
1. Introducción
En este lab, asumirás el rol de investigador principal de datos de una empresa de logística global. Se extravió un contenedor de carga valioso que transportaba figuras coleccionables preciosas de Android. Para encontrar su última ubicación conocida y rastrear su ruta, debes agregar manifiestos de envío fragmentados de socios de logística regionales y archivos de registro de transpondedores no estructurados. Para ello, configurarás un data lakehouse de datos abiertos de Google Cloud moderno.

Actividades
- Configura la extensión del kit de agentes de datos de Google Cloud en el editor de Cloud Shell.
- Crea un bucket de Cloud Storage y aprovisiona un catálogo de REST de Apache Iceberg de Lakehouse y un espacio de nombres.
- Asigna una tabla externa de BigLake a manifiestos de socios en formato JSON sin procesar en Cloud Storage para descubrir la pista de partida del barco.
- Carga y procesa registros de texto no estructurados del transpondedor con Managed Service para Apache Spark sin servidores. Realiza normalizaciones de regex y extracciones de pistas dinámicas para segmentar la ubicación de la carga útil perdida.
- Escribe las métricas de registro analizadas como una tabla de Apache Iceberg a través del catálogo de REST.
- Chatea con un agente de IA sobre tus datos de Apache Iceberg con Conversational Analytics para descubrir pistas ocultas sobre tu envío perdido.
- Aprovecha las estadísticas de datos automáticas con Knowledge Catalog para generar metadatos sobre tus datos.
- Establece parámetros de protección para la transferencia de datos creando una taxonomía de seguridad y usando Knowledge Catalog para aplicar un control de acceso detallado a través del enmascaramiento de los IDs de custodios sensibles.
Requisitos
- Un navegador web, como Chrome
- Un proyecto de Google Cloud con facturación habilitada.
- Conocimientos básicos de consultas SQL y comandos de terminal
Costo y duración esperados
- Tiempo para completar: Alrededor de 45 minutos
- Costo estimado: Menos de USD 5.00
2. Antes de comenzar
Crea o selecciona un proyecto de Google Cloud
- En la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para confirmar que la facturación esté habilitada en un proyecto.
Configura el entorno
Ejecutarás la mayoría de los comandos desde la terminal integrada en el Editor de Cloud Shell, un entorno de desarrollo basado en la nube que viene precargado con herramientas para desarrolladores y el SDK de Google Cloud estándar.
- Abre el Editor de Cloud Shell en una pestaña nueva.
- Ejecuta el siguiente comando en la terminal para clonar el repositorio:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - Determina tu ID del proyecto: También puedes presionar
Ctrl+Shift+Ven Windows o Linux, oCmd+Ven macOS para pegar esto en la terminal:export PROJECT_ID="<YOUR_PROJECT_ID>" - Ahora, configúralo en tu entorno.
gcloud config set project $PROJECT_ID - Selecciona una región.
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - Habilita las APIs necesarias.
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
Instalar extensión
Ahora configurarás la extensión Google Data Agent Kit, una herramienta para interactuar con las herramientas de datos de Google Cloud directamente en tu IDE.
- En la barra de actividades de la izquierda del editor, haz clic en el ícono de Extensiones (o presiona
Ctrl+Shift+Xen Windows o Linux, oCmd+Xen macOS). - En el cuadro de búsqueda de extensiones, escribe
Google Cloud Data Agent Kit. - Selecciona la extensión oficial en los resultados y haz clic en Instalar. Si se te solicita, selecciona “Sí, confío en los autores”.
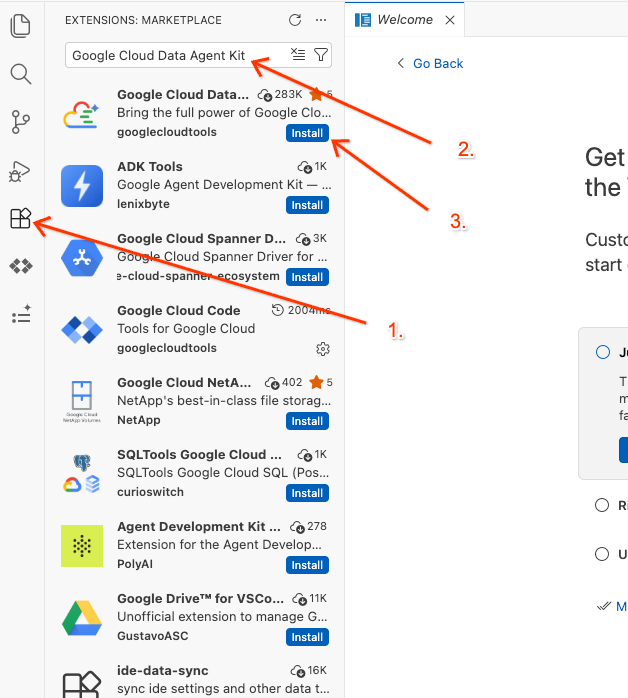
- Una vez que se instale correctamente, deberías ver el ícono de Google Cloud Data Agent Kit en la barra de actividad. Haz clic en él.
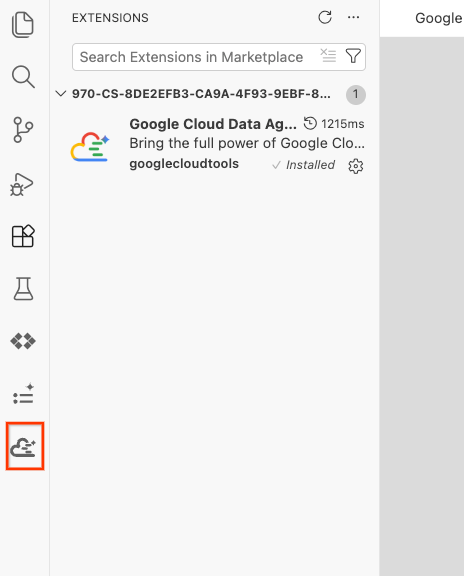
- Haz clic en Sign into cloud.
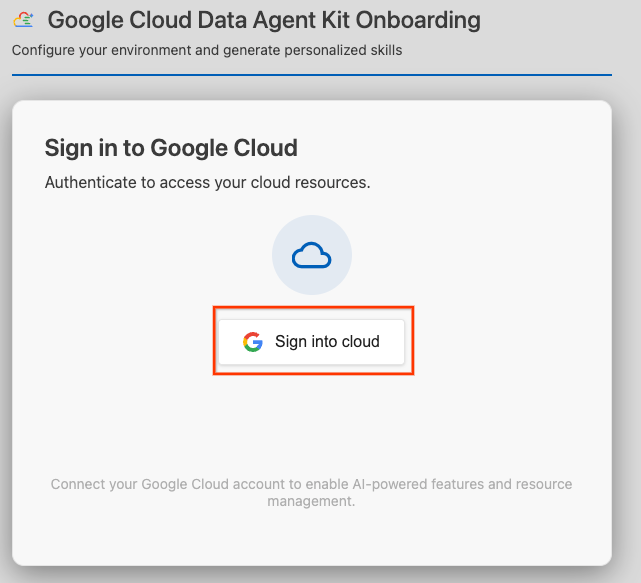
- Haz clic en Configurar servidores de MCP.
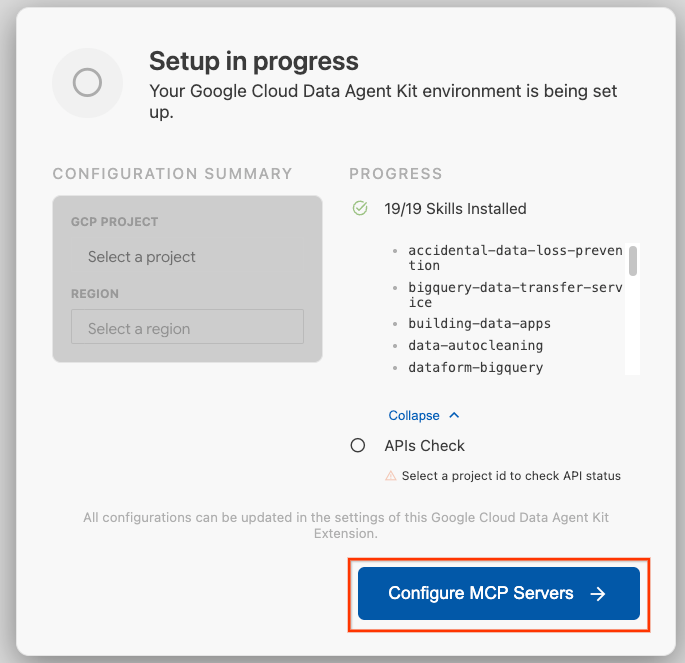
- Selecciona BigQuery, Knowledge Catalog, Apache Spark y AlloyDB. Usarás AlloyDB en el lab 2. Luego, haz clic en Comenzar.
