
1. Einführung
In diesem Lab schlüpfen Sie in die Rolle eines leitenden Datenanalysten für ein globales Logistikunternehmen. Ein wertvoller Frachtcontainer mit kostbaren Android-Sammelfiguren ist verschwunden! Um die letzte bekannte Position zu ermitteln und die Route nachzuvollziehen, müssen Sie fragmentierte Versandmanifeste von regionalen Logistikpartnern und unstrukturierte Transponderprotokolldateien zusammenführen. Dazu konfigurieren Sie ein modernes Google Cloud Open Data Lakehouse.

Aufgaben
- Konfigurieren Sie die Google Cloud Data Agent Kit-Erweiterung im Cloud Shell-Editor.
- Erstellen Sie einen Cloud Storage-Bucket und stellen Sie einen Lakehouse Apache Iceberg REST-Katalog und einen Namespace bereit.
- Ordnen Sie eine BigLake rohen JSON-Partnermanifesten in Cloud Storage zu, um den Hinweis auf die Abfahrt des Schiffs zu finden.
- Unstrukturierte Transponder-Textprotokolle mit Managed Service for Apache Spark serverless laden und verarbeiten. Führen Sie Regex-Normalisierungen und die dynamische Extraktion von Hinweisen durch, um das Ziel der verlorenen Nutzlast zu ermitteln.
- Die geparsten Logmesswerte werden über den REST-Katalog als Apache Iceberg-Tabelle geschrieben.
- Mit konversationeller Analyse können Sie mit einem KI-Agenten über Ihre Apache Iceberg-Daten chatten, um verborgene Hinweise zu Ihrer verlorenen Sendung zu finden.
- Nutzen Sie automatisierte Datenstatistiken mit Knowledge Catalog, um Metadaten zu Ihren Daten zu generieren.
- Richten Sie Ingestion Guardrails ein, indem Sie eine Sicherheitstaxonomie erstellen und Knowledge Catalog verwenden, um eine detaillierte Zugriffssteuerung durch Maskieren sensibler Custodian-IDs anzuwenden.
Voraussetzungen
- Ein Webbrowser wie Chrome.
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
- Grundkenntnisse in SQL-Abfragen und Terminalbefehlen
Erwartete Kosten und Dauer
- Zeitaufwand: ca. 45 Minuten.
- Geschätzte Kosten: Weniger als 5,00 $.
2. Hinweis
Google Cloud-Projekt erstellen oder auswählen
- Wählen Sie in der Google Cloud Console ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Umgebung konfigurieren
Die meisten Befehle werden über das integrierte Terminal im Cloud Shell Editor ausgeführt. Das ist eine cloudbasierte Entwicklungsumgebung, in der Entwicklertools und das Standard-Google Cloud SDK vorinstalliert sind.
- Öffnen Sie den Cloud Shell-Editor in einem neuen Tab.
- Führen Sie im Terminal den folgenden Befehl aus, um das Repository zu klonen:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - Legen Sie Ihre Projekt-ID fest. Sie können auch
Ctrl+Shift+Vunter Windows/Linux oderCmd+Vunter macOS drücken, um den Text in das Terminal einzufügen:export PROJECT_ID="<YOUR_PROJECT_ID>" - Konfigurieren Sie es nun in Ihrer Umgebung.
gcloud config set project $PROJECT_ID - Wählen Sie eine Region aus.
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - Aktivieren Sie die erforderlichen APIs.
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
Erweiterung installieren
Als Nächstes konfigurieren Sie die Erweiterung „Google Data Agent Kit“, ein Tool für die Interaktion mit den Datentools von Google Cloud direkt in Ihrer IDE.
- Klicken Sie in der linken Aktivitätsleiste des Editors auf das Symbol Erweiterungen (oder drücken Sie
Ctrl+Shift+Xunter Windows/Linux oderCmd+Xunter macOS). - Geben Sie im Suchfeld für Erweiterungen
Google Cloud Data Agent Kitein. - Wählen Sie die offizielle Erweiterung aus den Ergebnissen aus und klicken Sie auf Installieren. Wählen Sie bei Aufforderung „Ja, ich vertraue den Erstellern“ aus.
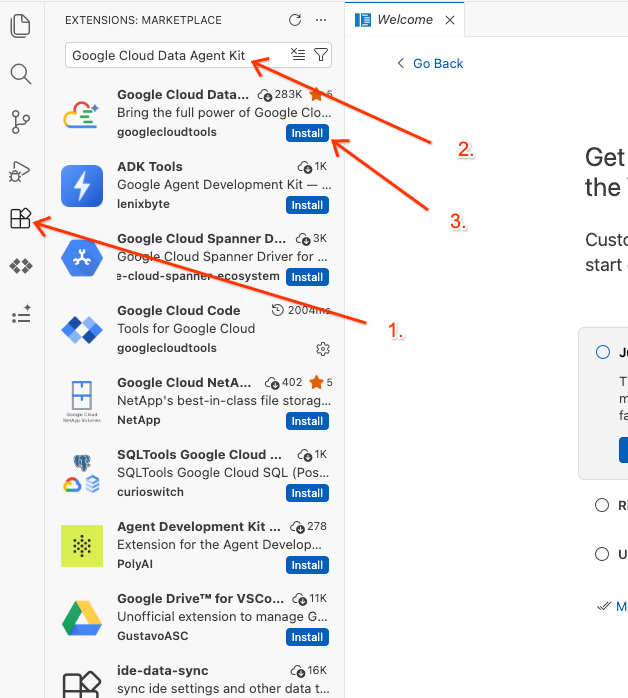
- Nach der erfolgreichen Installation sollte das Symbol Google Cloud Data Agent Kit in der Aktivitätsleiste angezeigt werden. Klicken Sie darauf.
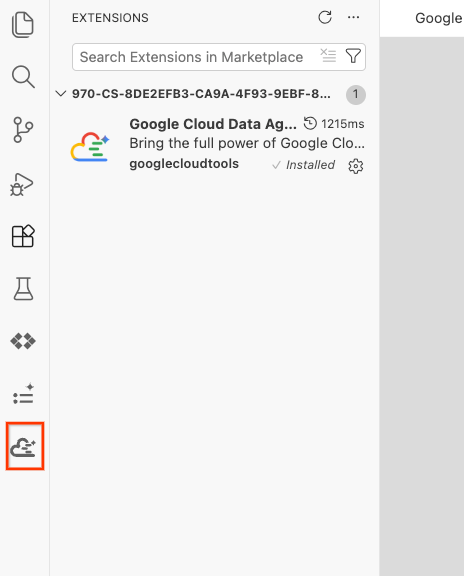
- Klicken Sie auf Bei der Cloud anmelden.
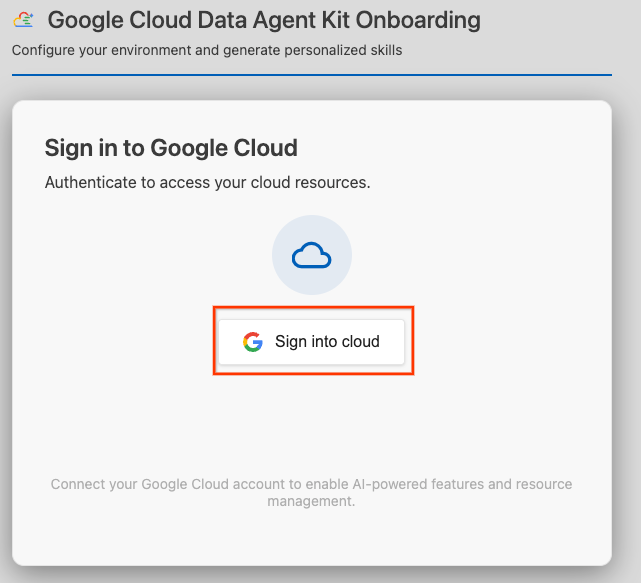
- Klicken Sie auf MCP-Server konfigurieren.
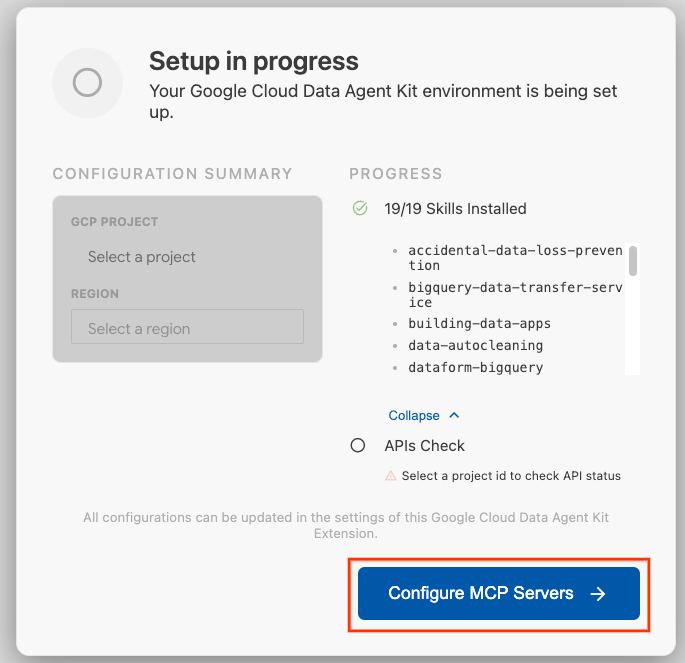
- Wählen Sie BigQuery, Knowledge Catalog, Apache Spark und AlloyDB aus. In Lab 2 verwenden Sie AlloyDB. Klicken Sie dann auf Jetzt starten.
