
1. Introduction
C'est lundi matin et le directeur financier vient de vous envoyer un message. La valeur moyenne des commandes a baissé de 7% ce mois-ci, mais le revenu total est resté stable. Quelque chose ne colle pas et le conseil d'administration veut des réponses d'ici vendredi.
Votre entreprise, Cymbal Pets, est l'un des plus grands marchands en ligne de produits pour animaux de compagnie aux États-Unis. Les données dont vous avez besoin sont dispersées dans trois services Google Cloud : les données transactionnelles dans BigQuery, les fiches client et produit dans Cloud SQL et les fichiers marketing dans Cloud Storage. Normalement, pour mener une enquête multiservice comme celle-ci, vous devez passer d'une console à l'autre, écrire un boilerplate de connexion et assembler manuellement les résultats.
Dans cet atelier de programmation, vous allez utiliser le Google Cloud Data Agent Kit (DAK) dans l'IDE Antigravity pour examiner l'anomalie en langage naturel. Vous décrivez ce que vous recherchez, et l'agent d'IA gère les connexions, le code SQL et les jointures multiservices entre BigQuery, Cloud SQL et Cloud Storage. Une fois l'enquête résolue, vous demanderez à l'agent de créer un pipeline dbt qui opérationnalise vos conclusions, de déboguer un véritable bug de modélisation des données et de fournir une recommandation basée sur des prévisions au directeur financier.
Objectifs de l'atelier
- Découvrez les assets de données dans BigQuery, Cloud SQL et Cloud Storage à l'aide du Knowledge Catalog.
- Examiner une anomalie en interrogeant plusieurs services dans une même conversation à l'aide des outils MCP
- Créez un pipeline dbt pour organiser et joindre des données multiservices avec des modèles intermédiaires et des tests automatisés.
- Déboguer un problème de modélisation des données pendant que l'agent effectue un auto-diagnostic et refactorise un bug de distribution ramifiée
- Prédire les tendances futures et fournir une recommandation basée sur les données à l'aide de
AI.FORECASTde BigQuery
Prérequis
- Un navigateur Web (par exemple, Chrome)
- Un projet Google Cloud avec facturation activée
- Connaissances de base de SQL et de la console Google Cloud
Cet atelier de programmation s'adresse aux experts en données de niveau intermédiaire (ingénieurs analytiques, analystes de données, data scientists).
Les ressources créées dans cet atelier de programmation devraient coûter moins de 5 $.
2. Avant de commencer
Dans cette section, vous allez exécuter un script de configuration qui provisionne l'intégralité de votre environnement de laboratoire : un ensemble de données BigQuery avec des données de commande, une instance Cloud SQL Postgres avec des données client et produit, et un bucket Cloud Storage avec des enregistrements de campagnes promotionnelles. L'exécution du script prend environ 8 à 10 minutes, le provisionnement de Cloud SQL étant le principal facteur limitant.
Démarrer Cloud Shell
Vous allez utiliser Google Cloud Shell pour exécuter le script de configuration.
- Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.

- Une fois connecté, définissez votre ID de projet et confirmez votre environnement :
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
Un message de ce type doit s'afficher :
Your active configuration is: [cloudshell-####] Updated property [core/project]
Cloner le dépôt
Clonez le dépôt de l'atelier de programmation dans votre environnement Cloud Shell :
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/agentic-data-labs
git checkout main
cd codelabs/agentic-data-labs/
Exécuter le script d'installation
Le script de configuration prépare l'ensemble de votre environnement de laboratoire en quelques minutes. Il gère l'activation des API, le chargement et l'augmentation des données BigQuery, l'importation des assets promotionnels dans GCS, puis génère automatiquement un nœud de calcul en arrière-plan pour provisionner et configurer Cloud SQL Postgres en arrière-plan pendant que vous commencez l'atelier de programmation.
Le script génère automatiquement un mot de passe Cloud SQL sécurisé et l'enregistre automatiquement dans votre fichier .env.
cd ~/devrel-demos/codelabs/agentic-data-labs/scripts
chmod +x setup.sh setup_sql.sh
./setup.sh
Une fois l'opération terminée, un récapitulatif de votre environnement de premier plan s'affiche :
╔══════════════════════════════════════════════════════╗
║ Base Setup complete! ║
╚══════════════════════════════════════════════════════╝
Your core BigQuery and GCS assets are ready.
Cloud SQL is currently provisioning in the background and will be fully ready by Step 4.
BigQuery: YOUR_PROJECT_ID.cymbal_pets
├── orders
└── order_items
GCS: gs://YOUR_PROJECT_ID-cymbal-pets-raw
└── promo_events.json
Pendant que vous passez aux étapes suivantes de l'atelier, la base de données est provisionnée et initialisée en arrière-plan. Vous pouvez suivre sa progression à tout moment dans un panneau de terminal distinct à l'aide de la commande suivante :
tail -f /tmp/cloudsql_setup.log
Notez l'architecture des données : les données transactionnelles (commandes et articles commandés) se trouvent dans BigQuery, tandis que les données opérationnelles (clients, profils d'animaux et produits) se trouvent dans Cloud SQL. Cette répartition reflète la façon dont les données sont souvent distribuées entre les services dans les organisations réelles, et c'est ce qui rend une investigation multiservice intéressante.
Récapitulatif de la section : vous avez exécuté le script de configuration pour amorcer votre environnement de laboratoire et lancé le provisionnement de la base de données en arrière-plan.
3. Configurer l'IDE et le kit d'agent de données
Ouvrir l'IDE Antigravity
Vous n'avez pas besoin d'attendre la fin de l'opération Cloud SQL. Ouvrez l'IDE Antigravity et connectez-le à votre projet Google Cloud.
- Si vous ne l'avez pas déjà fait, téléchargez et installez l'IDE Antigravity depuis la page de téléchargement de Google Antigravity.
- Lancez l'application de bureau Antigravity IDE.
- Créez un dossier vide sur votre machine locale (par exemple,
agentic-data-labs) et ouvrez-le dans l'IDE en sélectionnant Ouvrir le dossier. Il servira d'espace de travail local pour l'atelier de programmation.
Installer l'extension Data Agent Kit
L'extension Google Cloud Data Agent Kit offre une intégration approfondie aux services de données Google Cloud directement dans votre éditeur. Vous pouvez ainsi interagir avec BigQuery, Cloud SQL, Cloud Storage et d'autres services sans changer de contexte.
- Dans l'IDE Antigravity, cliquez sur l'icône Extensions dans la barre d'activité, tout à gauche de l'écran (elle ressemble à quatre carrés).
- Dans la barre de recherche en haut du volet "Extensions", saisissez
Google Cloud Data Agent Kit. - Recherchez l'extension Google Cloud Data Agent Kit publiée par
googlecloudtools. - Cliquez sur le bouton Install (installer).
- Une invite peut s'afficher et vous demander si vous faites confiance à l'éditeur "googlecloudtools" et à ses extensions. Cliquez sur Faire confiance aux éditeurs et installer pour continuer.
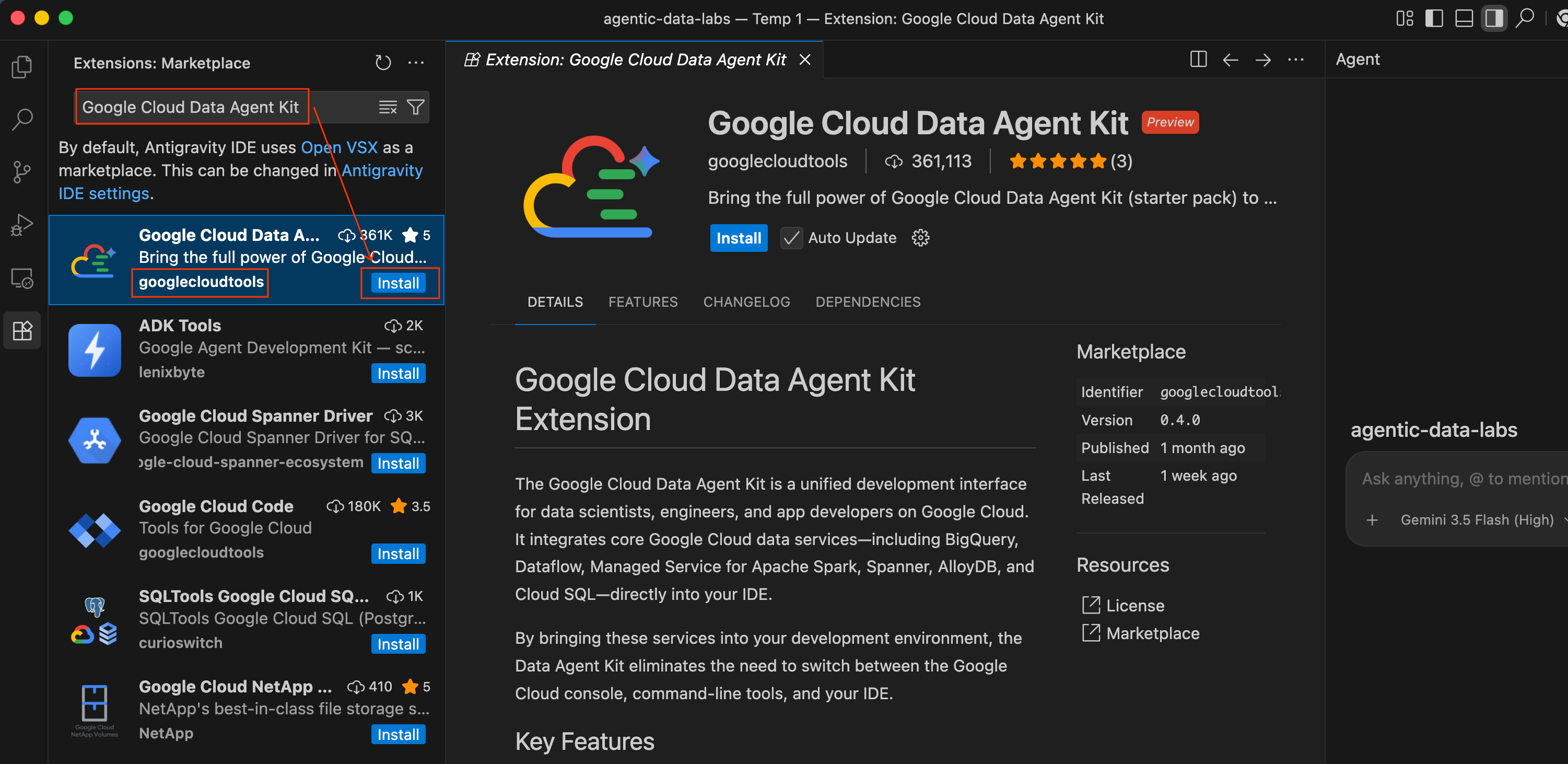
Une fois installé, une nouvelle icône Google Cloud Data Agent Kit s'affiche dans la barre d'activité, tout à gauche de l'IDE Antigravity.
