die Tools übergeben wurden, und den ausgeführten SQL-Code. - Ausgeführt:Wenn Sie diese Elemente maximieren, sehen Sie alle Terminalbefehle, die der Agent ausgeführt hat, z. B.
gcloud config list.
- Untersucht:Wenn Sie diese Elemente maximieren, sehen Sie, wie der Agent Dateien liest, Ordner durchsucht oder MCP-Tools wie
- Überprüfen Sie die Ergebnisse. Der KI-Agent sollte eine Tabelle mit monatlichen durchschnittlichen Bestellwerten zurückgeben. Sehen Sie sich die Zahlen selbst an: In den Vormonaten lag der Wert bei etwa 110 $, im Januar sank er auf etwa 103 $. Das ist die Anomalie, die der CFO gemeldet hat.
Nach Channel aufschlüsseln
Der durchschnittliche Bestellwert ist gesunken. Woher kommt dieser Rückgang? Das lässt sich ganz einfach herausfinden.
- Geben Sie im Chatbereich Folgendes ein:
January looks lower than the prior months. Break down January's AOV by order_type to see what's going on? - Der Agent führt eine weitere BigQuery-Abfrage aus, diesmal gruppiert nach
order_type. Sehen Sie sich die Ergebnisse genau an.Sie sollten etwas Auffälliges sehen: Der durchschnittliche Bestellwert für Online und Offline bleibt bei etwa 110 $. Es gibt jedoch einen neuen Channel, B2B-Wholesale, mit einem viel niedrigeren durchschnittlichen Bestellwert (etwa 75 $). Dieser neue Channel zieht den kombinierten Durchschnitt nach unten. - Der Agent kann proaktiv vorschlagen, die B2B-Kunden zu untersuchen. Wenn nicht, ist das in Ordnung. Das kommt im nächsten Schritt.
Zusammenfassung des Abschnitts:Sie haben den AOV-Rückgang im Januar selbst anhand eines neutralen Datenabzugs erkannt und dann nach „order_type“ aufgeschlüsselt, um B2B-Wholesale als neuen Channel zu identifizieren, der den kombinierten Durchschnittswert senkt. Als Nächstes müssen Sie herausfinden, wer diese B2B-Kunden sind.
6. Dienstgrenze überschreiten
Sie haben B2B-Wholesale als anomalen Channel in BigQuery identifiziert, die Kundendaten befinden sich jedoch in Cloud SQL. Mit dem Data Agent Kit können Sie die Unterhaltung fortsetzen und die Dienstgrenze wird berücksichtigt.
B2B-Kunden untersuchen
- Geben Sie im Chatbereich Folgendes ein:
Who are these B2B customers? Their profiles should be in our Cloud SQL database. Check for: - Who they are - When they signed up - Whether they're new or existing customers - Behalten Sie den Chatbereich im Blick. Dieses Mal sollte ein anderes MCP-Tool angezeigt werden. Der Agent fragt jetzt Cloud SQL anstelle von BigQuery ab.Er stellt eine Verbindung zur Cloud SQL Postgres-Instanz
cymbal-pets-opsher und führt eine Abfrage für die Tabellecustomersaus. Klicken Sie auf Details anzeigen, um den SQL-Code zu sehen. - Überprüfen Sie die Ergebnisse. Der Agent sollte mehrere wichtige Erkenntnisse liefern:
- Alle B2B-Kunden haben
customer_type = 'Business' - Sie haben sich alle innerhalb der letzten 30 Tage (Januar 2025) angemeldet.
- Die
last_name-Werte sind Unternehmensnamen wie „Pet Supply Co“, „Animal Care LLC“ und „Happy Paws Inc“. - Es gibt etwa 100 Nutzer in dieser Kohorte, die es vor diesem Monat noch nicht gab.
- Alle B2B-Kunden haben
Gutscheincode verknüpfen
- Der Agent stellt möglicherweise von selbst fest, dass viele B2B-Bestellungen in BigQuery einen
promo_code-Wert vonBIGORDER25haben. Wenn das der Fall ist, umso besser. Die Untersuchung läuft.Wenn der Kundenservicemitarbeiter den Gutscheincode nicht erwähnt, weise ihn darauf hin:I noticed a promo_code field on the orders table in BigQuery. Check what promo codes appear on the B2B-Wholesale orders? - Der Kundenservicemitarbeiter fragt BigQuery noch einmal ab und stellt fest, dass etwa 92% der B2B-Großhandelsbestellungen
promo_code = 'BIGORDER25'enthalten. Fast alle B2B-Aktivitäten sind an eine einzelne Werbekampagne gebunden.Der Kundenservicemitarbeiter sollte nun wissen wollen, woher dieser Gutscheincode stammt. Es kann gefragt werden, ob es an anderer Stelle in der Umgebung Werbedaten gibt. (In Cloud Storage ist sie vorhanden.)
Zusammenfassung des Abschnitts:Der Agent hat Cloud SQL abgefragt und festgestellt, dass es sich bei den B2B-Kunden um neue Unternehmen handelt, die sich im Januar 2025 registriert haben. In Kombination mit dem BigQuery-Ergebnis, dass etwa 92% der Bestellungen promo_code = 'BIGORDER25' enthalten, deutet die Spur nun auf eine Werbekampagne hin. Zeit, die Quelle zu finden.
