
1. 개요
'다크 데이터'의 고통은 모두 잘 알고 있습니다. SQL 쿼리 및 BI 대시보드에 완전히 표시되지 않는 클라우드 스토리지 버킷에 있는 PDF, 이미지, 텍스트 파일입니다. 이 데이터를 활용하려면 기존에는 복잡한 OCR 파이프라인, 수동 데이터 입력 또는 불안정한 맞춤 스크립트가 필요했습니다.
더 이상은 그럴 필요가 없습니다.
이 실습에서는 텍스트, 표, 이미지를 포함하는 400개의 구조화되지 않은 PDF 파일을 관계가 자동으로 추론되는 깔끔하게 구조화된 BigQuery 테이블로 변환하는 방법을 보여드리겠습니다. BigQuery Knowledge Catalog와 Dataplex를 사용하면 몇 분 만에 이 작업을 완료할 수 있습니다.
빌드할 항목
실제 사례를 살펴보기 위해 빠르게 성장하는 프로즌 요거트 프랜차이즈라는 가상의 비즈니스를 살펴보겠습니다.
이 Froyo 비즈니스의 데이터를 관리한다고 가정해 보겠습니다. 수백 개의 레시피와 공급업체 사양 시트가 모두 PDF로 저장되어 있습니다. 비즈니스 리더는 매장 관리자와 고객이 제품 세부정보를 쿼리할 수 있도록 AI 에이전트를 출시하려고 합니다.
악몽 같은 시나리오를 살펴보겠습니다. 한 고객이 '미드나잇 스월 프로요에 관심이 있습니다. 알레르기 유발 물질이 있나요?'
이 질문에 답하려면 시스템에서 일반적으로 다음을 수행해야 합니다.
- 'Midnight Swirl' 레시피 PDF를 찾습니다.
- 재료 (예: '코코아 파우더', '유제품 베이스', '유화제 X')를 읽습니다.
- 수십 개의 공급업체 PDF를 검색하여 특정 성분의 사양 시트를 찾습니다.
- 공급업체 시트에서 해당 성분과 관련된 숨겨진 알레르기 유발 물질을 확인합니다.
런타임에 400개의 원시 PDF를 읽어 즉석에서 이 작업을 수행하는 AI 에이전트를 빌드하려고 하면 속도가 느리고 비용이 많이 들며 엉뚱한 대답을 할 가능성이 높습니다. 대신 시맨틱 추론을 사용하여 이 모든 것을 먼저 관계형 데이터베이스로 추출하여 향후 AI 에이전트가 매우 빠르고 사실적인 SQL 데이터를 기반으로 100% 작동하도록 할 것입니다.
빌드를 시작해 보겠습니다.
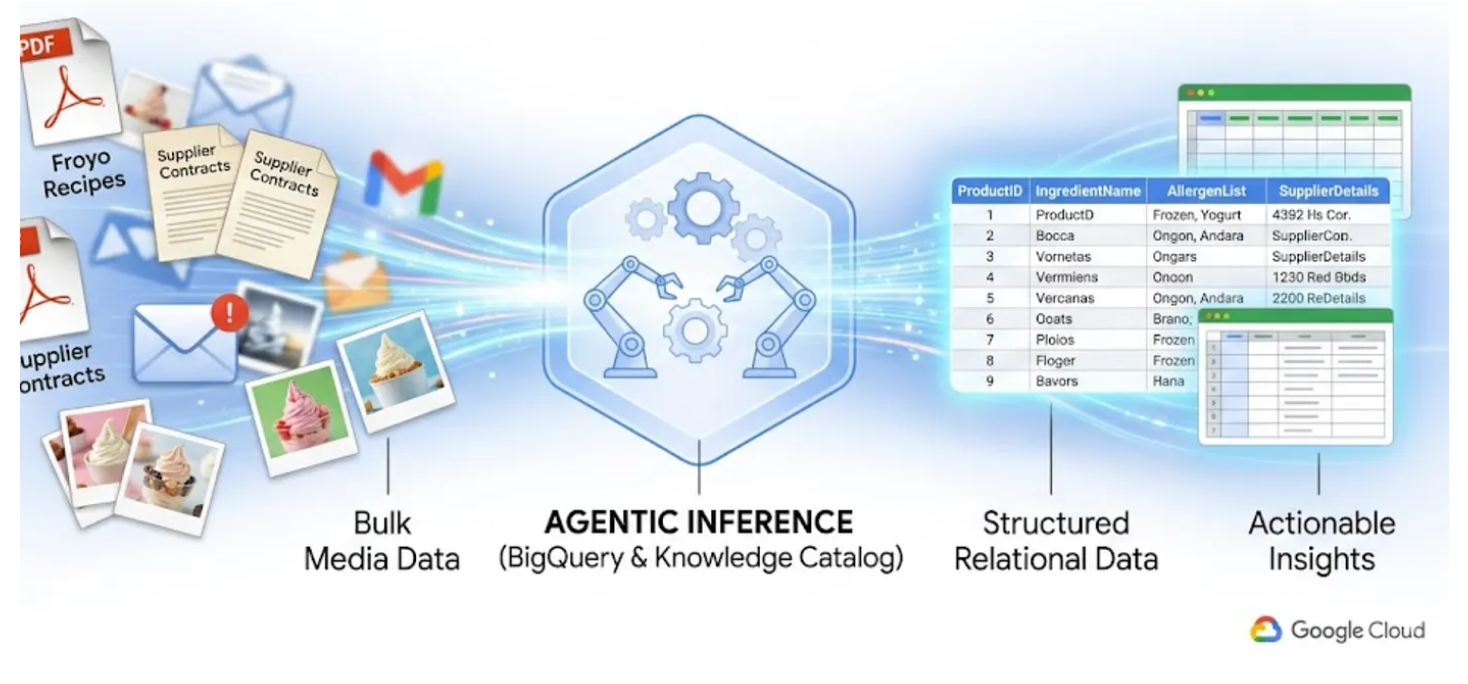
학습할 내용
- 소스 파일 (PDF)용 Cloud Storage 버킷을 설정하는 방법
- Knowledge Catalog에서 데이터 스캔 작업과 시맨틱 추론을 설정하고 실행하여 소스 PDF에서 데이터를 추출하고 연결과 컨텍스트를 시맨틱으로 추론하여 BigQuery에 저장하는 방법
- BigQuery 에이전트를 사용하여 새로 생성된 데이터 세트와 채팅하는 방법
요구사항
2. 시작하기 전에
프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있어야 하므로 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
- Google Cloud에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다. Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.

