
1. परिचय
इस लैब में, आपको एक ग्लोबल लॉजिस्टिक्स फ़र्म के लिए, लीड डेटा की जाँच करने वाले व्यक्ति की भूमिका निभानी होगी. कीमती Android फ़िगरीन के कलेक्शन ले जा रहा एक कार्गो कंटेनर गायब हो गया है! इसकी पिछली जगह की जानकारी और रास्ते का पता लगाने के लिए, आपको लॉजिस्टिक्स पार्टनर से मिली शिपिंग मेनिफ़ेस्ट और ट्रांसपॉन्डर की लॉग फ़ाइलों को इकट्ठा करना होगा. इसके लिए, आपको Google Cloud Open Data Lakehouse को कॉन्फ़िगर करना होगा.

आपको क्या करना होगा
- Cloud Shell Editor में, Google Cloud Data Agent Kit एक्सटेंशन को कॉन्फ़िगर करें.
- Cloud Storage बकेट बनाएं और Lakehouse Apache Iceberg REST कैटलॉग और नेमस्पेस उपलब्ध कराएं.
- जहाज़ के रवाना होने के बारे में सुराग पाने के लिए, Cloud Storage में मौजूद पार्टनर के रॉ JSON मेनिफ़ेस्ट में BigLake बाहरी टेबल को मैप करें.
- Managed Service for Apache Spark सर्वरलेस का इस्तेमाल करके, ट्रांसपॉन्डर के बिना स्ट्रक्चर वाले टेक्स्ट लॉग लोड और प्रोसेस करें. खोए हुए पेलोड डेस्टिनेशन को टारगेट करने के लिए, रेगुलर एक्सप्रेशन (रेगुलर एक्सप्रेशन) को सामान्य बनाएं और डाइनैमिक सुराग एक्सट्रैक्ट करें.
- पार्स की गई लॉग मेट्रिक को REST कैटलॉग के ज़रिए, Apache Iceberg टेबल के तौर पर लिखें.
- कन्वर्सेशनल ऐनलिटिक्स का इस्तेमाल करके, एआई एजेंट से अपने Apache Iceberg डेटा के बारे में चैट करें. इससे आपको अपने खोए हुए शिपमेंट के बारे में छिपी हुई जानकारी मिल सकती है.
- अपने डेटा के बारे में मेटाडेटा जनरेट करने के लिए, नॉलेज कैटलॉग की मदद से, डेटा के बारे में अपने-आप जनरेट होने वाली इनसाइट का फ़ायदा लें.
- सुरक्षा से जुड़ी टैक्सोनॉमी बनाकर और नॉलेज कैटलॉग का इस्तेमाल करके, डेटा को सुरक्षित तरीके से इकट्ठा करने के लिए दिशा-निर्देश तय करें. साथ ही, संवेदनशील कस्टोडियन आईडी को मास्क करके, ऐक्सेस कंट्रोल को बेहतर तरीके से लागू करें.
आपको किन चीज़ों की ज़रूरत होगी
- कोई वेब ब्राउज़र, जैसे कि Chrome.
- बिलिंग की सुविधा वाला Google क्लाउड प्रोजेक्ट.
- बुनियादी एसक्यूएल क्वेरी और टर्मिनल कमांड के बारे में जानकारी होनी चाहिए.
अनुमानित लागत और अवधि
- पूरा होने में लगने वाला समय: ~45 मिनट.
- अनुमानित लागत: 500 रुपये से कम.
2. शुरू करने से पहले
Google Cloud प्रोजेक्ट बनाना या चुनना
- Google Cloud Console में जाकर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू होने की पुष्टि करने का तरीका जानें.
एनवायरमेंट को कॉन्फ़िगर करना
ज़्यादातर कमांड, Cloud Shell Editor में इंटिग्रेट किए गए टर्मिनल से चलाई जाएंगी. यह क्लाउड पर आधारित डेवलपमेंट एनवायरमेंट है. इसमें डेवलपर टूल और स्टैंडर्ड Google Cloud SDK पहले से लोड होता है.
- Cloud Shell Editor को नए टैब में खोलें.
- रिपॉज़िटरी को क्लोन करने के लिए, टर्मिनल में यह कमांड चलाएं:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - अपना प्रोजेक्ट आईडी सेट करें. इसे टर्मिनल में चिपकाने के लिए, Windows/Linux पर
Ctrl+Shift+Vया macOS परCmd+Vदबाएं:export PROJECT_ID="<YOUR_PROJECT_ID>" - अब इसे अपने एनवायरमेंट में कॉन्फ़िगर करें.
gcloud config set project $PROJECT_ID - कोई देश/इलाका चुनें.
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - ज़रूरी एपीआई चालू करें.
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
एक्सटेंशन इंस्टॉल करें
अब आपको Google Data Agent Kit एक्सटेंशन कॉन्फ़िगर करना होगा. यह एक ऐसा टूल है जिसकी मदद से, Google Cloud के डेटा टूल के साथ सीधे तौर पर अपने आईडीई में इंटरैक्ट किया जा सकता है.
- एडिटर की बाईं ओर मौजूद गतिविधि बार में, एक्सटेंशन आइकॉन पर क्लिक करें. इसके अलावा, Windows/Linux पर
Ctrl+Shift+Xया macOS परCmd+Xदबाकर भी एक्सटेंशन आइकॉन पर क्लिक किया जा सकता है. - एक्सटेंशन के खोज बॉक्स में,
Google Cloud Data Agent Kitलिखें - नतीजों में से आधिकारिक एक्सटेंशन चुनें और इंस्टॉल करें पर क्लिक करें. अगर कहा जाए, तो "हां, मुझे लेखकों पर भरोसा है" चुनें.
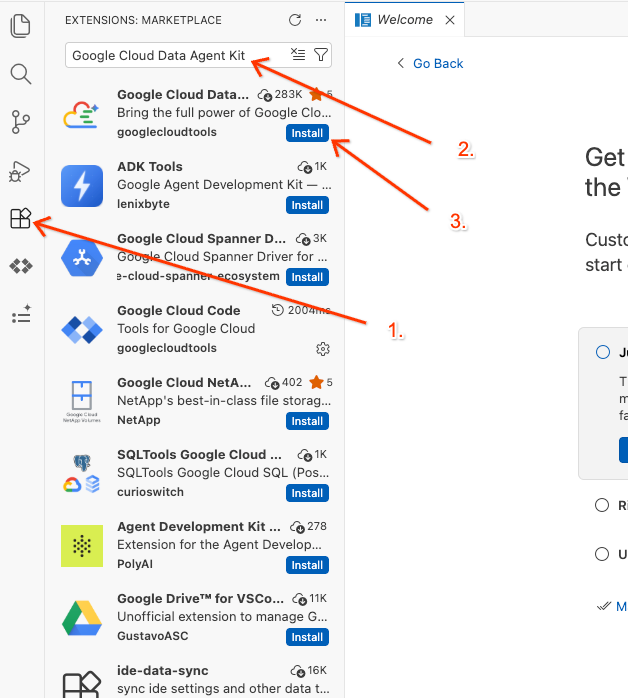
- इंस्टॉल हो जाने के बाद, आपको गतिविधि बार में Google Cloud Data Agent Kit आइकॉन दिखेगा! इस पर क्लिक करें.
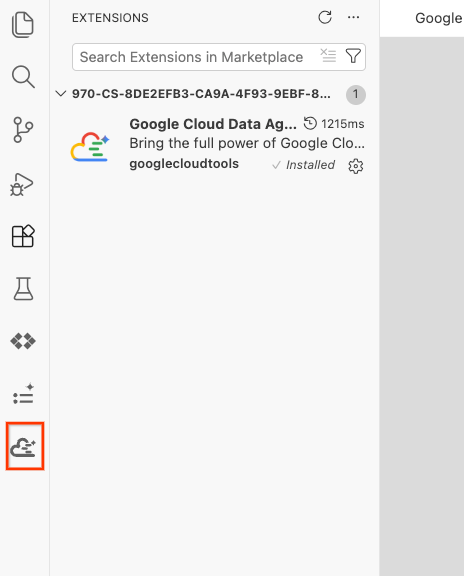
- क्लाउड में साइन इन करें पर क्लिक करें.
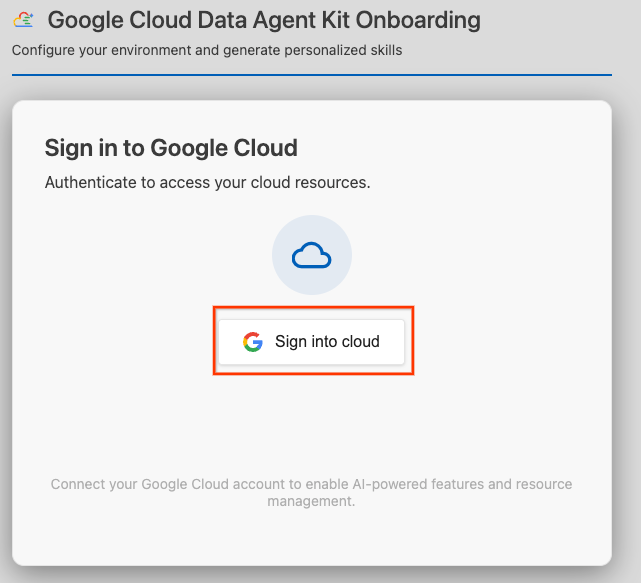
- एमसीपी सर्वर कॉन्फ़िगर करें पर क्लिक करें.
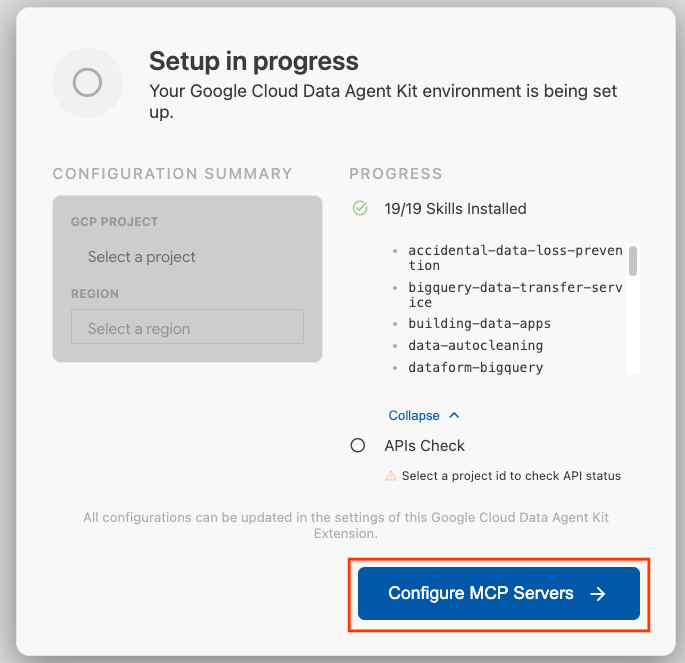
- BigQuery, Knowledge Catalog, Apache Spark, और AlloyDB चुनें. Lab 2 में AlloyDB का इस्तेमाल किया जाएगा. इसके बाद, शुरू करें पर क्लिक करें.
