
1. はじめに
月曜日の朝、CFO からメッセージが届きました。今月は平均注文額が 7% 減少しましたが、総収益は横ばいです。何か問題があり、取締役会は金曜日までに回答を求めています。
Cymbal Pets は、米国最大手のオンライン ペット用品小売業者の 1 つです。必要なデータは、3 つの Google Cloud サービスに分散しています。BigQuery のトランザクション データ、Cloud SQL の顧客と商品のレコード、Cloud Storage のマーケティング ファイルです。通常、このようなサービス間の調査を行うには、コンソールを切り替え、接続ボイラープレートを作成し、結果を手動でつなぎ合わせる必要があります。
この Codelab では、Antigravity IDE で Google Cloud Data Agent Kit(DAK)を使用して、自然言語で異常を調査します。検索する内容を記述すると、AI エージェントが BigQuery、Cloud SQL、Cloud Storage 間の接続、SQL、クロスサービス結合を処理します。ケースを解決したら、エージェントに dbt パイプラインを構築して調査結果を運用化し、実際のデータ モデリング バグをデバッグして、予測に基づく推奨事項を CFO に提供するよう依頼します。
演習内容
- Knowledge Catalogを使用して、BigQuery、Cloud SQL、Cloud Storage 全体でデータアセットを検出する
- MCP ツールを使用して、1 つの会話で複数のサービスをクエリして異常を調査する
- dbt パイプラインを構築する。ステージング モデルと自動テストを使用して、サービス間のデータをステージングして結合します。
- エージェントがファンアウト バグを自己診断してリファクタリングする際に、データ モデリングの問題をデバッグする
- BigQuery の
AI.FORECASTを使用して、将来の傾向を予測し、データドリブンの推奨事項を提供します。
必要なもの
- ウェブブラウザ(Chrome など)
- 課金を有効にした Google Cloud プロジェクト
- SQL と Google Cloud コンソールに関する基本的な知識
この Codelab は、中級のデータ実務者(分析エンジニア、データ アナリスト、データ サイエンティスト)を対象としています。
この Codelab で作成するリソースの費用は 5 ドル未満です。
2. 始める前に
このセクションでは、ラボ環境全体(注文データを含む BigQuery データセット、顧客データと商品データを含む Cloud SQL Postgres インスタンス、プロモーション キャンペーン レコードを含む Cloud Storage バケット)をプロビジョニングする設定スクリプトを実行します。スクリプトの完了には約 8 ~ 10 分かかります。Cloud SQL のプロビジョニングがボトルネックになります。
Cloud Shell の起動
Google Cloud Shell を使用して設定スクリプトを実行します。
- Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] アイコンをクリックします。

- 接続したら、プロジェクト ID を設定して環境を確認します。
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
次のようなメッセージが表示されます。
Your active configuration is: [cloudshell-####] Updated property [core/project]
リポジトリのクローンを作成する
Cloud Shell 環境に Codelab リポジトリのクローンを作成します。
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/agentic-data-labs
git checkout main
cd codelabs/agentic-data-labs/
設定スクリプトを実行する
設定スクリプトは、数分でラボ環境全体を準備します。API の有効化、BigQuery データの読み込みと拡張、プロモーション アセットの GCS へのアップロードを処理し、コードラボの開始時にバックグラウンド ワーカーを自動的に生成して、バックグラウンドで Cloud SQL Postgres をプロビジョニングして構成します。
スクリプトは、Cloud SQL パスワードを安全に自動生成し、.env ファイルに自動的に保存します。
cd ~/devrel-demos/codelabs/agentic-data-labs/scripts
chmod +x setup.sh setup_sql.sh
./setup.sh
完了すると、フォアグラウンド環境の概要が表示されます。
╔══════════════════════════════════════════════════════╗
║ Base Setup complete! ║
╚══════════════════════════════════════════════════════╝
Your core BigQuery and GCS assets are ready.
Cloud SQL is currently provisioning in the background and will be fully ready by Step 4.
BigQuery: YOUR_PROJECT_ID.cymbal_pets
├── orders
└── order_items
GCS: gs://YOUR_PROJECT_ID-cymbal-pets-raw
└── promo_events.json
