
1. Introdução
É segunda-feira de manhã, e o CFO acabou de mandar uma mensagem para você. O valor médio do pedido caiu 7% este mês, mas a receita total está estável. Algo não está certo, e o conselho quer respostas até sexta-feira.
Sua empresa, a Cymbal Pets, é uma das maiores varejistas on-line de produtos para animais de estimação nos EUA. Os dados necessários estão espalhados por três serviços do Google Cloud: dados de transações no BigQuery, registros de clientes e produtos no Cloud SQL e arquivos de marketing no Cloud Storage. Normalmente, para fazer uma investigação entre serviços como essa, é preciso alternar entre consoles, escrever modelos de conexão e juntar os resultados manualmente.
Neste codelab, você vai usar o Google Cloud Data Agent Kit (DAK) no IDE do Antigravity para investigar a anomalia usando linguagem natural. Você descreve o que está procurando, e o agente de IA processa as conexões, o SQL e as junções entre serviços no BigQuery, Cloud SQL e Cloud Storage. Depois de resolver o caso, peça ao agente para criar um pipeline dbt que operacionalize suas descobertas, depure um bug real de modelagem de dados e entregue uma recomendação baseada em previsão ao CFO.
Atividades deste laboratório
- Descubra recursos de dados no BigQuery, no Cloud SQL e no Cloud Storage usando o Knowledge Catalog.
- Investigue uma anomalia consultando vários serviços em uma única conversa usando as ferramentas do MCP
- Crie um pipeline do dbt para organizar e unir dados entre serviços com modelos de organização e testes automatizados.
- Depure um problema de modelo de dados enquanto o agente faz um autodiagnóstico e refatora um bug de distribuição de dados
- Preveja tendências futuras e ofereça uma recomendação orientada por dados usando o
AI.FORECASTdo BigQuery.
O que é necessário
- Um navegador da web, como o Chrome
- Tenha um projeto do Google Cloud com o faturamento ativado.
- Conhecimento básico de SQL e do console do Google Cloud
Este codelab é destinado a profissionais de dados intermediários (engenheiros de análise, analistas de dados, cientistas de dados).
Os recursos criados neste codelab custam menos de US $5.
2. Antes de começar
Nesta seção, você vai executar um script de configuração que provisiona todo o ambiente do laboratório: um conjunto de dados do BigQuery com dados de pedidos, uma instância do Cloud SQL Postgres com dados de clientes e produtos e um bucket do Cloud Storage com registros de campanhas promocionais. O script leva cerca de 8 a 10 minutos para ser concluído, com o provisionamento do Cloud SQL como gargalo.
Iniciar o Cloud Shell
Você vai usar o Google Cloud Shell para executar o script de configuração.
- Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud.

- Depois de se conectar, defina o ID do projeto e confirme o ambiente:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
Você verá uma mensagem semelhante a:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Clone o repositório
Clone o repositório do codelab no ambiente do Cloud Shell:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/agentic-data-labs
git checkout main
cd codelabs/agentic-data-labs/
Executar o script de configuração
O script de configuração prepara todo o ambiente do laboratório em alguns minutos. Ele lida com a ativação de APIs, o carregamento e o aumento de dados do BigQuery, o upload de recursos promocionais para o GCS e, em seguida, gera automaticamente um worker em segundo plano para provisionar e configurar o Cloud SQL Postgres em segundo plano enquanto você inicia o codelab.
O script gera automaticamente uma senha do Cloud SQL e a salva no arquivo .env.
cd ~/devrel-demos/codelabs/agentic-data-labs/scripts
chmod +x setup.sh setup_sql.sh
./setup.sh
Quando terminar, você verá um resumo do seu ambiente em primeiro plano:
╔══════════════════════════════════════════════════════╗
║ Base Setup complete! ║
╚══════════════════════════════════════════════════════╝
Your core BigQuery and GCS assets are ready.
Cloud SQL is currently provisioning in the background and will be fully ready by Step 4.
BigQuery: YOUR_PROJECT_ID.cymbal_pets
├── orders
└── order_items
GCS: gs://YOUR_PROJECT_ID-cymbal-pets-raw
└── promo_events.json
Enquanto você continua com as próximas etapas do laboratório, o banco de dados é provisionado e propagado em segundo plano. É possível monitorar o progresso a qualquer momento em um painel de terminal separado usando:
tail -f /tmp/cloudsql_setup.log
Observe a arquitetura de dados: os dados transacionais (pedidos e itens de pedidos) ficam no BigQuery, enquanto os dados operacionais (clientes, perfis de animais de estimação e produtos) ficam no Cloud SQL. Essa divisão reflete como os dados são distribuídos entre os serviços em organizações reais, e é isso que torna uma investigação entre serviços interessante.
Resumo da seção:você executou o script de configuração para inicializar o ambiente de laboratório e iniciou o provisionamento do banco de dados em segundo plano.
3. Configurar o IDE e o Data Agent Kit
Abra o IDE do Antigravity
Não é necessário esperar que o Cloud SQL termine. Abra o IDE Antigravity e conecte-o ao seu projeto do Google Cloud.
- Se ainda não tiver feito isso, faça o download e instale o IDE do Antigravity na página de download do Google Antigravity.
- Inicie o aplicativo para computador IDE do Antigravity.
- Crie uma pasta vazia na sua máquina local (por exemplo,
agentic-data-labs) e abra-a no ambiente de desenvolvimento integrado escolhendo Abrir pasta. Ele vai funcionar como seu espaço de trabalho local para o codelab.
Instalar a extensão do Data Agent Kit
A extensão Google Cloud Data Agent Kit oferece integração avançada com os serviços de dados do Google Cloud diretamente no seu editor. Assim, é possível interagir com o BigQuery, o Cloud SQL, o Cloud Storage e muito mais sem mudar de contexto.
- No IDE Antigravity, clique no ícone Extensões na barra de atividades, no lado esquerdo da tela (parece quatro quadrados).
- Na barra de pesquisa na parte de cima do painel "Extensões", digite
Google Cloud Data Agent Kit. - Localize a extensão chamada Google Cloud Data Agent Kit publicada por
googlecloudtools - Clique no botão Install.
- Uma mensagem pode aparecer perguntando: "Você confia no editor 'googlecloudtools' e nas extensões dele?". Clique em Confiar em editores e instalar para continuar.

Depois de instalado, um novo ícone do Google Cloud Data Agent Kit vai aparecer na barra de atividades, no canto esquerdo do IDE do Antigravity.
Autenticar e configurar a extensão
Após a instalação, conecte a extensão ao seu projeto do Google Cloud.
- Uma página de integração intitulada "Bem-vindo ao Google Cloud Data Agent Kit" será aberta automaticamente. Se você não estiver conectado à sua conta do Cloud, siga as instruções para permitir o acesso.
- Na seção Resumo da configuração, localize o campo do projeto. Clique no menu suspenso e selecione seu projeto do Google Cloud. Defina sua região como
us-central1. Em seguida, selecione Configurar servidores MCP.
