
1. مقدمة
في هذا التمرين العملي، ستتولّى دور محقّق رئيسي في بيانات العملاء المحتملين لدى شركة لوجستية عالمية. لقد فُقدت حاوية شحن عالية القيمة تحمل مجسّمات Android ثمينة. للعثور على آخر موقع جغرافي معروف لها وتتبُّع مسارها، عليك تجميع بيانات الشحن المجزّأة من شركاء الخدمات اللوجستية الإقليميين وملفات سجلّات جهاز الإرسال والاستقبال غير المنظَّمة. ولإجراء ذلك، عليك إعداد Google Cloud Open Data Lakehouse الحديث.

الإجراءات التي ستنفذّها
- إعداد إضافة "مجموعة أدوات Google Cloud Data Agent" في Cloud Shell Editor
- أنشئ حزمة Cloud Storage وقدِّم كتالوج Lakehouse Apache Iceberg REST ومساحة اسم.
- ربط جدول خارجي BigLake ببيانات JSON أولية خاصة بالشركاء في Cloud Storage للعثور على دليل مغادرة السفينة
- يمكنك تحميل سجلات نصية غير منظَّمة لجهاز الإرسال والاستقبال ومعالجتها باستخدام Managed Service for Apache Spark بدون خادم، وإجراء عمليات تسوية باستخدام التعبيرات العادية واستخراج الأدلة الديناميكية لاستهداف وجهة الحمولة المفقودة.
- اكتب مقاييس السجلّ المحلَّلة كـ جدول Apache Iceberg من خلال كتالوج REST.
- تحدّث مع وكيل يعمل بالذكاء الاصطناعي حول بيانات Apache Iceberg باستخدام الإحصاءات الحوارية للعثور على أدلة مخفية حول شحنتك المفقودة.
- يمكنك الاستفادة من إحصاءات البيانات المبرمَجة باستخدام كتالوج المعرفة لإنشاء بيانات وصفية حول بياناتك.
- ضَعوا ضوابط إدخال البيانات من خلال إنشاء تصنيف أمني واستخدام كتالوج المعرفة لتطبيق التحكّم الدقيق في الوصول من خلال إخفاء أرقام تعريف الجهات المسؤولة الحساسة.
المتطلبات
- متصفّح ويب، مثل Chrome
- مشروع Google Cloud تم تفعيل الفوترة فيه
- الإلمام باستعلامات SQL الأساسية وأوامر الجهاز
التكلفة والمدة المتوقّعتان
- الوقت المقدّر لإنهاء الدرس: حوالي 45 دقيقة
- التكلفة المقدّرة: أقل من 5.00 دولار أمريكي
2. قبل البدء
إنشاء مشروع على Google Cloud أو اختياره
- في Google Cloud Console، اختَر مشروعًا على Google Cloud أو أنشِئ مشروعًا.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. كيفية التأكّد من تفعيل الفوترة في مشروع
ضبط البيئة
ستنفّذ معظم الأوامر من الوحدة الطرفية المدمجة في محرّر Cloud Shell، وهي بيئة تطوير مستندة إلى السحابة الإلكترونية ومحمّلة مسبقًا بأدوات المطوّرين وحزمة Google Cloud SDK العادية.
- افتح محرِّر Cloud Shell في علامة تبويب جديدة.
- نفِّذ الأمر التالي في الوحدة الطرفية لاستنساخ المستودع:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - اضبط رقم تعريف مشروعك. يمكنك أيضًا الضغط على
Ctrl+Shift+Vفي نظام التشغيل Windows أو Linux، أوCmd+Vفي نظام التشغيل macOS للصق هذا النص في الوحدة الطرفية:export PROJECT_ID="<YOUR_PROJECT_ID>" - الآن، اضبطه في بيئتك.
gcloud config set project $PROJECT_ID - اختَر منطقة.
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - فعِّل واجهات برمجة التطبيقات المطلوبة.
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
تثبيت الإضافة
عليك الآن ضبط إضافة "حزمة أدوات Google Data Agent"، وهي أداة للتفاعل مع أدوات بيانات Google Cloud مباشرةً في بيئة التطوير المتكاملة.
- في شريط الأنشطة الأيمن في المحرّر، انقر على رمز الإضافات (أو اضغط على
Ctrl+Shift+Xفي نظام التشغيل Windows أو Linux، أوCmd+Xفي نظام التشغيل macOS). - في مربّع البحث عن الإضافات، اكتب:
Google Cloud Data Agent Kit - اختَر الإضافة الرسمية من النتائج وانقر على تثبيت. إذا طُلب منك ذلك، اختَر "نعم، أثق بالمؤلفين".
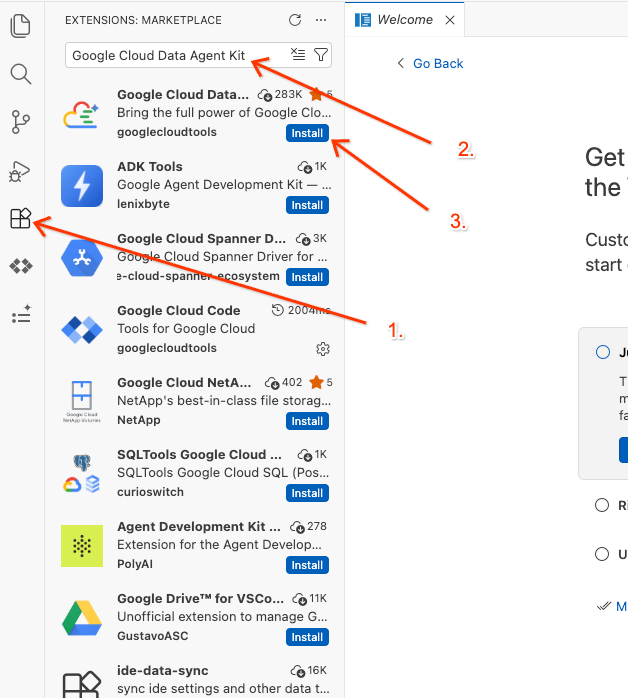
- بعد التثبيت بنجاح، من المفترض أن يظهر رمز Google Cloud Data Agent Kit في شريط الأنشطة. انقر عليه.
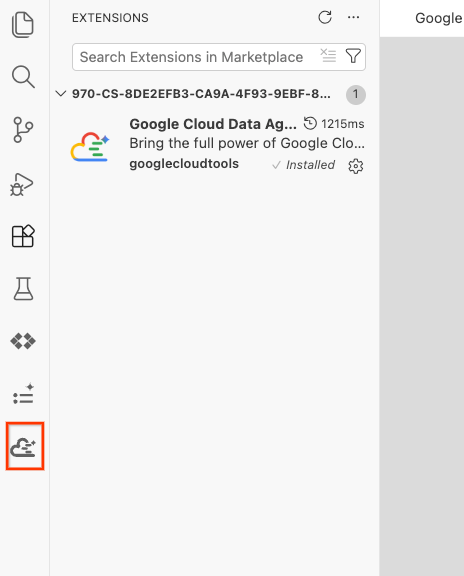
- انقر على تسجيل الدخول إلى السحابة الإلكترونية.
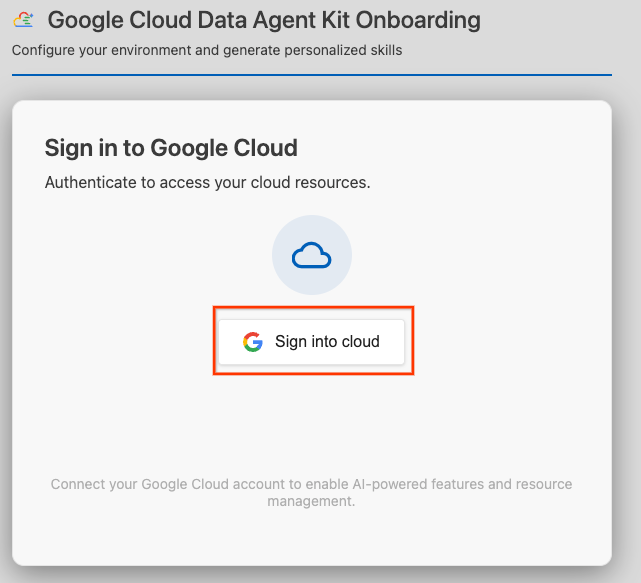
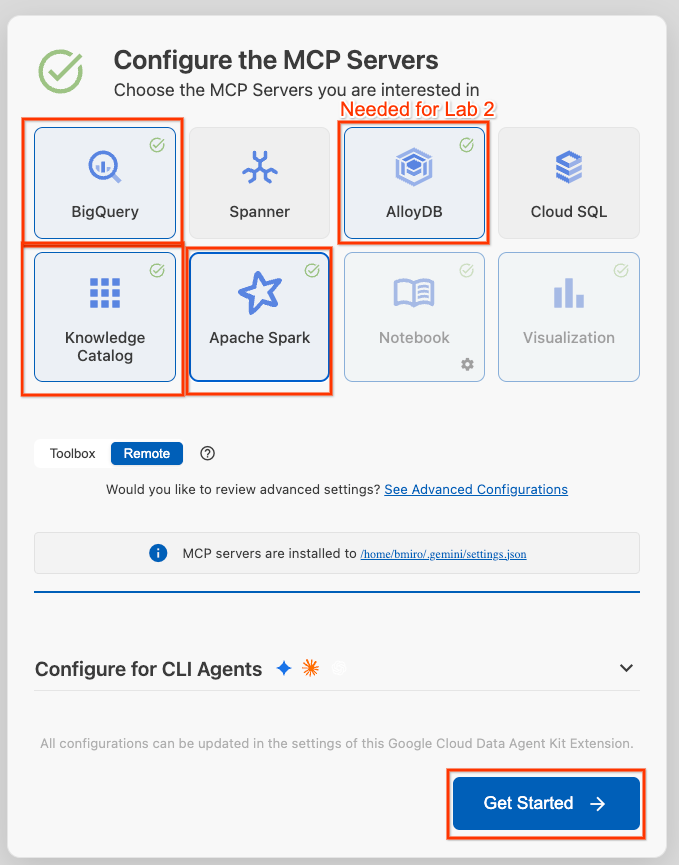
- انقر على ضبط خوادم MCP.
