
1. Wprowadzenie
Jest poniedziałkowy poranek, a dyrektor finansowy właśnie wysłał Ci wiadomość. Średnia wartość zamówienia spadła w tym miesiącu o 7%, ale łączne przychody pozostały na tym samym poziomie. Coś się nie zgadza, a zarząd chce uzyskać odpowiedzi do piątku.
Twoja firma, Cymbal Pets, jest jednym z największych sprzedawców artykułów dla zwierząt domowych w Stanach Zjednoczonych. Potrzebne Ci dane są rozproszone w 3 usługach Google Cloud: dane transakcyjne w BigQuery, rekordy klientów i produktów w Cloud SQL oraz pliki marketingowe w Cloud Storage. Zwykle przeprowadzenie takiego dochodzenia obejmującego różne usługi wymaga przełączania się między konsolami, pisania kodu połączenia i ręcznego łączenia wyników.
W tym ćwiczeniu użyjesz pakietu Google Cloud Data Agent Kit (DAK) w Antigravity IDE, aby zbadać anomalię za pomocą języka naturalnego. Opisujesz, czego szukasz, a agent AI zajmuje się połączeniami, SQL i łączeniami między usługami w BigQuery, Cloud SQL i Cloud Storage. Gdy rozwiążesz problem, poproś agenta o utworzenie potoku dbt, który umożliwi wykorzystanie Twoich odkryć, usunięcie błędu w modelowaniu rzeczywistych danych i przekazanie dyrektorowi finansowemu rekomendacji opartej na prognozie.
Jakie zadania wykonasz
- Odkrywaj zasoby danych w BigQuery, Cloud SQL i Cloud Storage za pomocą Knowledge Catalog.
- Analizowanie anomalii przez wysyłanie zapytań do wielu usług w ramach jednej rozmowy za pomocą narzędzi MCP
- Utwórz potok dbt, aby przygotowywać i łączyć dane z różnych usług za pomocą modeli przygotowujących i automatycznych testów.
- Debugowanie problemu z modelowaniem danych, gdy agent samodzielnie diagnozuje i refaktoryzuje błąd zwielokrotnienia wyjściowego.
- Prognozowanie przyszłych trendów i przedstawianie rekomendacji opartych na danych przy użyciu
AI.FORECASTBigQuery.
Czego potrzebujesz
- przeglądarka, np. Chrome;
- projekt Google Cloud z włączonymi płatnościami;
- Podstawowa znajomość SQL i konsoli Google Cloud
To ćwiczenie jest przeznaczone dla średnio zaawansowanych specjalistów ds. danych (inżynierów analitycznych, analityków danych, badaczy danych).
Zasoby utworzone w tym module powinny kosztować mniej niż 5 USD.
2. Zanim zaczniesz
W tej sekcji uruchomisz skrypt konfiguracji, który udostępni całe środowisko laboratorium: zbiór danych BigQuery z danymi zamówień, instancję Cloud SQL Postgres z danymi klientów i produktów oraz zasobnik Cloud Storage z rekordami kampanii promocyjnych. Wykonanie skryptu zajmuje około 8–10 minut, a wąskim gardłem jest udostępnianie Cloud SQL.
Uruchamianie Cloud Shell
Do uruchomienia skryptu konfiguracji użyjesz Google Cloud Shell.
- U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu ustaw identyfikator projektu i potwierdź środowisko:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
Wyświetli się komunikat podobny do tego:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Klonowanie repozytorium
Sklonuj repozytorium z ćwiczeniami do środowiska powłoki Cloud Shell:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/agentic-data-labs
git checkout main
cd codelabs/agentic-data-labs/
Uruchamianie skryptu konfiguracji
Skrypt konfiguracji przygotuje całe środowisko laboratorium w ciągu kilku minut. Umożliwia włączanie interfejsów API, wczytywanie i wzbogacanie danych BigQuery, przesyłanie komponentów promocyjnych do GCS, a następnie automatyczne uruchamianie procesu w tle, który udostępnia i konfiguruje Cloud SQL Postgres w tle, podczas gdy Ty rozpoczynasz ćwiczenie.
Skrypt bezpiecznie wygeneruje automatycznie hasło Cloud SQL i automatycznie zapisze je w pliku .env.
cd ~/devrel-demos/codelabs/agentic-data-labs/scripts
chmod +x setup.sh setup_sql.sh
./setup.sh
Po zakończeniu zobaczysz podsumowanie środowiska pierwszego planu:
╔══════════════════════════════════════════════════════╗
║ Base Setup complete! ║
╚══════════════════════════════════════════════════════╝
Your core BigQuery and GCS assets are ready.
Cloud SQL is currently provisioning in the background and will be fully ready by Step 4.
BigQuery: YOUR_PROJECT_ID.cymbal_pets
├── orders
└── order_items
GCS: gs://YOUR_PROJECT_ID-cymbal-pets-raw
└── promo_events.json
Podczas wykonywania kolejnych kroków modułu baza danych będzie w tle udostępniana i wypełniana danymi. Postępy możesz w dowolnym momencie monitorować w osobnym panelu terminala, korzystając z tych poleceń:
tail -f /tmp/cloudsql_setup.log
Zwróć uwagę na architekturę danych: dane transakcyjne (zamówienia i elementy zamówienia) znajdują się w BigQuery, a dane operacyjne (klienci, profile zwierząt i produkty) będą przechowywane w Cloud SQL. Ten podział odzwierciedla sposób, w jaki dane są często rozpowszechniane w usługach w prawdziwych organizacjach, i to właśnie sprawia, że badanie obejmujące wiele usług jest interesujące.
Podsumowanie sekcji: uruchomiono skrypt konfiguracji, aby zainicjować środowisko modułu, i rozpoczęto w tle udostępnianie bazy danych.
3. Konfigurowanie środowiska IDE i Data Agent Kit
Otwieranie Antigravity IDE
Nie musisz czekać na zakończenie działania Cloud SQL. Otwórz IDE Antigravity i połącz go z projektem Google Cloud.
- Jeśli jeszcze tego nie zrobisz, pobierz i zainstaluj środowisko IDE Antigravity ze strony pobierania Google Antigravity.
- Uruchom aplikację na komputery Antigravity IDE.
- Utwórz nowy, pusty folder na komputerze lokalnym (np.o nazwie
agentic-data-labs) i otwórz go w środowisku IDE, klikając Otwórz folder. Będzie to Twój lokalny obszar roboczy na potrzeby ćwiczenia.
Instalowanie rozszerzenia Data Agent Kit
Rozszerzenie Google Cloud Data Agent Kit zapewnia głęboką integrację z usługami danych Google Cloud bezpośrednio w edytorze, co umożliwia interakcję z BigQuery, Cloud SQL, Cloud Storage i innymi usługami bez przełączania kontekstu.
- W środowisku IDE Antigravity kliknij ikonę Rozszerzenia na pasku aktywności po lewej stronie ekranu (wygląda jak 4 kwadraty).
- Na pasku wyszukiwania u góry panelu Rozszerzenia wpisz
Google Cloud Data Agent Kit. - Znajdź rozszerzenie o nazwie Google Cloud Data Agent Kit opublikowane przez
googlecloudtools. - Kliknij przycisk Zainstaluj.
- Może pojawić się pytanie: „Czy ufasz wydawcy „googlecloudtools” i jego rozszerzeniom?”. Aby kontynuować, kliknij Zaufaj wydawcom i zainstaluj.
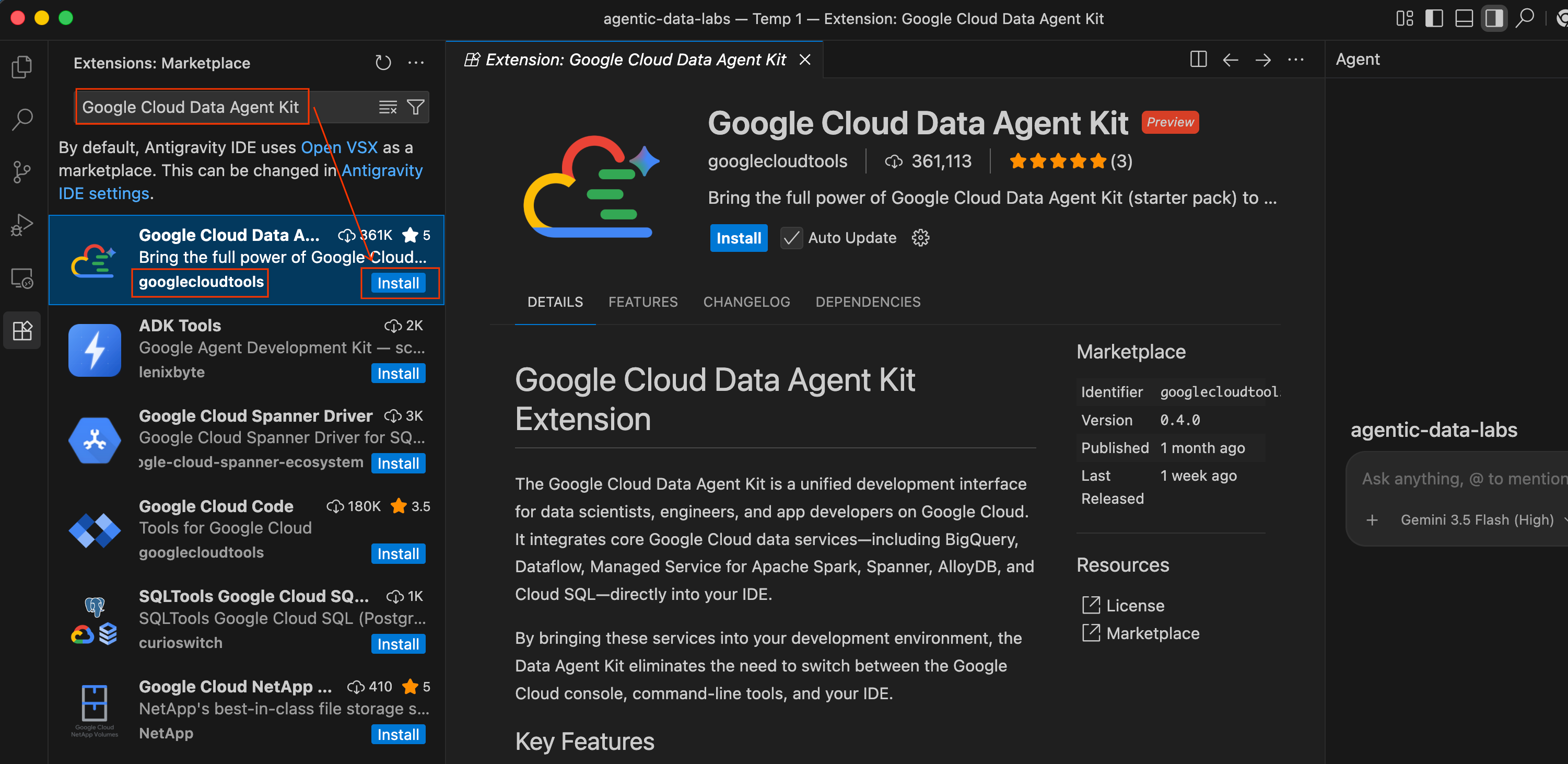
Po zainstalowaniu w pasku aktywności po lewej stronie środowiska Antigravity IDE pojawi się nowa ikona Google Cloud Data Agent Kit.
