
۱. مقدمه
صبح دوشنبه است و مدیر ارشد مالی همین الان با شما تماس گرفت. میانگین ارزش سفارشها در این ماه ۷ درصد کاهش یافته، اما درآمد کل ثابت مانده است. یک جای کار میلنگد و هیئت مدیره تا جمعه پاسخ میخواهد.
شرکت شما، Cymbal Pets، یکی از بزرگترین خردهفروشان آنلاین لوازم حیوانات خانگی در ایالات متحده است. دادههای مورد نیاز شما در سه سرویس Google Cloud پراکنده است: دادههای تراکنشی در BigQuery ، سوابق مشتری و محصول در Cloud SQL و فایلهای بازاریابی در Cloud Storage . معمولاً، جمعآوری یک تحقیق بین سرویسی مانند این به معنای جابجایی بین کنسولها، نوشتن متنهای تکراری و اتصال نتایج به صورت دستی است.
در این آزمایشگاه کد، شما از کیت عامل داده ابری گوگل (DAK) در محیط برنامهنویسی Antigravity برای بررسی ناهنجاری با استفاده از زبان طبیعی استفاده خواهید کرد. شما آنچه را که به دنبال آن هستید توصیف میکنید و عامل هوش مصنوعی، اتصالات، SQL و اتصالات بین سرویسی را در BigQuery، Cloud SQL و Cloud Storage مدیریت میکند. پس از حل مسئله، از عامل میخواهید که یک خط لوله داده ابری (dbt pipeline) بسازد که یافتههای شما را عملیاتی کند، یک اشکال واقعی در مدلسازی دادهها را اشکالزدایی کند و یک توصیه مبتنی بر پیشبینی را به مدیر ارشد مالی ارائه دهد.
کاری که انجام خواهید داد
- با استفاده از Knowledge Catalog، داراییهای داده را در BigQuery ، Cloud SQL و Cloud Storage کشف کنید.
- با استفاده از ابزارهای MCP ، با پرس و جو از چندین سرویس در یک مکالمه، یک ناهنجاری را بررسی کنید
- ساخت یک خط لوله dbt برای مرحلهبندی و اتصال دادههای بین سرویسها با مدلهای مرحلهبندی و تستهای خودکار
- اشکالزدایی یک مشکل مدلسازی دادهها، همزمان با خود-تشخیصی و اصلاح یک اشکال فانکشنال توسط عامل
- پیشبینی روندهای آینده و ارائه پیشنهاد مبتنی بر داده با استفاده از
AI.FORECASTBigQuery.FORECAST
آنچه نیاز دارید
- یک مرورگر وب مانند کروم
- یک پروژه گوگل کلود با قابلیت پرداخت صورتحساب
- آشنایی اولیه با SQL و کنسول ابری گوگل
این آزمایشگاه کد برای متخصصان داده سطح متوسط (مهندسان تجزیه و تحلیل، تحلیلگران داده، دانشمندان داده) است.
منابع ایجاد شده در این آزمایشگاه کد باید کمتر از ۵ دلار هزینه داشته باشند.
۲. قبل از شروع
در این بخش، یک اسکریپت راهاندازی اجرا خواهید کرد که کل محیط آزمایشگاه شما را آمادهسازی میکند: یک مجموعه داده BigQuery با دادههای سفارش، یک نمونه Cloud SQL Postgres با دادههای مشتری و محصول، و یک مخزن ذخیرهسازی ابری با سوابق کمپینهای تبلیغاتی. تکمیل این اسکریپت حدود ۸ تا ۱۰ دقیقه طول میکشد، و آمادهسازی Cloud SQL به عنوان گلوگاه عمل میکند.
شروع پوسته ابری
برای اجرای اسکریپت راهاندازی، از Google Cloud Shell استفاده خواهید کرد.
- روی فعال کردن پوسته ابری (Cloud Shell) در بالای کنسول گوگل کلود (Google Cloud Console) کلیک کنید.

- پس از اتصال، شناسه پروژه خود را تنظیم کرده و محیط خود را تأیید کنید:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
شما باید پیامی مشابه زیر را ببینید:
Your active configuration is: [cloudshell-####] Updated property [core/project]
مخزن را کلون کنید
مخزن codelab را در محیط Cloud Shell خود کلون کنید:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/agentic-data-labs
git checkout main
cd codelabs/agentic-data-labs/
اسکریپت راهاندازی را اجرا کنید
اسکریپت راهاندازی، کل محیط آزمایشگاه شما را در عرض چند دقیقه آماده میکند. این اسکریپت، فعالسازی APIها، بارگذاری و افزایش دادههای BigQuery، آپلود فایلهای تبلیغاتی در GCS و سپس بهطور خودکار یک Worker پسزمینه را برای آمادهسازی و پیکربندی Cloud SQL Postgres در پسزمینه، همزمان با شروع Codelab، مدیریت میکند.
این اسکریپت به طور خودکار و ایمن یک رمز عبور Cloud SQL تولید میکند و آن را در فایل .env شما ذخیره میکند.
cd ~/devrel-demos/codelabs/agentic-data-labs/scripts
chmod +x setup.sh setup_sql.sh
./setup.sh
پس از اتمام، خلاصهای از محیط پیشزمینه خود را مشاهده خواهید کرد:
╔══════════════════════════════════════════════════════╗
║ Base Setup complete! ║
╚══════════════════════════════════════════════════════╝
Your core BigQuery and GCS assets are ready.
Cloud SQL is currently provisioning in the background and will be fully ready by Step 4.
BigQuery: YOUR_PROJECT_ID.cymbal_pets
├── orders
└── order_items
GCS: gs://YOUR_PROJECT_ID-cymbal-pets-raw
└── promo_events.json
در حالی که شما مراحل بعدی آزمایشگاه را ادامه میدهید، پایگاه داده در پسزمینه در حال آمادهسازی و بارگذاری است. میتوانید پیشرفت آن را در هر زمان در یک پنل ترمینال جداگانه با استفاده از موارد زیر رصد کنید:
tail -f /tmp/cloudsql_setup.log
به معماری دادهها توجه کنید: دادههای تراکنشی (سفارشها و اقلام سفارش) در BigQuery نگهداری میشوند، در حالی که دادههای عملیاتی (مشتریان، پروفایلهای حیوانات خانگی و محصولات) در Cloud SQL نگهداری میشوند. این تقسیمبندی، نحوه توزیع دادهها بین سرویسها در سازمانهای واقعی را منعکس میکند و همین امر، بررسی بین سرویسها را جالب میکند.
خلاصه بخش: شما اسکریپت راهاندازی را برای راهاندازی مجدد محیط آزمایشگاه خود اجرا کردید و آمادهسازی پایگاه داده در پسزمینه را آغاز کردید.
۳. راهاندازی IDE و کیت Data Agent
نرمافزار Antigravity IDE را باز کنید.
لازم نیست منتظر بمانید تا Cloud SQL تمام شود! Antigravity IDE را باز کنید و آن را به پروژه Google Cloud خود متصل کنید.
- اگر هنوز Antigravity IDE را دانلود و نصب نکردهاید، آن را از صفحه دانلود Google Antigravity دانلود و نصب کنید.
- برنامه دسکتاپ Antigravity IDE را اجرا کنید.
- یک پوشه جدید و خالی روی دستگاه محلی خود ایجاد کنید (مثلاً با نام
agentic-data-labs) و با انتخاب Open Folder آن را در IDE باز کنید. این پوشه به عنوان فضای کاری محلی شما برای codelab عمل خواهد کرد.
افزونه Data Agent Kit را نصب کنید
افزونه Google Cloud Data Agent Kit ادغام عمیقی را با سرویسهای داده Google Cloud مستقیماً در ویرایشگر شما فراهم میکند و به شما امکان میدهد بدون تغییر زمینه، با BigQuery، Cloud SQL، Cloud Storage و موارد دیگر تعامل داشته باشید.
- در محیط توسعه آنتیگراویتی (Antigravity IDE)، روی آیکون افزونهها (Extensions) در نوار فعالیت (Activity Bar) در سمت چپ صفحه کلیک کنید (شکل آن شبیه چهار مربع است).
- در نوار جستجو در بالای پنل افزونهها، عبارت
Google Cloud Data Agent Kitتایپ کنید. - افزونهای به نام Google Cloud Data Agent Kit که توسط
googlecloudtoolsمنتشر شده است را پیدا کنید. - روی دکمه نصب کلیک کنید.
- ممکن است پیامی ظاهر شود که میپرسد: «آیا به ناشر «googlecloudtools» و افزونههای آن اعتماد دارید؟». برای ادامه، روی «اعتماد به ناشران و نصب» کلیک کنید.