S'authentifier et configurer l'extension
Une fois l'extension installée, associez-la à votre projet Google Cloud.
- Une page d'intégration intitulée "Bienvenue dans le kit d'agent de données Google Cloud" devrait s'ouvrir automatiquement. Si vous n'êtes pas connecté à votre compte Cloud, suivez les instructions pour autoriser l'accès.
- Dans la section Résumé de la configuration, recherchez le champ "Projet". Cliquez sur le menu déroulant et sélectionnez votre projet Google Cloud. Définissez votre région sur
us-central1. Sélectionnez ensuite Configurer les serveurs MCP.

- Dans le volet Configuration MCP, cliquez pour activer BigQuery et Cloud SQL. Cliquez ensuite sur Commencer.
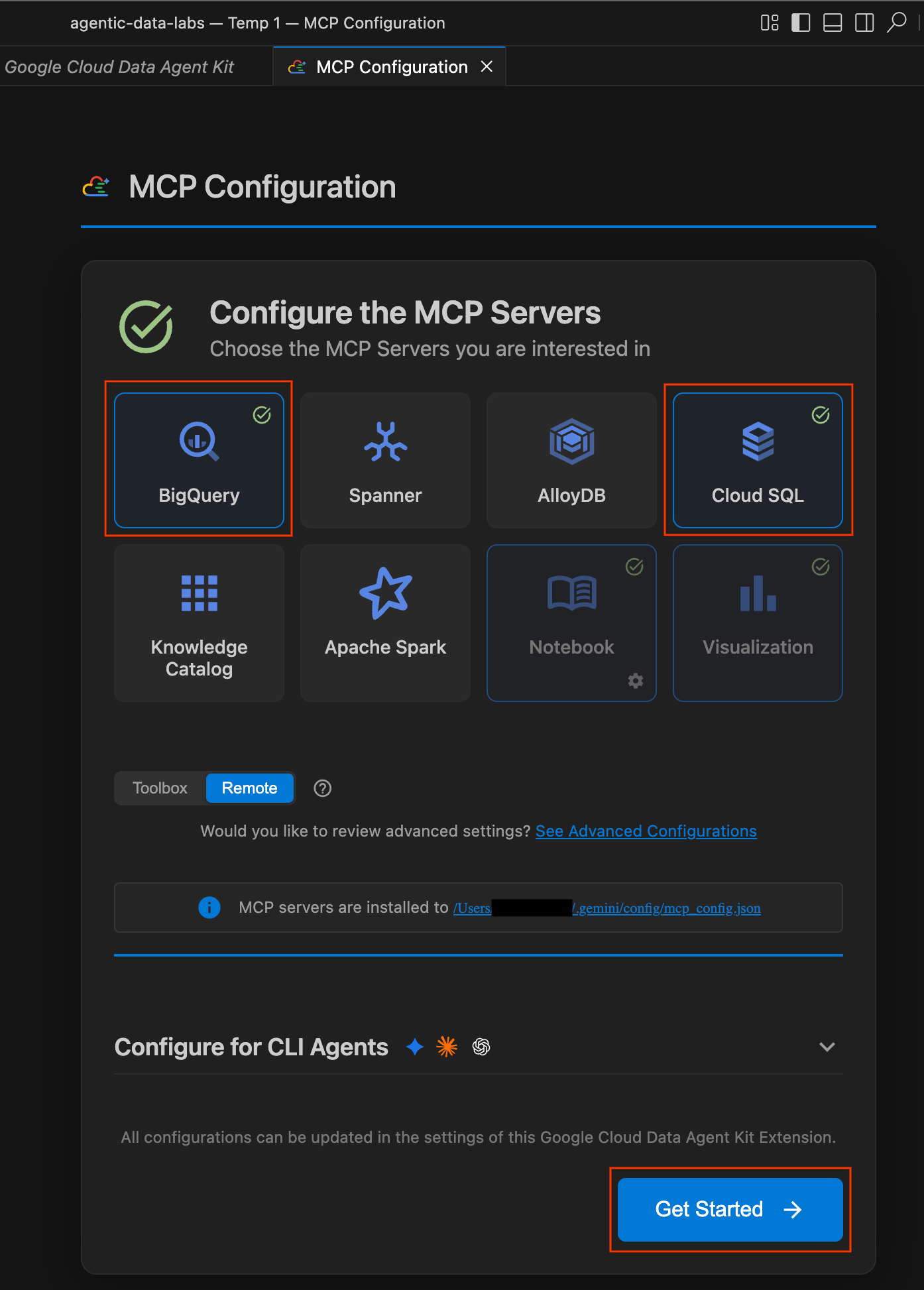
Explorer les options de configuration
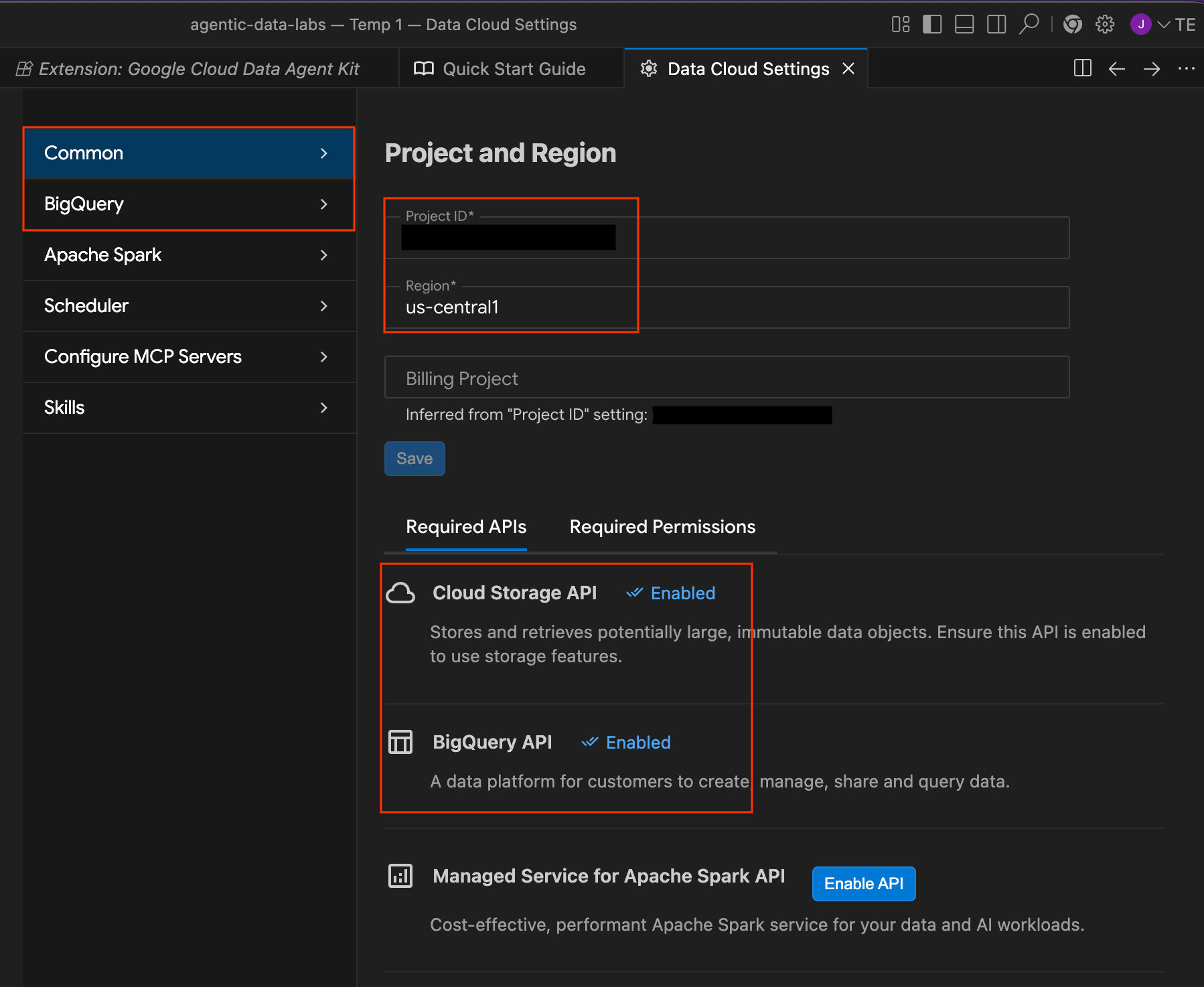
Une fois la configuration terminée, vous serez redirigé vers la page "Get started with Google Cloud Data Agent Kit" (Commencer à utiliser Google Cloud Data Agent Kit).
- Sous "Configuration", cliquez sur Premiers pas.
- Le panneau Configuration de l'agent de données s'ouvre. Explorez les onglets :
- Projet et région : vérifiez l'ID du projet sélectionné et assurez-vous que les API requises (API Cloud Storage, API BigQuery, API Catalog et API Cloud SQL Admin) sont activées.
