
1. Tổng quan
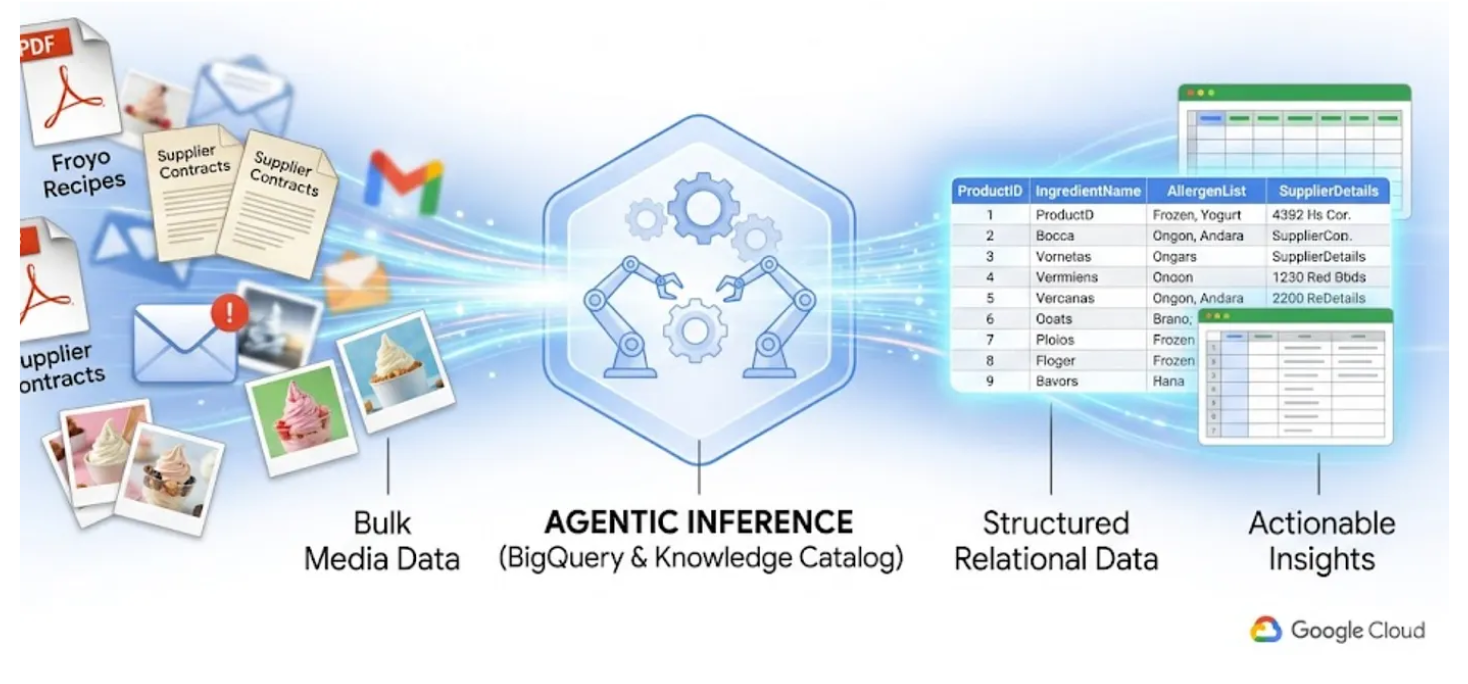
Tất cả chúng ta đều biết nỗi đau của "dữ liệu tối". Đó là các tệp PDF, hình ảnh và tệp văn bản nằm trong các vùng lưu trữ trên đám mây, hoàn toàn không xuất hiện trong các truy vấn SQL và trang tổng quan BI của bạn. Theo cách truyền thống, để khai thác dữ liệu này, bạn cần có các quy trình OCR phức tạp, nhập dữ liệu theo cách thủ công hoặc các tập lệnh tuỳ chỉnh dễ bị lỗi.
Giờ thì không còn chuyện đó nữa!
Trong phòng thí nghiệm này, tôi sẽ hướng dẫn bạn cách chuyển đổi 400 tệp PDF không có cấu trúc (bao gồm văn bản, bảng và hình ảnh) thành các bảng BigQuery có cấu trúc rõ ràng, trong đó các mối quan hệ được suy luận tự động giữa các bảng. Chúng ta sẽ thực hiện việc này trong vài phút bằng cách sử dụng Danh mục kiến thức BigQuery và Dataplex.
Sản phẩm bạn sẽ tạo ra
Để hiểu rõ hơn, hãy xem một doanh nghiệp hư cấu: một chuỗi cửa hàng Sữa chua đông lạnh đang phát triển nhanh chóng.
Giả sử bạn quản lý dữ liệu cho doanh nghiệp Froyo này. Bạn có hàng trăm công thức nấu ăn và bảng thông số kỹ thuật của nhà cung cấp, tất cả đều được lưu dưới dạng tệp PDF. Các nhà lãnh đạo doanh nghiệp muốn ra mắt một tác nhân AI để giúp người quản lý cửa hàng và khách hàng truy vấn thông tin chi tiết về sản phẩm.
Sau đây là một tình huống ác mộng: Khách hàng hỏi: "Tôi rất quan tâm đến món sữa chua đông lạnh Midnight Swirl của bạn. Có chất gây dị ứng nào trong đó không?"
Để trả lời câu hỏi này, hệ thống của bạn thường phải:
- Tìm tệp PDF công thức "Midnight Swirl" (Xoáy nước nửa đêm).
- Đọc các thành phần (ví dụ: "Bột ca cao", "Đường sữa", "Chất nhũ hoá X").
- Tìm kiếm trong hàng chục tệp PDF của Nhà cung cấp để tìm bảng thông số kỹ thuật cho những thành phần cụ thể đó.
- Kiểm tra trang tính của nhà cung cấp để tìm các chất gây dị ứng bị ẩn có liên quan đến những thành phần đó.
Việc cố gắng tạo một tác nhân AI có thể thực hiện việc này ngay lập tức bằng cách đọc 400 tệp PDF thô trong thời gian chạy sẽ rất chậm, tốn kém và dễ bị ảo giác. Thay vào đó, trước tiên, chúng ta sẽ sử dụng suy luận ngữ nghĩa để trích xuất tất cả dữ liệu này vào một cơ sở dữ liệu quan hệ, giúp tác nhân AI trong tương lai của chúng ta hoạt động cực kỳ nhanh chóng và dựa hoàn toàn vào dữ liệu SQL thực tế.
