
1. Ringkasan
Kita semua tahu masalah "data gelap". File PDF, gambar, dan file teks yang berada di bucket penyimpanan cloud, sama sekali tidak terlihat oleh kueri SQL dan dasbor BI Anda. Biasanya, untuk mengakses data ini diperlukan pipeline OCR yang kompleks, entri data manual, atau skrip kustom yang rentan.
Jangan khawatir.
Di lab ini, saya akan menunjukkan cara mengonversi 400 file PDF tidak terstruktur — yang mencakup teks, tabel, dan gambar — menjadi tabel BigQuery yang terstruktur dengan rapi dan hubungan antar-tabel disimpulkan secara otomatis. Kita akan melakukannya dalam hitungan menit menggunakan BigQuery Knowledge Catalog dan Dataplex.
Yang akan Anda build
Untuk mewujudkan hal ini, mari kita lihat bisnis fiktif: waralaba Yoghurt Beku yang berkembang pesat.
Bayangkan Anda mengelola data untuk bisnis Froyo ini. Anda memiliki ratusan resep dan lembar spesifikasi pemasok, semuanya disimpan sebagai PDF. Para pemimpin bisnis ingin meluncurkan agen AI untuk membantu pengelola toko dan pelanggan mengkueri detail produk.
Berikut skenario buruknya: Seorang pelanggan bertanya, "Saya sangat tertarik dengan froyo Midnight Swirl Anda. Apakah ada alergen di dalamnya?"
Untuk menjawabnya, sistem Anda biasanya harus:
- Temukan PDF resep "Midnight Swirl".
- Baca bahan-bahannya (misalnya, "Bubuk Kakao", "Dasar Susu", "Pengemulsi X").
- Telusuri puluhan PDF Pemasok untuk menemukan lembar spesifikasi bahan-bahan tertentu tersebut.
- Periksa lembar pemasok untuk mengetahui alergen tersembunyi yang terkait dengan bahan-bahan tersebut.
Mencoba membangun agen AI yang melakukan hal ini secara langsung dengan membaca 400 PDF mentah saat runtime akan lambat, mahal, dan rentan terhadap halusinasi. Sebagai gantinya, kita akan menggunakan inferensi semantik untuk mengekstrak semua ini ke dalam database relasional terlebih dahulu, sehingga agen AI kita di masa mendatang akan sangat cepat dan 100% didasarkan pada data SQL faktual.
Mulai membangun.
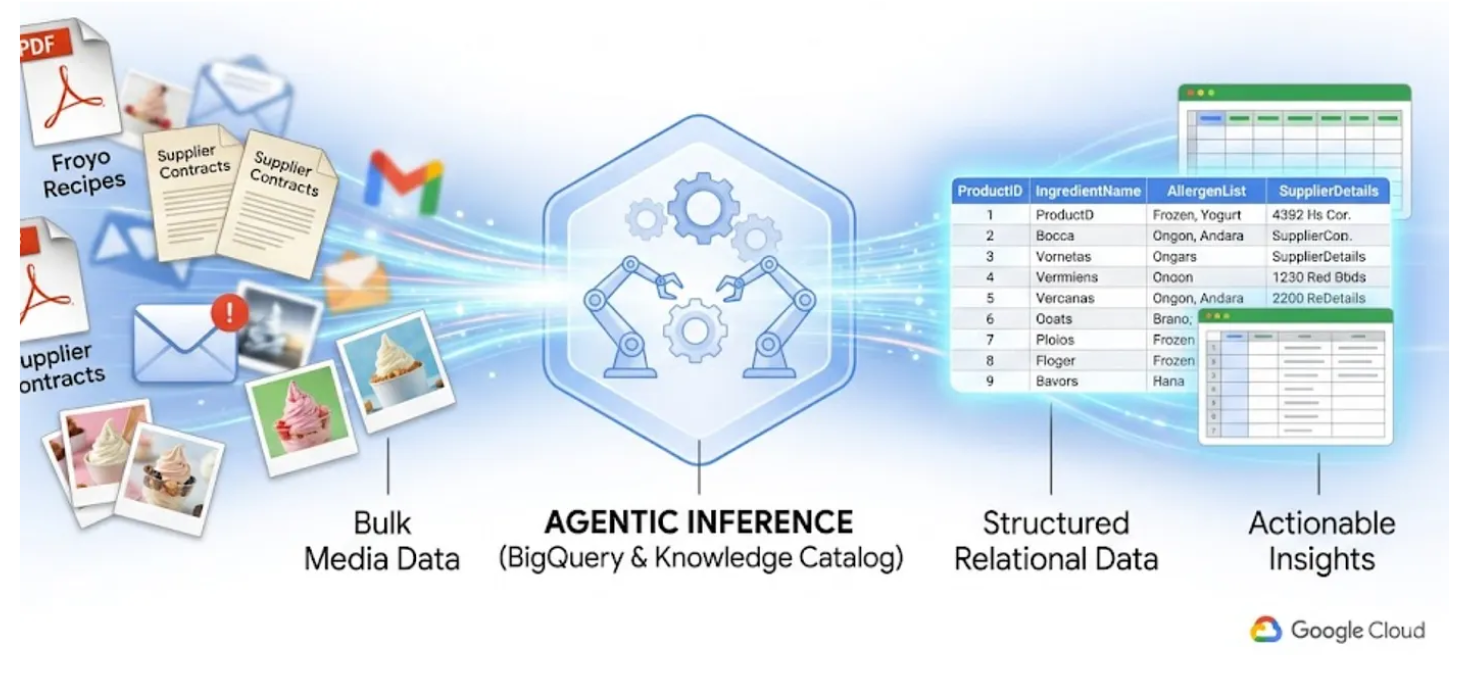
Yang akan Anda pelajari
- Cara menyiapkan bucket Cloud Storage untuk file sumber (PDF)
- Cara menyiapkan dan menjalankan tugas Datascan dan inferensi semantik di Knowledge Catalog untuk mengekstrak data dari PDF sumber dan menyimpulkan koneksi dan konteks secara semantik serta menyimpannya di BigQuery
- Cara menggunakan Agen BigQuery untuk melakukan percakapan dengan set data yang baru dibuat
Persyaratan
2. Sebelum memulai
Membuat project
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project.