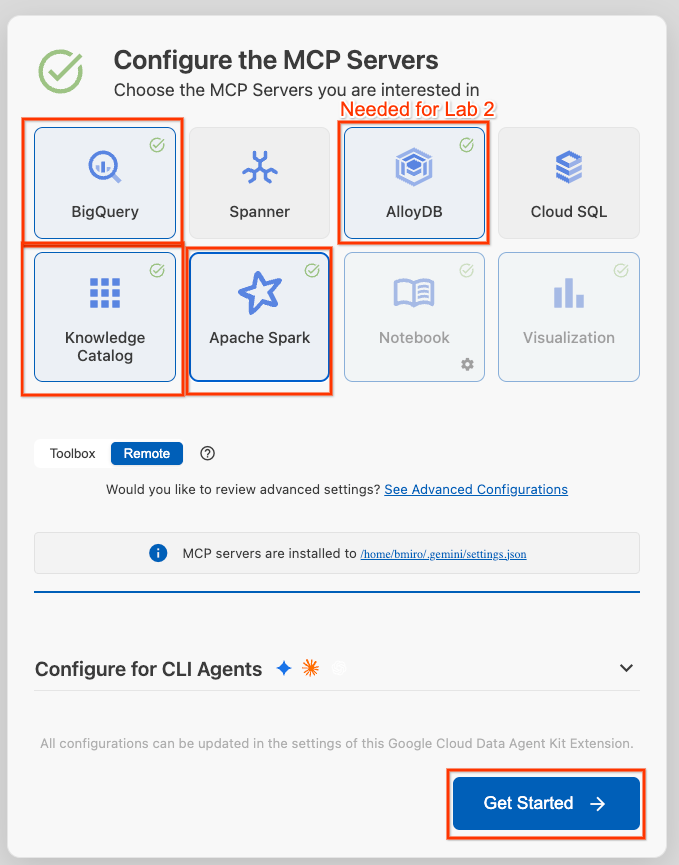
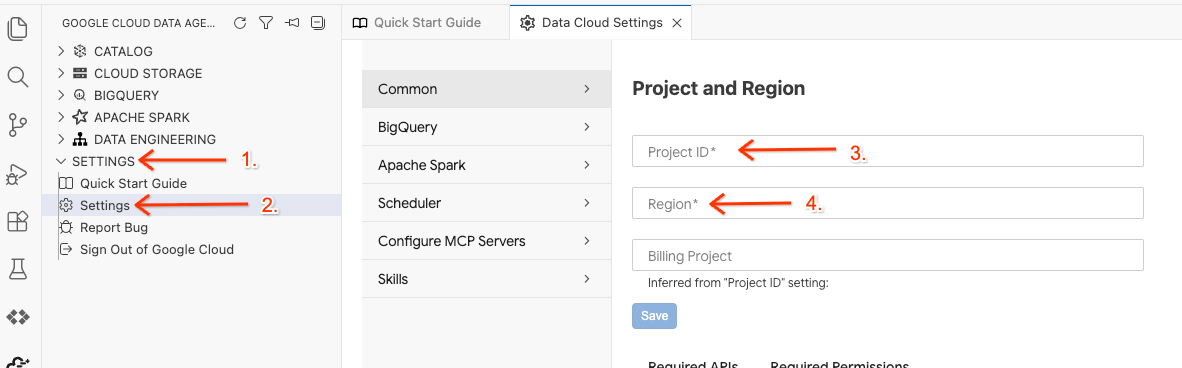
- Haz clic en el selector de ID del proyecto en la barra de estado inferior y elige tu proyecto activo de Google Cloud.
- En Data Agent Kit, haz clic en SETTINGS, luego en Settings y, en la pestaña Common, selecciona tu ID del proyecto y la región para ejecutar el lab, como us-central1.
- Haz clic en Configuración de BigQuery y reemplaza la región por la que seleccionaste anteriormente. Haga clic en Guardar.
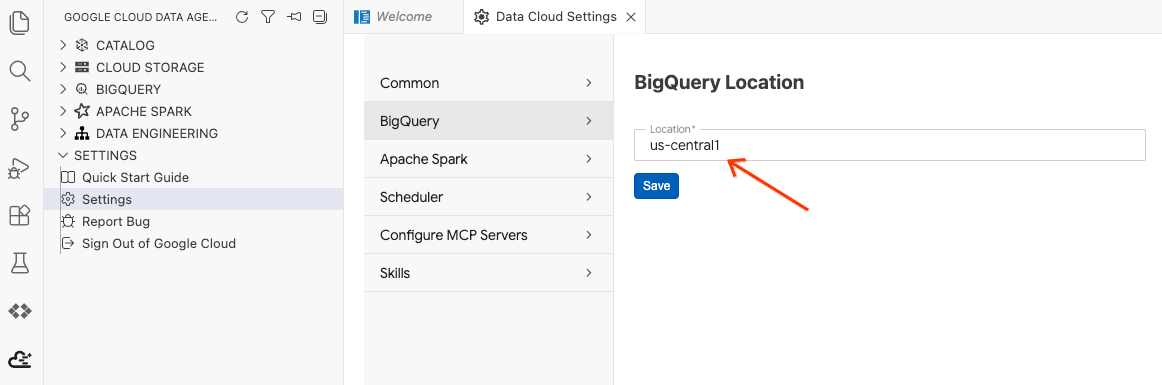
Ya puedes usar el Kit del agente de datos.
Ejecuta la secuencia de comandos de configuración del entorno
En la terminal, ejecuta la secuencia de comandos de configuración para crear los recursos en segundo plano necesarios para este lab y configurar los permisos de IAM:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
Deberías ver una serie de pasos de salida que muestran qué recursos se aprovisionan. Abordaremos estos temas a lo largo del lab.
Cuando veas un mensaje de finalización, podrás continuar:
==================================================== Environment Setup Complete! ====================================================
Ahora, comencemos la búsqueda.
3. Cómo transferir manifiestos de envío de socios
Los datos del manifiesto de envío de los buques asociados se almacenan en formato estándar de líneas JSON (JSONL) en tu bucket: gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl.
Antes de realizar un análisis detallado, crearás una tabla de BigLake administrada para estos datos no estructurados. Esto te permite explorar los datos de logística de los socios de inmediato con SQL estándar sin costos de importación duplicados.
Abre el espacio de trabajo en el editor y ejecuta la consulta
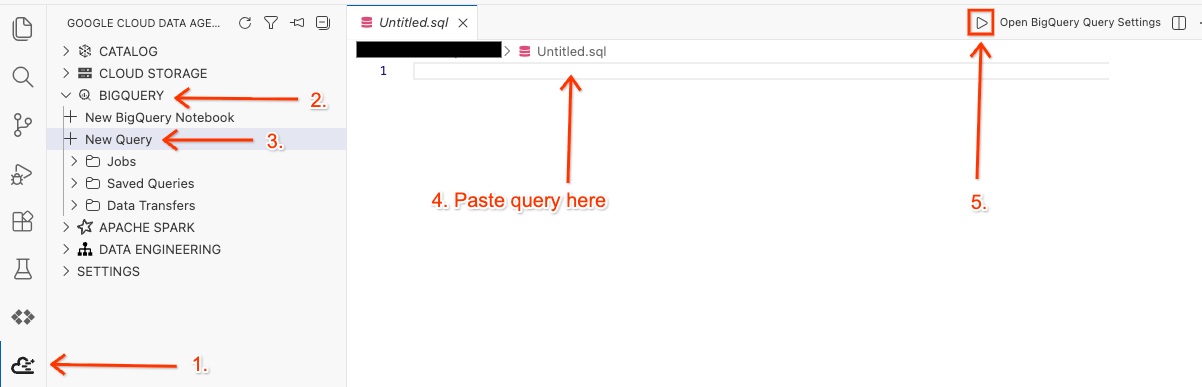
- En el editor de Cloud Shell, haz clic en el ícono de la extensión del kit de Google Cloud Data Agent en el panel lateral.
- Ve a BigQuery y selecciona + Consulta nueva.
- Copia la siguiente consulta en la ventana de consultas.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- Haz clic en Ejecutar.
- Para verificar que se creó la tabla, verás un mensaje de confirmación en el panel Resultados de la consulta que se abre automáticamente en la parte inferior.
Consulta la tabla externa para aislar los transpondedores vulnerados
Identifiquemos los transpondedores comprometidos localizando las fallas cuando seal_integrity_status se estableció en 0. Copia y ejecuta la siguiente consulta en la ventana de consultas que abriste antes:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
En el panel Resultados de la consulta, deberías ver un resultado similar al siguiente:
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0.1278 | usr_999_shadow |
4. Procesa registros no estructurados con Managed Service para Apache Spark
Encontraste la ubicación de inicio en los manifiestos estructurados, pero el transpondedor perdido dejó de funcionar por completo. El último ping del transpondedor dejó un mensaje críptico y no estructurado dentro de un archivo de registro de texto sin procesar en la ruta de GCS gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt.
Para procesar y asignar este registro de texto, extraer marcas de tiempo, camuflar identidades y ubicar la ruta de entrega de la carga, enviarás un trabajo de Apache Spark (PySpark) sin servidores a Managed Service para Apache Spark.
Managed Service para Apache Spark te permite ejecutar cargas de trabajo de Spark sin aprovisionar ni administrar un clúster. El servicio controla los recursos de procesamiento subyacentes y los ajusta automáticamente de forma dinámica, y solo pagas por la duración de la ejecución.
La secuencia de comandos hará lo siguiente:
- Ingiere el texto sin procesar, entre corchetes y no estructurado del transpondedor.
- Aplica filtros de extracción de regex de PySpark SQL para separar las marcas de tiempo, los metadatos del custodio y el contenido sin procesar.
- Dividir los registros desordenados en registros limpios a nivel de oraciones
- Extrae el objetivo de coordenadas de destino dinámico en el que finalizaron las salidas de la carga útil perdida.
- Conecta y escribe el DataFrame de registro procesado en tu catálogo de Apache Iceberg REST de Lakehouse como una nueva tabla de análisis visible directamente en BigQuery.
Corrige la secuencia de comandos de análisis de PySpark
Se han recibido informes de piratas de Python en el mar que causan todo tipo de problemas.
- Ejecuta el siguiente comando para abrir el archivo
process_maritime_logsen el editor de Cloud Shell.cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - Dedica un tiempo a leer el código y comprender lo que hace.
- Asegúrate de que nada en el código parezca sospechoso. Si necesitas borrar algo, asegúrate de guardar el archivo con
Ctrl + S(Windows/Linux) oCmd + S(Mac).