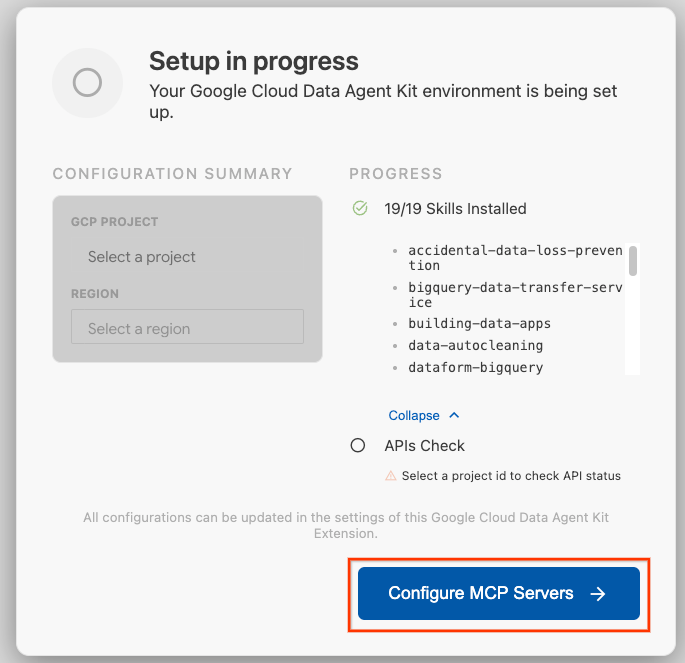
- اختَر BigQuery وKnowledge Catalog وApache Spark وAlloyDB، علمًا بأنّك ستستخدم AlloyDB في التمرين العملي 2، ثم انقر على البدء.
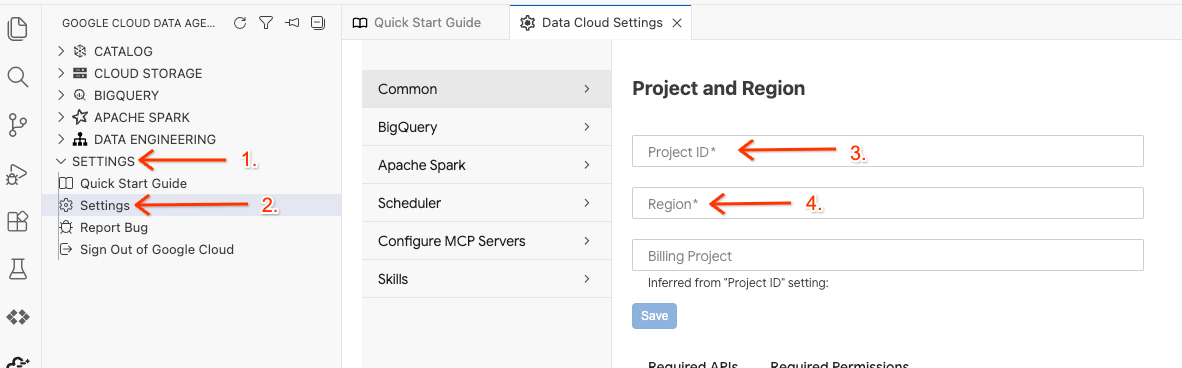
- انقر على أداة اختيار رقم تعريف المشروع في شريط الحالة أسفل الصفحة واختَر مشروعك النشط على Google Cloud.
- في Data Agent Kit، انقر على الإعدادات (SETTINGS)، ثم على الإعدادات (Settings)، وفي علامة التبويب عام (Common)، اختَر رقم تعريف المشروع (Project ID) والمنطقة (Region) لتشغيل مختبرك، مثل us-central1.
- انقر على إعدادات BigQuery واستبدِل المنطقة بالمنطقة التي اخترتها سابقًا. انقر على حفظ.
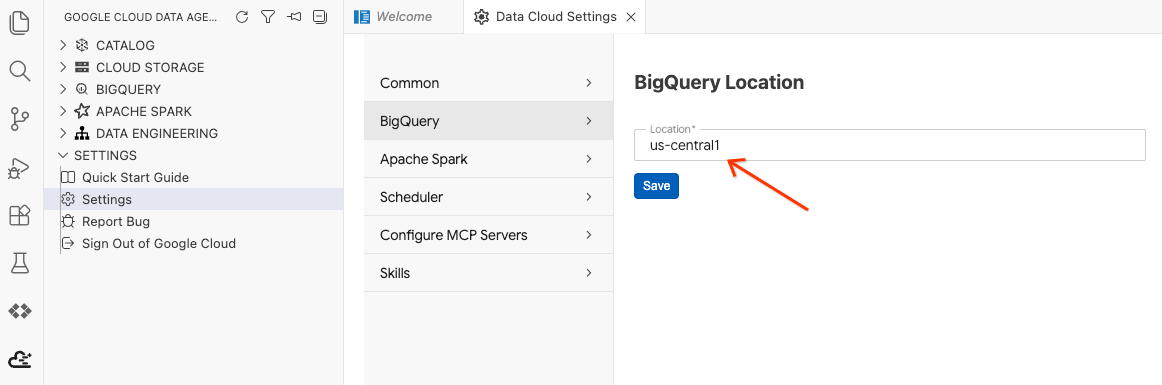
أنت الآن جاهز لاستخدام "حزمة أدوات وكيل البيانات".
تنفيذ نص إعداد البيئة البرمجي
في الوحدة الطرفية، شغِّل نص التهيئة البرمجي لإنشاء موارد الخلفية اللازمة لهذا المختبر وضبط أذونات إدارة الهوية وإمكانية الوصول (IAM):
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
ستظهر لك سلسلة من خطوات الإخراج توضّح الموارد التي يتم توفيرها. سنتناول هذه المفاهيم خلال الدرس التطبيقي.
بعد ظهور رسالة تفيد باكتمال العملية، يمكنك اتّباع الخطوات التالية:
==================================================== Environment Setup Complete! ====================================================
لنبدأ البحث الآن.
3- استيعاب بيانات الشحن الخاصة بشركاء الاستيعاب
يتم تخزين بيانات بيان الشحن من سفن الشركاء بتنسيق JSON Lines (JSONL) العادي في الحزمة: gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl.
قبل إجراء تحليلات تفصيلية، عليك إنشاء جدول BigLake مُدار لهذه البيانات غير المنظَّمة، ما يتيح لك استكشاف بيانات الخدمات اللوجستية الخاصة بالشركاء على الفور باستخدام لغة SQL العادية بدون تكاليف استيراد مكرّرة.
افتح مساحة العمل في "المحرّر" ونفِّذ طلب البحث.
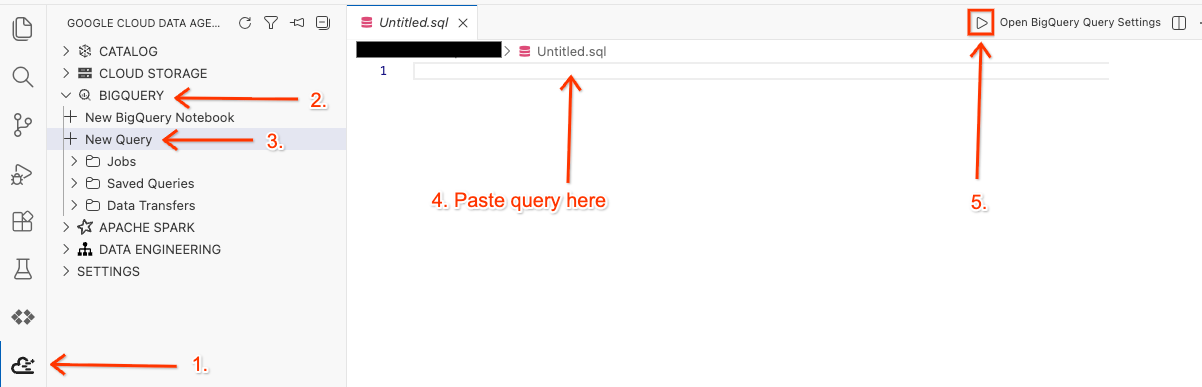
- في Cloud Shell Editor، انقر على رمز إضافة "مجموعة أدوات وكيل بيانات Google Cloud" في اللوحة الجانبية.
- انتقِل إلى BigQuery وانقر على + طلب بحث جديد.
- انسخ طلب البحث التالي في نافذة طلب البحث.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- انقر على تشغيل.
- للتأكّد من إنشاء الجدول، ستظهر لك رسالة نجاح في لوحة نتائج طلب البحث التي يتم فتحها تلقائيًا في أسفل الصفحة.
إرسال طلب بحث إلى الجدول الخارجي لعزل أجهزة الإرسال والاستقبال المخترَقة
لنحدّد أجهزة الإرسال والاستقبال المخترَقة من خلال تحديد حالات الأعطال عندما تم ضبط seal_integrity_status على 0. انسخ الاستعلام التالي وشغِّله في نافذة الاستعلام التي فتحتها من قبل:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
في لوحة نتائج الاستعلام، من المفترض أن تظهر لك نتيجة مشابهة لما يلي:
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0.1278 | usr_999_shadow |
4. معالجة السجلات غير المنظَّمة باستخدام Managed Service for Apache Spark
لقد عثرت على الموقع الجغرافي الأولي من البيانات الوصفية المنظَّمة، ولكن جهاز الإرسال والاستقبال المفقود توقّف عن العمل تمامًا. وقد ترك آخر إرسال لجهاز الإرسال والاستقبال رسالة غامضة غير منظَّمة داخل ملف سجلّ نصي أولي في مسار GCS gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt.
لمعالجة سجلّ النصوص هذا وتعيينه واستخراج الطوابع الزمنية وإخفاء الهويات وتحديد مسار الشحن، عليك إرسال مهمة Apache Spark (PySpark) بدون خادم إلى Managed Service for Apache Spark.