ラボの次の手順に進んでいる間、データベースはバックグラウンドでプロビジョニングされ、シード処理されます。別のターミナル パネルで、次のコマンドを使用して進行状況をいつでもモニタリングできます。
tail -f /tmp/cloudsql_setup.log
データ アーキテクチャに注目してください。トランザクション データ(注文と注文アイテム)は BigQuery に存在し、運用データ(顧客、ペットのプロフィール、商品)は Cloud SQL に存在します。この分割は、実際の組織でデータがサービス間で分散される方法を反映しており、サービス間の調査を興味深いものにしています。
セクションのまとめ: 設定スクリプトを実行してラボ環境をブートストラップし、バックグラウンド データベースのプロビジョニングを開始しました。
3. IDE と Data Agent Kit を設定する
Antigravity IDE を開く
Cloud SQL の完了を待つ必要はありません。Antigravity IDE を開いて、Google Cloud プロジェクトに接続します。
- まだインストールしていない場合は、Google Antigravity ダウンロード ページから Antigravity IDE をダウンロードしてインストールします。
- Antigravity IDE デスクトップ アプリケーションを起動します。
- ローカルマシンに新しい空のフォルダ(
agentic-data-labsなど)を作成し、[フォルダを開く] を選択して IDE で開きます。これが、Codelab のローカル ワークスペースとして機能します。
Data Agent Kit 拡張機能をインストールする
Google Cloud Data Agent Kit 拡張機能は、エディタ内で Google Cloud データ サービスと深く統合されており、コンテキストを切り替えることなく BigQuery、Cloud SQL、Cloud Storage などを操作できます。
- Antigravity IDE で、画面の左端にあるアクティビティ バーの [拡張機能] アイコン(4 つの正方形のようなアイコン)をクリックします。
- [拡張機能] ペインの上部にある検索バーに「
Google Cloud Data Agent Kit」と入力します。 googlecloudtoolsが公開した Google Cloud Data Agent Kit という名前の拡張機能を見つけます。- [Install] ボタンをクリックします。
- 「パブリッシャー「googlecloudtools」とその拡張機能を信頼しますか?」というメッセージが表示されることがあります。[Trust Publishers & Install] をクリックして続行します。
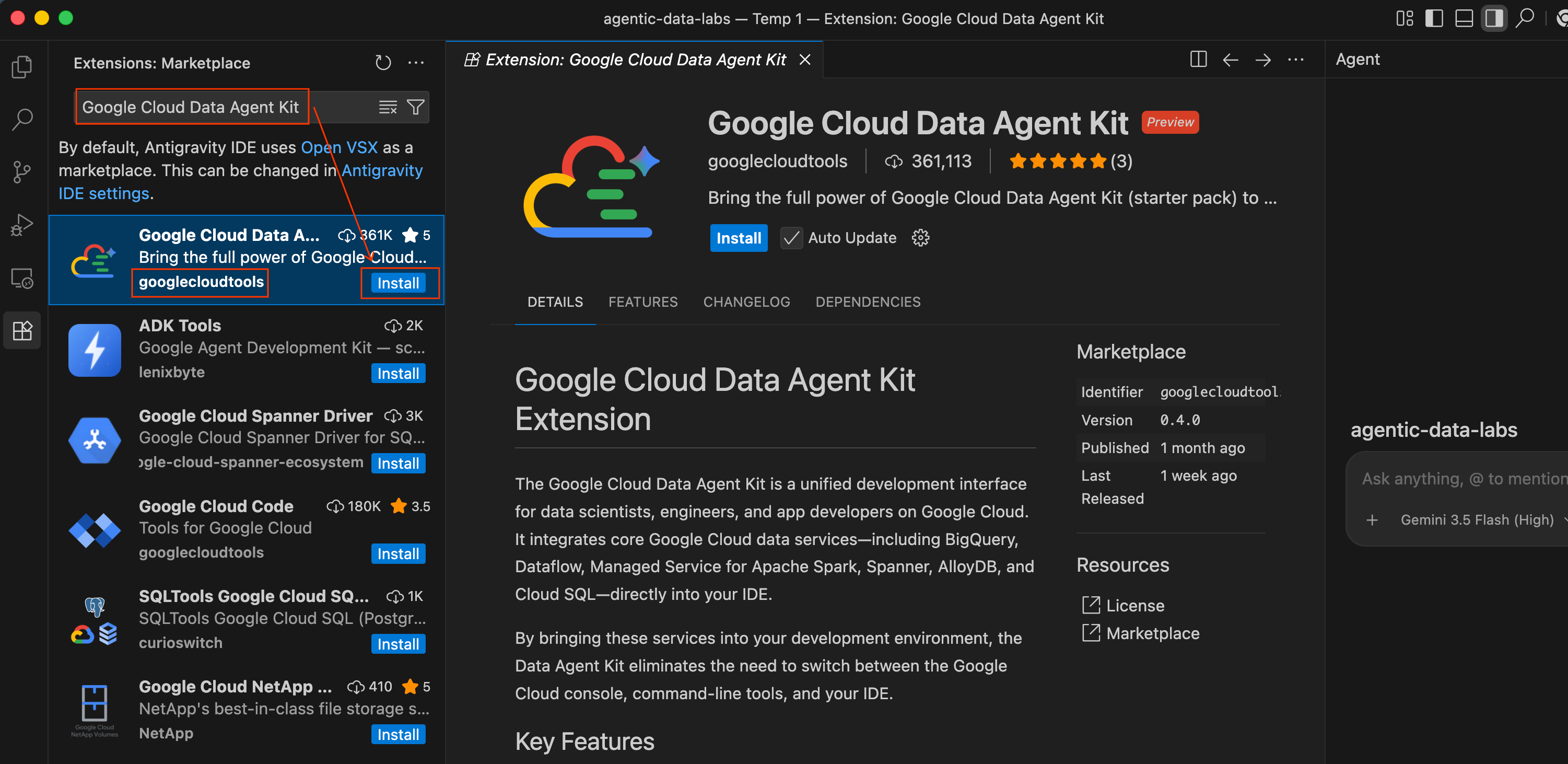
インストールが完了すると、Antigravity IDE の左端にあるアクティビティ バーに、新しい Google Cloud Data Agent Kit アイコンが表示されます。
拡張機能の認証と構成
インストール後、拡張機能を Google Cloud プロジェクトに接続します。
- 「Google Cloud Data Agent Kit へようこそ」というタイトルのオンボーディング ページが自動的に開きます。Cloud アカウントにログインしていない場合は、画面の指示に沿ってアクセスを許可します。
- [構成の概要] セクションで、プロジェクト フィールドを見つけます。プルダウンをクリックして、Google Cloud プロジェクトを選択します。リージョンを
us-central1に設定します。[Configure MCP Servers] を選択します。

- [MCP 構成] ペインで、[BigQuery] と [Cloud SQL] をクリックして有効にします。[使ってみる] をクリックします。
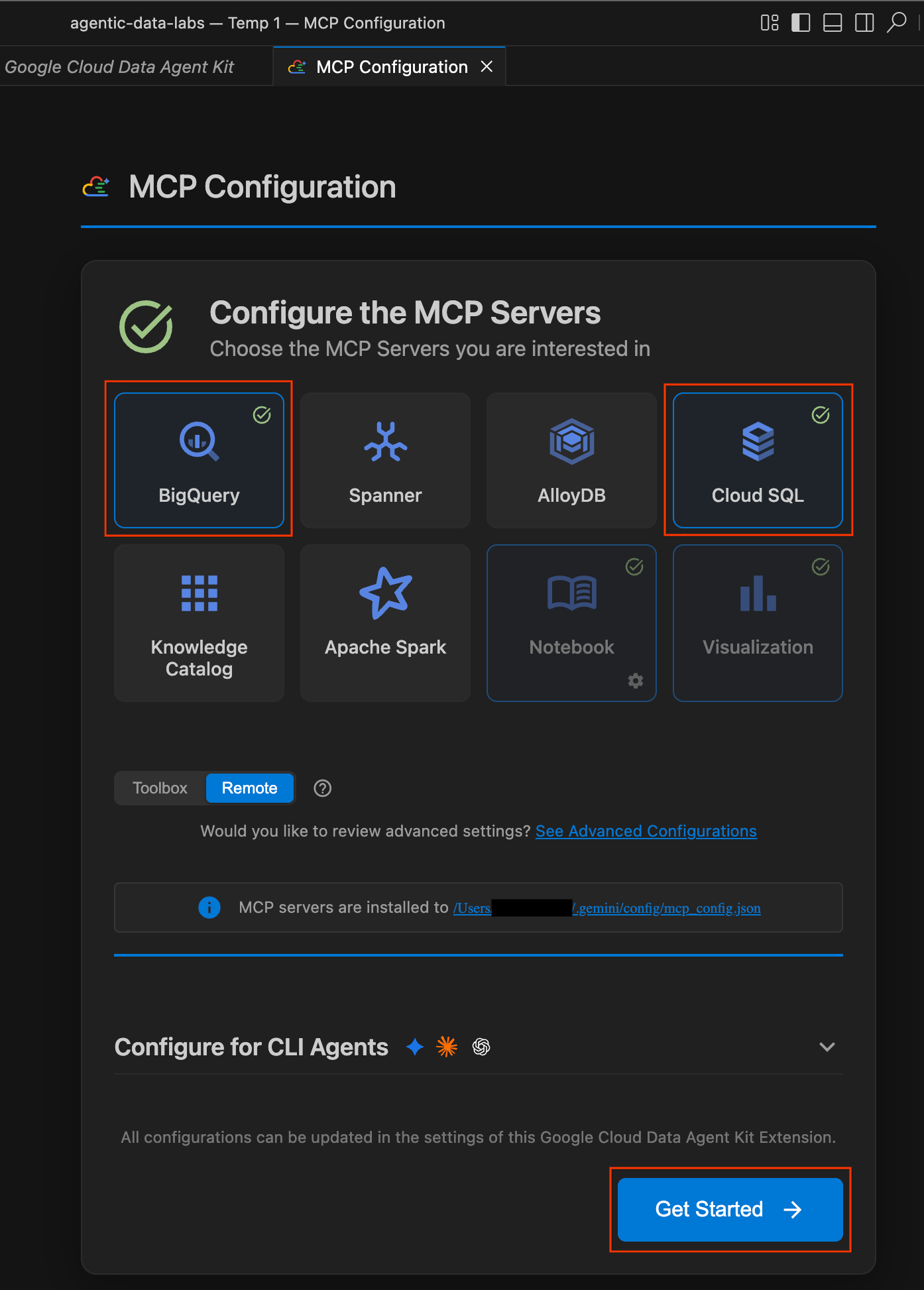
構成オプションを確認する
設定が完了すると、[Google Cloud Data Agent Kit を使ってみる] ページが表示されます。
- [設定と構成] で、[開始] をクリックします。
- [データ エージェントの構成] パネルが開きます。タブを確認します。
- プロジェクトとリージョン: 選択したプロジェクト ID を確認し、必要な API(Cloud Storage API、BigQuery API、Catalog API、Cloud SQL Admin API)が有効になっていることを確認します。
- BigQuery: BigQuery クエリのデフォルトの場所を構成します。リージョン
us-central1を使用します。 - MCP サーバーを構成する: AI エージェントがデータを安全に操作できるようにする、有効な MCP サーバー(BigQuery、Notebooks、Cloud SQL など)を表示します。
- スキル: エージェントに複雑なデータタスク用の特別な機能を提供する事前構築済みのスキルを確認します。
![[Data Agent Settings] パネル](https://codelabs.developers.google.com/static/dak-analytics-eng-antigravity-ide/img/dak_settings.png?hl=ja)
セクションのまとめ: Antigravity IDE を開き、Google Cloud プロジェクトに接続し、Data Agent Kit のリモート MCP サーバーを構成し、BigQuery に対してクエリを実行して接続を確認しました。
4. データを検出する
シーンを設定しましょう。状況は次のとおりです。CFO は、先月の平均注文額が 7% 減少したが、総収益は横ばいだと述べています。エージェントに調査を依頼する前に、まずどのようなデータを扱っているかを把握する必要があります。
