
1. 總覽
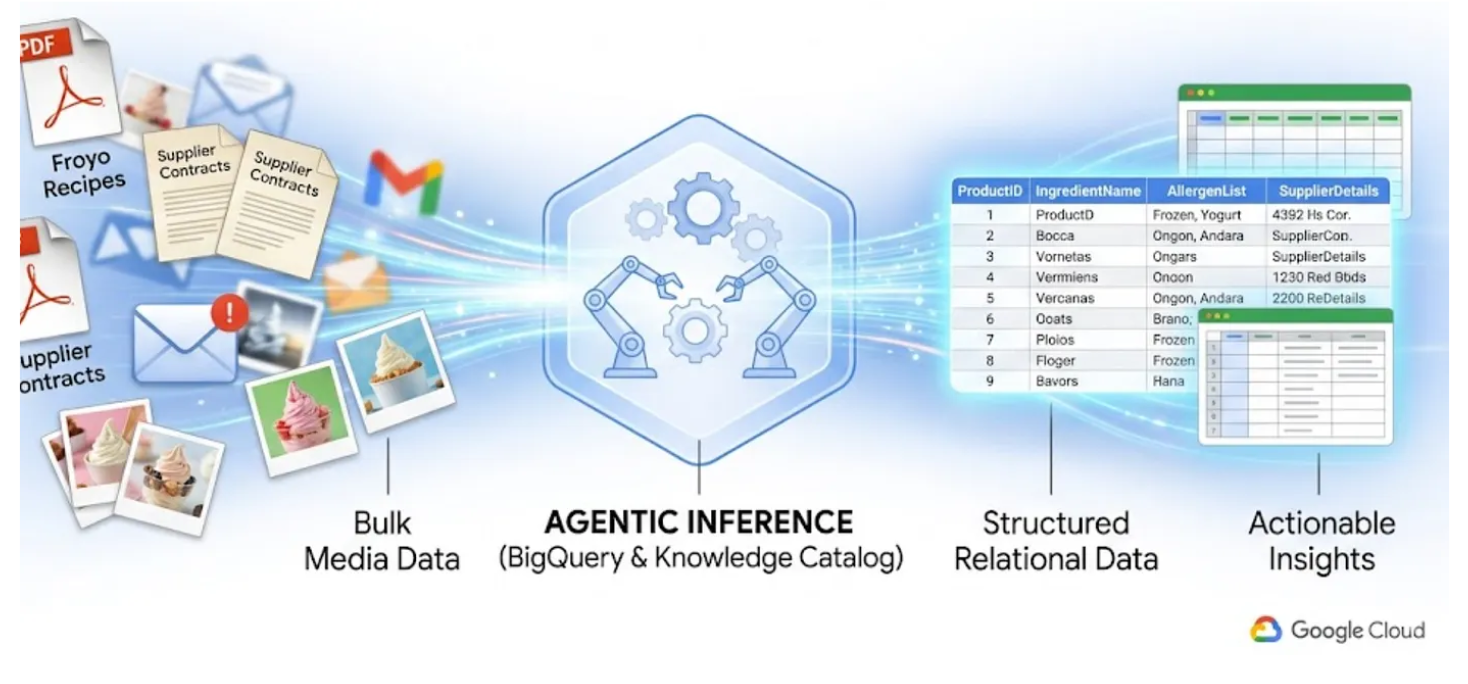
我們都知道「暗資料」的痛苦。這些檔案包括 PDF、圖片和文字檔,都存放在 Cloud Storage bucket 中,完全無法透過 SQL 查詢和 BI 資訊主頁存取。如要解鎖這類資料,過去需要複雜的 OCR 管道、手動輸入資料或容易出錯的自訂指令碼。
現在您不必再為此煩惱。
在本實驗室中,我將示範如何將 400 個非結構化 PDF 檔案 (包含文字、表格和圖片) 轉換為結構清楚的 BigQuery 資料表,並自動推斷資料表之間的關係。我們將使用 BigQuery Knowledge Catalog 和 Dataplex,在幾分鐘內完成這項作業。
建構項目
為求實際,我們以虛構的優格霜淇淋連鎖店為例,這家店的業務快速成長。
假設您負責管理這間 Froyo 企業的資料。您有數百份食譜和供應商規格表,全都儲存為 PDF 檔。企業領導人想推出 AI 代理,協助店長和顧客查詢產品詳細資料。
以下是夢魘情境:顧客詢問「我對你的午夜漩渦優格很感興趣,裡面有任何過敏原嗎?」
如要回答這個問題,系統通常必須:
- 找到「Midnight Swirl」食譜 PDF。
- 閱讀成分 (例如「可可粉」、「乳製品基底」、「乳化劑 X」)。
- 從數十份供應商 PDF 中搜尋,找出這些特定成分的規格表。
- 查看供應商資料表,找出與這些成分相關的隱藏過敏原。
如果想建立 AI 代理程式,在執行階段讀取 400 個原始 PDF,並即時執行這項作業,速度會很慢、成本高昂,而且容易產生錯覺。我們將改用語意推論,先將所有資料擷取到關聯式資料庫中,讓未來的 AI 代理速度飛快,且 100% 以實際的 SQL 資料為依據。
讓我們開始建構吧!
