
۱. مقدمه
در این آزمایشگاه، شما نقش یک محقق ارشد داده برای یک شرکت لجستیک جهانی را بر عهده خواهید گرفت. یک کانتینر باری با ارزش بالا که حامل مجسمههای کلکسیونی ارزشمند اندروید بوده، مفقود شده است! برای یافتن آخرین موقعیت شناخته شده آن و ردیابی مسیر آن، باید فهرستهای حمل و نقل تکه تکه شده از شرکای لجستیک منطقهای و فایلهای گزارش ترانسپوندر بدون ساختار را جمعآوری کنید. برای انجام این کار، یک Google Cloud Open Data Lakehouse مدرن را پیکربندی خواهید کرد.

کاری که انجام خواهید داد
- افزونه Google Cloud Data Agent Kit را در ویرایشگر Cloud Shell پیکربندی کنید.
- یک مخزن ذخیرهسازی ابری ایجاد کنید و یک کاتالوگ REST و فضای نام Lakehouse Apache Iceberg تهیه کنید.
- یک جدول خارجی BigLake را به مانیفستهای خام شریک JSON در Cloud Storage نگاشت کنید تا سرنخ حرکت کشتی را کشف کنید.
- بارگذاری و پردازش لاگهای متنی بدون ساختار فرستنده با استفاده از سرویس مدیریتشده برای آپاچی اسپارک بدون سرور. انجام نرمالسازیهای regex و استخراج سرنخ پویا برای هدف قرار دادن مقصد گمشدهی بار داده.
- معیارهای گزارش تجزیهشده را به عنوان یک جدول آپاچی آیسبرگ از طریق کاتالوگ REST بنویسید.
- با استفاده از Conversational Analytics با یک عامل هوش مصنوعی در مورد دادههای آپاچی آیسبرگ خود چت کنید تا سرنخهای پنهان در مورد محموله گمشده خود را کشف کنید.
- از بینشهای خودکار داده با کاتالوگ دانش برای تولید فراداده در مورد دادههای خود استفاده کنید.
- با ایجاد یک طبقهبندی امنیتی و استفاده از کاتالوگ دانش برای اعمال کنترل دسترسی دقیق از طریق پنهان کردن شناسههای حساس متولی، محافظهای ورود اطلاعات ایجاد کنید.
آنچه نیاز دارید
- یک مرورگر وب مانند کروم .
- یک پروژه گوگل کلود با قابلیت پرداخت.
- آشنایی با کوئریهای SQL و دستورات ترمینال.
هزینه و مدت زمان مورد انتظار
- زمان لازم برای تکمیل : حدود ۴۵ دقیقه
- هزینه تخمینی : کمتر از ۵.۰۰ دلار آمریکا
۲. قبل از شروع
یک پروژه Google Cloud ایجاد یا انتخاب کنید
- در کنسول گوگل کلود ، یک پروژه گوگل کلود انتخاب یا ایجاد کنید .
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه تأیید کنید که صورتحساب در یک پروژه فعال است .
پیکربندی محیط
شما بیشتر دستورات خود را از ترمینال یکپارچه در ویرایشگر Cloud Shell اجرا خواهید کرد، یک محیط توسعه مبتنی بر ابر که از قبل با ابزارهای توسعهدهنده و SDK استاندارد Google Cloud بارگذاری شده است.
- ویرایشگر Cloud Shell را در یک برگه جدید باز کنید.
- برای کلون کردن مخزن، دستور زیر را در ترمینال اجرا کنید:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - شناسه پروژه خود را تنظیم کنید. همچنین میتوانید با فشردن
Ctrl+Shift+Vدر ویندوز/لینوکس یاCmd+Vدر macOS این کد را در ترمینال پیست کنید:export PROJECT_ID="<YOUR_PROJECT_ID>" - حالا آن را در محیط خود پیکربندی کنید.
gcloud config set project $PROJECT_ID - یک منطقه را انتخاب کنید.
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - فعال کردن API های مورد نیاز
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
نصب افزونه
اکنون افزونه Google Data Agent Kit را پیکربندی خواهید کرد، ابزاری برای تعامل مستقیم با ابزارهای داده Google Cloud در IDE شما.
- در نوار فعالیت سمت چپ ویرایشگر، روی آیکون افزونهها کلیک کنید (یا
Ctrl+Shift+Xرا در ویندوز/لینوکس یاCmd+Xرا در macOS فشار دهید). - در کادر جستجوی افزونهها، عبارت زیر را تایپ کنید:
Google Cloud Data Agent Kit - افزونهی رسمی را از نتایج انتخاب کنید و روی نصب کلیک کنید. در صورت درخواست، «بله، من به نویسندگان اعتماد دارم» را انتخاب کنید.
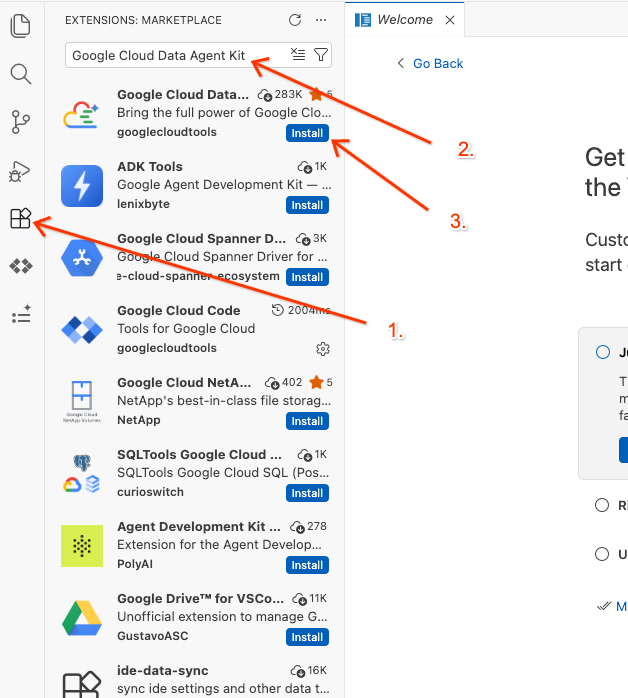
- پس از نصب موفقیتآمیز، باید آیکون Google Cloud Data Agent Kit را در نوار فعالیتها مشاهده کنید! روی آن کلیک کنید.
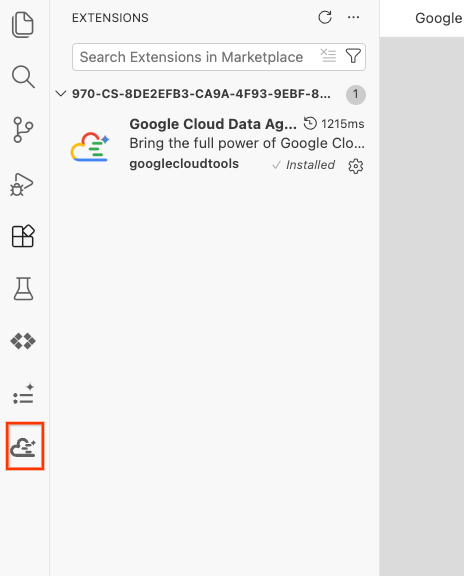
- روی ورود به فضای ابری کلیک کنید.
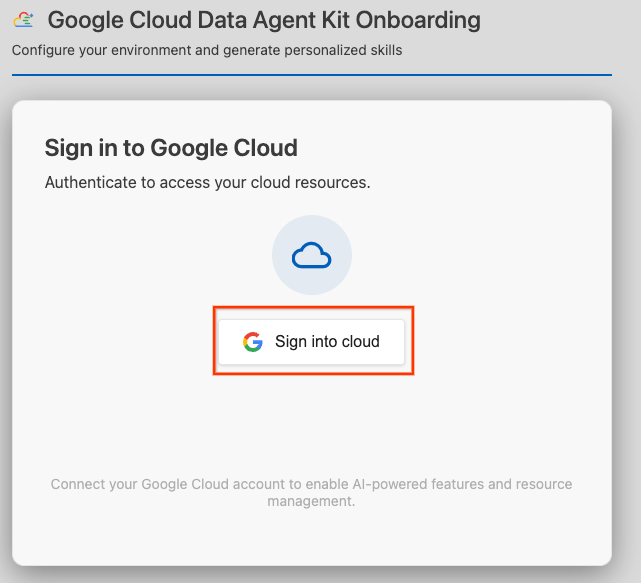
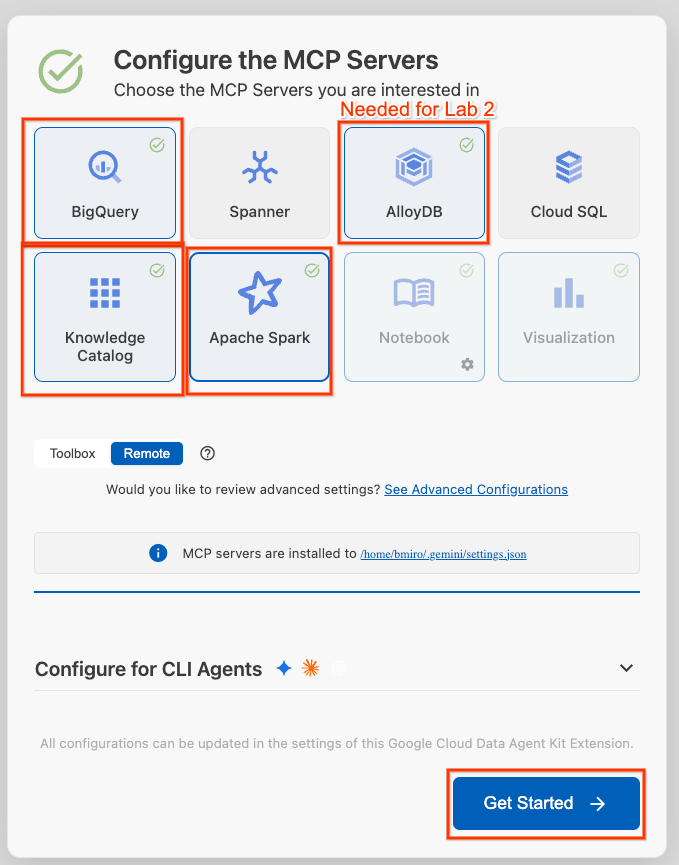
- روی پیکربندی سرورهای MCP کلیک کنید.