- Anda akan menggunakan Cloud Shell, lingkungan command line yang berjalan di Google Cloud. Klik Activate Cloud Shell di bagian atas konsol Google Cloud.

- Setelah terhubung ke Cloud Shell, Anda dapat memeriksa bahwa Anda sudah diautentikasi dan project sudah ditetapkan ke project ID Anda menggunakan perintah berikut:
gcloud auth list
- Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa perintah gcloud mengetahui project Anda.
gcloud config list project
- Jika Anda ingin melakukan autentikasi
gcloud auth login
- Jika project Anda belum ditetapkan, gunakan perintah berikut untuk menetapkannya:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Aktifkan API yang diperlukan: Jalankan perintah ini untuk mengaktifkan semua API yang diperlukan:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
Masalah Umum & Pemecahan Masalah
Sindrom "Project Hantu" | Anda menjalankan |
Penghalang Penagihan | Anda telah mengaktifkan project, tetapi lupa menambahkan akun penagihan. AlloyDB adalah mesin berperforma tinggi; AlloyDB tidak akan dimulai jika "tangki bahan bakar" (penagihan) kosong. |
Keterlambatan Penyebaran API | Anda mengklik "Aktifkan API", tetapi command line masih menampilkan |
Quags Kuota | Jika menggunakan akun uji coba yang baru, Anda mungkin mencapai kuota regional untuk instance AlloyDB. Jika |
Agen Layanan"Tersembunyi" | Terkadang, Agen Layanan AlloyDB tidak otomatis diberi peran |
3. Penyiapan Bucket Google Cloud Storage
Di bagian ini, Anda akan membuat struktur organisasi dalam BigQuery untuk menyimpan data resep dan pemasok Froyo, khususnya untuk detail produk Froyo. Tindakan ini juga membuat Koneksi Resource Cloud, yang berfungsi sebagai "jembatan" aman yang memungkinkan BigQuery membaca file dari sumber eksternal seperti Cloud Storage.
Sebelum memulai:
Repositori ini berisi resep, file PDF pemasok yang akan kita gunakan dalam project ini. Pastikan Anda mendownload file ini. Untuk mendownload file, lakukan hal berikut.
Di Cloud Shell, jalankan perintah berikut:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
Buka folder yang baru dibuat:
cd next-26-keynotes
Tarik folder data-cloud-demo
git sparse-checkout set genkey/data-cloud-demo
Setelah checkout selesai, buka folder data-cloud-demo dan ekstrak file ZIP untuk mengakses aset codelab.
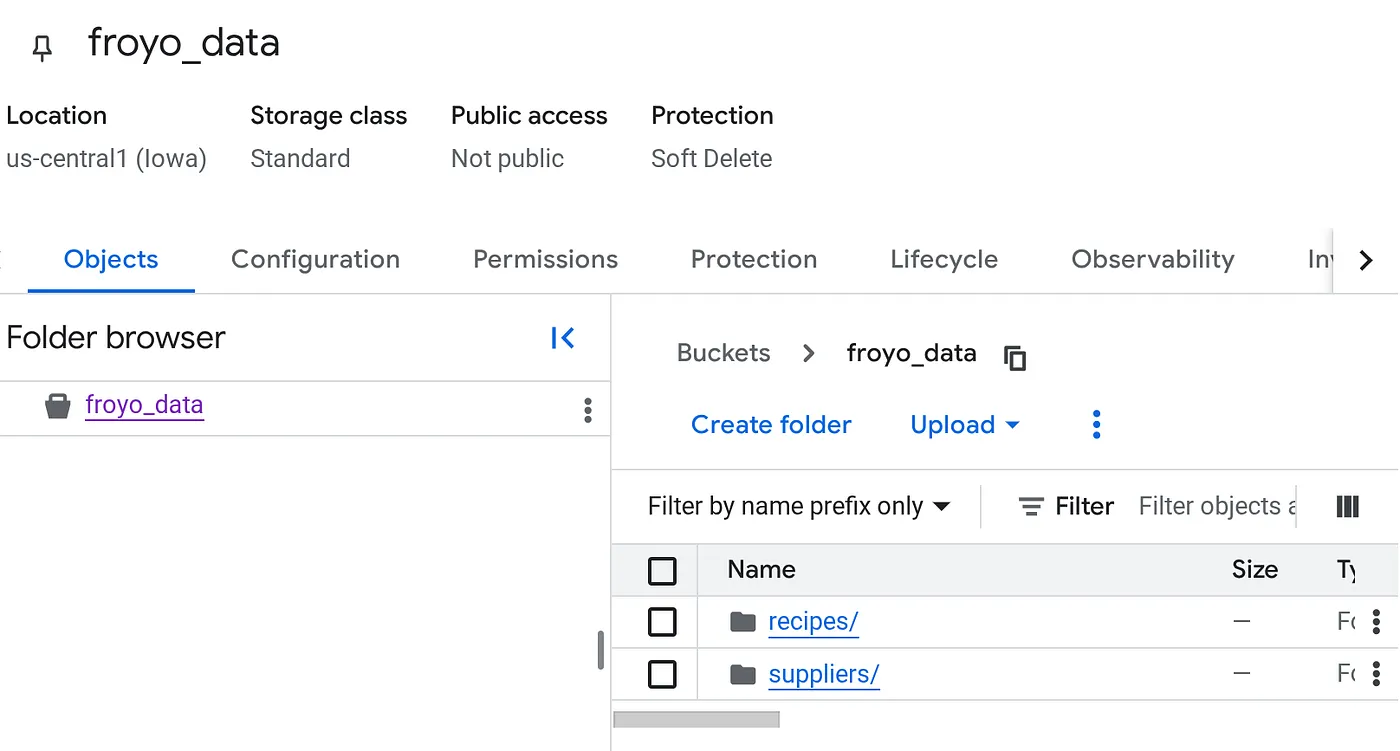
Buat bucket dan upload file PDF Froyo (resep & pemasok)
- Di konsol Google Cloud, buka halaman Cloud Storage Buckets.
- Klik Buat.
- Di halaman Buat bucket, masukkan informasi bucket Anda. Setelah setiap langkah berikut, klik Lanjutkan untuk melanjutkan ke langkah berikutnya:
- Di bagian Mulai, masukkan nama bucket. Contoh: froyo_data
- Di bagian Pilih tempat untuk menyimpan data Anda, pilih Region, lalu masukkan region Anda. us-central1
- Di bagian Choose how to control access to objects, hapus centang pada kotak Enforce public access prevention on this bucket.