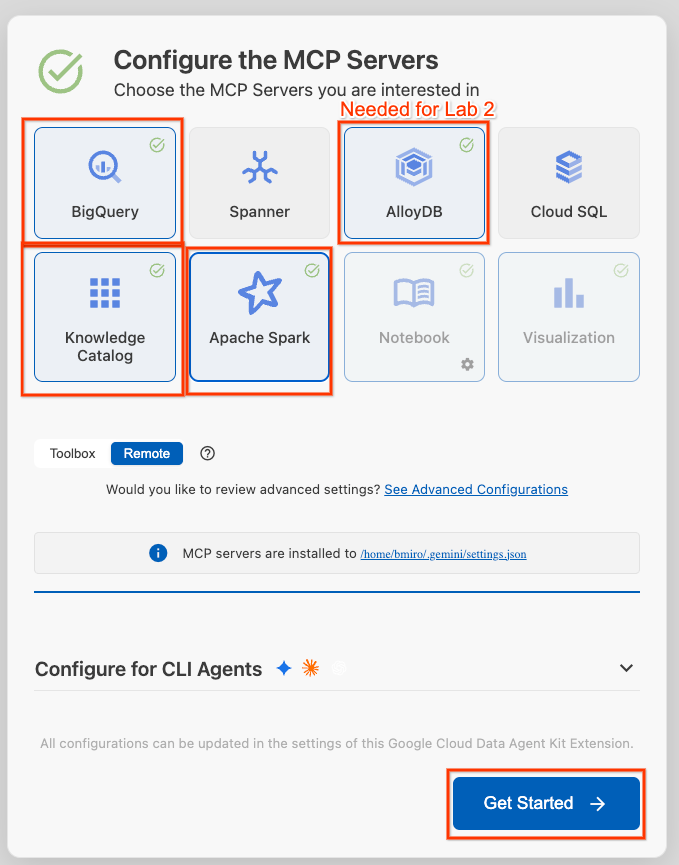
- Klicken Sie in der unteren Statusleiste auf die Auswahl für die Projekt-ID und wählen Sie Ihr aktives Google Cloud-Projekt aus.
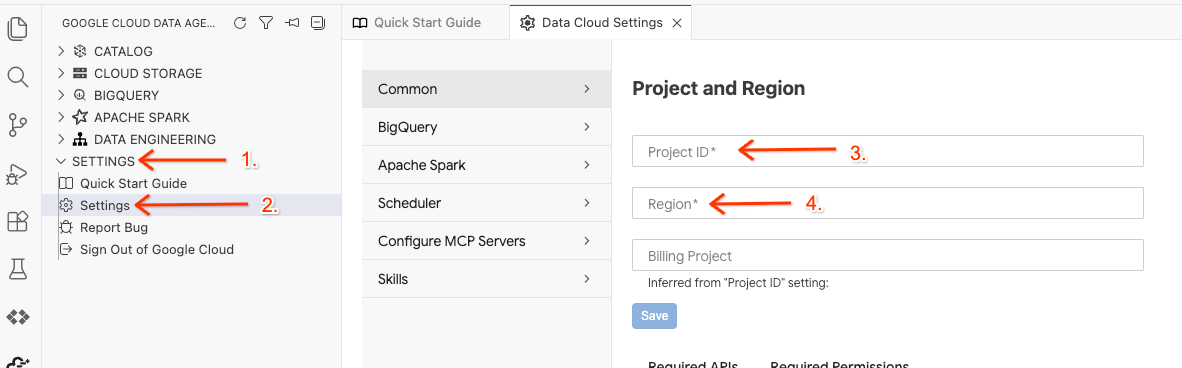
- Klicken Sie im Data Agent Kit auf SETTINGS (EINSTELLUNGEN) und dann auf Settings (Einstellungen). Wählen Sie auf dem Tab Common (Allgemein) die Project ID (Projekt-ID) und Region (Region) für das Lab aus, z. B. us-central1.
- Klicken Sie auf BigQuery-Einstellungen und ersetzen Sie die Region durch die zuvor ausgewählte Region. Klicken Sie auf Speichern.
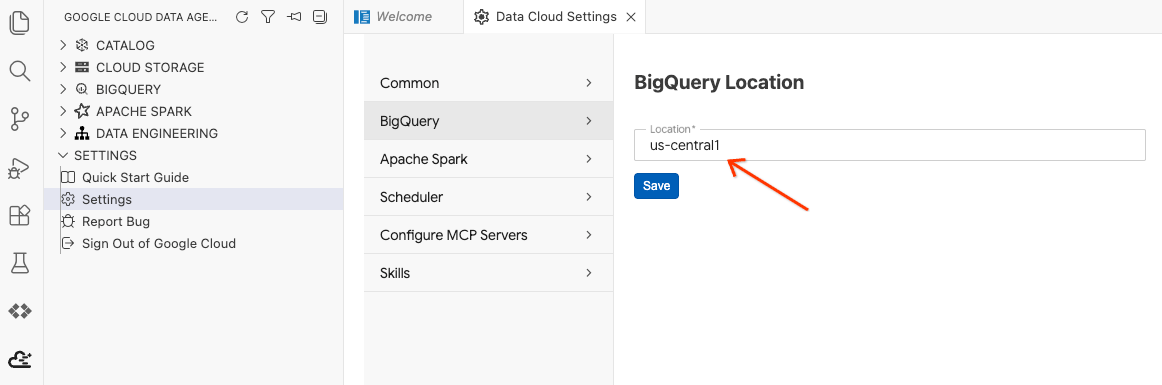
Sie können das Data Agent Kit jetzt verwenden.
Einrichtungsskript für die Umgebung ausführen
Führen Sie im Terminal das Setupscript aus, um die erforderlichen Hintergrundressourcen für dieses Lab zu erstellen und IAM-Berechtigungen zu konfigurieren:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
Sie sollten eine Reihe von Ausgabeschritten sehen, in denen die bereitgestellten Ressourcen aufgeführt sind. Wir werden sie im Laufe des Labs behandeln.
Wenn Sie eine Meldung sehen, dass der Vorgang abgeschlossen ist, können Sie fortfahren:
==================================================== Environment Setup Complete! ====================================================
Fangen wir also an!
3. Versandmanifeste von Partnern aufnehmen
Die Daten von Frachtpapieren von Partnerschiffen werden in Ihrem Bucket im Standard-JSON Lines-Format (JSONL) gespeichert: gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl.
Bevor Sie eine detaillierte Analyse durchführen, erstellen Sie eine verwaltete BigLake-Tabelle für diese unstrukturierten Daten. So können Sie Partnerlogistikdaten sofort mit Standard-SQL analysieren, ohne dass doppelte Importkosten anfallen.
Arbeitsbereich im Editor öffnen und Abfrage ausführen
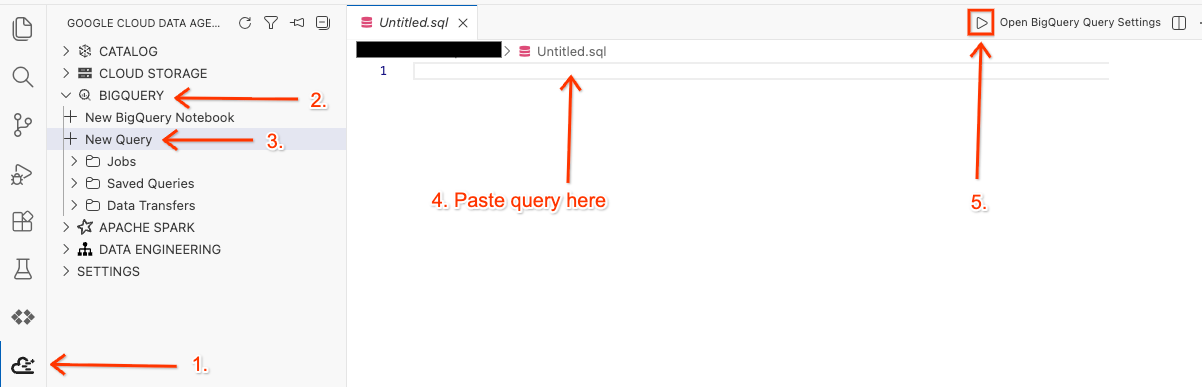
- Klicken Sie im Cloud Shell-Editor in der Seitenleiste auf das Symbol für die Google Cloud Data Agent Kit-Erweiterung.
- Rufen Sie BigQuery auf und wählen Sie + Neue Abfrage aus.
- Kopieren Sie die folgende Abfrage in das Abfragefenster.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- Klicken Sie auf Ausführen.
- Wenn die Tabelle erstellt wurde, wird im Bereich Abfrageergebnisse, der automatisch unten eingeblendet wird, eine Erfolgsmeldung angezeigt.
Externe Tabelle abfragen, um manipulierte Transponder zu isolieren
Wir identifizieren die manipulierten Transponder, indem wir Fehler finden, wenn seal_integrity_status auf 0 gesetzt wurde. Kopieren Sie die folgende Abfrage und führen Sie sie im zuvor geöffneten Abfragefenster aus:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
Im Bereich Abfrageergebnisse sollte eine Ausgabe ähnlich der folgenden angezeigt werden:
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | –0,1278 | usr_999_shadow |
4. Unstrukturierte Logs mit Managed Service for Apache Spark verarbeiten
Sie haben den Startort anhand der strukturierten Manifeste gefunden, aber der verlorene Transponder ist nicht mehr aktiv. Der letzte Transponder-Ping hat eine kryptische, unstrukturierte Nachricht in einer Rohtext-Protokolldatei im GCS-Pfad gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt hinterlassen.
Um dieses Textlog zu verarbeiten und zuzuordnen, Zeitstempel zu extrahieren, Identitäten zu verschleiern und die nachgelagerte Route der Ladung zu ermitteln, senden Sie einen serverlosen Apache Spark (PySpark)-Job an Managed Service for Apache Spark.
Mit Managed Service for Apache Spark können Sie Spark-Arbeitslasten ausführen, ohne einen Cluster bereitstellen oder verwalten zu müssen. Der Dienst verwaltet die zugrunde liegenden Rechenressourcen und skaliert sie dynamisch. Sie zahlen nur für die Ausführungsdauer.
Das Skript führt Folgendes aus:
- Nehmen Sie den unstrukturierten Transpondertext in Klammern auf.
- Wenden Sie PySpark SQL-Filter für den regulären Ausdruck an, um Zeitstempel, Metadaten des Custodian und Rohinhalte zu trennen.
- Teilen Sie die unübersichtlichen Protokolle in übersichtliche Datensätze auf Satzebene auf.
- Extrahieren Sie das dynamische Zielkoordinatenziel, an dem die verlorenen Nutzlastabfahrten endeten.