課程內容
- 如何設定來源檔案 (PDF) 的 Cloud Storage bucket
- 如何設定及執行 Knowledge Catalog 中的資料掃描工作和語意推論,從來源 PDF 檔案擷取資料,並以語意推論連結和內容,然後儲存在 BigQuery 中
- 如何使用 BigQuery 代理與新建立的資料集對話
需求條件
2. 事前準備
建立專案
- 在 Google Cloud 控制台的專案選取器頁面中,選取或建立 Google Cloud 專案。
- 確認 Cloud 專案已啟用計費功能。瞭解如何檢查專案是否已啟用計費功能。
- 您將使用 Cloud Shell,這是 Google Cloud 中執行的指令列環境。按一下 Google Cloud 控制台頂端的「啟用 Cloud Shell」。

- 連至 Cloud Shell 後,請使用下列指令確認驗證已完成,專案也已設為獲派的專案 ID:
gcloud auth list
- 在 Cloud Shell 中執行下列指令,確認 gcloud 指令已瞭解您的專案。
gcloud config list project
- 如要驗證
gcloud auth login
- 如果未設定專案,請使用下列指令設定:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- 啟用必要的 API:執行下列指令,啟用所有必要的 API:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
常見問題與疑難排解
「幽靈專案」 症候群 | 您執行了 |
帳單 路障 | 您已啟用專案,但忘記帳單帳戶。AlloyDB 是高效能引擎,如果「油箱」(帳單) 空了,就無法啟動。 |
API 傳播 延遲 | 您點選了「啟用 API」,但指令列仍顯示 |
配額 Quags | 如果您使用的是全新試用帳戶,可能會達到 AlloyDB 執行個體的區域配額。如果 |