Envía el trabajo de Spark sin servidores
Envía el trabajo con el SDK de gcloud. La configuración establece automáticamente el trabajo de PySpark para acceder al catálogo de Lakehouse.
Ejecuta el siguiente comando en la terminal del editor integrado.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
Espera unos minutos a que se inicie el entorno sin servidores, sube tu secuencia de comandos y ejecuta la lógica de procesamiento.
Cuando veas un resultado similar al siguiente, tu tabla procesada se guardará en el catálogo de Lakehouse como una tabla administrada de Apache Iceberg.
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
Obtén una vista previa de los registros procesados
En el editor de consultas de la extensión Data Agent Kit, copia la siguiente consulta para obtener una vista previa de los datos:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
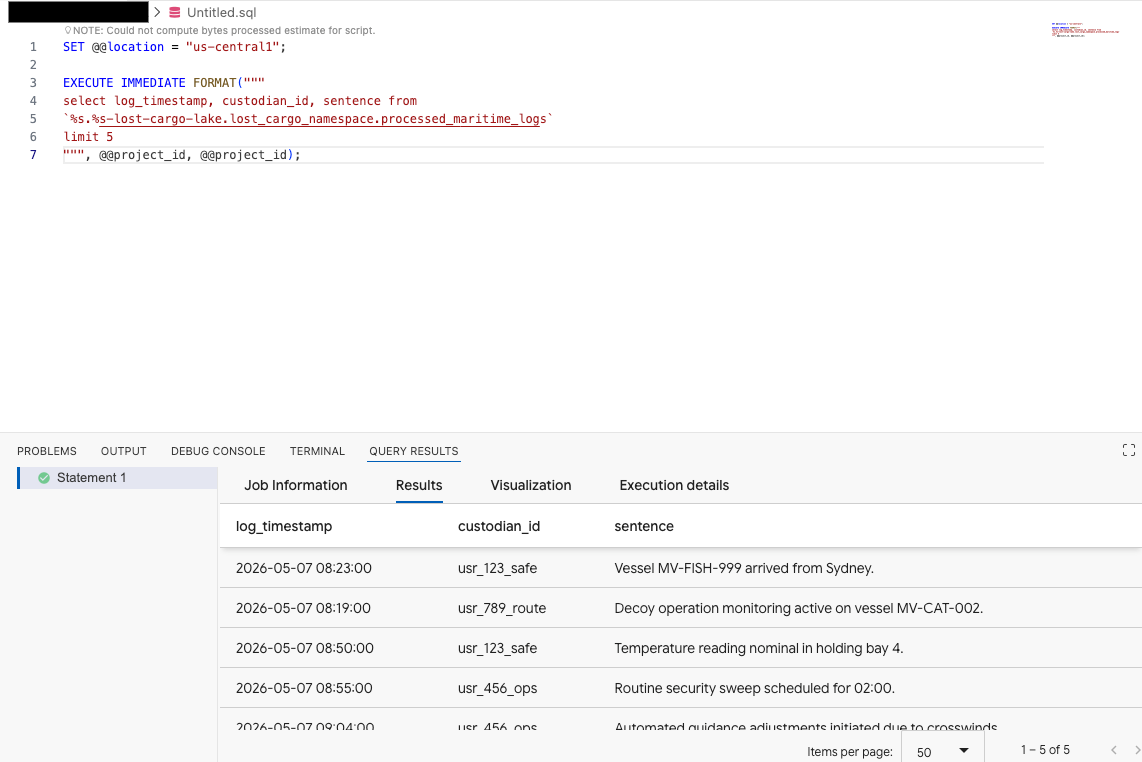
Esto demuestra que se puede acceder correctamente a la tabla de Iceberg registrada en el catálogo desde BigQuery.
Extrae la pista de destino
Ahora que tenemos los registros procesados, busquemos los registros que incluyen un destino objetivo. Desde allí, podemos buscar los registros que incluyen una mención de nuestra ciudad de origen.
En el editor de consultas, ejecuta la siguiente consulta, reemplaza <YOUR_REGION> por tu región y <ORIGIN_CITY> por la ciudad de origen que descubriste antes.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
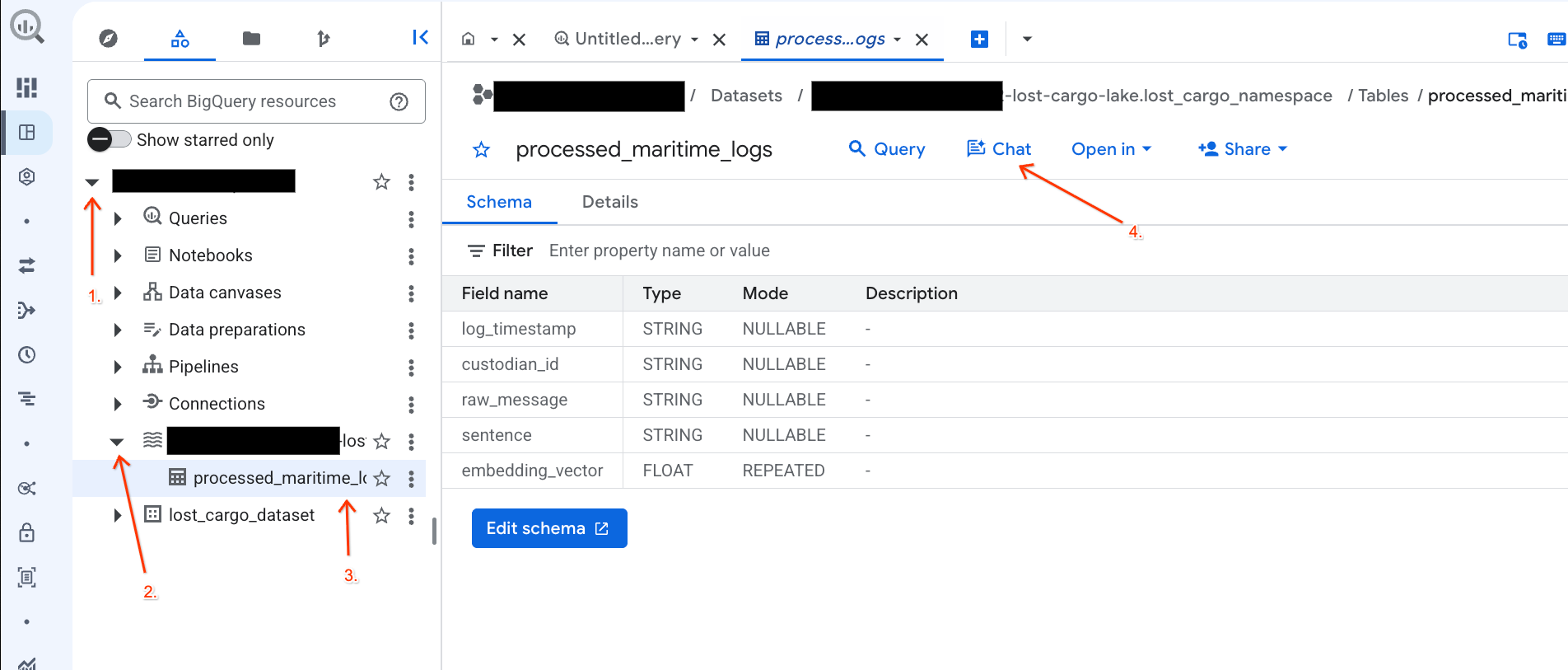
Chatea con tus datos en la consola de BigQuery con Conversational Analytics
En lugar de escribir consultas en SQL complejas para explorar tus datos, puedes usar Conversational Analytics para chatear con tus tablas en lenguaje natural.
- Ve a la consola de BigQuery.
- En el panel Explorador de la izquierda, expande tu proyecto y el conjunto de datos
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logspara abrir su pestaña de detalles. - Junto a Consulta, haz clic en Chat.
- En el panel de chat, escribe la siguiente pregunta y presiona Intro en el teclado para enviarla:
Based on this table, what color is the shipping container MV-CAT-001?
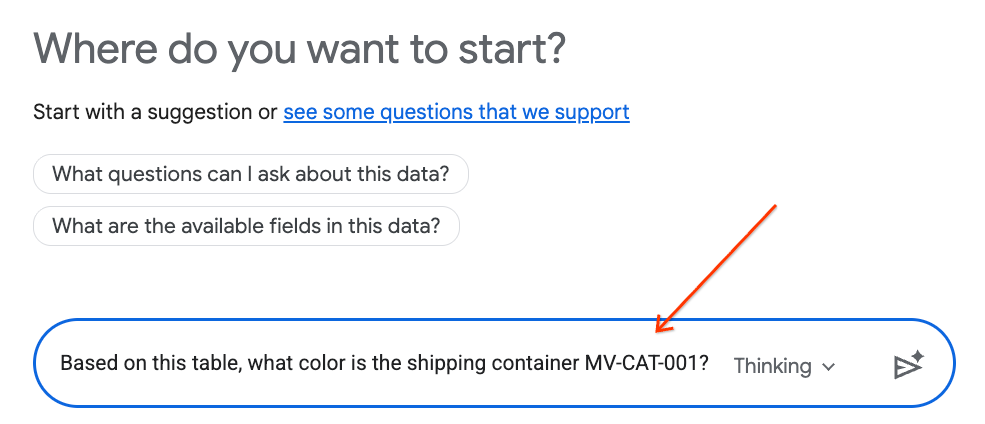
- Conversational Analytics (con tecnología de Gemini) analizará los datos de la tabla activa y responderá con el color.
