
1. Introduction
Dans cet atelier, vous allez jouer le rôle d'un responsable des investigations sur les données pour une entreprise de logistique internationale. Un conteneur de marchandises de grande valeur transportant de précieuses figurines Android a disparu ! Pour trouver sa dernière position connue et suivre son itinéraire, vous devez agréger les manifestes d'expédition fragmentés des partenaires logistiques régionaux et les fichiers journaux de transpondeur non structurés. Pour ce faire, vous allez configurer un data lakehouse ouvert Google Cloud moderne.

Objectifs de l'atelier
- Configurez l'extension Google Cloud Data Agent Kit dans l'éditeur Cloud Shell.
- Créez un bucket Cloud Storage et provisionnez un catalogue REST Apache Iceberg Lakehouse et un espace de noms.
- Mappez une table externe BigLake aux fichiers manifestes JSON bruts des partenaires dans Cloud Storage pour découvrir l'indice de départ du navire.
- Chargez et traitez les journaux de texte non structurés des transpondeurs à l'aide de Managed Service pour Apache Spark sans serveur. Effectuez des normalisations regex et une extraction dynamique des indices pour cibler la destination de la charge utile perdue.
- Écrivez les métriques de journaux analysées sous forme de table Apache Iceberg via le catalogue REST.
- Discutez avec un agent d'IA au sujet de vos données Apache Iceberg à l'aide de Conversational Analytics pour découvrir des indices cachés sur votre colis perdu.
- Exploitez les insights de données automatisés avec Knowledge Catalog pour générer des métadonnées sur vos données.
- Établissez des consignes d'ingestion en créant une taxonomie de sécurité et en utilisant Knowledge Catalog pour appliquer un contrôle d'accès précis en masquant les ID de responsable sensibles.
Prérequis
- Un navigateur Web tel que Chrome.
- Un projet Google Cloud avec facturation activée.
- Vous connaissez les requêtes SQL et les commandes de terminal de base.
Coût et durée attendus
- Durée : environ 45 minutes.
- Coût estimé : moins de 5 $ USD.
2. Avant de commencer
Créer ou sélectionner un projet Google Cloud
- Dans la console Google Cloud, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier que la facturation est activée sur un projet.
Configurer l'environnement
Vous exécuterez la plupart de vos commandes à partir du terminal intégré de l'éditeur Cloud Shell, un environnement de développement basé sur le cloud qui est préchargé avec des outils de développement et le SDK Google Cloud standard.
- Ouvrez l'éditeur Cloud Shell dans un nouvel onglet.
- Exécutez la commande suivante dans le terminal pour cloner le dépôt :
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - Définissez votre ID de projet. Vous pouvez également appuyer sur
Ctrl+Shift+Vsous Windows/Linux ou surCmd+Vsous macOS pour coller le texte dans le terminal :export PROJECT_ID="<YOUR_PROJECT_ID>" - Configurez-le maintenant dans votre environnement.
gcloud config set project $PROJECT_ID - Sélectionnez une région.
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - Activez les API requises.
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
Installer l'extension
Vous allez maintenant configurer l'extension Google Data Agent Kit, un outil permettant d'interagir avec les outils de données de Google Cloud directement dans votre IDE.
- Dans la barre d'activité de gauche de l'éditeur, cliquez sur l'icône Extensions (ou appuyez sur
Ctrl+Shift+Xsous Windows/Linux, ou surCmd+Xsous macOS). - Dans le champ de recherche des extensions, saisissez
Google Cloud Data Agent Kit. - Sélectionnez l'extension officielle dans les résultats, puis cliquez sur Installer. Si vous y êtes invité, sélectionnez "Oui, je fais confiance aux auteurs".
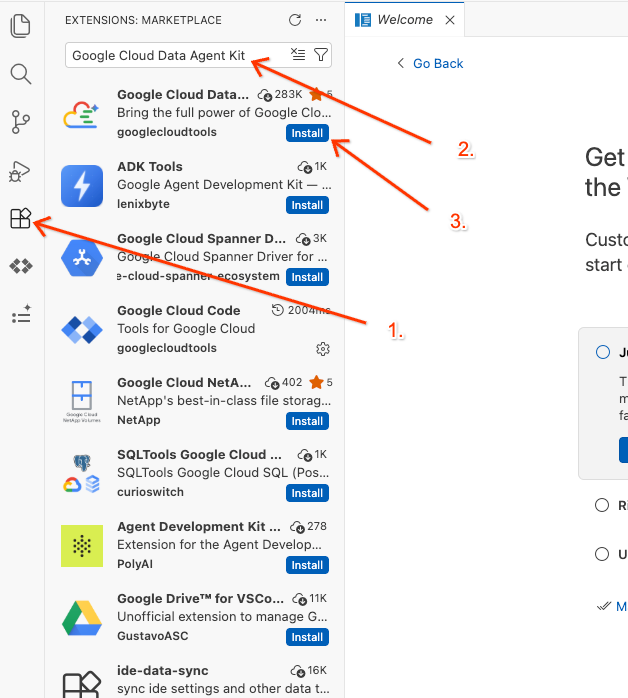
- Une fois l'installation réussie, l'icône Google Cloud Data Agent Kit devrait s'afficher dans la barre d'activité. Cliquez dessus.
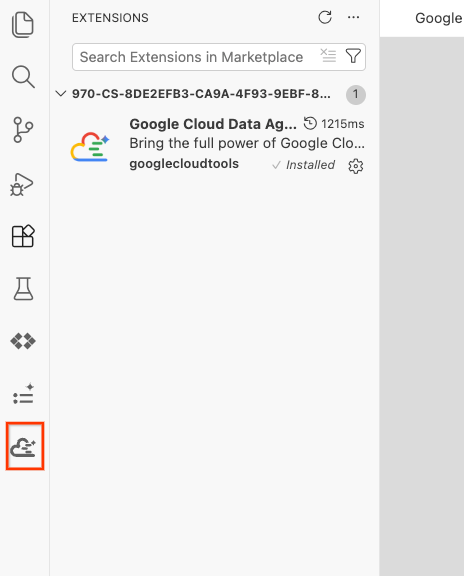
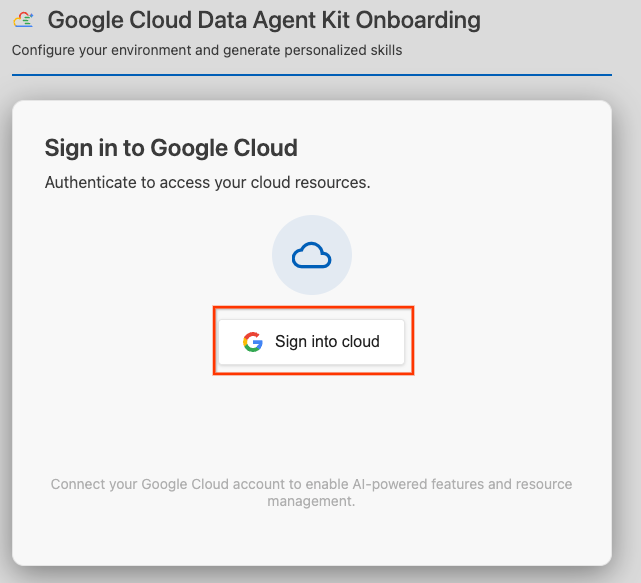
- Cliquez sur Se connecter au cloud.
- Cliquez sur Configurer les serveurs MCP.
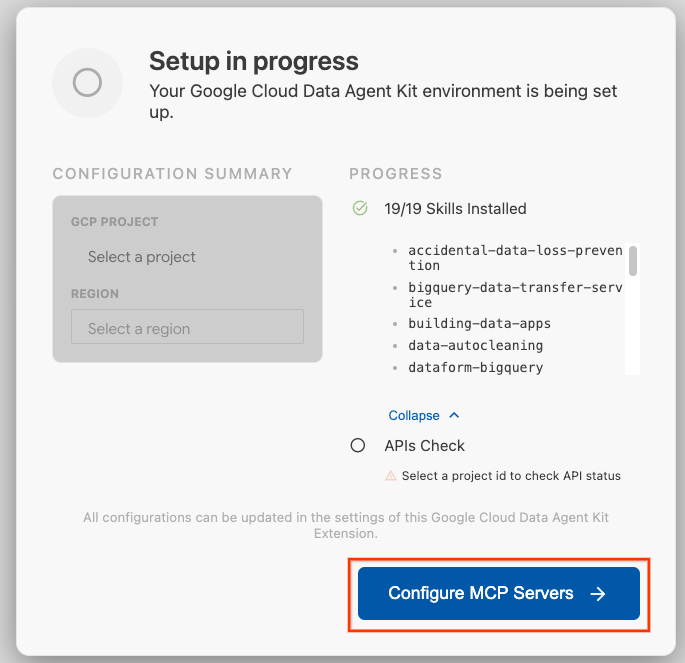
- Sélectionnez BigQuery, Knowledge Catalog, Apache Spark et AlloyDB. Vous utiliserez AlloyDB dans l'atelier 2. Cliquez ensuite sur Commencer.