7. Finde das fehlende Teil
Zwei Dienste sind ausgefallen, einer fehlt noch. Sie wissen, was passiert ist (B2B-Bestellungen senken den durchschnittlichen Bestellwert) und wer dafür verantwortlich ist (neue Geschäftskunden aus den letzten 30 Tagen). Jetzt müssen Sie herausfinden, warum. Die Antwort finden Sie in Cloud Storage.
GCS-Bucket prüfen
- Geben Sie im Chatbereich Folgendes ein:
Good catch on the promo code. We might have promotional campaign data in our GCS bucket. Can you check what's there? - Der Agent hat kein vorkonfiguriertes MCP-Tool für Cloud Storage. Daher wird automatisch auf das Terminaltool umgestellt, um
gcloud storage-Befehle auszuführen. Sie werden um die Berechtigung zum Ausführen von Befehlen wiegcloud storage lsgebeten. Lassen Sie diese Befehle zu und maximieren Sie dann im Chatbereich das Ausgeführt-Log, um die genauen CLI-Befehle zu sehen, die zum Lesen und Parsen der Dateipromo_events.jsonverwendet wurden. - Der Kundenservicemitarbeiter sollte drei Werbekampagnen in der Datei identifizieren:
Der GutscheincodeKampagne
Gutscheincode
Rabatt
Ziel
Daten
Sommer-Sale für Haustierpflege
PETSUMMER1515 % Rabatt
Alle
Juni 2024
B2B Wholesale Push
BIGORDER2525% Rabatt
B2B
Januar 2025
Urlaubsbonus für Treuemitglieder
LOYAL1010% Rabatt
Treuemitglieder
Dez. 2024
BIGORDER25ist der Kampagne B2B Wholesale Push zugeordnet: 25% Rabatt für B2B-Kunden bei einer Mindestbestellmenge von 50 Einheiten. Das ist der Beweis.
Zusammenfassung
- Bitten Sie den Agenten, alles zusammenzufassen, was er gefunden hat:
Put it all together. What happened to our average order value? - Der KI-Agent liefert eine klare, strukturierte Zusammenfassung, in der alle drei Datenquellen miteinander verknüpft werden. Darin sollte Folgendes erklärt werden:
- Der Rückgang des durchschnittlichen Bestellwerts ist real, aber er ist nicht auf einen Rückgang des bestehenden Geschäfts zurückzuführen. Der durchschnittliche Bestellwert (AOV) bleibt online und offline bei etwa 110 $.
- Im Januar 2025 wurde ein neuer B2B-Großhandelskanal eingeführt, über den etwa 25.000 Bestellungen mit einem viel niedrigeren durchschnittlichen Bestellwert (ca. 75–100 $) eingegangen sind.
- Die B2B-Kunden sind 100 neue Geschäftskonten, die sich alle in den letzten 30 Tagen registriert haben (Cloud SQL).
- Die Aktivität wird durch eine Werbekampagne („B2B Wholesale Push“) ausgelöst, die 25% Rabatt auf Großbestellungen mit einer Mindestmenge von 50 Einheiten (Cloud Storage) bietet.
- Der Umsatz ist unverändert, da das hohe Volumen an B2B-Bestellungen die niedrigeren Preise ausgleicht. Die Margen pro Einheit werden jedoch durch den Großhandelsrabatt von 25 % stark reduziert (um etwa 65 %). Dies gefährdet die Gesamtrentabilität erheblich, wenn Versand- und Betriebskosten berücksichtigt werden.
Zusammenfassung des Abschnitts:Sie haben in Cloud Storage den entscheidenden Beweis gefunden: eine B2B-Werbekampagne, die 25% Rabatt auf Großbestellungen bietet. Der Agent hat die Ergebnisse aller drei Dienste in einer klaren Zusammenfassung zusammengefasst. Die Prüfungsphase ist abgeschlossen. Als Nächstes setzen Sie diese Erkenntnisse in die Praxis um.
8. Pipeline erstellen
Du hast den Fall gelöst. Nun möchte der CFO, dass diese Analyse automatisch aktualisiert wird. In diesem Abschnitt bitten Sie den Agent, ein dbt-Projekt zu erstellen, in dem die BigQuery-Daten bereitgestellt und eine Fakttabelle für die laufende Analyse des durchschnittlichen Bestellwerts erstellt wird.
Hier wechselt der Agent von Ermittler zu Entwickler. Sie sehen, wie ein komplettes dbt-Projekt erstellt und die gesamte Pipeline ausgeführt wird – alles über einen einzigen Prompt.