- Stellen Sie eine Verbindung her und schreiben Sie den verarbeiteten Log-Dataframe als neue Analysetabelle zurück in Ihren Lakehouse Apache Iceberg REST Catalog, die direkt in BigQuery sichtbar ist.
PySpark-Analysescript korrigieren
Es gibt Berichte über Python-Piraten auf See, die alle möglichen Probleme verursachen.
- Führen Sie den folgenden Befehl aus, um die Datei
process_maritime_logsim Cloud Shell-Editor zu öffnen.cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - Nehmen Sie sich etwas Zeit, um den Code zu lesen und zu verstehen, was er bewirkt.
- Achten Sie darauf, dass nichts im Code verdächtig aussieht. Wenn Sie etwas löschen müssen, speichern Sie die Datei mit
Ctrl + S(Windows/Linux) oderCmd + S(Mac).
Serverlosen Spark-Job senden
Senden Sie den Job mit dem gcloud SDK. Die Konfiguration konfiguriert den PySpark-Job automatisch für den Zugriff auf den Lakehouse-Katalog.
Führen Sie den folgenden Befehl im Terminal Ihres integrierten Editors aus.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
Warten Sie einige Minuten, bis die serverlose Umgebung hochgefahren ist, laden Sie das Script hoch und führen Sie die Verarbeitungslogik aus.
Wenn Sie eine Ausgabe wie die folgende sehen, wird Ihre verarbeitete Tabelle als verwaltete Apache Iceberg-Tabelle im Lakehouse-Katalog gespeichert.
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
Verarbeitete Logs in der Vorschau ansehen
Kopieren Sie im Abfrageeditor der Data Agent Kit-Erweiterung die folgende Abfrage, um eine Vorschau der Daten zu sehen:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
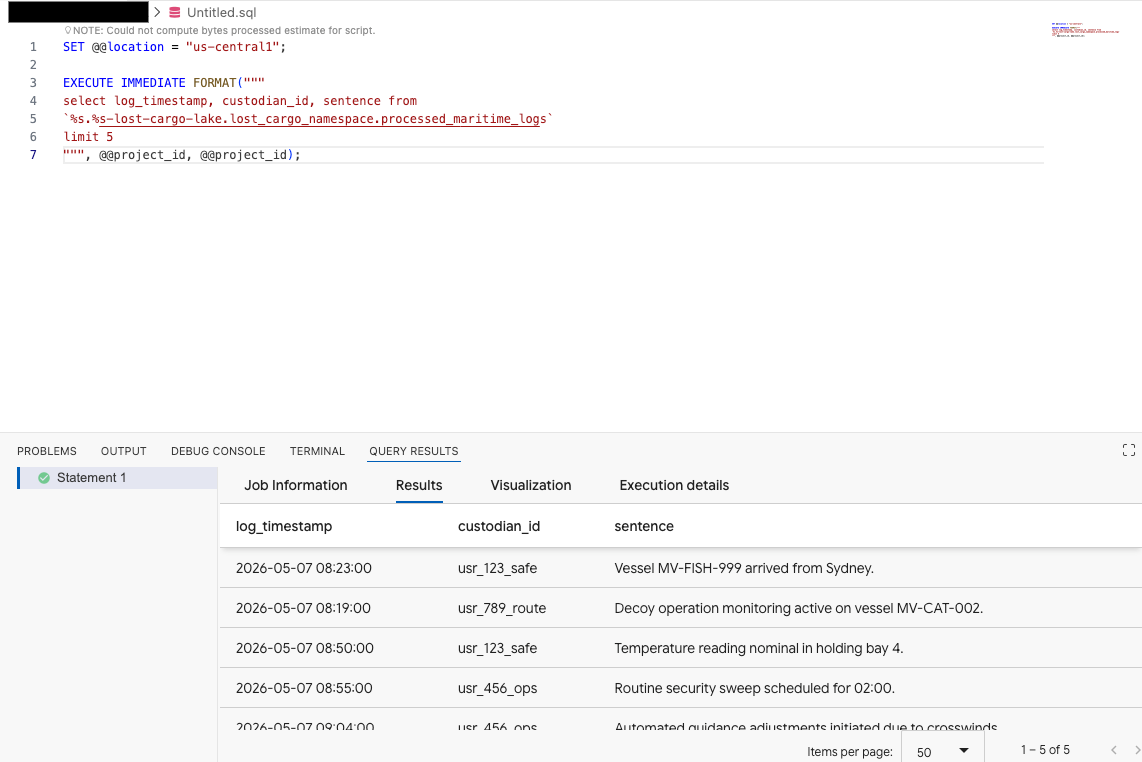
Das zeigt, dass auf die im Katalog registrierte Iceberg-Tabelle erfolgreich über BigQuery zugegriffen werden kann.
Hinweis zum Ziel extrahieren
Nachdem wir die verarbeiteten Logs haben, suchen wir nach den Logs, die ein Ziel enthalten. Dort können wir in den Protokollen nach Einträgen suchen, in denen unsere Herkunftsstadt erwähnt wird.
Führen Sie in Ihrem Abfrageeditor die folgende Abfrage aus. Ersetzen Sie dabei <YOUR_REGION> durch Ihre Region und <ORIGIN_CITY> durch die Stadt, die Sie zuvor ermittelt haben.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
Mit Daten in der BigQuery-Konsole chatten – konversationelle Analyse
Anstatt komplexe SQL-Abfragen zu schreiben, um Ihre Daten zu analysieren, können Sie Conversational Analytics verwenden, um sich in natürlicher Sprache mit Ihren Tabellen zu unterhalten.
- Rufen Sie die BigQuery-Konsole auf.
- Maximieren Sie im Bereich Explorer auf der linken Seite Ihr Projekt und das Dataset
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logs, um den Tab mit den Details zu öffnen. - Klicken Sie neben Abfrage auf Chat.
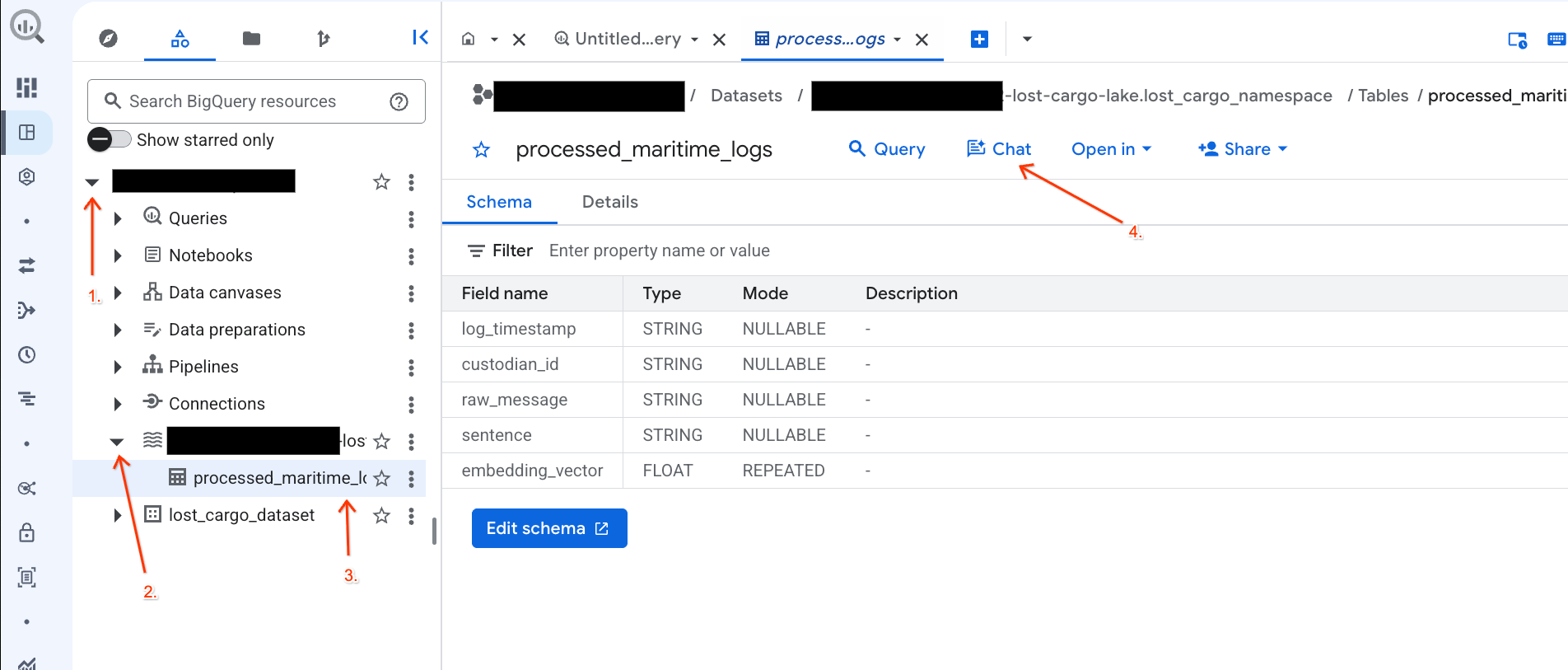
- Geben Sie im Chatbereich die folgende Frage ein und drücken Sie die Eingabetaste, um sie zu senden:
Based on this table, what color is the shipping container MV-CAT-001?
- Die konversationelle Analyse (basierend auf Gemini) analysiert die Daten der aktiven Tabelle und gibt die Farbe als Antwort zurück.
5. Zentralen Lakehouse-Katalog ansehen
Damit Open-Source-Verarbeitungs-Engines wie Apache Spark sicher und nahtlos in Unternehmensdaten-Engines wie BigQuery eingebunden werden können, wurde in Ihrem Setupscript ein Lakehouse Iceberg REST Catalog konfiguriert.
Der Apache Iceberg REST-Katalog dient als serverlose „Single Source of Truth“ für Tabellenmetadaten. Er verwaltet Schemas und partitioniert Tabellen dynamisch, während physische Parquet-Datendateien in Cloud Storage gespeichert werden.
Sehen wir uns diesen Katalog direkt in der Google Cloud Console an:
- Öffnen Sie die Lakehouse Console.
