
1. מבוא
בשיעור ה-Lab הזה תיכנסו לנעליו של חוקר נתונים מוביל בחברת לוגיסטיקה גלובלית. מישהו העלים מכולת מטען יקרת ערך שמכילה בובות אספנות יקרות של אנדרואיד! כדי למצוא את המיקום האחרון הידוע של המכולה ולעקוב אחרי המסלול שלה, תצטרכו לצבור נתונים ממניפסטים של משלוחים מפוצלים של שותפי לוגיסטיקה אזוריים ומקובצי יומן לא מובנים של משדרי תגובה. כדי לעשות זאת, תצטרכו להגדיר Google Cloud Open Data Lakehouse מודרני.

הפעולות שתבצעו:
- מגדירים את התוסף Google Cloud Data Agent Kit ב-Cloud Shell Editor.
- יוצרים קטגוריה של Cloud Storage ומקצים קטלוג REST של Lakehouse Apache Iceberg ומרחב שמות.
- ממפים טבלה חיצונית של BigLake למניפסטים של שותפים בפורמט JSON גולמי ב-Cloud Storage כדי לגלות את הרמז לגבי מועד ההפלגה של הספינה.
- טעינה ועיבוד של יומני טקסט לא מובנים של משדרים באמצעות Managed Service for Apache Spark serverless. ביצוע נורמליזציות של ביטויי regex וחילוץ רמזים דינמיים כדי לטרגט את יעד המטען הייעודי (payload) שאבד.
- כתיבת מדדי היומן המנותחים כטבלת Apache Iceberg דרך קטלוג REST.
- אפשר לשוחח עם סוכן AI על נתוני Apache Iceberg באמצעות ניתוח נתונים שימושי כדי לגלות רמזים חבויים לגבי המשלוח האבוד.
- אפשר להשתמש בתובנות אוטומטיות שמבוססות על נתונים באמצעות Knowledge Catalog כדי ליצור מטא-נתונים על הנתונים שלכם.
- כדי להגדיר אמצעי הגנה על נתונים שנכנסים למערכת, צריך ליצור טקסונומיה של אבטחה ולהשתמש בKnowledge Catalog כדי להחיל בקרת גישה מפורטת באמצעות מיסוך של מזהים רגישים של בעלי משמורת.
הדרישות
- דפדפן אינטרנט כמו Chrome.
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
- היכרות עם שאילתות SQL בסיסיות ופקודות טרמינל.
עלות ומשך צפויים
- זמן משוער לביצוע: כ-45 דקות.
- עלות משוערת: פחות מ-20.00 ILS.
2. לפני שמתחילים
יצירה או בחירה של פרויקט ב-Google Cloud
- במסוף Google Cloud, בוחרים פרויקט או יוצרים פרויקט חדש ב-Google Cloud.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. איך מוודאים שהחיוב מופעל בפרויקט
הגדרת הסביבה
רוב הפקודות יופעלו מהטרמינל המשולב ב-Cloud Shell Editor, סביבת פיתוח מבוססת-ענן שנטענת מראש עם כלי פיתוח ועם Google Cloud SDK רגיל.
- פותחים את Cloud Shell Editor בכרטיסייה חדשה.
- כדי לשכפל את המאגר, מריצים את הפקודה הבאה בטרמינל:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - מגדירים את מזהה הפרויקט. אפשר גם להשתמש בקיצור הדרך
Ctrl+Shift+Vב-Windows/Linux אוCmd+Vב-macOS כדי להדביק את הפקודה בטרמינל:export PROJECT_ID="<YOUR_PROJECT_ID>" - עכשיו מגדירים אותו בסביבה.
gcloud config set project $PROJECT_ID - בוחרים אזור.
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - מפעילים את ממשקי ה-API הנדרשים.
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
התקנת התוסף
עכשיו צריך להגדיר את התוסף Google Data Agent Kit, כלי לאינטראקציה עם כלי הנתונים של Google Cloud ישירות בסביבת הפיתוח המשולבת (IDE).
- בסרגל הפעילות הימני של כלי העריכה, לוחצים על סמל התוספים (או לוחצים על
Ctrl+Shift+Xב-Windows/Linux, או עלCmd+Xב-macOS). - בתיבת החיפוש של התוספים, מקלידים:
Google Cloud Data Agent Kit - בוחרים את התוסף הרשמי מתוך התוצאות ולוחצים על התקנה. אם מוצגת בקשה לעשות זאת, בוחרים באפשרות 'כן, אני סומך על המחברים'.
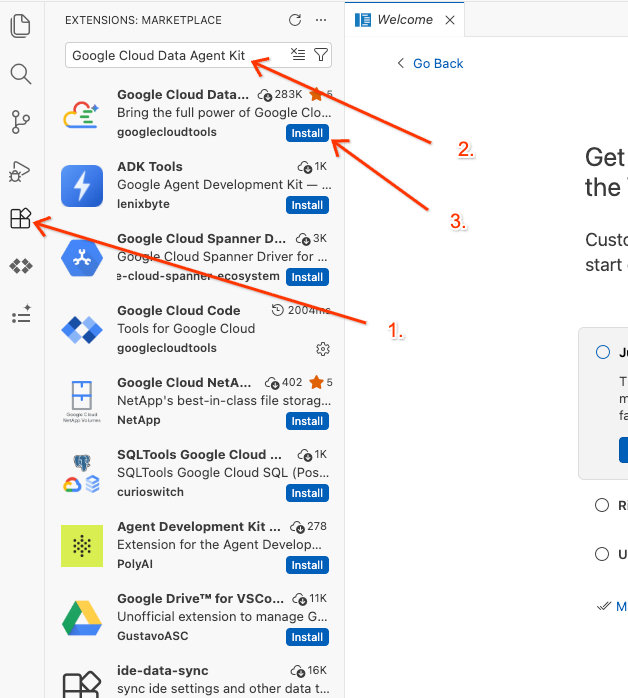
- אחרי ההתקנה, הסמל של Google Cloud Data Agent Kit אמור להופיע בסרגל הפעילות. לוחצים עליו.
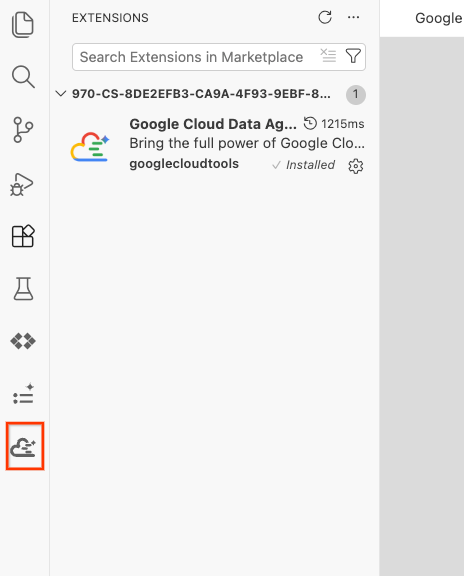
- לוחצים על כניסה לענן.
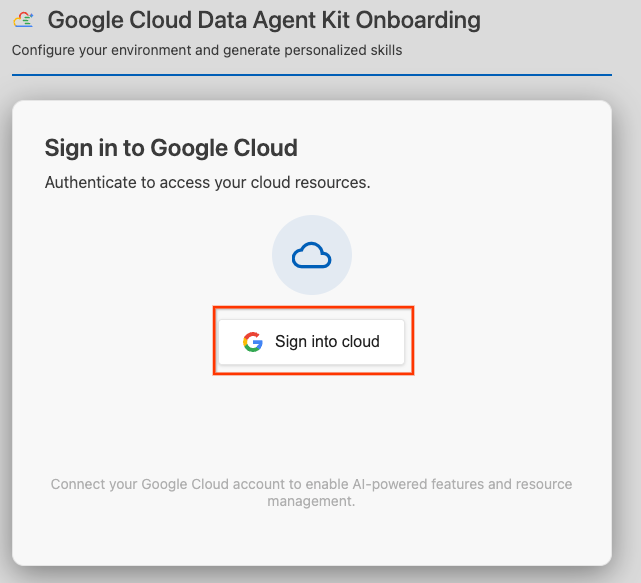
- לוחצים על Configure MCP Servers (הגדרת שרתי MCP).
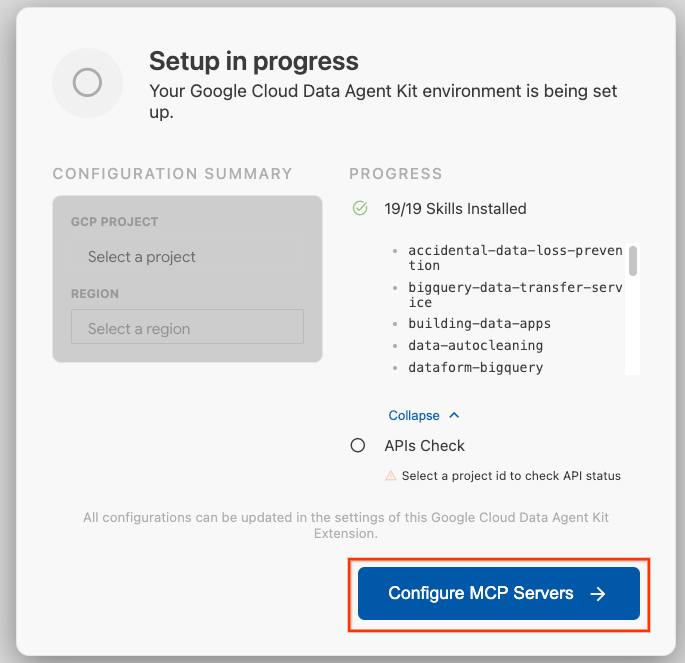
- בוחרים באפשרות BigQuery, Knowledge Catalog, Apache Spark ו-AlloyDB. תשתמשו ב-AlloyDB בשיעור Lab 2. לוחצים על שנתחיל?.