dbt-Projekt erstellen
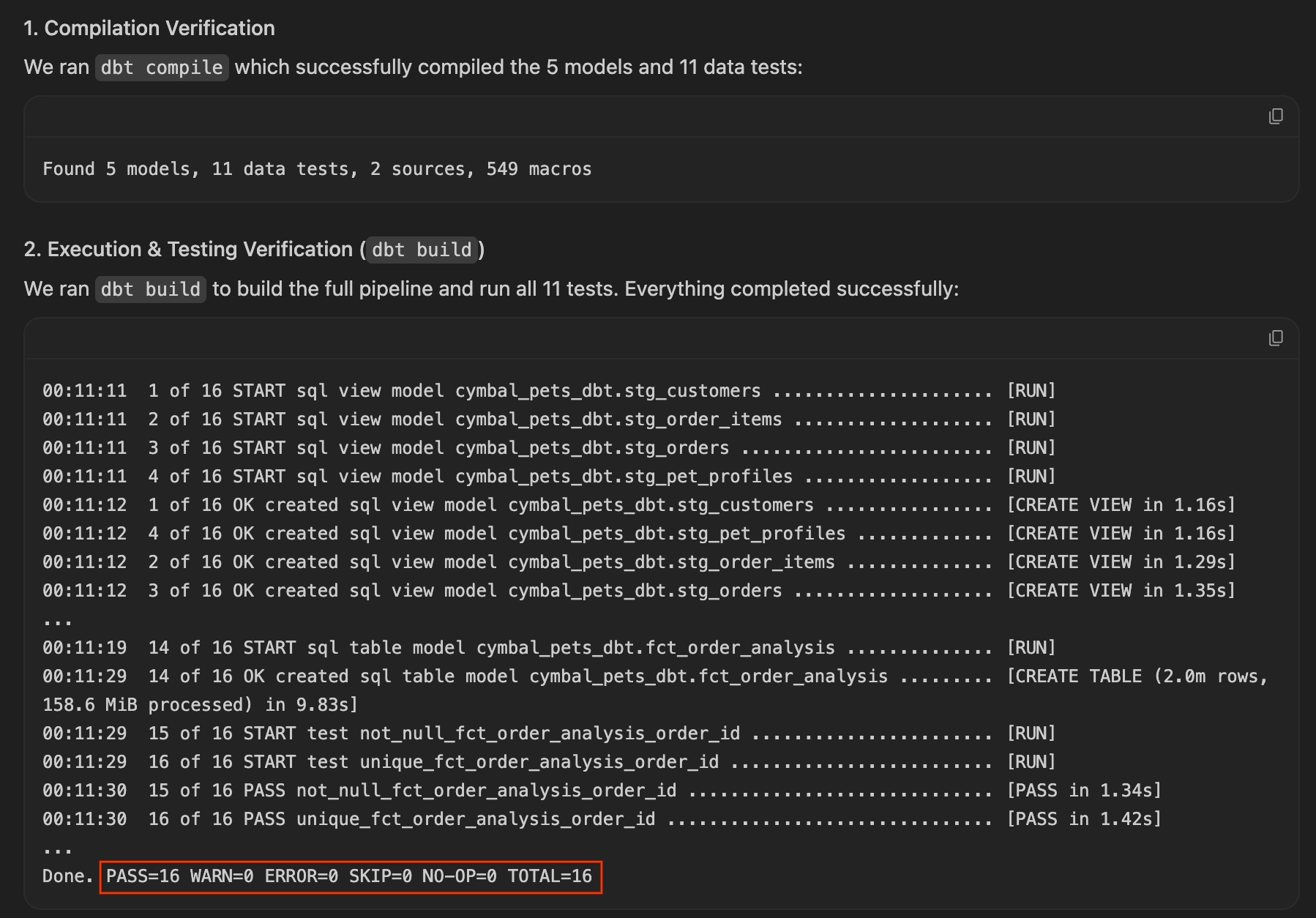
- Geben Sie im Chatbereich den folgenden Prompt ein. Diese Anleitung ist bewusst zielorientiert und nicht schrittweise. Sie sagen dem KI-Agenten was Sie möchten, nicht wie er es erstellen soll:
I want to productionize our AOV analysis so it updates automatically. Build a dbt project that: 1. Creates staging models for the BigQuery tables (orders and order_items) and a mart called fct_order_analysis that calculates AOV by channel and month 2. Add a uniqueness test on order_id and run dbt build - Selbstkorrektur beobachten:Wenn Sie das Log Worked for Ns (Funktioniert für Ns) maximieren, sehen Sie möglicherweise, dass der Agent nach
dbtsucht und, wenn er nicht gefunden wird, automatisch Befehle ausführt, um eine virtuelle Python-Umgebung (.venv) zu erstellen. Die Umgebung wird also automatisch eingerichtet.
