
1. Pengantar
Di lab ini, Anda akan berperan sebagai penyelidik data utama untuk perusahaan logistik global. Sebuah kontainer kargo bernilai tinggi yang membawa koleksi figurin Android berharga telah hilang. Untuk menemukan posisi terakhirnya dan melacak rutenya, Anda harus menggabungkan manifes pengiriman yang terfragmentasi dari partner logistik regional dan file log transponder yang tidak terstruktur. Untuk melakukannya, Anda akan mengonfigurasi Google Cloud Open Data Lakehouse modern.

Yang akan Anda lakukan
- Konfigurasi ekstensi Google Cloud Data Agent Kit di Cloud Shell Editor.
- Buat bucket Cloud Storage dan sediakan Lakehouse Apache Iceberg REST Catalog dan namespace.
- Memetakan tabel eksternal BigLake ke manifes partner JSON mentah di Cloud Storage untuk menemukan petunjuk keberangkatan kapal.
- Muat dan proses log teks transponder tidak terstruktur menggunakan Managed Service untuk Apache Spark serverless. Lakukan normalisasi regex dan ekstraksi petunjuk dinamis untuk menargetkan tujuan payload yang hilang.
- Tulis metrik log yang diuraikan sebagai tabel Apache Iceberg melalui katalog REST.
- Lakukan percakapan dengan agen AI tentang data Apache Iceberg Anda menggunakan Analisis Percakapan untuk menemukan petunjuk tersembunyi tentang pengiriman Anda yang hilang.
- Manfaatkan insight data otomatis dengan Knowledge Catalog untuk membuat metadata tentang data Anda.
- Tetapkan batas aman penyerapan data dengan membuat taksonomi keamanan dan menggunakan Knowledge Catalog untuk menerapkan kontrol akses terperinci melalui penyamaran ID kustodian sensitif.
Yang Anda butuhkan
- Browser web seperti Chrome.
- Project Google Cloud yang mengaktifkan penagihan.
- Pemahaman tentang kueri SQL dasar dan perintah terminal.
Perkiraan Biaya dan Durasi
- Waktu penyelesaian: ~45 menit.
- Estimasi Biaya: Kurang dari $5,00 USD.
2. Sebelum memulai
Membuat atau Memilih Project Google Cloud
- Di Konsol Google Cloud, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara mengonfirmasi bahwa penagihan diaktifkan pada suatu project.
Mengonfigurasi Lingkungan
Anda akan menjalankan sebagian besar perintah dari terminal terintegrasi di Cloud Shell Editor, lingkungan pengembangan berbasis cloud yang telah dilengkapi dengan alat developer dan Google Cloud SDK standar.
- Buka Cloud Shell Editor di tab baru.
- Jalankan perintah berikut di terminal untuk meng-clone repositori:
cd ~/ git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git cd ~/devrel-demos git sparse-checkout init --cone git sparse-checkout set data-analytics/data-cloud-roadshow/lab1 git checkout main cd data-analytics/data-cloud-roadshow/lab1 - Tetapkan project ID Anda. Anda juga dapat menekan
Ctrl+Shift+Vdi Windows/Linux, atauCmd+Vdi macOS untuk menempelkan ini ke terminal:export PROJECT_ID="<YOUR_PROJECT_ID>" - Sekarang, konfigurasikan di lingkungan Anda.
gcloud config set project $PROJECT_ID - Pilih region.
export REGION="<YOUR_REGION>" # Replace with the region you chose, such as "us-central1" - Mengaktifkan API yang diperlukan.
gcloud services enable \ bigquery.googleapis.com \ biglake.googleapis.com \ storage.googleapis.com \ dataplex.googleapis.com \ datacatalog.googleapis.com \ dataproc.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ cloudaicompanion.googleapis.com \ geminidataanalytics.googleapis.com
Instal Ekstensi
Sekarang Anda akan mengonfigurasi ekstensi Google Data Agent Kit, alat untuk berinteraksi dengan alat data Google Cloud secara langsung di IDE Anda.
- Di panel aktivitas kiri editor, klik ikon Ekstensi (atau tekan
Ctrl+Shift+Xdi Windows/Linux, atauCmd+Xdi macOS). - Di kotak penelusuran ekstensi, ketik:
Google Cloud Data Agent Kit - Pilih ekstensi resmi dari hasil, lalu klik Instal. Jika diminta, pilih "Ya, saya memercayai penulis".
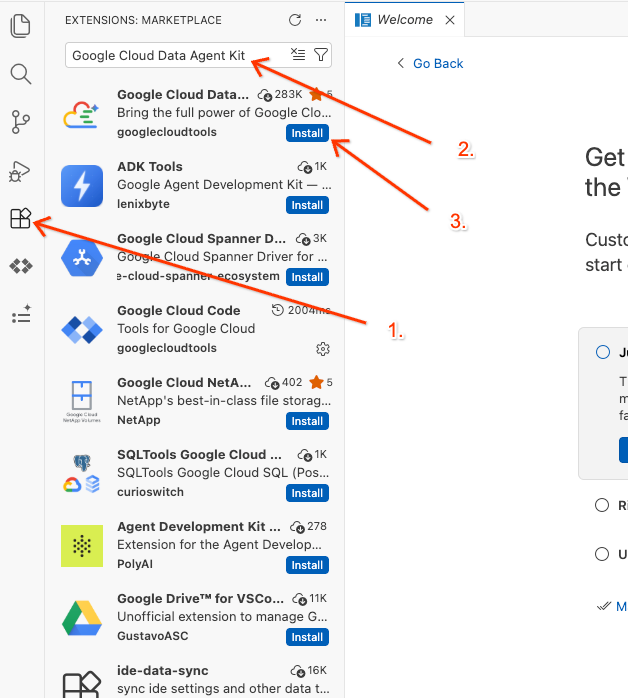
- Setelah berhasil diinstal, Anda akan melihat ikon Google Cloud Data Agent Kit ditampilkan di kolom aktivitas. Klik lab-report-service tersebut.
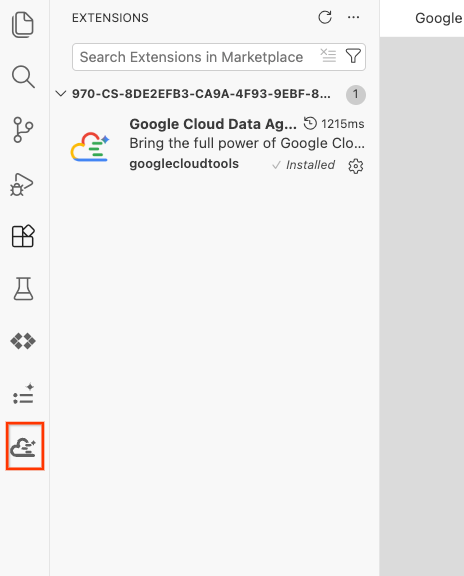
- Klik Sign in to cloud.
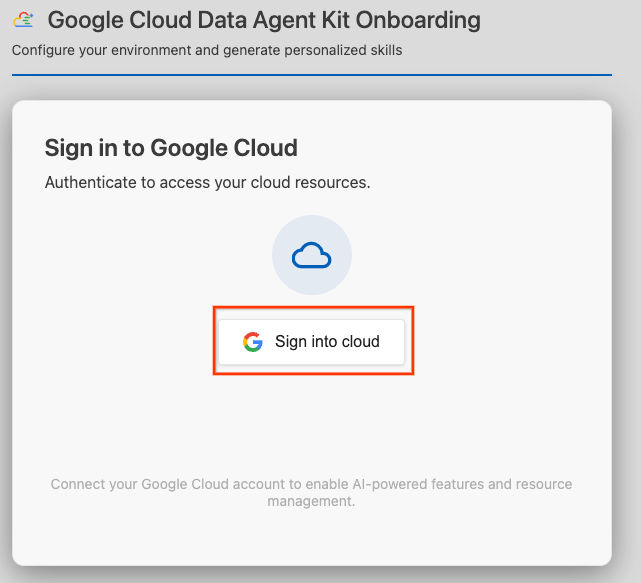
- Klik Configure MCP Servers.
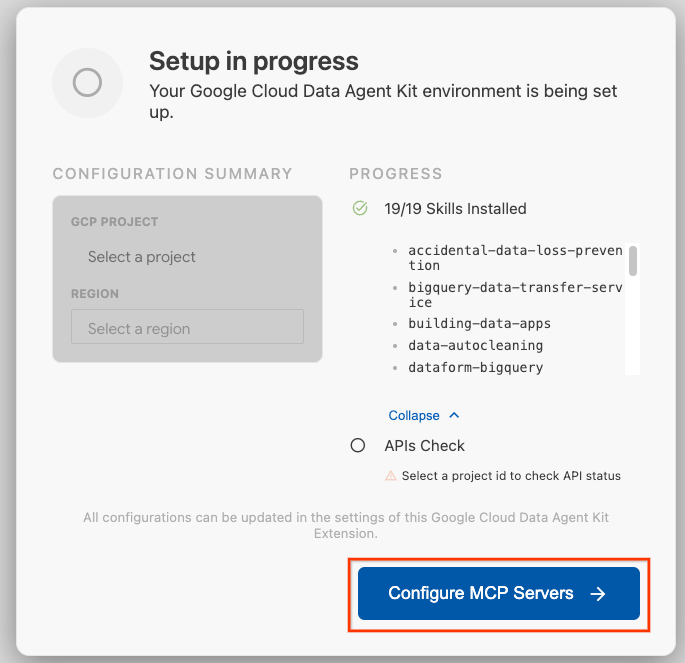
- Pilih BigQuery, Knowledge Catalog, Apache Spark, dan AlloyDB. Anda akan menggunakan AlloyDB di Lab 2. Kemudian, klik Mulai.