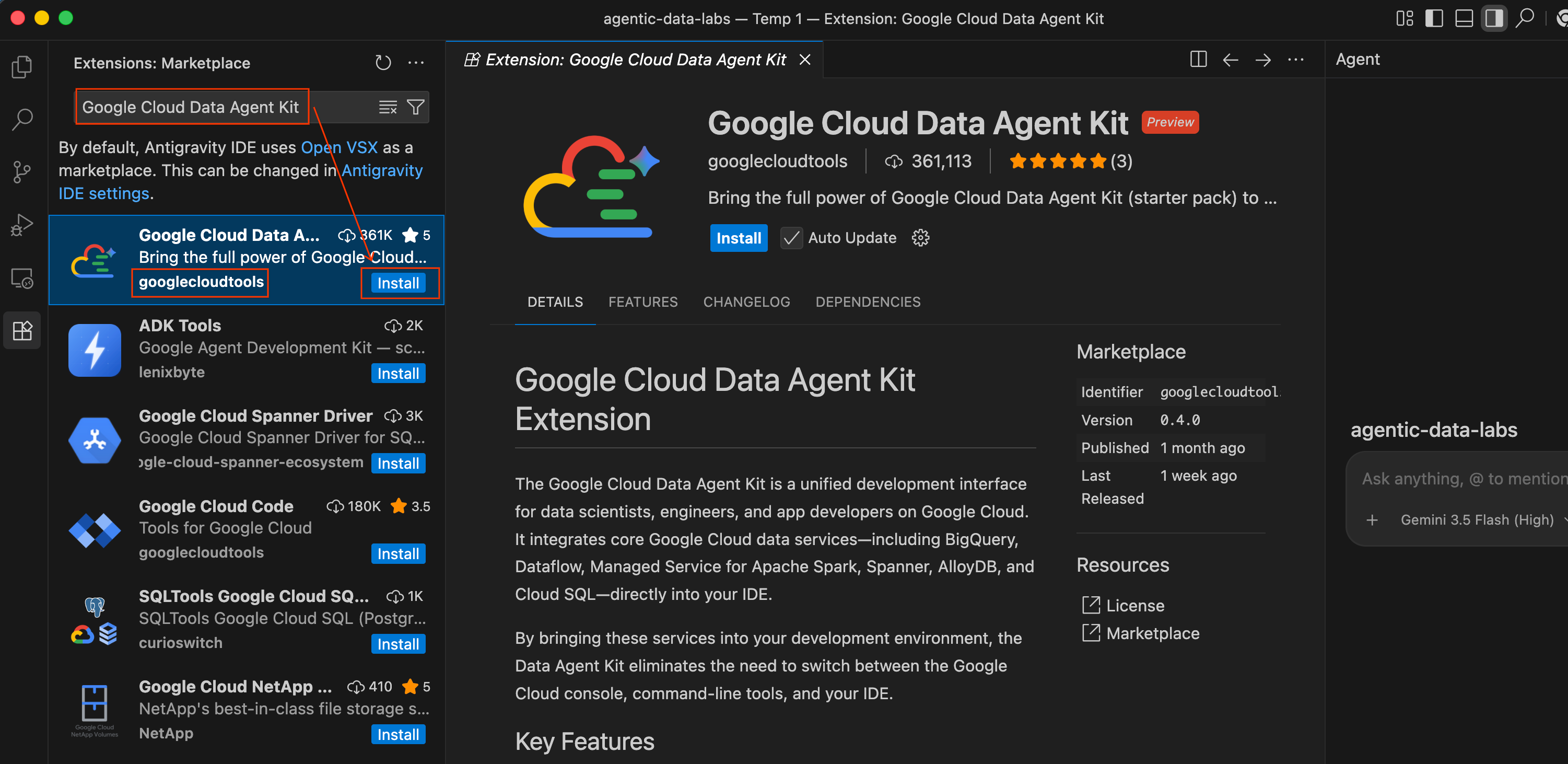
پس از نصب، آیکون جدید Google Cloud Data Agent Kit را در نوار فعالیت (Activity Bar) در سمت چپ Antigravity IDE مشاهده خواهید کرد.
تأیید اعتبار و پیکربندی افزونه
پس از نصب، افزونه را به پروژه Google Cloud خود متصل کنید.
- یک صفحهی شروع با عنوان «به کیت عامل دادههای ابری گوگل خوش آمدید» باید بهطور خودکار باز شود. اگر وارد حساب ابری خود نشدهاید، برای اجازه دسترسی، هرگونه درخواستی را دنبال کنید.
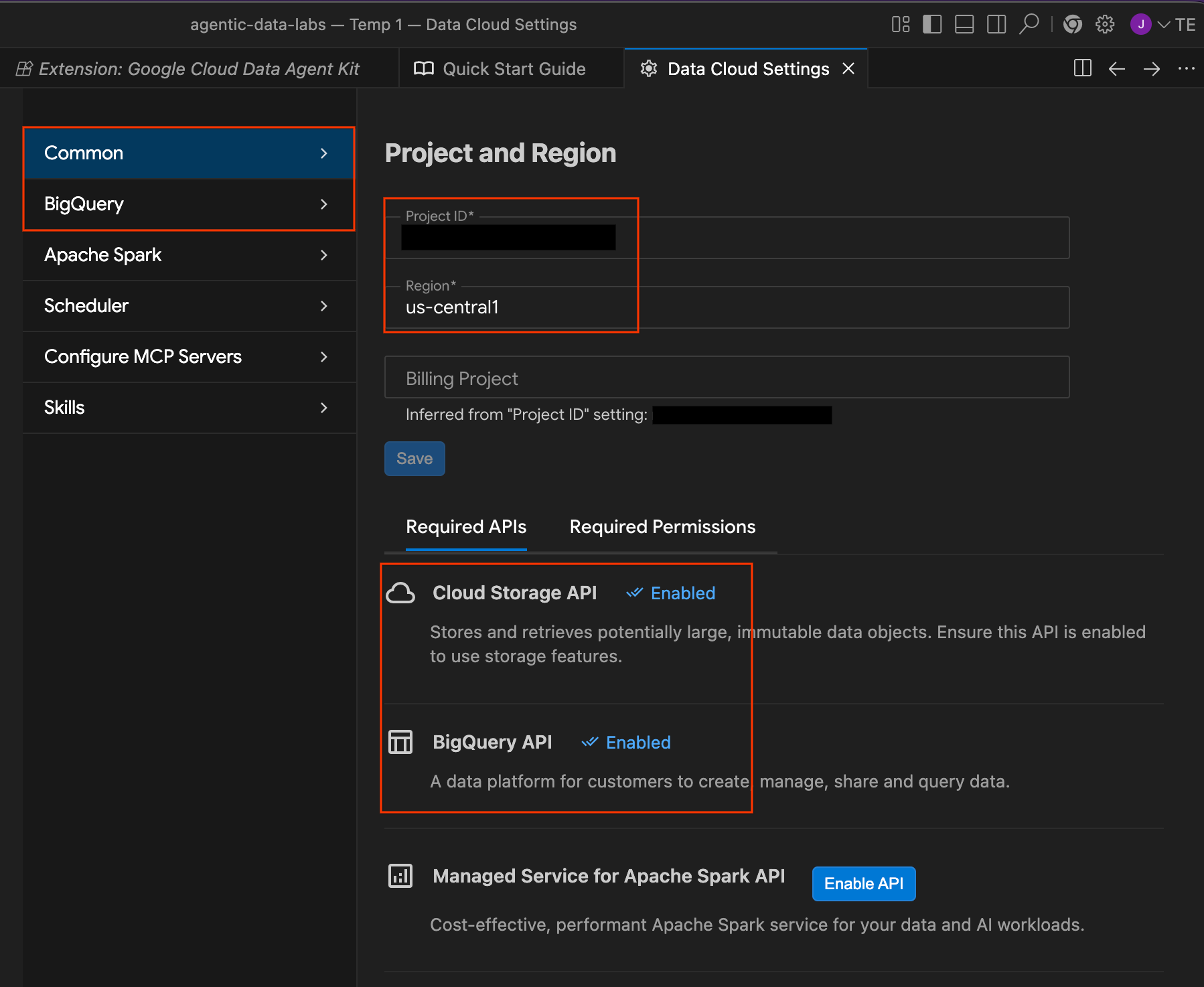
- در بخش خلاصه پیکربندی ، فیلد پروژه را پیدا کنید. روی منوی کشویی کلیک کنید و پروژه Google Cloud خود را انتخاب کنید. منطقه خود را به عنوان
us-central1تنظیم کنید. سپس پیکربندی سرورهای MCP را انتخاب کنید.

- در زیر پنل پیکربندی MCP ، برای فعال کردن BigQuery و Cloud SQL کلیک کنید. سپس روی Get Started کلیک کنید.

گزینههای پیکربندی را بررسی کنید
پس از اتمام راهاندازی، به صفحه «شروع به کار با Google Cloud Data Agent Kit» خواهید رسید.
- در قسمت «تنظیمات و پیکربندی»، روی «شروع به کار » کلیک کنید.
- این پنل پیکربندی عامل داده را باز میکند. تبها را بررسی کنید:
- پروژه و منطقه: شناسه پروژه انتخابی خود را تأیید کنید و بررسی کنید که APIهای مورد نیاز (Cloud Storage API، BigQuery API، Catalog API و Cloud SQL Admin API) فعال باشند.
- BigQuery: مکان پیشفرض برای کوئریهای BigQuery خود را پیکربندی کنید. از ناحیه
us-central1استفاده کنید. - پیکربندی سرورهای MCP: سرورهای MCP فعال (BigQuery، Notebooks، Cloud SQL و غیره) را که به عوامل هوش مصنوعی اجازه میدهند تا به طور ایمن با دادههای شما تعامل داشته باشند، مشاهده کنید.
- مهارتها: مهارتهای از پیش ساخته شدهای را بررسی کنید که قابلیتهای تخصصی را برای وظایف پیچیده داده در اختیار عاملها قرار میدهند.
خلاصه بخش: شما Antigravity IDE را باز کردید، آن را به پروژه Google Cloud خود متصل کردید، سرورهای MCP از راه دور Data Agent Kit را پیکربندی کردید و با اجرای یک پرس و جو در BigQuery، اتصال را تأیید کردید.
۴. دادههای خود را کشف کنید
وقت آن رسیده که صحنه را آماده کنیم. وضعیت از این قرار است: مدیر مالی میگوید میانگین ارزش سفارشها ماه گذشته ۷ درصد کاهش یافته، اما درآمد کل ثابت مانده است. قبل از اینکه از نماینده بخواهید موضوع را بررسی کند، ابتدا باید بفهمید با چه دادههایی کار میکنید.
در این بخش، شما به صورت دستی پنل Data Agent Kit را بررسی خواهید کرد تا با محیط آن آشنا شوید. درک دادهها قبل از شروع پرسوجو، اولین گام حیاتی در هر تحقیقی است.