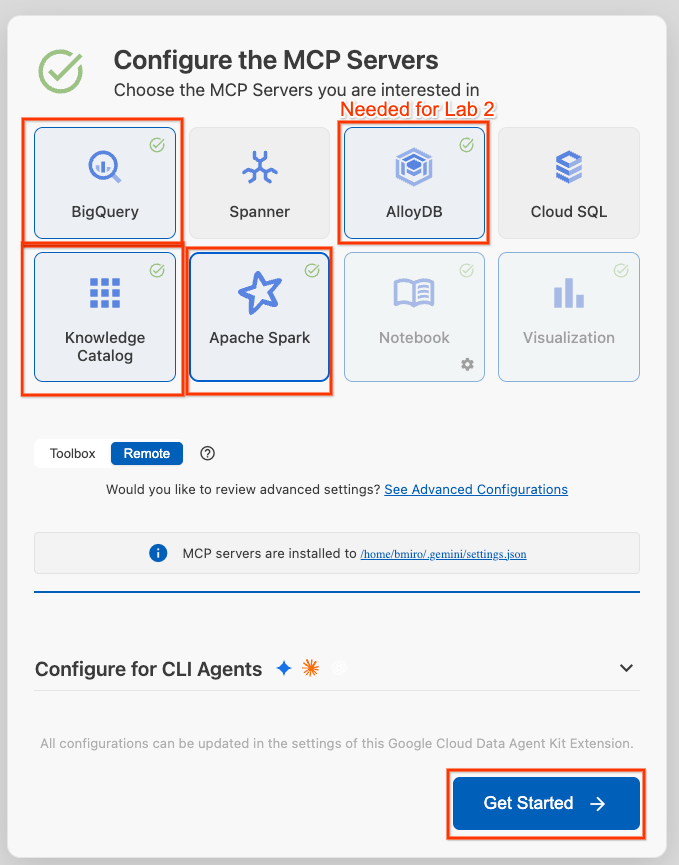
- Cliquez sur le sélecteur ID du projet dans la barre d'état en bas de l'écran, puis sélectionnez votre projet Google Cloud actif.
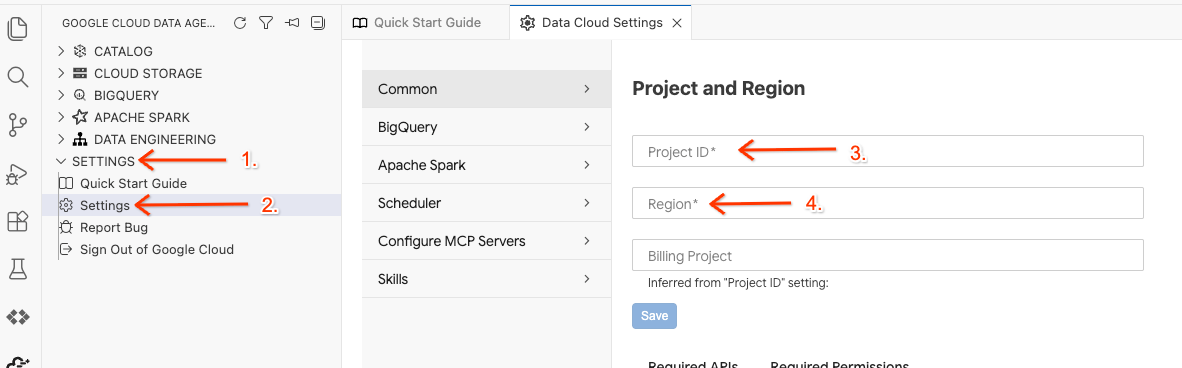
- Dans le kit de l'agent de données, cliquez sur SETTINGS (PARAMÈTRES), puis sur Settings (Paramètres). Dans l'onglet Common (Commun), sélectionnez votre Project ID (ID de projet) et votre Region (Région) pour exécuter votre atelier, par exemple us-central1.
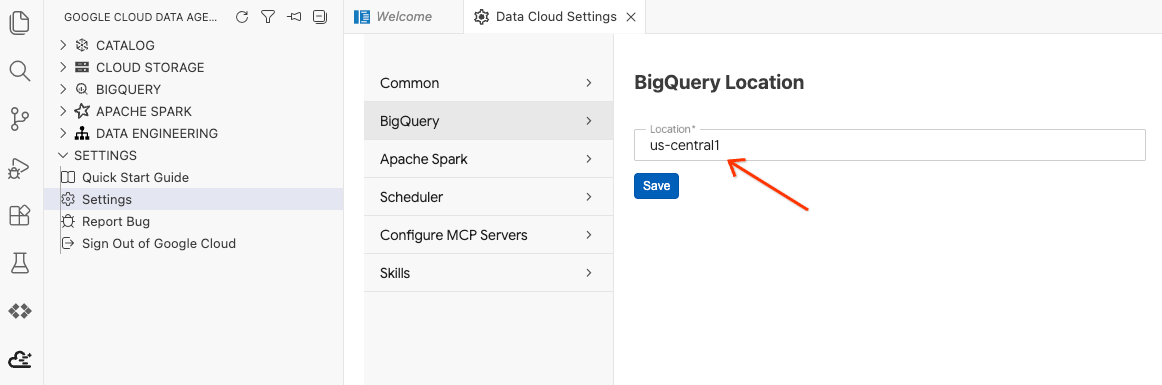
- Cliquez sur Paramètres BigQuery et remplacez la région par celle que vous avez sélectionnée précédemment. Cliquez sur Enregistrer.
Vous êtes maintenant prêt à utiliser le kit d'agent de données.
Exécuter le script de configuration de l'environnement
Dans le terminal, exécutez le script de configuration pour créer les ressources d'arrière-plan nécessaires à cet atelier et configurer les autorisations IAM :
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
Vous devriez voir une série d'étapes de sortie indiquant les ressources provisionnées. Nous les aborderons tout au long de l'atelier.
Une fois le message de confirmation affiché, vous pouvez continuer :
==================================================== Environment Setup Complete! ====================================================
C'est parti !
3. Ingérer les manifestes d'expédition des partenaires
Les données du manifeste d'expédition des navires partenaires sont stockées au format JSON Lines (JSONL) standard dans votre bucket : gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl.
Avant d'effectuer une analyse approfondie, vous allez créer une table BigLake régie pour ces données non structurées. Cela vous permettra d'explorer immédiatement les données logistiques des partenaires à l'aide du langage SQL standard, sans frais d'importation en double.
Ouvrez l'espace de travail dans l'éditeur et exécutez la requête.
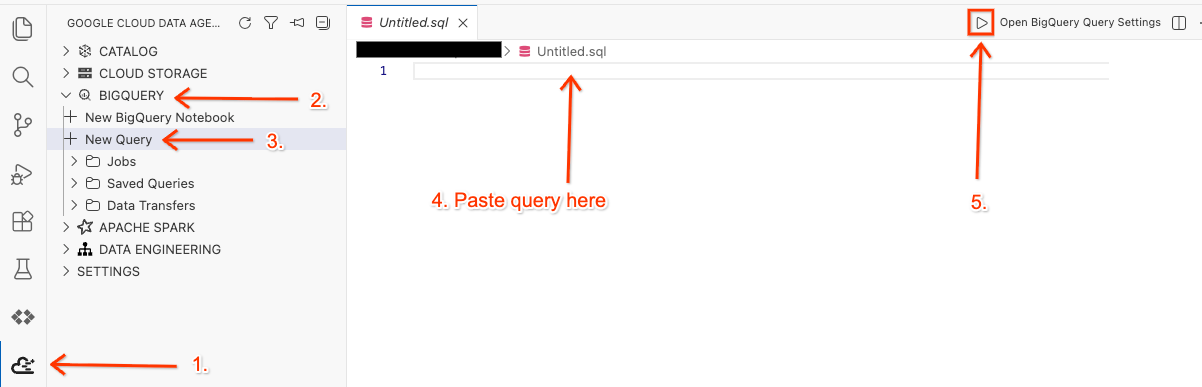
- Dans votre éditeur Cloud Shell, cliquez sur l'icône de l'extension Google Cloud Data Agent Kit dans le panneau latéral.
- Accédez à BigQuery et sélectionnez + Nouvelle requête.
- Copiez la requête suivante dans la fenêtre de requête.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- Cliquez sur Exécuter.
- Pour vérifier que la table a été créée, un message de confirmation s'affiche dans le panneau Résultats de la requête qui s'ouvre automatiquement en bas de l'écran.
Interroger la table externe pour isoler les transpondeurs piratés
Identifions les transpondeurs compromis en localisant les défaillances lorsque seal_integrity_status était défini sur 0. Copiez et exécutez la requête suivante dans la fenêtre de requête que vous avez ouverte précédemment :
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
Dans le panneau Résultats de la requête, vous devriez obtenir un résultat semblable à celui-ci :
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0.1278 | usr_999_shadow |
4. Traiter les journaux non structurés avec Managed Service pour Apache Spark
Vous avez trouvé l'emplacement de départ à partir des fichiers manifestes structurés, mais le transpondeur perdu est complètement hors service. Le dernier ping du transpondeur a laissé un message cryptique et non structuré dans un fichier journal en texte brut dans le chemin d'accès GCS gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt.
Pour traiter et mapper ce journal de texte, extraire les codes temporels, camoufler les identités et localiser l'itinéraire en aval de la cargaison, vous allez envoyer un job Apache Spark (PySpark) sans serveur à Managed Service pour Apache Spark.
Managed Service pour Apache Spark vous permet d'exécuter des charges de travail Spark sans avoir à provisionner ni gérer de cluster. Le service gère les ressources de calcul sous-jacentes et les met à l'échelle automatiquement de manière dynamique. Vous ne payez que la durée d'exécution.
Le script va :
- Ingérez le texte brut, entre crochets et non structuré du transpondeur.
- Appliquez des filtres d'extraction d'expressions régulières PySpark SQL pour séparer les codes temporels, les métadonnées du responsable et le contenu brut.
- Divisez les journaux désordonnés en enregistrements propres au niveau des phrases.