Hãy bắt đầu xây dựng!
Kiến thức bạn sẽ học được
- Cách thiết lập bộ chứa Cloud Storage cho các tệp nguồn (PDF)
- Cách thiết lập và chạy công việc Datascan và suy luận ngữ nghĩa trong Danh mục tri thức để trích xuất dữ liệu từ các tệp PDF nguồn, suy luận ngữ nghĩa về các mối kết nối và bối cảnh, đồng thời lưu trữ dữ liệu đó trong BigQuery
- Cách sử dụng tác nhân BigQuery để trò chuyện với tập dữ liệu mới tạo
Yêu cầu
2. Trước khi bắt đầu
Tạo dự án
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo bạn đã bật tính năng thanh toán cho dự án trên Cloud. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên một dự án hay không.
- Bạn sẽ sử dụng Cloud Shell, một môi trường dòng lệnh chạy trong Google Cloud. Nhấp vào Kích hoạt Cloud Shell ở đầu bảng điều khiển Google Cloud.

- Sau khi kết nối với Cloud Shell, bạn có thể kiểm tra để đảm bảo rằng bạn đã được xác thực và dự án được đặt thành mã dự án của bạn bằng lệnh sau:
gcloud auth list
- Chạy lệnh sau trong Cloud Shell để xác nhận rằng lệnh gcloud biết về dự án của bạn.
gcloud config list project
- Nếu bạn muốn xác thực
gcloud auth login
- Nếu bạn chưa đặt dự án, hãy dùng lệnh sau để đặt dự án:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Bật các API bắt buộc: Chạy lệnh này để bật tất cả các API bắt buộc:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
Các vấn đề thường gặp và cách khắc phục
Hội chứng "Dự án ma" | Bạn đã chạy |
Rào chắn thanh toán | Bạn đã bật dự án nhưng quên tài khoản thanh toán. AlloyDB là một công cụ hiệu suất cao; công cụ này sẽ không khởi động nếu "bình xăng" (thanh toán) trống. |
Độ trễ truyền API | Bạn đã nhấp vào "Bật API", nhưng dòng lệnh vẫn hiển thị |
Hạn mức Quags | Nếu đang sử dụng tài khoản dùng thử mới, bạn có thể đạt đến hạn mức theo khu vực cho các phiên bản AlloyDB. Nếu |
Nhân viên hỗ trợ dịch vụ"bị ẩn" | Đôi khi, AlloyDB Service Agent không được tự động cấp vai trò |
3. Thiết lập bộ chứa Google Cloud Storage
Trong phần này, bạn sẽ tạo một cấu trúc tổ chức trong BigQuery để lưu trữ dữ liệu về công thức và nhà cung cấp Froyo, đặc biệt là thông tin chi tiết về sản phẩm Froyo. Thao tác này cũng thiết lập một Cloud Resource Connection (Kết nối tài nguyên trên đám mây), đóng vai trò là "cầu nối" an toàn cho phép BigQuery đọc các tệp từ các nguồn bên ngoài như Cloud Storage.
Trước khi bắt đầu:
Kho lưu trữ này chứa các công thức, tệp PDF của nhà cung cấp mà chúng ta sẽ sử dụng trong dự án này. Hãy nhớ tải các tệp này xuống. Để tải các tệp xuống, hãy làm như sau.
Trong Cloud Shell, hãy chạy lệnh sau:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
Chuyển đến thư mục mới tạo:
cd next-26-keynotes
Kéo thư mục data-cloud-demo
git sparse-checkout set genkey/data-cloud-demo
Sau khi hoàn tất quy trình thanh toán, hãy chuyển đến thư mục data-cloud-demo rồi giải nén các tệp ZIP để truy cập vào các thành phần của lớp học lập trình.
Tạo bộ chứa và tải tệp PDF Froyo (công thức và nhà cung cấp) lên
- Trong Cloud Console của Google Cloud, hãy chuyển đến trang Bộ chứa Cloud Storage.
- Nhấp vào Tạo.
- Trên trang Tạo vùng lưu trữ, hãy nhập thông tin về vùng lưu trữ của bạn. Sau mỗi bước sau đây, hãy nhấp vào Tiếp tục để chuyển sang bước tiếp theo:
- Trong phần Bắt đầu, hãy nhập tên nhóm. Ví dụ: froyo_data
- Trong mục Chọn nơi lưu trữ dữ liệu của bạn, hãy chọn Khu vực rồi nhập khu vực của bạn. us-central1
- Trong phần Chọn cách kiểm soát quyền truy cập vào các đối tượng, hãy bỏ chọn hộp Thực thi biện pháp phòng tránh truy cập công khai trên bộ chứa này.
- Nhấp vào Tạo.
- Trong danh sách các nhóm, hãy nhấp vào nhóm mà bạn đã tạo.
- Trong thẻ Đối tượng của nhóm, hãy nhấp vào Tải lên rồi nhấp vào Tải thư mục lên.
- Chọn thư mục recipes mà bạn đã giải nén trong phần Trước khi bắt đầu của lớp học lập trình này.
- Nhấp Tải lên.
- Lặp lại quy trình tải lên cho thư mục suppliers.