- Cloud Shell에 연결되면 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
- 인증을 원하는 경우
gcloud auth login
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- 필요한 API 사용 설정: 다음 명령어를 실행하여 필요한 모든 API를 사용 설정합니다.
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
주의사항 및 문제 해결
'유령 프로젝트' 증후군 |
|
결제 바리케이드 | 프로젝트를 사용 설정했지만 결제 계정을 잊었습니다. AlloyDB는 고성능 엔진이므로 '연료 탱크' (결제)가 비어 있으면 시작되지 않습니다. |
API 전파 지연 | 'API 사용 설정'을 클릭했지만 명령줄에 여전히 |
할당량 Quags | 새 체험판 계정을 사용하는 경우 AlloyDB 인스턴스의 리전별 할당량에 도달할 수 있습니다. |
'숨겨진' 서비스 에이전트 | AlloyDB 서비스 에이전트에는 |
3. Google Cloud Storage 버킷 설정
이 섹션에서는 BigQuery 내에 조직 구조를 만들어 Froyo 제품 세부정보를 위한 Froyo 레시피 및 공급업체 데이터를 저장합니다. 또한 BigQuery가 Cloud Storage와 같은 외부 소스에서 파일을 읽을 수 있도록 하는 보안 '브리지' 역할을 하는 Cloud 리소스 연결을 설정합니다.
시작하기 전에
이 저장소에는 이 프로젝트에서 사용할 레시피와 공급업체 PDF 파일이 포함되어 있습니다. 이 파일을 다운로드해야 합니다. 파일을 다운로드하려면 다음 단계를 따르세요.
Cloud Shell에서 다음 명령어를 실행합니다.
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
새로 만든 폴더로 이동합니다.
cd next-26-keynotes
data-cloud-demo 폴더를 가져옵니다.
git sparse-checkout set genkey/data-cloud-demo
결제가 완료되면 data-cloud-demo 폴더로 이동하여 ZIP 파일을 추출하여 Codelab 애셋에 액세스합니다.
버킷을 만들고 Froyo (레시피 및 공급업체) PDF 파일 업로드
- Google Cloud 콘솔에서 Cloud Storage 버킷 페이지로 이동합니다.
- '만들기'를 클릭합니다.
- 버킷 만들기 페이지에서 버킷 정보를 입력합니다. 다음 각 단계를 완료한 후 계속을 클릭하여 다음 단계로 진행합니다.
- 시작하기 섹션에 버킷 이름을 입력합니다. 예: froyo_data
- 데이터 저장 위치 선택 섹션에서 리전을 선택한 후 리전을 입력합니다(us-central1).
- 객체 액세스를 제어하는 방식 선택 섹션에서 '이 버킷에 공개 액세스 방지 적용' 체크박스를 선택 해제합니다.
- '만들기'를 클릭합니다.
- 버킷 목록에서 만든 버킷을 클릭합니다.
- 버킷의 객체 탭에서 업로드, 폴더 업로드를 차례로 클릭합니다.
- 이 Codelab의 시작하기 전에 섹션에서 추출한 recipes 폴더를 선택합니다.
- ' 업로드'를 클릭하세요.
- suppliers 폴더에 대해 업로드 프로세스를 반복합니다.
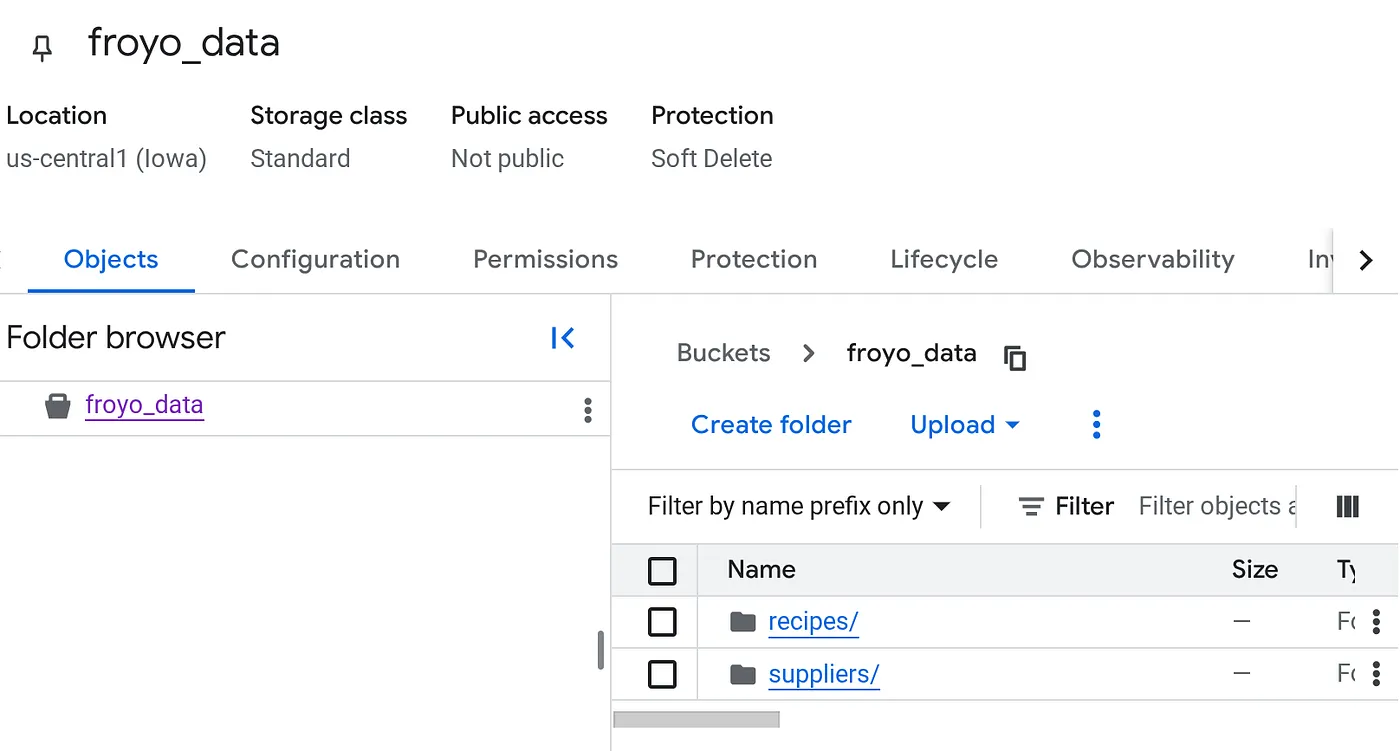
업로드되면 버킷 구조는 다음과 같이 표시됩니다 (버킷 이름이 무엇이든).