تتيح لك خدمة Managed Service for Apache Spark تشغيل مهام Spark بدون توفير مجموعة أو إدارتها، إذ تتولّى الخدمة إدارة موارد الحوسبة الأساسية وتوسيع نطاقها تلقائيًا بشكل ديناميكي، ولا تدفع إلا مقابل مدة التنفيذ.
سيؤدي النص البرمجي إلى ما يلي:
- استيعاب نص جهاز الإرسال والاستقبال غير المنظَّم بين قوسين
- تطبيق فلاتر استخراج التعبيرات العادية في PySpark SQL لفصل الطوابع الزمنية والبيانات الوصفية الخاصة بمسؤول الحفظ والمحتوى الأولي
- قسِّم السجلات غير المنظَّمة إلى سجلات نظيفة على مستوى الجملة.
- استخرِج إحداثيات الوجهة الديناميكية التي انتهت فيها عمليات مغادرة الحمولة المفقودة.
- يمكنك ربط إطار بيانات السجلّ الذي تمت معالجته وكتابته مرة أخرى في Lakehouse Apache Iceberg REST Catalog كجدول تحليلات جديد يمكن الاطّلاع عليه مباشرةً في BigQuery.
إصلاح نص تحليل PySpark
وردت تقارير عن قراصنة Python في البحر يتسبّبون في جميع أنواع المشاكل.
- نفِّذ الأمر التالي لفتح الملف
process_maritime_logsفي "محرِّر Cloud Shell".cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - خصِّص بعض الوقت لقراءة الرمز البرمجي وفهم ما يفعله.
- تأكَّد من عدم وجود أي شيء مريب في الرمز. إذا كنت بحاجة إلى حذف أي شيء، احرص على حفظ الملف باستخدام
Ctrl + S(في نظام التشغيل Windows أو Linux) أوCmd + S(في نظام التشغيل Mac).
إرسال مهمة Serverless Spark
أرسِل مهمة باستخدام حزمة تطوير البرامج (SDK) gcloud. يضبط ملف الإعدادات تلقائيًا مهمة PySpark للوصول إلى فهرس Lakehouse.
نفِّذ الأمر التالي في وحدة التحكّم المدمجة في المحرّر.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
انتظِر بضع دقائق حتى يتم إعداد بيئة بلا خادم، ثم حمِّل النص البرمجي ونفِّذ منطق المعالجة.
بعد ظهور نتيجة مشابهة لما يلي، يتم حفظ الجدول الذي تمت معالجته في كتالوج Lakehouse كجدول مُدار من Apache Iceberg.
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
معاينة السجلّات التي تمت معالجتها
في "محرّر طلبات البحث" الخاص بإضافة Data Agent Kit، انسخ طلب البحث التالي لمعاينة البيانات:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
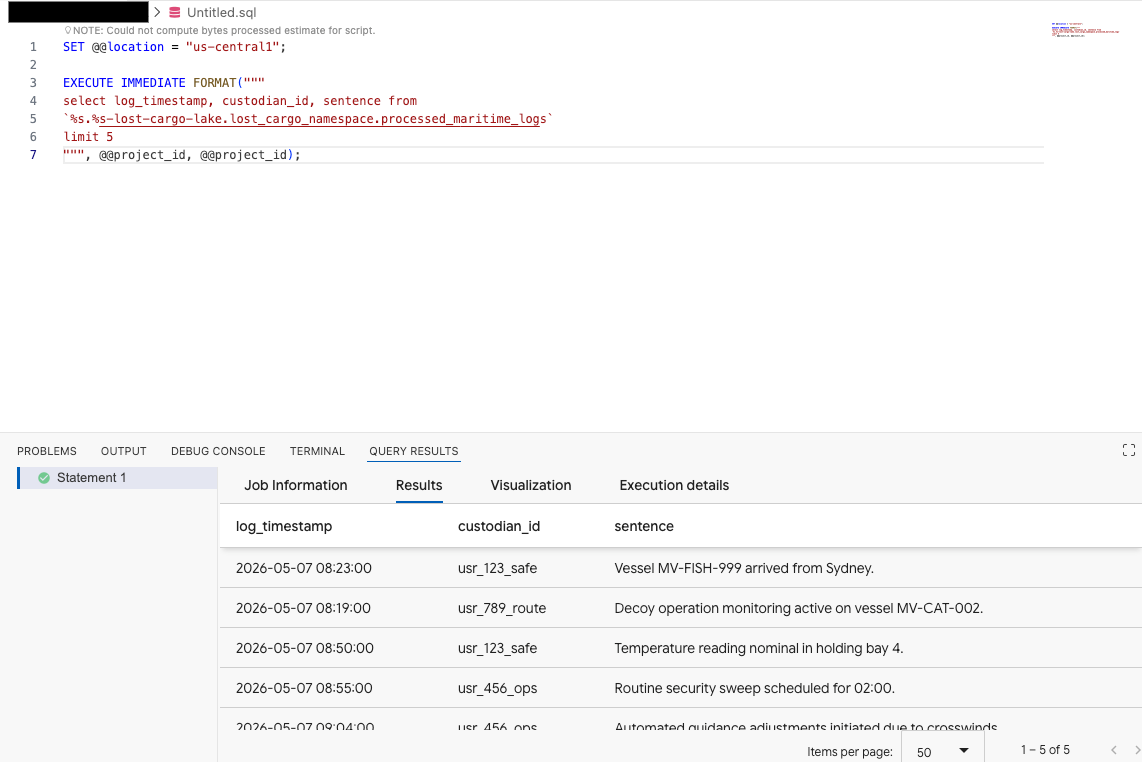
يوضّح هذا أنّه يمكن الوصول بنجاح إلى جدول Iceberg المسجّل في الفهرس من BigQuery.
استخراج دليل الوجهة
بعد أن حصلنا على السجلات التي تمت معالجتها، لنبحث عن السجلات التي تتضمّن وجهة مستهدَفة. من هناك، يمكننا البحث في السجلات التي تتضمّن إشارة إلى مدينة المنشأ.
في محرّر طلبات البحث، نفِّذ طلب البحث التالي، مع استبدال <YOUR_REGION> بمنطقتك و <ORIGIN_CITY> بمدينة المصدر التي عثرت عليها سابقًا.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
الدردشة مع بياناتك في وحدة تحكّم BigQuery باستخدام Conversational Analytics
بدلاً من كتابة طلبات بحث معقّدة باستخدام لغة الاستعلامات البنيوية (SQL) لاستكشاف بياناتك، يمكنك استخدام الإحصاءات الحوارية للدردشة مع جداولك باستخدام اللغة الطبيعية.
- انتقِل إلى وحدة تحكّم BigQuery.
- في لوحة المستكشف على يمين الصفحة، وسِّع مشروعك ومجموعة البيانات
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logsلفتح علامة تبويب التفاصيل الخاصة به. - بجانب طلب البحث، انقر على محادثة.
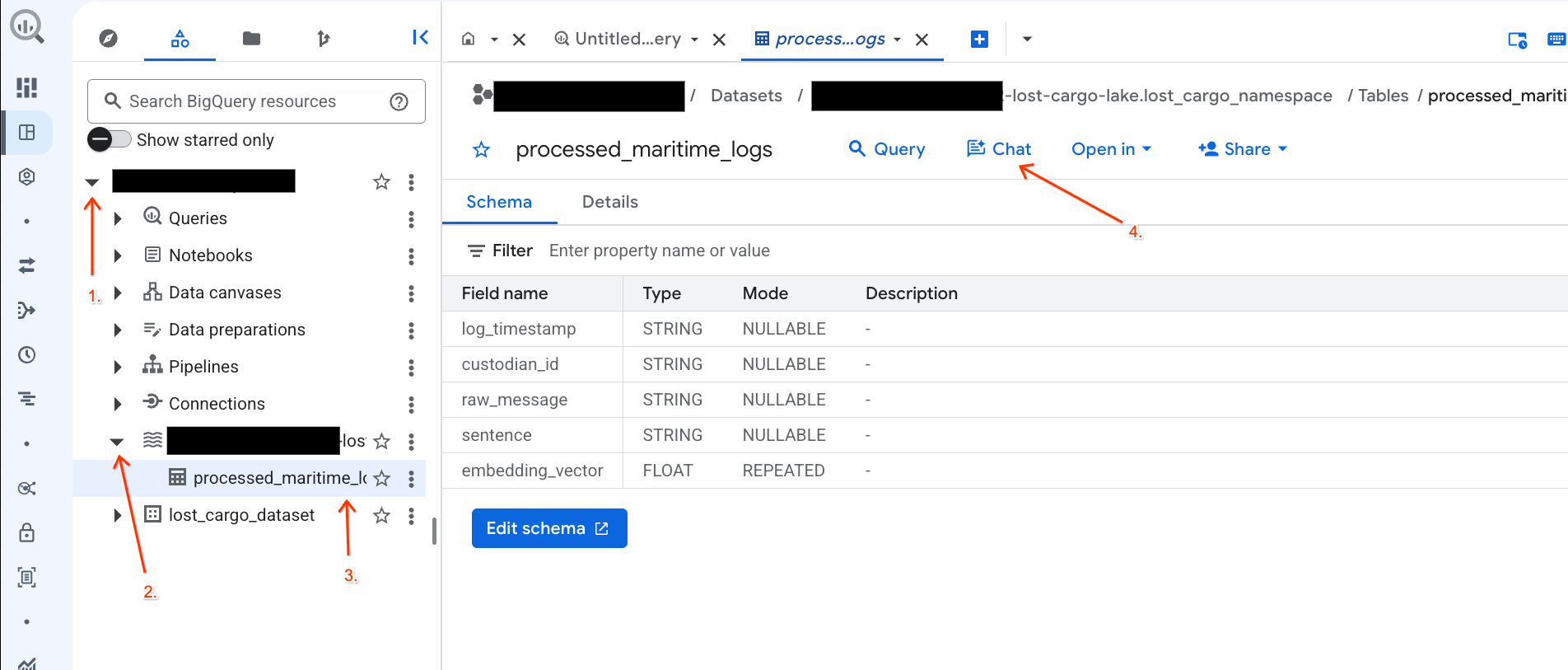
- في لوحة المحادثة، اكتب السؤال التالي واضغط على Enter في لوحة المفاتيح لإرساله:
Based on this table, what color is the shipping container MV-CAT-001?