このセクションでは、Data Agent Kit パネルを手動で確認して、概要を把握します。クエリを開始する前にデータを理解することは、あらゆる調査において重要な第一歩です。
BigQuery テーブルの詳細
- [Data Agent Kit] パネルの [CATALOG] で、プロジェクト → [BigQuery] →
cymbal_petsを開きます。 - [
orders] テーブルをクリックします。新しいタブが開き、テーブルの詳細が表示されます。 - テーブル ビューアの左側にあるタブを確認します。
- データ: 実際の行をプレビューします。データセットをスクロールして、列を確認します。
- スキーマ: 列の名前と型を確認します。
order_typeやpromo_codeなどのフィールドに注目してください。これらは後ほど重要になります。 - その他のタブ([詳細]、[分析情報]、[データ プロファイル] など): 通常は Google Cloud コンソールで確認できるメタデータ、データ リネージ、品質の詳細に、エディタを離れることなくアクセスできます。
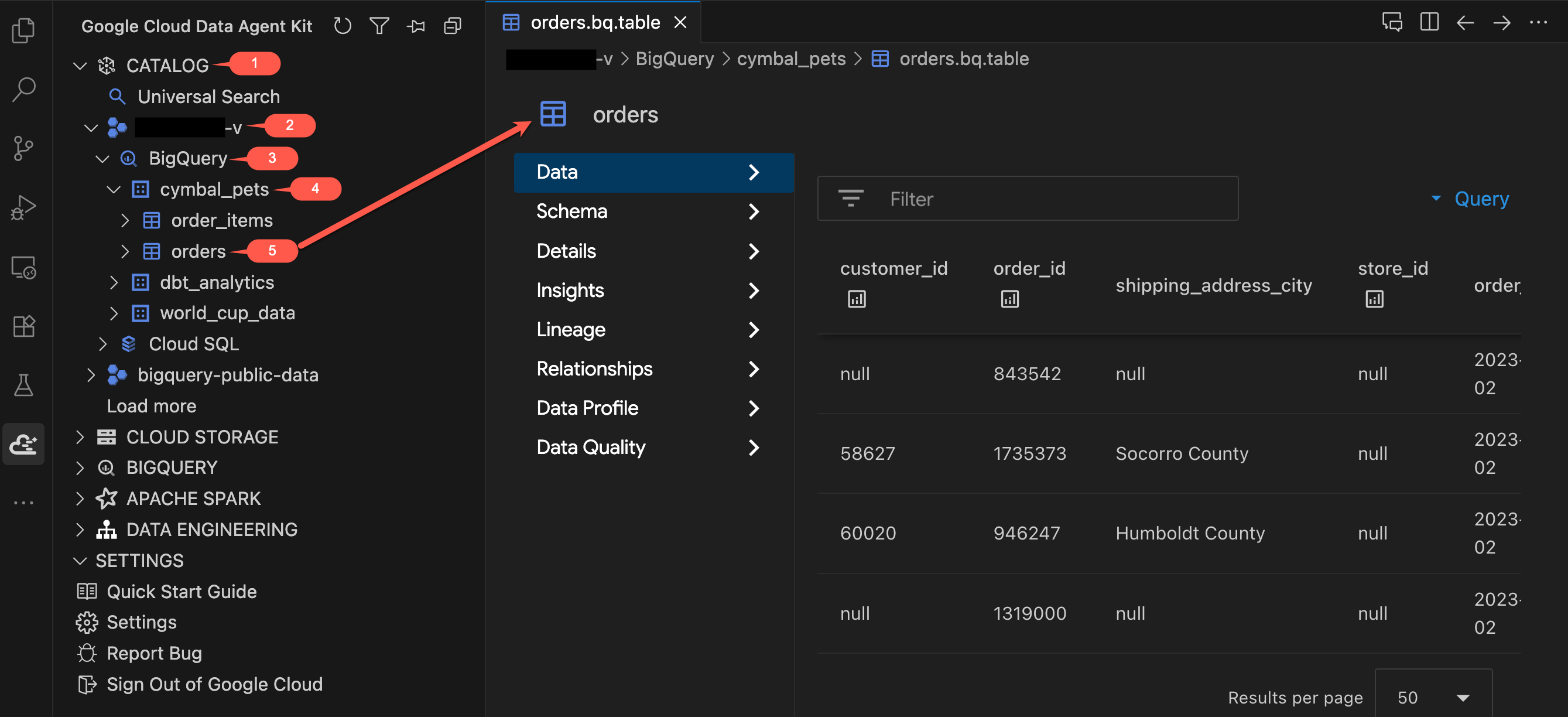
order_itemsテーブルをクリックして、スキーマを確認します。quantityフィールドとpriceフィールドに注目してください。
Cloud SQL テーブルを調べる
設定スクリプトは、顧客、ペット、商品のデータを Cloud SQL の PostgreSQL データベースにも配置しました。
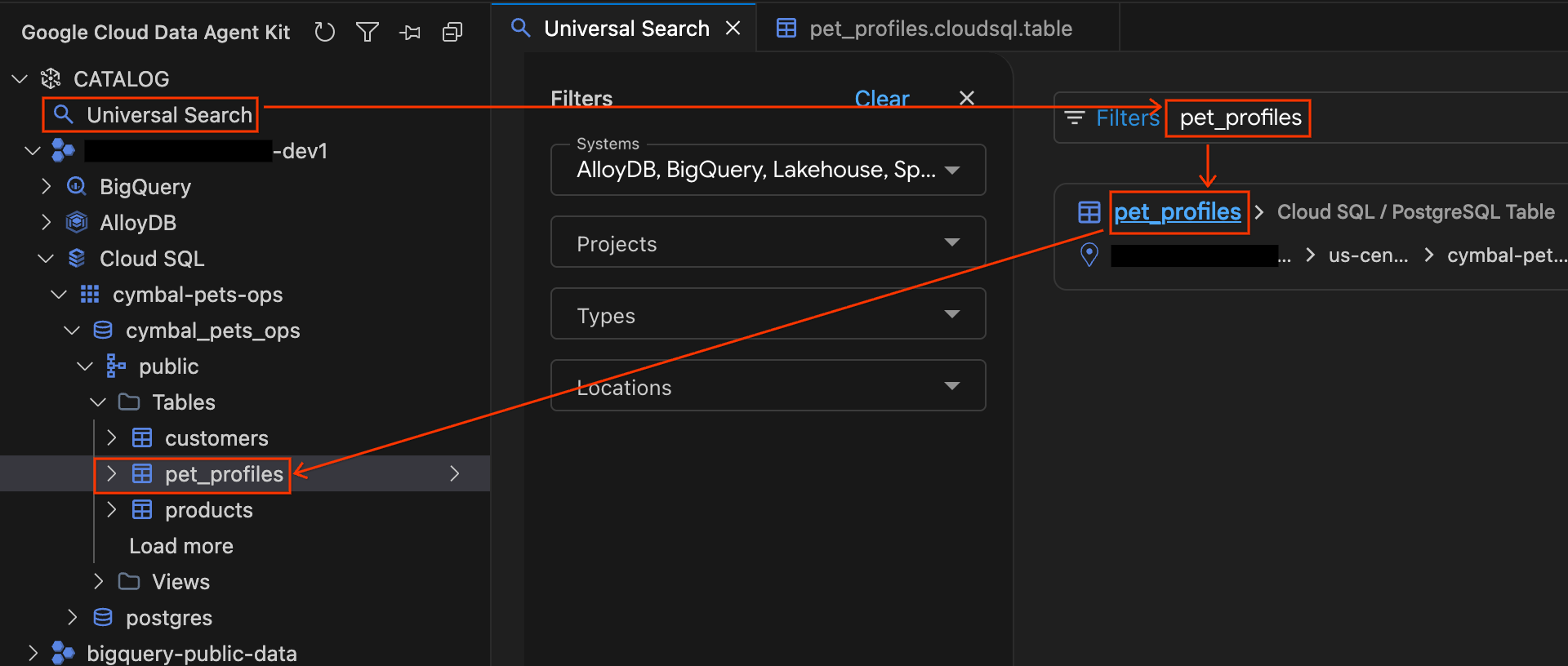
- [Data Agent Kit] パネルの [CATALOG] セクションで、[Universal Search] をクリックします。
- 検索ボックスに「
pet_profiles」と入力して、Enter を押します。 - 検索結果で、
pet_profilesの PostgreSQL テーブルの結果(プロジェクトの Cloud SQL インスタンスの下)をクリックします。サイドバーのアコーディオンが自動的に展開され、データベース ツリー内のテーブルの場所が正確に表示されます。ツリーのすぐ上にあるcustomersテーブルをクリックして詳細を開き、[スキーマ] タブと [詳細] タブを確認します。
Cloud Storage ファイルを調べる
最後に、マーケティング キャンペーンとプロモーション キャンペーンのレコードが Cloud Storage に未加工の JSON ファイルとして保存されます。
- 左側の [Data Agent Kit] パネルで、[CLOUD STORAGE] セクションを開きます。プロジェクトの未加工バケット(
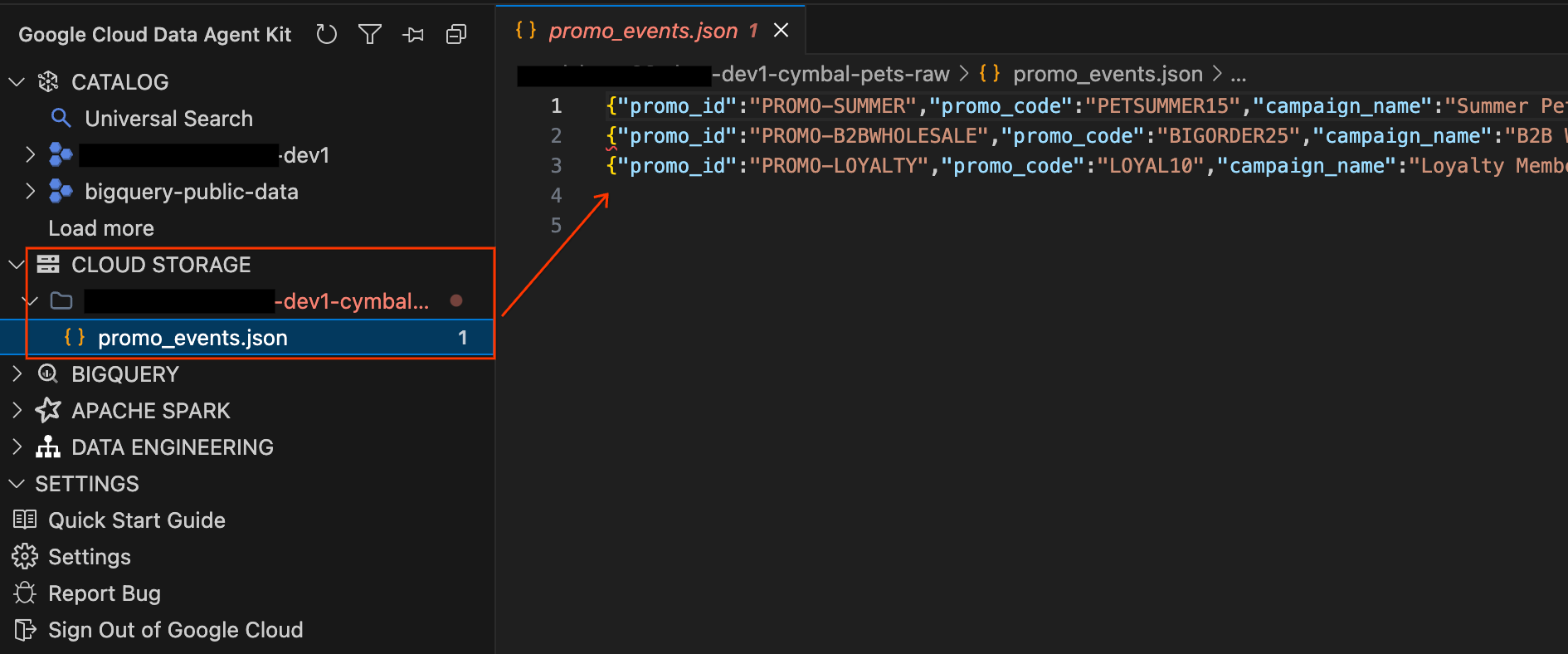
YOUR_PROJECT_ID-cymbal-pets-raw)を見つけます。 - バケット内の
promo_events.jsonファイルをクリックします。新しいエディタタブが開き、IDE 内でマーケティング キャンペーンの未加工の JSON Lines コンテンツを直接表示できます。
在庫情報を取得する
データ環境について、次のことがわかりました。
サービス | テーブル | What's There |
BigQuery |
| 約 190 万件のオーダー、約 430 万件の広告申込情報、期間 2023 ~ 2025 年 |
Cloud SQL |
| 約 92, 000 人のお客様、約 7, 600 件のペット プロフィール、206 個の商品 |
Cloud Storage |
| プロモーション キャンペーンの記録 |
データは 3 つのサービスに分散されています。従来のワークフローでは、接続を設定し、統合コードを記述して、結果を手動で結合する必要があります。次のステップでは、AI エージェントが 1 つの会話ですべてを処理できるようにします。
セクションのまとめ: Data Agent Kit パネルを使用して、BigQuery、Cloud SQL、Cloud Storage 全体のデータ アーキテクチャを手動で探索しました。データの保存場所と使用可能なフィールドがわかったので、調査を開始できます。
5. 数値で見る被害の統計
調査が開始されます。チャット ペインを使用して、AI エージェントに BigQuery から平均注文額(AOV)データを取得するよう依頼します。AOV は、注文あたりの平均金額を表すビジネス指標です。エージェントは MCP ツールを使用してユーザーに代わってクエリを実行し、実行されたすべての SQL クエリを確認できます。
平均注文額の推移を取得する
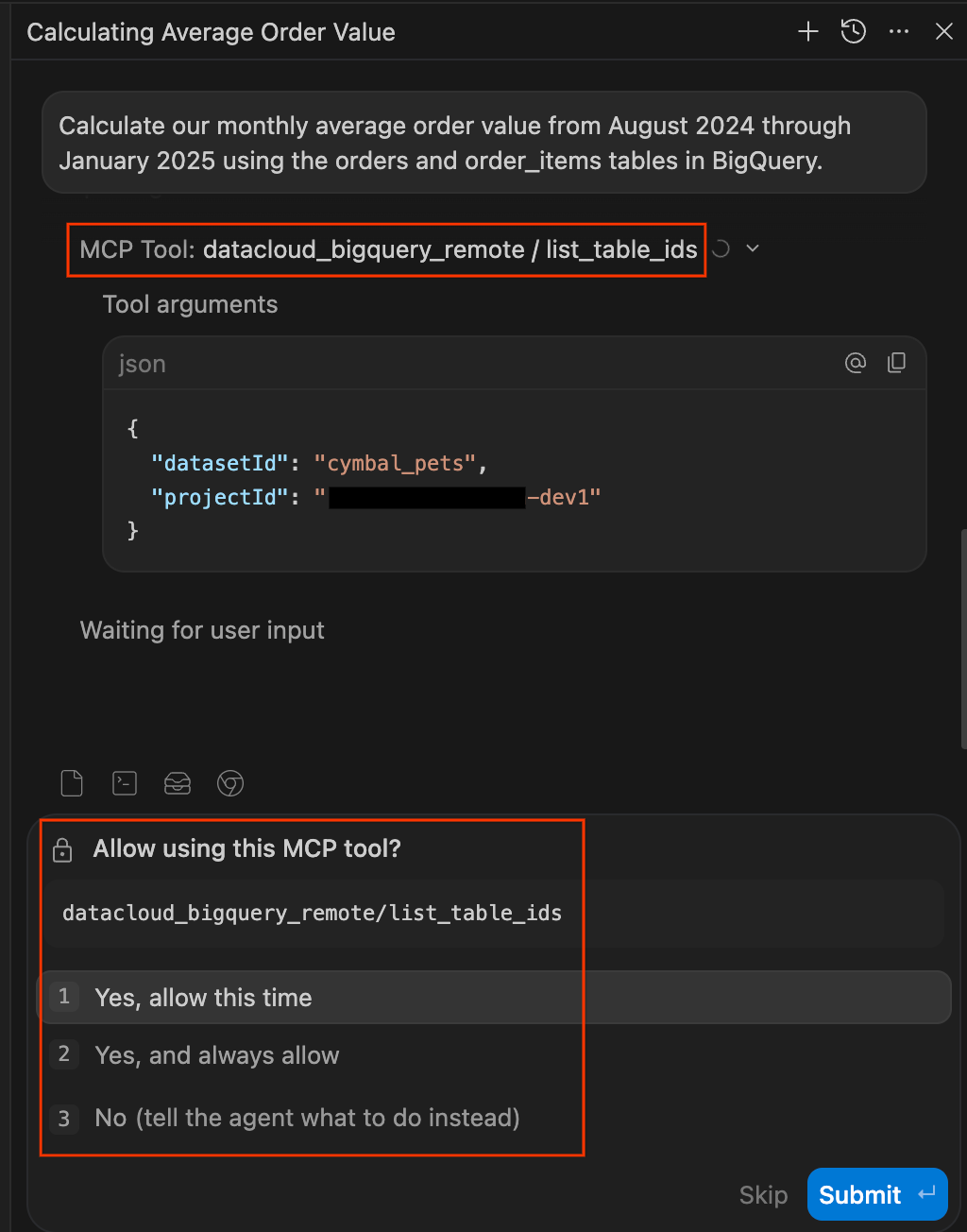
- IDE の右側にある [チャットペイン] に次のプロンプトを入力して、Enter キーを押します。
Calculate our monthly average order value from August 2024 through January 2025 using the orders and order_items tables in BigQuery. - データアクセス権限を承認します。AI エージェントがデータベースでクエリを実行することに注意することは健全なことです。Data Agent Kit は、データにアクセスする前に明示的な権限を求めることで、ユーザーが制御できるようにします。プロンプトが表示されたら、次のいずれかを選択します。
- 今回のみ許可: 1 回の使用を承認します(リスクの高いクエリの監査に最適です)。
- 常に許可: セッション中にこの特定のツールの使用を継続的に承認します。
- No: アクションを完全にブロックします。