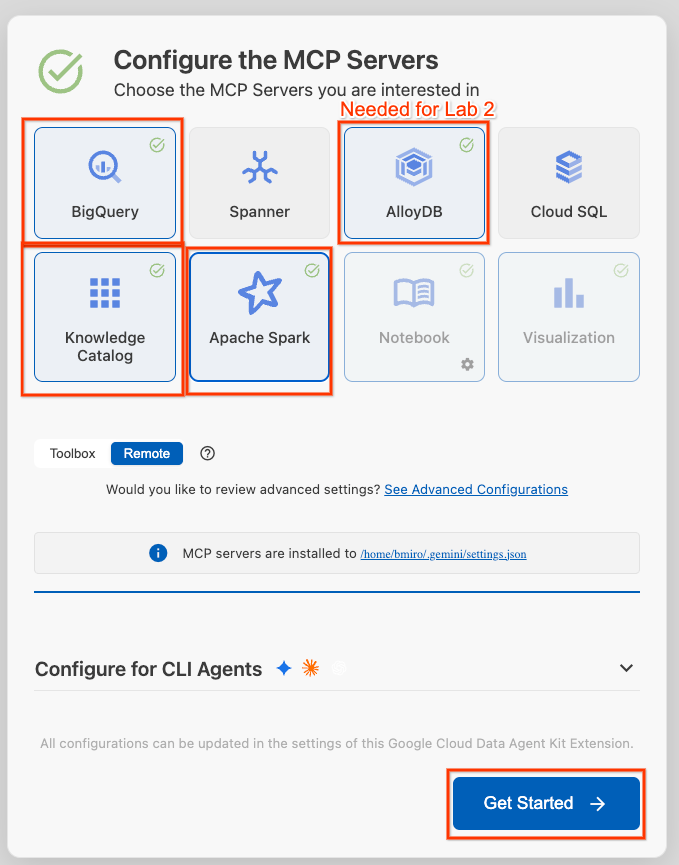
- לוחצים על בורר מזהה הפרויקט בסרגל הסטטוס התחתון ובוחרים את הפרויקט הפעיל ב-Google Cloud.
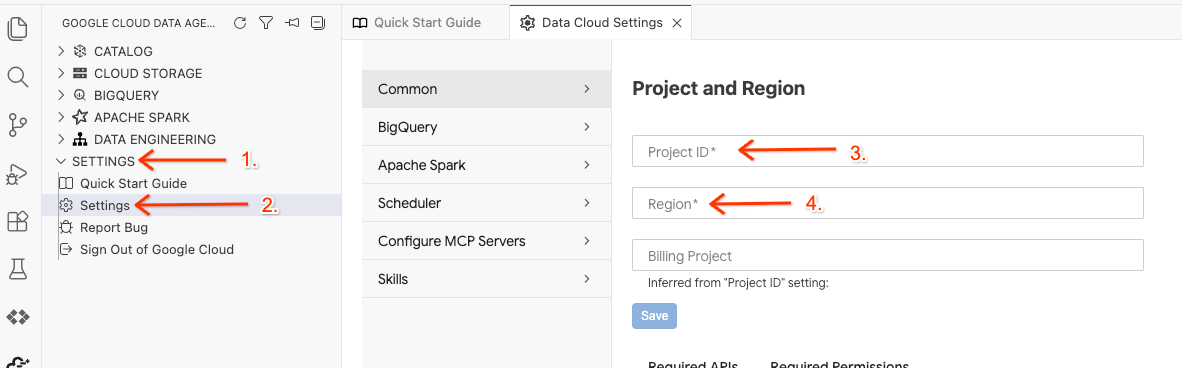
- ב-Data Agent Kit, לוחצים על SETTINGS (הגדרות) ואז על Settings (הגדרות). בכרטיסייה Common (כללי), בוחרים את Project ID (מזהה הפרויקט) ואת Region (האזור) להפעלת המעבדה, למשל us-central1.
- לוחצים על BigQuery Settings (הגדרות BigQuery) ומחליפים את Region (אזור) באזור שבחרתם קודם. לוחצים על שמירה.
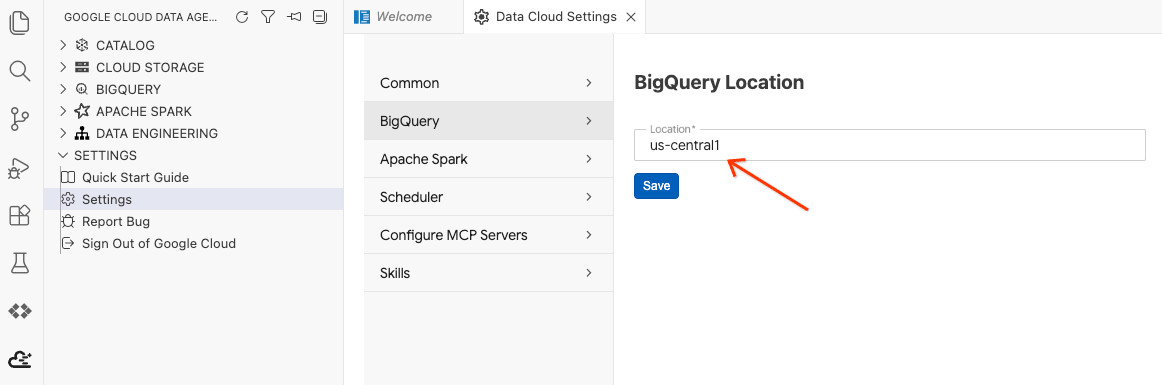
עכשיו אפשר להשתמש ב-Data Agent Kit!
הפעלת סקריפט להגדרת הסביבה
בטרמינל, מריצים את סקריפט ההגדרה כדי ליצור את משאבי הרקע הנדרשים לשיעור ה-Lab הזה ולהגדיר את הרשאות ה-IAM:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
יוצגו סדרה של שלבי פלט שמראים אילו משאבים מוקצים. נלמד על כל אלה במהלך שיעור ה-Lab.
אחרי שמופיעה הודעת סיום, אפשר להתחיל:
==================================================== Environment Setup Complete! ====================================================
עכשיו נתחיל את החיפוש.
3. העלאת מניפסטים של משלוחים משותפים
נתוני מניפסט המשלוח מכלי שיט של שותפים מאוחסנים בפורמט JSON Lines (JSONL) רגיל בקטגוריה שלכם: gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl.
לפני שתבצעו ניתוח נתונים מעמיק, תיצרו טבלת BigLake מנוהלת עבור הנתונים הלא מובנים האלה. כך תוכלו לבדוק את נתוני הלוגיסטיקה של השותף באופן מיידי באמצעות SQL סטנדרטי, בלי לשלם על ייבוא כפול.
פותחים את סביבת העבודה בכלי לעריכת שאילתות ומריצים את השאילתה
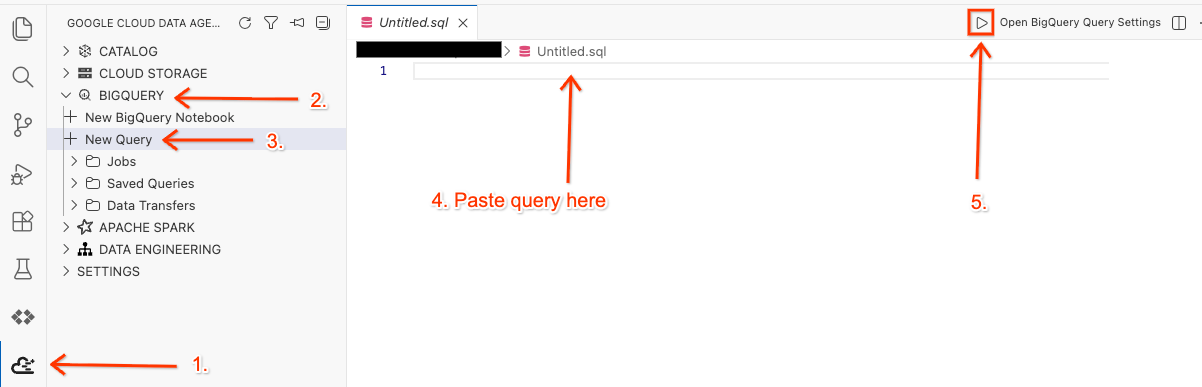
- ב-Cloud Shell Editor, לוחצים על סמל התוסף Google Cloud Data Agent Kit בחלונית הצדדית.
- עוברים אל BigQuery ובוחרים באפשרות + New Query (שאילתה חדשה).
- מעתיקים את השאילתה הבאה לחלון השאילתות.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- לוחצים על Run.
- כדי לוודא שהטבלה נוצרה, תופיע הודעה על הצלחה בחלונית Query Results שנפתחת אוטומטית בתחתית.
הפעלת שאילתה בטבלה החיצונית כדי לבודד משדרי תגובה שנפרצו
כדי לזהות את המשדרים שהופרצו, צריך לאתר כשלים כשערך המשתנה seal_integrity_status הוגדר כ-0. מעתיקים את השאילתה הבאה ומריצים אותה בחלון השאילתות שפתחתם קודם:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
בחלונית Query Results (תוצאות השאילתה), אמור להופיע פלט שדומה לזה:
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0.1278 | usr_999_shadow |
4. עיבוד יומנים לא מובנים באמצעות Managed Service for Apache Spark
מצאת את מיקום ההתחלה מהמניפסטים המובנים, אבל המשדר האבוד הפסיק לפעול לגמרי. הפינג האחרון של המשדר השאיר הודעה מוצפנת ולא מובנית בתוך קובץ יומן טקסט גולמי בנתיב GCS gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt.
כדי לעבד ולמפות את יומן הטקסט הזה, לחלץ חותמות זמן, להסוות זהויות ולאתר את המסלול של המטען במורד הזרם, תשלחו משימת Apache Spark (PySpark) ללא שרת אל Managed Service for Apache Spark.
Managed Service for Apache Spark מאפשר לכם להריץ עומסי עבודה של Spark בלי להקצות או לנהל אשכול. השירות מטפל במשאבי המחשוב הבסיסיים, מבצע שינוי גודל אוטומטי שלהם באופן דינמי, ואתם משלמים רק על משך הביצוע.
הסקריפט:
- הזנת הטקסט הגולמי של המשדר, הלא מובנה, שמוקף בסוגריים.
- מחילים מסנני חילוץ של ביטויים רגולריים ב-PySpark SQL כדי להפריד בין חותמות זמן, מטא-נתונים של בעלי משמורת ותוכן גולמי.
- פיצול היומנים המבולגנים לרשומות מסודרות ברמת המשפט.