5. Cómo ver el catálogo centralizado de Lakehouse
Para integrar motores de procesamiento de código abierto (como Apache Spark) de forma segura y sin problemas con motores de datos empresariales (como BigQuery), tu secuencia de comandos de configuración configuró un catálogo de REST de Iceberg de Lakehouse.
El catálogo REST de Apache Iceberg sirve como la "única fuente de verdad" sin servidor para los metadatos de la tabla, ya que administra los esquemas y las tablas de partición de forma dinámica mientras almacena los archivos de datos físicos de Parquet en Cloud Storage.
Examinemos este catálogo directamente en la consola de Google Cloud:
- Abre la consola de Lakehouse.
- En la pestaña Catálogos, busca tu catálogo de REST de Iceberg activo y haz clic en él:
-lost-cargo-lake
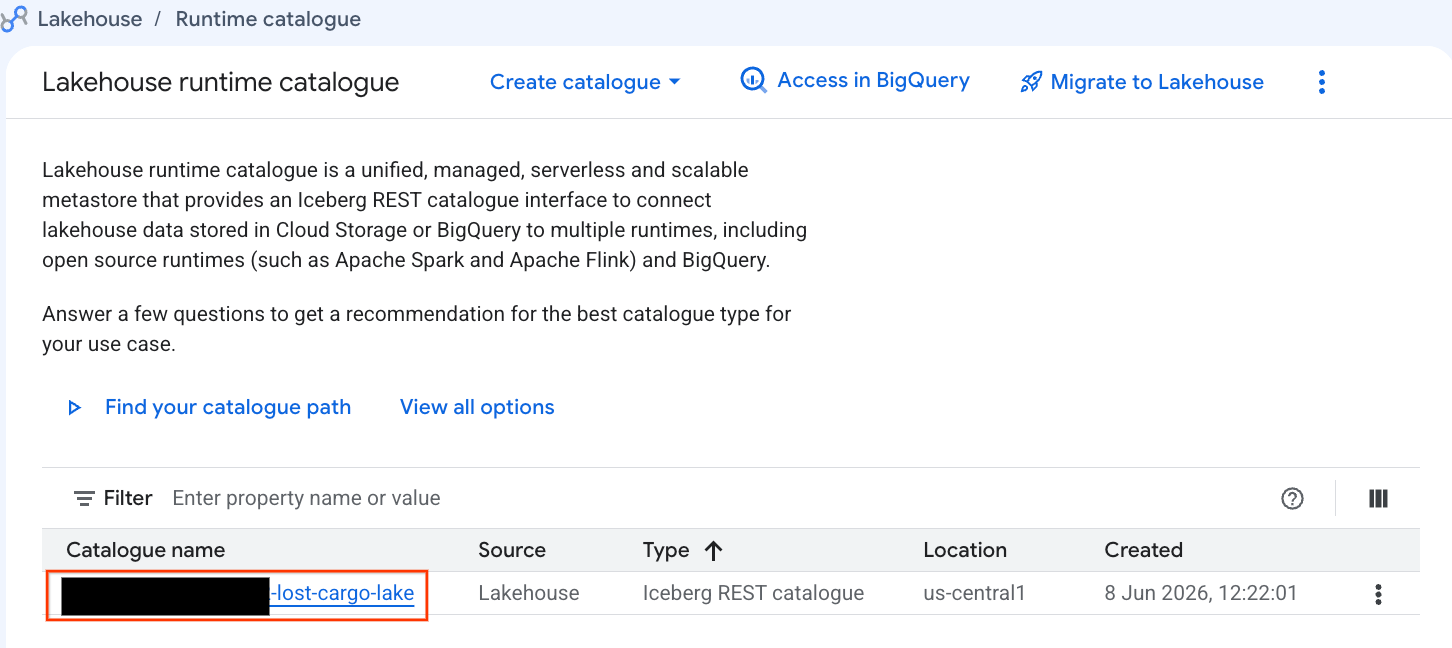
- En la vista de detalles del catálogo, en Namespaces, deberías ver
lost_cargo_namespace. Haz clic en ella.
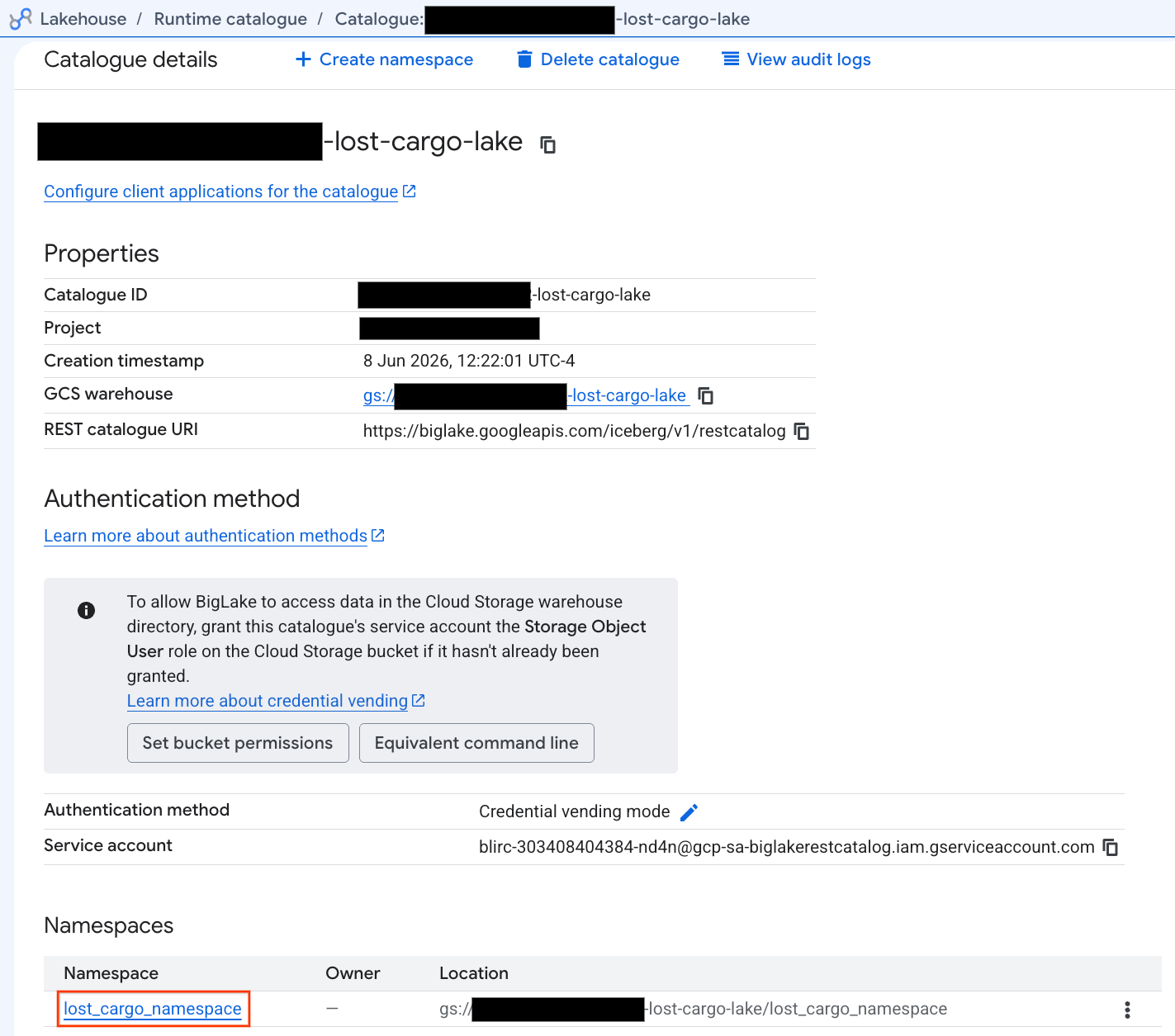
- Tu nueva tabla de Apache Iceberg, generada por PySpark, se registró automáticamente en este espacio de nombres de metastore y se pudo consultar de inmediato en BigQuery.
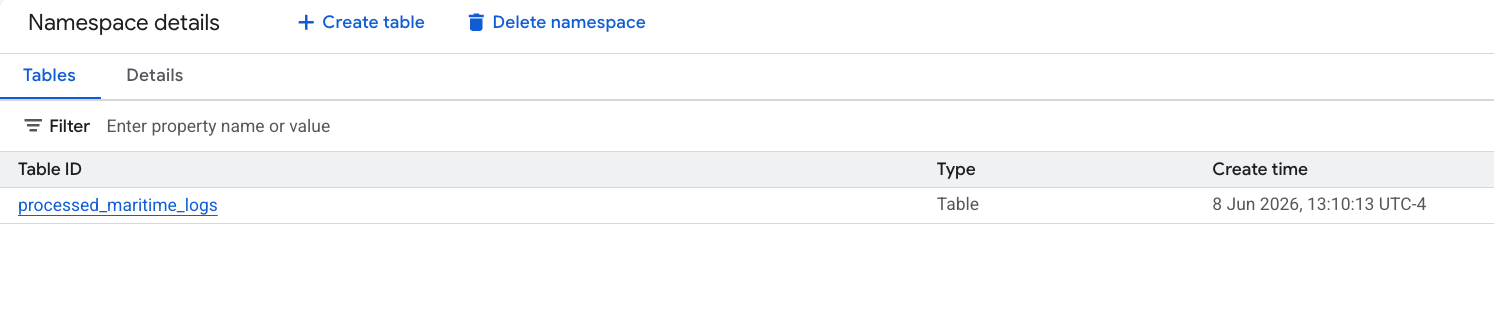
6. Genera estadísticas sobre la tabla de manifiestos de envío
Volvamos a analizar la tabla shipping_manifests para comprender su estructura y contenido con Estadísticas de datos de Knowledge Catalog. Enriquecer los metadatos permite que otros exploradores comprendan mejor la tabla para futuros análisis.