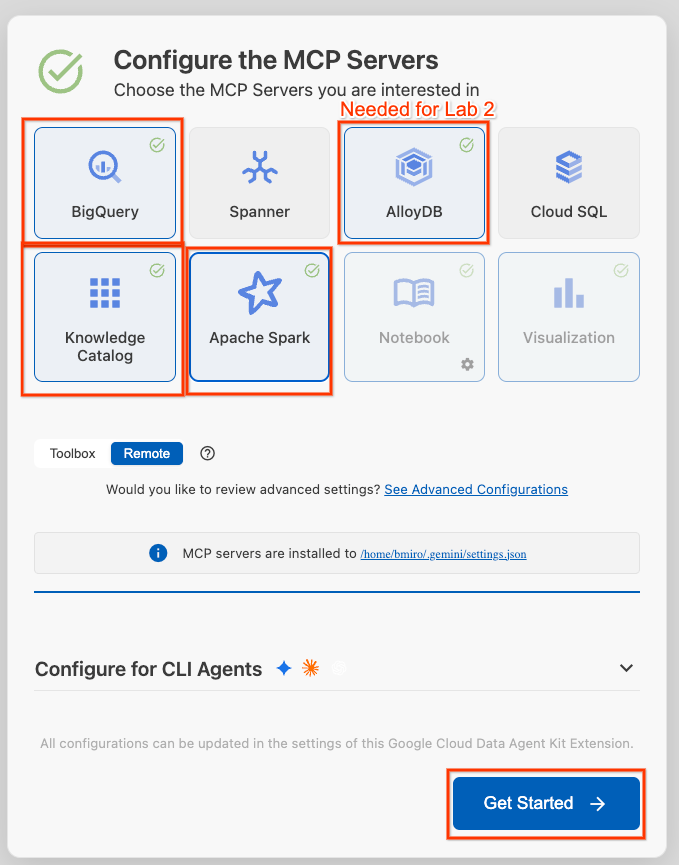
- Klik pemilih Project ID di status bar bawah, lalu pilih project Google Cloud aktif Anda.
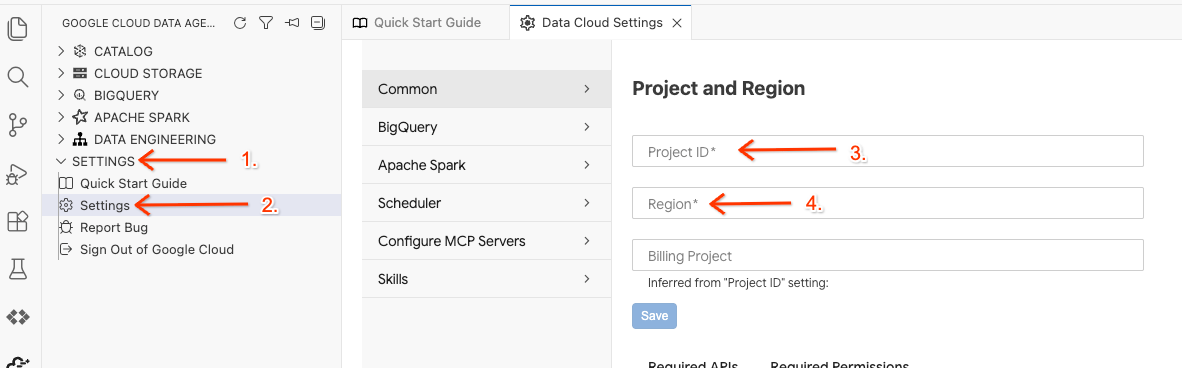
- Di Data Agent Kit, klik SETTINGS, lalu Settings, dan di tab Common, pilih Project ID dan Region untuk menjalankan lab, seperti us-central1.
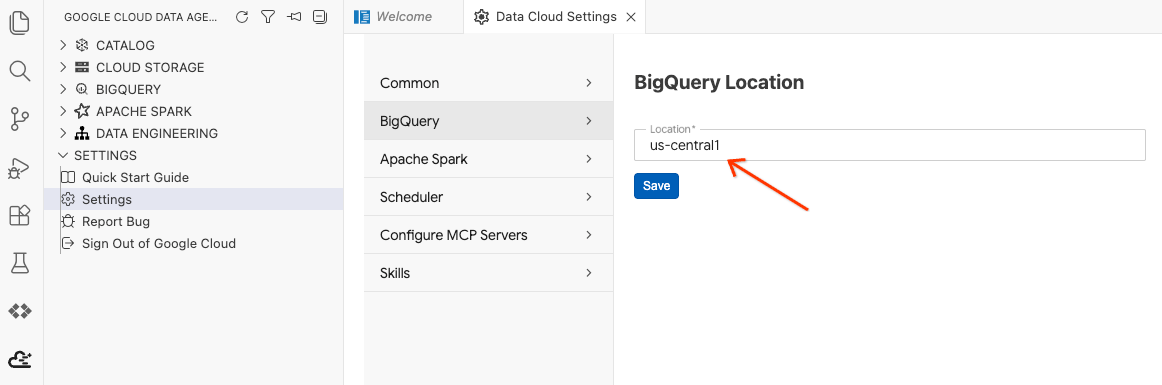
- Klik BigQuery Settings dan ganti Region dengan region yang Anda pilih sebelumnya. Klik Save.
Sekarang Anda siap menggunakan Kit Agen Data.
Jalankan Skrip Penyiapan Lingkungan
Di terminal, jalankan skrip penyiapan untuk membuat resource latar belakang yang diperlukan untuk lab ini dan mengonfigurasi izin IAM:
chmod +x setup_lab1.sh
./setup_lab1.sh
source .env
Anda akan melihat serangkaian langkah output yang menunjukkan resource yang sedang disediakan. Kita akan membahasnya di sepanjang lab ini.
Setelah melihat pesan penyelesaian, Anda siap melanjutkan:
==================================================== Environment Setup Complete! ====================================================
Sekarang, mari kita mulai penelusuran!
3. Menyerap Manifes Pengiriman Partner
Data manifes pengiriman dari kapal partner disimpan dalam format JSON Lines (JSONL) standar di bucket Anda: gs://${PROJECT_ID}-lost-cargo-lake/shipping_manifests/manifests.jsonl.
Sebelum melakukan analisis mendalam, Anda akan membuat tabel BigLake yang diatur untuk data tidak terstruktur ini. Dengan begitu, Anda dapat langsung menjelajahi data logistik partner menggunakan SQL standar tanpa biaya impor duplikat.
Buka Ruang Kerja di Editor dan jalankan kueri
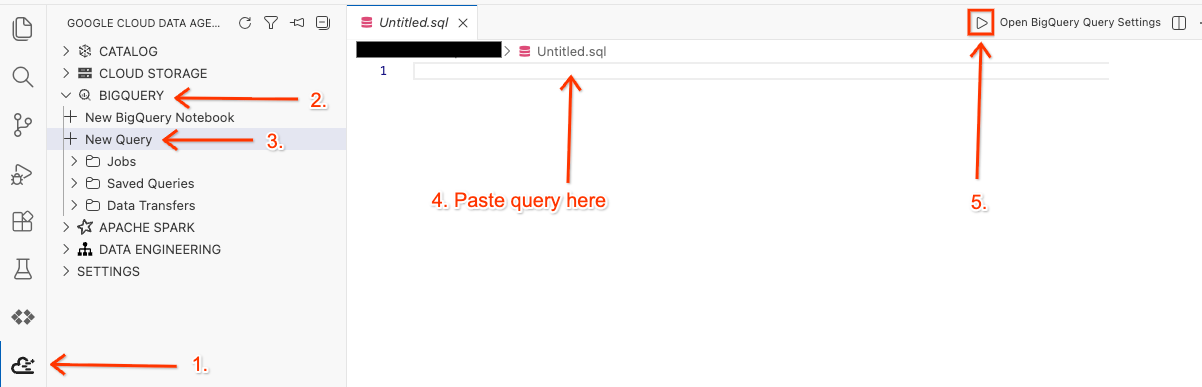
- Di Cloud Shell Editor, klik ikon Google Cloud Data Agent Kit extension di panel samping.
- Buka BigQuery, lalu pilih + New Query.
- Salin kueri berikut ke jendela kueri.
SET @@location = "<YOUR_REGION>"; --Update to your resource region, such as "us-central1". Make sure it is in quotes.
EXECUTE IMMEDIATE ("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.shipping_manifests`
(
shipment_id STRING,
timestamp TIMESTAMP,
last_ping_lat FLOAT64,
last_ping_long FLOAT64,
seal_integrity_status INT64,
custodian_id STRING OPTIONS(description='Masked identification token for official cargo custodian personnel.')
)
WITH CONNECTION `""" || @@location || """.conn`
OPTIONS (
format = 'NEWLINE_DELIMITED_JSON',
uris = ['gs://""" || @@project_id || """-lost-cargo-lake/shipping_manifests/*.jsonl']
)
""");
- Klik Run.
- Untuk memverifikasi bahwa tabel telah dibuat, Anda akan melihat pesan berhasil di panel Query Results yang otomatis terbuka di bagian bawah.
Buat kueri tabel eksternal untuk mengisolasi transponder yang terkompromi
Mari kita identifikasi transponder yang terganggu dengan menemukan kegagalan saat seal_integrity_status disetel ke 0. Salin dan jalankan kueri berikut di jendela kueri yang Anda buka sebelumnya:
SELECT shipment_id, last_ping_lat, last_ping_long, custodian_id
FROM `lost_cargo_dataset.shipping_manifests`
WHERE seal_integrity_status = 0;
Di panel Query Results, Anda akan melihat output yang serupa dengan ini:
shipment_id | last_ping_lat | last_ping_long | custodian_id |
MV-CAT-001 | 51.5074 | -0,1278 | usr_999_shadow |
4. Memproses Log Tidak Terstruktur dengan Managed Service untuk Apache Spark
Anda telah menemukan lokasi awal dari manifes terstruktur, tetapi transponder yang hilang telah benar-benar tidak aktif. Ping transponder terakhir meninggalkan pesan kriptik yang tidak terstruktur di dalam file log teks mentah di jalur GCS gs://${BUCKET_NAME}/raw_logs/maritime_logs.txt.
Untuk memproses dan memetakan log teks ini, mengekstrak stempel waktu, menyamarkan identitas, dan menemukan rute hilir kargo, Anda akan mengirimkan tugas Apache Spark (PySpark) serverless ke Managed Service untuk Apache Spark.
Managed Service for Apache Spark memungkinkan Anda menjalankan workload Spark tanpa menyediakan atau mengelola cluster. Layanan ini menangani resource komputasi pokok, menskalakannya secara dinamis, dan Anda hanya membayar durasi eksekusi.
Skrip akan:
- Masukkan teks transponder mentah, tidak terstruktur, dan dalam tanda kurung.
- Terapkan filter ekstraksi ekspresi reguler SQL PySpark untuk memisahkan stempel waktu, metadata kustodian, dan konten mentah.
- Membagi log yang tidak teratur menjadi rekaman tingkat kalimat yang rapi.
- Ekstrak target koordinat tujuan dinamis tempat keberangkatan muatan yang hilang berakhir.
- Hubungkan dan tulis kembali dataframe log yang diproses ke Lakehouse Apache Iceberg REST Catalog sebagai tabel analisis baru yang terlihat langsung dalam BigQuery.