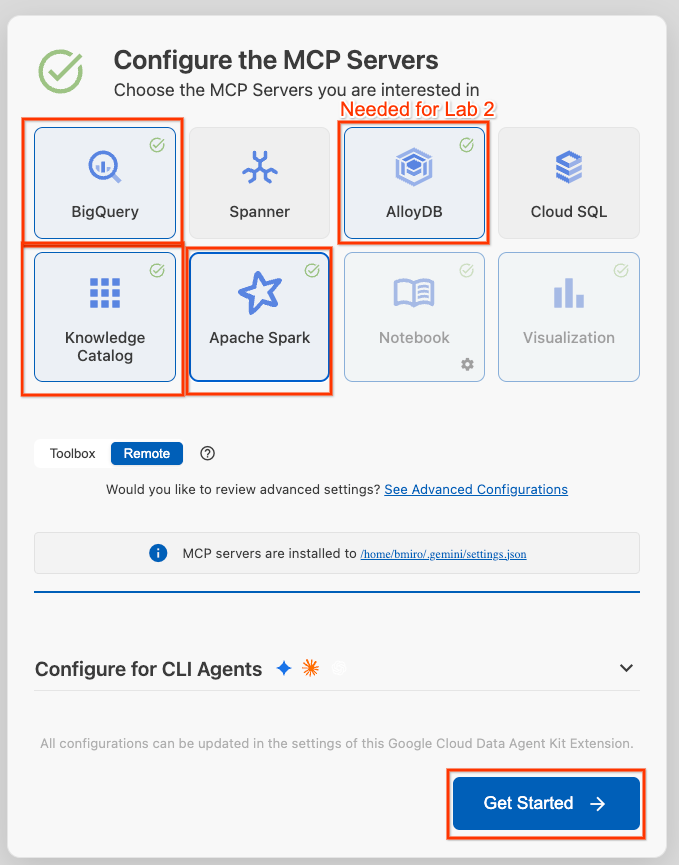
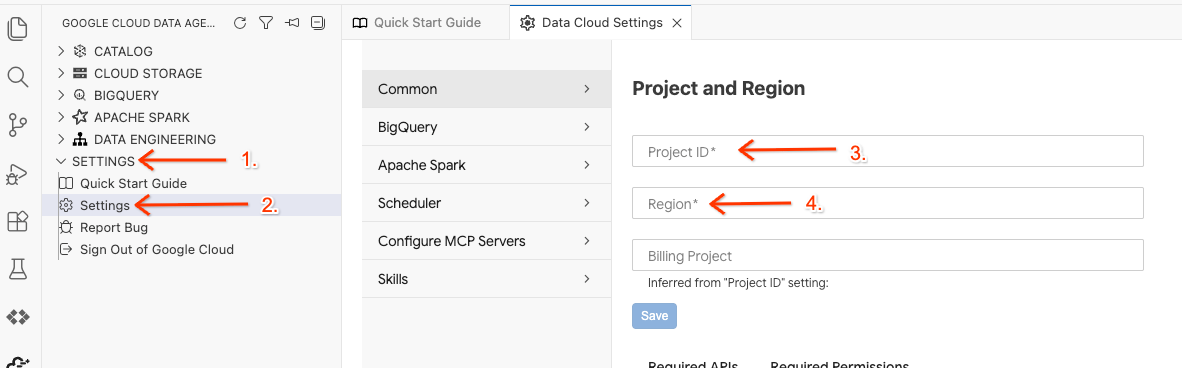
- सबसे नीचे मौजूद स्टेटस बार में, प्रोजेक्ट आईडी चुनने वाले टूल पर क्लिक करें. इसके बाद, चालू Google Cloud प्रोजेक्ट चुनें.
- डेटा एजेंट किट में, सेटिंग पर क्लिक करें. इसके बाद, सेटिंग पर क्लिक करें. इसके बाद, सामान्य टैब में जाकर, अपना प्रोजेक्ट आईडी और रीजन चुनें, ताकि लैब को चलाया जा सके. जैसे, us-central1.
- BigQuery की सेटिंग पर क्लिक करें. इसके बाद, रीजन को उस रीजन से बदलें जिसे आपने पहले चुना था. सेव करें पर क्लिक करें.
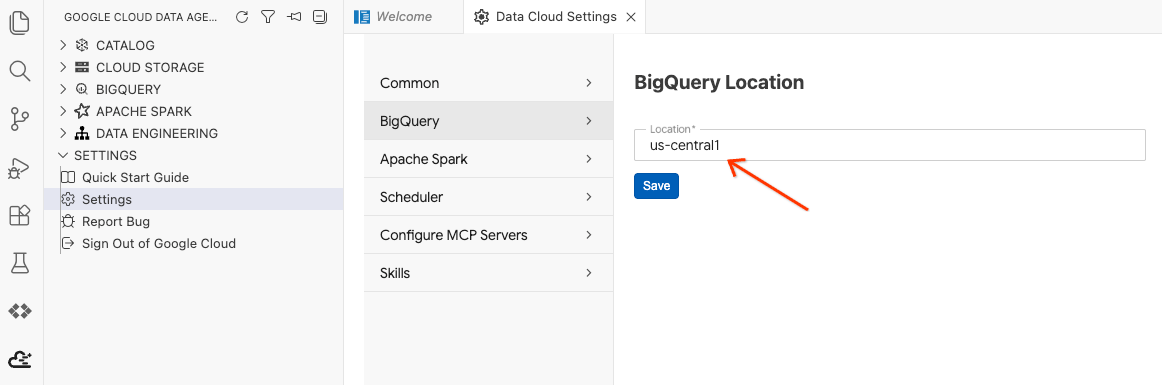
अब डेटा एजेंट किट का इस्तेमाल किया जा सकता है!
एनवायरमेंट सेटअप करने वाली स्क्रिप्ट को एक्ज़ीक्यूट करना
इस लैब के लिए ज़रूरी बैकग्राउंड संसाधन बनाने और IAM अनुमतियां कॉन्फ़िगर करने के लिए, टर्मिनल में सेटअप स्क्रिप्ट चलाएं:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
आपको आउटपुट के चरणों की एक सीरीज़ दिखेगी. इससे पता चलेगा कि कौनसे संसाधन उपलब्ध कराए जा रहे हैं. हम इस लैब में इन सभी के बारे में जानकारी देंगे.
प्रोसेस पूरी होने का मैसेज दिखने के बाद, ये काम किए जा सकते हैं:
==================================================== Environment Setup Complete! ====================================================
अब हम खोज शुरू करते हैं!
3. शिपिंग मेनिफ़ेस्ट को इनजेस्ट करने वाले पार्टनर
पार्टनर के जहाज़ों से मिलने वाले शिपिंग मेनिफ़ेस्ट डेटा को आपके बकेट में, स्टैंडर्ड JSON लाइन्स (JSONL) फ़ॉर्मैट में सेव किया जाता है: gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl.
डेटा का बारीकी से विश्लेषण करने से पहले, आपको इस अनस्ट्रक्चर्ड डेटा के लिए, मैनेज की गई BigLake टेबल बनानी होगी. इससे, पार्टनर के लॉजिस्टिक्स डेटा को तुरंत एक्सप्लोर किया जा सकता है. इसके लिए, आपको स्टैंडर्ड एसक्यूएल का इस्तेमाल करना होगा. साथ ही, इंपोर्ट करने के लिए डुप्लीकेट शुल्क नहीं देना होगा.
एडिटर में वर्कस्पेस खोलें और क्वेरी चलाएं
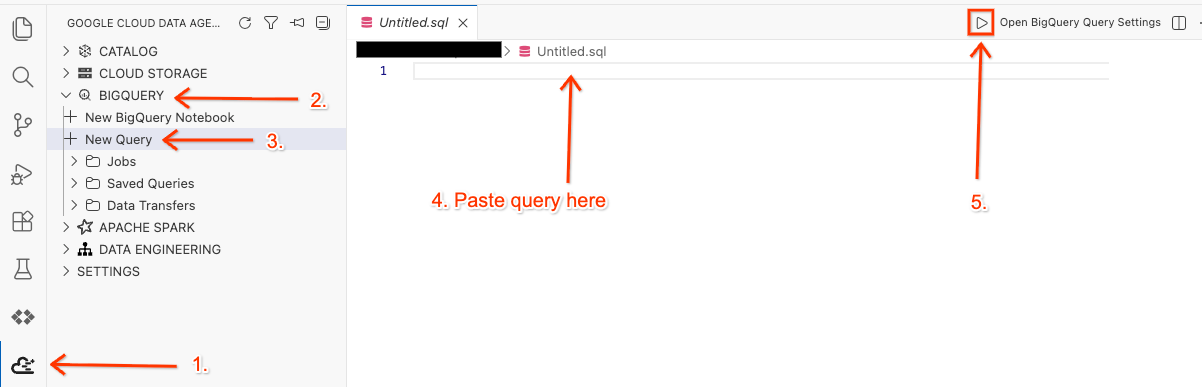
- Cloud Shell Editor में, साइड पैनल पर मौजूद Google Cloud Data Agent Kit एक्सटेंशन आइकॉन पर क्लिक करें.
- BigQuery पर जाएं और + नई क्वेरी चुनें.
- नीचे दी गई क्वेरी को क्वेरी विंडो में कॉपी करें.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- चलाएं पर क्लिक करें.
- टेबल बन गई है, इसकी पुष्टि करने के लिए आपको क्वेरी के नतीजे पैनल में एक मैसेज दिखेगा. यह पैनल, स्क्रीन पर सबसे नीचे अपने-आप खुल जाता है.
बाहरी टेबल से क्वेरी करके, हैक किए गए ट्रांसपॉन्डर का पता लगाना
आइए, उन ट्रांसपॉन्डर की पहचान करें जिनसे समझौता किया गया है. इसके लिए, यह पता लगाएं कि seal_integrity_status को 0 पर सेट करने के दौरान कौनसी गड़बड़ियां हुई थीं. आपने जो क्वेरी विंडो पहले खोली थी उसमें यह क्वेरी कॉपी करें और चलाएं:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
आपको क्वेरी के नतीजे वाले पैनल में, इससे मिलता-जुलता आउटपुट दिखेगा:
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0.1278 | usr_999_shadow |
4. Managed Service for Apache Spark की मदद से, बिना स्ट्रक्चर वाले लॉग प्रोसेस करना
आपको स्ट्रक्चर्ड मेनिफ़ेस्ट से शुरुआती जगह का पता चल गया है, लेकिन खोया हुआ ट्रांसपॉन्डर पूरी तरह से बंद हो गया है. ट्रांसपॉन्डर से मिले आखिरी पिंग में, GCS पाथ gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt में मौजूद रॉ टेक्स्ट लॉग फ़ाइल में एक मुश्किल और बिना स्ट्रक्चर वाला मैसेज मिला है.
इस टेक्स्ट लॉग को प्रोसेस और मैप करने के लिए, टाइमस्टैंप निकालें, पहचान छिपाएं, और कार्गो के डाउनस्ट्रीम रूट का पता लगाएं. इसके लिए, आपको Managed Service for Apache Spark को सर्वरलेस Apache Spark (PySpark) जॉब सबमिट करनी होगी.