Genera estadísticas de tablas en BigQuery Studio
- En la consola de Google Cloud, navega a BigQuery Studio.
- En el panel Explorador, expande tu proyecto, expande el conjunto de datos
lost_cargo_datasety haz clic en la tablashipping_manifests. - En el panel de detalles de la derecha, haz clic en la pestaña Estadísticas.
- Usa el menú desplegable para seleccionar Generar y publicar.
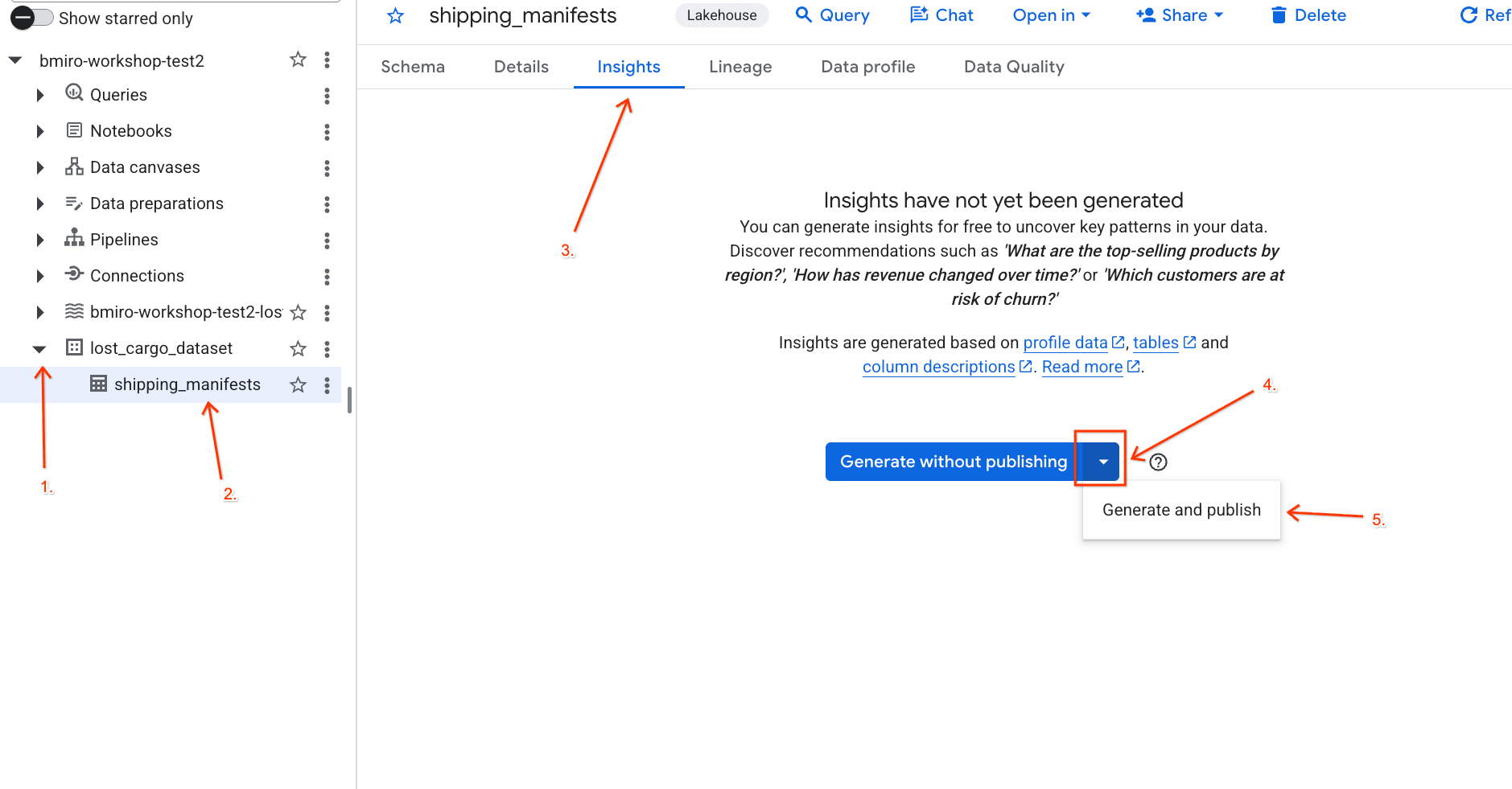
- Espera unos 3 minutos para que se complete la generación de estadísticas. Gemini analizará los metadatos de la tabla y generará preguntas en lenguaje natural y las consultas en SQL correspondientes.
- Cuando se complete el proceso, verás una Descripción de la tabla con una explicación en lenguaje natural de la tabla.
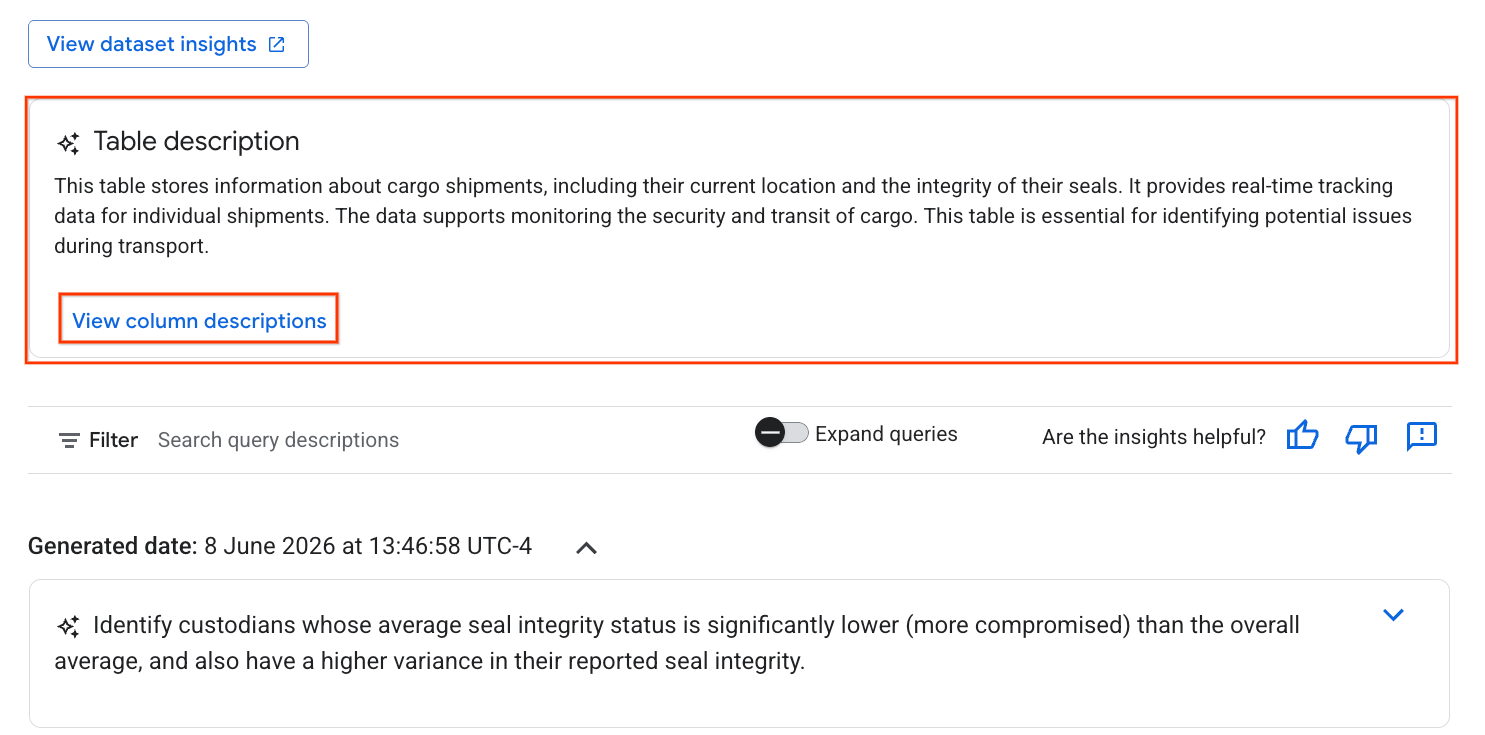
- Haz clic en Ver descripciones de las columnas para ver información sobre las columnas individuales.