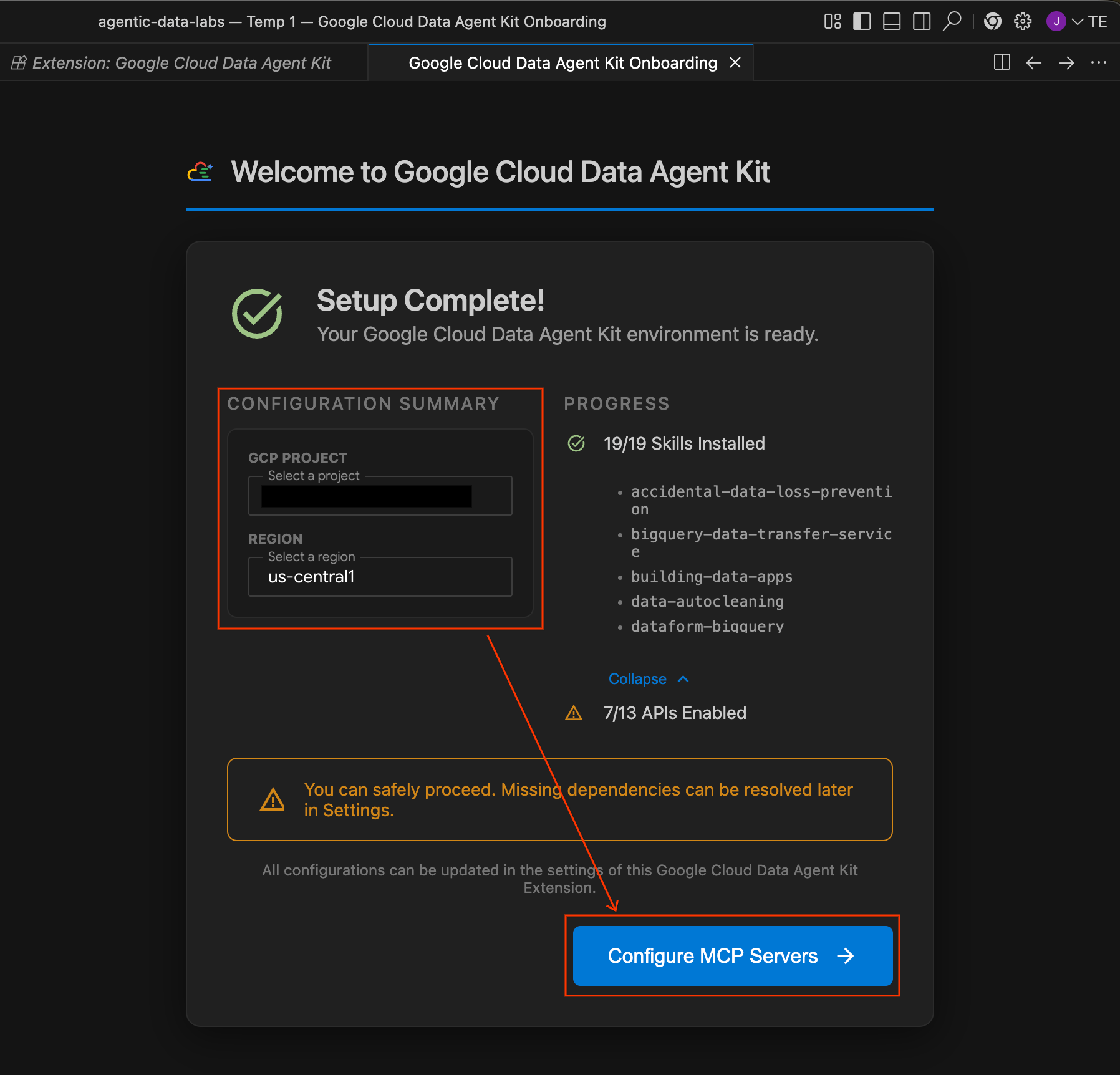
- No painel Configuração da MCP, clique para ativar o BigQuery e o Cloud SQL. Em seguida, clique em Começar.
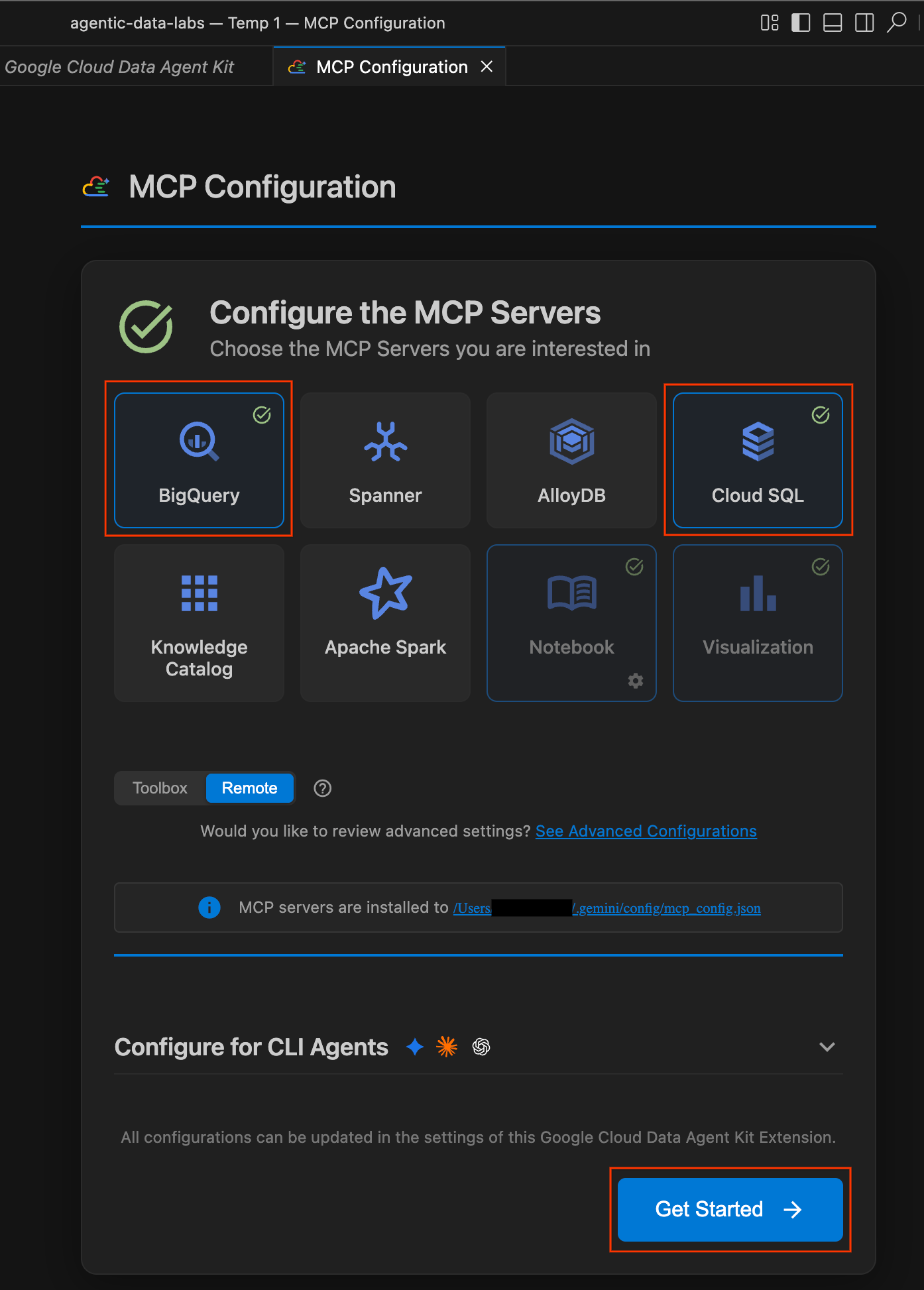
Conheça as opções de configuração
Quando a configuração for concluída, você vai acessar a página "Começar a usar o Google Cloud Data Agent Kit".
- Em "Configuração", clique em Começar.
- O painel Configuração do agente de dados será aberto. Confira as guias:
- Projeto e região:verifique o ID do projeto selecionado e se as APIs necessárias (API Cloud Storage, API BigQuery, API Catalog e API Cloud SQL Admin) estão ativadas.
- BigQuery:configure o local padrão para suas consultas do BigQuery. Use a região
us-central1. - Configurar servidores MCP:veja os servidores MCP ativados (BigQuery, Notebooks, Cloud SQL etc.) que permitem que os agentes de IA interajam com seus dados de forma segura.
- Habilidades:conheça as habilidades pré-criadas que oferecem aos agentes recursos especializados para tarefas complexas de dados.

Resumo da seção:você abriu o IDE Antigravity, conectou-o ao seu projeto do Google Cloud, configurou os servidores MCP remotos do Data Agent Kit e verificou a conexão executando uma consulta no BigQuery.
4. Descobrir seus dados
É hora de preparar o cenário. A situação é a seguinte: o CFO diz que o valor médio do pedido caiu 7% no mês passado, mas a receita total ficou estável. Antes de pedir que o agente investigue, entenda com quais dados você está trabalhando.
Nesta seção, você vai explorar manualmente o painel do Data Agent Kit para conhecer o ambiente. Entender seus dados antes de começar a consultá-los é uma primeira etapa essencial em qualquer investigação.
Conhecer as tabelas do BigQuery
- No painel do Data Agent Kit, em CATALOG, expanda seu projeto → BigQuery →
cymbal_pets. - Clique na tabela
orders. Uma nova guia será aberta mostrando os detalhes da tabela. - Confira as guias no lado esquerdo do visualizador de tabelas:
- Dados: pré-visualize as linhas reais. Role o conjunto de dados e examine as colunas.