- BigQuery : configurez l'emplacement par défaut de vos requêtes BigQuery. Utilisez la région
us-central1. - Configurer les serveurs MCP : affichez les serveurs MCP activés (BigQuery, Notebooks, Cloud SQL, etc.) qui permettent aux agents IA d'interagir de manière sécurisée avec vos données.
- Compétences : explorez les compétences prédéfinies qui offrent aux agents des capacités spécialisées pour les tâches de données complexes.
Récapitulatif de la section : vous avez ouvert l'IDE Antigravity, l'avez connecté à votre projet Google Cloud, avez configuré les serveurs MCP distants du kit d'agent de données et avez vérifié la connexion en exécutant une requête sur BigQuery.
4. Découvrir vos données
Il est temps de planter le décor. Voici la situation : le directeur financier indique que la valeur moyenne des commandes a baissé de 7% le mois dernier, mais que le revenu total est resté stable. Avant de demander à l'agent d'examiner les données, vous devez d'abord comprendre celles avec lesquelles vous travaillez.
Dans cette section, vous allez explorer manuellement le panneau Data Agent Kit pour vous familiariser avec son contenu. Comprendre vos données avant de commencer à les interroger est une première étape essentielle de toute enquête.
Explorer les tables BigQuery
- Dans le panneau "Data Agent Kit", sous CATALOGUE, développez votre projet → BigQuery →
cymbal_pets. - Cliquez sur la table
orders. Un nouvel onglet s'ouvre et affiche les détails de la table. - Explorez les onglets situés à gauche du tableau :
- Données : prévisualisez les lignes réelles. Faites défiler l'ensemble de données et examinez les colonnes.
- Schéma : examinez les noms et les types de colonnes. Notez les champs tels que
order_typeetpromo_code, qui seront importants plus tard. - Autres onglets (Détails, Insights, Profil de données, etc.) : Accédez aux métadonnées, à la traçabilité des données et aux informations sur la qualité que vous trouvez habituellement dans la console Google Cloud, sans quitter votre éditeur.
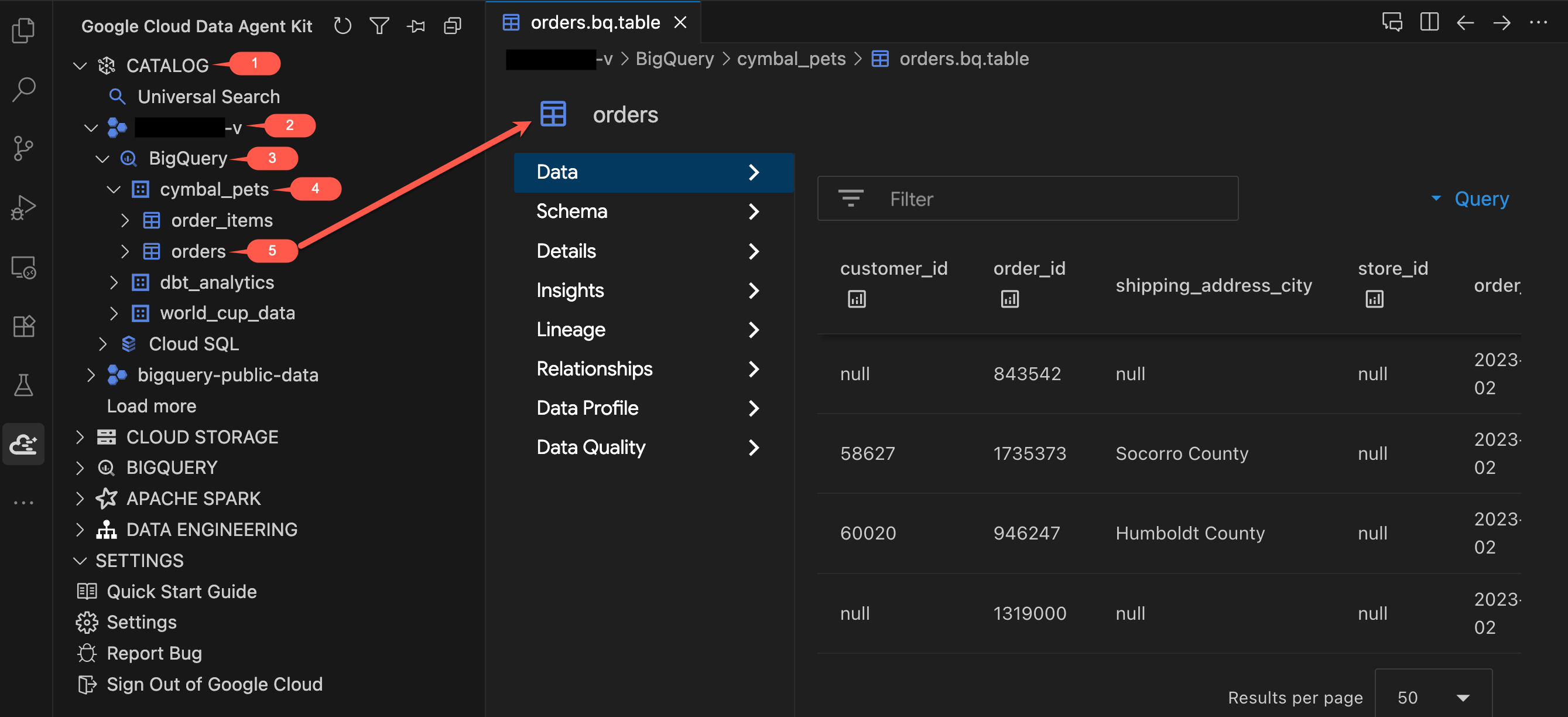
- Cliquez maintenant sur la table
order_itemset examinez son schéma. Notez les champsquantityetprice.
Explorer les tables Cloud SQL
Le script de configuration a également placé les données client, animal et produit dans une base de données PostgreSQL dans Cloud SQL.
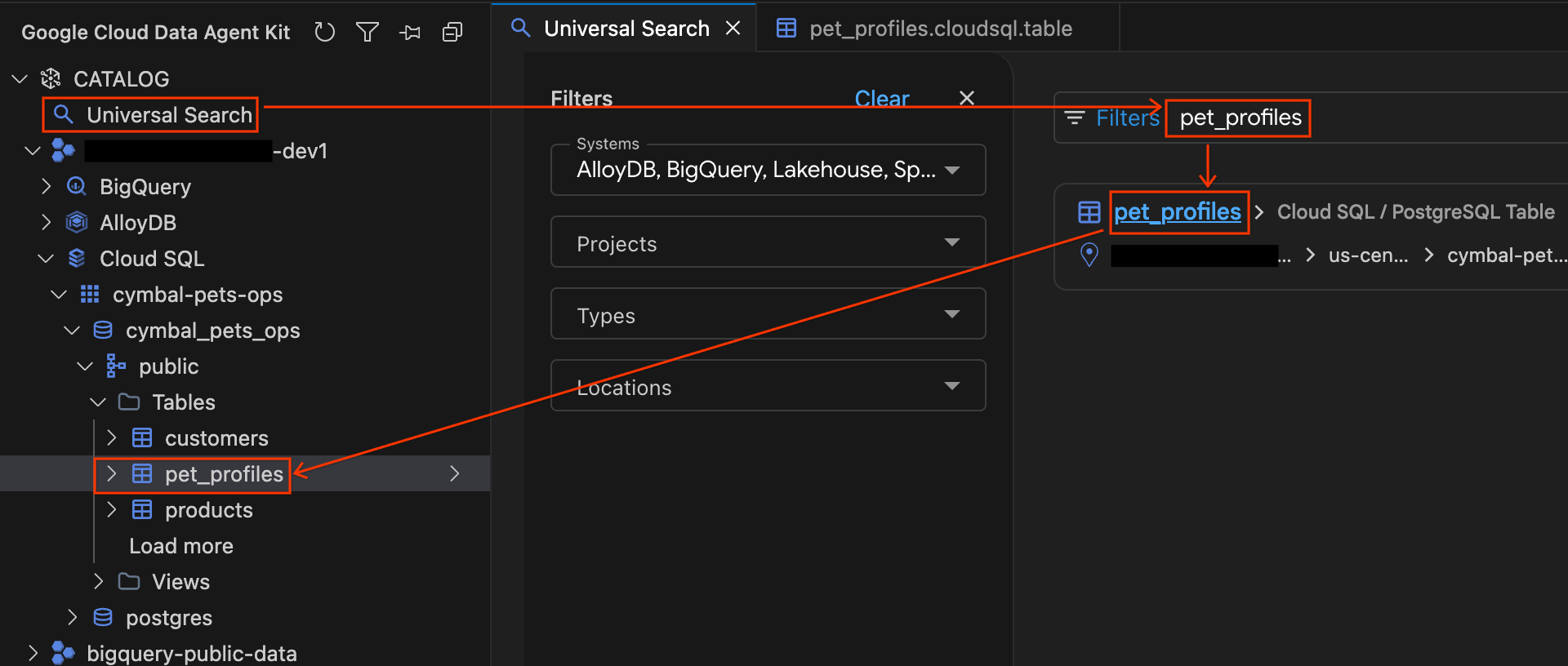
- Dans le panneau "Data Agent Kit", cliquez sur Recherche universelle dans la section CATALOGUE.
- Dans le champ de recherche, saisissez
pet_profileset appuyez sur Entrée. - Dans les résultats de recherche, cliquez sur le résultat de la table PostgreSQL pour
pet_profiles(sous l'instance Cloud SQL de votre projet). Notez que l'accordéon de la barre latérale se développe automatiquement, ce qui vous permet de voir exactement où se trouve la table dans l'arborescence de la base de données. Cliquez ensuite sur la tablecustomerssituée juste au-dessus dans l'arborescence pour ouvrir ses détails, puis explorez les onglets Schéma et Détails.