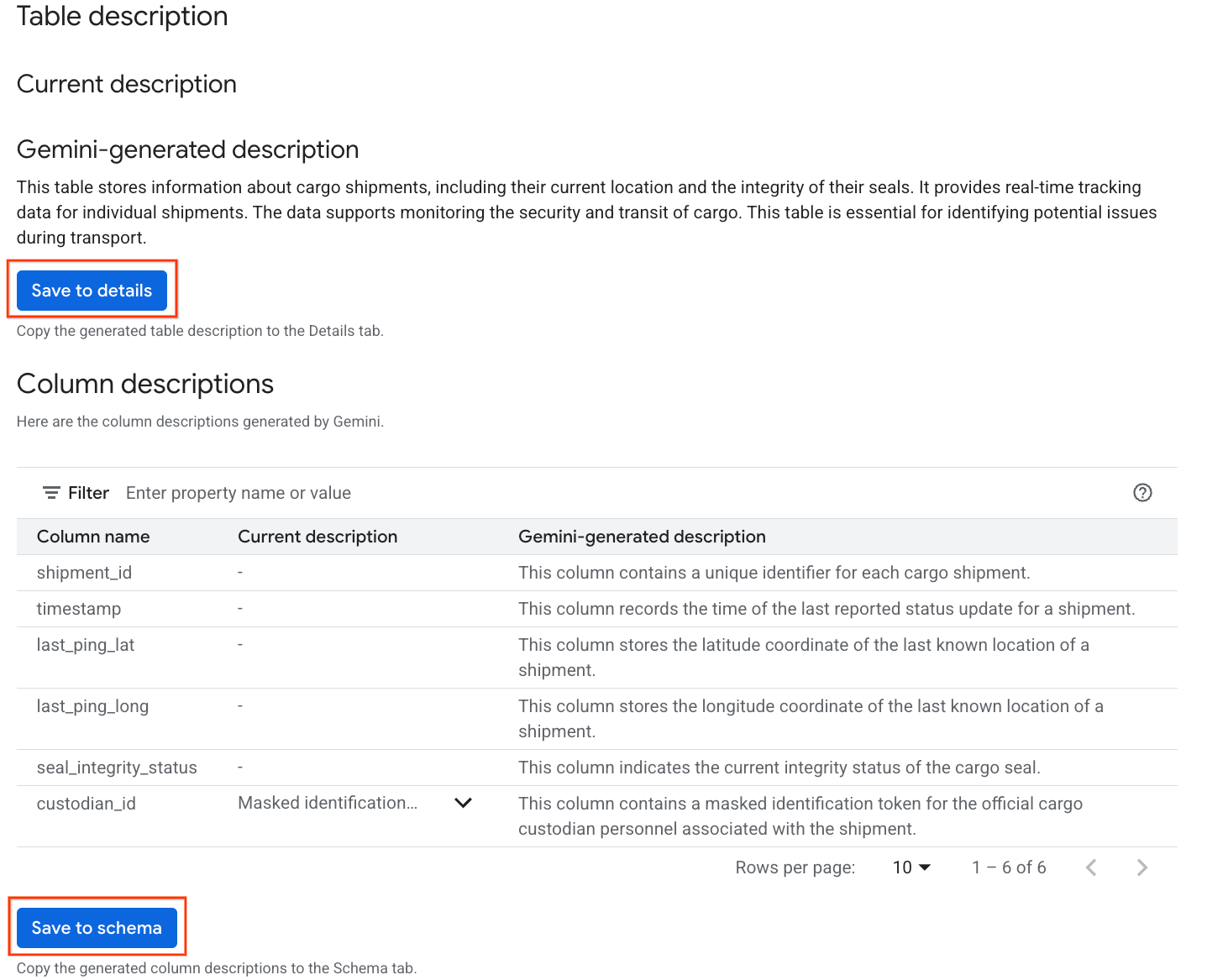
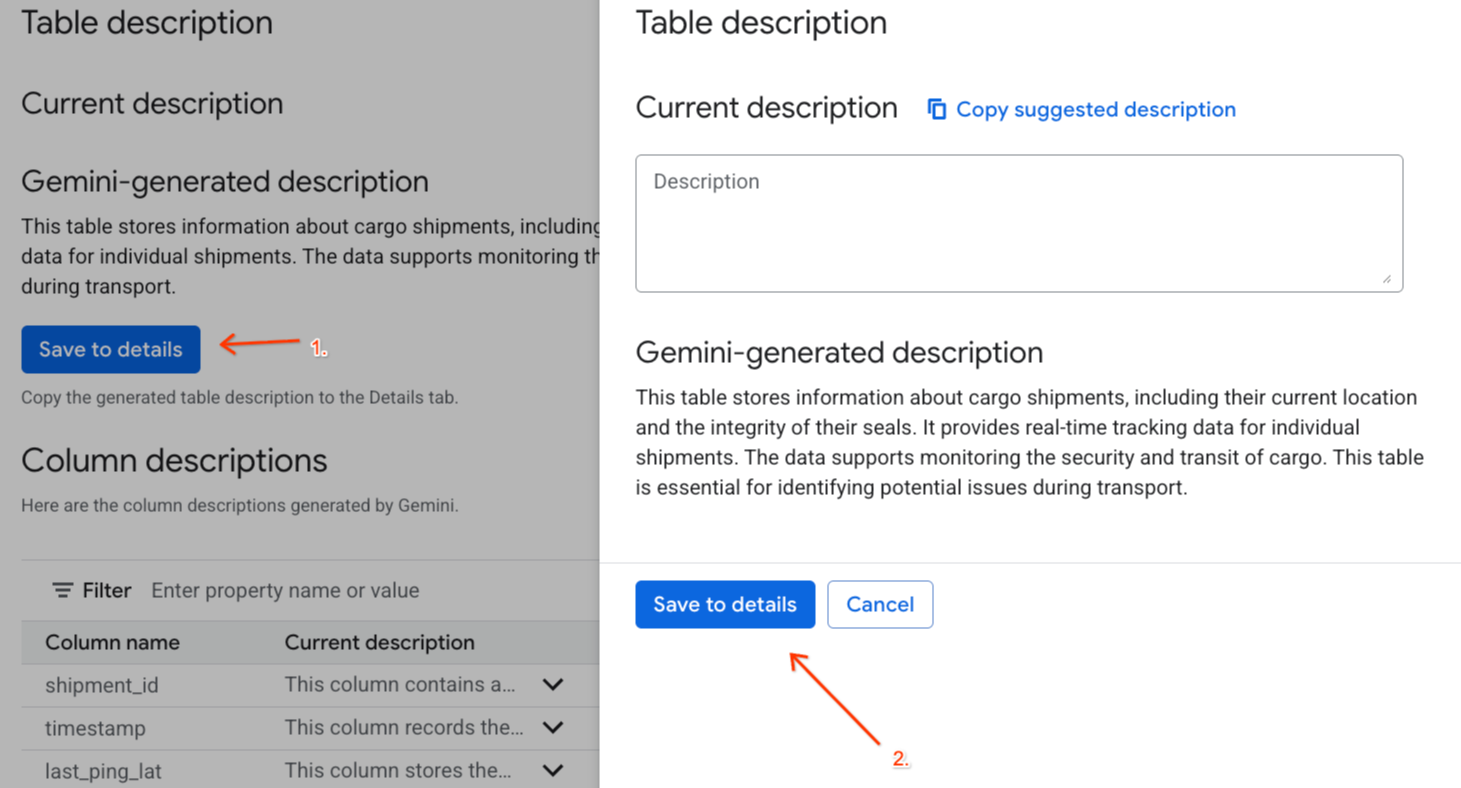
- Haz clic en Guardar en detalles en
Gemini generated descriptiony, luego, en Guardar en detalles en la ventana emergente.
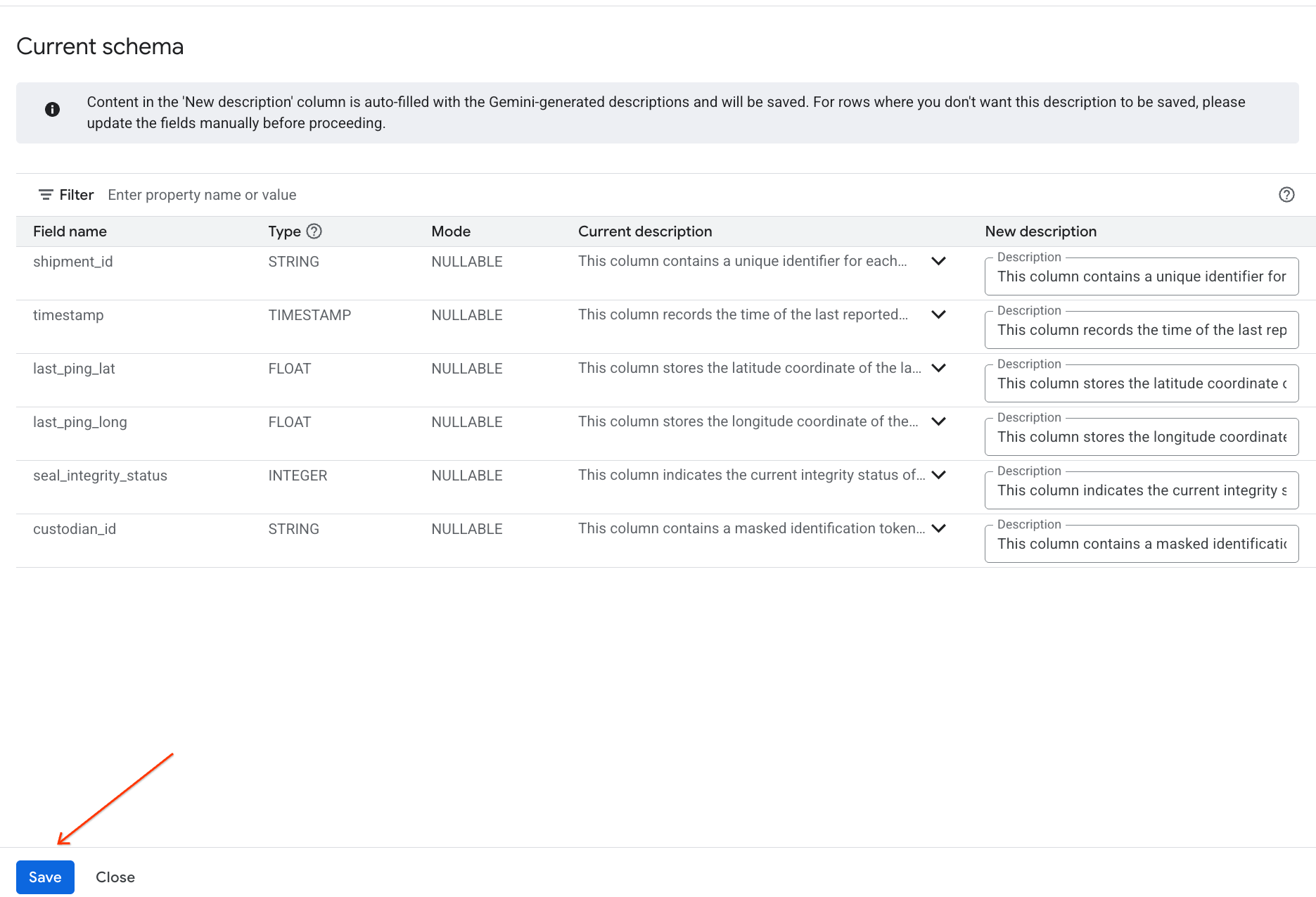
- De manera similar, haz clic en Guardar en el esquema para agregar las descripciones de las columnas a los metadatos de la tabla.