Uwierzytelnianie i konfigurowanie rozszerzenia
Po zainstalowaniu połącz rozszerzenie z projektem Google Cloud.
- Powinna się automatycznie otworzyć strona wprowadzająca o nazwie „Witamy w Google Cloud Data Agent Kit”. Jeśli nie jesteś zalogowany(-a) na konto Cloud, postępuj zgodnie z instrukcjami, aby zezwolić na dostęp.
- W sekcji Podsumowanie konfiguracji znajdź pole projektu. Kliknij menu i wybierz projekt w chmurze Google Cloud. Ustaw region jako
us-central1. Następnie kliknij Skonfiguruj serwery MCP.

- W panelu Konfiguracja MCP kliknij, aby włączyć BigQuery i Cloud SQL. Następnie kliknij Rozpocznij.
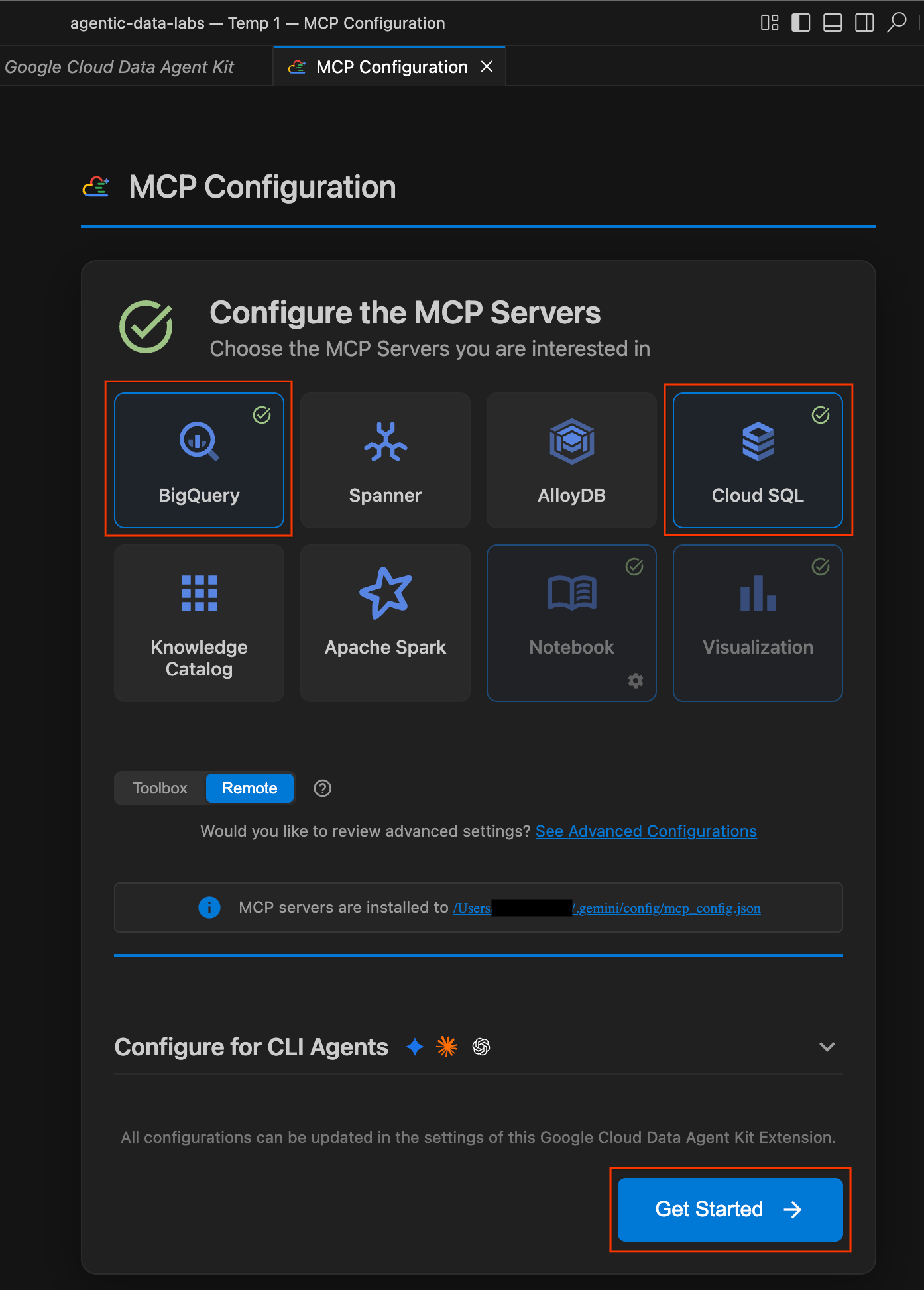
Poznaj opcje konfiguracji
Po zakończeniu konfiguracji otworzy się strona „Rozpocznij korzystanie z zestawu narzędzi Google Cloud Data Agent”.
- W sekcji „Konfiguracja” kliknij Rozpocznij.
- Otworzy się panel Konfiguracja agenta danych. Przeglądaj karty:
- Projekt i region: sprawdź wybrany identyfikator projektu i upewnij się, że wymagane interfejsy API (Cloud Storage API, BigQuery API, Catalog API i Cloud SQL Admin API) są włączone.
- BigQuery: skonfiguruj domyślną lokalizację zapytań BigQuery. Użyj regionu
us-central1. - Konfigurowanie serwerów MCP: wyświetl włączone serwery MCP (BigQuery, notatniki, Cloud SQL itp.), które umożliwiają agentom AI bezpieczną interakcję z Twoimi danymi.
- Umiejętności: poznaj gotowe umiejętności, które zapewniają agentom specjalistyczne możliwości wykonywania złożonych zadań związanych z danymi.

Podsumowanie sekcji: otwórz środowisko IDE Antigravity, połącz je z projektem Google Cloud, skonfiguruj zdalne serwery MCP pakietu Data Agent Kit i sprawdź połączenie, uruchamiając zapytanie w BigQuery.
4. Odkrywanie danych
Czas przygotować scenę. Sytuacja wygląda tak: dyrektor finansowy twierdzi, że w zeszłym miesiącu średnia wartość zamówienia spadła o 7%, ale przychody ogółem pozostały na tym samym poziomie. Zanim poprosisz agenta o zbadanie problemu, musisz najpierw zrozumieć, z jakimi danymi pracujesz.
W tej sekcji ręcznie zapoznasz się z panelem Data Agent Kit. Zrozumienie danych przed rozpoczęciem wysyłania zapytań jest kluczowym pierwszym krokiem w każdej analizie.
Poznaj tabele BigQuery
- W panelu Zestaw agentów danych w sekcji KATALOG rozwiń swój projekt → BigQuery →
cymbal_pets. - Kliknij tabelę
orders. Otworzy się nowa karta ze szczegółami tabeli. - Przejrzyj karty po lewej stronie przeglądarki tabeli:
- Dane: podgląd rzeczywistych wierszy. Przewiń zbiór danych i sprawdź kolumny.
- Schemat: sprawdź nazwy i typy kolumn. Zwróć uwagę na pola takie jak
order_typeipromo_code, które będą ważne później. - Inne karty (Szczegóły, Statystyki, Profil danych itp.): Uzyskuj dostęp do metadanych, historii danych i szczegółów jakości, które zwykle znajdziesz w konsoli Google Cloud, bez opuszczania edytora.