Managed Service for Apache Spark की मदद से, क्लस्टर को मैनेज किए बिना Spark वर्कलोड को चलाया जा सकता है. यह सेवा, कंप्यूटिंग के बुनियादी संसाधनों को मैनेज करती है. साथ ही, उन्हें ज़रूरत के हिसाब से अपने-आप बढ़ाती है. आपको सिर्फ़ एक्ज़ीक्यूशन की अवधि के लिए पेमेंट करना होता है.
स्क्रिप्ट में ये काम किए जाएंगे:
- ब्रैकेट में दिए गए, बिना स्ट्रक्चर वाले ट्रांसपॉन्डर टेक्स्ट को शामिल करें.
- टाइमस्टैंप, कस्टोडियन मेटाडेटा, और रॉ कॉन्टेंट को अलग करने के लिए, PySpark SQL रेगुलर एक्सप्रेशन एक्सट्रैक्शन फ़िल्टर लागू करें.
- बेतरतीब लॉग को साफ़-सुथरे, वाक्य-स्तर के रिकॉर्ड में बदलें.
- डाइनैमिक डेस्टिनेशन कोऑर्डिनेट टारगेट निकालें, जहां से पेलोड के रवाना होने की प्रोसेस बंद हो गई थी.
- प्रोसेस किए गए लॉग डेटाफ़्रेम को Lakehouse Apache Iceberg REST Catalog में वापस कनेक्ट करें और लिखें. इसे नई विश्लेषण टेबल के तौर पर लिखा जाता है, जो सीधे तौर पर BigQuery में दिखती है.
PySpark की विश्लेषण स्क्रिप्ट ठीक करना
समुद्र में Python Pirates के होने की खबरें मिली हैं. ये हर तरह की समस्याएं पैदा कर रहे हैं.
- Cloud Shell Editor में
process_maritime_logsफ़ाइल खोलने के लिए, यह कमांड चलाएं.cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - कोड को ध्यान से पढ़ें और समझें कि यह क्या काम कर रहा है.
- पक्का करें कि कोड में कुछ भी संदिग्ध न हो! अगर आपको कुछ भी मिटाना है, तो पक्का करें कि आपने फ़ाइल को
Ctrl + S(Windows/Linux) याCmd + S(Mac) का इस्तेमाल करके सेव किया हो.
बिना सर्वर वाला Spark जॉब सबमिट करना
gcloud SDK टूल का इस्तेमाल करके, नौकरी सबमिट करें. कॉन्फ़िगरेशन, PySpark जॉब को Lakehouse कैटलॉग ऐक्सेस करने के लिए अपने-आप कॉन्फ़िगर करता है.
अपने इंटिग्रेटेड एडिटर टर्मिनल में यह कमांड चलाएं.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
सर्वरलेस एनवायरमेंट को चालू होने में कुछ मिनट लगते हैं. इसके बाद, अपनी स्क्रिप्ट अपलोड करें और प्रोसेसिंग लॉजिक को लागू करें.
जब आपको इस तरह का आउटपुट दिखे, तो समझ लें कि प्रोसेस की गई आपकी टेबल, Lakehouse कैटलॉग में Apache Iceberg मैनेज की गई टेबल के तौर पर सेव हो गई है!
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
प्रोसेस किए गए लॉग की झलक देखना
डेटा एजेंट किट एक्सटेंशन के क्वेरी एडिटर में, डेटा की झलक देखने के लिए यह क्वेरी कॉपी करें:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
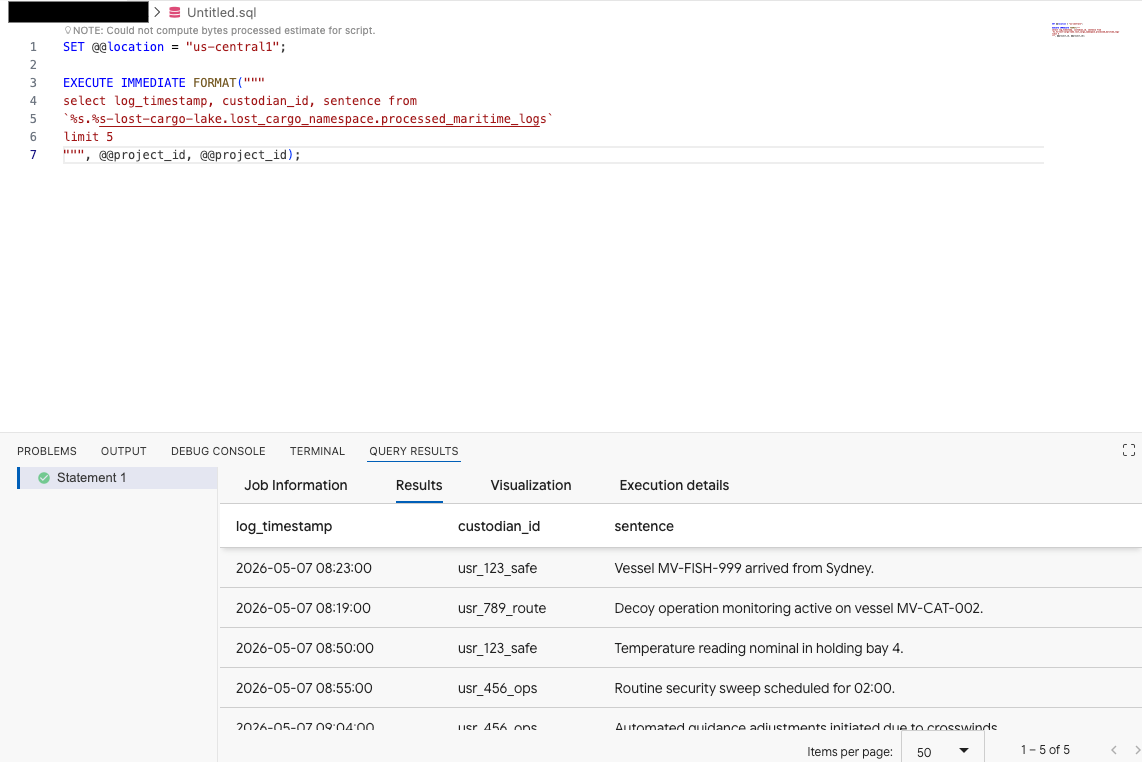
इससे पता चलता है कि कैटलॉग में रजिस्टर की गई Iceberg टेबल को BigQuery से ऐक्सेस किया जा सकता है!
डेस्टिनेशन का सुराग पाना
अब हमारे पास प्रोसेस किए गए लॉग हैं. इसलिए, आइए उन लॉग को खोजें जिनमें डेस्टिनेशन टारगेट शामिल है. इसके बाद, हम उन लॉग को खोज सकते हैं जिनमें हमारे मूल शहर का ज़िक्र किया गया है.
क्वेरी एडिटर में जाकर, यह क्वेरी चलाएँ. इसमें <YOUR_REGION> की जगह अपने देश/इलाके का नाम और <ORIGIN_CITY> की जगह उस शहर का नाम डालें जहाँ से यात्रा शुरू हुई थी.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
कन्वर्सेशनल ऐनलिटिक्स का इस्तेमाल करके, BigQuery कंसोल में अपने डेटा के साथ चैट करना
अपने डेटा को एक्सप्लोर करने के लिए, मुश्किल एसक्यूएल क्वेरी लिखने के बजाय, कन्वर्सेशनल ऐनालिटिक्स का इस्तेमाल करके, आम भाषा में अपनी टेबल के साथ चैट की जा सकती है!
- BigQuery Console पर जाएं.
- बाईं ओर मौजूद एक्सप्लोरर पैनल में, अपने प्रोजेक्ट और डेटासेट
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logsटेबल पर क्लिक करके, उसकी जानकारी वाला टैब खोलें. - क्वेरी के बगल में मौजूद, चैट पर क्लिक करें.
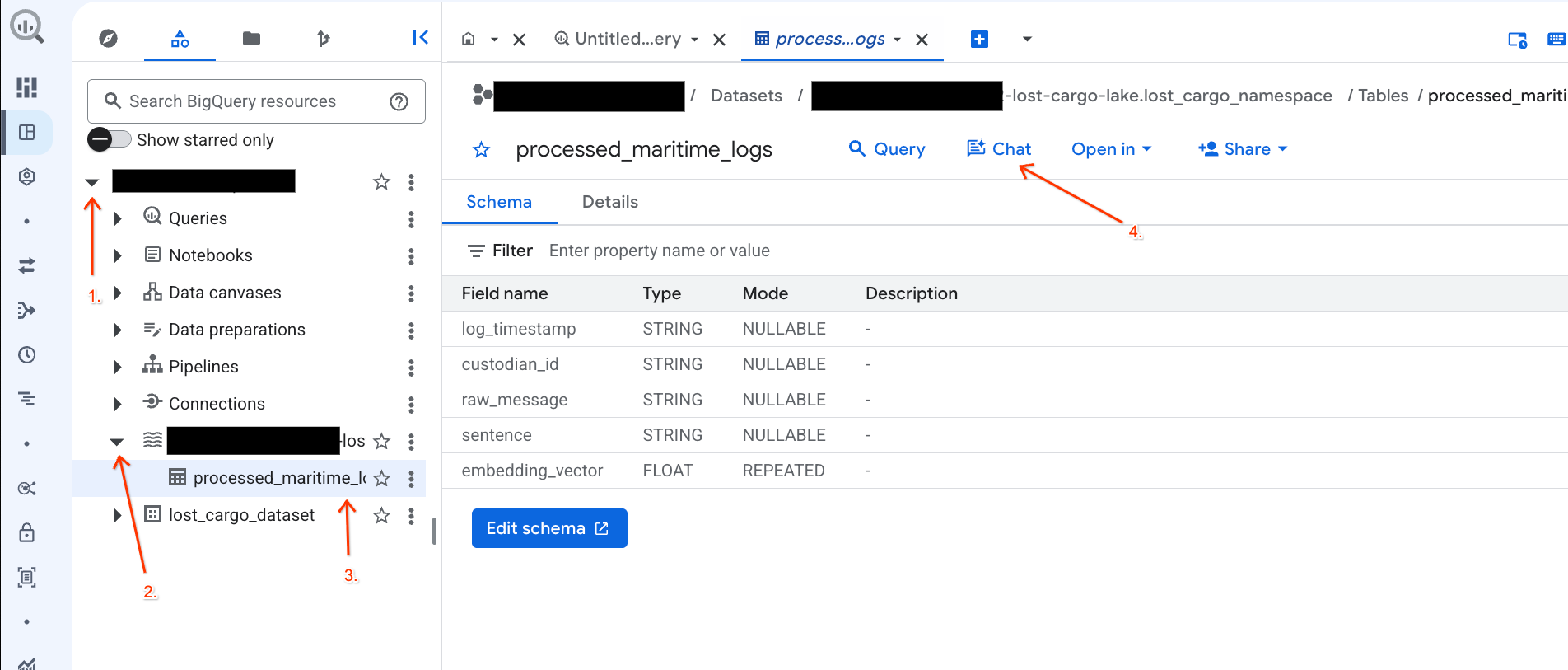
- चैट पैनल में, यह सवाल टाइप करें और भेजने के लिए अपने कीबोर्ड पर Enter दबाएं:
Based on this table, what color is the shipping container MV-CAT-001?