- מחפשים את היעד הדינמי של הקואורדינטות שבו הסתיים המסלול של מטען הייעוד שאבד.
- מתחברים ל-Lakehouse Apache Iceberg REST Catalog וכותבים את מסגרת הנתונים של היומן המעובד בחזרה ל-Catalog כטבלת ניתוח חדשה שמוצגת ישירות ב-BigQuery.
תיקון סקריפט הניתוח של PySpark
היו דיווחים על פיראטים של Python בים שגרמו לכל מיני בעיות.
- מריצים את הפקודה הבאה כדי לפתוח את הקובץ
process_maritime_logsב-Cloud Shell Editor.cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - כדאי להקדיש זמן לקריאת הקוד ולהבין מה הוא עושה.
- חשוב לוודא שאין בקוד שום דבר שנראה חשוד. אם צריך למחוק משהו, חשוב לשמור את הקובץ באמצעות
Ctrl + S(Windows/Linux) אוCmd + S(Mac).
שליחת משימת Serverless Spark
שולחים את העבודה באמצעות gcloud SDK. ההגדרה מגדירה אוטומטית את עבודת PySpark כדי לגשת לקטלוג Lakehouse.
מריצים את הפקודה הבאה בטרמינל של העורך המשולב.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
ממתינים כמה דקות עד שהסביבה ללא שרתים תופעל, הסקריפט יועלה והלוגיקה של העיבוד תופעל.
אחרי שיוצג פלט שדומה לזה שמופיע בהמשך, הטבלה המעובדת שלכם תיכנס לקטלוג Lakehouse כטבלה מנוהלת של Apache Iceberg.
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
תצוגה מקדימה של היומנים שעברו עיבוד
ב-Query editor של התוסף Data Agent Kit, מעתיקים את השאילתה הבאה כדי לראות תצוגה מקדימה של הנתונים:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
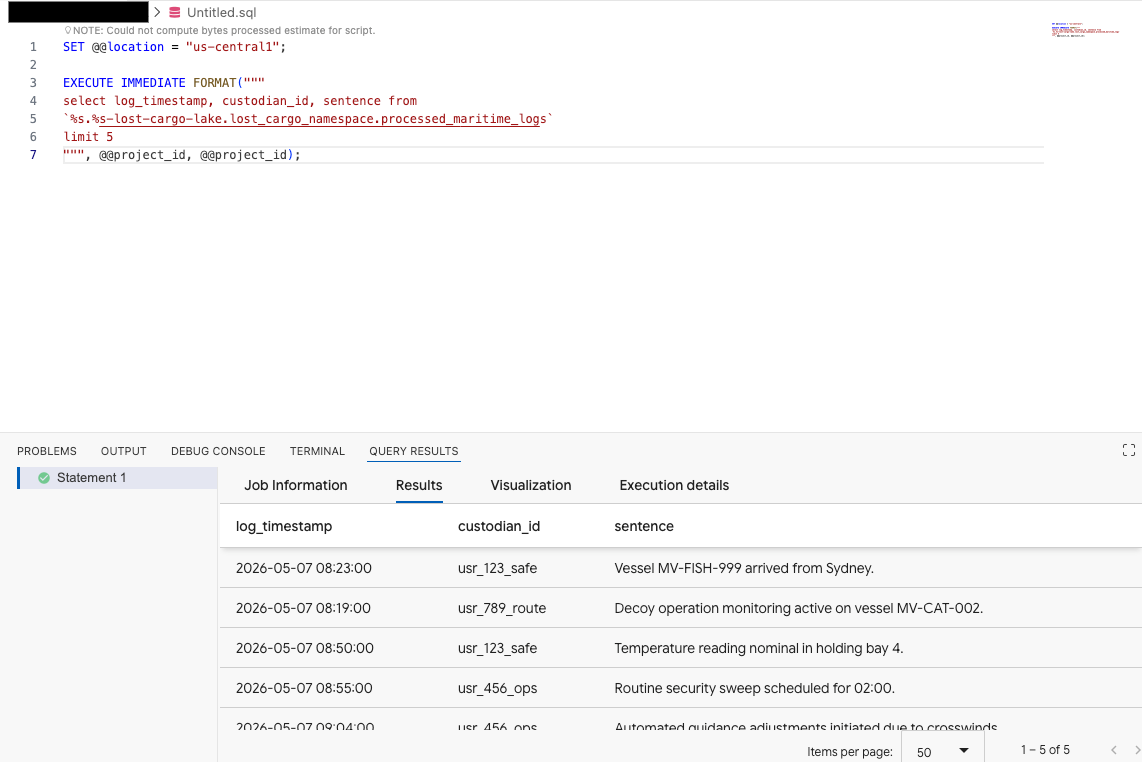
עכשיו אפשר לראות שאפשר לגשת לטבלת Iceberg שרשומה בקטלוג מ-BigQuery.
שליפת רמז לגבי היעד
עכשיו, אחרי שיש לנו את היומנים שעברו עיבוד, נחפש את היומנים שכוללים יעד. משם, אנחנו יכולים לחפש ביומנים רשומות שכוללות אזכור של עיר המוצא שלנו.
בעורך השאילתות, מריצים את השאילתה הבאה, מחליפים את <YOUR_REGION> באזור שלכם ואת <ORIGIN_CITY> בעיר המוצא שגיליתם קודם.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
שיחה עם הנתונים במסוף BigQuery באמצעות ניתוח נתוני שיחות
במקום לכתוב שאילתות SQL מורכבות כדי לבחון את הנתונים, אתם יכולים להשתמש בניתוח נתונים שיחתי כדי לשוחח עם הטבלאות בשפה טבעית.
- עוברים אל מסוף BigQuery.
- בחלונית Explorer בצד ימין, מרחיבים את הפרויקט ואת מערך הנתונים
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logsכדי לפתוח את כרטיסיית הפרטים שלה. - לצד שאילתה, לוחצים על צ'אט.
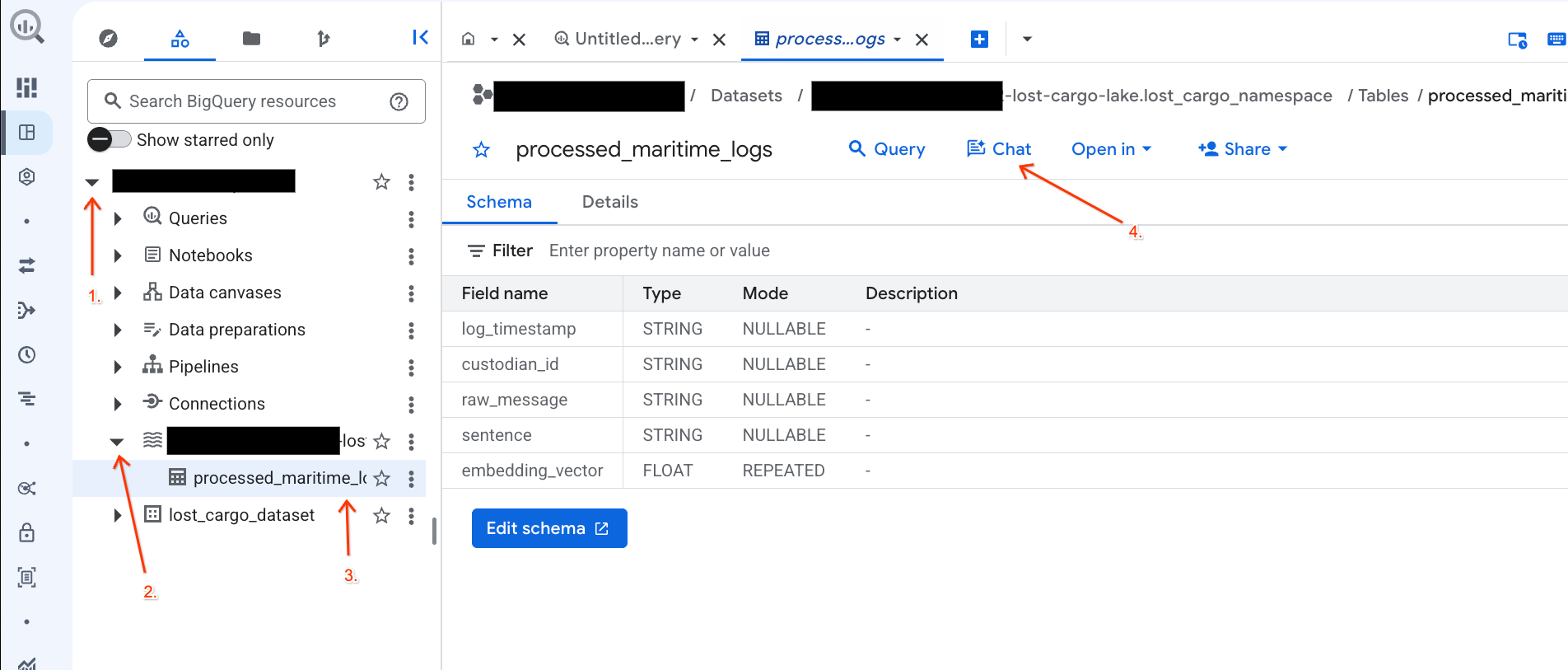
- בחלונית הצ'אט, מקלידים את השאלה הבאה ולוחצים על Enter במקלדת כדי לשלוח אותה:
Based on this table, what color is the shipping container MV-CAT-001?
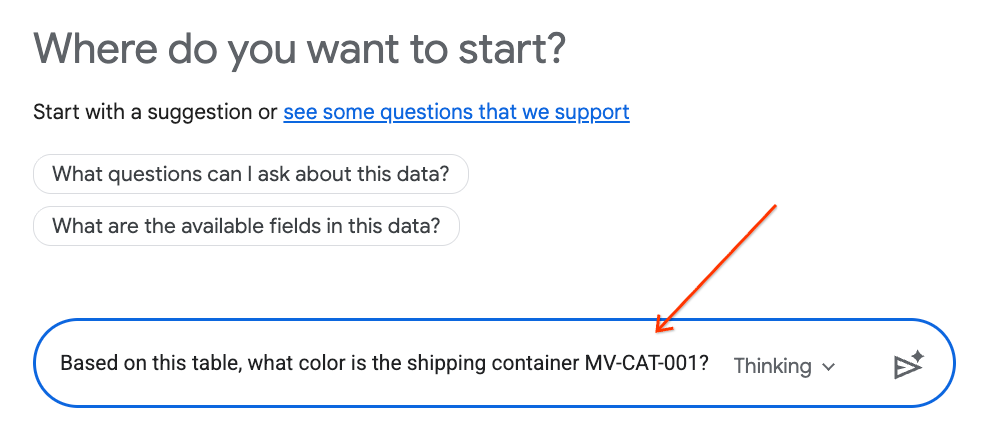
- הניתוח השיחתי (מבוסס Gemini) ינתח את הנתונים בטבלה הפעילה וישיב עם הצבע.