- Suchen Sie auf dem Tab Catalogs (Kataloge) nach Ihrem aktiven Iceberg-REST-Katalog
-lost-cargo-lake
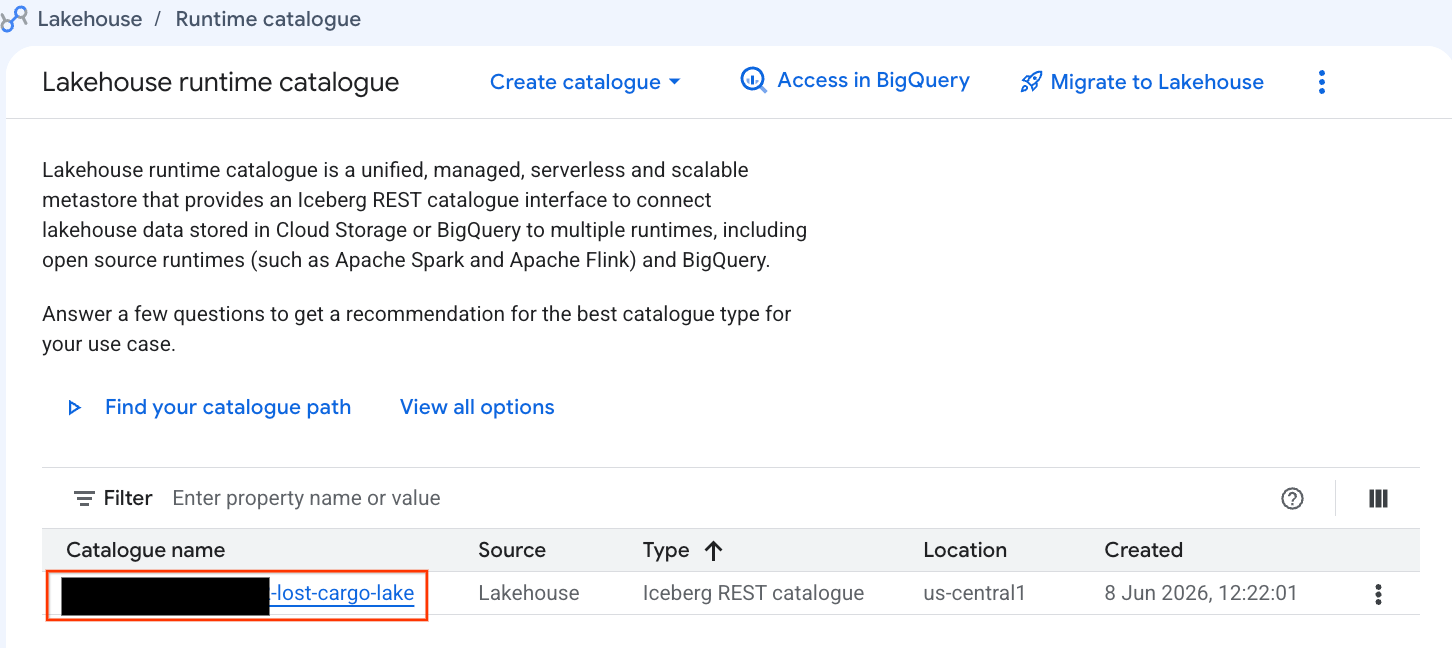
- In der Ansicht mit den Katalogdetails sollte unter Namespaces die Option
lost_cargo_namespaceangezeigt werden. Klicke darauf.
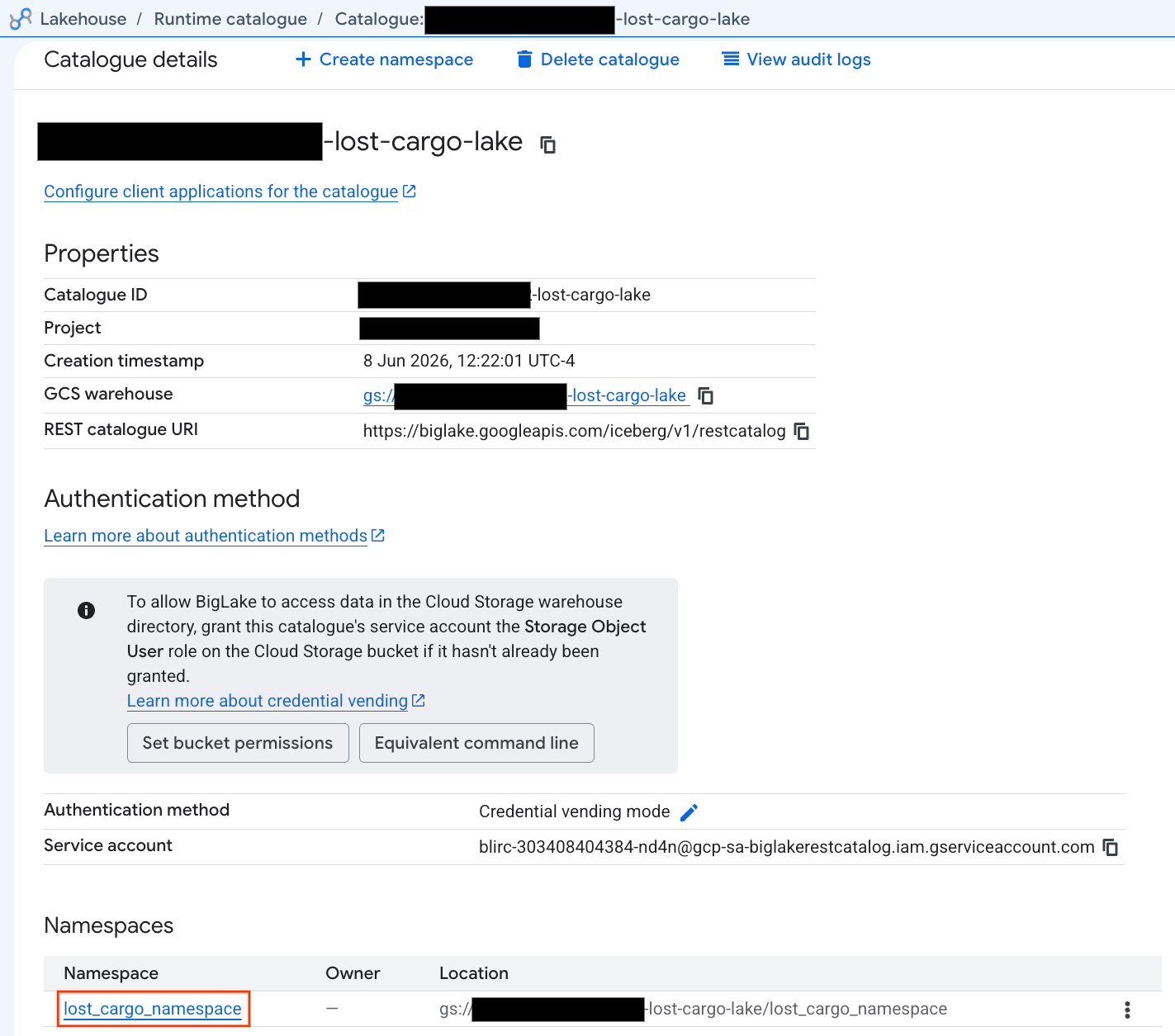
- Ihre neue Apache Iceberg-Tabelle, die von PySpark generiert wurde, wurde automatisch in diesem Metastore-Namespace registriert und konnte sofort in BigQuery abgefragt werden.
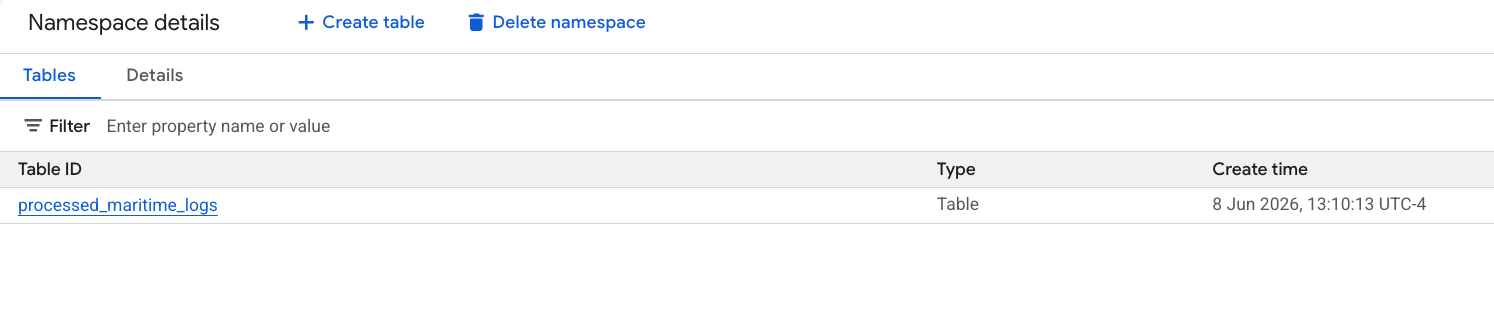
6. Statistiken für die Tabelle „Versandmanifeste“ generieren
Sehen wir uns die Tabelle shipping_manifests noch einmal an, um ihre Struktur und ihren Inhalt mithilfe von Knowledge Catalog Data Insights zu analysieren. Wenn Sie die Metadaten anreichern, können andere Nutzer die Tabelle für zukünftige Analysen besser nachvollziehen.
Tabellenstatistiken in BigQuery Studio generieren
- Rufen Sie in der Google Cloud Console BigQuery Studio auf.
- Maximieren Sie im Bereich Explorer Ihr Projekt und das Dataset
lost_cargo_datasetund klicken Sie auf die Tabelleshipping_manifests. - Klicken Sie rechts im Detailbereich auf den Tab Insights.
- Wählen Sie im Drop-down-Menü Generieren und veröffentlichen aus.