list_table_idsやexecute_sql_readonlyなど)を使用すると、すぐにいくつかのプロンプトが表示される可能性があります。これらのプロンプトも [常に許可] に設定していただいて構いません。
- エージェントの動作を確認します。チャット ペインは、エージェントが行ったすべての操作の透明性ログとしても機能します。エージェントはブラック ボックスではなく、推論とアクションをリアルタイムで表示します。
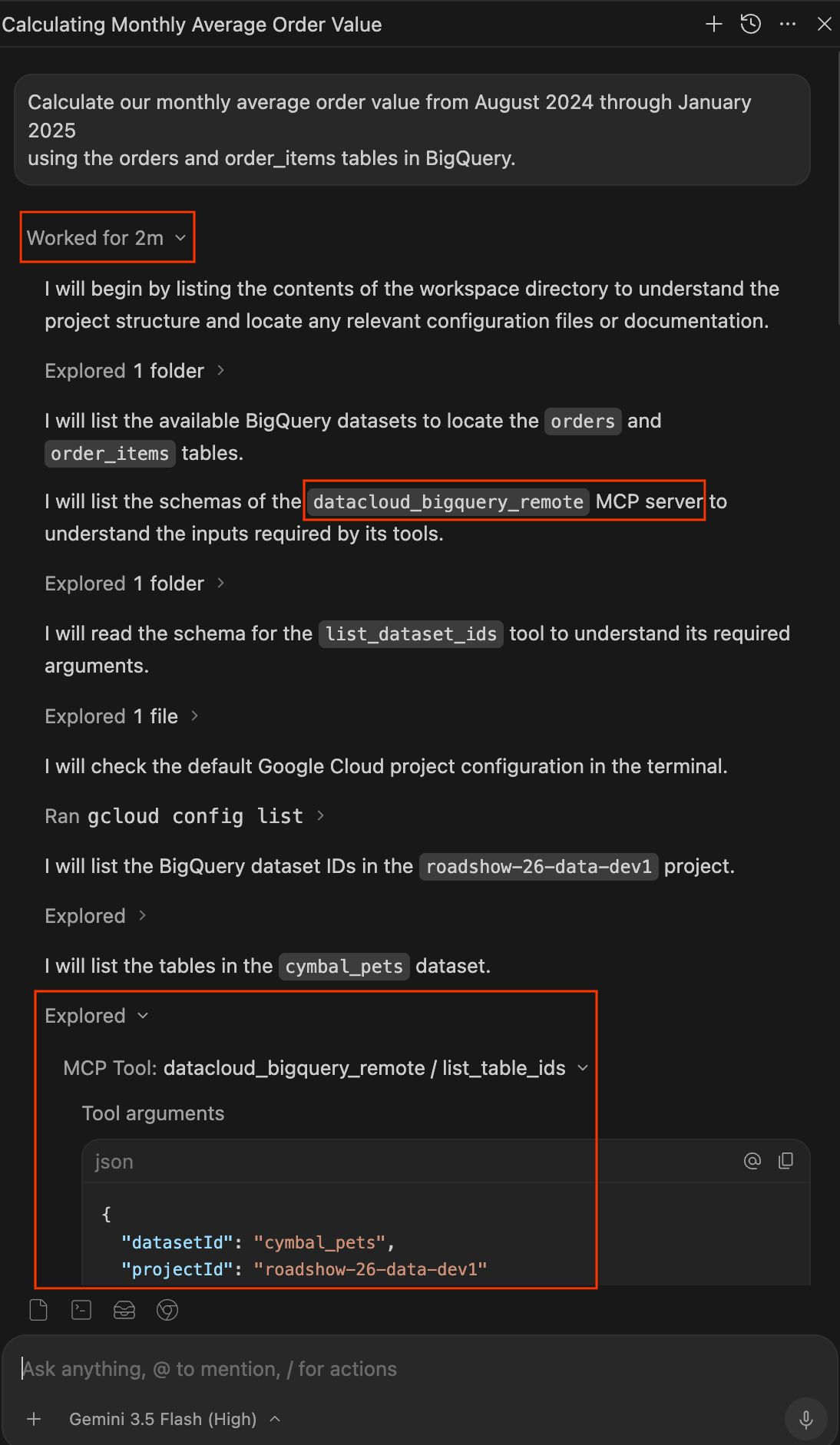
- エージェントが終了したら、プロンプトの下にある [Worked for Xm] プルダウンをクリックして、完全な作業ログを展開します。ここでは、回答がどのように生成されたかを詳しく調べることができます。
- Explored: これらの項目を展開すると、エージェントがファイルを読み取ったり、フォルダを参照したり、MCP ツール(
datacloud_bigquery_remote / list_table_idsやexecute_sql_readonlyなど)を呼び出したりしていることがわかります。ツールに渡された正確な JSON 引数と実行された SQL を確認できます。 - 実行: これらの項目を開くと、エージェントが実行したターミナル コマンド(
gcloud config listなど)が表示されます。
- Explored: これらの項目を展開すると、エージェントがファイルを読み取ったり、フォルダを参照したり、MCP ツール(
- 結果を確認します。エージェントは、月ごとの AOV 値の表を返す必要があります。ご自身で数値を確認してください。前月は$110 前後でしたが、1 月には$103 前後に下がっています。これは CFO がフラグを立てた異常です。
チャネル別のドリルダウン
全体的な AOV は減少しましたが、その原因は何でしょうか?Let's find out.(HONEY の節約額を確認してみましょう。)
- [チャット] ペインに次のように入力します。
January looks lower than the prior months. Break down January's AOV by order_type to see what's going on? - エージェントは別の BigQuery クエリを実行します。今回は
order_typeでグループ化します。結果をよく確認します。オンラインとオフラインの AOV は約 110 ドルで安定しています。ただし、平均注文額が大幅に低い(約 75 ドル)新しいチャネル B2B-Wholesale があります。この新しいチャネルがブレンド平均値を押し下げています。 - エージェントは、B2B 顧客の調査を積極的に提案する場合があります。もしそうでない場合でも、問題ありません。この操作は次のステップで行います。
セクションのまとめ: 1 月の AOV の低下を中立的なデータ抽出からご自身で確認し、order_type でドリルダウンして、B2B-Wholesale がブレンド平均を引き下げている新しいチャネルであることを特定しました。次に、これらの B2B 顧客が誰であるかを把握する必要があります。
6. サービス境界を越える
BigQuery で B2B-Wholesale が異常なチャネルとして特定されましたが、顧客データは Cloud SQL にあります。Data Agent Kit を使用すると、同じ会話を継続でき、サービス境界が処理されます。
B2B のお客様を調査する
- [チャットペイン] に次のように入力します。
Who are these B2B customers? Their profiles should be in our Cloud SQL database. Check for: - Who they are - When they signed up - Whether they're new or existing customers - [チャット] ペインをよく確認します。今回は別の MCP ツールが表示されます。エージェントは BigQuery ではなく Cloud SQL をクエリするようになりました。エージェントは
cymbal-pets-opsCloud SQL Postgres インスタンスに接続し、customersテーブルに対してクエリを実行します。[詳細を表示] をクリックして、SQL を表示します。 - 結果を確認します。エージェントは、いくつかの重要な調査結果を提示する必要があります。
- すべての B2B 顧客が
customer_type = 'Business'を持っています - 全員が過去 30 日以内(2025 年 1 月)に登録した
last_nameの値は、「Pet Supply Co」、「Animal Care LLC」、「Happy Paws Inc」などのビジネス名です。- このグループは今月初めて登場したもので、約 100 人のユーザーが該当します。
- すべての B2B 顧客が
プロモーション コードを接続する
- エージェントは、BigQuery の多くの B2B 注文に
promo_code値BIGORDER25が含まれていることに気づくことがあります。この観察結果が自動的に報告される場合は、それで構いません。調査は順調に進んでいます。エージェントがプロモーション コードについて言及していない場合は、次のように促します。I noticed a promo_code field on the orders table in BigQuery. Check what promo codes appear on the B2B-Wholesale orders? - エージェントは BigQuery に再度クエリを実行し、B2B-Wholesale 注文の約 92% に