- Esquema: analise os nomes e tipos de colunas. Observe campos como
order_typeepromo_code, que serão importantes mais tarde. - Outras guias (Detalhes, Insights, Perfil de dados etc.): Acesse metadados, linhagem de dados e detalhes de qualidade que você normalmente encontra no console do Google Cloud, tudo sem sair do editor.
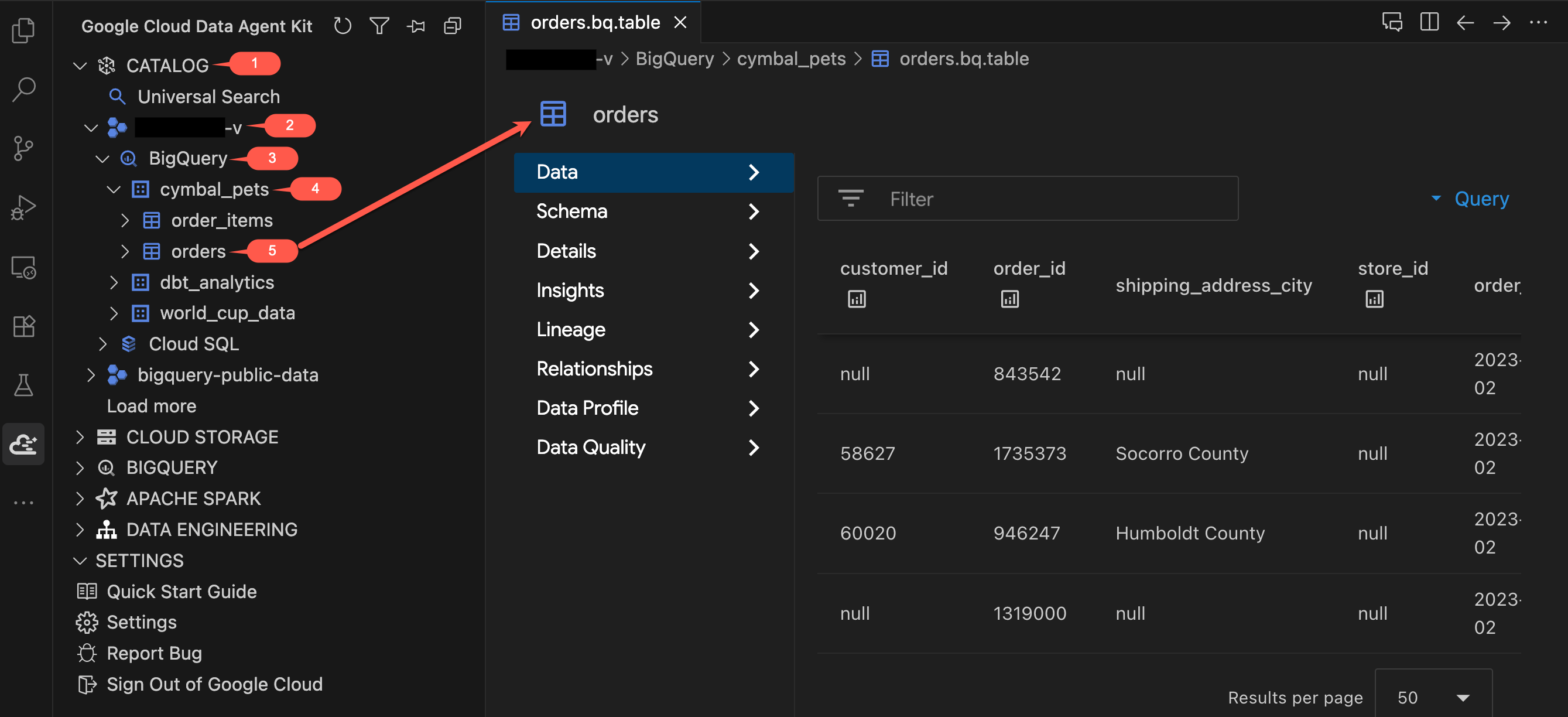
- Agora clique na tabela
order_itemse analise o esquema dela. Observe os camposquantityeprice.
Conheça as tabelas do Cloud SQL
O script de configuração também colocou dados de clientes, animais de estimação e produtos em um banco de dados PostgreSQL no Cloud SQL.
- No painel "Data Agent Kit", clique em Pesquisa universal na seção CATÁLOGO.
- Na caixa de pesquisa, digite
pet_profilese pressione Enter. - Nos resultados da pesquisa, clique no resultado da tabela do PostgreSQL para
pet_profiles(na instância do Cloud SQL do seu projeto). Observe que o acordeão da barra lateral se expande automaticamente, mostrando exatamente onde a tabela está na árvore do banco de dados. Agora clique na tabelacustomerslocalizada logo acima na árvore para abrir os detalhes dela e explore as guias Esquema e Detalhes.
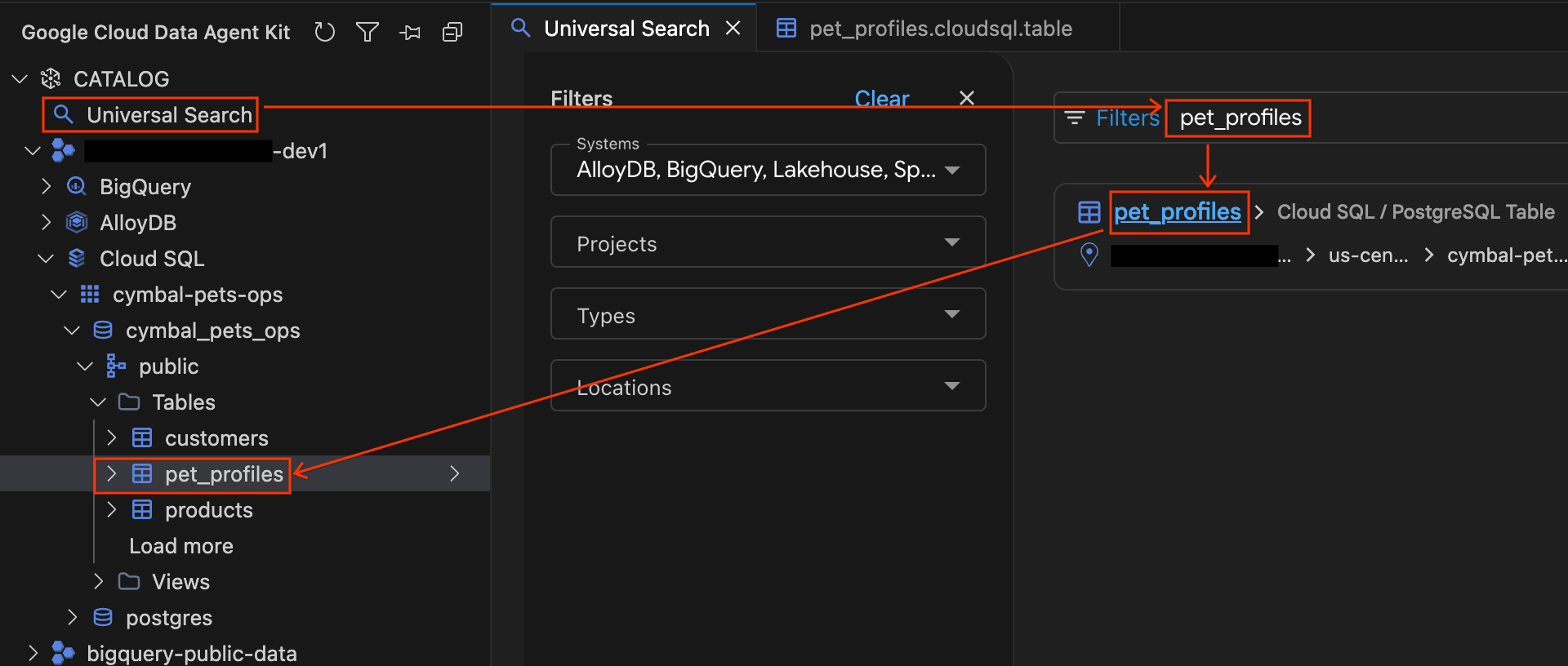
Conhecer os arquivos do Cloud Storage
Por fim, os registros de campanhas de marketing e promocionais são armazenados como arquivos JSON brutos no Cloud Storage.