「隱藏」服務專員 | 有時系統不會自動將 |
3. 設定 Google Cloud Storage Bucket
在本節中,您將在 BigQuery 中建立機構結構,專門儲存 Froyo 食譜和供應商資料,特別是 Froyo 產品詳細資料。此外,這項服務也會建立雲端資源連線,做為安全「橋樑」,讓 BigQuery 從 Cloud Storage 等外部來源讀取檔案。
事前準備:
這個存放區包含食譜和供應商 PDF 檔案,我們將在專案中使用這些檔案。請務必下載這些檔案。如要下載檔案,請按照下列步驟操作。
在 Cloud Shell 中執行下列指令:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
前往新建立的資料夾:
cd next-26-keynotes
拉取 data-cloud-demo 資料夾
git sparse-checkout set genkey/data-cloud-demo
結帳完成後,請前往 data-cloud-demo 資料夾,並解壓縮 ZIP 檔案,存取程式碼研究室資產。
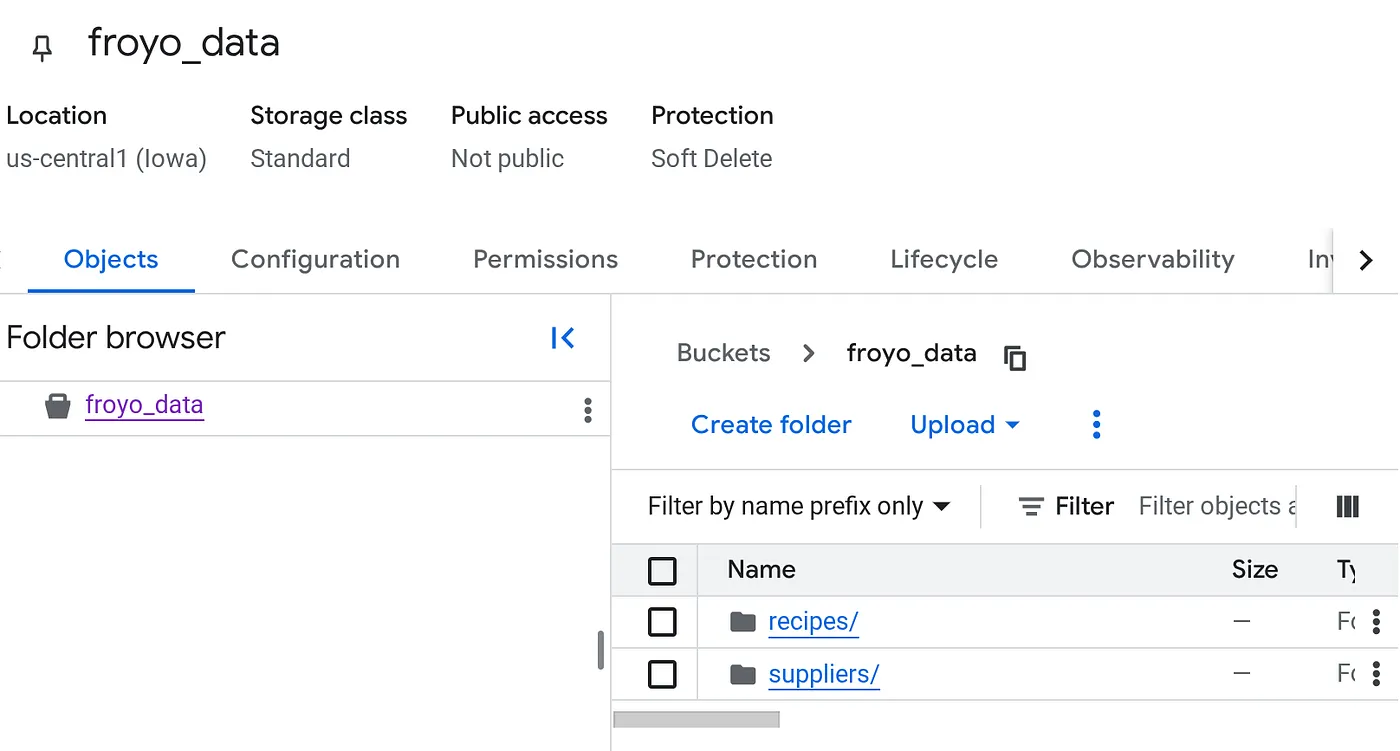
建立 bucket 並上傳 Froyo (食譜和供應商) PDF 檔案
- 前往 Google Cloud 控制台中的「Cloud Storage Buckets」(Cloud Storage 值區) 頁面。
- 按一下「建立」。
- 在「建立 bucket」頁面中,輸入 bucket 資訊。完成下列每個步驟後,請按一下「繼續」前往下一個步驟:
- 在「開始使用」部分,輸入 bucket 名稱。例如:froyo_data
- 在「選擇資料儲存的位置」專區中,選取「區域」,然後輸入您的區域。us-central1
- 在「選取如何控制物件的存取權」部分,取消勾選「強制禁止公開存取這個 bucket」核取方塊。