4. BigQuery 연결 설정
Cloud 리소스 연결을 만듭니다. 이렇게 하면 외부 파일에 액세스하는 BigQuery의 'ID 카드' 역할을 하는 고유한 서비스 계정이 생성됩니다.
- BigQuery 페이지로 이동합니다.
- 왼쪽 창에서 탐색기를 클릭합니다. 왼쪽 창이 표시되지 않으면 왼쪽 창 펼치기를 클릭하여 창을 엽니다.
- 탐색기 창에서 프로젝트 이름을 펼친 다음 연결을 클릭합니다.
- '연결' 페이지에서 '연결 만들기'를 클릭합니다.
- 연결 유형으로 Vertex AI 원격 모델, 원격 함수, BigLake, Spanner (Cloud 리소스)를 선택합니다.
- '연결 ID' 필드에 연결 ID 이름을 입력합니다.
- bq-connection. 이 ID는 이 Codelab의 후반부에서 데이터 스캔을 설정할 때 필요하므로 기록해 두세요.
- 위치 유형을 리전으로 설정한 다음 리전을 선택합니다. 예를 들면 us-central1입니다. 연결은 데이터 세트와 같은 리전에 있어야 합니다.
- 연결 만들기를 클릭합니다.
- '연결로 이동'을 클릭합니다.
- '연결 정보' 창에서 이후 단계에 사용할 서비스 계정 ID를 복사합니다. 서비스 계정은 bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com과 유사합니다.
5. 권한 설정
- Cloud Storage 객체 및 Knowledge Catalog에 액세스할 수 있도록 BigQuery 연결에 필요한 권한 부여
IAM 및 관리자 페이지로 이동하여 주 구성원별 보기 섹션에서 액세스 권한 부여 버튼을 클릭하고 마지막 단계에서 복사한 서비스 계정을 붙여넣어 주 구성원을 추가합니다. 역할 섹션에 다음 역할의 이름을 하나씩 추가하고 저장합니다.
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- Dataplex 서비스 계정에 Cloud Storage 버킷 액세스 권한 부여
IAM 및 관리자 페이지로 이동하여 주 구성원별로 보기 섹션에서 액세스 권한 부여 버튼을 클릭하고 새 주 구성원 텍스트 바에 dataplex라는 단어를 입력하여 주 구성원을 추가합니다. 자동 완성 목록에서 다음과 유사한 Dataplex 서비스 계정 주 구성원을 선택합니다(아래 서비스 계정 이메일 ID에 프로젝트 ID가 아닌 프로젝트 번호 사용).
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
어떤 이유로든 프로젝트 번호의 위 서비스 계정이 인식되지 않는 경우 프로젝트에서 아직 Dataplex 서비스를 초기화하지 않았기 때문일 수 있습니다. Cloud Shell 터미널로 이동하여 다음 명령어를 실행하여 API를 사용 설정합니다 (시작하기 전에 단계에서 아직 실행하지 않은 경우). gcloud services enable dataplex.googleapis.com
이후에도 Dataplex 서비스 계정이 인식되지 않으면 메타데이터 선별 페이지에서 테스트 Dataplex 검사 작업 생성을 강제 실행하고 '검색 작업 생성' 페이지에 세부정보를 입력합니다.
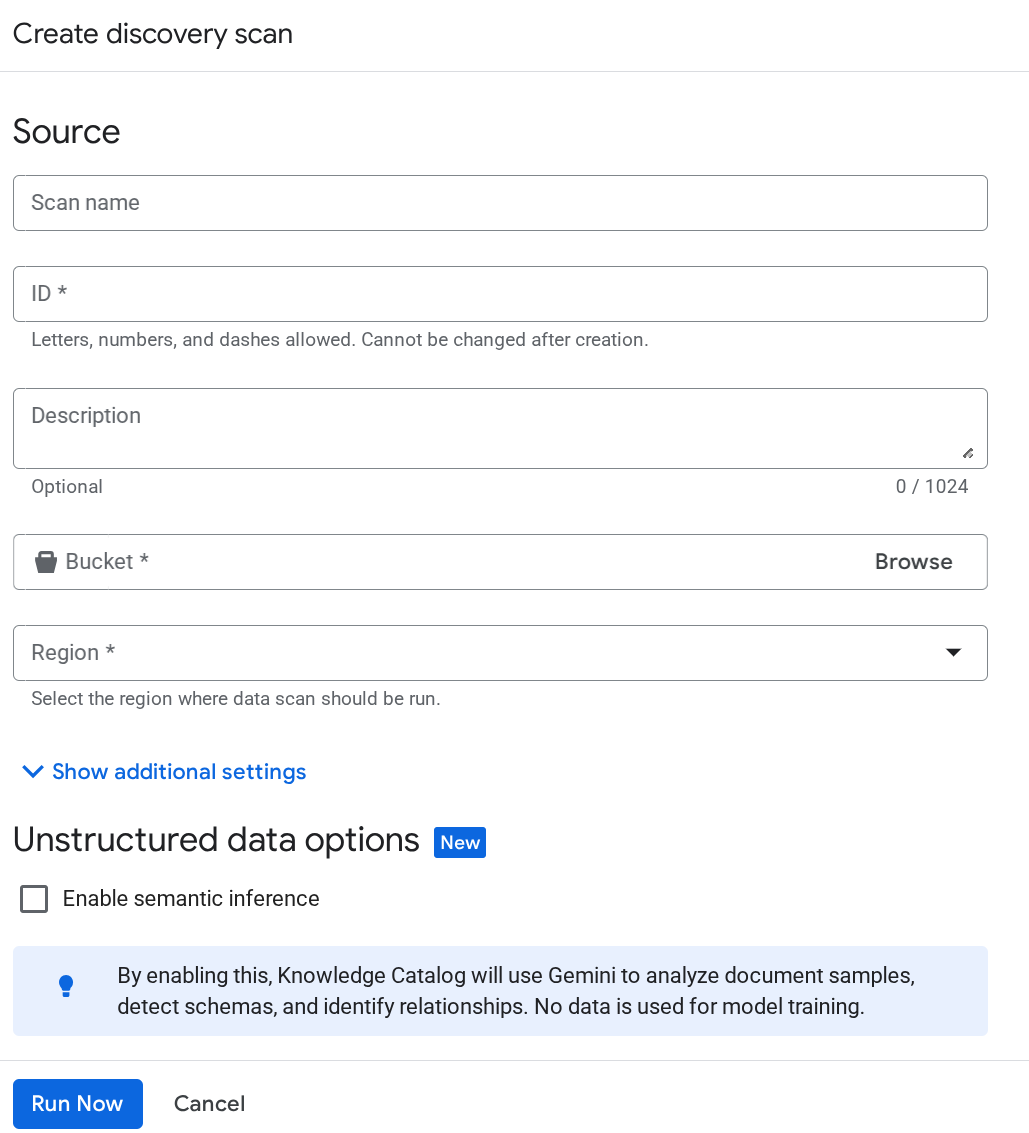
지금 실행을 클릭합니다. 작업은 실패하지만 이제 Dataplex 서비스의 서비스 계정 ID가 초기화됩니다.