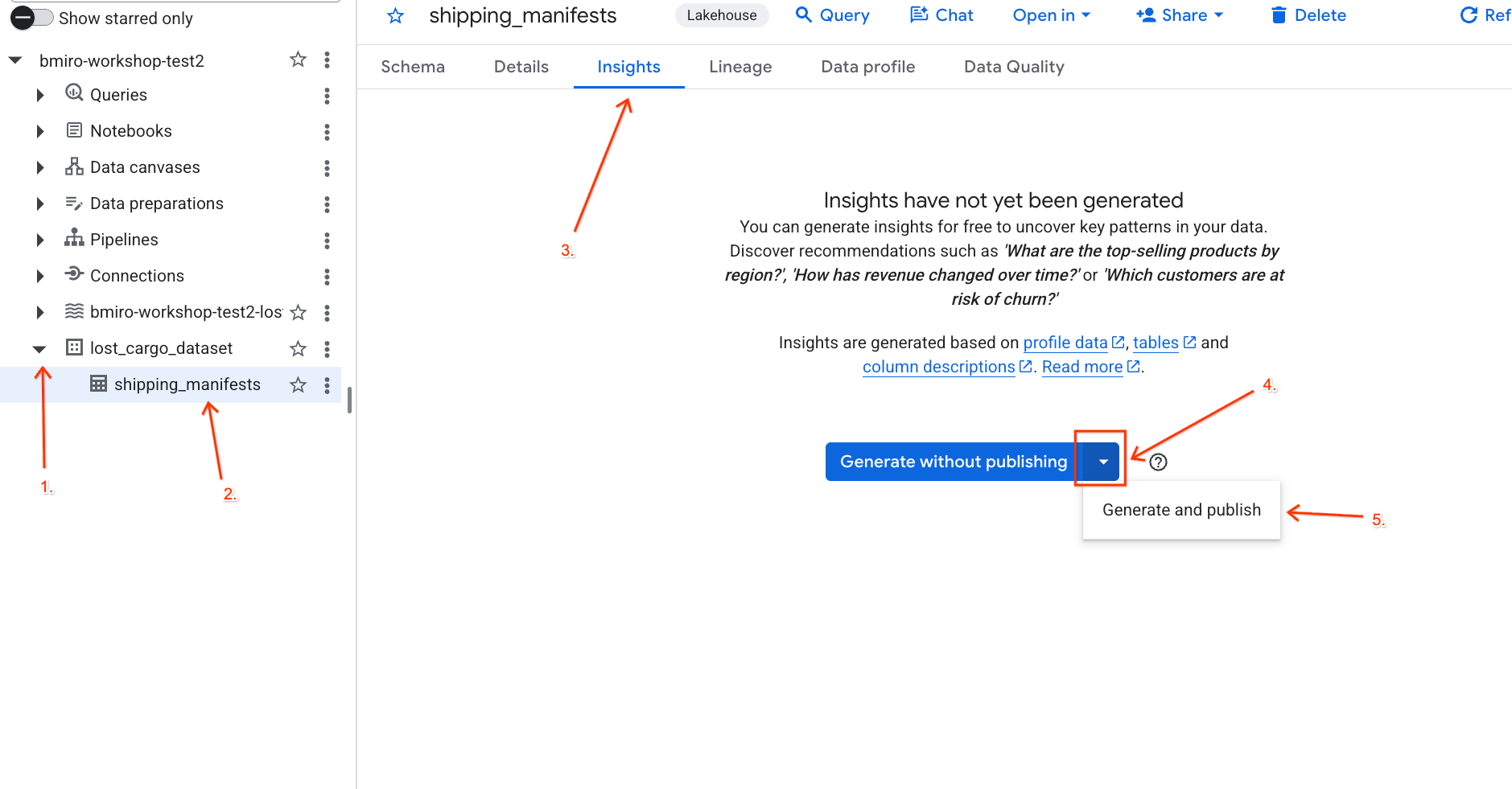
- Warten Sie etwa 3 Minuten, bis die Statistiken generiert wurden. Gemini analysiert die Tabellenmetadaten und generiert Fragen in natürlicher Sprache und entsprechende SQL-Abfragen.
- Anschließend wird eine Tabellenbeschreibung mit einer Erklärung der Tabelle in natürlicher Sprache angezeigt.
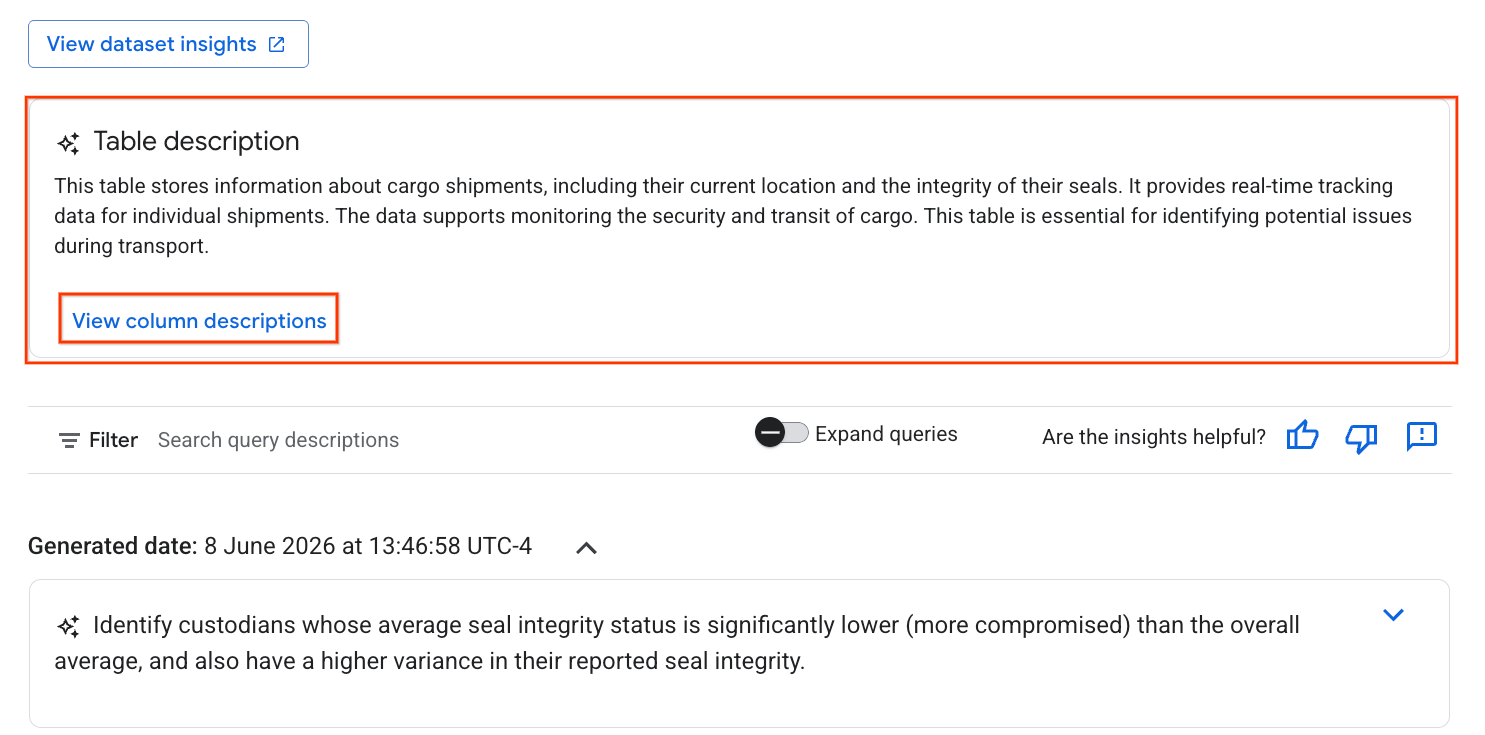
- Klicken Sie auf Spaltenbeschreibungen ansehen, um Informationen zu den einzelnen Spalten aufzurufen.
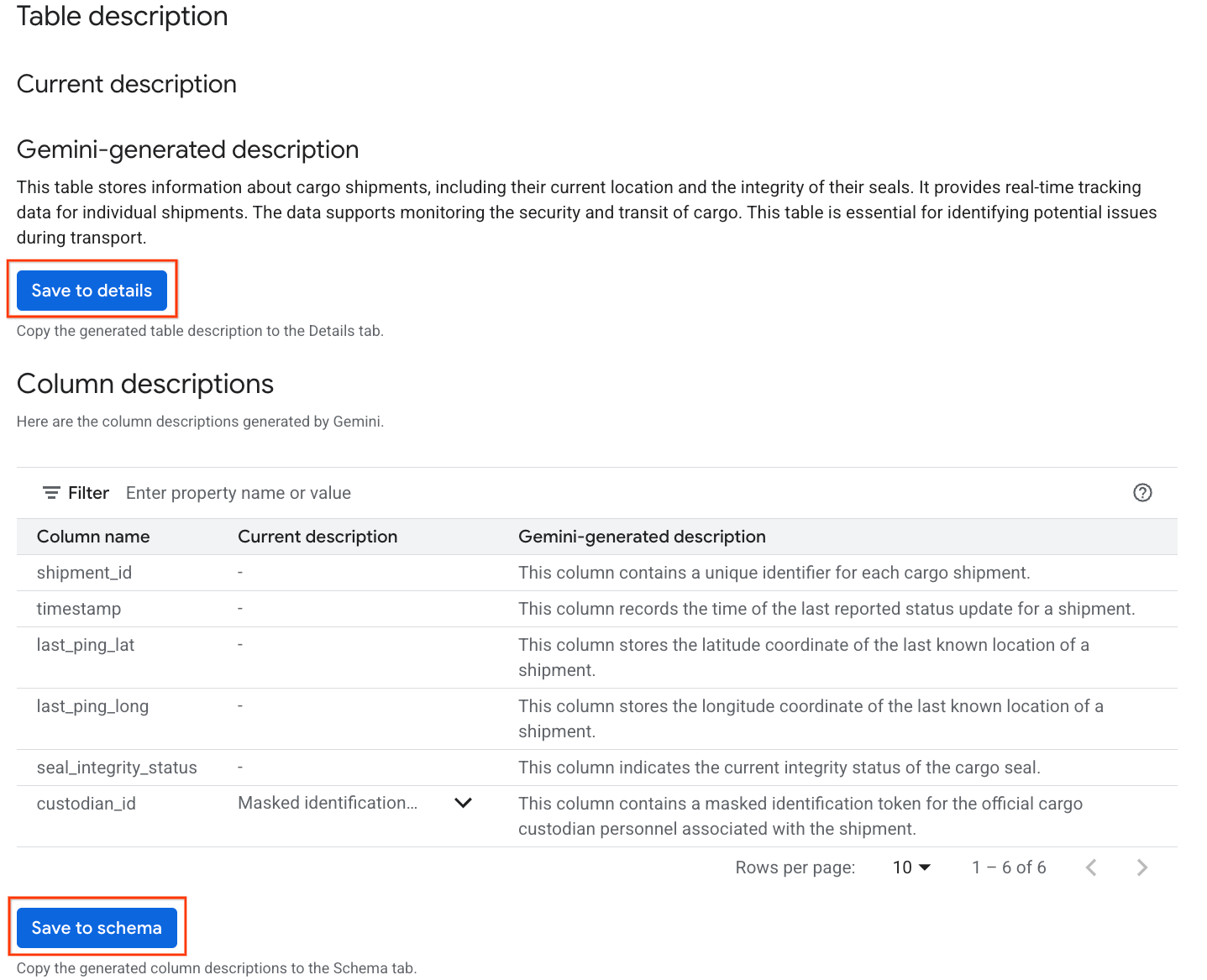
- Klicken Sie unter
Gemini generated descriptionauf In Details speichern und dann im Pop-up-Fenster auf In Details speichern.