- 按一下「建立」。
- 在值區清單中,按一下您建立的值區。
- 在 bucket 的「Objects」(物件) 分頁中,依序點選「Upload」(上傳) 和「Upload folders」(上傳資料夾)。
- 選取您在本程式碼研究室「事前準備」一節中解壓縮的 recipes 資料夾。
- 按一下 [上傳]。
- 針對「suppliers」資料夾重複上傳程序。
上傳後,值區結構應如下所示 (無論值區名稱為何):
4. 設定 BigQuery 連線
建立 Cloud 資源連結。這會產生專屬服務帳戶,做為 BigQuery 存取外部檔案的「身分證」。
- 前往「BigQuery」BigQuery頁面。
- 點選左側窗格中的「Explorer」。如果沒有看到左側窗格,請按一下「Expand left pane」(展開左側窗格) 開啟窗格。
- 在「Explorer」窗格中展開專案名稱,然後按一下「連線」。
- 在「連線」頁面中,按一下「建立連線」。
- 在「連線類型」中,選擇「Vertex AI 遠端模型、遠端函式、BigLake 和 Spanner (Cloud 資源)」。
- 在「連線 ID」欄位中,輸入連線 ID 名稱:
- bq-connection。請務必記下這個 ID,因為稍後在本程式碼研究室中設定資料掃描時,您會需要用到這個 ID。
- 將「位置類型」設為「區域」,然後選取區域。例如 us-central1。連線應與資料集等其他資源位於相同區域。
- 按一下「建立連線」。
- 按一下「前往連線」。
- 在「連線資訊」窗格,複製服務帳戶 ID,以便在後續步驟中使用。服務帳戶類似於 bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com。
5. 設定權限
- 授予 BigQuery 連線存取 Cloud Storage 物件和 Knowledge Catalog 的必要權限