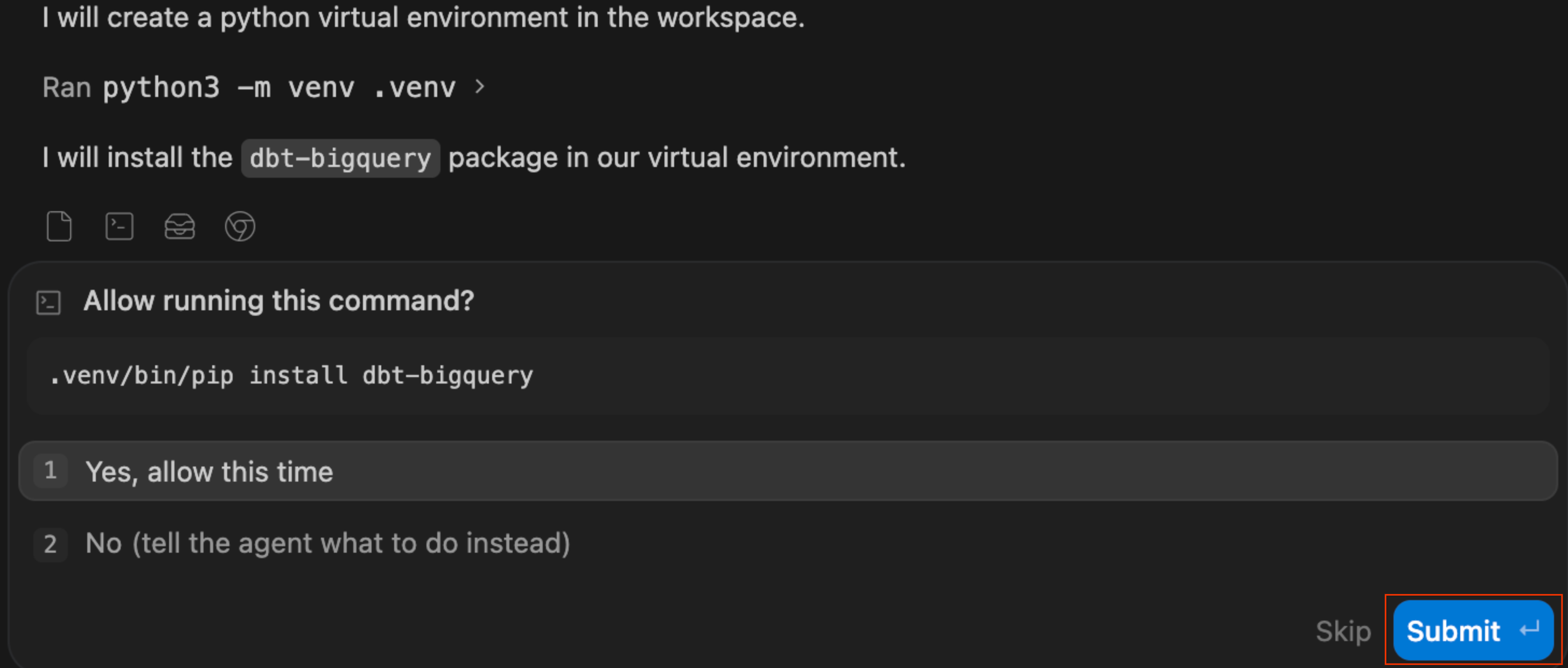
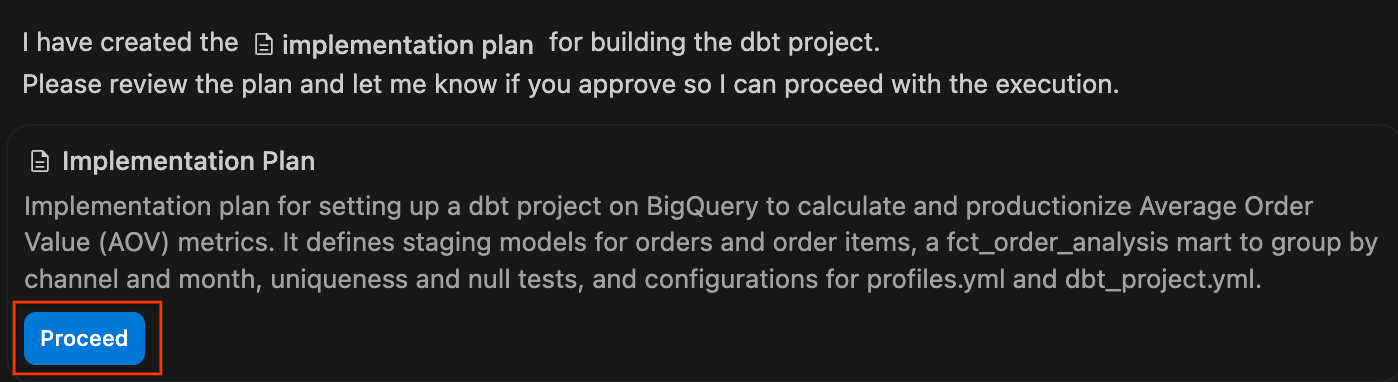
- Implementierungsplan prüfen:Der Agent generiert einen formalen Implementierungsplan. Sie können die vorgeschlagenen Dateien und die Architektur prüfen, bei Bedarf Kommentare hinzufügen und auf Weiter klicken, damit der Agent den Plan ausführt.