promo_code = 'BIGORDER25'が含まれていることを確認します。B2B アクティビティのほぼすべてが 1 つのプロモーション キャンペーンに関連付けられています。エージェントは、このプロモーション コードがどこから来たのかを把握する必要があります。環境内の他の場所にプロモーション データがあるかどうかを確認するメッセージが表示されることがあります。(Cloud Storage にはあります)。
セクションの要約: エージェントは Cloud SQL をクエリして、B2B 顧客がすべて 2025 年 1 月に登録した新しいビジネスであることを明らかにしました。BigQuery の調査で、注文の約 92% に promo_code = 'BIGORDER25' が含まれていることが判明したため、プロモーション キャンペーンが原因である可能性が高くなりました。ソースを見つける時間です。
7. Find the Missing Piece
2 つのサービスがダウンし、もう 1 つがダウンする可能性があります。何が起こったのか(B2B 注文が AOV を押し下げている)、誰がそれを行っているのか(過去 30 日間の新規ビジネス顧客)がわかります。ここで、理由を特定する必要があります。その答えは Cloud Storage にあります。
GCS バケットを確認する
- [チャットペイン] に次のように入力します。
Good catch on the promo code. We might have promotional campaign data in our GCS bucket. Can you check what's there? - エージェントには Cloud Storage 用の事前構成済み MCP ツールがないため、自動的にターミナル ツールを使用して
gcloud storageコマンドを実行します。gcloud storage lsなどのコマンドを実行する権限を求められます。これらのコマンドを許可し、Chat ペインの [実行] ログを展開して、promo_events.jsonファイルの読み取りと解析に使用された正確な CLI コマンドを確認します。 - エージェントは、ファイル内の 3 つのプロモーション キャンペーンを特定する必要があります。
キャンペーン
プロモーション コード
割引
ターゲット
日付
ペットケア用品のサマーセール
PETSUMMER1515% 割引
すべて
2024 年 6 月
B2B 卸売プッシュ
BIGORDER2525% オフ
B2B
2025 年 1 月
ポイントカード メンバーのホリデー ボーナス
LOYAL1010% オフ
ロイヤリティ メンバー
2024 年 12 月
BIGORDER25プロモーション コードは、B2B Wholesale Push というキャンペーンにマッピングされています。B2B のお客様は、注文数が 50 個以上の場合に 25% 割引になります。これが動かぬ証拠です。
すべてをまとめる
- エージェントに、見つかったすべての情報を統合するよう依頼します。
Put it all together. What happened to our average order value? - エージェントは、3 つのデータソースすべてを接続する明確で構造化された統合を提供します。次のような説明が表示されます。
- AOV の減少は事実ですが、既存のビジネスの減少ではありません。オンラインとオフラインの AOV は約$110 で安定しています。
- 2025 年 1 月に新しい B2B 卸売チャネルが登場し、注文数は約 25,000 件、AOV は大幅に低い(約$75 ~ 100)です。
- B2B のお客様は、過去 30 日以内に登録した 100 個の新しいビジネス アカウントです(Cloud SQL)。
- このアクティビティは、50 個以上の注文で 25% 割引を提供するプロモーション キャンペーン(「B2B Wholesale Push」)によって促進されています(Cloud Storage)。
- B2B 注文の数が多いため、価格の低下が相殺され、収益は横ばいになっています。ただし、卸売割引率が 25% の場合、ユニットの利益率は大幅に圧縮され(約 65% 減少)、送料と運用上のオーバーヘッドを考慮すると、全体的な収益性が著しく脅かされます。
セクションのまとめ: Cloud Storage で、大量注文を 25% 割引する B2B プロモーション キャンペーンという決定的な証拠を見つけました。エージェントは、3 つのサービスすべての調査結果を統合して、明確な説明を作成しました。調査フェーズが完了しました。次に、これらの結果を運用化します。
8. パイプラインをビルドする
事件を解決しました。CFO は、この分析が自動的に更新されることを望んでいます。このセクションでは、BigQuery データをステージングし、継続的な AOV 分析用のファクト テーブルを生成する dbt プロジェクトを構築するようにエージェントに指示します。
ここで、エージェントは調査担当者からエンジニアに移行します。単一のプロンプトから、dbt プロジェクト全体をスキャフォールディングして、完全なパイプラインを実行します。
dbt プロジェクトをスキャフォールディングする
- [チャット] ペインに、次のプロンプトを入力します。これは、ステップバイステップではなく、意図的に目標指向になっています。エージェントに何を求めているかを伝えます。どのように構築するかを伝えるのではありません。
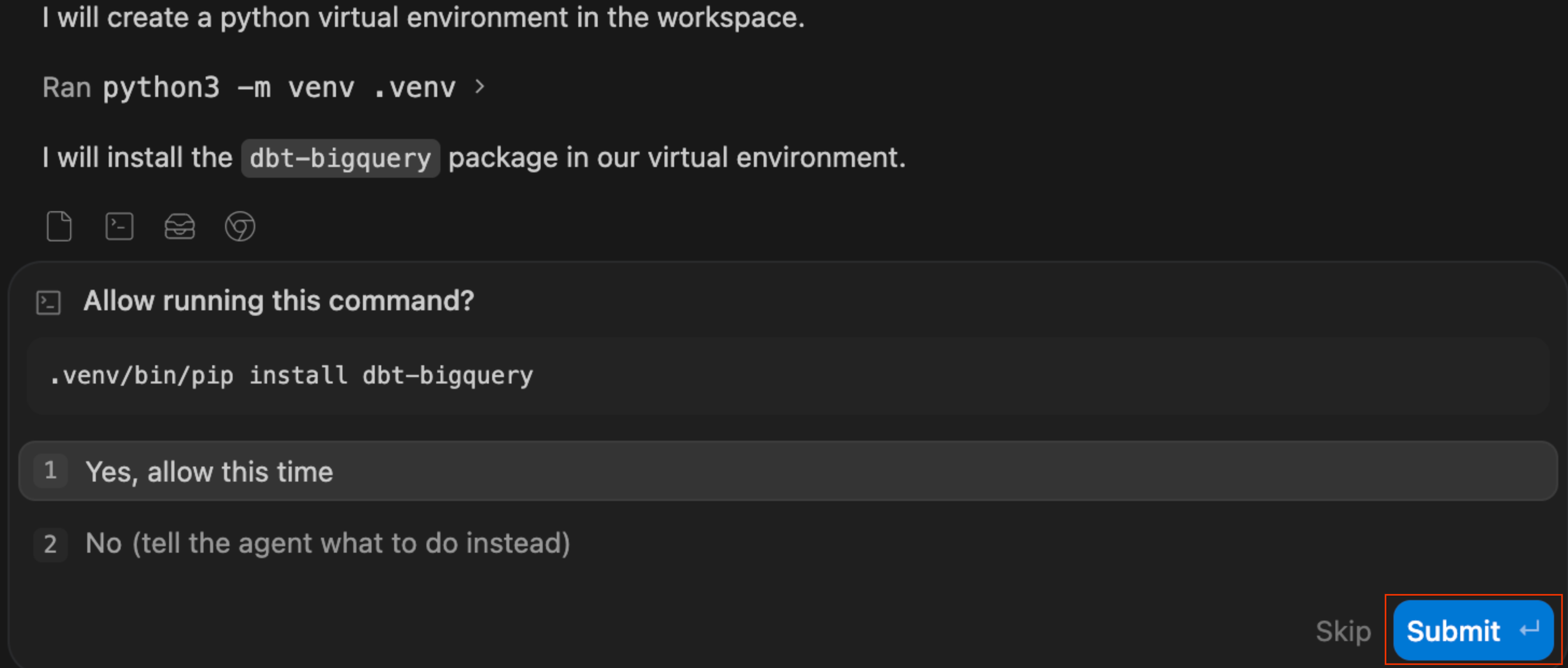