Memperbaiki Skrip Analisis PySpark
Ada laporan tentang Bajak Laut Python di laut yang menyebabkan berbagai masalah.
- Jalankan perintah berikut untuk membuka file
process_maritime_logsdi Cloud Shell Editor.cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1 cloudshell open ./process_maritime_logs.py - Luangkan waktu untuk membaca kode dan memahami fungsinya.
- Pastikan tidak ada yang mencurigakan dalam kode. Jika Anda perlu menghapus sesuatu, pastikan Anda menyimpan file menggunakan
Ctrl + S(Windows/Linux) atauCmd + S(Mac).
Mengirimkan Tugas Serverless Spark
Kirimkan tugas menggunakan SDK gcloud. Konfigurasi ini secara otomatis mengonfigurasi tugas PySpark untuk mengakses katalog Lakehouse.
Jalankan perintah berikut di terminal editor terintegrasi Anda.
cd ~/devrel-demos/data-analytics/data-cloud-roadshow/lab1
source .env
gcloud dataproc batches submit pyspark process_maritime_logs.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--deps-bucket=${BUCKET_NAME} \
--properties="\
spark.sql.defaultCatalog=cargo_catalog,\
spark.sql.catalog.${CATALOG_NAME}=org.apache.iceberg.spark.SparkCatalog,\
spark.sql.catalog.${CATALOG_NAME}.type=rest,\
spark.sql.catalog.${CATALOG_NAME}.uri=https://biglake.googleapis.com/iceberg/v1/restcatalog,\
spark.sql.catalog.${CATALOG_NAME}.warehouse=gs://${BUCKET_NAME},\
spark.sql.catalog.${CATALOG_NAME}.header.x-goog-user-project=${PROJECT_ID},\
spark.sql.catalog.${CATALOG_NAME}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\
spark.sql.catalog.${CATALOG_NAME}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token, \
spark.sql.catalog.${CATALOG_NAME}.header.X-Iceberg-Access-Delegation=vended-credentials" \
-- ${BUCKET_NAME}
Tunggu beberapa menit hingga lingkungan serverless dijalankan, skrip Anda diupload, dan logika pemrosesan dieksekusi.
Setelah Anda melihat output yang mirip dengan berikut ini, tabel yang diproses akan disimpan ke katalog Lakehouse sebagai tabel terkelola Apache Iceberg.
Batch [1fae0b4b42c045a084dd67917bd0c332] finished.
metadata:
'@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata
batch: projects/<YOUR_PROJECT>/locations/us-central1/batches/1fae0b4b42c045a084dd67917bd0c332
batchUuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
createTime: '2026-06-11T21:35:01.868157Z'
description: Batch
labels:
goog-dataproc-batch-id: 1fae0b4b42c045a084dd67917bd0c332
goog-dataproc-batch-uuid: 611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-drz-resource-uuid: batch-611b4465-fdac-4974-bc47-5f10adaf2a08
goog-dataproc-location: us-central1
operationType: BATCH
name: projects/<YOUR_PROJECT/regions/us-central1/operations/7e2044db-dd97-3270-b368-4dc4ba417574
Melihat Pratinjau Log yang Diproses
Di editor Kueri ekstensi Data Agent Kit, salin kueri berikut untuk melihat pratinjau data:
SET @@location = "<YOUR_REGION>"; -- e.g. "us-central1"
EXECUTE IMMEDIATE FORMAT("""
select log_timestamp, custodian_id, sentence from
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
limit 5
""", @@project_id, @@project_id);
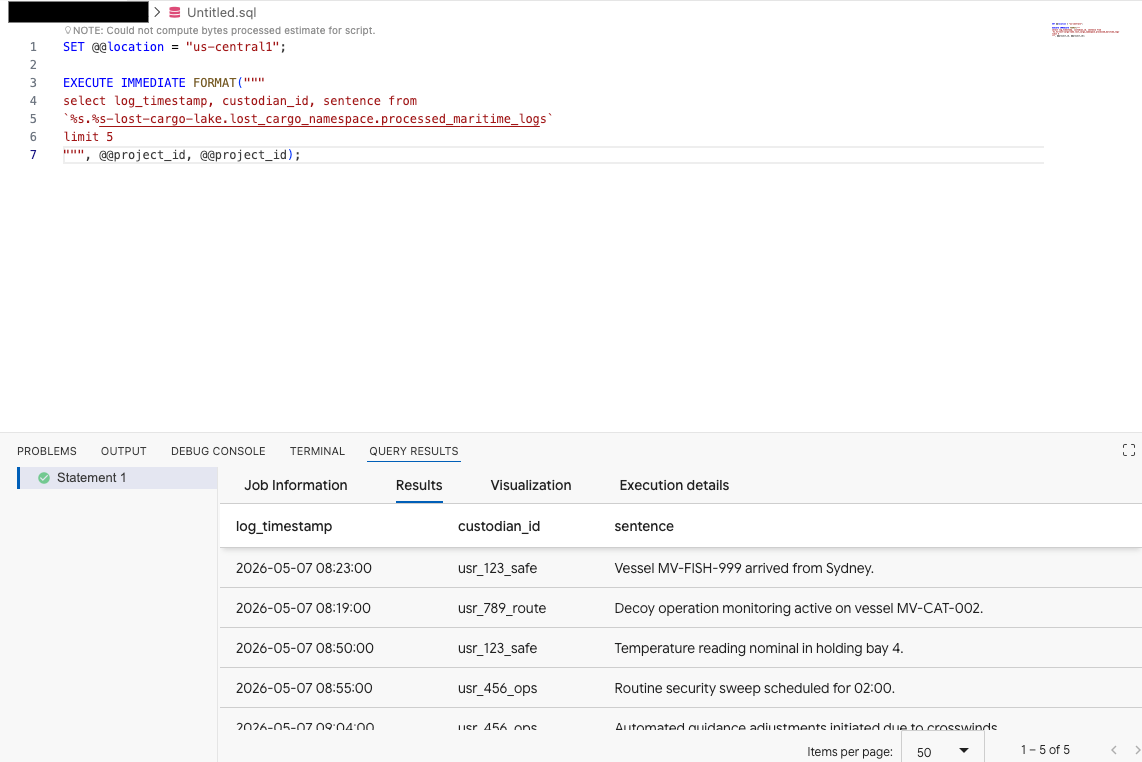
Hal ini menunjukkan bahwa tabel Iceberg yang terdaftar di katalog berhasil diakses dari BigQuery.
Mengekstrak Petunjuk Tujuan
Setelah memiliki log yang diproses, mari kita telusuri log yang menyertakan target tujuan. Dari sana, kita dapat menelusuri log yang menyertakan penyebutan kota asal kita.
Di editor kueri, jalankan kueri berikut, dengan mengganti <YOUR_REGION> dengan region Anda dan mengganti <ORIGIN_CITY> dengan kota asal yang Anda temukan sebelumnya.
SET @@location = "<YOUR_REGION>"; --e.g. "us-central1"
DECLARE origin_city STRING;
SET origin_city = "<ORIGIN_CITY>"; --e.g. "Boston". (It's not Boston)
EXECUTE IMMEDIATE FORMAT(r"""
SELECT
log_timestamp AS event_time,
custodian_id,
REGEXP_EXTRACT(raw_message, r'Destination:\s*([^.]+)') AS destination_target
FROM
`%s.%s-lost-cargo-lake.lost_cargo_namespace.processed_maritime_logs`
WHERE
-- STRPOS is highly optimized in BigQuery for a simple .contains() substring check
STRPOS(sentence, '%s') > 0;
""", @@project_id, @@project_id, origin_city);
Melakukan Chat dengan Data Anda di Konsol BigQuery menggunakan Analisis Percakapan
Daripada menulis kueri SQL yang kompleks untuk menjelajahi data, Anda dapat menggunakan Analisis Percakapan untuk melakukan percakapan dengan tabel menggunakan bahasa alami.
- Buka Konsol BigQuery.
- Di panel Explorer di sebelah kiri, luaskan project dan set data
-lost-cargo-lake.lost_cargo_namespace processed_maritime_logsuntuk membuka tab detailnya. - Di samping Query, klik Chat.
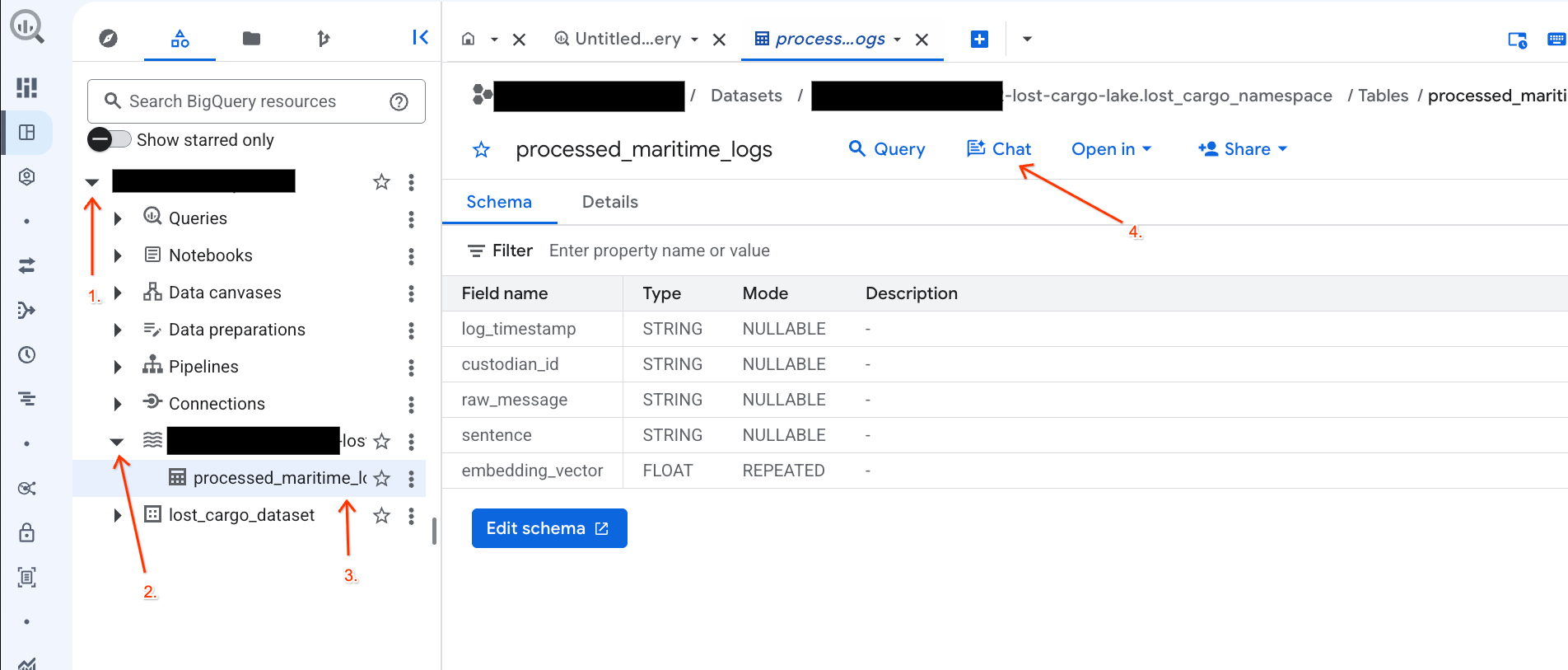
- Di panel chat, ketik pertanyaan berikut, lalu tekan Enter di keyboard untuk mengirim:
Based on this table, what color is the shipping container MV-CAT-001?