- Klik Buat.
- Pada daftar bucket, klik bucket yang Anda buat.
- Di tab Objects untuk bucket, klik Upload, lalu Upload folder.
- Pilih folder recipes yang Anda ekstrak di bagian Sebelum memulai codelab ini.
- Klik Upload.
- Ulangi proses upload untuk folder suppliers.
Setelah diupload, struktur bucket Anda akan terlihat seperti (apa pun nama bucketnya):
4. Penyiapan Koneksi BigQuery
Buat Koneksi Resource Cloud. Tindakan ini akan menghasilkan Akun Layanan unik yang bertindak sebagai "kartu identitas" BigQuery untuk mengakses file eksternal.
- Buka halaman BigQuery.
- Di panel kiri, klik Explorer. Jika Anda tidak melihat panel kiri, klik Luaskan panel kiri untuk membuka panel.
- Di panel Explorer, luaskan nama project Anda, lalu klik Koneksi.
- Di halaman Koneksi, klik Buat koneksi.
- Untuk Connection type, pilih Vertex AI model jarak jauh, fungsi jarak jauh, BigLake dan Spanner (Cloud Resource).
- Di kolom Connection ID, masukkan nama ID koneksi:
- bq-connection. Pastikan untuk mencatat ID ini karena Anda akan memerlukannya saat menyiapkan pemindaian data nanti dalam codelab ini.
- Tetapkan Location type ke Region, lalu pilih region. Misalnya, us-central1. Koneksi harus berada di region yang sama dengan resource Anda yang lain seperti set data.
- Klik Buat koneksi.
- Klik Buka koneksi.
- Di panel Connection info, salin ID akun layanan untuk digunakan pada langkah berikutnya. Akun layanan tersebut akan terlihat seperti bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
5. Penyiapan Izin
- Memberikan izin yang diperlukan ke koneksi BigQuery untuk mengakses objek Cloud Storage dan Knowledge Catalog
Buka halaman IAM & Admin, lalu di bagian View by Principals, klik tombol Grant access, tambahkan principal dengan menempelkan akun layanan yang Anda salin pada langkah terakhir. Di bagian peran, tambahkan nama peran berikut satu per satu dan simpan:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- Memberi izin Akun Layanan Dataplex untuk mengakses Bucket Cloud Storage
Buka halaman IAM & Admin dan di bagian View by Principals, klik tombol Berikan akses dan tambahkan akun utama dengan mengetik kata dataplex ke dalam kolom teks New principal. Dari daftar yang otomatis melengkapi, pilih principal Akun Layanan Dataplex yang terlihat mirip dengan ini: (gunakan nomor project, bukan project ID di ID email akun layanan di bawah)
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Jika karena alasan apa pun akun layanan di atas untuk nomor project Anda tidak dikenali, mungkin saja project belum menginisialisasi layanan Dataplex. Buka Terminal Cloud Shell dan coba aktifkan API (jika belum dilakukan pada tahap sebelum Anda memulai) dengan menjalankan perintah berikut: gcloud services enable dataplex.googleapis.com
Bahkan setelah itu, jika akun layanan untuk Dataplex tidak dikenali, paksa pembuatan tugas pemindaian Dataplex uji di halaman Penataan Metadata dan masukkan detailnya di halaman pembuatan Tugas penemuan:
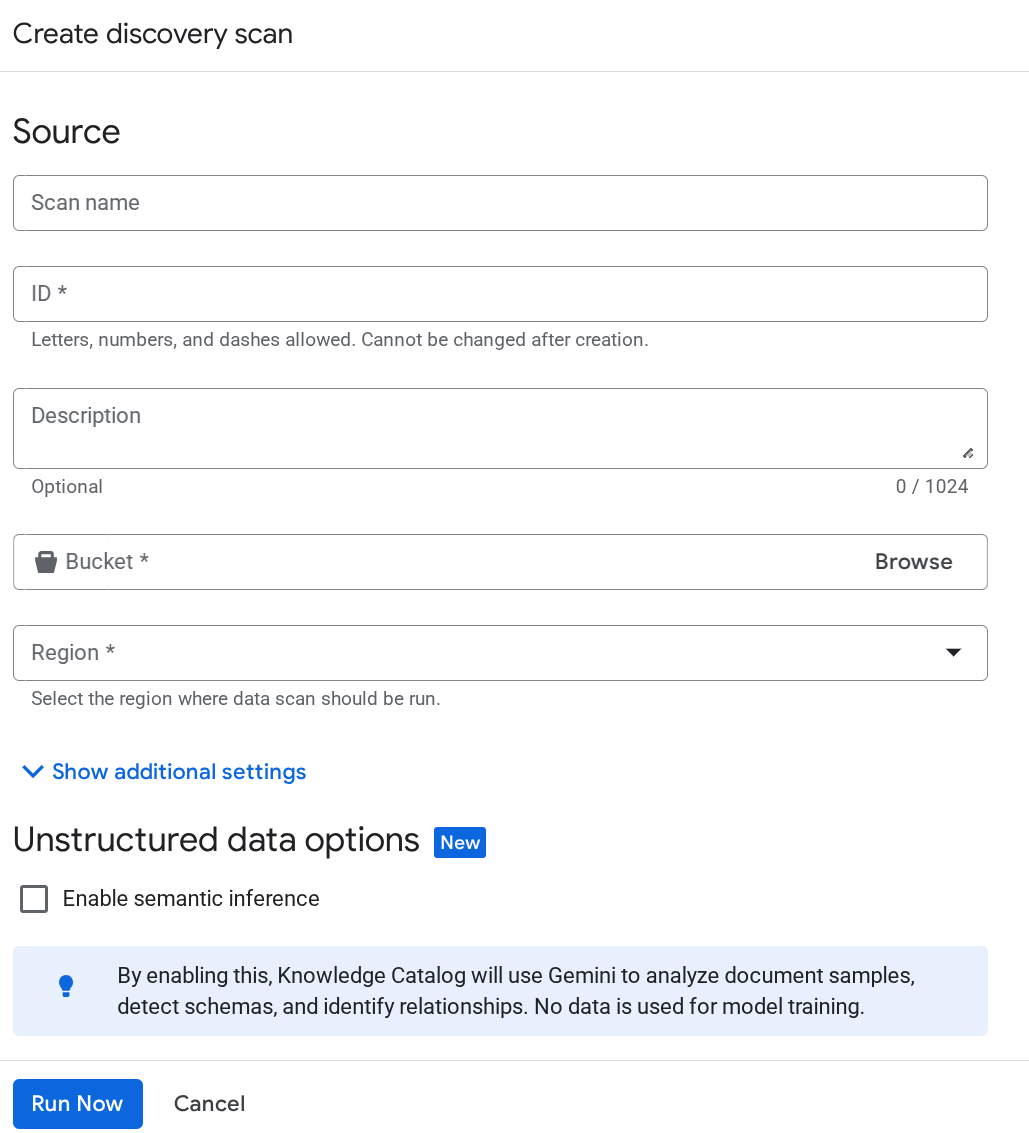
Klik Run Now. Pekerjaan akan gagal, tetapi hal ini akan memastikan ID akun layanan diinisialisasi untuk layanan Dataplex Anda sekarang.