جداول BigQuery را کاوش کنید
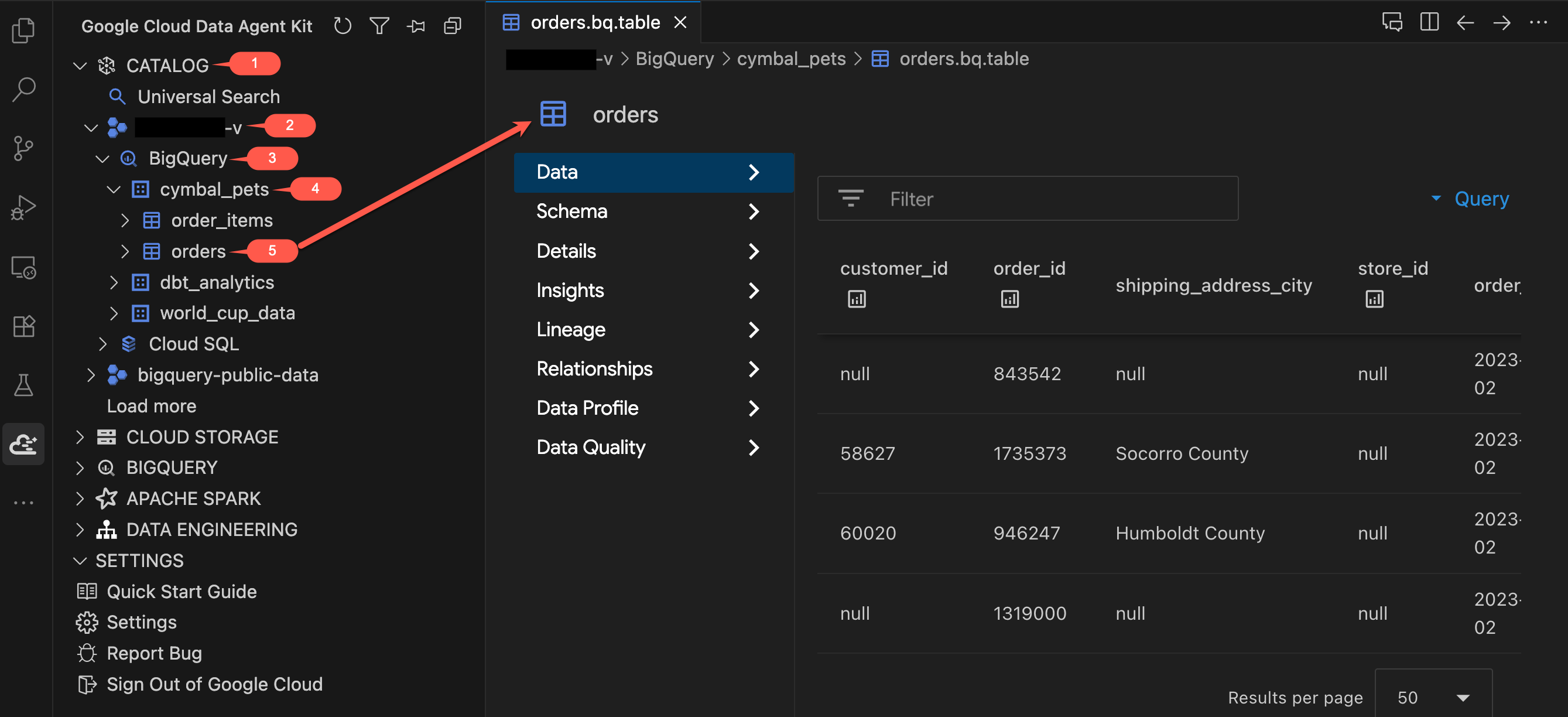
- در پنل Data Agent Kit، در زیر CATALOG ، پروژه خود را باز کنید → BigQuery →
cymbal_pets. - روی جدول
ordersکلیک کنید. یک برگه جدید باز میشود که جزئیات جدول را نشان میدهد. - زبانههای سمت چپ نمایشگر جدول را بررسی کنید:
- دادهها : پیشنمایش ردیفهای واقعی. در مجموعه دادهها پیمایش کنید و ستونها را بررسی کنید.
- طرحواره : نامها و انواع ستونها را مرور کنید. به فیلدهایی مانند
order_typeوpromo_codeتوجه کنید که بعداً مهم خواهند شد. - تبهای دیگر (جزئیات، بینشها، نمایه دادهها و غیره) : به فرادادهها، تبار دادهها و جزئیات کیفی که معمولاً در کنسول Google Cloud پیدا میکنید، دسترسی داشته باشید - همه اینها بدون ترک ویرایشگر شما.
- حالا روی جدول
order_itemsکلیک کنید و طرحواره آن را بررسی کنید. به فیلدهایquantityوpriceتوجه کنید.
جداول SQL ابری را کاوش کنید
اسکریپت راهاندازی همچنین دادههای مشتری، حیوان خانگی و محصول را در یک پایگاه داده PostgreSQL در Cloud SQL قرار داد.
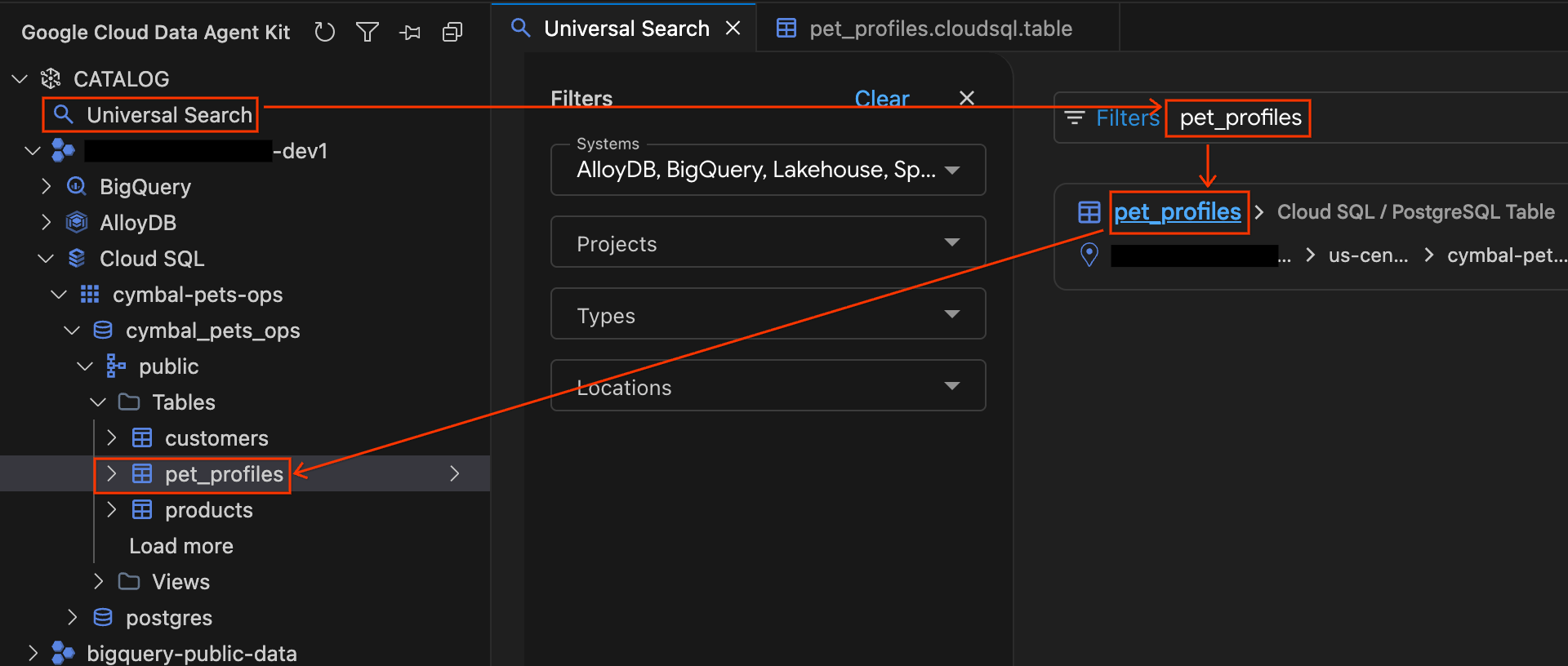
- در پنل Data Agent Kit، در بخش CATALOG روی Universal Search کلیک کنید.
- در کادر جستجو،
pet_profilesرا تایپ کنید و Enter را بزنید. - در نتایج جستجو، روی نتیجهی جدول PostgreSQL برای
pet_profiles(در زیر نمونهی Cloud SQL پروژهتان) کلیک کنید. توجه داشته باشید که آکاردئون نوار کناری به طور خودکار گسترش مییابد و دقیقاً محل قرارگیری جدول در درخت پایگاه داده را به شما نشان میدهد. اکنون روی جدولcustomersکه درست بالای آن در درخت قرار دارد کلیک کنید تا جزئیات آن باز شود و زبانههای Schema و Details را بررسی کنید.
کاوش در فایلهای ذخیرهسازی ابری
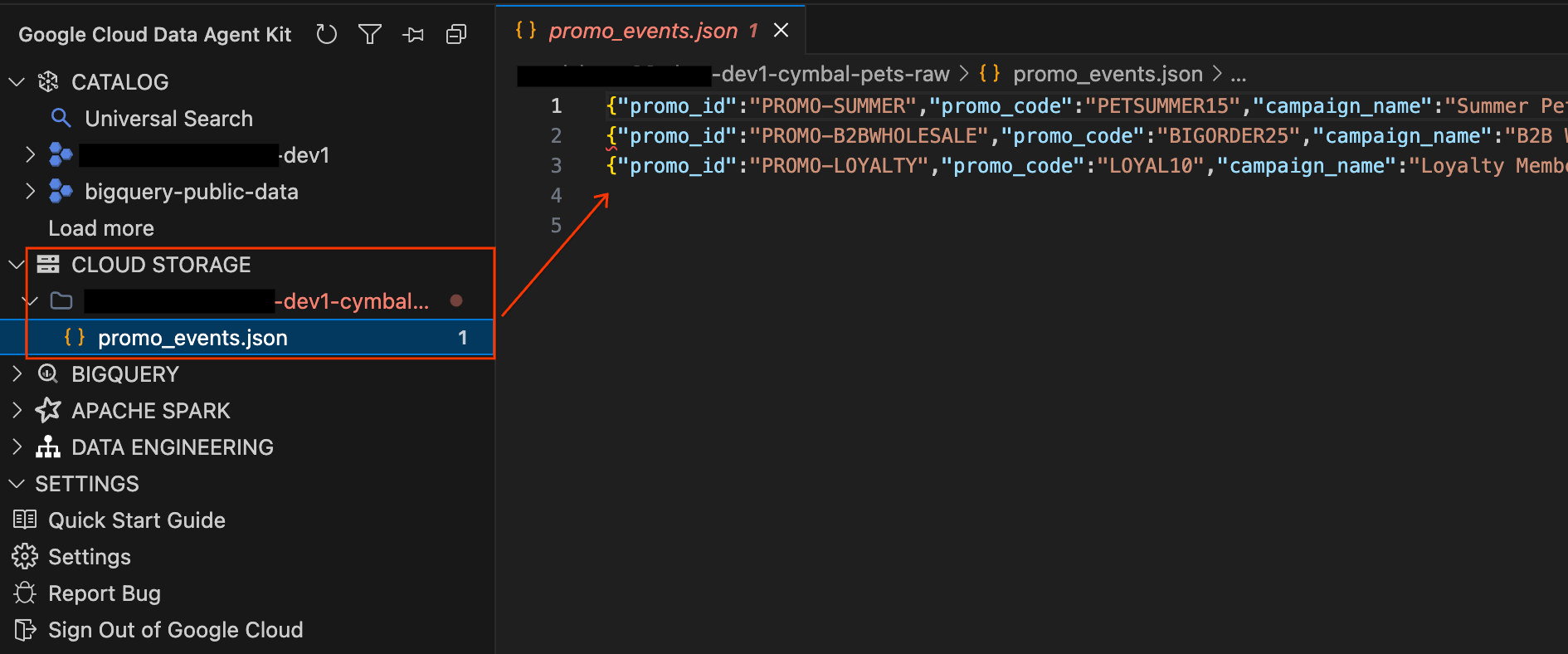
در نهایت، سوابق کمپینهای بازاریابی و تبلیغاتی به صورت فایلهای خام JSON در فضای ذخیرهسازی ابری ذخیره میشوند.