- Extrayez la cible de coordonnées de destination dynamique où les départs de la charge utile perdue se sont terminés.
- Connectez-vous et réécrivez le DataFrame de journaux traités dans votre catalogue REST Lakehouse Apache Iceberg en tant que nouvelle table d'analyse visible directement dans BigQuery.
Corriger le script d'analyse PySpark
Des pirates Python ont été signalés en mer, causant toutes sortes de problèmes.
- Exécutez la commande suivante pour ouvrir le fichier
process_maritime_logsdans l'éditeur Cloud Shell.cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - Prenez le temps de lire le code et de comprendre ce qu'il fait.
- Assurez-vous que rien dans le code ne semble suspect. Si vous devez supprimer des éléments, veillez à enregistrer le fichier à l'aide de
Ctrl + S(Windows/Linux) ouCmd + S(Mac).
Envoyer le job Spark sans serveur
Envoyez le job à l'aide du SDK gcloud. La configuration configure automatiquement le job PySpark pour accéder au catalogue Lakehouse.
Exécutez la commande suivante dans le terminal de votre éditeur intégré.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
Patientez quelques minutes pour que l'environnement serverless se lance, importez votre script et exécutez la logique de traitement.
Une fois que vous voyez un résultat semblable à ce qui suit, votre table traitée est enregistrée dans le catalogue Lakehouse en tant que table gérée Apache Iceberg.
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
Prévisualiser les journaux traités
Dans l'éditeur de requête de l'extension Data Agent Kit, copiez la requête suivante pour prévisualiser les données :
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
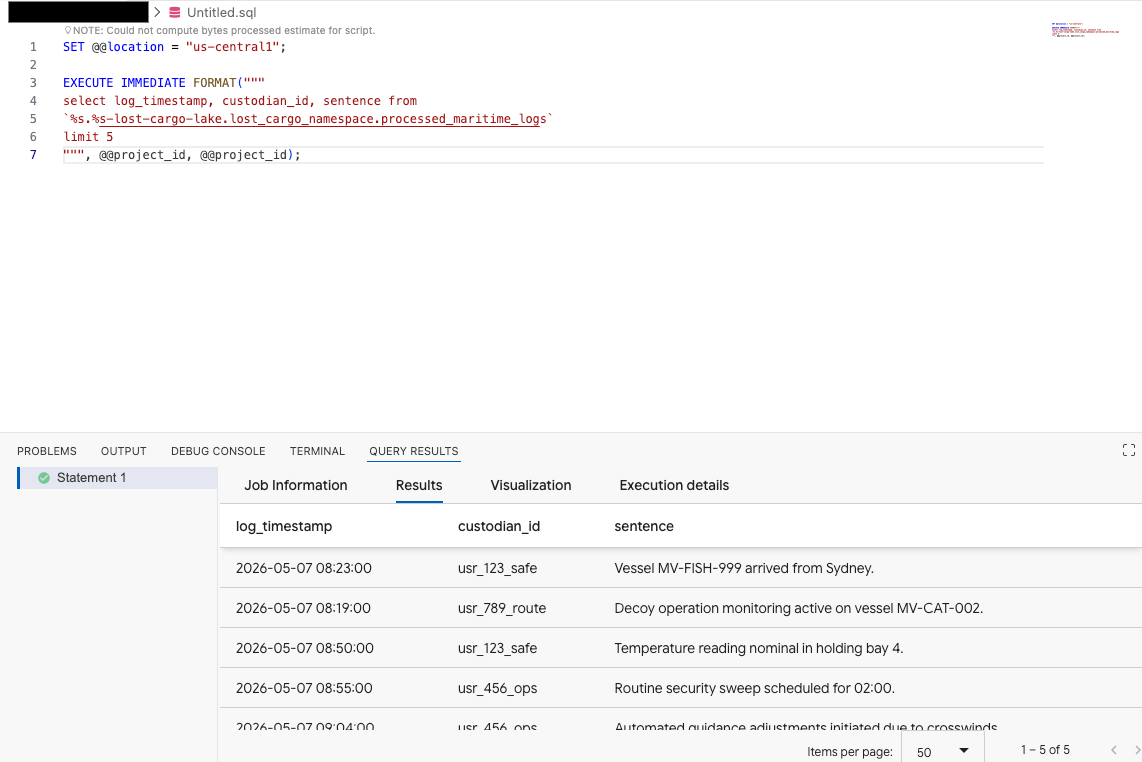
Cela montre que la table Iceberg enregistrée dans le catalogue est accessible depuis BigQuery.
Extraire l'indice de destination
Maintenant que nous disposons des journaux traités, recherchons ceux qui incluent une cible de destination. À partir de là, nous pouvons rechercher les journaux qui mentionnent notre ville d'origine.
Dans votre éditeur de requête, exécutez la requête suivante en remplaçant <YOUR_REGION> par votre région et <ORIGIN_CITY> par la ville d'origine que vous avez identifiée précédemment.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
Discuter avec vos données dans la console BigQuery à l'aide de l'analyse conversationnelle
Au lieu d'écrire des requêtes SQL complexes pour explorer vos données, vous pouvez utiliser Conversational Analytics pour discuter avec vos tables en langage naturel.
- Accédez à la console BigQuery.
- Dans le panneau Explorateur à gauche, développez votre projet et l'ensemble de données
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logspour ouvrir l'onglet "Détails". - À côté de Requête, cliquez sur Chat.
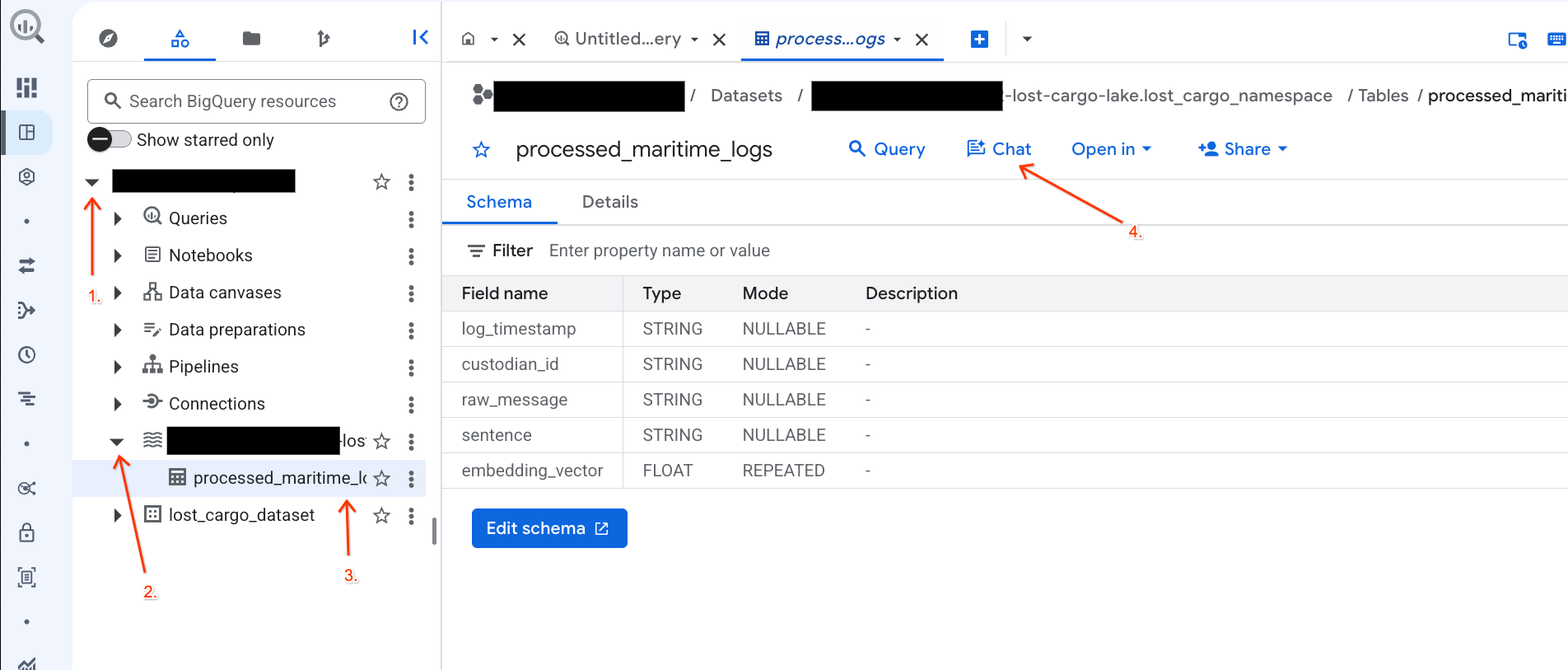
- Dans le panneau de chat, saisissez la question suivante, puis appuyez sur la touche Entrée de votre clavier pour l'envoyer :
Based on this table, what color is the shipping container MV-CAT-001?.

- Conversational Analytics (optimisé par Gemini) analysera les données du tableau actif et répondra avec la couleur.
5. Afficher le catalogue Lakehouse centralisé
Pour intégrer des moteurs de traitement Open Source (comme Apache Spark) de manière sécurisée et fluide avec des moteurs de données d'entreprise (comme BigQuery), votre script de configuration a configuré un catalogue REST Iceberg Lakehouse.
Le catalogue REST Apache Iceberg sert de "source unique de vérité" sans serveur pour les métadonnées des tables. Il gère les schémas et le partitionnement des tables de manière dynamique tout en stockant les fichiers de données Parquet physiques dans Cloud Storage.