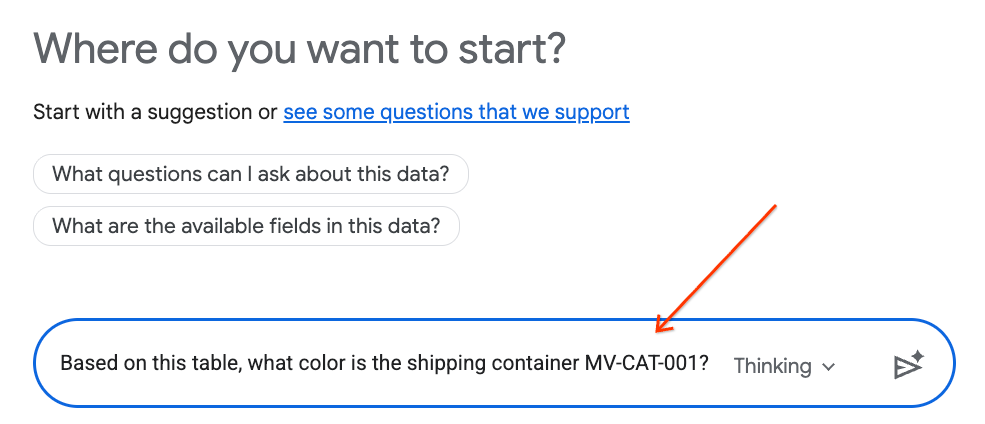
- कन्वर्सेशनल ऐनलिटिक्स (Gemini की मदद से काम करता है) चालू टेबल के डेटा का विश्लेषण करेगा और रंग के बारे में जवाब देगा.
5. सेंट्रलाइज़्ड लेकहाउस कैटलॉग देखना
ओपन-सोर्स प्रोसेसिंग इंजन (जैसे, Apache Spark) को एंटरप्राइज़ डेटा इंजन (जैसे, BigQuery) के साथ सुरक्षित और आसानी से इंटिग्रेट करने के लिए, आपकी सेटअप स्क्रिप्ट ने Lakehouse Iceberg REST Catalog को कॉन्फ़िगर किया है.
Apache Iceberg REST Catalog, टेबल के मेटाडेटा के लिए सर्वरलेस "सिंगल सोर्स ऑफ़ ट्रुथ" के तौर पर काम करता है. यह स्कीमा और पार्टीशनिंग टेबल को डाइनैमिक तरीके से मैनेज करता है. साथ ही, Cloud Storage में फ़िज़िकल Parquet डेटा फ़ाइलें सेव करता है.
आइए, इस कैटलॉग को सीधे Google Cloud Console में देखते हैं:
- Lakehouse Console खोलें.
- कैटलॉग टैब में, चालू Iceberg REST कैटलॉग ढूंढें और उस पर क्लिक करें:
-lost-cargo-lake
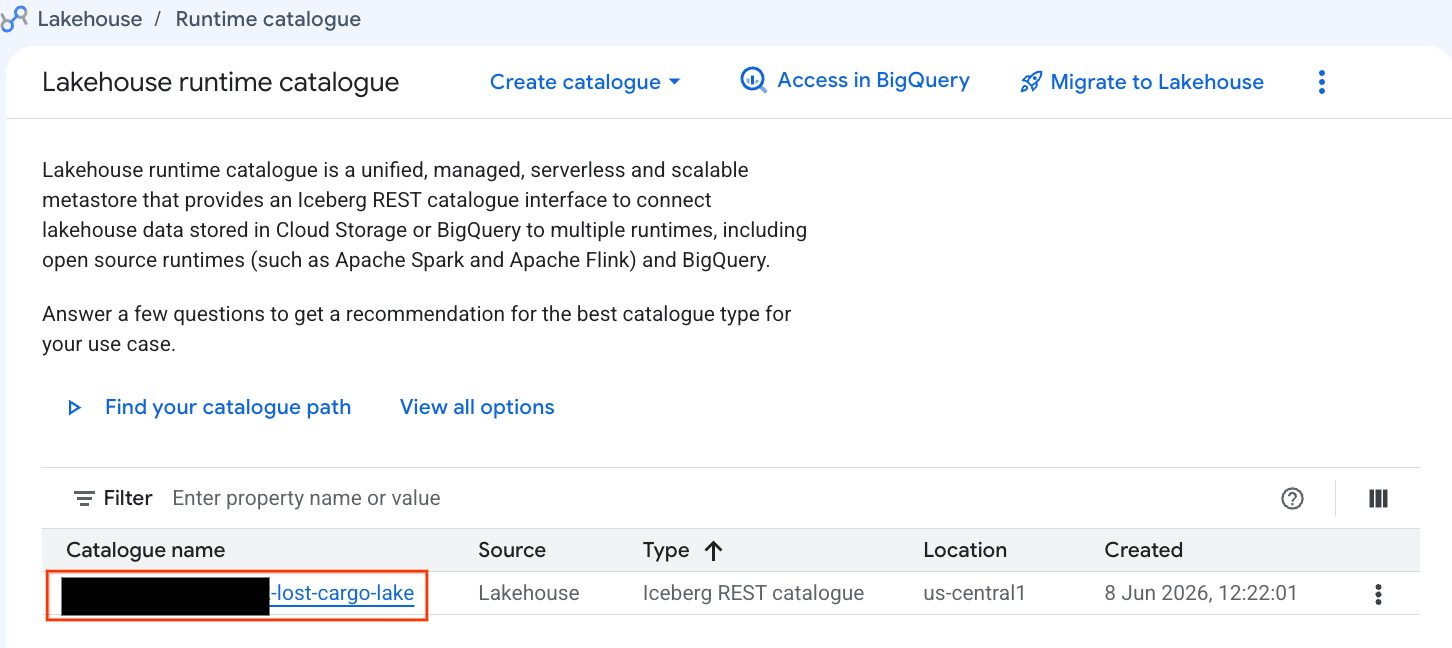
- कैटलॉग की जानकारी वाले व्यू में, नेमसpace के नीचे आपको
lost_cargo_namespaceदिखेगा. इस पर क्लिक करें.
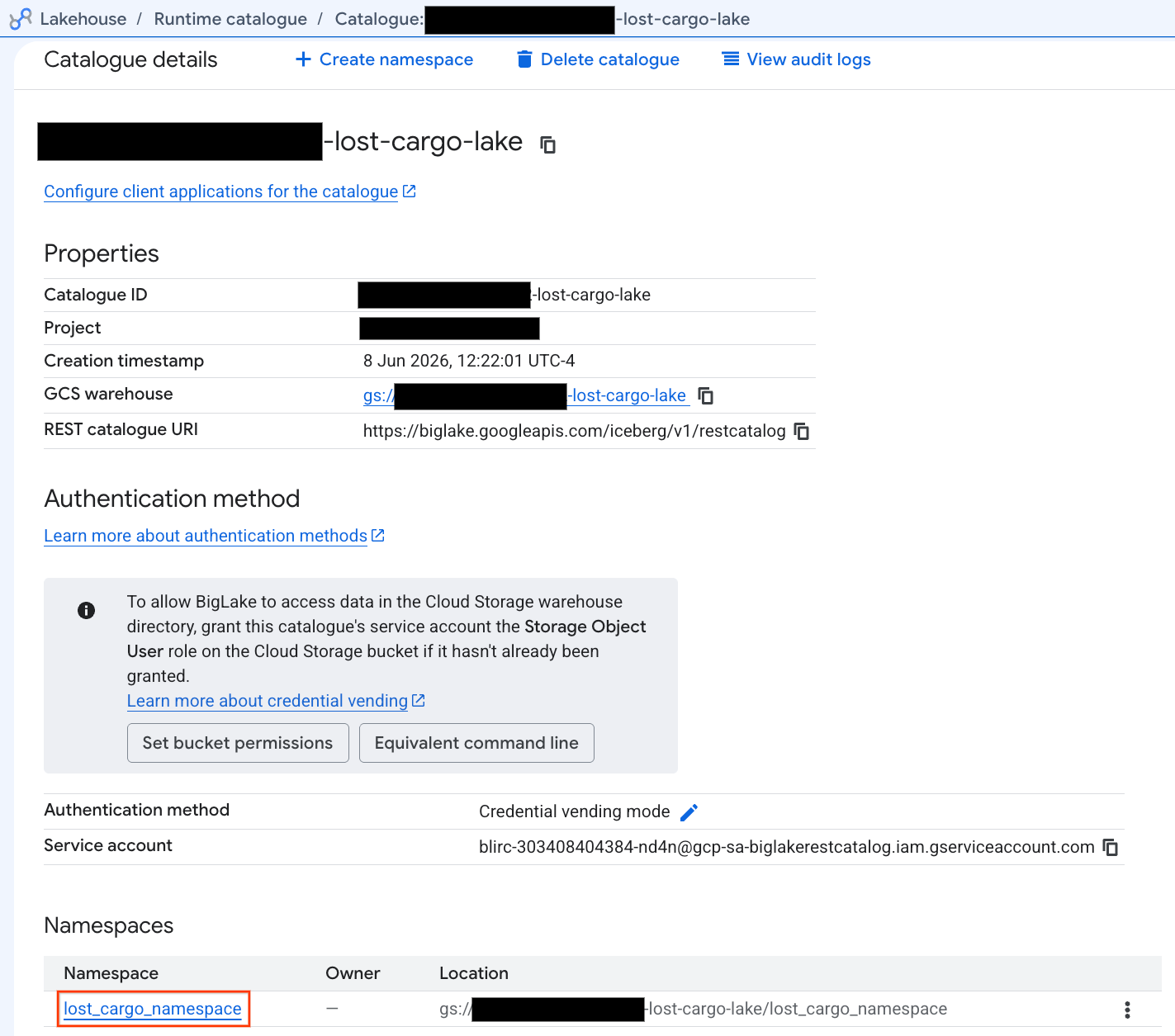
- PySpark से जनरेट की गई आपकी नई Apache Iceberg टेबल, इस मेटास्टोर नेमस्पेस में अपने-आप रजिस्टर हो जाती है. साथ ही, इसे BigQuery में तुरंत क्वेरी किया जा सकता है!
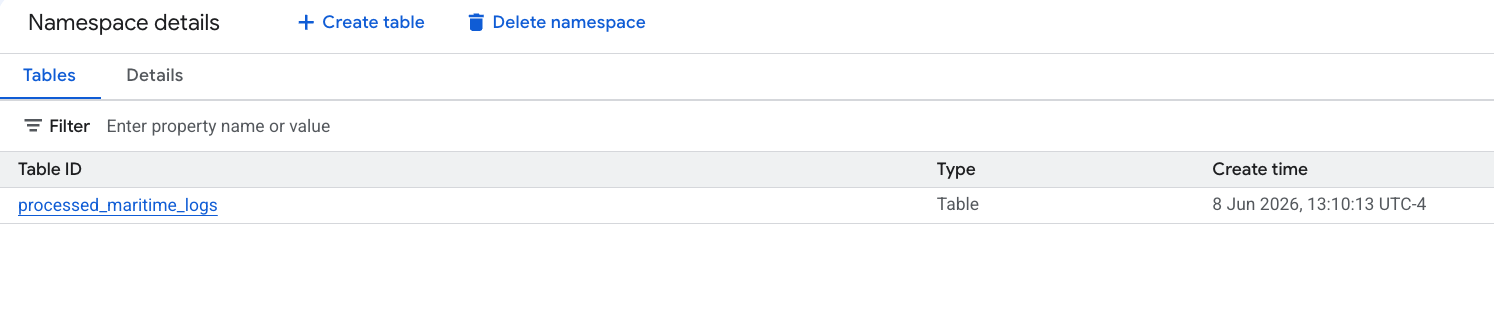
6. शिपिंग मैनिफ़ेस्ट टेबल में मौजूद डेटा के आधार पर अहम जानकारी जनरेट करना
आइए, shipping_manifests टेबल पर वापस जाएं और नॉलेज कैटलॉग डेटा इनसाइट का इस्तेमाल करके, इसके स्ट्रक्चर और कॉन्टेंट को समझें. मेटाडेटा को बेहतर बनाने से, अन्य एक्सप्लोरर आने वाले समय में विश्लेषण के लिए टेबल को बेहतर तरीके से समझ सकते हैं.