5. צפייה בקטלוג המרכזי של Lakehouse
כדי לשלב מנועי עיבוד בקוד פתוח (כמו Apache Spark) בצורה מאובטחת וחלקה עם מנועי נתונים ארגוניים (כמו BigQuery), סקריפט ההגדרה שלכם הגדיר קטלוג REST של Lakehouse Iceberg.
קטלוג Apache Iceberg REST משמש כ "מקור אמת יחיד (SSOT)" של מטא-נתונים של טבלאות, בלי שרת (serverless). הוא מנהל סכימות ומחיצות של טבלאות באופן דינמי, ומאחסן קבצי נתונים פיזיים בפורמט Parquet ב-Cloud Storage.
אפשר לעיין בקטלוג הזה ישירות במסוף Google Cloud:
- פותחים את Lakehouse Console.
- בכרטיסייה Catalogs (קטלוגים), מאתרים את קטלוג ה-REST הפעיל של Iceberg ולוחצים עליו:
-lost-cargo-lake
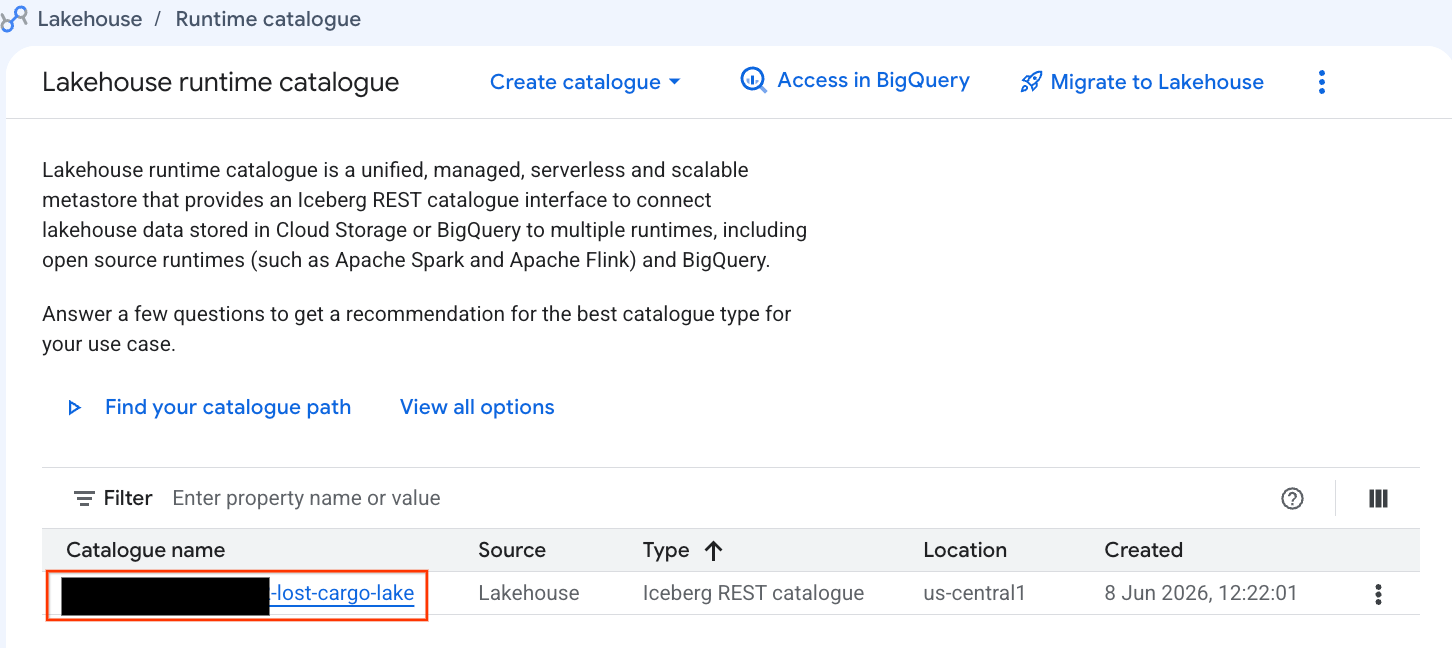
- בתצוגת הפרטים של הקטלוג, בקטע Namespaces (מרחבי שמות), אמור להופיע
lost_cargo_namespace. לוחצים עליו.
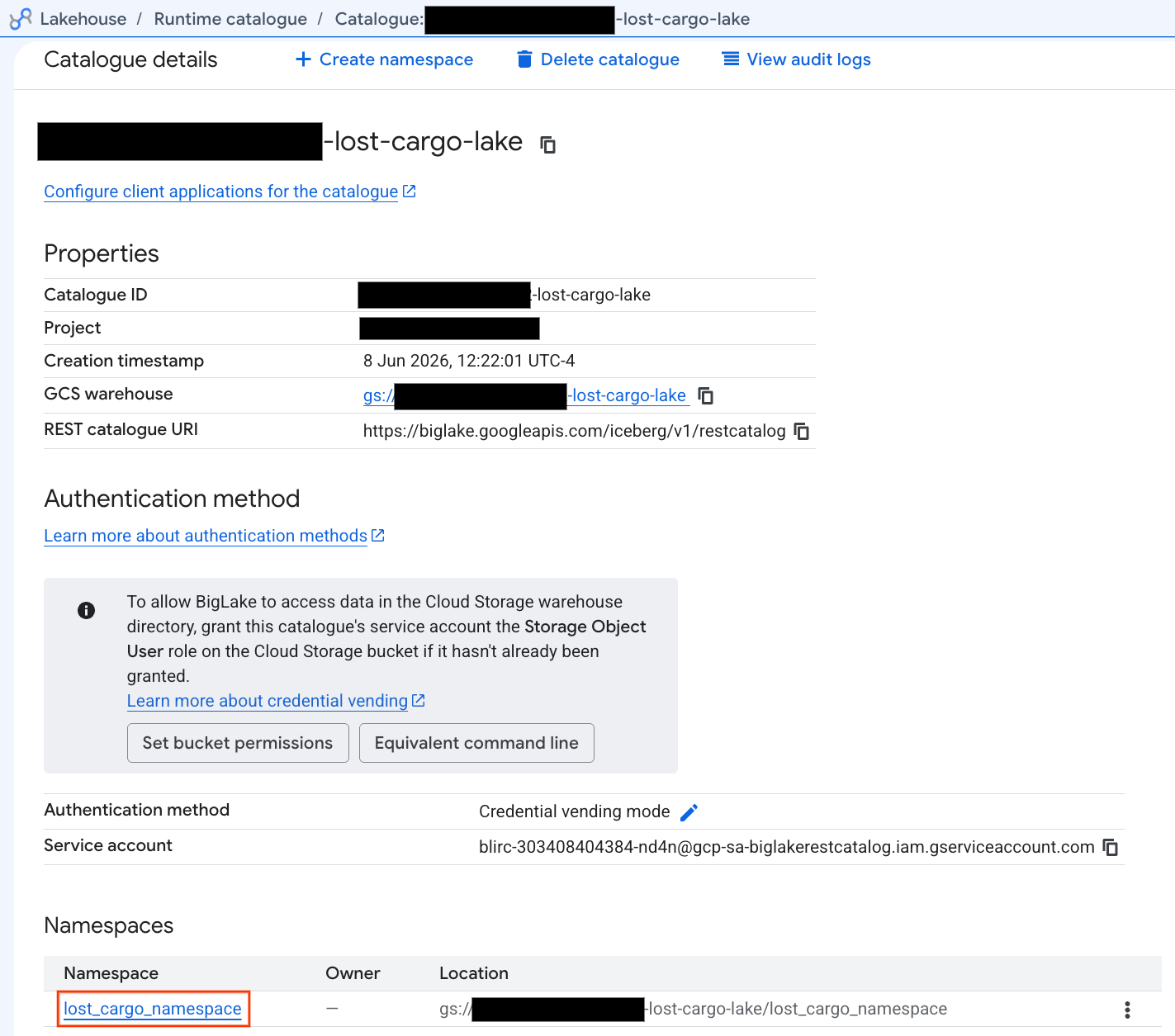
- הטבלה החדשה של Apache Iceberg שנוצרה על ידי PySpark נרשמה אוטומטית במרחב השמות של ה-metastore הזה, ואפשר להריץ עליה שאילתות באופן מיידי ב-BigQuery.
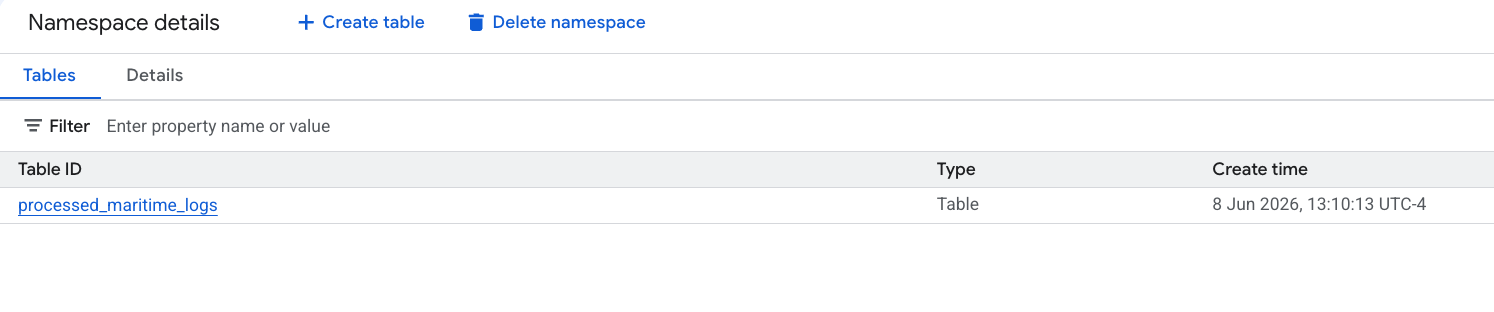
6. יצירת תובנות בטבלה של מניפסטים למשלוחים
נחזור לטבלת shipping_manifests כדי לנתח את המבנה והתוכן שלה באמצעות Knowledge Catalog Data Insights. העשרת המטא-נתונים תעזור למשתמשים אחרים ב-Exploration להבין טוב יותר את הטבלה לצורך ניתוח עתידי.