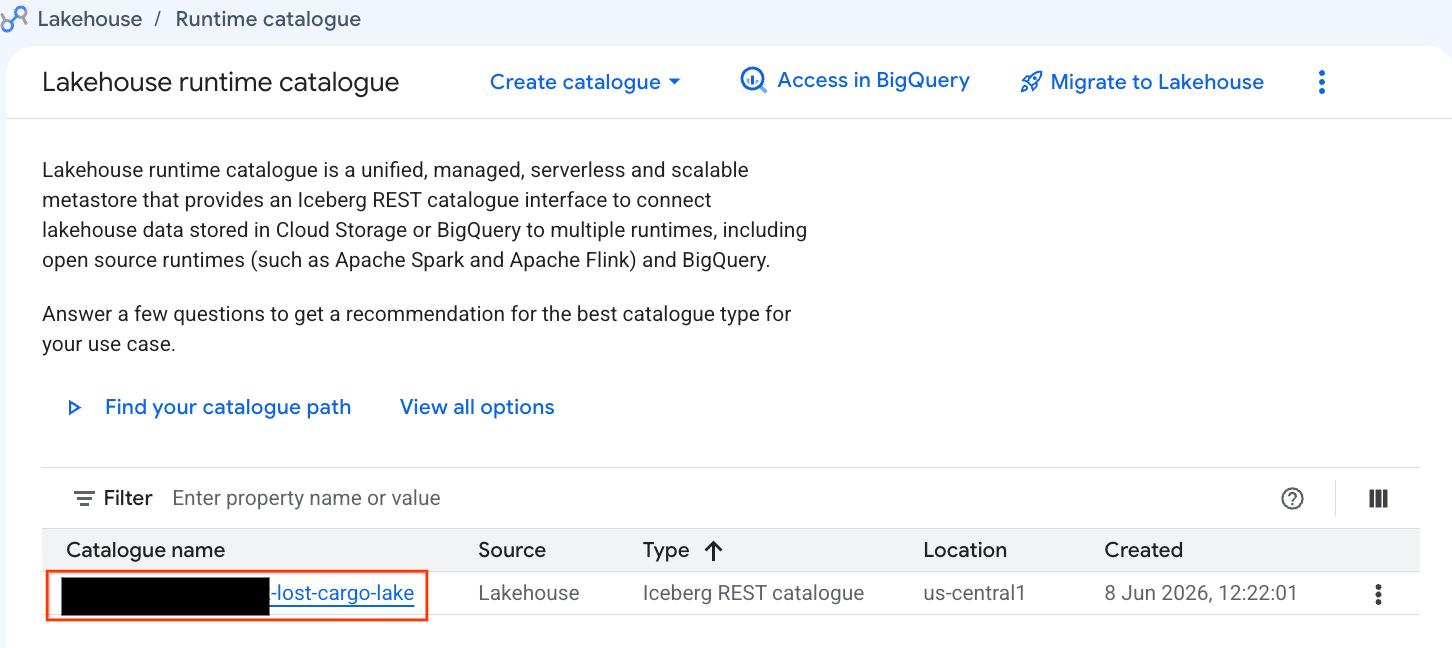
Examinons ce catalogue directement dans la console Google Cloud :
- Ouvrez la console Lakehouse.
- Dans l'onglet Catalogues, recherchez votre catalogue REST Iceberg actif et cliquez dessus :
-lost-cargo-lake
- Dans la vue détaillée du catalogue, sous Espaces de noms, vous devriez voir
lost_cargo_namespace. Cliquez dessus.
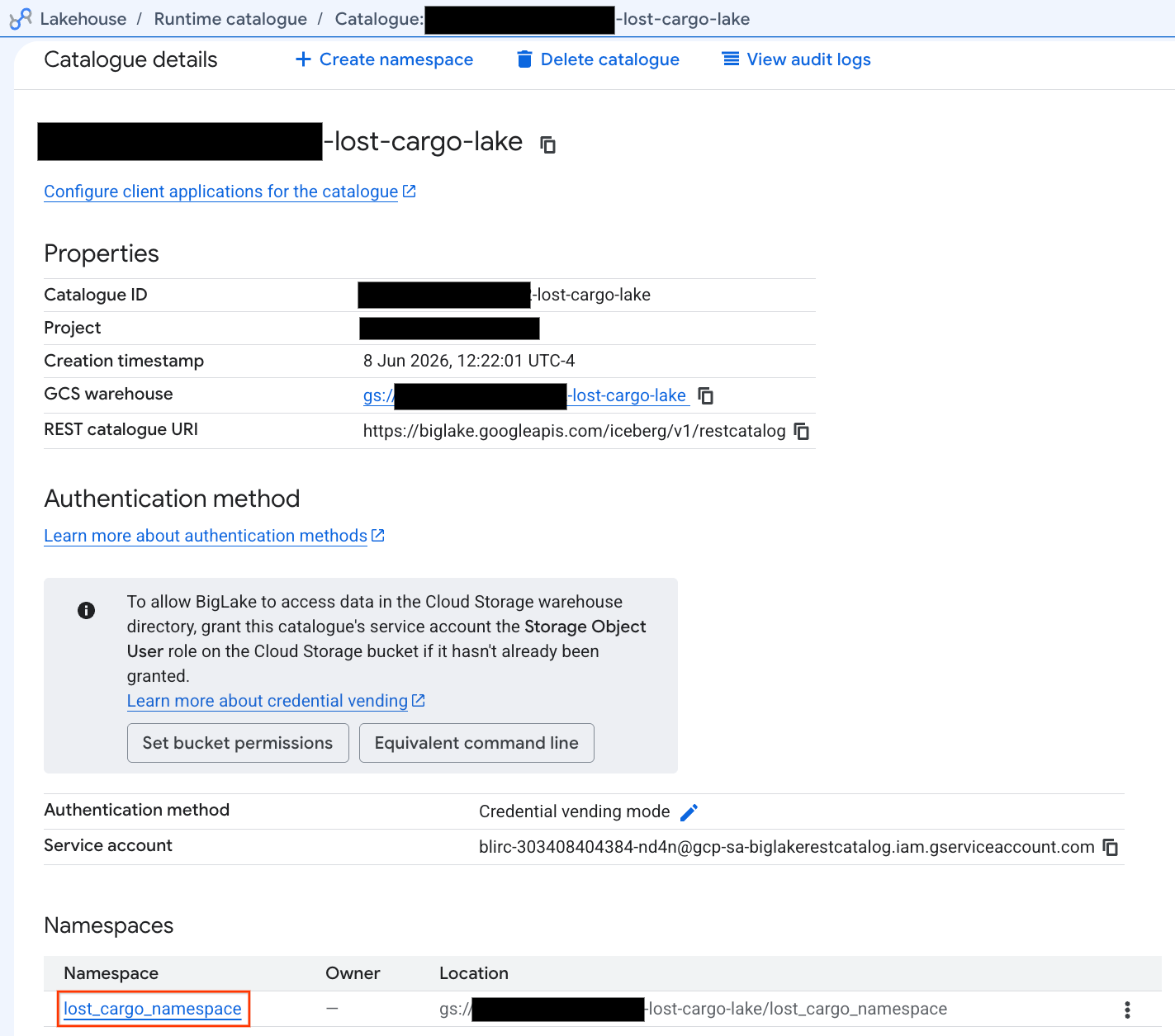
- Votre nouvelle table Apache Iceberg, générée par PySpark, a été automatiquement enregistrée dans cet espace de noms metastore et est devenue instantanément interrogeable dans BigQuery.
6. Générer des insights sur la table "Manifestes d'expédition"
Revenons en arrière et analysons la table shipping_manifests pour comprendre sa structure et son contenu à l'aide des insights sur les données du catalogue de connaissances. En enrichissant les métadonnées, les autres explorateurs peuvent mieux comprendre le tableau pour les futures analyses.
Générer des insights sur les tables dans BigQuery Studio
- Dans la console Google Cloud, accédez à BigQuery Studio.
- Dans le panneau Explorateur, développez votre projet, l'ensemble de données
lost_cargo_dataset, puis cliquez sur la tableshipping_manifests. - Dans le panneau des détails sur la droite, cliquez sur l'onglet Insights.
- Dans le menu déroulant, sélectionnez Générer et publier.
