
১. ভূমিকা
এই ল্যাবে, আপনি একটি বিশ্বব্যাপী লজিস্টিকস ফার্মের প্রধান ডেটা তদন্তকারীর ভূমিকা পালন করবেন। মূল্যবান অ্যান্ড্রয়েড ফিগারিন সংগ্রহযোগ্য সামগ্রী বহনকারী একটি উচ্চ-মূল্যের কার্গো কন্টেইনার নিখোঁজ হয়ে গেছে! এটির সর্বশেষ জানা অবস্থান খুঁজে বের করতে এবং এর গতিপথ শনাক্ত করতে, আপনাকে আঞ্চলিক লজিস্টিকস অংশীদারদের কাছ থেকে পাওয়া খণ্ডিত শিপিং ম্যানিফেস্ট এবং অসংগঠিত ট্রান্সপন্ডার লগ ফাইলগুলো একত্রিত করতে হবে। এটি করার জন্য, আপনাকে একটি আধুনিক গুগল ক্লাউড ওপেন ডেটা লেকহাউস কনফিগার করতে হবে।

আপনি যা করবেন
- ক্লাউড শেল এডিটর-এ গুগল ক্লাউড ডেটা এজেন্ট কিট এক্সটেনশনটি কনফিগার করুন।
- একটি ক্লাউড স্টোরেজ বাকেট তৈরি করুন এবং একটি লেকহাউস অ্যাপাচি আইসবার্গ রেস্ট ক্যাটালগ ও নেমস্পেস প্রোভিশন করুন।
- জাহাজটির প্রস্থানের সূত্র খুঁজে পেতে ক্লাউড স্টোরেজে থাকা র JSON পার্টনার ম্যানিফেস্টগুলোর সাথে একটি বিগলেক এক্সটার্নাল টেবিল ম্যাপ করুন।
- অ্যাপাচি স্পার্ক সার্ভারলেসের ম্যানেজড সার্ভিস ব্যবহার করে অসংগঠিত ট্রান্সপন্ডার টেক্সট লগ লোড ও প্রসেস করুন। হারিয়ে যাওয়া পেলোডের গন্তব্য শনাক্ত করতে রেজেক্স নরমালাইজেশন এবং ডাইনামিক ক্লু এক্সট্র্যাকশন সম্পাদন করুন।
- REST ক্যাটালগের মাধ্যমে পার্স করা লগ মেট্রিক্সগুলোকে একটি অ্যাপাচি আইসবার্গ টেবিল হিসেবে লিখুন।
- আপনার হারিয়ে যাওয়া চালান সম্পর্কে লুকানো সূত্র খুঁজে বের করতে কনভারসেশনাল অ্যানালিটিক্স ব্যবহার করে আপনার অ্যাপাচি আইসবার্গ ডেটা নিয়ে একজন এআই এজেন্টের সাথে চ্যাট করুন।
- আপনার ডেটা সম্পর্কে মেটাডেটা তৈরি করতে নলেজ ক্যাটালগের স্বয়ংক্রিয় ডেটা ইনসাইট ব্যবহার করুন।
- একটি নিরাপত্তা শ্রেণিবিন্যাস তৈরি করে এবং সংবেদনশীল কাস্টোডিয়ান আইডি মাস্কিংয়ের মাধ্যমে সূক্ষ্ম অ্যাক্সেস নিয়ন্ত্রণ প্রয়োগ করতে নলেজ ক্যাটালগ ব্যবহার করে ইনজেশন গার্ডরেল স্থাপন করুন।
আপনার যা যা লাগবে
- ক্রোমের মতো একটি ওয়েব ব্রাউজার।
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
- মৌলিক SQL কোয়েরি এবং টার্মিনাল কমান্ড সম্পর্কে ধারণা থাকা।
প্রত্যাশিত খরচ এবং সময়কাল
- সম্পূর্ণ করতে সময় : প্রায় ৪৫ মিনিট।
- আনুমানিক খরচ : ৫.০০ মার্কিন ডলারের কম।
২. শুরু করার আগে
একটি গুগল ক্লাউড প্রজেক্ট তৈরি করুন বা নির্বাচন করুন
- গুগল ক্লাউড কনসোলে , একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন ।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। একটি প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে নিশ্চিত করবেন, তা জানুন।
পরিবেশ কনফিগার করুন
আপনি আপনার বেশিরভাগ কমান্ড ক্লাউড শেল এডিটর- এর ইন্টিগ্রেটেড টার্মিনাল থেকে চালাবেন, যা একটি ক্লাউড-ভিত্তিক ডেভেলপমেন্ট এনভায়রনমেন্ট এবং এতে ডেভেলপার টুলস ও স্ট্যান্ডার্ড গুগল ক্লাউড এসডিকে আগে থেকেই লোড করা থাকে।
- একটি নতুন ট্যাবে ক্লাউড শেল এডিটর খুলুন।
- রিপোজিটরি ক্লোন করতে টার্মিনালে নিম্নলিখিত কমান্ডটি চালান:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - আপনার প্রজেক্ট আইডি সেট করুন। এছাড়াও, আপনি Windows/Linux-এ
Ctrl+Shift+V, অথবা macOS-এCmd+Vচেপে এটি টার্মিনালে পেস্ট করতে পারেন:export PROJECT_ID="<YOUR_PROJECT_ID>" - এখন আপনার পরিবেশে এটি কনফিগার করুন।
gcloud config set project $PROJECT_ID - একটি অঞ্চল নির্বাচন করুন।
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - প্রয়োজনীয় এপিআইগুলো সক্রিয় করুন।
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
এক্সটেনশন ইনস্টল করুন
এখন আপনি গুগল ডেটা এজেন্ট কিট এক্সটেনশনটি কনফিগার করবেন, যা আপনার IDE-তে সরাসরি গুগল ক্লাউডের ডেটা টুলগুলোর সাথে কাজ করার একটি টুল।
- এডিটরের বাম দিকের অ্যাক্টিভিটি বারে, এক্সটেনশন আইকনে ক্লিক করুন (অথবা Windows/Linux-এ
Ctrl+Shift+X, বা macOS-এCmd+Xচাপুন)। - এক্সটেনশন সার্চ বক্সে টাইপ করুন:
Google Cloud Data Agent Kit - ফলাফল থেকে অফিসিয়াল এক্সটেনশনটি নির্বাচন করুন এবং ইনস্টল-এ ক্লিক করুন। অনুরোধ করা হলে, "হ্যাঁ, আমি লেখকদের বিশ্বাস করি" নির্বাচন করুন।
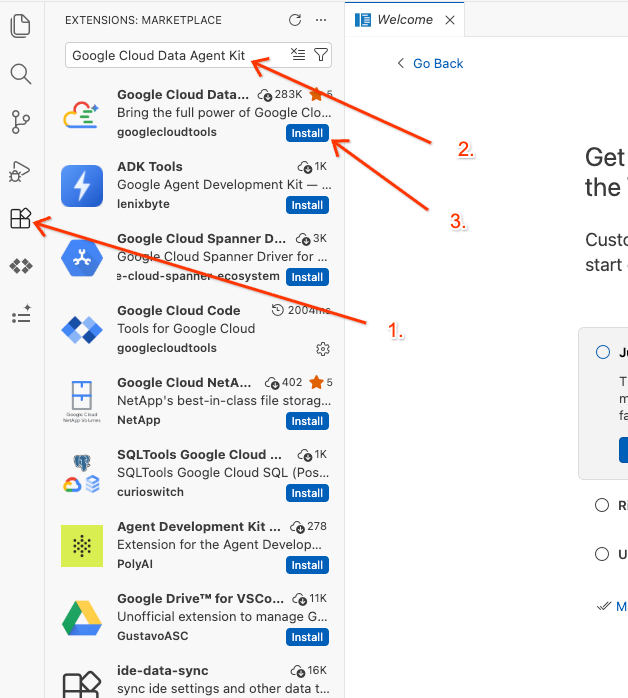