- Beobachten Sie den Chatbereich, während der Agent seinen Plan ausführt und die erforderlichen
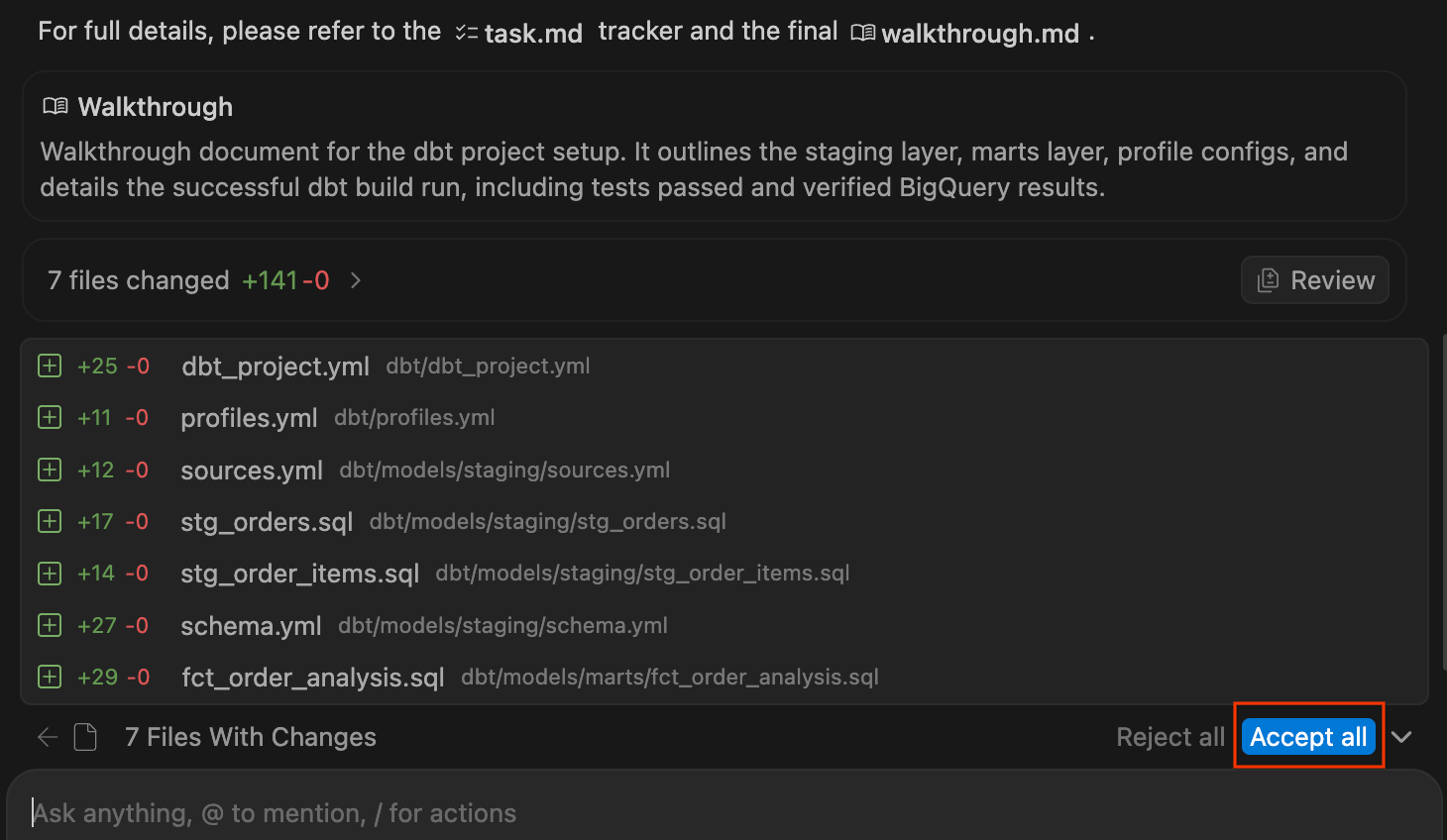
.sql-Dateien und YAML-Konfigurationen schreibt. Wenn der Vorgang abgeschlossen ist und das Projekt erfolgreich kompiliert wurde, wird eine Zusammenfassung der Änderungen angezeigt. Klicken Sie auf Alle annehmen, um diese Dateien Ihrem Arbeitsbereich hinzuzufügen.
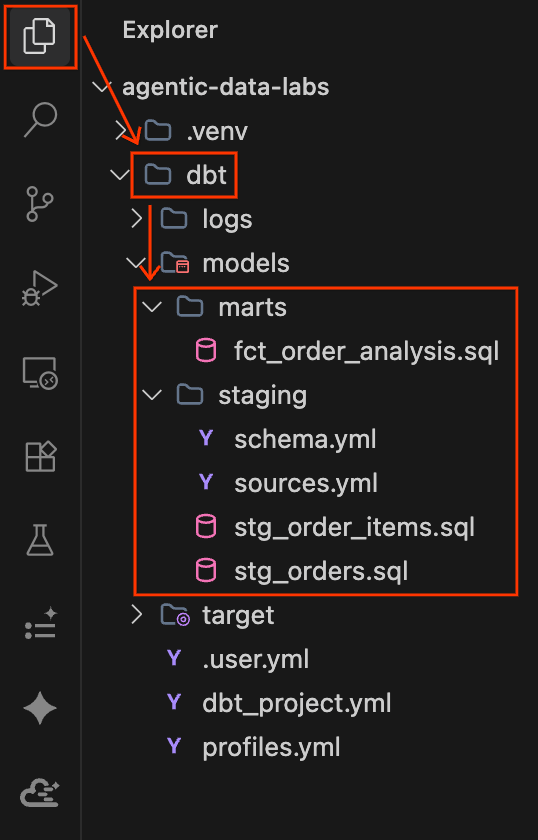
- Sehen Sie sich das neu generierte dbt-Projekt links im Explorer an. Die Struktur sollte etwa so aussehen:
dbt/ ├── models/ │ ├── marts/ │ │ └── fct_order_analysis.sql │ └── staging/ │ ├── schema.yml │ ├── sources.yml │ ├── stg_order_items.sql │ └── stg_orders.sql ├── dbt_project.yml └── profiles.yml
- Klicken Sie auf die
.sql-Modelldateien, um den vom Agent generierten SQL-Code zu prüfen. Achten Sie darauf, wie die folgenden Aspekte behandelt werden:- Staging-Modelle: Bereinigte, umbenannte Spalten mit Quellverweisen
- Das Mart-Modell: Die Join-Logik und die Berechnung des durchschnittlichen Bestellwerts nach Channel
- Prüfen Sie im Chatbereich, ob der Agent bestätigt, dass alle Modelle materialisiert und alle Tests bestanden wurden. Die Ergebnisse für den durchschnittlichen Bestellwert aus dem Mart sollten Ihre Erkenntnisse aus der Untersuchung bestätigen:
- Online: ~$110 - Offline: ~$110 - B2B-Wholesale: ~$75 to $77
Zusammenfassung des Abschnitts:Der Agent hat ein dbt-Projekt aus einem einzigen zielorientierten Prompt erstellt: Er hat Staging- und Mart-Modelle erstellt, dbt build erfolgreich ausgeführt und die AOV-Anomalie bestätigt. Als Nächstes stellen Sie eine komplexere Frage, um zu sehen, wie der Agent damit umgeht.