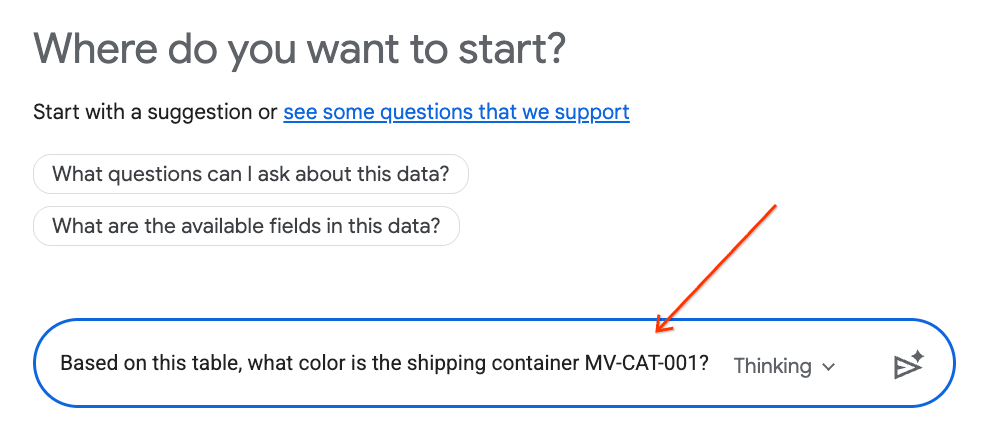
- ستحلّل ميزة "التحليلات الحوارية" (التي تستند إلى Gemini) بيانات الجدول النشط وستردّ باللون.
5- عرض "الكتالوج المركزي"
لدمج محركات المعالجة مفتوحة المصدر (مثل Apache Spark) بأمان وسلاسة مع محركات بيانات المؤسسة (مثل BigQuery)، أعدّ نص التهيئة البرمجي Lakehouse Iceberg REST Catalog.
يعمل Apache Iceberg REST Catalog كمصدر موثوق واحد بلا خادم لبيانات تعريف الجدول، ويدير المخططات وجداول التقسيم بشكل ديناميكي أثناء تخزين ملفات بيانات Parquet الفعلية في Cloud Storage.
لنطّلع على هذا الكتالوج مباشرةً في Google Cloud Console:
- افتح Lakehouse Console.
- في علامة التبويب كتالوجات، ابحث عن كتالوج Iceberg REST النشط وانقر عليه:
-lost-cargo-lake
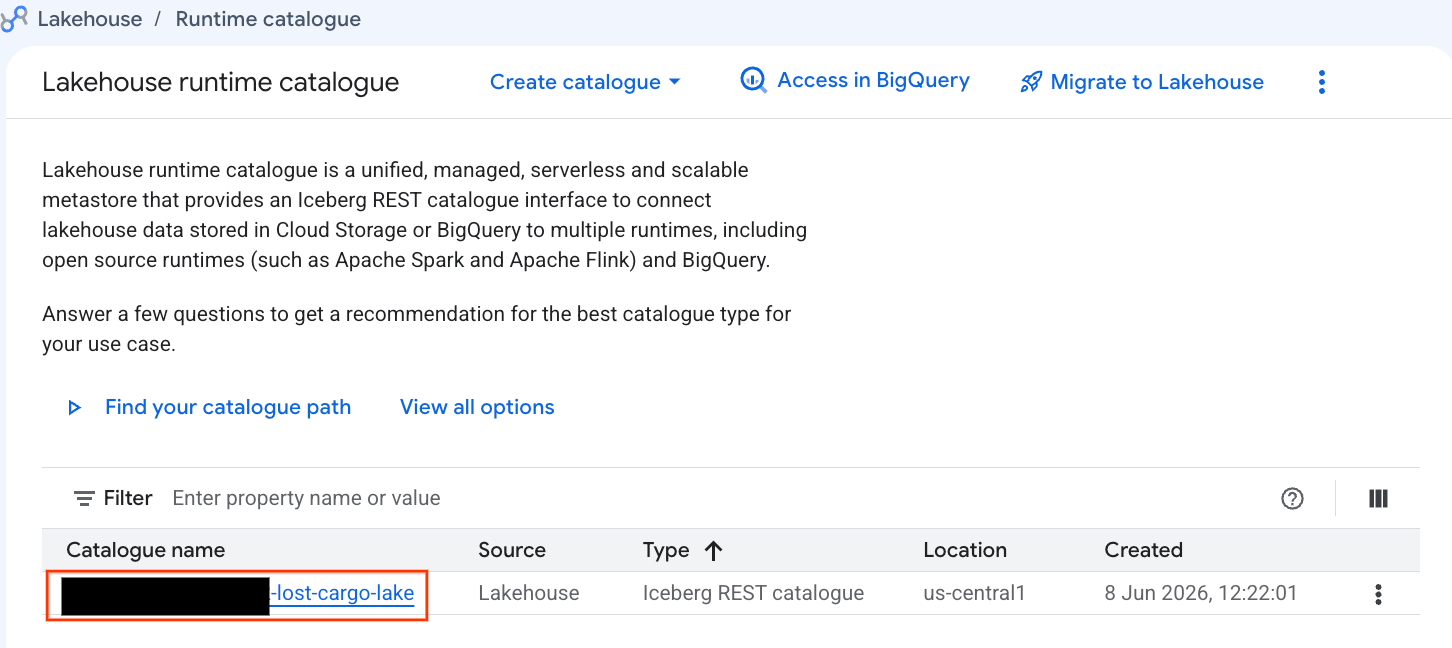
- في عرض تفاصيل الكتالوج، ضِمن مساحات الأسماء، يجب أن يظهر لك
lost_cargo_namespace. انقروا عليها.
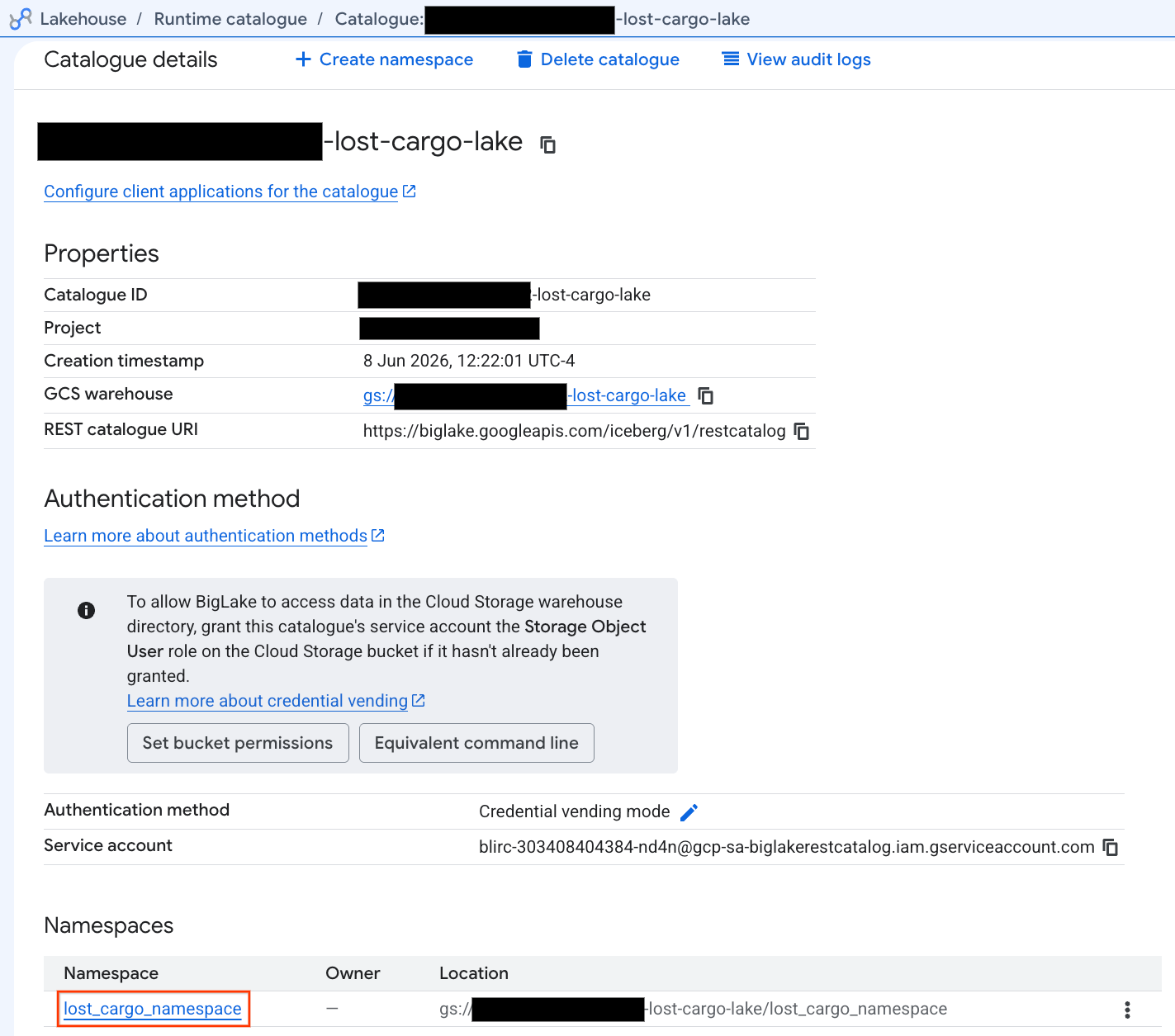
- تم تسجيل جدول Apache Iceberg الجديد الذي تم إنشاؤه بواسطة PySpark تلقائيًا ضمن مساحة اسم متجر البيانات الوصفية هذه وأصبح من الممكن الاستعلام عنه على الفور في BigQuery.