- সফলভাবে ইনস্টল হয়ে গেলে, আপনি অ্যাক্টিভিটি বারে Google Cloud Data Agent Kit আইকনটি দেখতে পাবেন! এটিতে ক্লিক করুন।
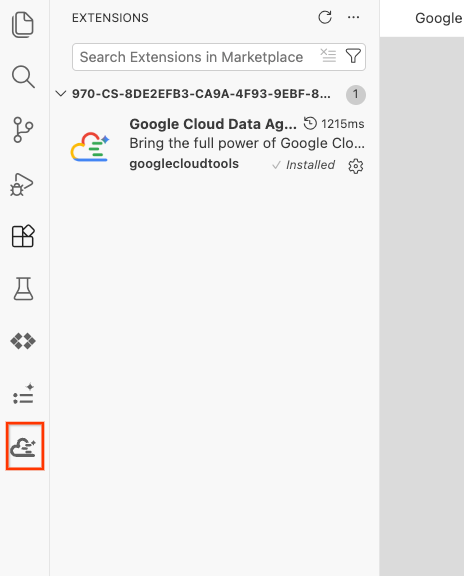
- ক্লাউডে সাইন ইন করতে ক্লিক করুন।
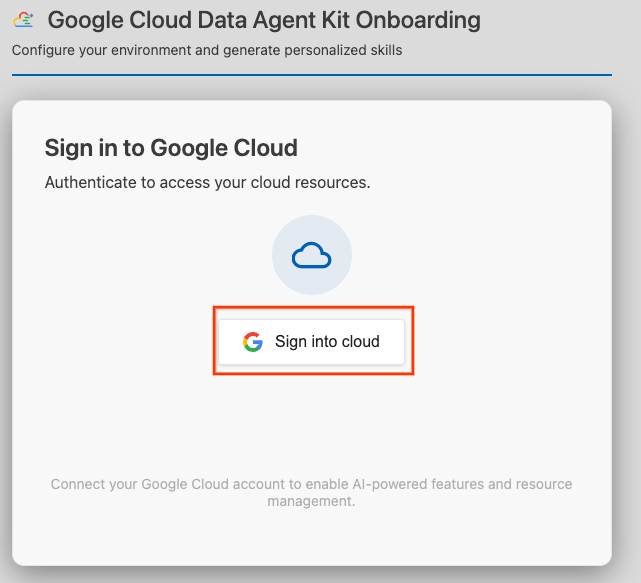
- MCP সার্ভার কনফিগার করুন -এ ক্লিক করুন।
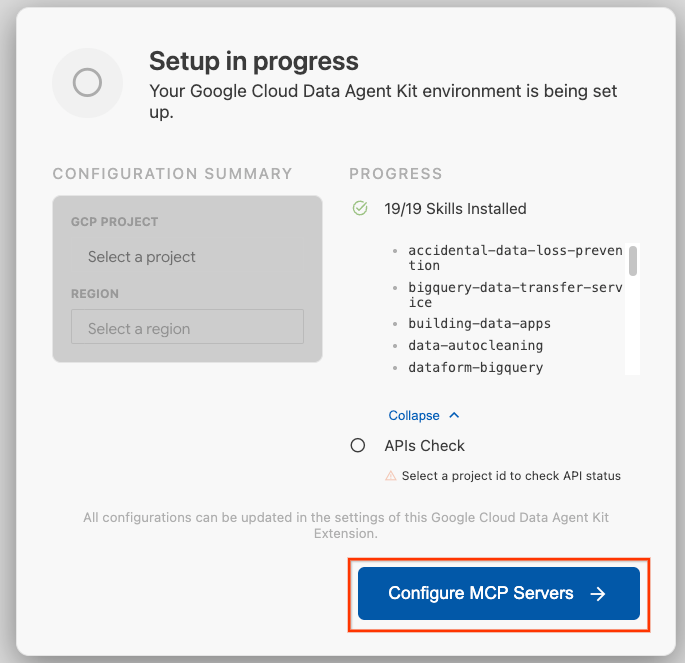
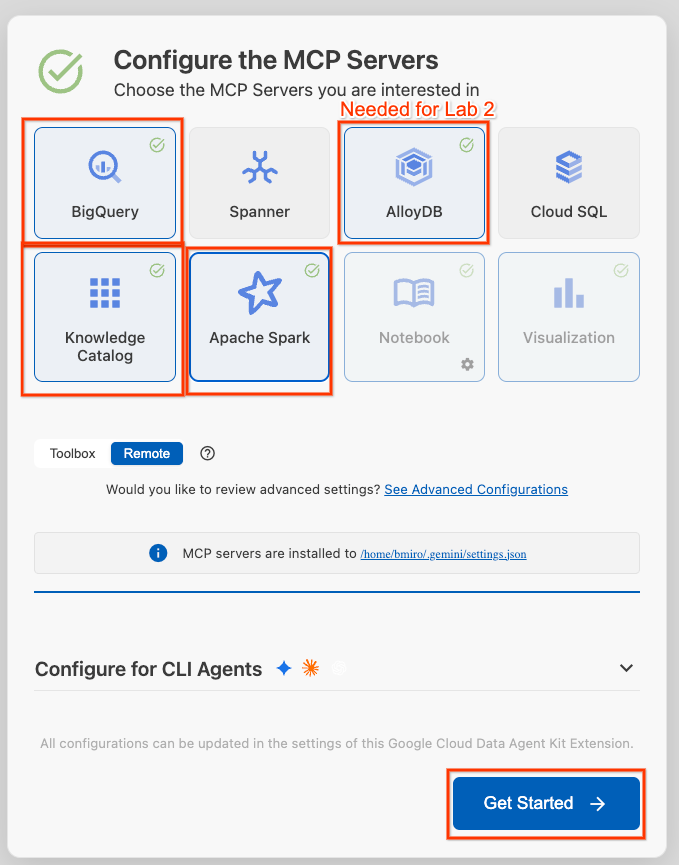
- BigQuery, Knowledge Catalog, Apache Spark, এবং AlloyDB নির্বাচন করুন। আপনি ল্যাব ২-এ AlloyDB ব্যবহার করবেন। তারপর Get Started-এ ক্লিক করুন।
- নিচের স্ট্যাটাস বারে থাকা প্রজেক্ট আইডি সিলেক্টরে ক্লিক করুন এবং আপনার সক্রিয় গুগল ক্লাউড প্রজেক্টটি বেছে নিন।
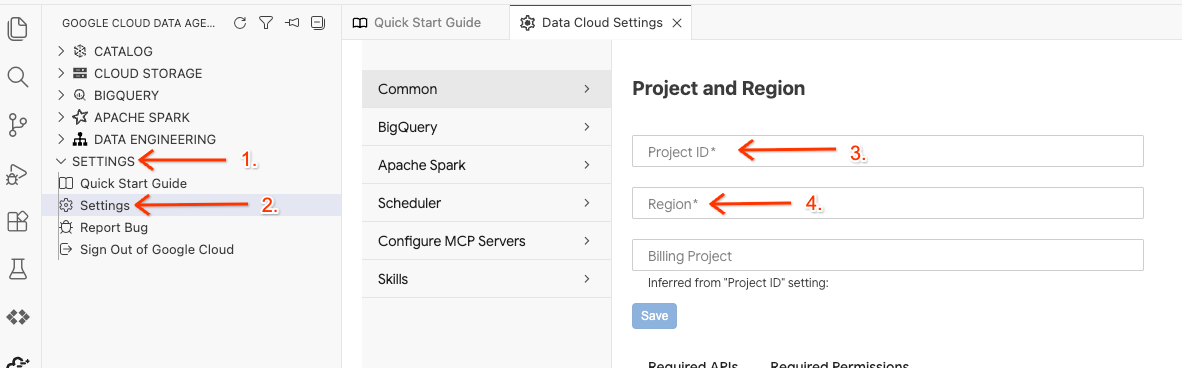
- ডেটা এজেন্ট কিট-এ, সেটিংস (SETTINGS)- এ ক্লিক করুন, তারপর সেটিংস (Settings) -এ যান এবং কমন (Common) ট্যাব থেকে আপনার ল্যাব চালানোর জন্য প্রজেক্ট আইডি ও অঞ্চল (Region) নির্বাচন করুন, যেমন us-central1 ।
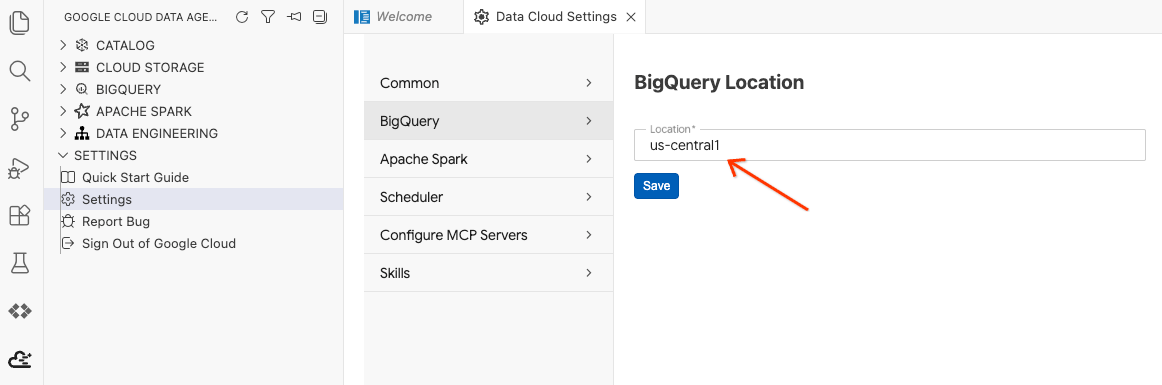
- BigQuery Settings-এ ক্লিক করুন এবং Region- এর জায়গায় আপনার পূর্বে নির্বাচিত অঞ্চলটি বসান। Save-এ ক্লিক করুন।
আপনি এখন ডেটা এজেন্ট কিটটি ব্যবহার করার জন্য প্রস্তুত!
পরিবেশ সেটআপ স্ক্রিপ্ট চালান
টার্মিনালে, এই ল্যাবের জন্য প্রয়োজনীয় ব্যাকগ্রাউন্ড রিসোর্স তৈরি করতে এবং IAM পারমিশন কনফিগার করতে সেটআপ স্ক্রিপ্টটি চালান:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
কী কী রিসোর্স সরবরাহ করা হচ্ছে, তা দেখানোর জন্য আপনি কয়েকটি আউটপুট ধাপ দেখতে পাবেন। আমরা এই ল্যাব জুড়ে এগুলো নিয়ে আলোচনা করব।
একবার আপনি সমাপ্তির বার্তা দেখতে পেলে, আপনি প্রস্তুত:
==================================================== Environment Setup Complete! ====================================================
এখন, চলো আমাদের অনুসন্ধান শুরু করা যাক!
৩. পার্টনার শিপিং ম্যানিফেস্ট গ্রহণ করুন
অংশীদার জাহাজগুলোর শিপিং ম্যানিফেস্ট ডেটা আপনার বাকেটে স্ট্যান্ডার্ড JSON লাইন (JSONL) ফরম্যাটে সংরক্ষিত থাকে: gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl ।
গভীর বিশ্লেষণ চালানোর আগে, আপনি এই অসংগঠিত ডেটার জন্য একটি নিয়ন্ত্রিত বিগলেক টেবিল তৈরি করবেন। এর ফলে আপনি ডুপ্লিকেট ইম্পোর্ট খরচ ছাড়াই স্ট্যান্ডার্ড SQL ব্যবহার করে তাৎক্ষণিকভাবে পার্টনার লজিস্টিকস ডেটা অন্বেষণ করতে পারবেন।
এডিটরে ওয়ার্কস্পেসটি খুলুন এবং কোয়েরিটি চালান।
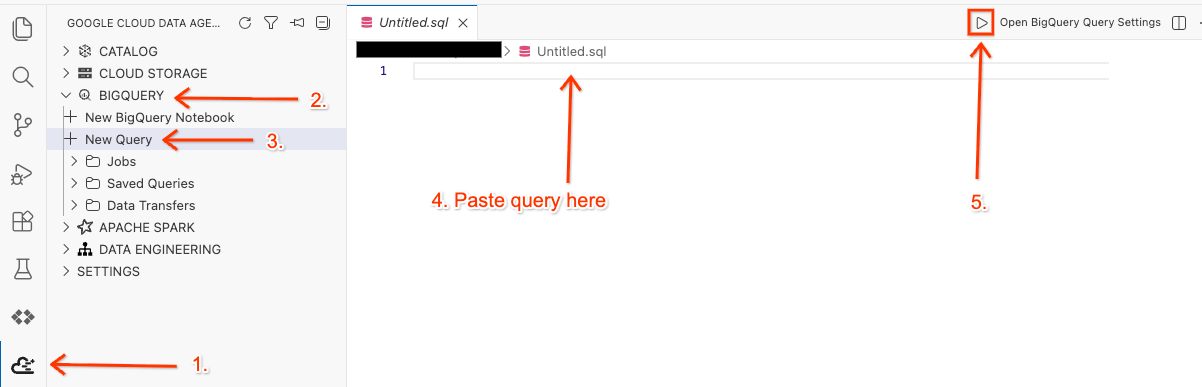
- আপনার ক্লাউড শেল এডিটর-এর সাইড প্যানেলে থাকা গুগল ক্লাউড ডেটা এজেন্ট কিট এক্সটেনশন আইকনটিতে ক্লিক করুন।
- BigQuery-তে যান এবং + New Query নির্বাচন করুন।
- নিম্নলিখিত কোয়েরিটি কোয়েরি উইন্ডোতে কপি করুন।
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- রান-এ ক্লিক করুন।
- টেবিলটি তৈরি হয়েছে কিনা তা যাচাই করার জন্য, আপনি নীচে স্বয়ংক্রিয়ভাবে স্লাইড করে খুলে যাওয়া 'কোয়েরি রেজাল্টস' প্যানেলে একটি সফলতার বার্তা দেখতে পাবেন।
ক্ষতিগ্রস্ত ট্রান্সপন্ডারগুলো শনাক্ত করতে বাহ্যিক টেবিলটি কোয়েরি করুন।
যখন seal_integrity_status মান 0 সেট করা ছিল, তখনকার ব্যর্থতাগুলো খুঁজে বের করে ক্ষতিগ্রস্ত ট্রান্সপন্ডারগুলো শনাক্ত করা যাক। পূর্বে খোলা কোয়েরি উইন্ডোতে নিম্নলিখিত কোয়েরিটি কপি করে চালান:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
কোয়েরি রেজাল্টস প্যানেলে আপনি এর অনুরূপ আউটপুট দেখতে পাবেন:
চালান_আইডি | শেষ_পিং_অক্ষাংশ | শেষ_পিং_দীর্ঘ | তত্ত্বাবধায়ক_আইডি |
এমভি-ক্যাট-০০১ | ৫১.৫০৭৪ | -০.১২৭৮ | usr_999_shadow |
৪. অ্যাপাচি স্পার্কের জন্য পরিচালিত পরিষেবা দিয়ে অসংগঠিত লগ প্রক্রিয়া করুন
আপনি কাঠামোগত ম্যানিফেস্টগুলো থেকে শুরুর অবস্থান খুঁজে পেয়েছেন, কিন্তু হারিয়ে যাওয়া ট্রান্সপন্ডারটি পুরোপুরি নিষ্ক্রিয় হয়ে গেছে। শেষ ট্রান্সপন্ডার পিংটি gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt GCS পাথের একটি র টেক্সট লগ ফাইলের ভেতরে একটি দুর্বোধ্য, অসংগঠিত বার্তা রেখে গেছে।