Kembali ke halaman IAM & Admin, lalu di bagian View by Principals, klik tombol Grant access, lalu klik tambahkan akun utama. Tempel akun layanan:
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Kemudian, berikan peran berikut ke Akun Layanan ini:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. Penyiapan Knowledge Catalog
Buat Knowledge Catalog untuk menyatukan data tidak terstruktur dan mengotomatiskan penemuan file tidak terstruktur (seperti resep PDF dan pemasok PDF).
Buat tugas DataScan dari konsol:
- Buka halaman Kurasi metadata.
- Klik Buat, lalu masukkan detail yang sesuai dengan penyiapan Anda:
Catatan Penting: Jangan lupa untuk mencentang Aktifkan Inferensi Semantik.
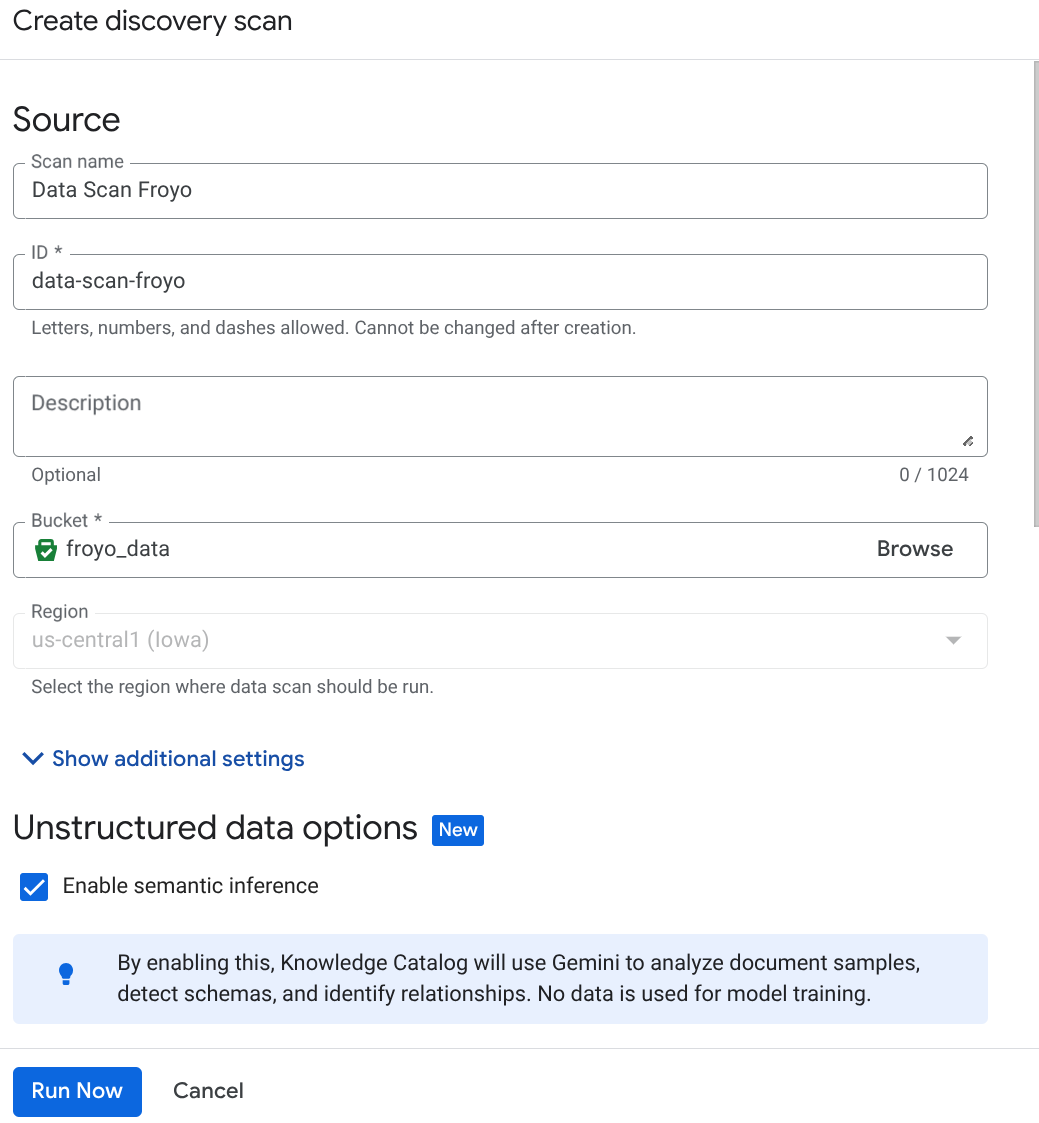
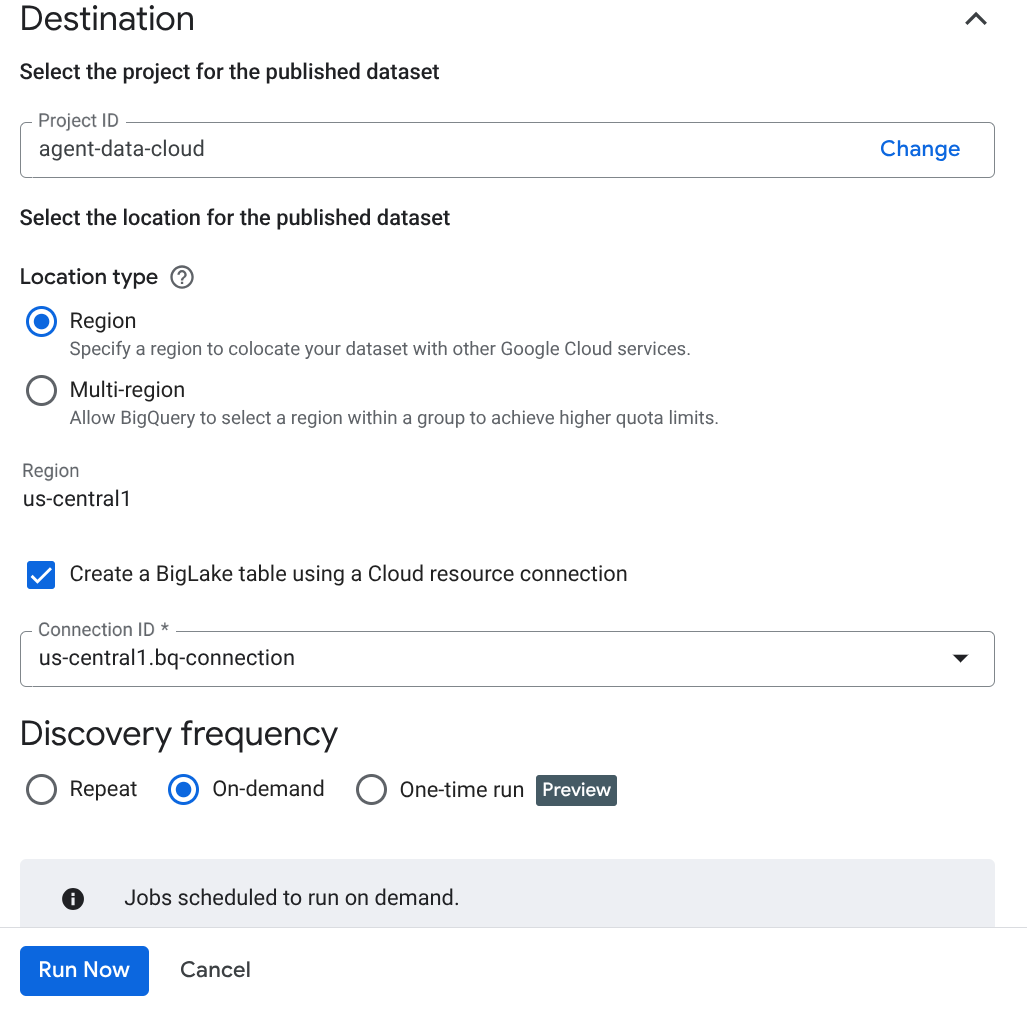
- Klik "Run Now".