- در پنل Data Agent Kit در سمت چپ، بخش CLOUD STORAGE را باز کنید. فایل خام پروژه خود (
YOUR_PROJECT_ID-cymbal-pets-raw) را پیدا کنید. - روی فایل
promo_events.jsonداخل سطل کلیک کنید. یک تب ویرایشگر جدید باز میشود که به شما امکان میدهد محتوای خام JSON Lines کمپینهای بازاریابی را مستقیماً در داخل IDE مشاهده کنید.
سهام بگیرید
آنچه اکنون در مورد چشمانداز دادهها میدانید، این است:
خدمات | جداول | چی اونجاست؟ |
بیگکوئری | | حدود ۱.۹ میلیون سفارش، حدود ۴.۳ میلیون قلم کالا، بازه زمانی ۲۰۲۳-۲۰۲۵ |
SQL ابری | | حدود ۹۲ هزار مشتری، حدود ۷.۶ هزار پروفایل حیوانات خانگی، ۲۰۶ محصول |
فضای ذخیرهسازی ابری | | سوابق کمپینهای تبلیغاتی |
دادهها در سه سرویس پخش شدهاند. در یک گردش کار سنتی، شما باید اتصالات را تنظیم کنید، کد یکپارچهسازی را بنویسید و نتایج را به صورت دستی به هم متصل کنید. در مرحله بعدی، به عامل هوش مصنوعی اجازه میدهید تا همه این کارها را از طریق یک مکالمه واحد انجام دهد.
خلاصه بخش: شما از پنل Data Agent Kit برای بررسی دستی معماری دادهها در BigQuery، Cloud SQL و Cloud Storage استفاده کردید. اکنون میدانید دادهها کجا ذخیره میشوند و چه فیلدهایی در دسترس هستند، بنابراین آماده شروع بررسی هستید.
۵. اعداد را دنبال کنید
اکنون تحقیقات آغاز میشود. شما از طریق پنل چت از عامل هوش مصنوعی میخواهید دادههای میانگین ارزش سفارش (AOV) را از BigQuery دریافت کند. AOV یک معیار تجاری است که نشان دهنده میانگین مبلغ خرج شده به ازای هر سفارش است. عامل با استفاده از ابزارهای MCP از طرف شما پرس و جو میکند و شما میتوانید هر پرس و جوی SQL که اجرا میکند را مشاهده کنید.
روند میانگین ارزش سفارش را بررسی کنید
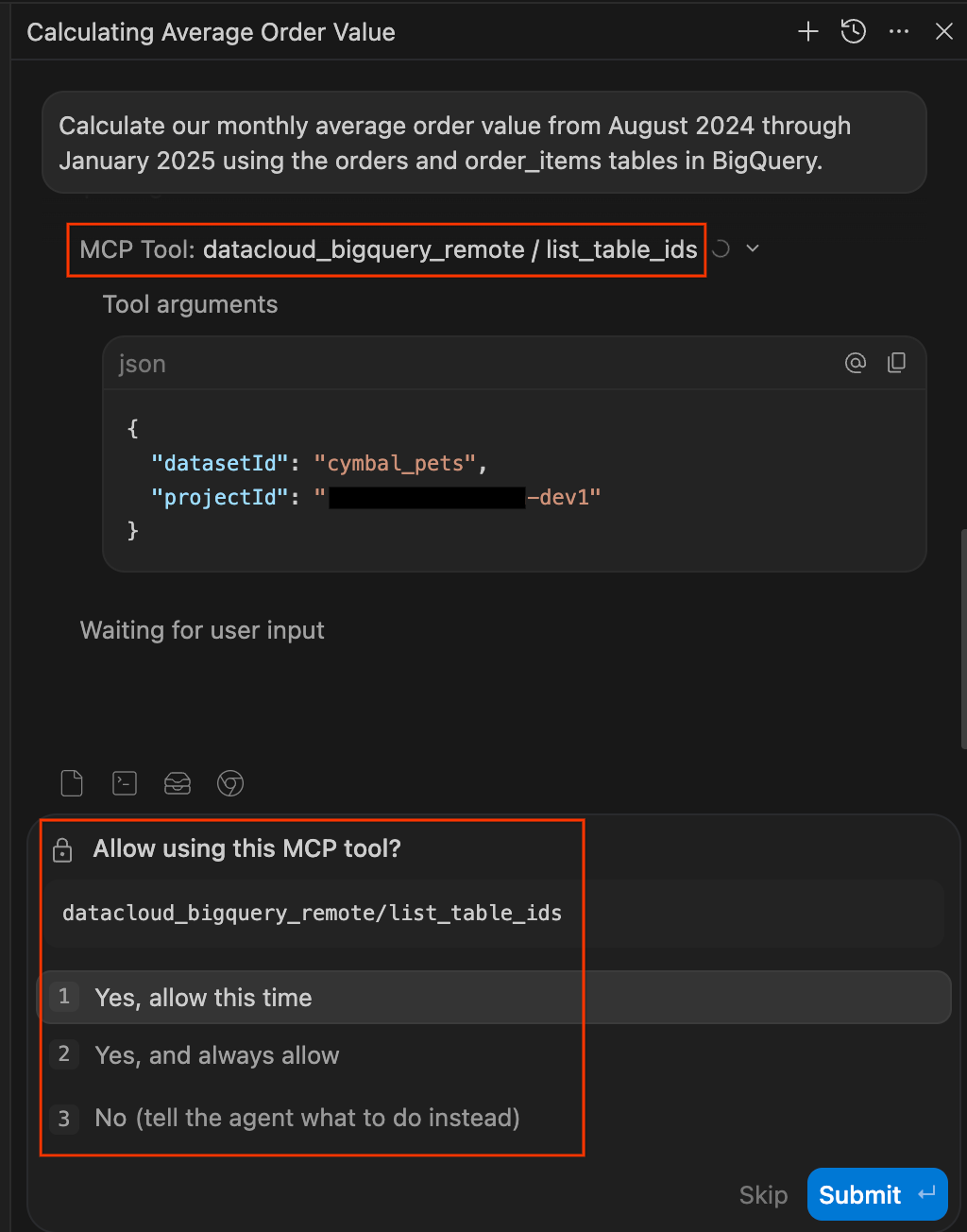
- در پنل چت در سمت راست IDE، عبارت زیر را تایپ کرده و Enter را فشار دهید:
Calculate our monthly average order value from August 2024 through January 2025 using the orders and order_items tables in BigQuery. - مجوزهای دسترسی به دادهها را تأیید کنید. احتیاط در مورد اجرای کوئریها توسط عاملهای هوش مصنوعی روی پایگاههای داده شما، امری سالم است. کیت عامل داده با مکث و درخواست مجوز صریح قبل از دسترسی به دادهها، کنترل را در دست شما نگه میدارد. در صورت درخواست، میتوانید موارد زیر را انتخاب کنید:
- این زمان را مجاز کنید: یک بار استفاده را تأیید میکند (ایدهآل برای حسابرسی پرسوجوهای پرخطر).
- همیشه مجاز: استفاده مداوم از این ابزار خاص را برای جلسه تأیید میکند.
- خیر: عمل را به طور کامل مسدود میکند.
list_table_idsیاexecute_sql_readonly) چند پیام دیگر نیز خواهید دید. در صورت تمایل میتوانید این موارد را نیز "همیشه اجازه دهید" (always allow).
- کار نماینده را تماشا کنید. صفحه چت به عنوان یک گزارش شفاف برای هر کاری که نماینده انجام میدهد، عمل میکند. به جای یک جعبه سیاه، نماینده استدلال و اقدامات خود را در زمان واقعی به شما نشان میدهد.