Explorer les fichiers Cloud Storage
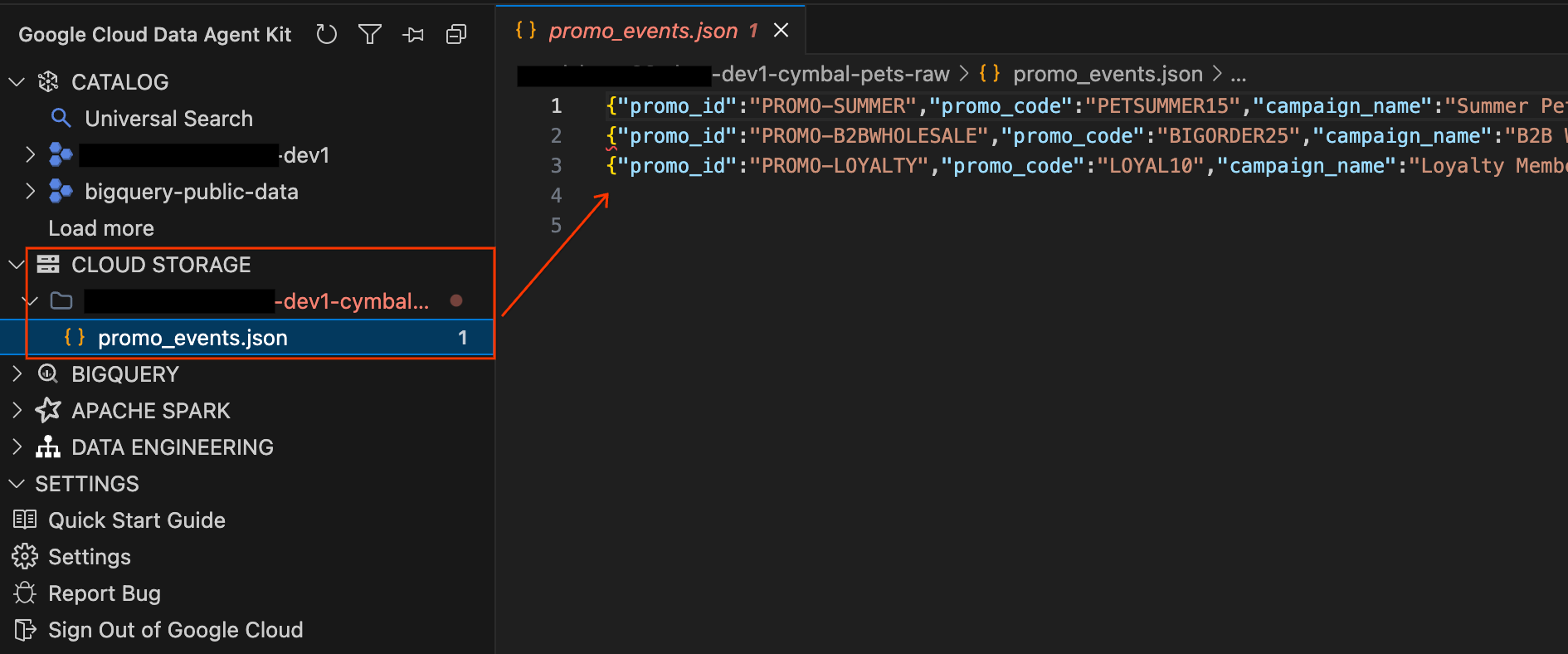
Enfin, les enregistrements des campagnes marketing et promotionnelles sont stockés sous forme de fichiers JSON bruts dans Cloud Storage.
- Dans le panneau "Data Agent Kit" (Kit d'agent de données) à gauche, développez la section CLOUD STORAGE (STOCKAGE CLOUD). Localisez le bucket brut de votre projet (
YOUR_PROJECT_ID-cymbal-pets-raw). - Cliquez sur le fichier
promo_events.jsondans le bucket. Un nouvel onglet d'éditeur s'ouvre, ce qui vous permet d'afficher le contenu JSON Lines brut des campagnes marketing directement dans l'IDE.
Faire l'inventaire
Voici ce que vous savez désormais sur le paysage des données :
Service | Tables | Contenu |
BigQuery |
| Environ 1,9 million de commandes, environ 4,3 millions d'éléments de campagne, période allant de 2023 à 2025 |
Cloud SQL |
| Environ 92 000 clients, 7 600 profils d'animaux de compagnie, 206 produits |
Cloud Storage |
| Enregistrements des campagnes promotionnelles |
Les données sont réparties dans trois services. Dans un workflow traditionnel, vous devez configurer des connexions, écrire du code d'intégration et joindre manuellement les résultats. À l'étape suivante, vous laisserez l'agent d'IA gérer tout cela en une seule conversation.
Récapitulatif de la section : vous avez utilisé le panneau Data Agent Kit pour explorer manuellement l'architecture des données dans BigQuery, Cloud SQL et Cloud Storage. Vous savez maintenant où se trouvent les données et quels champs sont disponibles. Vous êtes donc prêt à commencer votre enquête.
5. Suivez les chiffres
L'enquête commence maintenant. Vous allez utiliser le panneau "Chat" pour demander à l'agent IA d'extraire les données sur la valeur moyenne de la commande (VMC) de BigQuery. La valeur moyenne des commandes est une métrique commerciale qui représente le montant moyen dépensé par commande. L'agent effectuera des requêtes en votre nom à l'aide des outils MCP. Vous pourrez voir chaque requête SQL qu'il exécute.
Extraire la tendance de la valeur moyenne de la commande
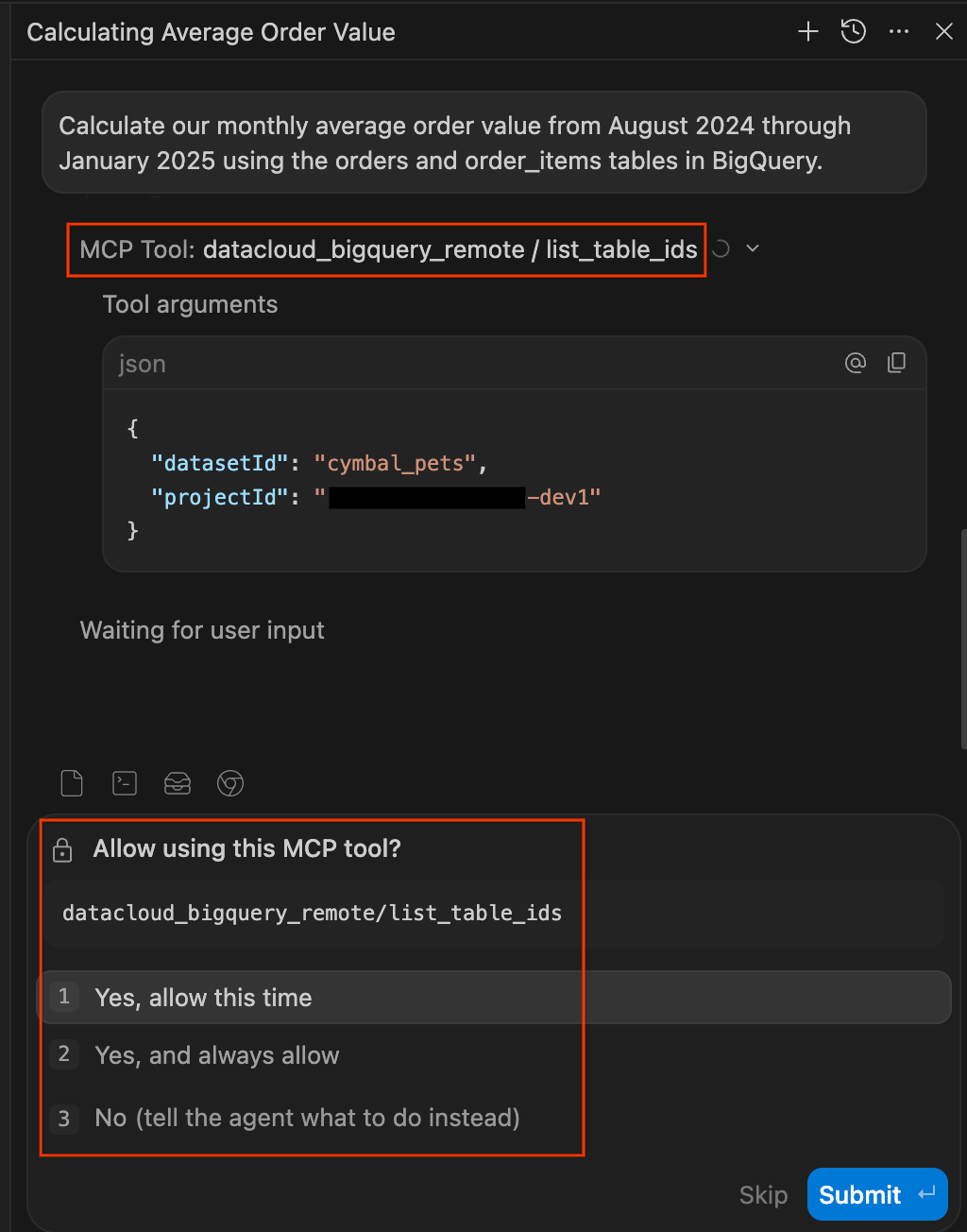
- Dans le volet de chat à droite de l'IDE, saisissez la requête suivante et appuyez sur Entrée :
Calculate our monthly average order value from August 2024 through January 2025 using the orders and order_items tables in BigQuery. - Approuvez les autorisations d'accès aux données. Il est normal d'être prudent quant aux agents d'IA qui exécutent des requêtes sur vos bases de données. Le kit d'agent de données vous permet de garder le contrôle en demandant une autorisation explicite avant d'accéder aux données. Lorsque vous y êtes invité, vous pouvez choisir l'une des options suivantes :
- Autoriser cette fois-ci : approuve une seule utilisation (idéal pour auditer les requêtes à haut risque).
- Toujours autoriser : approuve l'utilisation continue de cet outil spécifique pour la session.
- Non : bloque complètement l'action.
list_table_idsouexecute_sql_readonly). N'hésitez pas à "toujours autoriser" ces invites également.