BigQuery Studio में टेबल की अहम जानकारी जनरेट करना
- Google Cloud Console में, BigQuery Studio पर जाएं.
- एक्सप्लोरर पैनल में, अपने प्रोजेक्ट को बड़ा करें. इसके बाद,
lost_cargo_datasetडेटासेट को बड़ा करें औरshipping_manifestsटेबल पर क्लिक करें. - दाईं ओर मौजूद जानकारी वाले पैनल में, अहम जानकारी टैब पर क्लिक करें.
- ड्रॉपडाउन का इस्तेमाल करके, जनरेट करें और पब्लिश करें को चुनें.
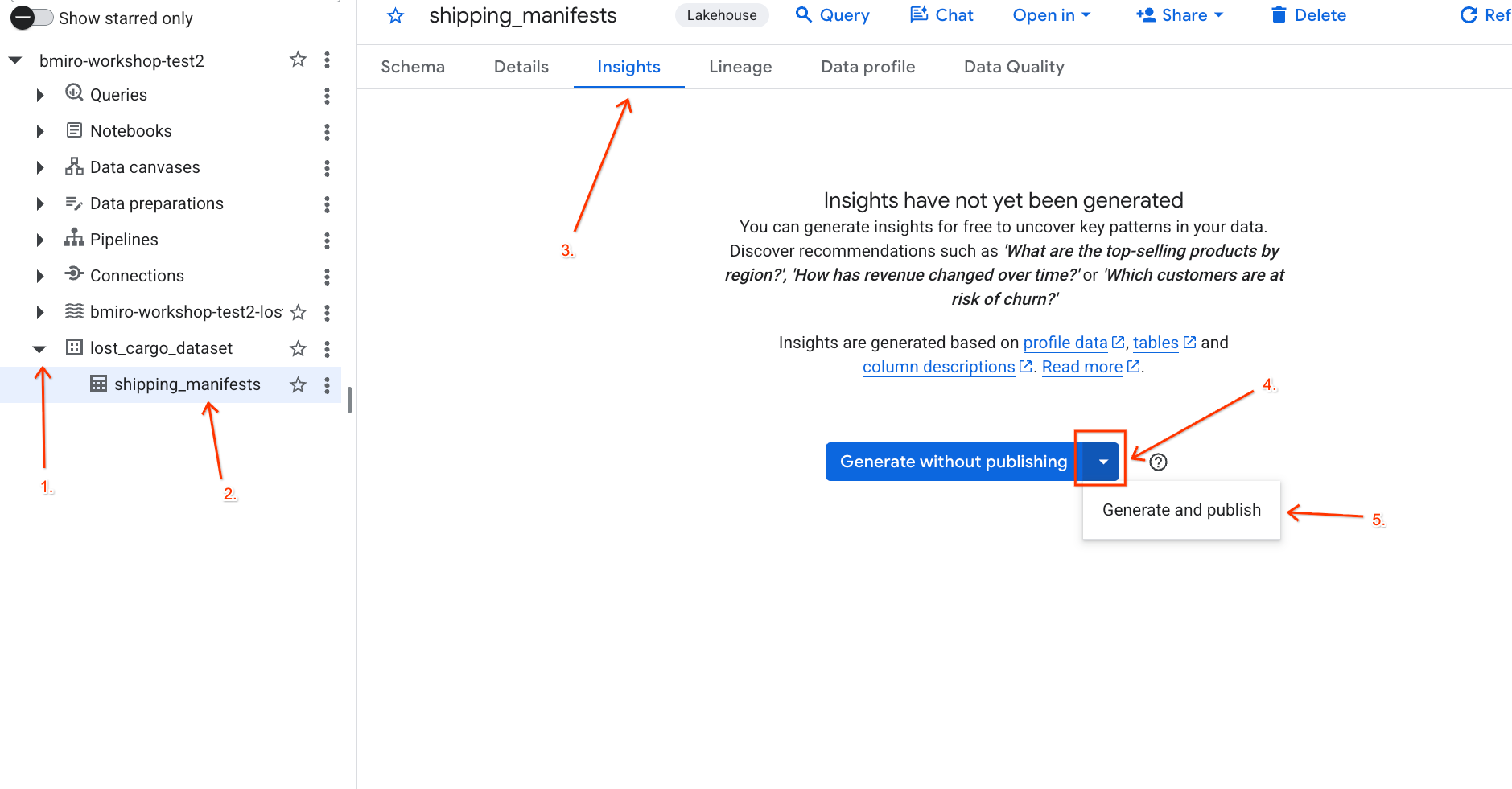
- नज़रिए जनरेट होने में करीब तीन मिनट लगते हैं. Gemini, टेबल के मेटाडेटा का विश्लेषण करेगा. इसके बाद, वह आम बोलचाल की भाषा में सवाल और उनसे जुड़ी एसक्यूएल क्वेरी जनरेट करेगा.
- इसके बाद, आपको टेबल का ब्यौरा दिखेगा. इसमें टेबल के बारे में आसान भाषा में जानकारी दी गई होगी.
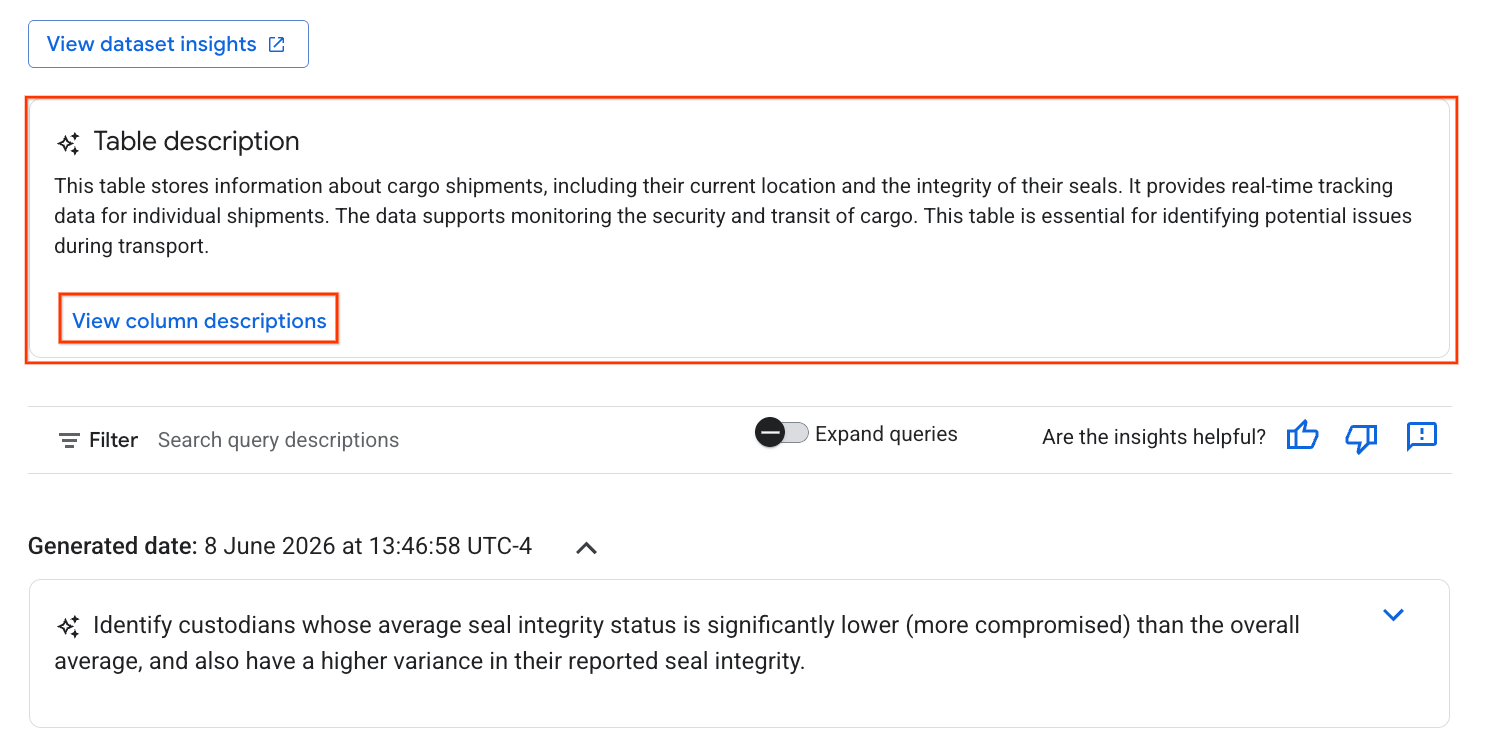
- अलग-अलग कॉलम के बारे में जानकारी देखने के लिए, कॉलम के ब्यौरे देखें पर क्लिक करें.