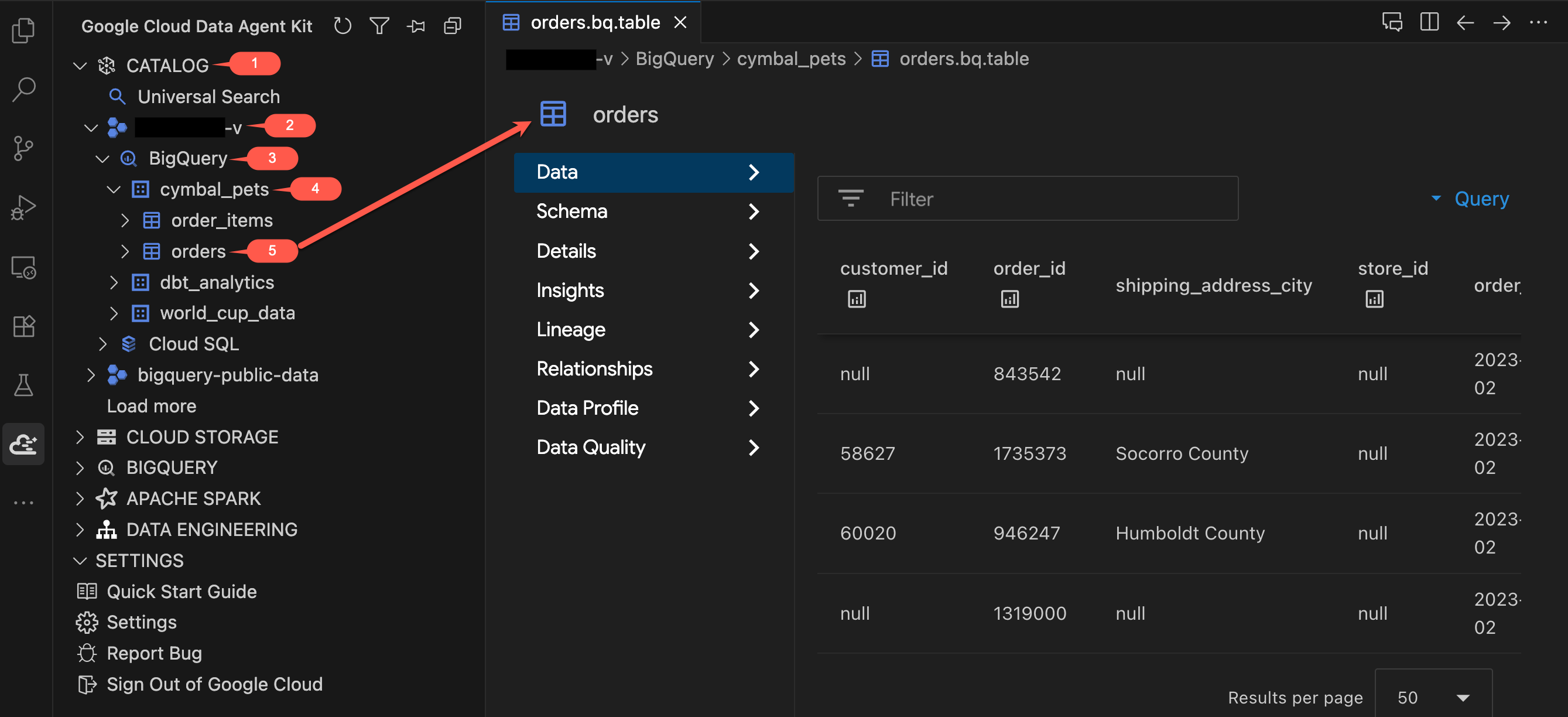
- Teraz kliknij tabelę
order_itemsi sprawdź jej schemat. Zwróć uwagę na polaquantityiprice.
Poznawanie tabel Cloud SQL
Skrypt konfiguracji umieścił też dane klientów, zwierząt i produktów w bazie danych PostgreSQL w Cloud SQL.
- W panelu Zestaw narzędzi Data Agent kliknij Wyszukiwanie uniwersalne w sekcji KATALOG.
- W polu wyszukiwania wpisz
pet_profilesi naciśnij Enter. - W wynikach wyszukiwania kliknij wynik PostgreSQL Table dla
pet_profiles(w instancji Cloud SQL projektu). Zwróć uwagę, że akordeon na pasku bocznym automatycznie się rozwinie, pokazując dokładnie, gdzie tabela znajduje się w drzewie bazy danych. Teraz kliknij tabelęcustomersznajdującą się bezpośrednio nad nią w drzewie, aby otworzyć jej szczegóły, i zapoznaj się z kartami Schema (Schemat) i Details (Szczegóły).
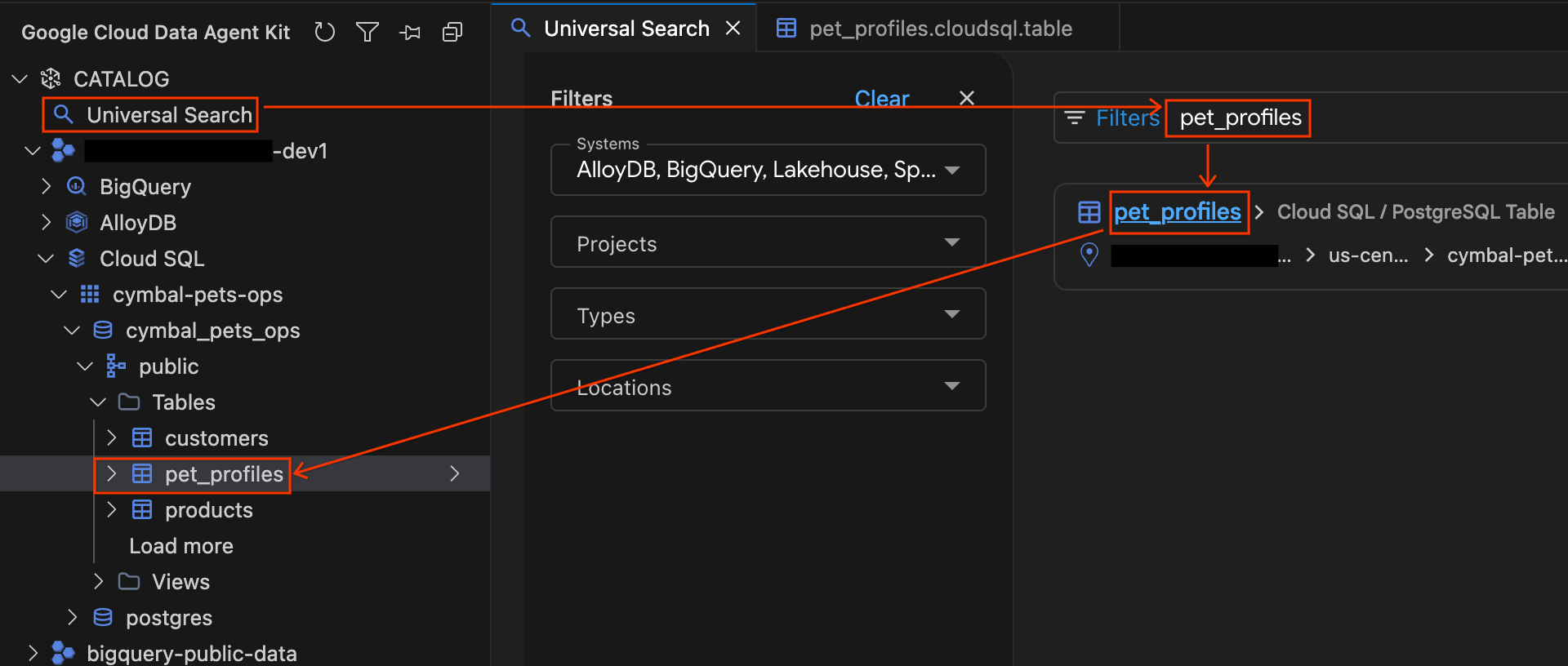
Przeglądanie plików w Cloud Storage
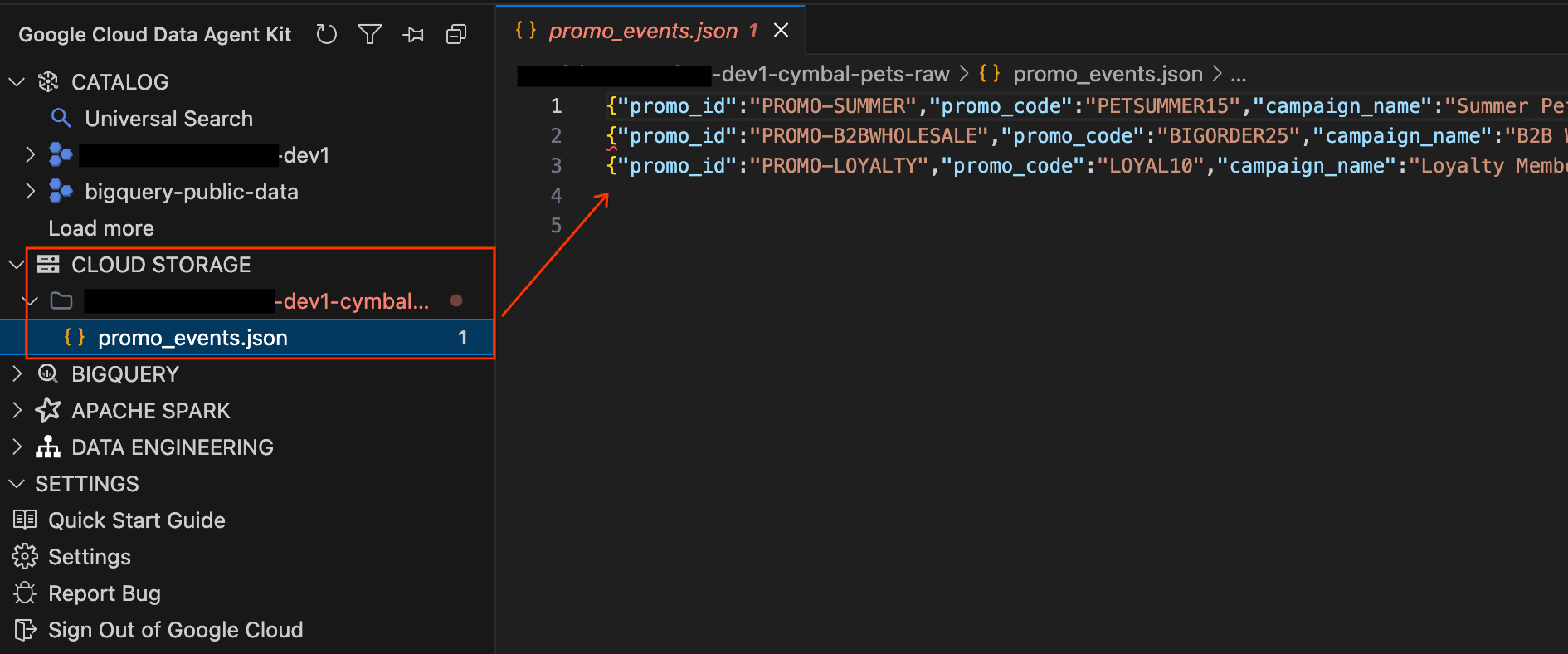
Na koniec rekordy kampanii marketingowych i promocyjnych są przechowywane jako nieprzetworzone pliki JSON w Cloud Storage.