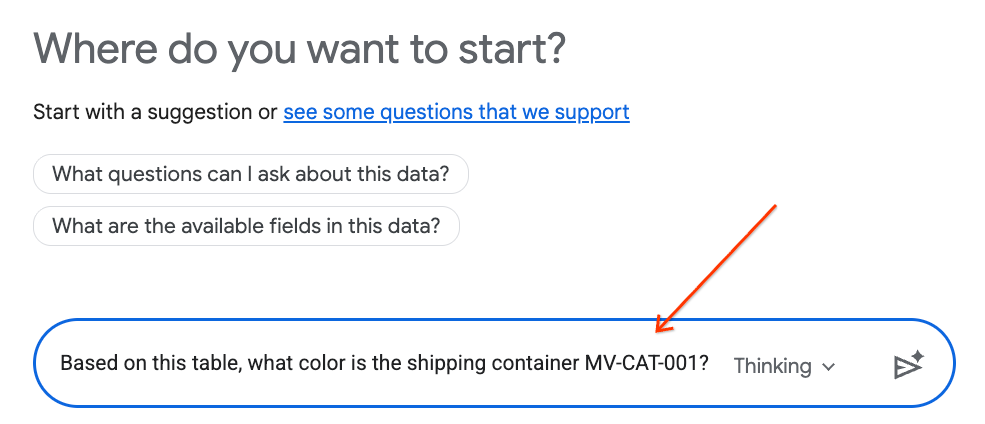
- Analisis Percakapan (yang didukung oleh Gemini) akan menganalisis data tabel aktif dan merespons dengan warna.
5. Melihat Katalog Lakehouse Terpusat
Untuk mengintegrasikan mesin pemrosesan open source (seperti Apache Spark) secara aman dan lancar dengan mesin data perusahaan (seperti BigQuery), skrip penyiapan Anda mengonfigurasi Lakehouse Iceberg REST Catalog.
Katalog REST Apache Iceberg berfungsi sebagai "sumber tepercaya tunggal" serverless untuk metadata tabel, mengelola skema dan mempartisi tabel secara dinamis sambil menyimpan file data Parquet fisik di Cloud Storage.
Mari kita periksa katalog ini langsung di Konsol Google Cloud:
- Buka Lakehouse Console.
- Di tab Catalogs, temukan dan klik Katalog REST Iceberg yang aktif:
-lost-cargo-lake
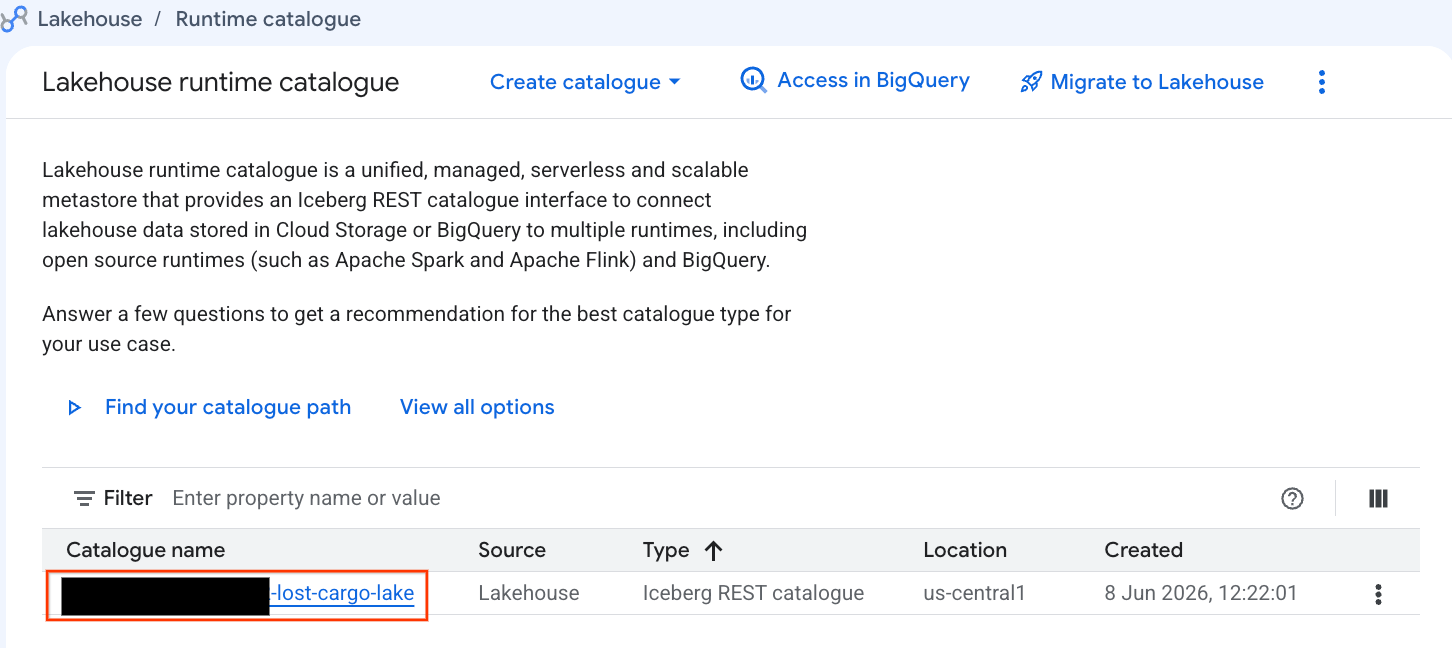
- Di tampilan detail katalog, di bagian Namespace, Anda akan melihat
lost_cargo_namespace. Klik tab tersebut.
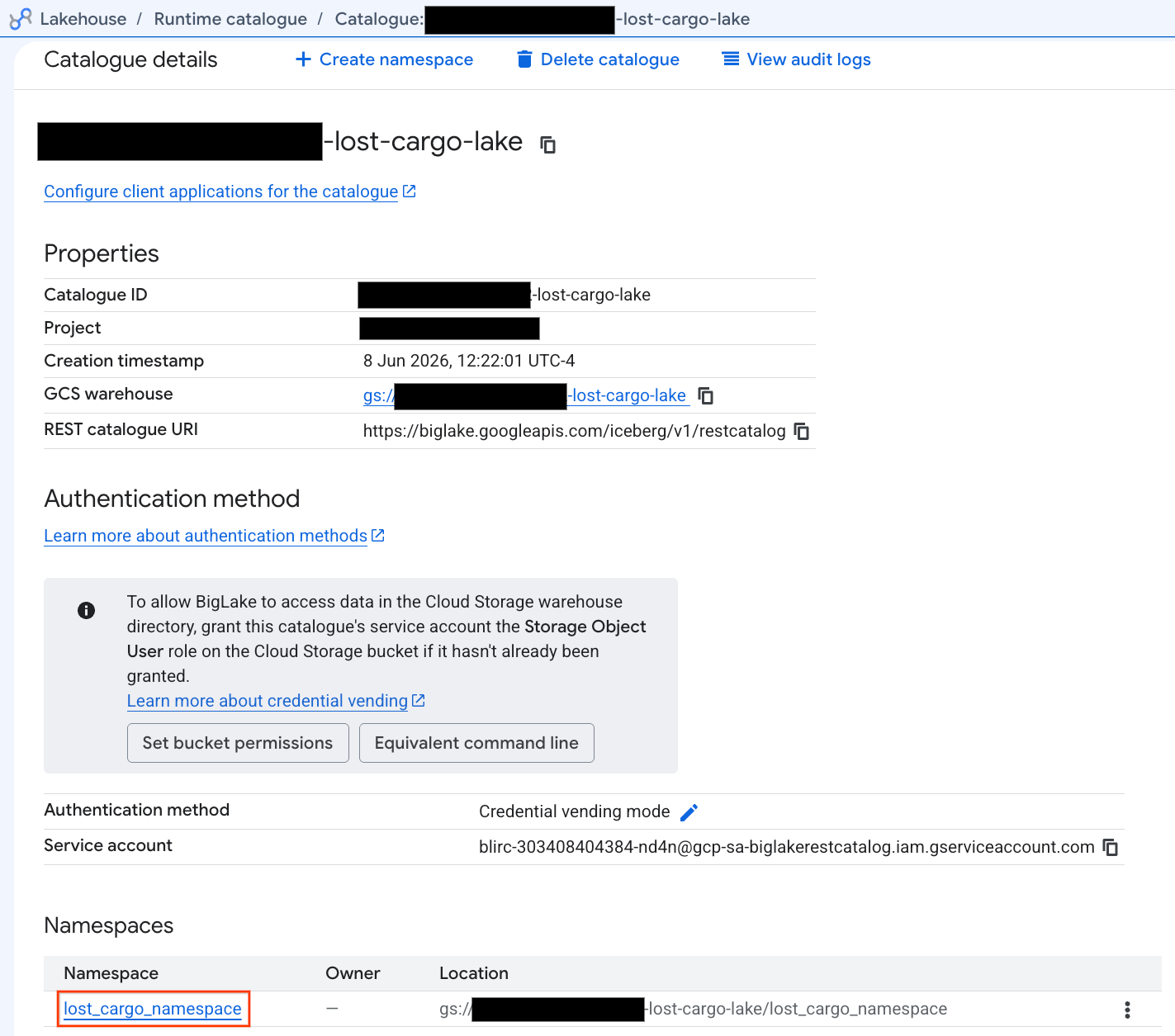
- Tabel Apache Iceberg baru Anda, yang dibuat oleh PySpark, otomatis terdaftar di namespace metastore ini dan langsung dapat dikueri di BigQuery.