এই টেক্সট লগটি প্রসেস ও ম্যাপ করতে, টাইমস্ট্যাম্প বের করতে, পরিচয় গোপন করতে এবং কার্গোর পরবর্তী গন্তব্যের পথ সনাক্ত করতে, আপনাকে ম্যানেজড সার্ভিস ফর অ্যাপাচি স্পার্ক- এ একটি সার্ভারলেস অ্যাপাচি স্পার্ক (পাইস্পার্ক) জব জমা দিতে হবে।
অ্যাপাচি স্পার্কের জন্য পরিচালিত পরিষেবা আপনাকে কোনো ক্লাস্টার স্থাপন বা পরিচালনা ছাড়াই স্পার্ক ওয়ার্কলোড চালাতে দেয়। এই পরিষেবাটি অন্তর্নিহিত কম্পিউট রিসোর্সগুলো পরিচালনা করে, সেগুলোকে স্বয়ংক্রিয়ভাবে গতিশীলভাবে স্কেল করে, এবং আপনাকে শুধুমাত্র কার্য সম্পাদনের সময়কালের জন্য অর্থ প্রদান করতে হয়।
স্ক্রিপ্টটি করবে:
- কাঁচা, বন্ধনীযুক্ত, অসংগঠিত ট্রান্সপন্ডার টেক্সটটি গ্রহণ করুন।
- টাইমস্ট্যাম্প, কাস্টোডিয়ান মেটাডেটা এবং মূল কন্টেন্ট আলাদা করতে পাইস্পার্ক এসকিউএল রেজেক্স এক্সট্র্যাকশন ফিল্টার প্রয়োগ করুন।
- অগোছালো লগগুলোকে পরিষ্কার, বাক্য-ভিত্তিক রেকর্ডে ভাগ করুন।
- সেই গতিশীল গন্তব্য স্থানাঙ্ক লক্ষ্যবস্তুটি বের করুন যেখানে হারিয়ে যাওয়া পেলোডগুলোর প্রস্থান শেষ হয়েছিল।
- প্রক্রিয়াকৃত লগ ডেটাফ্রেমটিকে সংযুক্ত করুন এবং আপনার লেকহাউস অ্যাপাচি আইসবার্গ REST ক্যাটালগে একটি নতুন অ্যানালিটিক্স টেবিল হিসেবে পুনরায় লিখুন, যা সরাসরি BigQuery-এর মধ্যে দৃশ্যমান হবে।
পাইস্পার্ক অ্যানালাইসিস স্ক্রিপ্টটি ঠিক করুন
সমুদ্রে পাইথন জলদস্যুরা নানা ধরনের সমস্যা সৃষ্টি করছে বলে খবর পাওয়া গেছে।
- আপনার ক্লাউড শেল এডিটরে
process_maritime_logsফাইলটি খুলতে নিম্নলিখিতটি চালান।cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - কিছু সময় নিয়ে কোডটি পড়ুন এবং এটি কী করছে তা বুঝুন।
- নিশ্চিত করুন কোডের মধ্যে সন্দেহজনক কিছু নেই! যদি কিছু মুছতে হয়, তাহলে
Ctrl + S(Windows/Linux) বাCmd + S(Mac) ব্যবহার করে ফাইলটি সেভ করে নিন।
সার্ভারলেস স্পার্ক জব জমা দিন
gcloud SDK ব্যবহার করে জবটি সাবমিট করুন। কনফিগারেশনটি স্বয়ংক্রিয়ভাবে PySpark জবটিকে Lakehouse ক্যাটালগ অ্যাক্সেস করার জন্য কনফিগার করে দেয়।
আপনার ইন্টিগ্রেটেড এডিটর টার্মিনালে নিম্নলিখিত কমান্ডটি চালান।
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
সার্ভারলেস এনভায়রনমেন্টটি চালু হওয়ার জন্য কয়েক মিনিট অপেক্ষা করুন, আপনার স্ক্রিপ্ট আপলোড করুন এবং প্রসেসিং লজিকটি কার্যকর করুন।
একবার আপনি নীচের মতো আউটপুট দেখতে পেলে, আপনার প্রক্রিয়াকৃত টেবিলটি লেকহাউস ক্যাটালগে একটি অ্যাপাচি আইসবার্গ পরিচালিত টেবিল হিসাবে সংরক্ষিত হয়ে যাবে!
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
প্রক্রিয়াকৃত লগগুলির পূর্বরূপ দেখুন
ডেটা এজেন্ট কিট এক্সটেনশনের কোয়েরি এডিটরে, ডেটা প্রিভিউ করার জন্য নিম্নলিখিত কোয়েরিটি কপি করুন:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
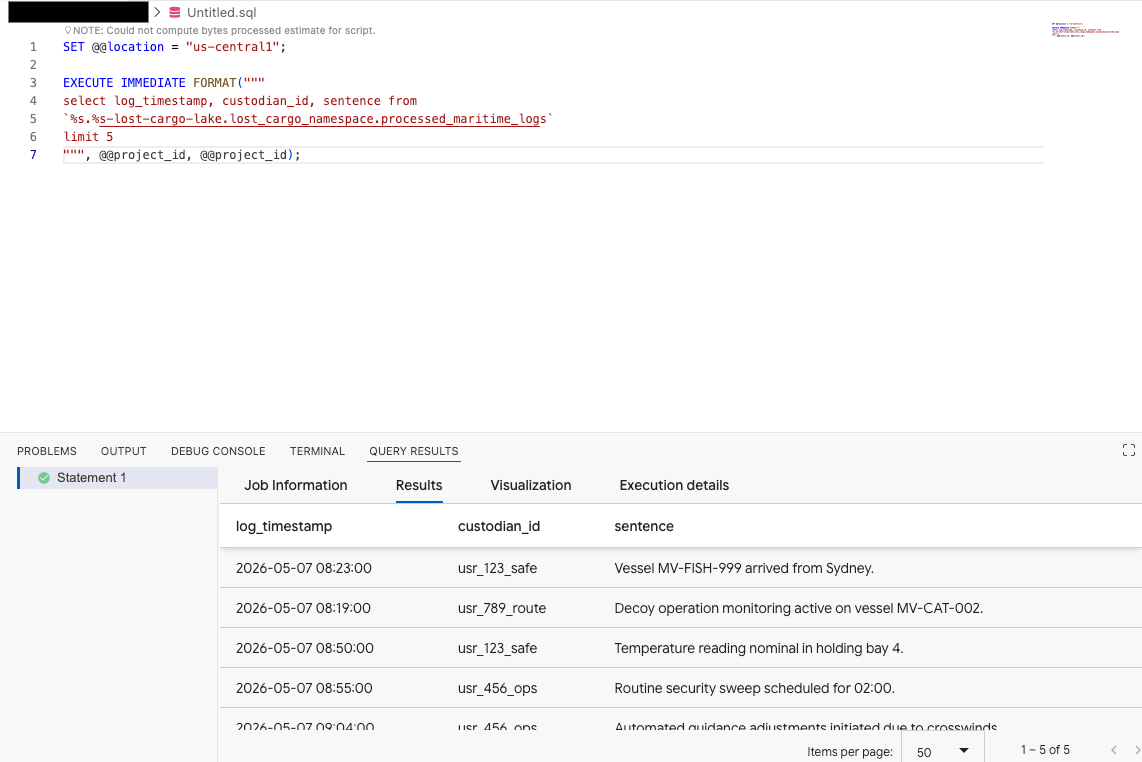
এর থেকে বোঝা যায় যে, ক্যাটালগে নিবন্ধিত Iceberg টেবিলটি BigQuery থেকে সফলভাবে অ্যাক্সেস করা যাচ্ছে!
গন্তব্যের সূত্রটি বের করুন
এখন যেহেতু আমাদের কাছে প্রক্রিয়াকৃত লগগুলো আছে, চলুন সেই লগগুলো খুঁজি যেগুলোতে একটি গন্তব্যস্থলের উল্লেখ আছে। সেখান থেকে, আমরা সেই লগগুলো খুঁজতে পারি যেগুলোতে আমাদের উৎস শহরের উল্লেখ রয়েছে।
আপনার কোয়েরি এডিটরে, নিম্নলিখিত কোয়েরিটি চালান, যেখানে <YOUR_REGION> এর জায়গায় আপনার অঞ্চল এবং <ORIGIN_CITY> এর জায়গায় আপনার পূর্বে আবিষ্কৃত উৎস শহরটি বসান।
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
কনভারসেশনাল অ্যানালিটিক্স ব্যবহার করে BigQuery কনসোলে আপনার ডেটার সাথে আলাপচারিতা করুন।
আপনার ডেটা অন্বেষণ করার জন্য জটিল SQL কোয়েরি লেখার পরিবর্তে, আপনি কনভারসেশনাল অ্যানালিটিক্স ব্যবহার করে স্বাভাবিক ভাষায় আপনার টেবিলগুলোর সাথে কথা বলতে পারেন!
- BigQuery কনসোলে যান।
- বাম দিকের এক্সপ্লোরার প্যানেলে, আপনার প্রজেক্ট এবং ডেটাসেটটি এক্সপ্যান্ড করুন।
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logsটেবিলের details ট্যাবটি খুলতে সেটিতে ক্লিক করুন। - Query- এর পাশে থাকা Chat-এ ক্লিক করুন।
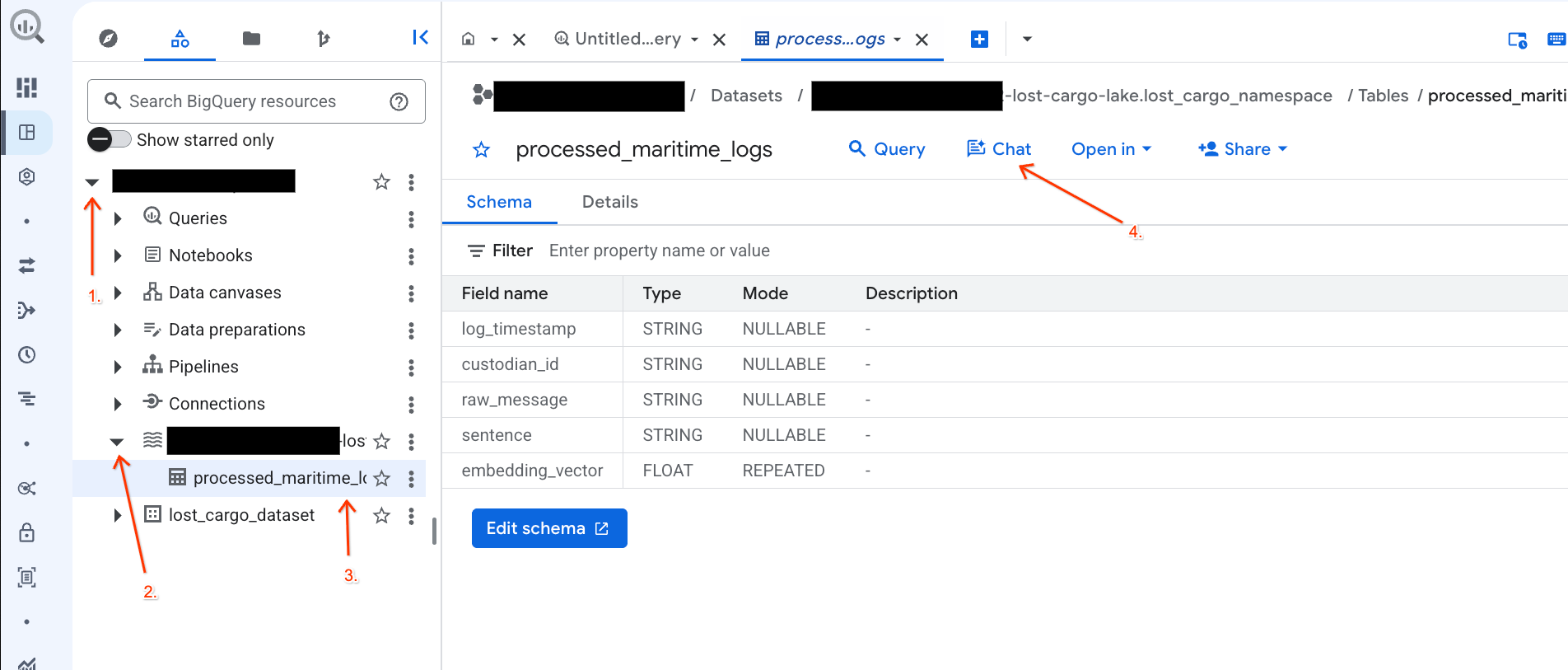
- চ্যাট প্যানেলে নিম্নলিখিত প্রশ্নটি টাইপ করুন এবং পাঠানোর জন্য আপনার কীবোর্ডের এন্টার চাপুন:
Based on this table, what color is the shipping container MV-CAT-001?