IAM 및 관리자 페이지로 돌아가 주 구성원별로 보기 섹션에서 액세스 권한 부여 버튼을 클릭하고 주 구성원 추가를 클릭합니다. 서비스 계정을 붙여넣습니다.
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
그런 다음 이 서비스 계정에 다음 역할을 부여합니다.
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. Knowledge Catalog 설정
Knowledge Catalog를 빌드하여 비정형 데이터를 통합하고 비정형 파일 (예: PDF 레시피 및 PDF 공급업체)의 검색을 자동화합니다.
콘솔에서 DataScan 작업을 만듭니다.
- 메타데이터 선별 페이지로 이동합니다.
- '만들기'를 클릭하고 설정에 해당하는 세부정보를 입력합니다.
중요: 'Enable Semantic Inference'(의미론적 추론 사용 설정)을 선택해야 합니다.
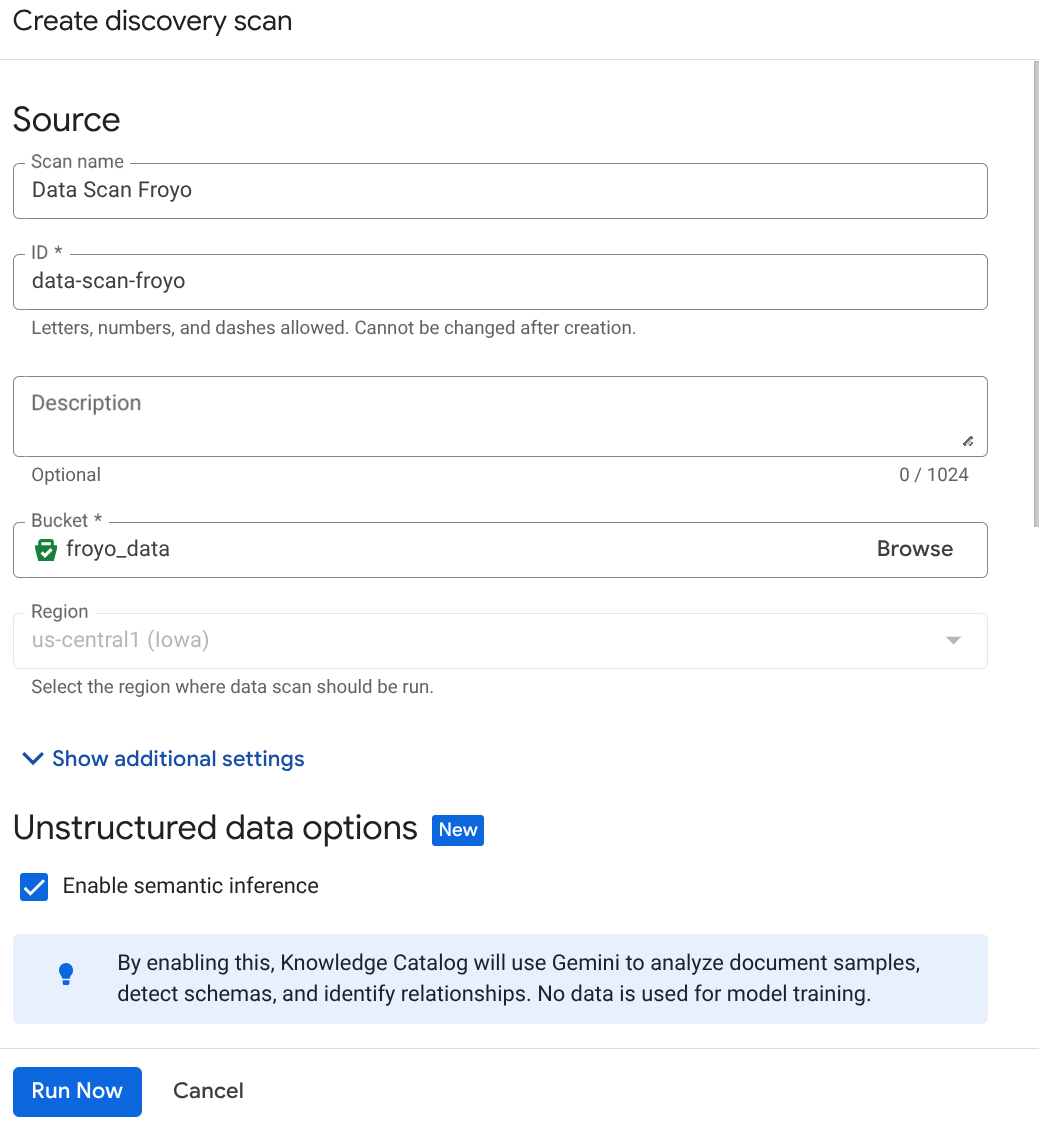
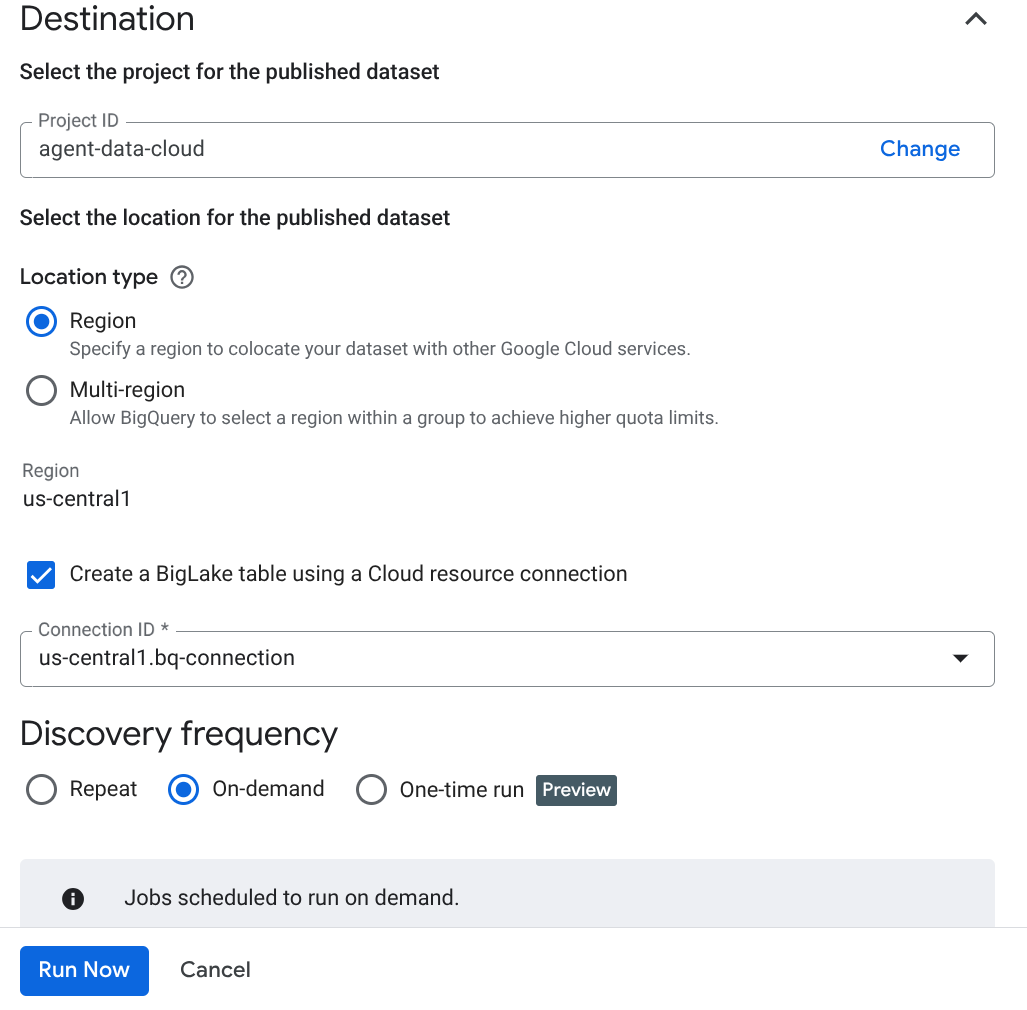
- '지금 실행'을 클릭합니다.
- 스캔 작업을 완료하는 데 다소 시간이 걸립니다. 작업이 완료되면 게시된 데이터 세트가 있는지 확인합니다. 작업 상태를 확인하려면 메타데이터 큐레이션 페이지의 Cloud Storage 검색 탭에서 최근 실행의 검색 스캔 이름을 클릭합니다. 아래와 같이 게시된 데이터 세트가 표시됩니다.
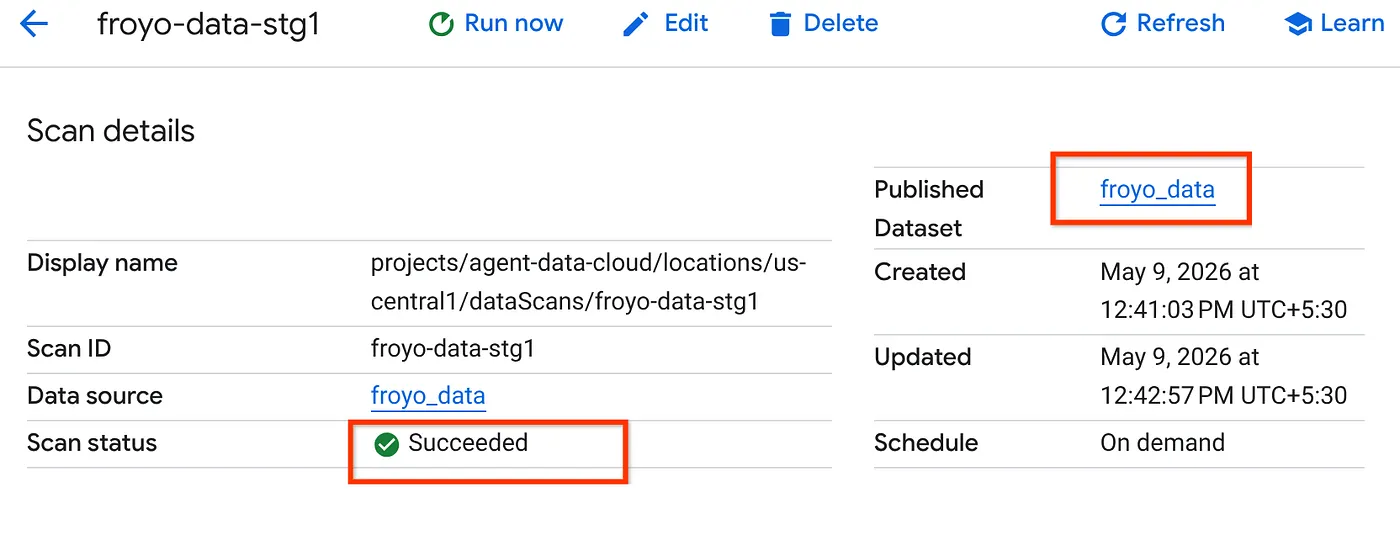
참고: 스캔 단계에서 오류가 발생하면 잠시 기다린 후 다시 시도하세요. 작업을 생성하고 실행을 완료하는 데 몇 분 정도 걸립니다.
- froyo_data 데이터 세트를 클릭하고 이동하여 BigQuery에서 테이블을 볼 수 있습니다. BigQuery에서 테이블 ID를 클릭하고 쿼리 편집기 탭에서 아래 쿼리를 실행합니다.