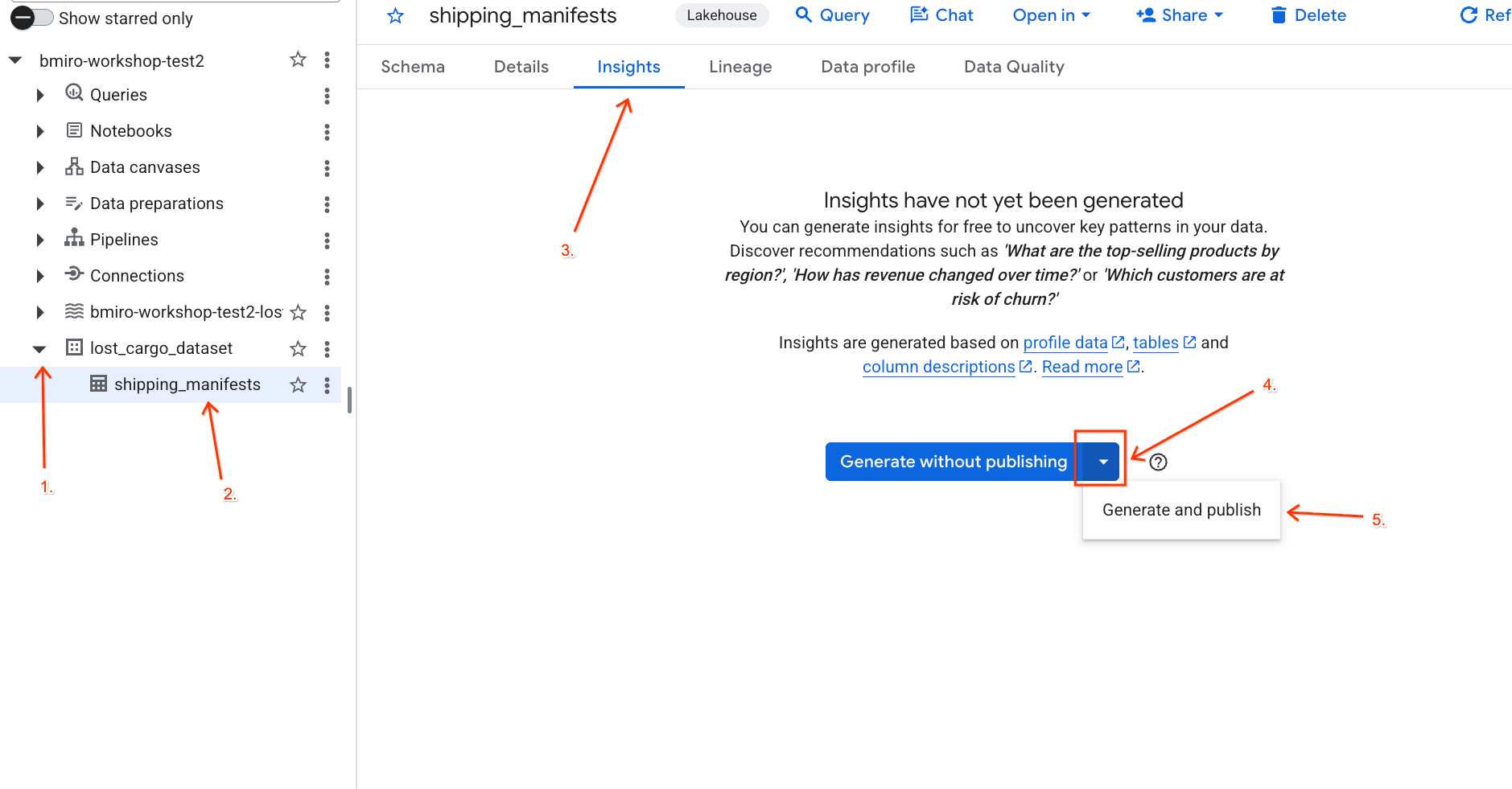
- Attendez environ trois minutes que les insights soient générés. Gemini analysera les métadonnées de la table et générera des questions en langage naturel ainsi que les requêtes SQL correspondantes.
- Une fois l'opération terminée, une description de la table s'affiche avec une explication en langage naturel.
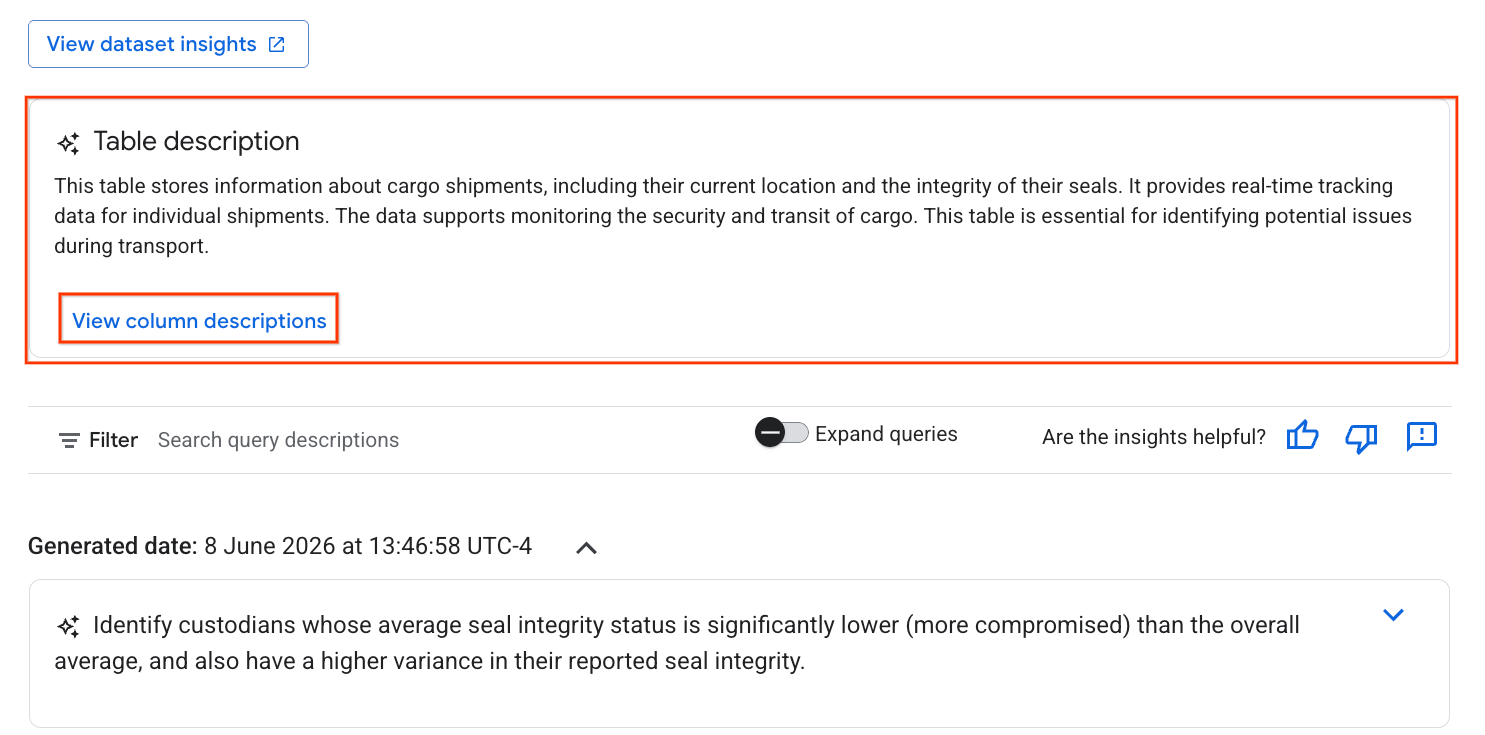
- Cliquez sur Afficher les descriptions des colonnes pour obtenir des informations sur chaque colonne.
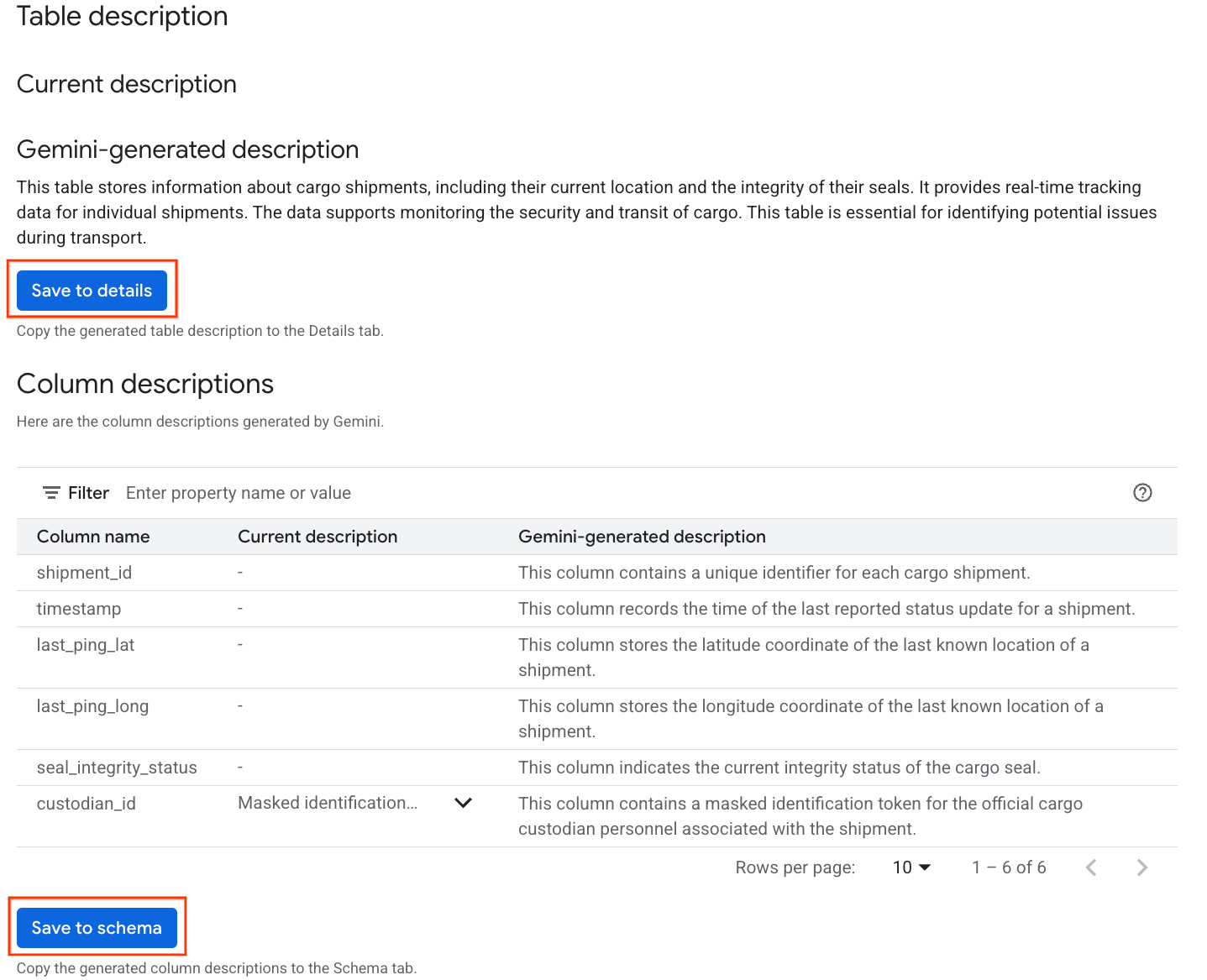
- Cliquez sur Enregistrer dans les détails sous
Gemini generated description, puis sur Enregistrer dans les détails dans la fenêtre pop-up.