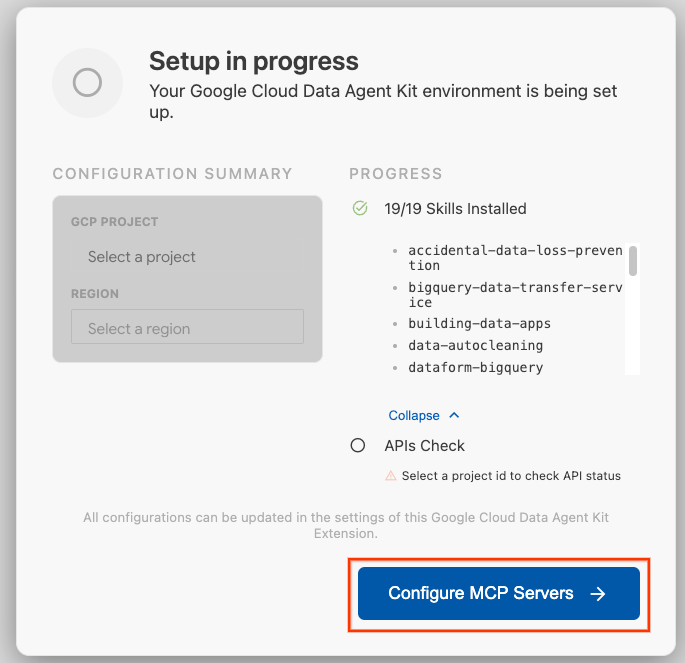
- BigQuery، Knowledge Catalog، Apache Spark و AlloyDB را انتخاب کنید. شما در تمرین ۲ از AlloyDB استفاده خواهید کرد. سپس روی Get Started کلیک کنید.
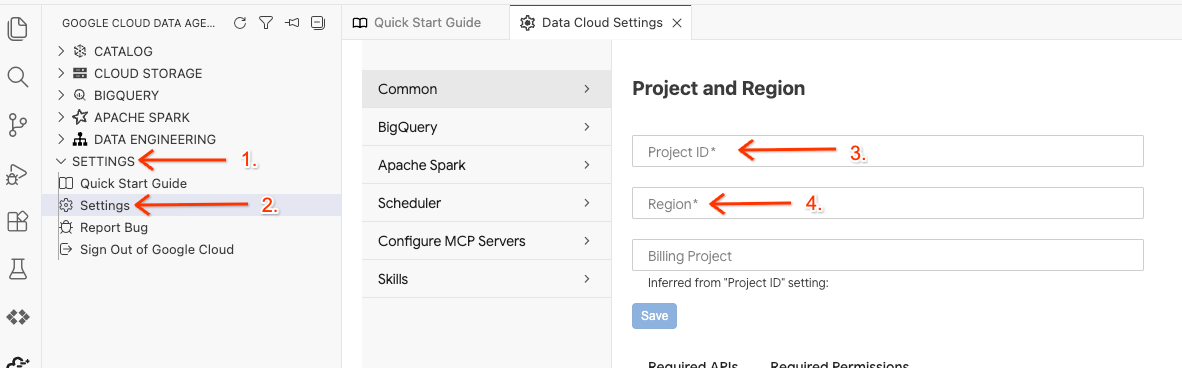
- روی انتخابگر شناسه پروژه در نوار وضعیت پایین کلیک کنید و پروژه فعال Google Cloud خود را انتخاب کنید.
- در Data Agent Kit، روی SETTINGS و سپس Settings کلیک کنید و در تب Common ، شناسه پروژه و منطقه مورد نظر برای اجرای آزمایشگاه خود، مانند us-central1 ، را انتخاب کنید.
- روی تنظیمات BigQuery کلیک کنید و منطقه را با منطقهای که قبلاً انتخاب کردهاید جایگزین کنید. روی ذخیره کلیک کنید.
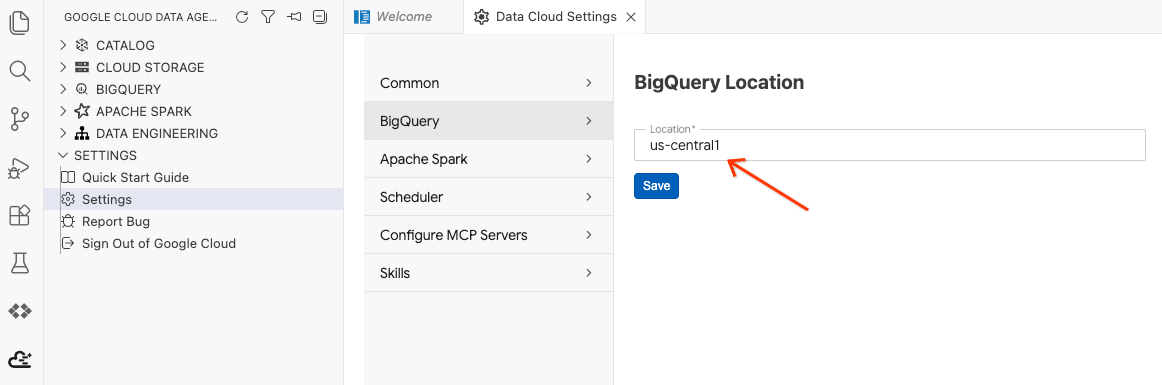
اکنون آماده استفاده از کیت عامل داده هستید!
اجرای اسکریپت تنظیمات محیط
در ترمینال، اسکریپت راهاندازی را اجرا کنید تا منابع پسزمینه لازم برای این آزمایشگاه ایجاد شود و مجوزهای IAM پیکربندی شوند:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
شما باید مجموعهای از مراحل خروجی را ببینید که نشان میدهد چه منابعی در حال تأمین هستند. ما این موارد را در طول تمرین پوشش خواهیم داد.
به محض اینکه پیام تکمیل را مشاهده کردید، آماده شروع هستید:
==================================================== Environment Setup Complete! ====================================================
حالا، بیایید جستجویمان را شروع کنیم!
۳. دریافت مانیفستهای حمل و نقل شریک
دادههای مانیفست حمل و نقل از کشتیهای همکار در قالب استاندارد JSON Lines (JSONL) در سطل شما ذخیره میشود: gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl .
قبل از انجام تجزیه و تحلیل عمیق، شما یک جدول BigLake مدیریتشده برای این دادههای بدون ساختار ایجاد خواهید کرد. این به شما امکان میدهد دادههای لجستیک شریک را بلافاصله با استفاده از SQL استاندارد و بدون هزینههای واردات تکراری بررسی کنید.
فضای کاری را در ویرایشگر باز کنید و کوئری را اجرا کنید
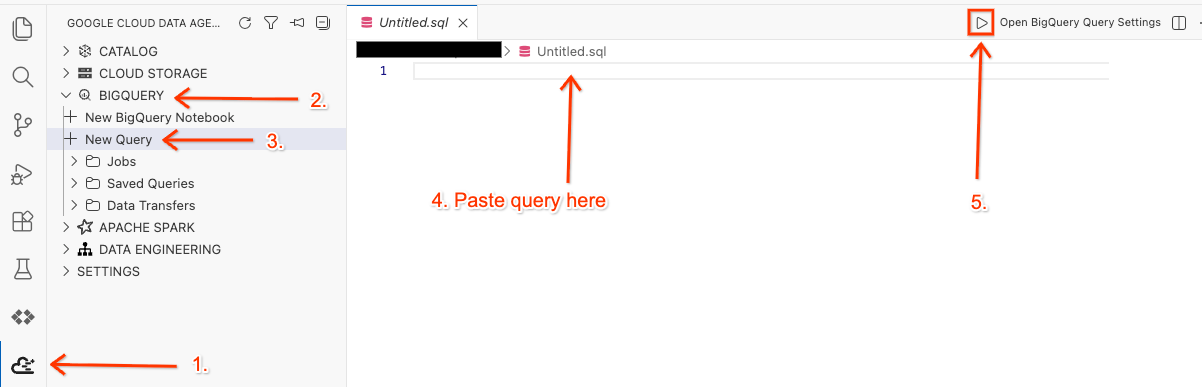
- در ویرایشگر Cloud Shell خود، روی آیکون افزونه Google Cloud Data Agent Kit در پنل کناری کلیک کنید.
- به BigQuery بروید و + New Query را انتخاب کنید.
- عبارت زیر را در پنجرهی جستجو کپی کنید.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- روی اجرا کلیک کنید.
- برای تأیید ایجاد جدول، یک پیام موفقیتآمیز در پنل نتایج پرسوجو که بهطور خودکار در پایین صفحه باز میشود، مشاهده خواهید کرد.
برای جداسازی فرستندههای آسیبپذیر، جدول خارجی را جستجو کنید
بیایید با یافتن خرابیهایی که هنگام تنظیم seal_integrity_status روی 0 رخ دادهاند، فرستندههای آسیبدیده را شناسایی کنیم. عبارت زیر را در پنجرهی جستجویی که قبلاً باز کردهاید، کپی و اجرا کنید:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
در پنل نتایج جستجو ، باید خروجی مشابه این را ببینید:
شناسه حمل و نقل | آخرین_پینگ_لات | آخرین_پینگ_طولانی | شناسه متولی |
MV-CAT-001 | ۵۱.۵۰۷۴ | -0.1278 | سایه usr_999 |
۴. پردازش لاگهای بدون ساختار با سرویس مدیریتشده برای آپاچی اسپارک
شما مکان شروع را از روی مانیفستهای ساختاریافته پیدا کردهاید، اما فرستندهی گمشده کاملاً خاموش شده است. آخرین پینگ فرستنده یک پیام رمزآلود و بدون ساختار را در یک فایل لاگ متنی خام در مسیر GCS gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt باقی گذاشته است.
برای پردازش و نگاشت این لاگ متنی، استخراج مهرهای زمانی، پنهانسازی هویتها و یافتن مسیر پاییندستی محموله، یک کار Apache Spark (PySpark) بدون سرور را به Managed Service for Apache Spark ارسال خواهید کرد.
سرویس مدیریتشده برای آپاچی اسپارک به شما امکان میدهد بارهای کاری اسپارک را بدون تأمین یا مدیریت یک کلاستر اجرا کنید. این سرویس منابع محاسباتی زیربنایی را مدیریت میکند، آنها را به صورت پویا خودکار مقیاسبندی میکند و شما فقط هزینه مدت زمان اجرا را پرداخت میکنید.