- No painel do Data Agent Kit à esquerda, expanda a seção CLOUD STORAGE. Localize o bucket bruto do seu projeto (
YOUR_PROJECT_ID-cymbal-pets-raw). - Clique no arquivo
promo_events.jsondentro do bucket. Uma nova guia do editor é aberta, permitindo que você veja o conteúdo bruto de linhas JSON das campanhas de marketing diretamente no ambiente de desenvolvimento integrado.

Fazer um inventário
Agora você já sabe o seguinte sobre o cenário de dados:
Serviço | Tabelas | O que há lá |
BigQuery |
| ~1,9 milhão de pedidos, ~4,3 milhões de itens de linha, período de 2023 a 2025 |
Cloud SQL |
| ~92 mil clientes, ~7,6 mil perfis de animais de estimação, 206 produtos |
Cloud Storage |
| Registros de campanhas promocionais |
Os dados são distribuídos em três serviços. Em um fluxo de trabalho tradicional, você precisaria configurar conexões, escrever código de integração e unir resultados manualmente. Na próxima etapa, você vai deixar o agente de IA cuidar de tudo isso em uma única conversa.
Resumo da seção:você usou o painel do Data Agent Kit para analisar manualmente a arquitetura de dados no BigQuery, no Cloud SQL e no Cloud Storage. Agora você sabe onde os dados estão e quais campos estão disponíveis. Portanto, pode começar a investigação.
5. Acompanhe os números
Agora a investigação começa. Você vai usar o painel de chat para pedir ao agente de IA que extraia dados do valor médio do pedido (AOV, na sigla em inglês) do BigQuery. O VMP é uma métrica de negócios que representa o valor médio em dólares gasto por pedido. O agente vai consultar em seu nome usando as ferramentas do MCP, e você poderá ver todas as consultas SQL executadas.
Extrair a tendência do valor médio do pedido
- No painel de chat à direita do ambiente de desenvolvimento integrado, digite o seguinte comando e pressione Enter:
Calculate our monthly average order value from August 2024 through January 2025 using the orders and order_items tables in BigQuery. - Aprovar permissões de acesso a dados. É bom ter cautela em relação aos agentes de IA que executam consultas nos seus bancos de dados. O Data Agent Kit mantém você no controle, pausando para pedir permissão explícita antes de acessar os dados. Quando solicitado, escolha:
- Permitir desta vez:aprova um único uso, ideal para auditar consultas de alto risco.
- Sempre permitir:aprova o uso contínuo dessa ferramenta específica para a sessão.
- Não:bloqueia a ação completamente.
list_table_idsouexecute_sql_readonly. Você pode "sempre permitir" essas solicitações também.
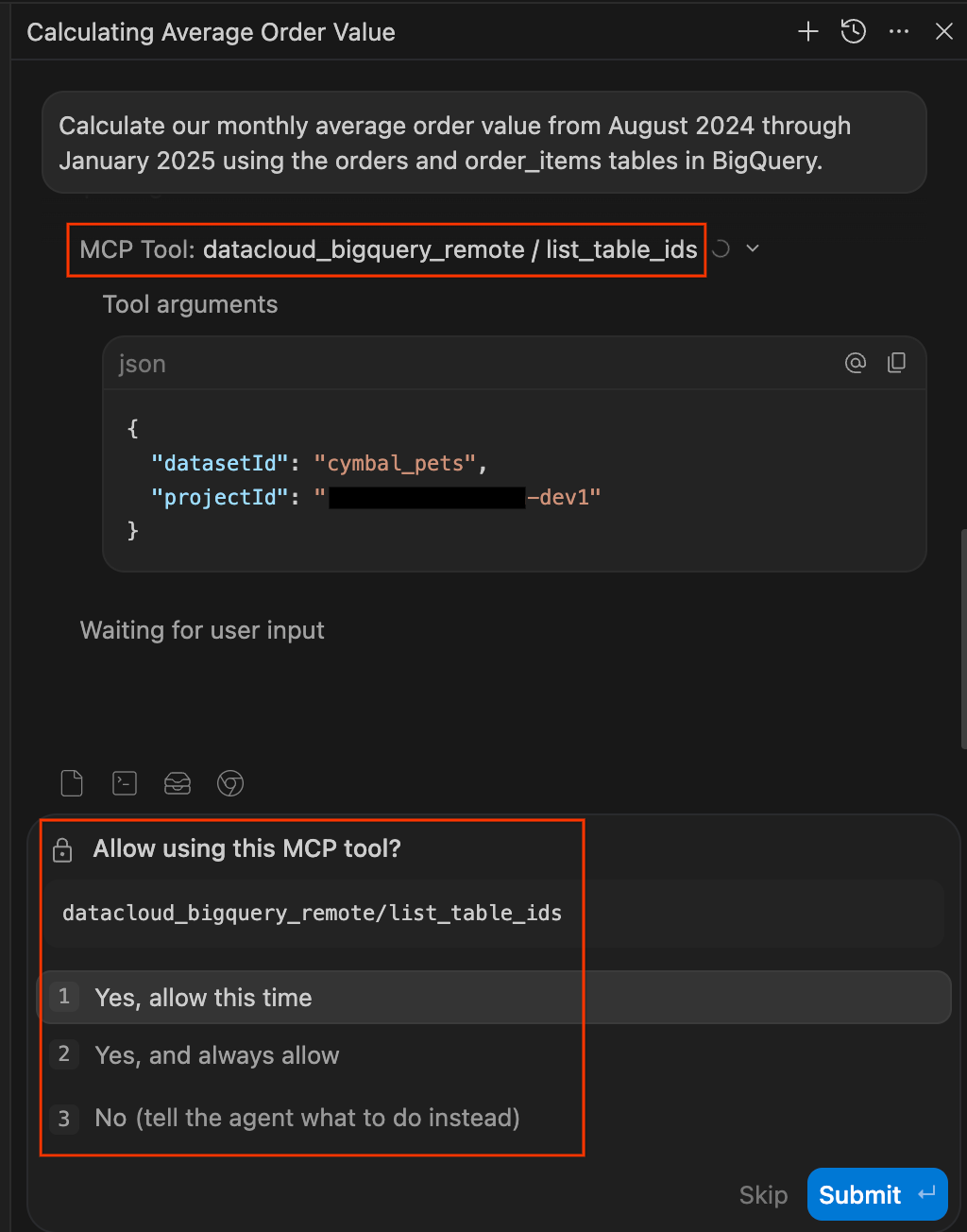
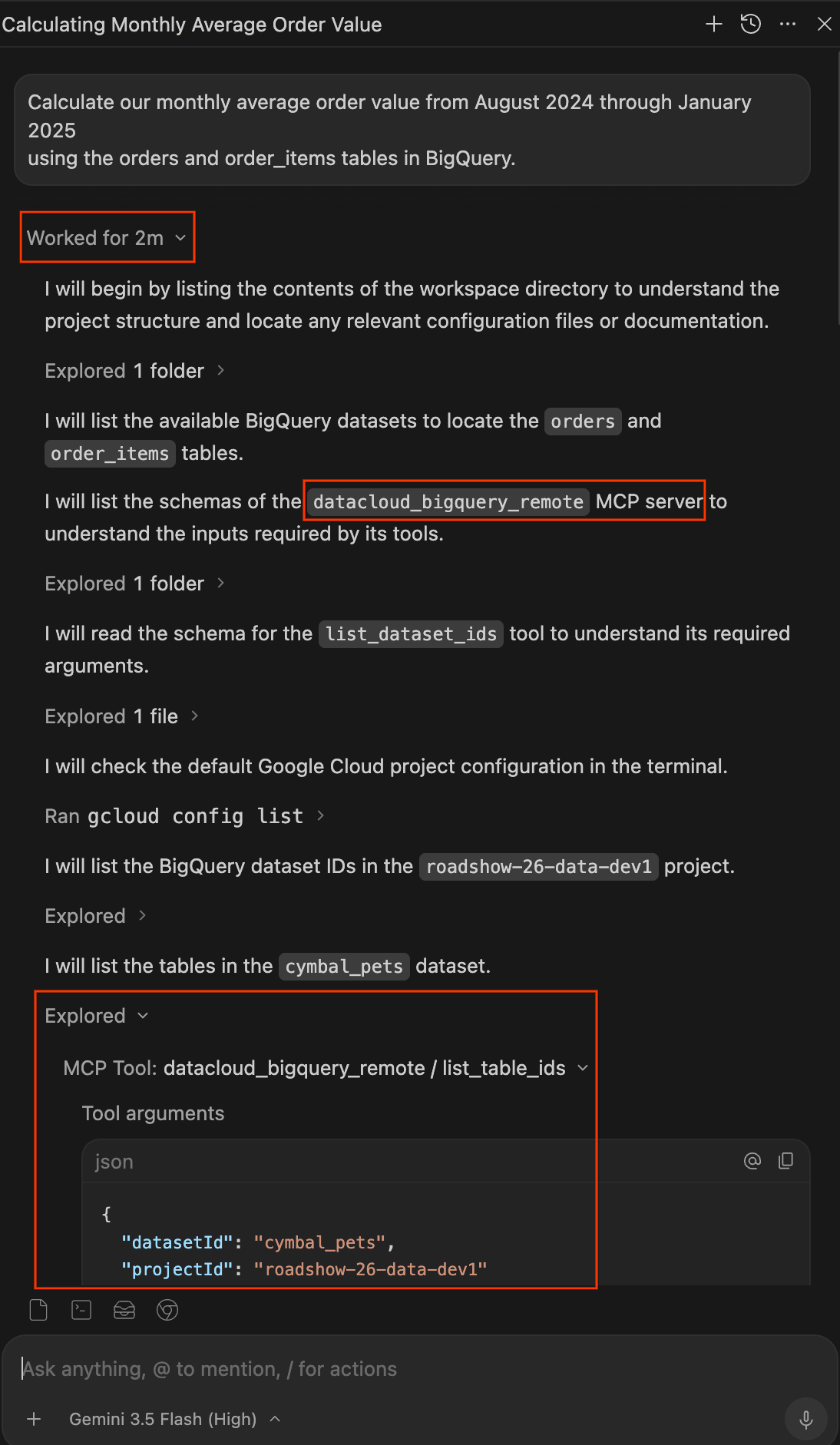
- Assista o agente trabalhar. O painel de chat também funciona como um registro de transparência de tudo o que o agente faz. Em vez de uma caixa preta, o agente mostra o raciocínio e as ações em tempo real.