前往「IAM 與管理」頁面,在「按照主體查看」部分中,按一下「授予存取權」按鈕,然後貼上您在上一個步驟中複製的服務帳戶,新增主體。在角色部分中,逐一新增下列角色名稱並儲存:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- 授予 Dataplex 服務帳戶存取 Cloud Storage Bucket 的權限
前往「IAM 與管理」頁面,在「按照主體查看」部分中,按一下「授予存取權」按鈕,然後在「新增主體」文字列中輸入「dataplex」,即可新增主體。從自動完成的清單中,選取類似於下列項目的 Dataplex 服務帳戶主體 (請在下方的服務帳戶電子郵件 ID 中使用專案編號,而非專案 ID):
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
如果系統因任何原因無法辨識上述專案編號的服務帳戶,可能是因為專案尚未初始化 Dataplex 服務。前往 Cloud Shell 終端機,然後執行下列指令來啟用 API (如果尚未在「事前準備」階段啟用):gcloud services enable dataplex.googleapis.com
即使這樣,如果系統仍無法辨識 Dataplex 的服務帳戶,請在「中繼資料管理」頁面強制建立測試 Dataplex 掃描工作,並在「探索工作建立」頁面中輸入詳細資料:
點選「立即執行」。這項工作會失敗,但可確保系統現在會為您的 Dataplex 服務初始化服務帳戶 ID。
返回「IAM 與管理」頁面,在「按照主體查看」部分,按一下「授予存取權」按鈕,然後按一下「新增主體」。貼上服務帳戶:
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
然後將下列角色授予這個服務帳戶:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. 設定 Knowledge Catalog