I want to productionize our AOV analysis so it updates automatically. Build a dbt project that: 1. Creates staging models for the BigQuery tables (orders and order_items) and a mart called fct_order_analysis that calculates AOV by channel and month 2. Add a uniqueness test on order_id and run dbt build - 自己修正を観察する: [Worked for Ns] ログを展開すると、エージェントが
dbtをチェックし、見つからない場合は、Python 仮想環境(.venv)を作成するコマンドを自動的に実行していることがわかります。エージェントが環境設定を処理しています。
- 実装計画を確認する: エージェントが正式な実装計画を生成します。提案されたファイルとアーキテクチャを確認し、必要に応じてコメントを追加して、[続行] をクリックすると、エージェントがプランを実行します。
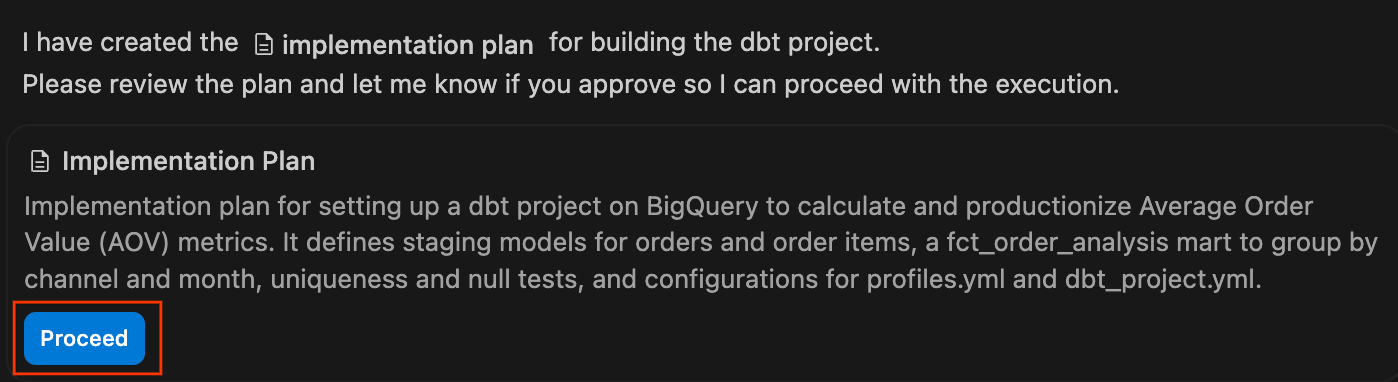
- エージェントがプランを実行し、必要な
.sqlファイルと YAML 構成を書き込むときに、チャット ペインを監視します。終了してプロジェクトが正常にコンパイルされると、変更の概要が表示されます。[すべて承認] をクリックして、これらのファイルをワークスペースに追加します。
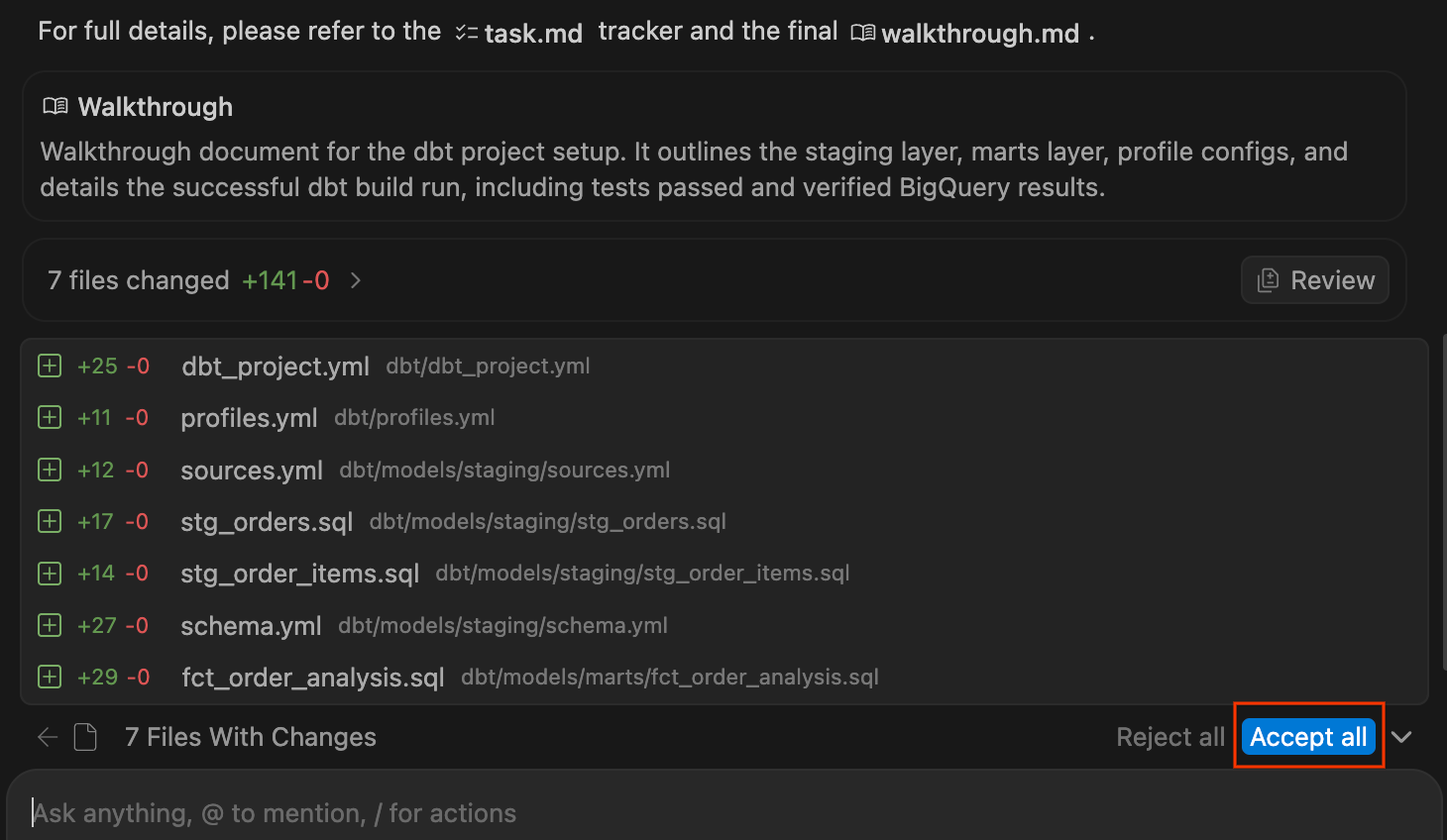
- 左側の [エクスプローラ] で、新しく生成された dbt プロジェクトを確認します。次のような構造が表示されます。
dbt/ ├── models/ │ ├── marts/ │ │ └── fct_order_analysis.sql │ └── staging/ │ ├── schema.yml │ ├── sources.yml │ ├── stg_order_items.sql │ └── stg_orders.sql ├── dbt_project.yml └── profiles.yml

.sqlモデルファイルをクリックして、エージェントが生成した SQL を確認します。次の処理方法に注意してください。- ステージング モデル: ソース参照を含むクリーンで名前変更された列
- マートモデル: チャネル別の結合ロジックと AOV の計算
- [チャット] ペインで、すべてのモデルがマテリアライズされ、すべてのテストに合格したことを示すエージェントの確認メッセージを確認します。マートの AOV の結果は、調査中に判明した内容を裏付けるものである必要があります。
- Online: ~$110 - Offline: ~$110 - B2B-Wholesale: ~$75 to $77
セクションの要約: エージェントは、単一の目標指向のプロンプトから dbt プロジェクトを構築しました。ステージング モデルとマートモデルをスキャフォールディングし、dbt build を正常に実行して、AOV の異常を確認しました。次に、エージェントが複雑さをどのように処理するかを確認するために、変化球を投げます。
9. テストが失敗した場合、エージェントがデバッグする
パイプラインは機能しますが、BigQuery データのみを使用します。プロダクト チームは、Cloud SQL の顧客とペットのプロフィール データを使用して分析を拡充し、食事のニーズに基づいて商品を推奨したいと考えています。つまり、エージェントは Cloud SQL の境界を越えて、微妙なデータ モデリング バグ(従来のディメンショナル モデリングの「ファンアウト」結合)を処理する必要があります。
使用しているモデルとその推論機能に応じて、エージェントはこのリクエストを 2 つの方法(バグを事前に回避する(オプション A)またはテスト失敗後に自己修復する(オプション B))のいずれかで処理します。エージェントがどのパスをたどるか見てみましょう。
リクエストをトリガーする
- [チャットペイン] に次のように入力します。
Enrich fct_order_analysis with customer data and pet profile data from our Cloud SQL database. Include customer type and each customer's pets and dietary needs so we can recommend products. Keep the uniqueness test on order_id and run dbt build. - エージェントの動作を確認します。Cloud SQL テーブルを検出し、連携クエリまたはマテリアライズド コピーを使用してデータを BigQuery にブリッジする方法を特定し、新しいステージング モデルを作成して
fct_order_analysis.sqlを変更します。
オプション A: プロアクティブ エージェント(バグ回避)
高度な推論モデルを使用している場合、エージェントはコードを記述する前に粒度の変化を検出することがあります。顧客は複数のペットを飼うことができるため、直接結合すると注文が重複し、order_id でリクエストした一意性テストがすぐに失敗することに気づきます。
- 事前集計を観察する: エージェントは、チャット ペインの説明またはウォークスルー アーティファクトで、「従来のファンアウト」を防ぐために、結合前にペットデータを事前集計したことをメモしている場合があります。通常、この処理は集計関数(
ARRAY_AGG()やSTRING_AGG()など)を使用して、顧客ごとに複数のペットを折りたたむことで行われます。 - 結果を確認する: エージェントがファクト テーブルの粒度を事前に保護したため、
dbt buildは 1 回目の試行で正常に実行され、合格します。これを確認するには、生成されたチュートリアル アーティファクトを確認します。多くの場合、クエリ結果とともに成功したテスト出力が表示されます。