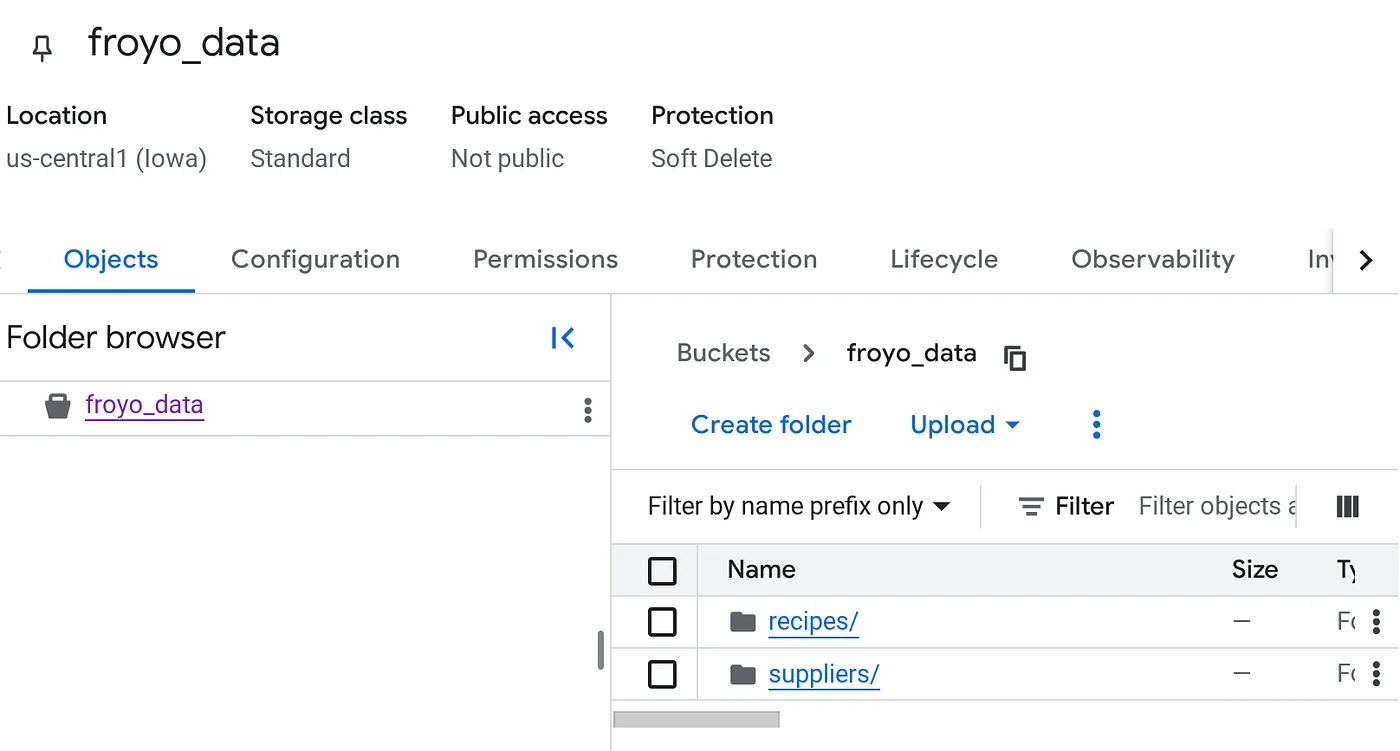
Sau khi tải lên, cấu trúc nhóm của bạn sẽ có dạng như sau (bất kể tên nhóm là gì):
4. Thiết lập mối kết nối BigQuery
Tạo một Cloud Resource Connection. Thao tác này sẽ tạo một Tài khoản dịch vụ duy nhất đóng vai trò là "thẻ căn cước" của BigQuery để truy cập vào các tệp bên ngoài.
- Chuyển đến trang BigQuery.
- Trong ngăn bên trái, hãy nhấp vào Trình khám phá. Nếu bạn không thấy ngăn bên trái, hãy nhấp vào biểu tượng Mở rộng ngăn bên trái để mở ngăn này.
- Trong ngăn Explorer (Trình khám phá), hãy mở rộng tên dự án của bạn, rồi nhấp vào Connections (Kết nối).
- Trên trang Kết nối, hãy nhấp vào Tạo kết nối.
- Đối với Loại kết nối, hãy chọn Mô hình từ xa Vertex AI, hàm từ xa, BigLake và Spanner (Tài nguyên trên đám mây).
- Trong trường Mã kết nối, hãy nhập tên mã kết nối:
- bq-connection. Hãy nhớ ghi lại mã nhận dạng này vì bạn sẽ cần đến mã này khi thiết lập tính năng quét dữ liệu sau này trong lớp học lập trình này.
- Đặt Loại vị trí thành Vùng, rồi chọn một vùng. Ví dụ: us-central1. Mối kết nối phải nằm trong cùng khu vực với các tài nguyên khác của bạn, chẳng hạn như tập dữ liệu.
- Nhấp vào Tạo mối kết nối.
- Nhấp vào Chuyển đến phần kết nối.
- Trong ngăn Thông tin kết nối, hãy sao chép mã tài khoản dịch vụ để sử dụng ở bước sau. Tài khoản dịch vụ này có dạng như bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
5. Thiết lập quyền
- Cấp các quyền cần thiết cho mối kết nối BigQuery để truy cập vào các đối tượng trong Cloud Storage và Danh mục tri thức
Chuyển đến trang IAM & Admin (Quản lý danh tính và quyền truy cập) rồi nhấp vào nút Grant access (Cấp quyền truy cập) trong phần View by Principals (Xem theo người dùng), thêm một người dùng bằng cách dán tài khoản dịch vụ mà bạn đã sao chép ở bước cuối cùng. Trong phần vai trò, hãy lần lượt thêm tên của các vai trò sau rồi lưu:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- Cấp quyền cho Tài khoản dịch vụ Dataplex để truy cập vào Bộ chứa Cloud Storage