- Quando o agente terminar, clique no menu suspenso Trabalhou por Xm abaixo do comando para abrir o registro de trabalho completo. Aqui você pode inspecionar exatamente como ele gerou a resposta:
- Explorado:expanda esses itens para ver o agente lendo arquivos, navegando por pastas ou chamando ferramentas do MCP (como
datacloud_bigquery_remote / list_table_idseexecute_sql_readonly). É possível conferir os argumentos JSON exatos transmitidos às ferramentas e o SQL executado. - Executado:expanda esses itens para conferir os comandos de terminal executados pelo agente, como
gcloud config list.
- Explorado:expanda esses itens para ver o agente lendo arquivos, navegando por pastas ou chamando ferramentas do MCP (como
- Analise os resultados. O agente precisa retornar uma tabela de valores de AOV mensais. Confira os números: os meses anteriores ficam em torno de US$110, e janeiro cai para cerca de US$103. Essa é a anomalia sinalizada pelo CFO.
Detalhamento por canal
O VMA geral caiu, mas de onde vem essa queda? Vamos descobrir.
- No painel "Chat", digite:
January looks lower than the prior months. Break down January's AOV by order_type to see what's going on? - O agente executa outra consulta do BigQuery, desta vez agrupando por
order_type. Analise os resultados com atenção.Você vai notar algo surpreendente: o VMA on-line e off-line permanece estável em US$110. Mas há um novo canal, B2B-Wholesale, com um VMP muito menor (cerca de US$75). Esse novo canal está reduzindo a média combinada. - O agente pode sugerir proativamente a investigação dos clientes B2B. Se não for, não tem problema. Você vai fazer isso na próxima etapa.
Resumo da seção:você identificou a queda no VMP de janeiro por conta própria com uma extração de dados neutra e depois detalhou por "order_type" para identificar B2B-Wholesale como o novo canal que reduziu a média combinada. Agora você precisa descobrir quem são esses clientes B2B.
6. Atravessar o limite do serviço
Você identificou B2B-Wholesale como o canal anômalo no BigQuery, mas os dados do cliente estão no Cloud SQL. Com o Data Agent Kit, você pode continuar a mesma conversa, e ele processa o limite do serviço.
Investigar os clientes B2B
- No painel de chat, digite:
Who are these B2B customers? Their profiles should be in our Cloud SQL database. Check for: - Who they are - When they signed up - Whether they're new or existing customers - Observe com atenção o painel de chat. Desta vez, uma ferramenta MCP diferente vai aparecer. O agente agora está consultando o Cloud SQL em vez do BigQuery.Ele se conecta à instância do Cloud SQL Postgres
cymbal-pets-opse executa uma consulta na tabelacustomers. Clique em Mostrar detalhes para ver o SQL. - Analise os resultados. O agente precisa apresentar várias descobertas importantes:
- Todos os clientes B2B têm
customer_type = 'Business' - Todos fizeram a inscrição nos últimos 30 dias (janeiro de 2025)
- Os valores de
last_namesão nomes de empresas como "Pet Supply Co", "Animal Care LLC" e "Happy Paws Inc". - São cerca de 100 pessoas, uma coorte que não existia antes deste mês.
- Todos os clientes B2B têm
Conectar o código promocional
- O agente pode perceber por conta própria que muitos pedidos B2B no BigQuery têm um valor
promo_codedeBIGORDER25. Se ele fizer essa observação, ótimo. A investigação está progredindo naturalmente.Se o agente não mencionar o código promocional, faça uma sugestão:I noticed a promo_code field on the orders table in BigQuery. Check what promo codes appear on the B2B-Wholesale orders? - O agente consulta o BigQuery novamente e descobre que aproximadamente 92% dos pedidos B2B no atacado têm
promo_code = 'BIGORDER25'. Quase toda a atividade B2B está vinculada a uma única campanha promocional.O agente precisa saber de onde veio esse código promocional. Ele pode perguntar se há dados promocionais em outro lugar no ambiente. (Existe no Cloud Storage.)
Resumo da seção:o agente consultou o Cloud SQL para revelar que os clientes B2B são todas as novas empresas que se inscreveram em janeiro de 2025. Combinado com a descoberta do BigQuery de que aproximadamente 92% dos pedidos têm promo_code = 'BIGORDER25', o rastreamento agora aponta para uma campanha promocional. Hora de encontrar a fonte.
7. Encontre a peça que falta
Dois serviços concluídos, falta um. Você sabe o que aconteceu (os pedidos B2B estão reduzindo o AOV) e quem está fazendo isso (novos clientes comerciais dos últimos 30 dias). Agora você precisa descobrir por quê, e a resposta está no Cloud Storage.
Verificar o bucket do GCS
- No painel de chat, digite:
Good catch on the promo code. We might have promotional campaign data in our GCS bucket. Can you check what's there? - O agente não tem uma ferramenta MCP pré-configurada para o Cloud Storage. Por isso, ele muda automaticamente para o uso da ferramenta de terminal para executar comandos
gcloud storage. Ele vai pedir permissão para executar comandos comogcloud storage ls. Permita esses comandos e expanda o registro Executado no painel de chat para conferir os comandos exatos da CLI usados para ler e analisar o arquivopromo_events.json. - O agente precisa identificar três campanhas promocionais no arquivo:
Aí está. O código promocionalCampanha
Código promocional
Desconto
Destino
Datas
Promoção de cuidados para pets de verão
PETSUMMER1515% de desconto
Todos
Junho de 2024
B2B Wholesale Push (em inglês)
BIGORDER2525% de desconto
B2B
Janeiro de 2025
Bônus de fim de ano para membros do programa de fidelidade
LOYAL1010% de desconto
Membros do programa de fidelidade
Dec 2024
BIGORDER25está associado a uma campanha chamada B2B Wholesale Push: 25% de desconto para clientes B2B com um pedido mínimo de 50 unidades. Essa é a prova definitiva.