建立 Knowledge Catalog,整合非結構化資料,並自動探索非結構化檔案 (例如 PDF 食譜和 PDF 供應商)。
從控制台建立 DataScan 工作:
重要事項:請務必勾選「啟用語意推論」。
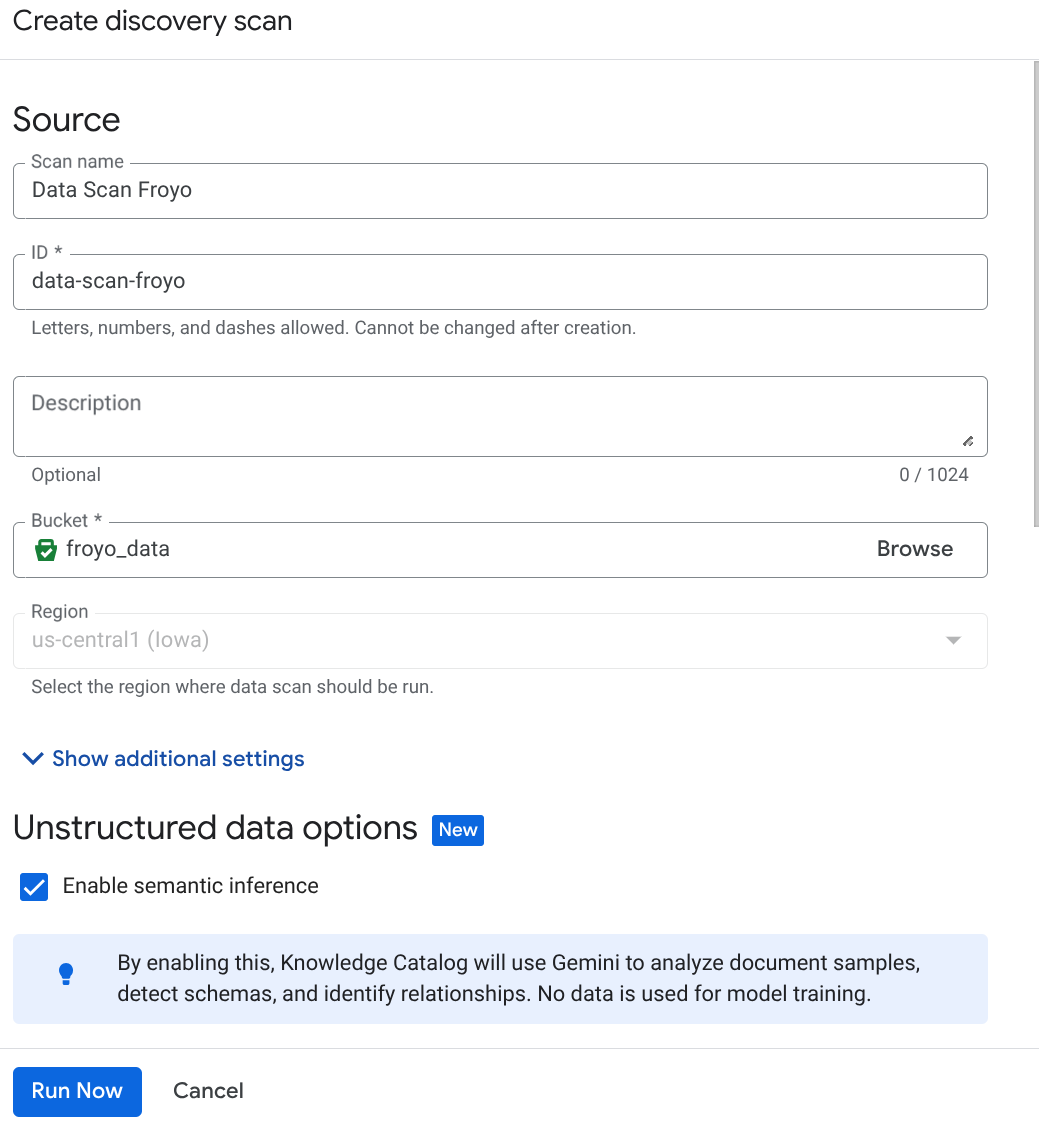
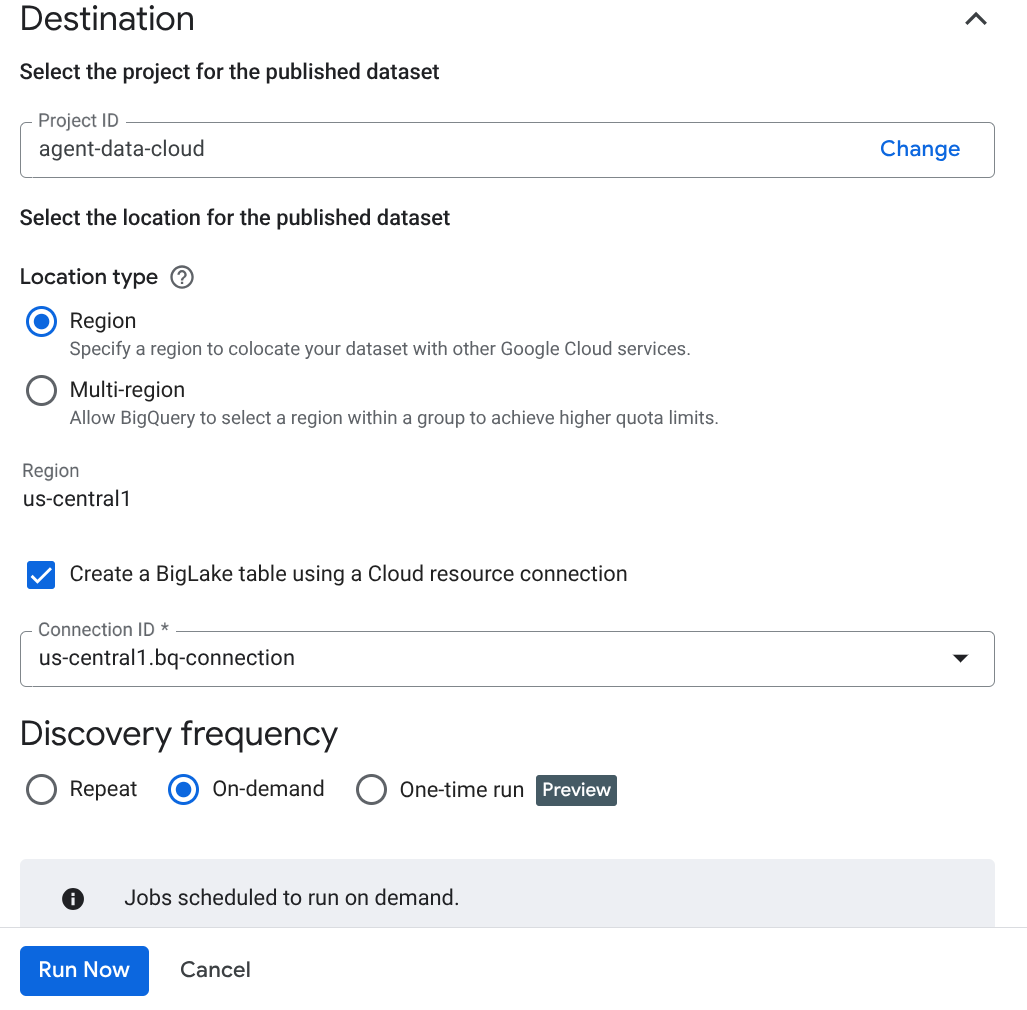
- 按一下「立即執行」。
- 掃描作業需要一段時間才能完成。工作完成後,請檢查「已發布的資料集」是否顯示。如要檢查工作狀態,請前往「Metadata curation」(中繼資料管理) 頁面,在 Cloud Storage 探索分頁中,按一下最近一次執行探索掃描的名稱,您應該會看到已發布的資料集,如下所示:
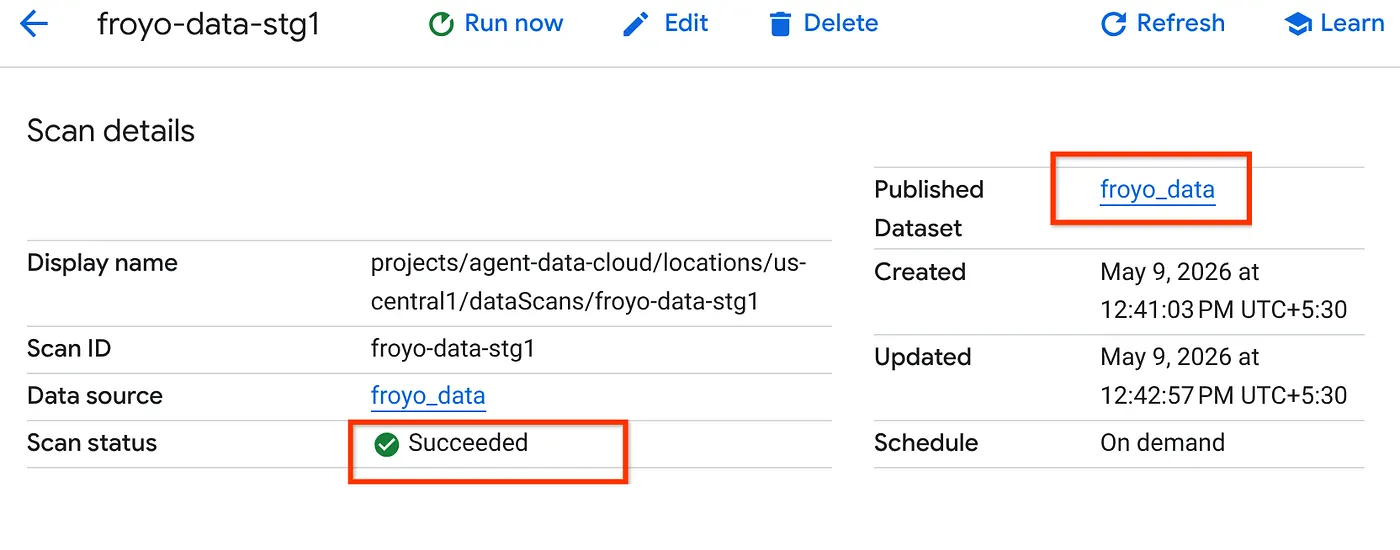
注意:如果在掃描步驟中發生錯誤,請稍候片刻再重試 (建立工作並完成執行作業需要幾分鐘)。
- 如要在 BigQuery 中查看資料表,請按一下並前往 froyo_data 資料集。在 BigQuery 中點選資料表 ID,然後在「查詢編輯器」分頁中執行下列查詢:
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
這會導致 400 (如果不是,您可以返回並再次執行 Datascan 工作)。
7. 語意資料擷取
太棒了!現在,我們來使用 Knowledge Catalog 擷取這些非結構化物件的推論結果。
我們將使用「洞察」功能生成 SQL 陳述式,從非結構化資料表擷取結構化資料
- 在 Google Cloud 控制台中,前往「Knowledge Catalog Search」(知識目錄搜尋) 頁面。
- 搜尋要查看洞察資料的資料集資料表。在搜尋列中輸入上一步的資料集 / 資料表名稱:「froyo_data」,然後按下 Enter 鍵