- Perlu waktu beberapa saat untuk menyelesaikan tugas pemindaian. Setelah tugas selesai, periksa apakah set data yang Dipublikasikan ada. Untuk memeriksa status tugas, Anda dapat memeriksa di halaman Kurasi metadata, di tab penemuan Cloud Storage, klik nama pemindaian penemuan dari tugas yang baru saja dijalankan. Anda akan melihat set data yang dipublikasikan seperti yang terlihat di bawah:
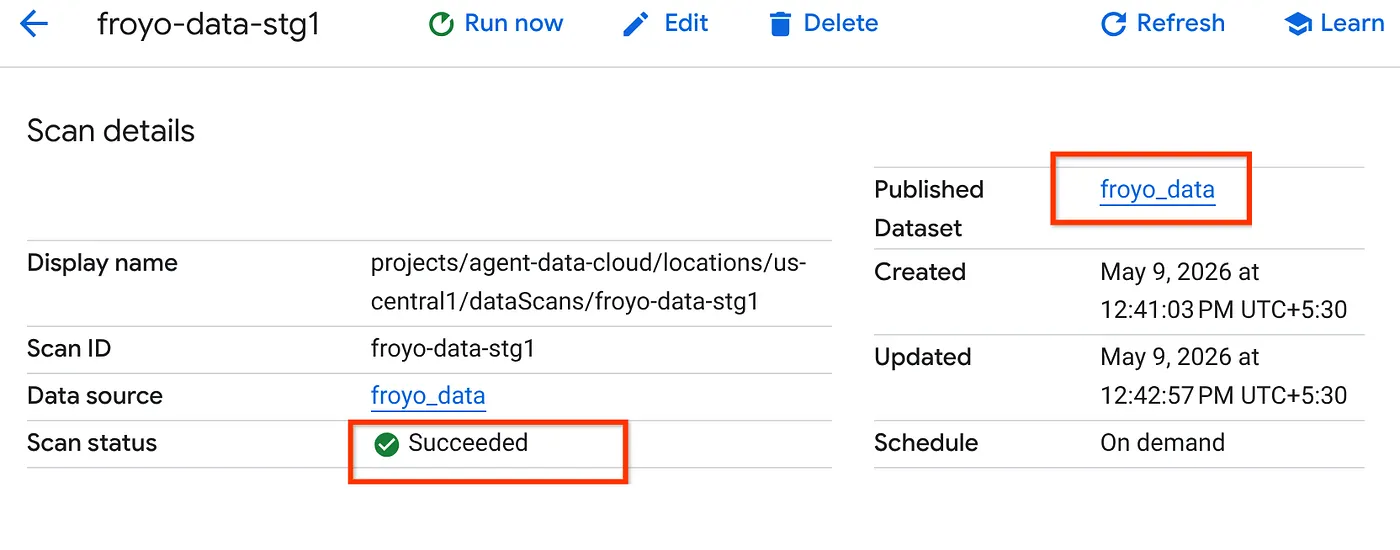
Catatan: Jika Anda mengalami error pada langkah pemindaian, tunggu beberapa saat, lalu coba lagi (diperlukan waktu beberapa menit untuk membuat tugas dan menyelesaikan eksekusi).
- Anda dapat melihat tabel di BigQuery dengan mengklik dan membuka set data froyo_data. Klik ID tabel di BigQuery dan jalankan kueri di bawah di tab Query Editor:
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
Hal ini akan menghasilkan 400 (jika tidak, Anda dapat kembali dan menjalankan tugas Pemindaian Data lagi).