יצירת תובנות לגבי טבלה ב-BigQuery Studio
- ב-מסוף Google Cloud, עוברים אל BigQuery Studio.
- בחלונית Explorer מרחיבים את הפרויקט, מרחיבים את מערך הנתונים
lost_cargo_datasetולוחצים על הטבלהshipping_manifests. - בחלונית הפרטים שמשמאל, לוחצים על הכרטיסייה תובנות.
- משתמשים בתפריט הנפתח כדי לבחור באפשרות יצירה ופרסום.
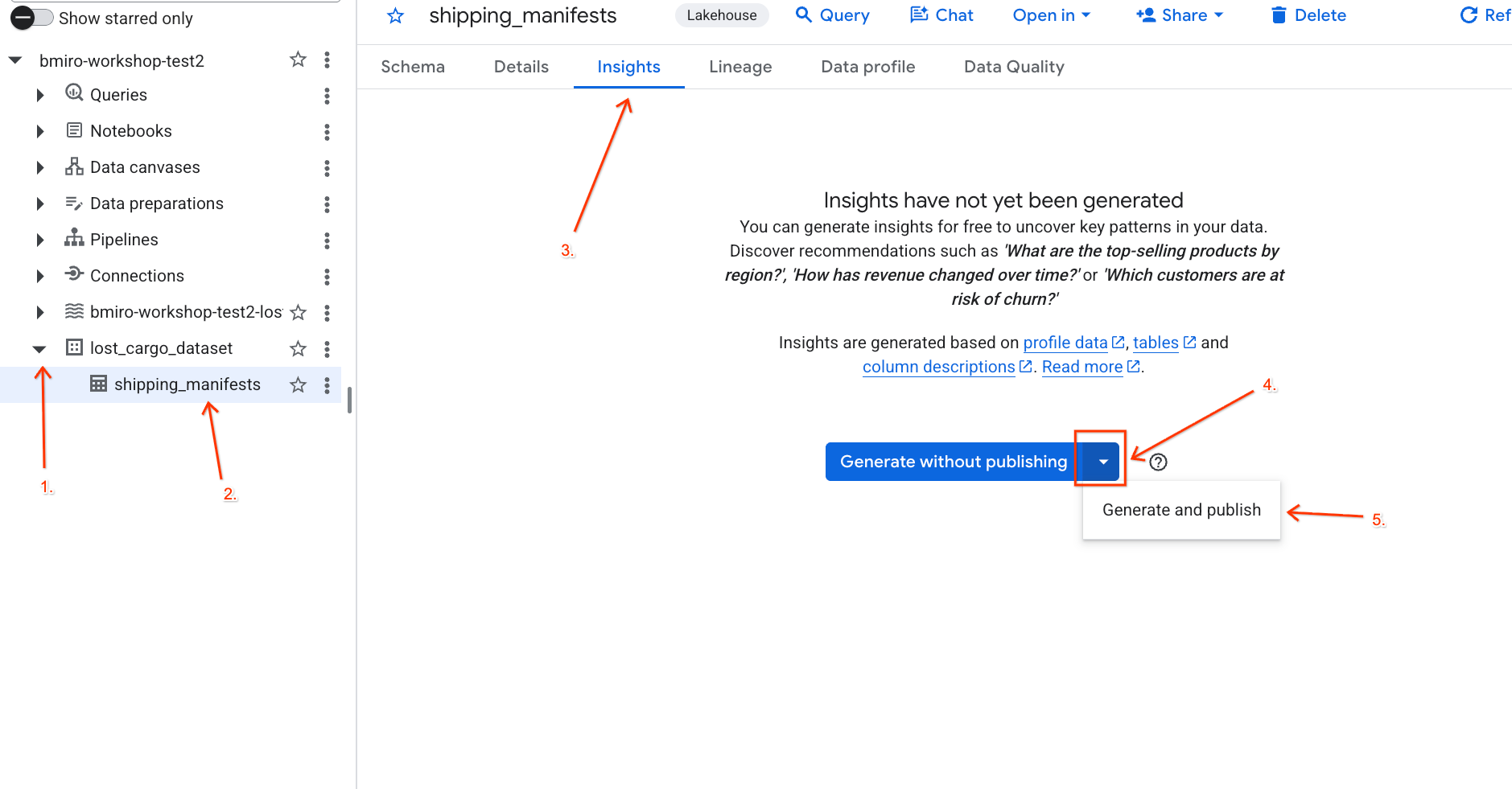
- ממתינים כ-3 דקות עד לסיום יצירת התובנות. Gemini ינתח את המטא-נתונים של הטבלה ויצור שאלות בשפה טבעית ושאילתות SQL תואמות.
- בסיום, תופיע תיאור הטבלה עם הסבר בשפה טבעית על הטבלה.
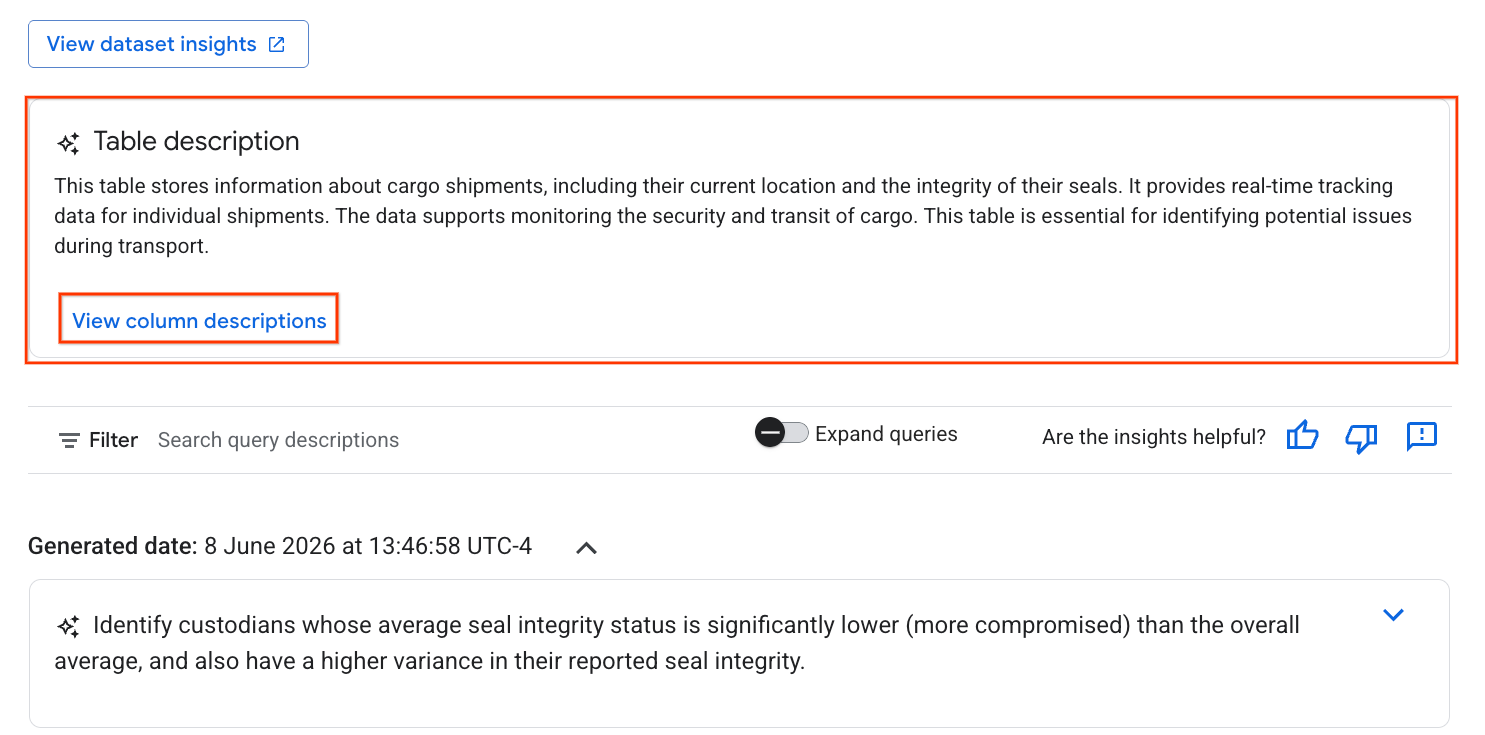
- לוחצים על הצגת תיאורי העמודות כדי לראות מידע על העמודות השונות.