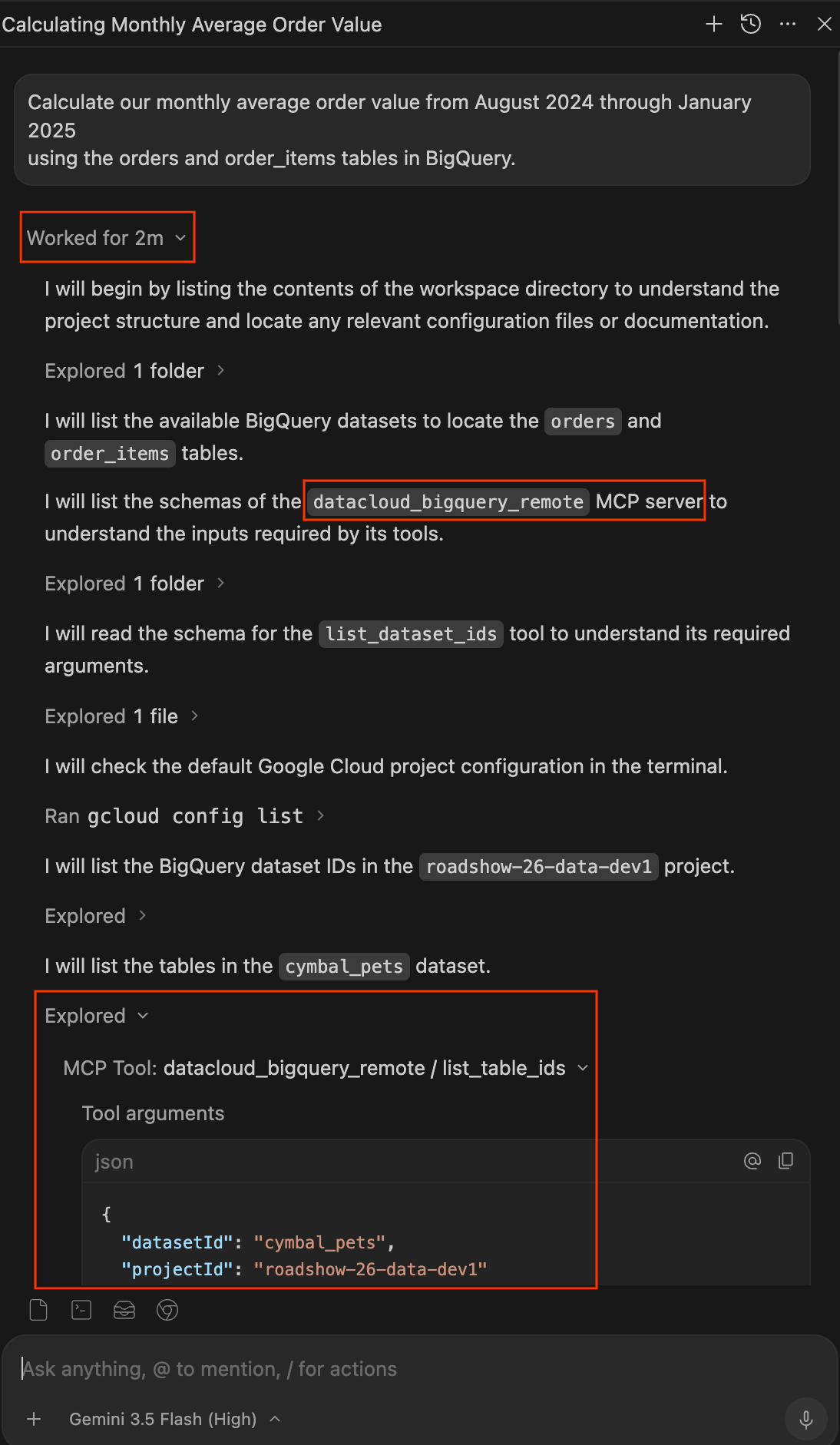
- پس از اتمام کار، روی منوی کشویی Worked for Xm در زیر اعلان خود کلیک کنید تا گزارش کامل کار را مشاهده کنید. در اینجا میتوانید دقیقاً بررسی کنید که چگونه پاسخ شما را دریافت کرده است:
- بررسیشده: این موارد را باز کنید تا ببینید عامل در حال خواندن فایلها، مرور پوشهها یا فراخوانی ابزارهای MCP (مانند
datacloud_bigquery_remote / list_table_idsوexecute_sql_readonly) است. میتوانید آرگومانهای JSON دقیق ارسالی به ابزارها و SQL اجرا شده را مشاهده کنید. - اجرا: این موارد را باز کنید تا هرگونه دستور ترمینالی که عامل اجرا کرده است، مانند
gcloud config listرا ببینید.
- بررسیشده: این موارد را باز کنید تا ببینید عامل در حال خواندن فایلها، مرور پوشهها یا فراخوانی ابزارهای MCP (مانند
- نتایج را بررسی کنید. نماینده باید جدولی از مقادیر ماهانه AOV را ارائه دهد. خودتان به اعداد نگاه کنید: ماههای قبل حدود ۱۱۰ دلار بوده، سپس در ژانویه به حدود ۱۰۳ دلار کاهش مییابد. این همان ناهنجاری است که مدیر ارشد مالی گزارش کرده است.
کانالها را بررسی کنید
AOV کلی کاهش یافته است، اما این کاهش از کجا ناشی میشود؟ بیایید بفهمیم.
- در پنل چت، تایپ کنید:
January looks lower than the prior months. Break down January's AOV by order_type to see what's going on? - عامل یک پرسوجوی BigQuery دیگر اجرا میکند، این بار بر اساس
order_typeگروهبندی میکند. نتایج را با دقت بررسی کنید. باید نکتهی قابل توجهی ببینید: AOV آنلاین و آفلاین روی حدود ۱۱۰ دلار ثابت باقی میمانند. اما یک کانال جدید به نام B2B-Wholesale با AOV بسیار پایینتر (حدود ۷۵ دلار) وجود دارد. این کانال جدید میانگین ترکیبی را پایین میکشد. - ممکن است نماینده به صورت پیشگیرانه پیشنهاد بررسی مشتریان B2B را بدهد. اگر این اتفاق نیفتد، اشکالی ندارد. این کار را در مرحله بعدی انجام خواهید داد.
خلاصه بخش: شما افت AOV ژانویه را از یک داده خنثی مشاهده کردید، سپس با استفاده از order_type بررسی کردید تا B2B-Wholesale به عنوان کانال جدیدی که میانگین ترکیبی را پایین میآورد، شناسایی کنید. اکنون باید بفهمید که این مشتریان B2B چه کسانی هستند.
۶. از مرز سرویس عبور کنید
شما B2B-Wholesale به عنوان کانال غیرعادی در BigQuery شناسایی کردهاید، اما دادههای مشتری در Cloud SQL قرار دارد. با Data Agent Kit، میتوانید همان مکالمه را ادامه دهید و این کیت، مرز سرویس را مدیریت میکند.
مشتریان B2B را بررسی کنید
- در پنل چت ، تایپ کنید:
Who are these B2B customers? Their profiles should be in our Cloud SQL database. Check for: - Who they are - When they signed up - Whether they're new or existing customers - با دقت به پنل چت نگاه کنید. این بار باید یک ابزار MCP متفاوت ظاهر شود. اکنون عامل به جای BigQuery، در حال پرس و جو از Cloud SQL است. عامل به نمونه
cymbal-pets-opsCloud SQL Postgres متصل میشود و یک پرس و جو را روی جدولcustomersاجرا میکند. برای مشاهده SQL، روی Show Details کلیک کنید. - نتایج را بررسی کنید. نماینده باید چندین یافته کلیدی را آشکار کند:
- همه مشتریان B2B دارای
customer_type = 'Business'هستند. - همه آنها ظرف 30 روز گذشته (ژانویه 2025) ثبت نام کرده اند
- مقادیر
last_nameآنها نامهای تجاری مانند "Pet Supply Co"، "Animal Care LLC" و "Happy Paws Inc" هستند. - حدود ۱۰۰ نفر از آنها وجود دارند، گروهی که قبل از این ماه وجود نداشتند.
- همه مشتریان B2B دارای
کد تخفیف را وصل کنید
- ممکن است نماینده خودش متوجه شود که بسیاری از سفارشهای B2B در BigQuery دارای مقدار
promo_codeبرابر باBIGORDER25هستند. اگر داوطلبانه این مشاهده را انجام دهد، عالی است. تحقیقات به طور طبیعی در حال پیشرفت است. اگر نماینده کد تخفیف را ذکر نکرد، آن را به او گوشزد کنید:I noticed a promo_code field on the orders table in BigQuery. Check what promo codes appear on the B2B-Wholesale orders? - نماینده دوباره از BigQuery پرسوجو میکند و متوجه میشود که تقریباً ۹۲٪ از سفارشهای عمدهفروشی B2B دارای
promo_code = 'BIGORDER25'هستند. تقریباً تمام فعالیتهای B2B به یک کمپین تبلیغاتی واحد گره خورده است. اکنون نماینده باید کنجکاو باشد که این کد تبلیغاتی از کجا آمده است. ممکن است بپرسد که آیا دادههای تبلیغاتی در جای دیگری از محیط وجود دارد یا خیر. (در Cloud Storage وجود دارد.)
خلاصه بخش: نماینده از Cloud SQL پرسوجو کرد تا نشان دهد که مشتریان B2B همگی کسبوکارهای جدیدی هستند که در ژانویه ۲۰۲۵ ثبتنام کردهاند. با توجه به یافته BigQuery مبنی بر اینکه حدود ۹۲٪ از سفارشات آنها حاوی promo_code = 'BIGORDER25' هستند، اکنون ردپا به یک کمپین تبلیغاتی اشاره دارد. وقت آن است که منبع را پیدا کنیم.
۷. قطعه گمشده را پیدا کنید
دو سرویس از کار افتادند، یکی دیگر باید برود. میدانید چه اتفاقی افتاده (سفارشهای B2B ارزش AOV را پایین میآورند) و چه کسی این کار را میکند (مشتریان تجاری جدید از 30 روز گذشته). حالا باید دلیلش را پیدا کنید و جواب در فضای ذخیرهسازی ابری است.
سطل GCS را بررسی کنید
- در پنل چت ، تایپ کنید:
Good catch on the promo code. We might have promotional campaign data in our GCS bucket. Can you check what's there? - این عامل ابزار MCP از پیش پیکربندیشدهای برای ذخیرهسازی ابری ندارد، بنابراین بهطور خودکار به استفاده از ابزار ترمینال خود برای اجرای دستورات
gcloud storageروی میآورد. برای اجرای دستوراتی مانندgcloud storage lsدرخواست مجوز میکند. به این دستورات اجازه دهید، سپس گزارش Ran را در پنجره چت باز کنید تا دستورات دقیق CLI که برای خواندن و تجزیه فایلpromo_events.jsonاستفاده کرده است را ببینید. - نماینده باید سه کمپین تبلیغاتی را در پرونده شناسایی کند:
بفرمایید. کد تخفیفکمپین
کد تخفیف
تخفیف
هدف
خرما
حراج تابستانی مراقبت از حیوانات خانگی
PETSUMMER15۱۵٪ تخفیف
همه
ژوئن ۲۰۲۴
فشار عمده فروشی B2B
BIGORDER25۲۵٪ تخفیف
کسب و کار به کسب و کار (B2B)
ژانویه ۲۰۲۵
جایزه تعطیلات اعضای وفادار
LOYAL10۱۰٪ تخفیف
اعضای وفادار
دسامبر ۲۰۲۴
BIGORDER25مربوط به کمپینی به نام «تشویق عمدهفروشی B2B» است: ۲۵٪ تخفیف برای مشتریان B2B با حداقل سفارش ۵۰ واحد. این مدرک محکمی است.