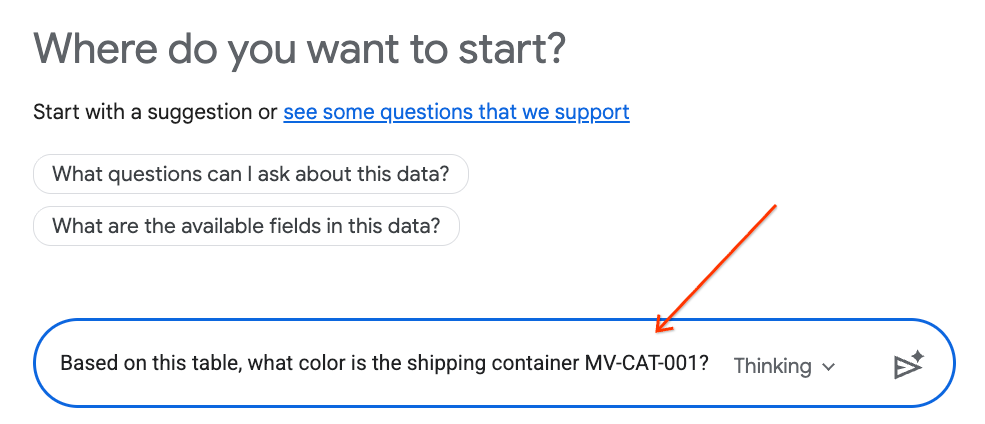
- কনভারসেশনাল অ্যানালিটিক্স (জেমিনি দ্বারা চালিত) সক্রিয় টেবিলের ডেটা বিশ্লেষণ করবে এবং রঙের মাধ্যমে প্রতিক্রিয়া জানাবে।
৫. কেন্দ্রীয় লেকহাউস ক্যাটালগটি দেখুন
ওপেন-সোর্স প্রসেসিং ইঞ্জিন (যেমন অ্যাপাচি স্পার্ক)-কে এন্টারপ্রাইজ ডেটা ইঞ্জিন (যেমন বিগকোয়েরি)-এর সাথে নিরাপদে ও নির্বিঘ্নে সংযুক্ত করার জন্য, আপনার সেটআপ স্ক্রিপ্ট একটি লেকহাউস আইসবার্গ রেস্ট ক্যাটালগ কনফিগার করেছে।
অ্যাপাচি আইসবার্গ রেস্ট ক্যাটালগ টেবিলের মেটাডেটার জন্য সার্ভারবিহীন "একমাত্র নির্ভরযোগ্য উৎস" হিসেবে কাজ করে, যা স্কিমা পরিচালনা করে এবং গতিশীলভাবে টেবিল পার্টিশন করে, এবং একই সাথে ফিজিক্যাল পার্কেট ডেটা ফাইলগুলো ক্লাউড স্টোরেজে সংরক্ষণ করে।
চলুন সরাসরি গুগল ক্লাউড কনসোলে এই ক্যাটালগটি পরীক্ষা করে দেখি:
- লেকহাউস কনসোলটি খুলুন।
- ক্যাটালগ ট্যাবে, আপনার সক্রিয় আইসবার্গ রেস্ট ক্যাটালগটি খুঁজুন এবং ক্লিক করুন:
-lost-cargo-lake
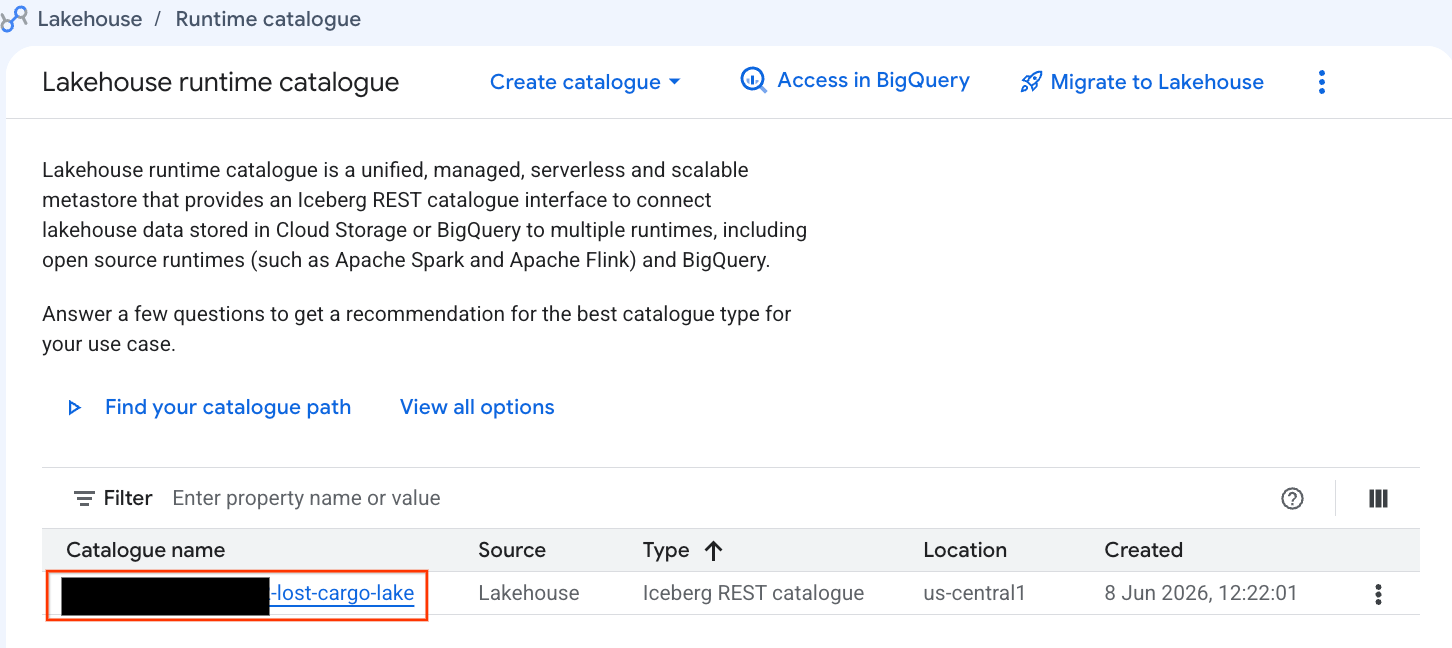
- ক্যাটালগের বিস্তারিত বিবরণে, নেমস্পেস (Namespaces) এর অধীনে আপনি
lost_cargo_namespaceদেখতে পাবেন। এটিতে ক্লিক করুন।
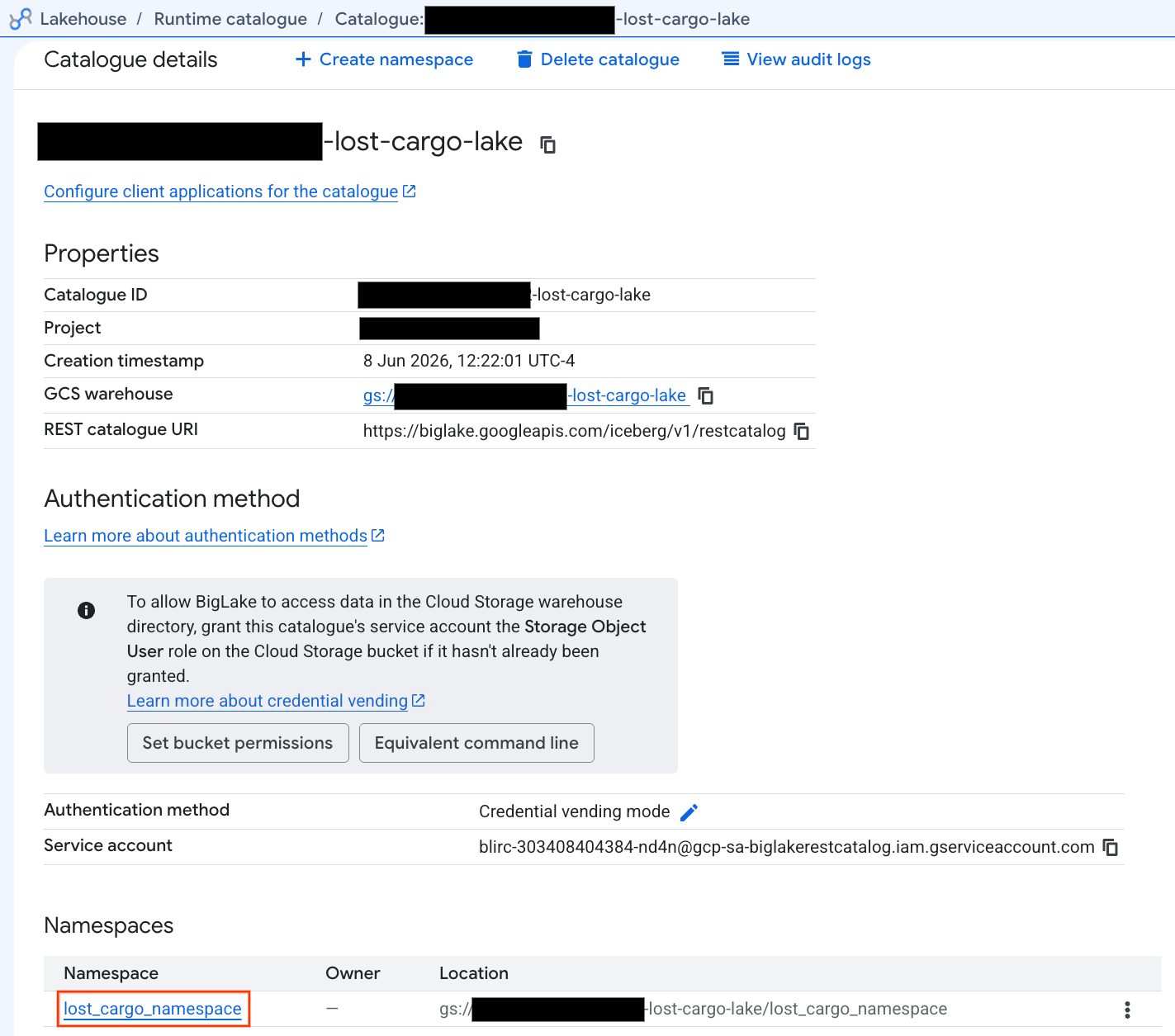
- PySpark দ্বারা তৈরি আপনার নতুন Apache Iceberg টেবিলটি স্বয়ংক্রিয়ভাবে মেটাস্টোর নেমস্পেসের অধীনে নিবন্ধিত হয়েছে এবং BigQuery জুড়ে তাৎক্ষণিকভাবে কোয়েরিযোগ্য হয়ে উঠেছে!