- W panelu Data Agent Kit po lewej stronie rozwiń sekcję CLOUD STORAGE (Cloud Storage). Znajdź zasobnik surowych danych projektu (
YOUR_PROJECT_ID-cymbal-pets-raw). - W zasobniku kliknij plik
promo_events.json. Otworzy się nowa karta edytora, na której możesz wyświetlić nieprzetworzone treści JSON Lines kampanii marketingowych bezpośrednio w IDE.
Take Stock
Oto co wiesz już o środowisku danych:
Usługa | Tabele | Co tam jest |
BigQuery |
| Około 1,9 mln zamówień i 4,3 mln elementów zamówienia, zakres dat 2023–2025 |
Cloud SQL |
| ~92 tys. klientów, ~7,6 tys. profili zwierząt, 206 produktów |
Cloud Storage |
| Rekordy kampanii promocyjnych |
Dane są rozproszone w 3 usługach. W tradycyjnym przepływie pracy musisz skonfigurować połączenia, napisać kod integracji i ręcznie połączyć wyniki. W następnym kroku pozwolisz agentowi AI zająć się tym wszystkim w ramach jednej rozmowy.
Podsumowanie sekcji: w panelu Data Agent Kit ręcznie zbadano architekturę danych w usługach BigQuery, Cloud SQL i Cloud Storage. Wiesz już, gdzie znajdują się dane i jakie pola są dostępne, więc możesz rozpocząć analizę.
5. Śledzenie liczb
Teraz rozpoczyna się dochodzenie. W panelu czatu poprosisz agenta AI o pobranie z BigQuery danych o średniej wartości zamówienia (AOV). Średnia wartość zamówienia to dane biznesowe przedstawiające średnią kwotę wydaną na zamówienie. Agent będzie wysyłać zapytania w Twoim imieniu za pomocą narzędzi MCP, a Ty będziesz mieć wgląd w każde zapytanie SQL, które wykona.
Pobierz trend średniej wartości zamówienia
- W panelu czatu po prawej stronie IDE wpisz ten prompt i naciśnij Enter:
Calculate our monthly average order value from August 2024 through January 2025 using the orders and order_items tables in BigQuery. - Zatwierdź uprawnienia dostępu do danych. Zachowanie ostrożności w przypadku agentów AI uruchamiających zapytania w bazach danych jest wskazane. Zestaw Data Agent Kit zapewnia Ci kontrolę, ponieważ przed uzyskaniem dostępu do danych wstrzymuje działanie i prosi o wyraźną zgodę. Gdy pojawi się odpowiedni komunikat, możesz wybrać:
- Zezwól tym razem: zatwierdza jednorazowe użycie (idealne do kontrolowania zapytań wysokiego ryzyka).
- Zawsze zezwalaj: zatwierdza bieżące używanie tego narzędzia w sesji.
- Nie: całkowicie blokuje działanie.
list_table_idslubexecute_sql_readonly). Możesz też wybrać opcję „Zawsze zezwalaj”.
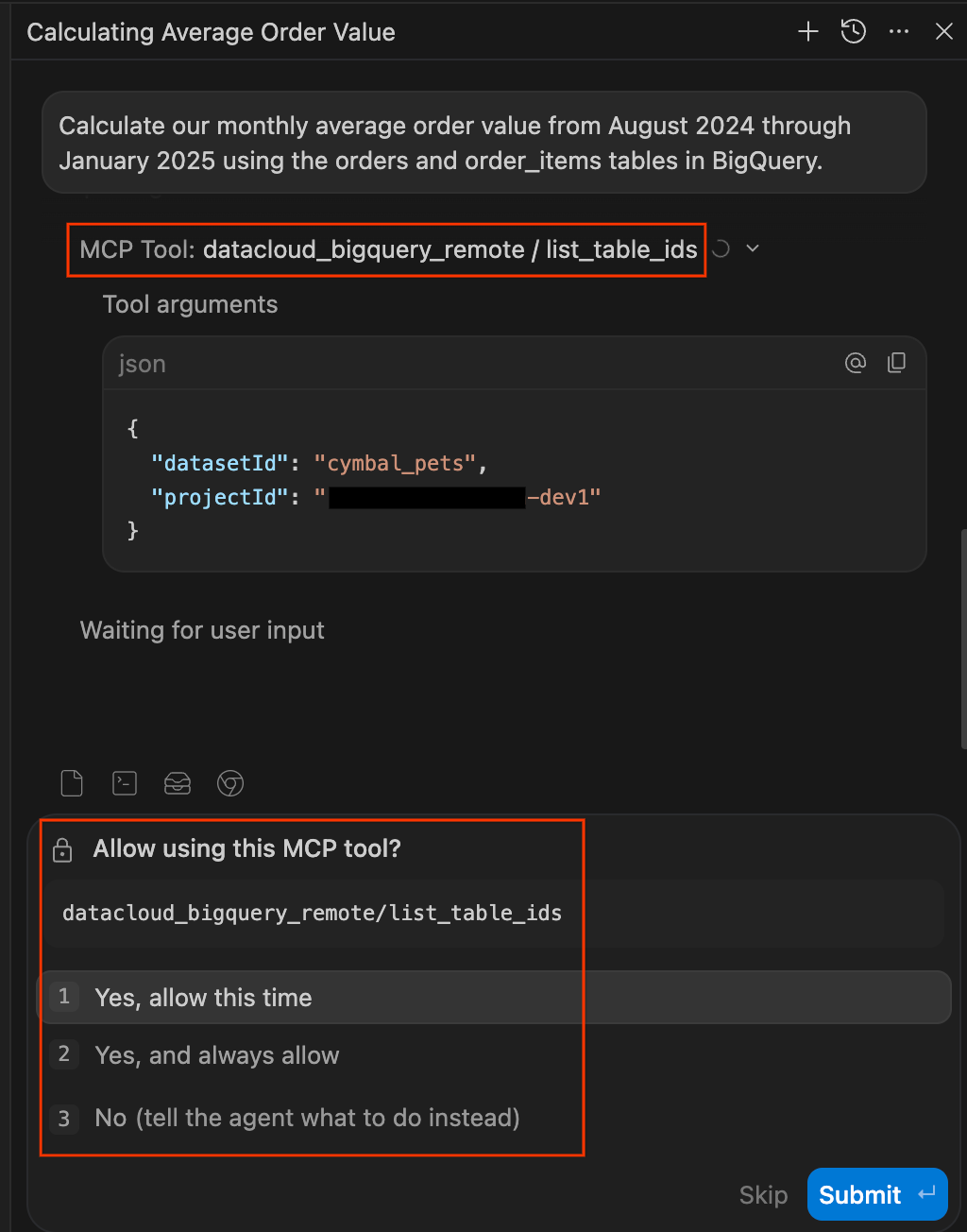
- Obserwuj pracę agenta. Panel czatu pełni też funkcję dziennika przejrzystości, w którym zapisywane są wszystkie działania agenta. Zamiast czarnej skrzynki agent pokazuje Ci w czasie rzeczywistym swoje rozumowanie i działania.
- Gdy agent skończy pracę, kliknij menu Worked for Xm (Pracował przez X minut) pod promptem, aby rozwinąć pełny dziennik pracy. Tutaj możesz dokładnie sprawdzić, jak uzyskano odpowiedź:
- Przetworzone: rozwiń te elementy, aby zobaczyć, jak agent odczytuje pliki, przegląda foldery lub wywołuje narzędzia MCP (np.
datacloud_bigquery_remote / list_table_idsiexecute_sql_readonly). Możesz wyświetlić dokładne argumenty JSON przekazywane do narzędzi i wykonywane zapytania SQL. - Uruchomiono: rozwiń te elementy, aby zobaczyć polecenia terminala wykonane przez agenta, np.
gcloud config list.
- Przetworzone: rozwiń te elementy, aby zobaczyć, jak agent odczytuje pliki, przegląda foldery lub wywołuje narzędzia MCP (np.