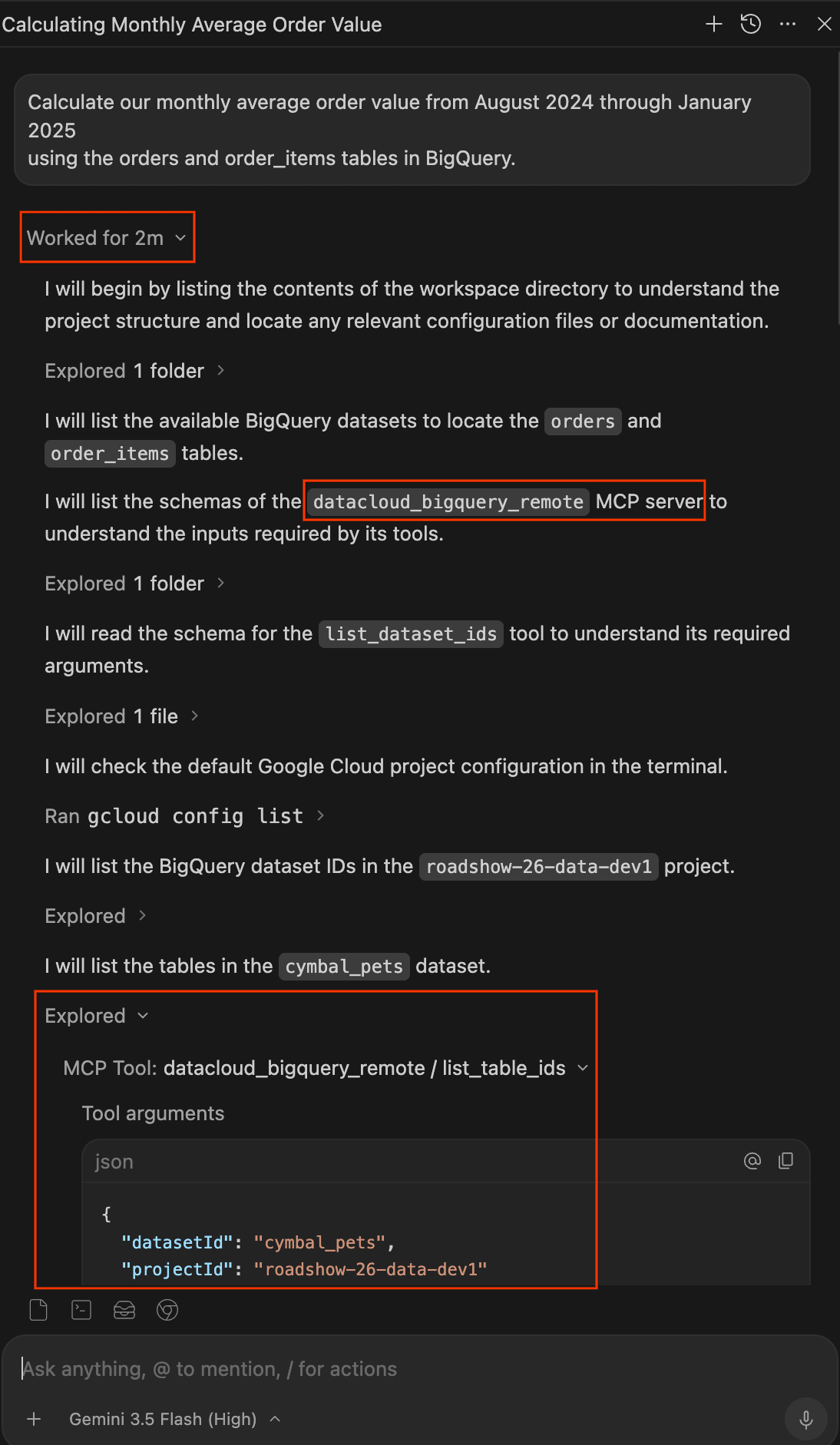
- Regardez l'agent travailler. Le volet "Chat" sert également de journal de transparence pour tout ce que fait l'agent. Au lieu d'une boîte noire, l'agent vous montre son raisonnement et ses actions en temps réel.
- Une fois l'agent terminé, cliquez sur le menu déroulant Fonctionne pour Xm sous votre requête pour développer le journal de travail complet. Vous pouvez examiner précisément comment il a trouvé votre réponse :
- Exploré : développez ces éléments pour voir l'agent lire des fichiers, parcourir des dossiers ou appeler des outils MCP (comme
datacloud_bigquery_remote / list_table_idsetexecute_sql_readonly). Vous pouvez afficher les arguments JSON exacts transmis aux outils et le code SQL exécuté. - Exécuté : développez ces éléments pour afficher les commandes de terminal exécutées par l'agent, telles que
gcloud config list.
- Exploré : développez ces éléments pour voir l'agent lire des fichiers, parcourir des dossiers ou appeler des outils MCP (comme
- Examinez les résultats. L'agent doit renvoyer un tableau des valeurs AOV mensuelles. Regardez les chiffres vous-même : les mois précédents sont autour de 110 $, puis janvier chute à environ 103 $. Il s'agit de l'anomalie signalée par le directeur financier.
Afficher le détail par canal
La valeur moyenne des commandes a baissé, mais d'où vient cette baisse ? Vérifions-le dès maintenant.
- Dans le volet "Discussion", saisissez :
January looks lower than the prior months. Break down January's AOV by order_type to see what's going on? - L'agent exécute une autre requête BigQuery, cette fois en regroupant les résultats par
order_type. Examinez attentivement les résultats.Vous devriez remarquer quelque chose de frappant : les valeurs moyennes des commandes en ligne et hors connexion restent stables à environ 110 $. Cependant, un nouveau canal, B2B-Wholesale, présente une valeur de commande moyenne beaucoup plus faible (environ 75 $). Ce nouveau canal fait baisser la moyenne combinée. - L'agent peut suggérer de manière proactive d'examiner les clients B2B. Si ce n'est pas le cas, ce n'est pas grave. Vous le ferez à l'étape suivante.
Récapitulatif de la section : vous avez vous-même repéré la baisse de l'AOV en janvier à partir d'une extraction de données neutre, puis vous avez analysé les données par order_type pour identifier B2B-Wholesale comme le nouveau canal qui fait baisser la moyenne pondérée. Vous devez maintenant identifier ces clients B2B.
6. Franchir la limite du service
Vous avez identifié B2B-Wholesale comme canal anormal dans BigQuery, mais les données client se trouvent dans Cloud SQL. Avec le kit d'agent de données, vous pouvez poursuivre la même conversation et gérer la limite de service.
Examiner les clients B2B
- Dans le volet de discussion, saisissez :
Who are these B2B customers? Their profiles should be in our Cloud SQL database. Check for: - Who they are - When they signed up - Whether they're new or existing customers - Observez attentivement le volet "Chat". Cette fois, un autre outil MCP devrait s'afficher. L'agent interroge désormais Cloud SQL au lieu de BigQuery.Il se connecte à l'instance Cloud SQL Postgres
cymbal-pets-opset exécute une requête sur la tablecustomers. Cliquez sur Afficher les détails pour afficher le code SQL. - Examinez les résultats. L'agent doit mettre en évidence plusieurs points clés :
- Tous les clients B2B disposent de
customer_type = 'Business' - Ils se sont tous inscrits au cours des 30 derniers jours (janvier 2025).
- Leurs valeurs
last_namesont des noms d'entreprise tels que "Pet Supply Co", "Animal Care LLC" et "Happy Paws Inc". - Il y en a environ 100, une cohorte qui n'existait pas avant ce mois-ci.
- Tous les clients B2B disposent de
Associer le code promotionnel
- L'agent peut remarquer de lui-même que de nombreuses commandes B2B dans BigQuery ont une valeur
promo_codedeBIGORDER25. Si elle fournit cette observation, c'est parfait. L'enquête progresse naturellement.Si l'agent ne mentionne pas le code promotionnel, relancez-le :I noticed a promo_code field on the orders table in BigQuery. Check what promo codes appear on the B2B-Wholesale orders? - L'agent interroge à nouveau BigQuery et constate qu'environ 92% des commandes B2B-Wholesale ont
promo_code = 'BIGORDER25'. Presque toutes les activités B2B sont liées à une seule campagne promotionnelle.L'agent doit maintenant se demander d'où provient ce code promotionnel. Il peut vous demander s'il existe des données promotionnelles ailleurs dans l'environnement. (Il existe dans Cloud Storage.)
Récapitulatif de la section : L'agent a interrogé Cloud SQL pour révéler que les clients B2B sont toutes de nouvelles entreprises qui se sont inscrites en janvier 2025. Combiné au résultat BigQuery indiquant qu'environ 92% de leurs commandes comportent promo_code = 'BIGORDER25', l'indice pointe désormais vers une campagne promotionnelle. Il est temps de trouver la source.
7. Trouve la pièce manquante
Deux services sont en baisse, il en reste un. Vous savez ce qui s'est passé (les commandes B2B font baisser la valeur moyenne des commandes) et qui est responsable (les nouveaux clients professionnels des 30 derniers jours). Vous devez maintenant trouver pourquoi, et la réponse se trouve dans Cloud Storage.
Vérifier le bucket GCS
- Dans le volet de discussion, saisissez :
Good catch on the promo code. We might have promotional campaign data in our GCS bucket. Can you check what's there? - L'agent ne dispose pas d'outil MCP préconfiguré pour Cloud Storage. Il passe donc automatiquement à l'utilisation de son outil de terminal pour exécuter les commandes
gcloud storage. Il vous demandera l'autorisation d'exécuter des commandes telles quegcloud storage ls. Autorisez ces commandes, puis développez le journal Exécuté dans le panneau "Chat" pour afficher les commandes CLI exactes utilisées pour lire et analyser le fichierpromo_events.json. - L'agent doit identifier trois campagnes promotionnelles dans le fichier :
Voilà, le code promotionnelCampagne
Code promotionnel
Remise
Cible
Dates
Promotions estivales sur les soins pour animaux de compagnie
PETSUMMER15-15 %
Tous
Juin 2024
Promotion B2B pour les grossistes
BIGORDER2525% de remise
B2B
Janvier 2025
Bonus de fin d'année pour les membres du programme de fidélité
LOYAL1010% de remise
Membres du programme de fidélité
Dec 2024
BIGORDER25correspond à une campagne intitulée B2B Wholesale Push : 25% de remise pour les clients B2B avec une quantité minimale de commande de 50 unités. C'est la preuve irréfutable.