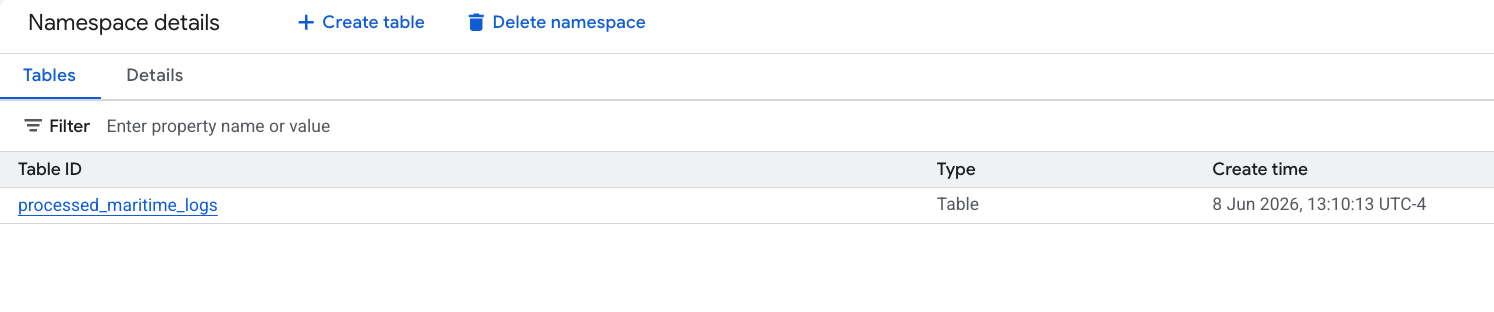
৬. শিপিং ম্যানিফেস্ট টেবিল সম্পর্কে অন্তর্দৃষ্টি তৈরি করুন
চলুন, নলেজ ক্যাটালগ ডেটা ইনসাইটস ব্যবহার করে shipping_manifests টেবিলটির গঠন ও বিষয়বস্তু বোঝার জন্য পুনরায় বিশ্লেষণ করি। মেটাডেটা সমৃদ্ধ করার মাধ্যমে, অন্যান্য এক্সপ্লোরাররা ভবিষ্যতের বিশ্লেষণের জন্য টেবিলটি আরও ভালোভাবে বুঝতে পারবে।
BigQuery Studio-তে টেবিল ইনসাইট তৈরি করুন
- Google Cloud Console-এ BigQuery Studio- তে যান।
- এক্সপ্লোরার প্যানেলে, আপনার প্রজেক্টটি এক্সপ্যান্ড করুন,
lost_cargo_datasetডেটাসেটটি এক্সপ্যান্ড করুন এবংshipping_manifestsটেবিলটিতে ক্লিক করুন। - ডানদিকের ডিটেইলস প্যানেলে, ইনসাইটস ট্যাবে ক্লিক করুন।
- জেনারেট এবং পাবলিশ নির্বাচন করতে ড্রপডাউনটি ব্যবহার করুন।
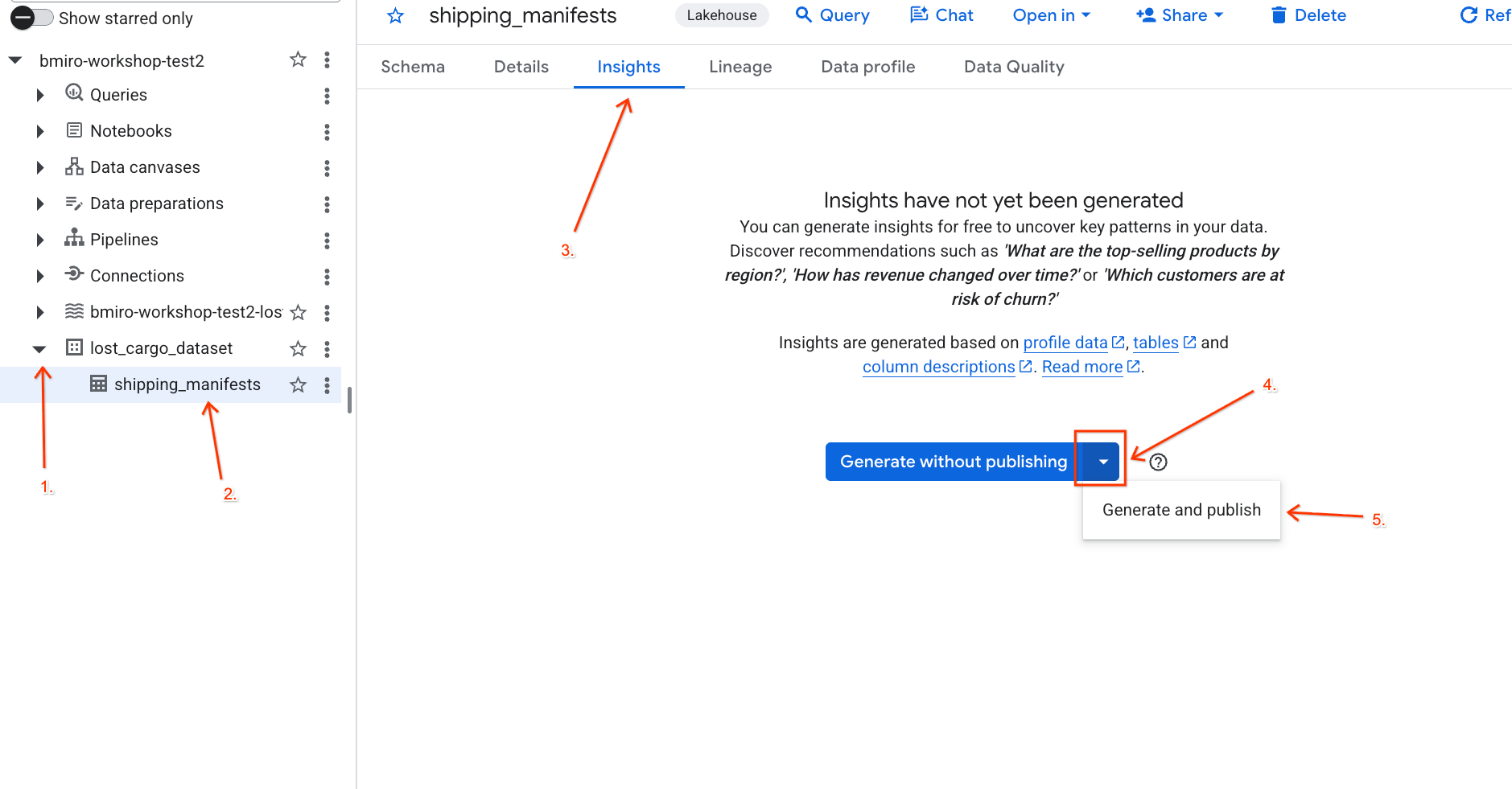
- ইনসাইটস তৈরি সম্পন্ন হতে প্রায় ৩ মিনিট অপেক্ষা করুন। জেমিনি টেবিলের মেটাডেটা বিশ্লেষণ করে স্বাভাবিক ভাষার প্রশ্ন এবং সংশ্লিষ্ট SQL কোয়েরি তৈরি করবে।
- একবার সম্পন্ন হলে, আপনি টেবিলের একটি বিবরণ দেখতে পাবেন, যেখানে টেবিলটির একটি স্বাভাবিক ভাষার ব্যাখ্যা থাকবে।
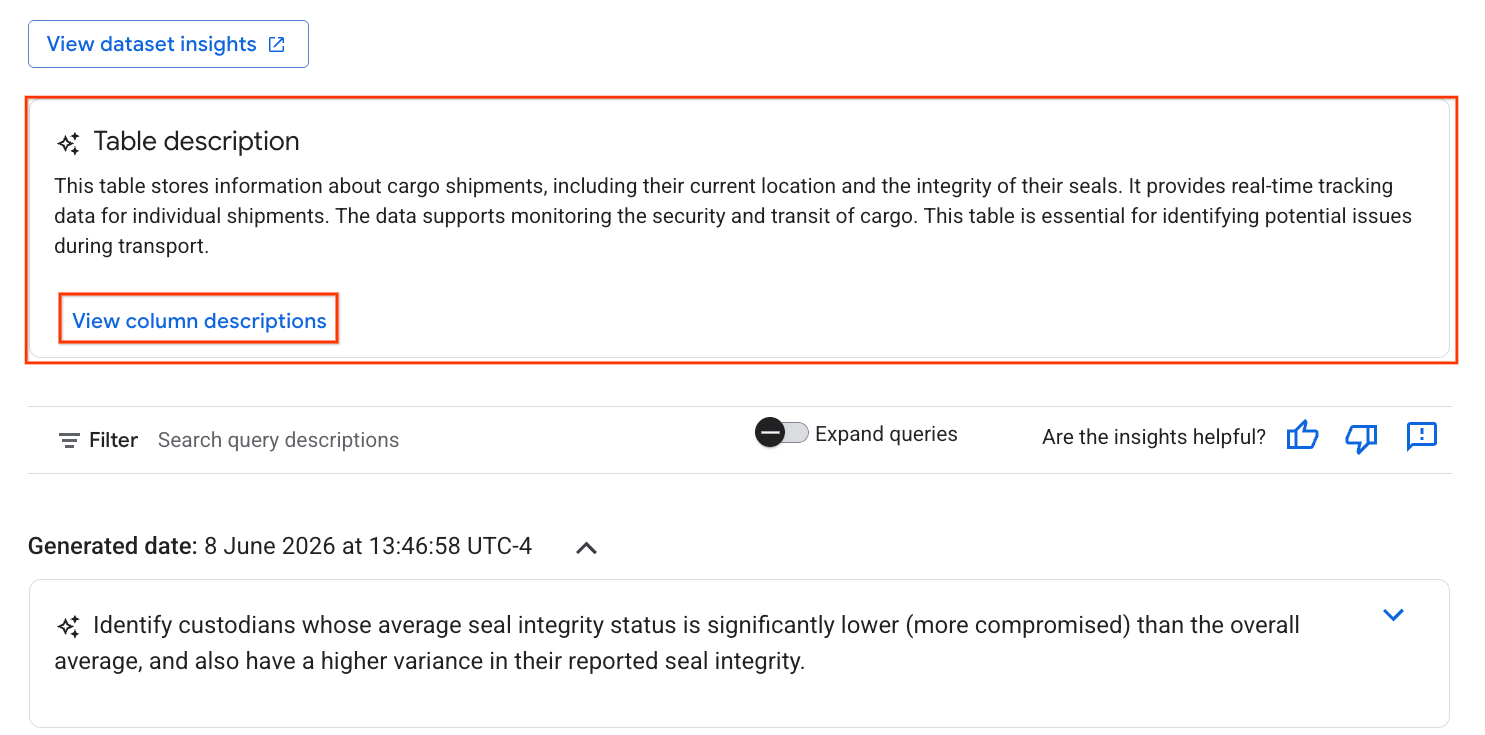
- প্রতিটি কলামের তথ্য দেখতে ‘View column descriptions’- এ ক্লিক করুন।
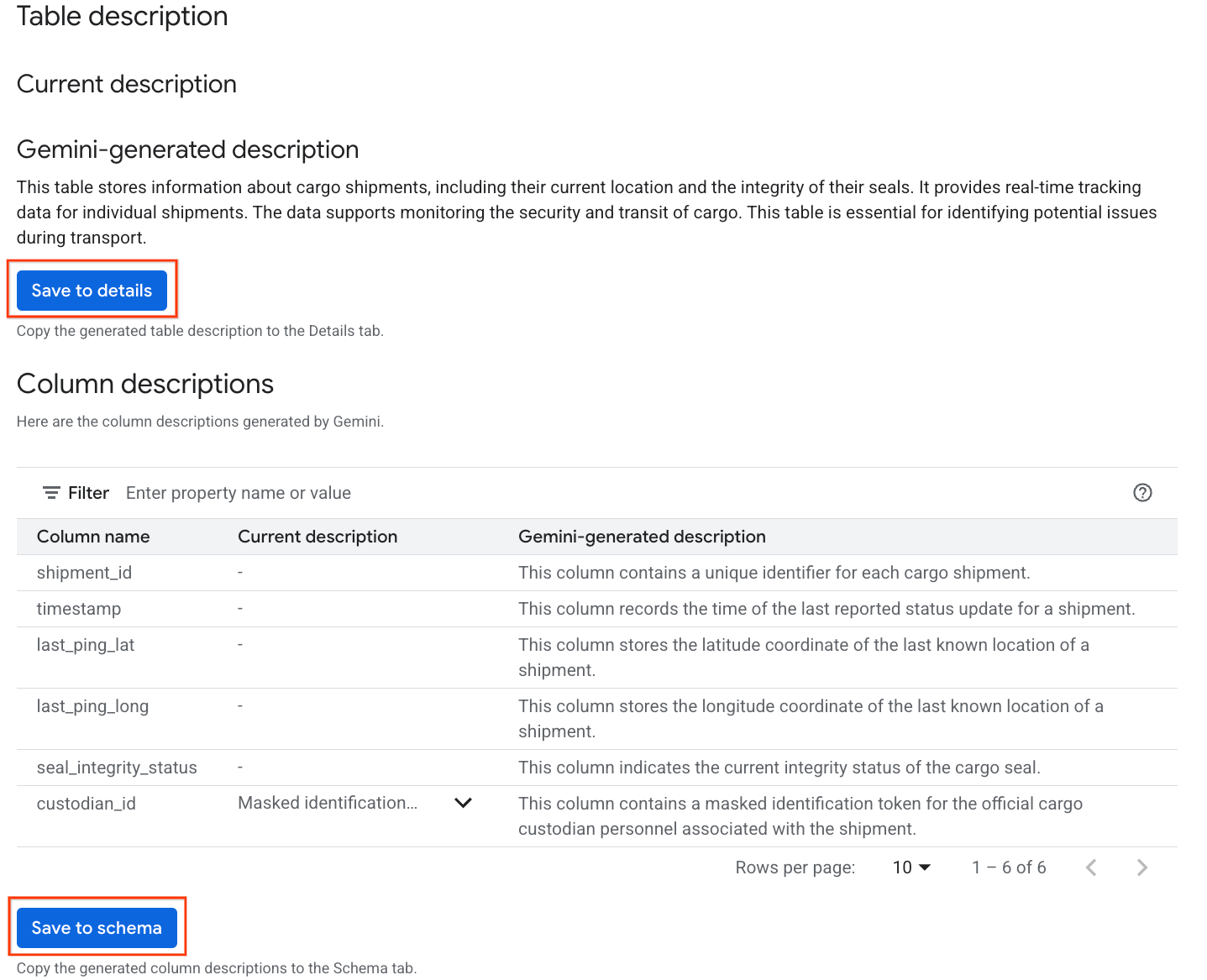
-
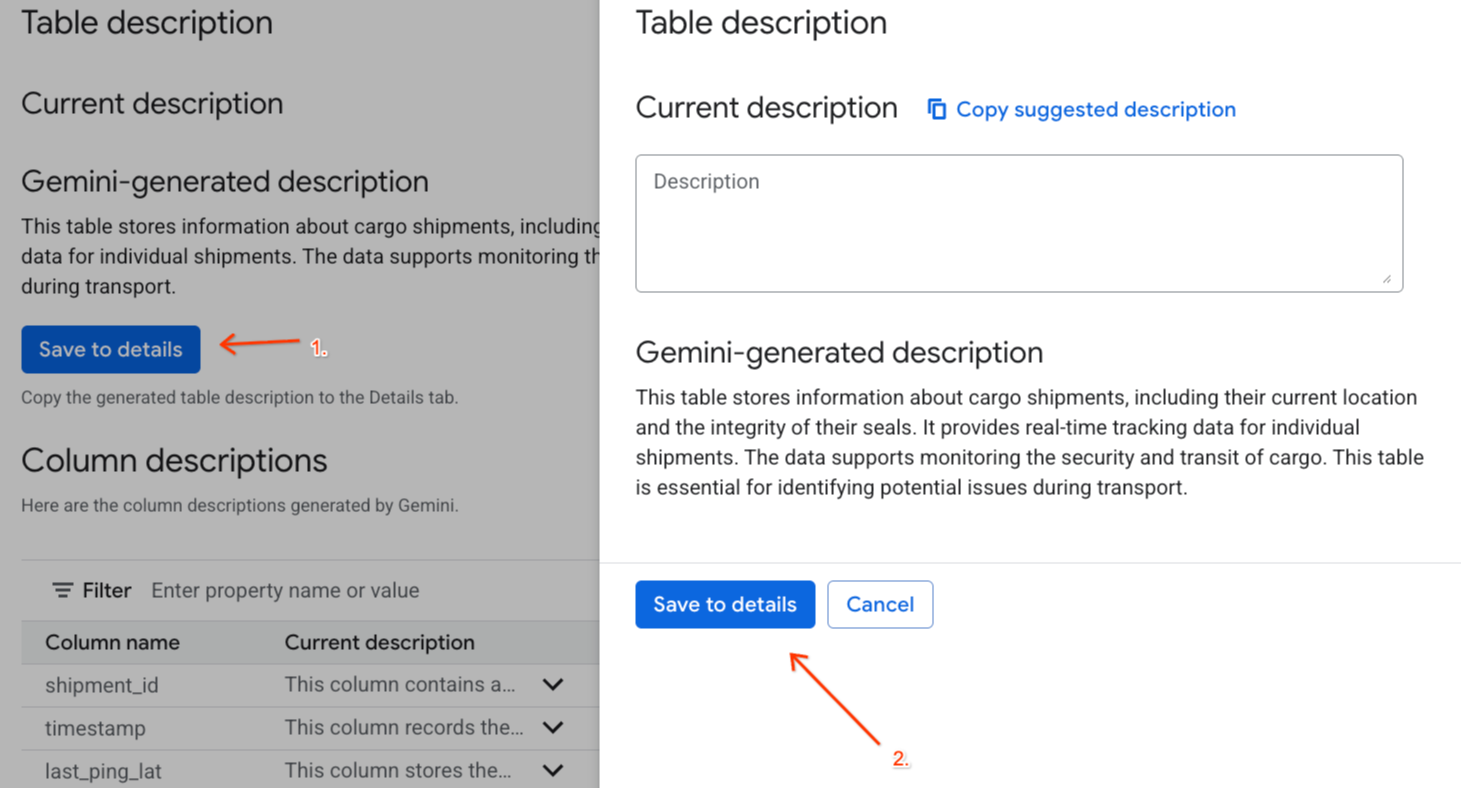
Gemini generated descriptionনিচে থাকা 'Save to details'- এ ক্লিক করুন এবং যে উইন্ডোটি পপ-আপ হবে, সেখানেও 'Save to details'- এ ক্লিক করুন।