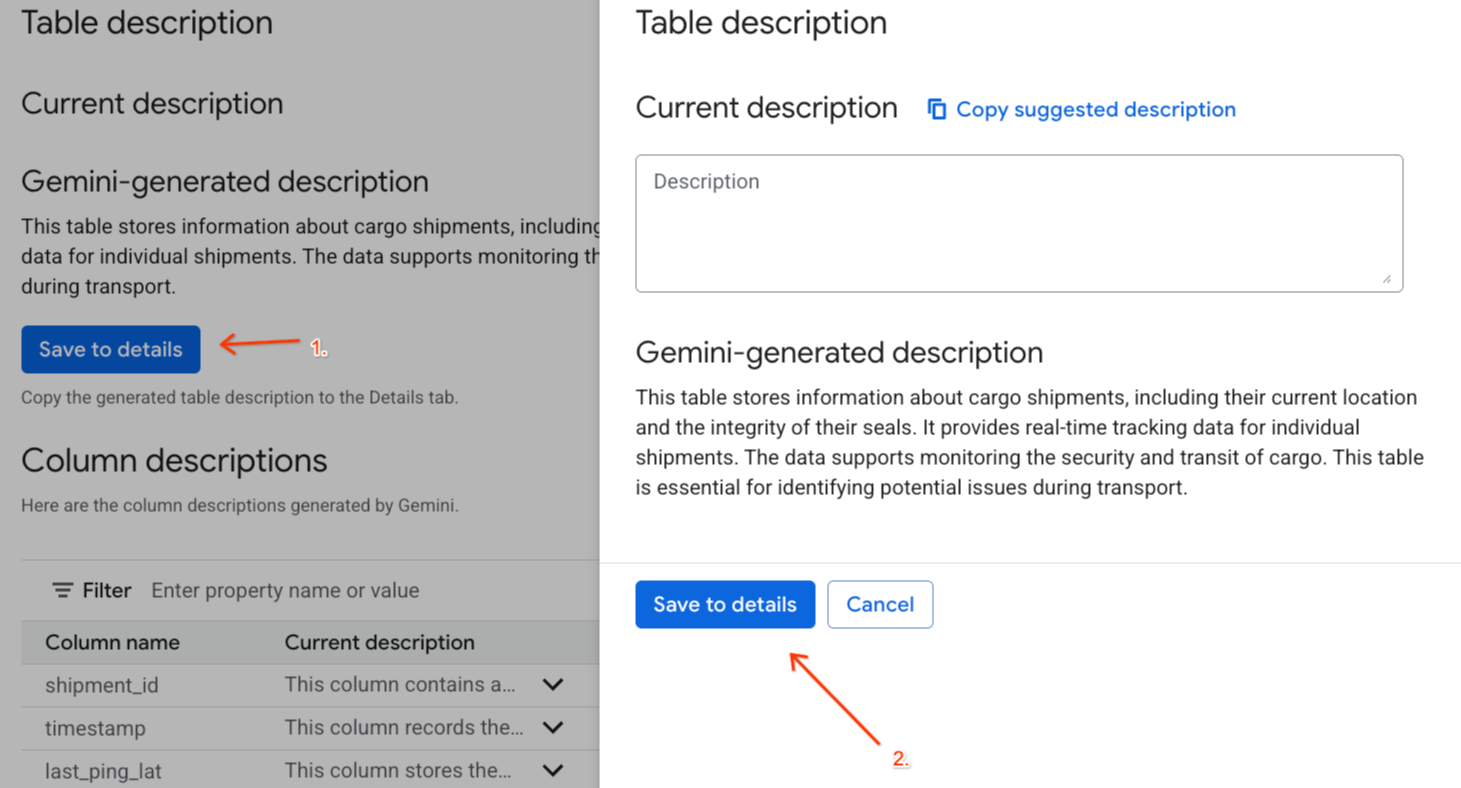
- De même, cliquez sur Enregistrer dans le schéma pour ajouter les descriptions de colonne aux métadonnées de la table.
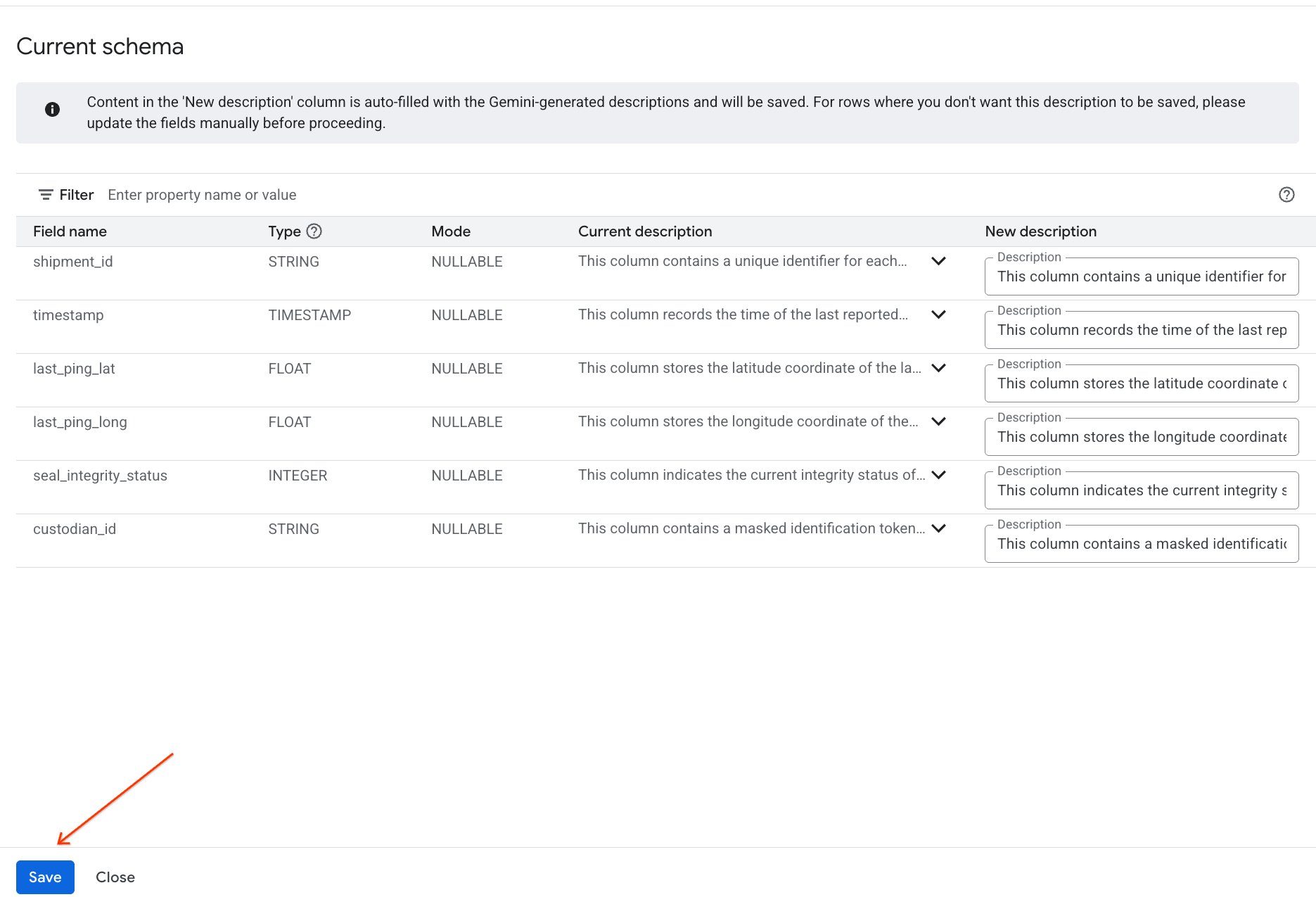
Examiner les insights générés
Vous verrez également une liste de questions suggérées. Vous pouvez cliquer sur n'importe quelle question pour afficher la requête SQL générée et l'exécuter afin d'explorer les données. Par exemple, vous pouvez voir des questions comme :
- "Quel est le nombre total d'envois ?"
- "List the unique custodian IDs."
L'exécution de ces requêtes vous aide à comprendre les données.
7. Implémenter le masquage et la gouvernance des données
Pour garantir que les comptes et noms d'utilisateur de recherche actifs ne peuvent pas être divulgués au cours de cette enquête en cours sur les marchandises, vous devez appliquer des protocoles de sécurité standards. Vous allez créer une taxonomie de tags avec stratégie de sécurité et configurer le masquage des données du Knowledge Catalog sur la colonne custodian_id sensible pour vérifier la confidentialité des données.
Par défaut, BigQuery refuse l'accès aux colonnes protégées par des tags avec stratégie. Pour interroger la table et vérifier les masques de données actifs, votre compte utilisateur doit disposer du rôle Lecteur masqué des règles de données BigQuery.