7. Ekstraksi Data Semantik
Bagus!! Sekarang, mari kita ekstrak inferensi untuk objek tidak terstruktur ini menggunakan Knowledge Catalog.
Kita akan menggunakan fitur Insight untuk membuat pernyataan SQL guna mengekstrak data terstruktur dari tabel tidak terstruktur
- Di konsol Google Cloud, buka halaman Penelusuran Knowledge Catalog.
- Telusuri tabel set data yang ingin Anda lihat insight-nya. Di kotak penelusuran, masukkan nama set data / tabel dari langkah sebelumnya: "froyo_data", lalu tekan enter
- Dari daftar hasil, klik entri TABEL (bukan yang set data)
- Anda akan melihat tab INSIGHTS. Klik tombol tersebut (jika Anda diminta untuk mengaktifkan API, ikuti langkah-langkahnya dan aktifkan API).
Jika Anda akhirnya mengaktifkan API pada tahap ini, Anda harus menjalankan kembali tugas pemindaian.
- Di tab INSIGHTS, Anda akan melihat drop-down tombol EKSTRAK. Klik opsi tersebut, lalu pilih opsi "Ekstrak dengan SQL".
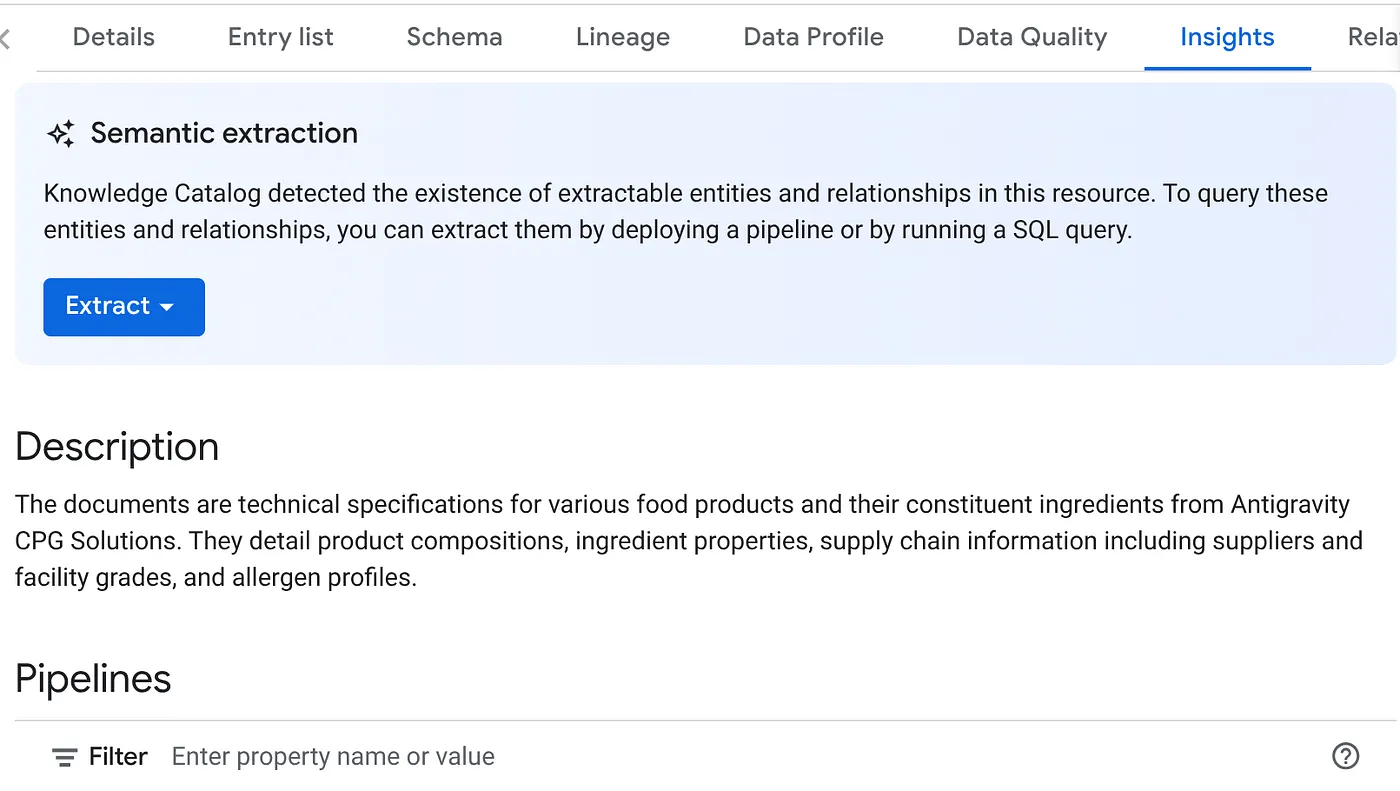
Di dialog pop-up "Ekstrak dengan SQL", tetapkan set data TUJUAN sebagai set data yang Anda lihat dalam hasil tugas Datascan. Mulai ketik namanya dan nama tersebut akan muncul di pelengkapan otomatis. Klik tombol "Ekstrak". Atau, Anda dapat membuat set data baru pada tahap ini dan mengekstraknya.
Tindakan ini akan membuka Editor Kueri BigQuery dengan tab yang diisi dengan SQL yang diekstrak dari inferensi pemindaian data.
8. Validasi SQL & Pembuatan Skema
Jika kueri yang dihasilkan tampak bagus dan relevan secara semantik dengan data tidak terstruktur Anda, lanjutkan dan eksekusi dengan mengklik tombol Jalankan di editor kueri. Proses pembuatan skema yang diperlukan untuk penyimpanan terstruktur media tidak terstruktur Anda akan memakan waktu beberapa menit.