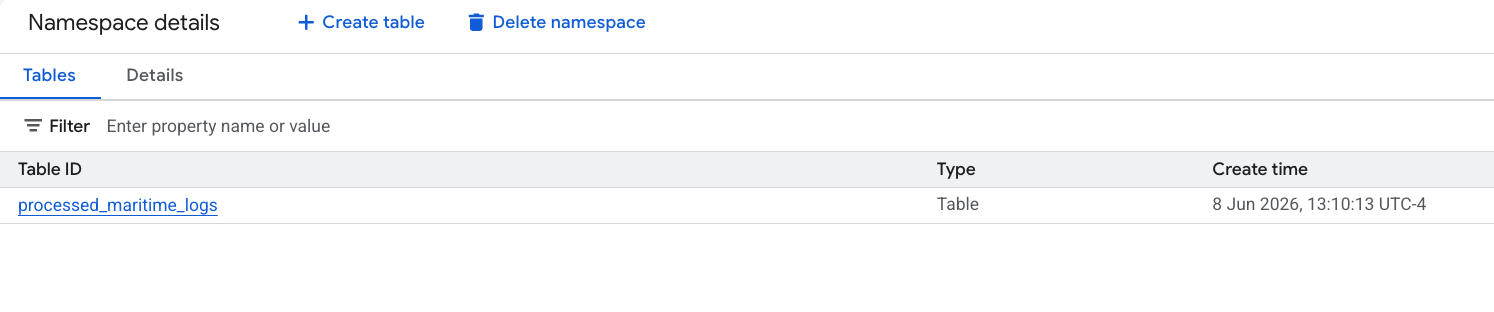
6. إنشاء إحصاءات في جدول "بيانات الشحن"
لنرجع إلى جدول shipping_manifests ونحلّله لفهم بنيته ومحتواه باستخدام إحصاءات بيانات "كتالوج المعرفة". ومن خلال تحسين البيانات الوصفية، يمكن للمستكشفين الآخرين فهم الجدول بشكل أفضل لإجراء التحليلات المستقبلية.
إنشاء "إحصاءات الجدول" في BigQuery Studio
- في Google Cloud Console، انتقِل إلى BigQuery Studio.
- في لوحة المستكشف، وسِّع مشروعك، ثم وسِّع مجموعة بيانات
lost_cargo_dataset، وانقر على جدولshipping_manifests. - في لوحة التفاصيل على يسار الصفحة، انقر على علامة التبويب الإحصاءات.
- استخدِم القائمة المنسدلة لاختيار إنشاء ونشر.
- انتظِر حوالي 3 دقائق حتى تكتمل عملية إنشاء الإحصاءات. سيحلّل Gemini البيانات الوصفية للجدول وينشئ أسئلة بلغة طبيعية واستعلامات SQL مطابقة.
- بعد اكتمال العملية، سيظهر وصف جدول يتضمّن شرحًا للجدول باللغة الطبيعية.
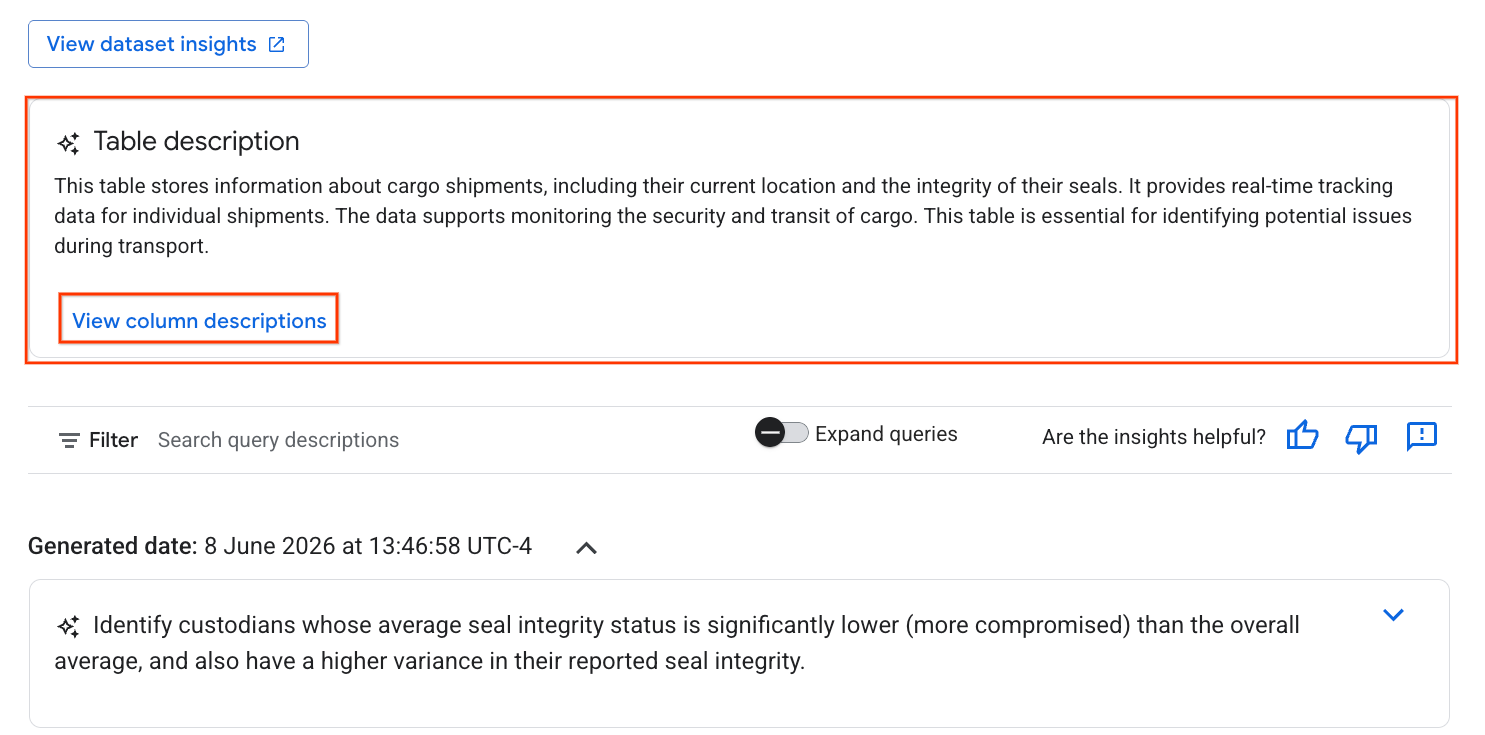
- انقر على عرض أوصاف الأعمدة للاطّلاع على معلومات حول الأعمدة الفردية.
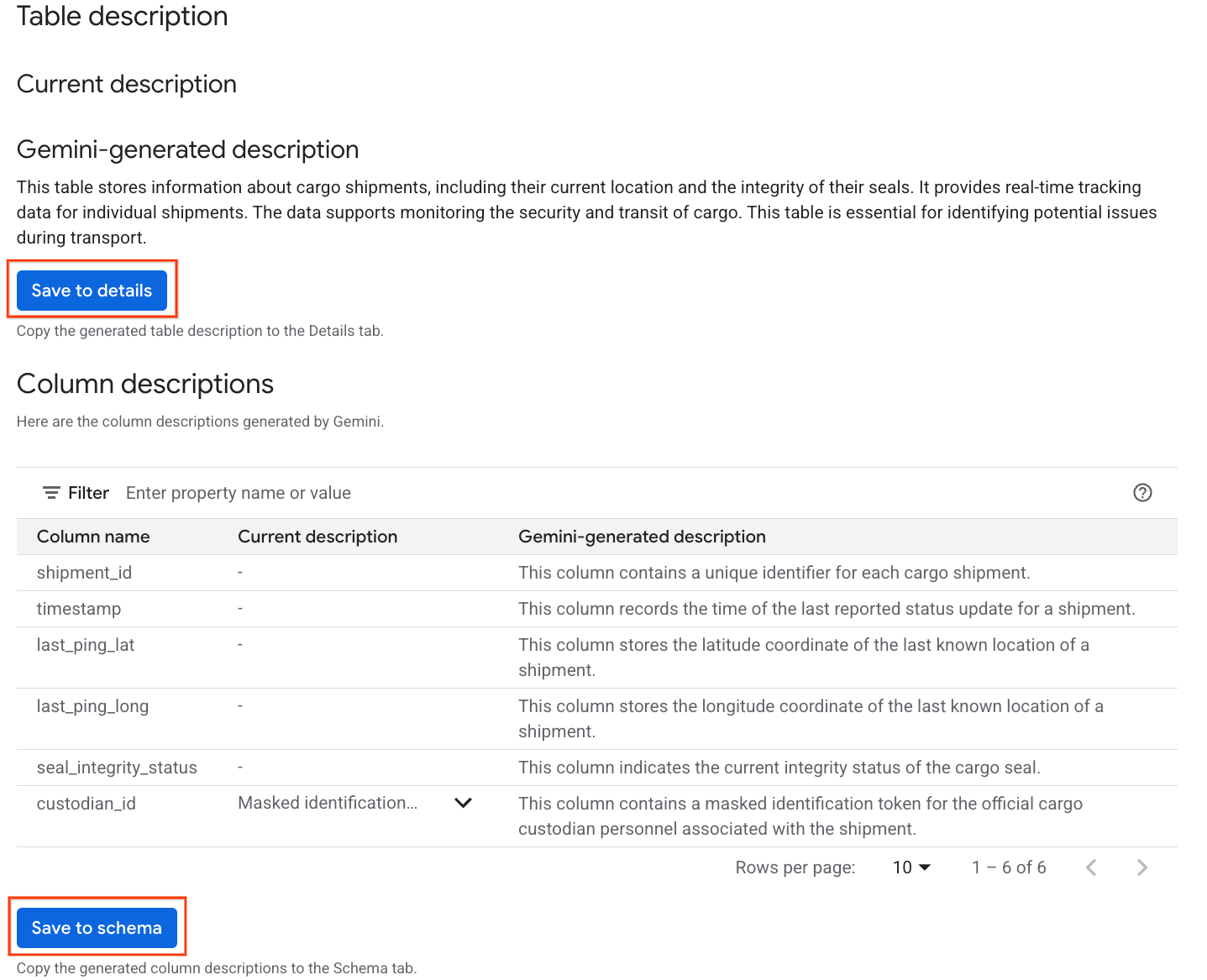
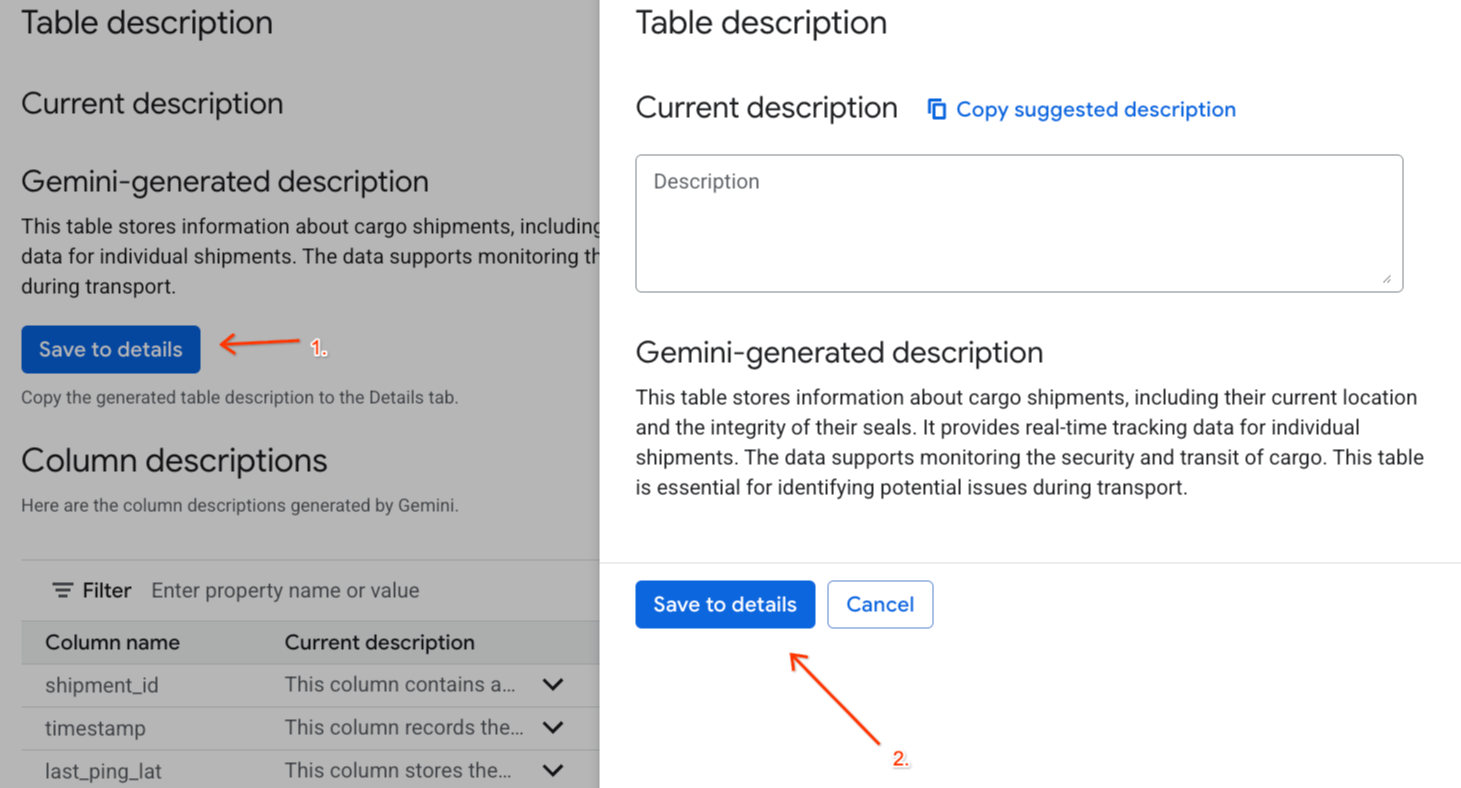
- انقر على حفظ في التفاصيل ضمن
Gemini generated description، ثم انقر على حفظ في التفاصيل في النافذة المنبثقة.