Ce rôle a été automatiquement associé à votre compte utilisateur actif lors de votre première exécution de setup_lab1.sh.
Créer la taxonomie et le tag avec stratégie
Créez une taxonomie de données et un tag avec stratégie associé pour gérer l'accès à vos données.
- Accédez à la page Catégories de tags avec stratégie.
- Cliquez sur + Créer une taxonomie.
- Configurez les paramètres :
- Nom de la taxonomie : saisissez
lost-cargo-en remplaçant par l'ID de votre projet. - Région : sélectionnez votre région.
- Pour le nom du tag avec stratégie, saisissez
MaskCustodianID. - Pour la description du tag avec stratégie :
Restricts visibility into cargo custodian usernames
- Nom de la taxonomie : saisissez
- Cliquez sur Créer pour enregistrer votre nouvelle taxonomie et votre nouvelle balise de règle.
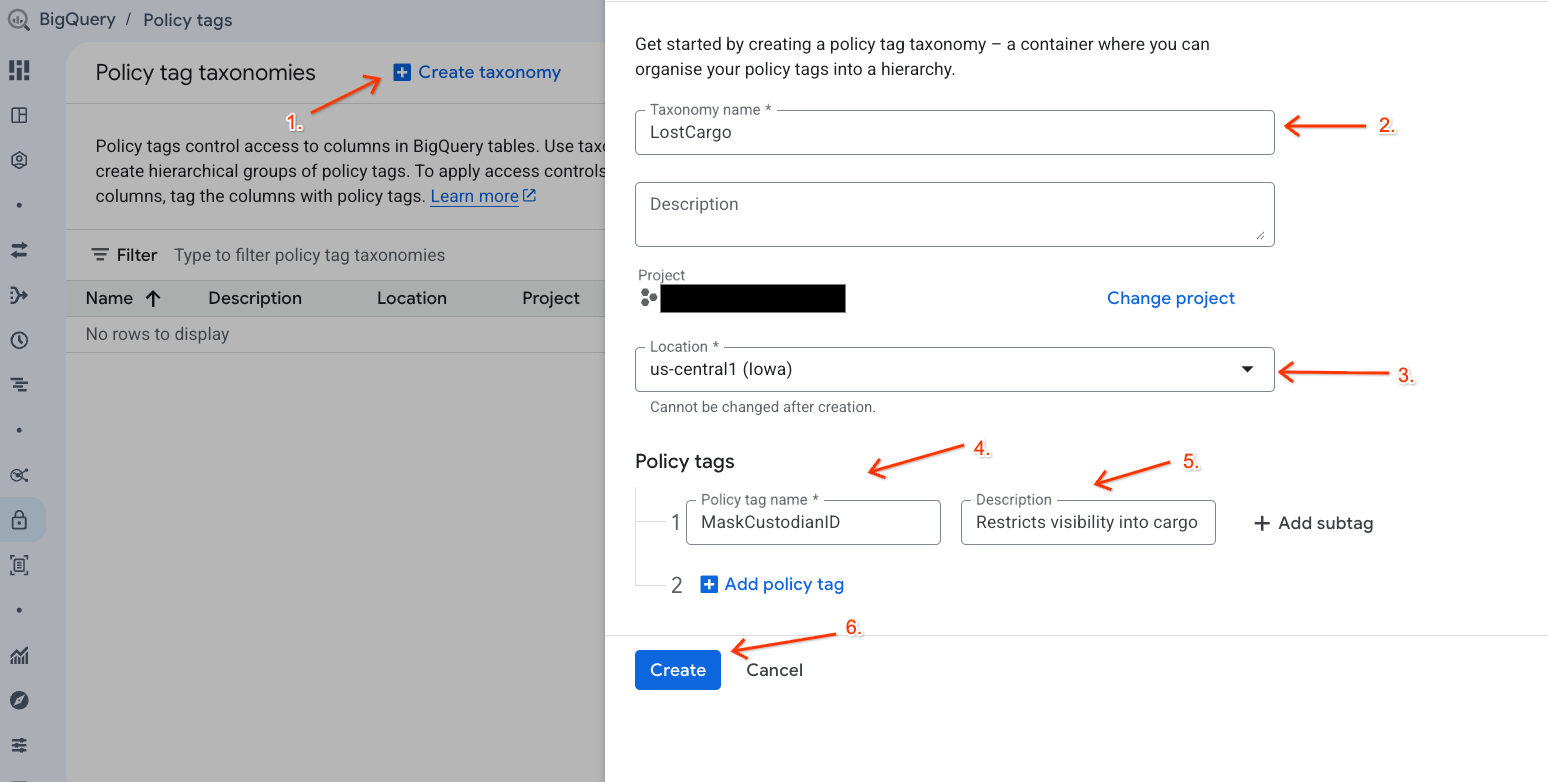
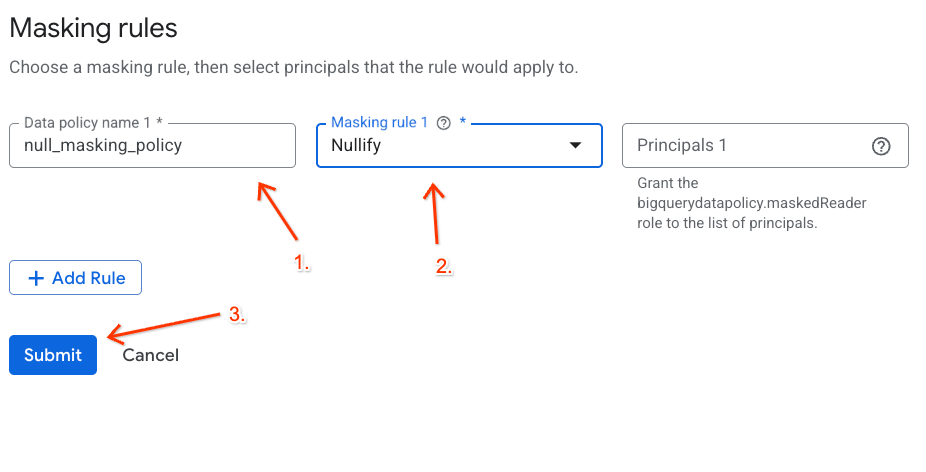
Créer la règle de masquage des données
Ensuite, configurez une règle de données pour définir comment les données sont masquées sous le tag de classification MaskCustodianID. Vous utiliserez la règle de masquage Toujours nul (qui remplace les valeurs correspondantes par des valeurs vides/nulles pour tous les acteurs non privilégiés).
- Sur la page Taxonomies de tags avec stratégie, cliquez sur la taxonomie que vous venez de créer dans la liste des taxonomies.
- Dans la liste de la hiérarchie, cliquez sur le tag
MaskCustodianIDpour le sélectionner, puis cliquez sur Gérer les règles relatives aux données.
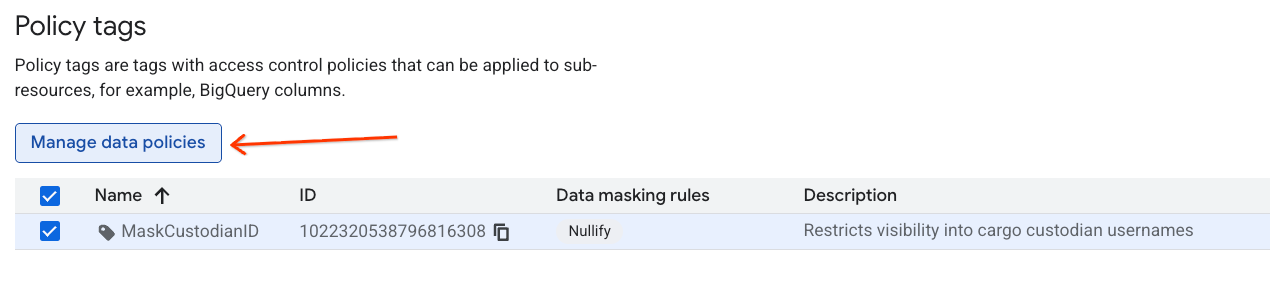
- Dans le panneau de droite, cliquez sur le bouton + Ajouter une règle.
- Configurez les détails de la règle dans le panneau qui s'affiche :
- Nom de la règle de données : saisissez
null_masking_policy(ne laissez pas le nom généré automatiquement, car nous y ferons référence dans les étapes suivantes). - Règle de masquage : sélectionnez
Nullifydans le menu déroulant.
- Nom de la règle de données : saisissez
- Cliquez sur Envoyer.
Attribuer le tag avec stratégie à votre colonne BigQuery
Une fois le tag avec stratégie et sa règle de masquage des données activés, mappez le tag de classification directement à la colonne custodian_id de votre table BigQuery de manifeste d'expédition des partenaires.
- Accédez à la BigQuery.
- Dans le panneau Explorateur à gauche, développez votre projet actif, l'ensemble de données
lost_cargo_dataset, puis cliquez sur la tableshipping_manifestspour ouvrir sa vue détaillée. - Cliquez sur Modifier le schéma.