همه را کنار هم بگذارید
- از نماینده بخواهید هر آنچه را که پیدا کرده است، ترکیب کند:
Put it all together. What happened to our average order value? - این عامل، یک ترکیب واضح و ساختاریافته ارائه میدهد که هر سه منبع داده را به هم متصل میکند. این ترکیب باید چیزی شبیه به موارد زیر را توضیح دهد:
- کاهش AOV واقعی است، اما این کاهش در کسب و کار موجود نیست. AOV آنلاین و آفلاین در حدود ۱۱۰ دلار ثابت مانده است.
- یک کانال جدید B2B-Wholesale در ژانویه ۲۰۲۵ ظاهر شد که حدود ۲۵۰۰۰ سفارش با AOV بسیار پایینتر (حدود ۷۵ تا ۱۰۰ دلار) داشت.
- مشتریان B2B، ۱۰۰ حساب تجاری جدید هستند که همگی در ۳۰ روز گذشته ثبتنام کردهاند (Cloud SQL).
- این فعالیت توسط یک کمپین تبلیغاتی ("فشار عمده فروشی B2B") هدایت میشود که 25٪ تخفیف برای سفارشهای عمده با حداقل 50 واحد (ذخیره سازی ابری) ارائه میدهد.
- درآمد ثابت است زیرا حجم بالای سفارشات B2B، قیمتهای پایینتر را جبران میکند. با این حال، حاشیه سود هر واحد به شدت تحت تأثیر تخفیف عمدهفروشی ۲۵ درصدی کاهش یافته است (حدود ۶۵٪ کاهش یافته است)، که با در نظر گرفتن هزینههای حمل و نقل و سربار عملیاتی، سودآوری کلی را به شدت تهدید میکند.
خلاصه بخش: شما سرنخ اصلی را در Cloud Storage پیدا کردید: یک کمپین تبلیغاتی B2B که 25٪ تخفیف برای سفارشهای عمده ارائه میدهد. نماینده، یافتهها را در هر سه سرویس در یک روایت واضح ترکیب کرد. مرحله تحقیق کامل شده است. در مرحله بعد، این یافتهها را عملیاتی خواهید کرد.
۸. ساخت خط لوله
شما معما را حل کردید. حالا مدیر ارشد مالی میخواهد این تحلیل بهطور خودکار بهروزرسانی شود. در این بخش، از نماینده میخواهید یک پروژه dbt بسازد که دادههای BigQuery را مرحلهبندی کرده و یک جدول حقایق برای تحلیل مداوم AOV تولید کند.
اینجاست که عامل از محقق به مهندس تغییر میکند. خواهید دید که کل یک پروژه dbt را چارچوببندی میکند و کل خط لوله را اجرا میکند، همه اینها از یک اعلان واحد.
پروژه dbt را داربست بندی کنید
- در پنل چت ، عبارت زیر را تایپ کنید. این عبارت عمداً هدفگرا است و نه گام به گام. شما به اپراتور میگویید که چه میخواهید، نه اینکه چگونه آن را بسازد:
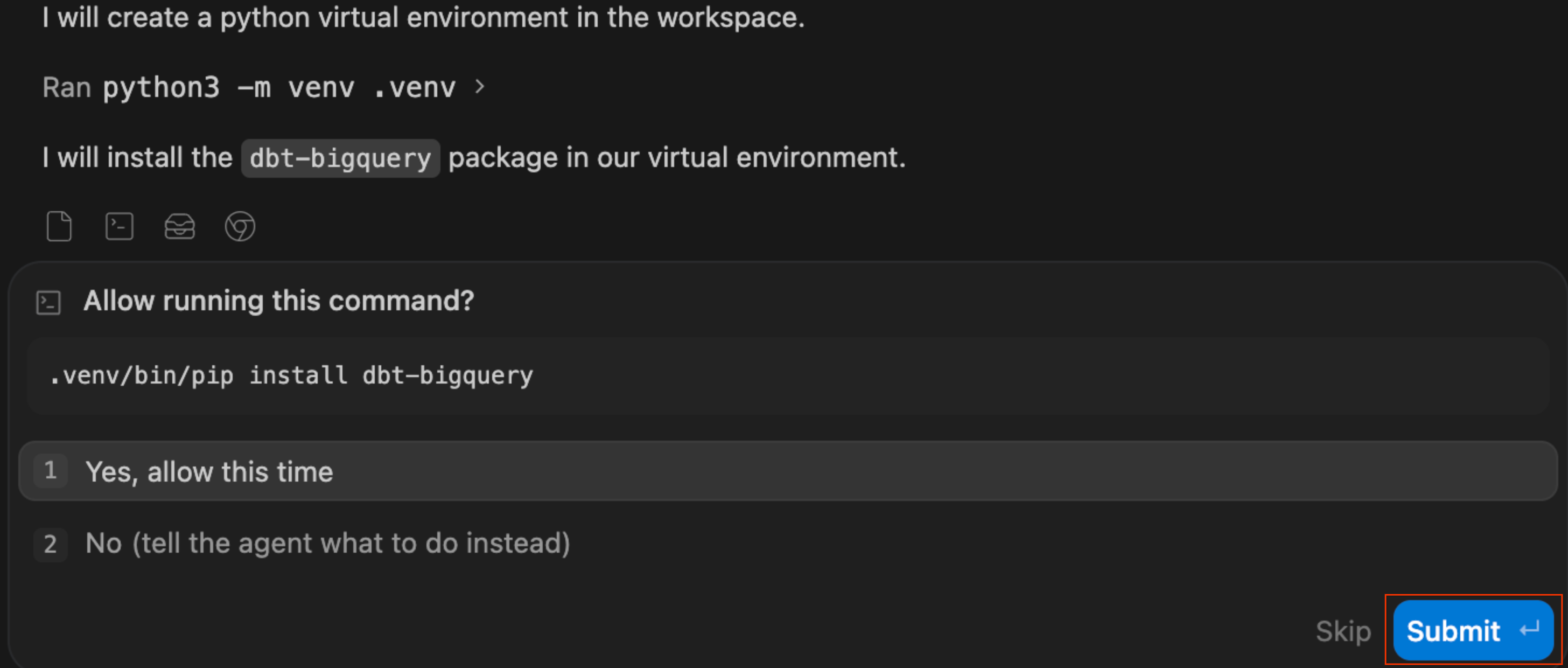
I want to productionize our AOV analysis so it updates automatically. Build a dbt project that: 1. Creates staging models for the BigQuery tables (orders and order_items) and a mart called fct_order_analysis that calculates AOV by channel and month 2. Add a uniqueness test on order_id and run dbt build - به خود-اصلاحی توجه کنید: اگر گزارش «Worked for Ns» را باز کنید، ممکن است ببینید که عامل
dbtرا بررسی میکند و پس از یافتن آن، به طور خودکار دستوراتی را برای ایجاد یک محیط مجازی پایتون (.venv) اجرا میکند. این برنامه تنظیمات محیط را برای شما انجام میدهد!
- بررسی طرح پیادهسازی: عامل یک طرح پیادهسازی رسمی ایجاد میکند. شما میتوانید فایلها و معماری پیشنهادی آن را بررسی کنید، در صورت نیاز نظرات خود را اضافه کنید و روی «ادامه» کلیک کنید تا عامل طرح را اجرا کند.
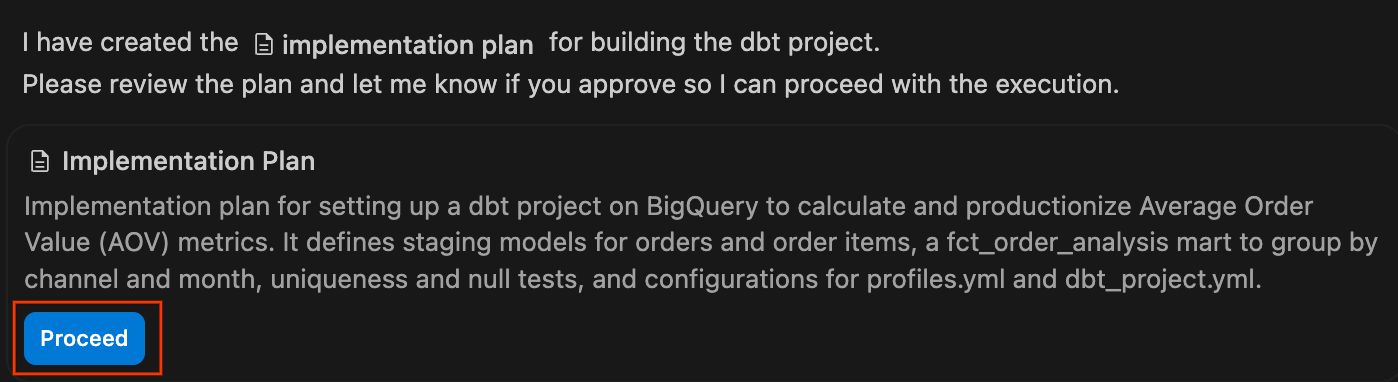
- در حالی که عامل، طرح خود را اجرا میکند و فایلهای
.sqlلازم و پیکربندیهای YAML را مینویسد، پنجره چت را تماشا کنید. پس از اتمام و کامپایل موفقیتآمیز پروژه، خلاصهای از تغییرات ارائه میشود. برای افزودن این فایلها به فضای کاری خود، روی «پذیرش همه» کلیک کنید.