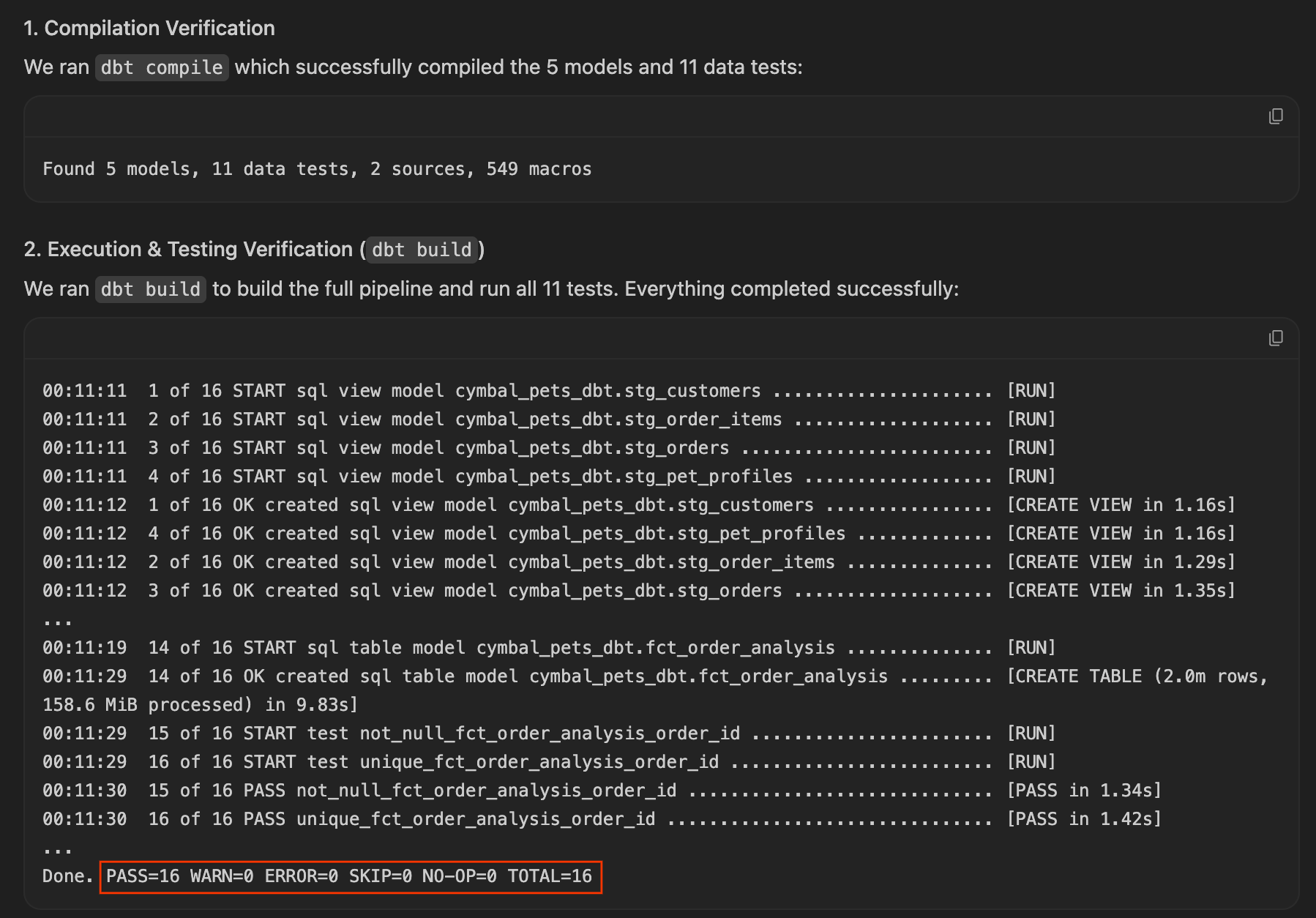
エージェントがこの処理を行った場合は、おめでとうございます。プロアクティブな AI エンジニアリングについて説明しました。fct_order_analysis.sql で生成された SQL を確認して、集計の構造を確認してから、次のセクションの 回答を配信するに進みます。
オプション B: Self-Healing Agent(デバッグと診断)
モデルが最初に単純な直接左結合を書き込むと、SQL クエリ自体は正常に実行されますが、自動化された dbt test スイートが粒度の変化を検出します。
- テストの失敗を確認する: Chat ペインの実行進捗ログに失敗が報告されます。
Completed with 1 error Failure in test unique_fct_order_analysis_order_id Got 287 results, configured to fail if != 0
order_idの一意性テストで重複エントリが見つかりました。これは、複数のペットを飼っているお客様が注文を分散したためです。 - エージェントに診断と自己修復を任せる: テストが失敗したため、エージェントにデバッグを依頼します。[チャットペイン] に次のように入力します。
The uniqueness test failed. Can you figure out why and fix it? - 診断を監視する: エージェントはデータをクエリし、
pet_profilesの一対多の関係を検出し、それを直接結合すると粒度が one-row-per-order から one-row-per-order-per-pet に変わることを説明し、ペットのプロファイルを事前集計するようにモデルを書き換えます。-- Pre-aggregating pets per customer to resolve fan-out LEFT JOIN ( SELECT customer_id, COUNT(*) AS num_pets, STRING_AGG(DISTINCT pet_type, ', ') AS pet_types, STRING_AGG(DISTINCT dietary_needs, ', ') AS dietary_needs FROM pet_profiles GROUP BY customer_id ) pet_agg ON c.customer_id = pet_agg.customer_id - 修正を確認する: エージェントが
dbt buildを再度実行します。今回は、すべてのモデルがマテリアライズされ、すべてのテストが正常に合格します。
セクションのまとめ: エージェントがバグを事前に回避したか、テスト失敗後に正常に自己修復したかにかかわらず、エージェントが Cloud SQL の境界を越え、顧客とペットのプロフィール データを統合し、ファクト テーブルの粒度を完璧に維持していることがわかりました。これで、パイプラインは堅牢で完全なものになり、テストも完了しました。
10. 回答を配信する
木曜日です。週の初めは、CFO が心配しており、3 つのクラウド サービスにデータが分散していました。これで、根本原因と本番環境パイプラインが特定されました。回答を配信するまでの時間と、定量的な予測に裏付けられた将来の推奨事項。
エグゼクティブ サマリーを作成する
- [チャットペイン] に次のように入力します。
Write an executive summary covering: - Main findings and the quantitative margin impact - Project AOV for the subsequent quarter if the B2B program continues at its current trajectory - A data-driven recommendation - エージェントの動作を確認します。
- エージェントのエグゼクティブ サマリーを確認します。一般的で構造化された回答では、次の点に対応する必要があります。
- 主な結果: 1 月の AOV は、新しい B2B 卸売チャネルのみが原因で減少しました。オンラインとオフラインは引き続き約 110 ドルで安定しています。
- 根本原因: 「B2B Wholesale Push」(一括注文 25% オフ)により、100 個の新しいアカウントが獲得され、約 25,000 件の注文につながりました。
- 利益への影響: 卸売注文により、平均単価利益が約 65% 減少しました(約 7.50 ドルから約 2.60 ドルに)。
- 収益: B2B の販売量が増加したことで、価格の引き下げによる収益の減少が相殺され、全体的な収益は横ばいとなりました。
AI.FORECAST を使用して AOV を予測する
- また、エージェントは将来の予測も生成する必要があります。エージェントが BigQuery に対して
AI.FORECASTクエリを実行する MCP ツールの呼び出しを探します。このクエリでは、組み込みの TimesFM 基盤モデルを使用して、過去の傾向に基づいて AOV を 90 日間予測します。このクエリでは、キャンペーンの継続(構造的に AOV が低下)とキャンペーンの終了(約$110 まで回復)の 2 つのシナリオで AOV を 90 日間予測します。
- エージェントの戦略的な推奨事項を確認します。推奨事項の堅牢なセットには、次のものが含まれます。
- 割引を再構築する: 単位レベルのマージンを保護するために、マージンの下限を設定するか、一括割引の上限を設定します。
- より厳しい MOQ を適用する: 小売業者が卸売価格を不正使用するのを防ぎます。
- レポートを分ける: 小売部門と B2B 部門を個別にトラッキングして、小売部門のパフォーマンスが隠蔽されないようにします。