Setelah selesai, Anda akan dapat memverifikasi skema dengan meluaskan set data di panel penjelajah BigQuery Studio seperti yang terlihat di bawah:
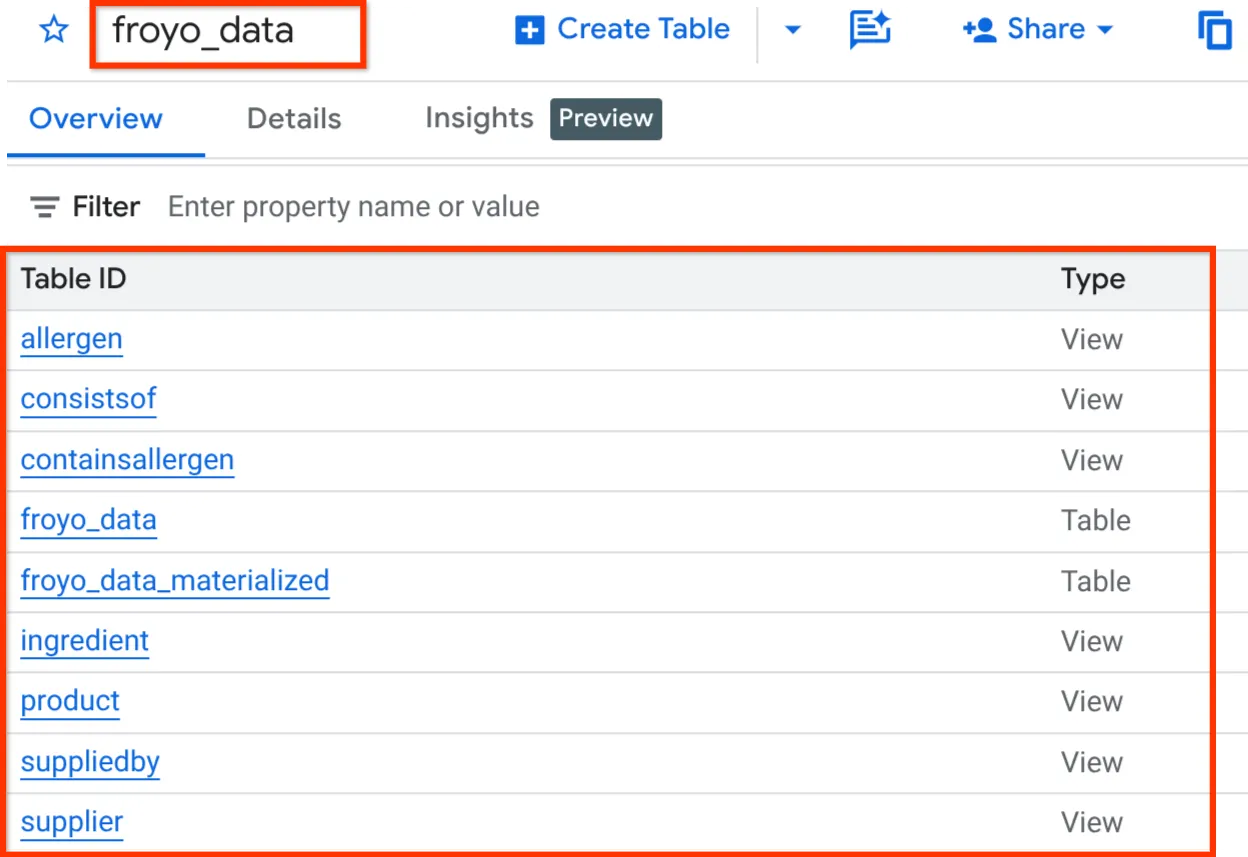
Oke!!! Sangat menyenangkan bahwa kita melakukan semua hal terkait database itu dengan sangat cepat. Sekarang saatnya untuk ujian terakhir.
Langkah-langkah untuk terus mengakses data tanpa akun penagihan:
- Anda bisa mendapatkan file csv data (Data BigQuery) dari link repo github di atas.
- Pertama, buat Set Data BigQuery dengan menjalankan perintah di bawah dari Terminal Cloud Shell:
bq mk --location us-central1 --dataset froyo_data
- Selanjutnya, download 8 file data (file csv) dari repositori github ke direktori kerja Anda dengan menjalankan perintah berikut satu per satu:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Jalankan perintah berikut satu per satu untuk membuat tabel ini dengan data di set data yang baru dibuat
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Setelah set data, tabel, dan data dibuat, Anda dapat melanjutkan untuk menguji dan menggunakan data yang baru saja kita bahas.
9. Ujian Terakhir!!!
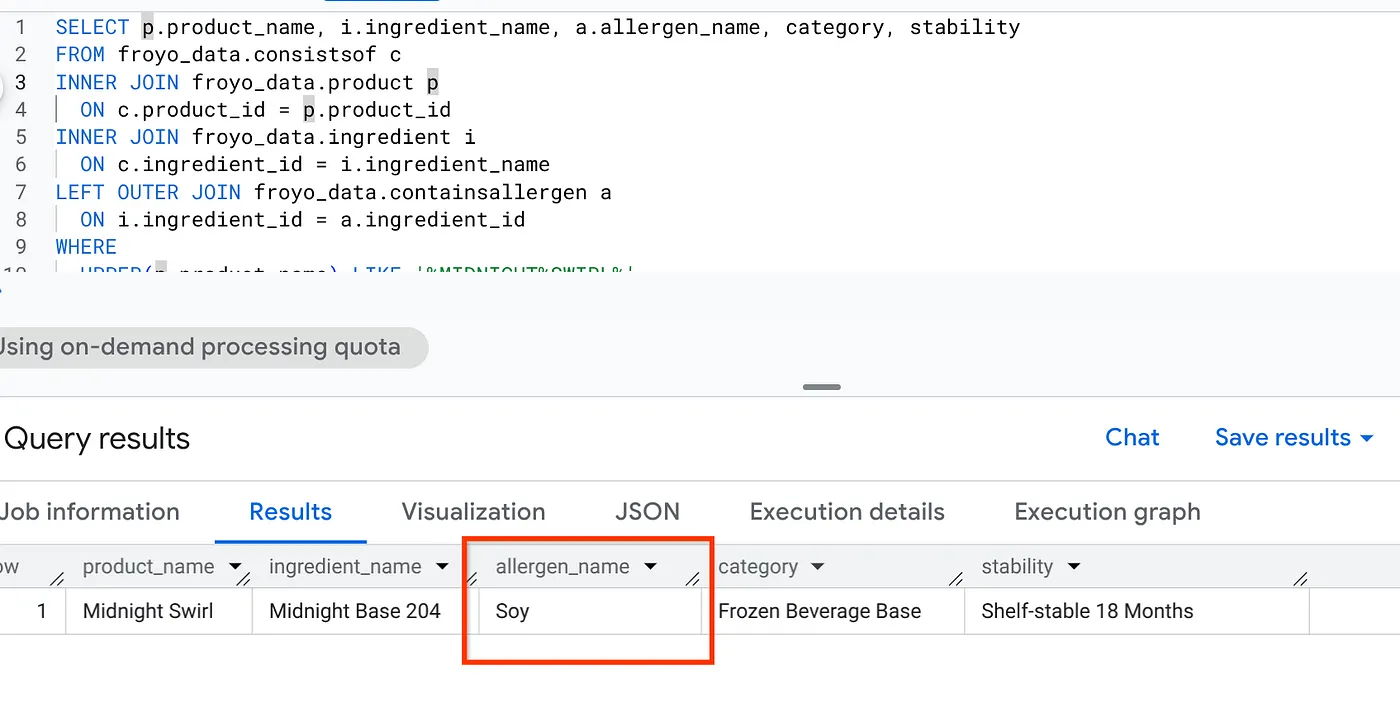
Misalnya, saya ingin agen saya merespons pertanyaan pengguna dengan informasi yang nyata, lengkap, dan terkoordinasi dengan baik yang didasarkan pada fakta. Saya akan mengajukan pertanyaan yang hanya dapat dijawab oleh agen dengan merujuk ke beberapa file media dan referensi dari sumber saya.