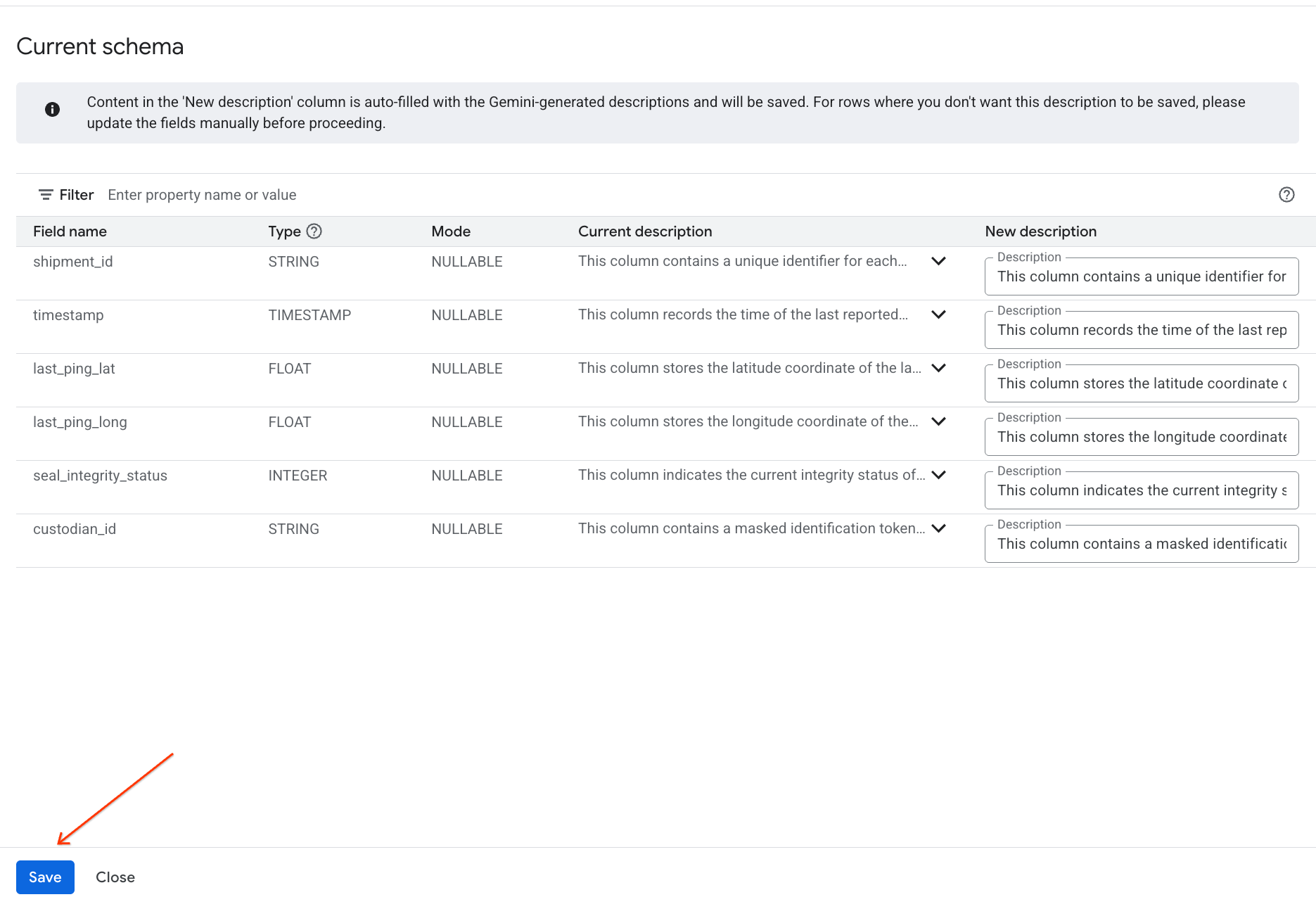
- وبالمثل، انقر على الحفظ في المخطط لإضافة أوصاف الأعمدة إلى البيانات الوصفية للجدول.
مراجعة الإحصاءات التي تم إنشاؤها
ستظهر لك أيضًا قائمة بالأسئلة المقترَحة. يمكنك النقر على أي سؤال للاطّلاع على طلب بحث SQL الذي تم إنشاؤه وتشغيله لاستكشاف البيانات. على سبيل المثال، قد تظهر لك أسئلة مثل:
- "ما هو إجمالي عدد الشحنات؟"
- "أدرِج أرقام التعريف الفريدة الخاصة بالوصي".
يساعدك تنفيذ طلبات البحث هذه في فهم البيانات.
7. تنفيذ إخفاء البيانات وإدارتها
لضمان عدم تسريب حسابات وأسماء مستخدمي الأبحاث النشطة أثناء التحقيق الجاري في الشحنة، عليك فرض بروتوكولات الأمان العادية. عليك إنشاء تصنيف لعلامات سياسة الأمان وإعداد إخفاء بيانات "كتالوج المعرفة" في العمود الحساس custodian_id للتحقّق من خصوصية البيانات.
بشكلٍ تلقائي، يرفض BigQuery الوصول إلى الأعمدة المحمية بعلامات السياسة. لطلب البحث في الجدول والتحقّق من أقنعة البيانات النشطة، يجب أن يتضمّن حساب المستخدم دور قارئ البيانات المقنّعة في سياسة بيانات BigQuery.
تم ربط هذا الدور تلقائيًا بحساب المستخدم النشط أثناء التنفيذ الأوّلي لـ setup_lab1.sh.
إنشاء علامة التصنيف وعلامة السياسة
أنشئ تصنيفًا للبيانات وعلامة سياسة مرتبطة لإدارة الوصول إلى بياناتك.