اسکریپت:
- متن خام، داخل پرانتز و بدون ساختار فرستنده را دریافت کنید.
- فیلترهای استخراج عبارات منظم PySpark SQL را برای جداسازی مهرهای زمانی، فرادادههای متولی و محتوای خام اعمال کنید.
- لاگهای نامرتب را به رکوردهای مرتب و در سطح جمله تقسیم کنید.
- مختصات مقصد پویا را از جایی که حرکت محموله گمشده به پایان رسیده است، استخراج کنید.
- اتصال و نوشتن مجدد دیتافریم لاگ پردازششده در کاتالوگ REST آپاچی Lakehouse شما به عنوان یک جدول تحلیلی جدید که مستقیماً در BigQuery قابل مشاهده است.
رفع مشکل اسکریپت تحلیل PySpark
گزارشهایی از دزدان دریایی پایتون در دریا وجود دارد که انواع مشکلات را ایجاد میکنند.
- برای باز کردن فایل
process_maritime_logsدر ویرایشگر Cloud Shell خود، دستور زیر را اجرا کنید.cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - کمی وقت بگذارید و کد را بخوانید و بفهمید چه کاری انجام میدهد.
- مطمئن شوید که هیچ چیز در کد مشکوک به نظر نمیرسد! اگر نیاز به حذف چیزی دارید، حتماً فایل را با استفاده از
Ctrl + S(ویندوز/لینوکس) یاCmd + S(مک) ذخیره کنید.
ارسال کار اسپارک بدون سرور
کار را با استفاده از gcloud SDK ارسال کنید. پیکربندی به طور خودکار کار PySpark را برای دسترسی به کاتالوگ Lakehouse پیکربندی میکند.
دستور زیر را در ترمینال ویرایشگر یکپارچه خود اجرا کنید.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
چند دقیقه صبر کنید تا محیط بدون سرور راهاندازی شود، اسکریپت شما آپلود شود و منطق پردازش اجرا شود.
زمانی که خروجی مشابه زیر را مشاهده کردید، جدول پردازششدهی شما به عنوان یک جدول مدیریتشده توسط آپاچی آیسبرگ در کاتالوگ لیکهاوس ذخیره میشود!
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
پیشنمایش گزارشهای پردازششده
در ویرایشگر کوئری افزونه Data Agent Kit، کوئری زیر را برای پیشنمایش دادهها کپی کنید:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
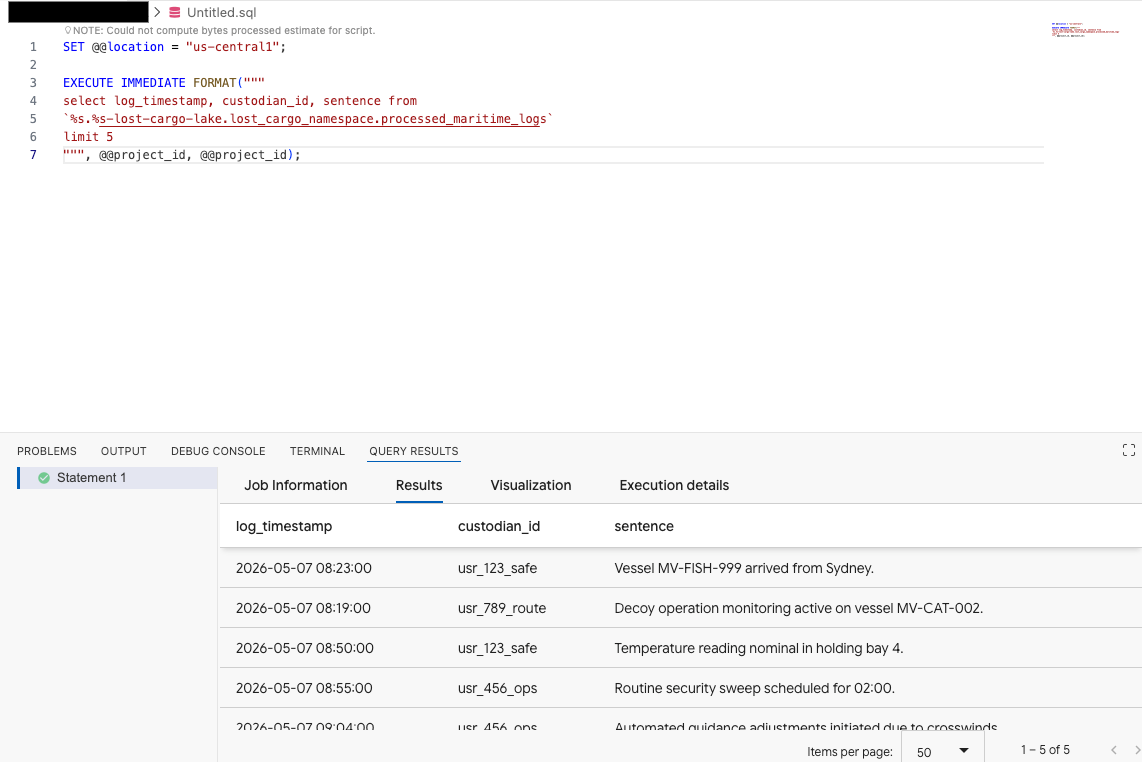
این نشان میدهد که جدول Iceberg ثبتشده در کاتالوگ با موفقیت از BigQuery قابل دسترسی است!
سرنخ مقصد را استخراج کنید
حالا که لاگهای پردازششده را داریم، بیایید لاگهایی را جستجو کنیم که شامل یک مقصد هدف هستند. از آنجا، میتوانیم لاگهایی را جستجو کنیم که شامل ذکر شهر مبدا ما هستند.
در ویرایشگر کوئری خود، کوئری زیر را اجرا کنید و <YOUR_REGION> را با منطقه خود و <ORIGIN_CITY> را با شهر مبدا که قبلاً کشف کردهاید، جایگزین کنید.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
با استفاده از Conversational Analytics در کنسول BigQuery با دادههای خود چت کنید
به جای نوشتن کوئریهای پیچیده SQL برای کاوش در دادههایتان، میتوانید از Conversational Analytics برای گفتگو با جداول خود با استفاده از زبان طبیعی استفاده کنید!
- به کنسول BigQuery بروید.
- در پنل Explorer در سمت چپ، پروژه و مجموعه داده خود را گسترش دهید
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logsکلیک کنید تا تب جزئیات آن باز شود. - در کنار «پرسوجو» ، روی «چت» کلیک کنید.
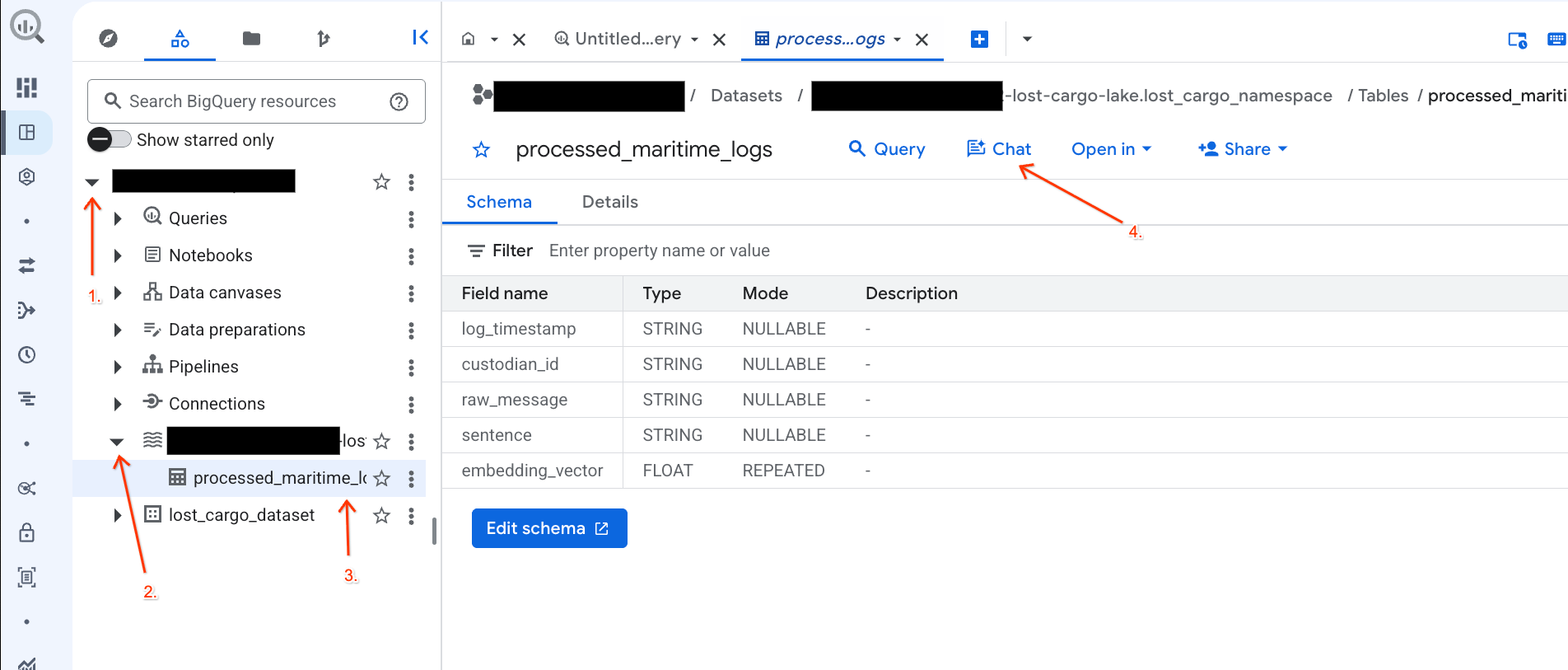
- در پنل چت، سوال زیر را تایپ کنید و برای ارسال، کلید Enter را روی صفحه کلید خود فشار دهید:
Based on this table, what color is the shipping container MV-CAT-001?
- ابزار Conversational Analytics (که توسط Gemini ارائه میشود) دادههای جدول فعال را تجزیه و تحلیل کرده و با رنگ مربوطه پاسخ میدهد.
۵. کاتالوگ مرکزی Lakehouse را مشاهده کنید
برای ادغام ایمن و یکپارچه موتورهای پردازش متنباز (مانند آپاچی اسپارک) با موتورهای داده سازمانی (مانند BigQuery)، اسکریپت راهاندازی شما یک Lakehouse Iceberg REST Catalog را پیکربندی کرد.