6. Membuat Insight di Tabel Manifes Pengiriman
Mari kita kembali dan menganalisis tabel shipping_manifests untuk memahami struktur dan kontennya menggunakan Insight Data Knowledge Catalog. Dengan memperkaya metadata, penjelajah lain dapat lebih memahami tabel untuk analisis mendatang.
Membuat Insight Tabel di BigQuery Studio
- Di Konsol Google Cloud, buka BigQuery Studio.
- Di panel Explorer, luaskan project Anda, luaskan set data
lost_cargo_dataset, lalu klik tabelshipping_manifests. - Di panel detail di sebelah kanan, klik tab Insight.
- Gunakan dropdown untuk memilih Buat dan publikasikan.
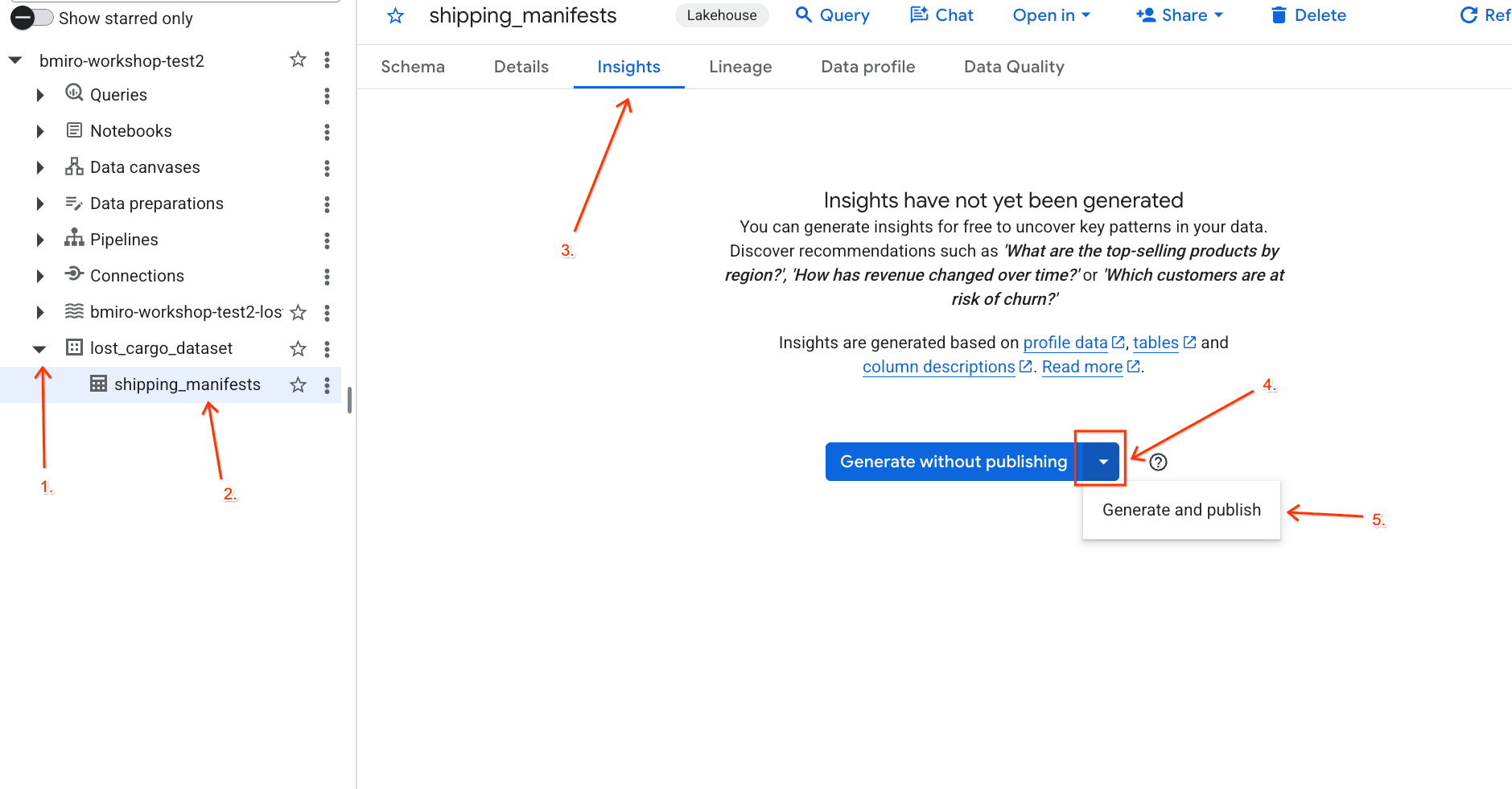
- Tunggu sekitar 3 menit hingga pembuatan insight selesai. Gemini akan menganalisis metadata tabel dan membuat pertanyaan bahasa alami serta kueri SQL yang sesuai.
- Setelah selesai, Anda akan melihat Deskripsi tabel dengan penjelasan tabel dalam bahasa alami.
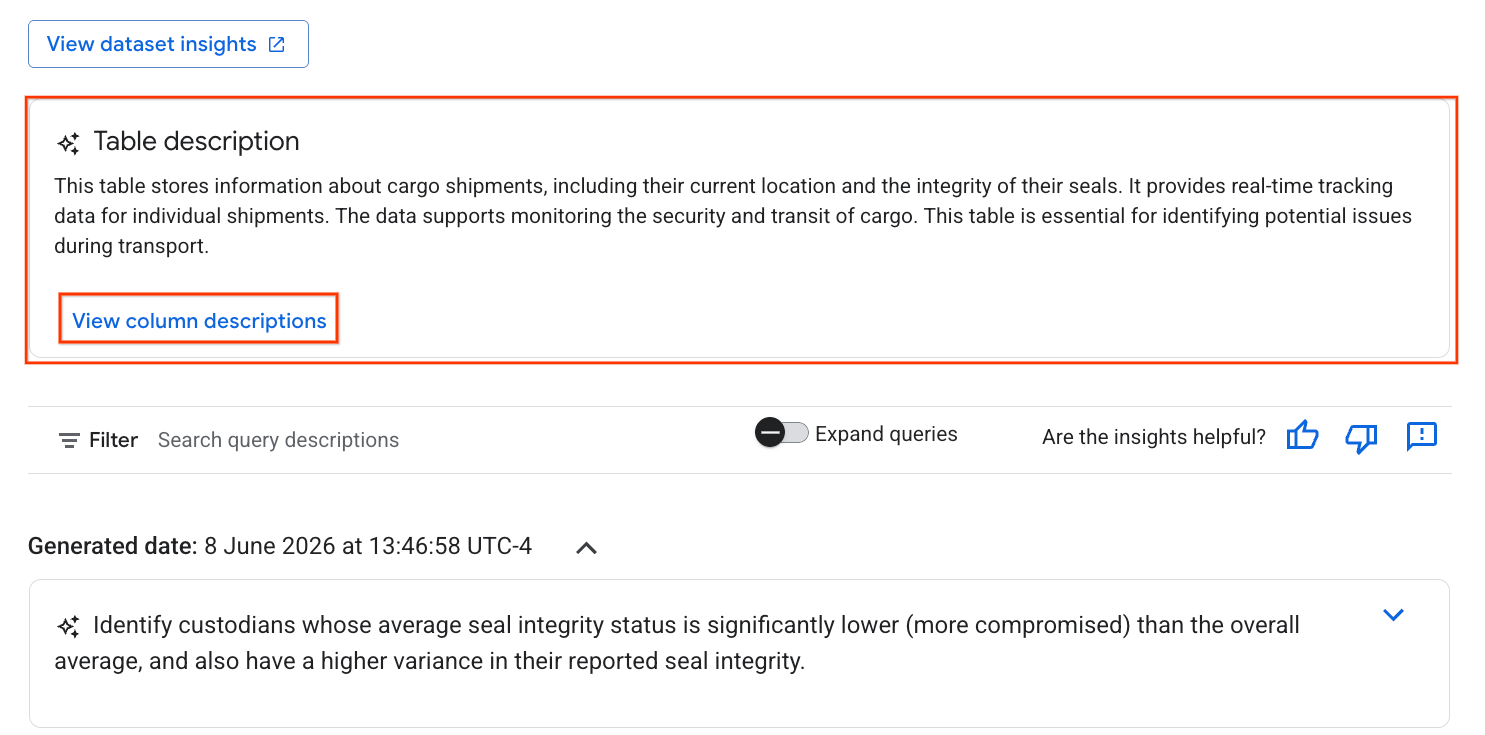
- Klik Lihat deskripsi kolom untuk melihat informasi tentang setiap kolom.