Atividade prática
- Peça ao agente para sintetizar tudo o que ele encontrou:
Put it all together. What happened to our average order value? - O agente oferece uma síntese clara e estruturada que conecta todas as três fontes de dados. Ele precisa explicar algo como:
- A queda no VMP é real, mas não é um declínio nos negócios atuais. O VMP on-line e off-line permanece estável em US$110.
- Um novo canal B2B de atacado surgiu em janeiro de 2025, com cerca de 25.000 pedidos e um VMP muito menor (US$ 75 a US$ 100).
- Os clientes B2B são 100 novas contas empresariais que se inscreveram nos últimos 30 dias (Cloud SQL).
- A atividade é impulsionada por uma campanha promocional ("B2B Wholesale Push") que oferece 25% de desconto em pedidos em massa com um mínimo de 50 unidades (Cloud Storage).
- A receita fica estável porque o alto volume de pedidos B2B compensa os preços mais baixos. No entanto, as margens unitárias são muito reduzidas (erodidas em cerca de 65%) com o desconto de 25% no atacado, o que ameaça seriamente a lucratividade geral quando os custos operacionais e de frete são considerados.
Resumo da seção:você encontrou a prova no Cloud Storage: uma campanha promocional B2B que oferece 25% de desconto em pedidos em massa. O agente sintetizou descobertas dos três serviços em uma narrativa clara. A fase de investigação foi concluída. Em seguida, você vai operacionalizar essas descobertas.
8. Criar o pipeline
Você resolveu o caso. Agora, o CFO quer que essa análise seja atualizada automaticamente. Nesta seção, você vai pedir ao agente para criar um projeto dbt que organiza os dados do BigQuery e produz uma tabela de fatos para análise contínua do VMP.
É aí que o agente muda de investigador para engenheiro. Ele vai criar um projeto dbt inteiro e executar o pipeline completo, tudo com um único comando.
Estruturar o projeto do dbt
- No painel de chat, digite o seguinte comando. Ele é propositalmente orientado por metas, e não por etapas. Você está dizendo ao agente o que quer, não como criar:
I want to productionize our AOV analysis so it updates automatically. Build a dbt project that: 1. Creates staging models for the BigQuery tables (orders and order_items) and a mart called fct_order_analysis that calculates AOV by channel and month 2. Add a uniqueness test on order_id and run dbt build - Observação de autocorreção:se você abrir o registro "Worked for Ns", poderá ver o agente verificar
dbte, ao descobrir que ele está faltando, executar automaticamente comandos para criar um ambiente virtual Python (.venv). Ele está cuidando da configuração do ambiente para você.
- Analise o plano de implementação:o agente vai gerar um plano de implementação formal. Você pode analisar os arquivos e a arquitetura propostos, adicionar comentários se necessário e clicar em Continuar para permitir que o agente execute o plano.
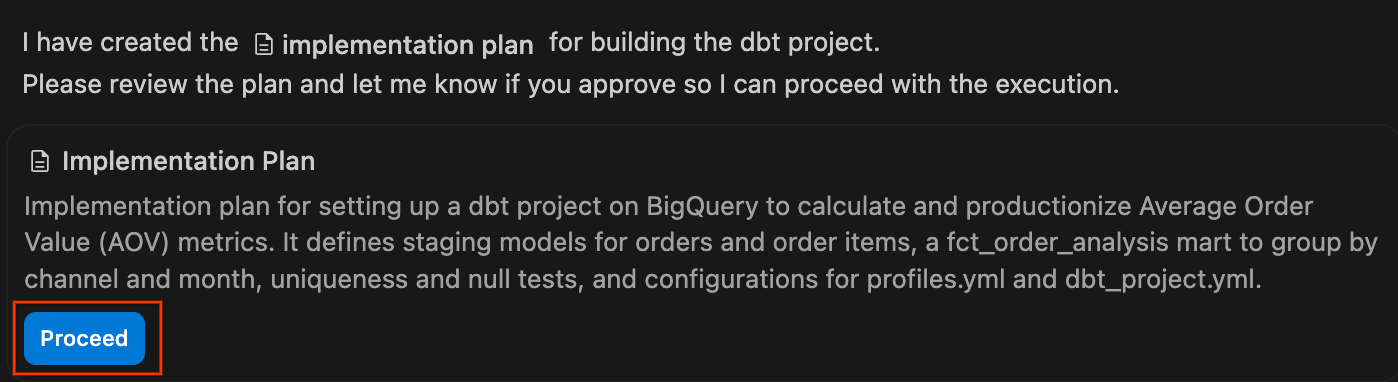
- Observe o painel de chat enquanto o agente executa o plano, gravando os arquivos
.sqle as configurações YAML necessários. Quando ele terminar e compilar o projeto com sucesso, vai apresentar um resumo das mudanças. Clique em Aceitar tudo para adicionar esses arquivos ao seu espaço de trabalho.
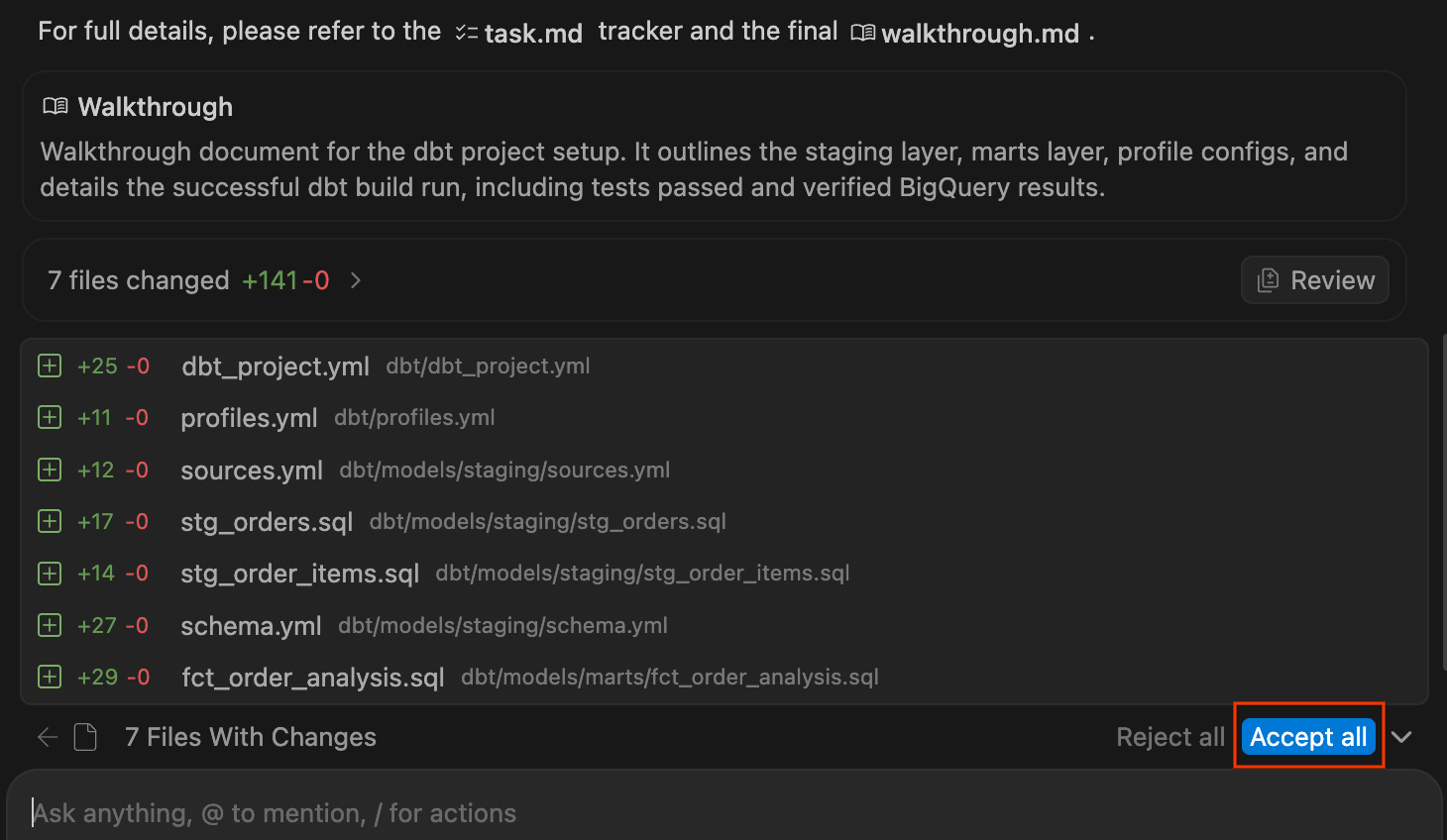
- Explore o projeto dbt recém-gerado no Explorer à esquerda. Você vai ver uma estrutura semelhante a esta:
dbt/ ├── models/ │ ├── marts/ │ │ └── fct_order_analysis.sql │ └── staging/ │ ├── schema.yml │ ├── sources.yml │ ├── stg_order_items.sql │ └── stg_orders.sql ├── dbt_project.yml └── profiles.yml

- Clique nos arquivos de modelo
.sqlpara analisar o SQL gerado pelo agente. Preste atenção em como ele lida com:- Modelos de teste: colunas limpas e renomeadas com referências de origem
- O modelo de mart: a lógica de junção e o cálculo do AOV por canal
- Confira no painel de chat se o agente confirmou que todos os modelos foram materializados e todos os testes foram aprovados. Os resultados do VMA da loja precisam confirmar o que você descobriu durante a investigação:
- Online: ~$110 - Offline: ~$110 - B2B-Wholesale: ~$75 to $77
Resumo da seção:o agente criou um projeto do dbt com base em um único comando orientado a metas: modelos de teste e de data mart estruturados, executou um dbt build com êxito e confirmou a anomalia do valor médio do pedido. Em seguida, você vai fazer uma pergunta mais complexa para ver como o agente lida com isso.