- 在結果清單中,按一下「TABLE」項目 (而非資料集項目)
- 畫面上應該會顯示「洞察」分頁標籤。按一下該連結 (如果需要啟用任何 API,請按照指示啟用 API)。
如果您最後在這個步驟啟用 API,請再次執行掃描作業。
- 在「洞察」分頁中,您會看到「擷取」按鈕下拉式選單。按一下該選項,然後選取「使用 SQL 擷取」選項。
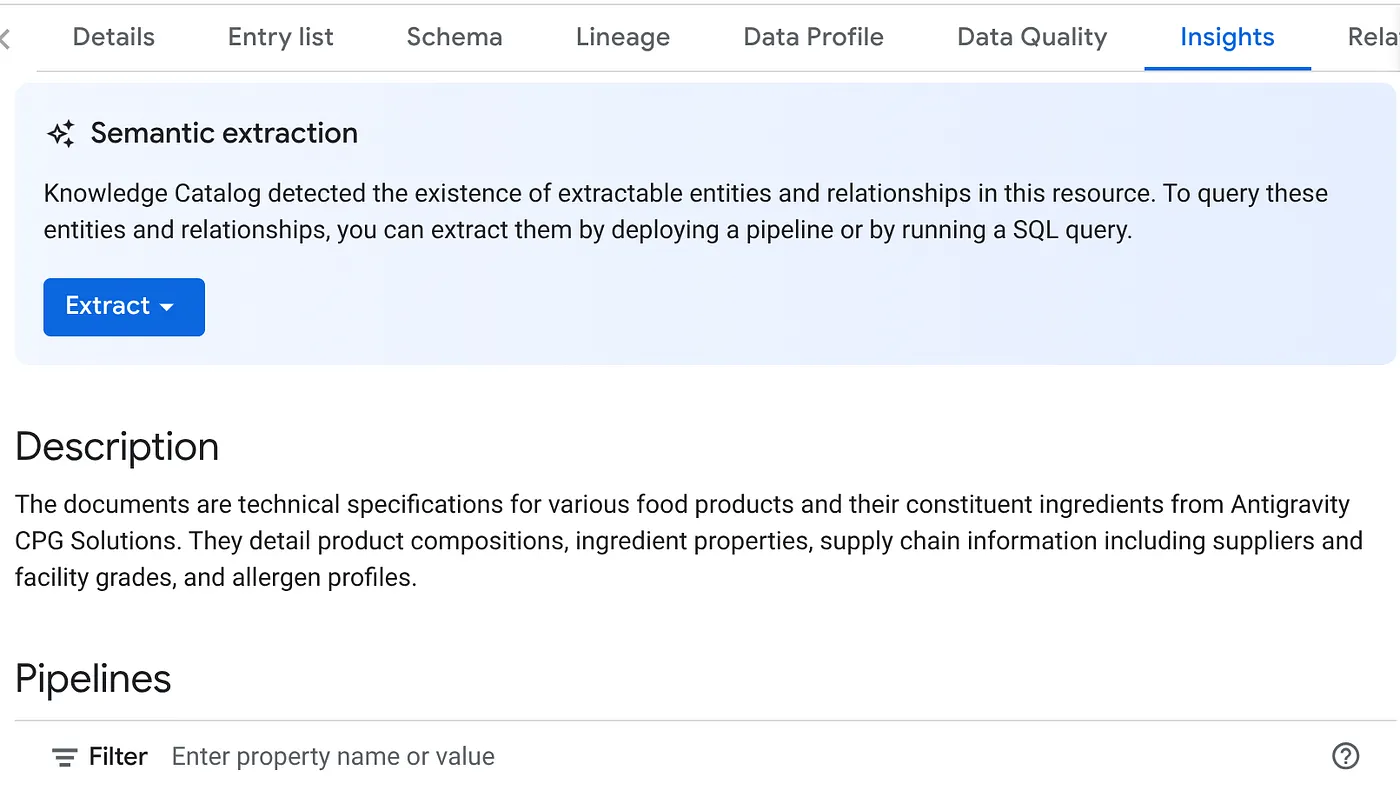
在「Extract with SQL」(使用 SQL 擷取) 對話方塊中,將「DESTINATION」資料集設為您在 Datascan 工作結果中看到的資料集。開始輸入名稱,系統就會自動完成。按一下「擷取」按鈕。或者,您也可以在這個時間點建立新的資料集並擷取資料。
這時應該會開啟 BigQuery 查詢編輯器,並在分頁中填入從資料掃描推論擷取的 SQL。
8. SQL 驗證和結構定義建立
如果生成的查詢看起來沒問題,且與非結構化資料在語意上相關,請按一下查詢編輯器中的「執行」按鈕運作執行查詢。建立結構化儲存非結構化媒體所需的結構定義,需要幾分鐘的時間。
完成後,您應該就能在 BigQuery Studio 的 Explorer 窗格中展開資料集,驗證結構定義,如下所示:
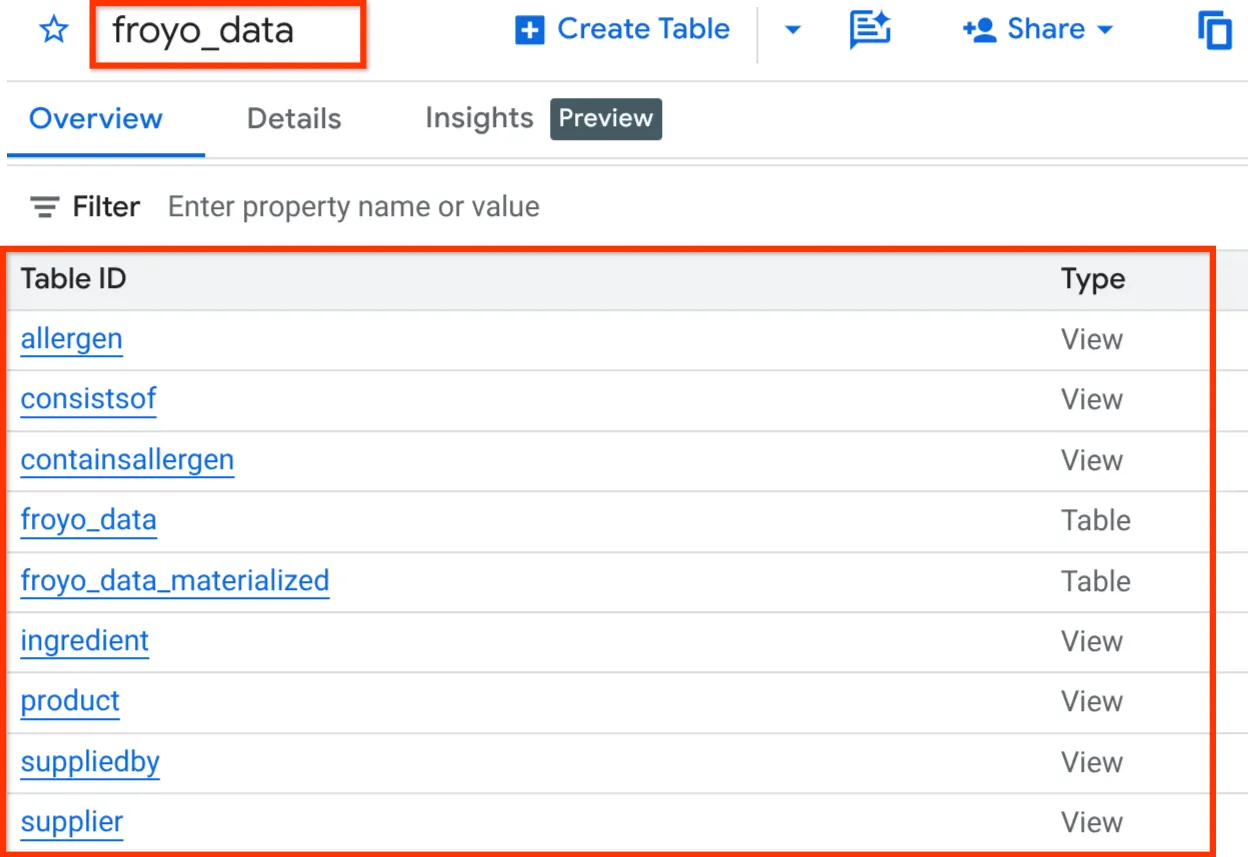
好的!我們很快就完成了所有資料庫相關作業,真是太棒了。現在可以進行最終測試了!
如要繼續使用資料,但不要帳單帳戶,請按照下列步驟操作:
- 您可以透過上方的 github repo 連結,取得資料 csv 檔案 (BigQuery 資料)。
- 首先,請從 Cloud Shell 終端機執行下列指令,建立 BigQuery 資料集:
bq mk --location us-central1 --dataset froyo_data