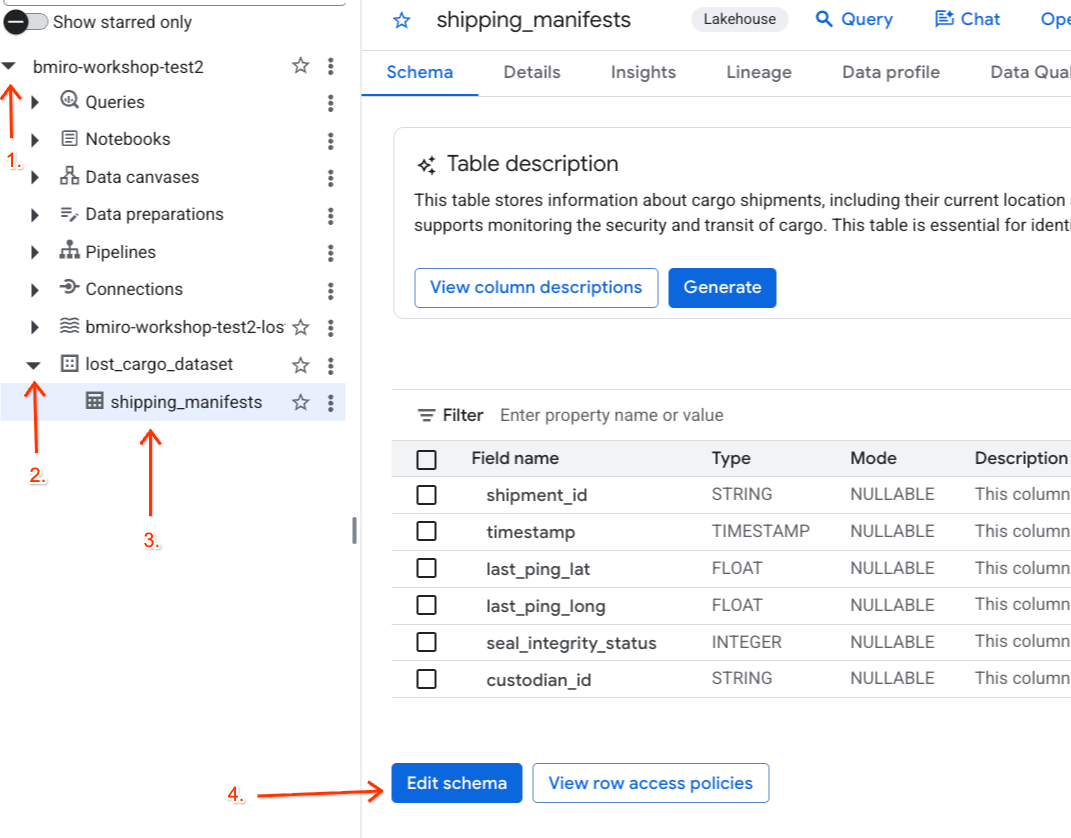
- Dans la liste des colonnes, cochez la case à côté de
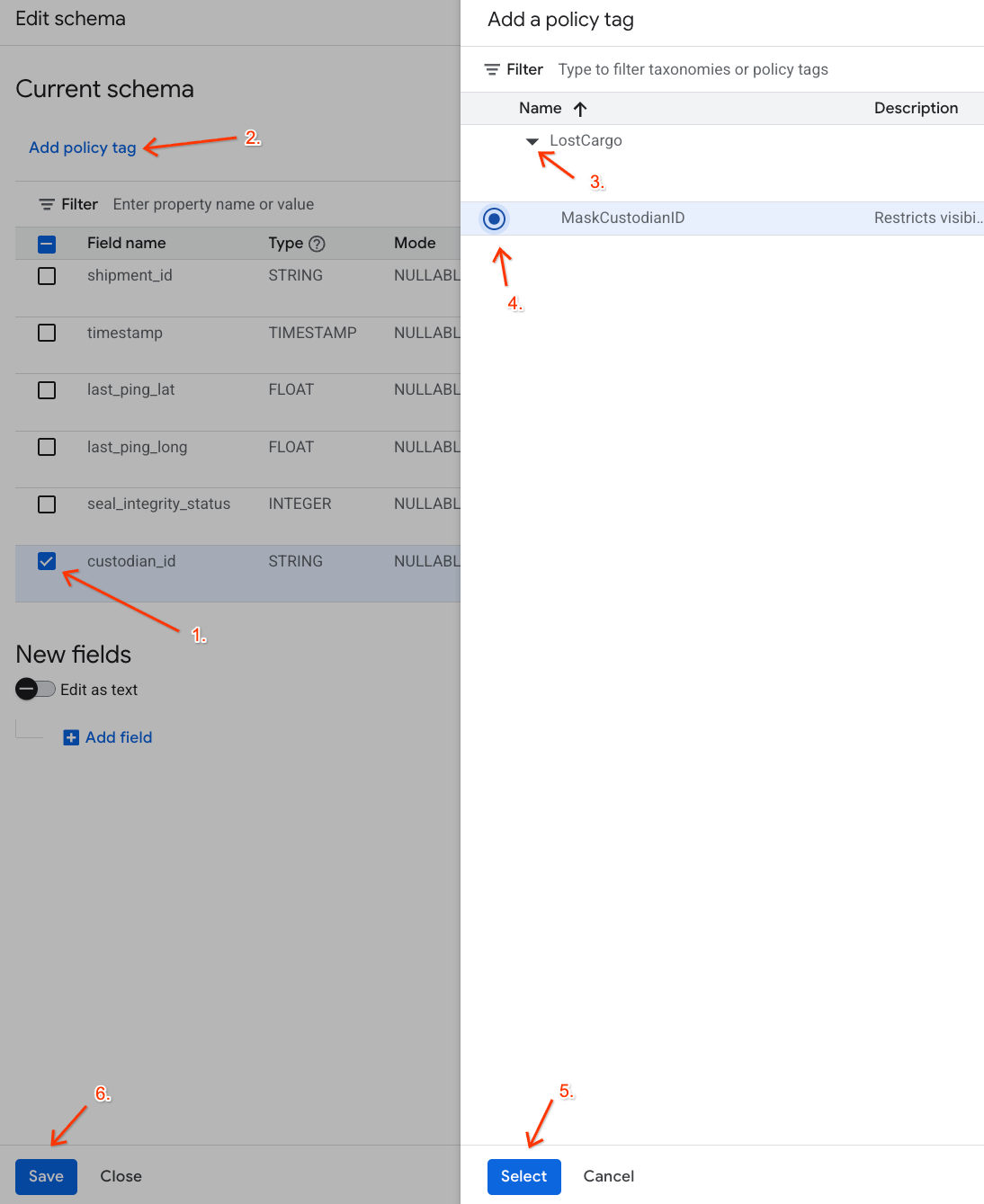
custodian_id. - Cliquez sur le bouton Ajouter un tag avec stratégie dans la barre d'outils supérieure de l'éditeur de schéma.
- Dans le panneau Ajouter un tag avec stratégie :
- Localisez et développez votre taxonomie
LostCargo. - Sélectionnez la bulle à côté de
MaskCustodianID. - Cliquez sur Sélectionner.
- Localisez et développez votre taxonomie
- Vérifiez que le tag
MaskCustodianIDest désormais visible dans la colonne Tag avec stratégie de la ligne représentantcustodian_id. - Cliquez sur Enregistrer.
Vérifier les restrictions liées aux règles
Maintenant que vous disposez du rôle Lecteur masqué au niveau du projet, vous pouvez interroger la table pour vérifier que la règle de masquage est active.
Revenez au kit de l'agent de données et exécutez la requête suivante :
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
La sortie obtenue doit ressembler à ceci :
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
Opération réussie ! Même si vous pouvez afficher les enregistrements shipment_id, le champ sensible custodian_id renvoie des masques sécurisés null pour éviter les fuites.
8. Effectuer un nettoyage
Pour éviter que les ressources créées pendant cet atelier de programmation soient facturées en permanence sur votre compte Google Cloud, exécutez les commandes suivantes dans votre terminal Cloud Shell pour supprimer vos ensembles de données et vos buckets :
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. Félicitations
Félicitations ! Vous avez terminé le premier module crucial de l'enquête Cargaison perdue. Vous avez établi une zone de recherche régie à l'aide des catalogues REST Iceberg Lakehouse, de la normalisation des journaux PySpark et du masquage précis des données.
Connaissances acquises
- Installer, configurer et configurer l'extension Data Agent Kit dans votre espace de travail IDE.
- Établissement d'un catalogue REST Iceberg Lakehouse sans serveur utilisant des identifiants vendus et des espaces de noms hiérarchiques.
- Ingestion de flux régionaux multiformats et création de tables externes BigQuery sur des buckets Cloud Storage.
- Lancer des jobs Apache Spark sans serveur pour analyser, normaliser, segmenter et réécrire les journaux de transpondeur non structurés dans BigQuery en tant que tables de catalogue Iceberg enregistrées.
- Créer des taxonomies de sécurité et mapper les règles de masquage des données Knowledge Catalog pour éviter les fuites d'identité sur les index de journaux sensibles.
- Générez et analysez des insights sur les métadonnées des tables à l'aide des insights sur les données BigQuery pour accélérer l'exploration des données.
Validation des indices collectés
Vérifiez que vous avez enregistré les indices définitifs suivants, nécessaires pour passer à la phase suivante de l'atelier :
- ID du colis perdu :
MV-CAT-001(dernier emplacement ping : Londres) - Destination cible prévue :
New York(et alias réel du transpondeur :MV-DOG-002) - Couleur du conteneur :
Crimson RED - Tag d'accès à la gouvernance :
MaskCustodianID
Prêt pour la prochaine phase ?
Maintenant que les itinéraires de départ / destination du transpondeur sont sécurisés, l'enquête se poursuit. Passez directement à l'atelier 2 pour examiner les caméras de sécurité à l'aide des modèles multimodaux Gemini, identifier visuellement le navire et effectuer des recherches vectorielles dans AlloyDB afin de vérifier les anomalies de falsification.
➡️ Passez à l'étape 2 : Analyse des données et insights multimodaux