Revisa las estadísticas generadas
También verás una lista de preguntas sugeridas. Puedes hacer clic en cualquier pregunta para ver la consulta en SQL generada y ejecutarla para explorar los datos. Por ejemplo, es posible que veas preguntas como las siguientes:
- "¿Cuál es la cantidad total de envíos?"
- "Enumera los IDs de custodio únicos".
Ejecutar estas consultas te ayuda a comprender los datos.
7. Implementa el enmascaramiento y la administración de datos
Para garantizar que no se filtren las cuentas y los nombres de usuario de investigación activos durante esta investigación de carga en curso, debes aplicar protocolos de seguridad estándares. Crearás una taxonomía de etiquetas de política de seguridad y configurarás el enmascaramiento de datos de Knowledge Catalog en la columna sensible custodian_id para verificar la privacidad de los datos.
De forma predeterminada, BigQuery deniega el acceso a las columnas protegidas por etiquetas de política. Para consultar la tabla y verificar las máscaras de datos activas, tu cuenta de usuario debe tener el rol de lector enmascarado de la política de datos de BigQuery.
Este rol se vinculó automáticamente a tu cuenta de usuario activa durante la ejecución inicial de setup_lab1.sh.
Crea la taxonomía y la etiqueta de política
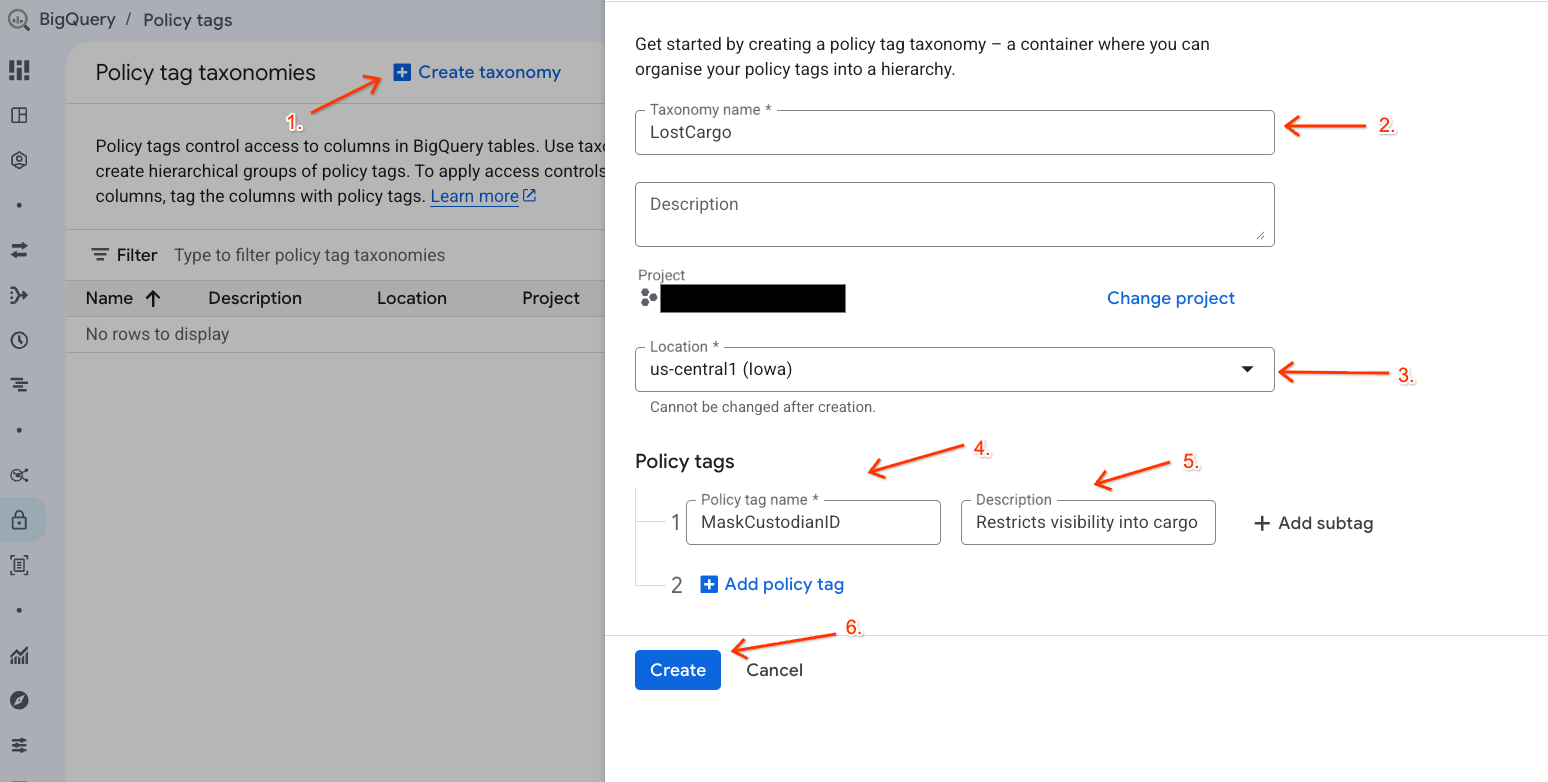
Crea una taxonomía de datos y una etiqueta de política asociada para administrar el acceso a tus datos.
- Ve a la página Taxonomías de etiquetas de política.
- Haz clic en + Crear taxonomía.
- Configura los parámetros:
- Nombre de la taxonomía: Ingresa
lost-cargo-y reemplazalost-cargo-por el ID del proyecto. - Región: Selecciona tu región.
- En el Nombre de la etiqueta de política, ingresa
MaskCustodianID. - Para la Descripción de la etiqueta de política, ingresa
Restricts visibility into cargo custodian usernames.
- Nombre de la taxonomía: Ingresa
- Haz clic en Crear para registrar tu nueva taxonomía y etiqueta de política.
Crea la política de enmascaramiento de datos
A continuación, configura una política de datos para definir cómo se enmascaran los datos con la etiqueta de clasificación MaskCustodianID. Usarás la regla de enmascaramiento Siempre nulo (reemplaza los valores coincidentes por devoluciones vacías o nulas para todos los actores no privilegiados).
- En la página Taxonomías de etiquetas de política, haz clic en la taxonomía que acabas de crear en la lista de taxonomías.
- En la lista de jerarquía, haz clic en la etiqueta
MaskCustodianIDpara seleccionarla y, luego, elige Administrar políticas de datos.
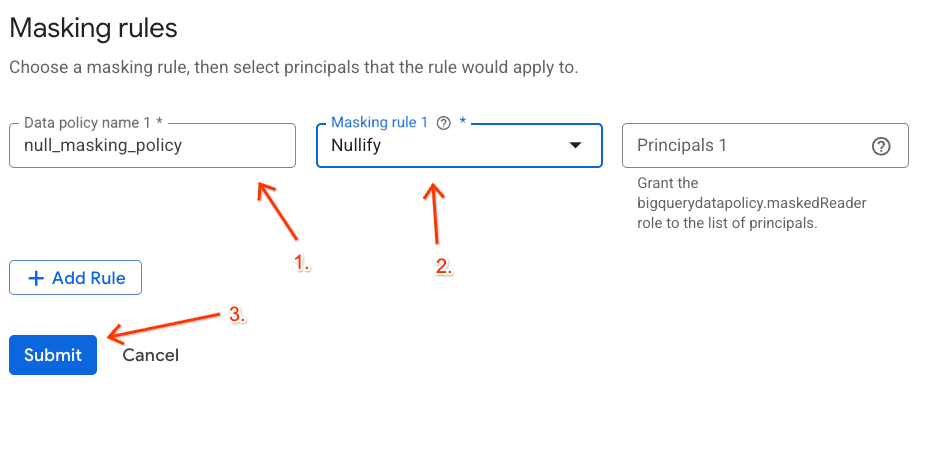
- En el panel de la derecha, haz clic en el botón + Agregar regla.
- Configura los detalles de la política en el panel que aparece:
- Nombre de la política de datos: Ingresa
null_masking_policy(no dejes que se genere automáticamente, ya que haremos referencia a él por su nombre en los próximos pasos). - Regla de enmascaramiento: Selecciona
Nullifyen el menú desplegable.
- Nombre de la política de datos: Ingresa
- Haz clic en Enviar.
Asigna la etiqueta de política a tu columna de BigQuery
Con la etiqueta de política y su regla de enmascaramiento de datos activas, asigna la etiqueta de clasificación directamente a la columna custodian_id en la tabla del manifiesto de envío de tu socio de BigQuery.
- Navega a la consola de BigQuery.