- انتقِل إلى صفحة تصنيفات علامات السياسات.
- انقر على + إنشاء تصنيف.
- اضبط المَعلمات:
- اسم التصنيف: أدخِل
lost-cargo-، واستبدِلها برقم تعريف مشروعك. - المنطقة: اختَر منطقتك.
- بالنسبة إلى علامة السياسة الاسم: أدخِل
MaskCustodianID - بالنسبة إلى علامة السياسة الوصف:
Restricts visibility into cargo custodian usernames
- اسم التصنيف: أدخِل
- انقر على إنشاء لتسجيل التصنيف الجديد وعلامة السياسة.
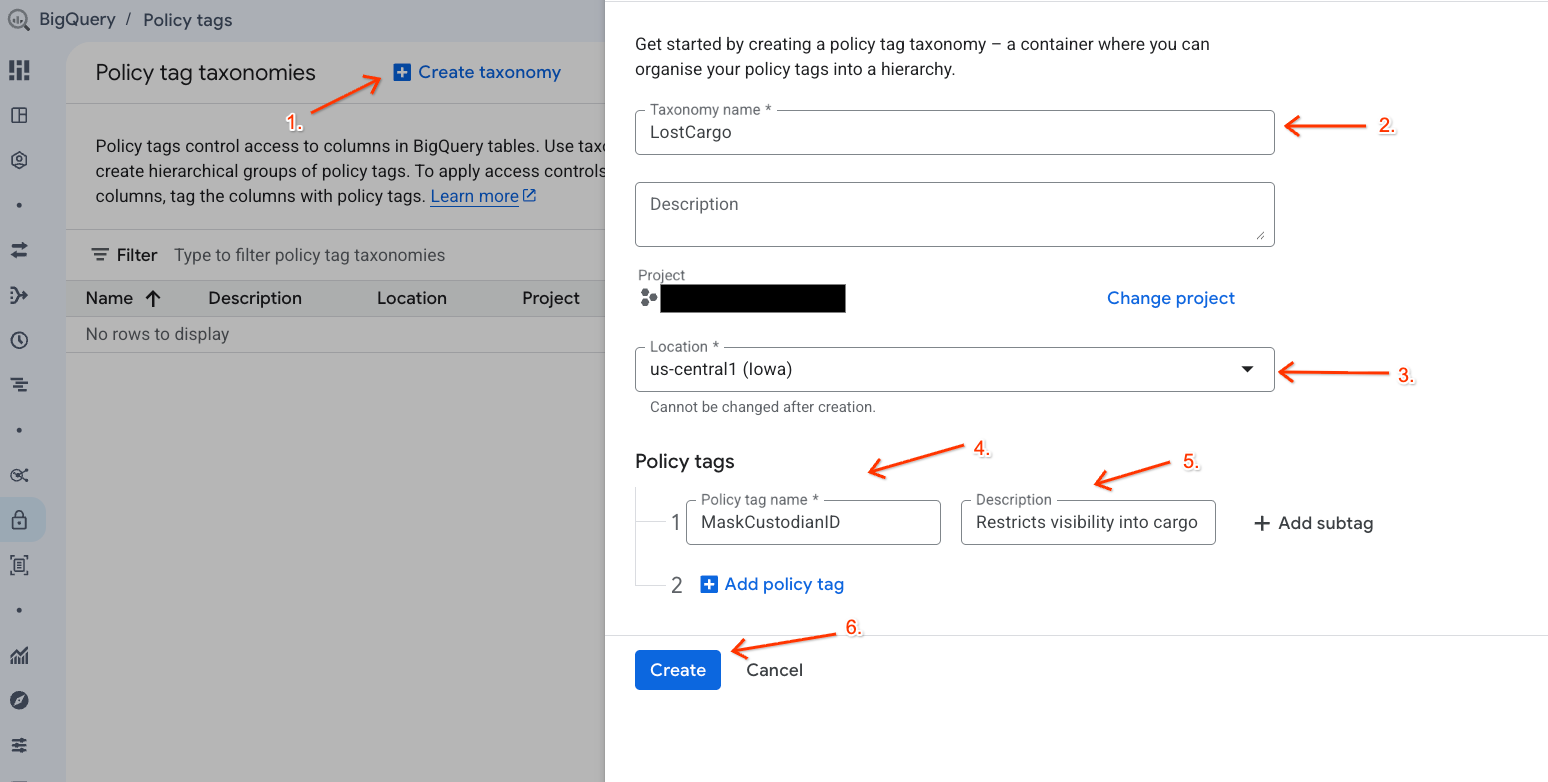
إنشاء سياسة إخفاء البيانات
بعد ذلك، اضبط سياسة بيانات لتحديد كيفية إخفاء البيانات ضمن علامة التصنيف MaskCustodianID. ستستخدِم قاعدة إخفاء البيانات دائمًا فارغ (استبدال القيم المطابقة بقيم فارغة/Null لجميع الجهات الفاعلة غير الحاصلة على امتيازات).
- في صفحة تصنيفات علامات السياسات، انقر على التصنيف الذي تم إنشاؤه حديثًا من قائمة التصنيفات.
- في قائمة التسلسل الهرمي، انقر على العلامة
MaskCustodianIDلاختيارها، ثم انقر على إدارة سياسات البيانات.
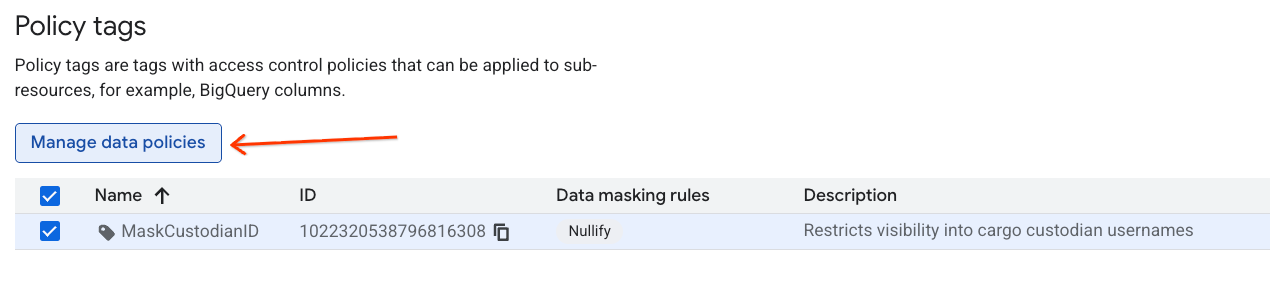
- في اللوحة على يسار الصفحة، انقر على الزر + إضافة قاعدة.
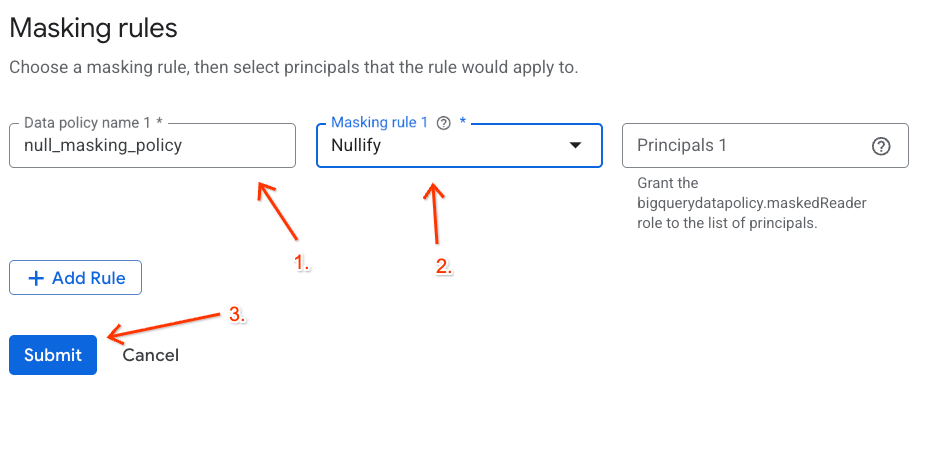
- اضبط تفاصيل السياسة في اللوحة التي تظهر:
- اسم سياسة البيانات: أدخِل
null_masking_policy(لا تترك الاسم منشأ تلقائيًا، لأنّنا سنشير إليه بالاسم في الخطوات التالية). - قاعدة الإخفاء: اختَر
Nullifyمن القائمة المنسدلة.
- اسم سياسة البيانات: أدخِل
- انقر على إرسال.
تخصيص "علامة السياسة" لعمود BigQuery
بعد تفعيل علامة السياسة وقاعدة إخفاء البيانات المرتبطة بها، اربط علامة التصنيف مباشرةً بالعمود custodian_id في جدول بيان الشحن الخاص بشركاء BigQuery.
- انتقِل إلى BigQuery.
- في لوحة المستكشف على يمين الصفحة، وسِّع مشروعك النشط، ثم وسِّع مجموعة بيانات
lost_cargo_dataset، وانقر على جدولshipping_manifestsلفتح العرض التفصيلي. - انقر على تعديل المخطط.