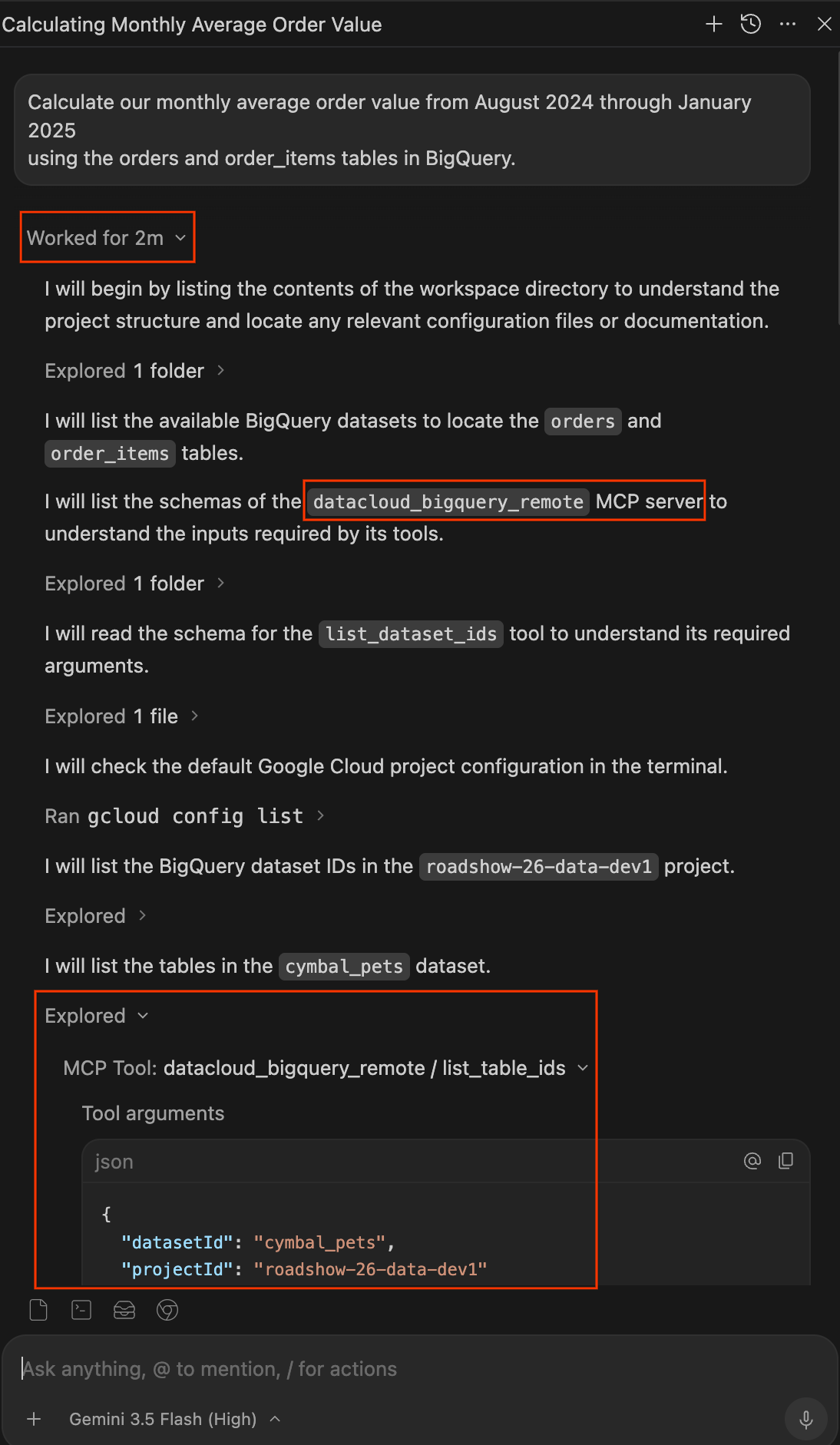
- Sprawdź wyniki. Agent powinien zwrócić tabelę miesięcznych wartości średniej wartości zamówienia. Sprawdź liczby: w poprzednich miesiącach wynosiły one około 110 USD, a w styczniu spadły do około 103 USD. To anomalia, na którą zwrócił uwagę dyrektor finansowy.
Przejście do bardziej szczegółowego widoku według kanału
Ogólna średnia wartość zamówienia spadła, ale skąd ten spadek się bierze? Zaraz się dowiemy.
- W panelu czatu wpisz:
January looks lower than the prior months. Break down January's AOV by order_type to see what's going on? - Agent uruchamia kolejne zapytanie BigQuery, tym razem grupując według
order_type. Dokładnie sprawdź wyniki.Powinny być zaskakujące: średnia wartość zamówienia online i offline utrzymuje się na stałym poziomie około 110 zł. Pojawił się jednak nowy kanał B2B-Wholesale, w którym średnia wartość zamówienia jest znacznie niższa (około 75 USD). Ten nowy kanał obniża średnią ważoną. - Przedstawiciel może aktywnie zaproponować zbadanie klientów B2B. Jeśli nie, to też w porządku. Zrobisz to w następnym kroku.
Podsumowanie sekcji: na podstawie neutralnego wyodrębnienia danych udało Ci się zauważyć spadek średniej wartości zamówienia w styczniu. Następnie przeanalizowałeś dane według typu zamówienia, aby zidentyfikować B2B-Wholesale jako nowy kanał, który obniża średnią ważoną. Teraz musisz dowiedzieć się, kim są ci klienci B2B.
6. Przekraczanie granicy usługi
W BigQuery zidentyfikowano B2B-Wholesale jako kanał z anomalią, ale dane klientów znajdują się w Cloud SQL. Dzięki zestawowi Data Agent Kit możesz kontynuować tę samą rozmowę, a zestaw zajmie się granicą usługi.
Sprawdzanie klientów B2B
- W panelu czatu wpisz:
Who are these B2B customers? Their profiles should be in our Cloud SQL database. Check for: - Who they are - When they signed up - Whether they're new or existing customers - Uważnie obserwuj panel czatu. Tym razem powinien pojawić się inny MCP Tool. Agent wysyła teraz zapytania do Cloud SQL zamiast do BigQuery.Łączy się z instancją Cloud SQL Postgres
cymbal-pets-opsi uruchamia zapytanie w tabelicustomers. Aby wyświetlić SQL, kliknij Pokaż szczegóły. - Sprawdź wyniki. Agent powinien przedstawić kilka kluczowych wniosków:
- Wszyscy klienci B2B mają
customer_type = 'Business' - Wszyscy zarejestrowali się w ciągu ostatnich 30 dni (w styczniu 2025 r.).
- Ich
last_nameto nazwy firm, np. „Pet Supply Co”, „Animal Care LLC” i „Happy Paws Inc”. - Jest ich około 100, a to grupa, która nie istniała przed tym miesiącem.
- Wszyscy klienci B2B mają
Połącz kod promocyjny
- Agent może samodzielnie zauważyć, że wiele zamówień B2B w BigQuery ma wartość
promo_coderównąBIGORDER25. Jeśli sam zaproponuje taką obserwację, świetnie. Sprawa jest w toku.Jeśli agent nie wspomina o kodzie promocyjnym, przypomnij mu o nim:I noticed a promo_code field on the orders table in BigQuery. Check what promo codes appear on the B2B-Wholesale orders? - Agent ponownie wysyła zapytanie do BigQuery i stwierdza, że około 92% zamówień B2B-Wholesale ma wartość
promo_code = 'BIGORDER25'. Prawie cała aktywność B2B jest powiązana z jedną kampanią promocyjną.Pracownik obsługi klienta powinien teraz zapytać, skąd pochodzi ten kod promocyjny. Może zapytać, czy w środowisku są gdzieś jeszcze dane promocyjne. (W Cloud Storage jest.)
Podsumowanie sekcji: agent wysłał zapytanie do Cloud SQL, aby dowiedzieć się, że klienci B2B to wszystkie nowe firmy, które zarejestrowały się w styczniu 2025 roku. W połączeniu z informacją z BigQuery, że około 92% zamówień zawiera promo_code = 'BIGORDER25', ślad prowadzi teraz do kampanii promocyjnej. Czas znaleźć źródło.
7. Znajdź brakujący element
Dwie usługi już działają, a jedna jeszcze nie. Wiesz już co się stało (zamówienia B2B obniżają średnią wartość zamówienia) i kto za to odpowiada (nowi klienci biznesowi z ostatnich 30 dni). Teraz musisz znaleźć odpowiedź na pytanie „dlaczego”, a znajdziesz ją w Cloud Storage.
Sprawdź zasobnik GCS
- W panelu czatu wpisz:
Good catch on the promo code. We might have promotional campaign data in our GCS bucket. Can you check what's there? - Agent nie ma wstępnie skonfigurowanego narzędzia MCP dla Cloud Storage, więc automatycznie przełącza się na używanie narzędzia terminalowego do uruchamiania poleceń
gcloud storage. Poprosi o uprawnienia do uruchamiania poleceń takich jakgcloud storage ls. Zezwól na te polecenia, a następnie rozwiń dziennik Uruchomiono w panelu czatu, aby zobaczyć dokładne polecenia interfejsu wiersza poleceń, których użyto do odczytania i przeanalizowania plikupromo_events.json. - Agent powinien zidentyfikować w pliku 3 kampanie promocyjne:
Oto on. Kod promocyjnyKampania
Kod promocyjny
Rabat
Cel
Daty
Letnia wyprzedaż produktów do pielęgnacji zwierząt
PETSUMMER15Rabat 15%
Wszystkie
czerwiec 2024 r.
B2B Wholesale Push
BIGORDER2525% zniżki
B2B
Styczeń 2025 r.
Bonus świąteczny dla uczestników programu lojalnościowego
LOYAL1010% zniżki
Uczestnicy programu lojalnościowego
Grudzień 2024 r.
BIGORDER25jest powiązany z kampanią o nazwie B2B Wholesale Push: 25% zniżki dla klientów B2B przy minimalnej ilości zamówienia wynoszącej 50 sztuk. To jest dowód.
Podsumowanie
- Poproś agenta o podsumowanie wszystkich znalezionych informacji:
Put it all together. What happened to our average order value? - Agent dostarcza jasną, uporządkowaną syntezę łączącą wszystkie 3 źródła danych. Powinno ono zawierać wyjaśnienie podobne do tego:
- Spadek średniej wartości zamówienia jest faktem, ale nie oznacza spadku w dotychczasowej działalności. Średnia wartość zamówienia online i offline utrzymuje się na stabilnym poziomie około 110 zł.
- W styczniu 2025 r. pojawił się nowy kanał B2B-Wholesale, który wygenerował około 25 tys. zamówień o znacznie niższej średniej wartości zamówienia (około 75–100 USD).
- Klienci B2B to 100 nowych kont firmowych, które zostały zarejestrowane w ciągu ostatnich 30 dni (Cloud SQL).
- Aktywność jest wynikiem kampanii promocyjnej („B2B Wholesale Push”) oferującej 25% rabatu na zamówienia hurtowe z minimalną liczbą 50 sztuk (Cloud Storage).
- Przychody są na tym samym poziomie, ponieważ duża liczba zamówień B2B rekompensuje niższe ceny. Jednak marże jednostkowe są znacznie niższe (zmniejszone o ok. 65%) w przypadku 25-procentowego rabatu hurtowego, co poważnie zagraża ogólnej rentowności po uwzględnieniu kosztów wysyłki i kosztów operacyjnych.