9. Wenn Tests fehlschlagen, führt der Agent das Debugging durch
Die Pipeline funktioniert, verwendet aber nur BigQuery-Daten. Das Produktteam möchte die Analyse mit Kunden- und Haustierprofildaten aus Cloud SQL anreichern, um Produkte basierend auf Ernährungsbedürfnissen empfehlen zu können. Das bedeutet, dass der Agent die Cloud SQL-Grenze überbrücken und einen subtilen Fehler bei der Datenmodellierung beheben muss – einen klassischen „Fan-Out“-Join für die Dimensionsmodellierung.
Je nach verwendetem Modell und seinen Reasoning-Funktionen wird der Agent diese Anfrage auf eine von zwei Arten bearbeiten: Proaktives Vermeiden des Fehlers (Option A) oder Selbstkorrektur nach einem fehlgeschlagenen Test (Option B). Sehen wir uns an, welchen Pfad Ihr KI-Agent nimmt.
Anfrage auslösen
- Geben Sie im Chatbereich Folgendes ein:
Enrich fct_order_analysis with customer data and pet profile data from our Cloud SQL database. Include customer type and each customer's pets and dietary needs so we can recommend products. Keep the uniqueness test on order_id and run dbt build. - Sehen Sie sich an, wie der Agent funktioniert. Dabei werden die Cloud SQL-Tabellen ermittelt, die Daten in BigQuery überbrückt (über eine föderierte Abfrage oder eine materialisierte Kopie), neue Staging-Modelle erstellt und
fct_order_analysis.sqlgeändert.
Option A: Der proaktive Kundenservicemitarbeiter (Vermeidung von Fehlern)
Wenn Sie ein erweitertes Modell für logisches Schlussfolgern verwenden, erkennt der Agent die Änderung der Granularität möglicherweise bevor er Code schreibt. Da ein Kunde mehrere Haustiere haben kann, werden bei einem direkten Join Bestellungen dupliziert und der von Ihnen angeforderte Eindeutigkeitstest für order_id schlägt sofort fehl.
- Proaktive Aggregation beobachten: Im Chatbereich oder im Walkthrough-Artefakt kann der Agent darauf hinweisen, dass er die Tierdaten vor dem Zusammenführen vorab aggregiert hat, um einen „klassischen Fan-Out“ zu verhindern. Dazu werden in der Regel mehrere Haustiere pro Kunde mithilfe einer Aggregationsfunktion (z.B.
ARRAY_AGG()oderSTRING_AGG()) zusammengefasst. - Ergebnisse prüfen: Der
dbt buildwird beim ersten Versuch erfolgreich ausgeführt und bestanden, da der Agent die Granularität der Faktenübersicht proaktiv geschützt hat. Sie können dies überprüfen, indem Sie das generierte Walkthrough-Artefakt ansehen. Dort wird häufig die erfolgreiche Testausgabe zusammen mit den Abfrageergebnissen angezeigt.
Wenn Ihr KI-Agent das getan hat, herzlichen Glückwunsch! Sie haben proaktives KI-Engineering kennengelernt. Sehen Sie sich den generierten SQL-Code in fct_order_analysis.sql an, um zu sehen, wie die Aggregation strukturiert ist. Fahren Sie dann mit dem nächsten Abschnitt Antwort liefern fort.
Option B: Self-Healing Agent (Debugging & Diagnostics)
Wenn das Modell zuerst einen naiven direkten Left Join schreibt, wird die SQL-Abfrage selbst erfolgreich ausgeführt, aber die automatisierte dbt test-Suite erkennt die Änderung der Granularität.