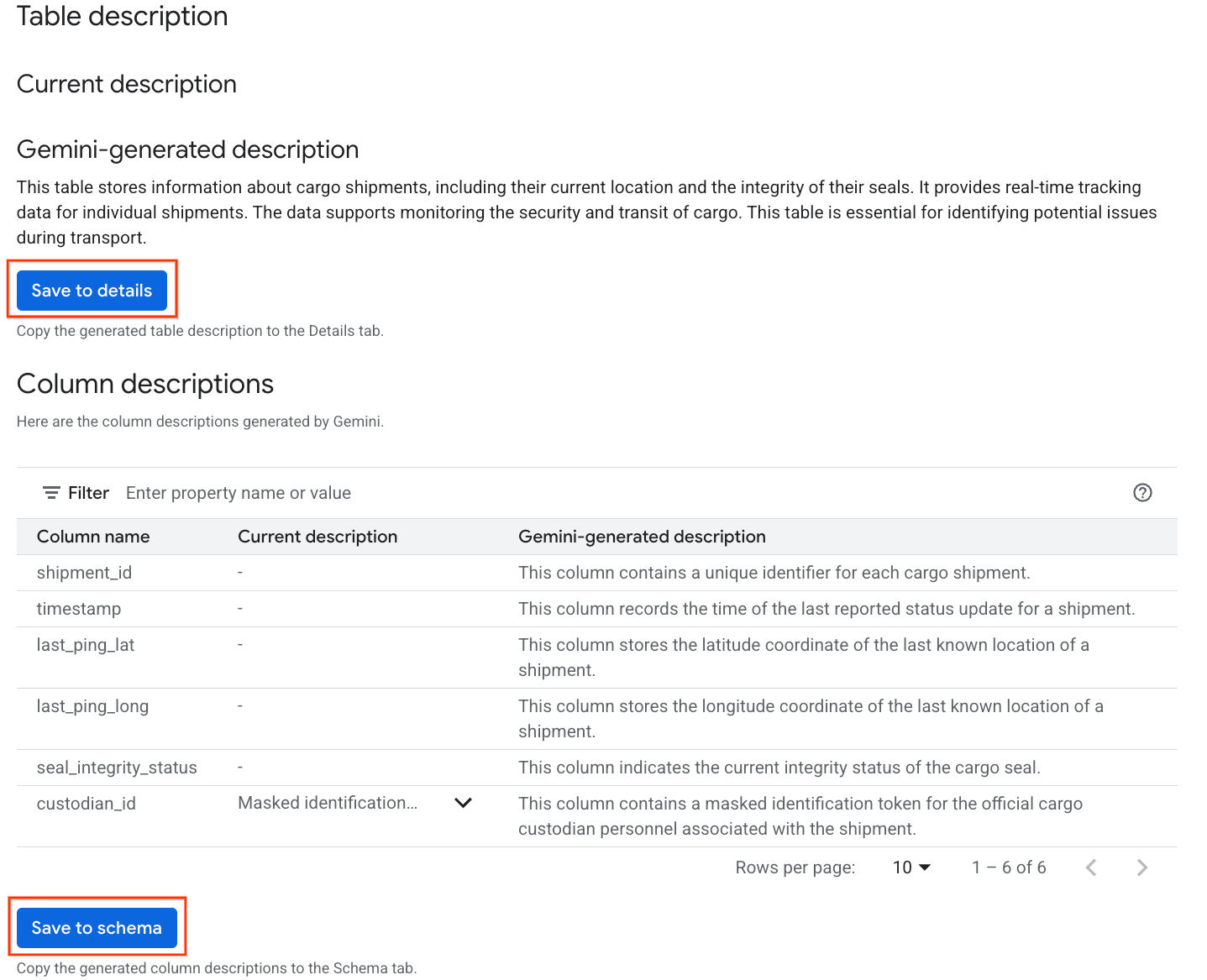
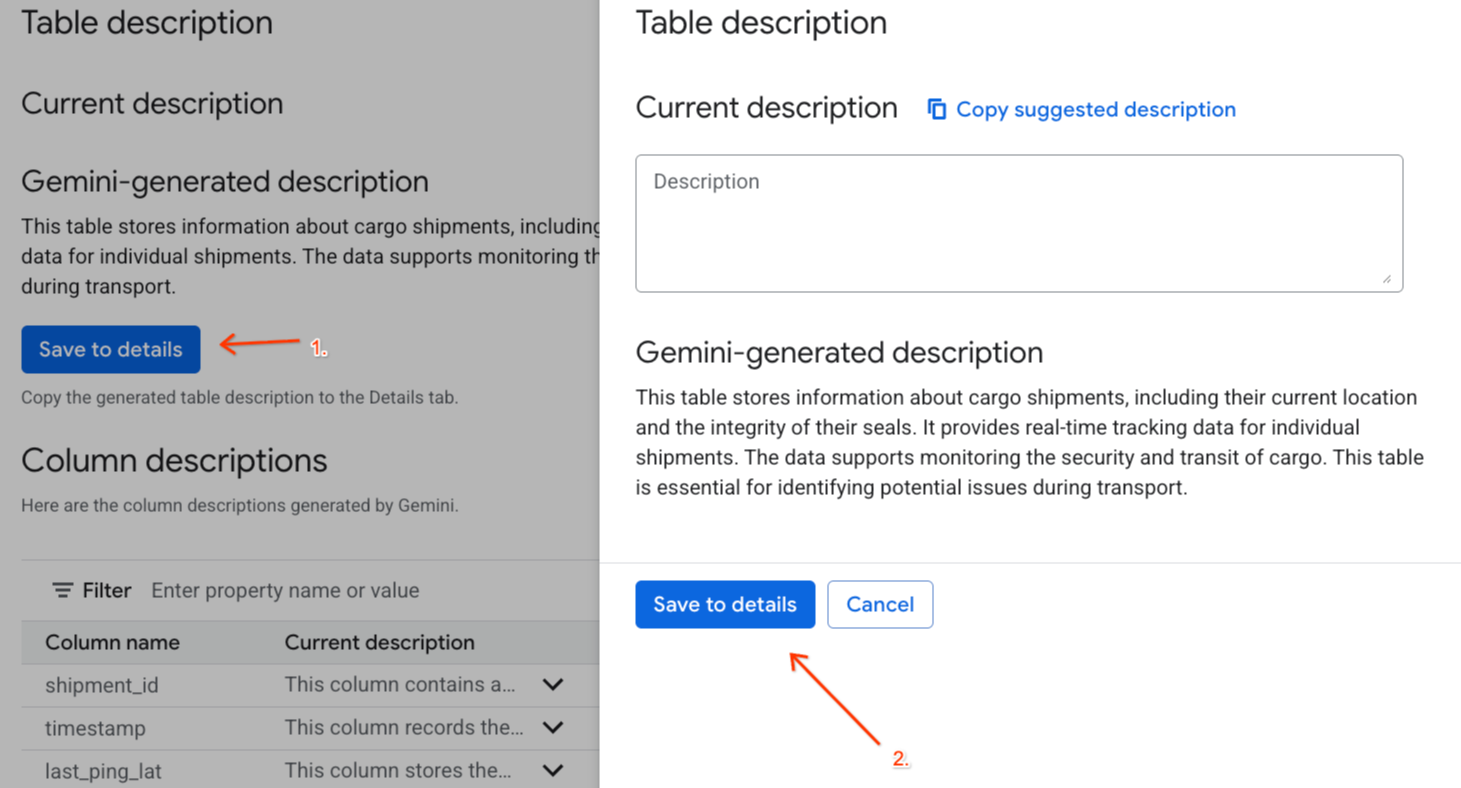
Gemini generated descriptionमें जाकर, जानकारी में सेव करें पर क्लिक करें. इसके बाद, पॉप-अप होने वाली विंडो में जानकारी में सेव करें पर क्लिक करें.
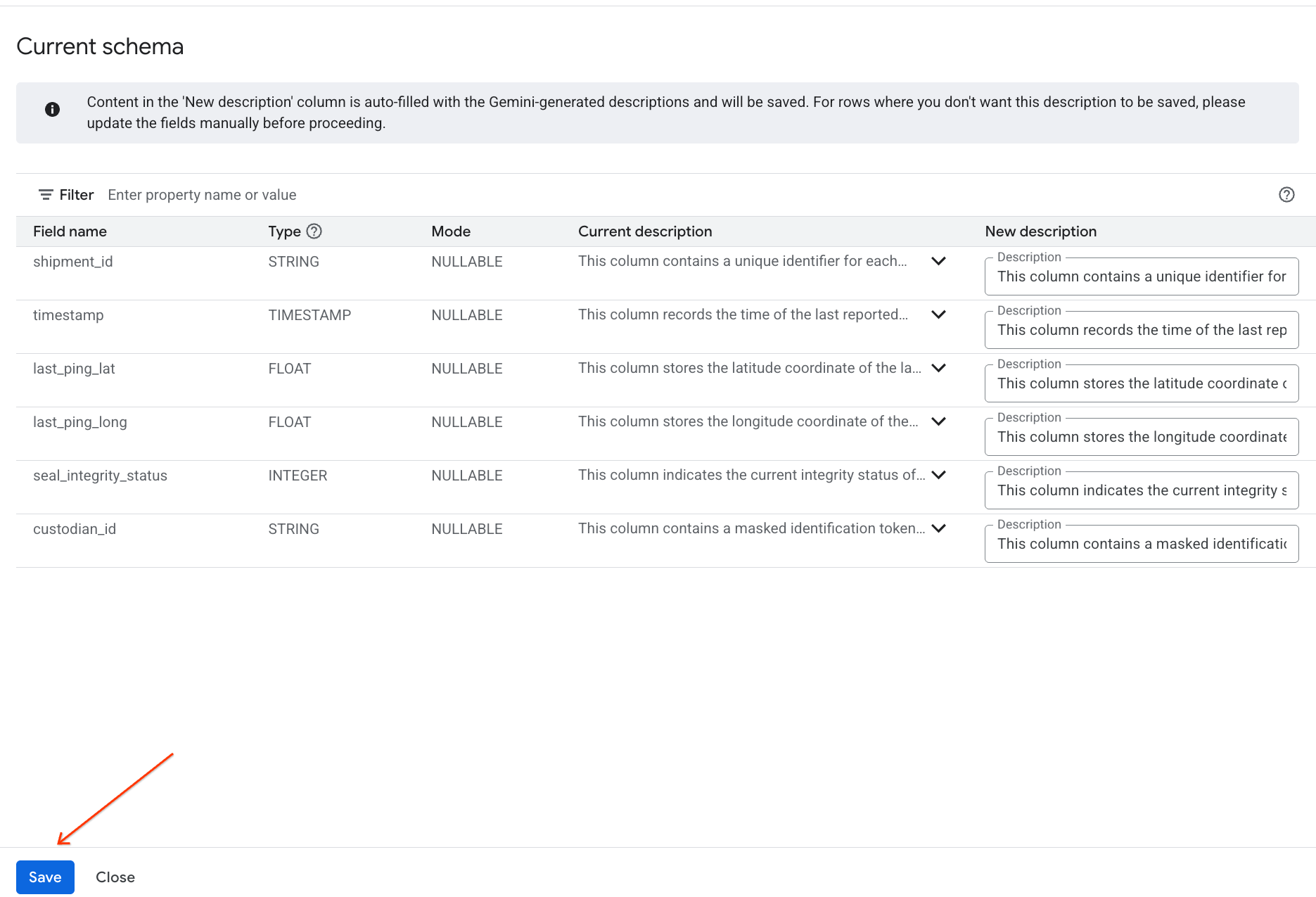
- इसी तरह, टेबल के मेटाडेटा में कॉलम के ब्यौरे जोड़ने के लिए, स्कीमा में सेव करें पर क्लिक करें.
जनरेट की गई अहम जानकारी की समीक्षा करना
आपको सुझाए गए सवालों की सूची भी दिखेगी. जनरेट की गई SQL क्वेरी देखने के लिए, किसी भी सवाल पर क्लिक करें. इसके बाद, डेटा एक्सप्लोर करने के लिए क्वेरी चलाएं. उदाहरण के लिए, आपको इस तरह के सवाल दिख सकते हैं:
- "कुल कितने शिपमेंट हैं?"
- "कस्टोडियन के यूनीक आईडी की सूची बनाओ."
इन क्वेरी को चलाने से, आपको डेटा को समझने में मदद मिलती है.
7. डेटा मास्किंग और गवर्नेंस लागू करना
यह पक्का करने के लिए कि कार्गो की जांच के दौरान, चालू रिसर्च खातों और उपयोगकर्ता नामों को लीक न किया जाए, आपको सुरक्षा के स्टैंडर्ड प्रोटोकॉल लागू करने होंगे. डेटा की निजता की पुष्टि करने के लिए, आपको सुरक्षा नीति टैग टैक्सोनॉमी बनानी होगी. साथ ही, संवेदनशील custodian_id कॉलम पर नॉलेज कैटलॉग डेटा मास्किंग को कॉन्फ़िगर करना होगा.