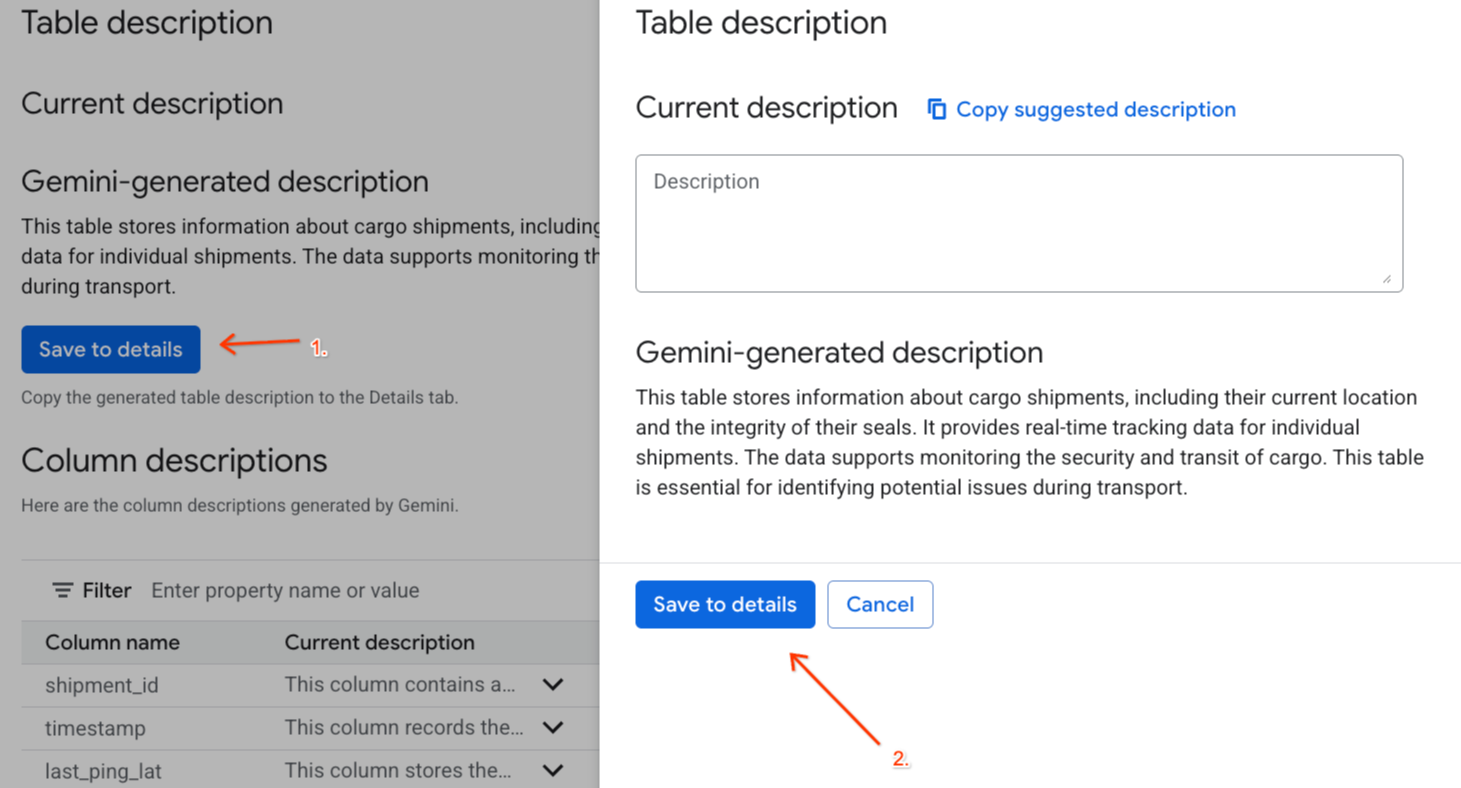
- Klicken Sie auf Im Schema speichern, um die Spaltenbeschreibungen den Tabellenmetadaten hinzuzufügen.
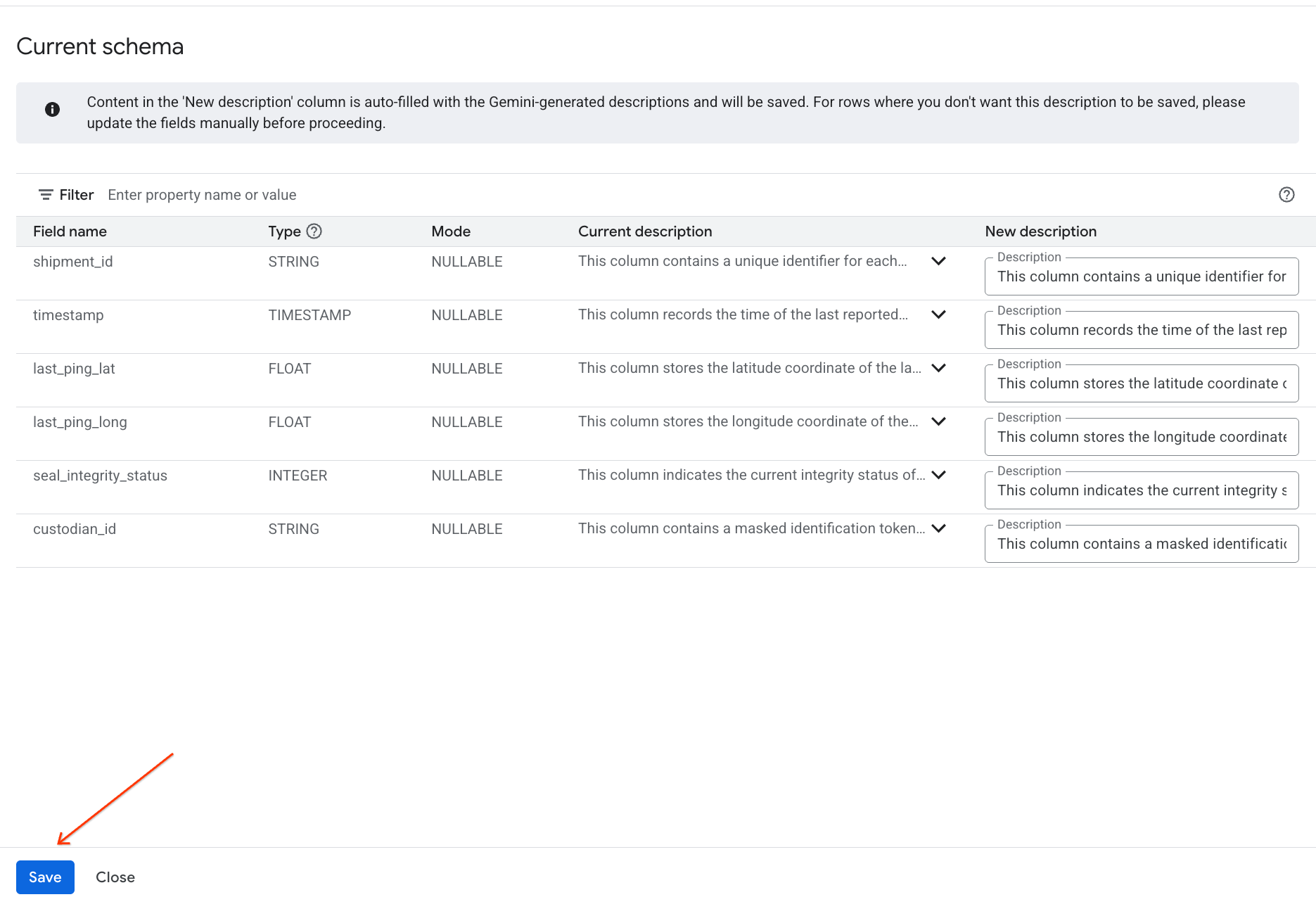
Generierte Statistiken ansehen
Außerdem wird eine Liste mit Vorschlägen für Fragen angezeigt. Sie können auf eine beliebige Frage klicken, um die generierte SQL-Abfrage aufzurufen und auszuführen, um die Daten zu analysieren. Beispiele:
- „Wie viele Sendungen gibt es insgesamt?“
- „Liste die eindeutigen Custodian-IDs auf.“
Wenn Sie diese Abfragen ausführen, können Sie die Daten besser nachvollziehen.
7. Datenmaskierung und Governance implementieren
Damit aktive Forschungsaccounts und Nutzernamen während dieser laufenden Untersuchung nicht offengelegt werden, müssen Sie die Standardsicherheitsprotokolle einhalten. Sie erstellen eine Taxonomie für Sicherheitsrichtlinien-Tags und konfigurieren die Knowledge Catalog-Datenmaskierung für die vertrauliche Spalte custodian_id, um den Datenschutz zu überprüfen.
Standardmäßig wird der Zugriff auf Spalten, die durch Richtlinien-Tags geschützt sind, in BigQuery verweigert. Wenn Sie die Tabelle abfragen und aktive Datenmasken überprüfen möchten, muss Ihrem Nutzerkonto die Rolle BigQuery Data Policy Masked Reader zugewiesen sein.