9. Quando os testes falham, o agente depura
O pipeline funciona, mas usa apenas dados do BigQuery. A equipe de produtos quer enriquecer a análise com dados de perfil de clientes e animais de estimação do Cloud SQL para recomendar produtos com base nas necessidades alimentares. Isso significa que o agente precisa fazer uma ponte entre o limite do Cloud SQL e processar um bug sutil de modelo de dados, uma junção de "distribuição de dados" clássica de modelagem dimensional.
Dependendo do modelo que você está usando e das capacidades de raciocínio dele, o agente vai processar essa solicitação de uma das duas maneiras: evitando proativamente o bug (opção A) ou autocorreção após uma falha no teste (opção B). Vamos ver qual caminho seu agente vai seguir!
Acionar a solicitação
- No painel de chat, digite:
Enrich fct_order_analysis with customer data and pet profile data from our Cloud SQL database. Include customer type and each customer's pets and dietary needs so we can recommend products. Keep the uniqueness test on order_id and run dbt build. - Assista o agente trabalhar. Ele vai descobrir as tabelas do Cloud SQL, descobrir como transferir os dados para o BigQuery (por consulta federada ou cópia materializada), criar novos modelos de staging e modificar
fct_order_analysis.sql.
Opção A: o agente proativo (evitar bugs)
Se você estiver usando um modelo de raciocínio avançado, o agente poderá detectar a mudança de granularidade antes de escrever qualquer código. Ele percebe que, como um cliente pode ter vários animais de estimação, uma junção direta vai duplicar os pedidos e falhar imediatamente no teste de exclusividade solicitado em order_id.
- Observe a agregação proativa: na explicação do painel de chat ou no artefato de tutorial, o agente pode observar que ele pré-agregou os dados de animais de estimação antes de juntá-los para evitar uma "distribuição de dados" clássica. Normalmente, isso é feito ao recolher vários animais de estimação por cliente usando uma função de agregação (por exemplo,
ARRAY_AGG()ouSTRING_AGG()). - Verifique os resultados: o
dbt buildé executado e aprovado na primeira tentativa porque o agente protegeu proativamente a granularidade da tabela de fatos. Para verificar isso, confira o artefato de tutorial gerado, que geralmente mostra a saída do teste bem-sucedido ao lado dos resultados da consulta.
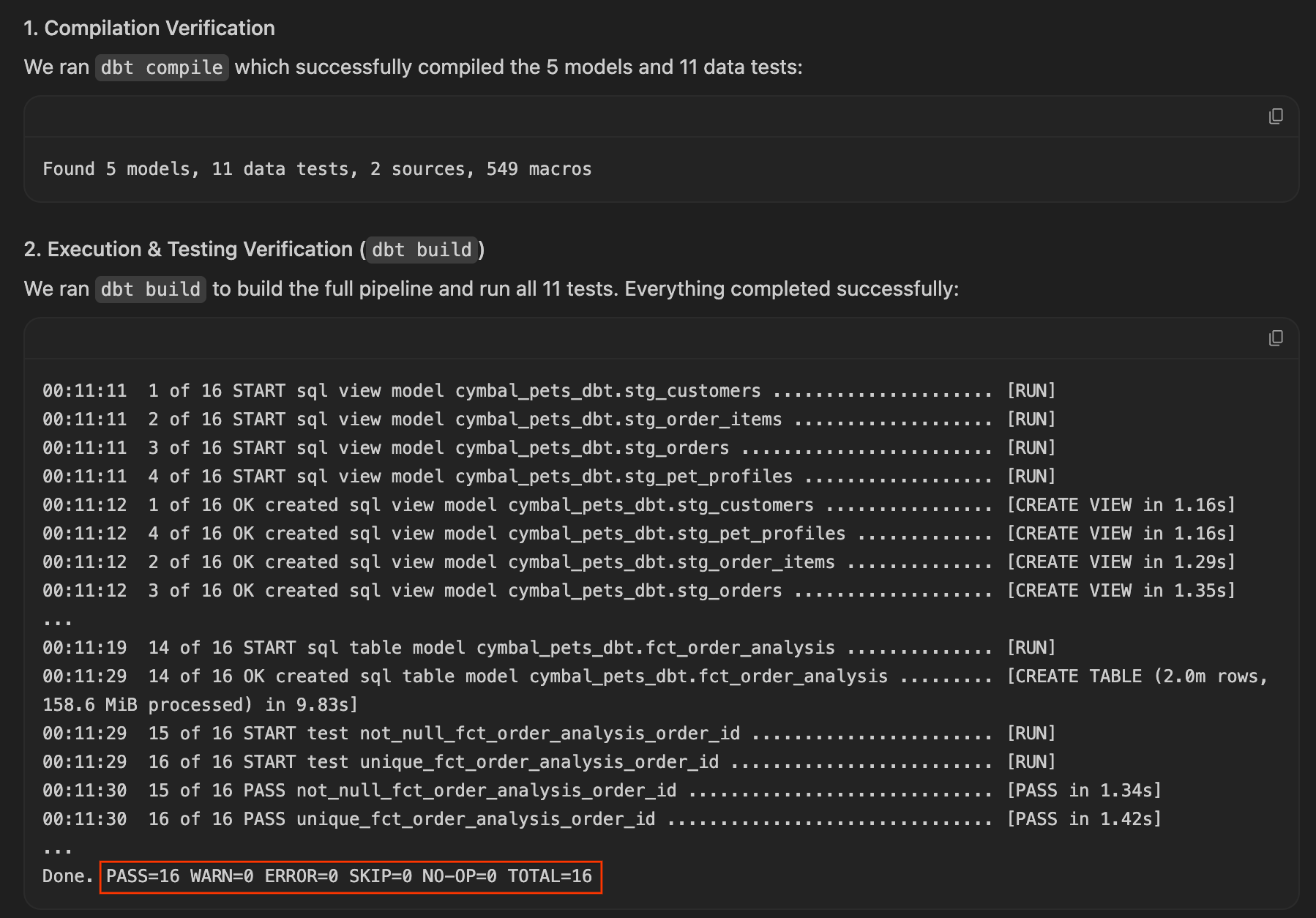
Se o seu agente fez isso, parabéns! Você viu a engenharia de IA proativa. Analise o SQL gerado em fct_order_analysis.sql para ver como ele estruturou a agregação e pule para a próxima seção, Fornecer a resposta.
Opção B: o agente de recuperação automática (depuração e diagnóstico)
Se o modelo escrever primeiro uma junção à esquerda direta e simples, a consulta SQL será executada com sucesso, mas o conjunto automatizado dbt test vai detectar a mudança de granularidade.