डिफ़ॉल्ट रूप से, BigQuery उन कॉलम का ऐक्सेस नहीं देता जिन्हें नीति टैग से सुरक्षित किया गया है. टेबल पर क्वेरी करने और डेटा मास्क करने की सुविधा चालू होने की पुष्टि करने के लिए, आपके उपयोगकर्ता खाते के पास BigQuery डेटा की नीति के तहत मास्क किए गए डेटा को पढ़ने वाले व्यक्ति की भूमिका होनी चाहिए.
setup_lab1.sh का इस्तेमाल शुरू करने के दौरान, यह भूमिका आपके चालू उपयोगकर्ता खाते से अपने-आप जुड़ गई थी!
टैक्सोनॉमी और नीति टैग बनाना
अपने डेटा का ऐक्सेस मैनेज करने के लिए, डेटा टैक्सोनॉमी और उससे जुड़ा नीति टैग बनाएं.
- नीति टैग टैक्सोनॉमी पेज पर जाएं.
- + टैक्सनॉमी बनाएं पर क्लिक करें.
- पैरामीटर कॉन्फ़िगर करें:
- टैक्सोनॉमी का नाम:
lost-cargo-डालें. इसकी जगह अपना प्रोजेक्ट आईडी डालें. - देश/इलाका: अपना देश/इलाका चुनें.
- नीति टैग नाम के लिए:
MaskCustodianIDडालें - नीति टैग ब्यौरा के लिए:
Restricts visibility into cargo custodian usernames
- टैक्सोनॉमी का नाम:
- अपनी नई टैक्सोनॉमी और नीति टैग को रजिस्टर करने के लिए, बनाएं पर क्लिक करें.
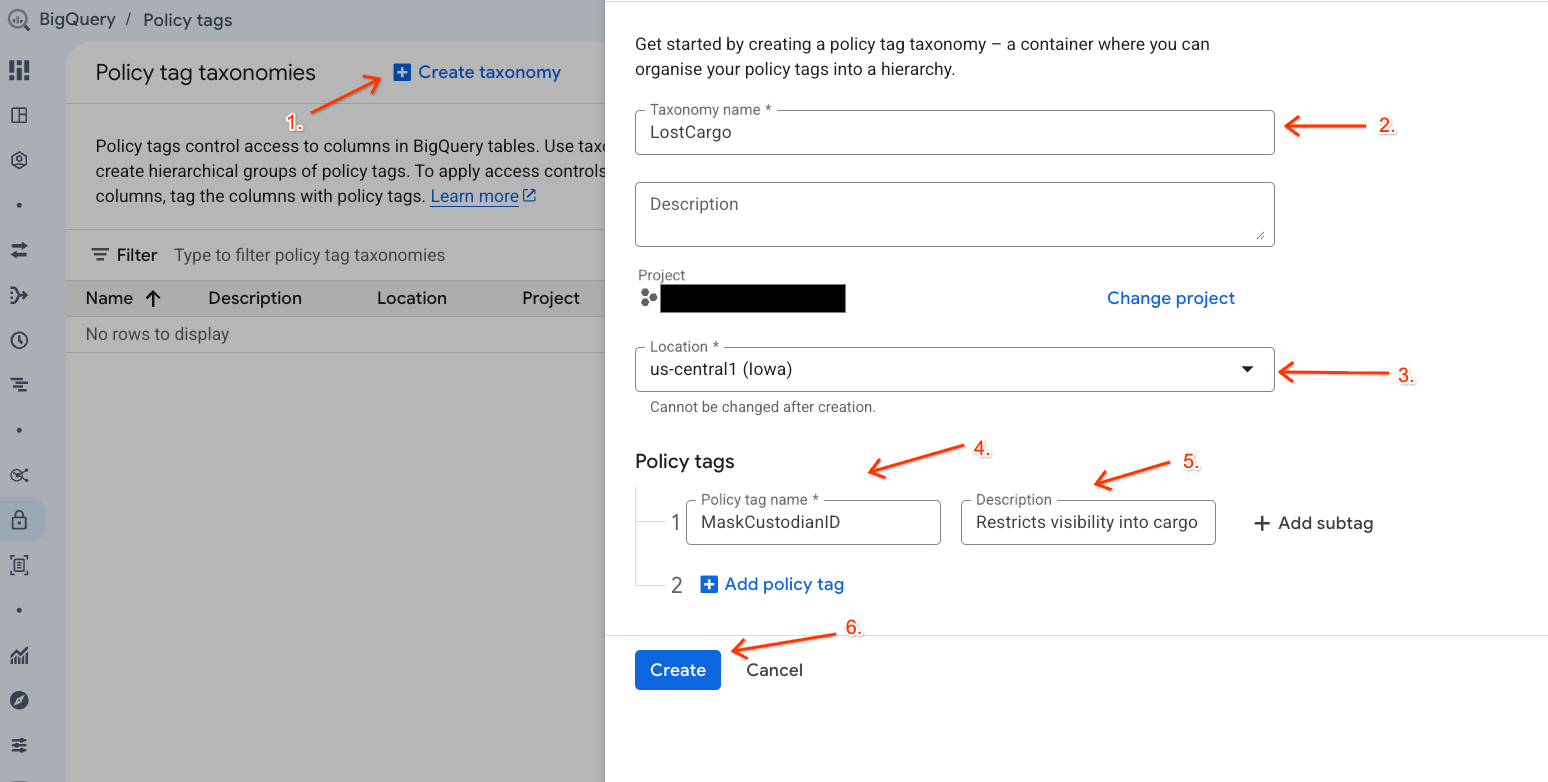
डेटा मास्किंग की नीति बनाना
इसके बाद, डेटा नीति कॉन्फ़िगर करें. इससे यह तय किया जा सकेगा कि MaskCustodianID क्लासिफ़िकेशन टैग के तहत डेटा को कैसे मास्क किया जाएगा. आपको हमेशा शून्य मास्क करने के नियम का इस्तेमाल करना होगा. इससे, मिलती-जुलती वैल्यू को खाली/शून्य वैल्यू से बदला जा सकेगा. यह नियम, बिना अनुमति वाले सभी लोगों के लिए लागू होगा.
- नीति टैग टैक्सोनॉमी पेज पर, टैक्सोनॉमी की सूची में से, नई बनाई गई टैक्सोनॉमी पर क्लिक करें.
- क्रम के हिसाब से व्यवस्थित की गई सूची में,
MaskCustodianIDटैग पर क्लिक करके उसे चुनें. इसके बाद, डेटा से जुड़ी नीतियों को मैनेज करें को चुनें.
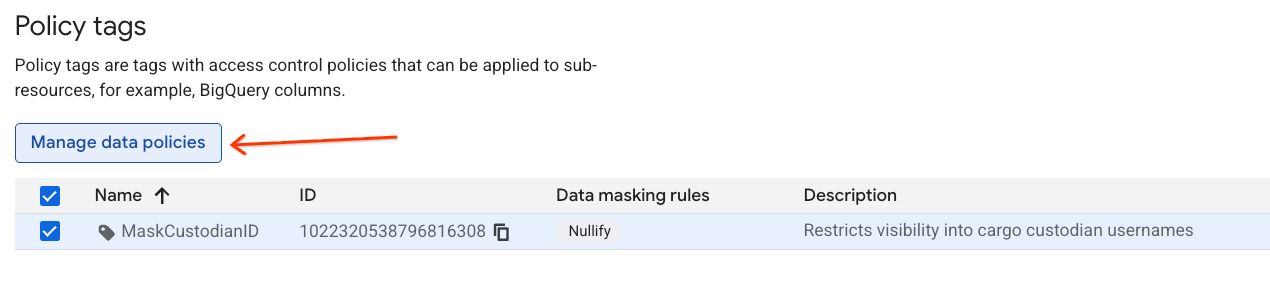
- दाईं ओर मौजूद पैनल में, + नियम जोड़ें बटन पर क्लिक करें.
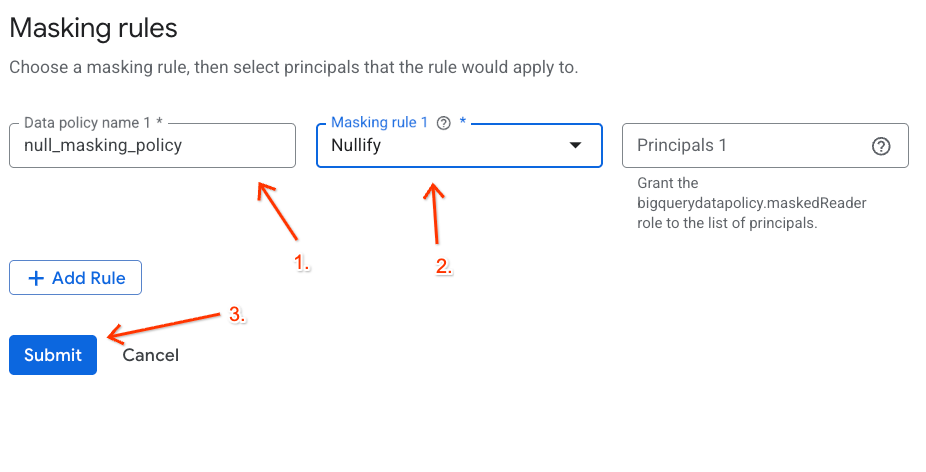
- दिखने वाले पैनल में, नीति की जानकारी कॉन्फ़िगर करें:
- डेटा नीति का नाम:
null_masking_policyडालें. इसे अपने-आप जनरेट होने न दें, क्योंकि हम अगले चरणों में इसे नाम के हिसाब से रेफ़रंस करेंगे. - मास्किंग का नियम: ड्रॉपडाउन मेन्यू से
Nullifyचुनें.
- डेटा नीति का नाम:
- सबमिट करें पर क्लिक करें.
BigQuery कॉलम को नीति टैग असाइन करना
नीति टैग और डेटा मास्किंग के नियम के चालू होने पर, सीधे तौर पर क्लासिफ़िकेशन टैग को BigQuery पार्टनर की शिपिंग मैनिफ़ेस्ट टेबल में मौजूद custodian_id कॉलम पर मैप करें.
- BigQuery कंसोल पर जाएं.
- बाईं ओर मौजूद एक्सप्लोरर पैनल में, अपने चालू प्रोजेक्ट को बड़ा करें. इसके बाद,
lost_cargo_datasetडेटासेट को बड़ा करें औरshipping_manifestsटेबल पर क्लिक करके, उसकी ज़्यादा जानकारी वाला व्यू खोलें. - स्कीमा में बदलाव करें पर क्लिक करें.