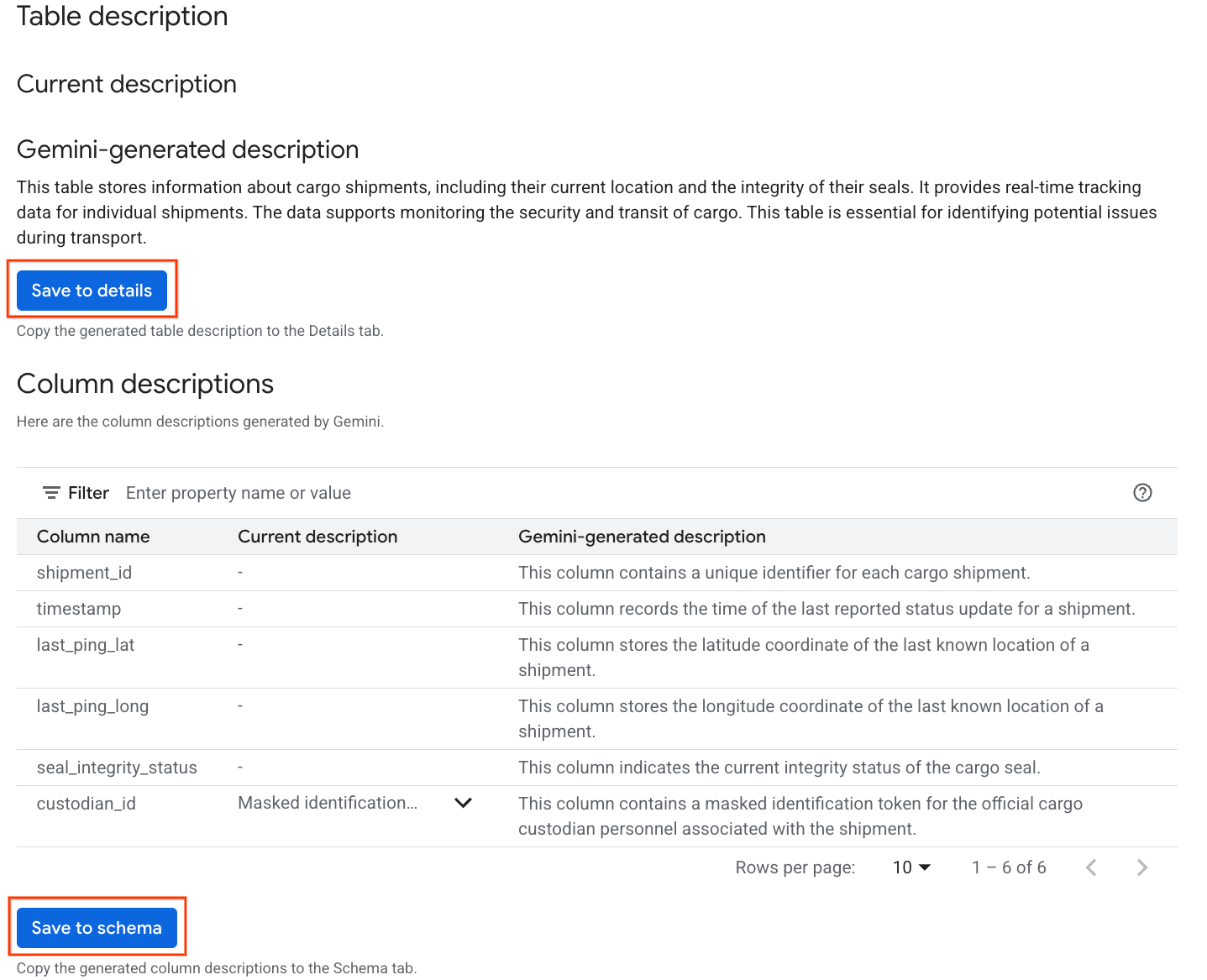
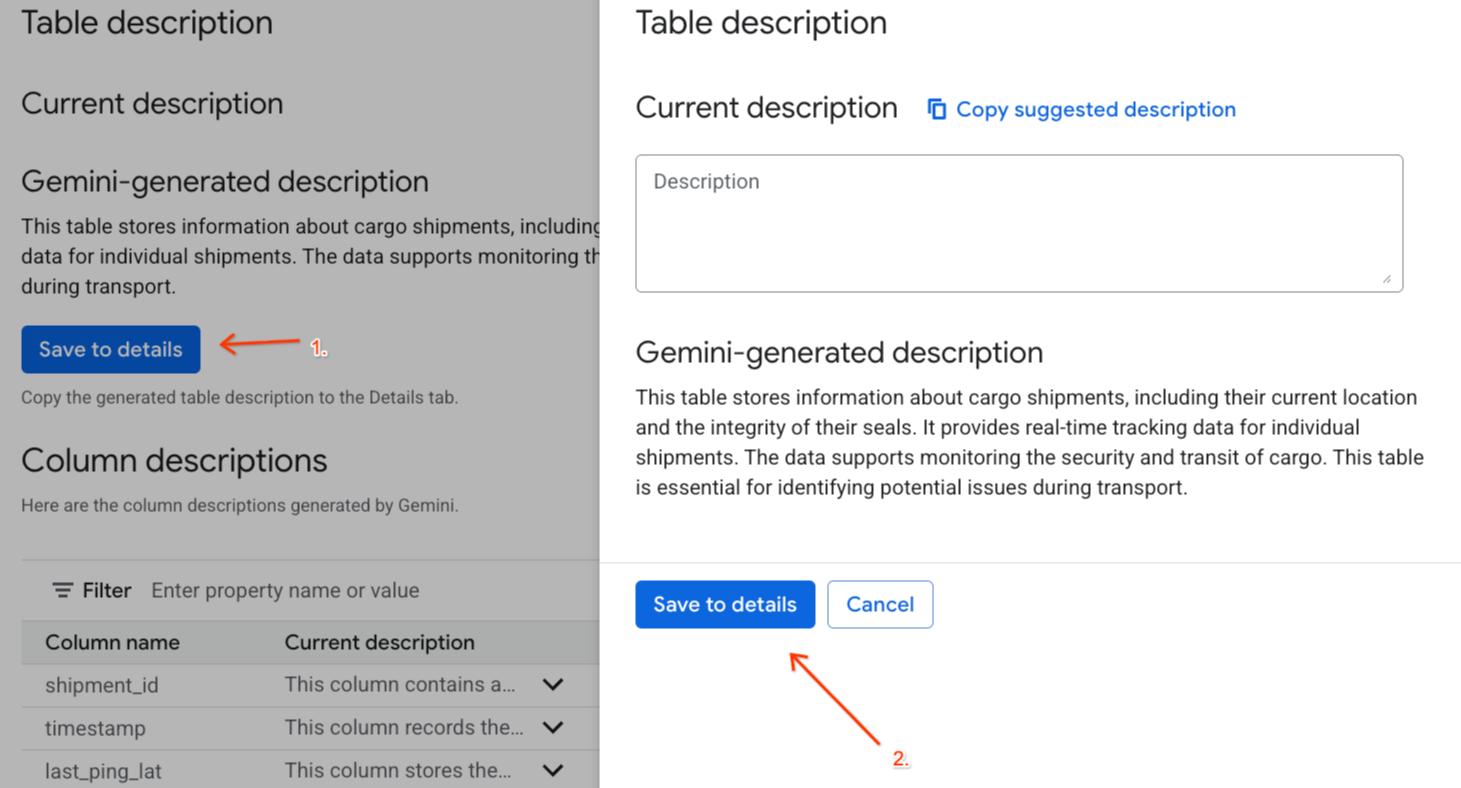
- לוחצים על שמירה בפרטים בקטע
Gemini generated descriptionולוחצים על שמירה בפרטים בחלון שמופיע.
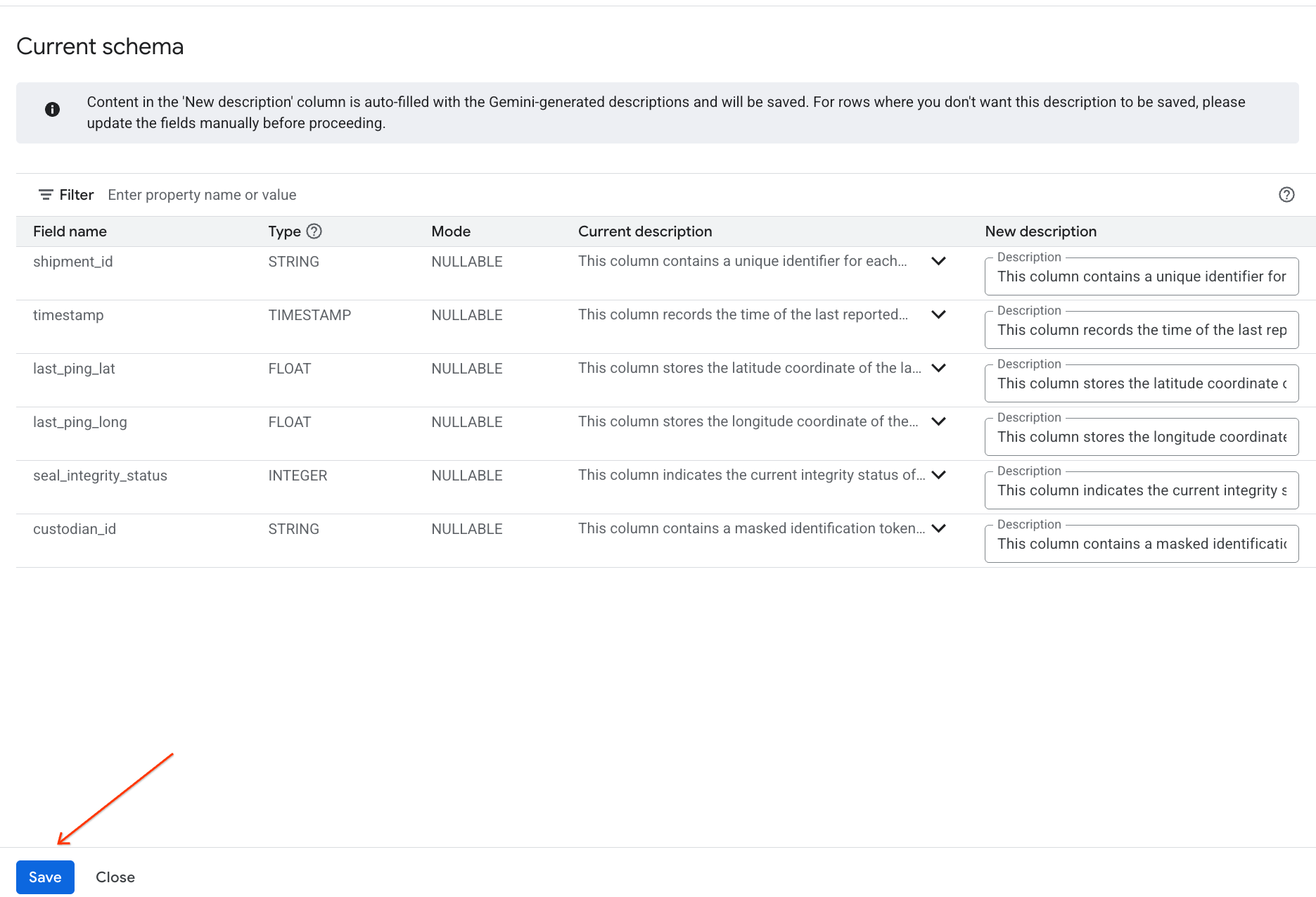
- באופן דומה, לוחצים על שמירה בסכימה כדי להוסיף את תיאורי העמודות למטא-נתונים של הטבלה.