Chuyển đến trang IAM và Quản trị. Trong mục Xem theo đối tượng chính, hãy nhấp vào nút Cấp quyền truy cập rồi thêm một đối tượng chính bằng cách nhập từ dataplex vào thanh văn bản Đối tượng chính mới. Trong danh sách tự động hoàn thành, hãy chọn đối tượng chính Tài khoản dịch vụ Dataplex có dạng như sau: (sử dụng số dự án chứ không phải mã dự án trong mã nhận dạng email của tài khoản dịch vụ bên dưới)
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Nếu vì lý do nào đó mà tài khoản dịch vụ nêu trên cho số dự án của bạn không được nhận dạng, thì có thể là do dự án chưa khởi chạy dịch vụ dataplex. Chuyển đến Cloud Shell Terminal và thử bật API (nếu bạn chưa thực hiện trong giai đoạn trước khi bắt đầu) bằng cách chạy lệnh sau: gcloud services enable dataplex.googleapis.com
Ngay cả sau đó, nếu tài khoản dịch vụ cho Dataplex không được nhận dạng, hãy buộc tạo một công việc quét Dataplex thử nghiệm trong trang Sắp xếp siêu dữ liệu và nhập thông tin chi tiết vào trang Tạo công việc Khám phá:
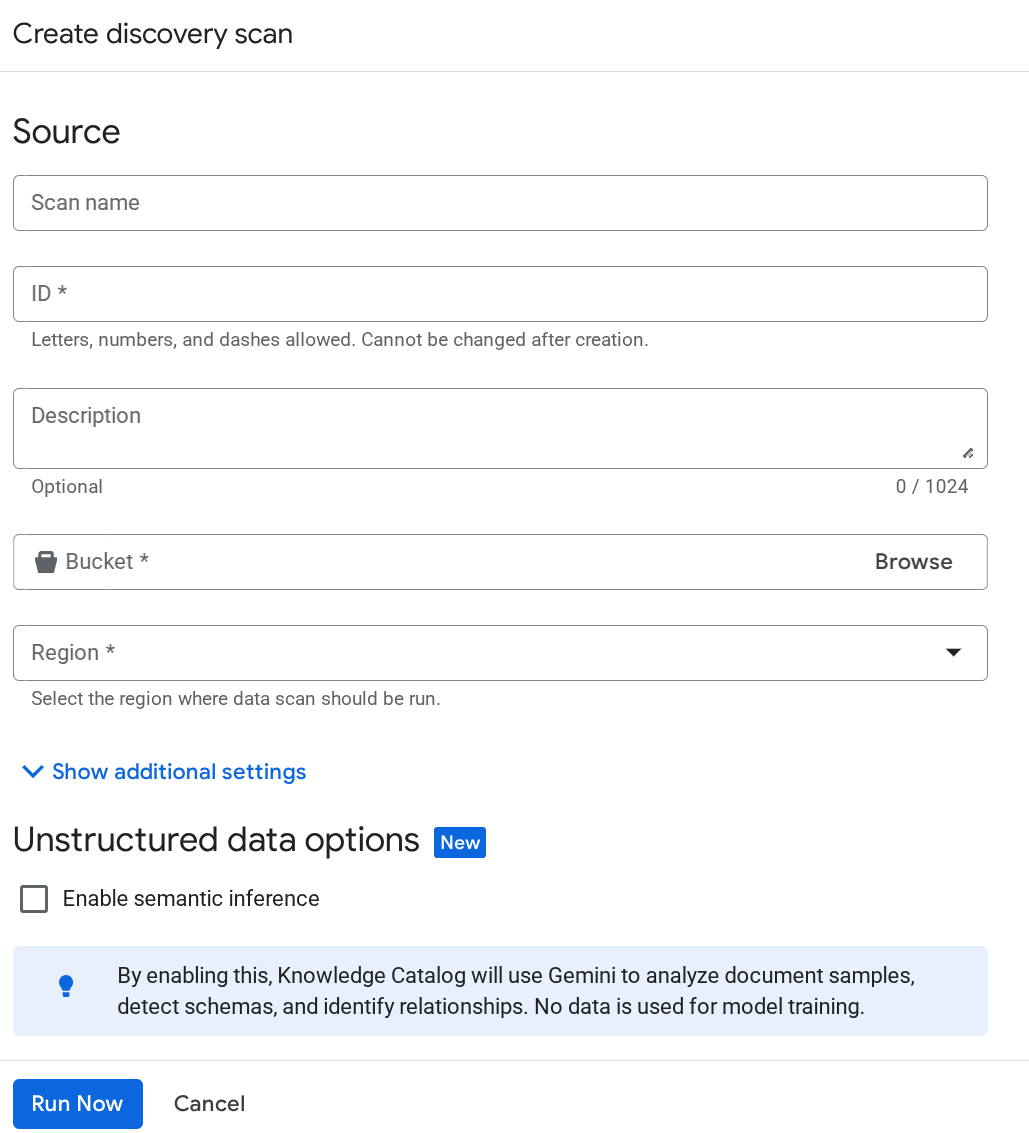
Nhấp vào Chạy ngay. Thao tác này sẽ không thành công, nhưng sẽ đảm bảo mã nhận dạng tài khoản dịch vụ được khởi tạo cho dịch vụ Dataplex của bạn.
Quay lại trang IAM & Admin (IAM và Quản trị) rồi trong phần View by Principals (Xem theo chủ thể), hãy nhấp vào nút Cấp quyền truy cập rồi nhấp vào nút Thêm chủ thể. Dán tài khoản dịch vụ:
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Sau đó, hãy cấp các vai trò sau cho Tài khoản dịch vụ này:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. Thiết lập Knowledge Catalog
Xây dựng Danh mục tri thức để hợp nhất dữ liệu không có cấu trúc và tự động hoá việc khám phá các tệp không có cấu trúc (chẳng hạn như công thức nấu ăn và nhà cung cấp dưới dạng tệp PDF).
Tạo lệnh DataScan từ bảng điều khiển:
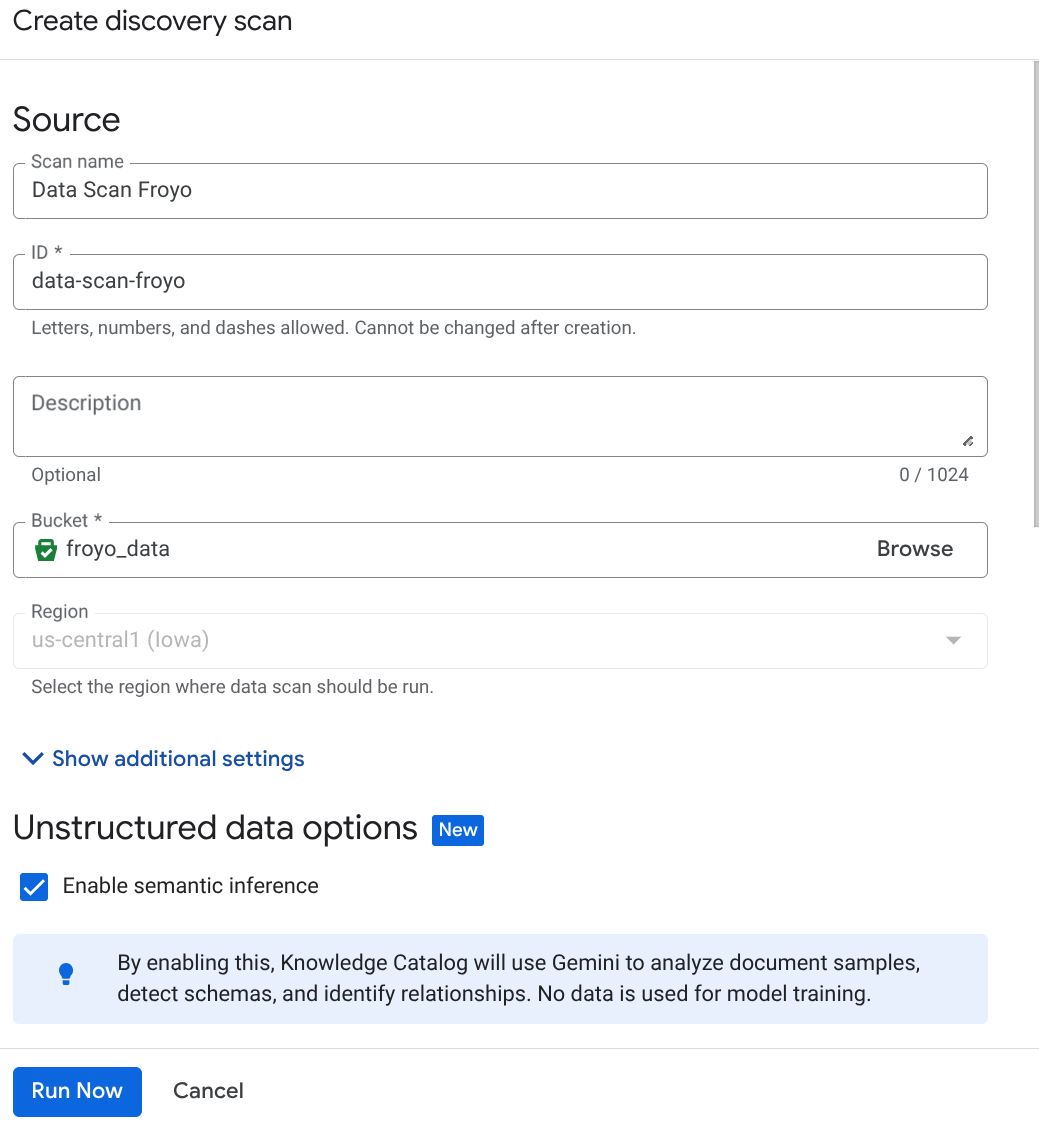
- Chuyển đến trang Tuyển chọn siêu dữ liệu.