Podsumowanie sekcji: w Cloud Storage znaleziono dowód: kampanię promocyjną B2B oferującą 25% zniżki na zamówienia hurtowe. Agent zsyntetyzował wyniki ze wszystkich 3 usług w jasną narrację. Etap analizy został zakończony. Następnie wprowadzisz te wnioski w życie.
8. Tworzenie potoku
Sprawa rozwiązana. Dyrektor finansowy chce, aby ta analiza była aktualizowana automatycznie. W tej sekcji poprosisz agenta o utworzenie projektu dbt, który przygotuje dane BigQuery i utworzy tabelę faktów do bieżącej analizy średniej wartości zamówienia.
W tym momencie agent przechodzi z roli badacza do roli inżyniera. Zobaczysz, jak tworzy cały projekt dbt i uruchamia pełną ścieżkę, a wszystko to na podstawie jednego prompta.
Utwórz szkielet projektu dbt
- W panelu czatu wpisz ten prompt: Jest to celowe podejście, a nie instrukcja krok po kroku. Mówisz agentowi, co chcesz, a nie jak to zbudować:
I want to productionize our AOV analysis so it updates automatically. Build a dbt project that: 1. Creates staging models for the BigQuery tables (orders and order_items) and a mart called fct_order_analysis that calculates AOV by channel and month 2. Add a uniqueness test on order_id and run dbt build - Obserwuj autokorektę: jeśli rozwiniesz log „Worked for Ns”, możesz zobaczyć, że agent sprawdza, czy istnieje plik
dbt, a gdy go nie znajdzie, automatycznie uruchamia polecenia tworzące wirtualne środowisko Pythona (.venv). Zajmuje się on konfiguracją środowiska za Ciebie.
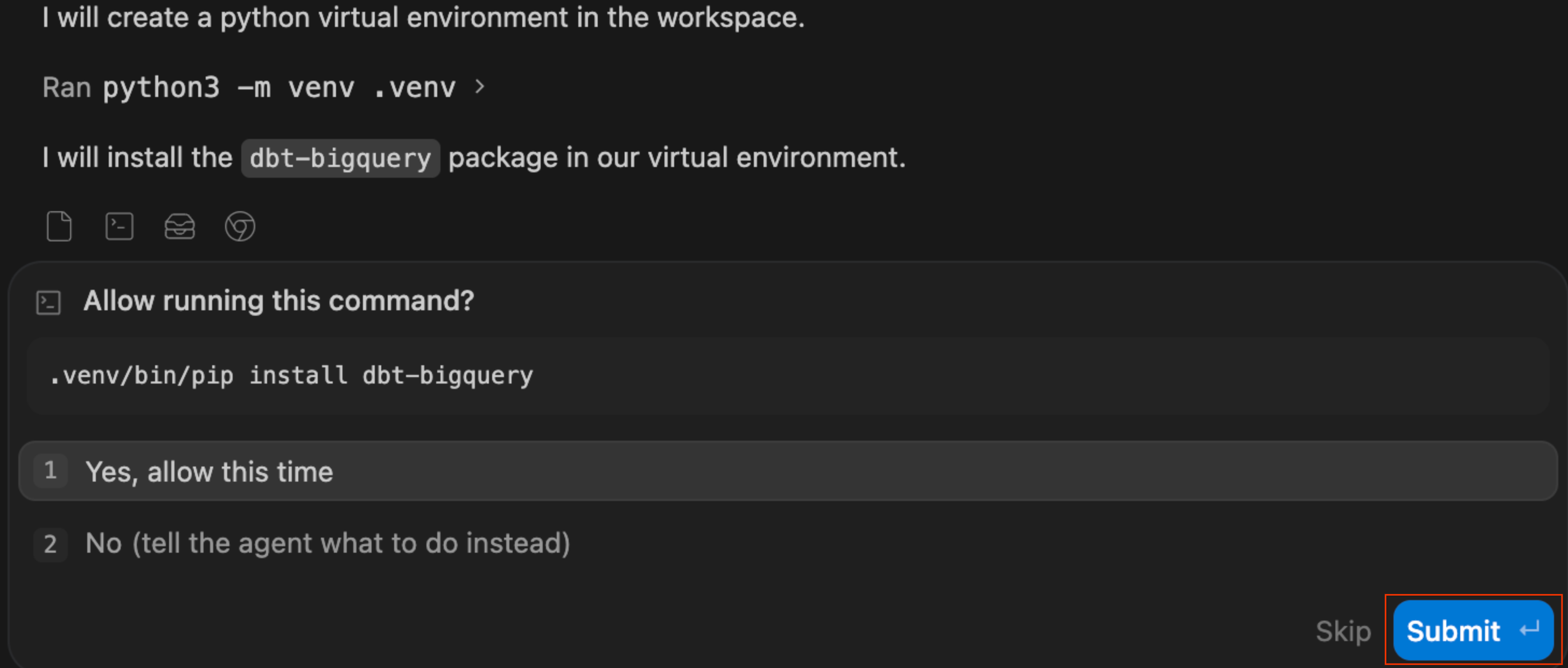
- Sprawdź plan wdrożenia: agent wygeneruje formalny plan wdrożenia. Możesz sprawdzić proponowane pliki i architekturę, w razie potrzeby dodać komentarze i kliknąć Dalej, aby umożliwić agentowi wykonanie planu.
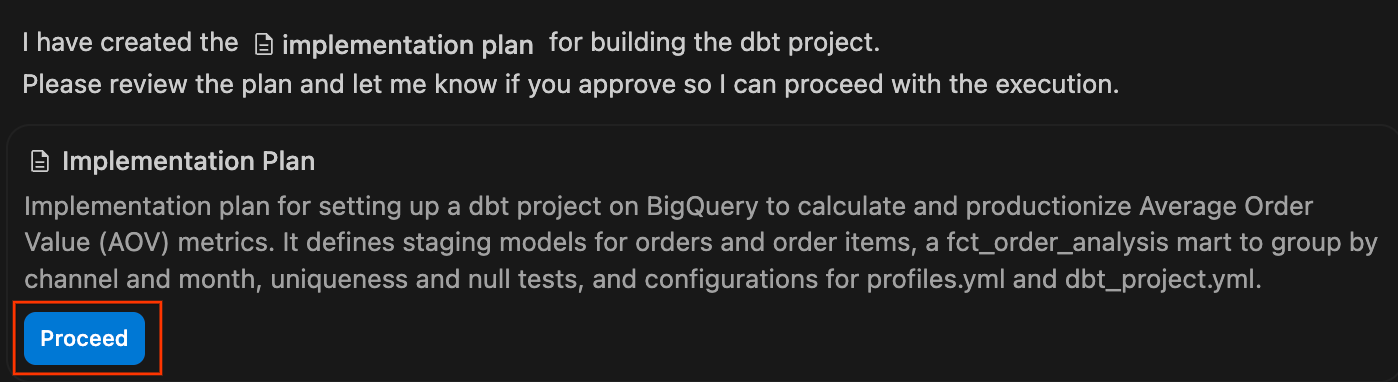
- Obserwuj panel czatu, gdy agent wykonuje swój plan, zapisując niezbędne
.sqlpliki i konfiguracje YAML. Po zakończeniu i pomyślnej kompilacji projektu wyświetli podsumowanie zmian. Aby dodać te pliki do obszaru roboczego, kliknij Zaakceptuj wszystkie.
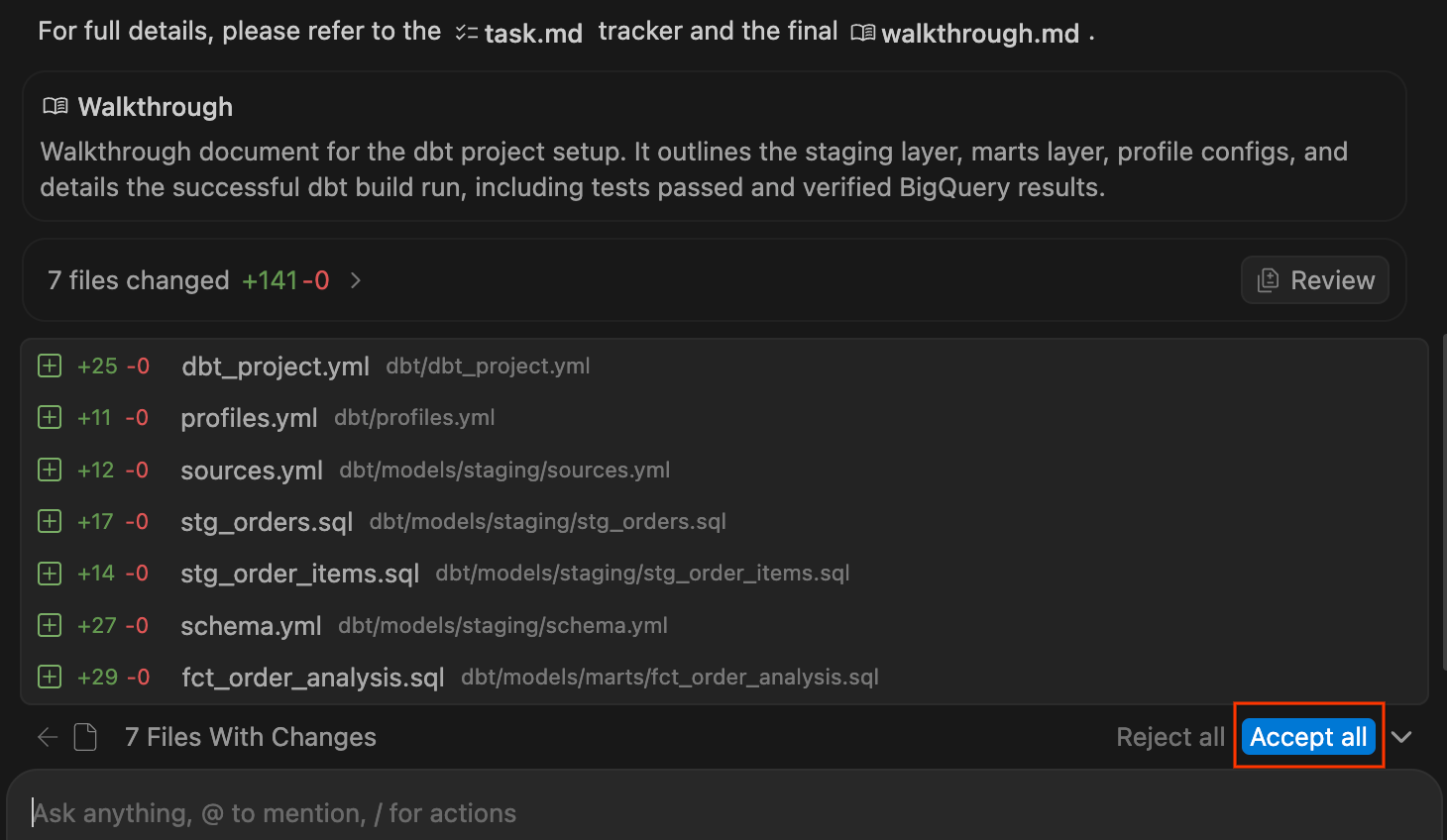
- Zapoznaj się z nowo wygenerowanym projektem dbt w Eksploratorze po lewej stronie. Powinna pojawić się struktura podobna do tej:
dbt/ ├── models/ │ ├── marts/ │ │ └── fct_order_analysis.sql │ └── staging/ │ ├── schema.yml │ ├── sources.yml │ ├── stg_order_items.sql │ └── stg_orders.sql ├── dbt_project.yml └── profiles.yml

- Kliknij pliki modelu
.sql, aby sprawdzić wygenerowane przez agenta zapytanie SQL. Zwróć uwagę na to, jak obsługuje:- Modele tymczasowe: oczyszczone kolumny o zmienionych nazwach z odwołaniami do źródeł.