Synthèse
- Demandez à l'agent de synthétiser tout ce qu'il a trouvé :
Put it all together. What happened to our average order value? - L'agent fournit une synthèse claire et structurée reliant les trois sources de données. Il doit expliquer quelque chose comme :
- La baisse du panier moyen est réelle, mais elle ne correspond pas à une diminution de l'activité existante. La valeur moyenne des commandes en ligne et hors connexion reste stable, à environ 110 $.
- Un nouveau canal B2B-Wholesale est apparu en janvier 2025, avec environ 25 000 commandes à un AOV beaucoup plus faible (environ 75 à 100 $).
- Les clients B2B sont 100 nouveaux comptes professionnels qui se sont tous inscrits au cours des 30 derniers jours (Cloud SQL).
- L'activité est générée par une campagne promotionnelle ("B2B Wholesale Push") offrant 25% de remise sur les commandes groupées d'au moins 50 unités (Cloud Storage).
- Les revenus sont stables, car le volume élevé de commandes B2B compense les prix plus bas. Toutefois, les marges unitaires sont fortement comprimées (érodées d'environ 65%) avec la remise de 25% sur le prix de gros, ce qui menace sérieusement la rentabilité globale lorsque les frais d'expédition et les frais généraux opérationnels sont pris en compte.
Récapitulatif de la section : Vous avez trouvé la preuve dans Cloud Storage : une campagne promotionnelle B2B offrant 25% de remise sur les commandes groupées. L'agent a synthétisé les résultats des trois services dans un récit clair. La phase d'investigation est terminée. Vous allez ensuite opérationnaliser ces résultats.
8. Créer le pipeline
Vous avez résolu le problème. Le directeur financier souhaite désormais que cette analyse soit mise à jour automatiquement. Dans cette section, vous allez demander à l'agent de créer un projet dbt qui prépare les données BigQuery et produit une table de faits pour l'analyse continue de la valeur moyenne des commandes.
C'est là que l'agent passe du rôle d'enquêteur à celui d'ingénieur. Vous verrez qu'il échafaude un projet dbt entier et exécute l'intégralité du pipeline, le tout à partir d'une seule invite.
Créer la structure du projet dbt
- Dans le volet de discussion, saisissez le prompt suivant. Il est délibérément axé sur les objectifs plutôt que sur les étapes. Vous indiquez à l'agent ce que vous voulez, et non comment le créer :
I want to productionize our AOV analysis so it updates automatically. Build a dbt project that: 1. Creates staging models for the BigQuery tables (orders and order_items) and a mart called fct_order_analysis that calculates AOV by channel and month 2. Add a uniqueness test on order_id and run dbt build - Observer l'auto-correction : si vous développez le journal "Worked for Ns", vous pouvez voir l'agent rechercher
dbtet, s'il le trouve manquant, exécuter automatiquement des commandes pour créer un environnement virtuel Python (.venv). Il gère la configuration de l'environnement pour vous.
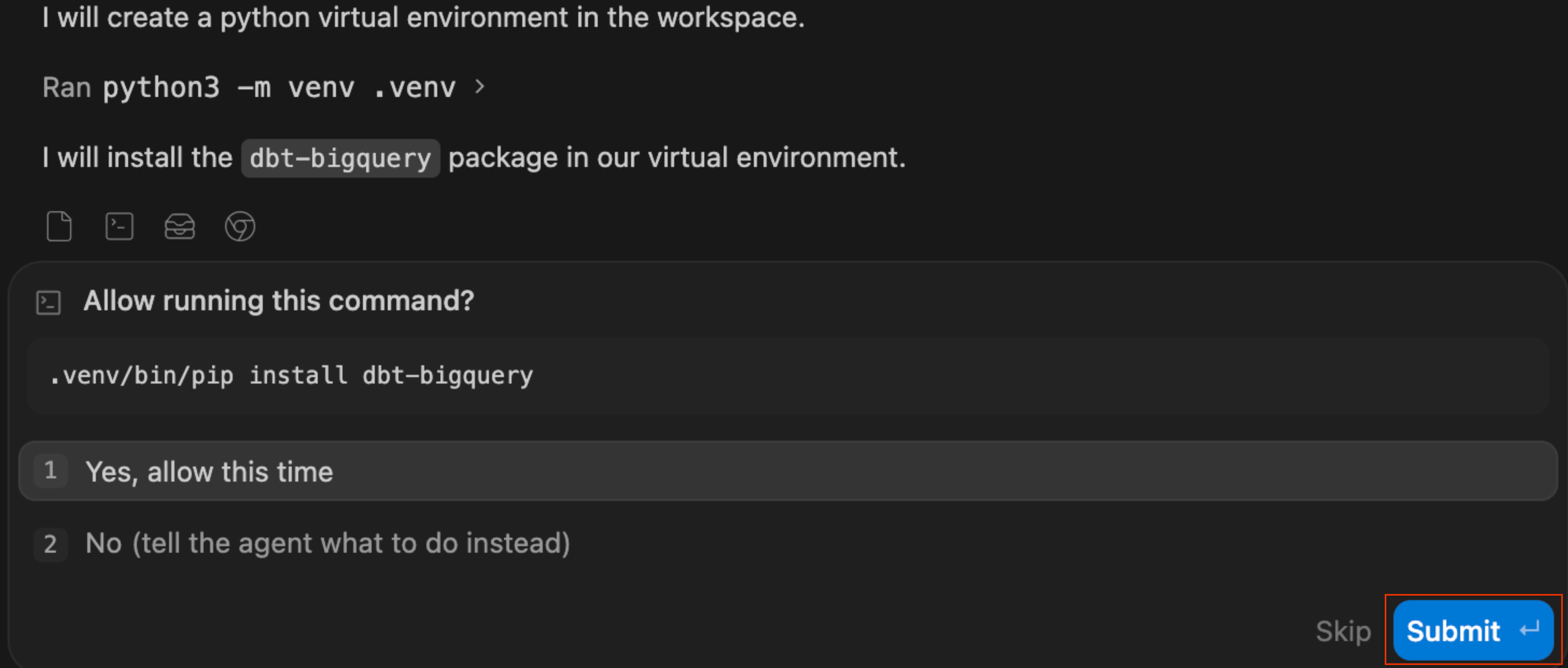
- Examiner le plan d'implémentation : l'agent génère un plan d'implémentation formel. Vous pouvez examiner les fichiers et l'architecture proposés, ajouter des commentaires si nécessaire, puis cliquer sur Continuer pour permettre à l'agent d'exécuter le plan.
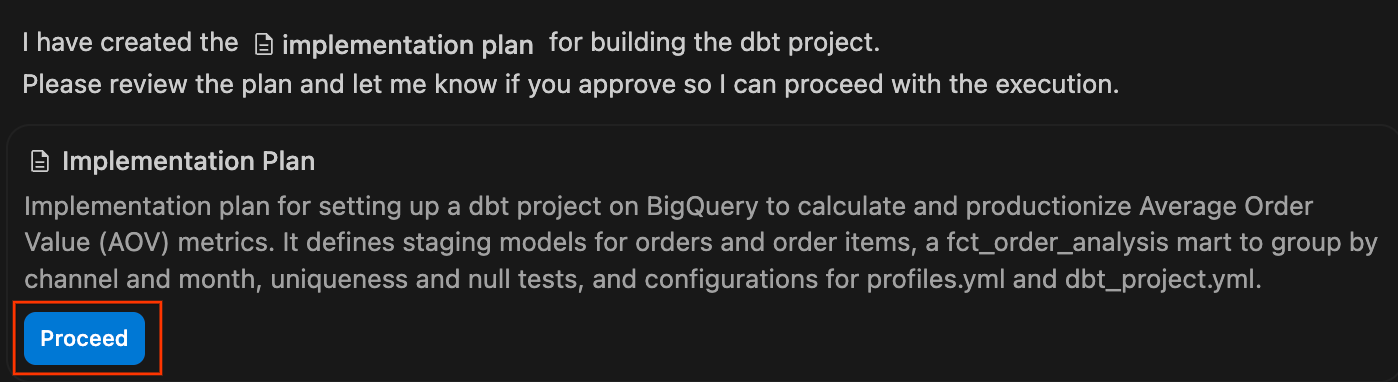
- Observez le volet "Chat" pendant que l'agent exécute son plan, en écrivant les fichiers
.sqlet les configurations YAML nécessaires. Une fois la compilation du projet terminée, un récapitulatif des modifications s'affiche. Cliquez sur Tout accepter pour ajouter ces fichiers à votre espace de travail.