کاتالوگ REST آپاچی آیسبرگ به عنوان «منبع واحد حقیقت» بدون سرور برای متادیتای جداول عمل میکند، طرحوارهها را مدیریت میکند و جداول را به صورت پویا پارتیشنبندی میکند، در حالی که فایلهای داده فیزیکی پارکت را در فضای ذخیرهسازی ابری ذخیره میکند.
بیایید این کاتالوگ را مستقیماً در کنسول ابری گوگل بررسی کنیم:
- کنسول Lakehouse را باز کنید.
- در تب کاتالوگها ، کاتالوگ REST فعال Iceberg خود را پیدا کرده و روی آن کلیک کنید:
-lost-cargo-lake
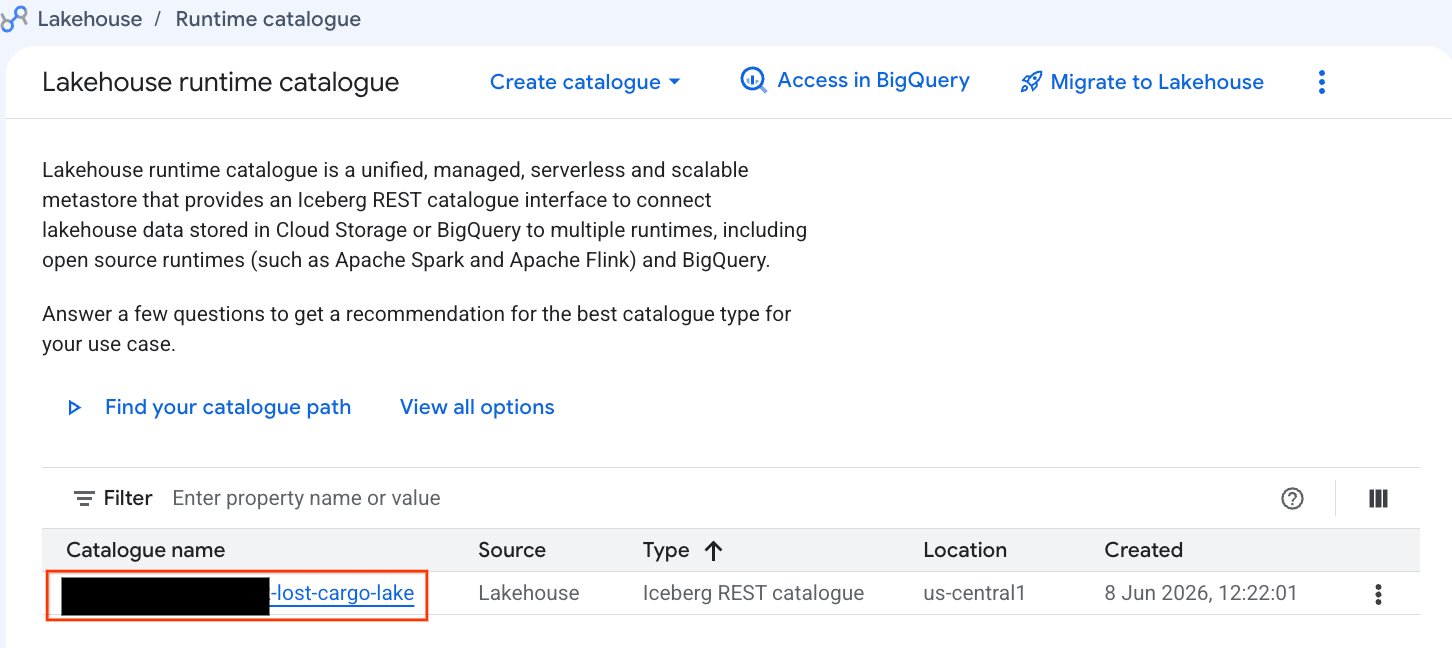
- در نمای جزئیات کاتالوگ، در قسمت Namespaces باید
lost_cargo_namespaceببینید. روی آن کلیک کنید.
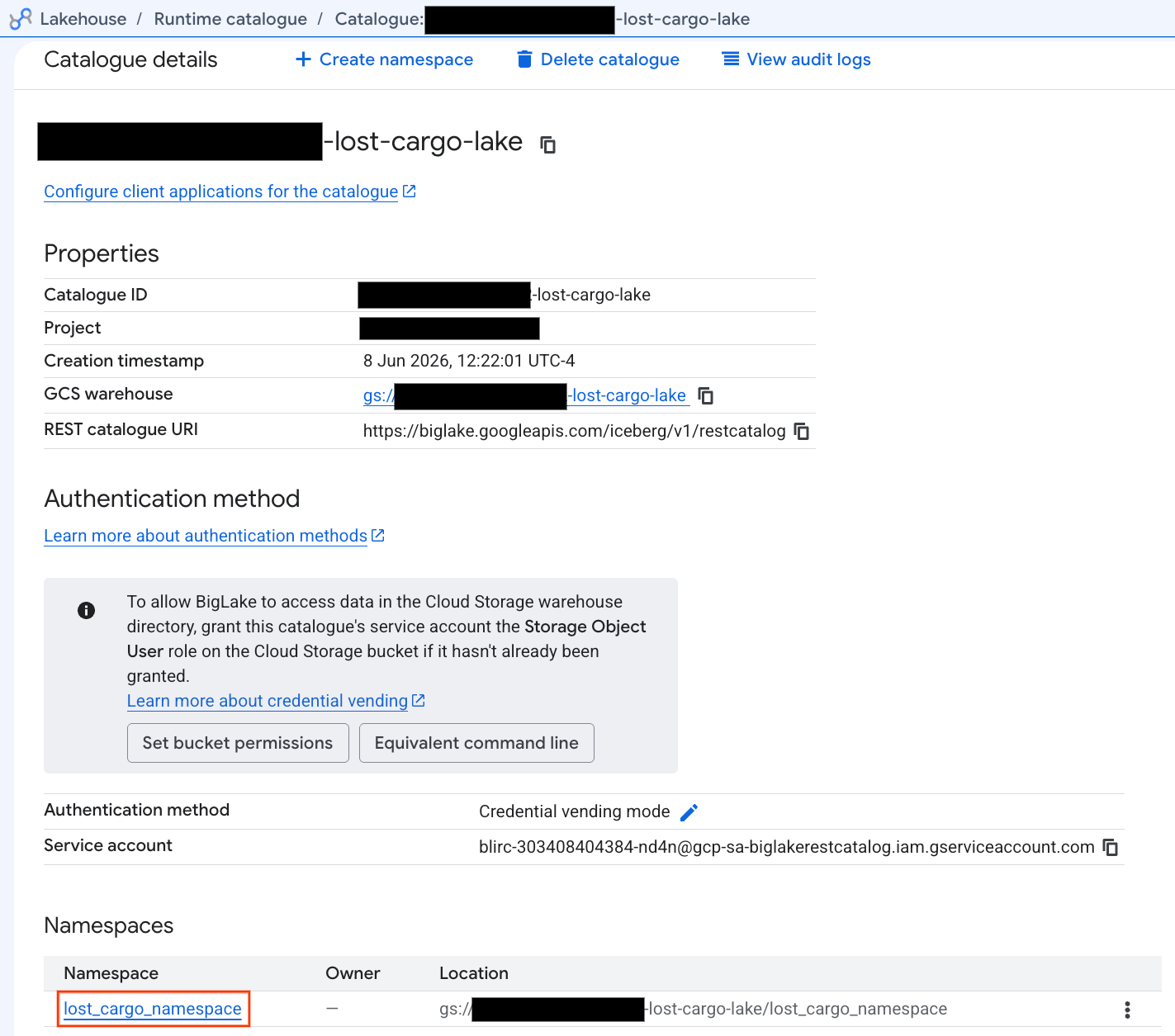
- جدول جدید آپاچی آیسبرگ شما، که توسط PySpark تولید شده است، به طور خودکار تحت این فضای نام متااستور ثبت شده و فوراً در BigQuery قابل پرس و جو شد!
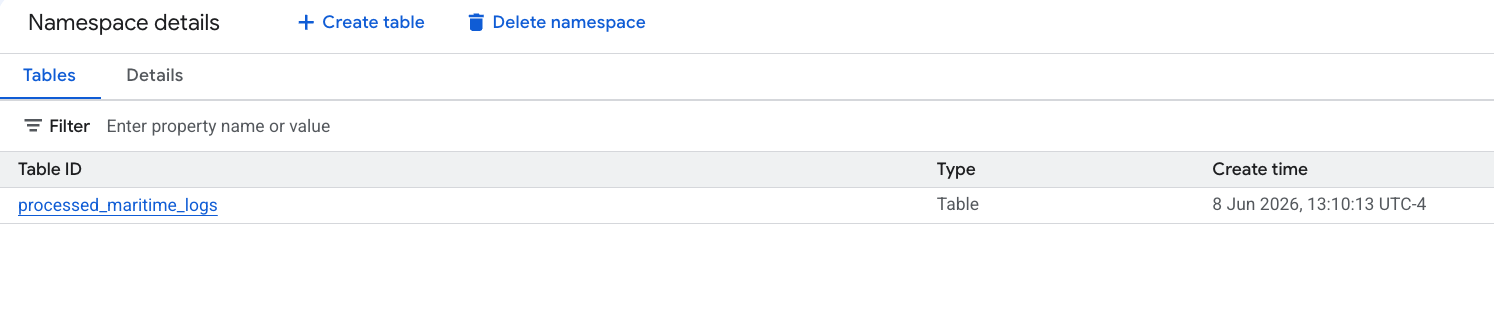
۶. ایجاد بینش در جدول مانیفستهای حمل و نقل
بیایید برگردیم و جدول shipping_manifests تجزیه و تحلیل کنیم تا ساختار و محتوای آن را با استفاده از Knowledge Catalog Data Insights درک کنیم. با غنیسازی فراداده، سایر کاوشگران میتوانند جدول را برای تجزیه و تحلیلهای آینده بهتر درک کنند.
ایجاد بینش جدول در BigQuery Studio
- در کنسول گوگل کلود، به BigQuery Studio بروید.
- در پنل اکسپلورر ، پروژه خود را گسترش دهید، مجموعه داده
lost_cargo_datasetرا باز کنید و روی جدولshipping_manifestsکلیک کنید. - در پنل جزئیات در سمت راست، روی برگه Insights کلیک کنید.