- Nhấp vào Tạo rồi nhập thông tin chi tiết tương ứng với chế độ thiết lập của bạn:
Lưu ý quan trọng: Đừng quên đánh dấu vào ô Bật suy luận ngữ nghĩa.
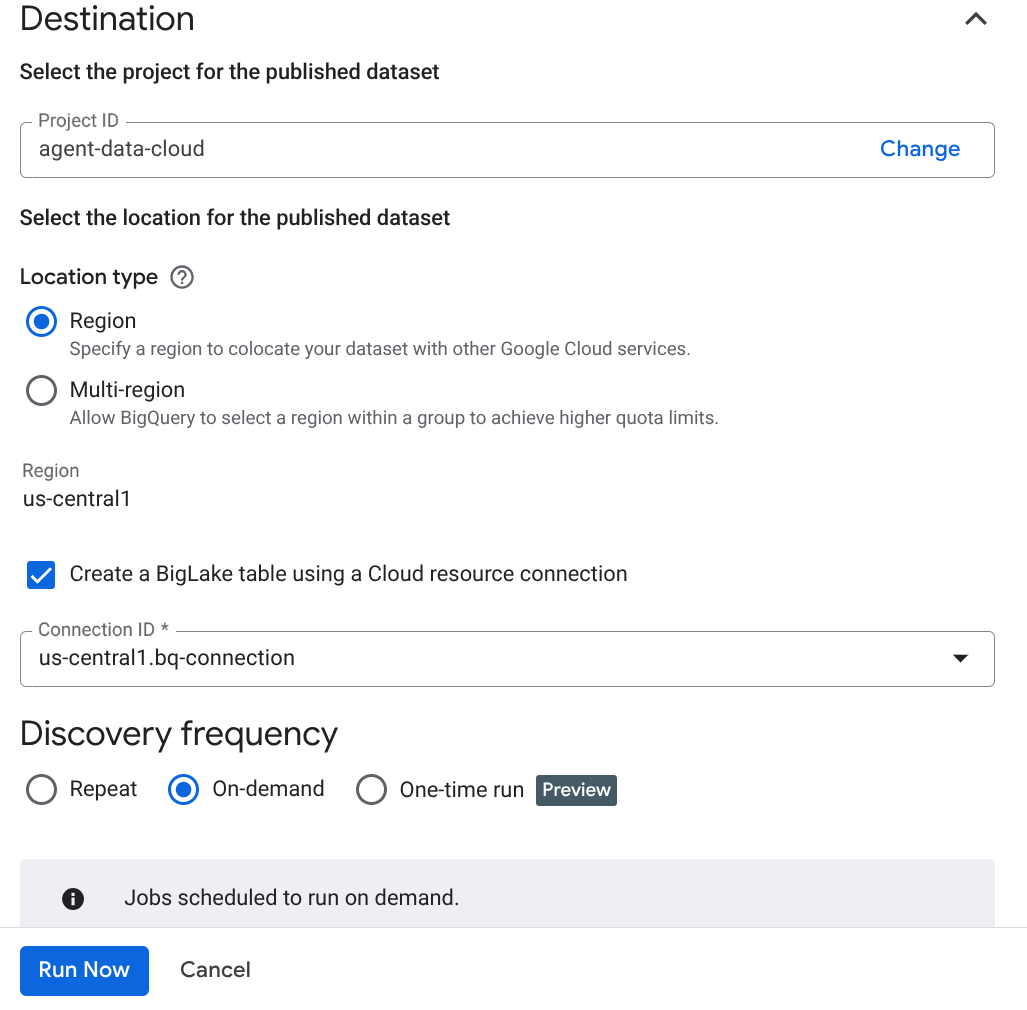
- Nhấp vào "Chạy ngay".