- پروژه dbt تازه ایجاد شده را در اکسپلورر سمت چپ بررسی کنید. باید ساختاری مشابه زیر را ببینید:
dbt/ ├── models/ │ ├── marts/ │ │ └── fct_order_analysis.sql │ └── staging/ │ ├── schema.yml │ ├── sources.yml │ ├── stg_order_items.sql │ └── stg_orders.sql ├── dbt_project.yml └── profiles.yml
- برای بررسی SQL تولید شده توسط عامل، روی فایلهای مدل
.sqlکلیک کنید. به نحوه مدیریت آن توجه کنید:- مدلهای مرحلهبندی : ستونهای تمیز و تغییر نام یافته با ارجاعات منبع
- مدل مارت : منطق اتصال و محاسبه AOV بر اساس کانال
- برای تأیید کارشناس مبنی بر تحقق همه مدلها و موفقیتآمیز بودن همه آزمایشها، به پنل چت مراجعه کنید. نتایج AOV از مارت باید یافتههای شما را در طول تحقیقات تأیید کند:
- Online: ~$110 - Offline: ~$110 - B2B-Wholesale: ~$75 to $77
خلاصه بخش: عامل یک پروژه dbt را از یک دستور هدفگرا ساخت: مدلهای مرحلهبندی و mart داربستبندی شده، یک dbt build موفق را اجرا کرد و ناهنجاری AOV را تأیید کرد. در مرحله بعد، شما یک آزمایش انجام خواهید داد تا ببینید که عامل چگونه پیچیدگی را مدیریت میکند.
۹. وقتی تستها با شکست مواجه میشوند، عامل اشکالزدایی میکند
این خط لوله کار میکند، اما فقط از دادههای BigQuery استفاده میکند. تیم محصول میخواهد تجزیه و تحلیل را با دادههای پروفایل مشتری و حیوان خانگی از Cloud SQL غنی کند تا بتواند محصولات را بر اساس نیازهای غذایی توصیه کند. این بدان معناست که عامل باید مرز Cloud SQL را پل بزند و یک اشکال ظریف مدلسازی داده را برطرف کند - یک اتصال "fan-out" مدلسازی ابعادی کلاسیک.
بسته به مدلی که استفاده میکنید و قابلیتهای استدلال آن، عامل این درخواست را به یکی از دو روش زیر مدیریت خواهد کرد: اجتناب فعال از باگ (گزینه الف) یا خوددرمانی پس از شکست آزمایش (گزینه ب). بیایید ببینیم عامل شما کدام مسیر را انتخاب میکند!
درخواست را فعال کنید
- در پنل چت ، تایپ کنید:
Enrich fct_order_analysis with customer data and pet profile data from our Cloud SQL database. Include customer type and each customer's pets and dietary needs so we can recommend products. Keep the uniqueness test on order_id and run dbt build. - کار عامل را تماشا کنید. این عامل جداول Cloud SQL را کشف میکند، نحوهی اتصال دادهها به BigQuery (از طریق پرسوجوی فدرال یا کپی مادی) را کشف میکند، مدلهای مرحلهبندی جدید ایجاد میکند و
fct_order_analysis.sqlرا تغییر میدهد.
گزینه الف: عامل پیشگیرانه (جلوگیری از باگ)
اگر از یک مدل استدلال پیشرفته استفاده میکنید، عامل ممکن است قبل از نوشتن هر کدی، تغییر دانه را تشخیص دهد. این عامل متوجه میشود که از آنجایی که یک مشتری میتواند چندین حیوان خانگی داشته باشد، یک اتصال مستقیم، سفارشها را تکرار میکند و بلافاصله آزمون منحصر به فرد بودن درخواست شده در order_id را رد میکند.
- به تجمیع فعال توجه کنید : در توضیحات صفحه چت یا مصنوعات راهنمای گام به گام، ممکن است نماینده خاطرنشان کند که قبل از اتصال دادههای حیوانات خانگی، آنها را از قبل تجمیع کرده است تا از "انباشت کلاسیک" جلوگیری کند. این کار معمولاً با حذف چندین حیوان خانگی به ازای هر مشتری با استفاده از یک تابع تجمیع (مثلاً
ARRAY_AGG()یاSTRING_AGG()) انجام میشود. - بررسی نتایج :
dbt buildاجرا میشود و در اولین تلاش با موفقیت انجام میشود، زیرا عامل به طور پیشگیرانه از جزئیات جدول فکت محافظت کرده است. میتوانید این موضوع را با بررسی مصنوع Walkthrough تولید شده تأیید کنید، که اغلب خروجی تست موفقیتآمیز را در کنار نتایج پرس و جو نشان میدهد.
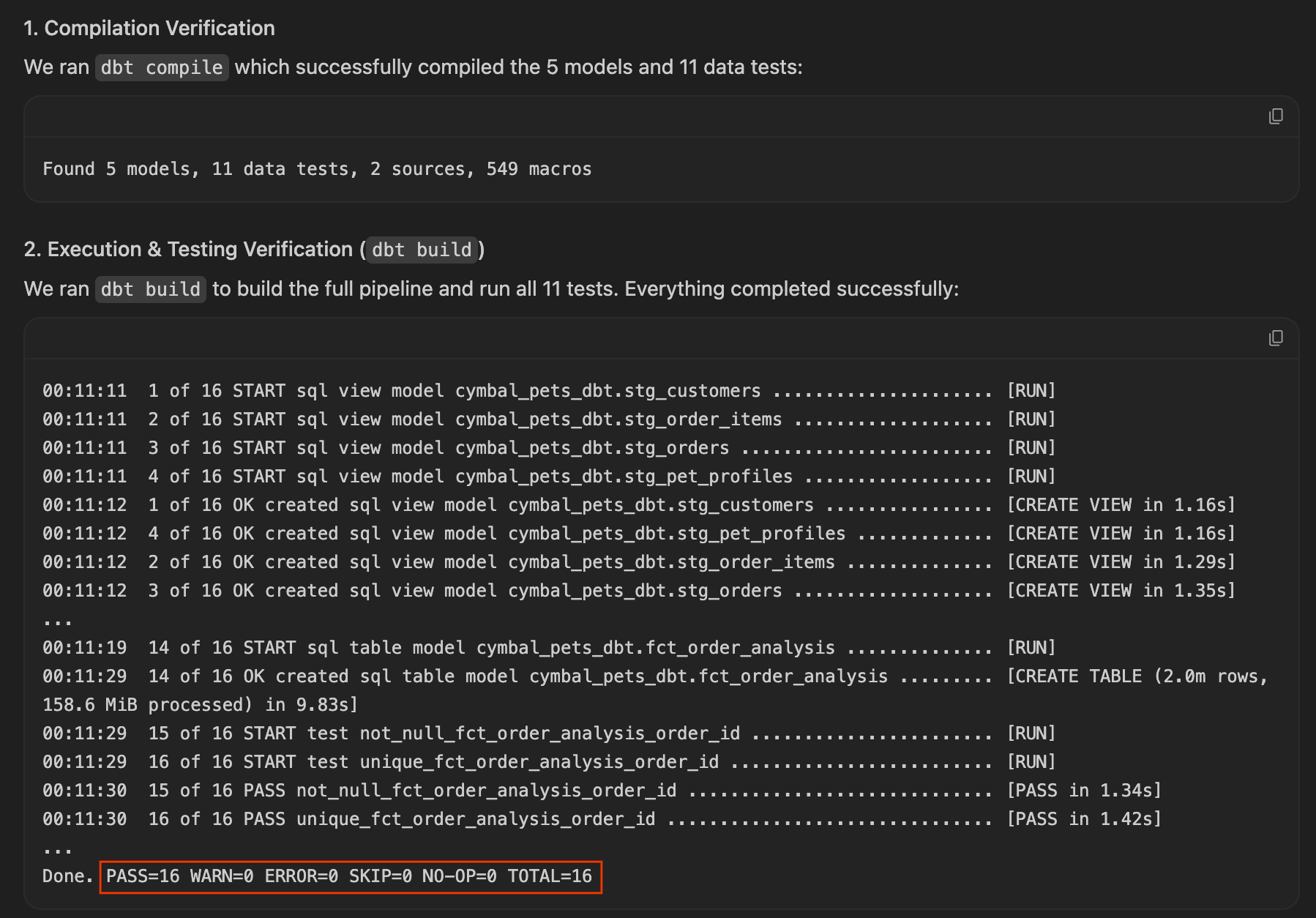
اگر نماینده شما این کار را انجام داده، تبریک میگویم! شما شاهد مهندسی هوش مصنوعی پیشگیرانه بودهاید. لحظهای وقت بگذارید و SQL تولید شده در fct_order_analysis.sql را بررسی کنید تا ببینید چگونه تجمیع را ساختاردهی کرده است، سپس به بخش بعدی، Deliver the Answer ، بروید.
گزینه ب: عامل خوددرمان (اشکالزدایی و تشخیص)
اگر مدل ابتدا یک اتصال چپ مستقیم ساده بنویسد، خود پرسوجوی SQL با موفقیت اجرا میشود، اما مجموعه dbt test تغییر دانه را تشخیص میدهد!
- مشاهدهی شکست تست : شکست گزارششده را در گزارشهای پیشرفت اجرای پنل چت مشاهده خواهید کرد:
Completed with 1 error Failure in test unique_fct_order_analysis_order_id Got 287 results, configured to fail if != 0
order_idورودیهای تکراری را نشان داد، زیرا مشتریانی که چندین حیوان خانگی داشتند، سفارشها را به صورت پراکنده ارسال میکردند. - بگذارید عامل تشخیص دهد و خود را درمان کند : از آنجایی که آزمایش ناموفق بود، از عامل بخواهید آن را اشکالزدایی کند. در پنجره چت ، تایپ کنید:
The uniqueness test failed. Can you figure out why and fix it? - تشخیص را مشاهده کنید : عامل دادهها را جستجو میکند، رابطه یک به چند را در
pet_profilesکشف میکند، توضیح میدهد که اتصال مستقیم آن، دانه را از یک ردیف به ازای هر سفارش به یک ردیف به ازای هر سفارش به ازای هر حیوان خانگی تغییر میدهد و مدل را برای پیشجمعبندی پروفایلهای حیوان خانگی بازنویسی میکند:-- Pre-aggregating pets per customer to resolve fan-out LEFT JOIN ( SELECT customer_id, COUNT(*) AS num_pets, STRING_AGG(DISTINCT pet_type, ', ') AS pet_types, STRING_AGG(DISTINCT dietary_needs, ', ') AS dietary_needs FROM pet_profiles GROUP BY customer_id ) pet_agg ON c.customer_id = pet_agg.customer_id - رفع مشکل را تأیید کنید : عامل دوباره
dbt buildاجرا میکند و این بار همه مدلها پیادهسازی میشوند و همه آزمایشها با موفقیت انجام میشوند!