- از منوی کشویی برای انتخاب «تولید و انتشار» استفاده کنید.
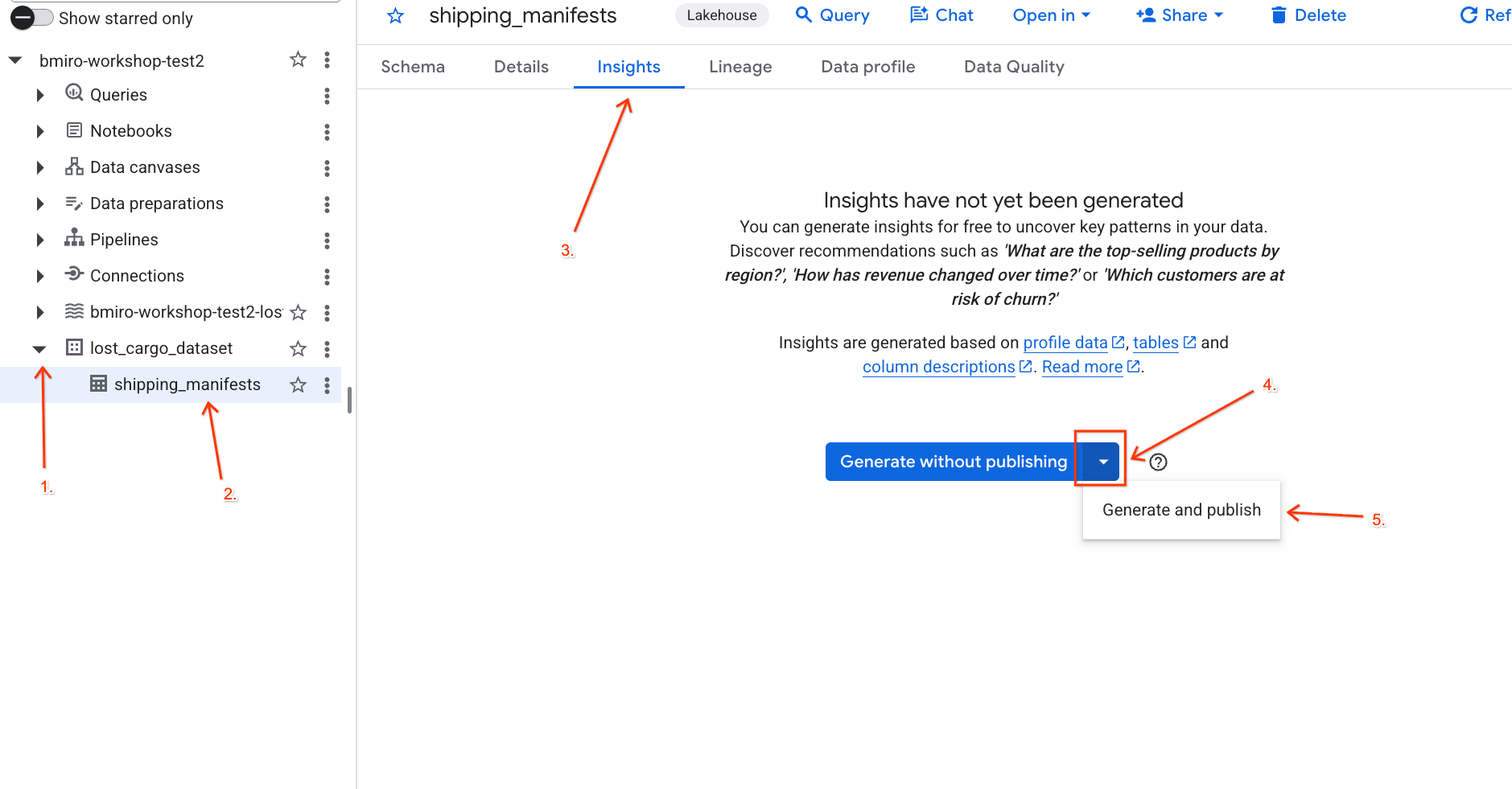
- حدود ۳ دقیقه صبر کنید تا تولید بینشها کامل شود. Gemini متادیتای جدول را تجزیه و تحلیل کرده و سوالات زبان طبیعی و کوئریهای SQL مربوطه را تولید میکند.
- پس از تکمیل، توضیحات جدول را با توضیحی به زبان طبیعی از جدول مشاهده خواهید کرد.
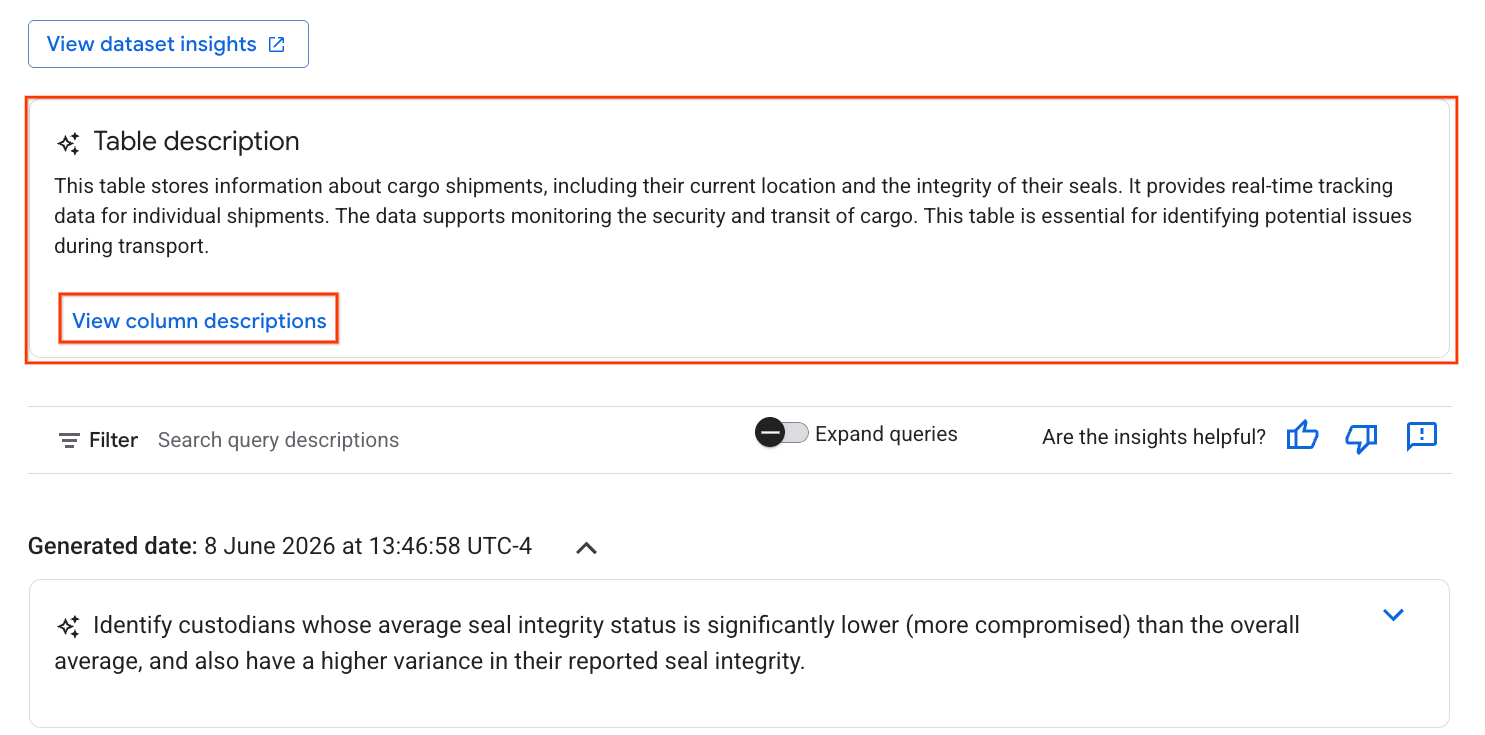
- برای مشاهده اطلاعات مربوط به هر ستون، روی «مشاهده توضیحات ستون» کلیک کنید.
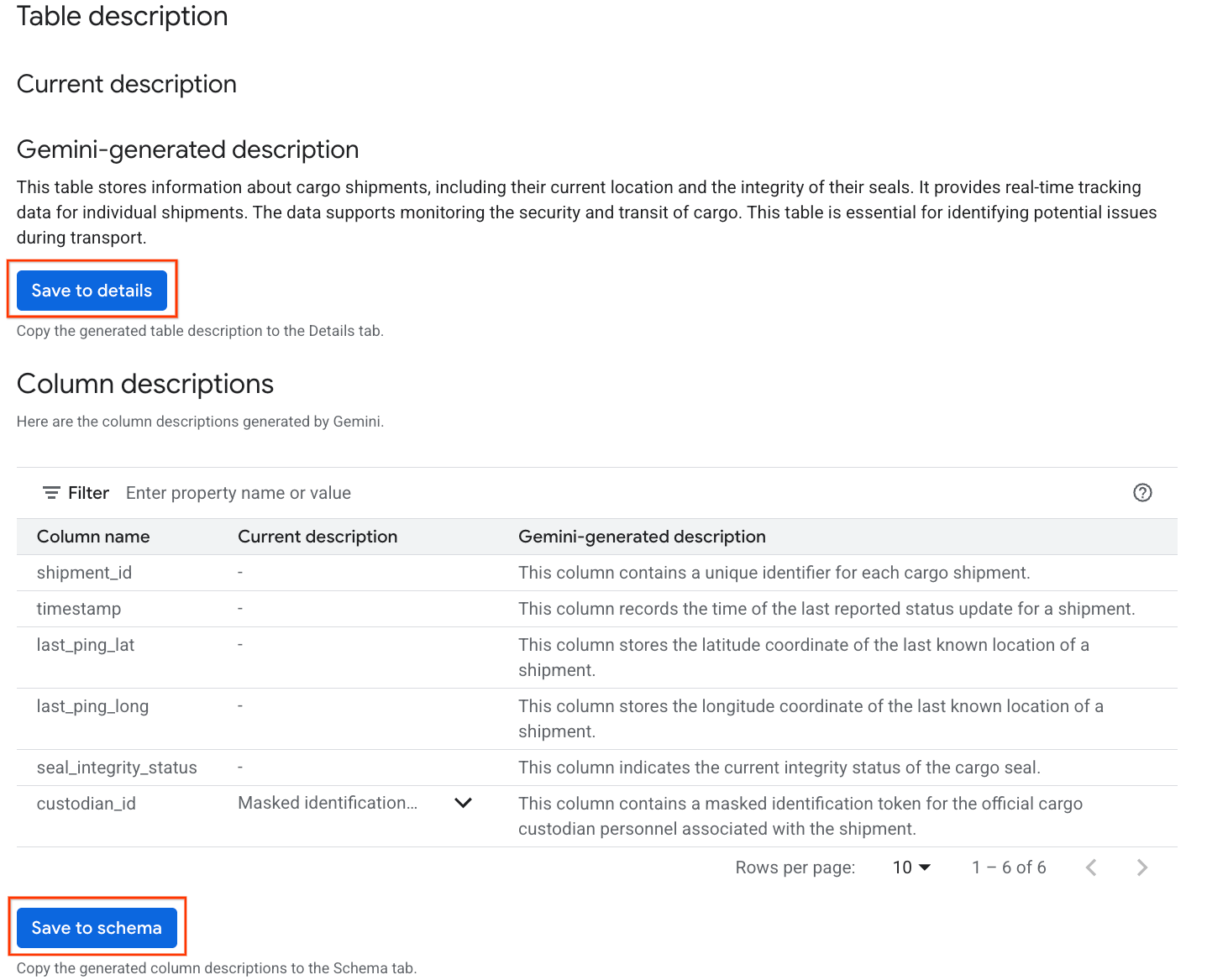
- در زیر
Gemini generated descriptionروی «ذخیره به جزئیات» کلیک کنید و در پنجرهای که ظاهر میشود، روی «ذخیره به جزئیات» کلیک کنید.