- Quá trình quét sẽ mất một khoảng thời gian để hoàn tất. Sau khi công việc hoàn tất, hãy kiểm tra xem Tập dữ liệu đã xuất bản có xuất hiện hay không. Để kiểm tra trạng thái của công việc, bạn có thể kiểm tra trong trang Tuyển chọn siêu dữ liệu, trong thẻ Khám phá Cloud Storage, hãy nhấp vào tên của các lần quét khám phá trong lần chạy gần đây. Bạn sẽ thấy tập dữ liệu đã xuất bản như bên dưới:
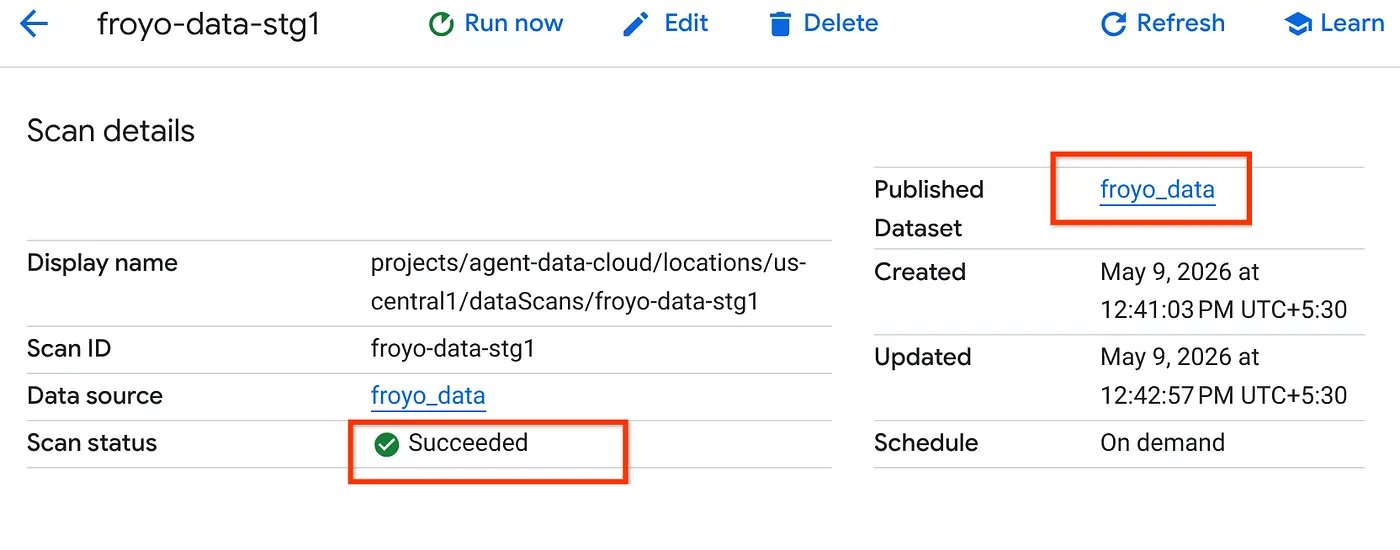
Lưu ý: Nếu bạn gặp lỗi ở bước quét, hãy đợi một lúc rồi thử lại (mất vài phút để tạo công việc và hoàn tất quá trình thực thi).
- Bạn có thể xem bảng trong BigQuery bằng cách nhấp vào tập dữ liệu froyo_data rồi chuyển đến tập dữ liệu đó. Nhấp vào mã nhận dạng bảng trong BigQuery rồi chạy truy vấn bên dưới trong thẻ Query Editor (Trình chỉnh sửa truy vấn):
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
Thao tác này sẽ cho ra kết quả là 400 (nếu không, bạn có thể quay lại và chạy lại lệnh Datascan).
7. Trích xuất dữ liệu ngữ nghĩa
Tuyệt vời!! Bây giờ, hãy trích xuất thông tin suy luận cho những đối tượng không có cấu trúc này bằng Knowledge Catalog.
Chúng ta sẽ sử dụng tính năng Thông tin chi tiết để tạo câu lệnh SQL nhằm trích xuất dữ liệu có cấu trúc từ bảng không có cấu trúc
- Trong Google Cloud Console, hãy chuyển đến trang Knowledge Catalog Search (Tìm kiếm danh mục kiến thức).
- Tìm bảng tập dữ liệu mà bạn muốn xem thông tin chi tiết. Trong thanh tìm kiếm, hãy nhập tên tập dữ liệu / bảng từ bước trước: "froyo_data" rồi nhấn phím Enter
- Trong danh sách kết quả, hãy nhấp vào mục BẢNG (không phải mục tập dữ liệu)
- Bạn sẽ thấy thẻ THÔNG TIN CHI TIẾT. Nhấp vào đó (nếu bạn cần bật API, hãy làm theo hướng dẫn và chỉ bật API).
Nếu đã bật API ở bước này, bạn phải chạy lại quy trình quét.
- Trong thẻ THÔNG TIN CHI TIẾT, bạn sẽ thấy trình đơn thả xuống của nút TRÍCH XUẤT. Nhấp vào biểu tượng đó rồi chọn "Trích xuất bằng SQL".
Trong hộp thoại "Trích xuất bằng SQL" bật lên, hãy đặt tập dữ liệu ĐÍCH là tập dữ liệu mà bạn thấy trong kết quả của công việc Datascan. Bắt đầu nhập tên của người đó và tên sẽ xuất hiện trong tính năng tự động hoàn thành. Nhấp vào nút "Trích xuất". Ngoài ra, bạn có thể tạo một tập dữ liệu mới tại thời điểm này và trích xuất.
Thao tác này sẽ mở Trình chỉnh sửa truy vấn BigQuery với một thẻ được điền sẵn SQL đã trích xuất từ suy luận quét dữ liệu.
8. Xác thực SQL và tạo giản đồ
Nếu cụm từ tìm kiếm được tạo có vẻ ổn và phù hợp về mặt ngữ nghĩa với dữ liệu không có cấu trúc của bạn, hãy tiếp tục kích hoạt cụm từ tìm kiếm đó bằng cách nhấp vào nút Chạy trên trình chỉnh sửa cụm từ tìm kiếm. Quá trình tạo lược đồ cần thiết cho bộ nhớ có cấu trúc của nội dung nghe nhìn không có cấu trúc sẽ mất vài phút.