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
결과는 400입니다 (아니면 돌아가서 데이터 스캔 작업을 다시 실행할 수 있음).
7. 시맨틱 데이터 추출
좋습니다. 이제 Knowledge Catalog를 사용하여 이러한 비구조화된 객체의 추론을 추출해 보겠습니다.
AI 통계 기능을 사용하여 비구조화된 표에서 구조화된 데이터를 추출하는 SQL 문을 생성합니다.
- Google Cloud 콘솔에서 Knowledge Catalog 검색 페이지로 이동합니다.
- 인사이트를 보려는 데이터 세트 테이블을 검색합니다. 검색창에 이전 단계의 데이터 세트 / 표 이름('froyo_data')을 입력하고 Enter 키를 누릅니다.
- 결과 목록에서 데이터 세트가 아닌 TABLE 항목을 클릭합니다.
- 인사이트 탭이 표시됩니다. 해당 버튼을 클릭합니다. API를 사용 설정해야 하는 경우 안내에 따라 API를 사용 설정합니다.
이 시점에서 API를 사용 설정한 경우 스캔 작업을 다시 실행해야 합니다.
- '통계' 탭에 '추출' 버튼 드롭다운이 표시됩니다. 이 버튼을 클릭하고 'SQL로 추출' 옵션을 선택합니다.
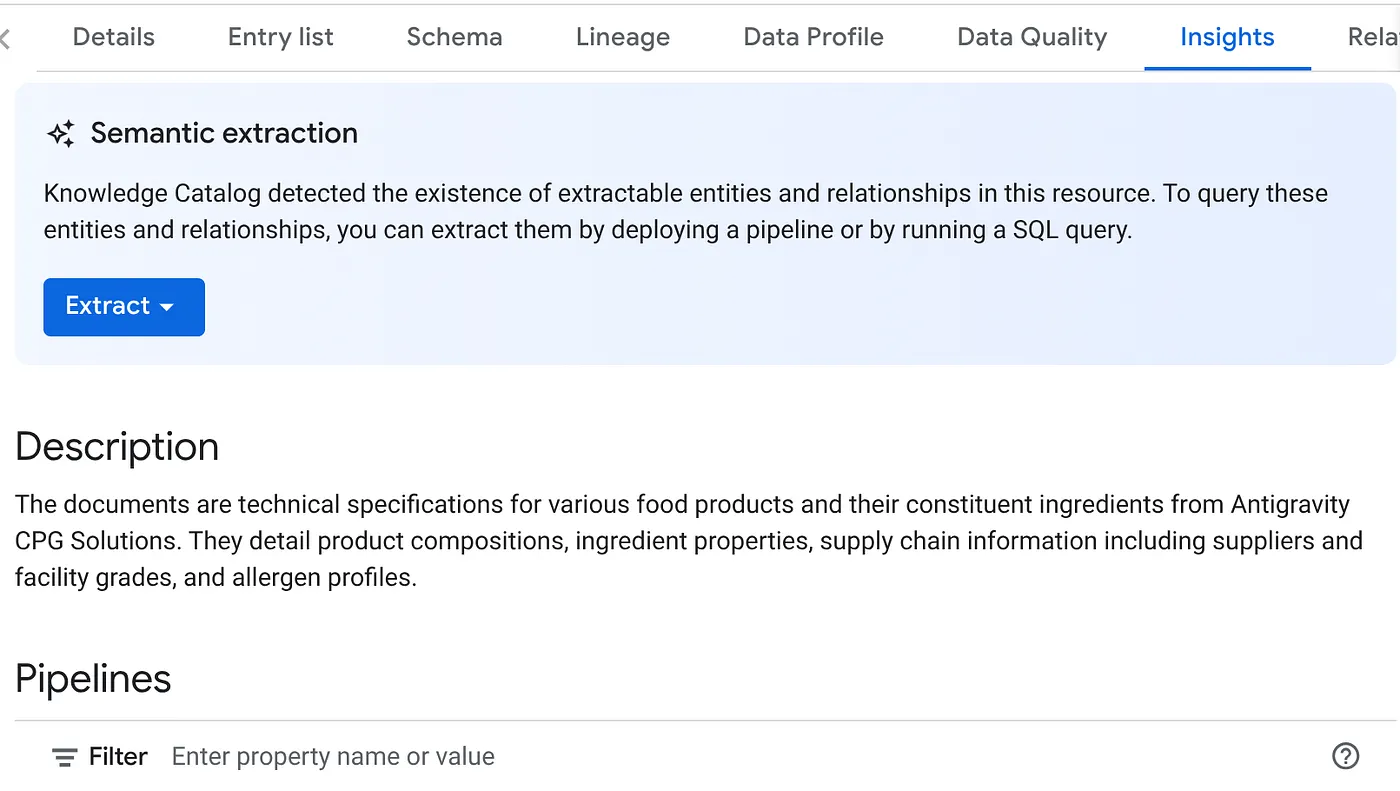
'SQL로 추출' 대화상자가 팝업되면 대상 데이터 세트를 데이터 스캔 작업 결과에 표시된 데이터 세트로 설정합니다. 이름을 입력하기 시작하면 자동 완성에 표시됩니다. '추출' 버튼을 클릭합니다. 또는 이 시점에서 새 데이터 세트를 만들어 추출할 수 있습니다.
데이터 스캔 추론에서 추출한 SQL로 탭이 채워진 BigQuery 쿼리 편집기가 열립니다.
8. SQL 검증 및 스키마 생성
생성된 쿼리가 적절하고 비정형 데이터와 의미적으로 관련이 있는 경우 쿼리 편집기에서 실행 버튼을 클릭하여 실행합니다. 구조화되지 않은 미디어의 구조화된 저장에 필요한 스키마를 만드는 데 몇 분 정도 걸립니다.
완료되면 아래와 같이 BigQuery Studio의 탐색기 창에서 데이터 세트를 펼쳐 스키마를 확인할 수 있습니다.