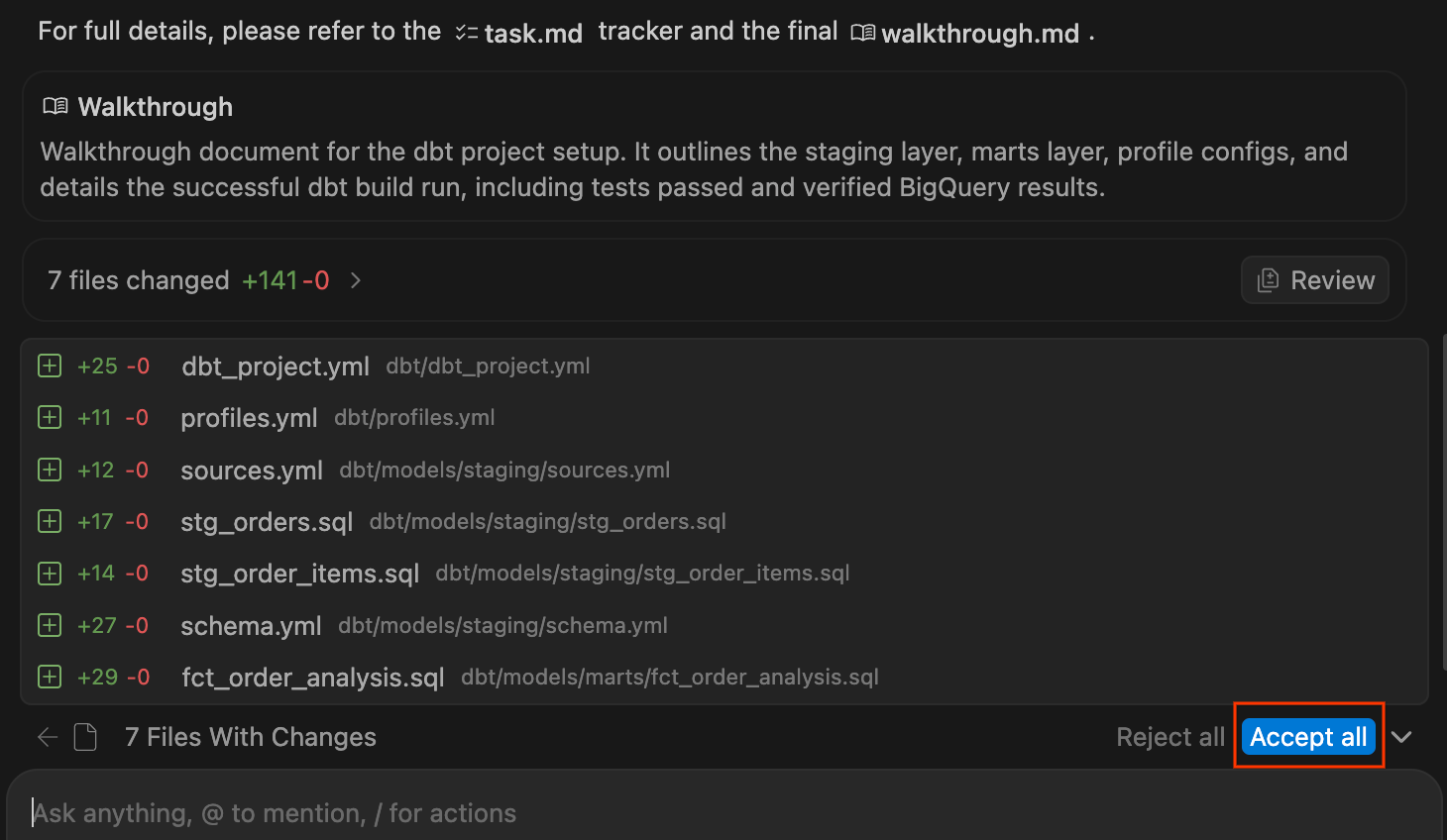
- Explorez le projet dbt nouvellement généré dans l'explorateur à gauche. La structure doit ressembler à ceci :
dbt/ ├── models/ │ ├── marts/ │ │ └── fct_order_analysis.sql │ └── staging/ │ ├── schema.yml │ ├── sources.yml │ ├── stg_order_items.sql │ └── stg_orders.sql ├── dbt_project.yml └── profiles.yml

- Cliquez sur les fichiers de modèle
.sqlpour examiner le code SQL généré par l'agent. Faites attention à la façon dont il gère les points suivants :- Modèles intermédiaires : colonnes nettoyées et renommées avec des références aux sources
- Le modèle de mart : logique de jointure et calcul de la valeur moyenne des commandes par canal
- Dans le panneau "Chat", vérifiez que l'agent confirme que tous les modèles ont été matérialisés et que tous les tests ont réussi. Les résultats de la valeur moyenne des commandes provenant du mart doivent confirmer ce que vous avez découvert au cours de l'enquête :
- Online: ~$110 - Offline: ~$110 - B2B-Wholesale: ~$75 to $77
Récapitulatif de la section : l'agent a créé un projet dbt à partir d'une seule requête axée sur un objectif : il a échafaudé des modèles de mise en scène et de mart, a exécuté un dbt build et a confirmé l'anomalie de la valeur moyenne des commandes. Ensuite, vous allez lui poser une question complexe pour voir comment il réagit.
9. Lorsque les tests échouent, l'agent débogue
Le pipeline fonctionne, mais il n'utilise que les données BigQuery. L'équipe produit souhaite enrichir l'analyse avec les données de profil des clients et de leurs animaux de compagnie provenant de Cloud SQL afin de pouvoir recommander des produits en fonction des besoins alimentaires. Cela signifie que l'agent doit franchir la limite Cloud SQL et gérer un bug subtil de modélisation des données, à savoir une jointure de distribution ramifiée classique de modélisation dimensionnelle.
Selon le modèle que vous utilisez et ses capacités de raisonnement, l'agent traitera cette demande de deux manières : en évitant de manière proactive le bug (option A) ou en s'autoréparant après un échec du test (option B). Voyons quel chemin emprunte votre agent !
Déclencher la demande
- Dans le volet de discussion, saisissez :
Enrich fct_order_analysis with customer data and pet profile data from our Cloud SQL database. Include customer type and each customer's pets and dietary needs so we can recommend products. Keep the uniqueness test on order_id and run dbt build. - Regardez l'agent travailler. Il découvrira les tables Cloud SQL, trouvera comment transférer les données dans BigQuery (via une requête fédérée ou une copie matérialisée), créera de nouveaux modèles intermédiaires et modifiera
fct_order_analysis.sql.
Option A : L'agent proactif (évitement des bugs)
Si vous utilisez un modèle de raisonnement avancé, l'agent peut détecter le changement de précision avant d'écrire du code. Il se rend compte que, puisqu'un client peut posséder plusieurs animaux de compagnie, une jointure directe dupliquera les commandes et échouera immédiatement au test d'unicité que vous avez demandé sur order_id.
- Observer l'agrégation proactive : dans l'explication du volet de chat ou l'artefact de tutoriel, l'agent peut noter qu'il a pré-agrégé les données sur les animaux de compagnie avant de les joindre pour éviter une "distribution ramifiée classique". Pour ce faire, il regroupe généralement plusieurs animaux par client à l'aide d'une fonction d'agrégation (par exemple,
ARRAY_AGG()ouSTRING_AGG()). - Vérifiez les résultats :
dbt builds'exécute et réussit du premier coup, car l'agent a protégé de manière proactive la précision de la table de faits. Vous pouvez le vérifier en consultant l'artefact de procédure pas à pas généré, qui affiche souvent les résultats des tests réussis à côté des résultats de la requête.
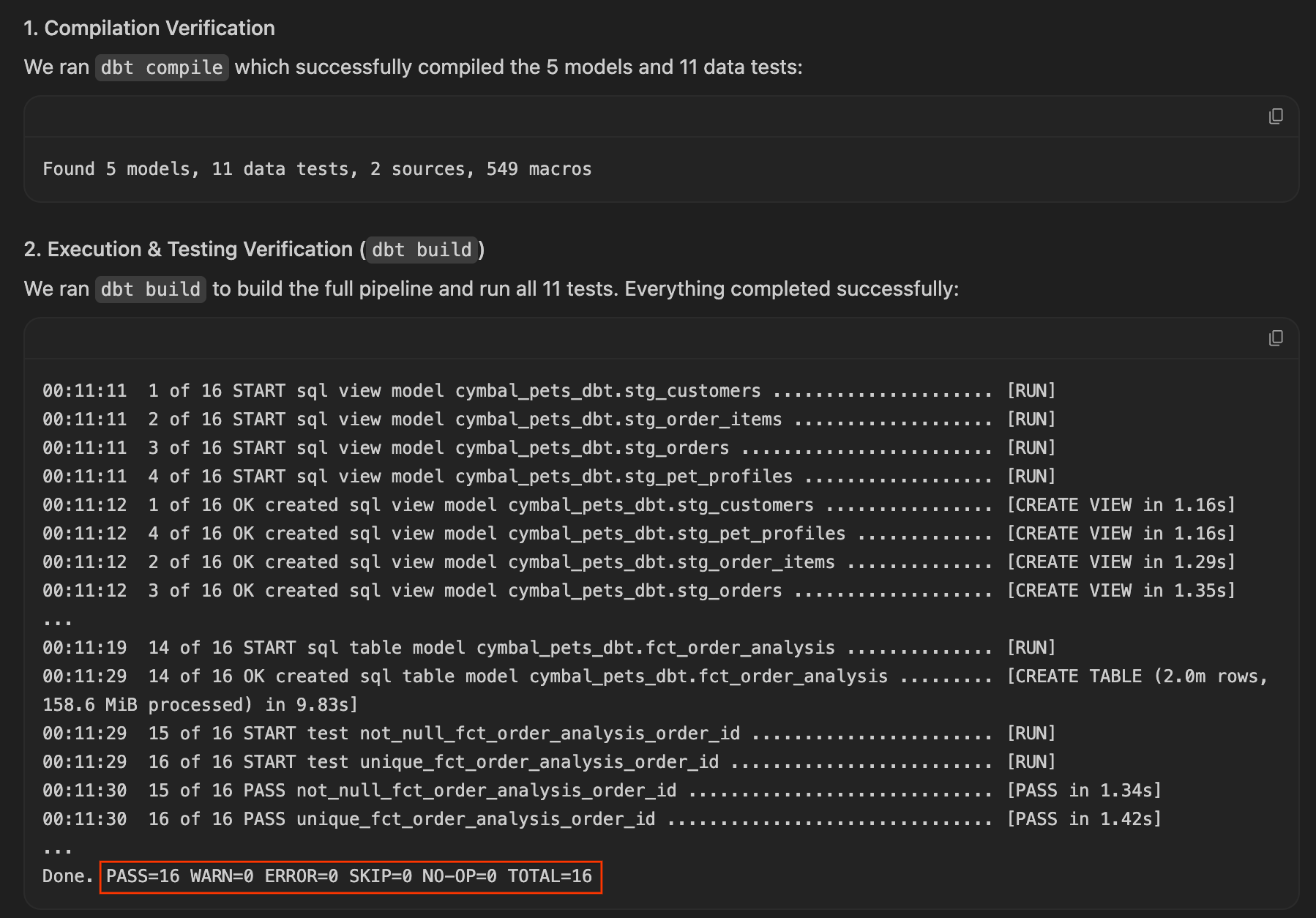
Si votre agent a fait cela, félicitations ! Vous avez vu comment l'IA peut être proactive. Prenez le temps d'examiner le code SQL généré dans fct_order_analysis.sql pour voir comment l'agrégation est structurée, puis passez à la section suivante, Fournir la réponse.