خلاصه بخش: چه عامل شما به طور پیشگیرانه از بروز اشکال جلوگیری کرده باشد و چه پس از یک شکست آزمایشی با موفقیت خود را ترمیم کرده باشد، دیدهاید که چگونه مرز Cloud SQL را پر میکند، دادههای پروفایل مشتری و حیوان خانگی را ادغام میکند و جزئیات جدول حقایق را به طور کامل حفظ میکند. این خط لوله اکنون قوی، کامل و کاملاً آزمایش شده است!
۱۰. پاسخ را ارائه دهید
پنجشنبه است. شما هفته را با یک مدیر مالی نگران و دادههای پراکنده در سه سرویس ابری شروع کردید. حالا ریشه مشکل و یک خط تولید دارید. وقت آن است که پاسخ را ارائه دهید، همراه با یک توصیه آیندهنگر که با یک پیشبینی کمی پشتیبانی میشود.
خلاصه اجرایی را بنویسید
- در پنل چت ، تایپ کنید:
Write an executive summary covering: - Main findings and the quantitative margin impact - Project AOV for the subsequent quarter if the B2B program continues at its current trajectory - A data-driven recommendation - کار نماینده را تماشا کنید.
- خلاصه اجرایی نماینده را مرور کنید. یک پاسخ معمول و ساختارمند باید موارد زیر را در بر بگیرد:
- یافته اصلی : AOV ژانویه صرفاً به دلیل کانال جدید B2B-Wholesale کاهش یافت. آنلاین و آفلاین در حدود ۱۱۰ دلار ثابت ماندند.
- علت ریشهای : «فشار عمدهفروشی B2B» (۲۵٪ تخفیف برای سفارشهای عمده) ۱۰۰ حساب کاربری جدید جذب کرد و منجر به حدود ۲۵۰۰۰ سفارش شد.
- تأثیر حاشیه سود : سفارشات عمدهفروشی، میانگین سود واحد را حدود ۶۵ درصد کاهش دادند (از حدود ۷.۵۰ دلار به حدود ۲.۶۰ دلار).
- درآمد : درآمد کلی ثابت مانده است زیرا حجم بالای معاملات B2B، قیمتهای پایینتر را جبران میکند.
پیشبینی AOV با AI.FORECAST
- عامل همچنین باید یک پیشبینی آیندهنگر ایجاد کند. به دنبال فراخوانی ابزار MCP باشید که در آن عامل یک پرسوجوی
AI.FORECASTرا در BigQuery اجرا میکند. این پرسوجو از مدل پایه داخلی TimesFM برای پیشبینی AOV به مدت ۹۰ روز بر اساس روندهای تاریخی استفاده میکند. این پرسوجو باید AOV را تحت دو سناریو ۹۰ روز به جلو پیشبینی کند: ادامه کمپین (AOV با کاهش ساختاری) در مقابل خاتمه کمپین (بازیابی تا حدود ۱۱۰ دلار).
- توصیههای استراتژیک نماینده را بررسی کنید. مجموعهای قوی از توصیهها میتواند شامل موارد زیر باشد:
- تغییر ساختار تخفیفها : برای محافظت از حاشیه سود در سطح واحد، تخفیفهای کف حاشیه سود یا سقف تخفیفهای عمده را اعمال کنید.
- اعمال حداقل مقادیر سفارش (MOQ) سختگیرانهتر : از سوءاستفاده خریداران خردهفروش از قیمتگذاری عمدهفروشی جلوگیری کنید.
- گزارشدهی جداگانه : بخشهای خردهفروشی و B2B را بهطور مستقل پیگیری کنید تا از پنهان کردن عملکرد خردهفروشی جلوگیری شود.
داستان کامل
آنچه روز دوشنبه به عنوان مانوری برای مقابله با کاهش ۷ درصدی میانگین ارزش سفارش آغاز شد، برای مدیر ارشد مالی به یک نتیجهی روشن رسیده است:
- سلامت خردهفروشی : کانالهای اصلی خردهفروشی در ابتدا سالم و پایدار باقی میمانند.
- هجوم عمدهفروشی : کاهش AOV کاملاً به دلیل کانال جدید عمدهفروشی B2B و کمپین
BIGORDER25است. - تأثیر حاشیه سود : تخفیف عمده ۲۵ درصدی، حاشیه سود هر واحد را به شدت کاهش داد و سودآوری را با وجود درآمد ثابت، تهدید کرد.
- پیشبینی استراتژیک : پیشبینی
AI.FORECASTنشان میدهد که تغییر ساختار ردیفهای عمدهفروشی، AOV ترکیبی را بازیابی خواهد کرد.
شما یک توصیه مبتنی بر دادهها برای تعیین کف حاشیه سود عمدهفروشی و گزارشهای جداگانه خردهفروشی/B2B ارائه میدهید.
خلاصه بخش: شما از نماینده خواستید که یک خلاصه اجرایی با تحلیل حاشیه سود بنویسد، یک پیشبینی هوش مصنوعی ایجاد کند و یک توصیه مبتنی بر داده ارائه دهد. تحقیقات کامل شده است.
۱۱. تمیز کردن
برای جلوگیری از هزینههای مداوم برای حساب Google Cloud خود، منابع ایجاد شده در این codelab را با اجرای اسکریپت teardown حذف کنید.
- در پنل ترمینال در پایین Antigravity IDE (یا در Cloud Shell)، به دایرکتوری codelab بروید و دستور زیر را اجرا کنید:
cd ~/devrel-demos/codelabs/agentic-data-labs/scripts
chmod +x teardown.sh
./teardown.sh
- اسکریپت تمام منابعی را که قصد حذف آنها را دارد نمایش میدهد و قبل از ادامه، درخواست تأیید میکند:
- نمونه SQL ابری (
cymbal-pets-ops): این گرانترین منبع است - مجموعه داده BigQuery (
cymbal_pets): همه جداول و مدلها - مخزن ذخیرهسازی ابری (
gs://YOUR_PROJECT_ID-cymbal-pets-raw) - اتصال BigQuery (
cymbal-pets-cloudsql)
- نمونه SQL ابری (
- برای تأیید،
yرا تایپ کنید. عملیات جداسازی حدود ۲-۳ دقیقه طول میکشد.
[INFO] Deleting Cloud SQL instance cymbal-pets-ops... [ OK ] Cloud SQL instance deleted. [INFO] Deleting BigQuery dataset cymbal_pets... [ OK ] BigQuery dataset deleted. [INFO] Deleting GCS bucket gs://YOUR_PROJECT_ID-cymbal-pets-raw... [ OK ] GCS bucket deleted.
۱۲. تبریک میگویم!
شما با موفقیت تحقیق در مورد حیوانات خانگی سیمبال (Cymbal Pets Investigation) را به پایان رساندید! شما با استفاده از یک عامل هوش مصنوعی که در کل مجموعه دادههای گوگل کلود شما کار میکند، از یک سوال مبهم در مورد مدیر مالی به یک توصیه کاملاً عملیاتی و مبتنی بر پیشبینی تبدیل شدید.
کاری که شما انجام دادید
- 🔍 کاوش در سرویسها : با استفاده از کاتالوگ دانش کیت Data Agent ، داراییها را در BigQuery ، Cloud SQL و Cloud Storage کشف و پیشنمایش کردم.
- 🕵️♂️ بررسی شده با هوش مصنوعی : با استفاده از ابزارهای MCP، چندین سرویس را در یک مکالمه در صفحه چت جستجو کردم تا ناهنجاری AOV را تا یک کمپین تبلیغاتی عمده B2B ردیابی کنم.
- 🔧 ساخت یک خط تولید : یک پروژه کامل dbt را برای پاکسازی، اتصال و آزمایش دادههای تراکنشی و مشتری، پیادهسازی کردم.
- 🐛 اشکالزدایی یک باگ fan-out : مشاهده شد که عامل بهطور خودکار یک مشکل جزئینگر بودن را تشخیص داده و مدل dbt SQL را برای پیشجمعبندی پروفایلهای مشتریان، بازسازی میکند.
- 📈 پیشبینی و توصیه :
AI.FORECASTداخلی BigQuery برای مدلسازی روندهای AOV استفاده شد و یک توصیه دادهمحور به مدیر ارشد مالی ارائه شد.
مفاهیم کلیدی
مفهوم | آنچه آموختید |
ابزارهای MCP | اتصالات امن و قابل حسابرسی که به عامل هوش مصنوعی اجازه میدهد از طرف شما به سرویسهایی مانند BigQuery، Cloud SQL، Spanner و سایر پایگاههای داده پرسوجو کند، به طوری که هر تماس در پنل چت قابل مشاهده باشد. |
مهارتهای عامل | مجموعه دستورالعملهای از پیش ساخته شده (مانند |
تحقیقات متقابل خدمات | این عامل چندین سرویس Google Cloud را در یک مکالمه واحد پرس و جو میکند - بدون تنظیم اتصال، بدون تغییر زمینه بین کنسولها |
راهنمایی هدفمند | به نماینده بگویید چه میخواهید ("یک پروژه dbt بسازید که AOV را از طریق کانال محاسبه کند") به جای اینکه بگویید چگونه ، و اجازه دهید رویکرد پیادهسازی را انتخاب کند. |
کیت عامل داده | افزونهای که همه چیز - ابزارهای MCP، مهارتهای عامل و کشف دادهها - را به هم متصل میکند و به شما امکان دسترسی به کل دادههای Google Cloud خود را از طریق IDE مورد نظر شما میدهد. |
مراحل بعدی
- برای کسب اطلاعات بیشتر در مورد قابلیتهای Data Agent Kit، مستندات آن را مطالعه کنید.
- درباره توابع BigQuery ML و AI از جمله
AI.FORECAST،AI.GENERATEوAI.EMBEDاطلاعات کسب کنید. - سعی کنید تحقیقات متقابل خود را با Antigravity IDE بر روی دادههای خودتان بسازید.