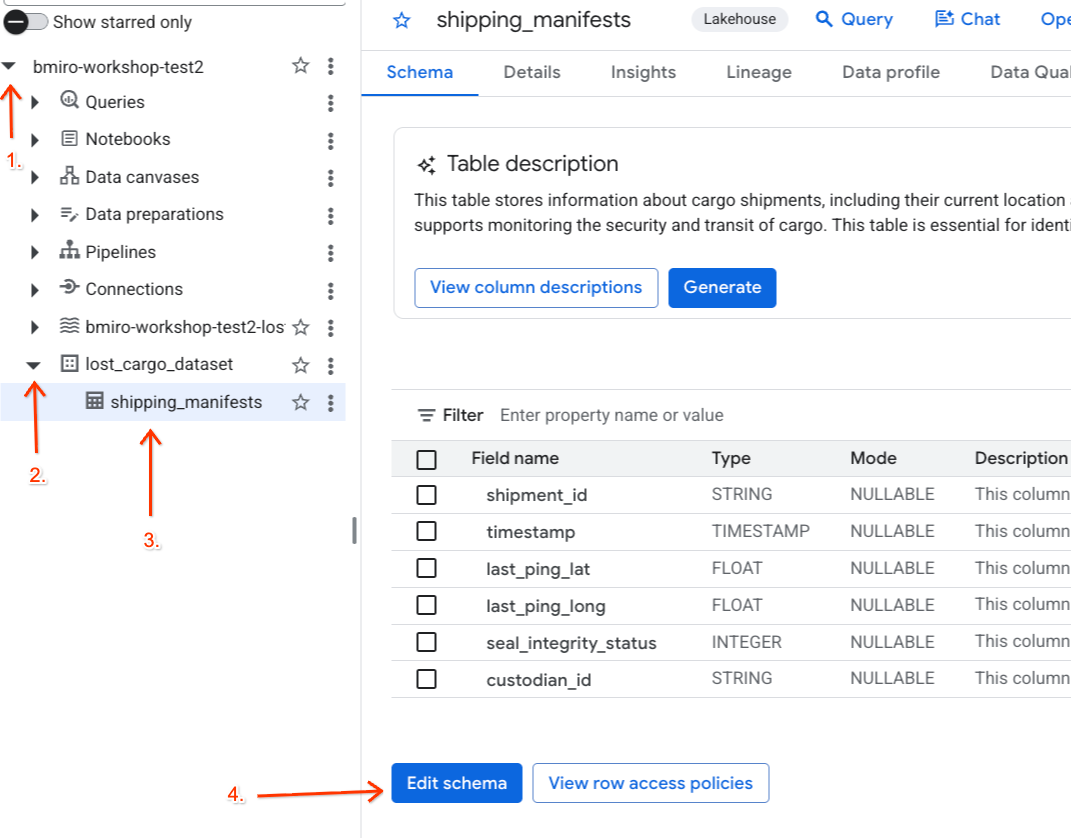
- En el panel Explorador de la izquierda, expande tu proyecto activo, expande el conjunto de datos
lost_cargo_datasety haz clic en la tablashipping_manifestspara abrir su vista detallada. - Haz clic en Editar esquema.
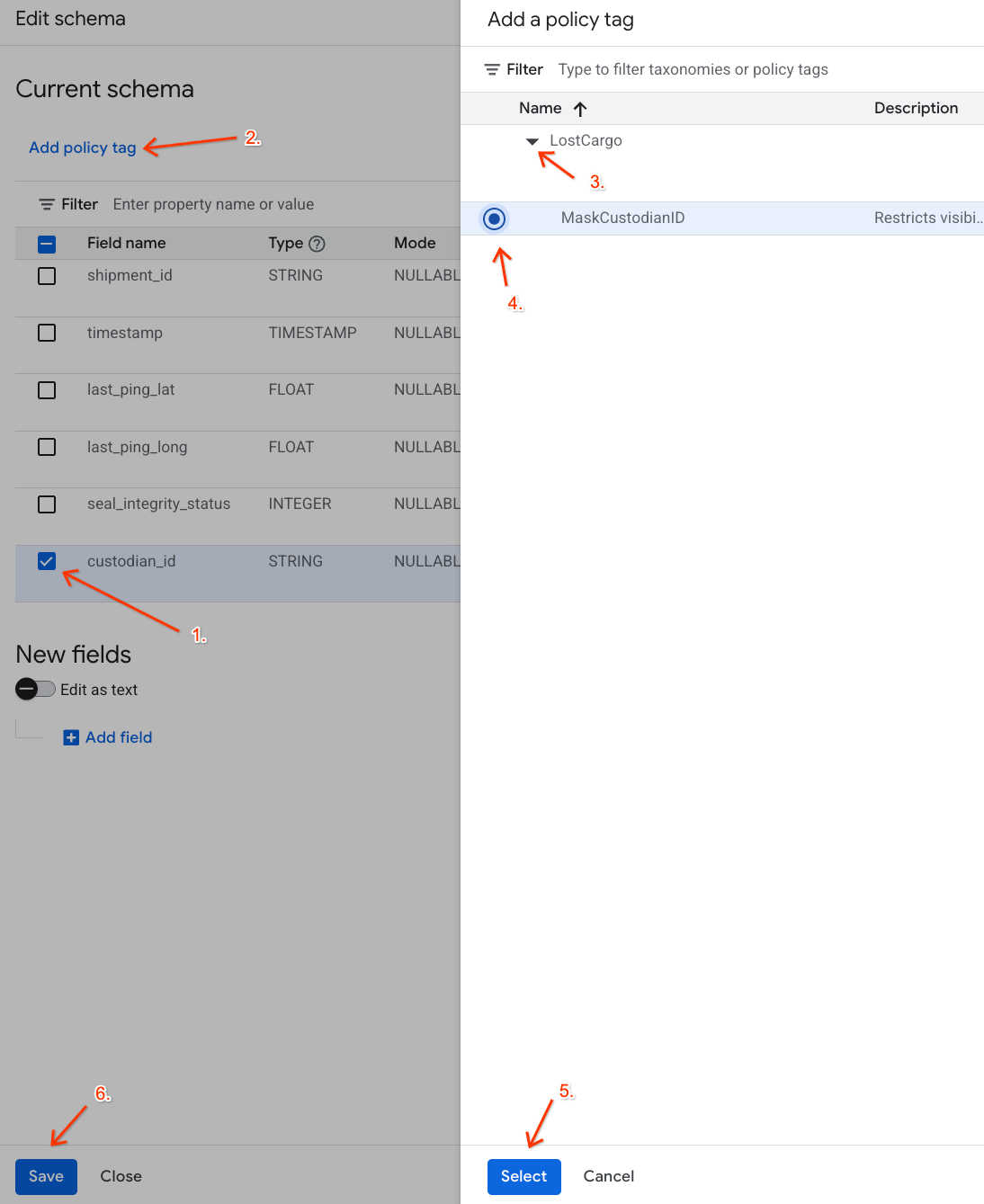
- En la lista de columnas, marca la casilla junto a
custodian_id. - Haz clic en el botón Agregar etiqueta de política en la barra de herramientas superior del editor de esquemas.
- En el panel Agregar una etiqueta de política, haz lo siguiente:
- Ubica y expande tu taxonomía
LostCargo. - Selecciona la burbuja junto a
MaskCustodianID. - Haz clic en Seleccionar.
- Ubica y expande tu taxonomía
- Verifica que la etiqueta
MaskCustodianIDahora sea visible en la columna Etiqueta de política de la fila que representacustodian_id. - Haz clic en Guardar.
Verifica las restricciones de la política
Ahora que tienes el rol de Lector enmascarado a nivel del proyecto, puedes consultar la tabla para verificar que la política de enmascaramiento esté activa.
Regresa al Kit del agente de datos y ejecuta la siguiente consulta:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
Debería ver un resultado similar al siguiente:
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
¡Listo! Aunque puedes ver los registros shipment_id, el campo sensible custodian_id devuelve máscaras null seguras para evitar filtraciones.
8. Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos creados durante este codelab, ejecuta estos comandos en tu terminal de Cloud Shell para descartar tus conjuntos de datos y buckets:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. Felicitaciones
¡Felicitaciones! Completaste con éxito el primer módulo crucial de la investigación de Carga perdida. Estableciste una zona de búsqueda gobernada con catálogos de REST de Lakehouse Iceberg, normalización de registros de PySpark y enmascaramiento de datos detallado.
Qué aprendiste
- Instalar, configurar y establecer la extensión Data Agent Kit en el espacio de trabajo de tu IDE
- Establecer un catálogo de REST de Iceberg de Lakehouse sin servidores que utilice credenciales vendidas y espacios de nombres jerárquicos
- Ingiere feeds regionales multiformato y crea tablas externas de BigQuery en buckets de Cloud Storage.
- Lanzamos trabajos de Apache Spark sin servidores para analizar, normalizar, segmentar y volver a escribir los registros no estructurados del transpondedor en BigQuery como tablas de catálogo de Iceberg registradas.
- Crear taxonomías de seguridad y asignar políticas de enmascaramiento de datos de Knowledge Catalog para evitar filtraciones de identidad en índices de registros sensibles
- Generar y analizar estadísticas de metadatos de tablas con estadísticas de datos de BigQuery para acelerar la exploración de datos.
Verificación de pistas recopiladas
Verifica que hayas registrado las siguientes pistas definitivas necesarias para pasar a la siguiente fase del lab:
- ID de envío perdido:
MV-CAT-001(última ubicación de ping: Londres) - Destino objetivo planificado:
New York(y alias verdadero del transpondedor:MV-DOG-002) - Color del contenedor:
Crimson RED - Etiqueta de acceso de administración:
MaskCustodianID
¿Todo listo para la próxima fase?
Ahora que las rutas de salida y destino del transpondedor son seguras, la investigación avanza. Ve directamente al lab 2 para examinar cámaras de seguridad con modelos de Gemini multimodales, identificar visualmente la embarcación y realizar búsquedas de vectores en AlloyDB para verificar anomalías de manipulación.
➡️ Continúa con el paso dos: Análisis de datos y estadísticas multimodales