בדיקת התובנות שנוצרו
תוצג גם רשימה של שאלות מוצעות. אפשר ללחוץ על כל שאלה כדי לראות את שאילתת ה-SQL שנוצרה ולהריץ אותה כדי לבדוק את הנתונים. לדוגמה, יכול להיות שיוצגו שאלות כמו:
- "What is the total number of shipments?"
- "List the unique custodian IDs." (תציג את מזהי הנאמנים הייחודיים).
הפעלת השאילתות האלה עוזרת להבין את הנתונים.
7. הטמעה של אנונימיזציה של נתונים ומשילות מידע
כדי להבטיח שחשבונות פעילים למחקר ושמות משתמשים לא ייחשפו במהלך החקירה המתמשכת הזו של מטען, עליך לאכוף פרוטוקולי אבטחה סטנדרטיים. כדי לוודא שפרטיות הנתונים נשמרת, תיצרו טקסונומיה של תגי מדיניות אבטחה ותגדירו Knowledge Catalog Data Masking בעמודה הרגישה custodian_id.
כברירת מחדל, BigQuery חוסם את הגישה לעמודות שמוגנות באמצעות תגי מדיניות. כדי להריץ שאילתה בטבלה ולאמת את מסכות הנתונים הפעילות, לחשבון המשתמש שלכם צריכה להיות מוקצית ההרשאה BigQuery Data Policy Masked Reader.
התפקיד הזה שויך אוטומטית לחשבון המשתמש הפעיל שלכם במהלך ההפעלה הראשונית של setup_lab1.sh.
יצירת הטקסונומיה ותג המדיניות
כדי לנהל את הגישה לנתונים, יוצרים טקסונומיה של נתונים ותג מדיניות שמשויך אליה.
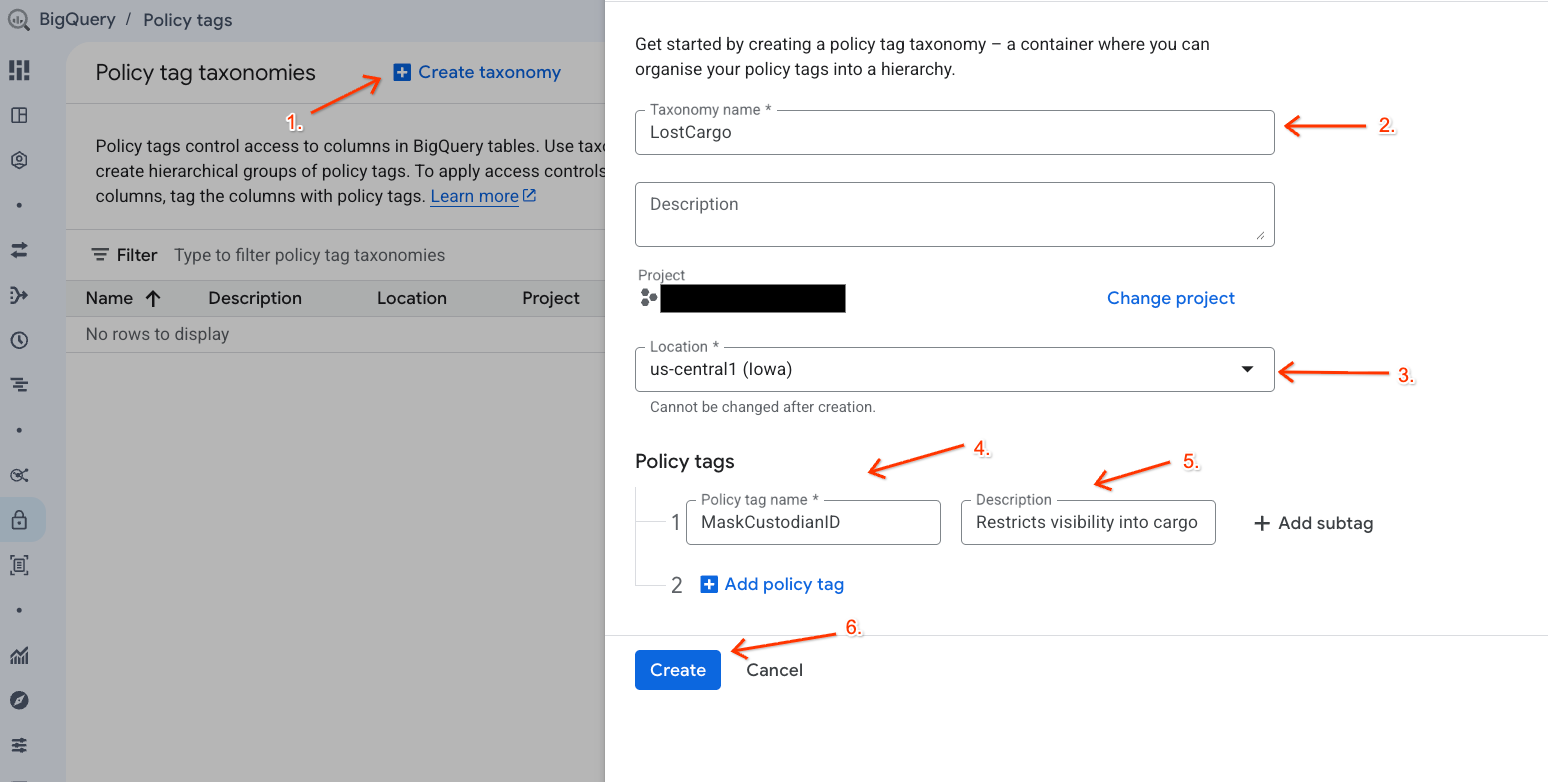
- עוברים לדף טקסונומיות של תגי מדיניות.
- לוחצים על + יצירת טקסונומיה.
- מגדירים את הפרמטרים:
- Taxonomy name (שם הטקסונומיה): מזינים
lost-cargo-ומחליפים את הערך במזהה הפרויקט. - אזור: בוחרים את האזור שלכם.
- בקטע Policy tag Name (שם תג המדיניות): מזינים
MaskCustodianID - בקטע תיאור של תג המדיניות:
Restricts visibility into cargo custodian usernames
- Taxonomy name (שם הטקסונומיה): מזינים
- לוחצים על יצירה כדי לרשום את הטקסונומיה החדשה ואת תג המדיניות.
יצירת מדיניות להסתרת נתונים
לאחר מכן, מגדירים מדיניות נתונים כדי להגדיר איך הנתונים יוסתרו תחת תג הסיווג MaskCustodianID. תשתמשו בכלל ההסתרה Always Null (החלפת ערכים תואמים בהחזרות ריקות או Null לכל השחקנים שאינם בעלי הרשאות).
- בדף טקסונומיות של תגי מדיניות, לוחצים על הטקסונומיה החדשה שנוצרה מתוך רשימת הטקסונומיות.
- ברשימת ההיררכיה, לוחצים על התג
MaskCustodianIDכדי לבחור אותו ואז בוחרים באפשרות ניהול מדיניות נתונים.
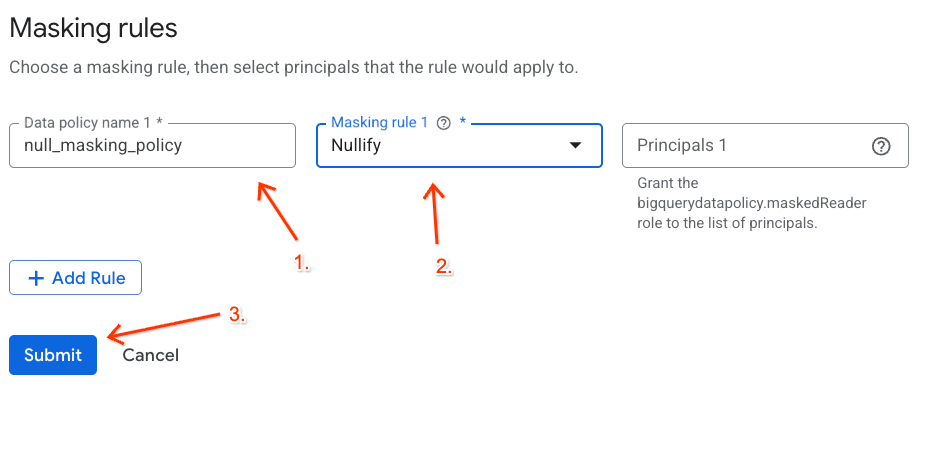
- בחלונית השמאלית, לוחצים על הלחצן + הוספת כלל.
- מגדירים את פרטי המדיניות בחלונית שמופיעה:
- שם מדיניות הנתונים: מזינים
null_masking_policy(לא משאירים את השם שנוצר אוטומטית, כי נתייחס אליו בשם בשלבים הבאים). - כלל מיסוך: בוחרים באפשרות
Nullifyמהתפריט הנפתח.
- שם מדיניות הנתונים: מזינים
- לוחצים על שליחה.
הקצאת תג המדיניות לעמודה ב-BigQuery
אחרי שמפעילים את תג המדיניות ואת כלל מיסוך הנתונים שלו, ממפים את תג הסיווג ישירות לעמודה custodian_id בטבלת מניפסט המשלוחים של השותף ב-BigQuery.