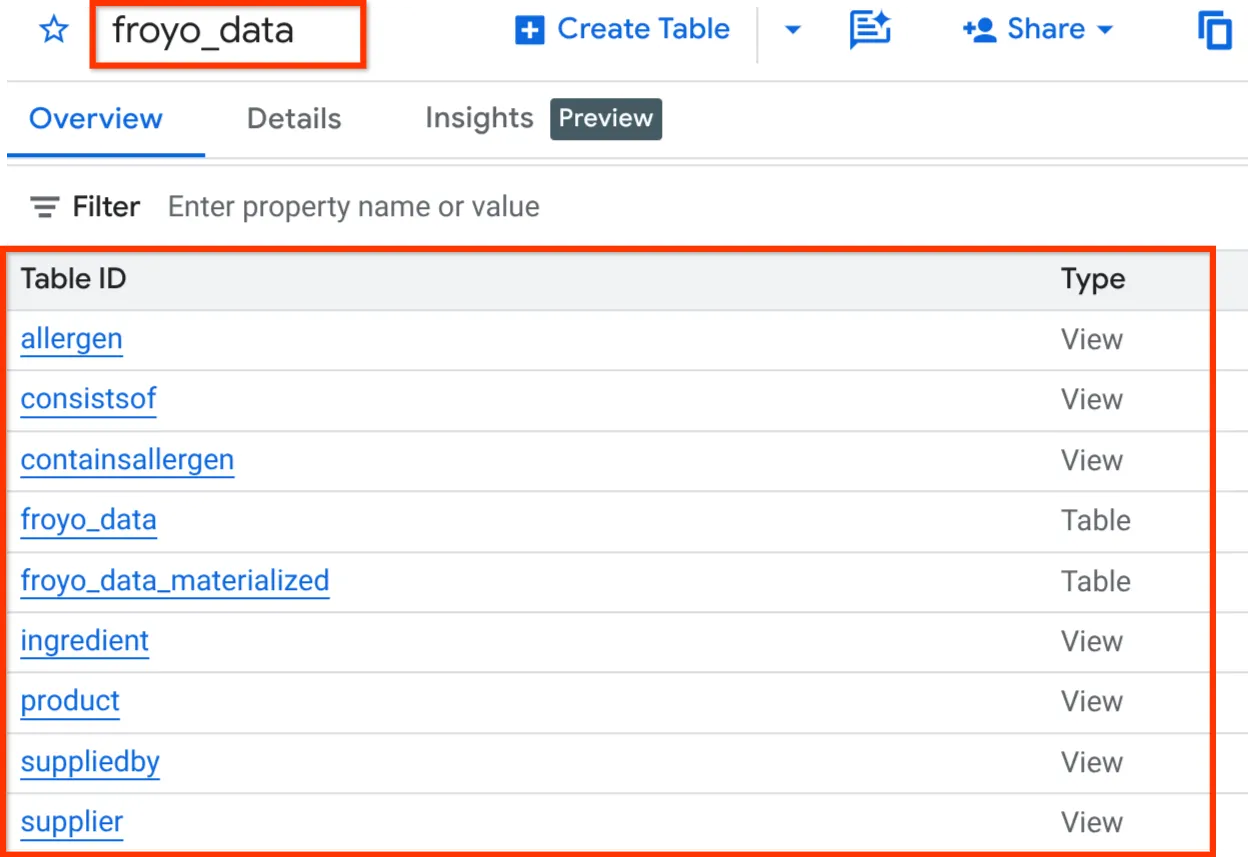
좋아!!! 데이터베이스 작업을 정말 빠르게 처리해서 좋았어요. 이제 최종 테스트를 진행할 차례입니다.
결제 계정 없이 데이터를 계속 사용하는 단계:
- 위의 GitHub 저장소 링크에서 데이터 csv 파일 (BigQuery 데이터)을 가져올 수 있습니다.
- 먼저 Cloud Shell 터미널에서 아래 명령어를 실행하여 BigQuery 데이터 세트를 만듭니다.
bq mk --location us-central1 --dataset froyo_data
- 다음으로, 다음 명령어를 하나씩 실행하여 GitHub 저장소에서 작업 디렉터리로 8개의 데이터 파일 (CSV 파일)을 다운로드합니다.
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- 다음 명령어를 하나씩 실행하여 새로 만든 데이터 세트의 데이터로 이러한 테이블을 만듭니다.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
데이터 세트, 테이블, 데이터가 생성되면 방금 논의한 데이터를 테스트하고 경험할 수 있습니다.
9. 궁극의 테스트!!!
에이전트가 사실에 기반한 실제적이고 완전하며 잘 구성된 정보로 사용자의 질문에 답변하도록 하고 싶다고 가정해 보겠습니다. 에이전트가 내 소스의 여러 미디어 파일과 참조를 참조해야만 대답할 수 있는 질문을 할 거야.
사용자 질문은 다음과 같습니다.
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
이제 일반 검색 또는 LLM 검색에서 '재료 없음'이라고 표시됩니다. 하지만 Google은 모든 비정형 미디어를 구조화된 데이터로 변환하는 완전한 의미론적 추론을 구축했습니다. 이 정보를 가져오는 간단한 SQL은 다음과 같습니다.