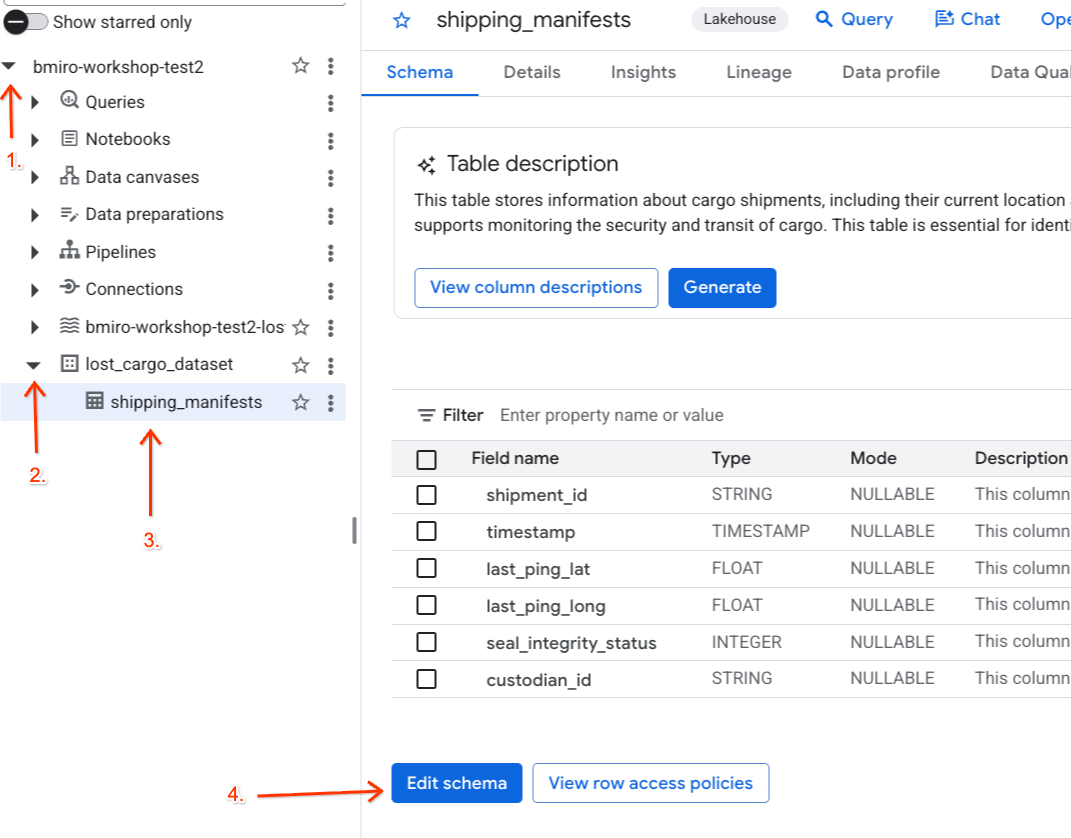
- कॉलम की सूची में,
custodian_idके बगल में मौजूद बॉक्स को चुनें. - स्कीमा एडिटर के सबसे ऊपर मौजूद टूलबार में, नीति टैग जोड़ें बटन पर क्लिक करें.
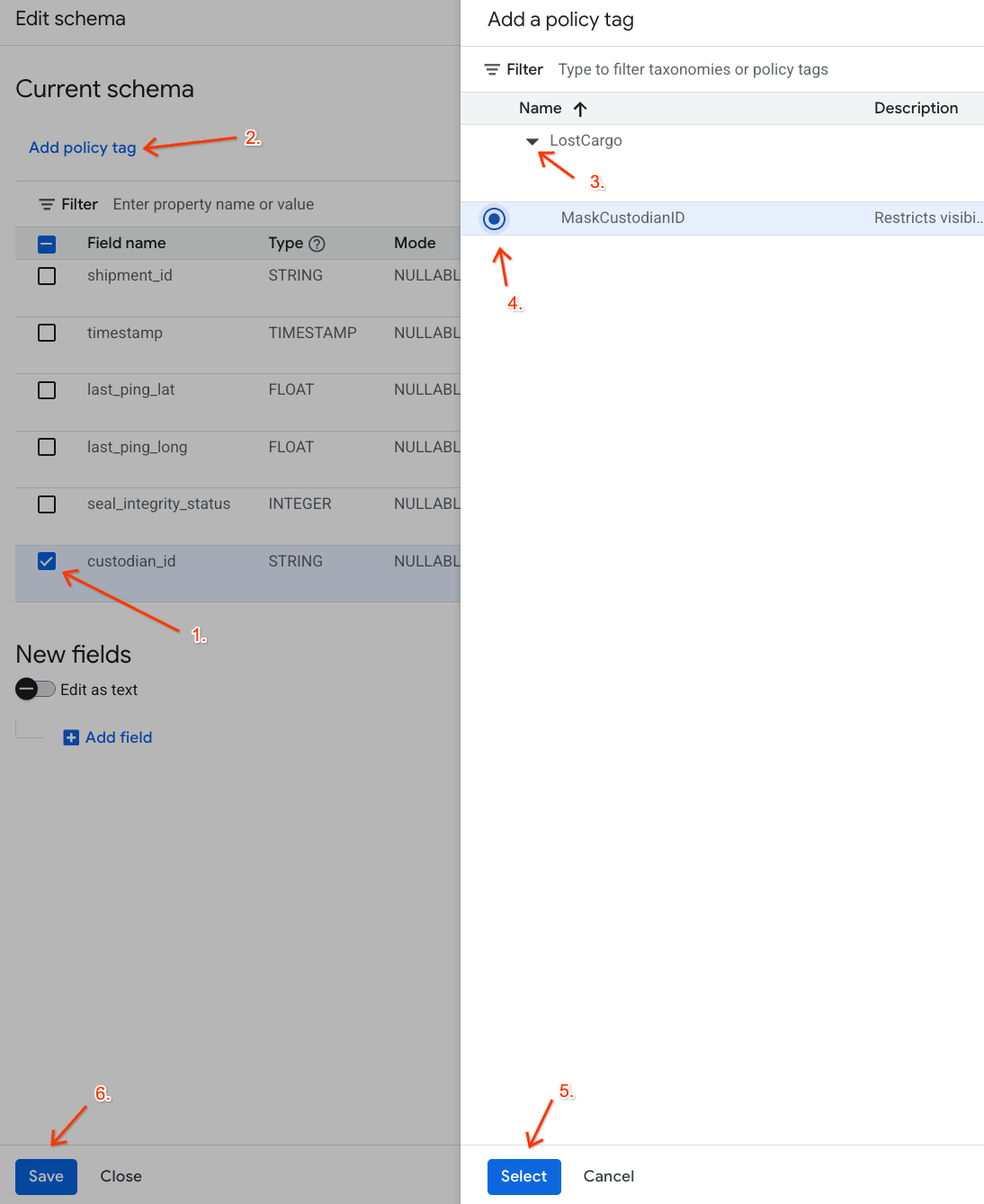
- नीति टैग जोड़ें पैनल में जाकर:
- अपनी
LostCargoटैक्सोनॉमी ढूंढें और उसे बड़ा करें. MaskCustodianIDके बगल में मौजूद बबल को चुनें.- चुनें पर क्लिक करें.
- अपनी
- पुष्टि करें कि
custodian_idको दिखाने वाली लाइन में, नीति टैग कॉलम में अबMaskCustodianIDटैग दिख रहा हो. - सेव करें पर क्लिक करें.
नीति से जुड़ी पाबंदियों की पुष्टि करना
अब आपके पास प्रोजेक्ट लेवल पर Masked Reader की भूमिका है. इसलिए, टेबल से क्वेरी करके यह पुष्टि की जा सकती है कि मास्किंग की नीति लागू है.
डेटा एजेंट किट पर वापस जाएं और यह क्वेरी चलाएं:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
आपको इससे मिलता-जुलता आउटपुट दिखेगा:
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
हो गया! shipment_id रिकॉर्ड देखे जा सकते हैं. हालांकि, संवेदनशील custodian_id फ़ील्ड, सुरक्षित null मास्क दिखाता है, ताकि डेटा लीक न हो!
8. व्यवस्थित करें
इस कोडलैब के दौरान बनाई गई संसाधनों के लिए, अपने Google Cloud खाते से शुल्क लिए जाने से रोकने के लिए, अपने डेटासेट और बकेट को हटाने के लिए, Cloud Shell टर्मिनल में ये कमांड चलाएं:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. बधाई हो
बधाई हो! आपने खोए हुए कार्गो की जांच का पहला ज़रूरी मॉड्यूल पूरा कर लिया है. आपने Lakehouse Iceberg REST कैटलॉग, PySpark लॉग नॉर्मलाइज़ेशन, और फ़ाइन-ग्रेन्ड डेटा मास्किंग का इस्तेमाल करके, खोज के लिए एक ऐसा ज़ोन बनाया है जिस पर डेटा-गवर्नेंस के नियम लागू होते हैं.
आपने क्या सीखा
- अपने आईडीई वर्कस्पेस में Data Agent Kit एक्सटेंशन को इंस्टॉल करना, सेट अप करना, और कॉन्फ़िगर करना.
- बेचे गए क्रेडेंशियल और क्रमबद्ध नेमस्पेस का इस्तेमाल करके, सर्वरलेस लेकहाउस आइसबर्ग REST कैटलॉग बनाना.
- अलग-अलग फ़ॉर्मैट वाले रीजनल फ़ीड को शामिल करना और Cloud Storage बकेट पर BigQuery की बाहरी टेबल बनाना.
- सर्वर के बिना Apache Spark जॉब लॉन्च करना. इससे, ट्रांसपॉन्डर के अनस्ट्रक्चर्ड लॉग को पार्स, सामान्य, सेगमेंट, और वापस BigQuery में लिखा जा सकता है. ऐसा, रजिस्टर की गई Iceberg कैटलॉग टेबल के तौर पर किया जाता है.
- सुरक्षा टैक्सनॉमी बनाना और नॉलेज कैटलॉग की डेटा मास्किंग नीतियों को मैप करना, ताकि संवेदनशील लॉग इंडेक्स पर पहचान से जुड़ी जानकारी लीक होने से रोकी जा सके.
- डेटा एक्सप्लोरेशन (विश्लेषण का तरीका) को बेहतर बनाने के लिए, BigQuery की डेटा इनसाइट सुविधा का इस्तेमाल करके, टेबल के मेटाडेटा की अहम जानकारी जनरेट करना और उसका विश्लेषण करना.
इकट्ठा किए गए सुरागों की पुष्टि
पुष्टि करें कि आपने अगले लैब फ़ेज़ में जाने के लिए, ज़रूरी सुराग रिकॉर्ड किए हैं:
- खोए हुए शिपमेंट का आईडी:
MV-CAT-001(पिछली पिंग की गई जगह: लंदन) - टारगेट किया गया डेस्टिनेशन:
New York(और ट्रांसपोंडर का असली नाम:MV-DOG-002) - कंटेनर का रंग:
Crimson RED - गवर्नेंस ऐक्सेस टैग:
MaskCustodianID
क्या आप अगले चरण के लिए तैयार हैं?
ट्रांसपॉन्डर के रवाना होने / पहुंचने के रास्ते सुरक्षित होने के बाद, जांच आगे बढ़ती है! सीधे Lab 2 पर जाएं. इसमें मल्टीमॉडल Gemini मॉडल का इस्तेमाल करके, सुरक्षा कैमरों की जांच की जाती है. साथ ही, जहाज़ की पहचान की जाती है और AlloyDB में वेक्टर सर्च की जाती है, ताकि छेड़छाड़ की असामान्यताओं की पुष्टि की जा सके!
➡️ दूसरे चरण पर जाएं: डेटा का विश्लेषण करना और मल्टीमॉडल इनसाइट पाना