Diese Rolle wurde bei der ersten Ausführung von setup_lab1.sh automatisch an Ihr aktives Nutzerkonto gebunden.
Taxonomie und Richtlinien-Tag erstellen
Erstellen Sie eine Datentaxonomie und ein zugehöriges Richtlinien-Tag, um den Zugriff auf Ihre Daten zu verwalten.
- Rufen Sie die Seite Richtlinien-Tag-Taxonomien auf.
- Klicken Sie auf + Taxonomie erstellen.
- Konfigurieren Sie die Parameter:
- Name der Taxonomie: Geben Sie
lost-cargo-ein und ersetzen Sie dabeilost-cargo-durch Ihre Projekt-ID. - Region: Wählen Sie Ihre Region aus.
- Geben Sie für das Richtlinien-Tag Name Folgendes ein:
MaskCustodianID - Für Beschreibung des Richtlinien-Tags:
Restricts visibility into cargo custodian usernames
- Name der Taxonomie: Geben Sie
- Klicken Sie auf Erstellen, um die neue Taxonomie und das neue Richtlinien-Tag zu registrieren.
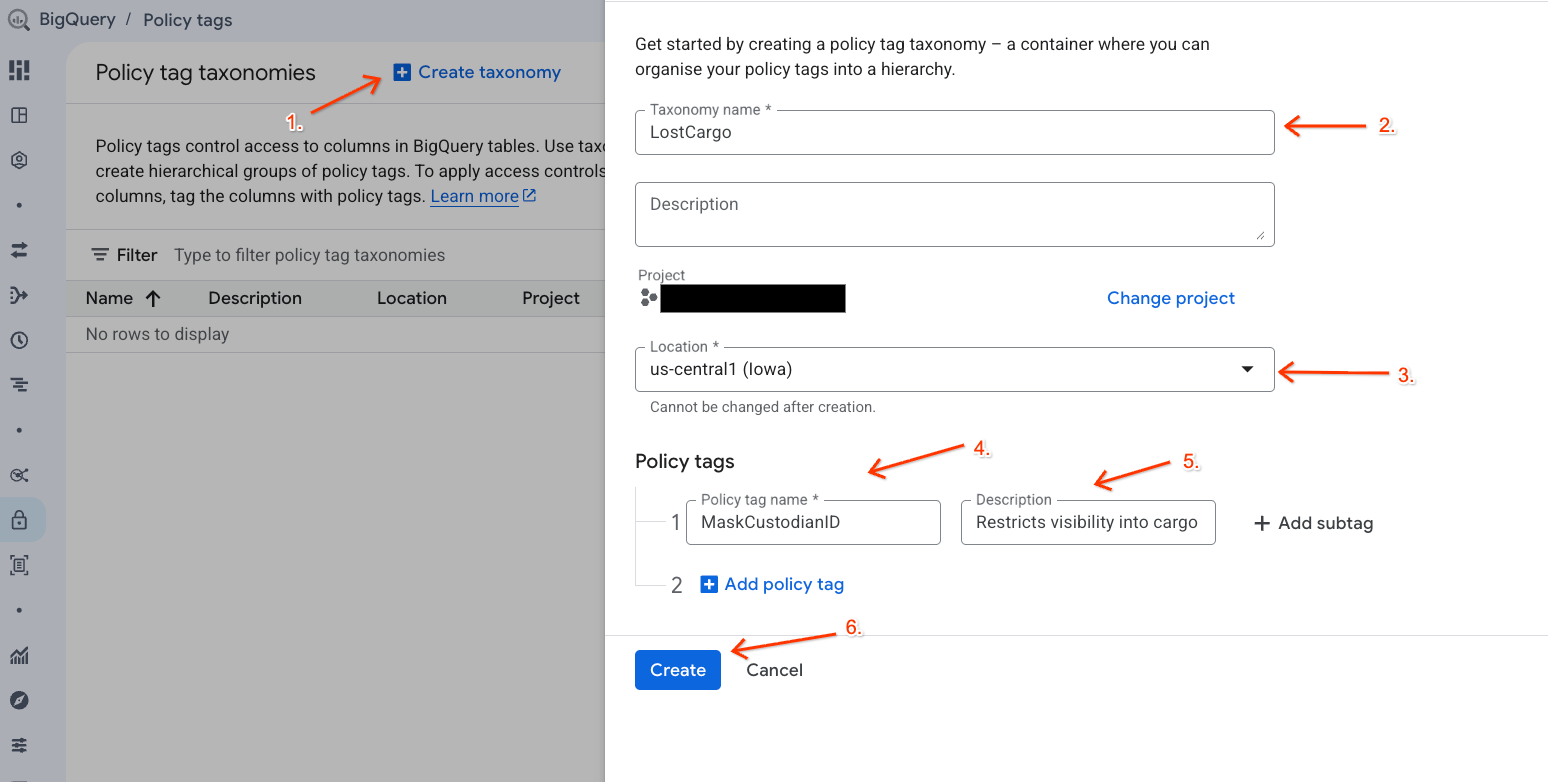
Richtlinie zur Datenmaskierung erstellen
Konfigurieren Sie als Nächstes eine Datenrichtlinie, um festzulegen, wie die Daten unter dem Klassifizierungstag MaskCustodianID maskiert werden. Sie verwenden die Maskierungsregel Immer Null, bei der übereinstimmende Werte für alle nicht privilegierten Akteure durch leere/Null-Rückgaben ersetzt werden.
- Klicken Sie auf der Seite Richtlinien-Tag-Taxonomien in der Liste der Taxonomien auf die neu erstellte Taxonomie.
- Klicken Sie in der Hierarchieliste auf das Tag
MaskCustodianID, um es auszuwählen, und wählen Sie dann Datenrichtlinien verwalten aus.
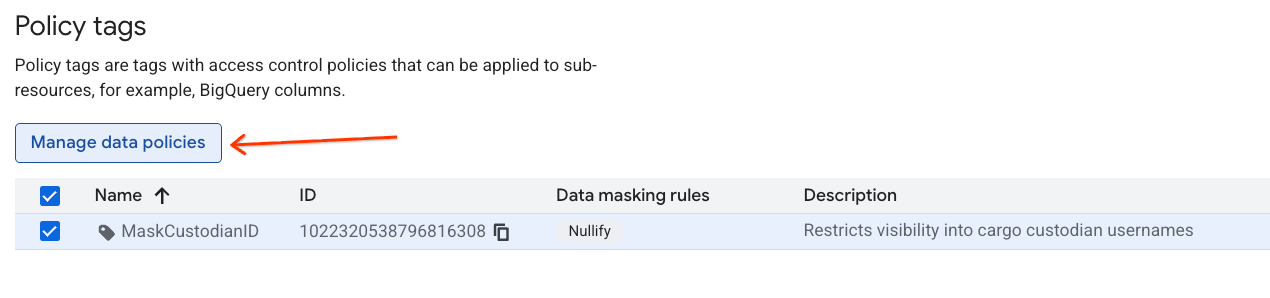
- Klicken Sie im rechten Bereich auf die Schaltfläche + Regel hinzufügen.
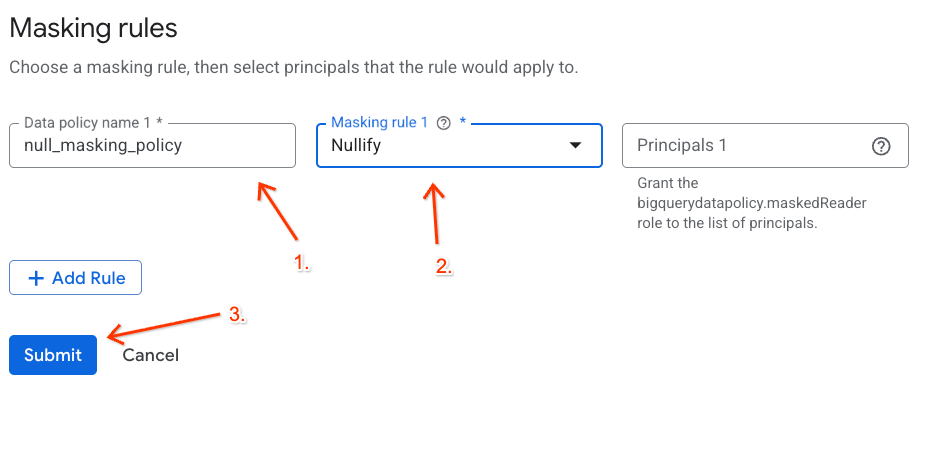
- Konfigurieren Sie die Richtliniendetails im angezeigten Bereich:
- Name der Datenrichtlinie: Geben Sie
null_masking_policyein. Lassen Sie den Namen nicht automatisch generieren, da wir in den nächsten Schritten darauf verweisen. - Maskierungsregel: Wählen Sie im Drop-down-Menü
Nullifyaus.
- Name der Datenrichtlinie: Geben Sie
- Klicken Sie auf Senden.