- Model mart: logika łączenia i obliczanie średniej wartości zamówienia według kanału
- Sprawdź w panelu czatu, czy pracownik obsługi klienta potwierdził, że wszystkie modele zostały zmaterializowane i wszystkie testy zostały zaliczone. Wyniki AOV z platformy powinny potwierdzać to, co zostało ustalone podczas analizy:
- Online: ~$110 - Offline: ~$110 - B2B-Wholesale: ~$75 to $77
Podsumowanie sekcji: agent utworzył projekt dbt na podstawie jednego prompta zorientowanego na cel: utworzył modele przejściowe i mart, uruchomił dbt build i potwierdził anomalię AOV. Następnie zadaj agentowi trudne pytanie, aby sprawdzić, jak radzi sobie ze złożonymi problemami.
9. Gdy testy się nie powiodą, agent przeprowadza debugowanie
Potok działa, ale używa tylko danych BigQuery. Zespół produktu chce wzbogacić analizę o dane klientów i profilów zwierząt z Cloud SQL, aby móc rekomendować produkty na podstawie potrzeb żywieniowych. Oznacza to, że agent musi przekroczyć granicę Cloud SQL i poradzić sobie z subtelnym błędem modelowania danych – klasycznym złączeniem „zwielokrotnienie wyjściowe” modelowania wielowymiarowego.
W zależności od modelu, którego używasz, i jego możliwości rozumowania agent obsłuży to żądanie na 2 sposoby: proaktywnie unikając błędu (opcja A) lub samodzielnie naprawiając błąd po niepowodzeniu testu (opcja B). Zobaczmy, jaką ścieżkę wybierze Twój agent.
Wyzwalanie żądania
- W panelu czatu wpisz:
Enrich fct_order_analysis with customer data and pet profile data from our Cloud SQL database. Include customer type and each customer's pets and dietary needs so we can recommend products. Keep the uniqueness test on order_id and run dbt build. - Obserwuj pracę agenta. Wykryje tabele Cloud SQL, określi, jak przenieść dane do BigQuery (za pomocą zapytania federacyjnego lub zmaterializowanej kopii), utworzy nowe modele tymczasowe i zmodyfikuje
fct_order_analysis.sql.
Opcja A. Proaktywny agent (zapobieganie błędom)
Jeśli używasz zaawansowanego modelu rozumowania, agent może wykryć zmianę ziarna przed napisaniem kodu. System zdaje sobie sprawę, że klient może mieć wiele zwierząt, więc bezpośrednie złączenie spowoduje zduplikowanie zamówień i natychmiastowe niepowodzenie testu niepowtarzalności, o który prosisz w przypadku pola order_id.
- Obserwuj proaktywne agregowanie: w wyjaśnieniu w panelu czatu lub w instrukcji agent może zauważyć, że wstępnie zagregował dane o zwierzętach, zanim je połączył, aby zapobiec „klasycznemu rozgałęzieniu”. Zazwyczaj robi to, zwijając wiele zwierząt domowych na klienta za pomocą funkcji agregacji (np.
ARRAY_AGG()lubSTRING_AGG()). - Sprawdź wyniki: reguła
dbt builddziała i przechodzi test za pierwszym razem, ponieważ agent aktywnie chroni szczegółowość tabeli faktów. Możesz to sprawdzić, przeglądając wygenerowany artefakt Walkthrough, który często zawiera wyniki testu wraz z wynikami zapytania.
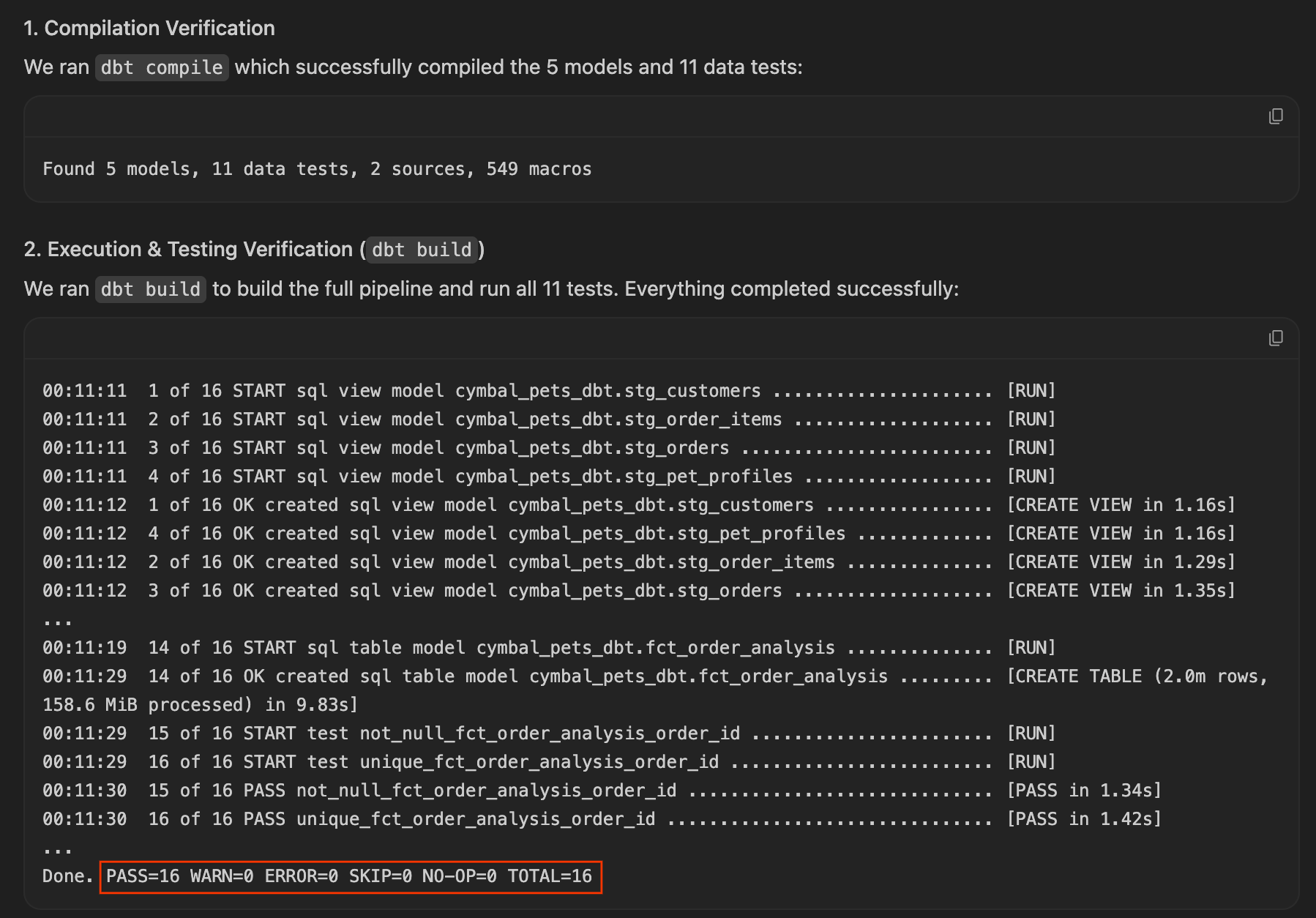
Jeśli Twój agent to zrobił, gratulacje. Widzisz proaktywne inżynierowanie AI. Poświęć chwilę na sprawdzenie wygenerowanego zapytania SQL w fct_order_analysis.sql, aby zobaczyć, jak jest skonstruowana agregacja, a następnie przejdź do następnej sekcji Przekazywanie odpowiedzi.
Opcja B. Agent samonaprawczy (debugowanie i diagnostyka)
Jeśli model najpierw napisze prosty bezpośredni lewy join, zapytanie SQL zostanie uruchomione, ale automatyczny pakiet dbt test wykryje zmianę ziarna.