Berikut pertanyaan pengguna saya:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
Sekarang, penelusuran umum atau penelusuran LLM akan menampilkan "Nol bahan". Namun, kami membangun inferensi semantik lengkap yang mengonversi semua media tidak terstruktur kami menjadi data terstruktur. Berikut adalah SQL sederhana yang akan mengambil informasi ini:
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
Hore! Lihat hasilnya:
10. Pembersihan
Setelah lab ini selesai, jangan lupa untuk menghapus tugas pemindaian dan tabel BigQuery yang dibuat oleh tugas tersebut.
Buka https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery. Pilih tugas yang ingin Anda hapus dengan mengklik elipsis vertikal di sampingnya, lalu klik HAPUS.
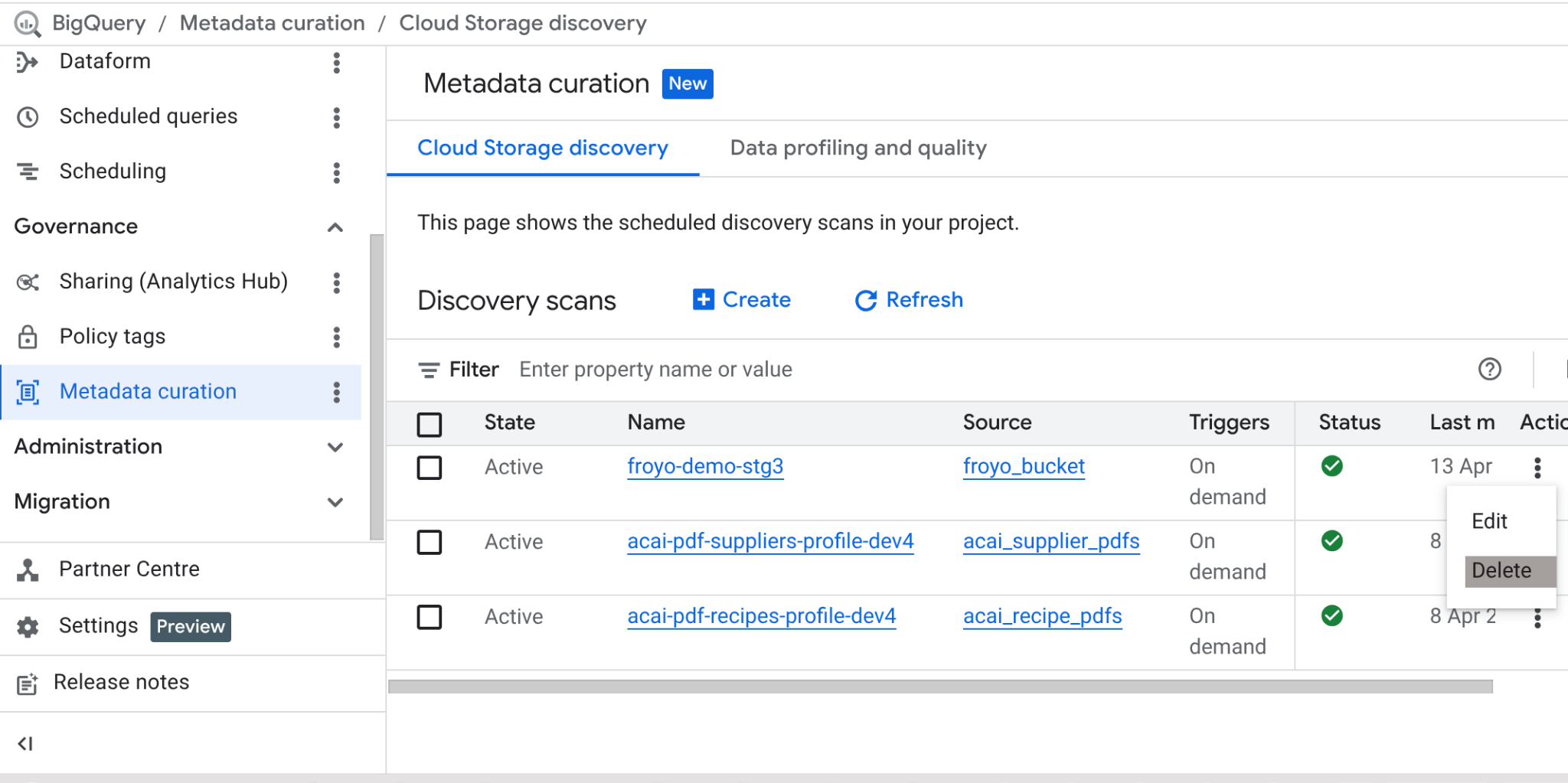
Tindakan ini akan membersihkan tugas.
11. Selamat
Implementasi kami berhasil mengidentifikasi alergen tersembunyi. Tidak ada lagi data gelap, teman-teman!!! Di bagian 2, kita akan menggabungkan data BigQuery ini dalam sistem transaksional dengan AlloyDB untuk menyatukan kebutuhan data aplikasi agentik kita.