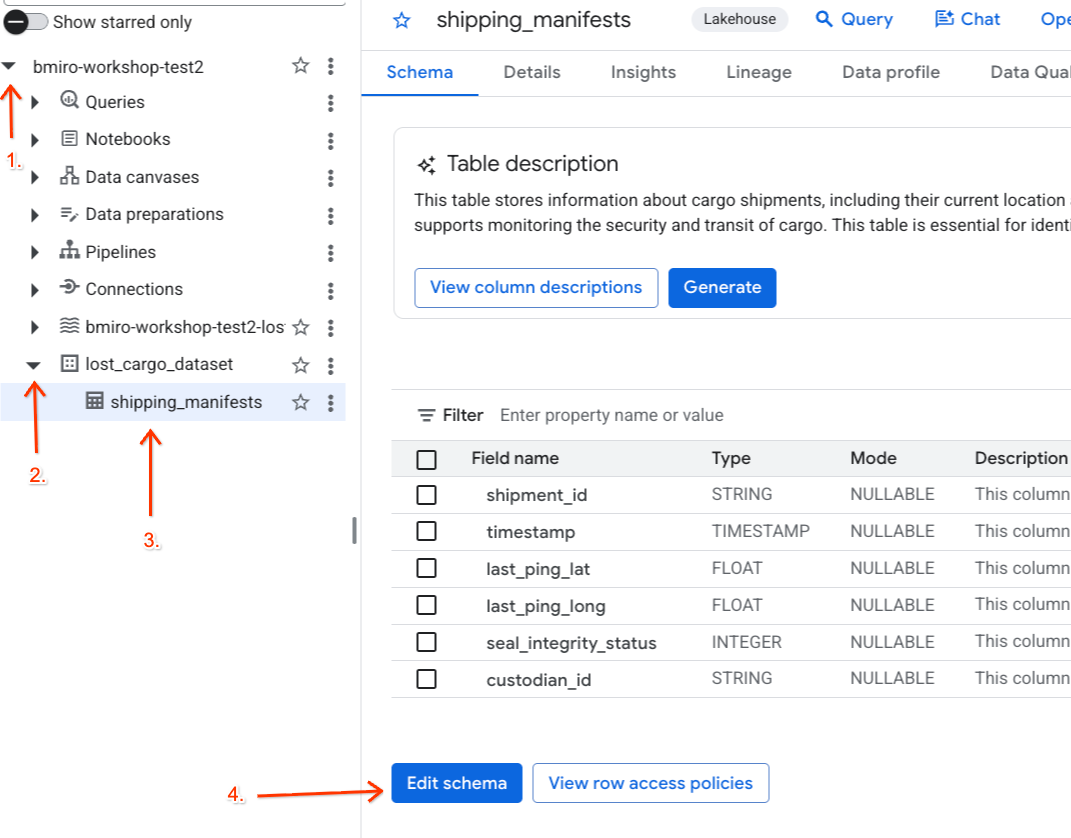
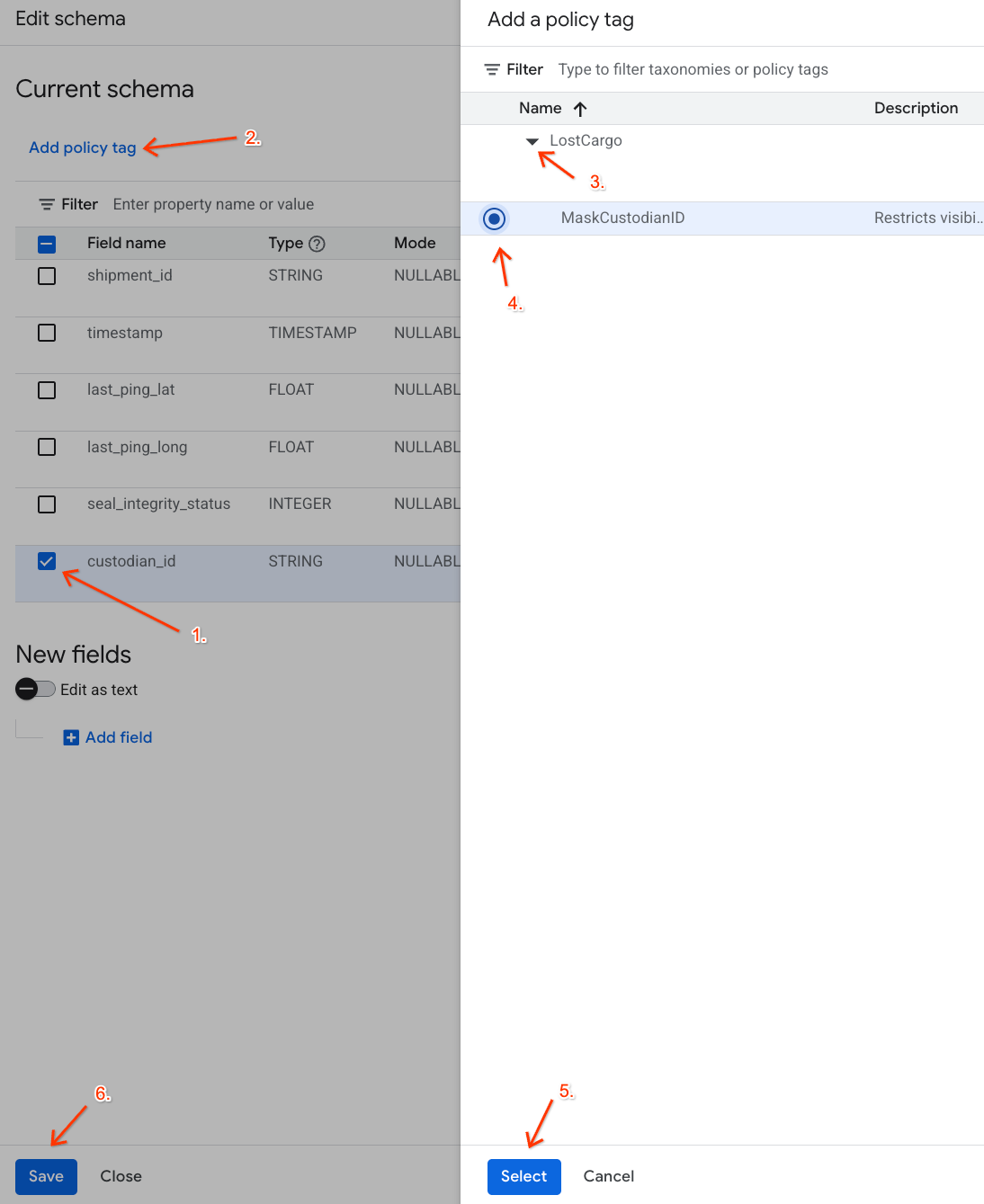
- في قائمة الأعمدة، ضَع علامة في المربّع بجانب
custodian_id. - انقر على الزر إضافة علامة سياسة في شريط الأدوات العلوي لمحرّر المخطط.
- في لوحة إضافة علامة سياسة:
- ابحث عن تصنيف
LostCargoووسِّعه. - انقر على الفقاعة بجانب
MaskCustodianID. - انقر على اختيار.
- ابحث عن تصنيف
- تأكَّد من أنّ العلامة
MaskCustodianIDظاهرة الآن ضمن عمود علامة السياسة في الصف الذي يمثّلcustodian_id. - انقر على حفظ.
التحقّق من القيود المفروضة بموجب السياسة
بعد حصولك على دور "قارئ البيانات المحجوبة" على مستوى المشروع، يمكنك طلب البحث في الجدول للتأكّد من أنّ سياسة حجب البيانات مفعَّلة.
ارجع إلى "حزمة أدوات وكيل البيانات" ونفِّذ طلب البحث التالي:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
ينبغي أن تظهر مُخرجات مشابهة لما يلي:
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
اكتمال النقل بنجاح على الرغم من إمكانية عرض سجلّات shipment_id، يعرض الحقل الحسّاس custodian_id أقنعة آمنة null لمنع تسرُّب البيانات.
8. تَنظيم
لتجنُّب تحصيل رسوم مستمرة على حسابك على Google Cloud مقابل الموارد التي تم إنشاؤها أثناء هذا الدرس التطبيقي حول الترميز، نفِّذ الأوامر التالية في نافذة Cloud Shell لإزالة مجموعات البيانات والحِزم:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9- تهانينا
تهانينا! لقد أكملت بنجاح الوحدة الأولى الحاسمة من تحقيق الشحنة المفقودة. لقد أنشأت منطقة بحث منظَّمة باستخدام كتالوجات Lakehouse Iceberg REST، وتسوية سجلّات PySpark، وإخفاء البيانات بدقة.
ما تعلّمته
- تثبيت إضافة Data Agent Kit وإعدادها وضبطها داخل مساحة عمل بيئة التطوير المتكاملة
- إنشاء كتالوج Iceberg REST بدون خادم باستخدام بيانات الاعتماد التي توفّرها الجهة الخارجية ومساحات الأسماء الهرمية
- استيعاب خلاصات متعددة التنسيقات على مستوى المنطقة وإنشاء جداول خارجية في BigQuery على مجموعات بيانات Cloud Storage
- تشغيل مهام Apache Spark بدون خادم لتحليل سجلّات جهاز الإرسال والاستقبال غير المنظَّمة وتوحيد تنسيقها وتقسيمها وكتابتها مرة أخرى في BigQuery كجداول مسجَّلة في فهرس Iceberg
- إنشاء تصنيفات أمان وربط سياسات إخفاء بيانات "كتالوج المعرفة" لمنع تسرُّب الهوية في فهارس السجلّات الحسّاسة
- إنشاء إحصاءات حول بيانات وصفية للجداول وتحليلها باستخدام إحصاءات بيانات BigQuery لتسريع عملية استكشاف البيانات
التحقّق من صحة الأدلة التي تم جمعها
تأكَّد من تسجيل الأدلة القاطعة التالية المطلوبة للانتقال إلى مرحلة التمرين المعملي التالية:
- معرّف الشحنة المفقودة:
MV-CAT-001(آخر موقع تم إرسال إشارة منه: لندن) - وجهة الاستهداف المُخطَّط لها:
New York(والاسم المستعار الصحيح لجهاز الإرسال والاستقبال:MV-DOG-002) - لون الحاوية:
Crimson RED - علامة إذن الوصول إلى الحوكمة:
MaskCustodianID
هل أنت مستعد للمرحلة التالية؟
بعد تأمين مسارات المغادرة والوجهة لجهاز الإرسال والاستقبال، يمكننا المضي قدمًا في التحقيق. انتقِل مباشرةً إلى المختبر 2 لفحص كاميرات المراقبة باستخدام نماذج Gemini المتعدّدة الوسائط، وتحديد السفينة بصريًا، وإجراء عمليات بحث متّجه في AlloyDB للتحقّق من أيّ حالات شاذة مرتبطة بالتلاعب.
➡️ متابعة الخطوة الثانية: تحليل البيانات والإحصاءات المتعدّدة الوسائط