- Obserwuj niepowodzenie testu: w dziennikach postępu wykonywania w panelu czatu zobaczysz raport o niepowodzeniu:
Completed with 1 error Failure in test unique_fct_order_analysis_order_id Got 287 results, configured to fail if != 0
order_idwykazał duplikaty, ponieważ klienci z kilkoma zwierzętami domowymi rozdzielili zamówienia. - Pozwól agentowi przeprowadzić diagnostykę i samodzielnie rozwiązać problem: ponieważ test się nie powiódł, poproś agenta o jego debugowanie. W panelu czatu wpisz:
The uniqueness test failed. Can you figure out why and fix it? - Obejrzyj diagnozę: agent wyszuka dane, wykryje relację jeden-do-wielu w
pet_profiles, wyjaśni, że bezpośrednie połączenie zmienia poziom szczegółowości z jeden wiersz na zamówienie na jeden wiersz na zamówienie na zwierzę i przepisze model, aby wstępnie zagregować profile zwierząt:-- Pre-aggregating pets per customer to resolve fan-out LEFT JOIN ( SELECT customer_id, COUNT(*) AS num_pets, STRING_AGG(DISTINCT pet_type, ', ') AS pet_types, STRING_AGG(DISTINCT dietary_needs, ', ') AS dietary_needs FROM pet_profiles GROUP BY customer_id ) pet_agg ON c.customer_id = pet_agg.customer_id - Weryfikacja poprawki: agent ponownie uruchamia
dbt buildi tym razem wszystkie modele są realizowane, a wszystkie testy przechodzą pomyślnie.
Podsumowanie sekcji: niezależnie od tego, czy agent proaktywnie uniknął błędu, czy też po niepowodzeniu testu udało mu się samodzielnie naprawić problem, widzisz, że przekracza on granicę Cloud SQL, integruje dane profilu klienta i zwierzęcia oraz zachowuje idealną szczegółowość tabeli faktów. Potok jest teraz niezawodny, kompletny i w pełni przetestowany.
10. Przekaż odpowiedź
Jest czwartek. Tydzień zaczął się od zaniepokojonego dyrektora finansowego i rozproszonych danych w 3 usługach w chmurze. Znasz już przyczynę problemu i masz potok produkcyjny. Czas potrzebny na udzielenie odpowiedzi wraz z rekomendacją na przyszłość popartą prognozą ilościową.
Napisz streszczenie
- W panelu czatu wpisz:
Write an executive summary covering: - Main findings and the quantitative margin impact - Project AOV for the subsequent quarter if the B2B program continues at its current trajectory - A data-driven recommendation - Obserwuj pracę agenta.
- Sprawdź streszczenie agenta. Typowa i dobrze skonstruowana odpowiedź powinna zawierać:
- Główne wnioski: średnia wartość zamówienia w styczniu spadła wyłącznie z powodu nowego kanału B2B-Wholesale. Wartości online i offline utrzymują się na stabilnym poziomie około 110 zł.
- Przyczyna: promocja „B2B Wholesale Push” (25% zniżki na zamówienia hurtowe) przyciągnęła 100 nowych kont, co przełożyło się na około 25 tys. zamówień.
- Wpływ na marżę: zamówienia hurtowe obniżyły średni zysk na jednostkę o ok. 65% (z ok. 7,50 PLN do ok. 2,60 PLN).
- Przychody: stałe łączne przychody, ponieważ duża liczba transakcji B2B kompensuje niższe ceny.
Prognozowanie średniej wartości zamówienia za pomocą funkcji AI.FORECAST
- Agent powinien też wygenerować prognozę na przyszłość. Poszukaj wywołania narzędzia MCP, w którym agent uruchamia zapytanie
AI.FORECASTw BigQuery. Wykorzystuje wbudowany model podstawowy TimesFM do prognozowania wartości zamówienia w przyszłości na podstawie trendów historycznych. Zapytanie powinno prognozować wartość zamówienia w przyszłości w 2 scenariuszach: kontynuacja kampanii (strukturalnie obniżona wartość zamówienia) i zakończenie kampanii (wzrost do około 110 zł).
- Sprawdź strategiczne rekomendacje agenta. Kompletny zestaw rekomendacji może obejmować:
- Zrestrukturyzuj zniżki: wprowadź minimalne marże lub ogranicz zniżki zbiorcze, aby chronić marże na poziomie jednostkowym.
- Wymuszanie bardziej rygorystycznych minimalnych ilości zamówienia: zapobiegaj nadużywaniu cen hurtowych przez kupujących detalicznych.
- Osobne raportowanie: śledź oddziały detaliczne i B2B niezależnie od siebie, aby uniknąć maskowania skuteczności sprzedaży detalicznej.
Pełna historia
To, co zaczęło się w poniedziałek jako alarm próbny związany z 7-procentowym spadkiem średniej wartości zamówienia, ma dla dyrektora finansowego jasne rozwiązanie:
- Retail Health: podstawowe kanały sprzedaży detalicznej pozostają w dobrej kondycji i na stabilnym poziomie.
- Wzrost sprzedaży hurtowej: spadek średniej wartości zamówienia jest w całości spowodowany nowym kanałem sprzedaży hurtowej B2B i kampanią
BIGORDER25. - Wpływ na marżę: rabat zbiorczy w wysokości 25% znacznie obniżył marże jednostkowe, zagrażając rentowności pomimo stałych przychodów.
- Prognoza strategiczna:
AI.FORECASTprognoza pokazuje, że restrukturyzacja poziomów cen hurtowych przywróci średnią wartość zamówienia.
Dostarczasz rekomendację opartą na danych, aby ustalić minimalne marże hurtowe i oddzielne raportowanie sprzedaży detalicznej i B2B.
Podsumowanie sekcji: poproszono agenta o napisanie podsumowania z analizą marży, wygenerowanie prognozy AI.FORECAST i przedstawienie rekomendacji opartej na danych. Analiza została zakończona.
11. Czyszczenie
Aby uniknąć obciążenia konta Google Cloud bieżącymi opłatami, usuń zasoby utworzone w tym laboratorium, uruchamiając skrypt czyszczący.
- W panelu Terminal u dołu Antigravity IDE (lub w Cloud Shell) przejdź do katalogu codelab i uruchom:
cd ~/devrel-demos/codelabs/agentic-data-labs/scripts
chmod +x teardown.sh
./teardown.sh
- Skrypt wyświetli wszystkie zasoby, które planuje usunąć, i poprosi o potwierdzenie przed kontynuowaniem:
- Instancja Cloud SQL (
cymbal-pets-ops): to najdroższy zasób. - Zbiór danych BigQuery (
cymbal_pets): wszystkie tabele i modele - Zasobnik Cloud Storage (
gs://YOUR_PROJECT_ID-cymbal-pets-raw) - Połączenie z BigQuery (
cymbal-pets-cloudsql)
- Instancja Cloud SQL (
- Wpisz
y, aby potwierdzić. Rozbiórka trwa około 2–3 minuty.
[INFO] Deleting Cloud SQL instance cymbal-pets-ops... [ OK ] Cloud SQL instance deleted. [INFO] Deleting BigQuery dataset cymbal_pets... [ OK ] BigQuery dataset deleted. [INFO] Deleting GCS bucket gs://YOUR_PROJECT_ID-cymbal-pets-raw... [ OK ] GCS bucket deleted.
12. Gratulacje!
Udało Ci się ukończyć śledztwo w sprawie Cymbal Pets. Od ogólnego pytania dyrektora finansowego do w pełni operacyjnej rekomendacji opartej na prognozach, z użyciem agenta AI, który działa w całym środowisku danych Google Cloud.
Co udało Ci się osiągnąć
- 🔍 Przeglądanie w różnych usługach: wykrywanie i podgląd zasobów w BigQuery, Cloud SQL i Cloud Storage za pomocą zestawu Data Agent Kit i jego katalogu wiedzy.
- 🕵️♂️ Sprawdzono za pomocą AI: zapytano o wiele usług w ramach jednej rozmowy na panelu czatu, korzystając z narzędzi MCP, aby prześledzić anomalię AOV w kampanii promocyjnej B2B.
- 🔧 Utworzono potok produkcyjny: utworzono kompletny projekt dbt do oczyszczania, łączenia i testowania danych transakcyjnych i danych o klientach.
- 🐛 Usunięto błąd zwielokrotnienia wyjściowego: agent automatycznie zdiagnozował problem z granularnością i przeprowadził refaktoryzację modelu SQL dbt, aby wstępnie agregować profile zwierząt domowych klientów.
- 📈 Prognozy i rekomendacje: wykorzystano wbudowaną funkcję
AI.FORECASTBigQuery do modelowania trendów AOV i przekazano dyrektorowi finansowemu rekomendację opartą na danych.
Kluczowych pojęć
Pomysł | Czego się dowiedziałeś(-aś) |
Narzędzia MCP | Bezpieczne połączenia podlegające audytowi, które umożliwiają agentowi AI wysyłanie w Twoim imieniu zapytań do usług takich jak BigQuery, Cloud SQL, Spanner i inne bazy danych. Każde wywołanie jest widoczne w panelu czatu. |
Umiejętności agenta | Gotowe zestawy instrukcji (np. |
Analiza obejmująca różne usługi | Agent wysyła zapytania do wielu usług Google Cloud w ramach jednej rozmowy – nie wymaga to konfiguracji połączenia ani przełączania kontekstu między konsolami. |
Promptowanie zorientowane na cel | Powiedz agentowi, co chcesz zrobić („utwórz projekt dbt, który oblicza średnią wartość zamówienia według kanału”), zamiast mówić mu, jak to zrobić, i pozwól mu wybrać sposób wdrożenia. |
Data Agent Kit | Rozszerzenie, które łączy wszystko ze sobą – narzędzia MCP, umiejętności agenta i odkrywanie danych – zapewniając dostęp do wszystkich danych Google Cloud z wybranego środowiska IDE. |
Dalsze kroki
- Więcej informacji o jego możliwościach znajdziesz w dokumentacji Data Agent Kit.
- Dowiedz się więcej o funkcjach BigQuery ML i AI, w tym
AI.FORECAST,AI.GENERATEiAI.EMBED. - Wypróbuj tworzenie własnego dochodzenia obejmującego różne usługi za pomocą Antigravity IDE na podstawie własnych danych.