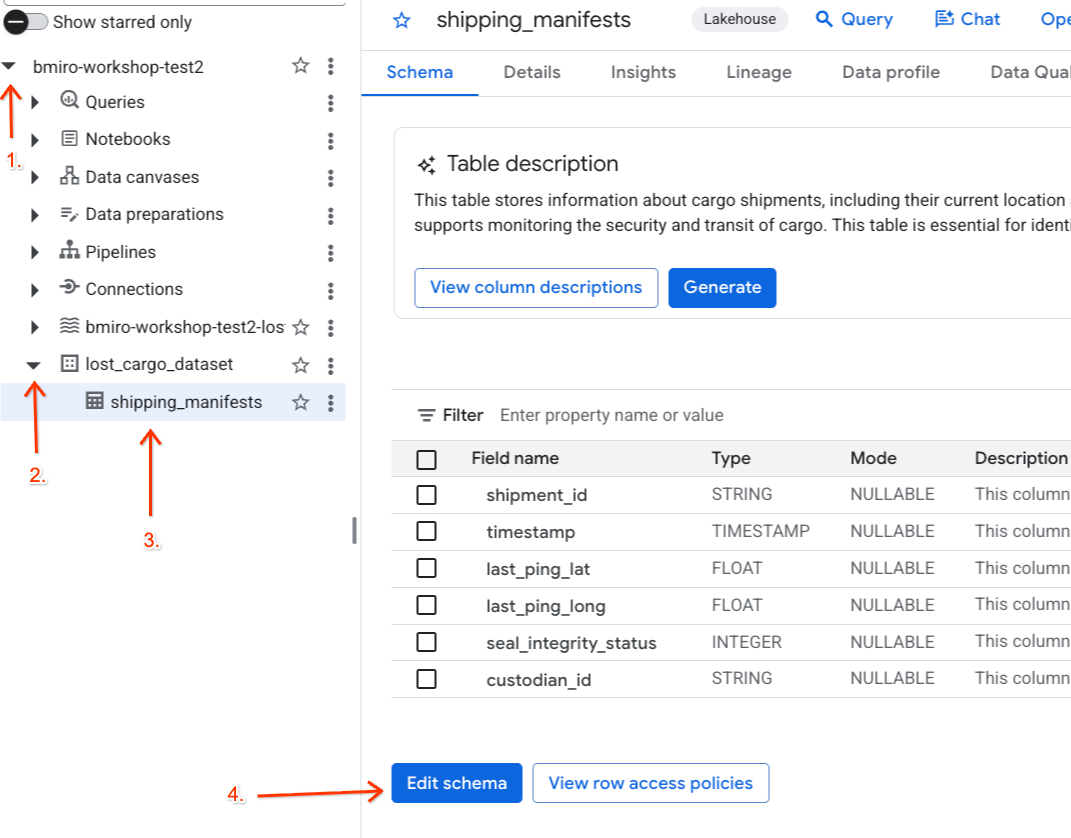
- עוברים אל מסוף BigQuery.
- בחלונית Explorer שמימין, מרחיבים את הפרויקט הפעיל, מרחיבים את מערך הנתונים
lost_cargo_datasetולוחצים על הטבלהshipping_manifestsכדי לפתוח את התצוגה המפורטת שלה. - לוחצים על עריכת סכימה.
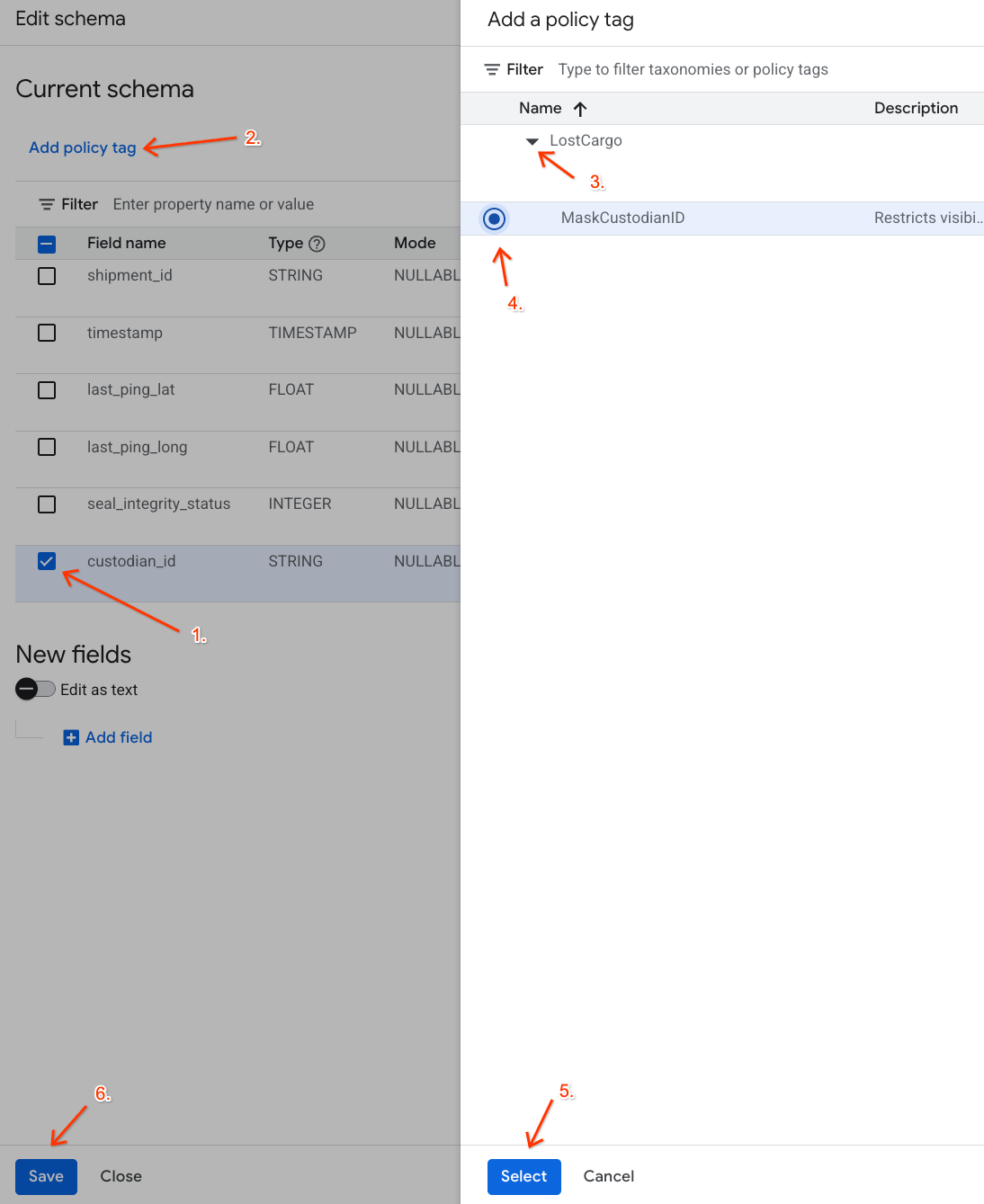
- ברשימת העמודות, מסמנים את התיבה לצד
custodian_id. - לוחצים על הלחצן הוספת תג מדיניות בסרגל הכלים העליון של עורך הסכימה.
- בחלונית הוספת תג מדיניות:
- מאתרים את הטקסונומיה
LostCargoומרחיבים אותה. - לוחצים על העיגול לצד
MaskCustodianID. - לוחצים על בחירה.
- מאתרים את הטקסונומיה
- מוודאים שהתג
MaskCustodianIDמופיע עכשיו בעמודה תג מדיניות בשורה שמייצגת אתcustodian_id. - לוחצים על שמירה.
אימות הגבלות המדיניות
עכשיו, אחרי שיש לכם את התפקיד Masked Reader ברמת הפרויקט, אתם יכולים להריץ שאילתה בטבלה כדי לוודא שמדיניות המיסוך פעילה.
חוזרים ל-Data Agent Kit ומריצים את השאילתה הבאה:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
הפלט אמור להיראות כך:
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
הצלחת! למרות שאתם יכולים לראות את רשומות shipment_id, השדה הרגיש custodian_id מחזיר מסכות מאובטחות null כדי למנוע דליפות.
8. הסרת המשאבים
כדי להימנע מחיובים שוטפים בחשבון Google Cloud על המשאבים שנוצרו במהלך ה-codelab הזה, מריצים את הפקודות הבאות במסוף Cloud Shell כדי להסיר את מערכי הנתונים והקטגוריות:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. מזל טוב
מעולה! השלמת בהצלחה את המודול הראשון והחשוב של החקירה Lost Cargo. הקמתם אזור חיפוש מנוהל באמצעות קטלוגים של Lakehouse Iceberg REST, נורמליזציה של יומנים ב-PySpark והסתרת נתונים ברמת גרנולריות גבוהה.
מה למדתם
- התקנה, הגדרה וקביעת הגדרות של התוסף Data Agent Kit בסביבת העבודה של IDE.
- הקמת קטלוג REST של Iceberg Lakehouse ללא שרת באמצעות אישורים שנרכשו ומרחבי שמות היררכיים.
- הטמעה של פידים אזוריים בגיוון פורמטים ויצירה של טבלאות חיצוניות ב-BigQuery על פני קטגוריות של Cloud Storage.
- הפעלת משימות Apache Spark בלי שרת (serverless) כדי לנתח, לנרמל, לפלח ולכתוב יומנים לא מובנים של משדרים בחזרה ל-BigQuery כטבלאות רשומות בקטלוג Iceberg.
- יצירת טקסונומיות של אבטחה ומיפוי של כללי מדיניות להסתרת נתונים ב-Knowledge Catalog כדי למנוע דליפות של פרטים מזהים במדדי יומנים רגישים.
- יצירה וניתוח של תובנות לגבי מטא-נתונים של טבלאות באמצעות תובנות מנתונים ב-BigQuery כדי להאיץ את תהליך בחינת הנתונים.
אימות באמצעות רמזים שנאספו
מוודאים שרשמתם את הרמזים הבאים שנדרשים כדי להתחיל את השלב הבא בשיעור ה-Lab:
- מזהה משלוח שאבד:
MV-CAT-001(המיקום האחרון שזוהה: לונדון) - יעד מתוכנן:
New York(ומשיב משדר, כינוי אמיתי:MV-DOG-002) - צבע המאגר:
Crimson RED - תג גישה לניהול:
MaskCustodianID
מוכנים לשלב הבא?
עכשיו, כשמסלולי ההמראה והיעד של המשדר מאובטחים, אפשר להמשיך בחקירה. אפשר לעבור ישירות אל מעבדה 2 כדי לבדוק מצלמות אבטחה באמצעות מודלים של Gemini multimodal, לזהות את כלי השיט באופן חזותי ולבצע חיפושים וקטוריים ב-AlloyDB כדי לאמת אנומליות של שיבוש!
➡️ המשך לשלב השני: ניתוח נתונים ותובנות מרובות-אופנים