Sau khi hoàn tất, bạn có thể xác minh giản đồ bằng cách mở rộng tập dữ liệu trong ngăn trình khám phá của BigQuery Studio như minh hoạ dưới đây:
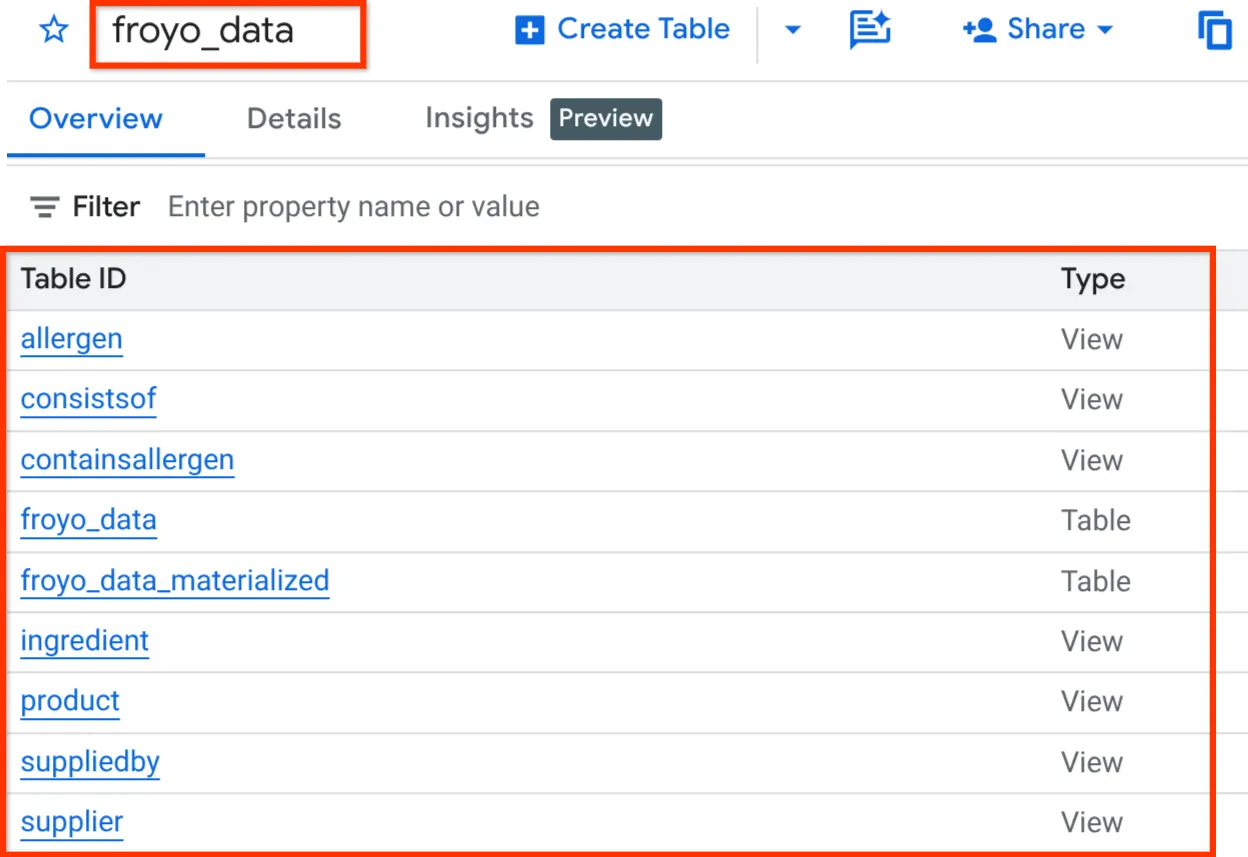
Được rồi!!! Thật tuyệt khi chúng tôi có thể làm tất cả những việc liên quan đến cơ sở dữ liệu một cách nhanh chóng. Giờ là lúc bạn thực hiện bài kiểm tra cuối cùng!
Các bước để tiếp tục trải nghiệm dữ liệu mà không cần tài khoản thanh toán:
- Bạn có thể tải tệp csv (Dữ liệu BigQuery) từ đường liên kết repo trên github.
- Trước tiên, hãy tạo Tập dữ liệu BigQuery bằng cách chạy lệnh bên dưới từ Cloud Shell Terminal:
bq mk --location us-central1 --dataset froyo_data
- Tiếp theo, hãy tải 8 tệp dữ liệu (tệp csv) từ kho lưu trữ github vào thư mục làm việc của bạn bằng cách chạy lần lượt các lệnh sau:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Chạy từng lệnh sau đây để tạo các bảng này bằng dữ liệu trong tập dữ liệu bạn vừa tạo
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Sau khi tạo tập dữ liệu, bảng và dữ liệu, bạn có thể tiến hành kiểm thử và trải nghiệm dữ liệu mà chúng ta vừa thảo luận.
9. Bài kiểm tra cuối cùng!!!
Giả sử tôi muốn tác nhân của mình trả lời các câu hỏi của người dùng bằng thông tin thực tế, đầy đủ và được sắp xếp hợp lý dựa trên các dữ kiện. Tôi sẽ đặt một câu hỏi mà tác nhân chỉ có thể trả lời bằng cách tham khảo nhiều tệp đa phương tiện và tài liệu tham khảo trong nguồn của tôi.
Đây là câu hỏi của tôi:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
Giờ đây, một cụm từ tìm kiếm chung hoặc một cụm từ tìm kiếm LLM sẽ cho biết "Không có thành phần". Nhưng chúng tôi đã xây dựng một suy luận ngữ nghĩa đầy đủ để chuyển đổi tất cả nội dung nghe nhìn không có cấu trúc thành dữ liệu có cấu trúc. Sau đây là một câu lệnh SQL đơn giản sẽ tìm nạp thông tin này:
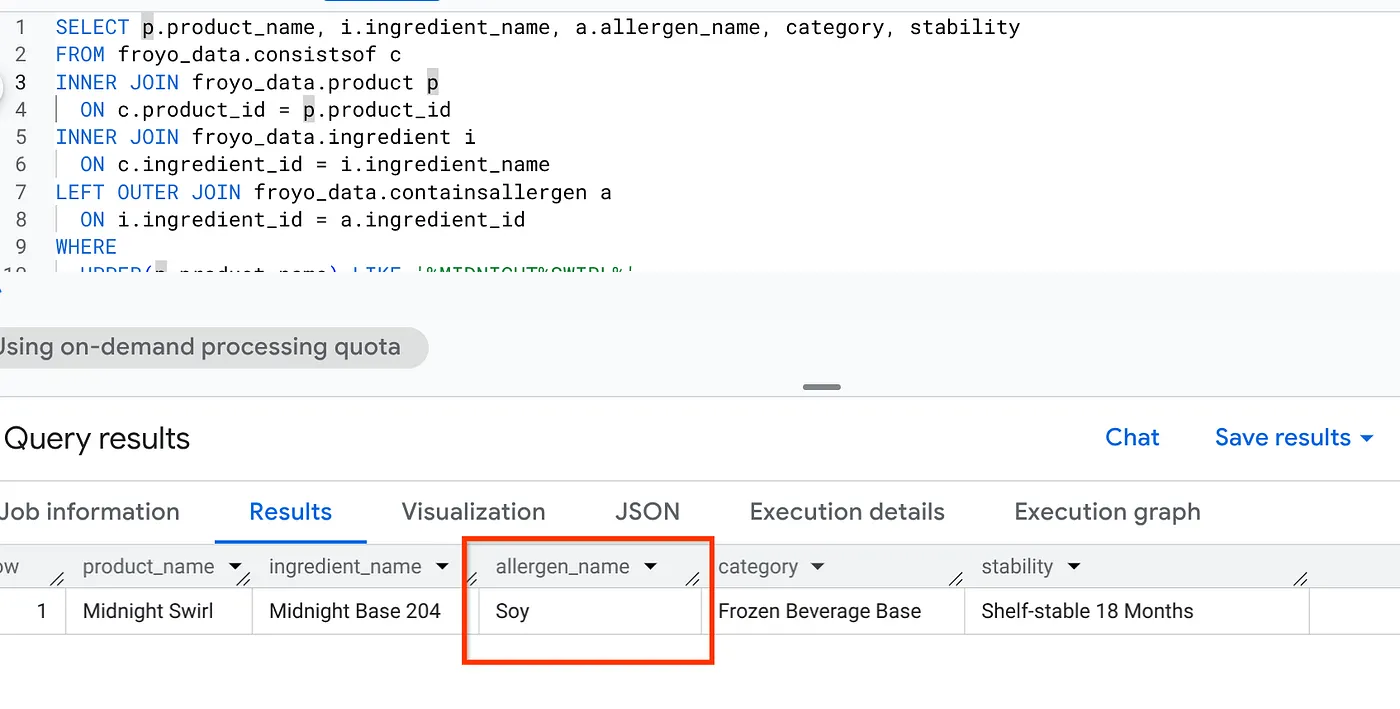
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
Thật tuyệt vời! Xem kết quả:
10. Dọn dẹp
Sau khi hoàn tất bài thực hành này, đừng quên xoá công việc quét và các bảng BigQuery mà công việc này đã tạo.