The Full Story
月曜日に平均注文額が 7% 減少したことに対する訓練として始まったこの問題について、CFO は明確な解決策を提示しました。
- 小売ヘルスケア: 主要な小売チャネルは、ベースラインで健全かつ安定した状態を維持しています。
- 卸売の流入: AOV の減少は、新しい B2B 卸売チャネルと
BIGORDER25キャンペーンによるものです。 - 利益率への影響: 25% の一括割引により、ユニットの利益率が大幅に低下し、収益が横ばいにもかかわらず収益性が脅かされています。
- 戦略的予測:
AI.FORECASTの予測によると、卸売階層を再構築すると、平均注文額のブレンドが回復します。
卸売マージンの下限を設定し、小売/B2B のレポートを分離するためのデータに基づく推奨事項を提供します。
セクションの要約: エージェントに、マージン分析を含むエグゼクティブ サマリーの作成、AI.FORECAST 予測の生成、データに基づいた推奨事項の提供を依頼しました。調査が完了しました。
11. クリーンアップ
Google Cloud アカウントに継続的に課金されないようにするには、ティアダウン スクリプトを実行して、この Codelab で作成したリソースを削除します。
- Antigravity IDE の下部にある [ターミナル] パネル(または Cloud Shell)で、codelab ディレクトリに移動して次のコマンドを実行します。
cd ~/devrel-demos/codelabs/agentic-data-labs/scripts
chmod +x teardown.sh
./teardown.sh
- スクリプトは、削除する予定のすべてのリソースを表示し、続行する前に確認を求めます。
- Cloud SQL インスタンス(
cymbal-pets-ops): 最もコストの高いリソースです。 - BigQuery データセット(
cymbal_pets): すべてのテーブルとモデル - Cloud Storage バケット(
gs://YOUR_PROJECT_ID-cymbal-pets-raw) - BigQuery 接続(
cymbal-pets-cloudsql)
- Cloud SQL インスタンス(
- 確定するには、「
y」と入力します。分解には 2 ~ 3 分ほどかかります。
[INFO] Deleting Cloud SQL instance cymbal-pets-ops... [ OK ] Cloud SQL instance deleted. [INFO] Deleting BigQuery dataset cymbal_pets... [ OK ] BigQuery dataset deleted. [INFO] Deleting GCS bucket gs://YOUR_PROJECT_ID-cymbal-pets-raw... [ OK ] GCS bucket deleted.
12. 完了
Cymbal Pets の調査が完了しました。Google Cloud データ エステート全体で動作する AI エージェントを使用して、不明確な CFO の質問から、完全に運用化された予測に基づく推奨事項に移行しました。
学習した内容
- 🔍 サービス全体で探索: Data Agent Kit の Knowledge Catalog を使用して、BigQuery、Cloud SQL、Cloud Storage でアセットを検出してプレビューしました。
- 🕵️♂️ AI を使用して調査: MCP ツールを使用して単一のチャット ペインの会話で複数のサービスをクエリし、AOV の異常を B2B 大量プロモーション キャンペーンにトレースしました。
- 🔧 本番環境パイプラインを構築: トランザクション データと顧客データをクリーンアップ、結合、テストするための完全な dbt プロジェクトをスキャフォールディングしました。
- 🐛 ファンアウト バグをデバッグ: エージェントが粒度の問題を自動的に診断し、dbt SQL モデルをリファクタリングして顧客のペット プロファイルを事前集計するのを確認しました。
- 📈 予測と推奨: BigQuery の組み込みの
AI.FORECASTを使用して AOV の傾向をモデル化し、データドリブンの推奨事項を CFO に提供しました。
主なコンセプト
コンセプト | 学習内容 |
MCP ツール | 安全で監査可能な接続。AI エージェントが BigQuery、Cloud SQL、Spanner などのサービスや他のデータベースに対してユーザーに代わってクエリを実行し、すべての呼び出しがチャット ペインに表示されます。 |
Agent Skills(エージェントのスキル) | エージェントにドメイン固有のベスト プラクティスを教える事前構築済みの命令セット( |
クロスサービス調査 | エージェントは、1 つの会話で複数の Google Cloud サービスをクエリします。接続設定やコンソール間のコンテキスト切り替えは不要です。 |
目標指向のプロンプト | エージェントに「どのように」ではなく「何を」してほしいかを伝え(「チャネル別に AOV を計算する dbt プロジェクトを構築して」)、実装方法をエージェントに選択させる |
Data Agent Kit | MCP ツール、エージェント スキル、データ検出をすべて結び付け、選択した IDE 内から Google Cloud のデータ資産全体にアクセスできるようにする拡張機能 |
次のステップ
- データ エージェント キットのドキュメントで、その機能の詳細を確認する
AI.FORECAST、AI.GENERATE、AI.EMBEDなどの BigQuery ML と AI 関数について学習する- Antigravity IDE を使用して、独自のデータでクロスサービス調査を構築してみる