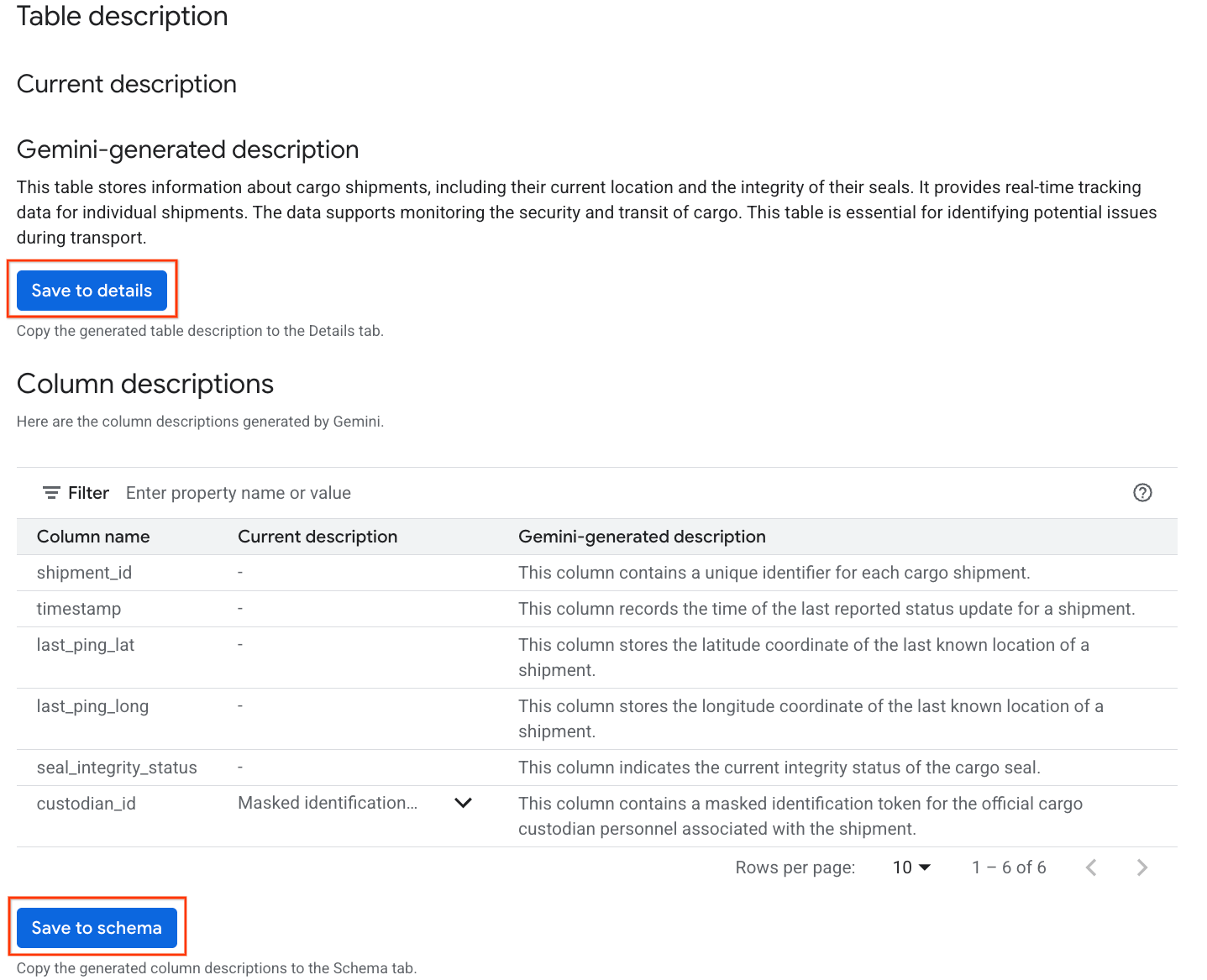
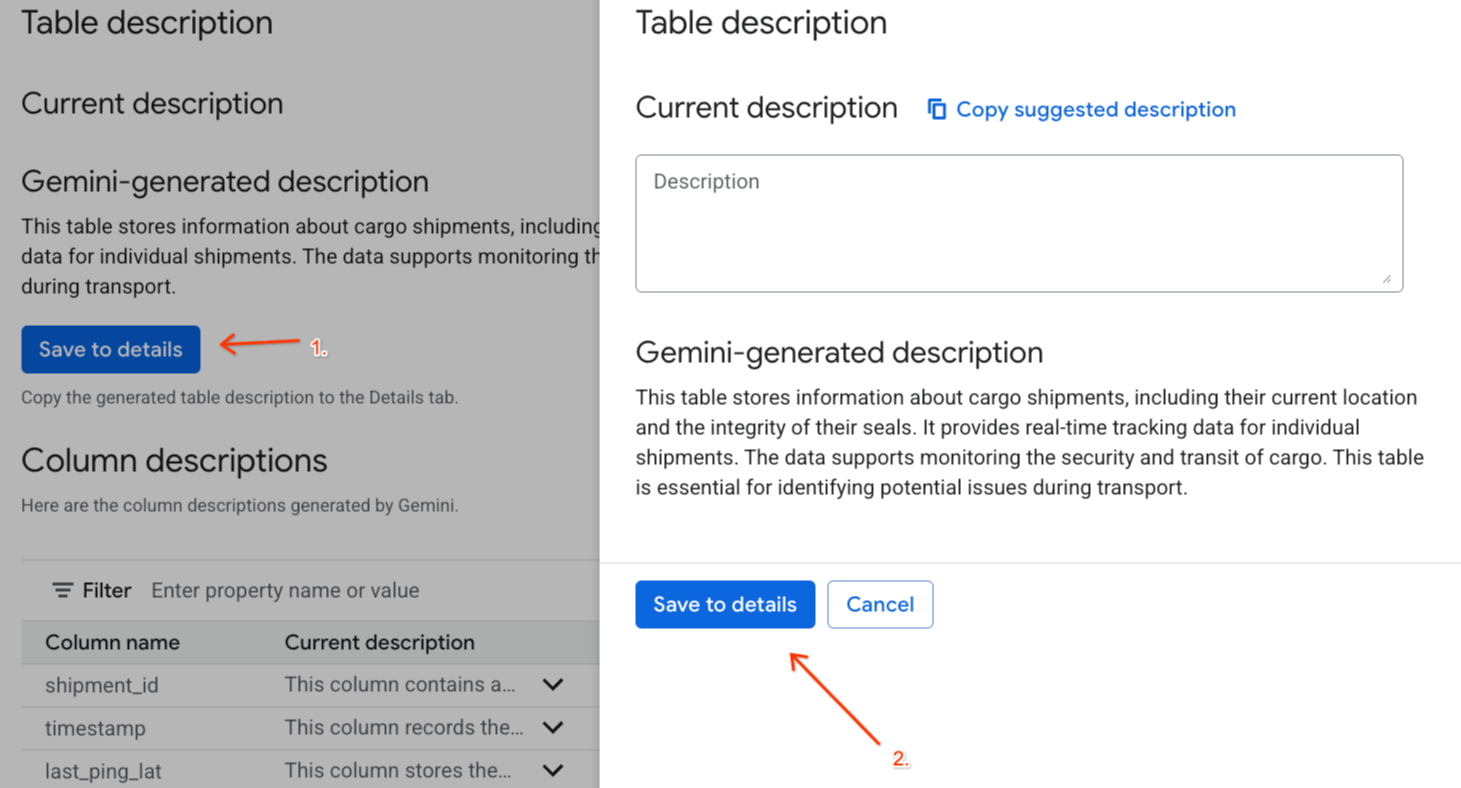
- Klik Simpan ke detail di bagian
Gemini generated description, lalu klik Simpan ke detail di jendela yang muncul.
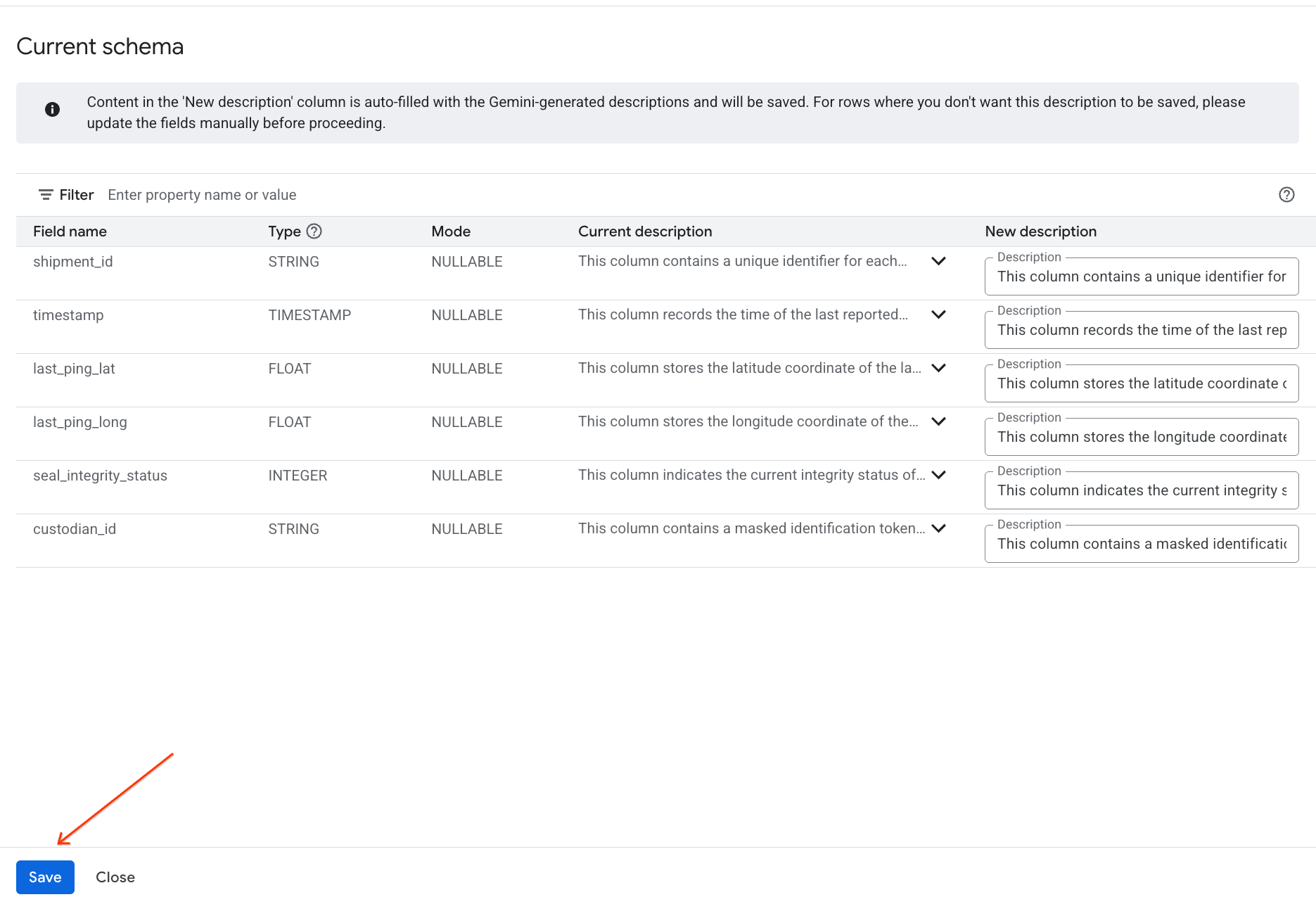
- Demikian pula, klik Simpan ke skema untuk menambahkan deskripsi kolom ke metadata tabel.
Meninjau Insight yang Dihasilkan
Anda juga akan melihat daftar saran pertanyaan. Anda dapat mengklik pertanyaan apa pun untuk melihat kueri SQL yang dihasilkan dan menjalankannya untuk menjelajahi data. Misalnya, Anda mungkin melihat pertanyaan seperti:
- "Berapa total jumlah pengiriman?"
- "Cantumkan ID kustodian unik."
Menjalankan kueri ini akan membantu Anda memahami data.
7. Menerapkan Penyamaran dan Tata Kelola Data
Untuk menjamin bahwa akun dan nama pengguna riset aktif tidak dapat bocor selama penyelidikan kargo yang sedang berlangsung ini, Anda harus menerapkan protokol keamanan standar. Anda akan membuat Taksonomi Tag Kebijakan Keamanan dan mengonfigurasi Penyamaran Data Knowledge Catalog pada kolom custodian_id yang sensitif untuk memverifikasi privasi data.