- Testfehler beobachten: Der Fehler wird in den Ausführungsfortschrittsprotokollen im Chatbereich gemeldet:
Completed with 1 error Failure in test unique_fct_order_analysis_order_id Got 287 results, configured to fail if != 0
order_idwurden doppelte Einträge gefunden, weil Kunden mit mehreren Haustieren die Bestellungen aufgeteilt haben. - KI-Agenten Diagnose und Selbstkorrektur durchführen lassen: Da der Test fehlgeschlagen ist, bitten Sie den KI-Agenten, den Fehler zu beheben. Geben Sie im Chatbereich Folgendes ein:
The uniqueness test failed. Can you figure out why and fix it? - Diagnose ansehen: Der KI-Agent fragt die Daten ab, erkennt die 1:n-Beziehung in
pet_profiles, erklärt, dass durch das direkte Verknüpfen die Granularität von eine Zeile pro Bestellung in eine Zeile pro Bestellung pro Haustier geändert wird, und schreibt das Modell neu, um die Haustierprofile vorab zu aggregieren:-- Pre-aggregating pets per customer to resolve fan-out LEFT JOIN ( SELECT customer_id, COUNT(*) AS num_pets, STRING_AGG(DISTINCT pet_type, ', ') AS pet_types, STRING_AGG(DISTINCT dietary_needs, ', ') AS dietary_needs FROM pet_profiles GROUP BY customer_id ) pet_agg ON c.customer_id = pet_agg.customer_id - Fehlerbehebung überprüfen: Der Agent führt
dbt buildnoch einmal aus. Dieses Mal werden alle Modelle erstellt und alle Tests bestehen.
Zusammenfassung des Abschnitts:Ihr Agent hat den Fehler proaktiv vermieden oder sich nach einem fehlgeschlagenen Test selbst korrigiert. Er hat die Cloud SQL-Grenze überschritten, Kunden- und Haustierprofildaten integriert und die perfekte Granularität der Fakten-Tabelle beibehalten. Die Pipeline ist jetzt robust, vollständig und vollständig getestet.
10. Antwort bereitstellen
Es ist Donnerstag. Sie haben die Woche mit einem besorgten CFO und verstreuten Daten in drei Cloud-Diensten begonnen. Sie haben jetzt die Ursache und eine Produktionspipeline. Zeit, um die Antwort zu liefern, zusammen mit einer zukunftsorientierten Empfehlung, die durch eine quantitative Prognose untermauert wird.
Executive Summary verfassen
- Geben Sie im Chatbereich Folgendes ein:
Write an executive summary covering: - Main findings and the quantitative margin impact - Project AOV for the subsequent quarter if the B2B program continues at its current trajectory - A data-driven recommendation - Sehen Sie dem Agenten bei der Arbeit zu.
- Zusammenfassung des KI-Agenten ansehen Eine typische und gut strukturierte Antwort sollte Folgendes enthalten:
- Wichtigste Erkenntnis: Der durchschnittliche Bestellwert im Januar ist ausschließlich aufgrund des neuen B2B-Großhandelskanals gesunken. Online und offline bleiben die Preise stabil bei etwa 110 $.
- Hauptursache: Durch die Aktion „B2B Wholesale Push“ (25% Rabatt auf Großbestellungen) wurden 100 neue Konten gewonnen, was zu etwa 25.000 Bestellungen führte.
- Auswirkung auf die Marge: Durch Großhandelsbestellungen sank der durchschnittliche Stückgewinn um etwa 65% (von etwa 7,50 $ auf etwa 2,60 $).
- Umsatz: Der Gesamtumsatz bleibt unverändert, da das hohe B2B-Volumen die niedrigeren Preise ausgleicht.
Durchschnittlichen Bestellwert mit AI.FORECAST vorhersagen
- Der Agent sollte auch eine zukunftsorientierte Prognose erstellen. Suchen Sie nach einem MCP-Tool-Aufruf, bei dem der Agent eine
AI.FORECAST-Abfrage für BigQuery ausführt. Dazu wird das integrierte TimesFM-Foundation Model verwendet, um den durchschnittlichen Bestellwert basierend auf bisherigen Trends für die nächsten 90 Tage zu prognostizieren. Mit der Abfrage soll der durchschnittliche Bestellwert für die nächsten 90 Tage in zwei Szenarien prognostiziert werden: Fortsetzung der Kampagne (strukturell niedriger durchschnittlicher Bestellwert) und Beendigung der Kampagne (Erholung auf etwa 110 $).
- Sehen Sie sich die strategischen Empfehlungen des KI-Agenten an. Ein umfassendes Set von Empfehlungen könnte Folgendes umfassen:
- Rabatte neu strukturieren: Führen Sie Mindestmargen ein oder begrenzen Sie Mengenrabatte, um die Margen auf Einheitenebene zu schützen.
- Strengere Mindestbestellmengen durchsetzen: So verhindern Sie, dass Einzelhandelskunden Großhandelspreise missbrauchen.
- Separate Berichte: Verfolgen Sie die Einzelhandels- und B2B-Bereiche unabhängig voneinander, um die Einzelhandelsleistung nicht zu verschleiern.
Die ganze Geschichte
Was am Montag mit einer Übung aufgrund eines Rückgangs des durchschnittlichen Bestellwerts um 7% begann, hat für den CFO eine klare Lösung:
- Einzelhandel: Die wichtigsten Einzelhandelskanäle sind weiterhin gesund und stabil.
- Großhandelszufluss: Der Rückgang des durchschnittlichen Bestellwerts ist ausschließlich auf den neuen B2B-Großhandelskanal und die
BIGORDER25-Kampagne zurückzuführen. - Auswirkung auf die Marge: Der Mengenrabatt von 25% hat die Margen pro Einheit stark geschmälert und die Rentabilität trotz eines gleichbleibenden Umsatzes gefährdet.
- Strategische Prognose: Eine
AI.FORECAST-Prognose zeigt, dass durch die Umstrukturierung der Großhandelsebenen der durchschnittliche Bestellwert wiederhergestellt wird.