- Observe a falha do teste: ela vai aparecer nos registros de progresso da execução do painel de chat:
Completed with 1 error Failure in test unique_fct_order_analysis_order_id Got 287 results, configured to fail if != 0
order_idencontrou entradas duplicadas porque os clientes com vários animais de estimação espalharam os pedidos. - Deixe o agente diagnosticar e se recuperar: como o teste falhou, peça ao agente para depurar. No painel de chat, digite:
The uniqueness test failed. Can you figure out why and fix it? - Assista ao diagnóstico: o agente vai consultar os dados, descobrir a relação de um para muitos em
pet_profiles, explicar que a junção direta muda a granularidade de uma linha por pedido para uma linha por pedido por animal de estimação e reescrever o modelo para pré-agregar os perfis de animais de estimação:-- Pre-aggregating pets per customer to resolve fan-out LEFT JOIN ( SELECT customer_id, COUNT(*) AS num_pets, STRING_AGG(DISTINCT pet_type, ', ') AS pet_types, STRING_AGG(DISTINCT dietary_needs, ', ') AS dietary_needs FROM pet_profiles GROUP BY customer_id ) pet_agg ON c.customer_id = pet_agg.customer_id - Verificar a correção: o agente executa
dbt buildnovamente, e desta vez todos os modelos são materializados e todos os testes são aprovados.
Resumo da seção:seja evitando proativamente o bug ou se recuperando após uma falha no teste, o agente demonstrou capacidade de transpor o limite do Cloud SQL, integrar dados de perfil de clientes e animais de estimação, além de manter a granularidade perfeita da tabela de fatos. O pipeline agora está robusto, completo e totalmente testado.
10. Entregar a resposta
É quinta-feira. Você começou a semana com um CFO preocupado e dados espalhados por três serviços de nuvem. Agora você tem a causa raiz e um pipeline de produção. É hora de dar a resposta, junto com uma recomendação prospectiva apoiada por uma previsão quantitativa.
Escreva o resumo executivo
- No painel de chat, digite:
Write an executive summary covering: - Main findings and the quantitative margin impact - Project AOV for the subsequent quarter if the B2B program continues at its current trajectory - A data-driven recommendation - Assista o agente trabalhar.
- Analise o resumo executivo do agente. Uma resposta típica e bem estruturada deve abordar:
- Principal descoberta: o AOV de janeiro caiu apenas devido ao novo canal B2B-Wholesale. On-line e off-line permanecem estáveis em US$110.
- Causa principal: a promoção "B2B Wholesale Push" (25% de desconto em pedidos em massa) atraiu 100 novas contas, gerando cerca de 25.000 pedidos.
- Impacto na margem: os pedidos no atacado reduziram o lucro médio por unidade em cerca de 65% (de US$7,50 para US$2,60).
- Receita: receita geral estável, já que o alto volume de B2B compensa os preços mais baixos.
Prever o VMA com AI.FORECAST
- O agente também precisa gerar uma projeção para o futuro. Procure uma chamada da ferramenta MCP em que o agente executa uma consulta
AI.FORECASTno BigQuery. Isso usa o modelo de fundação TimesFM integrado para projetar o VMA em 90 dias com base em tendências históricas. A consulta deve projetar o VMA em 90 dias em dois cenários: continuação da campanha (VMA estruturalmente deprimido) x encerramento da campanha (recuperação para ~$110).
- Analise as recomendações estratégicas do agente. Um conjunto robusto de recomendações pode incluir:
- Reestruture os descontos: implemente preços mínimos de margem ou limite os descontos em massa para proteger as margens no nível da unidade.
- Imponha MOQs mais rigorosos: evite que compradores de varejo abusem dos preços de atacado.
- Relatórios separados: acompanhe as divisões de varejo e B2B de forma independente para não mascarar a performance do varejo.
A história completa
O que começou na segunda-feira como um simulado de incêndio devido a uma queda de 7% no valor médio do pedido tem uma resolução clara para o CFO:
- Saúde do varejo: os principais canais de varejo permanecem íntegros e estáveis no nível de referência.
- Aumento no atacado: a queda no VMC é totalmente devido ao novo canal de atacado B2B e à campanha
BIGORDER25. - Impacto na margem: o desconto por atacado de 25% reduziu muito as margens unitárias, ameaçando a lucratividade apesar da receita estável.
- Previsão estratégica: uma projeção
AI.FORECASTmostra que a reestruturação dos níveis de atacado vai restaurar o VMP combinado.
Você oferece uma recomendação baseada em dados para estabelecer limites mínimos de margem no atacado e relatórios separados de varejo/B2B.
Resumo da seção:você pediu para o agente escrever um resumo executivo com análise de margem, gerar uma projeção AI.FORECAST e fornecer uma recomendação baseada em dados. A investigação foi concluída.
11. Limpeza
Para evitar cobranças contínuas na sua conta do Google Cloud, exclua os recursos criados neste codelab executando o script de encerramento.
- No painel Terminal na parte de baixo do IDE do Antigravity (ou no Cloud Shell), acesse o diretório do codelab e execute:
cd ~/devrel-demos/codelabs/agentic-data-labs/scripts
chmod +x teardown.sh
./teardown.sh
- O script vai mostrar todos os recursos que planeja excluir e pedir confirmação antes de continuar:
- Instância do Cloud SQL (
cymbal-pets-ops): é o recurso mais caro. - Conjunto de dados do BigQuery (
cymbal_pets): todas as tabelas e modelos - Bucket do Cloud Storage (
gs://YOUR_PROJECT_ID-cymbal-pets-raw) - Conexão do BigQuery (
cymbal-pets-cloudsql)
- Instância do Cloud SQL (
- Digite
ypara confirmar. A desmontagem leva cerca de 2 a 3 minutos.
[INFO] Deleting Cloud SQL instance cymbal-pets-ops... [ OK ] Cloud SQL instance deleted. [INFO] Deleting BigQuery dataset cymbal_pets... [ OK ] BigQuery dataset deleted. [INFO] Deleting GCS bucket gs://YOUR_PROJECT_ID-cymbal-pets-raw... [ OK ] GCS bucket deleted.
12. Parabéns!
Você concluiu A investigação dos bichinhos de estimação de Cymbal. Você passou de uma pergunta vaga do CFO para uma recomendação totalmente operacionalizada e respaldada por previsões, usando um agente de IA que funciona em todo o patrimônio de dados do Google Cloud.
O que você realizou
- 🔍 Explorado em vários serviços: ativos descobertos e visualizados em BigQuery, Cloud SQL e Cloud Storage usando o Knowledge Catalog do Data Agent Kit.
- 🕵️♂️ Investigação com IA: consultou vários serviços em uma única conversa no painel de chat usando as ferramentas do MCP para rastrear a anomalia do VMA até uma campanha promocional B2B em massa.
- 🔧 Criou um pipeline de produção: gerou um projeto completo do dbt para limpar, unir e testar dados transacionais e dados do cliente.
- 🐛 Depuração de um bug de distribuição de dados: o agente diagnosticou automaticamente um problema de granularidade e refatorou o modelo SQL dbt para pré-agregar perfis de animais de estimação dos clientes.
- 📈 Previsto e recomendado: usamos o
AI.FORECASTintegrado do BigQuery para modelar tendências de AOV e entregamos uma recomendação baseada em dados ao CFO.
Principais conceitos
Conceito | O que você aprendeu |
Ferramentas do MCP | Conexões seguras e auditáveis que permitem que o agente de IA consulte serviços como BigQuery, Cloud SQL, Spanner e outros bancos de dados em seu nome, com cada chamada visível no painel de chat |
Habilidades do agente | Conjuntos de instruções pré-criados (como |
Investigação entre serviços | O agente consulta vários serviços do Google Cloud em uma única conversa, sem configuração de conexão nem troca de contexto entre consoles. |
Comandos orientados a metas | Dizer ao agente o que você quer ("crie um projeto do dbt que calcule o VMP por canal") em vez de como, e deixar que ele escolha a abordagem de implementação |
Data Agent Kit | A extensão que une tudo: ferramentas do MCP, habilidades do agente e descoberta de dados. Assim, você tem acesso a todos os seus dados do Google Cloud no IDE de sua preferência. |
Próximas etapas
- Leia a documentação do Data Agent Kit para saber mais sobre os recursos dele.
- Saiba mais sobre as funções de IA e do BigQuery ML, incluindo
AI.FORECAST,AI.GENERATEeAI.EMBED. - Crie sua própria investigação entre serviços com o IDE do Antigravity usando seus dados