Secara default, BigQuery menolak akses ke kolom yang dilindungi oleh tag kebijakan. Untuk membuat kueri tabel dan memverifikasi penyamaran data aktif, akun pengguna Anda harus memiliki peran BigQuery Data Policy Masked Reader.
Peran ini otomatis terikat ke akun pengguna aktif Anda selama eksekusi awal setup_lab1.sh.
Buat Taksonomi dan Tag Kebijakan
Buat taksonomi data dan tag kebijakan terkait untuk mengelola akses ke data Anda.
- Buka halaman Taksonomi tag kebijakan.
- Klik + Buat Taksonomi.
- Konfigurasi parameter:
- Nama taksonomi: Masukkan
lost-cargo-, ganti dengan project ID Anda. - Region: Pilih region Anda.
- Untuk Nama tag kebijakan: Masukkan
MaskCustodianID - Untuk Deskripsi tag Kebijakan:
Restricts visibility into cargo custodian usernames
- Nama taksonomi: Masukkan
- Klik Buat untuk mendaftarkan taksonomi dan tag kebijakan baru Anda.
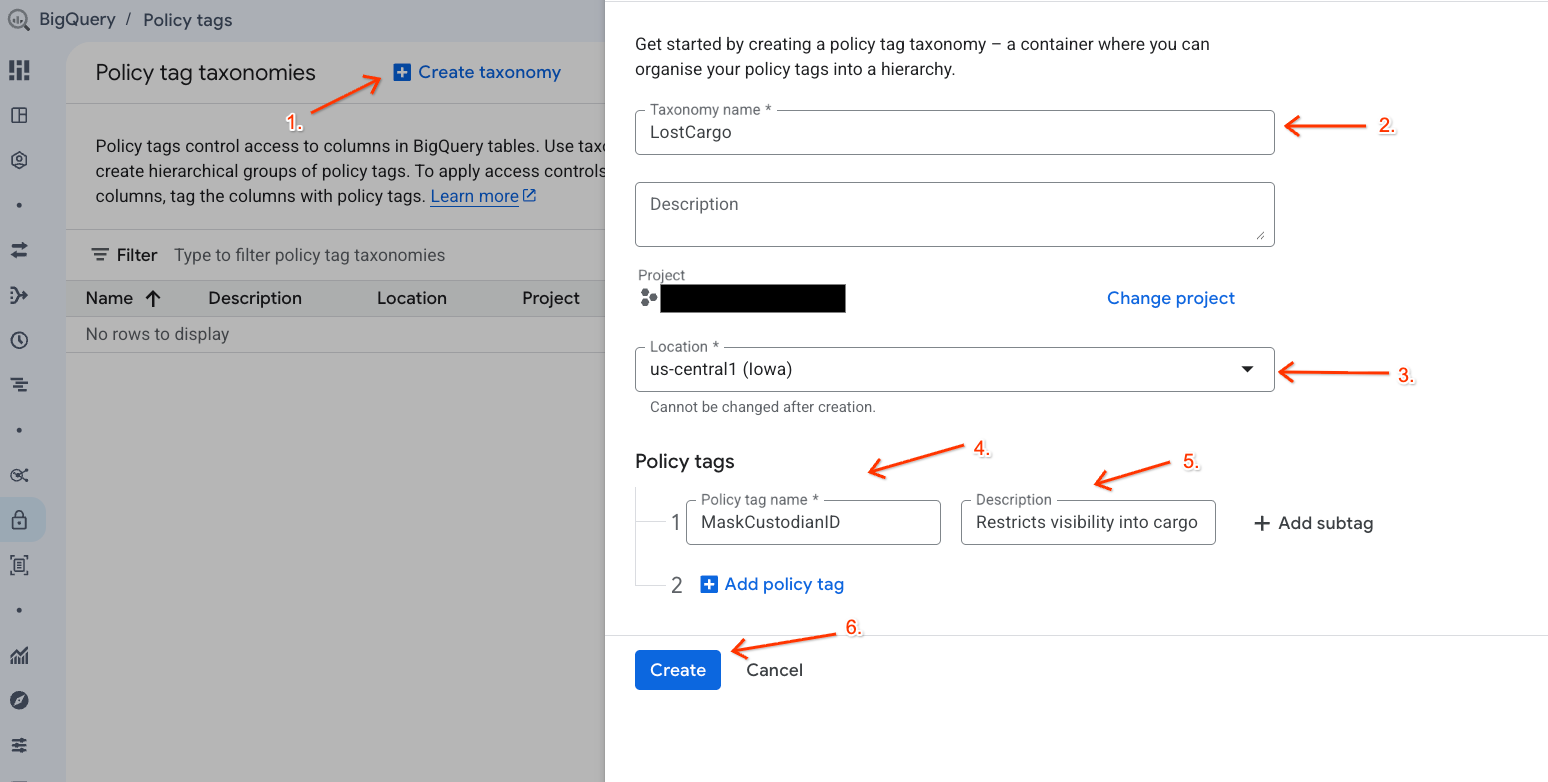
Membuat Kebijakan Penyamaran Data
Selanjutnya, konfigurasi kebijakan data untuk menentukan cara data disamarkan dengan tag klasifikasi MaskCustodianID. Anda akan menggunakan aturan penyamaran Selalu Null (mengganti nilai yang cocok dengan nilai kosong/Null yang ditampilkan untuk semua aktor yang tidak memiliki hak istimewa).
- Di halaman Taksonomi tag kebijakan, klik taksonomi yang baru dibuat dari daftar taksonomi Anda.
- Di daftar hierarki, klik tag
MaskCustodianIDuntuk memilihnya, lalu pilih Kelola kebijakan data.
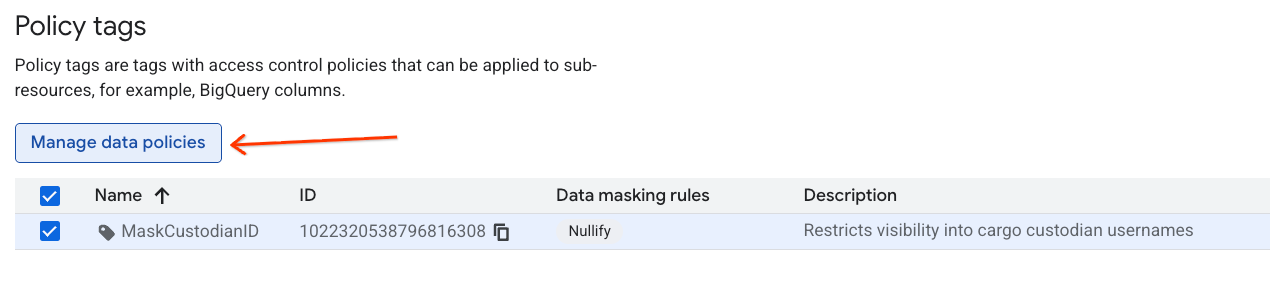
- Di panel sebelah kanan, klik tombol + Tambahkan Aturan.
- Konfigurasi detail kebijakan di panel yang muncul:
- Nama kebijakan data: Masukkan
null_masking_policy(jangan biarkan nama kebijakan data dibuat secara otomatis, karena kita akan merujuknya berdasarkan nama pada langkah berikutnya). - Aturan penyamaran: Pilih
Nullifydari menu dropdown.
- Nama kebijakan data: Masukkan
- Klik Kirim.
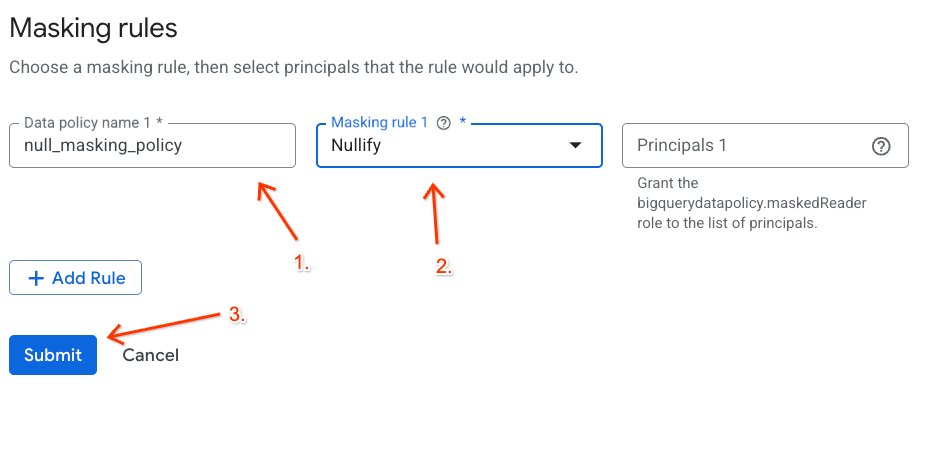
Tetapkan Tag Kebijakan ke Kolom BigQuery Anda
Dengan tag kebijakan dan aturan masking datanya yang aktif, petakan tag klasifikasi langsung ke kolom custodian_id dalam tabel manifes pengiriman partner BigQuery Anda.
- Buka konsol BigQuery.
- Di panel Explorer di sebelah kiri, luaskan project aktif Anda, luaskan set data
lost_cargo_dataset, lalu klik tabelshipping_manifestsuntuk membuka tampilan detailnya. - Klik Edit Schema.