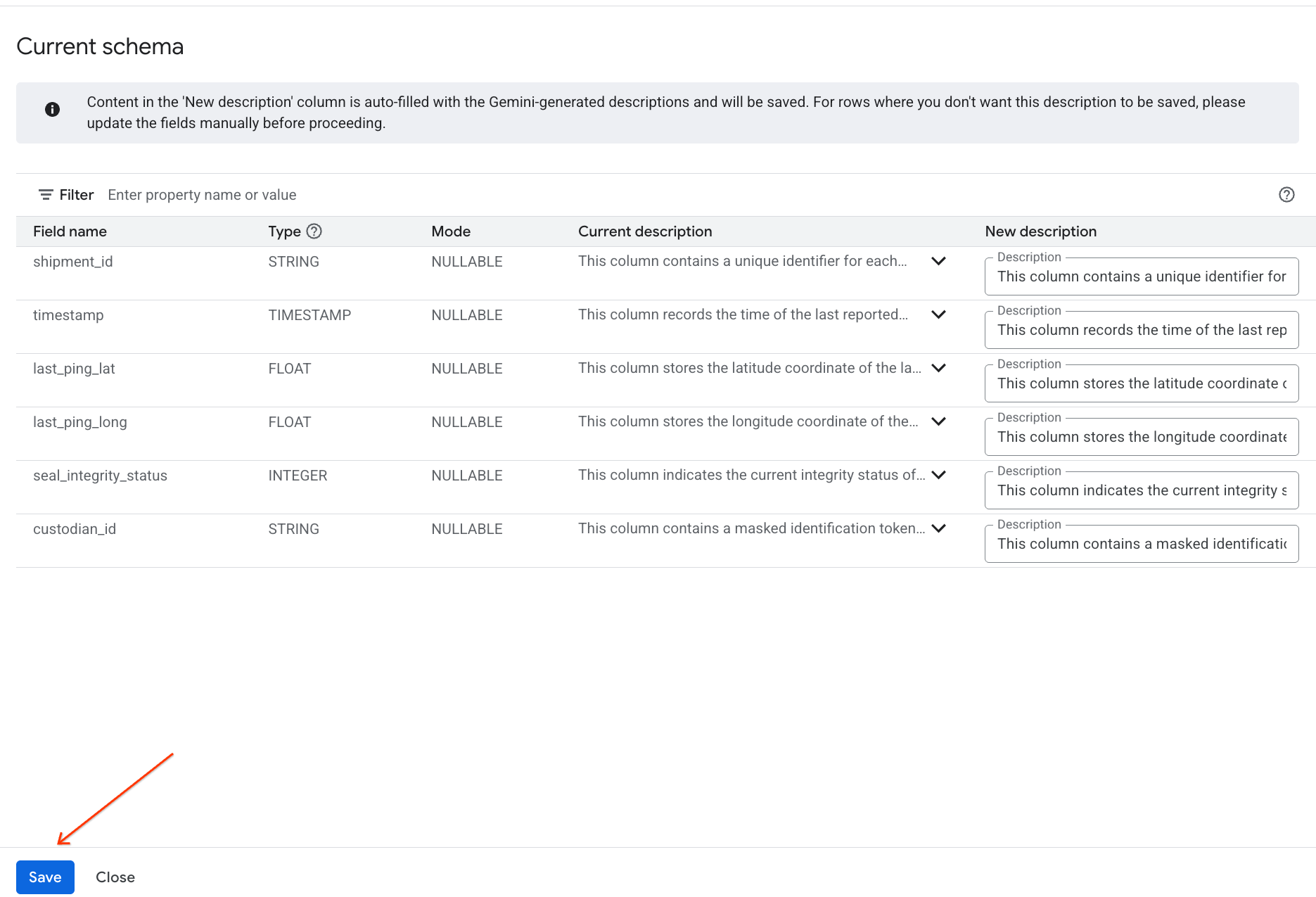
- একইভাবে, টেবিলের মেটাডেটাতে কলামের বিবরণগুলো যোগ করতে ‘Save to schema’-তে ক্লিক করুন।
পর্যালোচনা থেকে প্রাপ্ত অন্তর্দৃষ্টি
আপনি প্রস্তাবিত প্রশ্নগুলির একটি তালিকাও দেখতে পাবেন। আপনি যেকোনো প্রশ্নে ক্লিক করে তৈরি হওয়া SQL কোয়েরিটি দেখতে এবং ডেটা বিশ্লেষণ করার জন্য সেটি চালাতে পারেন। উদাহরণস্বরূপ, আপনি এই ধরনের প্রশ্ন দেখতে পারেন:
- চালানের মোট সংখ্যা কত?
- অনন্য তত্ত্বাবধায়ক আইডিগুলো তালিকাভুক্ত করুন।
এই কোয়েরিগুলো চালালে আপনি ডেটা বুঝতে পারবেন।
৭. ডেটা মাস্কিং ও গভর্নেন্স বাস্তবায়ন করুন
এই চলমান কার্গো তদন্ত চলাকালীন সক্রিয় গবেষণা অ্যাকাউন্ট এবং ইউজারনেম যাতে ফাঁস না হয়, তা নিশ্চিত করতে আপনাকে অবশ্যই স্ট্যান্ডার্ড নিরাপত্তা প্রোটোকল প্রয়োগ করতে হবে। ডেটার গোপনীয়তা যাচাই করার জন্য আপনি একটি সিকিউরিটি পলিসি ট্যাগ ট্যাক্সোনমি তৈরি করবেন এবং সংবেদনশীল custodian_id কলামের উপর নলেজ ক্যাটালগ ডেটা মাস্কিং কনফিগার করবেন।
ডিফল্টরূপে, BigQuery পলিসি ট্যাগ দ্বারা সুরক্ষিত কলামগুলিতে অ্যাক্সেস দেয় না। টেবিলটি কোয়েরি করতে এবং সক্রিয় ডেটা মাস্ক যাচাই করতে, আপনার ব্যবহারকারী অ্যাকাউন্টে অবশ্যই BigQuery Data Policy Masked Reader রোলটি থাকতে হবে।
setup_lab1.sh প্রথমবার চালানোর সময় এই রোলটি স্বয়ংক্রিয়ভাবে আপনার সক্রিয় ইউজার অ্যাকাউন্টের সাথে যুক্ত হয়ে গিয়েছিল!