- 接著,請逐一執行下列指令,從 GitHub 存放區將 8 個資料檔案 (CSV 檔案) 下載到工作目錄:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- 依序執行下列指令,使用新建立資料集中的資料建立這些資料表
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
建立資料集、資料表和資料後,即可測試並體驗我們剛才討論的資料。
9. 終極測試!
假設我希望代理程式根據事實,以真實、完整且精心安排的資訊回覆使用者的問題。我將提出一個問題,代理只能參考來源中的多個媒體檔案和參考資料來回答。
我的使用者問題如下:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
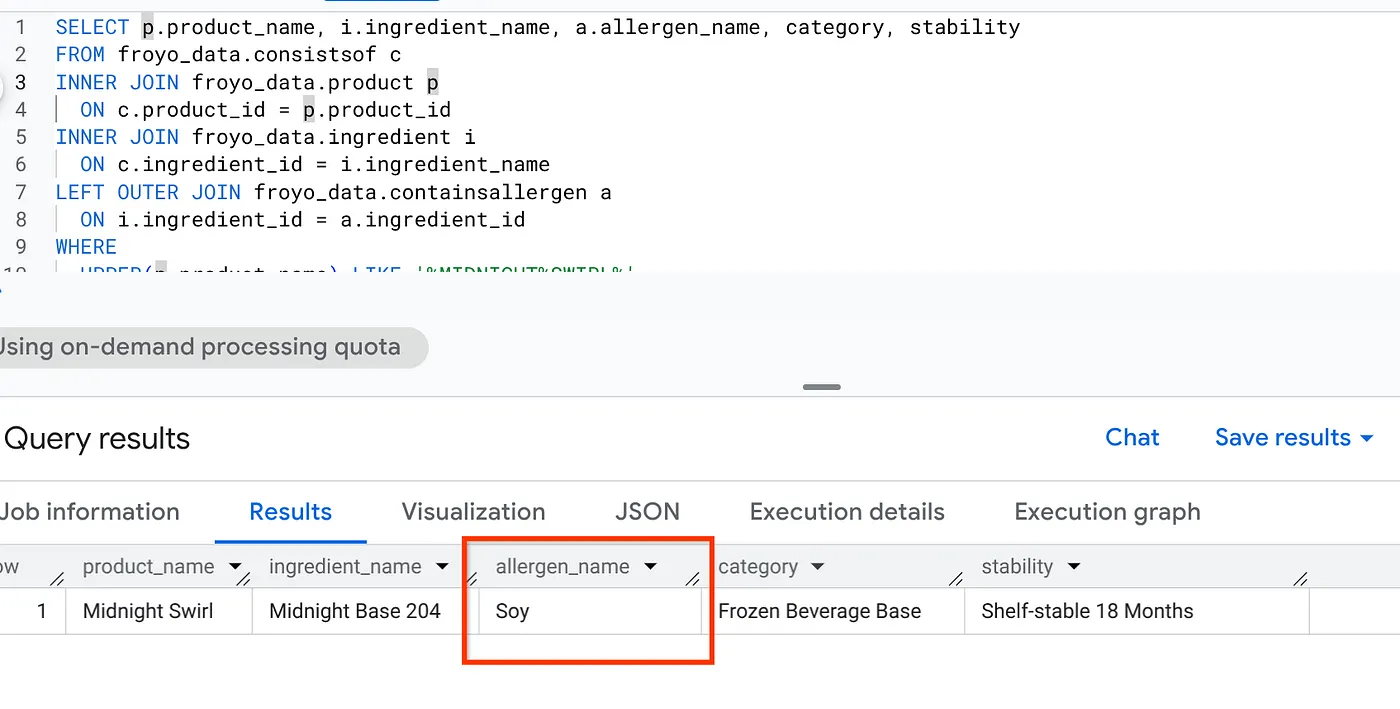
現在,一般搜尋或 LLM 搜尋會顯示「零種食材」。但我們建構了完整的語意推論,將所有非結構化媒體轉換為結構化資料。以下是擷取這項資訊的簡單 SQL:
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
太厲害了!查看結果:
10. 清理
完成本實驗室後,請務必刪除掃描工作,以及工作建立的 BigQuery 資料表。
前往 https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery。找出要刪除的工作,然後按一下旁邊的垂直省略號,並點選「刪除」。
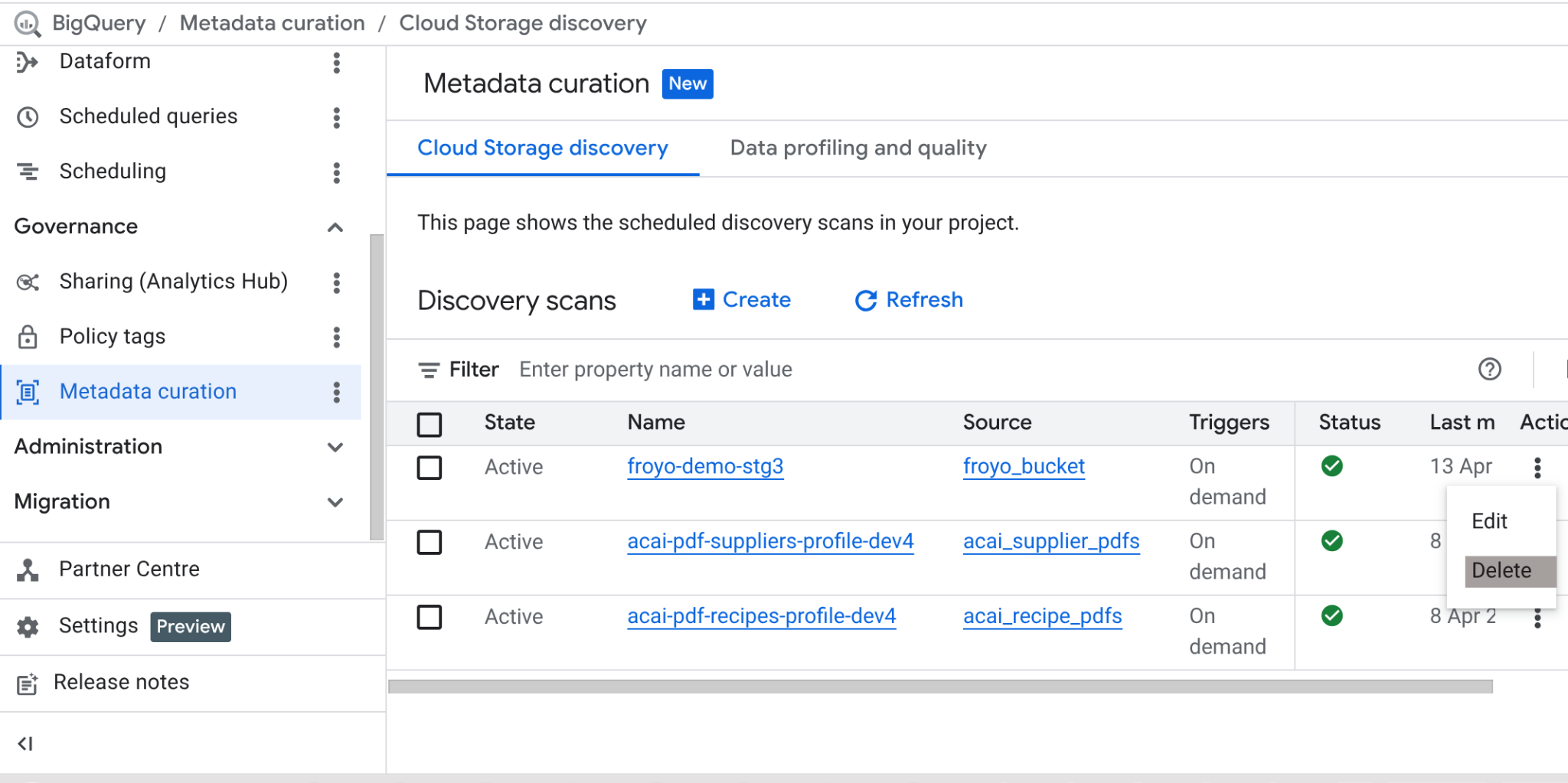
這樣應該就能清理工作。
11. 恭喜
我們的實作方式成功找出隱藏的過敏原。各位,我們再也不需要暗資料了!在第 2 部分中,我們會將這個 BigQuery 資料與 AlloyDB 中的交易系統聯合,以滿足代理程式應用程式的資料需求。