Richtlinien-Tag Ihrer BigQuery-Spalte zuweisen
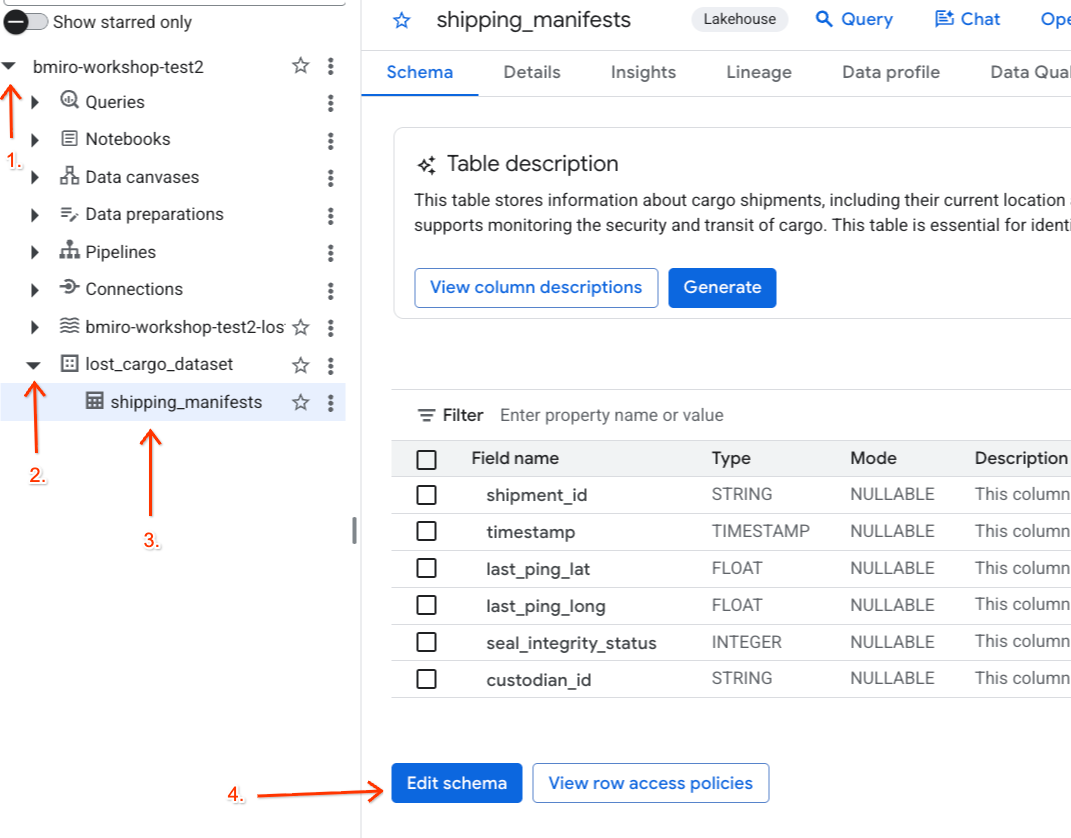
Wenn das Richtlinien-Tag und die zugehörige Datenmaskierungsregel aktiv sind, ordnen Sie das Klassifizierungs-Tag direkt der Spalte custodian_id in der BigQuery-Tabelle mit dem Versandmanifest Ihres Partners zu.
- Rufen Sie die BigQuery auf.
- Maximieren Sie im Bereich Explorer auf der linken Seite Ihr aktives Projekt, maximieren Sie das Dataset
lost_cargo_datasetund klicken Sie auf die Tabelleshipping_manifests, um die Detailansicht zu öffnen. - Klicken Sie auf Schema bearbeiten.
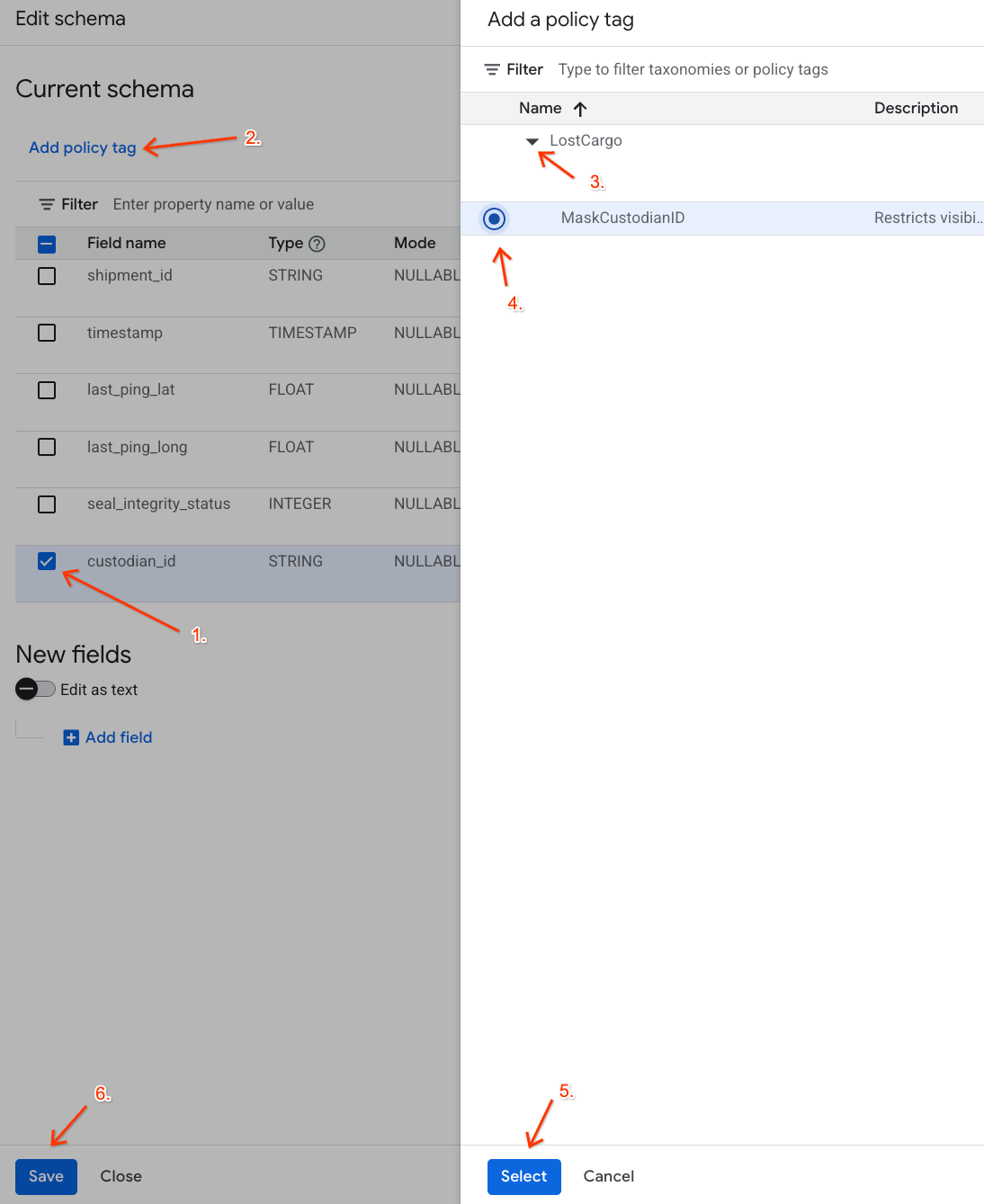
- Klicken Sie in der Spaltenliste das Kästchen neben
custodian_idan. - Klicken Sie in der Symbolleiste des Schema-Editors auf die Schaltfläche Richtlinien-Tag hinzufügen.
- Im Bereich Richtlinien-Tag hinzufügen:
- Suchen Sie Ihre
LostCargo-Taxonomie und maximieren Sie sie. - Wählen Sie das Bläschen neben
MaskCustodianIDaus. - Klicken Sie auf Auswählen.
- Suchen Sie Ihre
- Prüfen Sie, ob das Tag
MaskCustodianIDjetzt in der Spalte Richtlinien-Tag in der Zeile fürcustodian_idangezeigt wird. - Klicken Sie auf Speichern.
Richtlinienbeschränkungen prüfen
Nachdem Sie die Rolle „Masked Reader“ auf Projektebene haben, können Sie die Tabelle abfragen, um zu prüfen, ob die Maskierungsrichtlinie aktiv ist.
Kehren Sie zum Data Agent Kit zurück und führen Sie die folgende Abfrage aus:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
Die Ausgabe sollte in etwa so aussehen:
shipment_id | custodian_id |
NORMAL-001 | Null |
NORMAL-002 | Null |
MV-CAT-001 | Null |
Fertig! Sie können zwar die shipment_id-Datensätze aufrufen, aber das vertrauliche Feld custodian_id gibt sichere null-Masken zurück, um Datenlecks zu verhindern.
8. Bereinigen
Führen Sie die folgenden Befehle in Ihrem Cloud Shell-Terminal aus, um Ihre Datasets und Buckets zu löschen und so zu vermeiden, dass Ihrem Google Cloud-Konto die in diesem Codelab erstellten Ressourcen laufend in Rechnung gestellt werden:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. Glückwunsch
Glückwunsch! Sie haben das erste wichtige Modul der Untersuchung Verlorene Fracht abgeschlossen. Sie haben eine regulierte Suchzone mit Lakehouse Iceberg-REST-Katalogen, PySpark-Log-Normalisierung und detaillierter Datenmaskierung eingerichtet.
Das haben Sie gelernt
- Installieren, Einrichten und Konfigurieren der Data Agent Kit-Erweiterung in Ihrem IDE-Arbeitsbereich.
- Einrichtung eines serverlosen Lakehouse Iceberg-REST-Katalogs mit bereitgestellten Anmeldedaten und hierarchischen Namespaces.
- Aufnahme von regionalen Feeds in mehreren Formaten und Erstellung externer BigQuery-Tabellen für Cloud Storage-Buckets.
- Serverlose Apache Spark-Jobs werden gestartet, um unstrukturierte Transponderprotokolle zu parsen, zu normalisieren, zu segmentieren und als registrierte Iceberg-Katalogtabellen zurück in BigQuery zu schreiben.
- Sicherheitsklassifikationen erstellen und Knowledge Catalog-Richtlinien zur Datenmaskierung zuordnen, um Identitätslecks bei sensiblen Log-Indizes zu verhindern.
- Mit BigQuery-Datenstatistiken können Sie Tabellenmetadatenstatistiken generieren und analysieren, um die Datenexploration zu beschleunigen.
Überprüfung der gesammelten Hinweise
Prüfen Sie, ob Sie die folgenden wichtigen Hinweise aufgezeichnet haben, die für die nächste Lab-Phase erforderlich sind:
- Verlorene Versand-ID:
MV-CAT-001(letzter Ping-Standort: London) - Geplantes Ziel:
New York(und Transponder-Alias:MV-DOG-002) - Containerfarbe:
Crimson RED - Governance Access Tag:
MaskCustodianID
Bereit für die nächste Phase?
Nachdem die Transponderrouten für Abfahrt / Zielort gesichert sind, geht die Untersuchung weiter. Starten Sie direkt mit Lab 2, um Sicherheitskameras mit multimodalen Gemini-Modellen zu untersuchen, das Schiff visuell zu identifizieren und Vektorsuchen in AlloyDB durchzuführen, um Manipulationsanomalien zu überprüfen.
➡️ Mit Schritt 2 fortfahren: Datenanalyse und multimodale Statistiken