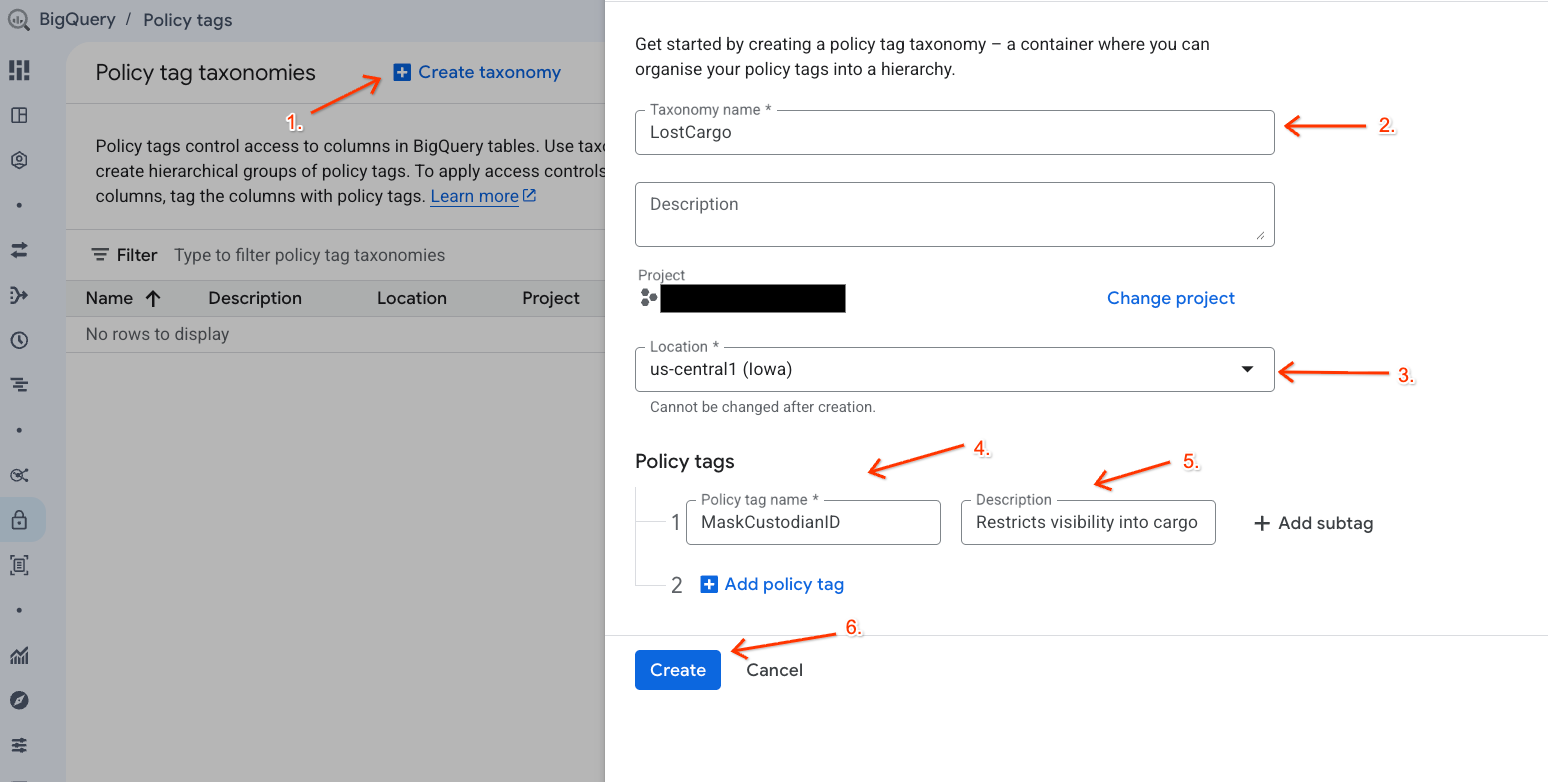
ট্যাক্সোনমি এবং পলিসি ট্যাগ তৈরি করুন
আপনার ডেটাতে অ্যাক্সেস ব্যবস্থাপনার জন্য একটি ডেটা ট্যাক্সোনমি এবং সংশ্লিষ্ট পলিসি ট্যাগ তৈরি করুন।
- পলিসি ট্যাগ ট্যাক্সোনমি পেজে যান।
- + Create Taxonomy-তে ক্লিক করুন।
- প্যারামিটারগুলো কনফিগার করুন:
- শ্রেণিবিন্যাসের নাম :
lost-cargo-প্রবেশ করানlost-cargo-আপনার প্রজেক্ট আইডি দিয়ে প্রতিস্থাপন করুন। - অঞ্চল : আপনার অঞ্চল নির্বাচন করুন।
- পলিসি ট্যাগ নামের জন্য:
MaskCustodianIDপ্রবেশ করান - পলিসি ট্যাগ বিবরণের জন্য:
Restricts visibility into cargo custodian usernames
- শ্রেণিবিন্যাসের নাম :
- আপনার নতুন ট্যাক্সোনমি এবং পলিসি ট্যাগ নিবন্ধন করতে Create-এ ক্লিক করুন।
ডেটা মাস্কিং পলিসি তৈরি করুন
এরপরে, MaskCustodianID ক্লাসিফিকেশন ট্যাগের অধীনে ডেটা কীভাবে মাস্ক করা হবে তা নির্ধারণ করতে একটি ডেটা পলিসি কনফিগার করুন। আপনি Always Null মাস্কিং নিয়মটি ব্যবহার করবেন (যা সমস্ত নন-প্রিভিলেজড অ্যাক্টরের জন্য মিলে যাওয়া মানগুলিকে খালি/Null রিটার্ন দিয়ে প্রতিস্থাপন করে)।
- পলিসি ট্যাগ ট্যাক্সোনমি পেজে, আপনার ট্যাক্সোনমির তালিকা থেকে নতুন তৈরি করা ট্যাক্সোনমিটিতে ক্লিক করুন।
- হায়ারার্কি তালিকায়,
MaskCustodianIDট্যাগটি নির্বাচন করতে সেটিতে ক্লিক করুন এবং তারপরে Manage data policies নির্বাচন করুন।
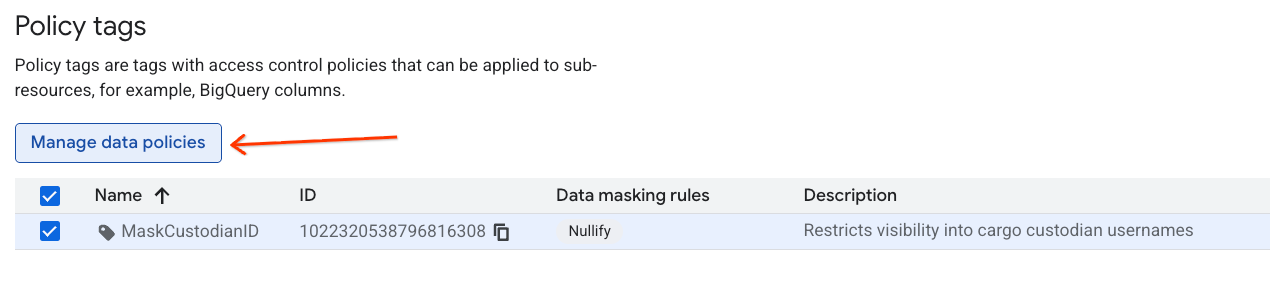
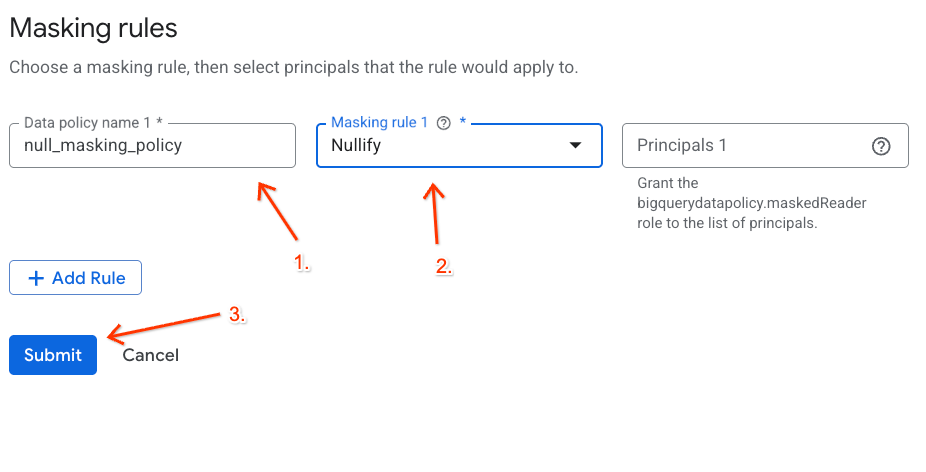
- ডানদিকের প্যানেলে, + Add Rule বাটনটিতে ক্লিক করুন।
- প্রদর্শিত প্যানেলে পলিসির বিবরণ কনফিগার করুন:
- ডেটা পলিসির নাম :
null_masking_policyলিখুন (এটি স্বয়ংক্রিয়ভাবে তৈরি হওয়া অবস্থায় রাখবেন না, কারণ পরবর্তী ধাপগুলিতে আমরা এই নামটি ব্যবহার করব)। - মাস্কিং নিয়ম : ড্রপডাউন মেনু থেকে
Nullifyনির্বাচন করুন।
- ডেটা পলিসির নাম :
- সাবমিট-এ ক্লিক করুন।
আপনার BigQuery কলামে পলিসি ট্যাগটি নির্ধারণ করুন।
পলিসি ট্যাগ এবং এর ডেটা মাস্কিং রুল সক্রিয় থাকা অবস্থায়, আপনার BigQuery পার্টনার শিপিং ম্যানিফেস্ট টেবিলের ` custodian_id কলামে ক্লাসিফিকেশন ট্যাগটি সরাসরি ম্যাপ করুন।
- BigQuery কনসোলে যান।
- বাম দিকের এক্সপ্লোরার প্যানেলে, আপনার সক্রিয় প্রজেক্টটি এক্সপ্যান্ড করুন,
lost_cargo_datasetডেটাসেটটি এক্সপ্যান্ড করুন এবং এর বিস্তারিত ভিউ খোলার জন্যshipping_manifestsটেবিলটিতে ক্লিক করুন। - স্কিমা সম্পাদনা করুন- এ ক্লিক করুন।
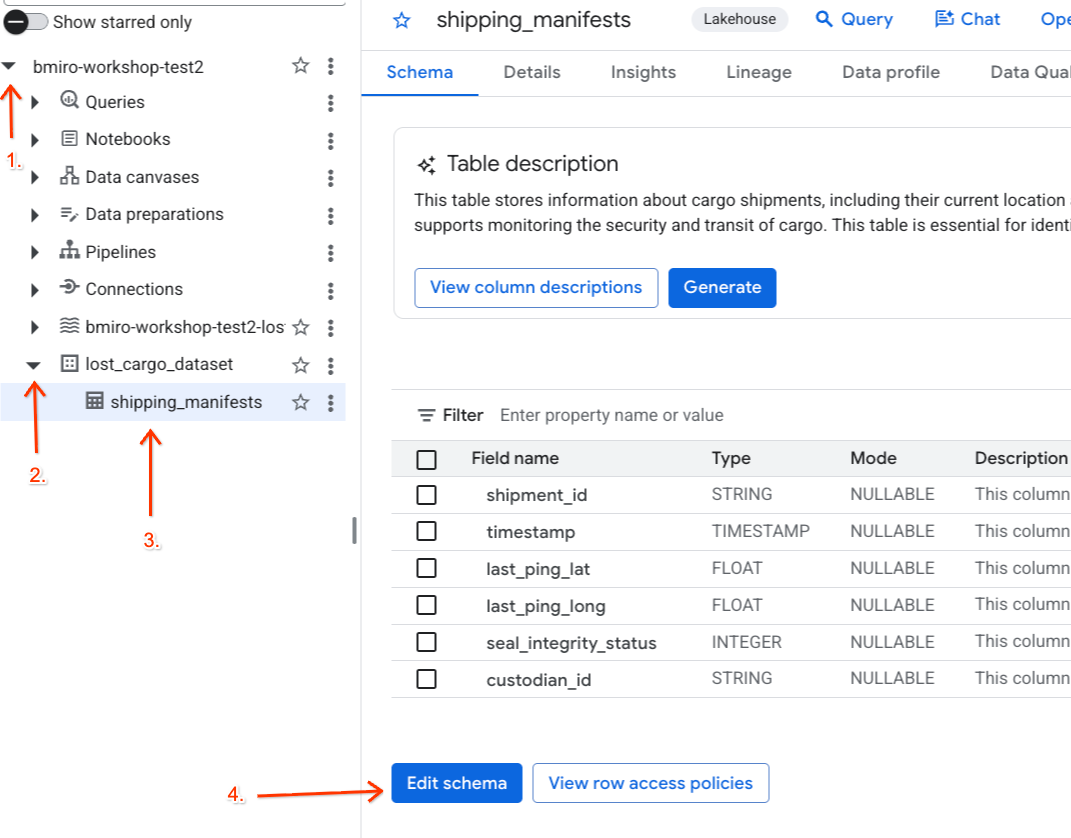
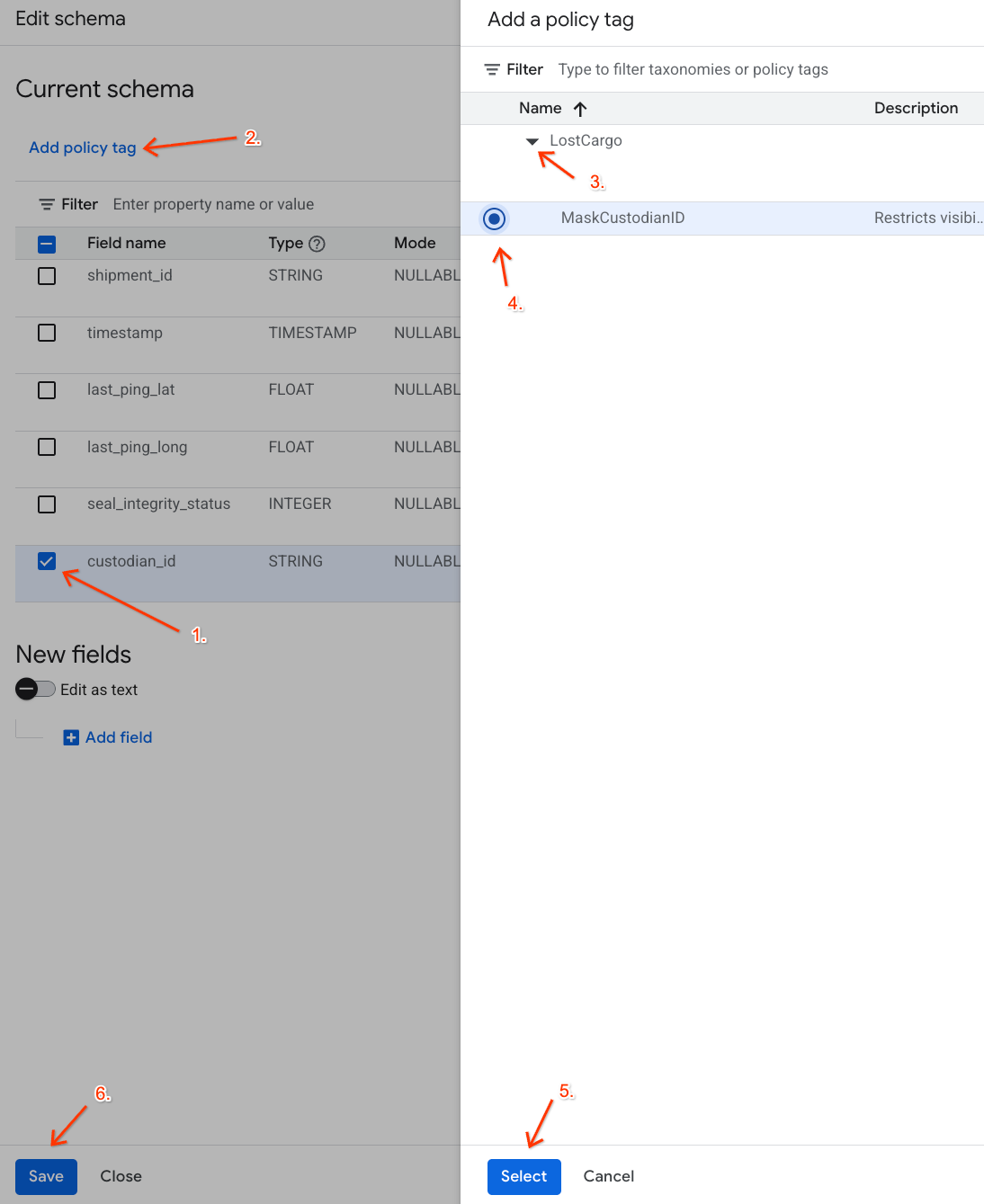
- কলামের তালিকায়,
custodian_idএর পাশের বক্সে টিক দিন। - স্কিমা এডিটরের উপরের টুলবারে থাকা 'অ্যাড পলিসি ট্যাগ' বোতামটিতে ক্লিক করুন।
- পলিসি ট্যাগ যোগ করার প্যানেলে:
- আপনার
LostCargoশ্রেণিবিন্যাসটি সনাক্ত করুন এবং প্রসারিত করুন। -
MaskCustodianIDএর পাশের বাবলটি সিলেক্ট করুন। - নির্বাচন করুন- এ ক্লিক করুন।
- আপনার
- যাচাই করুন যে
custodian_idপ্রতিনিধিত্বকারী সারির Policy tag কলামের অধীনেMaskCustodianIDট্যাগটি এখন দৃশ্যমান আছে। - সংরক্ষণ করুন- এ ক্লিক করুন।