Sie geben eine datengestützte Empfehlung ab, um Mindestmargen für den Großhandel und separate Berichte für den Einzelhandel/B2B-Bereich einzuführen.
Zusammenfassung des Abschnitts:Sie haben den Agent gebeten, eine Zusammenfassung für Führungskräfte mit einer Margenanalyse zu erstellen, eine AI.FORECAST-Prognose zu generieren und eine datengestützte Empfehlung zu geben. Die Prüfung ist abgeschlossen.
11. Bereinigen
Wenn Sie vermeiden möchten, dass Ihrem Google Cloud-Konto laufend Gebühren berechnet werden, löschen Sie die in diesem Codelab erstellten Ressourcen, indem Sie das Teardown-Script ausführen.
- Wechseln Sie im Bereich Terminal unten in der Antigravity IDE (oder in Cloud Shell) zum Codelab-Verzeichnis und führen Sie Folgendes aus:
cd ~/devrel-demos/codelabs/agentic-data-labs/scripts
chmod +x teardown.sh
./teardown.sh
- Im Script werden alle Ressourcen angezeigt, die gelöscht werden sollen. Sie werden aufgefordert, die Aktion zu bestätigen, bevor sie ausgeführt wird:
- Cloud SQL-Instanz (
cymbal-pets-ops): Dies ist die teuerste Ressource. - BigQuery-Dataset (
cymbal_pets): Alle Tabellen und Modelle - Cloud Storage-Bucket (
gs://YOUR_PROJECT_ID-cymbal-pets-raw) - BigQuery-Verbindung (
cymbal-pets-cloudsql)
- Cloud SQL-Instanz (
- Geben Sie zur Bestätigung
yein. Das Zerlegen dauert etwa 2 bis 3 Minuten.
[INFO] Deleting Cloud SQL instance cymbal-pets-ops... [ OK ] Cloud SQL instance deleted. [INFO] Deleting BigQuery dataset cymbal_pets... [ OK ] BigQuery dataset deleted. [INFO] Deleting GCS bucket gs://YOUR_PROJECT_ID-cymbal-pets-raw... [ OK ] GCS bucket deleted.
12. Glückwunsch!
Du hast Die Cymbal Pets-Ermittlung erfolgreich abgeschlossen. Sie haben aus einer vagen Frage des CFO eine vollständig operationalisierte, auf Prognosen basierende Empfehlung gemacht, indem Sie einen KI-Agenten verwendet haben, der für alle Ihre Google Cloud-Daten funktioniert.
Ihre Erfolge
- 🔍 Dienstübergreifend untersucht: Assets in BigQuery, Cloud SQL und Cloud Storage wurden mithilfe des Data Agent Kit-Knowledge Catalog ermittelt und in der Vorschau angezeigt.
- 🕵️♂️ Mit KI untersucht: Es wurden mehrere Dienste in einem einzigen Chatfenster mit MCP-Tools abgefragt, um die AOV-Anomalie auf eine B2B-Werbekampagne zurückzuführen.
- 🔧 Produktionspipeline erstellt: Ein vollständiges dbt-Projekt wurde eingerichtet, um Transaktions- und Kundendaten zu bereinigen, zusammenzuführen und zu testen.
- 🐛 Fan-out-Fehler behoben: Der Agent hat automatisch ein Granularitätsproblem diagnostiziert und das dbt-SQL-Modell umgestaltet, um Kundenprofile für Haustiere vorab zu aggregieren.
- 📈 Prognostiziert und empfohlen: Das integrierte
AI.FORECASTvon BigQuery wurde verwendet, um AOV-Trends zu modellieren und dem CFO eine datengestützte Empfehlung zu geben.
Wichtige Konzepte
Konzept | Das haben Sie gelernt |
MCP-Tools | Sichere, prüfbare Verbindungen, mit denen der KI-Agent in Ihrem Namen Dienste wie BigQuery, Cloud SQL, Spanner und andere Datenbanken abfragen kann. Jeder Aufruf ist im Chatbereich sichtbar. |
Agent Skills | Vordefinierte Anweisungssätze (z. B. |
Dienstübergreifende Untersuchung | Der Agent fragt mehrere Google Cloud-Dienste in einem einzigen Gespräch ab – ohne Verbindungsaufbau und ohne Kontextwechsel zwischen Konsolen. |
Zielorientierte Prompts | Dem Agenten mitteilen, was Sie möchten („Erstelle ein dbt-Projekt, in dem der durchschnittliche Bestellwert nach Channel berechnet wird“), anstatt wie, und ihm die Wahl des Implementierungsansatzes überlassen |
Data Agent Kit | Die Erweiterung, die alles zusammenbindet – MCP-Tools, Agent-Skills und Datenermittlung – und Ihnen Zugriff auf alle Ihre Google Cloud-Daten direkt in Ihrer bevorzugten IDE bietet |
Nächste Schritte
- Dokumentation zum Data Agent Kit lesen, um mehr über die Funktionen zu erfahren
- Informationen zu BigQuery ML und KI-Funktionen, einschließlich
AI.FORECAST,AI.GENERATEundAI.EMBED - Eigene dienstübergreifende Analysen mit der Antigravity IDE für Ihre Daten erstellen