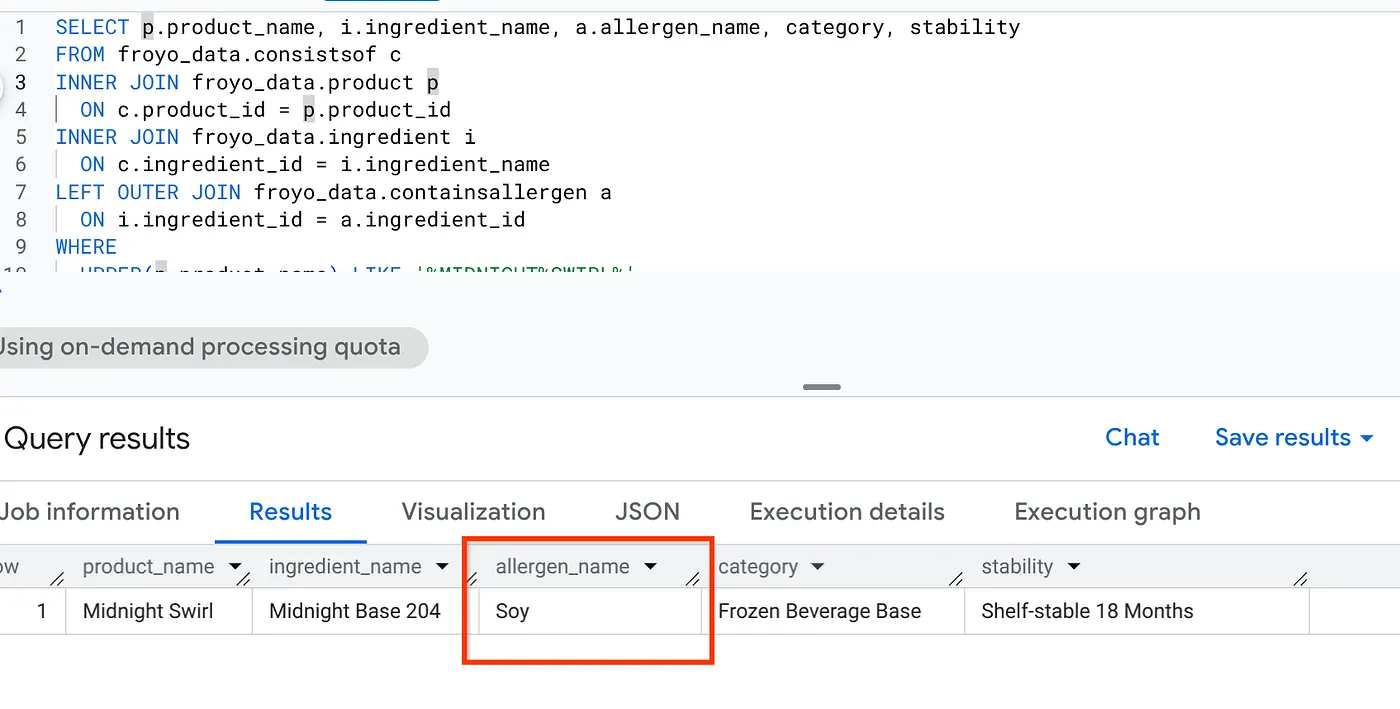
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
축하합니다. 결과를 확인합니다.
10. 삭제
이 실습을 완료한 후에는 스캔 작업과 작업에서 생성한 BigQuery 테이블을 삭제해야 합니다.
https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery로 이동합니다. 옆에 있는 세로 점을 클릭하여 삭제할 작업을 선택하고 삭제를 클릭합니다.
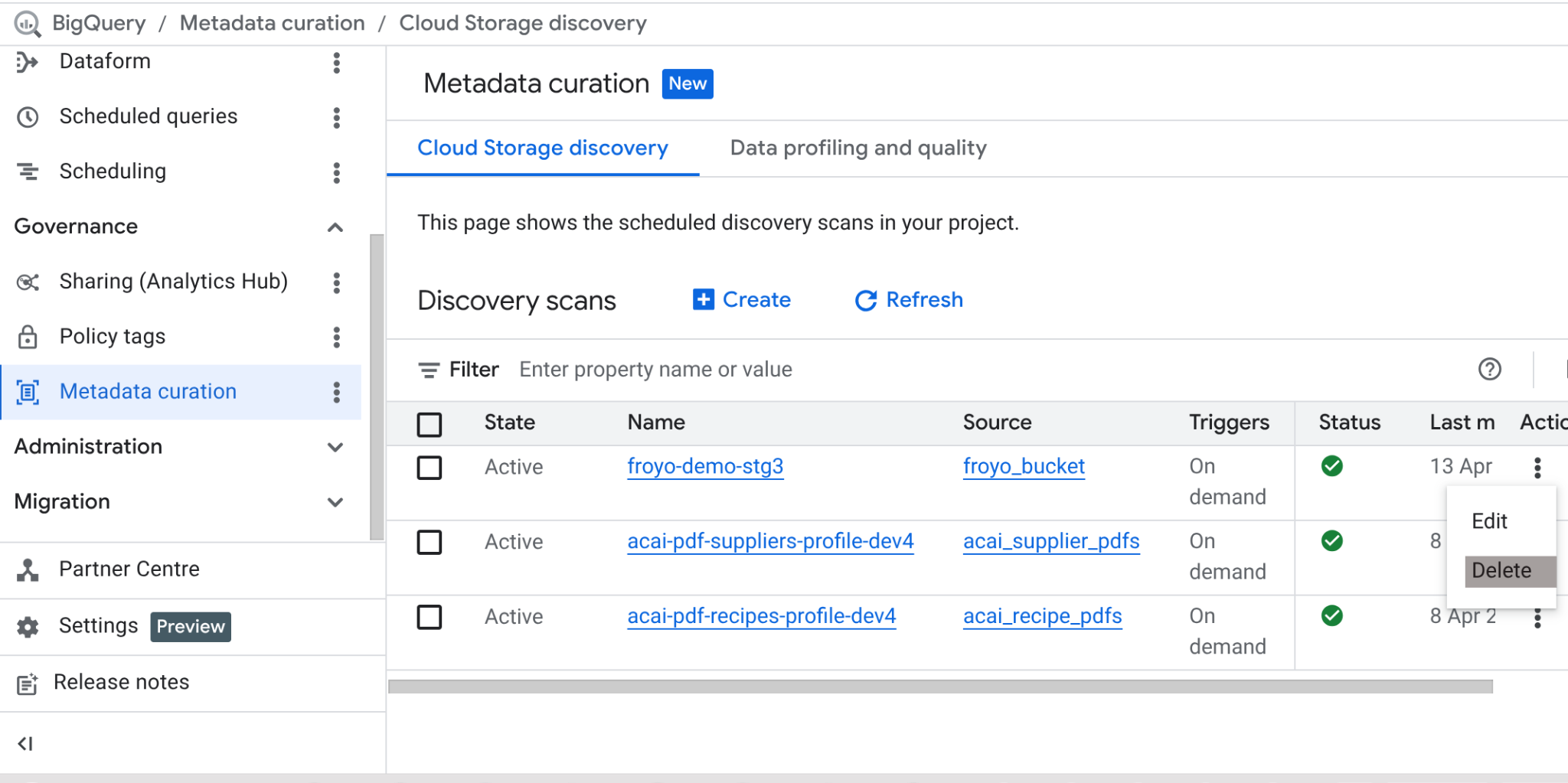
작업이 정리됩니다.
11. 축하합니다
Google의 구현은 숨겨진 알레르기 유발 물질을 성공적으로 식별할 수 있었습니다. 더 이상 다크 데이터는 없습니다. 파트 2에서는 트랜잭션 시스템에서 AlloyDB와 이 BigQuery 데이터를 제휴하여 에이전트 애플리케이션의 데이터 요구사항을 통합합니다.