নীতিগত সীমাবদ্ধতা যাচাই করুন
এখন যেহেতু আপনার প্রজেক্ট লেভেলে মাস্কড রিডার রোলটি আছে, আপনি টেবিলটি কোয়েরি করে মাস্কিং পলিসিটি সক্রিয় আছে কিনা তা যাচাই করতে পারেন।
ডেটা এজেন্ট কিট-এ ফিরে যান এবং নিম্নলিখিত কোয়েরিটি চালান:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
আপনি নিম্নলিখিতের অনুরূপ আউটপুট দেখতে পাবেন:
চালান_আইডি | তত্ত্বাবধায়ক_আইডি |
স্বাভাবিক-০০১ | নাল |
স্বাভাবিক-০০২ | নাল |
এমভি-ক্যাট-০০১ | নাল |
সফল! যদিও আপনি shipment_id রেকর্ডগুলো দেখতে পাচ্ছেন, তথ্য ফাঁস রোধ করার জন্য সংবেদনশীল custodian_id ফিল্ডটি সুরক্ষিত null মাস্ক রিটার্ন করে!
৮. পরিষ্কার করুন
এই কোডল্যাবের সময় তৈরি করা রিসোর্সগুলির জন্য আপনার Google Cloud অ্যাকাউন্টে চলমান চার্জ এড়াতে, আপনার ডেটাসেট এবং বাকেটগুলি ড্রপ করতে আপনার ক্লাউড শেল টার্মিনালে এই কমান্ডগুলি চালান:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
৯. অভিনন্দন
অভিনন্দন! আপনি লস্ট কার্গো তদন্তের প্রথম গুরুত্বপূর্ণ মডিউলটি সফলভাবে সম্পন্ন করেছেন। আপনি লেকহাউস আইসবার্গ REST ক্যাটালগ, পাইস্পার্ক লগ নর্মালাইজেশন এবং ফাইন-গ্রেইনড ডেটা মাস্কিং ব্যবহার করে একটি নিয়ন্ত্রিত অনুসন্ধান এলাকা প্রতিষ্ঠা করেছেন।
আপনি যা শিখেছেন
- আপনার IDE ওয়ার্কস্পেসের ভিতরে ডেটা এজেন্ট কিট এক্সটেনশনটি ইনস্টল, সেট আপ এবং কনফিগার করা।
- ভেন্ডেড ক্রেডেনশিয়াল এবং হায়ারারকিক্যাল নেমস্পেস ব্যবহার করে একটি সার্ভারলেস লেকহাউস আইসবার্গ REST ক্যাটালগ স্থাপন করা।
- বিভিন্ন ফরম্যাটের আঞ্চলিক ফিড গ্রহণ করা এবং ক্লাউড স্টোরেজ বাকেটের উপর BigQuery এক্সটার্নাল টেবিল তৈরি করা।
- অসংগঠিত ট্রান্সপন্ডার লগগুলোকে পার্স, নর্মালাইজ, সেগমেন্ট এবং নিবন্ধিত আইসবার্গ ক্যাটালগ টেবিল হিসেবে বিগকোয়েরিতে পুনরায় লেখার জন্য সার্ভারলেস অ্যাপাচি স্পার্ক জব চালু করা হচ্ছে।
- সংবেদনশীল লগ সূচকগুলিতে পরিচয় ফাঁস রোধ করার জন্য নিরাপত্তা শ্রেণিবিন্যাস তৈরি করা এবং নলেজ ক্যাটালগ ডেটা মাস্কিং নীতিগুলির ম্যাপিং করা।
- ডেটা অন্বেষণকে ত্বরান্বিত করতে BigQuery ডেটা ইনসাইটস ব্যবহার করে টেবিলের মেটাডেটা সংক্রান্ত তথ্য তৈরি ও বিশ্লেষণ করা।
সংগৃহীত সূত্র যাচাইকরণ
পরবর্তী ল্যাব পর্বে প্রবেশ করার জন্য প্রয়োজনীয় নিম্নলিখিত সুনির্দিষ্ট সূত্রগুলো আপনি লিপিবদ্ধ করেছেন কিনা তা যাচাই করুন:
- হারিয়ে যাওয়া চালানের আইডি :
MV-CAT-001(শেষ পিং-এর স্থান: লন্ডন ) - পরিকল্পিত গন্তব্যস্থল :
New York(এবং ট্রান্সপন্ডারের আসল ছদ্মনাম:MV-DOG-002) - পাত্রের রঙ :
Crimson RED - গভর্নেন্স অ্যাক্সেস ট্যাগ :
MaskCustodianID
পরবর্তী পর্যায়ের জন্য প্রস্তুত?
এখন যেহেতু ট্রান্সপন্ডারের প্রস্থান/গন্তব্য রুটগুলো সুরক্ষিত, তদন্ত এগিয়ে যাবে! মাল্টিমোডাল জেমিনি মডেল ব্যবহার করে নিরাপত্তা ক্যামেরা পরীক্ষা করতে, দৃশ্যত জাহাজটি শনাক্ত করতে এবং টেম্পারিংয়ের অসঙ্গতি যাচাই করার জন্য AlloyDB-তে ভেক্টর অনুসন্ধান চালাতে সরাসরি ল্যাব ২- এ প্রবেশ করুন!
➡️ দ্বিতীয় ধাপে এগিয়ে যান: ডেটা বিশ্লেষণ ও মাল্টিমোডাল অন্তর্দৃষ্টি