Option B : L'agent d'autoréparation (débogage et diagnostics)
Si le modèle écrit d'abord une jointure gauche directe naïve, la requête SQL s'exécutera correctement, mais la suite dbt test automatisée détectera le changement de niveau de précision.
- Observer l'échec du test : l'échec est indiqué dans les journaux de progression de l'exécution du volet "Chat" :
Completed with 1 error Failure in test unique_fct_order_analysis_order_id Got 287 results, configured to fail if != 0
order_ida détecté des entrées en double, car les clients possédant plusieurs animaux de compagnie ont réparti les commandes. - Laisser l'agent diagnostiquer et résoudre le problème lui-même : puisque le test a échoué, demandez à l'agent de le déboguer. Dans le volet de discussion, saisissez :
The uniqueness test failed. Can you figure out why and fix it? - Regardez le diagnostic : l'agent interroge les données, découvre la relation un-à-plusieurs dans
pet_profiles, explique que la jointure directe modifie la précision de une ligne par commande en une ligne par commande et par animal, et réécrit le modèle pour préagréger les profils d'animaux :-- Pre-aggregating pets per customer to resolve fan-out LEFT JOIN ( SELECT customer_id, COUNT(*) AS num_pets, STRING_AGG(DISTINCT pet_type, ', ') AS pet_types, STRING_AGG(DISTINCT dietary_needs, ', ') AS dietary_needs FROM pet_profiles GROUP BY customer_id ) pet_agg ON c.customer_id = pet_agg.customer_id - Vérifier la correction : l'agent exécute
dbt buildà nouveau, et cette fois, tous les modèles se matérialisent et tous les tests réussissent !
Récapitulatif de la section : que votre agent ait évité le bug de manière proactive ou qu'il se soit autoréparé après un échec du test, vous avez vu comment il a franchi la limite de Cloud SQL, intégré les données des profils client et animal de compagnie, et maintenu une granularité parfaite de la table de faits. Le pipeline est désormais robuste, complet et entièrement testé.
10. Fournir la réponse
C'est jeudi. Vous avez commencé la semaine avec un directeur financier inquiet et des données éparpillées dans trois services cloud. Vous avez maintenant la cause racine et un pipeline de production. Temps nécessaire pour fournir la réponse, ainsi qu'une recommandation prospective appuyée par une prévision quantitative.
Rédige la synthèse
- Dans le volet de discussion, saisissez :
Write an executive summary covering: - Main findings and the quantitative margin impact - Project AOV for the subsequent quarter if the B2B program continues at its current trajectory - A data-driven recommendation - Observez l'agent au travail.
- Examinez la synthèse de l'agent. Une réponse typique et bien structurée doit aborder les points suivants :
- Principale conclusion : la baisse de la valeur moyenne des commandes en janvier est uniquement due au nouveau canal B2B-Wholesale. Les revenus générés en ligne et hors connexion restent stables, à environ 110 $.
- Cause première : La promotion "B2B Wholesale Push" (25% de remise sur les commandes groupées) a attiré 100 nouveaux comptes, générant environ 25 000 commandes.
- Impact sur la marge : les commandes en gros ont comprimé le bénéfice moyen par unité d'environ 65% (de ~7,50 $ à ~2,60 $).
- Revenus : revenus globaux stables, car le volume B2B élevé compense les prix plus bas.
Prévoir la valeur moyenne des commandes avec AI.FORECAST
- L'agent doit également générer une projection prospective. Recherchez un appel MCP Tool où l'agent exécute une requête
AI.FORECASTsur BigQuery. Elle utilise le modèle de fondation TimesFM intégré pour projeter la valeur moyenne des commandes sur 90 jours en fonction des tendances historiques. La requête doit projeter la valeur moyenne des commandes sur 90 jours dans deux scénarios : la poursuite de la campagne (valeur moyenne des commandes structurellement basse) et l'arrêt de la campagne (retour à environ 110 $).
- Examinez les recommandations stratégiques de l'agent. Voici quelques exemples de recommandations solides :
- Restructurez les remises : implémentez des marges minimales ou plafonnez les remises groupées pour protéger les marges au niveau des unités.
- Appliquer des quantités minimales de commande plus strictes : empêchez les acheteurs de profiter des prix de gros.
- Rapports distincts : suivez les divisions retail et B2B de manière indépendante pour éviter de masquer les performances retail.
L'histoire complète
Ce qui a commencé lundi comme un exercice d'incendie suite à une baisse de 7% de la valeur moyenne des commandes a une solution claire pour le directeur financier :
- Retail Health : les principaux canaux de vente au détail restent sains et stables au niveau de référence.
- Afflux de ventes en gros : la baisse de la valeur moyenne des commandes est entièrement due au nouveau canal B2B "Ventes en gros" et à la campagne
BIGORDER25. - Impact sur la marge : la remise groupée de 25% a fortement érodé les marges unitaires, menaçant la rentabilité malgré des revenus stables.
- Prévisions stratégiques : une projection
AI.FORECASTmontre que la restructuration des niveaux de vente en gros permettra de rétablir la valeur moyenne des commandes combinée.
Vous fournissez une recommandation basée sur les données pour établir des marges brutes minimales et séparer les rapports sur les ventes au détail/B2B.
Récapitulatif de la section : vous avez demandé à l'agent de rédiger un résumé, d'analyser les marges, de générer une prévision AI.FORECAST et de fournir une recommandation basée sur les données. L'investigation est terminée.
11. Effectuer un nettoyage
Pour éviter que les ressources créées dans cet atelier de programmation soient facturées en permanence sur votre compte Google Cloud, supprimez-les en exécutant le script de suppression.
- Dans le panneau Terminal en bas de l'IDE Antigravity (ou dans Cloud Shell), accédez au répertoire de l'atelier de programmation et exécutez la commande suivante :
cd ~/devrel-demos/codelabs/agentic-data-labs/scripts
chmod +x teardown.sh
./teardown.sh
- Le script affichera toutes les ressources qu'il prévoit de supprimer et demandera une confirmation avant de continuer :
- Instance Cloud SQL (
cymbal-pets-ops) : il s'agit de la ressource la plus coûteuse. - Ensemble de données BigQuery (
cymbal_pets) : toutes les tables et tous les modèles - Bucket Cloud Storage (
gs://YOUR_PROJECT_ID-cymbal-pets-raw) - Connexion BigQuery (
cymbal-pets-cloudsql)
- Instance Cloud SQL (
- Saisissez
ypour confirmer. Le démontage prend environ deux à trois minutes.
[INFO] Deleting Cloud SQL instance cymbal-pets-ops... [ OK ] Cloud SQL instance deleted. [INFO] Deleting BigQuery dataset cymbal_pets... [ OK ] BigQuery dataset deleted. [INFO] Deleting GCS bucket gs://YOUR_PROJECT_ID-cymbal-pets-raw... [ OK ] GCS bucket deleted.
12. Félicitations !
Vous avez terminé L'enquête sur les Cymbal Pets. Vous êtes passé d'une question vague du directeur financier à une recommandation entièrement opérationnalisée et étayée par des prévisions, à l'aide d'un agent d'IA qui fonctionne sur l'ensemble de votre patrimoine de données Google Cloud.
Ce que vous avez accompli
- 🔍 Exploration dans les services : les composants découverts et prévisualisés dans BigQuery, Cloud SQL et Cloud Storage à l'aide du Knowledge Catalog du Data Agent Kit.
- 🕵️♂️ Enquête menée avec l'IA : plusieurs services ont été interrogés dans une même conversation du panneau de chat à l'aide des outils MCP pour remonter à la source de l'anomalie de valeur moyenne des commandes, qui s'est avérée être une campagne promotionnelle B2B groupée.
- 🔧 Création d'un pipeline de production : création d'un projet dbt complet pour nettoyer, joindre et tester les données transactionnelles et client.
- 🐛 Débogage d'un bug de distribution ramifiée : l'agent a automatiquement diagnostiqué un problème de granularité et refactorisé le modèle SQL dbt pour pré-agréger les profils d'animaux de compagnie des clients.
- 📈 Prévision et recommandation : utilisé la fonction
AI.FORECASTintégrée à BigQuery pour modéliser les tendances de la valeur moyenne des commandes et fournir une recommandation basée sur les données au directeur financier.
Concepts clés
Concept | Ce que vous avez appris |
Outils MCP | Des connexions sécurisées et auditables qui permettent à l'agent d'IA d'interroger des services tels que BigQuery, Cloud SQL, Spanner et d'autres bases de données en votre nom, chaque appel étant visible dans le volet "Chat" |
Compétences agentiques | Ensembles d'instructions prédéfinis (comme |
Investigation multiservice | L'agent interroge plusieurs services Google Cloud dans une même conversation, sans configuration de connexion ni changement de contexte entre les consoles. |
Requêtes axées sur des objectifs | Indiquer à l'agent ce que vous voulez ("crée un projet dbt qui calcule la valeur moyenne des commandes par canal") plutôt que comment, et le laisser choisir l'approche d'implémentation |
Data Agent Kit | Extension qui lie le tout (outils MCP, compétences des agents et découverte des données), vous donnant accès à l'ensemble de votre patrimoine de données Google Cloud depuis l'IDE de votre choix |
Étapes suivantes
- Pour en savoir plus sur ses fonctionnalités, consultez la documentation du kit Data Agent.
- En savoir plus sur les fonctions d'IA et de BigQuery ML, y compris
AI.FORECAST,AI.GENERATEetAI.EMBED - Essayez de créer votre propre enquête multiservice avec l'IDE Antigravity sur vos propres données