Truy cập vào https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery. Chọn công việc bạn muốn xoá bằng cách nhấp vào dấu ba chấm dọc bên cạnh công việc đó rồi nhấp vào XOÁ.
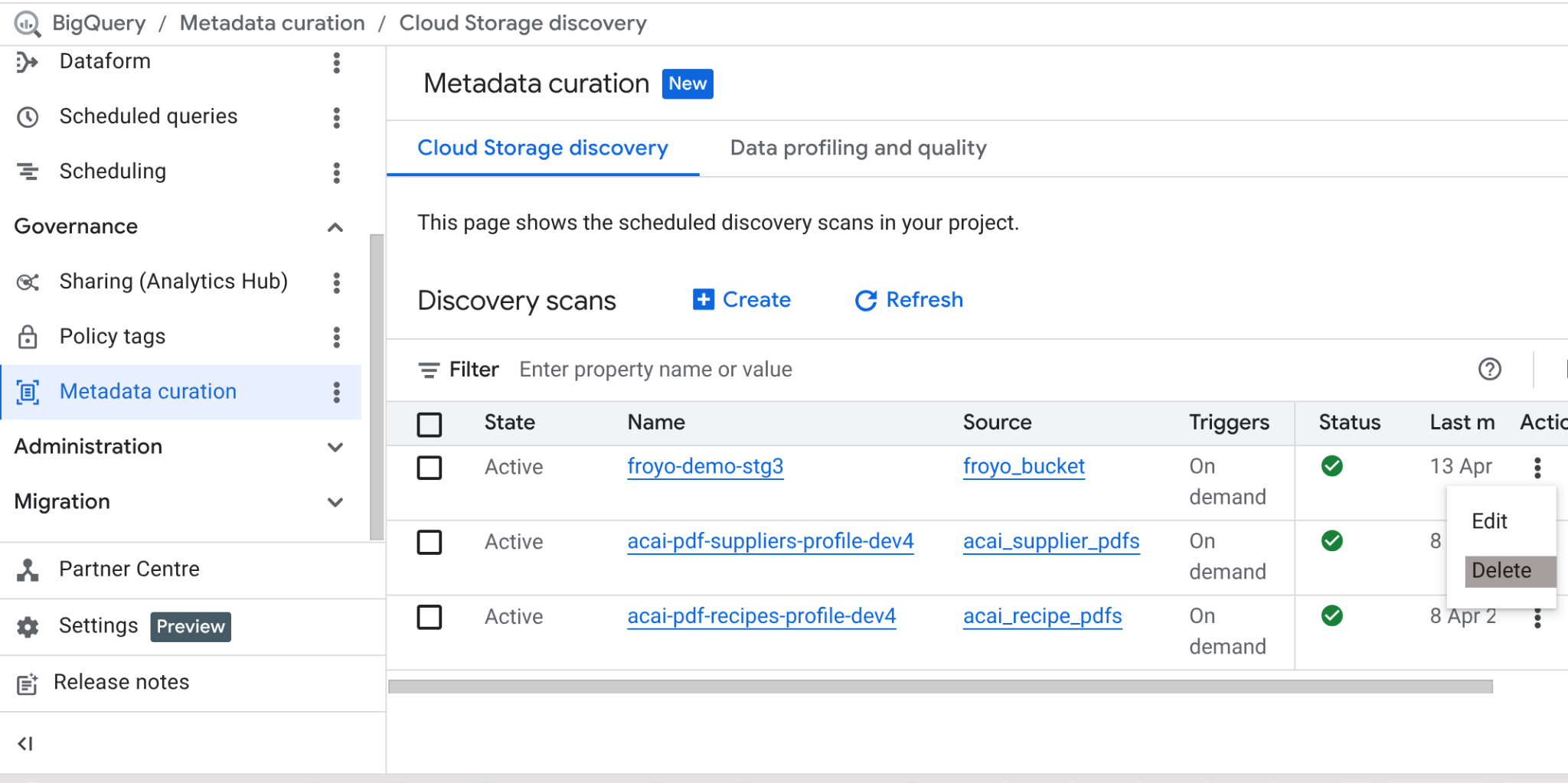
Thao tác này sẽ dọn dẹp công việc.
11. Xin chúc mừng
Việc triển khai của chúng tôi đã xác định được chất gây dị ứng bị ẩn. Không còn dữ liệu tối nữa, mọi người ơi!!! Trong phần 2, chúng ta sẽ liên kết dữ liệu BigQuery này trong một hệ thống giao dịch với AlloyDB để hợp nhất nhu cầu về dữ liệu cho ứng dụng dựa trên tác nhân của mình.