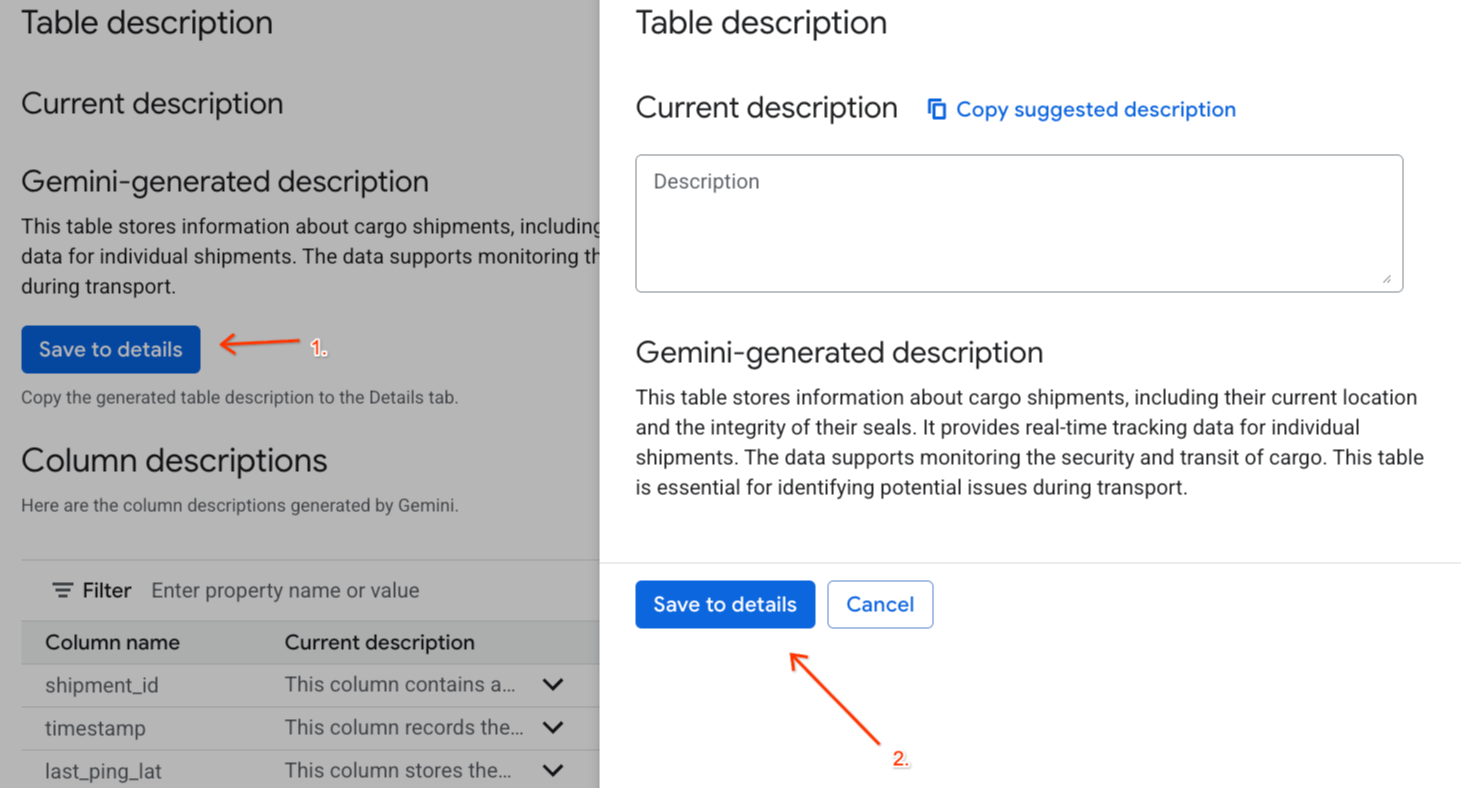
- به همین ترتیب، برای افزودن توضیحات ستون به فراداده جدول، روی «ذخیره در طرحواره» کلیک کنید.
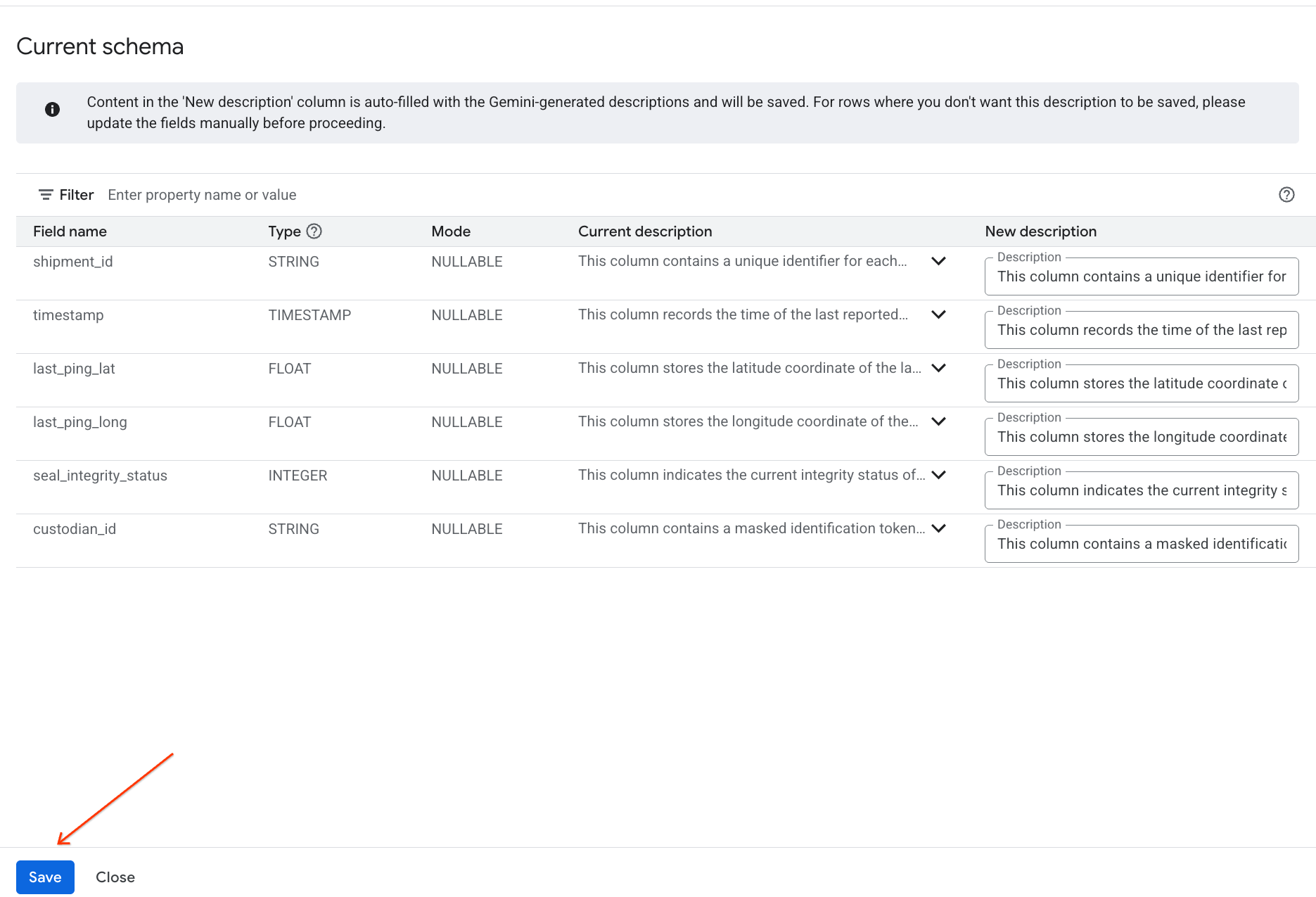
بینشهای ایجاد شده توسط بررسی
همچنین لیستی از سوالات پیشنهادی را مشاهده خواهید کرد. میتوانید روی هر سوال کلیک کنید تا کوئری SQL تولید شده را مشاهده کنید و آن را برای بررسی دادهها اجرا کنید. به عنوان مثال، ممکن است سوالاتی مانند موارد زیر را ببینید:
- «تعداد کل محمولهها چقدر است؟»
- «شناسههای متولی منحصر به فرد را فهرست کنید.»
اجرای این کوئریها به شما کمک میکند تا دادهها را درک کنید.
۷. پیادهسازی پوشش دادهها و مدیریت آنها
برای تضمین اینکه حسابهای کاربری و نامهای کاربری فعال تحقیقاتی در طول این تحقیقات مداوم محموله فاش نشوند، باید پروتکلهای امنیتی استاندارد را اجرا کنید. شما یک طبقهبندی برچسب سیاست امنیتی ایجاد خواهید کرد و پوشش دادههای کاتالوگ دانش را روی ستون حساس custodian_id پیکربندی خواهید کرد تا حریم خصوصی دادهها را تأیید کنید.