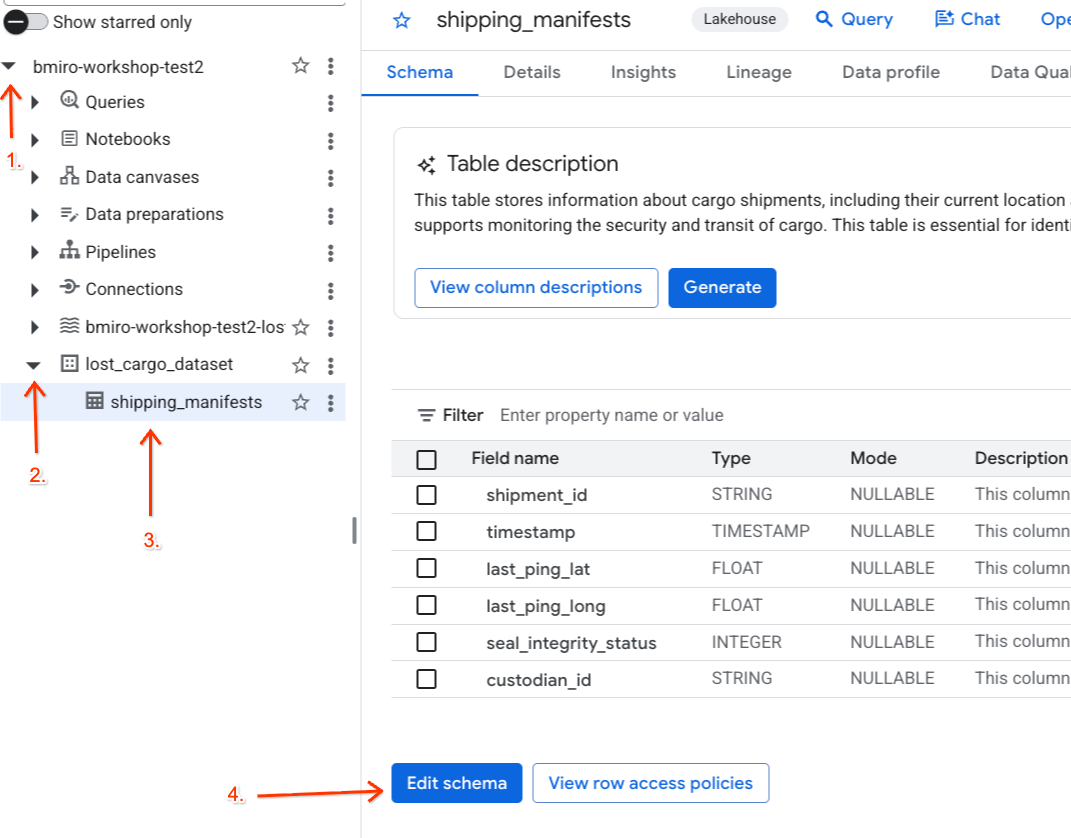
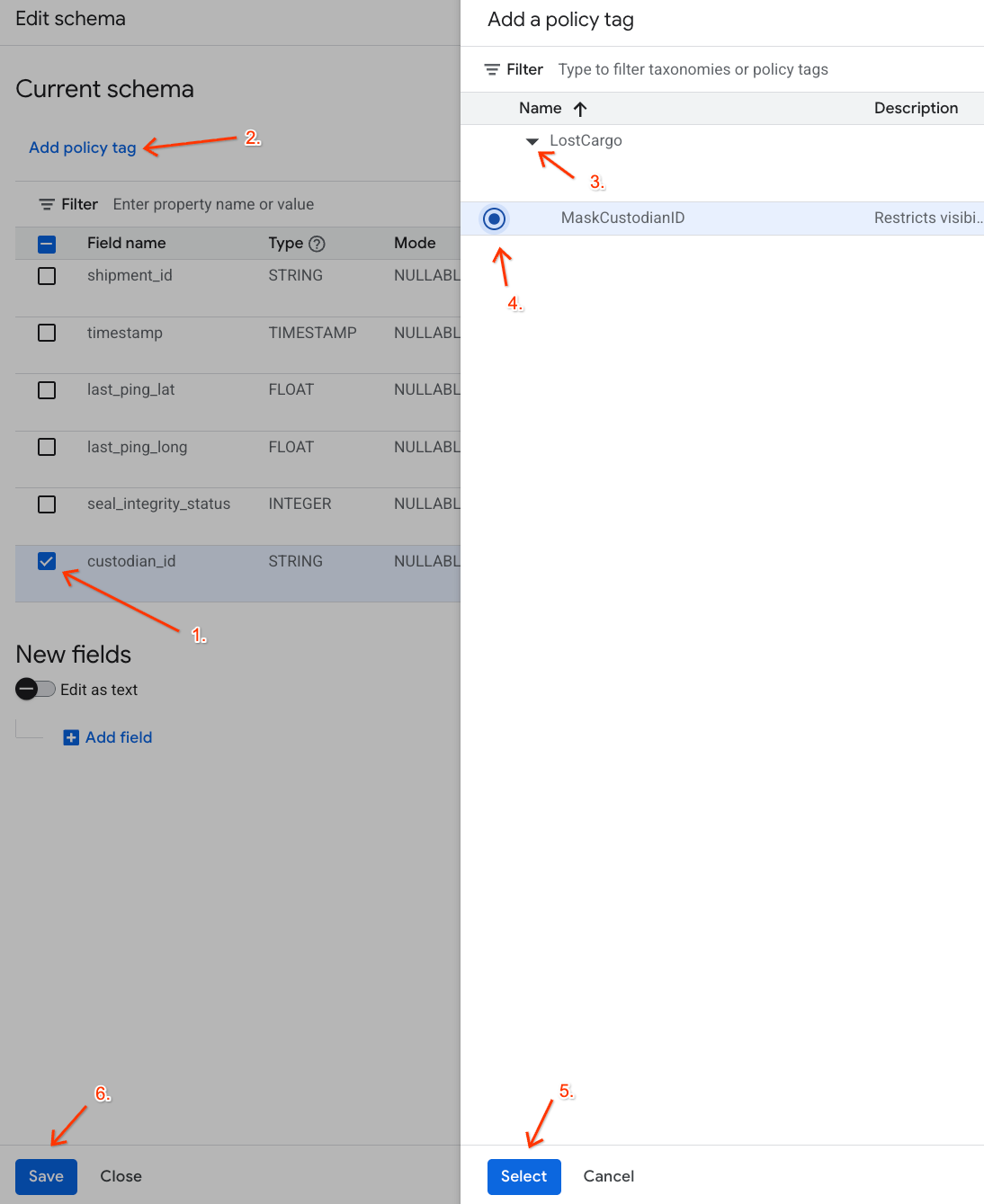
- Dalam daftar kolom, centang kotak di samping
custodian_id. - Klik tombol Tambahkan tag kebijakan di toolbar atas editor skema.
- Di panel Tambahkan tag kebijakan:
- Temukan dan luaskan taksonomi
LostCargoAnda. - Pilih balon di samping
MaskCustodianID. - Klik Pilih.
- Temukan dan luaskan taksonomi
- Pastikan tag
MaskCustodianIDkini terlihat di kolom Tag kebijakan pada baris yang merepresentasikancustodian_id. - Klik Simpan.
Memverifikasi Pembatasan Kebijakan
Setelah memiliki peran Masked Reader di tingkat project, Anda dapat membuat kueri tabel untuk memverifikasi bahwa kebijakan penyamaran aktif.
Kembali ke Data Agent Kit dan jalankan kueri berikut:
SELECT shipment_id, custodian_id
FROM lost_cargo_dataset.shipping_manifests
LIMIT 5;
Anda akan melihat output yang mirip dengan berikut ini:
shipment_id | custodian_id |
NORMAL-001 | null |
NORMAL-002 | null |
MV-CAT-001 | null |
Berhasil! Meskipun Anda dapat melihat shipment_id, kolom custodian_id sensitif menampilkan mask null yang aman untuk mencegah kebocoran.
8. Pembersihan
Agar tidak menimbulkan biaya berkelanjutan pada akun Google Cloud Anda untuk resource yang dibuat selama codelab ini, jalankan perintah berikut di terminal Cloud Shell untuk menghapus set data dan bucket Anda:
# Verify active variables
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-lost-cargo-lake"
# Delete Knowledge Catalog security taxonomies
export TAXONOMY_NAME=$(gcloud data-catalog taxonomies list --location=us-central1 --filter="displayName:LostCargo" --format="value(name)")
if [[ -n "$TAXONOMY_NAME" ]]; then
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://datacatalog.googleapis.com/v1/${TAXONOMY_NAME}" || true
fi
# Delete Lakehouse Iceberg REST Catalog tables and namespaces
gcloud biglake iceberg tables delete processed_maritime_logs \
--catalog=${BUCKET_NAME} \
--namespace=lost_cargo_namespace \
--quiet || true
gcloud biglake iceberg namespaces delete lost_cargo_namespace \
--catalog=${BUCKET_NAME} \
--quiet || true
# Delete Lakehouse Iceberg REST Catalog
gcloud biglake iceberg catalogs delete ${BUCKET_NAME} --quiet || true
# Delete dependencies bucket
gcloud storage rm -r gs://${BUCKET_NAME} || true
# Delete BigQuery dataset and tables
bq rm -r -f -d ${PROJECT_ID}:lost_cargo_dataset || true
9. Selamat
Selamat! Anda telah berhasil menyelesaikan modul penting pertama dalam penyelidikan Lost Cargo. Anda telah membuat zona penelusuran yang dikelola menggunakan Katalog REST Iceberg Lakehouse, normalisasi log PySpark, dan penyamaran data terperinci.
Yang telah Anda pelajari
- Menginstal, menyiapkan, dan mengonfigurasi ekstensi Data Agent Kit di dalam ruang kerja IDE Anda.
- Membuat katalog REST Iceberg Lakehouse serverless yang memanfaatkan kredensial yang disediakan dan ruang nama hierarkis.
- Menyerap feed regional multi-format dan membuat tabel eksternal BigQuery melalui bucket Cloud Storage.
- Meluncurkan tugas Apache Spark serverless untuk mengurai, menormalisasi, menyegmentasikan, dan menulis kembali log transponder tidak terstruktur ke BigQuery sebagai tabel katalog Iceberg terdaftar.
- Membangun taksonomi keamanan dan memetakan kebijakan penyamaran data Knowledge Catalog untuk mencegah kebocoran identitas pada indeks log sensitif.
- Membuat dan menganalisis insight metadata tabel menggunakan Insight data BigQuery untuk mempercepat eksplorasi data.
Verifikasi Petunjuk yang Dikumpulkan
Pastikan Anda telah merekam petunjuk pasti berikut yang diperlukan untuk memulai fase lab berikutnya:
- ID Pengiriman yang Hilang:
MV-CAT-001(lokasi ping terakhir: London) - Tujuan Target yang Direncanakan:
New York(dan alias sebenarnya transponder:MV-DOG-002) - Warna Container:
Crimson RED - Tag Akses Tata Kelola:
MaskCustodianID
Siap untuk fase berikutnya?
Setelah rute Keberangkatan / Tujuan transponder diamankan, penyelidikan akan dilanjutkan. Langsung buka Lab 2 untuk memeriksa kamera keamanan menggunakan model Gemini multimodal, mengidentifikasi kapal secara visual, dan melakukan penelusuran vektor di AlloyDB untuk memverifikasi anomali gangguan.
➡️ Lanjutkan dengan Langkah Kedua: Analisis Data & Insight Multimodal