به طور پیشفرض، BigQuery دسترسی به ستونهای محافظتشده توسط برچسبهای سیاست را رد میکند. برای پرسوجو از جدول و تأیید ماسکهای داده فعال، حساب کاربری شما باید نقش BigQuery Data Policy Masked Reader را داشته باشد.
این نقش به طور خودکار در طول اجرای اولیه setup_lab1.sh به حساب کاربری فعال شما متصل شد!
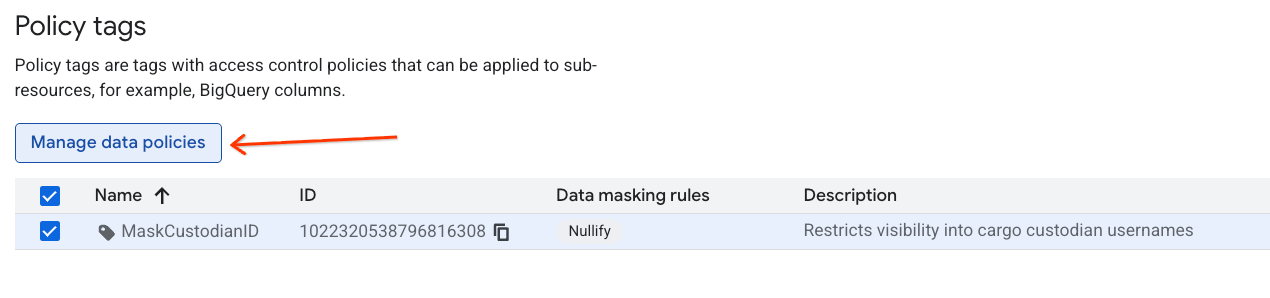
ایجاد برچسب طبقهبندی و سیاست
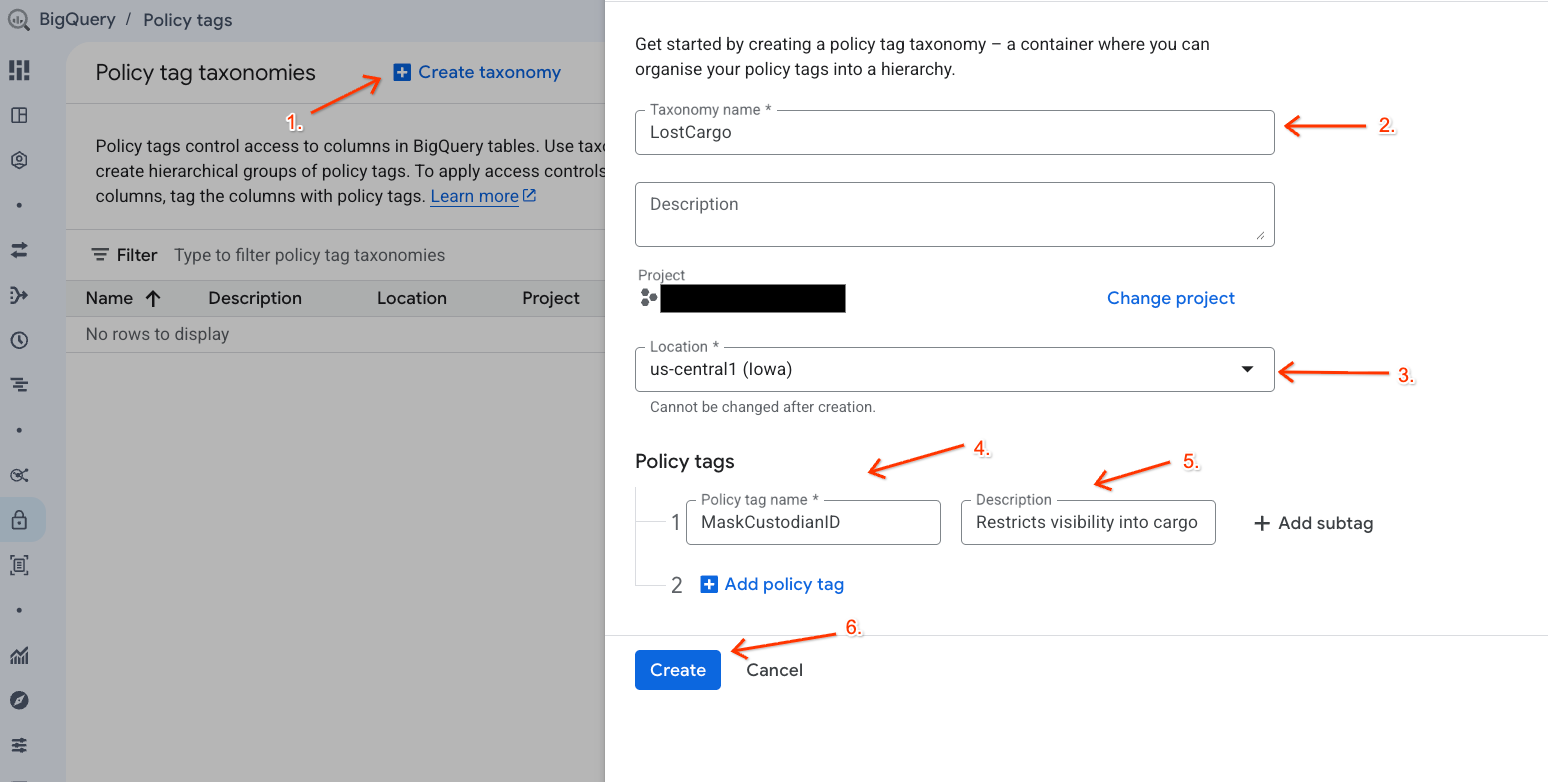
یک طبقهبندی دادهها و برچسب سیاست مرتبط با آن برای مدیریت دسترسی به دادههای خود ایجاد کنید.
- به صفحه دستهبندیهای برچسب سیاست بروید.
- روی + ایجاد طبقهبندی کلیک کنید.
- پارامترها را پیکربندی کنید:
- نام طبقهبندی : وارد کردن
lost-cargo-، با شناسه پروژه خود جایگزین کنید. - منطقه : منطقه خود را انتخاب کنید.
- برای نام برچسب Policy:
MaskCustodianIDرا وارد کنید. - توضیحات برچسب سیاست:
Restricts visibility into cargo custodian usernames
- نام طبقهبندی : وارد کردن
- برای ثبت برچسب طبقهبندی و سیاست جدید خود، روی ایجاد کلیک کنید.
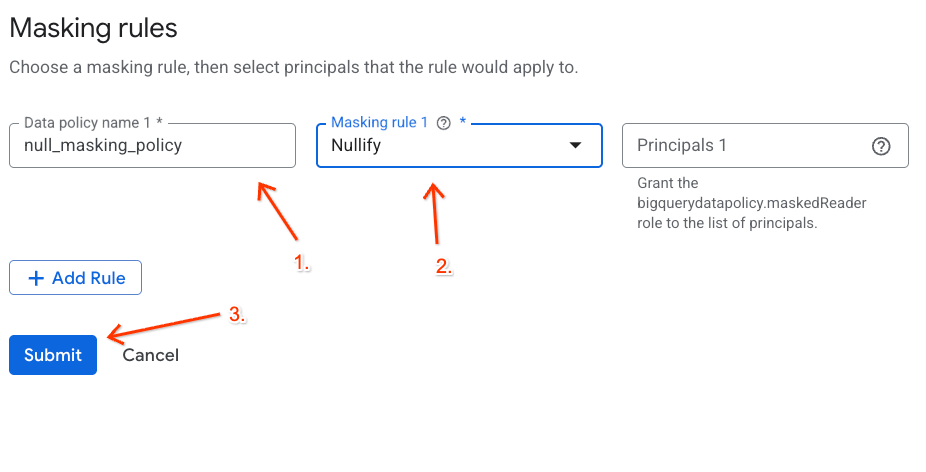
ایجاد سیاست پوشش داده
در مرحله بعد، یک سیاست داده پیکربندی کنید تا نحوه پنهانسازی دادهها تحت برچسب طبقهبندی MaskCustodianID را تعریف کند. شما از قانون پنهانسازی Always Null استفاده خواهید کرد (جایگزینی مقادیر منطبق با مقادیر خالی/Null برای همه بازیگران بدون امتیاز).
- در صفحه دستهبندیهای برچسب سیاست ، روی دستهبندی جدید ایجاد شده از فهرست دستهبندیهای خود کلیک کنید.
- در فهرست سلسله مراتب، روی برچسب
MaskCustodianIDکلیک کنید تا انتخاب شود و سپس مدیریت سیاستهای داده را انتخاب کنید.
- در پنل سمت راست، روی دکمه + افزودن قانون کلیک کنید.
- جزئیات سیاست را در پنلی که ظاهر میشود پیکربندی کنید:
- نام سیاست داده :
null_masking_policyرا وارد کنید (آن را به صورت خودکار تولید نکنید، زیرا در مراحل بعدی به آن با نام ارجاع خواهیم داد). - قانون پوشش : از منوی کشویی،
Nullifyانتخاب کنید.
- نام سیاست داده :
- روی ارسال کلیک کنید.
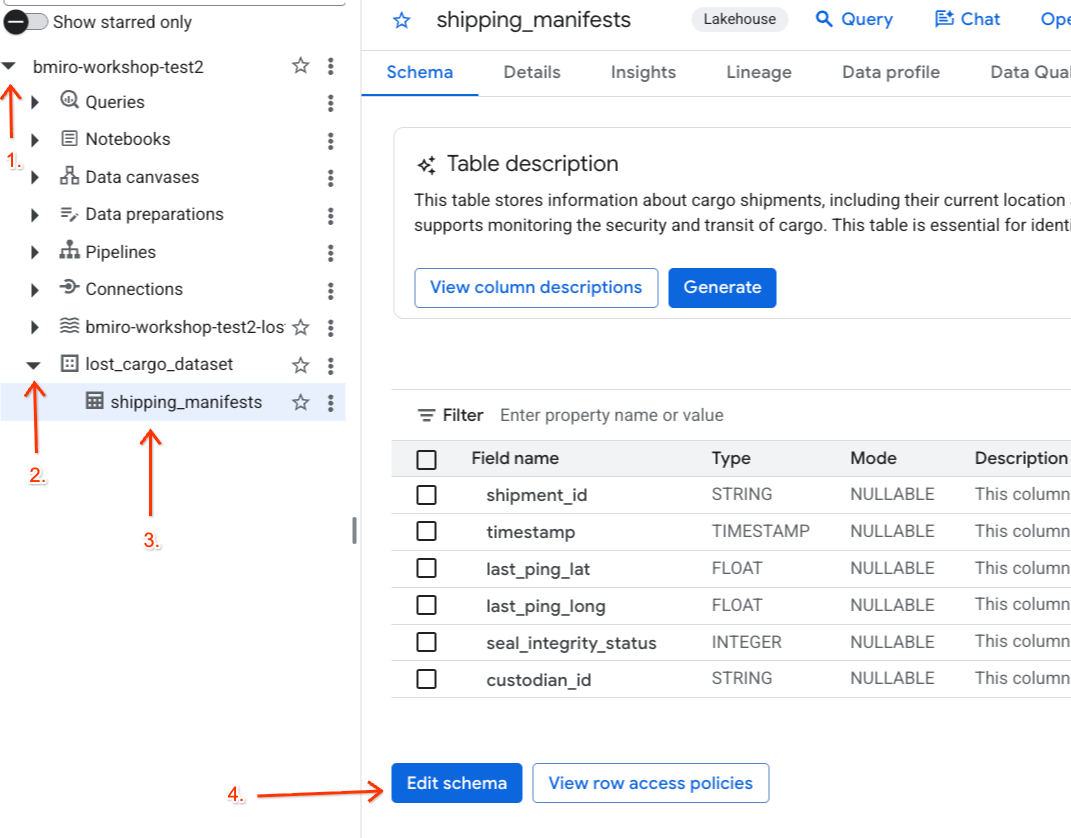
برچسب سیاست را به ستون BigQuery خود اختصاص دهید
با فعال بودن تگ policy و قانون پوشش داده آن، تگ طبقهبندی را مستقیماً به ستون custodian_id در جدول مانیفست حمل و نقل شریک BigQuery خود نگاشت کنید.
- به کنسول BigQuery بروید.
- در پنل Explorer در سمت چپ، پروژه فعال خود را گسترش دهید، مجموعه داده
lost_cargo_datasetرا باز کنید و روی جدولshipping_manifestsکلیک کنید تا نمای دقیق آن باز شود. - روی ویرایش طرحواره کلیک کنید.
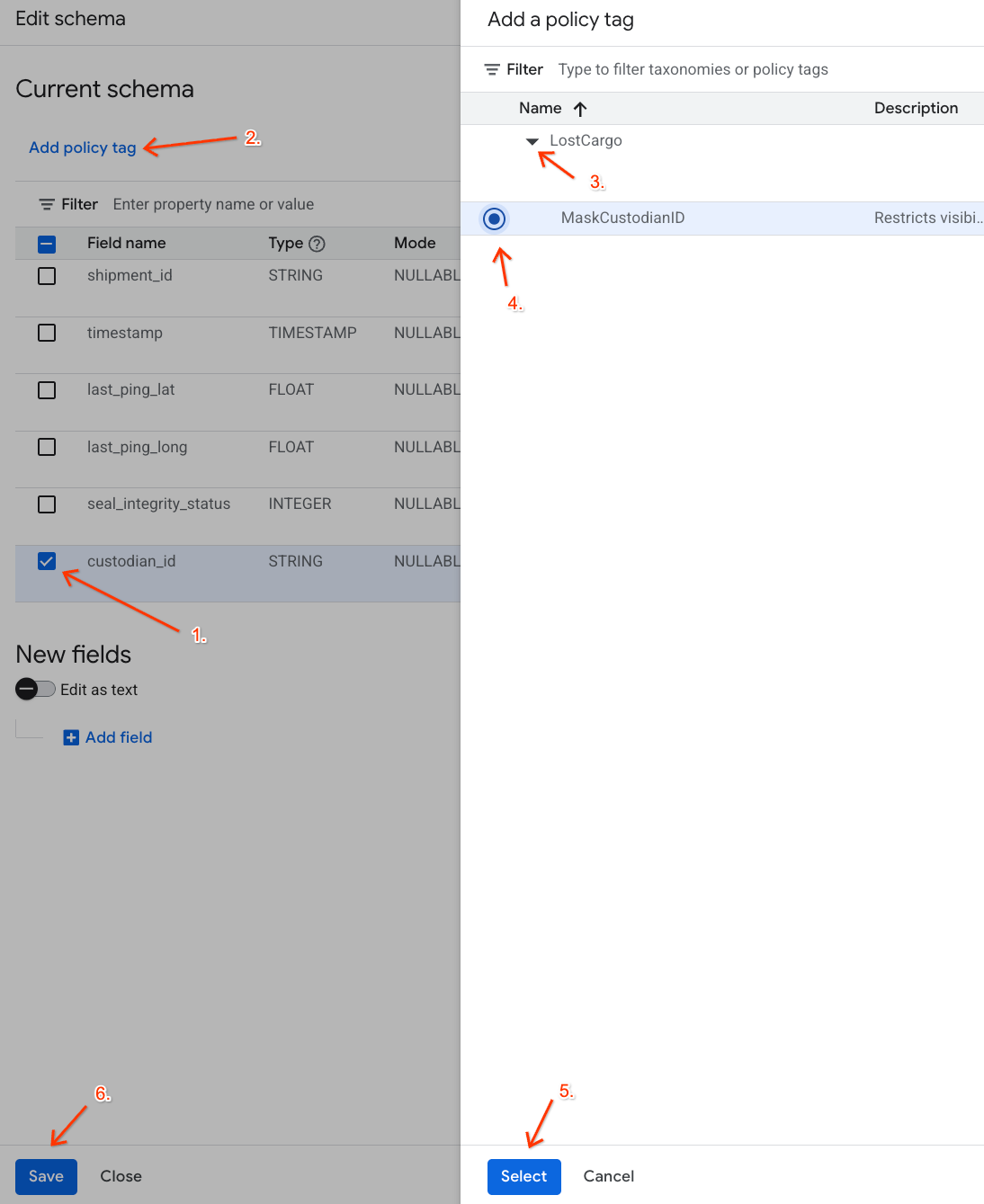
- در لیست ستونها، کادر کنار
custodian_idعلامت بزنید. - روی دکمهی «افزودن برچسب سیاست» در نوار ابزار بالای ویرایشگر طرحواره کلیک کنید.
- در پنل افزودن برچسب سیاست :
- طبقهبندی
LostCargoخود را پیدا کرده و گسترش دهید. - حباب کنار
MaskCustodianIDرا انتخاب کنید. - روی انتخاب کلیک کنید.
- طبقهبندی
- تأیید کنید که برچسب
MaskCustodianIDاکنون در زیر ستون برچسب Policy در ردیفی که نشاندهندهcustodian_idاست، قابل مشاهده است. - روی ذخیره کلیک کنید.
محدودیتهای سیاست را تأیید کنید
اکنون که نقش Masked Reader را در سطح پروژه دارید، میتوانید با پرسوجو از جدول، فعال بودن سیاست Masking را تأیید کنید.
به Data Agent Kit برگردید و کوئری زیر را اجرا کنید:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
باید خروجی مشابه زیر را ببینید:
شناسه حمل و نقل | شناسه متولی |
معمولی-001 | تهی |
معمولی-002 | تهی |
MV-CAT-001 | تهی |
موفقیت! با اینکه میتوانید رکوردهای shipment_id را مشاهده کنید، فیلد حساس custodian_id برای جلوگیری از نشت، ماسکهای null امن را برمیگرداند!
۸. تمیز کردن
برای جلوگیری از هزینههای مداوم برای حساب Google Cloud خود برای منابع ایجاد شده در طول این codelab، این دستورات را در ترمینال Cloud Shell خود اجرا کنید تا مجموعه دادهها و سطلهای خود را رها کنید:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
۹. تبریک
تبریک! شما با موفقیت اولین ماژول حیاتی تحقیق محموله گمشده را به پایان رساندید. شما یک منطقه جستجوی تحت کنترل با استفاده از کاتالوگهای REST Lakehouse Iceberg، نرمالسازی لاگ PySpark و پوشش دادههای دقیق ایجاد کردهاید.
آنچه آموختهاید
- نصب، راهاندازی و پیکربندی افزونه Data Agent Kit در فضای کاری IDE شما.
- ایجاد یک کاتالوگ REST بدون سرور Lakehouse Iceberg با استفاده از اعتبارنامههای فروش رفته و فضاهای نام سلسله مراتبی.
- دریافت فیدهای منطقهای چند فرمتی و ساخت جداول خارجی BigQuery روی مخازن ذخیرهسازی ابری.
- راهاندازی وظایف Apache Spark بدون سرور برای تجزیه، نرمالسازی، قطعهبندی و نوشتن مجدد گزارشهای ترانسپوندر بدون ساختار در BigQuery به عنوان جداول کاتالوگ ثبتشده Iceberg.
- ایجاد طبقهبندیهای امنیتی و نگاشت سیاستهای پوشش دادههای کاتالوگ دانش برای جلوگیری از نشت هویت در شاخصهای حساس لاگ.
- تولید و تحلیل بینشهای فراداده جدول با استفاده از بینشهای داده BigQuery برای تسریع کاوش دادهها.
تأیید سرنخهای جمعآوریشده
تأیید کنید که سرنخهای قطعی زیر را که برای شروع مرحله آزمایشگاهی بعدی لازم است، ثبت کردهاید:
- شناسه محموله گمشده :
MV-CAT-001(آخرین محل پینگ: لندن ) - مقصد برنامهریزیشده :
New York(و نام مستعار واقعی فرستنده:MV-DOG-002) - رنگ ظرف :
Crimson RED - برچسب دسترسی به حکومت :
MaskCustodianID
آمادهای برای مرحلهی بعدی؟
حالا که مسیرهای مبدا/مقصد فرستنده امن شدهاند، تحقیقات ادامه پیدا میکند! مستقیماً به آزمایشگاه ۲ بروید تا دوربینهای امنیتی را با استفاده از مدلهای چندوجهی Gemini بررسی کنید، کشتی را به صورت بصری شناسایی کنید و جستجوهای برداری را در AlloyDB انجام دهید تا ناهنجاریهای دستکاری را تأیید کنید!
➡️ ادامه با مرحله دوم: تحلیل دادهها و بینشهای چندوجهی